
Abstract
The pipe sizing of water networks via evolutionary algorithms is of great interest because it allows the selection of alternative economical solutions that meet a set of design requirements. However, available evolutionary methods are numerous, and methodologies to compare the performance of these methods beyond obtaining a minimal solution for a given problem are currently lacking. A methodology to compare algorithms based on an efficiency rate (E) is presented here and applied to the pipe-sizing problem of four medium-sized benchmark networks (Hanoi, New York Tunnel, GoYang and R-9 Joao Pessoa). E numerically determines the performance of a given algorithm while also considering the quality of the obtained solution and the required computational effort. From the wide range of available evolutionary algorithms, four algorithms were selected to implement the methodology: a PseudoGenetic Algorithm (PGA), Particle Swarm Optimization (PSO), a Harmony Search and a modified Shuffled Frog Leaping Algorithm (SFLA). After more than 500,000 simulations, a statistical analysis was performed based on the specific parameters each algorithm requires to operate, and finally, E was analyzed for each network and algorithm. The efficiency measure indicated that PGA is the most efficient algorithm for problems of greater complexity and that HS is the most efficient algorithm for less complex problems. However, the main contribution of this work is that the proposed efficiency ratio provides a neutral strategy to compare optimization algorithms and may be useful in the future to select the most appropriate algorithm for different types of optimization problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The optimal sizing of pipes in water distribution networks (WDNs) is an issue that continues to require investigation. Optimal design refers to sizing the pipes of a WDN to ensure that various requirements at the nodes (demands and pressure) and the lines (velocity) are met while reducing the financial costs of the new pipes to be installed. A wide variety of factors affect this problem. Therefore, optimal design for pipe sizing is not a direct and determined problem.
One of the complexities of WDN pipe sizing is the choice of pipe diameters as decision variables. In this case, the constraints are the implicit functions of these variables and require solving the conservation of mass and energy equations to determine the pressure heads at the nodes. Currently, traditional methods based on mathematical techniques are limited to the location of the local minima of the objective function, which depend on the starting point of convergence.
Until a few years ago, water distribution design, upgrade, or rehabilitation was based on trial and error, which was guided by experience. However, in the last three decades, a number of researchers have attempted to solve the problem of WDN optimal design by applying mathematical programming techniques.
The optimization of a WDN is by nature nonlinear. Notwithstanding, researchers have used linear programming to reduce the original nonlinear problem complexity by solving a sequence of approximate linear sub-problems (Alperovits and Shamir 1977). This approach has been adapted and improved by many researchers. Subsequent studies applied standard nonlinear programming methods (NLPs) to network design problems. However, NLPs are subject to significant limitations: they do not guarantee global optima and typically use continuous diameters as decision variables.
More recently, the application of heuristic and/or evolutionary techniques has proven to be useful for solving WDN optimization problems. Evolutionary Algorithms (EAs) are a set of optimization techniques based on the natural processes of evolution. Generally, EAs try to optimize an objective function for a given design problem by exploiting the information from a random initial solution. The search space is then explored based on this information to create new populations that contain new solutions. According to established criteria, individuals who are best adapted survive, and less adapted individuals perish.
In this work, the WDN design problem is formulated as a cost minimization problem with pipe sizes as the decision variables. To date, many studies that utilized many different algorithms have been published on this topic. Generally, researchers attempt to solve some of the benchmarking problems available in the literature, matching (or not) the best solution known to date in each of them. However, the performances of these algorithms have rarely been compared by taking into account anything but the best solution obtained.
The drawback of these types of methods is the large number of simulations required to find an optimal solution. In addition, these techniques are subject to certain parameters whose calibration determines the proper performance of the algorithm. Consequently, the most suitable calibration for each algorithm and problem is not immediately evident. Therefore, a simple methodology to compare different algorithms to each other needs to be defined to enable an understanding of the strengths and weaknesses of each algorithm according to the characteristics of the problem under analysis.
This paper presents a methodology to compare the performances of EAs. This methodology defines an efficiency rate (E), which relates the quality of the solution obtained to the computational effort involved to reach that solution.
Subsequently, this methodology was applied to the results obtained by four EAs for the pipe-sizing problem of four benchmarking networks. The selected algorithms included a PseudoGenetic Algorithm (PGA), a modified Particle Swarm Optimization Algorithm (PSO), a modified Shuffled Frog Leaping Algorithm (SFLA) and a Harmony Search Algorithm (HS). This work also includes a previous parameter calibration to determine the best E values. Overall, at least 25,000 different simulations were performed for each network and algorithm, which totals more than 500,000 simulations.
The results identify the most efficient of the four analyzed algorithms. The methodology can be applied to many other evolutionary algorithms that have not been considered in this work because the main objective of this study was to present an efficiency rate that neutrally compares algorithm performance. This methodology is simple and can be easily reproduced by any researcher to evaluate the performance of a heuristic or evolutionary algorithm.
2 WDN Design Based on Evolutionary Algorithms
All evolutionary methods share some basic principles, such as a data structure that stores the characteristics of a given individual, an objective function that measures the quality of the solution, a selection mechanism to ensure the survival of the best individuals and a set of parameters that modify these individuals.
In the field of WDN, some researchers have successfully applied EA to optimal reservoir operations (Ostadrahimi et al. 2011), the calibration of water quality models (Afshar et al. 2011; Haddad et al. 2013), complex supply systems (Chung and Lansey 2008; Louati et al. 2011), hydraulic pressure control in WDNs (Araujo et al. 2006) and Best Management Practice models (Artita et al. 2013; Iglesias-Rey et al. 2014). Similarly, in recent years many researchers have applied these algorithms to multi-objective optimization problems related to water networks (Afshar et al. 2013; Barlow and Tanyimboh 2014; Wang et al. 2014)
Consequently, some of these evolutionary optimization techniques, such as Genetic Algorithms (Savic and Walters 1997), SFLA (Eusuff and Lansey 2003) or Harmony search (Geem 2006), have been successfully applied to WDN design. Some previous studies (Kollat and Reed 2006; Marchi et al. 2014) compare some of these techniques based on different absolute criteria, but previous studies have not yet defined a method that relates the quality of the obtained solutions to the computational effort required to reach it.
Among the design issues of interest, this work considers the pipe-sizing problem. Therefore, for a given network layout and demand, this problem requires that the cost of a given pipe network be minimized. Furthermore, the objective function is subject to the constraints of the problem (pressure, velocity, etc.). The details of the methodology and the objective function used in the structure of the algorithms can be found in Mora-Melia et al. 2013.
3 Selection of Evolutionary Algorithms
All EAs are a combination of deterministic and random approaches, and the efficiency of the algorithm depends on the search process. Thus, each EA features different parameters that maintain the diversity in the algorithm population while guiding the search process. Analogously, the random elements ensure the flexibility and robustness of the search pattern, and the obtained results are generally highly sensitive to the values of these parameters. Therefore, an adequate parameter pre-calibration is paramount.
Four algorithms were selected from the currently available algorithms in the literature. These algorithms were selected because they have already been successfully applied to various problems related to the WDN design in the original form of the algorithm. Thus, the algorithms developed in this work include evolutionary methodologies based on PGA, PSO, SFLA and HS. Although other EAs may have also been included, the architectures of these algorithms are sometimes highly problem-specific. Therefore, the inclusion of additional algorithms was not favorable due to space limitations and the required parameter calibration explanations, which are given below, particularly because this work primarily intends to describe the implementation of a comparative performance standard methodology for WDNs.
Genetic algorithms were one of the first heuristic methodologies applied to the design of water networks. The method of the proposed PGA tests the evolution of a random population via a parallelism that is similar to the laws of natural selection, which occurs in a classic GA. Three calibration parameters control the process: the Population size (P), Crossover frequency (Pc) and Mutation frequency (Pm). The different stages of the optimization process and the complete description of the PGA can be found in Mora (2013).
The PSO heuristic technique was proposed by Kennedy and Eberhart 1995 and is inspired by the social behavior of a flock of migrating birds that attempt to reach an unknown destination. Each particle (bird) contains a solution for the optimization problem because it moves in the search space with a velocity vector that is initially selected at random. The PSO was originally developed to optimize continuous spaces, but this work utilizes an adaptation designed for the study of discrete spaces Jin et al. (2007).
PSO also features several parameters to calibrate, such as the Population size (P), the velocity limit of birds (Vlim) and the learning factors C1 and C2. Nevertheless, the original PSO algorithm often easily falls into local optima, causing early convergences. Therefore, the authors have introduced a new parameter in the formulation of this algorithm, the Confusion Probability (Pc). This parameter determines the number of particles that do not follow the social learning of other particles in each iteration.
The original SFLA (Eusuff and Lansey 2003) has been applied to several problems, including WDN design. However, the original SFLA is often trapped in local optima. To avoid this problem, this work includes a search-acceleration factor (C) proposed by Elbeltagi, Hegazy, and Grierson (2007), creating a modified form of the algorithm. This modification has not been applied to problems related to WDNs.
Up to five different parameters are used to control the optimization process in the modified SFLA: the number of memeplexes (m), number of frogs per memeplex (n), the number of evolutionary steps (Ns), the size of sub-memeplex (Q) and the search-acceleration factor (C). For the SFLA, P is determined by the product m × n.
Finally, the HS Algorithm simulates the evolution of a random population via a parallelism similar to the improvisation process by which musicians finds the best harmony (Geem 2006). HS can handle discrete and continuous variables and has been successfully applied to computer science, engineering and economic problems. This work includes the original method but applies it to four WDN pipe-sizing problems. Like other methodologies, the HS algorithm features a set of three parameters to be calibrated: Harmony memory size (P), Harmony Memory Considering Rate (HMCR) and Pitch Adjustment Rate (PAR).
4 Efficiency Criteria
This work defines Efficiency (E) as a mathematical tool that relates the quality of the solution obtained to the computational effort that requires each EA to find the final design solution. E is an original concept proposed by the authors and represents a neutral and objective strategy to compare the performance of different algorithms applied to solve the same problem, in this case, the optimal pipe sizing of a WDN. To relate the concepts of quality and computational effort, two rates must be formulated beforehand.
First, ηquality represents the quality of the solution. In this work, the quality of the solution is related to the rate of successful solutions obtained for a specific WDN problem that satisfy constrains imposed on the objective function. Importantly, ηquality can be defined according to the requirements of the solutions to be generated. However, quickly obtaining a set of solutions close to the lowest cost solution may sometimes be preferable. Therefore, a “good solution” may be defined as a combination of solutions whose cost does not exceed a certain threshold over the minimum cost. Hence, the quality index can be defined as follows:
where Nsuccessful is the number of “lowest” or “good” (sufficiently low) cost solutions, depending on the optimization goal, and Nsim is the total number of simulations performed.
Second, the term ƞconvergence is related to the speed of convergence and requires the algorithm to reach the final solution. If time factors are considered, the measurement of this rate is not a trivial task, and results may significantly vary by computer. The number of factors that can influence the run time is extensive: the algorithm structure, OS, processor speed and number of processors, RAM memory and cache, GPU, etc.
One of the main objectives of the proposed methodology is the development of a tool that can be easily reproduced and used by other researchers to compare the performance of algorithms on the same basis. Therefore, time alone is not an adequate measure of convergence.
Alternatively, the convergence time can be measured by directly counting the number of operations that constitute the algorithm during operation. Thus, the term ƞconvergence refers to the number of objective function (OF) evaluations performed by the algorithm before finding the final solution to the problem.
Evaluating the OF represents a call to the hydraulic calculation package and does not necessarily coincide with the number of generations of the algorithm. The maximum number of evaluations of the OF at each generation is equal to the initial population size. Thus, between two different generations of a given algorithm, only the solutions that have experienced a change from the previous generation are re-evaluated. The number of calls made by each algorithm to a hydraulic package is one of the main differences between the rates at which different algorithms converge on the solution.
The ratio of ηquality and ƞconvergence defines E and indicates the performance of the algorithm. Specifically, the magnitude of E directly correlates with the solution quality and inversely correlates with the computational resources required to reach this solution. Therefore, E is a neutral measure to compare the different optimization algorithms.
E reports the number of “successful” evaluations obtained per call of the OF. Similarly, 1/E gives the number of evaluations of the OF to be performed by the algorithm to find a successful solution of the optimization problem.
E depends on both the optimization problem analyzed and the algorithm-specific defining parameters. The results of this work show the best calibration ranges for each algorithm to maximize E, whereas the complete statistical analysis was based on more than 500,000 simulations.
5 Methodology and Case Studies
Optimization methodologies based on EA cannot ensure that a problem global minimum is found. Therefore, researchers have utilized a series of benchmarking networks to compare algorithms. Currently, this type of problem can be classified into four groups (small, medium, intermediate and large), according to the size of the search space. Wang et al. (2014) provided a detailed description of these benchmark problems, including the number of decision variables, the range of the diameters and other information. Similarly, the performance of the algorithm depends not only on the nature of the problem but also on the calibration of the algorithm parameters.
This paper proposes a method to measure the efficiency of optimization algorithms for WDN pipe sizing. The proposed methodology includes two steps. First, the different algorithm parameters for each network are calibrated. As such, the adopted methodology for tuning evolutionary parameters begins with the selection of the problem. Next, the proposed methodology applies several algorithm trial runs and tunes the operators. Finally, the results are statistically analyzed to ensure the best possible configuration based on the quality of the solutions and the convergence speed of the algorithm.
According to this calibration protocol, the most feasible combinations of different parameters within given intervals were tested for each algorithm. The initial range of values considered was obtained from recommended sets of values found in the literature for each algorithm and from values given in the authors’ previous work (Mora-Melia et al. 2010; 2013). The majority of simulations to obtain the EA parameters were performed with a specific application developed by the authors. To summarize the range of parameter values described above, Table 2 shows all parameters considered for each of the techniques described and the calibration range considered.
Note that the algorithm parameters can be divided into two groups. Specifically, the only parameter common to all techniques is the initial size of the random population (P). The size of P needs to be sufficient to guarantee the diversity of solutions and must grow with the number of chain bits.
Conversely, each algorithm features specific parameters, and a proper calibration helps reduce the randomness factor and improves the effectiveness of the search for minima. These features ultimately significantly increase the probability of success. This work considers only the calibration of specific parameters, whereas the population is considered constant at P = 100 individuals.
After the parameters are calibrated, the second step of the methodology begins, which consists of calculating the efficiency rates according to Eqs. (1) and (2). As noted earlier, the efficiency of the algorithm directly correlates with the number of successful simulations per OF evaluation.
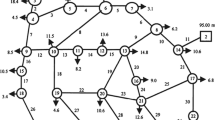
As indicated above, the benchmarking networks can be classified into four groups. In this work, three medium-sized benchmarking networks were used to analyze the behavior of algorithms from the standpoint of this new efficiency rate: Hanoi (Fujiwara and Khang 1990), New York Tunnel (Schaake and Lai 1969), and GoYang (Kim et al. 1994). Several researchers have tested different models for these networks. Consequently, many solutions are available in the literature, which allows the results to be compared and the conclusions to be extended to networks with a search space of this order of magnitude.
A fourth benchmarking network was included in the analysis: the R-9 network of Joao Pessoa (Gomes et al. 2009). The search space of this network is also medium-sized but closer to the next category of benchmarking problem sizes (intermediate). This network was included to study a more complex network within the size limits defined by the above classification.
Table 1 summarizes the most relevant operating conditions of all networks, the range of diameters available and other information:
For the analyzed networks, all implemented EAs reached the best solution available in the literature to date. However, for the R-9 network of Joao Pessoa, the best solution available in the literature corresponds to the one obtained in this work. Due to the high solution variability, each problem was solved at least 200 times for each parameter combination and algorithm.
In addition, solving WDN problems with this type of methodology requires the adoption of a hydraulic solver. Here, the required calculations were performed using EPANET2 (Rossman 2000) and its library, the EPANET Toolkit because this solver is extensively used in the field.
6 Results
To ensure a representative sample and perform a reliable statistical analysis, each algorithm was run at least 25,000 times for each network. A statistical analysis of the results based on ηquality, ƞconvergence and E is given below. First, the difficulty of pipe-sizing problems was analyzed. Figure 1 shows the histogram of solutions for the four selected problems, considering all simulations and algorithms.

Histogram of solutions for selected problems
GoYang is a simpler problem because the probability of finding local solutions close to the best solution identified is high (99 % of simulations has a lower overrun of 0.3 % than the optimum). Therefore, the dispersion of solutions to the GoYang problem was lowest (only 303 different solutions for all runs) than that of other problems, despite the second largest solution space of this problem. In contrast, the dispersion of results was highest for the Joao Pessoa problem, with 16,101 different solutions found.
This dispersion is a key point to determine the complexity of the problem. The complexity of the problem is sometimes associated with only the size of the solution space; however, the optimization process is likely to become more complex as the number of local minima near the optimum solution increases. This information is rarely published in the literature but is easy to obtain as the simulations are performed.
The first step of the methodology based on E includes the calculation of the quality and convergence rates. After performing the simulations, test runs were classified depending on the calibration parameters and their success rate.
For the Hanoi, New York and GoYang networks, the success rate is the ratio of the number of times the minimum was achieved to the total number of simulations required. For the Joao Pessoa network, the low cost solution lacks sufficient replication due to the size and complexity of the problem as well as the absence of thorough studies in the literature. Thus, solutions whose cost did not exceed 1 % of the global minimum cost were considered successful.
Figure 2 shows the success rate obtained for each network. The left side of each graph shows the total rate of minimal solutions obtained for each network without any calibration, whereas the right side shows the same success rate once the algorithm parameters had been properly calibrated.

Success rate obtained for each network and algorithm. Importance of calibration parameters
Figure 2 clearly reflects the importance of calibration parameters for EA. For all WDNs analyzed, the optimal combination of parameters allows all algorithms to significantly increase the number of successful solutions. Note that the number of successful solutions inversely correlates with the number of local minima of networks for all algorithms. Specifically, the number of minima is directly related to the complexity of the network and the algorithm performance when searching for the global minima. Furthermore, the importance of parameters in enhancing the search process varies by parameter. Some parameters are extremely value-sensitive, whereas others minimally affect the effectiveness of the algorithm. Table 2 shows the specific parameters considered, the calibration range considered and the optimum parameter calibration for each network and algorithm. The repeatability of obtaining minimal solutions is related to the quality parameter in the efficiency of the algorithms, i.e., to ηquality in Eq. (2).
For the PGA, the mutation parameter is the most sensitive parameter. Thus, minima are rarely obtained outside the recommended range. The crossing parameter did not differ across the considered range in three of the four networks, but Pc > 60 % slightly improves the results for the New York network.
For the PSO algorithm, among the four parameters analyzed, the minimum solution is sensitive to Vlim and Pconf: minima of the cost function were not identified outside the proposed ranges of these parameters. C1 and C2 operate analogously within the range considered, with slight improvements in the solutions when C1 and C2 are close to 2, as recommended in the literature.
For the HS Algorithm, two parameters are critical to the performance of the algorithm. Particularly, the pitch adjustment (PAR), a convergence parameter, is important: PAR values higher than 50 % prevent the algorithm from obtaining a feasible solution. Moreover, the effectiveness of the algorithm inversely correlates with the magnitude of PAR For the HMCR, the HS algorithm converges to feasible solutions over the entire considered range. However, the operation of the algorithm remarkably improves for HMCR > 85 %.
Finally, the behavior of the calibration parameters of SFLA significantly differs from the behavior of the above-described parameters. The accelerator coefficient (C) is the most relevant parameter, and values close to 2 provide the best success rate for all but the New York network (where C = 1.5). In contrast, the success rate is essentially independent of the submemeplex size (Q). Finally, the number of evolutionary steps (Ns) directly correlates with the frequency of the minimum cost solution.
Several elements influence the convergence speed of each algorithm (ηconvergence). Specifically, differences in the optimization process of each algorithm are important differentiating factors in the eventual degree of convergence. However, the calibration of parameters plays a key role in the speed of convergence to the final solution.
Figure 3 shows the average number of evaluations of the objective function for each algorithm and network for the best possible parametric calibration. In each graph, the most sensitive parameter remains constant at its optimum quality calibration value, whereas the full ranges of the remaining parameters are presented.

Number of evaluations of the OF based on the most sensitive parameters
The differences in the convergence speed between the different algorithms are remarkable and vary by network. As expected, the number of OF evaluations is higher for the Hanoi and Joao Pessoa networks because these networks are more complex. The HS algorithm requires fewer OF evaluations to converge to the final solution for all analyzed networks. In contrast, the SFLA algorithm requires more OF evaluations to reach the final solution. The largest difference between HS and SFLA algorithms is in the Hanoi network, where SFLA required 12.5 times the number of evaluations conducted by HS to converge on a solution. The behavior of PGA and PSO is situated between the extremes of HS and SFLA but much more similar to that of the HS algorithm for almost all networks.
The relationship between the calibration of specific algorithm parameters and the OF evaluations is discussed below. For the PSO algorithm, the figure clearly shows the positive correlation between the number of evaluations of the objective function and Pconf. Because the probability of finding minimal solutions also decreases as Pconf increases, studying a wider range of values was not indicated.
Figure 3 indicates that the PAR does not indicate the rate of the convergence speed of the HS algorithm. Additionally, the PAR values do not exceed 40 % in Hanoi and New York networks because feasible solutions were not identified.
Furthermore, a relationship between Pc and the speed of convergence could not be established for PGA. Thus, OF evaluations slightly decrease as Pc increases for the New York network, whereas this trend is reversed in the Joao Pessoa network. Pc did not correlate with the number of OF evaluations for the Hanoi and GoYang networks.
For the modified SFL algorithm, the speed of convergence is independent of the size of submemeplex (Q) (Fig. 3). Moreover, the number of evolutionary steps (Ns) significantly increases the number of OF evaluations, which decelerates convergence. This situation is logical and is not represented graphically because Ns is by definition a multiplier of OF evaluations.
Finally, the rate between ηquality and ηconvergence allows the calculation of efficiency rates according to Eq. 2. Figure 4 shows E for obtaining successful solutions for all tested networks.

Efficiency of EA in obtaining successful solutions for the four selected networks
PGA is far superior to PSO, HS and SFLA for the Hanoi and Joao Pessoa networks. Numerically, the E of PGA is 15 times larger than that of PSO for the Hanoi network. In other words, for each successful solution obtained by PSO, PGA obtains 15 successful solutions. Moreover, the E value of PGA is approximately 2.9 times higher than those of HS and SFLA.
For the Joao Pessoa network, the E value of PGA is 9.5, 4 and 2.1 times higher than those of the PSO, SFLA and HS algorithms, respectively. Therefore, we can conclude that the PGA algorithm is the most efficient algorithm to solve complex problems, i.e., problems with a greater dispersion due to a high number of local minima near the global minimum cost.
However, the performance of the HS algorithm significantly improves for less complex networks. Thus, the HS algorithm was most efficient in finding low cost solutions for the New York and GoYang networks. These two networks represent the lowest dispersion of solutions near the minimum within the tested ranges (see Fig. 1). Thus, the efficiency of the optimally calibrated HS was 2.6, 4.3 and 4.8 fold higher than those of the optimally calibrated PGA, PSO and SFLA algorithms, respectively, for the New York Tunnel network.
The difference between HS and the other networks is lower for the GoYang network. Specifically, HS is 1.1, 1.74 and 1.14 times more efficient than PGA, PSO and SFLA, respectively. This significant improvement in the efficiency of the HS algorithm is due to an early convergence of the algorithm to its final solution. For networks characterized by a small number of local minima and/or a smaller field of possible solutions, such as the New York and GoYang networks, the HS algorithm is the most efficient methodology.
The great disadvantage of HS is its robustness. Figure 4 indicates the sensitivity of solutions to the value of PAR for all networks. Specifically, HS operates effectively over only a very narrow range of PAR, and the efficiency of HS is consequently very low because PAR requires calibration. Conversely, PGA and SFLA are much more robust because they perform acceptably over broader parameter ranges. Thus, these EAs do not require a highly sensitive calibration to obtain acceptable efficiencies.
7 Conclusions
WDN design using evolutionary and/or metaheuristic methods is highly interesting because it allows the solution to search beyond the local minimums of the objective function. Many different techniques are currently available for WDN design, and an objective methodology to compare the performances of different algorithms is considered to be of great interest to the scientific community
This work presents a methodology for comparing algorithms based on an efficiency rate (E), which relates the quality of the solution to the computational effort required to reach it.
The proposed methodology has been applied here to water network pipe-sizing problem. Among different available Evolutionary Algorithms, a PseudoGenetic Algorithm (PGA), a Particle Swarm Optimization Algorithm (PSO), a Harmony Search Algorithm (HS) and a modified Shuffled Frog Leaping Algorithm (SFLA) were studied. The presented methodology was tested on four benchmark networks: Hanoi, New York Tunnel, GoYang and R-9 Joao Pessoa.
However, many factors can influence the optimization process, such as the problem characteristics, variable coding, objective function considered and specific algorithm operators. Therefore, a thorough parameter calibration prior to implementing the described methodology is important.
Based on the statistical analysis of the results for the proposed four evolutionary algorithms selected as well as the concept of Efficiency (E) defined in this work, the following conclusions can be drawn:
-
The defined efficiency ratio faithfully describes the level of performance of the algorithm while considering both the ability to obtain the best possible solution and the number of objective function evaluations required to reach this solution (the inverse of E).
-
A proper calibration of the specific parameters for each algorithm is crucial to maximize the efficiency. Therefore, PGA and SFLA were the most robust techniques because they can perform best over wider parameter ranges.
-
According to the efficiency rate, PGA is the most efficient algorithm for sizing more complex networks (Hanoi and R-9 Joao Pessoa). Specifically, PGA and SFLA are more likely to identify the lowest-cost solution, but the computational effort required for PGA is much lower. Finally, HS and PSO algorithms do not find many minimal solutions for the most complex problems, which severely decreases their efficiency.
-
In terms of efficiency, the HS algorithm is best for simpler pipe-sizing problems (New York and GoYang networks). In these two networks, all techniques successfully more frequently identified minimal solutions, but HS required fewer OF evaluations to meet the convergence criterion and obtain the final solution.
-
Although the selected optimization models may not necessarily represent the best algorithm performance given in the literature, the PSO algorithm is clearly the worst algorithm in terms of efficiency of all tested algorithms tested in this work. This poor performance is due to difficulties encountered by PSO when finding optimal solutions. Furthermore, the computational effort of PSO is not lower than those of other methodologies.
The authors of this paper consider the proposed methodology presented in this paper to be simple and reproducible by other researchers intending to measure the performance of their algorithms. This methodology will likely constitute a useful tool for future fair comparisons of algorithm performance.
References
Afshar A, Kazemi H, Saadatpour M (2011) Particle swarm optimization for automatic calibration of large scale water quality model (CE-QUAL-W2): application to Karkheh Reservoir, Iran. Water Resour Manag 25:2613–2632. doi:10.1007/s11269-011-9829-7
Afshar A, Shojaei N, Sagharjooghifarahani M (2013) Multiobjective calibration of reservoir water quality modeling using Multiobjective Particle Swarm Optimization (MOPSO). Water Resour Manag 27:1931–1947. doi:10.1007/s11269-013-0263-x
Alperovits E, Shamir U (1977) Design of optimal water distribution systems. Water Resour Res 13:885–900. doi:10.1029/WR013i006p00885
Araujo LS, Ramos H, Coelho ST (2006) Pressure control for leakage minimisation in water distribution systems management. Water Resour Manag 20:133–149. doi:10.1007/s11269-006-4635-3
Artita KS, Kaini P, Nicklow JW (2013) Examining the possibilities: generating alternative watershed-scale BMP designs with evolutionary algorithms. Water Resour Manag 27:3849–3863. doi:10.1007/s11269-013-0375-3
Barlow E, Tanyimboh TT (2014) Multiobjective memetic algorithm applied to the optimisation of water distribution systems. Water Resour Manag 28:2229–2242. doi:10.1007/s11269-014-0608-0
Chung G, Lansey K (2008) Application of the shuffled frog leaping algorithm for the optimization of a general large-scale water supply system. Water Resour Manag 23:797–823. doi:10.1007/s11269-008-9300-6
Elbeltagi E, Hegazy T, Grierson D (2007) A modified shuffled frog-leaping optimization algorithm: applications to project management. Struct Infrastruct Eng 3:53–60. doi:10.1080/15732470500254535
Eusuff MM, Lansey KE (2003) Optimization of water distribution network design using the shuffled frog leaping algorithm. J Water Resour Plan Manag 129:210–225. doi:10.1061/(ASCE)0733-9496(2003)129:3(210)
Fujiwara O, Khang DB (1990) A two-phase decomposition method for optimal design of looped water distribution networks. Water Resour Res 26:539–549. doi:10.1029/WR026i004p00539
Geem ZW (2006) Optimal cost design of water distribution networks using harmony search. Eng Optim 38:259–277. doi:10.1080/03052150500467430
Gomes H, de Bezerra STM, de Carvalho P, Salvino M (2009) Optimal dimensioning model of water distribution systems. Water SA 35:421–431. doi:10.4314/wsa.v35i4
Haddad OB, Tabari MMR, Fallah-Mehdipour E, Mariño MA (2013) Groundwater model calibration by meta-heuristic algorithms. Water Resour Manag 27:2515–2529. doi:10.1007/s11269-013-0300-9
Iglesias-Rey PL, Martínez-Solano FJ, Mora-Meliá D, Martínez-Solano PD (2014) BBLAWN: a combined use of best management practices and an optimization model based on a pseudo-genetic algorithm. Procedia Eng 89:29–36. doi:10.1016/j.proeng.2014.11.156
Jin Y-X, Cheng H-Z, Yan J, Zhang L (2007) New discrete method for particle swarm optimization and its application in transmission network expansion planning. Electr Power Syst Res 77:227–233. doi:10.1016/j.epsr.2006.02.016
Kennedy J, Eberhart R (1995) Particle swarm optimization. Proceedings of ICNN’95 - International Conference on Neural Networks. IEEE, pp 1942–1948. doi:10.1109/ICNN.1995.488968
Kim JH, Kim TG, Kim JH, Yoon YN (1994) A study on the pipe network system design using non-linear programming. J Korean Water Resour Assoc 27:59–67
Kollat JB, Reed PM (2006) Comparing state-of-the-art evolutionary multi-objective algorithms for long-term groundwater monitoring design. Adv Water Resour 29:792–807. doi:10.1016/j.advwatres.2005.07.010
Louati MH, Benabdallah S, Lebdi F, Milutin D (2011) Application of a genetic algorithm for the optimization of a complex reservoir system in tunisia. Water Resour Manag 25:2387–2404. doi:10.1007/s11269-011-9814-1
Marchi A, Dandy G, Wilkins A, Rohrlach H (2014) Methodology for Comparing Evolutionary Algorithms for Optimization of Water Distribution Systems. doi: 10.1061/(ASCE)WR.1943-5452.0000321
Mora-Melia D, Iglesias-Rey P, Fuertes-Miquel V, Martinez-Solano F (2010) Application of the harmony search algorithm to water distribution networks design. Taylor & Francis Group. pp 265–271. doi: 10.1201/b10999-67
Mora-Melia D, Iglesias-Rey PL, Martinez-Solano FJ, Fuertes-Miquel VS (2013) Design of water distribution networks using a pseudo-genetic algorithm and sensitivity of genetic operators. Water Resour Manag 27:4149–4162. doi:10.1007/s11269-013-0400-6
Ostadrahimi L, Mariño MA, Afshar A (2011) Multi-reservoir operation rules: multi-swarm PSO-based optimization approach. Water Resour Manag 26:407–427. doi:10.1007/s11269-011-9924-9
Rossman LA (2000) EPANET 2.0 User’s manual. EPA/600/R-00/057, Water Supply and Water Resources Div., National Risk Management Research Laboratory, Cincinnatti (USA)
Savic DA, Walters GA (1997) Genetic algorithms for least-cost design of water distribution networks. J Water Resour Plan Manag 123:67–77. doi:10.1061/(ASCE)0733-9496(1997)123:2(67)
Schaake J, Lai FH (1969) Linear programming and dynamic programming application to water distribution network design. M.I.T. Hydrodynamics Laboratory, Cambridge
Wang Q, Guidolin M, Savic D, Kapelan Z (2014) Two-Objective Design of Benchmark Problems of a Water Distribution System via MOEAs: Towards the Best-Known Approximation of the True Pareto Front. J Water Resour Plan Manag 04014060. doi: 10.1061/(ASCE)WR.1943-5452.0000460
Acknowledgments
This research study was funded by the Chilean CONICYT grant under the Program FONDECYT Initiation for research in 2013 and 2014 (Project folio 11130666 and 11140128, respectively).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mora-Melia, D., Iglesias-Rey, P.L., Martinez-Solano, F.J. et al. Efficiency of Evolutionary Algorithms in Water Network Pipe Sizing. Water Resour Manage 29, 4817–4831 (2015). https://doi.org/10.1007/s11269-015-1092-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-015-1092-x