
Abstract
A regional flood frequency analysis based on the index flood method is applied using probability distributions commonly utilized for this purpose. The distribution parameters are calculated by the method of L-moments with the data of the annual flood peaks series recorded at gauging sections of 13 unregulated natural streams in the East Mediterranean River Basin in Turkey. The artificial neural networks (ANNs) models of (1) the multi-layer perceptrons (MLP) neural networks, (2) radial basis function based neural networks (RBNN), and (3) generalized regression neural networks (GRNN) are developed as alternatives to the L-moments method. Multiple-linear and multiple-nonlinear regression models (MLR and MNLR) are also used in the study. The L-moments analysis on these 13 annual flood peaks series indicates that the East Mediterranean River Basin is hydrologically homogeneous as a whole. Among the tried distributions which are the Generalized Logistic, Generalized Extreme Vaules, Generalized Normal, Pearson Type III, Wakeby, and Generalized Pareto, the Generalized Logistic and Generalized Extreme Values distributions pass the Z statistic goodness-of-fit test of the L-moments method for the East Mediterranean River Basin, the former performing yet better than the latter. Hence, as the outcome of the L-moments method applied by the Generalized Logistic distribution, two equations are developed to estimate flood peaks of any return periods for any un-gauged site in the study region. The ANNs, MLR and MNLR models are trained and tested using the data of these 13 gauged sites. The results show that the predicting performance of the MLP model is superior to the others. The application of the MLP model is performed by a special Matlab code, which yields logarithm of the flood peak, Ln(QT), versus a desired return period, T.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many recorded annual flood peaks series are too short to allow for a reliable estimation of extreme floods, or even there is not a flow-gauging facility close to the site of interest. Because overestimation of design floods causes too high structural costs, while their underestimation results in excessive flood damage costs and even loss of lives, prediction of future floods of high return periods must be reasonably accurate. Hydrological events such as annual maximum flow (also called annual flood peak, herein) or annual maximum precipitation are random variables. The regional flood frequency analysis involves (1) identification of a homogeneous region, (2) selection of the probability distribution suitable for this homogeneous region, and (3) estimation of flood peak quantiles at (un-gauged) sites of interest; and, the first two steps are carried out using the recorded data from all gauged sites of acceptable record lengths in the region. In this study, a regional flood frequency analysis is applied to 13 selected gauging stations in The East Mediterranean River Basin in Turkey where the parameters of the candidate distributions are estimated by the method of L-moments.
If flood frequency characteristics of all stations in a geographical region are close to each other, then it is a homogeneous region from the aspect of flood frequency analysis. As verified by many relevant studies, the regional flood frequency curve of a homogeneous area is more reliable than at-site frequency curves obtained from too short recorded series in that region (e.g., Hosking and Wallis 1993; Saf 2009). For example, in a comprehensive report by the World Meteorological Organization (WMO), it is stated that: “At–site/regional methods are better than at–site methods even in the presence of a modest amount of heterogeneity.” (Cunnane 1989). Similarly, in the Abstract of their paper, which explores the suitability of various probability distributions based on L-moments diagrams using flood flow data at 61 sites across Australia, Vogel et al. (1993a) say: “Recent research indicates that regional index-flood type procedures should be more accurate and more robust than the type of at-site procedures evaluated here.”.
The probability weighted moments (PWM) and estimation of parameters of a probability distribution by the PWM method was introduced by Greenwood et al. (1979). Since then this method has been used widely in both practice and research. Hosking et al. (1986) presented the algorithm of parameter estimation by the PWM method for the Generalized Extreme Vaules (GEV) distribution and showed that the PWM method is superior to the maximum-likelihood (ML) method for the GEV distribution. Similarly, in the ‘Concluding Remarks’ chapter of the WMO report (Cunnane 1989), it is stated that: “Parameter estimation by PWM, which is relatively new, is as easy to apply as ordinary moments, is usually unbiased, and is almost as efficient as ML. Indeed in small samples PWM may be as efficient as ML. With a suitable choice of distribution PWM estimation also contributes to robustness and is attractive from that point of view. Another attraction of the PWM method is that it can be easily used in regional estimation schemes.”. Yet, it is a known fact that the magnitudes of the parameters of a distribution by the method of PWM are the same as those by the method of L-moments. Therefore, the magnitudes of any return-period flood peaks obtained by either the PWM method or the L-moments method are equal. The L-moments method applied for regional flood frequency analysis as presented by Hosking and Wallis (1997) is superior to the PWM method however, because (1) it delineates boundaries of a homogeneous region based on a heteorogenity measure, which depicts the deviation of L-variation coefficients (L-Cv’s) of individual series from the overall weighted average regional L-Cv, and (2) it determines the probability distribution most suitable to a homogeneous region by a goodness-of-fit measure, which is quantification of closeness of plots of coefficients of L-kurtosis (L-Ck) versus L-skewness (L-Cs) of both the probability distributions and of the sample series. In this study the index flood approach is used as the tool of the regional flood frequency analysis, which is in parallel with the remarks given in this WMO report: “PWM based regional index flood procedures are most efficient and least biased and are easy to apply.” (Cunnane 1989).
Regional flood frequency analysis is a necessary practice because of two reasons: (1) the need for estimation of design flood magnitudes for hydraulic structures on natural streams which have no gauged records, and (2) too short records when they exist (e.g., Acreman and Sinclair 1986; Berthet 1994; Burn 1990; Dalrymple 1960; Meigh et al. 1997; Ouarda et al. 2008; Parida et al. 1998; Rao and Hamed 1997; Saf 2009; Stedinger and Tasker 1985; Zrinji and Burn 1994, 1996). To perform a regional flood frequency analysis, the drainage basin of interest must be hydrologically a homogeneous region or it must be subdivided into homogeneous regions. The homogenity test by the index flood method was first introduced by Dalrymple (1960). Wiltshire (1986) pointed out some drawbacks of Dalrymple test and proposed a cluster analysis in light of physical basin characteristics. In 1960’s through 80’s, prior to the development of the L-moments method and ANNs techniques, distribution parameters were computed mostly by the method of moments and sometimes by the ML method, and classical regression analysis was resorted to for regionalized equations which were based on a set of covariates available at gauged sites to predict flood peak magnitudes of desired return periods at ungauged sites. Ouarda et al. (2008) give a detailed summary of the conventional methods for regional flood frequency analysis other than the L-moments and the artificial neural networks (ANNs) methods, which they categorize as hierarchical clustering, canonical correlation, and canonical krieging, applied by the commonly used probability distributions like Gumbel, 2- and 3-parameter Log-Normal, Pearson-III, Log-Pearson-III, and GEV, whose parameters are computed by the methods of ML and moments. Soon after this paper, Shu and Ouarda (2008) present the ‘adaptive neuro-fuzzy inference system’ method for regional flood frequency analysis, also. An extensive review and comparative evaluation of different regionalization methods is also given by Grehys (1996).
Hosking (1986, 1990) defined the L-moments as linear combinations of the PWMs and used L-moment ratio diagrams to choose more suitable probability distributions in a homogeneous region. Hosking and Wallis (1993, 1997) extended the use of L-moments for regional frequency analysis and developed statistics to measure possible discordancy of individual sites, homogeneity of all the sites in the region, and goodness-of-fit of candidate probability distributions. Bobee and Rasmussen (1995) state: “L-moment ratio diagrams have become popular tools for regional distribution identification, and for testing for outlier stations.”. The parameters of probability distributions estimated by the L-moments method from a recorded sample series are more robust to the possible outliers in the series, and compared with conventional moments, L-moments are less subject to bias in estimation (Vogel and Fennesy 1993; Hosking and Wallis 1997). Vogel and Fennesy (1993); Vogel et al. (1993a, b); Karim and Chowdhury (1995); Madsen et al. (1997); Mkhandi and Kachroo (1997); Rao et al. (1997); Parida et al. (1998); Sankarasubramanian and Srinivasan (1999); Kjeldsen et al. (2002); Jaiswal et al. (2003); Kumar et al. (2003); Yue and Wang (2004); Atiem and Harmancioglu (2006); Ellouze and Abida (2008), and Saf (2009) have investigated various issues involved in the regional flood frequency analysis by the L-moments approach.
The Artificial Neural Networks (ANNs), essentially a powerful black-box model, have a flexible mathematical structure that is capable of identifying complex non-linear relationships between inputs and outputs without predefined knowledge of the underlying physical processes involved in the transformation. The ANNs models are useful and efficient particularly for problems where characteristics of the cause-effect processes are difficult to describe using physical equations (French et al. 1992; Minns and Hall 1996). Jingyi and Hall (2004) applied the geographical approaches known as Ward’s Cluster Method, the Fuzzy C-means Method, and the Kohonen Neural Network method to 86 sites in the basins of Gan River and Ming River, both in southeast of China, to delineate homogeneous regions based on site characteristics and showed that lower standard errors of estimate are produced using an Artificial Neural Networks (ANNs) application.
Dawson et al. (2006) applied ANNs on data from the Centre for Ecology and Hydrology’s Flood Estimation Handbook and used the index flood method to predict T-year flood events for 850 catchments across the UK, and they concluded that ANNs were more reliable than multiple regression models.
In this study, a regional flood frequency analysis based on the index flood procedure using the L-moments method is applied to the Eeast Mediterranean River Basin, which is one of the 26 major basins in Turkey. Next, the Artificial Neural Network models of (1) the Radial Basis Neural Networks (RBNN), (2) the Generalized Regression Neural Networks (GRNN), and (3) the Multi-Layer Perceptrons (MLP) are investigated as alternatives to the L-moments method. And, the Multiple-linear and multiple-nonlinear regression models (MLR and MNLR) are also used in the analysis. A few of the gauged sites with fairly long records are treated as if they were ungauged, and the results of these six different methods are compared.
Geostatistics is a new technique in water resources engineering for regionalized quantification of probabilistic variables. This method interpolates the value of a random variable (e.g., the elevation, z, of the landscape) as a function of the geographic location of an ungauged site from observations at nearby gauged stations. The geostatistical variogram is a function describing the degree of spatial dependence of a random variable and is defined as the variance of the difference between field values at two locations across realizations of the field (Cressie 1993). Our study gets inspired from this technique and we use the spatial locations (latitude, longitude, and altitude) in modeling regional flood frequency analysis. The spatial distribution of logarithms of annual flood peaks (Ln(Q)) observed from the gauging stations are estimated by means of five independent variables, which are: drainage area (DA), elevation above sea level (EASL) (altitude), longitude (LO), and latitude (LA) of the gauging site, and return period (T), which is computed by frequency analysis applied on the annual flood peaks series observed at that gauging site. Because initial regression trials indicated a more meaningful relationship between Ln(Q) versus the independent variables, Ln(Q) was chosen as the dependent variable instead of Q.
2 L-Moments Method as Related to the Regional Flood Frequency Analysis
2.1 L-moments and L-moment Ratios
L-moments are linear combinations of probability weighted moments and are defined as (Hosking 1990; Hosking and Wallis 1997)
where, M100 is the zeroth, M110 is the first, M120 is the second, and M130 is the third probability weighted moments. The L-mean, λ1, is a measure of central tendency which is the same as the conventional mean and the L-standart deviation, λ2, is a measure of dispersion, as λ3 and λ4 are third and fourth L-moments. M110 is the expected value of the random variable, x, weighted by its probability of non-exceedance, P nex . M120 and M130 are the expected values of x weighted by (P nex )2 and (P nex )3, respectively. The j’th probability-weighted moment is defined as
where, l.b. and u.b. are the lower and upper bound values of the random variable, x, which are the end values of its range, f(x) is its probability density function, and P nex is its non-exceedence probability defined as: P nex = Prob(l.b. < x ≤ X), X being a numerical magnitude of x in: (l.b. < X ≤ u.b.) whenever it occurs randomly.
The dimensionless L-moment ratios are (Hosking 1990; Hosking and Wallis 1997):
Stedinger et al. (1993) present a good summary of the L-moments method applied to various distributions and give the relationships among the distribution parameters and the L-moments. Hosking and Wallis (1997) say: “L-moment ratios measure the shape of a distribution independently of its scale of measurement.”. For a probability distribution that takes only positive values, τ2 varies within the interval: 0 ≤ τ2 < 1, and the ranges of the other ratios are: −1 < τ3 < +1, and −1 < τ4 < +1. Actually, these properties of the L-moment ratios are claimed to be an advantage over the conventional coefficients of skewness and of kurtosis, because as the latter may assume very high magnitudes affected by possible outliers, the former always remain in the reasonable and confined interval of (−1, +1) (e.g., Hosking 1990; Hosking and Wallis 1997; Vogel and Fennesy 1993).
The arithmetic average of a sample series is the estimate of λ1. In order to compute the sample estimates of the L-coefficients of variation, skewness, and kurtosis, firstly, the 1st, 2nd, and 3rd sample probability weighted moments are computed as averages of magnitudes of n number of elements in the sample series multiplied by 1st, 2nd, and 3rd powers of their Pnex’s, respectively, which are estimated by a suitable plotting position formula.
2.2 L-moments Method for Regional Flood Frequency Analysis
The index-flood method with the L-moments approach is explained with examples in the book by Hosking and Wallis (1997), and it is rephrased concisely by most relevant papers (e.g., Abolverdi and Khalili 2010; Atiem and Harmancioglu 2006; Hussain and Pasha 2009; Kumar et al. 2003; Parida, et al. 1998; Saf 2009). Therefore, the rewording of this method will not be rewritten here in order to save space. Succintly however, the steps are summarized below.
Firstly, the boundaries of a potentially homogeneous region from the aspect of flood frequency analysis are estimated taking into consideration geographical, topographical, and meteorological conditions of the area. The second step is to search for those single gauged sites which may be discordant from the rest of the group. This is done by discordancy test, which is based on comparing the individual L-coefficients of variation, skewness, and kurtosis with the averaged group L-coefficients. The stations which are found to be discordant are discarded from the rest of the analyses. The next step is the homogeneity test by three standardized homogeneity statistics, which are based on differences of individual L-moment ratios from those averaged ones computed by weighting the lengths of the individual series by the total number of elements of all the single series in the region. The third step is determination of those probability distributions more suitable for the region by a goodness-of-fit procedure known as the Z DIST statistic, which is based on computing a standardized statistic measuring the differences of plotted points of L-Kc versus L-Sc computed out of the sample series from the theoretical values of L-Kc versus L-Sc of the candidate probability distributions, and checking whether │Z DIST│ is smaller than 1.64, the quantile of the standard normal distribution for a tail probability of 5 % corresponding to a confidence of 90 %.
The same procedure described in Chapter 4 of the book by Hosking and Wallis (1997) is applied to the East Mediterranean River Basin using the Fortran computer programs provided to the authors by Hosking himself.
3 Study Area
The annual instantaneous flood peaks, the series of the highest instantaneous flow rate in a particular water year over the period of record, were picked for 13 stream-gauging stations in the East Mediterranean River Basin (SWW 1994), whose record lengths varied between 10 and 39. Some characteristic information of the annual flood peaks series recorded in this basin is given in Table 1.
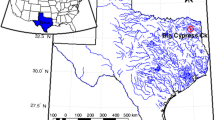
The stream-gauging stations in Turkey are owned and operated by two governmental bureaus, which are the General Directorates of Electrical Power Resources Survey and Development Administration (known as EIE in Turkey), and of State Water Works (known as DSI in Turkey). The total drainage area at the most downstream site is 22048 km2, and the mean annual runoff of the basin is 11.07 km3/year. Hence, the mean annual yield is 15.6 l/s/km2. Fig. 1 shows the boundary of the basin area and the locations of the gauging stations of the East Mediterranean River Basin.

Map of the East Mediterranean River Basin
Actually, in this basin there are a few small basins side by side with streams of small to moderate sizes discharging to the Mediterranean Sea, which are all bordered from north by Toros Mountains paralleling the shoreline. Because of the similarities in their geographical terrains, vegetation patterns, and climate, and because there is significant orographic precipitation at the seaward sides of the Toros Mountains, the EIE in Turkey, grouped all these small watersheds in one large basin called the East Mediterranean River Basin.
4 Regression Techniques
Before the development of the L-moments method by Hosking and Wallis (1993, 1997), classical regression analysis with multiple independent variables were common for regional flood frequency analysis (e.g., Dalrymple 1960; Ouarda et al. 2008; Wiltshire 1986). In the following two subsections, the multiple regressions used in this study are briefly summarized.
4.1 Multiple Linear Regression (MLR)
MLR is a method that can be used to model a linear relationship between a dependent variable and a few independent variables. The model is defined as follows with y as the dependent variable versus a number of independent variables: x 1 , x 2 ,...., x p :
where ε, the “noise” variable, is a normally distributed random variable with a mean value of zero and a standard deviation of σ, for which an unbiased estimate can be made based on the recorded data. The values of the coefficients β 0 , β 1 , β 2 , . . ., β p are to be estimated so as to minimize the sum of squares of differences between the observed y values in the recorded series and the ones predicted by Eq. (3) (Chapra and Canale 2002).
4.2 Multiple Non-Linear Regression (MNLR)
The basic concept of nonlinear regression is similar to that of linear regression, namely to relate a dependent variable to the independent variables, with the exception of a nonlinear analytical relationship. The non-linear regression used in this study is
or,
where, y is the dependent variable, C i’s are the regression coeffcients, d is the multiplicative error term, and p is the number of independent variables.
5 Artificial Neural Network Methods
5.1 The Multi-Layer Perceptrons (MLP)
A Multi-Layer Perceptrons (MLP) model distinguishes itself by the presence of one or more hidden layers, whose computation nodes are called “hidden neurons of hidden layers”. An MLP network structure is shown in Fig. 2. The function of hidden neurons is to intervene between the external input and the network output in some useful manner. By adding one or more hidden layers, the network is then enabled to extract higher order statistics. In a rather loose sense, the network acquires a global perspective despite its local connectivity due to the extra set of synaptic connections and the extra dimension of NN inter-connections. Each neuron in a specific layer is fully or partially connected to many other neurons via weighted connections. The scalar weights determine the strength of the connections between interconnected neurons. A zero weight refers to no connection between two neurons and a negative weight refers to a prohibitive relationship. The detailed theoretical information about MLP can be found at Haykin (1998) and Govindaraju and Rao (2000).

Typical ANN configuration with one hidden layer
MLP is trained using the Levenberg–Marquardt technique because it is more powerful and faster than the conventional gradient descent algorithms (Hagan and Menhaj 1994; El-Bakyr 2003; Cigizoglu and Kisi 2005).
MLP can have more than one hidden layers; however, theoretical studies have shown that a single hidden layer is sufficient for MLP to approximate any complex nonlinear function (Cybenco 1989; Hornik et al. 1989). Therefore, in this study, a one-hidden-layer MLP was used. Throughout all the MLP simulations, the adaptive learning rates were used to speed up training. While the number of network inputs and outputs is dependent on the problem input and data, the number of hidden layer neurons must be specified by the user. Therefore, determination of the optimum number of the hidden layer neurons is very important in order to predict a parameter accurately by ANNs. Although most of the empirical approaches proposed in the literature for determining the number of hidden layer neurons depend on the numbers of input and/or output neurons (Paola 1994; Kanellopoulos and Wilkinson 1997; Gahegan et al. 1999), none of these suggestions are universally accepted (Kavzog¡lu 2001). A common strategy for finding the optimum number of hidden layer neurons starts with a few numbers of neurons and keeps increasing the number of neurons while monitoring the performance criteria, until no significant improvement is observed (Goh 1995). Accordingly, here, the number of hidden layer neurons was found using the simple trial-and-error method in all the applications.
In this study, the performance of various network models with different hidden layer neuron amounts was examined to choose an appropriate number of hidden layer neurons. Hence, two neurons were used in the hidden layer at the beginning of the process, and then the number of neurons was increased stepwise by adding one neuron at each step until no significant improvement was noted. While the number of hidden layer neurons is found using simply the trial-and-error method in all applications, the choice of the activation functions may, however, strongly influence the complexity and performance of neural networks. Various activation functions have been described in the literature (e.g., Duch and Jankovski 1999), while the most commonly used nonlinear functional forms in spatial analysis are the sigmoid (logistic) and tangent hyperbolic functions (Dawson and Wilby 1998). Here, after having tested different activation function combinations, the sigmoid and linear functions were used for the activation functions of the hidden and output nodes, respectively. These sigmoid functions were employed to generate a degree of non-linearity between the input(s) and output(s). The function is called sigmoid because it is produced by a mathematical function having an “S” shape. Often, the sigmoid function refers to the special case of the basic formula for logistic function defined as:
where k is the coeffcient that adjusts the abruptness of the function and hj is the sum of the weighted input. This function maps any value to a new value between 0.0 and 1.0. The hyperbolic tangent function is also utilized as an alternate to the logistic funtion. In fact, both the function are in sigmoid form. Mathematically, yhe hyperbolic tangent function is given as
One important thing to note the tangent sigmoid activation function is that its output range is (−1, 1) (Maier 1995). The pure linear activation function is a simply a linear function that produces the same out put as its net input.
5.2 The Radial Basis Function-Based Neural Network (RBNN)
Radial Basis Function-Based Neural Networks (RBNN) was introduced to the Artifical Neural Networks literature by Broomhead and Lowe (1988). RBNN consists of two layers whose output nodes form a linear combination of the basis functions. The basis functions in the hidden layer produce a significant non-zero response to input stimulus only when the input falls within a small localized region of the input space. Hence, this paradigm is also known as a localized receptive field network (Lee and Chang 2003). The relation between inputs and outputs is illustrated in Fig. 3. Transformation of the inputs is essential for fighting the curse of dimensionality in empirical modeling. The type of input transformation of the RBNN is the local nonlinear projection using a radial fixed shape basis function. After nonlinearly squashing the multi-dimensional inputs without considering the output space, the radial basis functions play a role as regressors. Since the output layer implements a linear regressor, the only adjustable parameters are the weights of this regressor. These parameters can therefore be determined using the linear least squares method, which gives an important advantage for convergence. The basic concept and algorithm of the RBNN model are described in Lee and Chang (2003).

The RBNN network structure
5.3 The Generalized Regression Neural Networks (GRNN)
A schematic depiction of Generalized Regression Neural Networks (GRNN) is shown in Fig. 4. Tsoukalas and Uhrig (1997) describe the theory of GRNN, which consists of four layers: input layer, pattern layer, summation layer, and output layer. The number of input units in the first layer is equal to the total number of variables. The first layer is fully connected to the second, pattern layer, where each unit represents a training pattern and its output is a measure of the distance of the input from the stored patterns. Each pattern layer unit is connected to the two neurons in the summation layer: S−summation neuron and D−summation neuron. The S−summation neuron computes the sum of the weighted outputs of the pattern layer while the D−summation neuron calculates the non-weighted outputs of the pattern neurons. The connection weight between the i th neuron in the pattern layer and the S−summation neuron is O i ; the target output value corresponding to the i th input pattern. For D−summation neuron, the connection weight is unity. The output layer merely divides the output of each S−summation neuron by that of each D−summation neuron, yielding the predicted value to an unknown input vector μ as:
where n indicates the number of training patterns and the Gaussian D function in Eq. (8) is defined as:
where, p indicates the number of elements of an input vector. μ j and μ ij represent the j th element of μ and μ i , respectively. ζ is generally referred to as the spread factor, whose optimal value is often determined experimentally (Kim et al. 2003). A large spread corresponds to a smooth approximation function. Too large a spread means a lot of neurons will be required to fit a fast changing function. Too small a spread means many neurons will be required to fit a smooth function, and the network may not generalize well. In this study, different spreads were tried to find the best value for the given problem. The GRNN does not require an iterative training procedure as in the back-propagation method (Specht 1991).

Schematic diagram of a GRNN model
6 Results and Discussions
6.1 L-moments Analysis
A regional flood frequency analysis by the index flood method coupled with the L-moments method is applied to the East Mediterranean River Basin in Turkey using the recorded annual flood peaks series of 13 stream-gauging stations in it. The geographical position of the studied basin, the natural streams and the locations of the gauging sites are shown in Fig. 1. Some relevant numerical information is given in Table 1, and the L-Cv, L-Cs, and L-Ck values computed using the recorded sample series of these 13 stations are given in Table 2. Values of the site discordancy measure, D i , the heterogeneity measure, H, and the goodness-of-fit measure, Z DIST, are computed for the whole region using the Fortran computer program developed and provided by Hosking (1991). The maximum value of Discordancy, D i , is 2.71, which suggests that no site is discordant because 2.71 is less than 3.0, meaning all the 13 gauged sites will be included in the homogeneity test. The heterogeneity measures, H(1) and H(3), computed by carrying out 500 simulations using the data of 13 sites are 0.21 and 0.25, which indicate that the East Mediterranean River Basin as a whole is a homogeneous region, because both H(1) and H(3) are smaller than 1.0 (Hosking and Wallis 1997).
The goodness-of-fit value, Z DIST, is computed for the distributions of Generalized Logistic, Generalized Extreme Values, Generalized Normal, Pearson Type III, and Generalized Pareto, and as seen in Table 3 the Z DIST is smaller than 1.64 for two of these distributions for the East Mediterranean River Basin, which are Generalized Logistic (GLO) and Generalized Extreme Values (GEV). So, either one of the GLO and GEV distributions can be used as the probability distribution suitable for this homogeneous region. Interestingly, these two distributions seem to be the most suitable for regional frequency analysis in homogeneous regions at many parts of the world. For example, Ellouze and Abida (2008) found the GEV distribution as the best in seven and the GLO distribution as the best in three homogeneous regions in Tunisia. Also, Noto and Loggia (2009) found GEV to be the most suitable distribution for all five homogeneous regions of Sicily, Italy.
The magnitudes of the regional parameters for the GEV and GLO distributions as well as the 5-parameter Wakeby distribution are given in Table 4. Because of the analytical form of its distribution function, the Wakeby distribution cannot be numerically included in the Z DIST goodness-of-fit test, similar to 3-parameter distributions (Hosking and Wallis 1997). However, with its five parameters, more than most of the well-known distributions, it has a wider range of distributional shapes than the other distributions, and therefore the Wakeby distribution is recommended as a parent distribution in regional flood frequency analysis by Hosking and Wallis (1997).
Using the GEV, GLO, and Wakeby distributions, standardized quantiles have been computed at the selected return periods of T = 1.11111, 1.25, 2, 5, 10, 20, 100, 200, 500 and 1000 years and plotted against the respective return periods (Table 5). Next, data generated for each site are fitted to the regional distribution, and the simulated dimensionless quantile estimates for each site and the region are computed. It is then possible to obtain the flood estimates for each site by multiplying the dimensionless quantiles by the sample means of each site. For ungauged catchments however, the at-site means can not be computed because of the absence of the observed data. Hence, similar to many others, in this study a regional regression expression has been developed relating the mean annual flood peak to the catchment area, which, for the East Mediterranean River Basin has turned out to be Eq. (10) below.
where, A is the drainage area in km2, and the equation is fairly meaningful with a determination coefficient of R 2 = 0.79.
Although both GLO and GEV distributions passed the Z DIST test, GLO performed better than GEV in the East Mediterranean River Basin (0.20 << 1.56, in Table 3), and therefore the former may be preferred in the regional flood frequency analysis. Hence, the flood peak quantile having a probability of non-exceedance of F can be computed by Eq. (11) below, which is developed using the GLO distribution.
6.2 Regression Analysis
The spatial distribution of logarithms of annual flood peaks (Ln(Q)) observed from the gauging stations has been estimated by means of five independent variables, which are: drainage area (DA), elevation above sea level (EASL), longitude (LO) and latitude (LA) of the gauging site, and return period (T), which is computed by frequency analysis applied on the observed annual flood peaks series of that gauging site. Initial regression trials indicated a more meaningful relationship between Ln(Q) versus the independent variables instead of Q as the dependent variable. In modeling studies, the available data is generally divided into two sub-sets: a training set and an independent validation set (Maier and Dandy 2000). Before application of the MLR, MNLR and the other ANN methods, the available dataset were randomly divided into two independent parts. The training data was used for learning, and the testing data was used for comparison of the models. To overcome some extrapolation difficulties in prediction of the extreme values, the minimum and maximum magnitudes of the variables used in the modelling were set in the training data. Ten gauging stations were selected for the training phase and the rest three gauging stations for testing. The minimum and maximum values of the model variables are summarized in Table 6. Next, both MLR and MNLR techniques were applied to the training dataset, which resulted in the following expressions to offer the best statistical fit for the dataset trained, respectively:
The t values of the coefficients of Equtaions (12) and (13) were found to be 17.6, −11.0, −10.6, 5.2, 6.3 and 17.3, −11.8, −10.0, 11.7, 7.2 for DA, EASL, LO, LA and F, respectively, all of them passing the t-test having 222 degrees of freedom with a probability of non-exceedance of 0.99.
6.3 Analysis of Artificial Intelligence Methods
Three different ANN models, namely RBNN, GRNN and MLP, were developed to improve the outputs of the MLR and MNLR techniques for regional flood frequency analysis at ungauged sites. For this purpose, three different artificial neural network program codes were written in MATLAB programming language. The tangent sigmoid, logarithmic sigmoid, and pure linear transfer functions were tried as activation functions for hidden and output layer neurons to determine the best network model. The most appropriate results were obtained by the ANN model comprising 5 input, 8 hidden and 1 output layer neurons, denoted as ANN(5, 8, 1), using the logarithmic sigmoid activation functions for both hidden and output layer neurons.
For the RBNN applications, different numbers of hidden layer neurons and spread constants were examined in the study. The number of hidden layer neurons that gave the minimum root mean square errors (RMSE) was found to be 6. The spread is a constant which is selected before the RBNN simulation. The larger the spread is the smoother the function approximation will be. Too large a spread means a lot of neurons will be required to fit a fast changing function. Too small a spread means many neurons will be required to fit a smooth function, and the network may not generalize well. The spread that gave the minimum MSE was 0.48. This was found with a simple trial-error method adding some loops to the program codes. The spread parameter values providing the best testing performance of the GRNN model was equal to 0.01 with 228 hidden layer neurons.
Magnitudes of the root mean square error (RMSE), mean absolute error (MAE), mean absolute relative error (MARE), which are defined by Eqs. 14–16 below, and R2 (determination coefficient) values by the MLR, MNLR, ANNs, and L-moments methods for both training and testing phases are given in Table 7.
in which N is the number of elements in the series.
As seen from Table 7, the MLP model provided the smallest RMSE (0.173), MAE (0.146), and MARE (2.7 %) for the testing phase. The L-moments and MLP models gave similar results for the training phase. According to the test results, the MLP estimations are slightly better than those of the L-moments and these two produced more accurate results than the GRNN, RBNN, MLR, and MNLR models.
Although GRNN gave better statistical results in comparison with RBNN in the training phase, the RBNN model gave better predictions in the testing phase, because of the large number of hiden layer neurons of the GRNN algorithm. It can be seen from Table 7 that ANNSs performed better than MLR and MNLR in both training and testing phases.
A comparison between the MLR and ANN models for logs of maximum discharge values, Ln(Q), is presented in Table 8 and shown in Fig. 5 in terms of residual analysis. The determination coefficient (R2) of the predicted versus observed values (according to a linear regression equation as Predicted = a + b × Observed) and analysis of the residuals were calculated for the East Mediterranean Drainage Basin. The MLP and L-moments approaches gave more accurate results than those of the RBNN, GRNN, MLR, and MNLR models. The MLP model performed better in terms of sum of square errors (SSE), mean, and linear biases (2.75, 0.0012, and −0.003, respectively) than the L-moments (8.27, −0.271, and −0.145 for SSE, mean, and linear biases, respectively). These two methods gave more accurate results than those of the others. The regression analysis of predicted and measured Ln(Q) values obtained by MNLR and MLR had the biggest SSE, mean, and linear biases. As seen from Fig. 5, both MLR and MNLR overestimated the small values and underestimated the high values. The RBNN and GRNN models had large distribution of residuals. The L-moments had high mean and linear biases, therefore it overestimates for the most parts of the floods.

Residual (= observed – predicted) values compared with the observed Ln(Q) for the MLR, MNLR, RBNN, GRNN, MLP, and L-moments models
The performances of all methods analysed herein are shown in Figs. 6 and 7, which indicate that MLR and MNLR are unsatisfactory in prediction of Ln(Q) values in comparison with the artificial neural network methods of RBNN, GRNN, MLP, and with L-moments. The MLP and L-moments models seem to provide similar accuracy and both are significantly superior to the RBNN, GRNN models. Although the L-moments model has high R2 values than MLP, the L-moments estimations are over the exact fit line, whereas the MLP estimations are distributed around it.

Histogram of the estimated flood values by MLR, MNLR, RBNN, GRNN, MLP, and L-moments in testing dataset

Scatter plot of the estimated flood values by MLR, MNLR, RBNN, GRNN, MLP, and L-moments in testing dataset
7 Conclusions
The hydrological homogeneity of the East Mediterranean River Basin in Turkey from the standpoint of annual flood peaks frequency is analyzed and a regional equation for the T-year flood peak is developed by the method of L-moments. Next, black-box models by the Artificial Neural Networks (ANNs) methods of multi-layer perceptrons (MLP), radial basis function-based neural networks (RBNN), and generalized regression neural networks (GRNN), and by multiple linear regression, and by multiple nonlinear regression are also developed for prediction of flood peaks of various return periods at ungauged sites in this basin. The MLP model is observed to provide estimates close to the L-moments approach. The MLR and MNLR models produce less accurate results than those of the three ANNs models and L-moments. For the testing phase, the MLP model yield slightly better results with the smallest MARE and RMSE statistics (2.7 % and 0.173 m3/s, respectively) than the L-moments method (5.0 % and 0.298 m3/s, respectively). These two models perform better than the RBNN, GRNN, MLR, and MNLR models. The MLP model proposed herein yields an acceptable accuracy, with less computational effort, and a smaller amount of input data, in comparison with more detailed models such as the L-moments method. This study indicates that the MLP model can be employed successfully in estimation of flood peaks at ungauged sites in a hydrologically homogeneous region. As an outcome of this study, the natural logarithm of an annual flood peak of any return period (T) can be reasonably estimated for any ungauged site of a natural stream in the East Mediterranean River Basin as a function of the drainage area (DA), elevation above sea level (EASL), longitude (LO) and latitude (LA) of the site, and the return period (T). For a hydrologically homogeneous basin or sub-basin elsewhere in the world, it is believed that a similar model can be developed for rational prediction of annual flood peaks at both gauged and ungauged sites.
References
Abolverdi J, Khalili D (2010) Development of regional rainfall annual maxima for Southwestern Iran by L-moments. Water Resour Manag 24:2501–2526
Acreman MC, Sinclair CD (1986) Classification of drainage basins according to their physical characteristics; an application for flood frequency analysis in Scotland. J Hydrol 84:365–380
Atiem IA, Harmancioglu N (2006) Assessment of regional floods using L-moments approach: the case of the River Nile. Water Resour Manag 20:723–747
Berthet HG (1994) Station-year approach: tool for estimation of design floods. J Water Resour Plan Manag ASCE 120(2):135–160
Bobee B, Rasmussen PF (1995) Recent advances in flood frequency analysis. U.S. National Report to International Union of Geodesy and Geophysics 1991–1994. Rev Geophys 33(supp):1111–1116
Broomhead D, Lowe D (1988) Multivariable functional interpolation and adaptive networks. Complex Syst 2:321–355
Burn DH (1990) Evaluation of regional flood frequency analysis with a region of influence approach. Water Resour Res 26(10):2257–2265
Chapra SC, Canale RP (2002) Numerical Methods for Engineers, 4th edn. McGraw-Hill, New York
Cigizoglu HK, Kisi O (2005) Flow prediction by three back-propagation techniques using k-fold partitioning of neural network training data. Nord Hydrol 36(1):49–64
Cressie N (1993) Statistics for spatial data, revised edition. Wiley Interscience, New York
Cunnane C (1989) Distributions for Flood Frequency Analysis. WMO Operational Hydrology Report No.33. World Meteorological Organization, Geneva
Cybenco G (1989) Approximation by superposition of a sigmoidal function. Math Control Signals Syst 2:303–314
Dalrymple T (1960) Flood frequency analyses. US Geological Survey Water Supply Paper no. 1543-A:11–51
Dawson WC, Wilby R (1998) An artificial neural network approach to rainfall-runoff modelling. Hydrol Sci J 43(1):47–66
Dawson CW, Abrahart RJ, Shamseldin AY, Wilby RL (2006) Flood estimation at ungauged sites using artificial neural Networks. J Hydrol 319:391–409
Duch W, Jankovski N (1999) Survey of neural transfer functions. Neural Comput Surv 2:163–212
El-Bakyr MY (2003) Feed forward neural networks modeling for K-P interactions. Chaos, Solitons Fractals 18(5):995–1000
Ellouze M, Abida H (2008) Regional flood frequency analysis in Tunisia: identification of regional distributions. Water Resour Manag 22(8):943–957
French MN, Krajewski WF, Cuykendall RR (1992) Rainfall Forecasting in space and time using neural network. J Hydrol 137:1–31
Gahegan M, German G, West G (1999) Improving neural network performance on the classification of complex geographic datasets. Geogr Syst 1:3–22
Goh ATC (1995) Back-propagation neural networks for modeling complex systems. Artif Intell Eng 9(3):143–151
Govindaraju RS, Rao AR (2000) Artificial Neural Networks in Hydrology. Kluwer Academy, Norwell, 329 p
Greenwood JA, Landwehr JM et al (1979) Probability weighted moments: definition and relation to parameters of several distributions expressible in inverse form. Water Resour Res 15(5):1049–1054
Grehys G (1996) Presentation and review of some methods for regional flood frequency analysis. J Hydrol 186:63–84
Hagan MT, Menhaj MB (1994) Training feed forward networks with the Marquardt algorithm. IEEE Trans Neural Netw 6:861–867
Haykin S (1998) Neural Networks - A Comprehensive Foundation, 2nd edn. Prentice-Hall, Upper Saddle River, pp 26–32
Hornik K, Stinchcombe M, White H (1989) Multilayer feed forward networks are universal approximators. Neural Netw 2:359–366
Hosking JRM (1986) The Theory of Probability Weighted Moments. Research Rep. RC 12210. IBM Research Division, Yorktown Heights, 160 pp
Hosking JRM (1990) L-moments: analysis and estimation of distributions using lineer combinations of order statistics. J R Stat Soc 52(2):105–124
Hosking JRM (1991) Approximations for use in Constructing L-moments Ratio Diagrams. Res Report, RC-16635, vol 3. IBM Res Division, New York
Hosking JRM, Wallis JR (1993) Some statistics useful in regional frequency analysis. Water Resour Res 29(2):271–281
Hosking JRM, Wallis JR (1997) Regional Frequency Analysis - an Approach based on L-moments. Cambridge University Pres, New York
Hussain Z, Pasha GR (2009) Regional flood frequency analysis of the seven sites of Punjab, Pakistan, using L-moments. Water Resour Manag 23:1917–1933
Jaiswal RK, Goel NK, Singh P, Thomas T (2003) L-moment based flood frequency modelling. Inst Eng (India) 84:6–10
Jingyi Z, Hall MJ (2004) Regional flood frequency analysis for the Gan-Ming River basin in China. J Hydrol 296:98–117
Kanellopoulos I, Wilkinson GG (1997) Strategies and best practice for neural network image classification. Int J Remote Sens 18(4):711–725
Karim MDA, Chowdhury JU (1995) A comparison of four distributions used in flood frequency analysis in Bangladesh. Hydrol Sci J 40(1):55–66
Kavzoğlu T (2001) An investigation of the design and use of feed-forward artificial neural networks in the classification of remotely sensed images, Ph.D. dissertation, University of Nottingham, Nottingham, United Kingdom, 308 p
Kim B, Kim S, Kim K (2003) Modelling of plasma etching using a generalized regression neural network. Vacuum 71(4):497–503
Kjeldsen TR, Smithers JC, Schulze RE (2002) Regional flood frequency analysis in the KwaZulu-Natal province, South Africa, using the index-flood method. J Hydrol 255:194–211
Kumar R, Chatterjee C, Panigrihy N, Patwary BC, Singh RD (2003) Development of regional flood formulae using L-moments for gauged and ungauged catchments of North Brahmaputra River system. Inst Eng (India) 84:57–63
Lee GC, Chang SH (2003) Radial basis function networks applied to DNBR calculation in digital core protection systems. Ann Nucl Energ 30:1561–1572
Madsen H, Pearson CP, Rosbjerg D (1997) Comparison of annual maximum series and partial duration series mthods for modeling extreme hydrologic events 2. Regional modeling. Water Resour Res 33(4):759–769
Maier HR (1995) A review of artificial neural networks. Research Report No. R131. School of Civil and Environmental Engineering, The University of Adelaide, South Australia
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting water resources variables: A review of modeling issues and applications. Environ Modell Softw 15:101–124
Meigh JR, Farquharson FAK, Sutcliffe JV (1997) A worldwide comparison of regional flood estimation methods and climate. Hydrol Sci J 42(2):225–244
Minns AW, Hall MJ (1996) Artificial neural networks as rainfall-runoff models. Hydrol Sci J 41(3):399–417
Mkhandi S, Kachroo S (1997) Regional flood frequency analysis for Southern Africa, Southern African FRIEND, Technical documents in Hydrology No.15, Unesco, Paris
Noto LV, Loggia G (2009) Use of L-moments approach for regional flood frequency analysis in Sicily, Italy. Water Resour Manag 23:2207–2229
Ouarda TBMJ, Ba KM, Diaz-Delgado C, Carsteanu A, Chokmani K, Gingras H, Quentin E, Trujillo E, Bobee B (2008) Intercomparison of regional flood frequency estimation methods at ungauged sites for a Mexican case study. J Hydrol 348:40–58
Paola JD (1994) Neural network classification of multispectral imagery, MSc. dissertation, The University of Arizona, Tucson, Arizona, 169 p
Parida BP, Kachroo RK, Shrestha DB (1998) Regional flood frequency analysis of Mahi-Sabarmati Basin (Subzone 3-a) using index flood procedure with L-moments. Water Resour Manag 12:1–12
Rao AR, Hamed KH (1997) Regional frequency analysis of Wabash River flood data by L-moments. J Hydrol Eng 2(4):169–179
Saf B (2009) Regional flood frequency analysis using L-moments for the West Mediterranean Region of Turkey. Water Resour Manag 23(3):531–551
Sankarasubramanian A, Srinivasan K (1999) Investigation and comparison of sampling properties of L-moments and conventional moments. J Hydrol 218:13–34
Shu C, Ouarda TBMJ (2008) Regional flood frequency analysis at ungauged sites using tha adaptive neuro-fuzzy inference system. J Hydrol 349:31–43
Specht DF (1991) A general regression neural network. IEEE Trans Neural Netw 2(6):568–576
State Water Works, SWW (1994) The annual maximum flow of Turkish Rivers. The General Directorate of State Water Works Publication, Ankara, Turkey
Stedinger JR, Tasker GD (1985) Regional hydrologic analysis 1. Ordinary, weighted and generalized least squares compared. Water Resour Res 21(9):1421–1432
Stedinger JR, Vogel RM, Georgiou EF (1993) Frequency Analysis of Extreme Events, Chapter 18. In: Maidment DJ (ed) Handbook of Hydrology. McGraw-Hill, NewYork
Tsoukalas LH, Uhrig RE (1997) Fuzzy and neural approaches in engineering. Wiley, NewYork
Vogel RM, Fennesy MN (1993) L moment diagrams should replace product moment diagrams. Water Resour Res 29(6):1745–1752
Vogel RM, McMahon TA, Chiew FHS (1993a) Floodflow frequency model selection in Australia. J Hydrol 146:421–449
Vogel RM, Wilbert OT Jr, McMahon TA (1993b) Flood-flow frequency model selection in Southwestern United States. J Water Resour Plan Manag ASCE 119(3):353–366
Wiltshire SW (1986) Identification of homogeneous regions for flood frequency analysis. J Hydrol 84:287–302
Yue S, Wang CY (2004) Possible regional probability distribution type of Canadian annual streamflow by L-moments. Water Resour Manag 18:425–438
Zrinji Z, Burn DH (1994) Flood frequency analysis for ungauged sites using a region of influence approach. J Hydrol 153:1–21
Zrinji Z, Burn DH (1996) Regional flood frequency with hierarchical region of influence. J Water Resour Plan Manag ASCE 122(4):245–252
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Seckin, N., Cobaner, M., Yurtal, R. et al. Comparison of Artificial Neural Network Methods with L-moments for Estimating Flood Flow at Ungauged Sites: the Case of East Mediterranean River Basin, Turkey. Water Resour Manage 27, 2103–2124 (2013). https://doi.org/10.1007/s11269-013-0278-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-013-0278-3