
Abstract
In this paper, we propose the use of a semantic image, an improved representation for video analysis, principally in combination with Inception networks. The semantic image is obtained by applying localized sparse segmentation using global clustering prior to the approximate rank pooling, which summarizes the motion characteristics in single or multiple images. It incorporates the background information by overlaying a static background from the window onto the subsequent segmented frames. The idea is to improve the action–motion dynamics by focusing on the region, which is important for action recognition and encoding the temporal variances using the frame ranking method. We also propose the sequential combination of Inception-ResNetv2 and long–short-term memory network (LSTM) to leverage the temporal variances for improved recognition performance. Extensive analysis has been carried out on UCF101 and HMDB51 datasets, which are widely used in action recognition studies. We show that (1) the semantic image generates better activations and converges faster than its original variant, (2) using segmentation prior to approximate rank pooling yields better recognition performance, (3) the use of LSTM leverages the temporal variance information from approximate rank pooling to model the action behavior better than the base network, (4) the proposed representations are adaptive as they can be used with existing methods such as temporal segment and I3D ImageNet + Kinetics network to improve the recognition performance, and (5) the four-stream network architecture pre-trained on ImageNet + Kinetics and fine-tuned using the proposed representation achieves the state-of-the-art performance, 99.1% and 83.7% recognition accuracy on UCF101 and HMDB51, respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Human action recognition from videos has been an active research area due to its variety of applications such as surveillance, healthcare, robotics, and so forth. The performance of action recognition has drastically been improved in recent years, mainly due to the deep network architectures. However, the optimal representation of the videos is still an ongoing research issue. In the last decade, researchers have proposed local spatiotemporal descriptors based on motion, gradient, dense trajectories, dense sampling, and spatiotemporal interest points (Jain et al. 2013; Laptev 2005; Wang et al. 2013) for action recognition. Furthermore, the advancement in object recognition techniques motivated the research community to combine these descriptors with well-developed encoding schemes like fisher vectors (Wang and Schmid 2013).
Many recent works rely on the contents in image sequences rather than modeling their dynamics. These contents are understood from the images which are then fed to the discriminative learning methods as their input. Thanks to the convolutional and recurrent neural networks (RNNs), the features are learned in an end to end manner to solve specific problems such as action recognition. However, using these discriminative learning methods does not solve the problem of better representations as they are largely based on spatiotemporal filters for classifying actions. Earlier works focused on the representation such as dynamic textures introduced by Doretto et al. (2003) and flow-based appearance proposed by Wang and Schmid (2013). Fernando et al. (2015) proposed a way to represent the motion dynamics of image sequences by their temporal order. These representations were successful in improving the performance of an action recognition system. Bilen et al. (2016, 2018) extended the idea to construct a dynamic image using the temporal order of image sequences. The idea was to incorporate the motion dynamics into a single image. The image can be fed to any standard convolutional neural network (CNN) for an end to end learning. All the existing representations have a common goal: modeling the action–motion dynamics to improve the performance. The CNNs extract features such as spatiotemporal, edge, and gradient features based on the progression of convolutional layers. In this work, we extend the notion of Bilen et al. by using the temporal order of image sequences after performing the segmentation and incorporating semantics, i.e., background information; we refer to this representation as a semantic image (SemI). The idea is to improve the action–motion dynamics by providing frames with sparse characteristics such that the region of interest should be focused more rather than the whole image. It is proved that incorporating background information can have a positive influence on recognition performance (Yue-Hei Ng et al. 2015). In this regard, we overlay a static background on all the subsequent segmented frames to impose the semantic information in a single SemI. It is apparent that in video analysis, the background changes frequently. In this regard, we divide the whole video into windows of overlapping frames, and a static background from each subset of frames is overlaid to the subsequent segmented frames in that window. In this way, we incorporate the changing background information in multiple SemI. The SemI improves video representation in terms of compactness, flexibility, effectiveness, and adaptability. The compactness refers to the summarization of motion from all video frames on to a single image along with semantic information. The flexibility refers to the use of the representation throughout the network architecture. The effectiveness is the ability to handle back-propagation for end-to-end learning. The SemI can also be used with existing network architectures, which shows the adaptability trait.
It is apparent that the representations play an important part in the recognition pipeline, but without a good learning method, the representations cannot achieve their true potential. Existing works mainly use CNN, RNN, or LSTM, which is a variant of RNN. Both of the networks, CNN and RNN, have their advantages and disadvantages. For instance, RNNs are good at temporal modeling, but they cannot extract high-level features, while CNNs are good at extracting high-level features but do not perform well when dealing with sequential modeling. Additionally, existing works employ mostly the pre-trained networks such as CaffeNet (Jia et al. 2014), AlexNet (Krizhevsky et al. 2012), ResNet (He et al. 2016) and the similar ones, which increase the depth of the network but not the width. These pre-trained models have specific filter sizes defined in each convolutional layer. The provision of liberty to the network for selecting the filter size has a profound effect on the object recognition studies, i.e., Inception networks. However, such networks have not been extensively studied for action recognition studies so far.
In this work, we propose semantic image networks which use SemI to train the sequential residual LSTM (SR-LSTM). We construct semantic images by performing segmentation with localized sparse segmentation using global clustering (LSSGC) and overlaying the background information on to the subsequent segmented frames followed by the approximate rank pooling (Bilen et al. 2016). The term sparse segmentation refers to the segmentation of regions which are of interest concerning the field-of-view. We apply the approximate rank pooling on the semantic images to summarize motion with respect to the temporal order of frames. Some examples of semantic images are shown in Fig. 1. It can be visualized that the semantic images not only summarize the repeated motions as shown for ‘Apply Eye Makeup’ but also the direction of the motion. For instance, the horizontal motion is indicated in ‘Archery’ and ‘Boxing Punching Bag’ whereas the vertical motion is indicated in ‘Handstand Walking’ Action.

Semantic images derived from RGB video frames. From left to right (i) Apply Eye Makeup, (ii) Archery, (iii) Handstand Pushups, and (iv) boxing punching bag. The top row shows RGB images whereas the bottom one shows semantic images
The SR-LSTM uses the pre-trained Inception-ResNetv2 (Szegedy et al. 2017) network sequenced with LSTM to perform an end-to-end learning. The reason for using such architecture and configuration is three-fold. The first is to give liberty to the network for choosing the filter size by using inception modules in the pre-trained architecture. The second is to get improved performance for action recognition, and the third is to model temporal variances better for temporally ordered frames. Previous studies have tried to combine the characteristics of both CNN and LSTM which have been proved to be beneficial (Donahue et al. 2017), nevertheless modeling the temporal information from plain RGB sequences have limited benefits. In this study, we leverage the temporal variances incorporated in SemI with LSTM to handle the sequential modeling of data in a better way. The approximate rank pooling is applied to the windows of partially overlapped frames; therefore, a frame can have a high rank in the first window but may achieve a lower rank in the next one in case if it occurs in an overlap. This kind of phenomena is referred to as temporal variance in our study. The contributions of this study are summarized as follows:
We propose a method (LSSGC) for dynamically segmenting the image.
We introduce a semantic image to represent motion dynamics over a sequence of frames.
We propose an SR-LSTM based semantic image network to leverage temporal information and variance.
We report the comparative analysis with deep learning-based segmentation method for construction of the semantic image.
We use the semantic images with four-streams, temporal segment networks, and I3D network pre-trained on ImageNet + kinetics to show that the proposed representation is adaptable.
We report state-of-the-art results on both UCF101 and HMDB51 datasets.
The rest of the paper is structured as follows: Sect. 2 consolidates the existing works carried out for action recognition. Section 3 defines the methodology for LSSGC, adding semantics to the segmentation, and approximate rank pooling for constructing semantic images. Section 4 provides details regarding SR-LSTM. The experimental results and discussion are presented in Sect. 5, followed by the conclusion and future work in Sect. 6.
2 Related Works
In this section, we provide a comprehensive review for state-of-the-art methods on action recognition using videos along with some distinction with respect to the image modalities, network characteristics, multiple streams, and long–short term dynamics.
2.1 RGB Images
The majority of the existing works for action recognition is based on the stack of still images. Researchers have used both deep learning and shallow learning methods for recognition of action using RGB images. Fernando et al. (2015) proposed rank pooling on RGB images to explore the temporal changes in videos. The study combines the temporally aligned videos with different parametric models such as rank support vector machines (Rank SVM) and support vector regression (SVR) (Smola and Schölkopf 2004) to measure the performance of action recognition. They suggested that the effect of rank pooling can improve the performance up to 7–10% in comparison to the average pooling layers. Wang and Schmid (2013) proposed improved dense trajectories (IDT) from a series of still images. These trajectories are computed using speed up robust features (SURF) (Willems et al. 2008) and dense optical flows combined with random sample consensus (RANSAC) (Fischler and Bolles 1981). They claimed that IDTs could help to improve many motion-based detectors. The stack of RGB images has also been used with deep learning architectures for action recognition. Yue-Hei Ng et al. (2015) used the sequence of RGB images along with the background information, suggesting that some activities are only performed at a specific place such as “hockey penalty” and “basketball” will always be played in ground and basketball court, respectively. They used convolutional neural networks (CNNs) along with the long–short-term memory networks (LSTM) to classify the action. The study achieved 88.6% accuracy on UCF101 dataset. Simonyan and Zisserman (2014) used the combination of stacked RGB images and optical flows with CNNs to improve the action recognition performance. They reported the mean class accuracy on UCF101 and HMDB51 to be 86.9% and 58.0%, respectively. In our study, we also use RGB images but to transform them into semantic images. We also use the network based on RGB images for our two- and four-stream networks.
2.2 Motion Information
Motion information is considered to be of vital importance when classifying human actions. Methods capturing motion information from a sequence of images have been extensively used in existing studies. The techniques for summarizing motions include motion history images (MHI) and motion energy images (MEI) (Bobick and Davis 2001), dynamic textures (Kellokumpu et al. 2008), and optical flows (Ali and Shah 2010). Bobick and Davis (2001) introduced the concept of MHI for action and motion recognition from videos. The MEIs find the regions where motion is present and highlight those image regions to show different motion patterns. MEI uses spatial motion-distribution pattern by computing the image differences and summing their squares. The MHI is the encoded version of MEI which computes the motion of each pixel at a given location. Optical flow based methods use principle components for summarizing the motion between successive frames. Ali and Shah (2010) proposed the use of optical flows for generating kinematic features. These features are then trained using multiple instances learning for performing action recognition. Ke et al. (2005) performed action detection and recognition by computing optical flows from sub-spaces volumes of the image sequences. As discussed in the previous subsection, many two-stream networks use the optical flow images as one of the modality to train it with the combination of RGB images or other representations (Feichtenhofer et al. 2016b; Simonyan and Zisserman 2014). Another form of image representation is the dynamic image which was introduced by Bilen et al. (2016). The dynamic image summarizes the motion dynamics of a video in a single image. Unlike the MEI and MHI, the summarization in dynamic images is based on the ranking order of the frames proposed in Fernando et al. (2015). The concept of ranking frames can also be applied to optical flows for generating dynamic optical flows. In our work, we also apply the approximate rank pooling for ordering the frames. However, we apply the approximate rank pooling on the segmented images, which are then fused with a static background. We show that such kind of pre-processing improves the action–motion dynamics as well as the performance in terms of action recognition accuracy.
2.3 Spatio-temporal Dynamics
The techniques using spatiotemporal dynamics are evolved from patterns extracted using sequence data, which were initially used for texture recognition (Doretto et al. 2003). These techniques take into account the sequential data and estimate the parameters of the model using an autoregressive moving average for constructing dynamic textures. Kellokumpu et al. (2008) applied the dynamic textures for time-varying sequences to recognize human actions. The creation of dynamic textures was based on local binary patterns (LBP) (Ojala et al. 2002) descriptors which help to encode the micro-texture for the 2D neighborhood of the pixels; they referred to it as binary strings. Le et al. (2011) extended the idea to use independent subspace analysis (ISA) with the dynamic textures to recognize human actions. The representations using ISA were extracted hierarchically to handle invariant representations, which improved the accuracy of the recognition task. Nonetheless, these techniques capture the motion dynamics from an action video, but they do not consider the video sequence for modeling the motion characteristics.
2.4 Spatio-temporal Volumes
In recent years, the researchers have considered the use of 3D volumes, which adds a third dimension to the 2D images, i.e., time. These 3D volumes are derived from spatiotemporal templates (Pirsiavash et al. 2009; Rodriguez et al. 2008; Shechtman and Irani 2005). Ji et al. (2013) proposed the 3D CNNs which capture the spatial as well as temporal information from the videos. The spatial information is captured using 2D, and the motion information from multiple frames is accounted for the third dimension to learn the features. Tran et al. (2015) proposed the use of convolutional 3D features (C3D) which were learned using 3D CNNs on large-scale datasets. Their study showed that using many feature representations such as IDTs, optical flows, and so forth, 3D CNNs can boost performance. Hara et al. (2018) recently proposed the use of 3D kernels with very deep CNNs to boost the performance of different recognition tasks. They employed ResNeXt101 using 3D kernels while experimenting with a larger number of filters, i.e., 64 and achieved better results for UCF101 and HMDB51 as compared to the filter size of 32. Tran et al. (2018) evaluated several forms of spatiotemporal convolutional networks and proposed separate 3D convolutional blocks for spatial and temporal streams. Xie et al. (2018) pointed out that the 3D CNNs are computationally complex models. Therefore, they tried to seek a balance between speed and accuracy by replacing 3D convolutional blocks with 2D convolutions towards the bottom of their architecture. Diba et al. (2018) proposed the addition of spatio-temporal channel correlations (STC) as residual units in the 3D CNN architecture. The idea was to model the correlations between the channels of 3D CNN for extracting temporal and spatial features. Chen et al. (2018b) also tried to reduce the computational complexity of 3D CNNs by slicing the original network into fibers, i.e., ensemble of lightweight networks. The multiplexer modules were introduced to improve the information flow between fiber units. The problem with 3D CNNs is that they require a large number of annotations to bring the natural representation of frame sequences. Moreover, the use of 3D filters increases the number of parameters for the employed network architecture, which increases the computational complexity. An alternative way of using spatiotemporal information is to employ multi-stream networks with different modalities as performed in Simonyan and Zisserman (2014). In this work, we too exploit the use of multiple modalities such as semantic images and semantic optical flows to extract spatiotemporal information.
2.5 Multi-stream Networks
Multi-stream networks refer to the combination of single stream networks trained on a specific modality such as RGB, optical flow, and so forth while using their late fusion for drawing final classification label. The multi-stream networks have been used in a variety of domains. Earlier examples of multi-stream networks include Siamese architecture, which learns to classify the input and measure the similarity between the output of the classification (Chopra et al. 2005). Simonyan and Zisserman (2014) used the pre-computed optical flows along with the RGB images to train the two-stream CNNs to boost the recognition result. Feichtenhofer et al. (2016b) extended the idea by fusing the architectures at various levels of CNN architecture. The fusion was based on 3D CNNs to combine different modalities for an end to end training. Bilen et al. (2016) presented the idea of using two-stream networks on different combinations such as RGB, optical flows, dynamic images, and dynamic optical flows. In Bilen et al. (2018) the authors extended their work by employing four-stream networks using multiple dynamic and RGB images, optical flows and dynamic optical flows with very deep network architecture, i.e., ResNeXt50 and ResNeXt101. They reported the state-of-the-art results on UCF101 and HMDB51 datasets with 95.5% and 72.5%, respectively. Similar to the existing studies, we also explore the use of two- and four-stream networks to boost our recognition performance.
2.6 Long- and Short-Term Dynamics
In the previous subsections, we mostly mentioned the studies which capture short-term dynamics, i.e., from smaller windows. Another category of deep architectures uses recurrent neural networks (RNN), which are capable of capturing long-term motion dynamics. Donahue et al. (2017) proposed the use of sequential networks comprising of CNN for feature extraction and LSTM for modeling the temporal dependencies. Srivastava et al. (2015) proposed an LSTM based autoencoder which reconstructs the next frame by taking into account the current one. Their study used the representations from the LSTM autoencoder for further classification of actions. Ma et al. (2018) extended the work of Simonyan and Zisserman (2014) by combining the two stream, i.e., RGB and stacked optical flows with the LSTMs to model the temporal dependencies. In our work, we also use approximate rank pooling for long-term dynamics of the video sequences and sequence LSTMs with Inception-ResNetv2 to model the temporal variance.
2.7 Other Works
There are other works on action recognition which do not solely focus on the video representations or network architectures. However, they do focus on contextual information, which can help to improve the action recognition task. Jain et al. (2015) proposed the method to model human–object interaction by considering the object detection used for a particular action. They used motion characteristics alongside the objects to recognize actions. Wang et al. (2015) combined the characteristics of handcrafted features and deep learning network features to train in an end to end manner. They referred to the method as trajectory-pooled deep convolutional descriptors (TDD). Cheron et al. (2015) proposed pose-based CNN by extracting the poses from the actors and then extracting appearance and optical flow-based features from each of the body parts. The resultant normalized feature vector was then trained using SVM to predict the action label. Wang et al. (2016b) presented the good practices for training deep learning architectures on such video representations using sample-based approaches. They show that such learning strategy can boost the action recognition results. Wang et al. (2018a) proposed appearance and relation networks (ARTNet) which use SMART blocks to model the appearance and relation using multiplicative interactions. Chen et al. (2018c) proposed the two-step attention networks (A2 double attention networks) which transform the 2D features from entire space into a compact set in order to distribute it to the respective locations through attention pooling. In our work, we use the semantic images and semantic optical flows using temporal segment networks (Wang et al. 2016b) to prove the adaptability of the proposed representations. Most of the recent works use knowledge transfer approaches such as existing networks pre-trained on Sports 1 M or kinetics dataset. In this work, we use the I3D network pre-trained on ImageNet + kinetics as the knowledge transfer mechanism to boost the recognition accuracy.
3 Semantic Images
In this section, we present our methodology to construct semantic images. The proposed method heavily relies on the segmentation process. Therefore, we first explain the segmentation method followed by the process of overlaying the static background on the subsequent segmented frames. We also explain the method of approximate rank pooling for construction of SemI, and SemM, accordingly. When approximate rank pooling is applied to the segmented images overlaid by the static background, we refer to this process as SemI. Semantic maps (SemM) are generated when approximate rank pooling is applied to the intermediate layers of our network architecture, which is to show the flexibility of the proposed representation.
3.1 Image Segmentation using LSSGC
The proposed LSSGC algorithm is obtained by slightly modifying piecewise-constant active contour model (Vese and Chan 2002) such that the constant vectors are replaced by the centroid values acquired using global k-means algorithm (Likas et al. 2003) and its direct multiplication with Heaviside function vectors to obtain the segmented image with sparse characteristics. The resultant segmented image is then fused with a color map from the Potts model proposed in Storath and Weinmann (2014) to minimize the loss of region. The modification allows important regions to be segmented for adding semantics and summarizing motion dynamics. The global k-means algorithm starts by placing the cluster centers at arbitrary positions and move them to minimize the clustering error. The vector of quantized colors in global k-means clustering is determined using General Lloyd Algorithm (Allen and Gray 2012), which computes the distortion for centroid values of each cluster, as shown in Eq. (1).
where \( \varTheta \) refers to the distortion value computed for each pixel \( i \) in the nth cluster \( C = \left( {c_{1} , \ldots ,c_{N} } \right) \) having a specific centroid value \( c_{n} \), where \( n = 1, \ldots ,N \). The value of centroid will be updated based on the weight \( \omega \) of the color pixel as shown in, Eq. (2).
Once we obtain the centroid for each cluster, we can use the cluster values for segmentation method using Mumford–Shah energy function for the piecewise-constant case (Vese and Chan 2002) as defined in Eq. (3). We forward the computed centroid values to the equation such that the centroid values will replace the constant vector of averages, and the class will replace the cluster label.
The variable \( \varPhi \) is the vector of level set functions, \( I \) is the image function with pixel values at the location \( \left( {x,y} \right) \), and \( \chi_{n} \) is the characteristic function for cluster \( n \). The variable \( v \) is a fixed parameter weight for controlling the associated energy. The second term in Eq. (3) refers to the Heaviside function vector i.e. \( {\text{H}}\left( \varPhi \right) = \left( {H\left( {\phi_{1} } \right), \ldots ,H\left( {\phi_{m} } \right)} \right) \) which outputs 0 s or 1 s with respect to the level set functions, where \( m \) is the number of level set functions. In Vese and Chan (2002), the clusters were referred to the average constant values and can be considered as initial contour values. We know for \( n \) clusters there are \( 2^{m} \) level set functions which will perform the level set evolution for the given contour. In the proposed method, we want to make the contour points adaptive and make the region larger as the epochs continue. In simple words, we will determine the initial contour points by using global k-means clustering through which the evolution of the piecewise constant model will be performed for j iterations. The global k-means clustering method will repeat for z epochs by decreasing the clusters and the level set functions along with the increase of region size. The output of segmentation will then be added to the Potts Model label map for obtaining the final segmented image. The modified piecewise constant model for one channel is shown in Eq. (4)
where \( {\text{c}} = \left( {{\text{c}}_{1} , \ldots ,c_{n} } \right) \) are the cluster means assigned using global k-means clustering and \( \varPhi = \left( {\upphi_{1} , \ldots ,\phi_{m} } \right) \) such that \( m = \log \left( n \right)/\log \left( 2 \right) \). It should be noted that unlike the super pixel segmentation of Vese and Chan (2002) where alternate combinations of Heaviside function vectors are multiplied with the area of cluster centers, we directly multiply the function vectors with each cluster to obtain the sparse segmented map. The segmented map will only register the pixels which are strongly related to a clustered region. This modification also makes the process faster as we get a single label for each pixel with respect to the cluster mean. We eliminated the addition of the function vectors as we obtain the final label map using the Potts model.
An example of global k-means clustering for an image with 8 clusters is shown in Fig. 2. Considering the clusters, the equation will minimize the image with respect to the 8 cluster centers using 3 level set functions. The value in Eq. (4) will be minimized using Euler–Lagrange with respect to c and \( \varPhi \) by dynamic programming scheme. Equation (4) will be applied to each of the channel, separately. The segmented images generated from each of the channel will then be combined in order to obtain the color image. The pseudo code for segmenting the image is presented in algorithm 1. We initially select the value of n to be 16 which will set the number of level sets m = 4. The values z and a are set to be 4 and 5, respectively. The algorithm will reduce the number of clusters by the factor of 2, which reduces the number of level sets and increase the size of the region with the progression of each epoch. As the size of the region increases, we increase the circular window size accordingly, which is denoted by p, which was initially set to be 9 × 9. We refer to this technique as LSSGC.


Example of image clusters using global k-means clustering
The advantages of performing segmentation before approximate rank pooling are twofold. The first is that the focus of the CNNs would be on the action–motion dynamics due to the sparse characteristics of the image, unlike the existing ones which focus on all the pixels to represent motion (see Fig. 1). Since the segmented images do not exhibit different characteristics for gender and skin color, it avoids visual bias, which is the second advantage of prior segmentation, as shown in Fig. 3. For instance, in “Apply Eye Makeup,” all the participants except one is black colored female, but the segmented image removes the skin color to avoid the visual bias.

Example of segmented images from action ‘Apply Eye Makeup’ of UCF101 dataset. First row images are from subject 04, whereas the second-row images are from subject 25. It can be noticed that segmentation removes the visual bias of skin color from both subjects
3.2 Adding Semantics to the Segmented Image
In the related works, we referred to the study describing the importance of the background information which can help in improving the recognition results (Yue-Hei Ng et al. 2015). We overlay a static background to all the subsequent frames to provide the semantic information. The process flow for overlaying background on to the segmented images is shown in Fig. 4, accordingly. First, the background image is estimated using the median filter method. Once the background image is computed, we generate a silhouette image by converting the logical image to black and white with an image opening operation. In parallel, the frames are segmented using algorithm 1 presented in the previous sub-section. All the subsequent frames except frame 1 are then fused with the silhouette image. The fusion of images is just the overlaying of the silhouette image to all the subsequent frames based on alpha blending (Yatziv and Sapiro 2006). The fused segmented images are then fed to the approximate rank pooling for constructing SemI.

Process flow for adding semantic information to the segmented frames
3.3 Approximate Rank Pooling for Semantic Images
The computation of SemI is based on the approximate rank pooling (ARP) (Bilen et al. 2016). The ARP is basically an optimization problem which is solved by the Eq. (5). To make our description more comprehensive, we describe the pooling mechanism briefly.
where
The parameter vector is denoted by \( \fancyscript{s} \) which defines the scores for the frames in a video. The mapping function \( \zeta \left( \cdot \right) \) maps the sequences of segmented \( {\mathcal{T}} \) segmented frames \( I^{\prime} \) to the vector \( \fancyscript{s} \). The feature vector from the segmented frames is denoted by \( \psi \), and \( {\mathcal{Z}}(\fancyscript{t}|\fancyscript{s}) \) is the inner product of the parameter vector with the time average of the feature vector \( {\mathcal{A}}_{\fancyscript{t}} \), i.e., \( {\mathcal{Z}}\left(\fancyscript{t}| \fancyscript{s}\right) = \langle{\fancyscript{s}, \mathcal{A}}_{\fancyscript{t}}\rangle \). The average feature vector is defined as \( {\mathcal{A}}_{\fancyscript{t}} = \frac{1}{\fancyscript{t}}\sum \psi (I_{\fancyscript{t}}^{\prime}) \). The constraint with respect to the variable \( \fancyscript{q} \) is defined as \( \fancyscript{t} < q \Rightarrow {\mathcal{Z}}\left(\fancyscript{t}| \fancyscript{s}\right) < Z(q|s) \) suggesting that the larger scores are associated with the later times. The first term of the function \( {\text{E}}\left(\fancyscript{s} \right) \) is the hinge-loss considering the incorrectly ranked pair \( \fancyscript{t} < q \) based on the scores. The condition for correctly ranked pairs is \( {\mathcal{Z}}\left(\fancyscript{t}|\fancyscript{s} \right) + 1 < {\mathcal{Z}}(\fancyscript{q}|\fancyscript{s}) \). The second term of the function \( {\text{E}}\left(\fancyscript{s} \right) \) is the standard quadratic regularization term. For further details and examples refer to (Bilen et al. 2018).
3.4 Approximate Rank Pooling for Semantic Maps
The SemIs are constructed from the segmented frames at the input level whereas for the SemMs the segmented images are fed to CNNs as input and the ARP is applied at intermediate layers of the same architecture. Applying the rank pooling at an intermediate level does not result in straightforward back propagation due to the dependency on the features and their intermediate averages. For intermediate layers, the formulation is shown in Eq. (6).
where \( \fancyscript{m}^{\left(\ell \right)} \) represent the feature maps on the layer \( \ell \). We dropped the term \( \psi \) from Eq. (5) as the architecture will extract the feature maps on its own. The feature maps computed at layer \( \left( {\ell - 1} \right) \) are denoted by \( \left({\fancyscript{m}_{1}^{{\left({\ell - 1} \right)}}, \ldots,\fancyscript{m}_{{\mathcal{T}}}^{{\left({\ell - 1} \right)}}} \right) \) for \( {\mathcal{T}} \) image sequences. If we rewrite Eq. (6) with respect to the temporal average of the input patterns \( {\mathcal{A}}_{\fancyscript{t}} \) it can be represented as Eq. (7)
where \( \alpha_{\fancyscript{t}} \) is the co-efficient vector and is given as \( 2 - \left({1 + {\mathcal{T}}} \right) \) (Bilen et al. 2016). Since \( \fancyscript{m}^{\left(\ell \right)} \) is a linear function of the previous layer feature maps \( {\mathcal{A}}_{\fancyscript{t}} \), thus, it can alternatively be written as \( \left({\fancyscript{m}_{1}^{{\left({\ell - 1} \right)}}, \ldots,\fancyscript{m}_{{\mathcal{T}}}^{{\left({\ell - 1} \right)}}} \right)\fancyscript{m}_{\fancyscript{t}}^{{\left({\ell - 1} \right)}} \), substituting the values of \( {\mathcal{A}} \)’s with \( \fancyscript{m} \)’s, we can rewrite Eq. (7) as shown below
As suggested in Bilen et al. (2016) due to the gradient computation of \( \fancyscript{m}^{\left(\ell \right)} \) with respect to the data points \( \fancyscript{m}^{{\left({\ell - 1} \right)}} \) is a challenging derivation. However, if the coefficients are independent of the features \( \psi \left({I_{\fancyscript{t}}^{\prime}} \right) \) and their intermediate averages \( {\mathcal{A}}_{\fancyscript{t}} \), the derivative of the ARP can be computed with the vectorized coefficients as \( \frac{{\partial {\text{vec}}\fancyscript{m}^{\left(\ell \right)}}}{{\partial \left({{\text{vec}}\fancyscript{m}^{{\left({\ell - 1} \right)}}} \right)^{\intercal}}} = \alpha_{\fancyscript{t}} {\mathbb{I}} \), where \( {\mathbb{I}} \) refers to the identity matrix. This expression can be obtained by taking the derivative of Eq. (7) while keeping \( \alpha_{\fancyscript{t}} \) constant and removing its dependency on the video frames i.e. \( \fancyscript{m}_{\fancyscript{t}}^{{\left({\ell - 1} \right)}} \) term.
4 Proposed Network Architecture
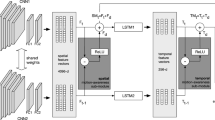
We used the Inception-ResNetv2 pre-trained network (Szegedy et al. 2017) for single SemI and single SemM, and the SR-LSTM for multiple SemI, respectively, as shown in Fig. 5. Inception network architecture (Szegedy et al. 2016) has become very popular due to its improvement in the object recognition task. However, the problem with very deep Inception networks is the degradation phenomenon and vanishing gradients (He and Sun 2015). The Inception-ResNetv2 network was designed to overcome this problem, resulting in being more accurate and faster than existing approaches. The stem of the Inception-ResNetv2 is the same as that of the inceptionv4 network. The detailed composition of stems and inception cells can be found in Szegedy et al. (2017). For the single SemI, the ARP is applied at the input level and a single motion summarization image was generated from the whole video. The temporal pooling layer was employed for the input to the fully connected layer. For constructing single SemM, we consider three intermediate levels. The ResNet Inception Branching number (RIPB) is the branching scenario for different intermediate levels. We do not construct the SemMs on each branching factor at once. Rather we repeat the experiments for one of the branching factors at a time to evaluate the performance. For multiple SemI, we break the video into segments for duration \( \uptau \) and stride \( {\mathfrak{S}} \), respectively. The extracted frames from the current segment partially overlap with the previous one. We stack the LSTM layers in sequence with Inception-ResNetv2 to capture the temporal dependencies and variances which is referred to as SR-LSTM.

Proposed network architecture for (i) single SemI with Inception-ResNetv2, (ii) single SemM with Inception-ResNetv2, and c multiple SemI with SR-LSTM
The idea for using LSTMs in sequence with CNN architecture was motivated from Donahue et al. (2017) where they used CNNs for extracting visual features and LSTMs for sequence learning to recognize actions or predict the descriptions for images and videos, accordingly. Similarly, the SR-LSTM can also be used for visual description applications, but in this work, we only focus on action recognition problem. For each segment of duration \( \uptau \) from which the SemIs are constructed, we apply the temporal i.e., max pooling on the feature’s maps. The features pooled using temporal layer are then fed to the LSTMs which learn the temporally pooled features embedded with ranking scores in a sequential manner. As the frames are scored based on their ranks the temporal variance increases between each frame separated by \( \uptau \). For instance, the video is divided into multiple clips with certain overlapping for creating multiple SemI, the ranking of a particular frame in one clip may not be the same in the other. This creates temporal variances between the clips which can be efficiently modeled using LSTM layers. The temporal variance concept is one of the keystones for stacking LSTM with Inception-ResNetv2 in a sequential manner. The reason for not using LSTM for single SemI and single SemM is that it cannot leverage the temporal information effectively with them. The SR-LSTM network with multiple SemI proves to be quite effective in terms of modeling the temporal information and variances.
The SR-LSTM performs the scaling of residual filters before its input to the subsequent connection. The residuals are scaled to stabilize the training process. We observed that as the number of filters increases the residual connections get unstable. The observation is compliant with the studies in Szegedy et al. (2017) and He et al. (2016). As the study (He et al. 2016) suggested there are two ways to stabilize the training process for inception-resnets. The first is to use the two-phase training mechanism which trains the network with very low learning rate in its first phase, followed by the training with a high learning rate in the latter phase. The second way is to scale down the residuals before adding the activations from previous layer. We tried the two-phase learning mechanism with SR-LSTM but found that the training process was still unstable. Therefore, we scaled down the residuals before its addition with the activations of a previous layer. The implementation details for SR-LSTM are provided in the experimental and results section.
5 Experiments and Results
This section first reveals the implementation details for all the networks used such as ResNeXt50, ResNeXt101, DeepLabv3+ (Chen et al. 2018a), Inception-ResNetv2, and SR-LSTM. The proposed representation SemI uses a super pixel segmentation method before adding semantics, i.e., background information. In this regard, we first compare the performance of LSSGC with the deep learning-based segmentation method proposed in Chen et al. (2018a). It is well stated that our work is an extension of the representation technique, i.e., dynamic images. Thus, we first compare the performance of semantic and dynamic images with respect to the activations generated from ResNeXt101’s convolutional layers along with the training and validation loss graphs obtained from ResNeXt variants. It will provide an insight as to why the SemI performs better than the dynamic ones. Next, we will provide quantitative analysis on SemI with another competitor in terms of representation, i.e., motion history images. We show that that the SemI performs very well than the motion history images. We then analyze the performance of single SemM by employing approximate rank pooling at different layers and also compare with the performance of single dynamic maps to prove its efficacy. We explain the process of generating multiple SemI to escalate the receptive size of the network by increasing the data magnitude. Next, we compare the performance of multiple SemI with that of the multiple dynamic images to show the recognition performance. Optical flows have also been used to represent motion dynamics and have achieved remarkable results as reported in the existing studies. We also generate semantic optical flows (SemOF) and report the classification results on UCF101 and HMDB51 datasets, accordingly. We compare the performance of SR-LSTM with Inception-ResNetv2 to show that the proposed architecture can perform well on both the datasets. We present some applications with respect to the proposed representation, such as its usage in two-stream, four-stream, and temporal segment networks. Currently, there is a trend to use the transfer learning approach, i.e., using Kinetics pre-trained network, to boost the recognition accuracy even further. In this regard, we fine-tune the I3D network pre-trained on ImageNet + Kinetics (Carreira and Zisserman 2017) using SemI and SemOF to report the state-of-the-art results.
5.1 Implementation Details
Since we are using various networks for comparison and evaluation; we describe the implementation details of each network one by one followed by the details for RGB and optical flows. All the networks in this study are trained using MATLAB R2018. The training was performed on GPU using Intel Core i7 clocked at 3.4 GHz with 64 GB RAM and NVIDIA GeForce GTX 1070.
5.1.1 ResNeXts
To perform a fair comparison, we use two networks, i.e., ResNeXt50 and ResNeXt101 (Xie et al. 2017) using (32 × 4d) variant as they have been used for earlier study employing dynamic images. We use the same network settings and protocol for both dynamic and semantic images to perform the comparisons with respect to activations, training loss, and average accuracy.
5.1.2 DeepLabv3+
The model DeepLabv3+ is trained on the popular PASCAL VOC 2012 dataset (Everingham et al. 2010) comprising of 20 foreground object classes including categories of person, animals, vehicles, indoor objects, and one background class. We adopt the implementation of semantic image segmentation with the same network settings and parameters reported in Chen et al. (2018a). The reason for choosing DeepLabv3+ model is two-fold: the first is the availability of the pre-trained network for re-use and the second is that the network is proposed recently with notable results.
5.1.3 Inception-ResNetv2 and SR-LSTM
To train Inception-ResNetv2, we first resize our input frames to 299 × 299, which is the input required by the original network. We fine-tuned the network using RMSProp with a decay rate of 0.8 and an epsilon value of 0.9. The learning rate was set to 0.04, decayed after every epoch using an exponential rate of 0.85, and the drop out ratio was set to 0.5. We also used the gradient clipping (Pascanu et al. 2013) to stabilize the training. Since the scaling of residuals is required to overcome the training instability, in this regard, we scale down the residuals with a factor of 0.25 before they are added with the activations of the next layer. We break the Inception-ResNetv2 at 540th layer named as ‘block17_15’ and add a temporal pooling layer to sequentially connect with LSTM as shown in Fig. 5. We used 2 layers of LSTM with 100 hidden units. We used the ADAM optimizer (Kingma and Ba 2014) with default parameters, i.e., 0.9 and 0.999. The initial learning rate was set to 0.0009 and was decreased by the factor of 0.04 after every epoch. To fine-tune the network on RGB and multiple SemI, the training takes approximately 8.5–11 h, whereas on warped optical flows and SemOF the training time increases to approximately 48–55 h. At the testing phase, frames from a single video on average takes around 3.48 s for the segmentation and addition of background, and less than 1 s for approximate rank pooling. The test time using multiple SemI is 5 times more than that of the single SemI.
5.1.4 RGB and Optical Flow
The RGB frames are obtained by converting each video to the frame sequences. The warped optical flows were pre-computed using the method proposed in Wang and Schmid (2013), and the flow fields were stored as JPEG images. We rescaled the range of flow values within [0, 255] after clipping with 20 pixels of displacement.
5.2 LSSGC Versus Other Segmentations
In this subsection, we compare the performance of LSSGC with supervised as well as unsupervised segmentation methods for action recognition. As we modify the super pixel segmentation method proposed by Vese and Chan (2002), it is therefore necessary to compare our results with the base segmentation method. Furthermore, we also compare the LSSGC results with simple linear iterative clustering (SLIC) method (Achanta et al. 2012) to show the effectiveness of the proposed segmentation method. For the supervised segmentation, we used the pre-trained model DeepLabv3+, which uses dilated convolutions (Atrous) for segmenting the image based on the object classes. We follow the same protocol, i.e., performing the segmentation and then applying the approximate rank pooling to generate the motion summarized image. Figure 6 shows examples of segmented images using LSSGC and DeepLabv3+, along with their respective motion-summarized images. We also report the performance comparison for the methods in Table 1. The results show that the SemI using LSSGC achieves 10.5%, 5.0%, and 10.1% better accuracy on UCF101 than the one using DeepLabv3+, super pixel segmentation, and SLIC method, respectively. The major reason for such difference in accuracy is that the supervised segmentation, similar to the 3D CNNs, needs a large number of annotations for each object and background in the action videos which is time consuming and costly. Failing to categorize each object accurately in the videos leads to low action recognition rates. The superior performance in comparison to the unsupervised segmentation methods is due to the fact that those segmentations try to assign all the pixels to a particular region which results in non-sparse representation. The semantic information when added does not contribute much due to the non-sparse characteristics. It is similar to the dynamic images except that the pixels are grouped in different regions representing different colors. As the RGB information from the original representation is partially lost and there is less room for the semantics, the performance degrades in comparison to the SemI and the dynamic image. Considering the quantitative results, we will use the SemI based on LSSGC for further experiments and analysis.

An example of a segmented image using LSSGC and DeepLabv3+ along with their respective motion-summarized images
5.3 Single SemI Versus Single Dynamic Image
Our proposed work is an extension to dynamic image construction, so naturally, the question arises why there is a need for SemI? To address this question, we first compare the performance of a single dynamic image with that of a single SemI using the activations generated from ResNeXt101’s first and third convolutional layer. The activations for the action ‘Apply Eye Makeup’ are computed from the first convolutional layer and are shown in Fig. 7. The activations are a good way to qualitatively measure the representations as they exhibit more smooth and less noisy patterns (Fei-Fei et al. 2017; Olah et al. 2017). By visualizing the activations, it is apparent that a single SemI generates better activations as compared to a single dynamic image. The same pattern can also be noticed for the action ‘Archery’ whose activations are computed from the third convolutional layer, as shown in Fig. 8. After visualizing the difference, we can say that a single SemI generates smoother and less noisy patterns suggesting that the prior segmentation does improve the action–motion dynamics, qualitatively.

Activations generated for action ‘Apply Eye Makeup’ from the first convolutional layer of ResNeXt101. The top image represents the RGB frame. The left image below is generated using a single dynamic image, whereas the right one is generated using single SemI

Activations generated for action ‘Archery’ from the third convolutional layer of ResNeXt101. The top image represents the RGB image. The left image below is generated using a single dynamic image, whereas the right one is generated using single SemI
Next, we compare the single dynamic image and single SemI with the training and validation loss using ResNeXt101, as shown in Fig. 9. The single SemI shows the trend of faster convergence while yielding low validation error as compared to the single dynamic image. Moreover, the single SemI shows a smaller gap between validation and training loss which is considered to be better bias-variance tradeoff in machine learning theory as compared to its counterpart (Geman et al. 1992; Li et al. 2016). We believe that the results prove the effectiveness of a single SemI in comparison to a single dynamic image.

Training and validation loss of a single dynamic image and a single SemI. From the top (i) loss from ResNeXt101 using a single dynamic image, and (ii) loss from ResNeXt101 using a single SemI. We can notice a better bias-variance trade-off while using single SemI compared to the single dynamic image
5.4 Single SemI Versus Existing Representations
In this subsection, we provide the qualitative and quantitative analysis for single SemI with a single dynamic image and a motion history image. We also compare the results of a single SemI with mean and max pooled images, which are also considered to be an alternative for generating motion summarized images (Bilen et al. 2018). The experiments are carried out using ResNeXt50, ResNeXt101, and Inception-ResNetv2 on UCF101 split 1 only. All the representations such as SemI, mean pooled image, max pooled image, motion history image, and single dynamic image are computed offline prior to the training of the networks. We qualitatively compare RGB images, single dynamic image, motion history image, and single SemI in Fig. 10. The visual difference in the representation can easily be noticed. The motion history image (MHI) fails to represent the motion of actions ‘biking’ and ‘lunges’ clearly, almost all the pixels become white as the motion is present in all regions throughout the frames. The limitation of the dynamic images can be visualized from ‘basketball’, ‘lunges’, and ‘pizza tossing’ actions as it either fails to represent the motion with respect to the background (see basketball action) or it cannot capture the motion dynamics to its full potential (see lunges and pizza tossing) as compared to the SemI. For instance, in ‘lunges’ action, the hand movement in a single dynamic image is not clear, whereas the single SemI maps the motion well enough. Similarly, for ‘pizza tossing’ action, the circular motion of hands is quite visible with a single SemI as compared to the dynamic image. We present the comparative analysis for MHI, mean pooled, max pooled, single dynamic image, and single SemI, in Table 1, respectively.

Visualizing different image representations. From top to bottom, RGB image, MHI, single dynamic image, and single SemI. The pixels are mostly bright for MHI images are the motion is performed throughout the frames. The single dynamic image omits out the motion characteristics due to the averaging of pixels which do not change throughout the frames. The single SemI uses prior segmentation, which segments different regions as per the motion characteristics to improve the action–motion dynamics. The representations clearly show the difference
The quantitative results show that the single SemI achieved 13.0%, 7.5%, 11.8%, and 1.5% gain in accuracies over single MHI, mean, max, and single dynamic image using ResNeXt101, respectively. The result proves our assumption that the use of prior segmentation and the addition of semantic information (background) can help in modeling better action–motion dynamics as compared to the existing representations. Intuitively, there are several reasons why the single SemI improves the recognition results. One thing which is observed from Fig. 10 is that the segmentation quantizes the input image such that the semantic information could be added and leveraged by the classifier to learn the respective action. For instance, the single dynamic image averages out the basketball court. Even if one needs to add the semantic information, i.e., background to the dynamic image, it will not change the resultant representation. On the other hand, the single SemI provides the room for the background information to be incorporated in such a way that the motion information is retained along with the addition of semantic information which was not possible otherwise. The same phenomenon could be noticed in biking, billiards, and pizza tossing action. It is further noticed that when applying Inception-ResNetv2, we can boost the accuracy further by 2.5% and 1.6% in comparison to the ResNeXt architectures. As the Inception-ResNetv2 is found to be consistently better than ResNeXt50 and ResNeXt101 we will only report the results using Inception-ResNetv2 for our further analysis.
5.5 Single Semantic Map
In the previous subsection, we used single SemI, which was generated using approximate rank pooling before feeding them to the deep learning architecture. To generate the single SemM, we move the approximate rank pooling layer deeper in the architecture, which also proves the flexibility of the representation method. We compare the performance of ARP at different branching factors of Inception-ResNetv2 architecture (see Fig. 5). The visualization of the single dynamic map and single SemM is shown in Fig. 11, which are acquired using RIPB2 of the Inception-ResNetv2. The strength of SemM is advocated by visualizing the maps of ‘cliff diving’ action where the single dynamic map fails to capture any motion characteristic.

Visualization of RGB and segmented images when applied ARP after the first convolution layer of ResNeXt101
The comparison of mean class accuracy on UCF101 and HMDB51 datasets using a single dynamic map and single SemM is reported in Table 2. We show that by using single SemM, we can achieve better recognition results than that of the single dynamic map. The single SemM can achieve better recognition results than that of the single dynamic map when using either of ResNeXt and InceptionResNetv2 architecture.
We achieve the best accuracy of 75.9% while breaking the network at RIPB 2 and 47.1% on HMDB51 by breaking the network at RIPB 3 with SemM. Considering the margin of gain we get, i.e., 3.2% and 4.3% on UCF101 and HMDB51; we can say that the single SemM improves the recognition results as well as benefits the boost in accuracy with RIPB using Inception-ResNetv2. Although the results are promising and in compliance with Bilen et al. (2016) it was observed that for each dataset the branching factor needs to be optimized which is apparent from the results shown in Table 2. To determine the branching point for ARP layer using very deep networks, a lot of experiments needs to be conducted. Furthermore, the performance may not be generalized for multiple datasets using the same branching point which is another point of concern. In this regard, we only use the SemI for further experiments and analysis.
5.6 Multiple Semantic Images
Although it is presented in quantitative results that single SemI performs better than the existing video representations which summarize the motion in a single image, the accuracy is still not enough to compete with state-of-the-art methods. One reason for not attaining higher accuracy is the lack of annotated data needed to fine tune the network. Unfortunately, UCF101 and HMDB51 datasets have few videos for each category, therefore extracting multiple SemI could help in overcoming the said problem. The extraction of multiple SemI is accomplished by breaking each video in clips, i.e., duration of frames. In this regard, each video is divided into multiple clips with partially overlapping frames. It can also be considered as a data augmentation step where we increase the volume of data by dividing the original video to several clips with duration \( \uptau \) and stride \( {\mathfrak{S}} \). For the network architecture Inception-ResNetv2, we add the temporal pooling layer (max pooling) to merge all the subsequences into one due to the best reported accuracy in Bilen et al. (2018). In order to show that the use of multiple SemIs can model better action–motion dynamics for complex actions and many temporal changes, we visualize the SemI with different window sizes in Fig. 12. It can be visually noticed that for the periodic and longer motions such as ‘biking’ action, the multiple SemI stretches the same motion dynamics onto the subsequent frames which introduces the motion blur kind of effect. The actions such as ‘hula hoop’ benefits from the long-term motion dynamics yet the motion is quite well preserved even with 10 frames. We can also notice a disadvantage of using the whole video length for summarization as depicted in ‘pommel horse’ action. The single SemI does not capture the complex motion pattern for this action. Due to the repetition of the same action over and over, the motion is averaged out. However, using fewer frames, i.e., 50 or 10, can reduce the said limitation.

Visual Analysis of multiple SemIs with respect to the varying window sizes. The top row shows the original RGB frame, the second row shows the SemI for window size 10, the third row comprises of images with window size 50, and the bottom row depicts the single SemI
In this regard, we will first perform analysis using different window sizes and strides, as shown in Table 3. We computed the mean class accuracy for UCF101’s first split and noticed that the best accuracy is achieved by using the duration of 15 with 40% overlap. It is interesting to see that the larger window sizes yield less accuracy for action recognition in comparison to the smaller ones. The reason for such phenomenon is illustrated in Fig. 12 (Pommel Horse action). As the window size gets larger, the background, as well as the repetitive action, is averaged out, leading to the reduction in recognition performance. We experimented with several window sizes and strides, but only report the best and notable results to explain its effect on recognition performance. For our further experiments, we will use \( \uptau = 15 \) and \( {\mathfrak{S}} = 9 \), respectively.
We now compare the recognition accuracy of multiple SemI with multiple dynamic images and RGB images in Table 4. The reason for the better performance of multiple SemI is similar to that of a single SemI. The dynamic images average out the semantic information (background), which helps to improve the recognition performance as proved in Table 1 and visualized in Fig. 12 (see Pommel Horse action). Another key advantage of multiple SemI is that it leverages the semantic information to model the change in the background from multiple windows. The dynamic images on UCF101 dataset attained ~ 1% less accuracy using Inception-ResNetv2 in comparison to the static RGB images; this observation complies with the study (Bilen et al. 2018) where multiple dynamic images fail to achieve better accuracy than the baseline. It is also interesting to note that the multiple SemIs improve the recognition accuracy by 0.3% with Inception-ResNetv2 which is commendable when compared to the performance of dynamic images. For HMDB51, multiple SemI achieved recognition accuracy of 59.9%, which is 5.3% and 1.7% better than those of static RGB images and multiple dynamic images, respectively. We believe that the reason for the better gain is from the ability of multiple SemIs to represent more intricate action–motion dynamics and to leverage the semantic information better due to the complexity of backgrounds in HMDB51 dataset.
5.7 Warped and Semantic Optical Flows
As illustrated in previous subsections, the ARP transforms the segmented frames to semantic images, i.e., low-level to mid-level motion representation. The optical flows are another example of mid-level motion representation which has been used extensively in terms of two-stream networks. It was proved in Bilen et al. (2018) that applying the ARP to optical flows transforms the mid-level representation to high-level, which can improve the recognition results. To this extent, we apply the ARP to the warped optical flows (WOF) from the segmented images overlaid with background information to generate semantic optical flows (SemOF). Similar to the previous analysis, we apply ARP to 15 optical flow frames for generating SemOF. We first visualize the warped optical flows and semantic optical flows in Fig. 13 to analyze the difference qualitatively. It can be visualized that the SemOF capture long-term motion dynamics as compared to the warped optical flows. This is because the warped optical flows can only calculate the motion patterns between subsequent frames—for instance, the SemOF for action ‘boxing punching bag’ and ‘billiards’ exhibit history of temporal actions for a longer span as compared to the warped optical flows.

Visualizing the static RGB images in the first row, SemI in the second row, WOF in the third row, and SemOF in the fourth row
We also compare the performance of warped and dynamical optical flows with the SemOF quantitatively to prove its efficacy, as shown in Table 5. The SemOF achieved 2.3%, 0.4%, and 3.6%, 0.3%, better accuracy on UCF101 and HMDB51 than warped and dynamic optical flows, respectively. These results were obtained using Inception-ResNetv2. The results prove that the transition from mid-level to high-level motion representation improves the recognition performance.
5.8 SR-LSTM Versus Inception-ResNetv2 and ResNeXts
So far, we have used two deep networks, i.e., Inception-ResNetv2 and ResNeXts. We showed that the Inception-ResNetv2 could achieve better results than the ResNeXts. Considering that both the networks extract different features which are illustrated by the frequency responses obtained using the first convolutional layer as shown in Fig. 14, we assume that the features extracted by Inception-ResNetv2 are more effective as compared to the ResNeXt architecture. The frequency responses were obtained by passing the RGB image and applying the max pooling to select the filter activation with maximum values. We then plot the frequency responses of the green channel for the selected activation. The ResNeXt101 weight shows the bandpass filter in the centers in a particular direction surrounded by the low pass filters in other direction. With respect to the signal processing analogy, we realize that the filters cut-off the upper half of the frequency range for most of the signal, which is similar to the antialiasing filter. On the other hand, the frequency response of Inception-ResNetv2’s max pooled image shows two high pass filters appearing on the horizontal edges while small magnitude low pass filters are present on the extreme ends. We assume that the low pass filters smooth the edges while the intensities in a particular range of two scales are computed for feature maps.

Visualizing the frequency response of the maximum filters using green channels for ResNeXt101 and Inception-ResNetv2 networks
We know the SemI use ARP which retains the temporal information from the video sequences by ranking them. In this regard, we assume that by stacking the LSTM network in sequence with Inception-ResNetv2 the recognition results can be improved due to the learning of temporal variances introduced when dividing the video into different windows. We refer to this network as SR-LSTM. To prove the validity of our assumption, we carried out experiments on multiple dynamic images, multiple SemI, WOF, dynamic optical flows, and SemOF using SR-LSTM and computed the mean class accuracy as shown in Table 6.
The trend shows that the SR-LSTM can improve the recognition performance for all the modalities used for action recognition. It is to be noted that all of these modalities somehow incorporate temporal information, let it be ARP or motion information from warped optical flows.
One interesting result which can be noticed is that the SemOF alone can achieve better results than the multiple dynamic images which incorporate both appearance and motion information. The probable reason is the combination of frame ranking with the optical flow images. The results comply with the study of Bilen et al. (2018) where the dynamic optical flows yield the recognition performance at par with multiple dynamic images, and the assumption of long-term motion helping the SemOF to perform better is also in agreement with the study (Varol et al. 2018).
The assumption of SR-LSTM leveraging the temporal information for improving the recognition holds since the recognition results are boosted for all the modalities. The multiple dynamic images see 1.2% growth from Inception-ResNetv2 networks. The gain for multiple SemI is noted to be 1.4% compared to the baseline architecture. Warped optical flows record 1.0% gain, whereas the dynamic optical flows show 1.3% gain in accuracy. All these gains are reported from UCF101 dataset. The similar trends are observed for HMDB51 as well. The highest gain for HMDB51 was observed for multiple SemI gaining 3.0% accuracy over Inception-ResNetv2.
5.9 Two- and Four-Stream Networks
It is well established throughout Sect. 2 that the researchers use multi-stream networks for boosting the recognition performance by combining the results of networks trained using different modalities. We performed the analysis for multi-stream networks using the combination of modalities such as RGB, multiple SemI, WOF, and SemOF. Each of the streams in multi-stream networks is trained separately for different modalities, but their results are combined using average scores for each class. The final classification label will be drawn by selecting the class having a maximum average score. Our proposed multi-stream networks, i.e., two- and four-stream network, are depicted in Fig. 15. The analysis for late fusion is performed using the SR-LSTM network as it achieved the best results for recognition on both datasets. The mean class accuracies for UCF101 and HMDB51 datasets using multi-stream networks are presented in Table 7. It can be observed that the static RGB + WOF yield less accuracy on UCF101 but performs better on HMDB51 in comparison to multiple SemI + warped optical flows. The results make sense as the SemI and WOF both exhibit mid-level motion information; therefore, for some actions, the representation seems redundant. On the other hand, RGB frames and WOF felicitate each other as the former has low-level, whereas the latter exhibits mid-level motion information.

Illustration of multi-stream network architecture using our proposed video representations
The best results are achieved using multiple SemI and SemOF using a two-stream variant which gives a boost of 6.1%, 4.4%, 8.4%, and 4.9% accuracy over individual modalities of static RGB, multiple SemI, WOF, and SemOF on UCF101. Similarly, the gain is noted to be 15.5%, 7.2%, 13.3%, and 7.7% from the individual modalities of static RGB images, multiple SemI, warped optical flows, and SemOF on HMDB51. Finally, the maximum accuracy was achieved using a four-stream variant which gives a boost of 1.2% and 3.4% over two-stream variant for UCF101 and HMDB51 datasets, respectively.
5.10 Temporal Segment Networks
The temporal segment network has proved that using good practices for making deep architectures learn can improve the recognition results for applications such as action recognition. The main characteristics of temporal segment networks include a sparse sampling of short snippets from the video and the consensus among the snippets for drawing out the predictions. The temporal segment networks have been used for two and three modalities in their original work (Wang et al. 2016b). One more parameter which is of the sheer importance is the segment number. It was shown in the study (Wang et al. 2018b) that using a higher number of segments yields better performance but with slower recognition. In this paper, we use the same architecture and method to train the network, but instead of using RGB and optical flows, we use multiple SemI and SemOF, respectively. To match the number of samples, we only consider the last two frames in a window to generate the WOF. The comparative analysis of different modalities using temporal segment networks is shown in Table 7. All the results reported using the same credits to determine the consensus of specific modality proposed in Wang et al. (2018b) and “5” as the number of segments. The results show that the three modalities with temporal segment networks achieve better results than our two-stream networks on both the datasets.
5.11 Fine-Tuning Using I3D + Kinetics
We proved the adaptability of SemI and SemOF by using these modalities with TSN. In this subsection, we evaluated I3D which considers inception as its base network and is pre-trained on ImageNet + Kinetics dataset. We fine-tune the network on UCF and HMDB51 dataset using SemI and SemOF modalities. For this experiment, we use the learning rate of 0.02 for 5k steps, 0.01 for another 1k step, and 0.001 for more 2k steps, respectively. As the original literature provides separate pre-trained networks for RGB and optical flows, we use the network pre-trained on RGB to fine-tune the SemI and the network pre-trained on optical flows to fine-tune the SemOF. Similar to the previous experiments, the classification scores from multiple streams will be combined to report the recognition accuracy from two-stream and four-stream networks. The results are shown in Table 8.
The results are evident that the proposed representations, i.e., SemI and SemOF, yield better classification accuracy in comparison to the RGB and optical flows. We also show that the two-stream and four-streams using I3D network pre-trained on ImageNet + Kinetics and fine-tuned on the proposed representation achieve 99.1% and 83.7% recognition accuracies which are 1.2% and 3.2% better for UCF101 and HMDB51, respectively, in comparison to its original variant.
5.12 Comparison with State-of-the-Art Methods
In this section, we compare our experimental results with the state-of-the-art methods for action recognition using videos. We mentioned in Sect. 2 that most of the existing studies perform late fusion with improved dense trajectories (IDTs) to boost their recognition accuracy. In this regard, we divide the state-of-the-art results into two categories. The first includes the results without the use of IDTs so that the method could be judged on its intrinsic characteristics. The second present the recognition accuracies from the methods when combined with IDTs, accordingly. We assume that such categorization of results for comparison would be fair enough. We present the results without combining IDTs in Table 9.
We further divided the methods in Table 9 into four categories, i.e. single-stream, two-streams, temporal segment networks, and four-stream networks. It can be noticed that our two-stream SemIN outperforms many state-of-the-art methods; however, the best results were achieved using two-stream I3D networks using SemI and SemOF as the learning representations. It should also be noticed that when the I3D method was only trained on HMDB51 and UCF101, even our two-stream networks outperformed their methods. The two-stream I3D (SemI + SemOF) improves the accuracy by 1.2% and 0.9% on HMDB51 and UCF101 datasets, respectively, in comparison to the original two-stream I3D pre-trained on ImageNet + kinetics. It further supports our claim that the proposed representations are not only better than the conventional ones, i.e. (RGB and OF) but also the existing ones such as DI, DOF, and MHI.
The temporal segment network with proposed representations not only improves the accuracy of the original study but also achieves better results than the existing works in its respective category, i.e. 95.2% and 71.8% for UCF101 and HMDB51, respectively.
We also achieved better results with four-stream SemIN (using the network pre-trained on ImageNet) by attaining 95.9% and 73.5% on UCF101 and HMDB51 dataset. The four-stream SemIN improves the recognition accuracy by 0.4% and 1.0% for UCF101 and HMDB51 from the one proposed in Bilen et al. (2018). The four-stream SemIN achieving more than 95% and 70% accuracy on UCF101 and HMDB51 with the network pre-trained using ImageNet only, is a remarkable feat. It can also be noticed that the studies which use the ImageNet pre-trained network do not surpass the accuracy achieved with four-stream SemIN. The result supports the fact that the intrinsic characteristics of the proposed representation (SemI and SemOF) which embeds the semantic information and the network architecture (SR-LSTM) which sequences the LSTM with Inception-ResNetv2 are the reasons behind improved accuracy. The four-stream I3D networks pre-trained on ImageNet + Kinetics dataset outperforms all the state-of-the-art methods.
We also perform the fusion of two-stream and four-stream networks with IDTs for comparison with state-of-the-art works, as reported in Table 10. It should be noted that for fusing IDTs we only use the four-stream SemIN instead of I3D variant. It is surprising that the results from our four-stream networks outperform existing state-of-the-art methods combined with IDTs. The result implies that the improvement in accuracy is mostly due to the intrinsic characteristics of our video representation and network architecture. The combination of our four-stream networks with IDTs provides 1.5% and 3.3% boost of accuracy on UCF101 and HMDB51, respectively.
5.13 Discussion
In this section, we provide some insights with respect to the experimental analysis. The discussion here is based on the four-stream SemIN as we want to highlight the improvement based on intrinsic characteristics of the proposed representation rather than the networks pre-trained on kinetic sequences. It was found that the best relative performance when using multiple SemI was obtained for ‘Nun Chucks’ and ‘Pull Up’ action on UCF101 and HMDB51, respectively. However, when compared with static RGB images, the best accuracy improvement was obtained for ‘High Jump’ action on UCF101 while on the HMDB51 the best improvement was recorded for ‘Sommer Sault’ and ‘throw’ action, respectively. We also found that some ‘Pizza Tossing’ and ‘Salsa Spin’ actions were confused with ‘Nun Chucks’ due to the similar circular motions, which are interestingly very different actions as per their characteristics. Furthermore, as pointed out in Bilen et al. (2018), the ‘Breast Stroke’ was confused with ‘Rowing’ and ‘Front Crawling’ actions. For the two-stream networks the actions which achieved the best relative performance on HMDB51 were ‘Pull Up,’ ‘Ride Bike,’ and ‘Golf’ whereas for the UCF101 the actions were ‘Nun Chucks’ and ‘Jumping Jack.’ The four-stream network proposed in Bilen et al. (2018) suggested the most challenging actions be ‘Pizza Tossing,’ ‘Lunges,’ ‘Hammer Throw,’ ‘Shaving Beard,’ and ‘Brushing Teeth’ with their respective accuracies of 74, 74.6, 77.2, 78.7 and 80.2%. Our proposed four-stream network improved the accuracy for each of these actions by 2.6%, 6.4%, 15.6%, 7.8%, and 0.3%, respectively. The most challenging actions on HMDB51 were found to be ‘Sword’ and ‘Wave.’ We assume that similar motion characteristics may be the reason due to which certain actions are confused with one another. However, if combined with the pose analysis or facial landmarks, the SemI may overcome the shortcomings mentioned above.
6 Conclusion and Future Work
In this paper, we propose an improvement to work presented in Bilen et al. (2018) by segmenting the image and overlaying it with a static background. Such pre-processing method for adding semantics not only improves the action–motion dynamics but also is helpful in mapping semantic information for many actions which are performed at a particular location such as ‘Basketball,’ ‘Breast Stroke,’ and more. We also exploit the design choices for computing semantic maps across intermediate layers of Inception-ResNetv2 to prove the flexibility of the representation method. We present the SR-LSTM network, which is the result of sequentially combining the base network, i.e., Inception-ResNetv2 with LSTMs. The experimental results show that LSTMs help to model the temporal dynamics from the extracted features by the network across time. The use of temporal information encoded by approximate rank pooling helps LSTMs to learn temporal dependencies and temporal variances to improve the recognition performance. It is reflected by the mean class accuracy on both UCF101 and HMDB51 datasets. Our two- and four-stream variants of SR-LSTM networks show promising results and achieve state-of-the-art performance. The maximum accuracy we achieved so far is from four-stream I3D networks using SemI and SemOF, i.e., 99.1% and 83.7% on UCF101 and HMDB51. The modalities were also trained using temporal segment networks, which elicited a positive trend towards the improvement in recognition performance.
We already discussed some of the limitations with respect to the confusing classes in the previous section. Moreover, the SemI and SemOF do not map the motion dynamics well for many complex actions such as ‘Pommel Horse’ or the actions with abrupt motions such as ‘Cricket Shot’ and ‘Parallel Bars.’ Furthermore, the SemOF reveal similar motion characteristics for ‘Shaving Beard,’ ‘Brushing Teeth,’ and ‘Applying Lipstick’ which does not contribute to improving the recognition performance. We believe that by adding another semantic information such as objects, can improve the recognition performance where the objects are distinguishable for each of the above-mentioned actions. In future, we want to explore the use of SemI for cross domain and transfer learning approaches by considering the mutual actions in both datasets such as ‘Golf,’ ‘Dive,’ ‘Fencing,’ ‘Jump,’ ‘Pull Up,’ and more.
References
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., & Süsstrunk, S. (2012). SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on Pattern Analysis and Machine Intelligence,34(11), 2274–2282. https://doi.org/10.1109/TPAMI.2012.120.
Ali, S., & Shah, M. (2010). Human action recognition in videos using kinematic features and multiple instance learning. IEEE Transactions on Pattern Analysis and Machine Intelligence,32(2), 288–303. https://doi.org/10.1109/TPAMI.2008.284.
Allen, G., & Gray, R. M. (2012). Vector quantization and signal compression (Vol. 159). Berlin: Springer.
Bilen, H., Fernando, B., Gavves, E., & Vedaldi, A. (2018). Action recognition with dynamic image networks. IEEE Transactions on Pattern Analysis and Machine Intelligence,40(12), 2799–2813. https://doi.org/10.1109/TPAMI.2017.2769085.
Bilen, H., Fernando, B., Gavves, E., Vedaldi, A., & Gould, S. (2016). Dynamic image networks for action recognition. In 2016 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 3034–3042). IEEE. https://doi.org/10.1109/cvpr.2016.331.
Bobick, A. F., & Davis, J. W. (2001). The recognition of human movement using temporal templates. IEEE Transactions on Pattern Analysis and Machine Intelligence,23(3), 257–267. https://doi.org/10.1109/34.910878.
Carreira, J., & Zisserman, A. (2017). Quo vadis, action recognition? A new model and the kinetics dataset. In 2017 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 4724–4733). IEEE. https://doi.org/10.1109/cvpr.2017.502.
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., & Adam, H. (2018a). Encoder–decoder with atrous separable convolution for semantic image segmentation. In European conference on computer vision (pp. 833–851). https://doi.org/10.1007/978-3-030-01234-2_49.
Chen, Y., Kalantidis, Y., Li, J., Yan, S., & Feng, J. (2018b). Multi-fiber networks for video recognition. In European conference on computer vision (pp. 364–380). https://doi.org/10.1007/978-3-030-01246-5_22.
Chen, Y., Kalantidis, Y., Li, J., Yan, S., & Feng, J. (2018c). A2-nets: Double attention networks. In 32nd Conference on neural information processing systems (NeurIPs) (pp. 352–361).
Cheron, G., Laptev, I., & Schmid, C. (2015). P-CNN: Pose-based CNN features for action recognition. In IEEE international conference on computer vision (ICCV) (pp. 3218–3226). IEEE. https://doi.org/10.1109/iccv.2015.368.
Chopra, S., Hadsell, R., & LeCun, Y. (2005). Learning a similarity metric discriminatively, with application to face verification. In IEEE computer society conference on computer vision and pattern recognition (CVPR’05) (Vol. 1, pp. 539–546). IEEE. https://doi.org/10.1109/cvpr.2005.202.
de Souza, C. R., Gaidon, A., Vig, E., & López, A. M. (2016). Sympathy for the details: Dense trajectories and hybrid classification architectures for action recognition. In European conference on computer vision (pp. 697–716). https://doi.org/10.1007/978-3-319-46478-7_43.
Diba, A., Fayyaz, M., Sharma, V., Arzani, M. M., Yousefzadeh, R., Gall, J., & Van Gool, L. (2018). Spatio-temporal channel correlation networks for action classification. In European conference on computer vision (pp. 299–315). https://doi.org/10.1007/978-3-030-01225-0_18.
Diba, A., Sharma, V., & Van Gool, L. (2017). Deep temporal linear encoding networks. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 1541–1550). IEEE. https://doi.org/10.1109/cvpr.2017.168.
Donahue, J., Hendricks, L. A., Rohrbach, M., Venugopalan, S., Guadarrama, S., Saenko, K., et al. (2017). Long-term recurrent convolutional networks for visual recognition and description. IEEE Transactions on Pattern Analysis and Machine Intelligence,39(4), 677–691. https://doi.org/10.1109/TPAMI.2016.2599174.
Doretto, G., Chiuso, A., Wu, Y. N., & Soatto, S. (2003). Dynamic textures. International Journal of Computer Vision,51(2), 91–109. https://doi.org/10.1023/a:1021669406132.
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., & Zisserman, A. (2010). The Pascal visual object classes (VOC) challenge. International Journal of Computer Vision,88(2), 303–338. https://doi.org/10.1007/s11263-009-0275-4.
Feichtenhofer, C., Pinz, A., & Wildes, R. (2016a). Spatiotemporal residual networks for video action recognition. In Advances in neural information processing systems (pp. 3468–3476).
Feichtenhofer, C., Pinz, A., & Zisserman, A. (2016b). Convolutional two-stream network fusion for video action recognition. In 2016 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 1933–1941). IEEE. https://doi.org/10.1109/cvpr.2016.213.
Fei-Fei, L., Johnson, J., & Yeung, S. (2017). Visualizing what ConvNets learn. Retrieved from October 6, 2018, http://cs231n.github.io/understanding-cnn/.
Fernando, B., Gavves, E., Jose Oramas, M., Ghodrati, A., & Tuytelaars, T. (2015). Modeling video evolution for action recognition. In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 5378–5387). IEEE. https://doi.org/10.1109/cvpr.2015.7299176.
Fischler, M. A., & Bolles, R. C. (1981). Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM,24(6), 381–395. https://doi.org/10.1145/358669.358692.
Geman, S., Bienenstock, E., & Doursat, R. (1992). Neural networks and the bias/variance dilemma. Neural Computation,4(1), 1–58. https://doi.org/10.1162/neco.1992.4.1.1.
Hara, K., Kataoka, H., & Satoh, Y. (2018). Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet. In IEEE international conference on computer vision and pattern recognition (pp. 6546–6555).
He, K., & Sun, J. (2015). Convolutional neural networks at constrained time cost. In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 5353–5360). IEEE. https://doi.org/10.1109/cvpr.2015.7299173.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In 2016 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 770–778). IEEE. https://doi.org/10.1109/cvpr.2016.90.
Jain, M., Jegou, H., & Bouthemy, P. (2013). Better exploiting motion for better action recognition. In 2013 IEEE conference on computer vision and pattern recognition (pp. 2555–2562). IEEE. https://doi.org/10.1109/cvpr.2013.330.
Jain, M., van Gemert, J. C., & Snoek, C. G. M. (2015). What do 15,000 object categories tell us about classifying and localizing actions? In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 46–55). IEEE. https://doi.org/10.1109/cvpr.2015.7298599.
Ji, S., Xu, W., Yang, M., & Yu, K. (2013). 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence,35(1), 221–231. https://doi.org/10.1109/TPAMI.2012.59.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., et al. (2014). Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM international conference on multimedia—MM’14 (pp. 675–678). New York, NY: ACM Press. https://doi.org/10.1145/2647868.2654889.
Ke, Y., Sukthankar, R., & Hebert, M. (2005). Efficient visual event detection using volumetric features. In Tenth IEEE international conference on computer vision (ICCV’05) (pp. 166–173). IEEE. https://doi.org/10.1109/iccv.2005.85.
Kellokumpu, V., Zhao, G., & Pietikainen, M. (2008). Human activity recognition using a dynamic texture based method. In Proceedings of the British machine vision conference (pp. 88.1–88.10). British Machine Vision Association. https://doi.org/10.5244/c.22.88.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. http://arxiv.org/abs/1412.6980.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in neural information processing systems (NIPS) (pp. 1–9).
Laptev, I. (2005). On space–time interest points. International Journal of Computer Vision,64(2–3), 107–123. https://doi.org/10.1007/s11263-005-1838-7.
Le, Q. V., Zou, W. Y., Yeung, S. Y., & Ng, A. Y. (2011). Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In IEEE International conference on computer vision and pattern recognition (pp. 3361–3368). IEEE. https://doi.org/10.1109/cvpr.2011.5995496.
Li, C., Chen, C., Carlson, D., & Carin, L. (2016). Preconditioned stochastic gradient langevin dynamics for deep neural networks. In Proceedings of the thirtieth association for the advancement of artificial intelligence (AAAI) conference on artificial intelligence (pp. 1788–1794).
Likas, A., Vlassis, N., & Verbeek, J. (2003). The global k-means clustering algorithm. Pattern Recognition,36(2), 451–461. https://doi.org/10.1016/S0031-3203(02)00060-2.
Ma, C.-Y., Chen, M.-H., Kira, Z., & AlRegib, G. (2018). TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition. Signal Processing: Image Communication. https://doi.org/10.1016/j.image.2018.09.003.
Ojala, T., Pietikainen, M., & Maenpaa, T. (2002). Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence,24(7), 971–987. https://doi.org/10.1109/TPAMI.2002.1017623.
Olah, C., Mordvintsev, A., & Schubert, L. (2017). Feature visualization. Distill. https://doi.org/10.23915/distill.00007.
Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. In Proceedings of the 30th international conference on machine learning (pp. 1310–1318).
Peng, X., Zou, C., Qiao, Y., & Peng, Q. (2014). Action recognition with stacked fisher vectors. In European conference on computer vision (pp. 581–595). https://doi.org/10.1007/978-3-319-10602-1_38.
Perronnin, F., Sánchez, J., & Mensink, T. (2010). Improving the fisher kernel for large-scale image classification. In European conference on computer vision (pp. 143–156). https://doi.org/10.1007/978-3-642-15561-1_11.
Pirsiavash, H., Ramanan, D., & Fowlkes, C. C. (2009). Bilinear classifiers for visual recognition. In Neural information processing systems (NIPS) (pp. 1482–1490).
Rodriguez, M. D., Ahmed, J., & Shah, M. (2008). Action MACH a spatio-temporal maximum average correlation height filter for action recognition. In IEEE conference on computer vision and pattern recognition (pp. 1–8). IEEE. https://doi.org/10.1109/cvpr.2008.4587727.
Shechtman, E., & Irani, M. (2005). Space–time behavior based correlation. In IEEE computer society conference on computer vision and pattern recognition (CVPR’05) (Vol. 1, pp. 405–412). IEEE. https://doi.org/10.1109/cvpr.2005.328.
Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems (pp. 1–9).
Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and Computing,14(3), 199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88.
Srivastava, N., Mansimov, E., & Slakhudinov, R. (2015). Unsupervised learning of video representations using LSTMs. In Proceedings of the 32nd international conference on machine learning (pp. 843–852).
Storath, M., & Weinmann, A. (2014). Fast partitioning of vector-valued images. SIAM Journal on Imaging Sciences,7(3), 1826–1852. https://doi.org/10.1137/130950367.
Sun, L., Jia, K., Yeung, D.-Y., & Shi, B. E. (2015). Human action recognition using factorized spatio-temporal convolutional networks. In 2015 IEEE international conference on computer vision (ICCV) (pp. 4597–4605). IEEE. https://doi.org/10.1109/iccv.2015.522.
Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. A. (2017). Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Thirty-first association for the advancement of artificial intelligence (AAAI) (pp. 4278–4284).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 2818–2826). IEEE. https://doi.org/10.1109/cvpr.2016.308.
Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning spatiotemporal features with 3D convolutional networks. In 2015 IEEE international conference on computer vision (ICCV) (pp. 4489–4497). IEEE. https://doi.org/10.1109/iccv.2015.510.
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., & Paluri, M. (2018). A closer look at spatiotemporal convolutions for action recognition. In IEEE/CVF conference on computer vision and pattern recognition (pp. 6450–6459). IEEE. https://doi.org/10.1109/cvpr.2018.00675.
Varol, G., Laptev, I., & Schmid, C. (2018). Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence,40(6), 1510–1517. https://doi.org/10.1109/TPAMI.2017.2712608.
Vese, L. A., & Chan, T. F. (2002). A multiphase level set framework for image segmentation using the Mumford and Shah model. International Journal of Computer Vision,50(3), 271–293. https://doi.org/10.1023/A:1020874308076.
Wang, H., Kläser, A., Schmid, C., & Liu, C.-L. (2013). Dense trajectories and motion boundary descriptors for action recognition. International Journal of Computer Vision,103(1), 60–79. https://doi.org/10.1007/s11263-012-0594-8.
Wang, H., & Schmid, C. (2013). Action recognition with improved trajectories. In 2013 IEEE international conference on computer vision (pp. 3551–3558). IEEE. https://doi.org/10.1109/iccv.2013.441.
Wang, L., Li, W., & Van Gool, L. (2018a). Appearance- and-relation networks for video classification. In IEEE/CVF conference on computer vision and pattern recognition (pp. 1430–1439). IEEE. https://doi.org/10.1109/cvpr.2018.00155.
Wang, L., Qiao, Y., & Tang, X. (2015). Action recognition with trajectory-pooled deep-convolutional descriptors. In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 4305–4314). IEEE. https://doi.org/10.1109/cvpr.2015.7299059.
Wang, L., Qiao, Y., & Tang, X. (2016a). MoFAP: A multi-level representation for action recognition. International Journal of Computer Vision,119(3), 254–271. https://doi.org/10.1007/s11263-015-0859-0.
Wang L., Xiong Y., Wang Z., Qiao Y., Lin D., Tang X., & Van Gool L. (2016c). Temporal segment networks: towards good practices for deep action recognition. In European conference on computer vision (pp. 20–36). https://doi.org/10.1007/978-3-319-46484-8_2.
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., et al. (2018b). Temporal segment networks for action recognition in videos. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2018.2868668.
Wang, Y., Long, M., Wang, J., & Yu, P. S. (2017). Spatiotemporal pyramid network for video action recognition. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 2097–2106). IEEE. https://doi.org/10.1109/cvpr.2017.226.
Wang Y., Song J., Wang L., Gool L., & Hilliges O. (2016b). Two-stream SR-CNNs for action recognition in videos. In Proceedings of the British machine vision conference 2016 (pp. 108.1–108.12). British Machine Vision Association. https://doi.org/10.5244/c.30.108.
Willems, G., Tuytelaars, T., & Van Gool, L. (2008). An efficient dense and scale-invariant spatio-temporal interest point detector. In European conference on computer vision (pp. 650–663). https://doi.org/10.1007/978-3-540-88688-4_48.
Xie, S., Girshick, R., Dollar, P., Tu, Z., & He, K. (2017). Aggregated residual transformations for deep neural networks. In 2017 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 5987–5995). IEEE. https://doi.org/10.1109/cvpr.2017.634.
Xie, S., Sun, C., Huang, J., Tu, Z., & Murphy, K. (2018). Rethinking spatiotemporal feature learning: Speed–accuracy trade-offs in video classification. In European conference on computer vision (pp. 318–335). https://doi.org/10.1007/978-3-030-01267-0_19.
Yatziv, L., & Sapiro, G. (2006). Fast image and video colorization using chrominance blending. IEEE Transactions on Image Processing,15(5), 1120–1129. https://doi.org/10.1109/TIP.2005.864231.
Yue-Hei Ng, J., Hausknecht, M., Vijayanarasimhan, S., Vinyals, O., Monga, R., & Toderici, G. (2015). Beyond short snippets: Deep networks for video classification. In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (pp. 4694–4702). IEEE. https://doi.org/10.1109/cvpr.2015.7299101.
Zha, S., Luisier, F., Andrews, W., Srivastava, N., & Salakhutdinov, R. (2015). Exploiting image-trained CNN architectures for unconstrained video classification. http://arxiv.org/abs/1503.04144.
Zhao, G., & Pietikainen, M. (2007). Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence,29(6), 915–928. https://doi.org/10.1109/TPAMI.2007.1110.
Zhu, W., Hu, J., Sun, G., Cao, X., & Qiao, Y. (2016). A key volume mining deep framework for action recognition. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 1991–1999). IEEE. https://doi.org/10.1109/cvpr.2016.219.
Acknowledgements
This research was supported by Hankuk University of Foreign Studies Research Fund (Grant No. 2019), and also supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2018R1D1A1B07049113).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by Karteek Alahari.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Khowaja, S.A., Lee, SL. Semantic Image Networks for Human Action Recognition. Int J Comput Vis 128, 393–419 (2020). https://doi.org/10.1007/s11263-019-01248-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01248-3