
Abstract
The complete nucleotide sequences of two double-stranded (ds) RNA molecules, S1 (1,744 bp) and S2 (1,567 bp), isolated from an isolate HP62 of the Himalayan Dutch elm disease fungus, Ophiostoma himal-ulmi, were determined. RNA S1 had the potential to encode a protein, P1, of 539 amino acids (62.7 kDa), which contained sequence motifs characteristic of RNA-dependent RNA polymerases (RdRps). A database search showed that P1 was closely related to RdRps of members of the genus Partitivirus in the family Partitiviridae. RNA S2 had the potential to encode a protein, P2, of 430 amino acids (46.3 kDa), which was related to capsid proteins of members of the genus Partitivirus. Virus particles isolated from isolate HP62 were shown to be isometric with a diameter of 30 nm, and to contain dsRNAs S1 and S2 and a single capsid protein of 46 kDa. N-terminal sequencing of tryptic peptides derived from the capsid protein proved unequivocally that it is encoded by RNA S2 and corresponds to protein P2. It is concluded that O. himal-ulmi isolate HP62 contains a new member of the genus Partitivirus, which is designated Ophiostoma partitivirus 1. A phylogenetic tree of RdRps of members of the family Partitiviridae showed that there are least two RdRp lineages of viruses currently classified in the genus Partitivirus. One of these lineages contained viruses with fungal hosts and viruses with plant hosts, raising the possibility of horizontal transmission of partitiviruses between plants and fungi. The partitivirus RdRp and capsid proteins appear to have evolved in parallel with the capsid proteins evolving much faster than the RdRps.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Viruses have been developed as biological control agents for Cryphonectria parasitica, the fungus that causes chestnut blight [1, 2], and have potential for the control of other plant pathogenic fungi. As part of our programme aimed at developing viruses for control of fungi pathogenic to forest trees, we have discovered and characterized viruses in the Dutch elm disease fungi, Ophiostoma ulmi and O. novo-ulmi. These viruses consist of a single molecule of naked double-stranded RNA, located in the mitochondria, and have been placed in the genus Mitovirus in the family Narnaviridae [3–5].
We now report the discovery of a new virus in the third Dutch elm disease fungus, O. himal-ulmi [6]. We have isolated and characterized the virus particles and their dsRNA genome. The sequence and genome organization of this virus show that it can be classified in the genus Partitivirus of the family Partitiviridae and this is the first demonstration of a partitivirus in the genus Ophiostoma.
Materials and methods
Fungal isolate
O. himal-ulmi isolate HP62 has been described previously [6] and was maintained on malt extract agar (MEA, Oxoid) as described [7].
DsRNA isolation
Total nucleic acids were isolated as described [8] from fungal mycelium after 14 days growth on cellophane membranes overlaying MEA at 22°C. Single-stranded (ss) RNA and dsRNA were separated by precipitating ssRNA with 2 m LiCl and dsRNA with 5 M LiCl as described [8]. DsRNAs were separated by polyacrylamide gel electrophoresis [9] and extracted from the gel using an RNaid kit (Bio 101, Vista, CA, USA).
cDNA synthesis, cloning and sequence analysis
cDNA libraries were constructed using gel-purified dsRNA segments S1 and S2 from O. himal-ulmi isolate HP62. cDNA synthesis, cloning and screening of cDNA clones were carried out as described [8]. Determination of the ends of each dsRNA was done using a GIBCO BRL (Gaithersburg, MD, USA) 5′ RACE system [9]. Sequences of cDNA clones were obtained by the chain termination method [10] using dye-terminator cycle sequencing with AmpliTaq DNA polymerase FS (ABI PRISM 377). Sequence analysis was performed using the GCG version 8.1 programs [11]. Multiple sequence alignments, construction of phenograms, and bootstrapping analysis were accomplished with the CLUSTAL X programs [12]. The phylogenetic tree was displayed using the program TREEVIEW [13]. Incubations with S1 nuclease and DNase 1 were as described [3].
Isolation and purification of virus particles
Actively growing mycelium (60 g) was disrupted by grinding using a mortar and pestle with carborundum (6 g) and sufficient PBK buffer (0.03 M sodium phosphate, 0.3 M potassium chloride, pH 7.6) to form a smooth paste. The homogenate was diluted with PBK buffer to give a volume of 1.8 l, gently shaken at 4°C for 15 min and then centrifuged at 23000g for 45 min. To the supernatant were added 10 g polyethylene glycol-6000 and 1 g NaCl per 100 ml, and the mixture was stirred at 4°C for 2 h. The precipitate was collected by centrifugation at 15000g for 20 min and suspended in 100 ml PBK buffer. After centrifugation at 23000g for 20 min to remove unsuspended debris, the supernatant was centrifuged at 78000g to pellet the virus. The pelleted virus was resuspended in 1 ml PBK buffer and purified by sequential sedimentation through two 10–50% (w/v) sucrose density gradients. The virus band, identified by a blue-grey opalescence, was collected and dialyzed against 10 mM Tris–HCl, pH 7.6 buffer.
Electron microscopy
A 5-μl drop of virus suspension was placed on a carbon-collodion-coated grid and stained with 1% aqueous uranyl acetate. Grids were examined in a Philips CM 200 electron microscope and images were recorded at 50,000 × magnification.
Protein analysis
Virus particles were disrupted by mixing with one tenth volume of 10% SDS and heating to 100°C for 5 min. 0.5 volume of buffer containing 5% 2-mercaptoethanol, 62.5 mM Tris–HCl, pH 6.8, and 20% (v/v) glycerol was the added and the sample heated to 100°C for 5 min. The protein was analysed by electrophoresis through 10% polyacrylamide gels [14]. Protein digestion with trypsin, separation of tryptic peptides by high pressure liquid chromatography (HPLC) and N-terminal sequencing by Edman degradation were carried out by Dr. John Leszyk at the University of Massachusetts Medical School Worcester Foundation Campus Core laboratory for Protein Microsequencing and Mass Spectrometry.
Results
Isolation and characterization of dsRNAs from O. himal-ulmi
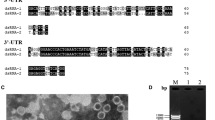
Total nucleic acids were extracted from O. himal-ulmi isolate HP62, ssRNA was precipitated with 2 M LiCl and dsRNA was precipitated with 5M LiCl. Analysis by polyacrylamide gel electrophoresis (PAGE) revealed two RNA segments, S1 and S2, of about 1.7 and 1.5 kbp, respectively (Fig. 1). Both RNA segments were resistant to S1 nuclease and DNase I (not shown), confirming that they are dsRNA.

Polyacrylamide gel electrophoresis of dsRNA from O. himal-ulmi isolate HP62. The gel was stained with ethidium bromide. The sizes of dsRNA markers (kbp) from O. novo-ulmi isolate Ld [4] are shown on the side of the gel
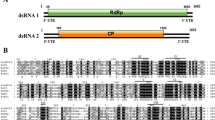
The complete nucleotide sequence of each dsRNA segment was determined from cDNA clones obtained using random primers, sequence-specific primers and 5′ RACE. Segment S1 comprised 1744 bp and segment S2 comprised 1567 bp. The EMBL database accession numbers for these sequences are S1 (AM087202) and S2 (AM087203). Segment S1 had the potential to encode a protein, P1, of 539 amino acids (calculated mass 62.7 kDa) on one strand, designated the plus strand. Segment S2 had the potential to encode a protein, P2, of 430 amino acids (calculated mass 46.3 kDa) on one strand, designated the plus strand. There were no significant open reading frames on the complementary (minus) strands of either RNA segment. The 5′ untranslated regions of the plus strands of segments S1 and S2 were 69 and 108 nucleotides, respectively, whereas the 3′ untranslated regions of the plus strands of segments S1 and S2 were 166 and 55 nucleotides, respectively. The 5′-terminal sequences of the two RNAs were almost identical, ACCGAAA for S1 and AUCGAAA for S2. Similarly there was a high degree of sequence similarity between the 3′-terminal sequences, with both segments containing the sequence UAUCAGG. This is consistent with evidence that for multicomponent RNA viruses, the 5′- and 3′-terminal sequences are important as recognition sites for the viral RNA RdRp [15].
A search of the UniProt database with the BLASTP program using the P1 amino acid sequence revealed highly significant similarities to RNA-dependent RNA polymerases (RdRps) of viruses of the family Partitiviridae. The most similar were the RdRps of Discula destructiva viruses 1 and 2 (DdV1 and DdV2) (71% and 71% identity, respectively), Penicillium stoloniferum virus S (PsV-S) (67% identity), Gremmeniella abietina virus MS1 (GaV-MS1) (66% identity), and Fusarium solanae solani virus (FsV). Analysis of the amino acid sequence of the P1 protein revealed motifs typical of RdRps, which could be aligned with similar motifs of a range of partitiviruses (Fig. 2). Hence the protein P1, encoded by O. himal-ulmi dsRNA S1, is a putative RdRp of a partitivirus, designated Ophiostoma partitivirus 1 (OPV1). A phylogenetic tree of the RdRps of these partitiviruses (Fig. 3) shows that the OPV1 RdRp clusters with the RdRps of DdV1, DdV2, PsV-S, GaV-MS1 and FsV with 100% bootstrap support.

Conserved amino acid sequence motifs in RdRps of partitiviruses. Motifs 2, 3, 4, and 5 were previously designated IV–VII by Koonin [16]. Motifs 1–5 were previously designated 3–7 by Bruenn [17]. Amino acids identical to those in the O. himal-ulmi P1 protein are shown in bold. Amino acids identical in all the sequences are shown by a star (*) below the sequences. The numbers of amino acids between each motif for each RdRp are indicated. Abbreviations, with Uniprot database accession numbers in parentheses, are: OPV1, Ophiostoma partitivirus 1; DdV1, Discula destructiva virus 1 (Q99D1); DdV2, Discula destructiva virus 2 (Q91H18); PsV-S, Penicillium stoloniferum virus S (Q6YDQ7); GaV-MS1, Gremmeniella abietina virus MS1 (Q6GYB9); FsV, Fusarium solanae virus (Q83328); PsV-F, Penicillium stoloniferum virus F (Q4G3H2); HmV, Helicobasidium mompa virus (Q8B0U3); HaV, Heterobasidion annosum virus (Q91T12); RnV1, Rosellinia necatrix virus (Q50LH7); AhV, Atkinsonella hypoxylon virus (Q85055); FpV, Fusarium poae (Q9YX75); RsV, Rhizoctonia solania solani virus (Q9Q9X2); OMV, Oyster mushroom virus (Q7TDZ9); PoV, Pleurotus ostreatus virus (Q5GHF1); CrV, Ceratocystis resinifera virus (Q5DM90); CCRSAV, Cherry chlorotic rusty spot associated virus (Q65A70); BCV, Beet cryptic virus (Q86632); PpV, Pyrus pyrifolia virus (Q92WP7); FCCV, Fragaria chiloensis cryptic virus (Q4FCM7); RYEV, Radish yellow edge virus (Q52UL1); WCCV, White clover cryptic virus (Q64FP0)

Neighbour-joining phylogenetic tree constructed using the RdRp sequences shown in Fig. 2, including the sequences between the motifs, using the program CLUSTAL X. Abbreviations are as in Fig. 2. Bootstrap numbers out of 1,000 replicates are given on the nodes. Only numbers greater than 900 are shown. The tree was rooted with the RdRp of Saccharomyces cerevisiae virus L-A (ScVLA), a member of the genus Totivirus in the family Totiviridae [Uniprot database accession no. Q87023], which was included as an outgroup
A search of the UniProt database with the BLASTP program using the P2 amino acid sequence revealed highly significant similarities to the capsid proteins of the partitiviruses DdV1 (52% identity), DdV2 (51% identity), PsV-S (51% identity), GaV-MS2 (51% identity), GaVMS1 (50% identity), and FsV (39% identity). An amino acid alignment of these six capsid proteins (Fig. 4) showed that they have identical amino acids at 83 positions. Hence the protein, P2, encoded by O. himal-ulmi dsRNA segment S2, is the putative capsid protein of the partitivirus OPV1.

Multiple alignment of amino acid sequences of partitivirus capsid proteins. The alignment was carried out with the program CLUSTAL X. (*) indicates identical residues; (.) and (..) indicate chemically similar residues, as defined by the program using the BLOSUM series
Isolation and characterization of OPV1 virus particles
OPV1 virus particles were isolated from homogenates of mycelium of O. himal-ulmi isolate HP24 by PEG precipitation, and differential and sucrose density gradient centrifugation. Electron microscopy revealed isometric particles of average diameter 29.7 nm (SD 1.8 nm; n = 30) (Fig. 5). Examination of dsRNA extracted from the purified virions by PAGE revealed two bands with the same mobility as those obtained by extraction of total RNA from O. himal-ulmi (not shown). Sequence analysis of these two RNAs showed that they are identical to RNAs S1 and S2. Examination of the OPV1 capsid protein by SDS-PAGE revealed a single band with an estimated mass of 46 kDa (not shown), the same mass as calculated for the protein encoded by O. himal-ulmi dsRNA segment S2. The 46-kDa band was extracted from a gel, blotted onto a membrane and digested with trypsin. The tryptic peptides were separated by HPLC and their masses determined by mass spectrometry. The N-terminal sequences of two of the peptides were determined by Edman degradation. Peptide 1 (mass 1372.48 Da) had the sequence SAVSSAPGAPASNQK, which corresponds to amino acids 29–43 of the protein P2 encoded by OPV1 dsRNA segment S2. Peptide 2 (mass 1435.63 Da) had the sequence FPVVFATGAGEPSR, which corresponds to amino acids 63–76 of the protein P2. This proves conclusively that dsRNA segment S2 encodes the OPV1 capsid protein.

Electron microscopy of purified OPV1 virions. The bar represents 100 nm
Discussion
The family Partitiviridae consists of viruses with isometric virions, 30–35 nm in diameter, a single major capsid protein of 42–73 kDa and a genome of two dsRNA segments each of 1.4–2.2 kbp [18]. Three genera in the family Partitiviridae have been described; the genus Partitivirus contains viruses of fungi, whereas the genera Alphacryptovirus and Betacryptovirus contain viruses of plants. The data reported in this paper clearly show that OPV1 is most closely related to fungal viruses in the genus Partitivirus. In the RdRp phylogenetic tree (Fig. 3), OPV1 and established fungal virus members of the genus Partitivirus, DdV1, DdV2, PsV-S, GaV-MS1 and FsV, form a cluster with 100% bootstrap support. The capsid protein sequences of these viruses were also closely related (Fig. 4), although less so than the RdRps, indicating a higher rate of evolution of the capsid proteins. There is a second well-supported fungal virus RdRp cluster, consisting of AhV, CrV, RsV, FpV, PoV and RnV1 (Fig. 3). The capsid proteins of viruses in the first RdRp cluster were not significantly related to those in the second RdRp cluster. The RdRp and capsid protein sequences of these two clusters therefore appear to have evolved in parallel and viruses in the two clusters may be regarded as two subgroups of the genus Partitivirus.
There are also two other well-supported RdRp clusters, one consisting of BCV (genus Alphacryptovirus) and two other plant viruses (FCCV and PpV) and the other consisting of a mixture of plant viruses (WCCV and RYEV, genus Alphacryptovirus) and fungal viruses (OMV, HaV and HmV, genus Partitivirus), together with CCRSAV, which may be a fungal or plant virus [19]. These two clusters also form a larger cluster with good (99.9%) bootstrap support. This raises the possibility of horizontal transfer of members of the family Partitiviridae between fungi and plants [20, 21]. This is quite feasible, since some of the viruses in these clusters have fungal hosts, which are pathogens of plants. The taxonomy of the Partitiviridae family may need to be revisited as molecular information of a wider range of viruses becomes available.
References
A.L. Dawe D.L. Nuss (2001) Annu. Rev. Genet. 35 1–29 Occurrence Handle11700275 Occurrence Handle1:CAS:528:DC%2BD38XlsVGl Occurrence Handle10.1146/annurev.genet.35.102401.085929
M.G. Milgroom P. Cortesi (2004) Annu. Rev. Phytopathol. 42 311–338 Occurrence Handle15283669 Occurrence Handle1:CAS:528:DC%2BD2cXotFyrtbc%3D Occurrence Handle10.1146/annurev.phyto.42.040803.140325
Y. Hong T.E. Cole C.M. Brasier K.W. Buck (1998) Virology 246 158–169 Occurrence Handle9657003 Occurrence Handle1:CAS:528:DyaK1cXktlOjtr0%3D Occurrence Handle10.1006/viro.1998.9178
Y. Hong S.L. Dover T.E. Cole C.M. Brasier K.W. Buck (1999) Virology 258 118–27 Occurrence Handle10329574 Occurrence Handle1:CAS:528:DyaK1MXivFOqtrg%3D Occurrence Handle10.1006/viro.1999.9691
K.W. Buck, C.M. Brasier, in dsRNA genetic elements: concepts and applications in agriculture, forestry and medicine, ed. by S.M. Tavantzis (CRC Press, Boca Raton, 2002) pp 165–190
C.M. Brasier M.D. Mehrotra (1995) Mycol. Res. 99 205 Occurrence Handle10.1016/S0953-7562(09)80887-3
H.J. Rogers K.W. Buck C.M. Brasier (1986) Plant Pathol. 35 277–287 Occurrence Handle1:CAS:528:DyaL28XlvVOrsL0%3D
Y. Hong S.L. Dover T.E. Cole C.M. Brasier K.W. Buck (1998) Virology 242 80–89 Occurrence Handle9501045 Occurrence Handle1:CAS:528:DyaK1cXhsl2hu7s%3D Occurrence Handle10.1006/viro.1997.8999
M.A. Frohman M.K. Dush G.R. Martin (1988) Proc. Natl. Acad. Sci. USA 85 8998–9002 Occurrence Handle2461560 Occurrence Handle1:CAS:528:DyaL1MXntVCmtQ%3D%3D Occurrence Handle10.1073/pnas.85.23.8998
F. Sanger S. Nicklen A.R. Coulson (1977) Proc. Natl. Acad. Sci. USA 74 5463–5467 Occurrence Handle271968 Occurrence Handle1:CAS:528:DyaE1cXhtlaru7Y%3D Occurrence Handle10.1073/pnas.74.12.5463
J. Devereux P. Haeberli O. Smithies (1984) Nucleic Acids Res. 12 539–549 Occurrence Handle6694906
J.D. Thompson T.J. Gibson F. Plewniak F. Jeanmougin D.G. Higgins (1997) Nucleic Acids Res. 24 4876–4882 Occurrence Handle10.1093/nar/25.24.4876
R.D.M. Page (1996) Comput. Applic. Biosci. 12 357–358 Occurrence Handle1:STN:280:ByiD2MfgtlA%3D
U.K. Laemmli (1970) Nature 227 680–685 Occurrence Handle5432063 Occurrence Handle1:CAS:528:DC%2BD3MXlsFags7s%3D Occurrence Handle10.1038/227680a0
K.W. Buck (1996) Adv. Virus Res. 47 159–251 Occurrence Handle8895833 Occurrence Handle1:CAS:528:DyaK2sXivVOksA%3D%3D
E.V. Koonin (1991) J. Gen. Virol. 72 2197–3206 Occurrence Handle1895057 Occurrence Handle10.1099/0022-1317-72-9-2197
J.A. Bruenn (1993) Nucleic Acids Res. 21 5667–5669 Occurrence Handle8284213 Occurrence Handle1:CAS:528:DyaK2cXhtVSnurg%3D
S.A. Ghabrial, K.W. Buck, B.I. Hillman, R.G. Milne, in Virus Taxonomy, VIIIth Report of the ICTV, eds. by C.M. Fauquet, M.A. Mayo, J. Maniloff, U. Desselberger, L.A. Ball (Elsevier/Academic Press, London, 2004) pp 581–590
R.H.A. Coutts, L. Covelli, F. Di Serio, A. Citir, S. Açikgöz, C. Hernández, A. Ragozzino, R. Flores, J. Gen. Virol. 85, 3399–3408 (2004)
K.W. Buck, in Molecular variability of fungal pathogens, eds. by P.D. Bridge, Y. Couteaudier, J.M. Clarkson (CAB International, Wallingford, 1998) pp 53–72
S.A. Ghabrial, Virus Genes 16, 119–131 (1998)
Acknowledgements
This work was supported by the UK Natural Environment Research Council as part of its Ecological Dynamics and Genetics (EDGE) program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Crawford, L.J., Osman, T.A.M., Booy, F.P. et al. Molecular Characterization of a Partitivirus from Ophiostoma Himal-ulmi . Virus Genes 33, 33–39 (2006). https://doi.org/10.1007/s11262-005-0028-6
Received:
Accepted:
Issue Date:
DOI: https://doi.org/10.1007/s11262-005-0028-6