
Abstract
At present, the cloud computing environment (CCE) has emerged as one of the significant technologies in communication, computing, and the Internet. It facilitates on-demand services of different types based on pay-per-use access such as platforms, applications and infrastructure. Because of its growing reputation, the massive requests need to be served in an efficient way which gives the researcher a challenging problem known as task scheduling. These requests are handled by method of efficient allocation of resources. In the process of resource allocation, task scheduling is accomplished where there is a dependency between tasks, which is a Directed Acyclic Graph (DAG) scheduling. DAG is one of the most important scheduling due to wide range of its applicable in different areas such as environmental technology, resources, and energy optimization. NP-complete is a renowned concern, so various models deals with NP-complete that have been suggested in the literature. However, as the Quality of Service (QoS)-aware services in the CCEplatform have turned into an attractive and prevalent way to provide computing resources emerges as a novel critical issue. Therefore, the key aim of this manuscript is to develop a novel DAG scheduling model for optimizing the QoS parameters in the CCEplatform and validation of this can be done with the help of extensive simulation technique. Each simulated result is compared with the existing results, and it is found that newly developed algorithm performs better in comparison to the state-of-the-art algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A cloud computing environment (CCE) can be utilized as a prominent model for business and high-performance computing which got additional attention from academia and industry [1, 2]. Due to the focus on a very high number of shared resources [2] into a resource group to achieve large-scale, robust, and efficient utilization of resources via the Internet with negligible managing and maintenance costs. Further, it provides different services to the users via cloud virtualization methods and it also provides customers to focus on business activities without expenses on various resources. Alternatively, for infrastructure-as-a-service (IaaS) facilitators viz. Amazon EC2, Google Drive, Microsoft Azure [3, 4] provide pooled resources by using virtual machines (VMs) to users on-demand(UOD). It can accuse the user’s charges which not only surgerate of resource utilization (RU) but also carry their significant benefit. There are three key groups of cloud service providers, such that public, private, and hybrid models [5]. The public model [6, 7] is most commonly used to organize the CCE platform, in which resources are possessed and functioned by the third-party service providers. The public cloud models send and impose services via Internet to end-users which are made for the service market adapted for organizations. On the other hand, private cloud models (such that IBM, Sun, and Cisco) are built for particular organizations. Precisely, reserved cloud models are accomplished and sustained by organizations and only organization members can access these models. However, to enhance the computing and storage capabilities, these private organizations strive to attain the public cloud resources also. Furthermore, hybrid cloud models [8,9,10] are evolved as encouraging computing prototypes that associate both cloud resources for better competence and scalability, also for attaining more plasticity and more disposition possibilities in hybrid cloud applications. Further, DAG scheduling [11] is frequently used in the scientific workflow model. A DAG scheduling contains numerous tasks/jobs and many dependencies between these tasks/jobs. In the CCE platform, users may buy various services facilitated by the CCE service provider to perform their acquiesced DAGs. Each DAG is typically linked with a deadline of execution to guarantee the quality of service (QoS) and low QoS typically enforces penalties; however, the provider of service may charge users based on makespan and QoS Parameters obtained during DAG Scheduling [12, 13]. Thus, to maximize profits along with guarantee QoS. Further, the applications of DAG scheduling in real-life problems [14, 15] are such as environmental technology; loop boundaries are identified during compile-time, data-flow computing problems, and various numerical methods, e.g. Gaussian elimination, Fourier transform, and its variants. In this paper, a novel heuristic-guided model with the QoS parameter optimization model is proposed to solve scheduling problems in DAGs in the CCE platform to get a near-optimal solution. So that the QoS parameters should be optimized to give better services to the user with optimal resource utilization.
After the introduction, the remaining parts of this manuscript are prearranged as given below. Section 2 contains a literature review and associated work. In Sect. 3, the proposed model and its formulation are given. Section 4 explains our concern to reducing scheduling length and cost. QoS Parameters in the DAG scheduling model with an algorithm are illustrated in Sect. 5. Section 6 describes the proposed algorithm (NHGCPM) with experiments simulation setup with the experimental results and corresponding analysis. The concluding remarks with future directions are mentioned in Sect. 7.
2 Literature review
Scheduling is a process that is used to allocate resources such that processor, bandwidth, frequency, memory, etc. to perform many jobs/tasks. The main role of task scheduling in cloud platforms is to optimize the total execution time [16]. This guarantees that a system is capable of serving each request to attain the desired QoS parameters. Suppose there is a list having n jobs /tasks to be scheduled on a system. Each task takes a certain amount of time and gives when stated in this way, the Scheduling problem is NP-hard [17,18,19,20], and we do not know about of any efficient, that is, polynomial-time algorithm for it. Generally, scheduling is of two types first is static, and the second is dynamic. Static scheduling identifies the properties of a parallel program like processing-time, communication-cost, dependencies on data, and many synchronizations before executing the program. In the parallel program, node and edge’s weighted DAG are indicated in which task/job processing times are represented by node’s weights and data dependencies; moreover, the communication-time between jobs/tasks is represented by edge, respectively. A DAG is a directed graph with no cycles and has particular importance nowadays. The key concepts are captured and analyzed using task scheduling models. The DAG scheduling is a very difficult problem since it has been proved that it is NP-complete [13, 21, 22]. Its major objective is to optimize the QoS parameters such as the makespan of a different application by appropriately assigning the tasks/jobs to the systems. There is two scheduling problems such as dynamic and static but this entire paper is based on the static scheduling problem. There are various good approximation algorithms [23, 24] for NP-hard/complete optimization problems like DAG scheduling [25]. The scheduling problem is NP-hard [8, 14, 18], and not know any polynomial-time(P) algorithm which is effective and efficient for the same. As a significance, the general preemptive scheduling problem is also falling in NP-complete [22, 25, 26].
In static scheduling algorithms, every piece of information is required for scheduling, such as the parallel application structure, execution time associated with each task/job, and transmission time between tasks/jobs must be recognized in advance. There are many methods to provide an approximate solution for DAG Scheduling. Furthermore, a few examples of existing DAG scheduling algorithms available in the literature are as follows: Heterogeneous Earliest Execution Time (HEFT), Critical Path on a Processor (CPOP), Critical Path on a Cluster (CPOC), Modified Critical Path (MCP), and Mapping Heuristic (MH) [27]. Topcuoglu et al.[28] considered a comparative and critical analysis among the HEFT, CPOP, and MH algorithms for different values of different DAG inputs. The results obtained in this study reveal that the performance of the HEFT algorithm is better than the CPOP, and MH algorithms. In the HEFT Algorithm, the idle time slot is high, and utilization of the resource is small due to the data’s excessive transmission delay between the jobs/tasks and the imbalanced structure of the DAG. Task scheduling performance may more improved by using prioritizing method and backfilling processes as suggested by Li et al. [29]. Some more task scheduling techniques [30,31,32] have been developed to optimize the scheduling length and other parameters of scheduling algorithms. To address the research gap a heuristic guided algorithm, i.e. a novel heuristic guided CPM (NHGCPM) is proposed to improve the performance.
The HEFT algorithm is typically used to obtain a scheduling length and also can be paralleled with different scheduling algorithms demonstrating a minimum time complexity. Moreover, it can be enhanced in two ways, firstly adding a new mechanism that can calculate the task priority, and secondly adding a novel mechanism that can improve the processor selection [33].Though this algorithm preschedules the residual task afore selected the scheduling tasks[34] and later calculated the relative duration of each DAG, moreover execution has become the most important part of the DAG. Therefore, each DAG can rearrange hybrid scheduling before the timeline, thus improving resource utilization. Nevertheless, various DAGs would be rejected when there is a resource shortage.
3 The Problem and the Proposed Model
The main objective of proposed model is to optimize the makespan-through appropriate allocation of the tasks to the nodes and arrangement of the execution sequence of the jobs/tasks. The performance of scheduling antecedence limits between jobs/tasks is conserved. The problem describes three key points related to jobs/task scheduling in CCE which can be applied in the DAG scheduling model, resource model, and the objective of scheduling [21, 25, 34].
3.1 DAG scheduling model
DAG model is the depiction of the application program using a directed graph (V, E) which is recognized as a DAG. It is denoted by Fw which is mathematically defined as Fw = {Xt, E, DT} where Xt = {x1, x2,…,xn} is the finite set of jobs/tasks of a given DAG, Fw,, E = {eij},eij is xi → xj edges between the tasks xi and xj. This is also known as dependency between the jobs/tasks. And DT is data transmission time which is linked with E and this time is taken between the jobs/tasks xi and xj.
A simple Fw is depicted in Fig. 1 which contains seven tasks. Here, x1 is an entry or starting job/task which does not have any parent jobs/tasks. Also, x7 is an end job/task or exit job/task and it also has not any children jobs/tasks.

Fw Simple Model with 7 jobs/tasks
The precedence constraint [21, 25, 33] should be kept between the jobs/tasks during the assignment of the jobs/tasks onto virtual machines (VMs) in the CCE platform.
3.2 Resource Allocation Model for CCE platform
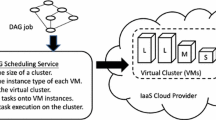
This section is related with the jobs/tasks allocation model with VMs which can be categorized into two different types such as homogenous and heterogeneous resource allocation models for the CCE platform. The homogeneous model comprises multiple VMs which are interconnected in the half-duplex mode, whereas the heterogeneous model contains multiple VMs which are interconnected in the full-duplex mode. Formally, this model consists of cloud server S = {si| i = 1 to pth servers} and each si having one or more VMs (M) [35].
The mapping of tasks of given Fw onto cloud server S is shown in Fig. 2 [20, 24, 34, 36,37,38]. If two jobs/tasks belong to the same cloud server, then their data transmission time should be null. i.e.

Mapping of Tasks onto VMs [38]
where Time depicts the transmission delay between the jobs/tasks xi and xj.
3.3 Objective function for the DAG scheduling
The objective function of the proposed model is to optimize the overall execution time of the tasks onto VM, i.e. to minimize the makespan of the DAG scheduling job/task [11, 12, 32].
where EFT is the earliest finished time of exit task xexit of given DAG Fw onto M.
3.3.1 Scheduling Attributes
Task scheduling attributes are very essential for allocation of the jobs/tasks onto machines as well as for finding the performance metrics of scheduling algorithms. The brief details of the attributes are as follows [32]:
-
a.
Estimated Computation Time(ECT) [38,39,40,41] is given as follows
$${ECT}_{ij}=\left[\begin{array}{ccc}{ECT}_{11}& {ECT}_{12}\cdots & {ECT}_{1n}\\ {ECT}_{21}& {ECT}_{22 }\dots ..& {ECT}_{2n}\\ {ECT}_{m1}& {ECT}_{m2}& {ECT}_{mn}\end{array}\right]$$(3)where ECTij is time of job/task xion machine Mj.
-
b.
Average ECT (AVG) [38, 42]of a job/task xi can be computed as the ratio of summation of ECT of all M and the total number of M. i.e.
$$AV{G}_{i}=\frac{\sum_{j=1}^{TotalM}EC{T}_{i,j}}{Total M}$$(4) -
c.
Critical Path(CP) [38, 43, 44] of Fw is given by equation
$$CP=\underset{\mathit{pat}h\mathit{\epsilon Fw}}{\mathrm{max}}\left\{length\left(path\right)\right\}$$(5)$$length\left(path\right)=\sum_{{x}_{i}\epsilon X}AVG\left({x}_{i}\right) +\sum_{e\epsilon E}{D}_{T}\left({x}_{i},{x}_{j}\right)$$(6) -
d.
Earliest Start Time (EST). [38, 45] is given as follows:
$$EST\left({x}_{i},{M}_{j}\right)=\left\{\begin{array}{ll}0 &\, \text{if} \, {x}_{i}\in {x}_{entry}\\ \underset{{x}_{i}\in \mathit{pred}\left({x}_{i}\right)}{\mathrm{max}}\{\mathit{EFT}({x}_{j},{M}_{j})+MET\left({x}_{i}\right)+{D}_{T}\left({x}_{i},{x}_{j}\right)\} &\text{otherwise}\end{array}\right\}$$(7) -
e.
Minimum Execution Time (MET) . [38, 46] is given as follows:
$$MET\left({x}_{i}\right)=min.\left\{ECT\left({x}_{i},{M}_{m}\right)\right\}$$(8) -
f.
Earliest Finished Time (EFT) . [38, 46] is given as follows:
$$EFT\left({x}_{i},{M}_{j}\right)=EC{T}_{ij}+EST\left({x}_{i},{M}_{j}\right)$$(9)
4 QoS Parameters used in Performance Analysis
In order to differentiate between the proposed model and heuristic models, performance metrics play a very important role. It helps to analyze the performance of models in various Fw models. There are several scheduling metrics but here it has been taken only six metrics such as Makespan, Scheduling-Length-Ratio (SLR), Speedup, Efficiency, Resource Utilization, and Cost. The details of the metrics are as follows:
-
a.
Makespan [35, 38, 42]: It is also called scheduling length and is defined as follows:
$$Makespan =Min.\{EFT({x}_{exit}, M)\}$$(10) -
b.
Scheduling Length Ratio (SLR) [38, 47, 48]:SLR can be computed as the ratio of Makespan and Critical Path tasks which takes minimum ECT value.
$$SLR=\frac{Makespan}{\sum_{{x}_{i}\in C{P}_{min}}Min(EC{T}_{i,j})}$$(11) -
c.
Speedup [42, 43, 47] It is defined as follows:
where is the total number of M.
$$Speedup=\frac{Min.\left[\sum_{j=1}^{m}ECTi,j\right]}{Makespan}$$(12) -
d.
Efficiency [42, 43, 47]: It can be computed as the ratio of Speedup and the total number of virtual machines. i.e.
$$Efficiency=\frac{Speedup}{m}\times 100$$(13) -
e.
Resource Utilization [36, 49]: It is measured by Average Resource Utilization(ARU) and the main goal of this metric is to increase the resource utilization.
$$ARU=\frac{\sum_{i=1}^{m}x\left({M}_{i}\right)}{Makespan\times m} \times100$$(14) -
f.
Cost [35, 38, 49]: The cost metric is very essential and it identifies the real cost of cloud resources used by end users. The general table for the cost metric is given in Table 1 [40]. It is defined as follows:
$$Cost=\sum {E}_{ij}\times C(V{M}_{j})$$(15)
where Eij is the execution time of the task xi on Mj and C(VMj) is the cost of Mj per unit time.
The existing scheduling algorithm considers specific characteristics in the CCE Platform for the proper allocation of resources. The complexity of the application, user need, and heterogeneity of the CCE platform prevent any DAG scheduling algorithm to achieve its optimal value of the QoS parameters to measure the relative performance.
5 Proposed algorithm Design and Analysis
The most widely used combinatorial optimization issues is the DAG scheduling issue, i.e. NP-Complete since it uses simple algorithms [13, 21, 22]. This can create problems that involves optimizing the QoS Parameters such as makespan and cost. To overcome this complex issue, there is an accurate method that indicates exponential time-complexity. Furthermore, such types of methods can only be used for small size issues. But for generalizion of these issues require an effective solution to optimize QoS parameters e.g. makespan, cost, throughput, etc. In the literature [27], many exact algorithms such as the HEFT and CPOP are designed to solve limited size DAG scheduling problems. The popular heuristic algorithms such as BFS and DFS methods [50] are the graph traversal methods. DFS is also known as an edge-oriented method that uses the stack technique for traversal in a graph whereas BFS is also known as a vertex-oriented method that uses the queue technique for traversal in a graph. These heuristics are easy to apply to simple search space problems but solving combinatorial issues is now become a major concern [50] such as DAG Scheduling using BFS and DFS. It motivates the authors to develop a novel algorithm referred to as a novel heuristic guided CPM (NHGCPM) to increase the performance of the existing system. The NHGCPM combines the advantages of both DFS [44], HEFT, and CPM to find a higher extent of convergence to improve the application flexibility. Further, on the basis of jobs/tasks, priority of given Fw and the priority is computed using DFS [50]. Figure 3 represents the process of the proposed model. There are two key steps are used in the novel method of the DAG scheduling which are given as follows:

Flowchart of NHGCPM Model
Step 1: This step is consisting of Task Stack (TS) and initially, it has only entry tasks of the given Fw model. The addition and deletion of the tasks/jobs as per the DFS method are performed. When the entry deletes for TS, it will be added to Ready Queue (RQ). This queue mostly comprises the priority of the tasks. All successors’ tasks of the entry tasks will be inserted into TS. Similarly, all non-entry tasks are deleted from TS and added into RQ but here, the successor tasks of non-entry tasks whether it will be included in TS or not depending on the successor’s tasks' present condition. The present condition means the successor task should be included in TS if and only if this task will not either TS or RQ. Otherwise, these tasks would be simple leave it, and not included as duplicates either in TS or RQ.
Step 2: This is the resource allocation step to the available virtual machine (VMs). In this step, the allocation of the tasks as per RQ, precedence constraint, Earliest start time first (EST), and Earliest finish time first (EFT). The priority of the task/job is in RQ but it should satisfy the precedence constraint before allocation to machines, if it is satisfied then allocation to VM as per EST and EFT of the task and machine. These attributes should be minimum. If any task/job does not satisfy the precedence constraint, in that case, the removed task will be added at the rear end of RQ. The complete description of the proposed model is described in Table 2.
6 Simulation environment and results discussion
The Simulation study has been conducted to test the performance of a novel developed model NHGCPM by simulating the benchmark the Cloud-Sim [6] which is used to generate based services for graph such as AWS Neptune., as a simulation platform using JAVA as a programming language. The components of the Cloud like data centers, brokers, hosts, and VM policies can be modeled by the Cloud-Sim toolkit. The analysis of the results is an essential and integral part of any research to find a good solution that helps to differentiate between the proposed model and the state of the art. This section presents the simulation result of the proposed model using three DAG Models as Fw Model1 [38] with 10 tasks {x1,…, x10}, Fw Model2[46] with 15 tasks {x1,…,x15} and Fw Model3 [38] with 26 tasks {x1,…,x26} as shown in Figures 4,7, and 10. Also, three models Expected time compute (ECT) value and cost value tables are shown in Tables 3, 4, 5, 6, 7, 8. The performance metrics such as makespan, speedup, efficiency, SLR, Average Resource Utilization (ARU), and Cost are used for comparison between the proposed model and the state-of-the-art models (Figs. 5, 6).

Fw Model1 with 10 tasks

Tasks Transformation to Priority Queue

Gantt. Chart for Fw Model.1

Fw Model2 with 15 tasks
As per the proposed model, finding the TS and RQ of the given Fw Model1 and also computing the priority of the tasks/jobs are shown in Fig. 4.
The assignment of the tasks/jobs onto VM as PQ and Precedence Constraint is given in the algorithm. The tasks/jobs are removed from the front end of the PQ, check its precedence constraint, if it is satisfied then assign to virtual machine otherwise insert at the rear end of PQ.
Consider a cloud server S = {s1,s2} having two servers s1 = {M1,M2} consists of two virtual machines and s2 = {M3} contains of only one virtual machine. The assignment of the tasks/jobs as per the proposed algorithm, NHGCPM and computes makespan 65 units.
Case 1: Fw Model1 with 10 Tasks
Case 2: Fw Model2 with 15 Tasks.
Similarly, for FwModel2 finding the TS and RQ of the given Fw Model2 and also computing the priority of the tasks in PQ as given in the proposed algorithm, NHGCPM, and process shown in Fig. 8.

Tasks Transformation to Priority Queue
The allocation of the tasks onto the virtual machine as PQ and Precedence Constraint is given in the algorithm. The tasks are removed from the front end of the PQ, check its precedence constraint, if it is satisfied then allocate to the virtual machine otherwise insert at the rear end of the PQ. Consider a cloud server S = {s1,s2} having two servers s1 = {M1,M2}and s2 = {M3,M4}, both servers consists of two virtual machines. The allocation of the tasks as per the proposed algorithm, NHGCPM and gives makespan 136 units as shown in Fig. 9.

Gantt. Chart Fw Model.2
Case 3:Fw Model3 with 26 Tasks
The allocation of the tasks onto the virtual machine as PQ and precedence constraint is given in the algorithm. The tasks are removed from the front end of the PQ, check its precedence constraint, if it is satisfied then allocate to virtual machine otherwise insert at the rear end of PQ (Figs. 10, 11). Consider a cloud server S = {CS1, CS2} having two servers CS1 = {V1,V2}and CS2 = {V3,V4}, both servers consists of two virtual machines. In Fig. 12, Gantt chart depicted the allocation of the tasks as per the proposed algorithm (NHGCPM) and it gives makespan 181 units.

Fw Model3 with 26 tasks

Tasks Transformation to Priority Queue (PQ)

Gantt. Chart for Fw Model.3
The details of the comparison between the proposed model and heuristic models using three DAG models are given in Table 9. Makespan is minimized in proposed model as compared to heuristic algorithms [38]. Other metrics results of heuristic algorithms are taken from [38]. The graphical representation of the scheduling algorithms is shown in Fig. 13, 14, 15, 16, 17, 18.

Comparative Study of Scheduling Length

Comparative Study of Speedup

Comparative Study of Efficiency

Comparative Study of SLR

Comparative Study of Resource Utilization

Comparative Study of Cost
Firstly, we consider the effect of QoS Parameters in the input DAG over the makespan considering different parameters is shown in Table 9. Table 9 clearly specifies that NHGCPM performs better compared to the state of the art for all different scenarios.
Figure 13 represents the effect of makespan in the input DAG over the makespan considering different parameters like HEFT, CPOP, ALAP, PETS. It specifies that NHGCPM performs better compared to the state-of-the-art algorithms considered for three different scenarios.
We consider the effect of Speedup in the input DAG over the makespan considering different parameters as shown in Fig. 14. It specifies that NHGCPM has highest values as compared to other parameters.
Comparative study of Efficiency has been done in which the input DAG has been compared over the makespan considering different parameters in Fig. 15. It specifies that NHGCPM performs better compared to the state-of-the-art algorithms considered for three different scenarios.
We consider the effect of SLR in the input DAG over the makespan considering different parameters is shown in Fig. 16. NHGCPM performs best as compared to other algorithms.
Figure 17 represents the effect of utilization in the input DAG over the makespan considering different parameters. It specifies that NHGCPM performs best with respect to the state-of-the-art algorithms is considered for three scenarios.
We consider the effect of cost in the input DAG over the makespan considering different parameters is shown in Fig. 18 and it specifies that NHGCPM performs best with respect to other algorithms the state-of-the-art algorithms is considered for three scenarios.
7 Conclusion and future scope
The proposed model tried to analyze the cost optimization problem for DAG scheduling in a cloud environment. Several types of VM instances can be assigned, when diverse services are requested by users. From the experimental evaluation and comprehensive analysis of the proposed model demonstrate that the proposed algorithm, “A Novel heuristic guided CPM (NHGCPM)”, outperforms the state-of-the-art algorithms with trade-offs between the several QoS Parameters.
However, it has been known that the most reliable and current platform is the QoS-driven public cloud services, and the QoS Parameters optimization emerges as a novel serious concern. Hence, we aimed to put forward a novel DAG scheduling model for this purpose to optimize the QoS parameters in a cloud environment, where task/job scheduling requires adopting resource provisioning to attain the near-optimal solution. This algorithm is widely replicated using a different benchmark, scientific and original DAGs used in environmental technology. All the implemented results are paralleled with other state-of-the-art DAG scheduling algorithms, and it has been suggested that the given method facilitates users in the cloud computing environment. Outcomes are correspondingly endorsed through the analysis of variance statistical tests. In future scope, we will focus on further optimizations of the proposed algorithm, NHGCPM, and extensions for the scientific workflow applications with various QoS parameters; moreover, it will be used in different real-time applications. Furthermore, future work is probable by learning the performance of current demand after making them security-guided and by incorporating different constraints.
Availability of data and material
Available on request.
References
Mutlag AA, Abd Ghani MK, Arunkumar N et al (2019) Enabling technologies for fog computing in healthcare IoT systems. Futur Gener Comput Syst 90:62–78. https://doi.org/10.1016/j.future.2018.07.049
Gai K, Guo J, Zhu L, Yu S (2020) Blockchain Meets Cloud Computing: A Survey. IEEE Commun Surv Tutorials 22:2009–2030. https://doi.org/10.1109/COMST.2020.2989392
Malla S, Christensen K (2020) HPC in the cloud: Performance comparison of function as a service (FaaS) vs infrastructure as a service (IaaS). Internet Technol Lett 3:e137. https://doi.org/10.1002/itl2.137
Scheuner J, Leitner P (2020) Function-as-a-Service performance evaluation: A multivocal literature review. J Syst Softw 170:110708. https://doi.org/10.1016/j.jss.2020.110708
Sharma S, Sajid M (2021) Integrated fog and cloud computing: issues and challenges. Int J Cloud Appl Comput (IGI) 11(4), Article 10
Buyya R, Pandey S, Vecchiola C (2009) Cloudbus toolkit for market-oriented cloud computing. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). pp 24–44
Marozzo F (2018) Infrastructures for high-performance computing: Cloud infrastructures. Encycl Bioinforma Comput Biol ABC Bioinforma 1–3:240–246. https://doi.org/10.1016/B978-0-12-809633-8.20374-9
Hammed SS, Arunkumar B (2020) A cost effective‐ secure algorithm for work‐flow scheduling in cloud computing. Internet Technol Lett e233. Doi: https://doi.org/10.1002/itl2.233
Zhou J, Wang T, Cong P et al (2019) Cost and makespan-aware workflow scheduling in hybrid clouds. J Syst Archit 100:101631. https://doi.org/10.1016/j.sysarc.2019.08.004
Sahitya A (2021) Importance of Fog Computing in. Integr Cloud Comput with Internet Things Found Anal Appl, p 211
Song A, Chen W-N, Luo X-N, et al (2020) Scheduling Workflows with Composite Tasks: A Nested Particle Swarm Optimization Approach. IEEE Trans Serv Comput
Jain R, Sharma N (2021) A QoS Aware Binary Salp Swarm Algorithm for Effective Task Scheduling in Cloud Computing. In: Progress in Advanced Computing and Intelligent Engineering. Springer, pp 462–473
Farid M, Latip R, Hussin M, Abdul Hamid NAW (2020) A survey on QoS requirements based on particle swarm optimization scheduling techniques for workflow scheduling in cloud computing. Symmetry (Basel) 12:551
da Silva EC, Gabriel PHR (2020) A Comprehensive Review of Evolutionary Algorithms for Multiprocessor DAG Scheduling. Computation 8:26
Hosseinzadeh M, Ghafour MY, Hama HK, et al (2020) Multi-objective task and workflow scheduling approaches in cloud computing: a comprehensive review. J Grid Comput, pp 1–30
.Li J, Zhang X, Han L et al. (2021) OKCM: improving parallel task scheduling in high-performance computing systems using online learning. J Supercomput 77:5960–5983
Woeginger GJ (2003) Exact algorithms for NP-hard problems: A survey. In: Combinatorial optimization—eureka, you shrink! Springer, pp 185–207
Hanen C (1994) Study of a NP-hard cyclic scheduling problem: The recurrent job-shop. Eur J Oper Res 72:82–101
Tong Z, Chen H, Deng X et al (2020) A scheduling scheme in the cloud computing environment using deep Q-learning. Inf Sci (Ny) 512:1170–1191
Du J, Leung JY-T (1989) Complexity of scheduling parallel task systems. SIAM J Discret Math 2:473–487
Pop F, Dobre C, Cristea V (2008) Performance analysis of grid DAG scheduling algorithms using MONARC simulation tool. In: 2008 International Symposium on Parallel and Distributed Computing, pp 131–138
Bozdag D, Ozguner F, Catalyurek UV (2008) Compaction of schedules and a two-stage approach for duplication-based DAG scheduling. IEEE Trans Parallel Distrib Syst 20:857–871
Kannan R, Karpinski M (2005) Approximation algorithms for NP-hard problems. Oberwolfach Reports 1:1461–1540
Hochba DS (1997) Approximation algorithms for NP-hard problems. ACM SIGACT News 28:40–52
Demirci G, Marincic I, Hoffmann H (2018) A divide and conquer algorithm for dag scheduling under power constraints. In: SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, pp 466–477
Epstein L, Tassa T (2006) Optimal preemptive scheduling for general target functions. J Comput Syst Sci 72:132–162
Sulaiman M, Halim Z, Waqas M et al (2021) A hybrid list-based task scheduling scheme for heterogeneous computing. J Supercomput 77:10252–10288
Topcuoglu H, Hariri S, Wu M-Y (2002) Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans parallel Distrib Syst 13:260–274
Li J, Zhang X, Han L et al (2021) OKCM: improving parallel task scheduling in high-performance computing systems using online learning. J Supercomput 77:5960–5983
Ramezani R (2021) Dynamic scheduling of task graphs in multi-FPGA systems using the critical path. J Supercomput 77:597–618
Chowdhary SK, Rao ALN (2021) QoS Enhancement in Cloud-IoT Framework for Educational Institution with Task Allocation and Scheduling with Task-VM Matching Approach. Wireless PersCommun 121:267–286
Medara R, Singh RS (2022) A Review on Energy-Aware Scheduling Techniques for Workflows in IaaS Clouds. Wireless PersCommun. https://doi.org/10.1007/s11277-022-09621-1
Xu Y, Li K, Hu J, Li K (2014) A genetic algorithm for task scheduling on heterogeneous computing systems using multiple priority queues. Inf Sci (Ny) 270:255–287
Xu X-J, Xiao C-B, Tian G-Z, Sun T (2016) Hybrid scheduling deadline-constrained multi-DAGs based on reverse HEFT. In: 2016 International Conference on Information System and Artificial Intelligence (ISAI), pp 196–202
Samimi P, Teimouri Y, Mukhtar M (2016) A combinatorial double auction resource allocation model in cloud computing. Inf Sci (Ny) 357:201–216
Rajak R, Shukla D, Alim A (2018) Modified critical path and top-level attributes (MCPTL)-based task scheduling algorithm in parallel computing. In: Soft Computing: Theories and Applications. Springer, pp 1–13
Rajak R (2018) Deterministic task scheduling method in multiprocessor environment. In: International Conference on Advances in Computing and Data Sciences, pp 331–341
Rajak N, Shukla D, (2019) Performance analysis of workflow scheduling algorithm in cloud computing environment using priority attribute. Int J Adv Sci Technol Australia 28(16):1810 – 1831
Braun TD, Siegel HJ, Beck N et al (2001) A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems. J Parallel Distrib Comput 61:810–837
Pop F, Dobre C, Cristea V (2009) Genetic algorithm for DAG scheduling in grid environments. In: 2009 IEEE 5th International Conference on Intelligent Computer Communication and Processing, pp 299–305
Canon L-C, Jeannot E (2009) Evaluation and optimization of the robustness of dag schedules in heterogeneous environments. IEEE Trans Parallel Distrib Syst 21:532–546
Raza Abbas Haidri (2020) ChittaranjanPadmanabhKatti, Prem Chandra Saxena, Cost effective deadline aware scheduling strategy for workflow applications on virtual machines in cloud computing. J King Saud Univ Comput Inf Sci 32(6):666–683
Darbha S, Aggarwal DP (1994) SDBS: A task duplication based optimal scheduling algorithm. In Proceedings of IEEE scalable high performance computing conference, Knoxville, TN, pp 756_61.
Sinnen O Task scheduling for parallel systems. Wiley-Interscience Publication (2007)
Kumar MS, Gupta I (2017) Jana PK Delay-based workflow scheduling for cost optimization in heterogeneous cloud system. In: 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, pp. 1–6
Gupta I, Kumar MS, Jana PK (2018) Efficient workflow scheduling algorithm for cloud computing system: a dynamic priority-based approach. Arab J Sci Eng 43(12):7945–7960
Hwang K (2005) Advanced computer architecture: parallelism,scalability, programmability, 5th reprint. New Delhi:TMH Publishing Company, pp 51_104
Akbar MF, Munir EU, Rafique M M, Malik, Khan SU, Yang LT (2016)zs List-Based Task Scheduling for Cloud Computing. In: IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical And Social Computing (CPSCom) and IEEE Smart Data (SmartData), Chengdu, pp 652–659
Kalra M, Singh S (2015) A review of metaheuristic scheduling techniques in cloud computing. Egypt informatics J 16:275–295
Cormen TH, Leiserson CE, Rivest RL, Stein C (2009) Introduction to algorithms. MIT press
Funding
None.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors declares that they have mo conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rajak, R., Kumar, S., Prakash, S. et al. A novel technique to optimize quality of service for directed acyclic graph (DAG) scheduling in cloud computing environment using heuristic approach. J Supercomput 79, 1956–1979 (2023). https://doi.org/10.1007/s11227-022-04729-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-022-04729-4