
Abstract
In mobile wireless broadcast networks, XML data is encrypted before it is sent over the broadcast channel in order to ensure the confidentiality of XML data. In these networks, mobile clients must not have access to all the XML data; rather they should have access to some parts of the XML data that are relevant to them and to which they are authorized to have access. In this paper, a new encrypted XML data stream structure is proposed which supports the confidentiality of XML data over the broadcast channel. In our proposed stream structure, the size of encrypted XML data stream is reduced by grouping the paths, XML nodes, texts, and attributes together. The proposed structure includes several indexes to skip from irrelevant data over the broadcast channel. The experimental results demonstrate that the use of our proposed stream structure efficiently disseminates XML data in mobile wireless broadcast networks in a secure manner and the indexes in our proposed stream structure improve the performance of XML query processing over the encrypted XML data stream.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
XML [1] is a de facto standard language for data dissemination over the Internet. Recently, many applications are using XML for data broadcasting in wireless broadcast environments such as traffic and travel information systems and weather information systems [2,3,4,5].
Data broadcasting in mobile wireless broadcast networks is an effective way to disseminate the data [6, 7]. Two issues, namely efficient access to the data and energy consumption of mobile devices in retrieving the data over the broadcast channel, are very important in this type of networks, because mobile devices have low battery power and limited processing resources [8, 9].
Generally, mobile devices work in two modes: the active mode and the doze mode [10, 11]. The active mode is when mobile devices are consuming the maximum amount of energy or battery power, while the doze mode is when they consume the least amount of energy [12, 13].
In mobile wireless broadcast networks, XML data is disseminated in two modes: the on-demand mode and the push-based mode [2,3,4,5]. In the on-demand mode [14,15,16,17,18,19], mobile clients send their XML queries to a broadcast server through an uplink channel; then, the broadcast server receives XML queries and processes them based on their priorities. After the XML queries are processed and the XML query results are prepared, the broadcast server sends the XML query results in a downlink channel. In the push-based mode [20,21,22,23,24], mobile clients do not send XML queries to the broadcast server; rather the server broadcasts the XML data through the broadcast channel and mobile clients listen to the broadcast channel and receive the required XML data. As no request is sent to the broadcast server for retrieving the XML data, this mode of data dissemination is thus more cost-effective than the on-demand mode in terms of energy consumption in mobile devices. It should be noted that this paper proposes an efficient XML data stream structure to disseminate the XML data in a secure manner over a wireless broadcast channel in the push-based mode.
Actually, two different performance metrics are used for assessing the access performance to the data in a wireless broadcast stream, namely access time and tuning time. Access time refers to the period of time that mobile clients listen to the broadcast channel (i.e., send their requests) until they completely receive the required data from the broadcast channel. Therefore, it is used to measure the efficient access to mobile wireless broadcast channels. Tuning time refers to the period of time that mobile clients are in the active mode in order to retrieve the desired data from the broadcast channel and it is thus used to measure the energy consumption of mobile devices for downloading the data over the broadcast channel [25, 26].
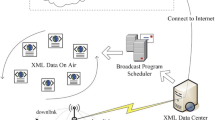
Figure 1 shows the XML data dissemination over a mobile wireless broadcast network in the push-based mode. As shown in Fig. 1, the broadcast server first retrieves the XML data from the XML data repository and then parses it using an XML parser. The broadcast server then converts the parsed XML document into an XML data stream via the stream generation algorithm. Next, the server broadcasts the XML data stream over a wireless broadcast channel. Suppose that the mobile client c wants to receive the XML data En. The period of time that the mobile client c listens to the broadcast channel until the XML data is received completely is referred to as the access time, which is equal to the time t4. The period of time that the mobile client c is in the active mode (i.e., when the XML data is being received) determines the tuning time, which is the sum of times t1 + t2 + t3. In fact, the times which the mobile client c does not retrieve the data from the broadcast channel and it is waiting for the desired data, it is in the doze mode and its energy consumption reduces significantly.

Mobile wireless broadcast network architecture for XML data broadcast [22]
In mobile wireless broadcast networks, the XML data is encrypted before it is sent over the broadcast channel in order to ensure the confidentiality of XML data [27]. In addition, in these networks, mobile clients must not have access to all the XML data; rather they should have access to some parts of the XML data that are relevant to them and to which they are authorized to have access [28,29,30,31,32,33,34,35,36]. A variety of indexing methods have recently been proposed for XML data broadcast in mobile wireless broadcast networks [20,21,22,23,24]. Although these indexing methods can process XML queries efficiently over a mobile wireless broadcast channel in terms of access time and tuning time, but they do not guarantee the confidentiality of XML data over a broadcast channel.
In the literature, the only stream structure that can broadcast the encrypted XML data over a mobile wireless broadcast channel is SecNode proposed by Fathi et al. [37, 38]. The SecNode structure uses the KeyID field (to encrypt/decrypt the XML nodes), the Min(NCS) field (to jump to the desired XML nodes over the encrypted XML data stream), the Min(NIS) field (to skip from the irrelevant data over the encrypted XML data stream), and the preorder field and the postorder field (to label the XML nodes in order to process the twig pattern XML queries over the encrypted XML stream).
The goal of this paper is to propose a stream structure to disseminate the encrypted XML data over a mobile wireless broadcast channel which contains several indexes to skip the irrelevant data during the process of XML queries over the broadcast channel. The proposed stream structure efficiently disseminates XML data over a mobile wireless broadcast channel in a secure manner and the indexes in our proposed stream structure improve the performance of XML query processing over the encrypted XML data stream in terms of access time and tuning time. Hence, the main contributions of this paper are summarized as follows:
We define a new encrypted XML data stream structure to selectively access the XML data over a mobile wireless broadcast channel. This proposed stream structure improves the performance of XML querying in terms of access time and tuning time by applying several indexes to skip from the irrelevant data over the encrypted XML data stream. The proposed stream structure also reduces the length of the encrypted XML data stream by grouping the paths, XML nodes, texts, and attributes together.
We explain how to process the different types of XML queries over the encrypted XML data stream efficiently in terms of access time and tuning time. The proposed stream structure contains three segments, namely “Index Segment,” “Data Segment,” and “Text & Attribute Segment.” These segments contain the information about the equivalent XML nodes and their child and sibling nodes, the structural information of equivalent XML nodes, the text and attributes values for each equivalent XML node, respectively. The mobile clients can efficiently process the simple path XML queries as well as the twig pattern XML queries using the information of these three segments.
We evaluate the performance of our proposed stream structure in processing the different types of XML queries by performing several experiments using the different XML data sets. Our proposed structure is compared with the SecNode structure proposed by [37, 38] since the SecNode structure is the only structure that broadcasts an encrypted XML data stream over a mobile wireless broadcast channel.
The rest of this paper is organized as follows: In Sect. 2, the existing research works on the XML data dissemination and secure XML data broadcast in mobile wireless broadcast channels are reviewed. In Sect. 3, the process of generating an encrypted XML data stream based on our proposed structure is explained. In Sect. 4, the process of XML querying over the encrypted XML data stream is described. In Sect. 5, the experimental results in processing the different types of XML queries over the encrypted XML data stream are presented. Finally, in Sect. 6, the paper is concluded with a conclusion and discussion of future works.
2 Related works
In this section, we first review different ways of XML data broadcast in mobile wireless broadcast networks and then explain different methods for secure XML data broadcasting.
2.1 XML data broadcast in mobile wireless broadcast networks
The first indexing method for XML data broadcast in mobile wireless broadcast networks has been proposed in [24]. A structure called S-Node has been introduced in [24] for XML data broadcast and process the simple path XML queries. Three indexing methods called OSA,Footnote 1 TSA,Footnote 2 and SPAFootnote 3 have been introduced for the proposed structure. In the OSA indexing method, each S-Node contains the address of the next sibling node in the XML data stream, which indicates the time interval between the current S-Node and the next sibling S-Node over the broadcast channel which has been delivered. This address is suitable for mobile clients in order to jump from the current S-Node into the next sibling S-Node when the current S-Node has no child node, while the next query node does not exist or the S-Node is not the query result. The OSA indexing method can reduce the energy consumed by mobile devices to retrieve the XML data from the broadcast channel. The TSA indexing method uses two different addresses in addition to having the fields of the OSA method. In the TSA indexing method, each S-Node may contain the address of the nearest sibling node with the same tag name for that which is called same-tag-address, as well as the address of the nearest sibling node with a different tag name which is called different-tag-address. The TSA indexing method uses two additional fields (i.e., same-tag-address and different-tag-address) to process the simple path XML queries. Therefore, it is more efficient than the OSA indexing method. The SPA indexing method contains another additional field called same-path-address, which refers to the nearest cousin/sibling node with the same path name. Using the SPA indexing method, a chain of S-Node containing the same-path-address for the XML data stream is constructed, which can contribute to more effective search on the XML data stream. Although the three OSA, TSA, and SPA indexing methods can significantly process the simple XML queries, they contain replicated XML node names in the XML data stream, which increase the XML data stream size and access time; moreover, these indexing methods cannot process the twig pattern XML queries.
An indexing method based on the path summarization technique [39,40,41] called PSFootnote 4 has been proposed in [20]. This method eliminates redundant node names in the XML data stream and thus reduces the XML data stream size and access time, but this indexing method cannot process the twig pattern XML queries.
A new structure called DIX has been proposed in [21] for XML data broadcast in mobile wireless broadcast networks. The DIX structure contains CLFootnote 5 field (the address of the nearest DIX node with the same depth and root-to-node path), FLFootnote 6 field (the address of the nearest DIX node with the same depth but different root-to-node path), and LPIFootnote 7 field (the root-to-node path). Using the LPI field, mobile clients can start process the XML querying over the XML data stream at any time without the need to wait for the next broadcast cycle starts. The CL index is used to jump forward to the next candidate node which may be the result of the XML query, while the FL index is used to ignore the irrelevant parts of the XML data stream. A cluster-based technique called C-DIX has also been proposed in [21]. If the nodes with the same features in the XML data stream are clustered, mobile clients can retrieve the XML data via access to a more limited parts in the XML data stream, meaning that the access time and the tuning time are reduced. Based on these observations, a clustering indexing method based on the depth of the XML nodes was proposed. In the C-DIX indexing method, similar XML nodes are clustered in the parts called CR,Footnote 8 which can have access from the current depth to the next depth via a field called Next Depth Pointer.
In [23], an indexing method called PS + Pre/Post has been proposed. This indexing method is actually a combination of the path summary technique [39,40,41] and the pre/post labeling scheme [42,43,44,45]. As this indexing method makes the use of the path summary technique, it can improve the access time and tuning time by eliminating the similar node names. It also uses the pre/post labeling scheme to label the XML nodes in order to process the twig pattern XML queries over the XML data stream.
In [22], a new technique called lineage encoding has been proposed to process the twig pattern XML queries over a broadcast channel. The proposed technique uses the two types of lineage encoding called lineage vertical (V) code and horizontal (H) lineage code. The lineage coding presents the parent–child relationships between XML nodes as a sequence of bit strings called lineage code (V, H). This lineage code is an effective and lightweight technique that supports the process of twig pattern XML queries over the XML data stream.
2.2 Secure XML data broadcast
In [46], a standard has been proposed for XML data encryption by World Wide Web Consortium [47]. According to this standard, the encrypted data retains the meaning and syntax of XML and adds only an element with an encrypted string called EncryptedData. This element has four sub-elements called EncryptionMethod, KeyInfo, CipherData, and EncryptionProperties. The EncryptionMethod represents an algorithm and the parameters used to encrypt/decrypt the XML data. The KeyInfo represents a key used for encryption/decryption (not including the key value). The CipherData has a CipherValue as the sub-element, and the CipherValue represents an encrypted string generated by encrypting the element name and body. The EncryptionProperties represents the additional information related to the EncryptedData element.
In [48], a new method called XFlat has been proposed to broadcast an encrypted XML view over the Internet. In the XFlat method, the XML tree is first decomposed into a set of XML sub-trees based on the accessibility of XML nodes. The sub-trees include a set of XML nodes with the same accessibility. The XFlat method then encrypts each tree individually and stores it in the last view of transmitted XML. In order to process the XML query over the encrypted XML views, the XFlat method uses the flat structure under the XML view to accelerate the processing of XML query.
In [49], a query-aware decryption method has been proposed for processing the XML queries against the encrypted XML data. To decrypt a part of the encrypted XML data which may contain the XML query results, an encrypted XML index is transmitted along with the encrypted XML data on the Internet. The index information determines the location of the XML query results in the XML data, and therefore, this prevents the unnecessary decryption during the process of XML querying.
Although these methods broadcast XML data securely over the Internet, they cannot be used for XML data broadcast in mobile wireless broadcast networks, because these methods consider efficiency and scalability, while the main concern in mobile wireless broadcast networks is the effective access to data stream over a broadcast channel and the reduction of energy consumption in mobile devices to retrieve data over a broadcast channel.
In [37, 38], an indexing method has been proposed to broadcast the encrypted XML data over a mobile wireless broadcast channel. In [37, 38], a structure called SecNode, which is actually an extension of the DIX structure proposed in [21], has been provided. The SecNode structure uses the KeyID field (to encrypt/decrypt the XML nodes), the Min(NCS) field (to jump to the desired XML nodes over the encrypted XML data stream), the Min(NIS) field (to skip from the irrelevant data over the encrypted XML data stream), and the preorder field and the postorder field (to label the XML nodes in order to process the twig pattern XML queries over the encrypted XML stream). In [37, 38], an authorization code (AC) has also been defined which authorizes different users in order to have access to the XML nodes. The proposed indexing method not only processes the simple path XML query, it can also process the twig pattern XML queries.
3 The proposed encrypted XML data stream structure
The XML document shown in Fig. 2 is used to explain our proposed stream structure. Figure 3 shows the tree structure of the XML document shown in Fig. 2. As shown Fig. 3, each XML node is assigned with two rectangles where the left and right rectangles represent the accessibility of an XML node to mobile clients of the groups g1 and g2, respectively. In Fig. 3, the gray rectangles represent accessibility of the XML nodes to mobile clients of the different groups, while the white rectangles represent non-accessibility of the XML nodes to mobile clients of the different groups. For example, the root node “SigmodRecord” is accessible to mobile clients of the group g1 and g2.

An example of the XML document

The tree structure of an XML document with the accessibility and labeling of the XML nodes
In order to generate an encrypted XML data stream based on our proposed structure, the paths, XML nodes, texts, and attributes are grouped together. In the following, we explain how to group the paths, XML nodes, texts, and attributes.
Definition 1
The root-to-node path of XML node e refers to a sequence of node names from the root node to the node e.
For example, in Fig. 3, the root-to-node path of the XML node “title” is “/SigmodRecord/issue/articles/article/title.”
In our proposed stream structure, the paths are summarized and separated based on the Definition 1. Figure 4 shows a tree generated based on the path summarization and separation concept. By summarizing and separating the paths, the size of encrypted XML data stream can be reduced.

The tree generated based on the path summarization and separation concept
In our proposed stream structure, all the XML nodes in the XML tree are labeled based on the pre/post labeling scheme [42,43,44,45]. In this XML labeling scheme, each XML node is labeled by the three values which are the preorder, postorder, and depth. These values are required for processing the twig pattern XML queries over the broadcast channel. This process will be explained in Sect. 4. Figure 3 shows the tree structure of the XML document shown in Fig. 2 when it is labeled by the pre/post labeling scheme.
Definition 2
Assume that U = {u1, u2,…, un} is a set of users (or mobile clients) and UG = {g1, g2,…, gm} is a set of user groups. We assume that M: U → UG is a function that maps a user in U into a group in UG. The accessibility code (AC) of XML node e in the XML tree is defined by ACe = a1a2… am where:
For example, in Fig. 3, the root node “SigmodRecord” is accessible to mobile clients of the user groups g1 and g2; therefore, its accessibility code will be: ACSigmodRecord = 11.
After labeling the XML nodes by the pre/post labeling scheme, the accessibility code (AC) for each XML node is calculated using the Definition 2.
Definition 3
The XML nodes are equivalent if they have the same root-to-node path.
For example, all the XML nodes with the node name “author” in Fig. 3 have the same root-to-node path (i.e., “/SigmodRecord/issue/articles/article/authors/author”). Therefore, these XML nodes are equivalent XML nodes.
In our proposed stream structure, the equivalent XML nodes are grouped together. By grouping the equivalent XML nodes, the size of encrypted XML data stream can be reduced.
After calculating the accessibility code (AC) of each XML node in the XML tree, the accessibility code (AC) of the equivalent XML nodes grouped together must be calculated.
Definition 4
The accessibility code (AC) of equivalent XML nodes grouped together with the node name e is defined by ACe = ACe1OR ACe2OR … OR ACek where OR is the OR-bit operator, \(\forall\) 1 ≤ i ≤ k, ei is an XML node in the XML tree, and \(\forall\) 1 ≤ i, j ≤ k, ei and ej are the equivalent XML nodes.
It should be noted that the OR-bit operator is applied on all the accessibility codes (ACs) of equivalent XML nodes to determine whether each equivalent XML nodes is accessible to mobile clients of a user group or not.
For example, as shown in Fig. 3, the set of equivalent XML nodes with the node name “author” is the XML nodes with the preorder 9, 10, 20, 21, and 27. The accessibility codes (ACs) of these equivalent XML nodes are 01, 11, 10, 10, and 11, respectively. Therefore, ACAuthor = 01 OR 11 OR 10 OR 10 OR 11 = 11.
Definition 5
Assume that E = {e1, e2, …, ek} is the set of equivalent XML nodes with the node name e ordered by preorder sequence and \(\forall\) 1 ≤ i ≤ k, the accessibility code (AC) of equivalent XML node ei is ACei = ai1ai2… aim where \(\forall\) 1 ≤ j ≤ m, aij can be 0 or 1 which determines the accessibility of mobile clients of the jth user group to the equivalent XML node ei. \(\forall\) 1 ≤ i ≤ k and 1 ≤ j ≤ m, the accessibility code of equivalent XML nodes with the node name e for mobile clients of the jth user group is defined by ACe,j = a1j | a2j | … | akj where | is the concatenation operator.
It should be noted that ACe,j specifies that which of the equivalent XML nodes with the node name e are accessible/inaccessible to users of the jth user group.
For example, as shown in Fig. 3, the set of equivalent XML nodes with the node name “author” is the XML nodes with the preorder 9, 10, 20, 21, and 27. The accessibility codes (ACs) of these equivalent XML nodes are 01, 11, 10, 10, and 11, respectively. Therefore, ACauthor,g1 = 0 | 1 | 1 | 1 | 1 = 01111 (meaning that the first equivalent XML node is only inaccessible to mobile clients of the user group “g1” from 5 equivalent XML nodes with the node name “author”) and ACauthor, g2 = 1 | 1 | 0 | 0 |1 = 11001 (meaning that the third and fourth equivalent XML nodes are inaccessible to mobile clients of the user group “g2” from 5 equivalent XML nodes with the node name “author”).
Generally, XML nodes in an XML document may have a text and some attributes. Each text has a value, and each attribute has a name and a value. By grouping the texts and attributes, the size of encrypted XML data stream can be reduced.
In our proposed stream structure, all the text values and attributes along with their names and values are extracted and grouped together. Figure 3 shows the attributes names of the XML document shown in Fig. 2 after extracting them. They are placed in the black rectangles.
Generally, our proposed stream structure contains three segments as follows:
Index Segment: This segment contains information about the equivalent XML nodes and their child and sibling nodes.
Data Segment: This segment contains the structural information of equivalent XML nodes. It should be noted that the text and attributes in the text & attribute segment can be accessible via the information existing in this segment.
Text & Attribute Segment: This segment contains the text and attributes values for each equivalent XML node.
The index segment contains the fields shown in Table 1 for each set of equivalent XML nodes grouped together.
The field ACe contains a set of accessibility codes for the equivalent XML nodes with the node name e. The field NXT-ADDe is the address of next set of equivalent XML nodes in the index segment. This field is used to skip from the irrelevant data in the index segment when the mobile client does not access to the current set of equivalent XML nodes. The field KeyIDe specifies the cryptography key identifier. It is used in the process of encryption/decryption of the equivalent XML nodes with the node name e. The fields LENe and NENe are the length and the name of equivalent XML nodes with the node name e, respectively. The field Depthe is the depth of equivalent XML nodes with the node name e. Table 2 shows the root-to-node paths, the equivalent XML node names, the length of equivalent XML nodes, and the depth of equivalent XML nodes of the XML document shown in Fig. 2. The field ADDe specifies the arrival time of the first bit of information for the set of equivalent XML node with the node name e in the data segment. In the index segment, there are two flags called HAS-Childe and HAS-Siblinge which can have values 0 or 1. A value of 0 means that the equivalent XML nodes with the node name e have no child or sibling node, while a value of 1 means that the equivalent XML nodes with the node name e have at least one child or a sibling node. If the field HAS-Childe has the zero value, the two fields COUNT-Childe and ADD-Childe are deleted from the index segment. If the field HAS-Siblinge has the zero value, the two fields COUNT-Siblinge and ADD-Siblinge are deleted from the index segment. The fields COUNT-Childe and COUNT-Siblinge specify the total number of child nodes and sibling nodes for the equivalent XML nodes with the name e in the index segment, respectively. The fields ADD-Childe and ADD-Siblinge specify the arrival times of the set of child nodes and sibling nodes for the equivalent XML nodes with the node name e in the index segment, respectively.
Definition 6
Suppose that A = {a1, a2, …, ap} is a set of child nodes for the equivalent XML nodes with the node name e and ACa = {\({\text{AC}}_{{a_{1} }}\), \({\text{AC}}_{{a_{2} }}\), …, \({\text{AC}}_{{a_{p} }}\)} is a set of accessibility codes of the child nodes and ADDa = {\({\text{ADD}}_{{a_{1} }}\), \({\text{ADD}}_{{a_{2} }}\), …, \({\text{ADD}}_{{a_{p} }}\)} is a set of addresses (i.e., the arrival times) of the child nodes in the index segment. The set of addresses of child nodes for the equivalent XML nodes with the node name e is defined as follows:
where m represents the total number of user groups UG and a pair of (\({\text{AC}}_{{a_{i} }} ,{\text{ADD}}_{{a_{i} }}\)) is ordered in an ascending order based on the arrival times of child nodes in the index segment.
Definition 7
Suppose that A = {a1, a2, …, ap} is a set of sibling nodes for the equivalent XML nodes with the node name e and ACa = {\({\text{AC}}_{{a_{1} }}\), \({\text{AC}}_{{a_{2} }}\), …, \({\text{AC}}_{{a_{p} }}\)} is a set of accessibility codes of the sibling nodes and ADDa = {\({\text{ADD}}_{{a_{1} }}\), \({\text{ADD}}_{{a_{2} }}\), …, \({\text{ADD}}_{{a_{p} }}\)} is a set of addresses (i.e., the arrival times) of the sibling nodes in the index segment. The set of addresses of sibling nodes for the equivalent XML nodes with the node name e is defined as follows:
where m represents the total number of user groups UG and a pair of (\({\text{AC}}_{{a_{i} }} ,{\text{ADD}}_{{a_{i} }}\)) is ordered in an ascending order based on the arrival times of sibling nodes in the index segment.
The second segment in our proposed stream structure is the data segment. This segment includes fields shown in Table 3 for each set of equivalent XML nodes with the node name e. It should be noted that if there is at least an attribute ATT for one of the equivalent XML nodes with the node name e, the attribute ATT contains the fields shown in Table 4.
The third segment in our proposed stream structure is the text & attributes segment. This segment includes fields shown in Table 5 for each equivalent XML node.
In general, it may be possible that some equivalent XML nodes have text and attributes.
Definition 8
Assume that E = {e1, e2, …, ek} is the set of equivalent XML nodes with the node name e ordered by preorder sequence and \(\exists\) 1 ≤ i ≤ k, the equivalent XML node ei has text. Therefore, each text of equivalent XML node ei has the following fields in the field TXT-ARRe:
\({\text{TXT-Value-Length}}_{{e_{i} }}\): The length of text value in the equivalent XML node ei.
\({\text{TXT-Value}}_{{e_{i} }}\): The value of text in the equivalent XML node ei.
Definition 9
Assume that E = {e1, e2, …, ek} is the set of equivalent XML nodes with the node name e ordered by preorder sequence and \(\exists\) 1 ≤ i ≤ k, the equivalent XML node ei has m attributes. Therefore, \(\forall\) 1 ≤ j ≤ m, the jth attribute of the equivalent XML node ei has the following fields in the field ATT-ARRe:
\({\text{ATT-Value-Length}}_{{e_{i} , j}}\): The length of jth attribute value in the equivalent XML node ei.
\({\text{ATT-Value}}_{{e_{i} , j}}\): The value of jth attribute in the equivalent XML node ei.
4 XML query processing based on our proposed XML data stream structure
In this section, the process of XML querying over a broadcast channel based on our proposed stream structure is explained.
4.1 The process of simple path XML queries
Generally, a simple path XML query is defined in the form of “/e1/e2/…/en [text() = “…”],” whereas \(\forall 1 \le k \le n\), \(e_{k}\) is an XML node name. However, the part of “[text() = “…”]” is optional in the general form of simple path XML query. In order to process a simple path XML query over a broadcast channel based on our proposed stream structure, the following steps are taken by the mobile client u:
Step 1 When the mobile client u sends the simple path XML query Q in the form of “e1/e2/…/en” over a broadcast channel, the accessibility of the mobile client u to access a set of the equivalent XML nodes is checked by the field AC in the index segment. In the case that the mobile client u does not access to a set of the equivalent XML nodes, the next set of equivalent XML nodes is checked. The field NXT-ADD is used by the mobile client u to skip from the irrelevant data in the index segment. This process is continued until the mobile client u reaches to a set of accessible equivalent XML nodes. Then, the mobile client u decrypts the information of the equivalent XML nodes using the field KeyID.
Step 2 If the name of equivalent XML nodes with the node name e (i.e., NENe) is equal to the last node of the simple path XML query (i.e., \(e_{n}\)) and the depth of the equivalent XML nodes with the node name e (i.e., Depthe) is equal to the depth of simple path XML query (i.e., n), the result of simple path XML query Q is the set of equivalent XML nodes with the node name e. Therefore, the field ADD of the equivalent XML nodes with the node name e (i.e., ADDe) is read to obtain the arrival time of information of these equivalent nodes in the data segment. In the case that the depth of equivalent XML nodes with the node name e (i.e., Depthe) is not equal to the depth of simple path XML query Q (i.e., n), the set of addresses of child nodes of the equivalent XML nodes with the node name e must be checked (i.e., ADD-Childe) to obtain the arrival times of the child nodes in the index segment. In the case that the name of equivalent XML nodes with the node name e (i.e., NENe) is different from the last node of the simple path XML query Q (i.e., \(e_{n}\)), but their depths are the same, the set of addresses of sibling nodes of the equivalent XML nodes with the node name e must be checked (i.e., ADD-Siblinge) to obtain the arrival times of sibling nodes in the index segment.
Step 3 When the mobile client u obtains the arrival time of the first bit of information for the set of equivalent XML nodes with the node name e (i.e., ADDe) in the data segment, the mobile client u goes into the doze mode until the related data arrives over the broadcast channel. When the data arrives over the broadcast channel, the mobile client u is activated to retrieve the data. In the case that the equivalent XML nodes with the node name e have the text and/or attribute(s) and the simple path XML query needs to retrieve the information of text and/or attribute(s), the mobile client u can obtain the arrival time of the first bit of information in the text & attribute segment using the field TXT-ATT-ADDe.
Example 1
Assume that the mobile client u from the user group g2 submits the simple path XML query Q = “/SigmodRecord/issue/volume” over the broadcast channel. Therefore, the accessibility of mobile client u to access the first set of the equivalent XML nodes with the node name “SigmodRecord” is checked by the field \({\text{AC}}_{\text{SigmodRecord}}\) in the index segment. Since the mobile client u has access to the set of equivalent XML nodes with the node name “SigmodRecord,” the mobile client u decrypts the information of this set of equivalent XML nodes using the field \({\text{KeyID}}_{\text{SigmodRecord}}\). Since the name of equivalent XML node “SigmodRecord” is different from the last node of simple path XML query Q (i.e., “volume”), the mobile client u has to wait for the next set of equivalent XML nodes. This process is continued until the set of equivalent XML nodes with the node name “volume” receives over the broadcast channel. Then, the mobile client u checks its accessibility to this set of equivalent XML nodes with the field \({\text{AC}}_{\text{volume}} .\) Since the mobile client u has access to a subset of the equivalent XML nodes with the node name “volume,” the mobile client u decrypts the information of this set of equivalent XML nodes using the field \({\text{KeyID}}_{\text{volume}}\). Next, the mobile client u obtains the arrival time of the first bit of information for the equivalent XML nodes with the node name “volume” (i.e., ADDvolume) in the data segment. Therefore, the mobile client u goes into the doze mode until the related data arrives over the broadcast channel. When the data arrives over the broadcast channel, the mobile client u is activated to retrieve the data. These equivalent XML nodes (i.e., XML nodes with the preorder 3 and 14) are candidates to be the result of the simple path XML query Q. Based on the accessibility of the mobile client u which is shown in Fig. 3, the mobile client u has access only to the XML node with the preorder 3. Therefore, this XML node is retrieved from the broadcast channel as the result of simple path XML query Q.
4.2 The process of twig pattern XML queries
In general, the twig pattern XML queries are divided into two categories:
The twig pattern XML queries having a predicate condition at the end of XPath expression. This type of twig pattern XML queries is defined in the form of “/e1/e2/…/en−i [en−i +1/…/en/text() = “…”],” whereas \(\forall 1 \le k \le n\), \(e_{k}\) is an XML node name.
The twig pattern XML queries having a predicate condition at the middle of XPath expression. This type of twig pattern XML queries is defined in the form of “/e1/e2/…/ei−1 [ei/…/ei+p/text() = “…”]/ei+p+1/…/en/,” whereas \(\forall 1 \le k \le n\), \(e_{k}\) is an XML node name.
In order to process the twig pattern XML queries in the form of “/e1/e2/…/en−i [en−i+1/…/en/text() = “…”],” the twig pattern XML query is divided into two simple path XML queries Q1 = “/e1/e2/…/en−i” and Q2 = “e1/e2/…/en[text() = “…”].” These two simple path XML queries can be processed by following the steps explained in the previous section. After downloading the results of the simple path XML queries Q1 and Q2, the mobile clients use the preorder, postorder, and depth values of the XML nodes in the query results to find the results set of the twig pattern XML query. This process is done by exploiting the following properties:
Property 1
An XML node α labeled by (preorderα, postorderα, depthα) is the ancestor of XML node β labeled by (preorderβ, postorderβ, depthβ) if and only if preorderα< preorderβand postorderα> postorderβ.
For example in Fig. 3, the XML node “issue” with the label (2, 11 2) is the ancestor of the XML node “initPage” with the label (11, 7, 5) since 2 < 11 and 11 > 7.
Property 2
An XML node α labeled by (preorderα, postorderα, depthα) is the descendant of XML node β labeled by (preorderβ, postorderβ, depthβ) if and only if preorderα> preorderβand postorderα< postorderβ.
For example in Fig. 3, the XML node “title” with the label (7, 3, 5) is the descendant of the node “articles” with the label (5, 10, 3) since 7 > 5 and 3 < 10.
Property 3
An XML node α labeled by (preorderα, postorderα, depthα) is the parent of XML node β labeled by (preorderβ, postorderβ, depthβ) if and only if preorderα< preorderβ, postorderα> postorderβand depthα= depthβ − 1.
For example in Fig. 3, the XML node “authors” with the label (8, 6, 5) is the parent of the node “author” with the label (9, 4, 6) since 8 < 9, 6 > 4 and also 5 = 6 − 1.
Property 4
An XML node α labeled by (preorderα, postorderα, depthα) is the child of XML node β labeled by (preorderβ, postorderβ, depthβ) if and only if preorderα> preorderβ, postorderα< postorderβand depthα= depthβ+ 1.
For example in Fig. 3, the XML node “number” with the label (15, 13, 3) is the child of the node “issue” with the label (13, 28, 2) since 15 > 13, 13 < 28 and also 3 = 2 + 1.
Example 2
Assume that the mobile client \(u\) from the user group g1 submits the twig pattern XML query Q = “/SigmodRecord/issue[number/text() = “1”].” The mobile client \(u\) divides this query to two simple path XML queries Q1 = “/SigmodRecord/issue” and Q2 = “/SigmodRecord/issue/number[text() = “1”].” The mobile client u can process these two simple path XML queries. The result of the query Q1 is the nodes “issue” with the labels (2, 11, 2) and (13, 28, 2). Also the result of the query Q2 is the node “number” with the label (4, 2, 3). Therefore regarding that the node “issue” with the label (2, 11, 2) is the parent of the node “number” with the label (4, 2, 3) based on the Property 3, it is concluded that the final result of twig pattern XML query Q will be equal to the node “issue” with the label (2, 11 2).
To process a twig pattern XML query in the form of “/e1/e2/…/ei−1[ei/…/ei+p/text() = “…”]/ei+p+1/…/en,” this query is first divided into two XML queries: Q1 = “/e1/e2/…/ei−1[ei/…/ei+p/text() = “…”]” and Q2 = “/e1/e2/…/en.” Then, the twig pattern XML query Q1 is divided into two simple path XML queries Q11 = “/e1/e2/…/ei−1” and Q12 = “/e1/e2/…/ei−1/ei/…/ei+p/text() = “…”].” The XML queries Q11, Q12, and Q2 are simple path XML queries, and they can be processed by following the steps explained in the previous section. After downloading the results of the simple path XML queries Q11, Q12, and Q2, the mobile client uses the preorder, postorder, and depth values of the XML nodes in the results of the queries Q11, Q12, and Q2 to find the result of the twig pattern XML query. This process is done by exploiting the Properties 1, 2, 3, and 4.
5 Performance evaluation
In this section, we evaluate the efficiency of our proposed encrypted XML data stream structure in processing the different types of XML queries over a mobile wireless broadcast channel.
All the experiments were conducted on a system with an Intel (R) Core i5-3337U-180 GHz processor, 4 GB RAM running Windows 10 Professional, and the server and client modules were implemented in Java.
5.1 Experimental settings
We logically modeled the encrypted XML data stream as a binary file, where the broadcast server writes a byte stream on the file and the mobile clients read the file and process the XML queries. We used the algorithm 3-DES for encryption/decryption. We assume that the cryptography key is first exchanged between the parties and only their KeyID is sent over the broadcast channel.
In our simulation model, we assumed that the broadcast bandwidth is fully utilized for broadcasting the encrypted XML data stream. To measure the access time and tuning time, we considered only the activity of a mobile client since the activity of a mobile client does not affect the performance of the XML querying at the other mobile clients [6,7,8,9].
We assumed that the encrypted XML data stream is disseminated and accessed in units with a fixed size (i.e., buckets), and thus, we measured the access time and tuning time in processing the XML queries by the number of buckets. A bucket is the smallest logical unit in a mobile wireless broadcast channel. In the view of assumption that the network speed is fixed, the number of buckets can be converted into time since the elapsed time for reading a bucket is computed as the bucket size divided by the network speed [5, 23]. To measure the performance variation based on the number of buckets, we used three different bucket sizes: 64, 128, and 256 bytes in our experiments. However, we only present the experimental results for the cases that the bucket size is set to 128 bytes since the experimental results were not dependent on the bucket size.
To measure the performance variation based on the types of the XML data sets, we used several real XML data sets. Table 6 shows the characteristics of the different XML data sets used in our experiments.
To measure the performance variation based on the types of the XML queries, we used different types of XPath queries [50]. The list of XPath queries used in our experiments is shown in Table 7.
In our simulation model, we randomly and uniformly selected the set of XML nodes from the XML data sets as the accessible nodes. We controlled the accessibility of the XML nodes with the accessibility ratio [37, 38]. The accessibility ratio is the fraction of the XML nodes in the XML data set which are accessible. To measure the performance variation based on the accessibility ratio of the XML nodes, we varied the accessibility ratio from 10 to 90% with an interval 20%.
Our proposed encrypted XML data stream structure was compared with the SecNode structure proposed by [37, 38] since the SecNode structure is the only structure that broadcasts an encrypted XML data stream over a mobile wireless broadcast channel. To do this comparison, we need to implement the SecNode structure as well. In order to reach the most accuracy in experimental results and comparison, this simulation has been conducted in the most similar state of the running computer, operating system, programming language, implementation of algorithms, and even type of variables.
The performance metrics used in our experiments were the size ratio, the tuning time ratio, and the access time ratio. They are defined as follows:
where \(\left| {SoS_{\alpha } } \right|\) represents the size of stream in the \(\alpha\) structure and \(NoB_{\alpha ,\beta }\) represents the number of buckets to read in the encrypted XML data stream in the \(\alpha\) structure once the mobile client is in the \(\beta\) mode.
5.2 Experimental results on the size ratio
Figure 5 shows the size ratio on the different XML data sets when the accessibility ratio is varied from 10 to 90%. As it is shown in Fig. 5, the size ratio is 26% in the Mondial data set, 21% in the SigmodRecord data set, and 33% in the Shakespeare data set. Therefore, the size of encrypted XML data stream in our proposed structure is less than the size of encrypted XML data stream in the SecNode structure. The reason is that the size of encrypted XML data stream in our proposed structure is reduced by grouping the paths, XML nodes, texts, and attributes together, while this information is repeated for each XML node in the SecNode structure. Moreover, it should be noted that the accessibility ratio does not affect the size of encrypted XML data stream in both structures (i.e., our proposed structure and the SecNode structure) in all the XML data sets since the XML nodes in the both structures are encrypted by the algorithm 3-DES with the same encryption key size.

Size ratio on the different XML data sets
5.3 Experimental results on the tuning time ratio
Figure 6a–c shows the tuning time ratio in processing the different types of XML queries when the accessibility ratio varies from 10 to 90%. From Fig. 6a–c, it is clear that our proposed encrypted XML data stream structure in comparison with the SecNode structure always presents a better tuning time.

a Tuning time ratio on the Mondial data set. b Tuning time ratio on the SigmodRecord data set. c Tuning time ratio on the Shakespeare data set
The reason for this reduction is because of the existence of several indexes in our proposed structure to skip from the irrelevant data over the stream. However, the improved value of tuning time is entirely dependent on the types of XML queries, the properties of XML data sets, the accessibility ratios, and the locations of accessible XML nodes over the encrypted XML data stream.
5.4 Experimental results on the access time ratio
Figure 7a–c shows the access time ratio in processing the different types of XML queries when the accessibility ratio varies from 10 to 90%.

a Access time ratio on the Mondial data set. b Access time ratio on the SigmodRecord data set. c Access time ratio on the Shakespeare data set
From Fig. 7a–c, it is clear that our proposed encrypted XML data stream structure in comparison with the SecNode structure always presents a better access time. The reason for this reduction is that the size of encrypted XML stream in our proposed structure is less than that in the SecNode structure. It means that mobile clients should wait less time to retrieve the desired data from the broadcast channel in comparison with the SecNode structure. However, the improved value of access time is entirely dependent on the types of XML queries, the properties of XML data sets, the accessibility ratios, and the locations of accessible XML nodes over the encrypted XML data stream.
6 Conclusion and future works
In this paper, a new encrypted XML data stream structure was proposed to securely disseminate the XML data in a mobile wireless broadcast channel. The proposed stream structure contains several indexes to skip from the irrelevant data over the encrypted XML data stream. In the proposed stream structure, the paths, XML nodes, texts, and attributes were grouped together in order to reduce the length of encrypted XML data stream.
The simulation results showed that the proposed structure improves the performance of XML query processing over the encrypted XML data stream in terms of access time and tuning time in comparison with the SecNode structure. The reason was that the length of encrypted XML data stream in our proposed structure was less than that in the SecNode structure.
In the future, we intend to investigate other issues which were not considered in this paper. In this paper, only a mobile wireless broadcast channel has been used to disseminate the encrypted XML data. As a future research, this assumption can be changed and the number of broadcast channels can be increased and the efficiency of mobile clients to process the different types of XML queries in this case can be investigated. In this paper, it is assumed that the broadcast channel is reliable and there is not any bucket lost over the channel. As a research work in the future, this assumption can also be changed and an indexing method can be offered for reliable broadcasting the encrypted XML data over a mobile wireless broadcast channel.
Notes
One-Sibling-Address.
Two-Sibling-Addresses.
Same-Path-Address.
Path Summary.
Clone node Link.
Foreign node Link.
Location Path Information.
Clustering Region.
References
Extensible Markup Language (XML) (2016) https://www.w3.org/XML
Boroujeni AB, Mirabi M (2016) A novel replication strategy for efficient XML data broadcast in wireless mobile networks. J Inf Sci Eng 32(2):309–327
Mirabi H, Mirabi M, Boroujeni AB (2016) An efficient XML data placement scheme over multiple wireless broadcast channels. J Inf Sci Eng 32(5):1183–1203
Javani M, Mirabi M (2017) An efficient index and data distribution scheme for XML data broadcast in mobile wireless networks. J Inf Sci Eng 33(1):159–182
Chung YD, Lee JY (2007) An indexing method for wireless broadcast XML data. Inf Sci 177(9):1931–1953
Imieĺinski T, Badrinath BR (1993) Data management for mobile computing. SIGMOD Record 22(1):34–39
Imielinski T, Viswanathan S, Badrinath BR (1994) Energy efficient indexing on air. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, Minneapolis, Minnesota, USA, pp 25–36
Acharya S, Alonso R, Franklin M, Zdonik S (1995) Broadcast disks: data management for asymmetric communication environments. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, San Jose, CA, USA, pp 199–210
Imielinski T, Viswanathan S, Badrinath BR (1997) Data on air: organization and access. IEEE Trans Knowl Data Eng 9(3):353–372
Chung YD, Kim MH (2001) Effective data placement for wireless broadcast. Distrib Parallel Databases 9(2):133–150
Chung YD, Bang SH, Kim MH (2002) An efficient broadcast data clustering method for multipoint queries in wireless information systems. J Syst Softw 64(3):173–181
Chen M-S, Wu K-L, Yu PS (2003) Optimizing index allocation for sequential data broadcasting in wireless mobile computing. IEEE Trans Knowl Data Eng 15(1):161–173
Lee C-C, Leu Y (2005) Efficient data broadcast schemes for mobile computing environments with data missing. Inf Sci 172(3–4):335–359
Qin Y, Sun W, Zhang Z, Yu P (2007) An efficient document-split algorithm for on-demand xml data broadcast scheduling. In: Proceedings of the IET Conference on Wireless, Mobile and Sensor Networks (CCWMSN07), Shanghai, China, pp 759–762
Sun W, Qin Y, Yu P, Zhang Z (2007), On-demand XML data broadcast in wireless computing environments. In: Proceedings of the Third International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, pp 3035–3038
Qin Y, Sun W, Zhang Z, Yu P, He Z, Query-grouping based scheduling algorithm for on-demand xml data broadcast. In: Proceedings of the 4th International Conference on Wireless Communications, Networking and Mobile Computing, (2008), Dalian, China, pp 1–4
Qin Y, Sun W, Zhang Z, Yu P, He Z, Chen W (2009) A novel air index scheme for twig queries in on-demand XML data broadcast. In: Proceedings of the 20th International Conference on Database and Expert Systems Applications (DEXA 2009), LNCS 5690, Linz, Austria, pp 412–426
Sun W, Yu P, Qing Y, Zhang Z, Zheng B (2009) Two-tier air indexing for on-demand XML data broadcast. In: Proceedings of the 29th IEEE International Conference on Distributed Computing Systems, Montreal, Quebec, Canada, pp 199–206
Qin Y, Wang H, Xia J (2011) Effective scheduling algorithm for on-demand XML data broadcasts in wireless environments. In: Proceedings of the Australasian Database Conference (ADC ‘11), Perth, Australia, pp 95–102
Park S-H, Choi J-H, Lee S (2006) An effective, efficient XML data broadcasting method in a mobile wireless network. In: Proceedings of the 17th International Conference on Database and Expert Systems Applications (DEXA 2006), LNCS 4080, Krakow, Poland, pp 358–367
Park JP, Park C-S, Chung YD (2010) Energy and latency efficient access of wireless XML data stream. J Database Manag 21(1):58–79
Park JP, Park C-S, Chung YD (2013) Lineage encoding: an efficient wireless XML data streaming supporting twig pattern queries. IEEE Trans Knowl Data Eng 25(7):1559–1573
Mirabi M, Ibrahim H, Fathi L (2014) PS + Pre/Post: a novel structure and access mechanism for wireless XML data stream supporting twig pattern queries. Pervasive Mob Comput 15:3–25
Park C-S, Kim CS, Chung YD (2005) Efficient stream organization for wireless broadcasting of XML data. In: Proceedings of the 10th Asian Computing Science Conference on Advances in Computer Science: Data Management on the Web, LNCS 3818, Kunming, China, pp 223–235
Su T-C, Liu C-M (2010) On-demand data broadcasting for data items with time constraints on multiple broadcast channels. In: Proceedings of the 15th International Conference on Database Systems for Advanced Applications (DASFAA 2010), LNCS 6193, (2010), Tsukuba, Japan, pp 458–469
Chung YD, Yoo S, Kim MH (2010) Energy and latency efficient processing of full-text searches on a wireless broadcast stream. IEEE Trans Knowl Data Eng 22(2):207–218
Safabahar B, Mirabi M (2017) A new structure and access mechanism for secure and efficient XML data broadcast in mobile wireless networks. J Syst Softw 125(3):119–132
Mirabi M, Ibrahim H, Fathi L, Udzir NI, Mamat A (2015) A dynamic compressed accessibility map for secure XML querying and updating. J Inf Sci Eng 31(1):59–93
Mirabi M, Ibrahim H, Udzir NI, Mamat A (2012) A compact bit string accessibility map for secure XML query processing. Procedia Comput Sci 10:1172–1179
Mirabi M, Ibrahim H, Udzir NI, Mamat A (2012) XML access control models and mechanisms: a survey. Int Rev Comput Softw 7(4):1518–1527
Mirabi M, Ibrahim H, Mamat A, Udzir NI (2011) Integrating access control mechanism with EXEL labeling scheme for XML document updating. In: Fong S (ed) Networked digital technologies. NDT 2011. Communications in Computer and Information Science, vol 136. Springer, Berlin
Mirabi M, Ibrahim H, Fathi L, Udzir NI, Mamat A (2011) An access control model for supporting XML document updating. In: Fong S (ed) Networked digital technologies. NDT 2011. Communications in Computer and Information Science, vol 136. Springer, Berlin
Bertino E, Ferrari E (2002) Secure and selective dissemination of XML documents. ACM Trans Inf Syst Secur 5(3):290–331
Geuer-Pollmann C (2002) XML pool encryption. In: Proceedings of the 2002 ACM Workshop on XML Security, Washington, DC, USA, pp 1–9
Miklau G, Suciu D (2003) Controlling access to published data using cryptography. In: Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany, pp 898–909
Ko H-K, Kim M-J, Lee S (2007) On the efficiency of secure XML broadcasting. Inf Sci 177(24):5505–5521
Fathi L, Ibrahim H, Mirabi M (2013) An air indexing method for encrypted XML data broadcast in mobile wireless network. In: Proceedings of the 12th International ACM Workshop on Data Engineering for Wireless and Mobile Access, New York, USA, pp 28–35
Fathi L, Ibrahim H, Mirabi M (2014) An energy conservation indexing method for secure XML data broadcast in mobile wireless networks. Pervasive Mob Comput 13:125–141
Haw S-C, Lee C-S (2009) Extending path summary and region encoding for efficient structural query processing in native XML databases. J Syst Softw 82(6):1025–1035
Haw S-C, Lee C-S (2011) Data storage practices and query processing in XML databases: a survey. Knowl Based Syst 24(8):1317–1340
Wong K-F, Yu JX, Tang N (2006) Answering XML queries using path-based indexes: a survey. World Wide Web 9(3):277–299
Mirabi M, Ibrahim H, Udzir NI, Mamat A (2012) An encoding scheme based on fractional number for querying and updating XML data. J Syst Softw 85(8):1831–1851
Mirabi M, Ibrahim H, Udzir NI, Mamat A (2011) Label size increment of bit string based labeling scheme in dynamic XML updating. In: Ariwa E, El-Qawasmeh E (eds) Digital enterprise and information systems. Communications in Computer and Information Science, vol 194. Springer, Berlin, pp 466–477
Mirabi M, Ibrahim H, Mamat A, Udzir NI, Fathi L (2010) Controlling label size increment of efficient XML encoding and labeling scheme in dynamic XML update. J Comput Sci 6(12):1535–1540
Mirabi M, Ibrahim H, Fathi L, Mamat A, Udzir NI (2011) A fractional number based labeling scheme for dynamic XML updating. In: Proceedings of the 3rd International Conference on Computing and Informatics (ICOCI 2011), Bandung, Indonesia, pp 194–200
Eastlake D, Reagle J, Hirsch F, Roessler T (2012) XML Encryption Syntax and Processing Version 1.1. http://www.w3.org/TR/xmlenc-core1/
World Wide Web Consortium (W3C) https://www.w3.org
Gao J, Wang T, Yang D (2008) XFlat: query-friendly encrypted XML view publishing. Inf Sci 178(3):774–787
Lee J-G, Whang K-Y (2006) Secure query processing against encrypted XML data using query-aware decryption. Inf Sci 176(13):1928–1947
Berglund A, Boag S, Chamberlin D, Fernández MF, Kay M, Robie J, Siméon J (2010) XML Path Language (XPath) 2.0, 2nd edn. http://www.w3.org/TR/2010/REC-xpath20-20101214
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Shokri, M., Mirabi, M. An efficient stream structure for broadcasting the encrypted XML data in mobile wireless broadcast channels. J Supercomput 75, 7147–7173 (2019). https://doi.org/10.1007/s11227-019-02920-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02920-8