
Abstract
Articles posted on a forum often contain new Internet words related to opinion elements (feature words and opinion words). Consequently, existing Chinese opinion-mining systems may exhibit low recall and precision because they cannot recognize these new Internet words. Therefore, we propose a simple algorithm to elaborate on the opinion elements of such articles by extracting the opinion elements. Moreover, when an opinion word is combined with a specific word or concatenated with another opinion word, it may cause a change in the polarity or meaning of the opinion. This fact is prone to cause difficulties by changing the polarity or meaning of certain opinion elements, leading to errors in the analysis results of the Chinese system. We designed three algorithms with context dependency to address this problem. In this paper, we develop a semi-automatic Chinese opinion-mining system with these algorithms to extract these new opinion elements. Then, we determine whether the new word identified through manual judgment is a useful opinion element for a specific domain and add it to the thesaurus. In comparison with semi-automatic annotation methods, our approach can save considerable labor. After a 20-month follow-up analysis, the experimental data indicated that the precision, recall, and F1 of the system reached 84.0, 89.4 %, and 0.865, respectively.
Similar content being viewed by others



Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Opinion-mining reviews are typically analyzed at various resolutions [1]. One is document-level opinion mining identifies the overall subjectivity or sentiment expressed on an entity in a review. The other is sentence-level which can associate opinions in detail with specific aspects of entity. Some related studies define the opinion elements to express people opinions toward entities such as products, services and their attributes for sentiment analysis [2–5]. In this paper, we focus on subjective sentences for sentence-level opinion mining. We use four types of opinion elements (topic, feature, item, and opinion word) to form an opinion sentence from sentences with subjective opinions. Topic is the subject or entity of people’s comments. That is usually a company or vendor name. Feature represents products or related services for the topic. If the review has more detail attributes about feature, we use items to represent them. Opinion words are usually emotional words or adjective word which to express the evaluation refers to the reviewers. Moreover, because we can have a preliminary understanding of the opinions of authors if the opinion sentence has a topic and opinion words, our definition of a complete opinion sentence, which is called a tuple, is one for which neither the topic nor the opinion word is a null (Ø) value. Therefore, in our opinion sentences, we use (topic, feature, item, opinion word), (topic, feature, Ø, opinion word), (topic, Ø, item, opinion word) or (topic, Ø, Ø, opinion word) to express the opinions of the authors.
Because articles posted on a forum often contain new Internet words that are not included in the default Chinese thesaurus, the system will not be able to recognize these new Internet words when it encounters them. This lack of recognition will further affect the precision and recall of the system in the extraction of opinion elements. However, in the Chinese articles, many features and opinion words are not nouns or adjectives and will cause errors in the extraction. The systematic precision of using POS or Parser is between 60 and 70 %, and the recall is 50 and 80 % [15–17]. To improve the precision and recall, we must use a manual annotation approach to extract new Internet words that lie outside the scope of the thesaurus to be opinion elements. Because manual annotation requires substantial labor, some studies have proposed the use of Semi-Automated Tagging to reduce labor [6]. However, the application of Semi-Automated Tagging still requires the manual inspection of all sentences, which requires considerable labor.
The method of opinion-element extraction and expansion developed for our system can process more than 2000 articles (more than 20,000 sentences) at approximately an hour by taking the reasonable approach of ignoring any opinion elements that appears only once (opinion elements which occur frequency equal 1); that is, we ignore the non-popular opinion elements that only appears once and find new useful opinion elements by manual judgment with frequency 2 above. It requires only approximately an hour to inspect more than 400 new possible words. By contrast, the inspection of the same number of sentences using the manual annotation approach requires approximately 4–7 days, and therefore, our method can save a considerable amount of manual inspection time.
The same Chinese word may have different meanings when used in different contexts. To evaluate the polarity of an opinion word, context dependency must be considered [7–9]. However, for a Chinese system, it is not sufficient to consider only the context of each word independently. When an opinion word is combined with a specific word or concatenated with another opinion word, it may cause a change in the polarity or meaning of the opinion [9]. It is also possible that a non-opinion word may become an opinion word and that the original opinion word may become a non-opinion word. Therefore, we also designed three algorithms to improve the capability of our system to cope with situations.
In this paper, we develop a semi-automatic rule-based Chinese opinion-mining system with above algorithms to extract these new opinion elements. The system extracts the possible opinion elements from an article based on its established thesaurus, then, we identify through manual judgment whether the possible opinion element is a useful opinion element for a specific domain and add it to the thesaurus. Since the syntax rule of a language is rather basic and static [1], in this paper, the opinion elements of articles were extracted based on lexicons and combined with the sentence patterns (general sentences, equative sentences, and comparative sentences) and context dependency to analyze the authors’ opinion tendencies. The experimental results show that the precision, recall, and F1 of the system reach 84.0, 89.4 %, and 0.865, respectively.
2 Related work
At present, there are few analogous traditional Chinese systems. Ku et al. [10] have developed CopeOpi, an opinion-analysis system for traditional Chinese. This system analyzes articles and their opinion tendencies based on the previously established NTUSD dictionary. Chien-Liang et al. [11] have established a system in the field of Chinese film, which allows the user to select the name of a film to be reviewed as well as certain characteristics related to the film. However, these systems do not address the question of thesaurus expansion to include new Internet words.
Several English-based studies have used existing dictionaries to elaborate opinion words. Compared with English, Chinese language is different from English in that there are many word combinations in Chinese, and there is no space between words [9]. There are few papers on the extraction and amplification of opinion elements in the Chinese opinion-mining system. Most studies use a natural-language technique combined with certain specific patterns to extract opinion elements [12–14, 21, 22]. The primary challenge in Chinese language is many new Internet words are not in the thesaurus [6, 15–17, 20]. Some studies of the extraction of opinion elements have used a manual approach to establish a thesaurus of features. Using manual annotation, it is possible to establish a complete thesaurus of opinion elements. Although the precision of this approach may be very high, it involves considerable labor, and the opinion elements must be annotated individually for each different domain [18].

Architecture of the proposed Chinese opinion-mining system
3 System architecture
The system architecture is presented in Fig. 1. The thesaurus of the system includes a general thesaurus, a general thesaurus of opinion words, and a thesaurus related to a specific domain. To be specific, the Chinese universal dictionary [19] is used as the general thesaurus for normal Chinese terms. The general thesaurus of opinion words contains a collection of many traditional, normal opinion words, and the domain-specific thesaurus contains only relevant topics, features, items, and opinion words that belong to the specific domain.
During system operation, after selecting comment data for a specific domain and the time interval of the analysis data: (1) the linguistic characteristics of the Chinese language differ greatly from English, there is no space between words in sentences. During the data pre-processing, we segment the text and label words. (2) We annotate the opinion elements and use the thesaurus to flag opinion words in the article. (3) We execute the algorithm to extract and expand upon opinion elements and store the results in the thesaurus. Moreover, we can edit the properties of the opinion elements, such as whether they belong to a specific domain, their polarity, and the context dependency among opinion elements, during stages (2) and (3). (4) We use various sentence patterns to combine the relevant opinion elements into an output opinion sentence, which is stored in the database. Marketers, manufacturers and consumers can directly acquire the information and statistical charts they desire using the analysis-report function of this system.
4 Algorithm for the extraction and expansion of opinion elements
On Internet forums, new Internet words periodically emerge, and these new words may become new opinion elements. We propose a word-hyphenation algorithm to extract new Internet words that may become new opinion elements from an article posted on an Internet forum. Moreover, we designed three algorithms, Algorithm-“OP+OP,” Algorithm-“OP+

+OP,” and Algorithm-“OP+

,” to address the possible change in the polarity or meaning of an opinion word when that opinion word is combined with a specific word or concatenated with other opinion words. Because most identified opinion elements are opinion words, in the experiment and the following description, we annotate and discuss the role of only opinion words. Because the word-hyphenation algorithm is the only algorithm discussed here that is relatively complicated, we provide a detailed discussion of this algorithm in this section.
4.1 The word-hyphenation algorithm
As depicted in Fig. 2, the word-hyphenation algorithm involves a four-step process.
Step I: Because a sentence that expresses an opinion requires at least a topic and an opinion word to be an opinion sentence, we process the article to extract segments that may be missing a topic or an opinion word. We illustrate this step using Example 1.
Example 1
“A

493,

!” (“The 493 program of telecommunication company A is very remarkable in the history of telecommunication!”)
In Example 1, the article contains “telecommunication company A” (topic), “493” (feature), and “

/very remarkable” (opinion word). However, the system does not recognize the opinion word. Therefore, the paragraph “

” will be extracted in this step.

Word-hyphenation algorithm

Procedure: word combination
Step II: The text of an article on an Internet forum often contains new Internet words or incorrect words that are not defined in the thesaurus. After the word hyphenation of the article, any text that cannot be recognized by the thesaurus will treated as n individual characters. Let \(P\{t_{1},t_{2},{\ldots },t_{n}\}\) be a contiguous set of individual characters, \(t_{1},\, t_{2},\, {\ldots }, t_{n}\), in the article; then, for each \(P\{t_{1},t_{2},{\ldots },t_{n}\}\), we can combine m contiguous single characters to form a new word, \(t_{s+1} {\ldots } t_{s+m}\), using the word-combination procedure presented in Fig. 3, where \(\leqq 2 m\leqq n\) and \(0\leqq s\leqq n-m\). For example, after the word hyphenation of the paragraph “

”, only one P{

} is found at this step. After the combination of “

”, “

”, “

”, and “

” using the word-combination procedure, six new possible words, “

”, “

”, “

”, “

”, “

”, “

”, and “

”, are generated. In particular, “

/very remarkable” is an opinion word that is considered to be a new Internet word.
Step III: Some people tend to use abbreviations to replace relatively long words that appear particularly often in features, products, or projects. If a particular short word is often used as an abbreviation, its frequency of occurrence should be higher than the corresponding long word that it abbreviates; we can directly replace the short word with the long word.
Step IV: Although we can rapidly determine whether new words are new opinion elements, we still must inspect all possible combinations. There are many new possible words with a frequency of occurrence of 1, but there is no significant difference between the number of opinion words with a frequency of 1 and above and the number of opinion words with a frequency of 2 and above. For example, for the experimental data considered in this paper, in the articles from July of 2011 on the Mobile01 forum, there are 2849 new possible words with a frequency of 1 and above, and 10 of these new possible words have been manually determined to be opinion words; there are 292 new possible words with a frequency of 2 and above, and 6 of these new possible words have been manually determined to be opinion words. Therefore, to reduce the time required for manual inspection, we do not manually inspect new possible words with a frequency of 1, and they are carried forward to the next iteration. If a new possible word is subsequently used again by the originator, it will be manually inspected when the accumulated frequency becomes greater than 1, and therefore, this new opinion word will be missed once at most.
4.2 Processing the changes in the polarity and meaning of an opinion word
In Chinese, when an opinion word (referred to as OP) is combined with a specific word or concatenated with other opinion words, it may generate a change in the polarity or meaning of the expressed opinion. Consequently, to process this change, we use three different algorithms to handle terms in the following three forms: “OP+OP,” “OP+

+OP,” and “OP+

.”
-
Algorithm - “OP+OP” When an opinion word \(OP_{1}\) is concatenated with another opinion word \(OP_{2}\), it might generate a new opinion word \(OP_{1}OP_{2}\), and the polarity of this new opinion word could be different from that of \(OP_{1}\). If this type of opinion word is not recognized, it will cause the accuracy and recovery rate of the system to decline. Hence, an algorithm to decipher this type of opinion word is required and manual intervention is required to determine whether the new opinion word belongs to the domain. Moreover, if both opinion words are positive opinion words, then the new opinion word generated by the combination of the two is also positive, whereas if at least one of them is a negative opinion word, then the new opinion word generated by the combination must be negative.
-
Algorithm - “OP+

+OP” For an opinion word OP, the term “OP+

+OP” is always an interrogative word in the Chinese language. For example, “

/good” is an opinion word, but “

/good or bad?” is an interrogative word. Therefore, to avoid such misinterpretation, this algorithm identifies words with the “OP+

+OP” form and adds them to the general thesaurus.
-
Algorithm - “OP+
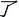
” When an opinion word is followed by a “

,” its tone will sometimes be reversed. In the telecommunication domain, “

/good” is an opinion word, whereas “

/a lot of” is not an opinion word. However, “

/much better” is once again an opinion word. Therefore, for vocabulary of this type, we must identify these words for manual judgment.










4.3 Experimental data for extracting and expanding opinion elements in the system
Here, we demonstrate how the system effectively reduces labor requirements and identifies relevant new opinion elements using various algorithms. The data source is articles from the comprehensive discussion forum on Mobile01 mobile communication, and the range of data is from July of 2011 to February of 2013, a total of 20 months. There is no restriction on the length of articles on Mobile01, each month contains 2613 articles and 22,230 sentences on average.
Unlike professional reviews written by experts, articles posted on Mobile01 are usually unformatted and very colloquial. These articles are often contain opinion elements that belong to other domains or new words. The system first uses the thesaurus to automatically flag opinion elements. It then manually determines which of these opinion elements belongs to the telecommunication domain, and they are added to the thesaurus for the telecommunication domain. For the first several months, the manual inspection required approximately one hour per month on average; for subsequent months, because the most commonly used opinion words had already been identified, the manual inspection required only approximately 20 min. In the following, we will analyze and discuss the performance and effects of the word-hyphenation algorithm.
Table 1 presents the results of analyzing an article using the word-hyphenation algorithm. In the table, the time costs are listed by date for the manual inspection of new possible words with a frequency of 1 and above and with a frequency of 2 and above. Some new possible words must be checked against the text that appears before and after them in the article, and such determinations usually take a long time. The “number of judgments based on context” represents the number of such determinations. According to Fig. 4, the time required for the manual inspection of new possible words with a frequency of 1 and above is approximately 3–5 times higher than that required for the manual inspection of new possible words with a frequency of 2 and above.
From September of 2012 to December of 2012, because a relatively large number of articles were posted during that time, a large number of manual judgments were required. But most new possible words are meaningless, there were few opinion words to be found. Moreover, for later months because the commonly used opinion words have extracted, the number appears to exhibit a trend of becoming less. Because of the word-hyphenation algorithm, we needed to spend only approximately one hour per month to evaluate approximately 400 new possible words. Without the assistance of algorithms, semi-automatic annotation methods required a manual search for opinion elements that would typically require 4–7 days to process one month of data. Our system offers a considerable reduction in labor and time costs.

Comparison of time cost (in minutes) for algorithm—“word hyphenation” above frequency 1 and above frequency 2
Table 2 presents the experimental results obtained using the algorithms that process the changes in the meanings of opinion words. The number of opinion words generated from the data by each algorithm was small, and for each month, only 5–10 min was required for the manual evaluation of these new opinion words.
5 Sentence patterns and the combination of opinion elements
With regard to the analysis of the opinion tendencies expressed by articles on online forums, three sentence patterns are summarized below in combination with the concepts of a default topic and clause priority.
5.1 Default topic and clause priority
Because there is no restriction on the length of articles that may be posted on Mobile01, if the author mentions a topic in the article, multiple sentences are typically used to thoroughly describe the topic. The author often uses subsequent clauses for supplementary description. The consideration of only clauses that contain topics would result in some clauses relevant to the topic at hand being discarded because some clauses do not mention a topic. As a result, the system would achieve only incomplete opinion expression, and the subsequent analysis would suffer from information loss. Therefore, we propose the concept of a default topic. If a topic is mentioned in the text of an article but not in all clauses, we apply the topic mentioned in the previous sentence to subsequent clauses, thereby avoiding the problem of incomplete opinions when the subsequent clauses do not mention a topic.
The combination of opinion elements primarily utilizes the nearby approach and clause priority. When a feature is mentioned in an earlier clause and another feature and an opinion word are also contained in the next clause, the relation between the feature and opinion word in the later clause is considered to have higher priority. The prior feature is replaced by the subsequent feature.
5.2 Sentence patterns
In the following, we introduce three sentence patterns: a general sentence, an equative sentence, and a comparative sentence. In fact, any sentence may contain two or more basic sentence patterns.
-
General sentence pattern When pairing opinion elements in general sentences, the default topic, i.e., the topic of the previous sentence, will be used when there is no topic mentioned in the sentence under consideration. When analyzing an article, its features, items, and opinion words will be paired according to the pairing method for opinion elements described above in the subsection pertaining to clause priority.
-
Equative sentence pattern The equative sentence pattern refers to the case in which opinion elements of the same type are connected with conjunctions. The standard pattern for an equative sentence is “A conjunction B conjunction C conjunction...D” (where A, B, C, and D are the same type of topic, feature, item, or opinion word). Because only one type of opinion element can be placed in the tuple, when opinion elements on the same level are connected with conjunctions, there must be a process for separation. A new tuple is added for each level of opinion elements. Then, the opinion elements are paired according to clause priority, as described above.
-
Comparative sentence pattern In articles posted to an online forum, comparisons are often presented between products or companies, and such comparisons use two types of comparative sentences.
-
1.
“A...

(more)...opinion word” (where A could be any combination of topic, feature, and item). This is a relatively simple sentence that describes only a unilateral good (or bad) opinion, and the pairing processing is the same as for general sentences. However, if the topic does not appear in the clause of such a comparative sentence, the default topic must be used.
-
2.
“A...

(than)...B...opinion word” (where A and B can be any combination of topic, feature, and item). For this type of comparative sentence, if there is no topic in front of “

/than,” the topic that appears in the nearest previous sentence will be used as the default topic; the feature portion of the sentence is also centered around “

/than.” If the topics of the two sentences are different and a feature is mentioned in the previous sentence but not the current one, then the feature referenced in the previous sentence is used for the sentence under consideration. We use a comparison of sentence properties to assign the opposite polarity to opinion words in the later sentence (add a negative word “not/

” before the opinion word that belongs to the later sentence).
-
1.





5.3 Statistical correction
We proposed a statistical correction method to correct the opinion tendency of authors with conflicting opinion outputs. There are two principles in this mechanism. The first is to correct based on the opinion tendency of the majority; the second is that the opinions published on the online forum by authors regarding the topic are mostly of negative opinion tendency. Based on these two principles, we correct sentences with contradictory opinions. First, determine whether there is an opinion confliction on the same statement in the output sentence of the author. The conflicting opinions are analyzed only when they have the same type of opinion words. The system determines whether there are more positive opinions than negative opinions in the output sentences from the same statement of the author. If so, the original negative tendency output is reversed to positive opinion tendency output, and vice versa. If the number of sentences with positive opinion tendency and negative opinion tendency output from the author are the same, the opinion tendency of other follow-up posts will be considered. We will be corrected based on the opinion tendency of the majority. But if there are no other follow-up posts, the positive opinion tendency is directly changed to negative tendency output.
5.4 System precision, recall, and F1 measure
This section discusses the experimental results. First, we present the experimental results of data in the telecommunication domain on the Mobile01 online forum, and then we discuss, with data, the factors that affect the precision and recall. We display the result of long-term tracking next. The approach of data assessment is to measure precision, recall, and F1, which are defined as follows:
A is the number of complete sentences output by the system that are correct outputs, B is the number of manually labeled complete sentences, C1 is the number of sentences output by the system that are incorrect in meaning, and C2 is the number of extra complete sentences found by the system. Table 3 is the schematic of the system output.
The approach used for data assessment is to evaluate the precision, recall, and F1. The long-term tracking results are presented in Fig. 5. This figure also contains the line graphs for the precision, recall, and F1 values for each month. The average precision, recall, and F1 values are 84.0, 89.4 %, and 0.865, respectively. According to the long-term tracking results, the precision and recall of the system proposed in this study indicate good, stable performance.

Long-term tracking results
6 Conclusions
In this paper, we established a Chinese opinion-mining system that can be applied to an Internet forum and analyzed the opinion trends expressed by the articles on one such forum. We proposed the thesaurus-based extraction of opinion elements from articles, and we designed algorithms for extracting and expanding the opinion elements considered by the system. This system has good performance and effectively reduces labor costs. The experimental results confirm that our method for the extraction and expansion of opinion elements can not only identify new words emerging in Internet usage, but also effectively reduce labor costs.
In future, we will work toward continuous improvement of this system. We will implement numerous additional functions in report analysis to allow the system to not only rapidly acquire the requested information, but also to track whether certain opinion tendencies may reflect a long-term pattern of malicious criticism by a particular reviewer and thus identify abnormal evaluations.
References
Zhen H, Kuiyu C, Jung-Jae K, Yang CC (2014) Identifying features in opinion mining via intrinsic and extrinsic domain relevance. Knowl Data Eng IEEE Trans 26:623–634
Li Z, Zhang M, Ma S, Zhou B, Sun Y (2009) Automatic extraction for product feature words from comments on the web. In: Presented at the Proceedings of the 5th Asia Information Retrieval Symposium on Information Retrieval Technology, Sapporo, Japan
Liu B, Zhang L (2012) A survey of opinion mining and sentiment analysis mining text data. In: Aggarwal CC, Zhai C (eds), Springer, US, pp 415–463
Kim S-M, Hovy E (2004) Determining the sentiment of opinions. In: Presented at the Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, p 1367
Liu B (2012) Sentiment analysis and opinion mining. In: Synthesis Lectures on Human Language Technologies, vol 5, pp 1–167. 23 May 2012
Liu B, Hu M, Cheng J (2005) Opinion observer: analyzing and comparing opinions on the Web. In: Presented at the Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan
Qiu G, Liu B, Bu J, Chen C (2009) Expanding domain sentiment lexicon through double propagation. In: Presented at the Proceedings of the 21st International Jont Conference on Artifical Intelligence. Pasadena, California, USA, pp 1199–1204
Chen M, Yao T (2010) Combining dependency parsing with shallow semantic analysis for Chinese opinion-element relation identification. In: Universal Communication Symposium (IUCS), 2010 4th International, pp 299-305
Jianping C, Ke Z, Hui W, Jiajun C, Fengcai Q, Ding W, Yanqing G (2014) Web-based traffic sentiment analysis: methods and applications. Intell Transp Syst IEEE Trans 15:844–853
Ku L-W, Ho H-W, Chen H-H (2009) Opinion mining and relationship discovery using CopeOpi opinion analysis system. J Am Soc Inf Sci Technol 60:1486–1503
Liu C-L, Hsaio W-H, Lee C-H, Lu G-C, Jou E (2012) Movie rating and review summarization in mobile environment. Syste Man Cybern Part C Appl Rev IEEE Trans 42:397–407
Kim S-M, Hovy E (2006) Extracting opinions, opinion holders, and topics expressed in online news media text. In: Presented at the Proceedings of the Workshop on Sentiment and Subjectivity in Text, Sydney, Australia
Qiu G, Wang C, Bu J, Liu K, Chen C (2008) Incorporate the Syntactic knowledge in opinion mining in user-generated content. WWW 2008
Qiu G, Liu B, Bu J, Chen C (2011) Opinion word expansion and target extraction through double propagation. Comput Linguist 37:9–27
Haiping Z, Zhengang Y, Ming X, Yueling S (2011) Feature-level sentiment analysis for Chinese product reviews. In: Computer Research and Development (ICCRD), 2011 3rd International Conference on, pp 135–140
Zhu S, Liu Y, Liu M, Tian P (2009) Research on feature extraction from Chinese text for opinion mining. In: Asian Language Processing, IALP ’09. International Conference on, 7–10
Wei W, Hongyan L, Jun H, Hui Y, Xiaoyong D (2008) Extracting feature and opinion words effectively from chinese product reviews. In: Fuzzy Systems and Knowledge Discovery, FSKD ’08, 5th International Conference on, 170–174
Nozomi K, Kentaro I, Yuji M (2007) Opinion mining from web documents: extraction and structurization. Inf Media Technol 2:326–337
Tsai C-H (1996) Tsai’s list of Chinese words [online]. http://technology.chtsai.org/wordlist/tsaiword.zip. Accessed 20 Feb 2015
Bin S, Kuiyu C (2006) Mining Chinese reviews. ICDM Workshops, 6th IEEE International Conference on, pp 585–589
Huang J, Etzioni O, Zettlemoyer L, Clark K, Lee C (2012) RevMiner: an extractive interface for navigating reviews on a smartphone. In: The Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology, Cambridge, Massachusetts, USA
Jin W, Ho HH, Srihari RK (2009) OpinionMiner: a novel machine learning system for web opinion mining and extraction. In: The Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, SJ., Chiang, RD. & Ji, ZH. Development of a Chinese opinion-mining system for application to Internet online forums. J Supercomput 73, 2987–3001 (2017). https://doi.org/10.1007/s11227-016-1816-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-016-1816-6