
Abstract
In this paper, a novel region-based approach for estimating the speed of a vehicle using wireless sensor networks is presented. Compared with a point-based approach, which is used to determine the vehicle arrival and departure points separately in each node, the proposed region-based approach is used to determine the speed of a vehicle at the server using the similarities among the sensor data received from two sensor nodes. In the proposed approach, a moving-average filter is applied to reduce noise in the sensor reading. Next, N-samples of data around a feature point with a first-order derivative larger than the chosen threshold are recorded. Delta coding is then applied to compress the data and minimize the power consumption required for communication from the sensor nodes to the server. Finally, the similarity of the data received from the two sensor nodes is measured to estimate the speed of the vehicle. More specifically, a similarity measure, a modified version of a cross-correlation function, is proposed. In addition, an evolutionary programming technique is adopted to find the optimal parameters for the threshold value of the first-order derivative and the number of samples that need to be sent to the server. Experimental results are provided to show the effectiveness of the proposed region-based vehicle speed estimation approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Various sensors such as CCD cameras, infrared cameras, microwave radar, and loop detectors are used to detect, classify, and measure the speed of vehicles, monitor road traffic volumes, and control traffic lights [1–5]. CCD and infrared cameras can be used for monitoring traffic flows within a wide road area, with the video sent to traffic-monitoring centers. Microwave radar can be used to detect vehicles in poor weather conditions based on radar echoes bouncing back from the vehicles. Inductive loop detectors are the most common systems for detecting vehicle presence and speed. Regarding the installation and maintenance, vision and infrared systems can be installed and maintained without interrupting traffic flows. However, the performance of vision and infrared systems may decrease owing to poor weather and illumination conditions [6]. On the contrary, loop detector systems require high maintenance costs and interrupt traffic flows during installation. Despite their high maintenance costs and the occurrence of traffic flow interruptions, inductive loop detectors are used to monitor the vehicle presence and speed with high accuracy.
A considerable amount of research has recently been conducted on the use of wireless sensor network (WSN) technologies, overcoming their limitations and introducing new services for various ITS applications [7–9]. Monitoring traffic information using WSNs can be done quite effectively, as WSNs can be deployed at any place where communication is possible and are easily adapted to various types of environments and applications. In addition, various sensors can be added to a sensor node to provide additional functionalities. For instance, temperature and humidity sensors can be added to check whether a road is icy or slippery [10]. Chen et al. [9] applied a WSN to collect and transfer traffic information at intersections, control traffic lights, and minimize the wait time at intersections. Marcin et al. [8] introduced sensor networks to build smart roads. They proposed a distributed system to collect traffic information of a few hundred meters ahead of the drivers and to provide a consistent view of the road conditions, helping drivers avoid potential dangers.
WSN technologies were also used for the vehicle detection and speed estimation to manage available parking spaces or to monitor traffic flows [11, 18–25]. Cheung et al. [11] developed a wireless sensor node using a magnetic sensor to monitor traffic flows. They proposed an adaptive threshold-based approach to effectively measure the speed of a vehicle, which is simple and computationally cheap to be implemented in a sensor node. A more detailed summary of previous researches on vehicle detection is shown in Table 1.
In this paper, a novel approach is presented to estimate the speed of a vehicle using a WSN-based traffic monitoring system developed by the Electronics Telecommunications Research Institute (ETRI) [7, 12]. More specifically, a region-based approach is presented to accurately detect the speed of a vehicle. Rather than determining the entrance and departure points of a vehicle at the node side, the vehicle entrance and departure points are determined at the server side. In the region-based method, multiple data points collected from each sensor node are sent to the server, and the speed of a vehicle as well as the vehicle entrance and departure points are calculated in the server side. The main contributions of this paper can be summarized as follows. First, a framework for a region-based approach is presented for estimating the speed of a vehicle using magnetic sensor nodes. Second, delta coding is adopted to compress the data and minimize the amount to be sent to the server. Third, N-samples of data regarding a feature point with a first-order derivative larger than a chosen threshold are sent to the server to minimize the computation and communication costs. Fourth, a similarity measure is presented to check the similarity of data received from two sensor nodes, allowing the speed of a vehicle to be estimated more accurately. Finally, an evolutionary programming technique is adopted to find the optimal parameters of the threshold value and the number of samples to be sent to the server. The organization of this paper is as follows. In Sect. 2, previous WSN-based researches for vehicle detection are presented. A matched filter and a finite state machine (FSM)-based approach are described in detail. In Sect. 3, a detailed explanation of the proposed region-based approach, including its framework, is presented. Exhaustive experimental results are shown in Sect. 4. Lastly, some concluding remarks and future research directions are given.
2 WSN-based vehicle detection approaches
With the advances in WSN technologies, WSNs using magnetic sensors are becoming more popular for various ITS applications [18–23]. Two of the most well-known approaches are described briefly in this section owing to their simplicity and low computational expense: a matched filter and an FSM-based algorithm.
2.1 A matched filter
To detect the presence of a vehicle, a simple filtering approach using a matched filter can be utilized. A matched filter is an optimal linear filter that detects a known signal \(s[n]\) by maximizing the signal-to-noise ratio (SNR), which is defined as
where \(h[n]\) is the modeled filter and \(x[k]\) is an observed signal consisting of a noise-free signal \(s[n]\) and additive noise \(n[k]\). Let data from a magnetic sensor be denoted as \((s(t)+n(t))\), where \(s(t)\) is generated from a passing vehicle and \(n(t)\) is caused by surrounding electromagnetic noise. If the signal \(s(t)\) can be known and modeled, it can be detected from a corrupted signal. In other words, a matched filter can be described as a cross-correlation between a known signal \(s(t)\) and data from a sensor node \((s(t)+n(t))\) that are corrupted by additive noise \(n(t)\) as follows.
where corr\((s(t), s(t))\) is the maximum value, while corr\((n(t), s(t))\) is low when a vehicle is detected. Zhang et al. [19] installed a magnetic sensor node at a roadside to monitor the traffic volume. Signals from the sensor node are collected to model a typical signal pattern of the vehicles. A Gaussian function is then used to build a model describing the signal pattern.
2.2 A finite state machine (FSM)
An FSM can be combined with a threshold-based approach to develop a vehicle detection system. In each state, it has a value representing the state. A state can be changed into another state if a certain condition is met. For instance, an FSM shown in Fig. 1, which has six states for detecting a vehicle, can be built. State 1 (S1) is used for determining the “baseline” of a signal. After starting/resetting the system, the baseline is determined and the current state is changed to State 2 (S2). State 2 is a state waiting for a signal \(s(t)\) that is bigger than a given threshold, i.e., Th_Base. If a signal is bigger than Th_Base, the current state is changed to State 3 (S3). State 3 is “Counting the number Over Threshold,” which counts the number of signals s(t) that are bigger than the value of Th_Base. If \(s(t)\) is smaller than Th_Base, the current state is changed to State 4 (S4), where \(s(t)\) is checked again. If \(s(t)\) \(<\) Th_Base successively, then the current state is changed to S2. If \(s(t)\) \(>\) Th_Base, then the current state is changed back to S3. In S3, if the number of \(s(t)\) signals is bigger than a given threshold, Th_V, the current state is changed to State 5 (S5) and it is declared that a vehicle arrival has been detected (Veh_Arr = ON). After a vehicle arrival is detected, s(t) is checked to determine whether it is lower than a given threshold, Th_Dep. If \(s(t)\) \(<\) Th_Dep, the current state is changed to State 6 (S6), and it is declared that a vehicle departure has been detected (Veh_Dep = ON). Finally, the current state is moved back to S1 and the baseline is determined again.

An FSM for detecting vehicle arrivals and departures
Knaian [18] presented a prototype system that utilizes a magnetoresistive magnetic sensor and a threshold-based vehicle detection approach. Nan et al. [20] also used a threshold-based approach and hierarchical three-node architecture to reduce power consumption. To determine the value of the baseline, a group of samples without any vehicle around the sensor node are recorded, and the average sample value can be used.
3 Vehicle speed estimation
Vehicle speed estimation approaches can be classified into point-based and region-based techniques. Threshold- and derivative-based approaches can be considered as point-based approaches. In this section, various speed-estimation algorithms including the proposed region-based approach are described in detail.
3.1 Point-based vehicle detection approaches
In a point-based approach, vehicle arrival and departure points are determined at the node side, and the results are sent to the server for further processing.
3.1.1 A threshold-based approach
A threshold-based approach is simple and computationally cheap [3, 15, 18]. To detect the vehicle arrival and departure points, a threshold is chosen and a sensor reading is compared with the chosen threshold. If a sensor reading is larger than the chosen threshold, a vehicle is declared as detected, as described in Sect. 2. The most important point is how to determine the threshold value that shows the best recognition performance.
3.1.2 A derivative-based approach
A derivative-based approach is based on the magnitude of the first-order derivative of the sensor readings. If the magnitude of the first-order derivative continues to increase and is larger than the chosen threshold value, a vehicle can be considered as having been detected. However, when no vehicles are present, the magnitude of the derivative is smaller than the chosen threshold. The strong point of a derivative-based approach as compared with a threshold-based approach is that it is not dependent on the baseline value. In a threshold-based approach, the baseline value is critical for the detection of a vehicle arrival and departure. However, a weak point of the derivative-based approach remains: when a vehicle stops or moves slowly over a sensor node, the magnitude of the derivative value is small and may be misconstrued as a vehicle departure. To overcome this problem, threshold- and derivative-based approaches can be combined together to improve the recognition performance. The whole process of a derivative-based approach is described in Fig. 2.

The whole process of vehicle detection for a derivative-based approach
To measure the speed of a vehicle, two sensor nodes, SN1 and SN2, are required. The vehicle arrival and departure points are detected by checking whether a sensor reading at each sensor node is larger or smaller than the given threshold values. The arrival and departure speeds of the vehicle are then determined as
where \(D_\mathrm{SN2-SN1} \) denotes the distance between two sensor nodes, and \(t_\mathrm{SN2arr} ,t_\mathrm{SN2dep} ,t_\mathrm{SN1arr} \) and \(t_\mathrm{SN1dep} \) are the vehicle arrival and departure times at sensor nodes 2 and 1, respectively. To remove the sensitivity difference between the two sensor nodes, the average speeds of \(v_\mathrm{arr}\) and \(v_\mathrm{dep}\) can be used. In this approach, the speed of a vehicle is determined based on the detected vehicle arrival and departure points at a sensor node, which is simple and computationally cheap to implement (please refer to [11] for more detailed information).
3.2 A region-based approach
In a point-based approach, the threshold value or magnitude of the derivative value is used to determine the vehicle arrival and departure points at each node. The weak point of a point-based approach is that the detection points are likely to be sensitive depending on the baseline value and the chosen threshold used in each node. Furthermore, the vehicle arrival and departure points are determined in each node separately. If the baseline and threshold values of one sensor node are set slightly lower, then the vehicle arrival points in that sensor node will be detected earlier. On the contrary, in a region-based approach, the speed of a vehicle is estimated at the server side based on raw sensor readings received from two sensor nodes. More specifically, a similarity in the data from two sensor nodes can be exploited in a region-based approach. As indicated in [11], data from two sensor nodes are similar as long as the speed is nearly constant as the vehicle passes over the two sensor nodes and the vertical shift of the moving vehicle is negligible.
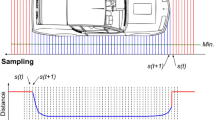
Figure 3a shows example data captured from two sensor nodes as a vehicle passes over them. The red line denotes sensor readings from node A, and the blue line indicates sensor readings from node B. Although the reading from each of the two sensor nodes may differ owing to a difference in their sensitivity, the overall shape of each reading is similar. By shifting data from one of the sensor nodes, it is clear that the shapes of the two sensor readings are similar, as shown in Fig. 3b. Thus, more accurate vehicle arrival and departure points can be determined at the server by matching the data received from the two sensor nodes.

An example of sensor readings from two sensor nodes: a the baseline of each sensor node is different owing to a sensitivity difference (the red and blue lines indicate the sensor readings from nodes A and B, respectively); and b an example of shifted data, showing that the shapes of the two signals are similar (color figure online)
3.2.1 Similarity-based vehicle arrival/departure estimation
Based on observations showing similar sensor readings from each of the two sensor nodes, as depicted in Fig. 3, the vehicle arrival and departure points can be determined by matching the signals from both nodes. In this paper, a novel computationally cheap similarity-based vehicle speed estimation method is proposed for operation in USN environments. In the proposed approach, rather than matching the whole signal from the two sensor nodes, a region of each signal is sent to the server. This region has to be chosen carefully to ensure that more accurate matching points can be determined. Suppose that a section of a signal is chosen and sent to the server, as shown in Fig. 4.

Region selection from sensor nodes for signal matching at a server node
There are several regions that can be chosen for the matching. R1 is a region that includes a detected point larger than the chosen threshold. The N points around the detected point, i.e., P1 through PN, are sent to the server. In the same manner, N points around a detected point smaller than the chosen threshold can also be chosen and sent to the server. A block diagram of the proposed similarity-based vehicle speed estimation approach is shown in Fig. 5. The detailed procedure of the proposed region-based approach is as follows:
-
Step 1: A moving-average filter is applied to reduce random noise in each sensor node:
$$\begin{aligned} D_\mathrm{A} [n]=\frac{1}{M}\sum \limits _{i=0}^{M-1} {s_\mathrm{A} [n+i],} \end{aligned}$$(4)where \(D_\mathrm{A}[n]\), \(s_\mathrm{A}[n]\), and M denote the filter output, original sensor reading of node A, and the size of the filter, respectively.
Fig. 5 
A block diagram of the proposed region-based vehicle speed estimation approach
-
Step 2: If the absolute value of the first-order derivative for a sequence of sensor readings is bigger than a chosen threshold, N points in the sequence are saved for matching:
$$\begin{aligned}&D_\mathrm{diff} [n]=D_\mathrm{A} [n]-D_\mathrm{A} [n-1],\nonumber \\&\mathrm{if}\,\left| {D_\mathrm{diff} [n]} \right| >\mathrm{Th}_\mathrm{D} \\&\quad \mathrm{then}\,\mathrm{save}\hbox { N points.}\nonumber \end{aligned}$$(5) -
Step 3: Data are compressed in each sensor node before being sent to the server. For data compression, lossless techniques such as the LZW [26], delta [27], and Huffman [28] techniques, and lossy methods such as vector quantization and JPEG, can be used. For WSN environments, a correlation-aware data dissemination used to exploit spatial and temporal correlations of traffic information [29]; a hybrid approach that combines lossy and lossless techniques [30]; K-RLE, in which K is determined based on a standard or Allan deviation [31]; and packet-level data compression that exploits the temporal correlation between two successively sent packets [32] have been proposed. For exact matching with low complexity, the delta coding technique was chosen for the proposed approach. For instance, the sequence of sensor readings in node A (\(D_\mathrm{A}[1], D_\mathrm{A}[2], {\ldots }, D_\mathrm{A}[n]\)) is converted into (DiffBaseA, \(C_\mathrm{A}[1], C_\mathrm{A}[2], {\ldots }, C_\mathrm{A}[n-1]\)), where \(C_\mathrm{A}[i] = D_\mathrm{A}[i+1] - D_\mathrm{A}[i]\), and DiffBaseA denotes the difference between the first data sample \(D_\mathrm{A}[1]\) and the baseline of node A.
-
Step 4: After the data are received from the two sensor nodes, the data are decompressed. A similarity measure function f(\(D_\mathrm{A} \times D_\mathrm{B}\)) is then called to locate the point where the sequences of the two sensor data match. To locate a matching point, a cross-correlation function can be used. In this paper, a modified version of a cross-correlation function, i.e., a similarity measure function, is proposed to reduce the computational costs, and is defined below:
$$\begin{aligned} \begin{array}{l} f(D_\mathrm{A} \times D_\mathrm{B} )[n] \\ \quad =\sum \limits _{i=-N/2}^{i=N/2} {\left| {D_\mathrm{A} [i]-(D_\mathrm{B} [n+i]+\mathrm{Diff}_\mathrm{Baseline} )} \right| } \\ \end{array}, \end{aligned}$$(6)where N denotes the number of samples sent to the server, \(\mathrm{Diff}_\mathrm{Baseline}\) indicates the difference between the two baselines of sensor nodes A and B (i.e., Diff\(_{\mathrm{Baseline}}=\mathrm{Base}_\mathrm{A}-\mathrm{Base}_\mathrm{B})\), and \(D_\mathrm{A}\) and \(D_\mathrm{B}\) denote N samples of data from sensor nodes A and B, as indicated in (5), respectively. Although their shapes are similar, the sensitivities of the two sensor nodes may be different. For instance, the sensor reading from node A is larger than that from node B, and thus the baseline of sensor node A, i.e., Base\(_\mathrm{A}\), is higher than that of sensor node B, i.e., Base\(_\mathrm{B}\).
-
Step 5: The vehicle speed is calculated based on a speed-estimation function defined as
$$\begin{aligned} \hat{n}&= \mathrm{Arg}\mathop {\min }\limits _n f(D_\mathrm{A} \times D_\mathrm{B} )[n]\end{aligned}$$(7)$$\begin{aligned} V(D_N )&= \frac{D_\mathrm{SN_A -SN_B } }{t2-t1+\hat{n}\times \,\mathrm{SamplingRate}}, \end{aligned}$$(8)where \(D_\mathrm{SN_A -SN_B } \) denotes the distance between the two sensor nodes, A and B, and \(t2\) and \(t1\) are the times at which a feature point is detected at nodes B and A, respectively. In (7), matching point \(\hat{n}\) can be found by locating the value of n that minimizes the similarity function defined in (6).

3.2.2 Evolutionary programming for parameter determination
Evolutionary programming is a stochastic optimization technique for iteratively seeking out better solutions. A set of solutions that minimize the cost function are generated through recombination, mutation, and selection processes. The general scheme of evolutionary programming is as follows [33, 34]:
BEGIN
-
INITIALIZE population with random solutions
-
REPEATUNTIL (TERMINATION CONDITION is met)
-
SELECT parents (survivors)
-
RECOMBINE pairs of parents
-
MUTATE the resulting offspring
-
EVALUATE new possible solutions
END
In the proposed region-based approach, the threshold value for the first-order derivative of the sensor readings, as shown in (5), and the number of samples to be sent to a server, as shown in (6), need to be determined. The threshold value for the magnitude of the first-order derivative and the minimum number of data samples to be sent that satisfy the following cost function are determined using evolutionary programming:
where\(V_{r_j } \)and \(N_\mathrm{DB}\) denote the reference velocity of the j-th vehicle and the total number of vehicles in the training database, respectively, and \(N\), Th\(_\mathrm{D}\), and Rate\(_{ T}\) indicate the number of data samples to be sent to the server, the threshold value, and the minimum target recognition rate. In addition, the training data have to be chosen carefully to cover the statistics of various vehicle data, so that the chosen parameters can be used during the recognition process.
4 Experimental results
In this section, exhaustive simulation results are presented to show the effectiveness of the proposed approach.
4.1 Experimental setup
For a live test, a testbed consisting of sensor nodes, a relay node, and a base station was built in an urban road near ETRI in Daejeon. The test site was a six-lane road, the average traffic volume of the test site was around 18,000 cars per day, and the speed of the vehicles was between 30 to 120 km/h.
The proposed WSN system is composed of four parts: sensor nodes, a relay node, a base station, and a monitoring server. We developed the sensor nodes using HMC1043 3 axis magnetometer sensors, an MSP430F2618 microcontroller, an on-board 2.4 GHz CC2520 radio transceiver with a data rate of 250 kbps, a Winizen chip antenna, and four-cell lithium-ion batteries that can supply 7,600 mAh at 3.6 V. The magnetic field in the vertical direction was sampled at a frequency of 128 Hz for vehicle detection. Each measurement was converted into a 16-bit binary representation using an ADC. The sensor nodes remained in low-power standby mode and only woke up when the magnetic signal crossed a given threshold. The relay node was used to transmit the data packets from the sensor nodes to the base station within a single hop, since the communication range of the sensor nodes buried under the ground was too short to directly communicate with the base station. While it lacked a magnetic sensor, note that the relay node otherwise had the same H/W specifications as the sensor nodes, along with an external antenna and a radio frequency (RF) power amplifier. The relay node was mounted on a pole on the side of the road, as shown in Fig. 6. The speeds of the vehicles were computed in real time at the base station based on the received sensor readings from the relay node. The monitoring server was used to record the estimated vehicle velocities and the performance of the proposed point- and region-based approaches. For medium access control, a time-division multiple access (TDMA) protocol was used. In addition, the sensor nodes and the base station were synchronized.

Photographs of our testbed: a a sensor node, b relay node, c base station, and d monitoring server
Data were collected over a period of 3 days. More specifically, the collection was conducted from 10 a.m. on May 15 to 10 a.m. on May 18, 2012, according to a Korean law regarding vehicle speed measurements. The recording was conducted for 30 min four times per day, during the day, and at dusk, night, and dawn, allowing various types of data with different statistics to be covered in the experiment. In addition, motorcycles and lane-changing vehicles were excluded from the simulation. The vehicle data collected were distributed as shown in Table 2.
4.2 Experimental results
4.2.1 Accuracy of vehicle speed detection
In our experiments, a laser detector was used to measure the vehicle speed that can be used for the ground truth and for calculating the performance of the proposed approach. The accuracy of the proposed region-based approach was verified based on a 100 % mean absolute percentage error (MAPE), as described in
where n, \(Y_i\), and \(X_i\) denote the number of vehicles, the estimated speed of the laser detector, and the estimated speed of the ith vehicle based on the proposed approach, respectively. If the reference laser speed was zero but the estimated vehicle speed was not, or if the value of 100 %-MAPE was negative, 100 %-MAPE was set to zero.
First, the vehicle speed was estimated using the point-based approach. Two sensor nodes were installed to detect the vehicle arrival and departure points. Experiments were performed for various distances between the two sensor nodes. The distances were varied from 1.5 to 6 m. The recognition results of the estimated vehicle speed for various sensor node distances are shown in Fig. 7. For each distance setup, the recognition rate of the vehicle speed estimation was calculated at four different times, i.e., during the day, and at dusk, night, and dawn.
Table 3 shows the recognition performance of the vehicle speed estimation using the point-based approach [11] for various distances at the arrival and departure points separately. As can be seen in Fig. 7 and Table 3, a 6-m distance showed the best recognition performance.

The recognition rates of the point-based approach for various sensor-node distances at four different times, i.e., during the day, and at dusk, night, and dawn
Second, the recognition performance of the proposed region-based approach was tested. In our simulation, the distance between the two sensor nodes was fixed at 6 m to compare with the performance of the point-based approach shown in Table 3. In our simulations, the target recognition rate was set to 96 %, and the first four data in Table 2, i.e., day1, dusk1, night1, and dawn1, were used to determine the parameters described in (9). In our simulations, the threshold value was determined as 3 \(\times \) sd, i.e., the standard deviation. The remaining data in Table 2 were used for performance testing. The test results of the region-based approach at the vehicle arrival and departure points are shown in Table 4. The simulations were again performed at four different times, i.e., during the day, and at dusk, night, and dawn, and the results from various numbers of data samples were included.
The average recognition rate at the vehicle arrival and departure points was calculated as shown in Table 5. As the window size required to send the recorded data samples to the server side increased, the recognition rate also gradually increased.
In our experiments, the proposed region-based approach outperformed the point-based approach. In the region-based approach, the average accuracy of the speed estimation was about 3 % higher than the point-based approach. In addition, as the number of data samples increased, the accuracy was also improved, which was due to the fact that the proposed approach determined the matching point between the two sensor nodes based on all the sensor readings within the data samples sent to the server.
4.2.2 Calculating the battery life
To compare the point- and region-based approaches, we define a model for estimating the battery life of a sensor node as (11). The current-consuming operations considered for the sensor nodes are as follows: the average current consumption for sensing (\(C_\mathrm{S})\), which includes the current consumption from sensing using a magnetic sensor and sampling using an analog-to-digital converter (ADC) for the microprocessor (MCU); the average current consumption for signal processing using the MCU (\(C_\mathrm{P})\), which runs the algorithm for vehicle detection; the average current consumption of the radio frequency (RF) transceiver (\(C_\mathrm{R})\), which includes the transmission of the data packets and listening to the channel; and the average current consumption of idle tasks by the MCU (\(C_\mathrm{I})\).
where \(L\) denotes the battery life (in years) of the sensor node and \(B\) is the battery capacity (mAH). To conserve power and hence extend the life of the battery, sensor nodes were developed to switch off their magnetic sensor, RF transceiver, and MCU when not needed.

The packet structure of the sensor nodes used for the a point- and b region-based approaches
The primary cause of the difference in the total energy consumed between the point- and region-based approaches is the average current consumption of the transmission of data packets through the RF transceiver. The average current consumption for the transmission of data packets is directly dependent on the volume of the data transmitted. In the point-based approach, time information of the vehicle arrival and departure points is sent to the base station. However, in the region-based approach, the vehicle arrival and departure points are detected in the sensor nodes, and multiple sensor readings around the detected vehicle arrival and departure points are sent to the base station. Figure 8 shows the packet structure used for our simulation for both the point- and region-based approaches.
In Fig. 8a, “source address” and “destination address” denote the identification of a sensor node and the identification of a relay node or base station. When the vehicle arrival and departure points are detected, time stamps are sent to the base station in the point-based approach. In the region-based approach, as shown in Fig. 8b, multiple sensor readings around the vehicle arrival and departure points are sent to the base station. BASE_T and BASE_V denote the time stamp and baseline values of a sensor node, respectively. Diff\(_\mathrm{Base}\) is the offset value of the first data sample from the baseline, and \(C[1], C[2]\), \({\ldots }\) \(C[n-1]\) is a sequence of converted sensor readings using the delta coding technique. The sizes of Diff\(_\mathrm{Base}\) and \(C[i]\) are 1 byte and 5 bits, respectively. The sampling frequency of each sensor node is 128 Hz (7.8 ms), and the time stamp of each \(C[i]\) reading can be calculated using BASE_T.
To ensure the accuracy of this simulation, we measured the current consumption profiles for each current-consuming operation performed at the sensor nodes. The profile for each operation was independently tested by tracking the CPU execution time at each power state; periodically broadcasting a message; and sampling and enabling, or disabling, the sensor. The battery life of the sensor nodes between the point- and region-based approaches is shown in Table 6.
As the number of data samples to be sent to the base station increased, the accuracy of the estimated vehicle speed also increased. However, the battery life of the sensor nodes decreased gradually for the region-based approach compared with the battery life for the point-based approach. The proposed region-based approach required a bit more power consumption. For instance, when the number of samples to be sent to the server was set to six, the battery life of the region-based approach decreased to 90.6 %.
5 Conclusions
In this paper, a novel region-based algorithm using a WSN for estimating the speed of a vehicle is presented. For the proposed approach, we presented (1) a framework for a region-based vehicle-detection approach, which is simpler and more accurate than a point-based approach; (2) a novel scheme to record N-samples of sensor readings to be sent to the server, which is based on the first-order derivative; (3) evolutionary programming used to find the optimal parameters and for determining the threshold value and number of data samples to be sent to the server; (4) a delta coding scheme to compress the data samples and minimize the power consumption required to send them; and (5) a similarity measure to match the data samples received from two sensor nodes and find the vehicle arrival and departure points.
ETRI has been developing a vehicle detection system using a WSN over the past several years [7, 12]. Rather than detecting the vehicle arrival and departure points in each sensor node, a region-based approach was presented with minimum power consumption, which was based on the idea that the shapes of the signals from two sensor nodes were similar and could be used for more accurate vehicle detection. However, there is a weak point that the proposed region-based approach requires more computational costs with additional power consumption. For future research, various feature points can be detected and tested. In addition to the vehicle arrival and departure points, the maximum and minimum points can be detected and sent to the server to evaluate the minimum number of data samples required by the server to achieve the same recognition performance. Furthermore, to minimize the power consumption, various compression algorithms could be investigated.
References
Gajda et al J (2001) A vehicle classification based on inductive loop detectors. In: Proceedings of IEEE International Conference on Instrumentation and Measurement Technology, pp 21–23
Xuan Y et al (2005) A high-range-resolution microwave radar system for traffic flow rate measurement. In: Proceedings of Intelligent Transportation Systems, pp 880–885
Iwasaki (2008) A method of robust moving vehicle detection for bad weather using an infrared thermography camera. In: Proceedings Of ICWAPR ’08, pp 86–90
Choi KH et al (2014) State machine and Downhill simplex approach for vision-based nighttime vehicle detection. ETRI J 36(3):439–449
Park HS et al (2013) In-vehicle AR-HUD system to provide driving-safety information. ETRI J 35(6):1038–1047
Tubaishat M et al (2009) Wireless Sensor networks in intelligent transportation systems. Wirel Commun Mobile Comput 9:287–302
Kim DH et al (2009) A feasibility study on crash avoidance at four-way stop-sign-controlled intersections using wireless sensor networks. IEICE Trans 95:1190–1193
Karpiriski M, Senart A, Cahill V (2006) Sensor networks for smart roads. In: Proceedings of IEEE International Conference on Pervasive Computing and Communications, pp 1–5
Chen W et al (2006) WITS: a wireless sensor network for intelligent transportation system. In: Proceedings of IMSCCS, pp 635–641
Yu T, Bo G, Ling T (2008) Design and application of wireless sensor networks for ground verification of remote sensing. In: Proceedings of international conference on apperceiving computing and intelligence analysis, pp 381–384
Cheung SY, Varaiya P (2007) Traffic surveillance by wireless sensor networks: final report. In: California PATH Research Report UCB-ITS-PRR-2007-4
Yoo JJ, Kim DH, Park JH (2010) Design and implementation of magnetic sensor network for detecting automobiles. In: Proceedings of IEEE 35th Conference on local computer networks, pp 929–932
Scarzello J, Usher G (1979) A low power magnetometer for vehicle detection. IEEE Trans Magn 13:1101–1103
Christou CT, Jacyna GM (2010) Vehicle detection and localization using unattended ground magnetometer sensors. In: Proceedings of 13th Conference on Information Fusion (FUSION), pp 1–8
Ding J et al (2004) Signal processing of sensor node data for vehicle detection. In: Proceedings of IEEE International Conference on Intelligent Transportation Systems, pp 70–75
Pelegri J, Alberola J, Llario V (2002) Vehicle detection and car speed monitoring system using GMR magnetic sensors. In: Proceedings of IEEE 28th Annual Conference of the Industrial Electronics, pp 1693–1695
Zhang L et al (2010) Piezoelectric detection device and experimental analysis of automobile wheelbase difference. In: Proceedings of the 2nd international conference on Signal Processing Systems (ICSPS), pp V1-407–V1-410
Knaian AN (2000) A wireless sensor network for roadbeds and intelligent transportation systems. MS thesis at the Electrical Engineering and Computer Science, MIT
Zhang y, Huang X, Cui L (2007) Lightweight signal processing in sensor node for real-time traffic monitoring. In: Proceedings of IEEE International Symposium on Communications and Information Technologies, pp 1407–1412
Nan D et al (2008) Low-power vehicle speed estimation algorithm based on WSN. In: Proceedings of 11th IEEE Conference on Intelligent Transportation Systems, pp 1015–1020
Franceschinis M et al (2009) Wireless sensor networks for intelligent transportation systems. In: Proceedings of IEEE Vehicular Technology Conference, pp 1–5
Kwong K et al (2010) Real-time measurement of link vehicle count and travel time in a road network. IEEE Trans Intell Transp Syst 11(4):814–825
Sifuentes E, Casas O, Pallas-Areny R (2011) Wireless magnetic sensor node for vehicle detection with optical wake-up. Sensors J IEEE 11(8):1669–1676
Guan X et al (2013) A vehicle detection algorithm based on wireless magnetic sensor networks. In: Proceedings International ICST Conference onCommunications and Networking, pp 669–674
Zhang Q et al (2013) Wireless magnetic sensor node for vehicle detection using finite element simulation. In: Proceedings of IEEE International Conference onInformation and Automation (ICIA), pp 248–251
Welch TA (1984) A technique for high-performance data compression. Computer 17(6):8–19
Aquino JFS et al (2008) A differential coding algorithm for wireless sensor networks. In: Proceedings of IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, pp 1–5
Marcelloni F, Vecchio M (2008) A simple algorithm for data compression in wireless sensor networks. IEEE Commun Lett 12(6):411–413
Skordylis A, Guitton A, Trigoni N (2006) Correlation-based data dissemination in traffic monitoring sensor networks. In: Proceedings of the 2006 ACM CoNEXT Conference
Byl AV, Neilson R, Wilkinson RH (2009) An evaluation of compression techniques for wireless sensor networks. In: Proceedings of AFRICON, pp 1–6
Capo-Chichi MEO, Friedt JM, Guyennet H (2010) Data compression for delay constrained applications in wireless sensor networks. In: Proceedings of SENSORCOMM, pp 101–107
Reindardt A, Hollick M, Steinmetz R (2009) Stream-oriented lossless packet compression in wireless sensor networks. In: Proceedings of SECON, pp 1–9
Taghanaki SA et al (2012) Nonlinear feature transformation and genetic feature selection: improving system security and decreasing computational cost. ETRI J 34(6):847–857
Sara GS et al (2012) A genetic-algorithm-based optimized clustering for energy-efficient routing in MWSN. ETRI J 34(6):922–931
Acknowledgments
This work was supported by the Ministry of Science, ICT and Future Planning/Korea Research Council for Industrial Science and Technology under an intelligent situation cognition and IoT basic technology development project “The Development of Wireless Automotive Sensor Networks Technology and Smart Vehicle”.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kim, DH., Choi, KH., Li, KJ. et al. Performance of vehicle speed estimation using wireless sensor networks: a region-based approach. J Supercomput 71, 2101–2120 (2015). https://doi.org/10.1007/s11227-014-1306-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-014-1306-7