
Abstract
This paper analyses the determinants of trust in a pool of 34 European countries over the period 2002–2012. We find that income inequality is negatively related with generalized trust when we analyze the pooled data of individuals with multilevel models, confirming a well-established result in the analysis of cross-country differences in trust. However, we are unable to find the same significant relationship when we estimate fixed effects models with a panel dataset composed by countries. It is plausible that unobserved effects may account for the significant and negative relationship between economic inequality and trust at the cross-sectional level. In contrast, in the fixed effects models, we find negative and significant effects of ethnic and linguistic fractionalization, discrimination (general or based on migrant status) and crime rates on trust.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
One of the components of social capital that has received a great deal of attention is generalized trust, which is generally measured by the responses of individuals to surveys of values and attitudes around the world. There are important differences in trust among countries and well known regional differences. For example, the Nordic countries display higher levels of trust than other European countries and the US. In turn, individuals from some developing countries are less trusting than individuals from European societies and other developed countries.
These differences in trust have led to the emergence of attempts to explain what leads individuals from different countries, or regions within a country, to vary in their trust levels. Among the explanations that one finds in the empirical literature is that trust is negatively associated with measures of income inequality like the Gini coefficient. Examples are in Knack and Keefer (1997), Uslaner (2002), Zak and Knack (2001), Knack and Zak (2002), Leigh (2006a), Bjørnskov (2007), Rothstein and Uslaner (2005), Berggren and Jordahl (2006), Rothstein and Uslaner (2005), Uslaner and Brown (2005), Fisher and Torgler (2013), Jordahl (2009) and Gustavsson and Jordahl (2008). Most of these studies rely on analyses of cross-sections of countries, so that omitted variable problems could be present. This means that income inequality might not be the variable really explaining the different observed levels of trust, so that one should refer to associations between trust and income inequality or other covariates. These differences could be explained by institutional and cultural characteristics of the countries which are generally omitted in cross-sectional analyses. An exception is Gustavsson and Jordahl (2008) who use a panel data of Swedish counties and instrumental variables to uncover a negative relation between trust and an inequality measure focused on differences in income at the bottom half of the income distribution (ratio P50–10).
Wilkinson and Pickett (2010) The Spirit Level and the replies it has provoked (e.g. Sunders 2010) have contributed to making the idea that trust, among other measures of social cohesion is hindered by the growing levels of income inequality. An assessment of such claims will require a closer look at the data and methods employed in establishing the link between income inequality and trust. The cross-country studies previously mentioned are prominent in the literature on trust, but they do not directly address the issue of the determinants of changes in trust, and therefore it is hard to establish a precise role of income inequality as one of those determinants. The aim of this paper is to study the determinants of general trust taking into account variation over time and country. In this way, we try to assess whether growing income inequality, as is widely claimed, has an effect on generalized trust.
This paper differs from the existing empirical literature in several respects. We use a harmonized dataset composed by the total number of available bi-annual rounds of the European Social Survey (ESS). This includes six rounds carried out between 2002 and 2012, which comprises a total of 34 countries and about 270,000 individuals. We first explore the determinants of generalized trust with the full sample of individuals by using multilevel models where the hierarchical order goes from individual to country to years. In doing this, we try to respect the multilevel structure of the data and pay particular attention to the effect of variables at the country level. We find that income inequality measured by the Gini index of net incomes and the top 1 % income share is negatively associated with generalized trust. This strategy allows us to compare our results with other empirical studies and report a negative association between income inequality and trust when one focuses on cross-country differences.
In a second step, we attempt to lessen potential problems of omitted variables present in the cross-country analysis that can cause biased estimators. Our strategy consists in constructing a panel dataset by collapsing (taking averages) some of the variables of interest of the ESS by country and year and apply fixed effects (FE) estimations. Given that trust and income inequality can vary greatly across countries but minimally over very short time periods (bi-annual rounds) we will perform FE estimations to the whole panel data sample and to a sample conformed by the countries observed in the extreme years of the ESS survey (2002 and 2012). The use of this last sample allows us to account for changes in trust and inequality that otherwise are difficult to observe every 2 years. Contrary to our first step analysis, the FE estimators fail to reveal any significant relation between any income inequality measure and trust under different specifications and in both panel data samples. This result is robust irrespective of whether we focus on the average level of trust in a country or different parts of the distribution of trust. Some variables in the panel data are significantly related to trust. GDP per capita positively affects trust, while that discrimination (general and based on migrant status), crime rates, and ethnic and linguistic fractionalization indexes have negative effects on trust. This is line with the findings of other studies that give a more important role to the ethnic fractionalization of the country in explaining differences of trust. These include Knack and Keefer (1997), Leigh (2006b), Gustavsson and Jordahl (2008), Alesina and La Ferrara (2002), Delhey and Newton (2005) and Putnam (2007). This may be interpreted as indicating that ethnic or racial homogeneity in a country leads to people to trust more. Other studies that find a positive role for GDP growth or GDP per capita in the formation of trust are Durlauf and Fafchamps (2004), Zak and Knack (2001), Beugelsdijk et al. (2004), Knack and Keefer (1997), Steijn and Lancee (2011) and Algan and Cahuc (2010).
The paper is organized as follows. In next section, we discus some theoretical relationships between trust and inequality. Section 3 describes the data to be used and some patterns of general trust across countries. Section 4 presents the results from the estimation with the pooled individual data. Section 5 presents the FE estimates with panel data. Finally, Sect. 6 concludes.
2 Trust and Inequality
When analysing trust, it is important to distinguish between particularized and generalized trust. The first type of trust is expressed to individuals that belong to the same close group like the family, friends, etc., while that generalized trust is expressed to individuals one does not know across society. People can express a great deal of particularized trust to their own group but little generalized trust to other fellow citizens. It is understood that countries with high generalized trust reveal that people share a common fate with other members of society regardless of socio-economic status, race, religion or other possible divisive dimensions. We are interested in studying generalized trust as this value reflects how much concern exits in the society about different people, in particular other people who can face socio-economic disadvantages. In this respect, Delhey and Newton (2005) interpret that when individuals answer about their values on generalized trust, they could be assessing the moral standard of their society.
In studying the role of universal or means-tested social programs on the formation of trust, Rothstein and Uslaner (2005) argue that generalized trust is caused by two different, though interrelated, types of equality: economic equality and equality of opportunity. The authors identify three ways on how universal programs can increase trust. These programs are more redistributive than programs targeted to the poor and hence can increase economic equality. Since these programs intend to treat all equally and reduce political discretion, they increase the sense of equality of opportunity in society. Programs targeted to the poor can exacerbate socio-economic divisions or even racial divisions if poverty is associated with race or social class. Contrary to this, universal programs can increase the perception of a shared fate in society. To make their argument credible, Rothstein and Uslaner (2005) base their theoretical claims on the role of the distribution of resources and opportunities in a society. A more equitable distribution of resources and opportunities will be the root of more general trust. This is why countries like the Nordic ones, with a history of more equality, show greater levels of general trust. In addition, differences among people are more marked with larger inequality. Then, if people perceive this sharper socio-economic differences, they will consider that other individuals are even more distanced from themselves and hence they will be less trusting. In his revision of the empirical literature on trust and inequality, Jordahl (2009) also argue in favour of a causal relationship from inequality to trust. Delhey and Newton (2005) treat income equality as a measure of class cleavage, so that societies will be more trusting if people are less divided by this class cleavage. Other cleavages along society can be alienated—and can affect trust—are religion, language and ethnicity.
Although we accord with the view of a causal relationship going from inequality to generalized trust, it is worth to mention the existence of feedback mechanisms that can obscure a clear-cut relation from inequality to trust. Decline in trust—or more generally in social capital—can also reinforce economic disparities as societies with lower social capital will be less supportive of universal policies, which are more effective in reducing inequality. This decline in support for universal policies and/or redistributive programs is related to the fact that in less trusting societies there is a lower sense of sharing a common fate among citizens. Another possible mechanism to reverse the causality relationship from inequality to trust is the potential positive effect of trust on economic growth (Zak and Knack 2001; Knack and Keefer 1997) and the effect of the latter in increasing/reducing income inequality (Persson and Tabellini 1994; Barro 1999; Banerjee and Duflo 2003; Herzer and Vollmer 2012).
As quoted in Rothstein and Uslaner (2005), it is difficult that trust can flourish in societies with strong social class divisions or in strong hierarchical cultures (Seligman 2000). The mentioned argument is that when economic resources are heavily stratified or when it is perceived that other people have unfair advantages, trust will not develop. In this environment it will be difficult that individuals from a given social class trust individuals from other classes, and that policies aimed to reduce inequality will be put in practice. In this way, cultural differences among regions due to different degrees of exacerbation of group differences by socio-economic position, race, ethnic group and religion can play a role in explaining different levels of trust. This is why one must pay attention to cultural characteristics of countries, which are generally omitted in the cross-sectional analyses of the determinants of trust.
3 Data
We use the ESS which has six available bi-annual rounds implemented between 2002 and 2012. This survey is designed to measure attitudes, beliefs, values and behaviour patterns of individuals in Europe. As argued and used in Hooghe and Reeskens (2008) and Hooghe et al. (2009), we measure trust with the three-item scale of general trust available in the ESS.Footnote 1 Each question must be answered by the individual in a scale from 0 to 10: (1) Generally speaking, would you say that most people can be trusted (=10) or that you can’t be too careful in dealing with people (=0)? (2) Do you think that most people would try to take advantage of you if they got the chance (=0) or would they try to be fair (=10)? and (3) Would you say that most of the time people try to be helpful (=10) or that they are mostly looking out for themselves (=0)? We take the first component of the reduced three items and adjust it to obtain a score from zero to ten. Regarding income inequality measures, we use the Standardized World Income Inequality Database (SWIID version 4.0) (see Solt 2009) because this—although not without its problems—provides the broadest coverage across countries and over time, allowing us to attain the largest number of observation points. The SWIID provides Gini indexes computed with incomes both before and after taxes and transfers, and the top 1 % income share. While the Gini index captures inequality along the total distribution of incomes, the top income share is useful to capture income concentration at the very top of the income distribution. We are confident that these three different measures cover different forms of income inequality and make our study more comprehensive. The Gini computed with pre-tax and pre-transfer income (market income) is particularly interesting because this measure should be less correlated with trust, as the role of the level of accomplished redistribution in the country (possibly correlated with trust) is less evident in the distribution of market incomes. This means that it is less obvious devising variables affecting trust and income inequality simultaneously. Furthermore, given the recently revival of the importance of top incomes (Atkinson et al. 2011) we consider the share of the top 1 % income in the income distribution as an additional measure of inequality in our analysis. This measure together with the Gini of net incomes are perhaps better “observed” by the individuals when forming their beliefs about the level of income inequality in the country. Due to personal circumstances affecting the final net income, it is less clear for individuals to grasp a good idea about differences in market incomes.
The other macro variable to be used in the analysis is real GDP per capita in PPP terms, taken from the World Development Indicators from the World Bank. The sample is composed of 152 country-year points and includes 270,689 respondents with non-missing information in the variables used in the econometric analysis. The number of countries is 34 and includes the EU-28 (except Malta) plus Norway, Iceland, Russia, Turkey, Switzerland, Ukraine and Israel.
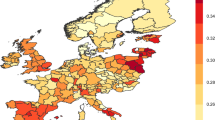
The data on general trust reveal a great deal of variability across countries and some changes over time. For example, the gross average score of all countries over the full period is 5.10 in a scale running from 0 to 10. The countries with the highest and lowest scores are Denmark with 6.80 and Turkey with 3.05, respectively. Confirming anticipated regional variation, the Nordic countries display the highest levels of trust (see Fig. 1).

Generalized trust by country, 2002–2012
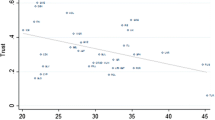
Figure 2 depicts a negative relation between trust and income inequality when we plot all the pairs of year and country points available. This result is well documented in other cross-country studies (e.g. Bjørnskov 2007). Figure 3 plots the points of biannual variation of the score on trust and Gini for all the country-year points with available data. The relationship between the changes in trust and Gini index over time is rather weak and shows an unexpected although low positive relation (correlation of only 0.04). The average score for trust shows interesting country variation but also hides important differences in the distribution of trust among countries. In the “Appendix” we show graphically that the Nordic countries have a clear left skewed distribution of trust. In contrast, other countries such as Greece and Slovenia are characterised by a distribution skewed to the right, and many others have a normal type distribution of trust. All these exploratory statistics are insightful, but we still need to implement a more robust analysis with the inclusion of controls at the individual and country level, which is done in the next section.

General trust and income inequality

Changes in trust and income inequality (biannual periods)
4 Empirical Strategy
Our aim is to analyse the main determinants of general trust, and in particular assess the effects of income inequality on the level of trust. We rely on the individual responses drawn from six waves of the ESS taken between 2002 and 2012, which account for about 270,000 persons comprised in 34 countries. We are aware that this pooling of cross-sections prevents us from interpreting results as causal effects, but it is still worth exploring the strength of the effects of inequality after including a variety of controls.
4.1 The Baseline Model
The dependent variable is the score of trust constructed with the first component of the reduced three-item scale of general trust available in the ESS. The lowest level of trust is zero and the maximum is ten. Since our data is nested in a hierarchical way from individuals to countries to years we will use multilevel modelling to account for variation at different levels. In this order, the levels are the individual, country and year. In addition, this modelling is also adequate in dealing with the correction of standard errors of explanatory variables at the country level, which is the case of the income inequality variables and GDP. We will perform multilevel estimations to the following specification:
The subscripts i, c and t stand for individual, country and year, respectively. The dependent variable y i,c,t measures the score in trust answered by the individual. The vector X c,t contains the inequality measures and GDP per capita (in logs) that are country and time specific. These contextual variables correspond to the previous year of survey’s year; for example, individuals surveyed in year 2012 are matched with contextual variables of 2011 and so on. The vector Z i,c,t includes different controls at the individual level that are common in the empirical literature; and ɛ i,c,t is the error term. Although the question on trust appeals for an ordinal scale with values from 0 to 10, we assume for simplicity—and given the large size of observations and three levels—that this variable behaves as a cardinal variable arising from different cut-off points of an underlying continuous variable. The descriptive statistics are reported in Table 1 and the multilevel estimations are in Table 2.
The variables of the vector Z i,c,t are individual specific and include some standard controls such as sex (male), age, the existence of a couple or spouse living with the respondent, education level in the form of ISCED dummies, belonging to a minority ethnic group in the country (ethnic), how religious is the individual regardless of any particular religion (religious) in a scale from 0 (not at all) to 10 (very religious). The ESS does not have a uniform question on personal income but we include a proxy that is asked over all waves. This is “which of the descriptions on this card comes closest to how you feel about your household’s income nowadays?” with four possible scales: living comfortably on present income (1), coping on present income (2), difficult on present income (3) and very difficult on present income (4). Other dummy variables are union membership (indicating current or past affiliation with a trade union or similar), retired and unemployed.
Another set of variables that we will use in some alternative specifications are related to personal experiences. The dummy variable discriminated is drawn from the question “Would you describe yourself as being a member of a group that is discriminated against in this country?” The interesting feature of this variable and additional ESS questions is that it is possible to know on what grounds the group of reference is discriminated against. We distinguish discrimination because of colour/race, nationality, religion, language and ethnic group. Furthermore, the variable discriminated (migration basis) takes value of one when the individual indicates any of the reasons mentioned, and zero otherwise. This variable enables us to analyse the effect of discrimination based on migration status on general trust. The dummy variable crime is built from the question “Have you or a member of your household been the victim of a burglary or assault in the last 5 years?”
4.2 First Results
Table 2 reports the results for different specifications of Eq. 1. All models consider the log of GDP per capita and one of the inequality measures. We don’t consider the variables for ethnic group and discrimination simultaneously because of correlation among them. The coefficients of the income inequality measures are negative and statistically significant in the case of the Gini of net incomes and the top 1 % income share. Approximately, a raise of one percentage point in the Gini of net incomes is associated with a reduction of 0.8 % in the score of trust score evaluated at sample means. In the case of the top 1 % income share, one percentage point raise in this share is associated with a decrease of 0.7 % in the score of trust. GDP per capita is positive and significant in each specification. In this regard, our results contrast with those reported by Steijn and Lancee (2011) who do not find a statically significant relationship between trust and income inequality once GDP per capita is controlled for. The positive association between GDP per capita and trust is in line with the findings of a large literature on the relations between trust and growth (Durlauf and Fafchamps 2004; Zak and Knack 2001; Beugelsdijk et al. 2004; Knack and Keefer 1997; Steijn and Lancee 2011; Algan and Cahuc 2010).
With respect to demographic characteristics, individuals who are male, single, younger, more educated, richer with better living conditions or more religious are more trustful. Furthermore, the individuals who belong to a minority ethnic group in the country are less trustful. Regarding the effect of attitudes and beliefs on trust, we observe that being discriminated in a general way or on the ground of variables potentially signalling a status of immigrant (colour/race, nationality, religion, language or ethnic) is associated with less trusting behaviour. Alesina and La Ferrara (2002) find that groups traditionally discriminated against (woman and blacks) are associated with low levels of trust in US localities. Moreover, Gustavsson and Jordahl (2008) find that the proportion of foreigners in the population reduces trust. The last result of the regressions shows that being a victim of crime is negatively associated to trust, which may be interpreted as an example of how trust is related to social cohesion.
5 Generalized Trust in Time Perspective
The preceding analysis has shown significant relationships between generalized trust and other important variables, in particular a negative relation between trust and income inequality when this is measured with the Gini of net incomes and the top 1 % income share. Even though we have controlled by the hierarchical setting of the data (individual, country and year), we cannot be fully confident that changes in income inequality over time have negative effects on changes in generalized trust. The way to study those changes is by following the same unit across time, which is only possible with a panel data structure. Furthermore, there are individual unobserved effects that are potentially related to the dependent variable, so that simple multilevel regressions will suffer from omitted variables problems (leading to inconsistent estimators). In a panel data set, a fixed effect (FE) estimator will allow us to control for time-invariant observed and unobserved effects. For example, differences in generalized trust may vary due to persistent factors of the country (institutions, culture, social beliefs, etc.) and not because of changes in economic inequality. This is the crucial factor distinguishing panel analysis from the analysis of the multilevel data of the previous section.
5.1 Regressions for the Average Score of Generalized Trust
Unfortunately we do not have a panel survey of individuals that would allow us to conduct a longitudinal analysis of trust in Europe at the individual level, but at least we can attempt to explore the relationship between trust and inequality at the country level. Our strategy consists in collapsing some of the variables of interest of the ESS by country and year. We take averages of generalized trust scores and other variables from individuals in each corresponding country-year point. The sample is composed by 152 country-year points (see Table 3).
Given the panel data structure of our sample, we use the following specification:
The subscript i stands for country and t for period. The dependent variable \(\bar{y}_{it}\) measures the mean of generalized trust for country i in period t. The vector \(\bar{X}_{it}\) contains variables that are country and period specific, such as the Gini coefficients and GDP per capita. The term α i is the period-invariant country unobserved effect; δ t is a common unobservable period-specific effect and μ it is the time-varying country specific idiosyncratic error. It is well established in the empirical literature that if α i is not controlled for and instead is let to be part of the composite error, the estimators will be inconsistent. A FE will take away the individual unobserved effects by subtracting the time means of each variable for every country in the model. As is standard in this procedure, the FE will allow the unobserved effect α i to be arbitrarily correlated with the time-varying explanatory variables.
We estimate FE models based on Eq. 2, use robust standard errors and include period dummies to control for time effects. We are aware of some possible small sample problems with our data, so that including many independent variables simultaneously will create multicollinearity and will be very difficult to test the effects of each variable on trust. Given the established importance of wealth on explaining differences on trust across counties, we will keep the log of GDP per capita as an independent variable and add different measures of inequality one by one in each model specification. Table 4 reports the results of the FE estimation with different specifications.
The log of GDP per capita is mostly significant and positively related with trust, which is in line with the previous cross-country multilevel results and is a well-established result in the empirical literature. Different from pervious regressions, none of the income inequality measures—Gini of net or market incomes and the top 1 % income share—show a statistically significant relationship with trust. The results also show that the proportions of individuals who have suffered discrimination (general or related to migration status) or any crime are negatively and significantly related to the average trust in the country. These results indicate that, even after controlling for unobserved country effects in our FE models, discrimination and crime appear as important variables in eroding trust. In particular, we observe that the effect of the rate of discrimination based on migrant status (colour/race, nationality, religion, language and ethnic group) is more severe than that of general discrimination. Furthermore, the proportion of individuals who self-select as belonging to any minority ethnic group in the country is negatively associated with trust, which is line with previous results.
The other two variables considered in the FE models correspond to indexes of ethnic and linguistic fractionalization computed with the individual observations of the ESS for each country and wave. The computation of these indexes follows closely the one proposed in Alesina and La Ferrara (2002). For a given year, the index is as follows:
where i stands for country and k represents any ethnic or linguistic group in the country. The term S ki is the share of group k in the total population of country i. This index is similar to the reverse of a Herfindahl concentration index, so that this is increasing in group heterogeneity. In the case of the linguistic fragmentation index, we first find the proportion of each language spoken in the country according to the individual responses of the ESS,Footnote 2 and then we compute the index as in Eq. 3. In the case of the index of ethnic fragmentation, the ESS asks if the individual belongs to a minority ethnic group but does not ask which one, and therefore we can only consider two ethnic groups in the computation of the index: any minority group and the dominant ethnic group. Both fractionalization indexes measure the probability that from two randomly drawn individuals in a country, each of them belong to different groups.
Only the linguistic fractionalization index shows a statistically significant relationship with trust at standard confidence intervals, although the pseudo ethnic fractionalization index is pretty close to be accepted (b = − 2.063; SD = 1.243; p value = 0.106). However, as noted before, the simple share of individuals of any minority ethnic in the country is significantly and negatively associated with trust. The negative relationship between any index of fractionalization (racial, ethnic or linguistic) and trust has been found in other studies that claim an important role of ethnic or racial diversity on lowering generalized trust (Knack and Keefer 1997; Leigh 2006b; Gustavsson and Jordahl 2008; Putnam 2007; Alesina and La Ferrara 2002; Delhey and Newton 2005). Different from these studies, Hooghe et al. (2009) show that the relationship between ethnic heterogeneity and social trust is not clear-cut and attention should be paid to the modelling strategy when analysing reduced units (countries). In our panel specification, we use a FE estimator in order to deal with unobserved heterogeneity at the country level and robust standard errors, so that our estimates are generated under a demanding structure, which differs from previous studies. Any meaningful and significant estimate arising from this structure should be good news, but we need to take results with caution because of small sample problems we cannot control for (selection, outliers, etc.).
Income inequality and trust can vary greatly across countries but minimally over short time periods. Moreover, different from other attitudes and public opinion, generalized trust can be a stable attitude. As we are interested in using the maximum possible variation over time, we have also run the FE models in a sample that includes 17 countries observed in 2002 and 2012, which are the most distanced period in the ESS. As the previous FE estimations, the results of the regressions on this reduced sample do not report any effect of income inequality on trust.
5.2 Regressions for the Distribution of Generalized Trust
As we observed in the illustrative graphs of the distribution of trust (see Fig. 4 in the Appendix) there are some countries that have experienced variations in different parts of this distribution. Focusing only on the mean value of trust can neglect some important movements in certain regions of the trust distribution. Therefore, we compute three new dependent variables to study the effects of income inequality on different parts of the trust distribution. These variables are the share of individuals in the country that report a score of trust (1) from 0 and 3, (2) from 4 to 6, and (3) from 7 to 10. We use the panel data of countries and specifications presented in the previous section and run FE models with each of these dependent variables.
Each panel of Table 5 reports the estimations for each dependent variable. Note that each row of each panel corresponds to a different regression and only reports the corresponding coefficient. The results show that none of the three measures of income inequality have effects on any section of the distribution of trust, which confirms our previous results with the use of the score of trust as dependent variable. An increase in the pseudo ethnic fractionalization index or in the share of the minority ethnic group in the country is associated with a reduction in the share of individuals with the highest trust levels, yet the relationship with the other sections of the distribution of trust is not significant. It seems that a change in the ethnic heterogeneity of the country is more relevant in explaining movements in the top part of the distribution of trust than in the bottom part of the distribution. In contrast, the index of linguistic fractionalization is significant in explaining changes in the bottom part of the distribution of trust, and not in other sections of the distribution. When significant, the coefficients of both fractionalization indexes and the share of ethnic minorities present the expected signs. The effects of the rate of general or migrant based discrimination on trust are significant and show the expected signs, confirming previous results. A rise of the discrimination rate is associated with a decrease of the top and middle section of the distribution of trust, and with an increase of the bottom part of the distribution. Furthermore, an increase of the rate of crime reduces the share of individuals with the highest values of trust, which is line with previous results. Although not reported in Table 5, GDP per capita is statistically significant and positively associated with the top share of the distribution of trust.
If we believe on the “feedback mechanisms” going from trust to inequality as discussed in Sect. 2, we note that the Gini computed with pre-tax and pre-transfer incomes is a “cleaner” measure to detect the effect of income inequality on trust as this index is less affected by trust. In contrast, it seems more evident that the Gini computed with incomes net of taxes and transfers is affected by redistributive policies implemented and supported in the country, which could be affected by the level of generalized trust through feedback mechanisms. Karabarbounis (2011) points out that the use of pre-tax incomes instead of net incomes to construct the measure of inequality relaxes somewhat the reverse causation because net incomes vary automatically with the fiscal system, whilst pre-tax incomes vary only through the endogenous response of labour supply or the general equilibrium effects on factor prices. Given the data limitations and the length of our panel, we cannot be very conclusive about the nature of the mentioned feedback mechanisms, but at least we have used model specifications with market income inequality in order to mitigate some potential problems of endogeneity.
6 Conclusions
This paper analyses the determinants of generalized trust in a pool of 34 European countries during the period 2002–2012 drawn from the ESS. In a pooled data composed of about 270,000 individuals we find—with multilevel models—that income inequality is negatively related to trust, which confirms a common result in the empirical literature on trust that focuses on cross-country differences. However, most of this literature does not take into account the problem of unobserved effects, which can lead to inconsistent estimators. Differences in generalized trust may vary due to persistent factors that are specific to the country (institutions, culture, etc.) and not because of changes in economic inequality. To try to overcome this limitation we use a FE estimator in a panel dataset of countries. This dataset was constructed by taking averages of some variables of interest from the ESS by country and year. Contrary to the multilevel models with individual data, the FE estimator fails to reveal any significant relation between any income inequality measure and trust under different specifications. This result is robust irrespective of whether we focus on the average level of trust in a country or different parts of the distribution of this score. However, we do find that GDP per capita is positively related to trust and that ethnic and linguistic fractionalization, discrimination (general or based on migrant status) and crime rates are negatively associated to trust. These results are in line with other studies that give a more important role to ethnic fragmentation of the country in explaining differences of trust.
Notwithstanding the relative short length of our dataset and some potential small sample problems, our results provide evidence that trust is not significantly related to growing income inequality in European countries once we allow for FE. These results challenge conventional evidence indicating a clear-cut relation between trust and inequality. Of course, it is important to bear in mind that generalized trust can be regarded as a stable attitude over time and hence it can be difficult to detect within-country changes. However, recall that we are also evaluating changes in different sections of the distribution of trust, so that we are reducing somehow this limitation.
One possible explanation why we obtain a significant relationship between income inequality and trust in the multilevel model and not in the FE model with panel data is that, in the first case, inequality can be correlated with specific characteristics of the country that are time invariant, such as institutions and culture, which are important determinants of trust. The FE applied to panel data are able to isolate income inequality from such country characteristics, so that we can better observe the effect of income inequality on trust, if any. We believe that further and more careful inspection on new datasets with more covered periods is well deserved to continue with the debate on the relationship between social attitudes and economic outcomes.
Notes
In our dataset, the Cronbach’ alpha of the three items of general trust is 0.784.
The question in the ESS survey is “What language or languages do you speak most often at home?” (first mentioned).
References
Alesina, A., & La Ferrara, E. (2002). Who trusts others? Journal of Public Economics, 85, 207–234.
Algan, Y., & Cahuc, P. (2010). Inherited trust and growth. American Economic Review, 100(5), 2060–2092.
Atkinson, A. B., Piketty, T., & Saez, E. (2011). Top incomes in the long run of history. Journal of Economic Literature, 49(1), 3–71.
Banerjee, A. V., & Duflo, E. (2003). Inequality and growth: What can the data say? Journal of Economic Growth, 8(3), 267–299.
Barro, R. J. (1999). Inequality, growth, and investment. NBER working paper No. 7038.
Berggren, N., & Jordahl, H. (2006). Free to trust? Economic freedom and social capital. Kyklos, 59, 141–169.
Beugelsdijk, S., de Groot, L. F., & Anton van Schaik, B. T. M. (2004). Trust and economic growth: A robustness analysis. Oxford Economic Papers New Series, 56(1), 118–134.
Bjørnskov, C. (2007). Determinants of generalized trust: A cross-country comparison. Public Choice, 130, 1–21.
Delhey, J., & Newton, K. (2005). Predicting cross-national levels of social trust: Global pattern or nordic exceptionalism? European Sociological Review, 21(4), 311–327.
Durlauf, S. N., & Fafchamps, M. (2004). Social Capital. In S. N. Durlauf & P. Aghion (Eds.), Handbook of economic growth. Amsterdam: North-Holland.
Fisher, J. A. V., & Torgler, B. (2013). Do positional concerns destroy social capital: Evidence from 26 countries. Forthcoming in Economic Inquiry.
Gustavsson, M., & Jordahl, H. (2008). Inequality and trust in Sweden: Some inequalities are more harmful than others. Journal of Public Economics, 92, 348–365.
Herzer, D., & Vollmer, S. (2012). Inequality and growth: evidence from panel cointegration. Journal of Economic Inequality, 10, 489–503.
Hooghe, M., & Reeskens, T. (2008). Cross-cultural measurement equivalence of generalized trust. Evidence from the European Social Survey (2002 and 2004). Social Indicators Research, 85(3), 515–532.
Hooghe, M., Reeskens, T., Stolle, D., & Trappers, A. (2009). Ethnic diversity and generalized trust in Europe. A cross-national multilevel study. Comparative Political Studies, 42, 198–223.
Jordahl, H. (2009). Economic inequality. In G. T. Svendsen & G. L. H. Svendsen (Eds.), Handbook of social capital. Cheltenham: Edward Elgar.
Karabarbounis, L. (2011). One dollar, one vote. The Economic Journal, 121, 621–649.
Knack, S., & Keefer, P. (1997). Does social capital have an economic pay-off? A cross country investigation. Quarterly Journal of Economics, 112, 1251–1288.
Knack, S., & Zak, P. J. (2002). Building trust: Public policy, interpersonal trust, and economic development. Supreme Court Economic Review, 10, 91–107.
Leigh, A. (2006a). Does equality lead to fraternity? Economics Letters, 93(1), 121–125.
Leigh, A. (2006b). Trust, inequality, and ethnic heterogeneity. Economic Record, 82(258), 268–280.
Persson, T., & Tabellini, G. (1994). Is inequality harmful for growth? American Economic Review, 84(3), 600–621.
Putnam, R. D. (2007). E pluribus unum: Diversity and community in the twenty-first century. Scandinavian Political Studies, 30(2), 137–174.
Rothstein, B., & Uslaner, E. M. (2005). All for all: Equality, corruption, and social trust. World Politics, 58(1), 41–72.
Seligman, A. B. (2000). The problem of trust. Princeton: Princeton University Press.
Solt, F. (2009). Standardizing the world income inequality database. Social Science Quarterly, 90(2), 231–242 (SWIID Version 3.1, December 2011).
Steijn, S., & Lancee, B. (2011). Does income inequality negatively affect general trust? Examining three potential problems with the inequality-trust hypothesis. GINI discussion paper No. 20.
Sunders, P. (2010). Beware false prophets. Equality, the good society and the spirit level. London: Policy Exchange.
Uslaner, E. M. (2002). The moral foundations of trust. Cambridge: Cambridge University Press.
Uslaner, E. M., & Brown, M. (2005). Inequality, trust, and civic engagement. American Politics Research, 33(6), 868–894.
Wilkinson, R., & Pickett, K. (2010). The spirit level. Why equality is better for everyone (2nd ed.). London: Penguin Books.
Zak, P. J., & Knack, S. (2001). Trust and growth. Economic Journal, 111(470), 291–321.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
See Fig. 4.

Distribution of trust by country in extreme years (unconditional score). Note In the case of Estonia, Iceland and Slovakia, the initial year is 2004; and in the case of Greece and Israel, the final year is 2010
Rights and permissions
About this article

Cite this article
Olivera, J. Changes in Inequality and Generalized Trust in Europe. Soc Indic Res 124, 21–41 (2015). https://doi.org/10.1007/s11205-014-0777-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-014-0777-5