
Abstract
In this paper we derive the asymptotic properties of the least squares estimator (LSE) of fractionally integrated autoregressive moving-average (FARIMA) models under the assumption that the errors are uncorrelated but not necessarily independent nor martingale differences. We relax the independence and even the martingale difference assumptions on the innovation process to extend considerably the range of application of the FARIMA models. We propose a consistent estimator of the asymptotic covariance matrix of the LSE which may be very different from that obtained in the standard framework. A self-normalized approach to confidence interval construction for weak FARIMA model parameters is also presented. All our results are done under a mixing assumption on the noise. Finally, some simulation studies and an application to the daily returns of stock market indices are presented to corroborate our theoretical work.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Long memory processes takes a large part in the literature of time series (see for instance Granger and Joyeux (1980), Fox and Taqqu (1986), Dahlhaus (1989), Hosking (1981), Beran et al. (2013), Palma (2007), among others). They also play an important role in many scientific disciplines and applied fields such as hydrology, climatology, economics, finance, to name a few. To model the long memory phenomenon, a widely used model is the fractional autoregressive integrated moving average (FARIMA, for short) model. Consider a second order centered stationary process \(X:=(X_t)_{t\in {\mathbb {Z}}}\) satisfying a FARIMA\((p,d_0,q)\) representation of the form
where \(d_0\in \left]-1/2,1/2\right[\) is the long memory parameter, L stands for the back-shift operator and \(a_0(L)=1-\sum _{i=1}^pa_{0i}L^i\) is the autoregressive (AR for short) operator and \(b_0(L)=1-\sum _{i=1}^qb_{0i}L^i\) is the moving average (MA for short) operator (by convention \(a_{00}=b_{00}=1\)). The operators \(a_0\) and \(b_0\) represent the short memory part of the model. Process \(\epsilon :=(\epsilon _t)_{t\in {\mathbb {Z}}}\) can be interpreted as in Francq and Zakoïan (1998) as the linear innovation of X, i.e. \(\epsilon _t=X_t-{\mathbb {E}}[X_t|{\mathbf {H}}_X(t-1)]\), where \({\mathbf {H}}_X(t-1)\) is the Hilbert space generated by \((X_s, s<t)\). The innovation process \(\epsilon \) is assumed to be a stationary sequence satisfying
- (A0)::
-
\({\mathbb {E}}\left[ \epsilon _t\right] =0, \ \mathrm {Var}\left( \epsilon _t\right) =\sigma _{\epsilon }^2 \text { and } \mathrm {Cov}\left( \epsilon _t,\epsilon _{t+h}\right) =0\) for all \(t\in {\mathbb {Z}}\) and all \(h\ne 0\).
Under the above assumptions the process \(\epsilon \) is called a weak white noise. Different sub-classes of FARIMA models can be distinguished depending on the noise assumptions. It is customary to say that X is a strong FARIMA\((p,d_0,q)\) representation and we will do this henceforth if in (1) \(\epsilon \) is a strong white noise, namely an independent and identically distributed (iid for short) sequence of random variables with mean 0 and common variance. A strong white noise is obviously a weak white noise because independence entails uncorrelatedness. Of course the converse is not true. Note that the independence hypothesis on the innovation can be tested using the distance correlation (see for instance Székely et al. (2007), Davis et al. (2018) and Aknouche and Francq (2021)). Between weak and strong noises, one can say that \(\epsilon \) is a semi-strong white noise if \({\epsilon }\) is a stationary martingale difference, namely a sequence such that \({\mathbb {E}}(\epsilon _{t}|\epsilon _{t-1},\epsilon _{t-2},\dots )=0\). An example of semi-strong white noise is the generalized autoregressive conditional heteroscedastic (GARCH) model (see Francq and Zakoïan (2019)). Martingale difference hypothesis can be tested using the procedures introduced for instance in Dominguez and Lobato (2003), Escanciano and Velasco (2006) and Hsieh (1989). If \(\epsilon \) is a semi-strong white noise in (1), X is called a semi-strong FARIMA\((p,d_0,q)\). If no additional assumption is made on \(\epsilon \), that is if \(\epsilon \) is only a weak white noise (not necessarily iid, nor a martingale difference), the representation (1) is called a weak FARIMA\((p,d_0,q)\). It is clear from these definitions that the following inclusions hold:
Nonlinear models are becoming more and more employed because numerous real time series exhibit nonlinear dynamics. For instance conditional heteroscedasticity can not be generated by FARIMA models with iid noises.Footnote 1 As mentioned by Francq and Zakoïan (2005, 1998) in the case of ARMA models, many important classes of nonlinear processes admit weak ARMA representations in which the linear innovation is not a martingale difference. The main issue with nonlinear models is that they are generally hard to identify and implement. These technical difficulties certainly explain the reason why the asymptotic theory of FARIMA model estimation is mainly limited to the strong or semi-strong FARIMA model.
Now we present some of the main works about FARIMA model estimation when the noise is strong or semi-strong. For the estimation of long-range dependent processes, the commonly used estimation method is based on the Whittle frequency domain maximum likelihood estimator (MLE) (see for instance Dahlhaus (1989), Fox and Taqqu (1986), Taqqu and Teverovsky (1997), Giraitis and Surgailis (1990)). The asymptotic properties of the MLE of FARIMA models are well-known under the restrictive assumption that the errors \(\epsilon _t\) are independent or martingale difference (see Beran (1995), Beran et al. (2013), Palma (2007), Baillie et al. (1996), Ling and Li (1997), Hauser and Kunst (1998), among others). Hualde and Robinson (2011), Nielsen (2015) and Cavaliere et al. (2017) have considered the problem of conditional sum of squares estimation (see Klimko and Nelson (1978)) and inference on parametric fractional time series models driven by conditionally (unconditionally) heteroskedastic shocks. All the works mentioned above assume either strong or semi-strong innovations. In the modeling of financial time series, for example, the GARCH assumption on the errors is often used (see for instance Baillie et al. (1996), Hauser and Kunst (1998)) to capture the conditional heteroscedasticity. The GARCH models are generally martingale differences. Various research works were devoted to testing the martingale difference hypothesis (see for example Dominguez and Lobato (2003), Escanciano and Velasco (2006) and Hsieh (1989)). In financial econometrics, the returns are often assumed to be martingale increments (though they are not generally independent sequences). However, many works have shown that for some exchange rates, the martingale difference assumption is not satisfied (see for instance Escanciano and Velasco (2006)). There is no doubt that it is important to have a soundness inference procedure for the parameter in the FARIMA model when the (possibly dependent) error is subject to unknown conditional heteroscedasticity. Little is thus known when the martingale difference assumption is relaxed. Our aim in this paper is to consider a flexible FARIMA specification and to relax the independence assumption (and even the martingale difference assumption) in order to be able to cover weak FARIMA representations of general nonlinear models.
A very few works deal with the asymptotic behavior of the MLE of weak FARIMA models. To our knowledge, Shao (2012, 2010b) are the only papers on this subject. Under weak assumptions on the noise process, the author has obtained the asymptotic normality of the Whittle estimator (see Whittle (1953)). Nevertheless, the inference problem is not fully addressed. This is due to the fact that the asymptotic covariance matrix of the Whittle estimator involves the integral of the fourth-order cumulant spectra of the dependent errors \(\epsilon _t\). Using non-parametric bandwidth-dependent methods, one builds an estimation of this integral but there is no guidance on the choice of the bandwidth in the estimation procedures (see Shao (2012), Taniguchi (1982), Keenan (1987), Chiu (1988) for further details). The difficulty is caused by the dependence in \(\epsilon _t\). Indeed, for strong noise, a bandwidth-free consistent estimator of the asymptotic covariance matrix is available. When \(\epsilon _t\) is dependent, no explicit formula for a consistent estimator of the asymptotic variance matrix seems to be provided in the literature (see Shao (2012)).
In this work we propose to adopt for weak FARIMA models the estimation procedure developed in Francq and Zakoïan (1998) so we use the least squares estimator (LSE for short). We show that a strongly mixing property and the existence of moments are sufficient to obtain a consistent and asymptotically normally distributed least squares estimator for the parameters of a weak FARIMA representation. For technical reasons, we often use an assumption on the summability of cumulants. This can be a consequence of a mixing and moments assumptions (see Doukhan and León (1989), for more details). These kind of hypotheses enable us to circumvent the problem of the lack of speed of convergence (due to the long-range dependence) in the infinite AR or MA representations. We fix this gap by proposing rather sharp estimations of the infinite AR and MA representations in the presence of long-range dependence (see Sect. 6.1 for details).
In our opinion there are three major contributions in this work. The first one is to show that the estimation procedure developed in Francq and Zakoïan (1998) can be extended to weak FARIMA models. This goal is achieved thanks to Theorems 1 and 2 in which the consistency and the asymptotic normality are stated. The second one is to provide an answer to the open problem raised by Shao (2012) (see also Shao (2010b)) on the asymptotic covariance matrix estimation. We propose in our work a weakly consistent estimator of the asymptotic variance matrix (see Theorem 5). Thanks to this estimation of the asymptotic variance matrix, we can construct a confidence region for the estimation of the parameters. Finally another method to construct such confidence region is achieved thanks to an alternative method using a self normalization procedure (see Theorem 8).
The paper is organized as follows. Section 2 shows that the least squares estimator for the parameters of a weak FARIMA model is consistent when the weak white noise \((\epsilon _t)_{t\in {\mathbb {Z}}}\) is ergodic and stationary, and that the LSE is asymptotically normally distributed when \((\epsilon _t)_{t\in {\mathbb {Z}}}\) satisfies mixing assumptions. The asymptotic variance of the LSE may be very different in the weak and strong cases. Section 3 is devoted to the estimation of this covariance matrix. We also propose a self-normalization-based approach to construct a confidence region for the parameters of weak FARIMA models which avoids to estimate the asymptotic covariance matrix. We gather in Section 7 all our figures and tables. These simulation studies and illustrative applications on real data are presented and discussed in Sect. 4. The proofs of the main results are collected in Sect. 6.
In all this work, we shall use the matrix norm defined by \(\Vert A\Vert =\sup _{\Vert x\Vert \le 1}\Vert Ax\Vert =\rho ^{1/2}( A^{'}A)\), when A is a \({\mathbb {R}}^{k_1\times k_2}\) matrix, \(\Vert x\Vert ^2=x'x\) is the Euclidean norm of the vector \(x\in {\mathbb {R}}^{k_2}\), and \(\rho (\cdot )\) denotes the spectral radius.
2 Least squares estimation
In this section we present the parametrization and the assumptions that are used in the sequel. Then we state the asymptotic properties of the LSE of weak FARIMA models.
2.1 Notations and assumptions
We make the following standard assumption on the roots of the AR and MA polynomials in (1).
- (A1)::
-
The polynomials \(a_0(z)\) and \(b_0(z)\) have all their roots outside of the unit disk with no common factors.
Let \(\varTheta ^{*}\) be the space
Denote by \(\varTheta \) the Cartesian product \(\varTheta ^{*}\times \left[ d_1,d_2\right] \), where \(\left[ d_1,d_2\right] \subset \left] -1/2,1/2\right[\) with \(d_1-d_0>-1/2\). The unknown parameter of interest \(\theta _0=(a_{01},a_{02},\ldots ,a_{0p},b_{01},b_{02},\ldots ,b_{0q},d_0)^\prime \) is supposed to belong to the parameter space \(\varTheta \).
The fractional difference operator \((1-L)^{d_0}\) is defined, using the generalized binomial series, by
where for all \(j\ge 0\), \(\alpha _j(d_0)=\varGamma (j-d_0)/\left\{ \varGamma (j+1)\varGamma (-d_0)\right\} \) and \(\varGamma (\cdot )\) is the Gamma function. Using the Stirling formula we obtain that for large j, \(\alpha _j(d_0)\sim j^{-d_0-1}/\varGamma (-d_0)\) (one refers to Beran et al. (2013) for further details).
For all \(\theta \in \varTheta \) we define \(( \epsilon _t(\theta )) _{t\in {\mathbb {Z}}}\) as the second order stationary process which is the solution of
Observe that, for all \(t\in {\mathbb {Z}}\), \(\epsilon _t(\theta _0)=\epsilon _t\) a.s. Given a realization \(X_1,\dots ,X_n\) of length n, \(\epsilon _t(\theta )\) can be approximated, for \(0<t\le n\), by \({\tilde{\epsilon }}_t(\theta )\) defined recursively by
with \({\tilde{\epsilon }}_t(\theta )=X_t=0\) if \(t\le 0\). It will be shown that these initial values are asymptotically negligible and, in particular, that \(\epsilon _t(\theta )-{\tilde{\epsilon }}_t(\theta )\rightarrow 0\) in \({\mathbb {L}}^2\) as \(t\rightarrow \infty \) (see Remark 12 hereafter). Thus the choice of the initial values has no influence on the asymptotic properties of the model parameters estimator.
Let \(\varTheta ^{*}_{\delta }\) denote the compact set
We define the set \(\varTheta _{\delta }\) as the Cartesian product of \(\varTheta ^{*}_{\delta }\) by \(\left[ d_1,d_2\right] \), i.e. \(\varTheta _{\delta }=\varTheta ^{*}_{\delta }\times \left[ d_1,d_2\right] \), where \(\delta \) is a positive constant chosen such that \(\theta _0\) belongs to \(\varTheta _{\delta }\).
The random variable \({\hat{\theta }}_n\) is called least squares estimator if it satisfies, almost surely,
Our main results are proven under the following assumptions:
- (A2)::
-
The process \((\epsilon _t)_{t\in {\mathbb {Z}}}\) is strictly stationary and ergodic.
The consistency of the least squares estimator will be proved under the three above assumptions ((A0), (A1) and (A2)). For the asymptotic normality of the LSE, additional assumptions are required. It is necessary to assume that \(\theta _0\) is not on the boundary of the parameter space \({\varTheta _\delta }\).
- (A3)::
-
We have \(\theta _0\in \overset{\circ }{\varTheta _\delta }\), where \(\overset{\circ }{\varTheta _\delta }\) denotes the interior of \(\varTheta _\delta \).
The stationary process \(\epsilon \) is not supposed to be an independent sequence. So one needs to control its dependency by means of its strong mixing coefficients \(\left\{ \alpha _{\epsilon }(h)\right\} _{h\ge 0}\) defined by
where \({\mathcal {F}}_{-\infty }^t=\sigma (\epsilon _u, u\le t )\) and \({\mathcal {F}}_{t+h}^{+\infty }=\sigma (\epsilon _u, u\ge t+h)\).
We shall need an integrability assumption on the moments of the noise \(\epsilon \) and a summability condition on the strong mixing coefficients \((\alpha _{\epsilon }(h))_{h\ge 0}\).
- (A4)::
-
There exists an integer \(\tau \ge 2\) such that for some \(\nu \in ]0,1]\), we have \({\mathbb {E}}|\epsilon _t|^{\tau +\nu }<\infty \) and \(\sum _{h=0}^{\infty }(h+1)^{k-2} \left\{ \alpha _{\epsilon }(h)\right\} ^{\frac{\nu }{k+\nu }}<\infty \) for \(k=1,\dots ,\tau \).
Note that (A4) implies the following weak assumption on the joint cumulants of the innovation process \(\epsilon \) (see Doukhan and León (1989), for more details).
- (A4’)::
-
There exists an integer \(\tau \ge 2\) such that \(C_\tau :=\sum _{i_1,\dots ,i_{\tau -1}\in {\mathbb {Z}}}|\mathrm {cum} (\epsilon _0,\epsilon _{i_1},\dots ,\epsilon _{i_{\tau -1}})|<\infty \ .\)
In the above expression, \(\mathrm {cum}(\epsilon _0,\epsilon _{i_1},\dots ,\epsilon _{i_{\tau -1}})\) denotes the \(\tau -\)th order cumulant of the stationary process. Due to the fact that the \(\epsilon _t\)’s are centered, we notice that for fixed (i, j, k)
Assumption (A4) is a usual technical hypothesis which is useful when one proves the asymptotic normality (see Francq and Zakoïan (1998) for example). Let us notice however that we impose a stronger convergence speed for the mixing coefficients than in the works on weak ARMA processes. This is due to the fact that the coefficients in the AR or MA representation of \(\epsilon _t(\theta )\) have no more exponential decay because of the fractional operator (see Sect. 6.1 for details and comments).
As mentioned before, Hypothesis (A4) implies (A4’) which is also a technical assumption usually used in the fractionally integrated ARMA processes framework (see for instance Shao (2010c)) or even in an ARMA context (see Francq and Zakoïan (2007); Zhu and Li (2015)). One remarks that in Shao (2010b), the author emphasized that a geometric moment contraction implies (A4’). This provides an alternative to strong mixing assumptions but, to our knowledge, there is no relation between this two kinds of hypotheses.
2.2 Asymptotic properties
The asymptotic properties of the LSE of the weak FARIMA model are stated in the following two theorems.
Theorem 1
(Consistency) Assume that \((\epsilon _t)_{t\in {\mathbb {Z}}}\) satisfies (1) and belongs to \({\mathbb {L}}^2\). Let \(( {\hat{\theta }}_n)_{n\ge 1}\) be a sequence of least squares estimators. Under Assumptions (A0), (A1) and (A2), we have
The proof of this theorem is given in Sect. 6.2.
In order to state our asymptotic normality result, we define the function
where the sequence \(\left( \epsilon _t(\theta )\right) _{t\in {\mathbb {Z}}}\) is given by (2). We consider the following information matrices
The existence of these matrices are proved when one demonstrates the following result.
Theorem 2
(Asymptotic normality) We assume that \((\epsilon _t)_{t\in {\mathbb {Z}}}\) satisfies (1). Under (A0)–(A3) and Assumption (A4) with \(\tau =4\), the sequence \(( \sqrt{n}( {\hat{\theta }}_n-\theta _0)) _{n\ge 1}\) has a limiting centered normal distribution with covariance matrix \(\varOmega :=J^{-1}(\theta _0)I(\theta _0)J^{-1}(\theta _0)\).
The proof of this theorem is given in Sect. 6.3.
Remark 3
Hereafter (see more precisely (55)), we will be able to prove that
Thus the matrix \(J(\theta _0)\) has the same expression in the strong and weak FARIMA cases (see Theorem 1 of Beran (1995)). On the contrary, the matrix \(I(\theta _0)\) is in general much more complicated in the weak case than in the strong case.
Remark 4
In the standard strong FARIMA case, i.e. when (A2) is replaced by the assumption that \((\epsilon _t)_{t\in {\mathbb {Z}}}\) is iid, we have \(I(\theta _0)=2\sigma _{\epsilon }^2J(\theta _0)\). Thus the asymptotic covariance matrix is then reduced as \(\varOmega _S:=2\sigma _{\epsilon }^2J^{-1}(\theta _0)\). Generally, when the noise is not an independent sequence, this simplification can not be made and we have \(I(\theta _0)\ne 2\sigma _{\epsilon }^2J(\theta _0)\). The true asymptotic covariance matrix \(\varOmega =J^{-1}(\theta _0)I(\theta _0)J^{-1}(\theta _0)\) obtained in the weak FARIMA framework can be very different from \(\varOmega _S\). As a consequence, for the statistical inference on the parameter, the ready-made softwares used to fit FARIMA do not provide a correct estimation of \(\varOmega \) for weak FARIMA processes because the standard time series analysis softwares use empirical estimators of \(\varOmega _S\). The problem also holds in the weak ARMA case (see Francq and Zakoïan (2007) and the references therein).This is why it is interesting to find an estimator of \(\varOmega \) which is consistent for both weak and (semi-)strong FARIMA cases.
Based on the above remark, the next section deals with two different methods in order to find an estimator of \(\varOmega \).
3 Estimating the asymptotic variance matrix
For statistical inference problem, the asymptotic variance \(\varOmega \) has to be estimated. In particular Theorem 2 can be used to obtain confidence intervals and significance tests for the parameters.
First of all, the matrix \(J(\theta _0)\) can be estimated empirically by the square matrix \({\hat{J}}_n\) of order \(p+q+1\) defined by:
The convergence of \({\hat{J}}_n\) to \(J(\theta _0)\) is classical (see Lemma 17 in Sect. 6.3 for details).
In the standard strong FARIMA case, in view of remark 4, we have \({\hat{\varOmega }}_S:=2{\hat{\sigma }}_{\epsilon }^2{\hat{J}}_n^{-1}\) with \({\hat{\sigma }}_{\epsilon }^2=Q_n({\hat{\theta }}_n)\). Thus \({\hat{\varOmega }}_S\) is a consistent estimator of \(\varOmega _S\). In the general weak FARIMA case, this estimator is not consistent when \(I(\theta _0)\ne 2\sigma _{\epsilon }^2J(\theta _0)\). So we need a consistent estimator of \(I(\theta _0)\).
3.1 Estimation of the asymptotic matrix \(I(\theta _0)\)
For all \(t\in {\mathbb {Z}}\), let
We shall see in the proof of Lemma 18 that
Following the arguments developed in Boubacar Mainassara et al. (2012), the matrix \(I(\theta _0)\) can be estimated using Berk’s approach (see Berk (1974)). More precisely, by interpreting \(I(\theta _0)/2\pi \) as the spectral density of the stationary process \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) evaluated at frequency 0, we can use a parametric autoregressive estimate of the spectral density of \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) in order to estimate the matrix \(I(\theta _0)\).
For any \(\theta \in \varTheta \), \(H_t(\theta )\) is a measurable function of \(\left\{ \epsilon _s,s\le t\right\} \). The stationary process \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) admits the following Wold decomposition \(H_t(\theta _0)=u_t+\sum _{k=1}^{\infty }\psi _ku_{t-k}\), where \((u_t)_{t\in {\mathbb {Z}}}\) is a \((p+q+1)-\)variate weak white noise with variance matrix \(\varSigma _u\).
Assume that \(\varSigma _u\) is non-singular, that \(\sum _{k=1}^{\infty }\left\| \psi _k\right\| <\infty \), and that \(\det (I_{p+q+1}+\sum _{k=1}^{\infty }\psi _kz^k)\ne 0\) if \(\left| z\right| \le 1\). Then \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) admits a weak multivariate \(\mathrm {AR}(\infty )\) representation (see Akutowicz (1957)) of the form
such that \(\sum _{k=1}^{\infty }\left\| \varPhi _k\right\| <\infty \) and \(\det \left\{ \varPhi (z)\right\} \ne 0\) if \(\left| z\right| \le 1\).
Thanks to the previous remarks, the estimation of \(I(\theta _0)\) is therefore based on the following expression
Consider the regression of \(H_t(\theta _0)\) on \(H_{t-1}(\theta _0),\dots ,H_{t-r}(\theta _0)\) defined by
where \(u_{r,t}\) is uncorrelated with \(H_{t-1}(\theta _0),\dots ,H_{t-r}(\theta _0)\). Since \({H}_t(\theta _0)\) is not observable, we introduce \({\hat{H}}_t\in {\mathbb {R}}^{p+q+1}\) obtained by replacing \(\epsilon _t(\cdot )\) by \({\tilde{\epsilon }}_t(\cdot )\) and \(\theta _0\) by \({\hat{\theta }}_n\) in (7):
Let \({\hat{\varPhi }}_r(z)=I_{p+q+1}-\sum _{k=1}^r{{\hat{\varPhi }}}_{r,k}z^k\), where \({{\hat{\varPhi }}}_{r,1},\dots ,{{\hat{\varPhi }}}_{r,r}\) denote the coefficients of the LS regression of \({\hat{H}}_t\) on \({\hat{H}}_{t-1},\dots ,{\hat{H}}_{t-r}\). Let \({\hat{u}}_{r,t}\) be the residuals of this regression and let \({\hat{\varSigma }}_{{\hat{u}}_r}\) be the empirical variance (defined in (11) below) of \({\hat{u}}_{r,1},\dots ,{\hat{u}}_{r,r}\). The LSE of \({\underline{\varPhi }}_r=\left( \varPhi _{r,1},\dots ,\varPhi _{r,r}\right) \) and \(\varSigma _{u_r}=\mathrm {Var}(u_{r,t})\) are given by
where
with by convention \({\hat{H}}_t=0\) when \(t\le 0\). We assume that \({\hat{\varSigma }}_{\underline{{\hat{H}}}_r}\) is non-singular (which holds true asymptotically).
In the case of linear processes with independent innovations, Berk (see Berk (1974)) has shown that the spectral density can be consistently estimated by fitting autoregressive models of order \(r=r(n)\), whenever r tends to infinity and \(r^3/n\) tends to 0 as n tends to infinity. There are differences with Berk (1974): \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) is multivariate, is not directly observed and is replaced by \(({\hat{H}}_t)_{t\in {\mathbb {Z}}}\). It is shown that this result remains valid for the multivariate linear process \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) with non-independent innovations (see Boubacar Mainassara et al. (2012); Boubacar Mainassara and Francq (2011), for references in weak (multivariate) ARMA models). We will extend the results of Boubacar Mainassara et al. (2012) to weak FARIMA models.
The asymptotic study of the estimator of \(I(\theta _0)\) using the spectral density method is given in the following theorem.
Theorem 5
We assume (A0)-(A3) and Assumption (A4’) with \(\tau =8\). In addition, we assume that the innovation process \((\epsilon _t)_{t\in {\mathbb {Z}}}\) of the FARIMA\((p,d_0,q)\) model (1) is such that the process \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) defined in (7) admits a multivariate AR\((\infty )\) representation (8), where \(\Vert \varPhi _k\Vert =\mathrm {o}(k^{-2})\) as \(k\rightarrow \infty \), the roots of \(\det (\varPhi (z))=0\) are outside the unit disk, and \(\varSigma _u=\mathrm {Var}(u_t)\) is non-singular. Then, the spectral estimator of \(I(\theta _0)\)
in probability when \(r=r(n)\rightarrow \infty \) and \(r^5(n)/n^{1-2(d_0-d_1)}\rightarrow 0\) as \(n\rightarrow \infty \) (remind that \(d_0\in [ d_1{,}d_2]\subset ] -1/2{,}1/2[\)).
The proof of this theorem is given in Sect. 6.4.
A second method to estimate the asymptotic matrix (or rather avoiding estimate it) is proposed in the next subsection.
3.2 A self-normalized approach to confidence interval construction in weak FARIMA models
We have seen previously that we may obtain confidence intervals for weak FARIMA model parameters as soon as we can construct a convergent estimator of the variance matrix \(I(\theta _0)\) (see Theorems 2 and 5 ). The parametric approach based on an autoregressive estimate of the spectral density of \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) that we used before has the drawback of choosing the truncation parameter r in (9). This choice of the order truncation is often crucial and difficult. So the aim of this section is to avoid such a difficulty.
This section is also of interest because, to our knowledge, it has not been studied for weak FARIMA models. Notable exception is Shao (2012) who studied this problem in a short memory case (see Assumption 1 in Shao (2012) that implies that the process X is short-range dependent).
We propose an alternative method to obtain confidence intervals for weak FARIMA models by avoiding the estimation of the asymptotic covariance matrix \(I(\theta _0)\). It is based on a self-normalization approach used to build a statistic which depends on the true parameter \(\theta _0\) and which is asymptotically distribution-free (see Theorem 1 of Shao (2012) for a reference in weak ARMA case). The idea comes from Lobato (2001) and has been already extended by Boubacar Maïnassara and Saussereau (2018); Kuan and Lee (2006); Shao (2010c, 2010a, 2012) to more general frameworks. See also Shao (2015) for a review on some recent developments on the inference of time series data using the self-normalized approach.
Let us briefly explain the idea of the self-normalization.
By a Taylor expansion of the function \(\partial Q_n(\cdot )/ \partial \theta \) around \(\theta _0\), under (A3), we have
where the \(\theta ^*_{n,i,j}\)’s are between \({\hat{\theta }}_n\) and \(\theta _0\). Using the following equation
we shall be able to prove that (12) implies that
This is due to the following technical properties:
-
the convergence in probability of \(\sqrt{n}\partial Q_n(\theta _0)/\partial \theta -\sqrt{n}\partial O_n(\theta _0)/\partial \theta \) to 0 (see Lemma 15 hereafter),
-
the convergence in probability of \([\partial ^2 Q_n(\theta _{n,i,j}^{*})/\partial \theta _i\partial \theta _j]\) to \(J(\theta _0)\) (see Lemma 17 hereafter),
-
the tightness of the sequence \((\sqrt{n}({\hat{\theta }}_n-\theta _0))_{n\ge 1}\) (see Theorem 2) and
-
the existence and invertibility of the matrix \(J(\theta _0)\) (see Lemma 16 hereafter).
Thus we obtain from (13) that
where (remind (7))
At this stage, we do not rely on the classical method that would consist in estimating the asymptotic covariance matrix \(I(\theta _0)\). We rather try to apply Lemma 1 in Lobato (2001). So we need to check that a functional central limit theorem holds for the process \(U:=(U_t)_{t\ge 1}\). For that sake, we define the normalization matrix \(P_{p+q+1,n}\) of \({\mathbb {R}}^{(p+q+1)\times (p+q+1)}\) by
where \({\bar{U}}_n = (1/n)\sum _{i=1}^n U_i\). To ensure the invertibility of the normalization matrix \(P_{p+q+1,n}\) (it is the result stated in the next proposition), we need the following technical assumption on the distribution of \(\epsilon _t\).
- (A5)::
-
The process \((\epsilon _t)_{t\in {\mathbb {Z}}}\) has a positive density on some neighborhood of zero.
Proposition 6
Under the assumptions of Theorem 2 and (A5), the matrix \(P_{p+q+1,n}\) is almost surely non singular.
The proof of this proposition is given in Sect. 6.5.
Let \((B_m(r))_{r\ge 0}\) be a m-dimensional Brownian motion starting from 0. For \(m\ge 1\), we denote by \({\mathcal {U}}_m\) the random variable defined by:
where
The critical values of \({\mathcal {U}}_m\) have been tabulated by Lobato (2001).
The following theorem states the self-normalized asymptotic distribution of the random vector \(\sqrt{n}({\hat{\theta }}_n-\theta _0)\).
Theorem 7
Under the assumptions of Theorem 2 and (A5), we have
The proof of this theorem is given in Sect. 6.6.
Of course, the above theorem is useless for practical purpose because the normalization matrix \(P_{p+q+1,n}\) is not observable. This gap will be fixed below when one replaces the matrix \(P_{p+q+1,n}\) by its empirical or observable counterpart
The above quantity is observable and we are able to state our Theorem which is the applicable version of Theorem 7.
Theorem 8
Under the assumptions of Theorem 2 and (A5), we have
The proof of this theorem is given in Sect. 6.7.
At the asymptotic level \(\alpha \), a joint \(100(1-\alpha )\%\) confidence region for the elements of \(\theta _0\) is then given by the set of values of the vector \(\theta \) which satisfy the following inequality:
where \({\mathcal {U}}_{p+q+1,\alpha }\) is the quantile of order \(1-\alpha \) for the distribution of \({\mathcal {U}}_{p+q+1}\).
Corollary 9
For any \(1\le i\le p+q+1\), a \(100(1-\alpha )\%\) confidence region for \(\theta _0(i)\) is given by the following set:
where \({\mathcal {U}}_{1,\alpha }\) denotes the quantile of order \(1-\alpha \) of the distribution for \({\mathcal {U}}_{1}\).
The proof of this corollary is similar to that of Theorem 8 when one restricts ourselves to a one dimensional case.
4 Numerical illustrations
In this section, we investigate the finite sample properties of the asymptotic results that we introduced in this work. For that sake we use Monte Carlo experiments. The numerical illustrations of this section are made with the open source statistical software R (see R Development Core Team, 2017) or (see http://cran.r-project.org/).
4.1 Simulation studies and empirical sizes for confidence intervals
We study numerically the behavior of the LSE for FARIMA models of the form
where the unknown parameter is taken as \(\theta _0=(a,b,d)=(-0.7,-0.2,0.4)\). First we assume that in (18) the innovation process \((\epsilon _t)_{t\in {\mathbb {Z}}}\) is an iid centered Gaussian process with common variance 1 which corresponds to the strong FARIMA case. In two other experiments we consider that in (18) the innovation processes \((\epsilon _t)_{t\in {\mathbb {Z}}}\) are defined respectively by
and
where \((\eta _t)_{t\ge 1}\) is a sequence of iid centered Gaussian random variables with variance 1. Note that the innovation process in (20) is not a martingale difference whereas it is the case of the noise defined in (19). The noise defined by (20) is an extension of a noise process in Romano and Thombs (1996).
We simulated \(N=1,000\) independent trajectories of size \(n=2,000\) of Model (18) in the three following case: the strong Gaussian noise, the semi-strong noise (19) and the weak noise (20).

LSE of \(N=1,000\) independent simulations of the FARIMA(1, d, 1) model (18) with size \(n=2,000\) and unknown parameter \(\theta _0=(a,b,d)=(-0.7,-0.2,0.4)\), when the noise is strong (left panel), when the noise is semi-strong (19) (middle panel) and when the noise is weak of the form (20) (right panel). Points (a)-(c), in the box-plots, display the distribution of the estimation error \({\hat{\theta }}_n(i)-\theta _0(i)\) for \(i=1,2,3\)

LSE of \(N=1,000\) independent simulations of the FARIMA(1, d, 1) model (18) with size \(n=2,000\) and unknown parameter \(\theta _0=(a,b,d)=(-0.7,-0.2,0.4)\). The top panels present respectively, from left to right, the Q-Q plot of the estimates \({\hat{a}}_n\), \({\hat{b}}_n\) and \({\hat{d}}_n\) of a, b and d in the strong case. Similarly the middle and the bottom panels present respectively, from left to right, the Q-Q plot of the estimates \({\hat{a}}_n\), \({\hat{b}}_n\) and \({\hat{d}}_n\) of a, b and d in the semi-strong and weak cases

LSE of \(N=1,000\) independent simulations of the FARIMA(1, d, 1) model (18) with size \(n=2,000\) and unknown parameter \(\theta _0=(a,b,d)=(-0.7,-0.2,0.4)\). The top panels present respectively, from left to right, the empirical distribution of the estimates \({\hat{a}}_n\), \({\hat{b}}_n\) and \({\hat{d}}_n\) of a, b and d in the strong case. Similarly the middle and the bottom panels present respectively, from left to right, the empirical distribution of the estimates \({\hat{a}}_n\), \({\hat{b}}_n\) and \({\hat{d}}_n\) of a, b and d in the semi-strong and weak cases. The kernel density estimate is displayed in full line, and the centered Gaussian density with the same variance is plotted in dotted line
Figures 1, 2 and 3 compare the empirical distribution of the LSE in these three contexts. The empirical distributions of \({\hat{d}}_n\) are similar in the three cases whereas the LSE \({\hat{a}}_n\) of a is more accurate in the weak case than in the strong and semi-strong cases. This last remark on the empirical distribution of \({\hat{a}}_n\) is in accordance with the results of Romano and Thombs (1996) who showed that, with weak white noises similar to (20), the asymptotic variance of the sample autocorrelations can be greater or less than 1 as well (1 is the asymptotic variance for strong white noises). The empirical distributions of \({\hat{b}}_n\) are more accurate in the strong case than in the weak case. Remark that in the weak case the empirical distributions of \({\hat{b}}_n\) are more accurate than the semi-strong ones.
Figure 4 compares standard estimator \({\hat{\varOmega }}_S=2{{\hat{\sigma }}}_\epsilon ^2{\hat{J}}_n^{-1}\) and the sandwich estimator \({\hat{\varOmega }}={\hat{J}}_n^{-1}{\hat{I}}^{\mathrm {SP}}_n{\hat{J}}_n^{-1}\) of the LSE asymptotic variance \(\varOmega \). We used the spectral estimator \({\hat{I}}^{\mathrm {SP}}_n\) defined in Theorem 5. The multivariate AR order r (see (9)) is automatically selected by AIC (we use the function VARselect() of the vars R package). In the strong FARIMA case we know that the two estimators are consistent. In view of the two upper subfigures of Fig. 4, it seems that the sandwich estimator is less accurate in the strong case. This is not surprising because the sandwich estimator is more robust, in the sense that this estimator remains consistent in the semi-strong and weak FARIMA cases, contrary to the standard estimator (see the middle and bottom subfigures of Fig. 4). The estimated asymptotic standard errors obtained from Theorem 2 of the estimated parameters are given by: 0.0308 in the strong case, 0.0465 in the semi-strong case and 0.0300 in the weak case for \({\hat{a}}_n\), 0.0539 in the strong case, 0.0753 in the semi-strong case and 0.0666 in the weak case for \({\hat{b}}_n\) and 0.0253 in the strong case, 0.0364 in the semi-strong case and 0.0264 in the weak case for \({\hat{d}}_n\).

Comparison of standard and modified estimates of the asymptotic variance \(\varOmega \) of the LSE, on the simulated models presented in Fig. 1. The diamond symbols represent the mean, over \(N=1,000\) replications, of the standardized errors \(n({\hat{a}}_n+0.7)^2\) for (a) (1.90 in the strong case and 4.32 (resp. 1.80) in the semi-strong case (resp. in the weak case)), \(n({\hat{b}}_n+0.2)^2\) for (b) (5.81 in the strong case and 11.33 (resp. 8.88) in the semi-strong case (resp. in the weak case)) and \(n({\hat{d}}_n-0.4)^2\) for (c) (1.28 in the strong case and 2.65 (resp. 1.40) in the semi-strong case (resp. in the weak case))

A zoom of the left-middle and left-bottom panels of Fig. 4

A zoom of the right-middle and right-bottom panels of Fig. 4
Figure 5 (resp. Fig. 6) presents a zoom of the left(right)-middle and left(right)-bottom panels of Fig. 4. It is clear that in the semi-strong or weak case \(n({\hat{a}}_n-a)^2\), \(n({\hat{b}}_n-b)^2\) and \(n({\hat{d}}_n-d)^2\) are, respectively, better estimated by \({\hat{J}}_n^{-1}{\hat{I}}^{\mathrm {SP}}_n{\hat{J}}_n^{-1}(1,1)\), \({\hat{J}}_n^{-1}{\hat{I}}^{\mathrm {SP}}_n{\hat{J}}_n^{-1}(2,2)\) and \({\hat{J}}_n^{-1}{\hat{I}}^{\mathrm {SP}}_n{\hat{J}}_n^{-1}(3,3)\) (see Fig. 6) than by \(2{{\hat{\sigma }}}_\epsilon ^2{\hat{J}}_n^{-1}(1,1)\), \(2{{\hat{\sigma }}}_\epsilon ^2{\hat{J}}_n^{-1}(2,2)\) and \(2{{\hat{\sigma }}}_\epsilon ^2{\hat{J}}_n^{-1}(3,3)\) (see Fig. 5). The failure of the standard estimator of \(\varOmega \) in the weak FARIMA framework may have important consequences in terms of identification or hypothesis testing and validation.
Now we are interested in standard confidence interval and the modified versions proposed in Sects. 3.1 and 3.2 . Table 1 displays the empirical sizes in the three previous different FARIMA cases. For the nominal level \(\alpha =5\%\), the empirical size over the \(N=1,000\) independent replications should vary between the significant limits 3.6% and 6.4% with probability 95%. For the nominal level \(\alpha =1\%\), the significant limits are 0.3% and 1.7%, and for the nominal level \(\alpha =10\%\), they are 8.1% and 11.9%. When the relative rejection frequencies are outside the significant limits, they are displayed in bold type in Table 1. For the strong FARIMA model, all the relative rejection frequencies are inside the significant limits for n large. For the semi-strong FARIMA model, the relative rejection frequencies of the standard confidence interval are definitely outside the significant limits, contrary to the modified versions proposed. For the weak FARIMA model, only the standard confidence interval of \({\hat{b}}_n\) is outside the significant limits when n increases. As a conclusion, Table 1 confirms the comments done concerning Fig. 4.
4.2 Application to real data
We now consider an application to the daily returns of four stock market indices (CAC 40, DAX, Nikkei and S&P 500). The returns are defined by \(r_t=\log (p_t/p_{t-1})\) where \(p_t\) denotes the price index of the stock market indices at time t. The observations cover the period from the starting date (March 1st 1990 for CAC 40, December 30th 1987 for DAX, January 5th 1965 for Nikkei and January 3rd 1950 for S&P 500) of each index to February 13th 2019. The sample size is 7,341 for CAC 40; 7,860 for DAX; 13,318 for Nikkei and 17,390 for S&P 500.
In Financial Econometrics the returns are often assumed to be a white noise. In view of the so-called volatility clustering, it is well known that the strong white noise model is not adequate for these series (see for instance Francq and Zakoïan (2019); Lobato et al. (2001); Boubacar Mainassara et al. (2012); Boubacar Maïnassara and Saussereau (2018)). A long-range memory property of the stock market returns series was largely investigated by Ding et al. (1993) which shows that there are more correlation between power transformation of the absolute return \(|r_t|^v\) (\(v>0\)) than returns themselves (see also Beran et al. (2013), Palma (2007), Baillie et al. (1996) and Ling and Li (1997)). We choose here the case where \(v=2\) which corresponds to the squared returns \((r_t^2)_{t\ge 1}\) process. This process have significant positive autocorrelations at least up to lag 100 (see Fig. 9) which confirm the claim that stock market returns have long-term memory (see Ding et al. (1993)).
We fit a FARIMA(1, d, 1) model to the squares of the 4 daily returns. As in Ling (2003), we denote by \((X_t)_{t\ge 1}\) the mean corrected series of the squared returns and we adjust the following model

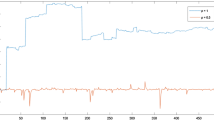
Closing prices of the four stock market indices from the starting date of each index to February 13th 2019

Returns of the four stock market indices from the starting date of each index to February 13th 2019

Sample autocorrelations of squared returns of the four stock market indices
Figure 7 (resp. Fig. 8) plots the closing prices (resp. the returns) of the four stock market indices. Figure 9 shows that squared returns \((X_t)_{t\ge 1}\) are generally strongly autocorrelated. Table 2 displays the LSE of the parameter \(\theta =(a,b,d)\) of each squared of daily returns. The p-values of the corresponding LSE, \({{\hat{\theta }}}_n=({\hat{a}}_n,{\hat{b}}_n,{\hat{d}}_n)\) are given in parentheses. The last column presents the estimated residual variance. Note that for all series, the estimated coefficients \(|{\hat{a}}_n|\) and \(|{\hat{b}}_n|\) are smaller than one and this is in accordance with our Assumption (A1). We also observe that for all series the estimated long-range dependence coefficients \({\hat{d}}_n\) are significant for any reasonable asymptotic level and are inside \(]-0.5{,}0.5[\). We thus think that the assumption (A3) is satisfied and thus our asymptotic normality theorem can be applied. Table 3 then presents for each series the modified confidence interval at the asymptotic level \(\alpha =5\%\) for the parameters estimated in Table 2.
5 Conclusion
Taking into account the possible lack of independence of the error terms, we show in this paper that we can fit FARIMA representations of a wide class of nonlinear long memory times series. This is possible thanks to our theoretical results and it is illustrated in our real cases and simulations studies.
This standard methodology (when the noise is supposed to be iid), in particular the significance tests on the parameters, needs however to be adapted to take into account the possible lack of independence of the errors terms. A first step has been done thanks to our results on the confidence intervals. In future works, we intent to study how the existing identification (see Boubacar Maïnassara (2012), Boubacar Maïnassara and Kokonendji (2016)) and diagnostic checking (see Boubacar Maïnassara and Saussereau (2018), Francq et al. (2005)) procedures should be adapted in the presence of long-range dependence framework and dependent noise.
It would also be interesting to study the adaptation of the exact maximum likelihood method of Sowell (1992) or the self-weighted LSE considered in Zhu and Ling (2011) to the case of weak FARIMA models.
6 Proofs
In all our proofs, K is a positive constant that may vary from line to line.
6.1 Preliminary results
In this subsection, we shall give some results on estimations of the coefficient of formal power series that will arise in our study. Some of them are well know and some others are new to our knowledge. We will make some precise comments hereafter.
We begin by recalling the following properties on power series. If for \(|z|\le R\), the power series \(f(z)=\sum _{i\ge 0}a_iz^i\) and \(g(z)=\sum _{i\ge 0}b_iz^i\) are well defined, then one has \((fg)(z)= \sum _{i\ge 0} c_iz^i\) is also well defined for \(|z|\le R\) with the sequence \((c_i)_{i\ge 0}\) which is given by \(c=a*b\) where \(*\) denotes the convolution product between a and b defined by \(c_i=\sum _{k=0}^i a_kb_{i-k}=\sum _{k=0}^i a_{i-k}b_{k}\). We will make use of the Young inequality that states that if the sequence \(a\in \ell ^{r_1}\) and \(b\in \ell ^{r_2}\) are such that \(\frac{1}{r_1}+\frac{1}{r_2}=1+\frac{1}{r}\) with \(1\le r_1,r_2,r \le \infty \), then
Now we come back to the power series that arise in our context. Remind that for the true value of the parameter,
Thanks to the assumptions on the moving average polynomials \(b_\theta \) and the autoregressive polynomials \(a_\theta \), the power series \(a_\theta ^{-1}\) and \(b_\theta ^{-1}\) are well defined.
Thus the functions \(\epsilon _t(\theta )\) defined in (2) can be written as
and if we denote \(\gamma (\theta )=(\gamma _i(\theta ))_{i\ge 0}\) the sequence of coefficients of the power series \(b^{-1}_{\theta }(z) a_{\theta }(z)(1-z)^{d}\), we may write for all \(t\in {\mathbb {Z}}\):
In the same way, by (22) one has
and if we denote \(\eta (\theta )=(\eta _i(\theta ))_{i\ge 0}\) the coefficients of the power series \((1-z)^{-d}a^{-1}_{\theta }(z) b_{\theta }(z)\) one has
We strength the fact that \(\gamma _0(\theta )=\eta _0(\theta )=1\) for all \(\theta \).
For large j, Hallin et al. (1999) have shown that uniformly in \(\theta \) the sequences \(\gamma (\theta )\) and \(\eta (\theta )\) satisfy
and
One difficulty that has to be addressed is that (24) includes the infinite past \((X_{t-i})_{i\ge 0}\) whereas only a finite number of observations \((X_t)_{1\le t\le n}\) are available to compute the estimators defined in (4). The simplest solution is truncation which amounts to setting all unobserved values equal to zero. Thus, for all \(\theta \in \varTheta \) and \(1\le t\le n\) one defines
where the truncated sequence \(\gamma ^t(\theta )= ( \gamma _i^t(\theta ))_{i\ge 0}\) is defined by
Since our assumptions are made on the noise in (1), it will be useful to express the random variables \(\epsilon _t(\theta )\) and its partial derivatives with respect to \(\theta \), as a function of \((\epsilon _{t-i})_{i\ge 0}\).
From (23), there exists a sequence \(\lambda (\theta )=(\lambda _i(\theta ))_{i\ge 0}\) such that
where the sequence \(\lambda (\theta )\) is given by the sequence of the coefficients of the power series \(b^{-1}_{\theta }(z) a_{\theta }(z)(1-z)^{d-d_0}a^{-1}_{\theta _0}(z) b_{\theta _0}(z)\). Consequently \(\lambda (\theta ) = \gamma (\theta )*\eta (\theta _0)\) or, equivalently,
As in Hualde and Robinson (2011), it can be shown using Stirling’s approximation that there exists a positive constant K such that
Equations (29) and (31) imply that for all \(\theta \in \varTheta \) the random variable \(\epsilon _t(\theta )\) belongs to \({\mathbb {L}}^2\), that the sequence \((\epsilon _t(\theta ))_t\) is an ergodic sequence and that for all \(t\in {\mathbb {Z}}\) the function \(\epsilon _t(\cdot )\) is a continuous function. We proceed in the same way as regard to the derivatives of \(\epsilon _t(\theta )\). More precisely, for any \(\theta \in \varTheta \), \(t\in {\mathbb {Z}}\) and \(1\le k,l \le p+q+1\) there exists sequences \(\overset{\mathbf{. }}{\lambda }_{k}(\theta )= (\overset{\mathbf{. }}{\lambda }_{i,k}(\theta ))_{i\ge 1}\) and \(\overset{\mathbf{.. }}{\lambda }_{k,l}(\theta )= (\overset{\mathbf{.. }}{\lambda }_{i,k,l}(\theta ))_{i\ge 1}\) such that
Of course it holds that \(\overset{\mathbf{. }}{\lambda }_{k}(\theta )=\frac{\partial \gamma (\theta )}{\partial \theta _k}*\eta (\theta _0)\) and \(\overset{\mathbf{.. }}{\lambda }_{k,l}( \theta )=\frac{\partial ^2\gamma (\theta )}{\partial \theta _k\partial \theta _{l}}*\eta (\theta _0)\).
Similarly we have
where \(\lambda ^t(\theta ) = \gamma ^t(\theta )*\eta (\theta _0)\), \(\overset{\mathbf{. }}{\lambda }^t_{k}(\theta )=\frac{\partial \gamma ^t(\theta )}{\partial \theta _k}*\eta (\theta _0)\) and \(\overset{\mathbf{.. }}{\lambda }^t_{k,l}( \theta )=\frac{\partial ^2\gamma ^t(\theta )}{\partial \theta _k\partial \theta _{l}}*\eta (\theta _0)\).
In order to handle the truncation error \(\epsilon _t(\theta )-{{\tilde{\epsilon }}}_t(\theta )\), one needs information on the sequence \(\lambda (\theta )-\lambda ^t(\theta )\). This is the purpose of the following lemma.
Lemma 10
For \(2\le r\le \infty \) and \(1\le k,l \le p+q+1 \), we have
and
for any \(\theta \in \varTheta _{\delta }\) if \(d_0\le 0\) and for \(\theta \) with non-negative memory parameter d if \(d_0>0\).
Proof
In view of (27), \(\eta (\theta _0)\in \ell ^{r_2}\) for \(r_2\ge 1\) when \(d_0<0\). If \(d_0=0\), \(\eta (\theta _0)\) is the sequence of coefficients of the power series \(a^{-1}_{\theta _0}(z) b_{\theta _0}(z)\), so it belongs to \(\ell ^{r_2}\) for all \(r_2\ge 1\) since in this case \(|\eta _j(\theta _0)|=\mathrm {O}(\rho ^j)\) for some \(0<\rho <1\) (see Francq and Zakoïan (1998)). Thanks to (26), when \(d_0\le 0\), Young’s inequality for convolution yields that for all \(r\ge 2\)
If \(d_0>0\), the sequence \(\eta (\theta _0)\) belongs to \(\ell ^{r_2}\) for any \(r_2>1/(1-d_0)\). Young’s inequality for convolution implies in this case that for all \(r\ge 2\)
with \(r_2=(1-(d_0+\beta ))^{-1}>1/(1-d_0)\) and \(r_1=r/(1+r(d_0+\beta ))\), for some \(\beta >0\) sufficiently small. Thus there exists K such that \(\parallel \eta (\theta _0)\parallel _{\ell ^{r_2}}\le K\). Similarly as before, we deduce when \(d\ge 0\) that
the conclusion follows by tending \(\beta \) to 0. The second and third points of the lemma are shown in the same way as the first. This is because from (26), the coefficients \(\partial \gamma _j(\theta )/\partial \theta _k\) and \(\partial ^2\gamma _j(\theta )/\partial \theta _k\partial \theta _l\) are \(\mathrm {O}(j^{-1-d+\zeta })\) for any small enough \(\zeta > 0\). The proof of the lemma is then complete.
\(\square \)
Remark 11
The above lemma implies that the sequence \( \overset{\mathbf{. }}{\lambda }_k\left( \theta _0\right) -\overset{\mathbf{. }}{\lambda ^t}_k\left( \theta _0\right) \) is bounded and more precisely there exists K such that
for any \(t\ge 1\) and any \(1\le k\le p+q+1\).
Remark 12
In order to prove our asymptotic results, it will be convenient to give an upper bound for the norms of the sequences introduced in Lemma 10 valid for any \(\theta \in \varTheta _{\delta }\). Since \(d_1-d_0>-1/2\), Estimation (31) entails that for any \(r\ge 2\),
This can easily be seen since \(\parallel \lambda (\theta )-\lambda ^t(\theta )\parallel _{\ell ^r}\le K(\sum _{i\ge t}i^{-r-r(d_1-d_0)})^{1/r}\le Kt^{-1+1/r-(d_1-d_0)}\). As in Hallin et al. (1999), the coefficients \(\overset{\mathbf{. }}{\lambda }_{j,k}(\theta )\) and \(\overset{\mathbf{.. }}{\lambda }_{j,k,l}(\theta )\) are \(\mathrm {O}(j^{-1-(d-d_0)+\zeta })\) for any small enough \(\zeta >0\), so we have
and
for any \(r\ge 2\), any \(1\le k,l\le p+q+1\) and all \(\theta \in \varTheta _{\delta }\).
One shall also need the following lemmas.
Lemma 13
For any \(2\le r\le \infty \), \(1\le k \le p+q+1 \) and \(\theta \in \varTheta \), there exists a constant K such that we have
Proof
The proof follows the same arguments as those developed in Remark 12.
\(\square \)
Lemma 14
There exists a constant K such that we have
Proof
For \(1\le k \le p+q+1 \), the sequence \(\overset{\mathbf{. }}{\lambda }_{k}(\theta )= (\overset{\mathbf{. }}{\lambda }_{i,k}(\theta ))_{i\ge 1}\) is in fact the sequence of the coefficients in the power series of
Thus \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \) is the \(i-\)th coefficient taken in \(\theta =\theta _0\). There are three cases.
- \(\diamond \):
-
\(k=1,\dots ,p\): Since
$$\begin{aligned} \frac{\partial }{\partial \theta _k }\left( b_\theta ^{-1}(z) a_{\theta }(z)(1-z)^{d-d_0} a_{\theta _0}^{-1}(z)b_{\theta _0}(z) \right) = -b_\theta ^{-1}(z) z^k (1-z)^{d-d_0} a_{\theta _0}^{-1}(z)b_{\theta _0}(z)\ , \end{aligned}$$we deduce that \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \) is the \(i-\)th coefficient of \(-z^k a_{\theta _0}^{-1}(z)\) which satisfies \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \le K \rho ^i\) for some \(0<\rho <1\) (see Francq and Zakoïan (1998) for example).
- \(\diamond \):
-
\(k=p+1,\dots ,p+q\): We have
$$\begin{aligned} \frac{\partial }{\partial \theta _k } \left( b_\theta ^{-1}(z) a_{\theta }(z)(1-z)^{d-d_0} a_{\theta _0}(z)b_{\theta _0}(z)\right) = \left( \frac{\partial }{\partial \theta _k } b_\theta ^{-1}(z)\right) a_{\theta }(z) (1-z)^{d-d_0} a_{\theta _0}^{-1}(z)b_{\theta _0}(z) \end{aligned}$$and consequently \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \) is the \(i-\)th coefficient of \((\frac{\partial }{\partial \theta _k } b_{\theta _0}^{-1}(z) ) b_{\theta _0}(z)\) which also satisfies \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \le K \rho ^i\) (see Francq and Zakoïan (1998)).
The last case will not be a consequence of the usual works on ARMA processes.
- \(\diamond \):
-
\(k=p+q+1\): In this case, \(\theta _k=d\) and so we have
$$\begin{aligned} \frac{\partial }{\partial \theta _k } \left( b_\theta ^{-1}(z) a_{\theta }(z)(1-z)^{d-d_0} a_{\theta _0}^{-1}(z)b_{\theta _0}(z)\right) = b_\theta ^{-1}(z)a_{\theta }(z) \mathrm {ln}(1-z)(1-z)^{d-d_0} a_{\theta _0}^{-1}(z)b_{\theta _0}(z) \end{aligned}$$and consequently \(\overset{\mathbf{. }}{\lambda }_{i,k}\left( \theta _0\right) \) is the \(i-\)th coefficient of \(\mathrm {ln}(1-z)\) which is equal to \(-1/i\).
The three above cases imply the expected result. \(\square \)
6.2 Proof of Theorem 1
Consider the random variable \(\mathrm {W}_n(\theta )\) defined for any \(\theta \in \varTheta \) by
where \(V(\theta )\!=\!{\mathbb {E}}[O_n(\theta )]-{\mathbb {E}}[O_n(\theta _0)]\). For \(\beta >0\), let \(S_\beta =\{\theta : \Vert \theta -\theta _0\Vert \le \beta \}\), \({\overline{S}}_\beta =\{\theta \in \varTheta _\delta : \theta \notin S_\beta \}\). It can readily be shown that
Since \(d_1-d_0>-1/2\), one has
We can therefore use the same arguments as those of Francq and Zakoïan (1998) to prove under (A1) and (A2) that for any \({\overline{\theta }}\in \varTheta _\delta \setminus \{\theta _0\}\), there exists a neighbourhood \(\mathrm {N}({\overline{\theta }})\) of \({\overline{\theta }}\) such that \(\mathrm {N}({\overline{\theta }})\subset \varTheta _\delta \) and
Note that \({\mathbb {E}}[O_n(\theta _0)]=\sigma _\epsilon ^2\). It follows from (42) that
for some positive constant K.
In view of (40), it is then sufficient to show that the random variable \(\sup _{\theta \in \varTheta _\delta }|Q_n(\theta )-{\mathbb {E}}[O_n(\theta )]|\) converges in probability to zero to prove Theorem 1. We use Corollary 2.2 of Newey (1991) to obtain this uniform convergence in probability. The set \(\varTheta _\delta \) is compact and \(({\mathbb {E}}[O_n(\theta )])_{n\ge 1}\) is a uniformly convergent sequence of continuous functions on a compact set so it is equicontinuous. We consequently need to show the following two points to complete the proof of the theorem:
-
For each \(\theta \in \varTheta _\delta \), \(Q_n(\theta )-{\mathbb {E}}[O_n(\theta )]=\mathrm {o}_{{\mathbb {P}}}(1).\)
-
There is \(B_n\) and \(h: [0,\infty )\rightarrow [0,\infty )\) with \(h(0)=0\) and h continuous at zero such that \(B_n=\mathrm {O}_{{\mathbb {P}}}(1)\) and for all \(\theta _1, \theta _2\in \varTheta _\delta \), \(|Q_n(\theta _1)-Q_n(\theta _2)|\le B_nh(\Vert \theta _1-\theta _2\Vert )\).
6.2.1 Pointwise convergence in probability of \(Q_n(\theta )-{\mathbb {E}}[O_n(\theta )]\) to zero
For any \(\theta \in \varTheta _\delta \), Remark 12, the Cauchy–Schwarz inequality and (41) yield that
We use the ergodic theorem and the continuous mapping theorem to obtain
Combining the results in (43) and (44), we deduce that for all \(\theta \in \varTheta _\delta \),
6.2.2 Tightness characterization
Observe that for any \(\theta _1, \theta _2\in \varTheta _\delta \), there exists \(\theta ^\star \) between \(\theta _1\) and \(\theta _2\) such that
As before, the uncorrelatedness of the innovation process \((\epsilon _t)_{t\in {\mathbb {Z}}}\) and Remark 12 entail that
Thanks to Markov’s inequality, we conclude that
The proof of Theorem 1 is then complete.
6.3 Proof of Theorem 2
By a Taylor expansion of the function \(\partial Q_n(\cdot )/ \partial \theta \) around \(\theta _0\) and under (A3), we have
where the \(\theta ^*_{n,i,j}\)’s are between \({\hat{\theta }}_n\) and \(\theta _0\). The Eq. (45) can be rewritten in the form:
Under the assumptions of Theorem 2, it will be shown respectively in Lemmas 15 and 17 that
and
As a consequence, the asymptotic normality of \(\sqrt{n}( {\hat{\theta }}_n-\theta _0)\) will be a consequence of the one of \(\sqrt{n}\partial /\partial \theta O_n(\theta _0)\).
Lemma 15
For \(1\le k\le p+q+1\), under the assumptions of Theorem 2, we have
Proof
Throughout this proof, \(\theta =(\theta _1,\ldots ,\theta _{p+q},d)'\in \varTheta _\delta \) is such that \(\max (d_0,0)<d\le d_2\) where \(d_2\) is the upper bound of the support of the long-range dependence parameter \(d_0\).
The proof is quite long so we divide it in several steps.
\(\diamond \) Step 1: preliminaries
For \(1\le k \le p+q+1\) we have
where
and
Using (32) and (35), the fourth term \(\varDelta _{n,4}^k(\theta _0)\) can be rewritten in the form:
Therefore, if we prove that the three sequences of random variables \(( \varDelta _{n,1}^k(\theta )+\varDelta _{n,3}^k(\theta ))_{n\ge 1}\), \(( \varDelta _{n,2}^k(\theta ))_{n\ge 1}\) and \(( \varDelta _{n,4}^k(\theta _0))_{n\ge 1}\) converge in probability to 0, then (47) will be true.
\(\diamond \) Step 2: convergence in probability of \(( \varDelta _{n,4}^k(\theta _0))_{n\ge 1}\) to 0
For simplicity, we denote in the sequel by \(\overset{\mathbf{. }}{\lambda }_{j,k}\) the coefficient \(\overset{\mathbf{. }}{\lambda }_{j,k}(\theta _0)\) and by \(\overset{\mathbf{. }}{\lambda }_{j,k}^t\) the coefficient \(\overset{\mathbf{. }}{\lambda }_{j,k}^t(\theta _0)\). Let \(\varrho (\cdot ,\cdot )\) be the function defined for \(1\le t,s\le n\) by
For all \(\beta >0\), using the symmetry of the function \(\varrho (t,s)\), we obtain that
By the stationarity of \((\epsilon _t)_{t\in {\mathbb {Z}}}\) which is assumed in (A2), we have
Since the noise is not correlated, we deduce that \({\mathbb {E}}\left[ \epsilon _0\epsilon _{-j_1}\right] =0\) and \({\mathbb {E}}\left[ \epsilon _0\epsilon _{s-t-j_2}\right] =0\) for \(1\le j_1, j_2\) and \(s\le t\). Consequently we obtain
If
Cesàro’s Lemma implies that the first term in the right hand side of (50) tends to 0. Thanks to Lemma 10 applied with \(r=\infty \) (or see Remark 11) and Assumption (A4’) with \(\tau =4\), we obtain that
hence (51) holds true. Concerning the second term of right hand side of the inequality (50), we have
where we have used the fact that the noise is not correlated, Lemma 10 with \(r=2\) and Cesàro’s Lemma. This ends Step 2.
\(\diamond \) Step 3: \((\varDelta _{n,2}^k(\theta ))_{n\ge 1}\) converges in probability to 0
For all \(\beta >0\), we have
First, using Lemma 13, we have
In view of (29), (34) and (52), we may write
We use Lemma 10, the fact that \(d>\max (d_0,0)\) and the fractional version of Cesàro’s LemmaFootnote 2 to obtain
This proves the expected convergence in probability.
\(\diamond \) Step 4: convergence in probability of \((\varDelta _{n,1}^k(\theta )+\varDelta _{n,3}^k(\theta ))_{n\ge 1}\) to 0
Note that, for all \(n\ge 1\), we have
A Taylor expansion of the function \((\epsilon _t-{\tilde{\epsilon }}_t)(\cdot )\) around \(\theta _0\) gives
where \(\theta ^\star \) is between \(\theta _0\) and \(\theta \). Following the same method as in the previous step we obtain
As in Hallin et al. (1999), it can be shown using Stirling’s approximation and the fact that \(d^\star >d_0\) that
for any small enough \(\zeta >0\). We then deduce that
The expected convergence in probability follows from (52), (54) and the fractional version of Cesàro’s Lemma.
\(\square \)
We show in the following lemma the existence and invertibility of \(J(\theta _0)\).
Lemma 16
Under Assumptions of Theorem 2, the matrix
exists almost surely and is invertible.
Proof
For all \(1\le i,j \le p+q+1 \), we have
Note that in view of (32), (33) and Remark 12, the first and second order derivatives of \(\epsilon _t(\cdot )\) belong to \({\mathbb {L}}^2\). By using the ergodicity of \((\epsilon _t)_{t\in {\mathbb {Z}}}\) assumed in Assumption (A2), we deduce that
By (29) and (32), \(\epsilon _t\) and \({\partial \epsilon _t(\theta _0)}/{\partial \theta }\) are non correlated as well as \(\epsilon _t\) and \({\partial ^2\epsilon _t(\theta _0)}/{\partial \theta \partial \theta }\). Thus we have
From (29) and (39) we obtain that
Therefore \(J(\theta _0)\) exists almost surely.
If the matrix \(J(\theta _0)\) is not invertible, there exists some real constants \(c_1,\dots ,c_{p+q+1}\) not all equal to zero such that \({\mathbf {c}}^{'}J(\theta _0){\mathbf {c}}=\sum _{i=1}^{p+q+1} \sum _{j=1}^{p+q+1}c_jJ(\theta _0)(j,i)c_i=0\), where \({\mathbf {c}}=(c_1,\dots ,c_{p+q+1})^{'}\). In view of (55) we obtain that
which implies that
Differentiating the Eq. (1), we obtain that
and by (56) we may write that
It follows that (1) can therefore be rewritten in the form:
Under Assumption (A1) the representation in (1) is unique (see Hosking (1981)) so
and
First, (58) implies that
and thus \(c_k = 0\) for \(p+1\le k\le p+q\).
Similarly, (57) yields that
Since \(\partial (1-L)^d / \partial d= (1-L)^{d}\mathrm {ln}(1-L)\), it follows that
where the sequence \((e_k)_{k\ge 1}\) is given by the coefficients of the power series \(a_{\theta _0}(L)\mathrm {ln} (1-L)\). Since \(e_0=0\) and \(e_1=-1 \), we obtain that
Since the polynomial \(a_{\theta _0}\) is not the null polynomial, this implies that \(c_{p+q+1}=0\) and then \(c_k\) for \(1\le k\le p\). Thus \({\mathbf {c}}=0\) which leads us to a contradiction. Hence \(J(\theta _0)\) is invertible.
\(\square \)
Lemma 17
For any \(1\le i,j\le p+q+1 \) and under the assumptions of Theorem 1, we have
where \(\theta ^*_{n,i,j}\) is defined in (45).
Proof
For any \(\theta \in \varTheta _\delta \), let
and
We have
So it is enough to show that the three terms in the right hand side of (60) converge in probability to 0 when n tends to infinity. Following the same arguments as the proof of Lemma 16 and applying the ergodic theorem, we obtain that
Let us now show that the random variable \(|J_{n}(\theta ^*_{n,i,j})(i,j)-J_{n}^{*}(\theta ^*_{n,i,j})(i,j)|\) converges in probability to 0. It can easily be seen that
Hence, by the Cauchy–Schwarz inequality and Remark 12 one has
Similar calculation can be done to obtain
It follows then using Cesàro’s Lemma that
which entails the expected convergence in probability to 0 of \(|J_{n}(\theta ^*_{n,i,j})(i,j)-J_{n}^{*}(\theta ^*_{n,i,j})(i,j)|\).
By a Taylor expansion of \(J_n^{*}(\cdot )(i,j)\) around \(\theta _0\), there exists \(\theta _{n,i,j}^{**}\) between \(\theta ^*_{n,i,j}\) and \(\theta _0\) such that
Since \(d_1-d_0>1/2\), it can easily be shown as before that
and
We use (61), (62), (63), the ergodic theorem and Theorem 1 to deduce the convergence in probability of \(|J_n^{*}(\theta ^*_{n,i,j})(i,j)-J_n^{*}(\theta _0)(i,j)|\) to 0.
The proof of the lemma is then complete. \(\square \)
The following lemma states the existence of the matrix \(I(\theta _0)\).
Lemma 18
Under the assumptions of Theorem 2, the matrix
exists.
Proof
By the stationarity of \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) (remind that this process is defined in (7)), we have
By the dominated convergence theorem, the matrix \(I(\theta _0)\) exists and is given by
whenever
For \(s\in {\mathbb {Z}}\) and \(1\le k\ \le p+q+1\), we denote \(H_{s,k}(\theta _0)=2\epsilon _s(\theta _0)\frac{\partial }{\partial \theta _k}\epsilon _s(\theta _0)\) the \(k-\)th entry of \(H_{s}(\theta _0)\). In view of (32) we have
where we have used Lemma 14. It follows that
Thanks to the stationarity of \((\epsilon _t)_{t\in {\mathbb {Z}}}\) and Assumption (A4’) with \(\tau =4\) we deduce that
and we obtain the expected result. \(\square \)
Lemma 19
Under Assumptions of Theorem 2, the random vector \(\sqrt{n}({\partial }/{\partial \theta })O_n(\theta _0)\) has a limiting normal distribution with mean 0 and covariance matrix \(I(\theta _0)\).
Proof
Observe that for any \(t\in {\mathbb {Z}}\)
because \({\partial \epsilon _t(\theta _0)}/{\partial \theta }\) belongs to the Hilbert space \({\mathbf {H}}_{\epsilon }(t-1)\) generated by the family \((\epsilon _s)_{s\le t-1}\). Therefore we have
For \(i\ge 1\), we denote by \( {\varLambda }_{i}\left( \theta _0\right) =(\overset{\mathbf{. }}{\lambda }_{i,1} \left( \theta _0\right) ,\dots , \overset{\mathbf{. }}{\lambda }_{i,p+q+1}\left( \theta _0\right) )'\) and we introduce for \(r\ge 1\)
From (32) we have
Since \(H_{t,r}(\theta _0)\) is a function of finite number of values of the process \((\epsilon _t)_{t\in {\mathbb {Z}}}\), the stationary process \((H_{t,r}(\theta _0))_{t\in {\mathbb {Z}}}\) satisfies a mixing property (see Theorem 14.1 in Davidson (1994), p. 210) of the form (A4). The central limit theorem for strongly mixing processes (see Herrndorf (1984)) implies that \(({1}/{\sqrt{n}})\sum _{t=1}^{n}H_{t,r}(\theta _0)\) has a limiting \({\mathcal {N}}(0,I_r(\theta _0))\) distribution with
Since \( \frac{1}{\sqrt{n}}\sum _{t=1}^{n}H_{t,r}(\theta _0)\) and \( \frac{1}{\sqrt{n}}\sum _{t=1}^{n}H_{t}(\theta _0)\) have zero expectation, we shall have
as soon as
As a consequence we will have \(\lim _{r\rightarrow \infty }I_r(\theta _0)=I(\theta _0)\). The limit in (66) is obtained as follows:
We use successively the stationarity of \((\epsilon _t)_{t\in {\mathbb {Z}}}\), Lemma 14 and Assumption (A4’) with \(\tau =4\) in order to obtain that
and we obtain the convergence stated in (66) when \(r\rightarrow \infty \).
Using Theorem 7.7.1 and Corollary 7.7.1 of Anderson (see Anderson (1971), pp. 425–426), the lemma is proved once we have, uniformly in n,
Arguing as before we may write
and we obtain that
which completes the proof. \(\square \)
No we can end this quite long proof of the asymptotic normality result.
Proof of Theorem 2
In view of Lemma 15, the Eq. (46) can be rewritten in the form:
From Lemma 19\( [({\partial ^2}/{\partial \theta _i\partial \theta _j})Q_n( \theta ^*_{n,i,j})]\sqrt{n}( {\widehat{\theta }}_n-\theta _0) \) converges in distribution to \({\mathcal {N}}(0,I(\theta _0))\). Using Lemma 17 and Slutsky’s theorem we deduce that
converges in distribution to \((J(\theta _0),Z)\) with \({\mathbb {P}}_{Z}={\mathcal {N}}(0,I)\). Consider now the function \(h:{\mathbb {R}}^{(p+q+1)\times (p+q+1)}\times {\mathbb {R}}^{p+q+1}\rightarrow {\mathbb {R}}^{p+q+1}\) that maps (A, X) to \(A^{-1}X\). If \(D_h\) denotes the set of discontinuity points of h, we have \({\mathbb {P}}((J(\theta _0),Z)\in D_h)=0\). By the continuous mapping theorem
converges in distribution to \(h(J(\theta _0),Z)\) and thus \(\sqrt{n}( {\hat{\theta }}_n-\theta _0)\) has a limiting normal distribution with mean 0 and covariance matrix \(J^{-1}(\theta _0)I(\theta _0)J^{-1}(\theta _0)\). The proof of Theorem 2 is then completed.
6.4 Proof of the convergence of the variance matrix estimator
We show in this section the convergence in probability of \({\hat{\varOmega }}:={\hat{J}}_n^{-1}{\hat{I}}_n^{SP}{\hat{J}}_n^{-1}\) to \(\varOmega \), which is an adaptation of the arguments used in Boubacar Mainassara et al. (2012).
Using the same approach as that followed in Lemma 17, we show that \({\hat{J}}_n\) converges in probability to J. We give below the proof of the convergence in probability of the estimator \({\hat{I}}_n^{SP}\), obtained using the approach of the spectral density, to I.
We recall that the matrix norm used is given by \(\left\| A\right\| =\sup _{\left\| x\right\| \le 1}\left\| Ax\right\| =\rho ^{1/2}( A^{'}A)\), when A is a \({\mathbb {R}}^{k_1\times k_2}\) matrix, \(\Vert x\Vert ^2=x^{'}x\) is the Euclidean norm of the vector \(x\in {\mathbb {R}}^{k_2}\), and \(\rho (\cdot )\) denotes the spectral radius. This norm satisfies
with \(a_{i,j}\) the entries of \(A\in {\mathbb {R}}^{k_1\times k_2}\). The choice of the norm is crucial for the following results to hold (with e.g. the Euclidean norm, this result is not valid).
We denote
where \(H_t:=H_t(\theta _0)\) is definied in (7) and \(\underline{{H}}_{r,t}=({H}_{t-1}^{'},\dots ,{H}_{t-r}^{'}) ^{'}\). For any \(n\ge 1\), we have
We then obtain
In view of (69), to prove the convergence in probability of \({\hat{I}}_n^{\mathrm {SP}}\) to \(I(\theta _0)\), it suffices to show that \({\hat{\varPhi }}_r(1)\rightarrow \varPhi (1)\) and \({\hat{\varSigma }}_{{\hat{u}}_r}\rightarrow \varSigma _u\) in probability. Let the \(r\times 1\) vector \(\mathbb {1}_r=(1,\dots ,1)^{'}\) and the \(r(p+q+1)\times (p+q+1)\) matrix \({\mathbf {E}}_r={I}_{p+q+1}\otimes \mathbb {1}_r\), where \(\otimes \) denotes the matrix Kronecker product and \({I}_m\) the \(m\times m\) identity matrix. Write \({\underline{\varPhi }}^{*}_r=(\varPhi _1,\dots ,\varPhi _r)\) where the \(\varPhi _i\)’s are defined by (8). We have
Under the assumptions of Theorem 5 we have
Therefore it is enough to show that \(\sqrt{r}\Vert \underline{{\hat{\varPhi }}}_r-{\underline{\varPhi }}_r\Vert \) and \(\sqrt{r}\Vert {\underline{\varPhi }}^{*}_r-{\underline{\varPhi }}_r\Vert \) converge in probability towards 0 in order to obtain the convergence in probability of \({\hat{\varPhi }}_r(1)\) towards \(\varPhi (1)\). From (9) we have
and thus
The vector \(u_{r,t}\) is orthogonal to \({\underline{H}}_{r,t}(\theta _0)\). It follows that
Consequently the least squares estimator of \(\varSigma _{u_r}\) can be rewritten in the form:
where
Similar arguments combined with (8) yield
By (72) we obtain
From Lemma 18 and under Assumptions of Theorem 5 we deduce that
Observe also that
Therefore the convergence \({\hat{\varSigma }}_{{\hat{u}}_r}\) to \(\varSigma _u\) will be a consequence of the four following properties:
-
\(\Vert {\hat{\varSigma }}_{{\hat{H}}}-\varSigma _{H}\Vert =\mathrm {o}_{{\mathbb {P}}}(1)\),
-
\({\mathbb {P}}-\lim _{n\rightarrow \infty }\Vert \underline{{\hat{\varPhi }}}_r -{\underline{\varPhi }}^{*}_r\Vert =0\),
-
\({\mathbb {P}}-\lim _{n\rightarrow \infty }\Vert {\hat{\varSigma }}^{'}_{{\hat{H}}, \underline{{\hat{H}}}_r}-\varSigma ^{'}_{H,{\underline{H}}_r} \Vert =0\) and
-
\(\Vert \varSigma ^{'}_{H,{\underline{H}}_r} \Vert =\mathrm {O}(1)\).
The above properties will be proved thanks to several lemmas that are stated and proved hereafter. This ends the proof of Theorem 5. For this, consider the following lemmas:
Lemma 20
Under the assumptions of Theorem 5, we have
Proof
See Lemma 1 in the supplementary material of Boubacar Mainassara et al. (2012). \(\square \)
Lemma 21
Under the assumptions of Theorem 5 there exists a finite positive constant K such that, for \(1\le r_1,r_2\le r\) and \(1 \le m_1,m_2\le p+q+1\) we have
Proof
We denote in the sequel by \(\overset{\mathbf{. }}{\lambda }_{j,k}\) the coefficient \(\overset{\mathbf{. }}{\lambda }_{j,k}(\theta _0)\) defined in (30).
Using the fact that the process \((H_t(\theta _0))_{t\in {\mathbb {Z}}}\) is centered and taking into consideration the strict stationarity of \((\epsilon _t)_{t\in {\mathbb {Z}}}\) we obtain that for any \(t\in {\mathbb {Z}}\)
where
and
Thanks to Lemma 14 one may use the product theorem for the joint cumulants ( Brillinger (1981)) as in the proof of Lemma A.3. in Shao (2011) in order to obtain that
where we have used the absolute summability of the k-th \((k=2,\dots ,8)\) cumulants assumed in (A4’) with \(\tau =8\).
Observe now that
For any \(h\in {\mathbb {Z}}\), from (29) we have
Under Assumption (A4’) with \(\tau =4\) and in view of Lemma 14 we may write that
Similarly, we obtain
Consequently \(T_{r1,m_1,r_2,m_2}^{(1)}<\infty \) and the same approach yields that \( T_{r1,m_1,r_2,m_2}^{(2)}<\infty \) and the lemma is proved. \(\square \)
Let \({\hat{\varSigma }}_{{\underline{H}}_r}\), \({\hat{\varSigma }}_{H}\) and \({\hat{\varSigma }}_{H,{\underline{H}}_r}\) be the matrices obtained by replacing \({\hat{H}}_t\) by \(H_t(\theta _0)\) in \({\hat{\varSigma }}_{\underline{{\hat{H}}}_r}\), \({\hat{\varSigma }}_{{\hat{H}}}\) and \({\hat{\varSigma }}_{{\hat{H}},\underline{{\hat{H}}}_r}\).
Lemma 22
Under the assumptions of Theorem 5, \(\sqrt{r}\Vert {\hat{\varSigma }}_{{\underline{H}}_r}-\varSigma _{{\underline{H}}_r}\Vert \), \(\sqrt{r}\Vert {\hat{\varSigma }}_{H,{\underline{H}}_r} -\varSigma _{H,{\underline{H}}_r}\Vert \) and \(\sqrt{r}\Vert {\hat{\varSigma }}_{H}-\varSigma _{H}\Vert \) tend to zero in probability as \(n\rightarrow \infty \) when \(r=\mathrm {o}(n^{1/3})\).
Proof
For \(1\le m_1,m_2 \le p+q+1 \) and \(1\le r_1,r_2 \le r \), the \(( \lbrace (r_1-1)(p+q+1)+m_1\rbrace ,\lbrace (r_2-1)(p+q+1)+m_2\rbrace )-\)th element of \({\hat{\varSigma }}_{{\underline{H}}_r}\) is given by:
For all \(\beta >0\), we use (68) and we obtain
The stationarity of the process \(\left( H_{t-r_1,m_1}(\theta _0)H_{t-r_2,m_2}(\theta _0)\right) _{t\in {\mathbb {Z}}}\) and Lemma 21 imply
Consequently we have
when \(r=\mathrm {o}(n^{1/3})\). The conclusion follows. \(\square \)
We show in the following lemma that the previous lemma remains valid when we replace \(H_t(\theta _0)\) by \({\hat{H}}_t\).
Lemma 23
Under the assumptions of Theorem 5, \(\sqrt{r}\Vert {\hat{\varSigma }}_{\underline{{\hat{H}}}_r}-\varSigma _{{\underline{H}}_r}\Vert \), \(\sqrt{r}\Vert {\hat{\varSigma }}_{{\hat{H}},\underline{{\hat{H}}}_r}-\varSigma _{H,{\underline{H}}_r}\Vert \) and \(\sqrt{r}\Vert {\hat{\varSigma }}_{{\hat{H}}}-\varSigma _{H}\Vert \) tend to zero in probability as \(n\rightarrow \infty \) when \(r=\mathrm {o}(n^{(1-2(d_0-d_1))/5})\).
Proof
As mentioned in the end of the proof of the previous lemma, we only have to deal with the term \(\sqrt{r}\Vert {\hat{\varSigma }}_{\underline{{\hat{H}}}_r} -\varSigma _{{\underline{H}}_r}\Vert \).
We denote \({\hat{\varSigma }}_{{\underline{H}}_{r,n}}\) the matrix obtained by replacing \({\tilde{\epsilon }}_t({\hat{\theta }}_n)\) by \(\epsilon _t({\hat{\theta }}_n)\) in \({\hat{\varSigma }}_{\underline{{\hat{H}}}_{r}}\). We have
By Lemma 22, the term \(\sqrt{r}\Vert {\hat{\varSigma }}_{{\underline{H}}_r}-\varSigma _{{\underline{H}}_r}\Vert \) converges in probability. The lemma will be proved as soon as we show that
when \(r=\mathrm {o}(n^{(1-2(d_0-d_1))/5})\). This is done in two separate steps.
Step 1: proof of (75). For all \(\beta >0\), we have
where
It is follow that
Observe now that
We replace the above identity in (77) and we obtain by Hölder’s inequality that
where
For all \(\theta \in \varTheta _{\delta }\) and \(t\in {\mathbb {Z}}\), in view of (29) and Remark 12, we have
It is not difficult to prove that \({\tilde{\epsilon }}_t(\theta )\) and \(\partial {\tilde{\epsilon }}_t(\theta )/\partial \theta \) belong to \({\mathbb {L}}^6\). The fact that \(\epsilon _t(\theta )\) and \(\partial \epsilon _t(\theta )/\partial \theta \) have moment of order 6 can be proved using the same method than in Lemma 21 using the absolute summability of the k-th \((k=2,\dots ,8)\) cumulants assumed in (A4’) with \(\tau =8\). We deduce that
Then we obtain
The same calculations hold for the terms \(T_{n,2}\), \(T_{n,3}\) and \(T_{n,4}\). Thus
and reporting this estimation in (78) implies that
Since \(2/7>(1+2(d_1-d_0))/5\), the sequence \(\sqrt{r}\left\| {\hat{\varSigma }}_{\hat{{\underline{H}}}_r} -{\hat{\varSigma }}_{{\underline{H}}_{r,n}}\right\| \) converges in probability to 0 as \(n\rightarrow \infty \) when \(r=r(n)=\mathrm {o}(n^{(1-2(d_0-d_1))/5})\).
Step 2: proof of (76). First we follow the same approach than in the previous step. We have
Since
one has
where
Taylor expansions around \(\theta _0\) yield that there exists \({\underline{\theta }}\) and \({\overline{\theta }}\) between \({\hat{\theta }}_n\) and \(\theta _0\) such that
and
with \(w_t=\left\| {\partial \epsilon _t({\underline{\theta }})}/{\partial \theta ^{'}}\right\| \) and \(q_t=\left\| {\partial ^2\epsilon _t({\overline{\theta }})}/{\partial \theta ^{'}\partial \theta _m}\right\| \). Using the fact that
and that \((\sqrt{n}( {\hat{\theta }}_n-\theta _0))_n\) is a tight sequence (which implies that \(\Vert {\hat{\theta }}_n-\theta _0\Vert =\mathrm {O}_{{\mathbb {P}}}(1/\sqrt{n})\)), we deduce that
The same arguments are valid for \(U_{n,2}\), \(U_{n,3}\) and \(U_{n,4}\). Consequently \( U_{n,1}+U_{n,2}+U_{n,3}+U_{n,4}=\mathrm {O}_{{\mathbb {P}}}(1/\sqrt{n})\) and (81) yields
When \(r=\mathrm {o}(n^{1/3})\) we finally obtain \(\sqrt{r}\Vert {\hat{\varSigma }}_{{\underline{H}}_{r,n}} -{\hat{\varSigma }}_{{\underline{H}}_r}\Vert =\mathrm {o}_{{\mathbb {P}}}(1)\).
\(\square \)
Lemma 24
Under the assumptions of Theorem 5, we have
Proof
Recall that by (8) and (71) we have
By the orthogonality conditions in (8) and (71), one has
and consequently
Using Lemmas 20 and 21, (82) implies that
Under Assumptions of Theorem 5, \(r\sum _{\ell \ge 1}\left\| \varPhi _{\ell +r}\right\| =\mathrm {o}(1)\) as \(r\rightarrow \infty \). The proof of the lemma follows. \(\square \)
Lemma 25
Under the assumptions of Theorem 5, we have
as \(n\rightarrow \infty \) when \(r=\mathrm {o}(n^{(1-2(d_0-d_1))/5})\) and \(r\rightarrow \infty \).
Proof
We have
and by induction we obtain
We have
Lemmas 20 and 23 imply the result. \(\square \)
Lemma 26
Under the assumptions of Theorem 5, we have
Proof
By (71), we have
and so we have \({\underline{\varPhi }}_r=\varSigma _{H,{\underline{H}}_r} \varSigma _{{\underline{H}}_r}^{-1}\). Lemmas 20, 23, 25 and (83) imply
and the lemma is proved. \(\square \)
6.5 Proof of Theorem 5
Since by Lemma 23 we have \(\Vert {\hat{\varSigma }}_{{\hat{H}}}-\varSigma _{H}\Vert =\mathrm {o}_{{\mathbb {P}}}(r^{-1/2})=\mathrm {o}_{{\mathbb {P}}}(1)\) and \(\Vert {\hat{\varSigma }}_{{\hat{H}},\underline{{\hat{H}}}_r}-\varSigma _{H,{\underline{H}}_r} \Vert =\mathrm {o}_{{\mathbb {P}}}(r^{-1/2})=\mathrm {o}_{{\mathbb {P}}}(1)\), and by Lemma 24\(\Vert \underline{{\hat{\varPhi }}}_r-{\underline{\varPhi }}^{*}_r\Vert =\mathrm {o}_{{\mathbb {P}}}(r^{-1/2})=\mathrm {o}_{{\mathbb {P}}}(1)\), Theorem 5 is then proved.
6.6 Invertibility of the normalization matrix \(P_{p+q+1,n}\)
The following proofs are quite technical and are adaptations of the arguments used in Boubacar Maïnassara and Saussereau (2018).
To prove Proposition 6, we need to introduce the following notation.
We denote \(S_t\) the vector of \({\mathbb {R}}^{p+q+1}\) defined by
and \(S_t(i)\) its \(i-\)th component. We have
If the matrix \(P_{p+q+1,n}\) is not invertible, there exists some real constants \(d_1,\dots ,d_{p+q+1}\) not all equal to zero, such that \({\mathbf {d}}^{'}P_{p+q+1,n}{\mathbf {d}}=0\), where \({\mathbf {d}}=(d_1,\dots ,d_{p+q+1})^{'}\). Thus we may write that \(\sum _{i=1}^{p+q+1}\sum _{j=1}^{p+q+1}d_jP_{p+q+1,n}(j,i)d_i=0\) or equivalently
Then
which implies that for all \(t\ge 1\)
So we have
We apply the ergodic theorem and we use the orthogonality of \(\epsilon _t\) and \((\partial /\partial \theta )\epsilon _t(\theta _0)\) in order to obtain that
Reporting this convergence in (85) implies that \(\sum _{i=1}^{p+q+1}d_iS_t(i)=0\) a.s. for all \(t\ge 1\). By (84), we deduce that
Thanks to Assumption (A5), \((\epsilon _t)_{t\in {\mathbb {Z}}}\) has a positive density in some neighborhood of zero and then \(\epsilon _t\ne 0\) almost-surely. So we would have \({\mathbf {d}}^{'}J^{-1}\frac{\partial \epsilon _t}{\partial \theta }=0\) a.s. Now we can follow the same arguments that we developed in the proof of the invertibility of J (see Proof of Lemma 16 and more precisely (56)) and this leads us to a contradiction. We deduce that the matrix \(P_{p+q+1,n}\) is non singular.
6.7 Proof of Theorem 7
The arguments follows the one in Boubacar Maïnassara and Saussereau (2018) in a simpler context.
Recall that the Skorohod space \({\mathbb {D}}^{\ell }[ 0{,}1]\) is the set of \({\mathbb {R}}^{\ell }-\)valued functions on [0, 1] which are right-continuous and has left limits everywhere. It is endowed with the Skorohod topology and the weak convergence on \({\mathbb {D}}^{\ell } [ 0{,}1]\) is mentioned by \(\xrightarrow []{{\mathbb {D}}^{\ell }}\). The integer part of x will be denoted by \(\lfloor x\rfloor \).
The goal at first is to show that there exists a lower triangular matrix T with nonnegative diagonal entries such that
where \((B_{p+q+1}(r))_{r\ge 0}\) is a \((p+q+1)-\)dimensional standard Brownian motion. Using (29), \(U_t\) can be rewritten as
The non-correlation between \(\epsilon _t\)’s implies that the process \((U_t)_{t\in {\mathbb {Z}}}\) is centered. In order to apply the functional central limit theorem for strongly mixing process, we need to identify the asymptotic covariance matrix in the classical central limit theorem for the sequence \((U_t)_{t\in {\mathbb {Z}}}\). It is proved in Theorem 2 that
where \(f_U(0)\) is the spectral density of the stationary process \((U_t)_{t\in {\mathbb {Z}}}\) evaluated at frequency 0. The existence of the matrix \(\varOmega \) has already been discussed (see the proofs of Lemmas 16 and 18 ).
Since the matrix \(\varOmega \) is symmetric positive definite, it can be factorized as \(\varOmega =TT^{'}\) where the \((p+q+1)\times (p+q+1)\) lower triangular matrix T has real positive diagonal entries. Therefore, we have
where \(I_{p+q+1}\) is the identity matrix of order \(p+q+1\).
As in the proof of the asymptotic normality of \((\sqrt{n}({\hat{\theta }}_n-\theta _0))_{n\ge 1}\), the distribution of \(n^{-1/2}\sum _{t=1}^nU_t\) when n tends to infinity is obtained by introducing the random vector \(U_t^k\) defined for any positive integer k by
Since \(U_t^k\) depends on a finite number of values of the noise process \((\epsilon _t)_{t\in {\mathbb {Z}}}\), it also satisfies a mixing property (see Theorem 14.1 in Davidson (1994), p. 210). The central limit theorem for strongly mixing process of Herrndorf (1984) shows that its asymptotic distribution is normal with zero mean and variance matrix \(\varOmega _k\) that converges when k tends to infinity to \(\varOmega \) (see the proof of Lemma 19):
The above arguments also apply to matrix \(\varOmega _k\) with some matrix \(T_k\) which is defined analogously as T. Consequently, we obtain
Now we are able to apply the functional central limit theorem for strongly mixing process of Herrndorf (1984) and we obtain that
Since
we may use the same approach as in the proof of Lemma 19 in order to prove that \(n^{-1/2}\sum _{t=1}^{n}((TT^{'})^{-1/2}-(T_kT_k^{'})^{-1/2})U_t^k\) converges in distribution to 0. Consequently we obtain that
In order to conclude that (86) is true, it remains to observe that uniformly with respect to n it holds that
where
By (67), one has
and since \(\lfloor nr\rfloor \le n\),
Thus (87) is true and the proof of (86) is achieved.
By (86) we deduce that
One remarks that the continuous mapping theorem on the Skorohod space yields
Using (86), (88) and the continuous mapping theorem on the Skorohod space, one finally obtains
The proof of Theorem 7 is then complete.
6.8 Proof of Theorem 8
In view of (14) and (17), we write \({{\hat{P}}}_{p+q+1,n}=P_{p+q+1,n}+ Q_{p+q+1,n}\) where
Using the same approach as in Lemma 17, \({\hat{J}}_n\) converges in probability to J. Thus we deduce that the first term in the right hand side of the above equation tends to zero in probability.
The second term is a sum composed of the following terms
Using similar arguments done before (see for example the use of Taylor’s expansion in Sect. 6.4, we have \(q_{s,t}^{i,j,k,l} = \mathrm {o}_{{\mathbb {P}}}(1)\) as n goes to infinity and thus \(Q_{p+q+1,n}= \mathrm {o}_{{\mathbb {P}}}(1)\). So one may find a matrix \(Q^*_{p+q+1,n}\) that tends to the null matrix in probability and such that
Thanks to the arguments developed in the proof of Theorem 7, \(n ({\hat{\theta }}_{n}-\theta _0)^{'} P_{p+q+1,n}^{-1}({\hat{\theta }}_{n}-\theta _0)\) converges in distribution. So \(n ({\hat{\theta }}_{n}-\theta _0)^{'}Q_{p+q+1,n}^*({\hat{\theta }}_{n}-\theta _0)\) tends to zero in distribution, hence in probability. Then \(n ({\hat{\theta }}_{n}-\theta _0)^{'}{{\hat{P}}}_{p+q+1,n}^{-1}({\hat{\theta }}_{n}-\theta _0)\) and \(n ({\hat{\theta }}_{n}-\theta _0)^{'} P_{p+q+1,n}^{-1}({\hat{\theta }}_{n}-\theta _0)\) have the same limit in distribution and the result is proved.
Notes
To cite few examples of nonlinear processes, let us mention the self-exciting threshold autoregressive (SETAR), the smooth transition autoregressive (STAR), the exponential autoregressive (EXPAR), the bilinear, the random coefficient autoregressive (RCA), the functional autoregressive (FAR) (see Tong (1990) and Fan and Yao (2008) for references on these nonlinear time series models).
Recall that the fractional version of Cesàro’s Lemma states that for \((h_t)_t\) a sequence of positive reals, \(\kappa >0\) and \(c\ge 0\) we have
$$\begin{aligned} \lim _{t\rightarrow \infty }h_tt^{1-\kappa }=\left| \kappa \right| c \Rightarrow \lim _{n\rightarrow \infty }\frac{1}{n^{\kappa }}\sum _{t=0}^n h_t=c. \end{aligned}$$
References
Aknouche A, Francq C (2021) Count and duration time series with equal conditional stochastic and mean orders. Economet Theory 37(2):248–280
Akutowicz EJ (1957) On an explicit formula in linear least squares prediction. Math Scand 5:261–266
Anderson TW (1971) The statistical analysis of time series. Wiley, New York
Baillie RT, Chung C-F, Tieslau MA (1996) Analysing inflation by the fractionally integrated ARFIMA-GARCH model. J Appl Economet 11(1):23–40
Beran J (1995) Maximum likelihood estimation of the differencing parameter for invertible short and long memory autoregressive integrated moving average models. J Roy Stat Soc Ser B 57(4):659–672
Beran J, Feng Y, Ghosh S, Kulik R (2013) Long-memory processes. Probabilistic properties and statistical methods. Springer, Heidelberg
Berk KN (1974) Consistent autoregressive spectral estimates. Ann Stat 2:489–502 (collection of articles dedicated to Jerzy Neyman on his 80th birthday)
Boubacar Maïnassara Y (2012) Selection of weak VARMA models by modified Akaike’s information criteria. J Time Series Anal 33(1):121–130
Boubacar Mainassara Y, Carbon M, Francq C (2012) Computing and estimating information matrices of weak ARMA models. Comput Stat Data Anal 56(2):345–361
Boubacar Mainassara Y, Francq C (2011) Estimating structural VARMA models with uncorrelated but non-independent error terms. J Multivar Anal 102(3):496–505
Boubacar Maïnassara Y, Kokonendji CC (2016) Modified Schwarz and Hannan-Quinn information criteria for weak VARMA models. Stat Inference Stoch Process 19(2):199–217
Boubacar Maïnassara Y, Saussereau B (2018) Diagnostic checking in multivariate ARMA models with dependent errors using normalized residual autocorrelations. J Am Stat Assoc 113(524):1813–1827
Brillinger DR (1981) Time series: data analysis and theory, vol 36. SIAM
Cavaliere G, Nielsen MØ, Taylor AR (2017) Quasi-maximum likelihood estimation and bootstrap inference in fractional time series models with heteroskedasticity of unknown form. J Economet 198(1):165–188
Chiu S-T (1988) Weighted least squares estimators on the frequency domain for the parameters of a time series. Ann Stat 16(3):1315–1326
Dahlhaus R (1989) Efficient parameter estimation for self-similar processes. Ann Stat 17(4):1749–1766
Davidson J (1994) Stochastic limit theory. An introduction for econometricians. Advanced texts in econometrics. The Clarendon Press, Oxford University Press, New York
Davis RA, Matsui M, Mikosch T, Wan P (2018) Applications of distance correlation to time series. Bernoulli 24(4A):3087–3116
Ding Z, Granger CW, Engle RF (1993) A long memory property of stock market returns and a new model. J Empir Finance 1:83–106
Dominguez MA, Lobato IN (2003) Testing the martingale difference hypothesis. Economet Rev 22(4):351–377
Doukhan P, León J (1989) Cumulants for stationary mixing random sequences and applications to empirical spectral density. Probab Math Stat 10:11–26
Escanciano JC, Velasco C (2006) Testing the martingale difference hypothesis using integrated regression functions (Nonlinear Modelling and Financial Econometrics). Comput Stat Data Anal 51(4):2278–2294
Fan J, Yao Q (2008) Nonlinear time series: nonparametric and parametric methods. Springer
Fox R, Taqqu MS (1986) Large-sample properties of parameter estimates for strongly dependent stationary Gaussian time series. Ann Stat 14(2):517–532
Francq C, Roy R, Zakoïan J-M (2005) Diagnostic checking in ARMA models with uncorrelated errors. J Am Stat Assoc 100(470):532–544
Francq C, Zakoïan J-M (1998) Estimating linear representations of nonlinear processes. J Stat Plann Inference 68(1):145–165
Francq C, Zakoïan J-M (2005) Recent results for linear time series models with non independent innovations. In: Statistical modeling and analysis for complex data problems, vol 1 of GERAD 25th Anniv Ser. Springer, New York, pp 241–265
Francq C, Zakoïan J-M (2007) HAC estimation and strong linearity testing in weak ARMA models. J Multivar Anal 98(1):114–144
Francq C, Zakoïan J-M (2019) GARCH models: structure, statistical inference and financial applications. Wiley
Giraitis L, Surgailis D (1990) A central limit theorem for quadratic forms in strongly dependent linear variables and its application to asymptotical normality of Whittle’s estimate. Probab Theory Related Fields 86(1):87–104
Granger CWJ, Joyeux R (1980) An introduction to long-memory time series models and fractional differencing. J Time Ser Anal 1(1):15–29
Hallin M, Taniguchi M, Serroukh A, Choy K (1999) Local asymptotic normality for regression models with long-memory disturbance. Ann Stat 27(6):2054–2080
Hauser M, Kunst R (1998) Fractionally integrated models with arch errors: with an application to the swiss 1-month Euromarket interest rate. Rev Quant Financ Acc 10(1):95–113
Herrndorf N (1984) A functional central limit theorem for weakly dependent sequences of random variables. Ann Probab 12(1):141–153
Hosking JRM (1981) Fractional differencing. Biometrika 68(1):165–176
Hsieh DA (1989) Testing for nonlinear dependence in daily foreign exchange rates. J Bus 62(3):339–368
Hualde J, Robinson PM (2011) Gaussian pseudo-maximum likelihood estimation of fractional time series models. Ann Stat 39(6):3152–3181
Keenan DM (1987) Limiting behavior of functionals of higher-order sample cumulant spectra. Ann Stat 15(1):134–151
Klimko LA, Nelson PI (1978) On conditional least squares estimation for stochastic processes. Ann Stat 6(3):629–642
Kuan C-M, Lee W-M (2006) Robust \(M\) tests without consistent estimation of the asymptotic covariance matrix. J Am Stat Assoc. 101(475):1264–1275
Ling S (2003) Adaptive estimators and tests of stationary and nonstationary short- and long-memory ARFIMA-GARCH models. J Am Stat Assoc 98(464):955–967
Ling S, Li WK (1997) On fractionally integrated autoregressive moving-average time series models with conditional heteroscedasticity. J Am Stat Assoc 92(439):1184–1194
Lobato IN (2001) Testing that a dependent process is uncorrelated. J Am Stat Assoc 96(455):1066–1076
Lobato IN, Nankervis JC, Savin NE (2001) Testing for autocorrelation using a modified box- pierce q test. Inter Econ Rev 42(1):187–205
Newey WK (1991) Uniform convergence in probability and stochastic equicontinuity. Econometrica 59(4):1161–1167
Nielsen MØ (2015) Asymptotics for the conditional-sum-of-squares estimator in multivariate fractional time-series models. J Time Ser Anal 36(2):154–188
Palma W (2007) Long-memory time series. Wiley series in probability and statistics. Theory and methods. Wiley, Hoboken
Romano JP, Thombs LA (1996) Inference for autocorrelations under weak assumptions. J Am Stat Assoc 91(434):590–600
Shao X (2010a) Corrigendum: a self-normalized approach to confidence interval construction in time series. J. R. Stat. Soc. Ser. B Stat. Methodol. 72(5):695–696
Shao X (2010b) Nonstationarity-extended Whittle estimation. Economet Theory 26(4):1060–1087
Shao X (2010c) A self-normalized approach to confidence interval construction in time series. J R Stat Soc Ser B Stat Methodol 72(3):343–366
Shao X (2011) Testing for white noise under unknown dependence and its applications to diagnostic checking for time series models. Economet Theory 27(2):312–343
Shao X (2012) Parametric inference in stationary time series models with dependent errors. Scand J Stat 39(4):772–783
Shao X (2015) Self-normalization for time series: a review of recent developments. J Am Stat Assoc 110(512):1797–1817
Sowell F (1992) Maximum likelihood estimation of stationary univariate fractionally integrated time series models. J Economet 53(1–3):165–188
Székely GJ, Rizzo ML, Bakirov NK (2007) Measuring and testing dependence by correlation of distances. Ann Stat 35(6):2769–2794
Taniguchi M (1982) On estimation of the integrals of the fourth order cumulant spectral density. Biometrika 69(1):117–122
Taqqu MS, Teverovsky V (1997) Robustness of Whittle-type estimators for time series with long-range dependence (Heavy tails and highly volatile phenomena). Commun. Statist. Stoch. Models 13(4):723–757
Tong H (1990) Non-linear time series: a dynamical system approach. Oxford University Press
Whittle P (1953) Estimation and information in stationary time series. Ark Mat 2:423–434
Zhu K, Li WK (2015) A bootstrapped spectral test for adequacy in weak ARMA models. J Econometr 187(1):113–130
Zhu K, Ling S (2011) Global self-weighted and local quasi-maximum exponential likelihood estimators for ARMA-GARCH/IGARCH models. Ann Stat 39(4):2131–2163
Acknowledgements
We sincerely thank the anonymous referees and Editor for helpful remarks.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Boubacar Maïnassara, Y., Esstafa, Y. & Saussereau, B. Estimating FARIMA models with uncorrelated but non-independent error terms. Stat Inference Stoch Process 24, 549–608 (2021). https://doi.org/10.1007/s11203-021-09243-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11203-021-09243-7
Keywords
- Nonlinear processes
- FARIMA models
- Least-squares estimator
- Consistency
- Asymptotic normality
- Spectral density estimation
- Self-normalization
- Cumulants