
Abstract
Recent price trends in housing markets may reflect herding of market participants. A natural question is whether such herding, to the extent that it occurred, reflects herding in forecasts of professional forecasters. Using survey data for Canada, Japan, and the United States, we did not find evidence of forecaster herding. On the contrary, forecasters anti-herd and, thereby, tend to intentionally scatter their forecasts around the consensus forecast. The extent of anti-herding seems to vary over time. For Canada and the United States, we found that more pronounced anti-herding leads to lower forecast accuracy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The U.S. subprime mortgage crisis of 2007/2008 has witnessed that developments in housing markets are of key importance for macroeconomic fluctuations. Given the major importance of housing markets, much recent research has been done to recover the interaction of housing markets with other important macroeconomic variables (Campbell and Cocco 2007; Goodhart and Hofmann 2008; Bjørnland and Jacobsen 2010). Moreover, much significant research has been done to analyze whether recurrent booms and eventual collapses of housing markets reflect deviations of house prices from fundamentals, speculative bubbles, money illusion, and market frenzies (Levin and Wright 1997; Himmelberg et al. 2005; Brunnermeier and Julliard 2008; Payne and Waters 2007). Boom-bust cycles in housing markets may reflect informational cascades and herding behavior on the side of market participants. A natural question, therefore, is whether such herding, to the extent that it occurred, reflects herding in forecasts of professional forecasters.
We used survey data for Canada, Japan, and the United States to recover potential signs of herding in forecasts of housing starts. Our survey data cover a sample period of more than 20 years and comprise more than 20,000 forecasts of housing starts for different forecasting horizons for Canada, Japan and the United States. Using this large set of survey data, we found no signs of forecaster herding. On the contrary, our results indicate that forecasters anti-herd. While herding arises if forecasts are biased towards the consensus forecast, anti-herding arises if forecasts are biased away from the consensus forecast. Anti-herding, thus, is consistent with the view that, for strategic or other reasons, forecasters intentionally scatter their forecasts around the consensus forecast. Our results suggest that the extent of anti-herding seems to vary over time. Furthermore, for Canada and the United States, we found that more pronounced anti-herding leads to lower forecast accuracy.
We used an empirical test developed by Bernhardt et al. (2006) to study whether forecasts of housing starts provide evidence of forecaster herding. This test is straightforward to implement and delivers results that can be easily interpreted in economic terms. Unlike empirical tests proposed in earlier literature, the empirical test suggested by Bernhardt et al. (2006) is robust to various sources of misspecification like market-wide shocks and optimism or pessimism among forecasters. To the best of our knowledge, their test has not yet been used to study forecaster herding in housing markets. In fact, empirical evidence is relatively silent with respect to signs of forecaster herding in housing markets. Earlier empirical research on forecaster herding based on the test developed by Bernhardt et al. (2006) has focused on oil-price forecasts and company earnings forecasts (Naujoks et al. 2009; Pierdzioch et al. 2010).
Herding and anti-herding imply that forecasters deliver biased forecasts. Biased forecasts do not fully reflect forecasters’ private information. Researchers and commentators often articulate concerns that biased forecasts may result in a poor aggregation of private information, potentially resulting in deviations of house prices from their fundamental values and in market frenzies. In order to develop a better understanding of market frenzies, much significant theoretical research has been done to study why forecasters may herd or anti-herd (Scharfstein and Stein 1990; Bikhchandani et al. 1992; and Laster et al. 1999, to name just a few).
We organize the remainder of our paper as follows. In Section “The Empirical Test of (Anti-)Herding”, we describe the empirical test for forecaster herding. In Section “The Survey Data”, we describe the survey data that we used in our empirical research and study the rationality of forecasts of housing starts. In Section “Results on Forecaster (Anti-)Herding”, we summarize our empirical results. We also briefly sketch the economic intuition underlying the model of forecaster (anti-)herding developed by Laster et al. (1999) to put our empirical evidence of anti-herding into perspective. In Section “Concluding Remarks”, we offer some concluding remarks.
The Empirical Test of (Anti-)Herding
The empirical test proposed by Bernhardt et al. (2006) is based on the idea that, given their information set and given a possibly asymmetric distribution over housing starts, forecasters form in period t a median-unbiased private forecast of housing starts in period t + k.Footnote 1 This private forecast is given by \(\hat{s}_{t,t+k}\), where i denotes a forecaster index. The probability that such an unbiased private forecast exceeds (is less than) future housing starts, s t + k , should be equal to 0.5. In particular, the probability that future housing starts overshoot (undershoot) the unbiased private forecast should not depend upon the publicly known consensus (that is, average) forecast, \(\bar{s}_{t,t+k}\).
Herding implies that a published forecast is biased towards the consensus forecast, such that the published biased forecast, \(\tilde{s}_{t,t+k}\), is smaller than the private forecast. As a result, if the biased published forecast exceeds the consensus forecast, the probability that the biased public forecast also exceeds future housing starts should be smaller than 0.5. Similarly, if a biased published forecast is less than the consensus forecast, the probability that the published biased forecast is also less than future housing starts should be smaller than 0.5. Anti-herding, in contrast, implies probabilities that are larger than 0.5 because, in this case, a forecasters’ public forecast is biased away from the consensus forecast.
It follows that, under the null hypothesis that published forecasts are unbiased, the conditional probability, P, that future housing starts undershoot an unbiased published forecast in case the unbiased published forecast exceeds the consensus forecast should be 0.5, regardless of the consensus forecast. Similarly, the conditional probability of overshooting in case of an unbiased published forecast that is less than the consensus forecast should also be 0.5. We have
If a forecaster does not publish an unbiased forecast but herds, the published forecast is biased towards the consensus forecast and, given that the published forecast exceeds the consensus forecast, the probability of undershooting is less than 0.5. Similarly, if the biased published forecast is less than the consensus forecast, then the probability of overshooting should also be less than 0.5. We have
If forecasters herd, the average of the two conditional probabilities is smaller than 0.5. If forecasters anti-herd, in contrast, the average of the two conditional probabilities should be larger than 0.5 because, in this case, we have
The test statistic, S, is defined as the average of the sample estimates of the two conditional probabilities used in Eqs. 3–6. If forecasters deliver unbiased forecasts (null hypothesis), the test statistic should assume the value S = 0.5. If forecasters herd, the test statistic should assume a value S < 0.5. If forecasters anti-herd, the test statistic should assume a value S > 0.5. The test statistic, S, has an asymptotic normal distribution.
Bernhardt et al. (2006) show that, for example, market-wide shocks and optimism or pessimism of forecasters do not distort the test statistic, S, under the null hypothesis of no herding (or anti-herding). For example, a sequence of positive market-wide shocks during a boom in the housing market raises (lowers) the conditional probability that future housing starts exceed (fall short of) forecasts of housing starts. The shift in the conditional probabilities, however, does not affect the test statistic, S, which is defined as the average of the two conditional probabilities. The averaging of the two conditional probabilities also prevents a distortion in the test statistic in case forecasters do not target the median but the mean of an asymmetric distribution over future housing starts. Furthermore, outliers and large disruptive events like sharp “trend reversals” in the housing market have only a minor effect on the conditional probabilities (i.e., empirical frequencies of events). Finally, the test statistic is conservative in the sense that its variance attains a maximum under the null hypothesis, making it more difficult to reject the null hypothesis of unbiasedness when we should do so.
The Survey Data
In Section “Descriptive Statistics”, we provide some descriptive statistics of the survey data. In Section “Rationality of Heterogeneous Forecasts”, we show that forecasts do not satisfy traditional rationality criteria.
Descriptive Statistics
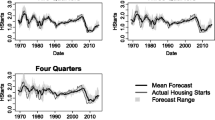
We analyzed monthly survey data of housing starts for Canada, Japan, and the United States compiled and published by Consensus Economics. Survey data are available for the sample period October 1989–December 2009 for Canada and the United States while for Japan housing starts forecasts are available since January 1991. Forecasts from 37, 41, and 64 forecasters are available for Canada, Japan and the United States.Footnote 2 The survey data contain forecasts for two different forecast horizons, that is, for the current year and the next year. We can, thus, analyze short-term forecasts and medium-term forecasts. In order to inspect the time-series dimension and the cross-sectional dimension of the survey data, Figs. 1, 2, and 3 plot time series of (1) the cross-sectional average of forecasts of housing starts (dashed lines), (2) actual housing starts (solid lines), and, (3) the cross-sectional heterogeneity of forecasts as measured by the cross-sectional range of forecasts (shaded areas).

Expected and actual housing starts in Canada. This figure shows the mean of the short-term forecasts of housing starts (dashed line), the actual housing starts (solid line), and the forecast range (shaded area) for Canada (in thds. units). The vertical distance between the mean forecast and the actual housing starts captures the forecast error

Expected and actual housing starts in Japan. This figure shows the mean of the short-term forecasts of housing starts (dashed line), the actual housing starts (solid line), and the forecast range (shaded area) for Japan (in mns. units). The vertical distance between the mean forecast and the actual housing starts captures the forecast error

Expected and actual housing starts in the U.S. This figure shows the mean of the short-term forecasts of housing starts (dashed line), the actual housing starts (solid line), and the forecast range (shaded area) for the U.S. (in mns. units). The vertical distance between the mean forecast and the actual housing starts captures the forecast error
The cross-sectional average of forecasts of housing starts broadly moves in tandem with actual housing starts. The scattering of forecasts around the cross-sectional average of forecasts, however, is substantial. For example, in the United States in February 2008 forecasts ranged from from 0.59 mn. to 1.3 mn. The cross-sectional heterogeneity of forecasts is largest in Canada and smallest in Japan, with the cross-sectional heterogeneity in the United States somewhere in between. As we shall report in Section “Results on Forecaster (Anti-)Herding”, anti-herding of forecasters may help to explain at least in part the cross-sectional heterogeneity of forecasts.
An interesting question, as far as Canada and the United States are concerned, is whether forecasters anticipated the recent turmoil in housing markets (Japan was in a recession since the mid 1990s). Upon comparing actual housing starts in Canada and the United States and forecasts thereof (Figs. 1 and 3), it becomes evident that forecasts, on average, fell short of actual housing starts when housing starts boomed. In other words, forecasters did not fully incorporate the upswing of housing starts into their forecasts, possibly indicating that forecasters, on average, believed to some extent in a trend reversal in the housing market.
The heterogeneity of forecasts, however, signals a substantial cross-sectional variation in the magnitude of a potential trend reversal. In fact, one can imagine a situation in which many forecasters deliver forecasts consistent with a trend reversal, and only a single “superstar” forecaster predicts, for strategic or other reasons, a large boom in housing starts (or a very large bust). If the forecast of the “superstar” forecaster is influential in the sense that many participants in housing markets use this forecast as a yardstick for their economic decisions, then the heterogeneity of forecasts may lead to “bandwagon” effects and large upswings (or sharp trend reversals) in housing markets. Because heterogeneity of forecasts may reflect anti-herding of forecasters, it is interesting to analyze whether forecasters (anti-)herd.
Rationality of Heterogeneous Forecasts
We now analyze whether forecasts satisfy two traditional rationality criteria (Ito 1990; MacDonald and Marsh 1996; Elliott and Ito 1999): the criterion of unbiasedness of forecasts and the criterion of orthogonality of forecasts. In order to explore whether heterogeneous forecasts represent unbiased predictors of future housing starts, we used the following regression model:
As for the notation, s t + k (E t [s t + k ]) denotes (expected) housing starts, where i denotes a forecaster index. Finally, ϵ i,t + k denotes a forecaster-specific error term. Unbiasedness of forecasters cannot be rejected if α = 0 and β = 1.
The estimation results summarized in Table 1 imply that the constant term (α) is significantly negative for short-term forecasts, reflecting that forecasters may be more optimistic than justified by movements in actual housing starts. The slope coefficient (β) is positive, implying that forecasters correctly forecast the direction of housing starts. However, for both short-term and medium-term forecasts, the slope coefficient is different from unity except for Japan in the case of medium-term forecasts. Unbiasedness of forecasts, thus, can be rejected.
The orthogonality criterion concerns the question whether forecast errors are uncorrelated with information available to forecasters in the period in which they make their forecasts. In order to assess the information sets of forecasters, we used forecasters’ projections of other macroeconomic variables, which is possible because Consensus Economics publishes the housing forecasts along with several other individual forecasts, such as GDP growth, inflation, and the Fed funds forecasts. GDP growth, the inflation rate, and the Fed Funds rate are likely to be important determinants of housing starts (Attanasio et al. 2009; Ludwig and Slok 2004; Goodhart and Hofmann 2008; Bjørnland and Jacobsen 2010). Orthogonality requires that forecasts of housing starts are tightly linked to contemporaneous forecasts of other macroeconomic variables. Alternatively, the forecast error should be uncorrelated with contemporaneous forecasts of other macroeconomic variables if forecasts satisfy the orthogonality criterion. Accordingly, we estimated the following regression model:
where E i,t [GDP t + k ] denotes the forecast of GDP growth while E i,t [CPI t + k ] and E i,t [i t + k ] denote the expected inflation rate and the expected short-term interest rate for the forecast horizon being analyzed. The orthogonality criterion is satisfied if the parameter restrictions α = β = γ = δ = 0 cannot be rejected. Table 2 summarizes the estimation results. All expected macroeconomic variables are significantly correlated with the forecast error in the short-term specifications. The significant constant term reflects that the bias in forecasts of housing starts is not only correlated with expected macroeconomic variables but also has a systematic component.
To sum up, forecasts of housing starts do not satisfy two traditional criteria of forecast, unbiasedness and forecast-error orthogonality. Our estimation results, thus, indicate that, when these traditional criteria are being used for forecast evaluation, the hypothesis of rationality of forecasts can be rejected. Violation of the two traditional rationality criteria, however, does not necessarily imply that forecasts are irrational, but could indicate, for example, that forecasters do not have a quadratic loss function (Elliott et al. 2008). Deviations from a standard quadratic loss function, in turn, may result in forecaster (anti-)herding as in the model developed by Laster et al. (1999). (Anti-) Herding of forecasters may, thus, help to explain why forecasts do not satisfy traditional rationality criteria.
Results on Forecaster (Anti-)Herding
Section “Empirical Results” contains our empirical results on forecaster (anti-) herding. Section “Theoretical Interpretation” sketches the main elements of a theoretical model that help to put our empirical results into perspective.
Empirical Results
Table 3 summarizes our empirical results. The general message conveyed by the results is that the test statistic, S, significantly exceeds 0.5 for all three countries, and for short-term and medium-term forecasts. In other words, our results provide strong evidence of anti-herding of forecasters.Footnote 3 For example, as for the United States (short-term forecasts), we estimate a conditional probability of undershooting (given that a forecast exceeded the consensus forecast) of 0.5, and a conditional probability of overshooting (given that a forecast was less than the consensus forecast) of 0.7, implying a test statistic of S = 0.6. The standard deviation is 0.0063, such that the test statistic significantly exceeds its unbiased-forecasts value of 0.5.
Given the substantial recent upswings and downswings of housing markets especially in Canada and the United States, we computed the test statistic, S, for a rolling-estimation window of four years length.Footnote 4 To this end, we started with the estimation window 1989 – 1993. We then rolled the estimation window one forecasting cycle forward, and dropped (added) the forecasts for 1989 (1994). We continued this process of dropping and adding forecasts until we reached the end of the sample period. Figures 4, 5, and 6 summarize the results. It is interesting to observe that, while the extent of anti-herding of forecasters seems to have slightly decreased in recent years in the case of Japan, the incidence of anti-herding has strengthened before the U.S. subprime mortgage crisis of 2007/2008 in the cases of Canada and the United States.

Time-varying s-statistic for Canada

Time-varying s-statistic for Japan

Time-varying s-statistic for the U.S.
In order to account for potential asymmetries in the incidence of anti-herding during periods of expected increases in housing starts versus periods of expected decreases in housing starts, we split up our sample of forecasters into a group that contains those forecasters (the optimists) who predict an increase in housing starts compared to the last period, and a group that contains forecasters (the pessimists) who predict a decrease in housing starts. Table 4 summarizes the results. In the case of short-term forecasts, we found significant evidence of anti-herding for both groups. In the case of medium-term forecasts, we found evidence of anti-herding of optimists. We found no evidence of herding or anti-herding of pessimists in the cases of Canada and Japan, and less pronounced evidence of anti-herding in the case of the United States.Footnote 5 It follows that, if activity in the housing market is expected to decrease in the medium run, forecasters anti-herd to a lesser extent than if activity in the housing market is expected to boom in the medium run. However, forecasters do not herd neither in times of expected booms nor in times of expected busts.Footnote 6
Our empirical results show that forecasts tend to be biased and that forecasters tend to anti-herd. Bringing these two empirical results together, a natural question is whether there is a systematic link between forecast accuracy and anti-herding of forecasters. In order to analyze this question, we proceeded in two steps. In a first step, we calculated the forecaster-specific Root Mean Squared Error (RMSE i ) as a measure of forecast accuracy for every forecaster over all forecasting cycles (number of periods: 245). In a second step, we computed the individual herding coefficients (S i ) for every forecaster. In order to empirically assess the significance of the correlation, we estimated the following regression model:
Table 5 reports the estimation results (together with Newey-West standard errors). For Canada and the United States, there is a clear-cut and statistically significant positive correlation between anti-herding and forecast accuracy. Hence, the more forecasters adhere to an anti-herding strategy, the lower is their forecast accuracy. Why, then, do forecasters anti-herd?
Theoretical Interpretation
The poor forecasting accuracy of anti-herding forecasters does not necessarily imply that forecasters who anti-herd are less “successful” than forecasters who deliver unbiased forecasters or who herd. Forecasting success, when viewed from the perspective of an individual forecaster, depends on a forecaster’s loss function, not necessarily only on forecast accuracy. Anti-herding, thus, can be a rational strategy even if it leads to lower forecast accuracy.Footnote 7
In order to illustrate this argument, we draw on a theoretical model developed by Laster et al. (1999). They argue that forecasters make forecasts for two groups of customers. Members of the first group of customers use the forecasts on a regular basis and buy the forecasts regularly. These customers are interested in an accurate forecasts and choose to buy forecasts from a forecaster who has delivered the most accurate forecasts over a longer time period. Members of the second group of customers only buy a forecast occasionally. As a consequence, they are not interested in a forecasters forecast accuracy computed over a long period of time. Rather, these customer buy from the forecaster who provided the best forecast in the last period. Accordingly, a forecasters profit function consists of two components as follows:
where Π denotes the profit from forecasting, and α denotes the relative importance of the first group of customers. The term |x 0 − x| denotes the absolute difference between the forecast (x) and the realized value (x 0) of the variable being forecasted. In other words, this term denotes the forecast accuracy. Any difference between the forecast and the subsequently realized value triggers a loss. Furthermore, the term in brackets captures that the second group of customers are willing to pay an amount of P that is divided up among those forecasters (n) who deliver a correct forecast. If the forecast turns out to be incorrect, a forecaster receives nothing.
Because the profit function consists of revenues from both groups of customers, forecasters have an incentive not to deliver the most accurate forecast. The higher the relative importance of the second group of customers is (1 − α), and the higher the revenues from these customers (P) are, the stronger is the incentive to depart from the consensus forecast. The economic intuition for this result is that if a forecaster delivers an “extreme” forecast that differs from the consensus forecast, the probability of winning part of the revenues, P, from the second group of customers is low. However, in case of an “extreme” forecast the number, n, of other forecasters who deliver the very same “extreme” forecast is small. As a consequence, anti-herding and the resulting scattering of forecasts can result in an increase in forecasters’ expected profit.
Concluding Remarks
We have used more than 20,000 forecasts to analyze whether forecasts of housing starts provide evidence of herding of forecasters. Our results suggest that forecasters do not herd. On the contrary, it seems that forecasters anti-herd. We have detected evidence of anti-herding in forecasts of housing starts for three countries (Canada, Japan, and the United States) and in a rolling-estimation-window analysis.
Our results do not only provide insights into how forecasters form forecasts, but may also be useful for recent policy debates. One such policy debate concerns the relevance of development in housing markets for monetary policy. Because developments in housing markets are likely to play a major role for the transmission of monetary policy, a natural question is whether central banks should account for developments in housing markets when forming their inflation projections. Inflation projections can be formed by using, for example, VAR-based forecasts of house prices and housing starts, or by using private-sector forecasts of housing starts. Our results demonstrate that, when central banks use private-sector forecasts, they should consider the possibility that forecasters anti-herd.
Notes
The index k denotes the forecasting horizon expressed in months (with k = 12,11, ..., 1 for short-term forecasts, and k = 24,23, ..., 13 for medium-term forecasts).
The forecasters participating in the survey work for institutions such as investment banks, large international corporations, economic research institutes, and at universities. A complete list of participants is available upon request.
Because forecasters simultaneously issue their forecasts, they may not know the consensus forecasts when delivering their forecasts of housing starts. For this reason, we used (i) the consensus of the last period as consensus forecast, and, (ii) we combined the short-term and medium-term forecasts. For example, we used the forecasts for the next year that were delivered in December to calculate the consensus for current-year forecasts delivered in January. The results (not reported, but available upon request) provide strong evidence of anti-herding.
A rolling window thus contains forecasts from 48 different forecasting cycles. The results are for short-term forecasts. Results for other rolling windows and results for medium-term forecasts (not reported, but available upon request) are qualitatively similar.
For the United States, we do not find evidence of herding or anti-herding on a five percent significance level.
Results are similar when one identifies the periods of booms and busts in the housing market by increases and decreases in the OFHEO index (data are only available for the United States). The results are not reported, but are available upon request.
It should be noted that the empirical results in Section “Empirical Results” do not depend on a specific forecaster loss function.
References
Attanasio, O. P., Blow, L., Hamilton, R., & Leicester, A. (2009). Booms and busts: Consumption, house prices and expectations. Economica, 76(301), 20–50.
Bernhardt, D., Campello, M., & Kutsoati E. (2006). Who herds? Journal of Financial Economics, 80(3), 657–675.
Bikhchandani, S., Hirshleifer, D., & Welch, I. (1992). A theory of fads, fashion, custom, and cultural change as informational cascades. Journal of Political Economy, 100(5), 992–1026.
Bjørnland, H. C., & Jacobsen, D. H. (2010). The role of house prices in the monetary policy transmission mechanism in small open economies. Journal of Financial Stability, 6(4), 218–229.
Brunnermeier, M. K., & Julliard, C. (2008). Money illusion and housing frenzies. Review of Financial Studies, 21(1), 135–180.
Campbell, J. Y., & Cocco, J. F. (2007). How do house prices affect consumption?—Evidence from micro data. Journal of Monetary Economics, 54(3), 591–621.
Elliott, G., & Ito, T. (1999). Heterogeneous expectations and tests of efficiency in the yen/dollar forward exchange rate market. Journal of Monetary Economics, 43(2), 435–456.
Elliott, G., Komunjer, I., & Timmermann, A. (2008). Biases in macroeconomic forecasts: Irrationality or asymmetric loss? Journal of the European Economic Association, 6(1), 122–157.
Goodhart, C., & Hofmann, B. (2008). House prices, money, credit, and the macroeconomy. Oxford Review of Economic Policy, 24(1), 180–205.
Himmelberg, C., Mayer, C., & Sinai, T. (2005). Assessing high house prices: Bubbles, fundamentals, and misperceptions, Journal of Economic Perspectives, 19(4), 67–92.
Ito, T. (1990). Foreign exchange rate expectations: Micro survey data. American Economic Review, 80(3), 434–449.
Laster, D., Bennett, P., & Geoum, I. S. (1999). Rational bias in macroeconomic forecasts. Quarterly Journal of Economics, 114(1), 293–318.
Levin, E. J., & Wright, R. E. (1997). The impact of speculation on house prices in the United Kingdom. Economic Modelling, 14(4), 567–585.
Ludwig, A., & Slok, T. (2004). The relationship between stock prices, house prices and consumption in OECD countries. Topics in Macroeconomics 4(1), Article 4.
MacDonald, R., & Marsh, I. W. (1996). Currency forecasters are heterogeneous: Confirmation and consequences. Journal of International Money and Finance, 15(5), 665–685.
Naujoks, M., Aretz, K., Kerl, A., & Walter, A. (2009). Do German security analysts herd? Financial Markets and Portfolio Management, 23(1), 3–29.
Payne, J. E., & Waters, G. A. (2007). Have equity REITs experienced periodically collapsing bubbles? Journal of Real Estate Finance and Economics, 34(2), 207–224.
Pierdzioch, C., Rülke, J. C., & Stadtmann, G. (2010). New evidence of anti-herding of oil-price forecasters. Energy Economics (forthcoming).
Scharfstein, D., & Stein, J. (1990). Herd behavior and investment. American Economic Review, 80(3), 465–479.
Author information
Authors and Affiliations
Corresponding author
Additional information
We are grateful to James B. Kau (the editor) and an anonymous referee for helpful comments and suggestions. The usual disclaimer applies.
Rights and permissions
About this article
Cite this article
Pierdzioch, C., Rülke, JC. & Stadtmann, G. Housing Starts in Canada, Japan, and the United States: Do Forecasters Herd?. J Real Estate Finan Econ 45, 754–773 (2012). https://doi.org/10.1007/s11146-010-9279-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11146-010-9279-7