
Abstract
We examined the role of different cognitive skills in word reading (accuracy and fluency) and spelling accuracy in syllabic Hiragana and morphographic Kanji. Japanese Hiragana and Kanji are strikingly contrastive orthographies: Hiragana has consistent character-sound correspondences with a limited symbol set, whereas Kanji has inconsistent character-sound correspondences with a large symbol set. One hundred sixty-nine Japanese children were assessed at the beginning of grade 1 on reading accuracy and fluency, spelling, phonological awareness, phonological memory, rapid automatized naming (RAN), orthographic knowledge, and morphological awareness, and on reading and spelling at the middle of grade 1. The results showed remarkable differences in the cognitive predictors of early reading accuracy and spelling development in Hiragana and Kanji, and somewhat lesser differences in the predictors of fluency development. Phonological awareness was a unique predictor of Hiragana reading accuracy and spelling, but its impact was relatively weak and transient. This finding is in line with those reported in consistent orthographies with contained symbol sets such as Finnish and Greek. In contrast, RAN and morphological awareness were more important predictors of Kanji than of Hiragana, and the patterns of relationships for Kanji were similar to those found in inconsistent orthographies with extensive symbol sets such as Chinese. The findings suggested that Japanese children learning two contrastive orthographic systems develop partially separate cognitive bases rather than a single basis for literacy acquisition.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
During the last decade we have witnessed a significant increase in the number of cross-linguistic studies examining the role of different cognitive skills on literacy development. Most studies have compared two or more alphabetic orthographies (e.g., Caravolas et al., 2012; Georgiou, Torppa, Manolitsis, Lyytinen, & Parrila, 2012; Moll et al., 2014; Patel, Snowling, & de Jong, 2004; Ziegler et al., 2010), but studies comparing alphabetic and non-alphabetic orthographies, such as Chinese, have also appeared (e.g., Georgiou et al., 2011; McBride-Chang et al., 2005; McBride-Chang & Kail, 2002). Jointly, these studies have led to substantial advancements in our understanding of language-specific and universal predictors of literacy acquisition (e.g., McBride-Chang et al., 2005; Perfetti, Cao, & Booth, 2013; Ziegler, Perry, Ma-Wyatt, Ladner, & Schulte-Körne, 2003).
Most cross-linguistic studies to date have been guided by the orthographic depth hypothesis (ODH; Katz & Frost, 1992), according to which the differences in orthographic depth lead to processing differences in naming and lexical decision. Orthographies have been put on a continuum ranging from consistent (or transparent) to inconsistent (or opaque) according to the degree of consistency in their spelling-sound correspondences (e.g., Aro & Wimmer, 2003; Ellis et al., 2004; Seymour, Aro, & Erskine, 2003). The ODH postulates that readers of consistent orthographies master basic reading skills relatively easily (e.g., Ellis et al., 2004; Seymour et al., 2003) and the cognitive foundation of their reading may be different from that of children learning to read in inconsistent orthographies (Georgiou et al., 2012; Moll et al., 2014; Patel et al., 2004; Ziegler et al., 2010). However, orthographic depth is only one dimension of complexity possibly affecting literacy acquisition and skills employed. An additional dimension is the size of the symbol sets available to represent sounds in different orthographies (Nag, 2007, 2014; Nag & Snowling, 2012). Nag (2007) refers to orthographies with large symbol inventories as extensive orthographies and to those with more limited inventories as contained orthographies. For example, Indian orthographies that use hundreds of symbols (Nag, Treiman, & Snowling, 2010) and Chinese orthography that contains 5000–6000 characters (Hanley, 2005) are characterized as extensive orthographies, while alphabetic orthographies with 24–36 letters (Nag, Caravolas, & Snowling, 2011) are characterized as contained orthographies. As learning the symbol set in an extensive orthography is a demanding and protracted process continuing well beyond the primary school education (e.g., Kannada: Nag & Snowling, 2012; Chinese: Hanley, 2005), it is likely that the cognitive skills employed during this process are, at least partially, different from those needed to learn a contained orthography. We call this the orthographic breadth hypothesis (OBH) and note that no cross-linguistic study has yet directly examined the impact of the size of symbol set on the cognitive foundation of children’s literacy development (Nag, 2014).
The current study took advantage of the unique characteristic of literacy acquisition in Japan, where children are exposed to and learn two very different orthographies—Kana (i.e., Hiragana and Katakana) and Kanji. In this study, we focused on Hiragana (Japanese children usually learn it first) and Kanji. As described in detail below, Hiragana and Kanji are strikingly contrastive orthographies: within the frameworks of the ODH and OBH, Hiragana is a consistent and contained orthography whereas Kanji is an inconsistent and extensive orthography. Consequently, we would expect that the cognitive predictors of Hiragana literacy development would be, at least partly, different from those of Kanji. In what follows, we will first describe Hiragana and Kanji and then review what existing studies have shown about their cognitive foundations.
Japanese writing system and reading instruction
In modern Japanese text, nouns and stems of verbs and adjectives are usually written in Kanji. Two different types of Kana play distinctive roles: Hiragana (cursive Kana) is used mainly to represent function words and inflectional affixes; Katakana (square Kana) is typically used for foreign names, loan-words, and onomatopoeic expressions. Although these scripts are used in standard Japanese texts simultaneously, children’s early literacy depends solely on Hiragana (Akita & Hatano, 1999). This means that children are not expected to show proficiency in Kanji literacy until they start to learn Kanji characters by the middle of grade 1.
Hiragana is unique to Japanese orthography and developed in the process of adapting the Chinese characters into the Japanese phonology (Akamatsu, 2005). Today, the Hiragana writing system consists of 46 basic characters. The basic Hiragana characters represent five vowels (a, i, u, e, o), 40 consonant-vowel (CV) combinations, and one nasal sound /n/.Footnote 1 Besides these basic Hiragana characters, 25 secondary characters that represent voiced and semi-voiced syllables are formed by adding two kinds of diacritical markers to the right top of basic characters; two small dots (e.g., ば /ba/) and a small circle (e.g., ぱ /pa/). In addition, there are four types of exceptions named ‘special sounds’, which contain two mora (a syllable like phonological unit) or have a single mora but a phonological structure other than CV or V, and are represented by sets of Hiragana characters. In the Hiragana writing system, 108 graphemes represent the same number of distinct mora permitted in Japanese phonology (for a more detailed description, see Taylor & Taylor, 2014). This number of graphemes is fairly small compared to an inconsistent alphabetic orthography, such as English (1120 graphemes; Coulmas, 2003). Each Hiragana character basically corresponds only to one mora, which makes it easy for children to learn to read. Indeed, about 95% of Japanese children learn to read the 46 basic Hiragana characters before they start formal education (Mikami, Nohara, & Tanabe, 2008a) as Hiragana characters are frequently introduced at home and in kindergarten or nursery homes informally. According to national survey data, about 86% of Japanese 3-year old children attend kindergarten or nursery homes (National Nursery Teachers Training Council, 2015). Mikami, Nohara, and Tanabe (2008b) reported that 50–60% of teachers teach Hiragana reading in kindergarten or nursery homes, although formal instruction in reading and spelling Hiragana starts at the beginning of grade 1.
Kanji characters originated from Chinese characters and are morphographs representing morphemic units as well as sounds.Footnote 2 A word can be represented by a single Kanji character or by multiple Kanji characters in the so-called compound Kanji words. The number of different Kanji characters that are used in newspapers is estimated to be approximately 3200 (Tajima, 1989). Like Chinese characters, Kanji characters consist of strokes and can be visually complex (e.g., 読 ‘reading’ consists of 14 strokes). The majority of Kanji characters have two types of phonological representations: the on-reading (on-yomi) and the kun-reading (kun-yomi). The on-reading is derived from the original Chinese pronunciation, whereas the kun-reading is based on the Japanese translation of the original Chinese character. Most Kanji characters have more than one on-reading reflecting the fact that they were introduced to Japanese several times in different periods. Therefore, a Kanji character frequently has multiple pronunciations depending on the context (e.g., 下 can be read as /shita/, /shimo/, /o/, /kuda/, /sa/, /ka/, and /ge/). The national curriculum by the Ministry of Education and Science states which Kanji characters the children are taught in each grade. Instruction in Kanji starts in grade 1 with 80 common characters. By grade 6, children learn a total of 1006 Kanji characters and the rate of Kanji use in children’s textbooks gradually increase as children advance in grades (Akita & Hatano, 1999). While the focus of initial literacy instruction is in Hiragana, the focus quickly shifts to learning Kanji literacy skills within the first half year of grade 1.
Cognitive predictors of Hiragana and Kanji acquisition
The cognitive predictors used in this study—phonological awareness, phonological memory, rapid automatized naming (RAN), orthographic knowledge, and morphological awareness—were chosen as potential difference makers on the basis of existing cross-linguistic studies (e.g., Caravolas et al., 2012; Furnes & Samuelsson, 2011; Georgiou et al., 2011, 2012; Mann & Wimmer, 2002; Moll et al., 2014; Vaessen et al., 2010; Ziegler et al., 2010) and within-language studies in different orthographies (e.g., Cho & Chiu, 2015; de Jong & van der Leij, 2003; Kim, 2011; Landerl & Wimmer, 2008; Lervåg, Bråten, & Hulme, 2009; McBride-Chang et al., 2005; Nag & Snowling, 2012; Park & Uno, 2015; Parrila, Kirby, & McQuarrie, 2004; Torppa, Lyytinen, Erskine, Eklund, & Lyytinen, 2010; Wijayathilake and Parrila 2014; Yeung et al., 2011). Briefly, these studies have indicated that (a) phonological awareness may be more important for literacy acquisition in inconsistent than in consistent contained orthographies (e.g., Georgiou, Parrila, & Papadopoulos, 2008; Mann & Wimmer, 2002; Moll et al., 2014), but may be more important in consistent than in inconsistent extensive orthographies (compare e.g., Kannada results in Nag & Snowling, 2012, and Chinese results in McBride-Chang et al., 2005); (b) phonological memory may have a limited role across orthographies (e.g., Chow, McBride-Chang, & Burgess, 2005; Georgiou et al., 2008; Lervåg et al., 2009; Parrila et al., 2004; Wijayathilake and Parrila 2014), but has predicted literacy skill acquisition in Japanese (see below); (c) RAN and orthographic knowledge are related to reading acquisition across orthographies (e.g., de Jong & van der Leij, 2003; Georgiou, Aro, Liao, & Parrila, 2016; Nag & Snowling, 2012; Wijayathilake & Parrila, 2014; for a recent review see Kirby, Georgiou, Martinussen, & Parrila, 2010), and (d) morphological awareness may be particularly important for learning an inconsistent extensive orthography (see e.g., Li, Shu, McBride-Chang, Liu, & Peng, 2012; McBride-Chang et al., 2005, for Chinese). Further, phonological awareness and orthographic knowledge may be particularly important for spelling development (e.g., Kim, 2011; Nikolopoulos, Goulandris, Hulme, & Snowling, 2006; Verhagen, Aarnoutse, & van Leeuwe, 2009; Yeung et al., 2011), and RAN seems to be more strongly related to word reading fluency than to accuracy (e.g., Georgiou et al., 2008; Juul, Poulsen, & Elbro, 2014; Moll et al., 2014; Nag & Snowling, 2012).
Existing studies in Japanese have simultaneously examined only a limited set of cognitive predictors and studies comparing Hiragana and Kanji learning are few. Similar to the studies in alphabetic orthographies, Japanese studies have consistently documented the important role of phonological processing skills on Hiragana reading development (e.g., Amano, 1988). In a study with some of the same predictors as in this study, Kobayashi, Haynes, Macaruso, Hook, and Kato (2005) found that RAN-Digits was the only significant predictor of Hiragana reading accuracy and fluency in kindergarten; phonological awareness (mora deletion) predicted Hiragana reading accuracy, whereas RAN-Hiragana predicted Hiragana reading fluency in grade 1; phonological memory did not predict unique variance in either grade. Inomata, Uno, and Haruhara (2013), in turn, showed that phonological awareness (reversed order word repetitionFootnote 3), phonological memory, and RAN (rapid alternating stimulus test using objects and digits) were significant predictors of Hiragana reading accuracy in kindergarten, whereas visual recognition ability (figure copying), phonological awareness, and phonological memory were significant predictors of Hiragana spelling. Finally, Kakihana, Ando, Koyama, Iitaka, and Sugawara (2009) examined the early Hiragana reading accuracy and fluency of 3- to 4-year old Japanese children. Their results showed that after controlling for age, phonological awareness (mora segmentation) was the only significant predictor of Hiragana reading accuracy (character-sound knowledge), but phonological awareness, phonological memory, and Hiragana orthographic knowledge were all related to Hiragana reading fluency.Footnote 4
Studies examining the predictors of Kanji literacy development are still relatively rare. To our knowledge, only two studies have investigated the cognitive skills that influence learning to read and spell in Hiragana and Kanji (Koyama, Hansen, & Stein, 2008; Uno, Wydell, Haruhara, Kaneko, & Shinya, 2009). Koyama et al. (2008) examined the contribution of low-level sensory processing (auditory frequency modulation sensitivity and visual motion sensitivity) and cognitive skills (phonological awareness, phonological memory, visual memory, and Kanji orthographic knowledge) to reading accuracy and spelling in grade 2 and grade 4 children. The results showed that after controlling for nonverbal IQ, Hiragana spelling was uniquely predicted by sensory processing skills, phonological awareness and phonological memory, but not visual memory. In turn, Kanji reading accuracy and spelling were uniquely predicted by visual long-term memory and phonological memory after controlling for age and nonverbal IQ, but not low-level sensory processing or phonological awareness. A cross-sectional study with grade 2–6 students by Uno et al. (2009) examined the relationship between vocabulary, visual recognition ability, visual memory, phonological memory and literacy skills in Hiragana, Katakana, and Kanji. They found that vocabulary had the strongest impact on Kanji reading accuracy for all grades with the exception of grade 6 in which phonological memory had the strongest impact. Kanji spelling was related to Katakana spelling and visual short-term memory. Unfortunately, none of the studies examined reading accuracy in Hiragana or reading fluency in Hiragana and Kanji.
In sum, existing studies indicate that phonological awareness, phonological memory, and RAN are related to early literacy skills in Hiragana, but likely less so in Kanji. However, the studies have some important limitations. First, only two studies have directly compared the literacy development in both Hiragana and Kanji (Koyama et al., 2008; Uno et al., 2009) and they included only grade 2 and older children. Given the findings of previous cross-sectional studies in Japanese suggesting that early literacy skills, especially reading fluency, develop most rapidly in grade 1 children (Inoue, Higashibara, Okazaki, & Maekawa, 2012; Kobayashi et al., 2010; Sambai et al., 2012), it is important to examine the cognitive predictors of literacy development during this period. Second, no studies have assessed reading accuracy, reading fluency, and spelling as outcome variables in the same study. In order to fully understand literacy development, it is necessary to assess all the outcome variables simultaneously. Third, given that previous studies have examined concurrent rather than longitudinal relationships, the direction of the effects is uncertain. Fourth, the existing studies have focused on a limited set of possible cognitive predictors indicated by cross-linguistic research, at times assessed with nonconventional tasks with unknown validity, making it difficult to determine the unique contributions of each. Finally, the relationship between morphological awareness and literacy development has never been examined in Japanese children despite its established importance in learning to read in different orthographies (e.g., Carlisle & Goodwin, 2013; Cho & Chiu, 2015; Kirby et al., 2012; Li et al., 2012).
The present study
In the current study, we examined the relative importance of phonological awareness, phonological memory, RAN, orthographic knowledge, and morphological awareness in predicting word reading (accuracy and fluency) and spelling in Hiragana and Kanji in grade 1. We administered the cognitive and Hiragana literacy tasks at the beginning of grade 1 and Hiragana and Kanji literacy tasks at the middle of grade 1. Based on the findings of existing cross-linguistic and Japanese studies reviewed above, we expected that (a) phonological awareness would be highly predictive of Hiragana literacy skill development, but less so for Kanji; (b) phonological memory would make a limited contribution to Hiragana and Kanji development; (c) RAN would be predictive of both Hiragana and Kanji reading accuracy and fluency, but not spelling; (d) orthographic knowledge would be associated with all literacy outcomes, and (e) morphological awareness would be particularly important for Kanji literacy development.
Given that Japanese children simultaneously learn two contrastive orthographies in Hiragana and Kanji, examining the cognitive predictors of their performance provides a unique “cross-orthography” research opportunity within one language and sample of children. In using one language, we avoid the problem of comparability of measures across languages prevalent in cross-linguistic research, and by examining acquisition of literacy skills in two orthographies by the same children, we control for within-child variables that are inevitable confounding variables in cross-linguistic research.
Method
Participants
Letters of information describing the present study were sent to parents of 485 children in 15 kindergartens/nurseries in nine Japanese cities when their children were at the end of kindergarten/nursery. We approached a large number of parents to obtain a sample of about 200 children expecting relatively low permission rate. From this initial pool, 169 children (83 girls and 86 boys; mean age = 80.1 months, SD = 3.6, at the first time of measurement) were given parental permission to participate in the study. Although our study involved grade 1 children, recruiting our sample while the children were in kindergarten/nursery was necessary for two reasons: (a) we wanted to have all of our children assessed within a short period of time (six weeks) at the beginning of grade 1 in order to reduce the variability in the timing of assessments, and (b) parental permission was required before we could obtain permission from school principals, teachers, and school boards. The children with parental permission from the 15 kindergartens/nurseries attended 34 different public elementary schools and were followed from the beginning (Time 1) to the middle (Time 2) of grade 1. All of them were native speakers of Japanese and none were identified as having intellectual, emotional, or sensory deficits. The demographic information (parents’ education and occupation) provided by the parents revealed that children came mostly from middle to upper-middle class families (Ministry of Internal Affairs and Communications, 2011). There was a small attrition from Time 1 to Time 2: four children (2.4% of the initial sample) withdrew from the study. All the subsequent analyses were conducted with the children who were assessed at both measurement points.
Materials
General cognitive abilities
General cognitive abilities were assessed with Block Design and Vocabulary from the Japanese version of the Wechsler Intelligence Scale for Children-Fourth Edition (WISC-IV; Japanese WISC-IV Publication Committee, 2010). Scaled scores were calculated based on Japanese norms. According to the publisher, the reliability coefficients in the norm sample were .72 and .70 for Block Design and Vocabulary, respectively (Japanese WISC-IV Publication Committee, 2010).
Phonological awareness
Elision was used to assess phonological awareness. The task consisted of four blocks of six items each. The first two blocks required children to say a word without saying one of its morae (e.g., /haNko/ ‘stamp’ without the /N/ is /hako/ ‘box’). The mora to be removed was always in the middle. The third and fourth blocks required the children to say a CVCV word without saying a designated sound in the word; the initial consonant in first six items (e.g., /same/ ‘shark’ without the /s/ is /ame/ ‘candy’); and the second consonant in the last six items (e.g., /fude/ ‘brush’ without the /d/ is /fue/ ‘pipe’). Testing was discontinued after four errors within a block. A child’s score was the number of correct items. Cronbach’s alpha reliability coefficient in our sample was .87.Footnote 5
Phonological memory
Forward Digit Span from the Japanese version of the WISC-IV was used. Scaled scores were calculated based on the national norms. The strings of digits were presented orally with a time interval of about 1 s in between each digit. The child had to repeat the digits in each string in the correct order. The strings started with only two digits, and one digit was added for each new digit string. The task was terminated when the child failed both trials of a given length. According to the publisher, the reliability coefficient of the test was .79 in the norm sample (Japanese WISC-IV Publication Committee, 2010).
Rapid automatized naming (RAN)
In this task, children were asked to name as fast as possible four recurring digits (4, 7, 5, and 2, pronounced as /yon/, /nana/, /go/, and /ni/, respectively) that were arranged in four rows of six. Before the timed naming, each child was asked to name the digits in a practice trial to ensure familiarity. The two pages were timed separately. A child’s score was the average time to name the digits across the two pages (in the second page the stimuli were re-arranged). Because only a few naming errors occurred (mean was less than 1), errors were not considered further. The correlation coefficient between the two trials was .85.
Orthographic knowledge
The Orthographic Choice task, modified from the Long Vowel Choice task (Kakihana et al., 2009), was used to assess children’s orthographic knowledge in Hiragana. One irregular spelling in the Japanese Hiragana is the long vowel. For example, in the case of double /o/ in words, the character う /u/ is used for the second /o/ instead of the character お /o/ (e.g., ぼうし /bo-u-shi/ for /bo-o-shi/ ‘hat’); in the case of double /e/, the character い /i/ is used for the second /e/ instead of the character え /e/ (e.g., とけい /to-ke-i/ for /to-ke-e/ ‘clock’). In this task, 20 Hiragana character strings with long vowels were presented on printed papers with five items per page. Half of the strings were spelled correctly (i.e., real words) and the other half incorrectly (i.e., pseudohomophones). The child was required to answer whether the string was spelled correctly or not. A child’s score was the number of correct responses. Cronbach’s alpha reliability coefficient in our sample was .73.
Morphological awareness
The Word Analogy task, modeled after the task developed by Kirby et al. (2012) and its Japanese adaptation (Hayashi & Murphy, 2013), was used to assess morphological awareness. In this task, the child was asked to produce the missing word in a target pair, on the basis of the morphological relationship between two words in the immediately preceding pair (e.g., /tabe-ru/ ‘eat’: /tabe-ta/ ‘ate’:: /nom-u/ ‘drink’: /noN-da/ ‘drank’). The task consisted of two subtasks, one with 10 inflectional and the other with 10 derivational items, given in a fixed order. A practice list with five items was presented first. The first two practice items were presented with pictures, whereas the remaining items were not. Both subtasks were discontinued after four consecutive errors. A child’s score was the total number of inflected and derived items correct. Cronbach’s alpha reliability coefficient in our sample was .85.
Reading accuracy
Hiragana reading accuracy testFootnote 6 consisted of 30 Hiragana nonwords taken from a test that was developed for the diagnosis of developmental dyslexia in Japanese (Research Group for Formulation of Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders, 2010). Each nonword consisted of four Hiragana characters. The nonwords were arranged in terms of increasing difficulty (i.e., the test started with the nonwords that consisted of only basic Hiragana characters, and gradually included exceptional spellings). The children were asked to read the nonwords presented on a sheet of paper as accurately as possible. Testing was discontinued after four consecutive errors. A child’s score was the number of items correct. Cronbach’s alpha reliability coefficient in our sample was .82. Kanji reading accuracy test consisted of 120 Kanji characters: 20 characters from each grade from 1 to 6 selected from the national curriculum. The characters were presented on paper with five characters per page and arranged in terms of increasing difficulty based on a national survey (Japan Foundation for Educational and Cultural Research, 1998). The children were asked to read the characters as accurately as possible. Testing was discontinued after six consecutive errors. A child’s score was the number of items correct. Cronbach’s alpha reliability coefficient in our sample was .97.
Reading fluency
Hiragana reading fluency test consisted of 104 Hiragana words taken from grade 1 textbooks; 87 simple words and 17 compound words. Each word consisted of four Hiragana characters. The words were arranged in terms of increasing difficulty in the same manner in which Hiragana decoding task was developed. The children were given the list of words, divided into four columns, and asked to read them as fast as possible. A short, 8-word practice list was presented first. The score was the number of words read correctly within 45 s. The correlation between the scores in two time points was .89. Kanji reading fluency test consisted of 56 one-character words and three two-character words (i.e., compound words). The words were taken from grade 1 textbooks and all the characters had been introduced by the time of testing. To avoid a possible ceiling effect (in a pilot study, some children read the whole list of items within the time limit), we extended the total number of the items to 100 by using 41 words twice and adding them after the first list in a different order.Footnote 7 The words were presented on paper and arranged semi-randomly in five columns with 10 items per column on two separate pages. The children were asked to read the words as fast as possible. A practice list with eight items was presented first. The number of items read correctly within a 45 s time limit was a child’s score. The correlation between reading fluency in Hiragana and Kanji scores was .66 at the middle of grade 1.
Spelling
Hiragana spelling to dictation was used as a measure of Hiragana spelling. In this task, children were required to write on a paper with numbered spaces a sound or a word that was dictated to them. The test consisted of 15 items; three voiceless sounds, three voiced or semi-voiced sounds, three special sounds with glides, and six words taken from a study by Kono, Hirabayashi, and Nakamura (2009). A child’s score was the number of items correct. Cronbach’s alpha reliability coefficient for this sample was .75. Kanji spelling test consisted of 120 Kanji characters chosen in the same manner in which Kanji reading accuracy test was developed. The items were presented on a paper with 10 items per page and arranged in terms of increasing difficulty based on the national survey (Japan Foundation for Educational and Cultural Research, 1998). The children were presented a short sentence written in Hiragana and asked to read the sentence and to spell the Kanji character corresponding to sounds and context. Testing was discontinued after six consecutive errors. A child’s score was the number of items correct. Cronbach’s alpha reliability coefficient in our sample was .81.
Procedure
Children were assessed in May/June of their grade 1 school year (Time 1 [T1]) and reassessed in November/December of the same year (Time 2 [T2]). Since the Japanese school year begins in April and ends in March, T1 was the beginning of grade 1 and T2 was the middle of grade 1. In T1, we administered the measures of general cognitive abilities, phonological awareness, phonological memory, RAN, orthographic knowledge, morphological awareness, and Hiragana literacy skills. The measures of Kanji literacy skills were not administered in T1 because no Kanji characters are introduced by that time, and therefore it was assumed that few children would be able to read or write any Kanji characters. In T2, we administered the measures of reading accuracy and fluency and spelling in both Hiragana and Kanji.
All children were tested individually in their schools during school hours by trained experimenters. Testing at T1 was divided into two 40-min sessions administered on two different days to avoid fatigue. Session A consisted of Block Design, Vocabulary, Elision, Digit Span, and Word Analogy. Session B consisted of Orthographic Choice, Digit Naming, Hiragana reading accuracy and fluency and Hiragana spelling. All children received Session A first and the order of the tasks within each session was fixed. Testing at T2 consisted of reading accuracy and fluency and spelling measures in both Hiragana and Kanji and was administered in one session.
Statistical analysis
To examine the contribution of different cognitive predictors on the children’s literacy skills both concurrently and longitudinally, we performed path analysis. The total data set had 8.3% missing data because some children did not complete one of the testing sessions (the exact group sizes are listed in Table 1). In addition, some measures were not normally distributed (see below). Because of this, we used full information maximum likelihood estimation (FIML) with non-normality–robust standard errors to analyze the covariance matrix of the observed variables using Mplus 7.3 (Muthén & Muthén, 1998–2015). FIML uses all available data for each participant and provides optimal estimates of covariances, path values, and standard errors (Graham, 2009). To evaluate model fit, we used chi-square values and four fit indexes: (a) the comparative fit index (CFI); (b) the Tucker–Lewis index (TLI); (c) the root-mean-square error of approximation (RMSEA); and (d) the standardized root-mean-square residual (SRMR). Non-significant chi-square values and both CFI and TLI values above .95 suggest a good model fit (Hu & Bentler, 1999). RMSEA values below or at .05 indicate a close fit, but values as high as .07 are regarded as acceptable (Browne & Cudeck, 1993). SRMR values of .08 or less indicate a close fit (Tabachnick & Fidell, 2012).
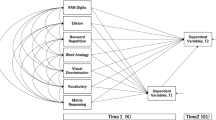
Separate models were constructed with reading accuracy and fluency and spelling in Hiragana and Kanji as outcome measures. The analysis was completed in two steps. The first step was to estimate the fit of a baseline model, depicted in Fig. 1, with all possible correlations between the predictor variables (Elision, Digit Span, RAN-Digits, Orthographic Choice, and Word Analogy) and all possible paths from the predictor variables to the outcome variable present in T1 and T2 (reading and spelling measures in Hiragana and Kanji). Time 1 Hiragana accuracy/fluency/spelling was used as an autoregressor for both Hiragana and Kanji Time 2 dependent measures. We decided to use Hiragana measures as an autoregressor for Kanji measures, because, based on previous findings (e.g., Kobayashi et al., 2005), the two were expected to be significantly correlated. Age, Block Design, and Vocabulary were included as control variables; thus, the evaluation of the impact of other cognitive predictors is rather conservative. In the second step, non-significant correlations and regression paths were dropped one at-a-time, until all remaining paths in the models were significant. This was done to increase the degrees of freedom and to compare the most parsimonious models in Hiragana and Kanji. Age, Block Design, and Vocabulary were retained in all models as control variables.

Baseline model of relations between predictor variables and outcome measures. RAN rapid automatized naming, DV dependent variable
Finally, we conducted mediation analyses (MacKinnon, Fairchild, & Fritz, 2007) to estimate the direct effects of the T1 predictors on T2 outcome variables, over and above their indirect effects via the T1 literacy measures. We used bootstrapping with 2000 resamples that allowed us to establish confidence intervals (CIs) for multiple indirect effects. If the bias-corrected bootstrapped confidence interval (Muthén & Muthén, 1998–2015) does not include zero, there is a 95% probability that the effect is significant (Shrout & Bolger, 2002).
Results
Preliminary data analysis
Descriptive statistics for the entire sample are shown in Table 1. First, we examined the distributional properties of the various measures in the study. RAN-Digits, Kanji reading accuracy and Kanji spelling were positively skewed. Log transformation was used to achieve normality. As was expected on the basis of previous findings (Mikami et al., 2008a; National Institute for Japanese Language and Linguistics, 1972), the distributions of Hiragana reading accuracy in both T1 and T2 and Hiragana spelling in T2 were negatively skewed and showed ceiling effects (16, 76, and 69% of the children had a perfect score for Hiragana reading accuracy in T1 and T2 and Hiragana spelling, respectively). Reflection plus log transformation was performed to improve the distributions (Tabachnick & Fidell, 2012). Despite this transformation, the scores in T2 did not reach normality and for this reason T2 Hiragana reading accuracy and spelling were not considered in further analyses. In addition, the distribution of Orthographic Choice was negatively skewed. Reflection plus log transformation was performed. Because the scores were reflected, we multiplied the reflected scores by −1 to correct for direction. The transformed scores were used in all further analyses.
Predictors of Hiragana and Kanji literacy skills
Table 2 displays the zero-order correlations between all variables, and Fig. 2 shows the final model for reading accuracy. The model provided an acceptable fit, although CFI and TLI were slightly lower than the recommended values, and accounted for a small proportion of the variance in Hiragana reading accuracy in T1 (R 2 = .24) and a small proportion of the variance in Kanji reading accuracy in T2 (R 2 = .29). There were three significant concurrent predictors of Hiragana reading accuracy: Elision (β = .180), Orthographic Choice (β = .181), and Word Analogy (β = .169). Block Design (β = .163) also predicted Hiragana reading accuracy in T1. Even after controlling for age, general cognitive abilities, and Hiragana reading accuracy in T1, there were two longitudinal predictors of Kanji reading accuracy: Orthographic Choice (β = .213) and Word Analogy (β = .275). Among the control variables, Vocabulary predicted Kanji reading accuracy in T2 (β = .214).

Model of reading accuracy. χ2(23) = 31.63, p = .108, CFI = .904, TLI = .929, RMSEA = .048, 90% CI [.000, .085], and SRMR = .073. RAN rapid automatized naming. *p < .05; **p < .01; ***p < .001
The second set of analyses examined the predictors of reading fluency in Hiragana and Kanji. The most parsimonious models are shown in Fig. 3. Both models provided a good fit to the data. The model for Hiragana fluency accounted for a moderate proportion of the variance in T1 (R 2 = .34) and a large proportion of the variance in T2 (R 2 = .80). There were three significant concurrent predictors of Hiragana reading fluency in T1: RAN-Digits (β = −.318), Orthographic Choice (β = .293), and Word Analogy (β = .219). Vocabulary (β = .162) also predicted Hiragana fluency in T1. Longitudinally, there was a strong autoregressive path from Hiragana reading fluency in T1 to T2 (β = .912), and Hiragana reading fluency in T1 was the only significant predictor of Hiragana reading fluency in T2. The model for Kanji fluency in T2 accounted for a moderate proportion of the variance (R 2 = .41). There was a significant path from Hiragana reading fluency in T1 to Kanji reading fluency in T2 (β = .497). However, even after controlling for age, general cognitive abilities, and Hiragana reading fluency in T1, there were two unique predictors of Kanji reading fluency: RAN-Digits (β = −.162) and Word Analogy (β = .192).

Models of reading fluency in Hiragana (a) and Kanji (b). a χ2(25) = 34.45, p = .120, CFI = .970, TLI = .979, RMSEA = .045, 90% CI [.000, .082], and SRMR = .079; b χ2(23) = 29.30, p = .171, CFI = .953, TLI = .965, RMSEA = .041, 90% CI [.000, .080], and SRMR = .076. Hiragana T1 models are slightly different because of the estimation of missing data. RAN rapid automatized naming. *p < .05; **p < .01; ***p < .001
The most parsimonious model for spelling is shown in Fig. 4. The model provided a good fit to the data and accounted for a moderate proportion of the variance in T1 Hiragana Spelling (R 2 = .36) and a small proportion of the variance in T2 Kanji spelling (R 2 = .24). There were three significant concurrent predictors of Hiragana spelling in T1: Elision (β = .226), RAN-Digits (β = −.162) and Orthographic Choice (β = .350). In addition, both Vocabulary (β = .147) and Block Design (β = .136) accounted for unique variance in Hiragana spelling in T1. There was a weak but significant path from Hiragana spelling in T1 to Kanji spelling in T2 (β = .211). Longitudinally, there were three unique predictors of Kanji spelling over the effect of control variables: Elision (β = .197), Digit Span (β = .171), and RAN-Digits (β = −.198).

Model of spelling. χ2(22) = 23.97, p = .349, CFI = .980, TLI = .984, RMSEA = .023, 90% CI [.000, .071], and SRMR = .072. RAN rapid automatized naming. *p < .05; **p < .01; ***p < .001
Mediation analysis
Table 3 shows the standardized estimates and confidence intervals of direct, indirect, and total effects of the predictors on T2 literacy skills in Hiragana and Kanji. The estimates indicate that Word Analogy and Orthographic Choice had not only a significant total effect, but also a significant direct effect on Kanji reading accuracy. None of the indirect effects of the predictors on Kanji reading accuracy was significant. In terms of reading fluency, Orthographic Choice and RAN-Digits had a significant total effect on Hiragana reading fluency, whereas RAN-Digits and Word Analogy had a significant total effect on Kanji reading fluency. Although none of the direct effects of the predictors were significant, RAN-Digits and Orthographic Choice had a significant indirect effect on Hiragana reading fluency, suggesting that the effect of these variables was fully mediated. On the other hand, RAN-Digits and Word Analogy had a significant direct effect on Kanji reading fluency after controlling for the indirect effects. In addition, RAN-Digits and Orthographic Choice also had a significant indirect effect on T2 Kanji reading fluency, consistent with partial mediation by T1 Hiragana reading fluency. Finally, Elision, Digit Span, and RAN-Digits had not only a significant total effect, but also a significant direct effect on Kanji spelling after controlling for the indirect effects of the predictors.
Discussion
The primary goal of our study was to examine the role of different cognitive skills in learning to read and spell a consistent contained orthography and an inconsistent extensive orthography within one language and sample of children. The results showed substantial differences in the cognitive predictors of early reading accuracy and spelling development in Hiragana and Kanji, and somewhat lesser differences in the predictors of fluency development.
With respect to reading accuracy, we found that Hiragana reading accuracy was concurrently predicted by phonological awareness, Hiragana orthographic knowledge, and morphological awareness. Phonological awareness was a unique predictor, a finding that is consistent with studies in alphabetic orthographies (e.g., Caravolas et al., 2012; Georgiou et al., 2012; Furnes & Samuelsson, 2011; Moll et al., 2014; Vaessen et al., 2010; Ziegler et al., 2010) and in Japanese Hiragana (Kakihana et al., 2009; Kobayashi et al., 2005). However, in line with the findings of previous studies in consistent contained orthographies such as Finnish, Dutch, and Greek (e.g., de Jong & van der Leij, 2003; Georgiou et al., 2012; Leppänen, Niemi, Aunola, & Nurmi, 2006), we found that the effect of phonological awareness was relatively weak and transient in Japanese Hiragana as well. In contrast to Hiragana reading accuracy, Kanji reading accuracy was longitudinally predicted by morphological awareness and Hiragana orthographic knowledge, even after controlling for age, general cognitive abilities, and Hiragana reading accuracy in T1. Interestingly, this pattern is very much in line with previous results reported in Chinese, an inconsistent extensive orthography (e.g., Li et al., 2012; McBride-Chang et al., 2005; Shu, McBride-Chang, Wu, & Liu, 2006; Yeung et al., 2011). In addition to these predictors, vocabulary also had a direct effect on Kanji reading accuracy in T2, consistent with Uno et al. (2009). In morphographic Kanji, the basic unit of writing is associated with a unit of meaning (i.e., morpheme) in the spoken language and Kanji script consists of a large number of visually complex characters made of strokes and stroke patterns. These characteristics may result in the significant effect of morphological awareness and Hiragana orthographic knowledge on Kanji reading accuracy. The association between Hiragana orthographic knowledge and Kanji reading accuracy is especially noteworthy, as it can be interpreted as a cross-orthography association. This finding suggests that both measures in the two orthographies may share common cognitive underpinnings such as orthographic sensitivity (Kakihana et al., 2009) and visual memory (Koyama et al., 2008).
RAN, Hiragana orthographic knowledge, and morphological awareness all made a concurrent contribution to Hiragana reading fluency. In addition, although none of the direct effects were statistically significant, RAN and Hiragana orthographic knowledge had a significant impact on Hiragana reading fluency in T2 indirectly through their effects on Hiragana reading fluency in T1 (Table 3). These variables have been the most important predictors of reading fluency also in consistent contained orthographies, such as Greek and Finnish (e.g., Georgiou et al., 2008; Torppa et al., 2010). The significant effect of Hiragana orthographic knowledge on Hiragana reading fluency may reflect the fact that many of the items used in the task have common character strings that can be decoded as orthographic units rather than character by character. This finding is in line with Kakihana et al.’s (2009) suggestion that the preferred Hiragana word reading strategy used by Japanese children relies on the orthographic unit rather than on single characters.
With respect to Kanji, we found that RAN and morphological awareness had strong impact on Kanji reading fluency in T2, after controlling for age, general cognitive abilities, and Hiragana reading fluency in T1. RAN contributed significantly to both Hiragana and Kanji, but the total effect of RAN on reading fluency was slightly stronger for Kanji than for Hiragana (Table 3). Notably, although the impact of RAN on Kanji reading fluency was partially mediated by T1 Hiragana reading fluency, only for Kanji did RAN have a significant direct effect in T2 fluency after controlling for the indirect effect. As such, the results of this study provide some support for the idea that RAN may be more important in extensive orthographies than in contained orthographies, an argument that is supported also by the findings of a recent meta-analysis (Araújo, Reis, Petersson, & Faísca, 2015). If RAN is an index of the ability to develop high-quality orthographic representations (Bowers & Wolf, 1993) and orthographic knowledge is a unique predictor of reading fluency (Barker, Torgesen, & Wagner, 1992), then RAN would be expected to contribute more to Kanji fluency than to Hiragana fluency because the former requires the development and access to a larger set of orthographic representations (see Cho & Chiu, 2015, for a similar finding in Korean Hangul and Hanja).
Phonological awareness, RAN, and Hiragana orthographic knowledge concurrently contributed to Hiragana spelling with additional contributions from vocabulary and non-verbal IQ (see Caravolas et al., 2012; Nielsen & Juul, 2016; Plaza & Cohen, 2007; Vaessen & Blomert, 2013, for similar findings in alphabetic orthographies). In contrast to Hiragana spelling, Kanji spelling was directly predicted by phonological awareness, phonological memory, and RAN after controlling for Hiragana spelling in T1. Of interest, a significant effect of phonological memory was only found when predicting Kanji spelling. This could reflect the general nature of how children learn to spell Kanji characters with multiple pronunciations depending on the context (Koyama et al., 2008), or it could reflect the specific task demands of our Kanji spelling task where children read a short sentence in Hiragana and then spelled the Kanji character corresponding to sounds and context. In this task, children with better phonological memory may avoid interference from Hiragana characters as they don’t have to look back at the Hiragana characters when trying to decide on Kanji character to spell. How phonological memory influences Kanji spelling requires further study.
Overall, our findings suggest that Japanese children learning two very different orthographic systems develop partially separate cognitive bases for literacy acquisition rather than rely on one. The patterns of the predictive relationships in Hiragana were relatively similar to those found in consistent contained orthographies such as Finnish, Dutch, and Greek (e.g., de Jong & van der Leij, 2003; Georgiou et al., 2012; Leppänen et al., 2006), whereas the patterns of the relationships in Kanji were similar to those found in inconsistent extensive orthographies such as Chinese (e.g., Li et al., 2012; McBride-Chang et al., 2005; Xue, Shu, Li, Li, & Tian, 2013; Yeung et al., 2011). Given the significant difference on surface characteristics between alphabetic orthographies and syllabic Hiragana, the former similarity is particularly informative. In fact, the predictors of Hiragana literacy skills were more similar to those in consistent contained alphabetic orthographies than to those in consistent extensive akshara orthographies (e.g., Kannada results in Nag & Snowling, 2012). This suggests that when consistency is controlled, the size of symbol set in the orthography may also determine which cognitive variables gain weight as predictors. The current results indicate that both depth and breadth of orthographies are important variables to consider when determinants of literacy acquisition are examined across languages, and that more studies are needed to enhance our understanding of the unique roles orthographic depth and breadth play in literacy acquisition.
Our results have some important educational implications. First, if the underlying cognitive foundations of normal literacy acquisition vary depending on the depth and breadth of orthographies in which children learn to read and spell, it is important that the instruction and assessments reflect these differences as they also predict differences in abnormal literacy acquisition. Comprehensive assessment batteries that include measures of phonological awareness, phonological memory, RAN, orthographic knowledge, and morphological awareness are needed to differentiate between different possible causes of difficulties in reading and spelling. Incidentally, our results also suggest that we should be able to find individuals who struggle more in learning one Japanese writing system than the other (e.g., we identified four children [2.4%] who had not mastered Hiragana reading accuracy by Time 2 although they scored above median on Kanji reading accuracy; see also Uno et al., 2009). Our results suggest that early phonological awareness tasks would be more likely to identify children who will struggle acquiring Hiragana literacy skills, but morphological awareness tasks would be more likely to identify children who may struggle acquiring Kanji literacy skills. This is an important issue that needs to be examined in future studies with larger samples of children.
Some limitations of our study should be noted. First, the study was carried out with children attending many different schools and who came from middle and upper-middle class families. In addition, because the participation was on a voluntary basis and the participation rate was relatively low (35%), a selection bias cannot be excluded. The findings need to be replicated with a possibly more representative sample. Second, most of our participants had already mastered reading basic Hiragana characters before entering primary school, the start point of this study, and this may have masked possible earlier relationships between predictors and the Hiragana outcome variables. Future studies with younger children are needed to more fully understand the predictors of the literacy development in Japanese Hiragana. Third, children’s proficiencies in each component skills of literacy across Hiragana and Kanji were not equivalent. This was inevitable because of the sequential acquisition of Hiragana and Kanji, but it may partly explain the differences of the associations of the literacy skills with cognitive predictors across the two orthographies. Fourth, the models in our study accounted for less variance in reading and spelling than similar models in alphabetic orthographies (e.g., Moll et al., 2014; Vaessen et al., 2010). Adding other cognitive predictors, such as visual memory, to the models may improve their explanatory power. Fifth, we assessed only lexical orthographic knowledge in Hiragana. Future studies should also examine the role of sub-lexical orthographic knowledge in Hiragana (e.g., how phonotactic regularities or orthographic conventions affect which character clusters are legitimate) and in Kanji (e.g., knowledge of radical position; Koyama et al., 2008) in Japanese literacy skills. Sixth, we used single observed variables instead of latent variables for each construct in the SEM analyses. When relationships among latent variables are examined, the relationships are free of measurement error because the error can be estimated and removed. On the other hand, SEM analyses using observed variables assume that the measures have perfect reliability coefficients, which clearly is not the case. Finally, our study covered only half a year and the effects of the predictor variables need be examined over a longer developmental period, in particular for Kanji.
To conclude, the current study examined the relative importance of different cognitive factors in predicting word reading (accuracy and fluency) and spelling accuracy in syllabic Hiragana and morphographic Kanji in grade 1 Japanese children. The results suggest that the cognitive predictors of individual differences in Japanese children’s literacy skills in Hiragana and Kanji are partly different. Phonological awareness was a unique predictor of Hiragana reading accuracy and spelling, although its impact was relatively weak and transient. This finding resembles those reported in consistent contained alphabetic orthographies such as Finnish, German, and Greek. In contrast, RAN and morphological awareness may be more important in Kanji than in Hiragana, and the pattern of relationships in Kanji was similar to those found in inconsistent extensive orthographies such as Chinese. The current findings add to the cross-orthographies literature on early literacy acquisition as this is the first analysis directly comparing cognitive factors underlying reading and spelling in contrastive orthographies within the same language and children.
Notes
We call syllabic Hiragana “characters” rather than “letters”, because Japanese language has many single syllable words (e.g., /ki/‘tree’, /te/‘hand’) and a single Hiragana can represent a word by itself.
Although the authors used this as a measure of phonological awareness, it is traditionally used to measure working memory.
In Kakihana et al.’s study, Hiragana reading fluency was only analyzed in the subsample of children who made no errors in the sentence reading fluency task.
Preliminary analysis showed that there was a ceiling effect with the syllable blocks (28 children [17%] had the maximum score) and a floor effect with the phoneme blocks (131 children [78%] could not correctly answer any items). These numbers indicate that separating syllable items from phoneme items would not allow to examine whether the effect is from syllable or phoneme awareness. Additionally, we confirmed that the children who were at ceiling in the syllable blocks also performed significantly better in the phoneme blocks (M = 2.4, SD 3.2) than those who were not at ceiling in the syllable blocks (M = 0.4, SD 1.4; Brunner–Munzel test, p < .001). This suggests that syllable deletion and phoneme deletion can be placed on a continuum of difficulty. Because of these reasons, we decided to use the Elision task that included both syllable elision and phoneme elision as a single measure of phonological awareness.
Although these reading accuracy measures in Hiragana and Kanji can also be called as Hiragana decoding and Kanji word recognition, respectively, we call both tests as measures of reading accuracy for the consistency of our description.
We did this by using 41 words twice rather than using other words because those 59 Kanji characters were taken from grade 1 textbooks as all had been introduced by the time of testing and other Kanji characters had not been taught to children yet.
References
Akamatsu, N. (2005). Literacy acquisition in Japanese–English bilinguals. In R. M. Joshi & P. G. Aaron (Eds.), Handbook of orthography and literacy (pp. 481–496). London: Routledge.
Akita, K., & Hatano, G. (1999). Learning to read and write in Japanese. In M. Harris & G. Hatano (Eds.), Learning to read and write: A cross-linguistic perspective (pp. 214–234). Cambridge: Cambridge University Press.
Amano, K. (1988). Phonemic analysis of words and literacy acquisition among children. Annual Report of Educational Psychology in Japan, 27, 142–164.
Araújo, S., Reis, A., Petersson, K. M., & Faísca, L. (2015). Rapid automatized naming and reading performance: A meta-analysis. Journal of Educational Psychology, 107, 868–883. doi:10.1037/edu0000006.
Aro, M., & Wimmer, H. (2003). Learning to read: English in comparison to six more regular orthographies. Applied Psycholinguistics, 24, 621–635. doi:10.1017/S0142716403000316.
Barker, T. A., Torgesen, J. K., & Wagner, R. K. (1992). The role of orthographic processing skills of five different reading tasks. Reading Research Quarterly, 27, 334–345. doi:10.2307/747673.
Bowers, P. G., & Wolf, M. (1993). Theoretical links among naming speed, precise timing mechanisms and orthographic skills in dyslexia. Reading and Writing: An Interdisciplinary Journal, 5, 69–85. doi:10.1007/BF01026919.
Browne, M. W., & Cudeck, R. (1993). Alternative ways in assessing model fit. In K. Bollen & J. S. Long (Eds.), Testing structural equation models (pp. 136–162). Newbury Park, CA: Sage.
Caravolas, M., Lervåg, A., Mousikou, P., Efrim, C., Litavsky, M., Onochie-Quintanilla, E., et al. (2012). Common patterns of prediction of literacy development in different alphabetic orthographies. Psychological Science, 23, 678–686. doi:10.1177/0956797611434536.
Carlisle, J. F., & Goodwin, A. (2013). Morphemes matter: How morphological knowledge contributes to reading and writing. In C. A. Stone, E. R. Silliman, B. J. Ehren, & G. P. Wallach (Eds.), Handbook of language and literacy: Development and disorders (2nd ed., pp. 265–282). New York, NY: Guilford.
Cho, J.-R., & Chiu, M. M. (2015). Rapid naming in relation to reading and writing in Korean (Hangul), Chinese (Hanja) and English among Korean children: A 1-year longitudinal study. Journal of Research in Reading, 38, 387–404. doi:10.1111/1467-9817.12020.
Chow, B. W.-Y., McBride-Chang, C., & Burgess, S. (2005). Phonological processing skills and early reading abilities in Hong Kong Chinese kindergarteners learning to read English as a second language. Journal of Educational Psychology, 97, 81–87. doi:10.1037/0022-0663.97.1.81.
Coulmas, F. (2003). Writing systems: An introduction to their linguistic analysis. Cambridge: Cambridge University Press.
de Jong, P. F., & van der Leij, A. (2003). Developmental changes in the manifestation of a phonological deficit in dyslexic children learning to read a regular orthography. Journal of Educational Psychology, 95, 22–40. doi:10.1037/0022-0663.95.1.22.
Ellis, N. C., Natsume, M., Stavropoulou, K., Hoxhallari, L., Daal, V. H. P., Polyzoe, N., et al. (2004). The effects of orthographic depth on learning to read alphabetic, syllabic, and logographic scripts. Reading Research Quarterly, 39, 438–468. doi:10.1598/RRQ.39.4.5.
Furnes, B., & Samuelsson, S. (2011). Phonological awareness and rapid automatized naming predicting early development in reading and spelling: Results from a cross-linguistic longitudinal study. Learning and Individual Differences, 21, 85–95. doi:10.1016/j.lindif.2010.10.005.
Georgiou, G. K., Aro, M., Liao, C.-H., & Parrila, R. (2016). Modeling the relationship between rapid automatized naming and literacy skills across languages varying in orthographic consistency. Journal of Experimental Child Psychology, 143, 48–64. doi:10.1016/j.jecp.2015.10.017.
Georgiou, G. K., Hirvonen, R., Liao, C.-H., Manolitsis, G., Parrila, R., & Nurmi, J.-E. (2011). The role of achievement strategies on literacy acquisition across languages. Contemporary Educational Psychology, 36, 130–141. doi:10.1016/j.cedpsych.2011.01.001.
Georgiou, G. K., Parrila, R., & Papadopoulos, T. C. (2008). Predictors of word decoding and reading fluency across languages varying in orthographic consistency. Journal of Educational Psychology, 100, 566–580. doi:10.1037/0022-0663.100.3.566.
Georgiou, G. K., Torppa, M., Manolitsis, G., Lyytinen, H., & Parrila, R. (2012). Longitudinal predictors of reading and spelling across languages varying in orthographic consistency. Reading and Writing: An Interdisciplinary Journal, 25, 321–346. doi:10.1007/s11145-010-9271-x.
Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual Review of Psychology, 60, 549–576. doi:10.1146/annurev.psych.58.110405.085530.
Hanley, J. R. (2005). Learning to read in Chinese. In M. J. Snowling & C. Hulme (Eds.), The science of reading: A handbook (pp. 316–335). Oxford: Blackwell.
Hayashi, Y., & Murphy, V. A. (2013). On the nature of morphological awareness in Japanese–English bilingual children: A cross-linguistic perspective. Bilingualism: Language and Cognition, 16, 49–67. doi:10.1017/S1366728912000181.
Hu, L., & Bentler, P. M. (1999). Cutoff criteria for fit indices in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6, 1–55. doi:10.1080/10705519909540118.
Inomata, T., Uno, A., & Haruhara, N. (2013). Investigation of cognitive factors affecting reading and spelling abilities of hiragana characters in kindergarten children. Japan Journal of Logopedics and Phoniatrics, 54, 122–128.
Inoue, T., Higashibara, F., Okazaki, S., & Maekawa, H. (2012). Relation between reading and phonological processing in children with reading difficulties: Reading latency and articulation time. Japanese Journal of Special Education, 49, 435–444. doi:10.6033/tokkyou.49.435.
Iwata, M. (1984). Kanji versus Kana: Neuropsychological correlates of the Japanese writing system. Trends in Neurosciences, 7, 290–293. doi:10.1016/S0166-2236(84)80198-8.
Japan Foundation for Educational and Cultural Research. (1998). Kanji mastery levels for each graders at Japanese elementary school. http://www.jfecr.or.jp/publication/pub-data/kanji/index.html
Japanese WISC-IV Publication Committee. (2010). Japanese version of Wechsler intelligence scale for children (4th ed.). Tokyo: Nihon Bunka Kagakusha.
Juul, H., Poulsen, M., & Elbro, C. (2014). Separating speed from accuracy in beginning reading development. Journal of Educational Psychology, 106, 1096–1106. doi:10.1037/a0037100.
Kakihana, S., Ando, J., Koyama, M., Iitaka, S., & Sugawara, I. (2009). Cognitive factors relating to the development early literacy in the Kana syllabary. Japanese Journal of Educational Psychology, 57, 295–308.
Katz, L., & Frost, R. (1992). The reading process is different for different orthographies: The orthographic depth hypothesis. In R. Frost & L. Katz (Eds.), Orthography, phonology, morphology, and meaning (pp. 67–84). Amsterdam, North-Holland: Elsevier.
Kim, Y.-S. (2011). Proximal and distal predictors of reading comprehension: Evidence from young Korean readers. Scientific Studies of Reading, 15, 167–190. doi:10.1080/10888431003653089.
Kirby, J. R., Deacon, S. H., Bowers, P. N., Izenberg, L., Wade-Woolley, L., & Parrila, R. (2012). Children’s morphological awareness and reading ability. Reading and Writing: An Interdisciplinary Journal, 25, 389–410. doi:10.1007/s11145-010-9276-5.
Kirby, J. R., Georgiou, G. K., Martinussen, R., & Parrila, R. (2010). Naming speed and reading: From prediction to instruction. Reading Research Quarterly, 45, 341–362. doi:10.1598/RRQ.45.3.4.
Kobayashi, M. S., Haynes, C. W., Macaruso, P., Hook, P. E., & Kato, J. (2005). Effects of mora deletion, nonword repetition, rapid naming, and visual search performance on beginning reading in Japanese. Annals of Dyslexia, 55, 105–128. doi:10.1007/s11881-005-0006-7.
Kobayashi, T., Inagaki, M., Gunji, A., Yatabe, K., Kaga, M., Goto, T., et al. (2010). Developmental changes in reading ability of Japanese elementary school children: Analysis of 4 Kana reading tasks. No To Hattatsu, 42, 15–21. doi:10.11251/ojjscn.42.15.
Kono, T., Hirabayashi, R., & Nakamura, K. (2009). Handwriting speed and accuracy of Japanese elementary school students when writing from dictation. Japanese Journal of Special Education, 46, 269–278.
Koyama, M. S., Hansen, P. C., & Stein, J. F. (2008). Logographic Kanji versus phonographic Kana in literacy acquisition. Annals of the New York Academy of Sciences, 1145, 41–55. doi:10.1196/annals.1416.005.
Landerl, K., & Wimmer, H. (2008). Development of word reading fluency and spelling in a consistent orthography: An 8-year follow-up. Journal of Educational Psychology, 100, 150–161. doi:10.1037/0022-0663.100.1.150.
Leppänen, U., Nieme, P., Aunola, K., & Nurmi, J.-E. (2006). Development of reading and spelling Finnish from preschool to Grade 1 and Grade 2. Scientific Studies of Reading, 10, 3–30. doi:10.1207/s1532799xssr1001_2.
Lervåg, A., Bråten, I., & Hulme, C. (2009). The cognitive and linguistic foundations of early reading development: A Norwegian latent variable longitudinal study. Developmental Psychology, 45, 764–781. doi:10.1037/a0014132.
Li, H., Shu, H., McBride-Chang, C., Liu, H., & Peng, H. (2012). Chinese children’s character recognition: Visuo-orthographic, phonological processing and morphological skills. Journal of Research in Reading, 35, 287–307. doi:10.1111/j.1467-9817.2010.0146208.7x.
MacKinnon, D. P., Fairchild, A. J., & Fritz, M. S. (2007). Mediation analysis. Annual Review of Psychology, 58, 593–614. doi:10.1146/annurev.psych.58.110405.085542.
Mann, V., & Wimmer, H. (2002). Phoneme awareness and pathways into literacy: A comparison of German and American children. Reading and Writing: An Interdisciplinary Journal, 15, 653–682. doi:10.1023/A:1020984704781.
McBride-Chang, C., Cho, J.-R., Liu, H., Wagner, R. K., Shu, H., Zhou, A., et al. (2005). Changing models across cultures: Associations of phonological awareness and morphological structure awareness with vocabulary and word recognition in second graders from Beijing, Hong Kong, Korea, and the United States. Journal of Experimental Child Psychology, 92, 140–160. doi:10.1016/j.jecp.2005.03.009.
McBride-Chang, C., & Kail, R. V. (2002). Cross-cultural similarities in the predictors of reading acquisition. Child Development, 73, 1392–1407. doi:10.1111/1467-8624.00479.
Mikami, H., Nohara, Y., & Tanabe, M. (2008a). Research on learning letters and reading readiness in early childhood. Bulletin of Nagoya University of Arts, 29, 345–365.
Mikami, H., Nohara, Y., & Tanabe, M. (2008b). Study on the ability necessary to preparation for learning in the primary school (3). Bulletin of Nagoya University of Arts Junior College, 40, 23–30.
Ministry of Internal Affairs and Communications. (2011). 2010 Population Census. http://www.e-stat.go.jp/SG1/estat/List.do?bid=000001034991&cycode=0
Moll, K., Ramus, F., Bartling, J., Bruder, J., Kunze, S., Neuhoff, N., et al. (2014). Cognitive mechanisms underlying reading and spelling development in five European orthographies. Learning and Instruction, 29, 65–77. doi:10.1016/j.learninstruc.2013.09.003.
Muthén, L. K., & Muthén, B. O. (1998–2015). Mplus user’s guide (7th ed.). Los Angeles, CA: Muthén & Muthén.
Nag, S. (2007). Early reading in Kannada: The pace of acquisition of orthographic knowledge and phonemic awareness. Journal of Research in Reading, 30, 7–22. doi:10.1111/j.1467-9817.2006.00329.x.
Nag, S. (2014). Alphabetism and the science of reading: From the perspective of the akshara languages. Frontiers in Psychology, 5(866), 1–3. doi:10.3389/fpsyg.2014.00866/full.
Nag, S., Caravolas, M., & Snowling, M. J. (2011). Beyond alphabetic processes: Literacy and its acquisition in the alphasyllabic languages. Reading and Writing: An Interdisciplinary Journal, 24, 615–622. doi:10.1007/s11145-010-9259-6.
Nag, S., & Snowling, M. J. (2012). Reading in an alphasyllabary: Implications for a language universal theory of learning to read. Scientific Studies of Reading, 16, 404–423. doi:10.1080/10888438.2011.576352.
Nag, S., Treiman, R., & Snowling, M. J. (2010). Learning to spell in alphasyllabary: The case of Kannada. Writing Systems Research, 2, 41–52. doi:10.1093/wsr/wsq001.
National Institute for Japanese Language and Linguistics. (1972). Reading and writing ability in pre-school children. Tokyo: Tokyo Shoseki.
National Nursery Teachers Training Council. (2015). Data on early childhood education. http://www.hoyokyo.or.jp/nursing_hyk/reference/27-2s7-10.pdf
Nielsen, A.-M. V., & Juul, H. (2016). Predictors of early versus later spelling development in Danish. Reading and Writing: An Interdisciplinary Journal, 29, 245–266. doi:10.1007/s11145-015-9591-y.
Nikolopoulos, D., Goulandris, N., Hulme, C., & Snowling, M. J. (2006). The cognitive bases of learning to read and spell in Greek: Evidence from a longitudinal study. Journal of Experimental Child Psychology, 94, 1–17. doi:10.1016/j.jecp.2005.11.006.
Park, H.-R., & Uno, A. (2015). Cognitive abilities underlying reading accuracy, fluency and spelling acquisition in Korean Hangul learners from Grades 1 to 4: A cross-sectional study. Dyslexia, 21, 235–253. doi:10.1002/dys.1500.
Parrila, R. K., Kirby, J. R., & McQuarrie, L. (2004). Articulation rate, naming speed, verbal short-term memory, and phonological awareness: Longitudinal predictors of early reading development? Scientific Studies of Reading, 8, 3–26. doi:10.1207/s1532799xssr0801_2.
Patel, T. K., Snowling, M. J., & de Jong, P. F. (2004). A cross-linguistic comparison of children learning to read in English and Dutch. Journal of Educational Psychology, 96, 785–797. doi:10.1037/0022-0663.96.4.785.
Perfetti, C., Cao, F., & Booth, J. R. (2013). Specialization and universals in the development of reading skill: How Chinese research informs a universal science of reading. Scientific Studies of Reading, 17, 5–21. doi:10.1080/10888438.2012.689786.
Plaza, M., & Cohen, H. (2007). The contribution of phonological awareness and visual attention in early reading and spelling. Dyslexia, 13, 67–76. doi:10.1002/dys.330.
Research Group for Formulation of Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders (Ed.). (2010). Diagnostic criteria and medical guideline for specific developmental disorders. Tokyo: Shindan To Chiryosha.
Sambai, A., Uno, A., Kurokawa, S., Haruhara, N., Kaneko, M., Awaya, N., et al. (2012). An investigation into kana reading development in normal and dyslexic Japanese children using length and lexicality effects. Brain and Development, 34, 520–528. doi:10.1016/j.braindev.2011.09.005.
Seymour, P. H. K., Aro, M., & Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. British Journal of Psychology, 94, 143–174. doi:10.1348/000712603321661859.
Shrout, P. E., & Bolger, N. (2002). Mediation in experimental and nonexperimental studies: New procedures and recommendations. Psychological Methods, 7, 422–445. doi:10.1037/1082-989X.7.4.422.
Shu, H., McBride-Chang, C., Wu, S., & Liu, H. (2006). Understanding Chinese developmental dyslexia: Morphological awareness as a core cognitive construct. Journal of Educational Psychology, 98, 122–133. doi:10.1037/0022-0663.98.1.122.
Smith, J. S. (1996). Japanese writing. In P. T. Daniels & W. Bright (Eds.), The world’s writing systems (pp. 209–217). Oxford: Oxford University Press.
Tabachnick, B. G., & Fidell, L. S. (2012). Using multivariate statistics (6th ed.). Boston, MA: Pearson.
Tajima, K. (1989). Computer and kanji. In K. Sato (Ed.), Kanji koza (Lectures on kanji) (Vol. 11, pp. 229–257)., Kanji to kokuji mondai (Kanji and the problems of the national language) Tokyo: Meijishoin.
Taylor, I., & Taylor, M. (2014). Writing and literacy in Chinese, Korean, and Japanese: Studies in written language and literacy 14 (2nd ed.). Philadelphia, PA: John Benjamins.
Torppa, M., Lyytinen, P., Erskine, J., Eklund, K., & Lyytinen, H. (2010). Language development, literacy skills, and predictive connections to reading in Finnish children with and without familial risk for dyslexia. Journal of Learning Disabilities, 43, 308–321. doi:10.1177/0022219410369096.
Uno, A., Wydell, T. N., Haruhara, N., Kaneko, M., & Shinya, N. (2009). Relationship between reading/writing skills and cognitive abilities among Japanese primary-school children: normal readers versus poor readers (dyslexics). Reading and Writing: An Interdisciplinary Journal, 22, 755–789. doi:10.1007/s11145-008-9128-8.
Vaessen, A., Bertrand, D., Tóth, D., Csépe, V., Faísca, L., Reis, A., et al. (2010). Cognitive development of fluent word reading does not qualitatively differ between transparent and opaque orthographies. Journal of Educational Psychology, 102, 827–842. doi:10.1037/a0019465.
Vaessen, A., & Blomert, L. (2013). The cognitive linkage and divergence of spelling and reading development. Scientific Studies of Reading, 17, 89–107. doi:10.1080/10888438.2011.614665.
Verhagen, W. G. M., Aarnoutse, C. A. J., & van Leeuwe, J. F. J. (2009). Spelling and word recognition in Grades 1 and 2: Relations to phonological awareness and naming speed in Dutch children. Applied Psycholinguistics, 31, 59–80. doi:10.1017/S0142716409990166.
Wijayathilake, M. A. D. K., & Parrila, R. (2014). Predictors of word reading skills in good and struggling readers in Sinhala. Writing Systems Research, 6, 120–131. doi:10.1080/17586801.2013.846844.
Xue, J., Shu, H., Li, H., Li, W., & Tian, X. (2013). The stability of literacy-related cognitive contributions to Chinese character naming and reading fluency. Journal of Psycholinguistic Research, 42, 433–450. doi:10.1007/s10936-012-9228-0.
Yeung, P.-S., Ho, C. S.-H., Chik, P. P.-M., Lo, L.-Y., Luan, H., Chan, D. W.-O., et al. (2011). Reading and spelling Chinese among beginning readers: What skills make a difference? Scientific Studies of Reading, 15, 285–313. doi:10.1080/10888438.2010.482149.
Ziegler, J. C., Bertrand, D., Toth, D., Csépe, V., Reis, A., Faisca, L., et al. (2010). Orthographic depth and its impact on universal predictors of reading: A cross-language investigation. Psychological Science, 21, 551–559. doi:10.1177/0956797610363406.
Ziegler, J. C., Perry, C., Ma-Wyatt, A., Ladner, D., & Schulte-Körne, G. (2003). Developmental dyslexia in different languages: Language-specific or universal? Journal of Experimental Child Psychology, 86, 169–193. doi:10.1016/S0022-0965(03)00139-5.
Acknowledgements
This work was supported by JSPS KAKENHI Grant No. 26780523 for Tomohiro Inoue. The authors are grateful to the children, parents, teachers, and school personnel who made this study possible. We further thank the following people for their help: Takako Oshiro, Hirofumi Imanaka, Hiroyuki Kitamura, Keiko Shindo, Katsutoshi Sato, Saori Beppu, Miyuki Nagaoka, and Haruka Watanabe.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Inoue, T., Georgiou, G.K., Muroya, N. et al. Cognitive predictors of literacy acquisition in syllabic Hiragana and morphographic Kanji. Read Writ 30, 1335–1360 (2017). https://doi.org/10.1007/s11145-017-9726-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-017-9726-4