
Abstract
The purpose of this study was to examine the cognitive-linguistic predictors of reading and writing skills in Japanese where syllabic Hiragana and morphographic Kanji are simultaneously used. We followed a sample of 170 Japanese children (Mage = 80.12 months, SD = 3.62) from the beginning of Grade 1 until the end of Grade 2 and assessed them on phonological awareness, rapid naming, morphological awareness, and Hiragana literacy skills (character recognition and writing) in Grade 1 and Kanji literacy skills in Grade 2. Results of path analysis showed that phonological awareness and rapid naming were associated with Hiragana literacy skills, which, in turn, predicted their counterparts in Kanji. In addition, morphological awareness predicted later Kanji literacy skills over and above the effects of early Hiragana literacy skills. Taken together, these findings suggest that the cognitive-linguistic foundations of literacy skills are not identical between Hiragana and Kanji and developing reading and writing skills in the two scripts may have a cross-script influence in literacy development.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Several studies have shown that children learning multiple orthographic systems at the same time develop partly separate cognitive bases for literacy skills in each orthography (e.g., Cheung et al., 2010; Sun et al., 2022; Zhang, 2017). However, most previous studies focused on bilingual contexts where children learn two or more orthographic systems of different languages, and there is paucity of studies that examined how reading and writing develop when children must learn multiple scripts simultaneously within one language, such as pinyin and characters in Chinese, two abjad scripts in Hebrew, and Kana and Kanji in Japanese (Hanley, 2005; Ravid, 2012; Taylor & Taylor, 2014). In addition, although several studies have reported a cross-script transfer of word reading skills in bilingual ‘biscriptal’ readers (e.g., Pasquarella et al., 2015; Shum et al., 2016), only a handful of studies have examined reading and writing simultaneously in the same model (see O’Brien et al., 2020; Sparks et al., 2008, for exceptions), and thus, whether reading in one script can influence writing in the other script and vice versa (i.e., cross-domain transfer) in multiscriptal learners remains largely unknown.Footnote 1 The present study aimed to address these gaps by examining reading and writing development in the hybrid writing system of Japanese where syllabic Hiragana and morphographic Kanji are used within one language (see below for more details).Footnote 2
Theories of cross-linguistic literacy development
According to the orthographic depth hypothesis (Katz & Frost, 1992), the differences in orthographic depth of each language (i.e., the degree of consistency in the grapheme-sound correspondences) lead to processing differences in reading and writing. Indeed, children learning a transparent orthography usually master basic reading and writing more quickly (e.g., Ellis et al., 2004; Seymour et al., 2003), and their cognitive-linguistic foundations of literacy skills have been shown to be somewhat different from those of children learning an opaque orthography (e.g., Georgiou et al., 2012; Ziegler et al., 2010). The influences of orthographic consistency on literacy development have also been reported in non-alphabetic orthographies, including Japanese (e.g., Inoue et al., 2017; Tanji & Inoue, 2021). In turn, according to the orthographic breadth hypothesis (Inoue et al., 2017), the inventory size (e.g., contained vs. extensive; Nag, 2007) of orthographies can also influence children’s literacy development. As learning the large symbol set in an extensive orthography (e.g., Indian orthographies, Chinese, and Japanese Kanji) is a demanding and protracted process continuing well beyond primary education as opposed to that in a contained orthography (e.g., alphabetic orthographies that use 24–36 letters), it is likely that cognitive-linguistic skills underlying these learning processes are at least partly different across orthographies.
Differences in processing demands for reading and writing across languages can also be inferred by the connectionist approach to word recognition. For example, the triangle model of reading (e.g., Harm & Seidenberg, 2004; Plaut et al., 1996; see also Yang et al., 2013, for its adaptation to Chinese) postulates that a child learning to read in English can compute the pronunciation of a word by relying not only on the orthography to phonology pathway but also on the semantics to phonology pathway. Simulation studies have also shown that the semantics to phonology pathway becomes more important in the computation of words with irregular (opaque) grapheme-phoneme mappings (Harm & Seidenberg, 2004; Plaut et al., 1996). Given these theoretical premises and empirical findings, it is reasonable to assume that the connections between phonology, orthography, and semantics are somewhat different between languages reflecting the specific characteristics of each orthography, such as their depth and breadth. For example, the orthography-phonology connections may be relatively stronger for transparent and contained orthographies (e.g., alphabetic orthographies, Japanese Hiragana), while the orthography-semantics connections may be relatively stronger for opaque and extensive orthographies (e.g., Chinese, Japanese Kanji; Yang et al., 2013). This, in turn, may evoke effects from different cognitive-linguistic skills.
Cognitive-linguistic skills in literacy development
An important question in this line of research is what cognitive-linguistic skills are significant predictors of literacy outcomes in each orthography. Previous cross-linguistic studies have focused mostly on phonological awareness and rapid automatized naming (RAN) and tested their predictive roles in literacy development by examining the longitudinal associations between them (e.g., Desrochers et al., 2018; Furnes & Samuelsson, 2011; Georgiou et al., 2012; Landerl et al., 2019; Moll et al., 2014; for a review, see Landerl et al., 2021). Phonological awareness has been shown to be important for learning to read and write because in any given language it is involved in both decoding and encoding processes in which the symbols (i.e., letters, characters) in words are matched to their corresponding sounds (i.e., phonemes, syllables) and vice versa (e.g., Georgiou et al., 2008; Moll et al., 2014; see Melby-Lervåg et al., 2012, for a meta-analysis of studies in alphabetic orthographies). A meta-analysis of previous studies in Chinese (Song et al., 2016), a non-alphabetic (morphosyllabic) orthography, reported moderate correlations of phonological awareness with reading (rs were .36 for reading accuracy and .39 for reading fluency).
Researchers have also examined the role of RAN in both reading and writing skills across languages. RAN, defined as the ability to name as fast as possible sequentially presented highly familiar visual stimuli (e.g., letters, digits, colors, objects), has been found to play an important role in literacy acquisition because it involves access and retrieval of phonological representations from long-term memory (see Kirby et al., 2010, for a review). Meta-analyses of studies across alphabetic and non-alphabetic orthographies reported moderate correlations between RAN and reading accuracy (r = .42; Araújo et al., 2015; see also Song et al., 2016) and between RAN and spelling/writing (r = .35; Chen et al., 2021). Interestingly, they also showed that the relationships of RAN with reading and writing were relatively stronger in opaque orthographies than in intermediate or transparent orthographies, suggesting that the RAN-reading and RAN-writing relationships may vary as a function of orthographic consistency.
Finally, beyond phonological awareness and RAN, morphological awareness, defined as the ability to reflect on and manipulate the morphemic units of words, has been found to support word reading and writing by facilitating the recognition of words’ morphological structure (e.g., Carlisle, 1995; Kuo & Anderson, 2006). A meta-analysis of existing studies in English and Chinese provided evidence for the relationship between morphological awareness and word reading with the average correlations of .46 for English and .39 for Chinese (Ruan et al., 2018). Previous longitudinal studies in Chinese suggested that morphological awareness may be particularly important for learning morphographic scripts, including Chinese, because of the critical role meaning plays in recognizing characters used in highly phonologically opaque orthographies (e.g., Li et al., 2012; Lin et al., 2019; McBride-Chang et al., 2008).
The Japanese writing system
The Japanese writing system uses four different types of script within one language: two types of syllabic kana (cursive Hiragana and more angular Katakana), morphographic Kanji, and alphabetic romaji (Koda, 2017; Taylor & Taylor, 2014). In this study, we focused on Hiragana and Kanji, the two scripts that are most frequently used in modern text in Japanese. Hiragana is a phonologically transparent phonetic (syllabic or moraic) script in which each character corresponds to the same syllable or mora (a syllable-like phonological unit) in all words (e.g., か can only be read as /ka/ across word contexts; Akamatsu, 2005; Smith, 1996). Of a total 108 graphemes in Hiragana that represent the same number of distinct mora used in Japanese phonology, 46 basic characters represent five vowels (a, i, u, e, o), 40 consonant–vowel (CV) combinations, and one nasal sound /n/. Twenty-five secondary characters are formed by adding two kinds of diacritical markers to the right top of basic characters and represent voiced and semi-voiced syllables (e.g., ば /ba/, ぱ /pa/). In addition, four types of special notations that consist of a set of Hiragana characters represent a single mora but a phonological structure other than CV or V (e.g., しゃ /sha/, きゅ /kyu/). It should be noted that although Hiragana has almost perfect one-to-one grapheme-sound correspondences, some characters represent two distinct pronunciations (e.g., は can be read /ha/ and /wa/) and some sounds are written with different characters depending on the context (e.g., the second part of the long vowel /oo/ is written with う /u/ instead of お /o/ in some words, ぼうし /booshi/ ‘hat’; for a more detailed description, see Taylor & Taylor, 2014).
In contrast, Kanji is a morphographic script originated from Chinese in which each character can represent multiple sounds and morphemes depending on the word context (e.g., 空 can mean ‘sky’ and ‘empty’, and it can be read as /sora/, /kuu/, /a/, and /kara/). A total of 2,136 Kanji characters are generally used in modern Japanese text, and most Kanji characters have two types of readings: On-reading (the original Chinese pronunciation), which is mainly used for compound words, and Kun-reading (the Japanese translation of the original Chinese character), which is more common for single-character words. We call Kanji “morphographic” instead of “morphosyllabic” because unlike morphosyllabic Chinese, where all characters represent single syllables, Kun-readings of Kanji characters are frequently multisyllabic (e.g., 人 /hito/ ‘person’, 車 /kuruma/ ‘car’). While Hiragana characters are used mainly to represent syntactic morphemes such as function words and inflectional affixes, Kanji characters are used for content morphemes such as nouns and root morphemes of verbs, adjectives, and adverbs (Taylor & Taylor, 2014).
Most Japanese children learn to read the 46 basic Hiragana characters even before they start formal education at school (Mikami et al., 2008) as Hiragana characters are frequently introduced at home and in kindergarten/nursery informally. Formal instruction of Hiragana commences at the beginning of Grade 1, and most children master the Hiragana orthography, including those with diacritic markers and special notations relatively quickly within the first few months (Ota et al., 2018). Children then start learning Kanji at around the middle of Grade 1 and are expected to learn a total of 1,026 Kanji characters set by the national standard curriculum (Ministry of Education, Culture, Sports, Science and Technology, 2017) by the end of primary education (Grade 6). Kanji instruction begins with 80 most common characters (e.g., 山 /yama/ ‘mountain’, 川 /kawa/ ‘river’) followed by 160 and 200 characters in Grades 2 and 3, respectively. Children’s early texts are written solely in Hiragana (e.g., わたしは こうえんに いく ‘I go to a park’), but the rate of Kanji use gradually increases as they learn more Kanji characters (e.g., 私は公園に行く ‘I go to a park’; the first, third, fourth, and sixth characters in the sentence are Kanji; see Koda, 2017, for a more detailed description). Hiragana is also used to help children learn Kanji characters by indicating their appropriate readings (e.g., when children learn the Kanji character 山 /yama/ ‘mountain’, its Hiragana transcription やま /ya-ma/ is also presented in small size on top of or beside the Kanji character as a phonetic guide) until they learn the Kanji characters.
Several studies in Japanese have examined the predictive role of cognitive-linguistic skills in literacy development in Hiragana and Kanji and have produced mixed results (e.g., Koyama et al., 2008; Muroya et al., 2017; Ogino et al., 2017; Takahashi, 2001; Tanji & Inoue, 2021). For example, Ogino et al. (2017) showed that whereas phonological awareness (assessed with a mora reversal task) and RAN predicted Hiragana reading accuracy in kindergarten, phonological awareness, but not RAN, predicted Kanji reading accuracy in Grade 2. In contrast, Tanji and Inoue (2021) showed that RAN and morphological awareness in kindergarten, but not phonological awareness, predicted Kanji reading accuracy in Grade 1. Interestingly, some studies have reported that despite the considerable differences in the cognitive-linguistic predictors of literacy skills between Hiragana and Kanji, there is a positive association in each literacy outcome across the two scripts (i.e., early Hiragana reading predicted later Kanji reading even when early Kanji reading was controlled; Inoue et al., 2019; Kobayashi et al., 2005), suggesting a cross-script transfer.
It should be noted, however, that existing studies on the cognitive-linguistic correlates of multiscriptal literacy development, including those in Japanese, have some important limitations. First, to date, only a handful of studies have tested the developmental relations between reading and writing simultaneously in multiscriptal contexts, and no studies in Japanese have examined the cross-domain effect of reading in Hiragana on writing in Kanji. Given the close developmental link between reading and writing skills (e.g., Ehri, 2000; Georgiou et al., 2020; Vaessen & Blomert, 2013; Ye et al., 2022), testing a model that includes both literacy outcomes is also important for examining the unique cognitive-linguistic predictors of each literacy outcome while controlling for the covariance between the two skills. Second, because most existing studies on multiscriptal literacy development have been conducted in a bilingual context, we cannot rule out the possibility that the potential differences in instructional methods and children’s relative proficiency between the first and second languages have influenced the observed results. In light of this, the hybrid writing system of Japanese gives us a great cross-scriptal research opportunity within the same language. Finally, most previous studies did not control for the potential confounding effects of environmental factors, such as parental teaching and education levels, when examining the cognitive-linguistic skills of literacy development. Previous studies have shown that parental teaching predicts children’s code-related skills, such as phonological awareness and letter knowledge (e.g., Hamilton et al., 2016; Inoue et al., 2020). Similarly, some studies in Japanese have shown that parents’ education is associated with children’s character knowledge in Hiragana and Kanji (e.g., Hamano & Uchida, 2012; Inoue et al., 2018). Given these findings, we controlled for the effects of these factors when examining the cognitive-linguistic predictors of literacy skills.
The present study
The purpose of this longitudinal study was twofold: (1) to examine the cognitive-linguistic predictors of reading and writing skills in syllabic Hiragana and morphographic Kanji; (2) to examine the cross-script (i.e., between Hiragana and Kanji) and cross-domain (i.e., between reading and writing) effects in the hybrid orthography of Japanese. Importantly, this study is among the first to test the cognitive-linguistic predictors of both reading and writing in the two different types of script in the same model while also controlling for the covariance between the two literacy outcomes.
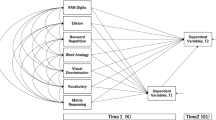
The hypothesized model is shown in Fig. 1. Based on the findings of previous studies (e.g., Inoue et al., 2017; Koyama et al., 2008; Ogino et al., 2017), we expected that the relative importance of cognitive-linguistic skills in literacy development would be moderated by the characteristics of the two scripts. Specifically, we expected that phonological awareness and RAN would be more closely associated with syllabic Hiragana because of its closer orthography to phonology associations (e.g., Kobayashi et al., 2005; Ogino et al., 2017), whereas morphological awareness would play a more important role in Kanji literacy development because of the critical role meaning plays in learning phonologically-opaque morphographic characters (e.g., Muroya et al., 2017; Tanji & Inoue, 2021). Additionally, we expected that early reading and writing in Hiragana would predict their counterparts in Kanji at a later time point because Hiragana is used to help children learn Kanji characters, and previous studies have shown that literacy skills in Hiragana and Kanji partly share their cognitive underpinnings (e.g., Inoue et al., 2017, 2019; Tanji & Inoue, 2021). We did not formulate any specific hypotheses for the influence of early reading/writing in Hiragana on later writing/reading in Kanji because no previous studies have examined the cross-domain associations between them.

Hypothesized Model for the Literacy Skills in Hiragana and Kanji
Method
Participants
One hundred seventy children (83 girls, 87 boys; Mage = 80.12 months, SD = 3.62, Range = 73–87 months) were recruited from public elementary schools in Japan to participate in a larger project examining early literacy development in Japanese. The schools were located in six different cities in order to increase the representation of different demographics in our sample. We followed the children from the beginning of Grade 1 (Time 1) to the end of Grade 2 (Time 2). All children were native speakers of Japanese, and none was experiencing any intellectual, sensory, or behavioral difficulties (based on parents’ and teachers’ reports). By Time 2, our sample consisted of 135 children. The children who withdrew from the study did not differ significantly from the remaining children in any measures in Grade 1 (ps > .10). Parents’ written consent was obtained prior to testing. Ethics permission was also obtained from Seigakuin University (ref. no.: 2013-001).
Measures
Phonological awareness
All cognitive-linguistic and literacy measures described below were originally developed for a larger longitudinal study on early literacy acquisition in Japanese (Inoue et al., 2017, 2020). Mora Deletion-Word and Mora Deletion-Nonword were used to assess phonological awareness. Mora deletion tasks have been used in several previous studies in Japanese, showing high internal consistency (Cronbach’s alpha reliability > .80) and predictive validity (i.e., significant associations with word reading skills; e.g., Kobayashi et al., 2005; Koyama et al., 2008). Children were orally presented a word/nonword and asked to say the word/nonword without saying one of its morae (e.g., “Say /kombu/ ‘seaweed.’ Now say /kombu/ without /m/.” The correct answer is /kobu/ ‘bump’). The tasks consisted of two blocks of six items each, and testing was discontinued after four errors within a block. A child’s score for each test was the number of correct items (max = 12). Cronbach’s alpha reliability in our sample were .87 for Mora Deletion-Word and .89 for Mora Deletion-Nonword, and the correlation between the two tasks was .76. A composite score for phonological awareness was subsequently created by averaging the z-scores of Mora Deletion-Word and Mora Deletion-Nonword and used in the analyses.
Rapid automatized naming (RAN)
Digit Naming and Color Naming were administered. In Digit Naming, children were asked to name as fast as possible four recurring digits (2, 4, 5, and 7, pronounced as /ni/, /yon/, /go/, and /nana/, respectively) arranged semi-randomly in four rows of six on each of two separate pages. In Color Naming, children were asked to name as fast as possible four recurring colors (blue, red, green, and yellow; pronounced /ao/, /aka/, /midori/, and /kiiro/). Before the timed naming, each child was asked to name the digits/colors to ensure familiarity. The two pages for each task were timed separately. A child’s score for each task was the average time to name the digits/colors across the two pages. Because only a few naming errors occurred (mean number of errors was less than one), they were not considered further. The correlations between the two trials were .82 for Digit Naming and .72 for Color Naming, and the correlation between the two tasks was .61. A composite score for RAN was subsequently created by averaging the z-scores of Digit Naming and Color Naming and used in the analyses.
Morphological awareness
The Word Analogy task (Muroya et al., 2017) was used. Children were orally presented by experimenters a model pair of two words followed by one of the target pair and then were asked to produce the missing word in the target pair on the basis of the morphological relationship between two words in the immediately preceding pair (e.g., “If I say /hirou/ ‘pick up’ and then I say /hirotta/ ‘picked up’; then I say /aruku/ ‘walk’, so then what should I say?”: The correct answer is /aruita/ ‘walked’; “If I say /hanashi/ ‘story’ and then I say /hanasu/ ‘to talk’; then I say /asobi/ ‘game’, so then what should I say?”: The correct answer is /asobu/ ‘to play’; see Muroya et al., 2017, for a complete list of the items). The task consisted of two blocks, one with 10 inflectional and the other with 10 derivational items, given in a fixed order. Both blocks were discontinued after four consecutive errors. A child’s score was the total number of correct responses in the two blocks (max = 20). Cronbach’s alpha reliability in our sample was .85.
Hiragana literacy skills
The Hiragana character recognition test consisted of 50 items: 10 basic characters (e.g., か /ka/, こ /ko/), 20 characters with diacritic marks (e.g., ぞ /zo/, ぴ /pi/), and 20 character pairs for special notations for glides (e.g., しゃ /sha/, きゅ /kyu/; see Appendix A). Given that most Japanese children master the basic 46 Hiragana characters before they start formal education at school (Mikami et al., 2008), we oversampled characters with diacritic marks and those using the special notation rules to avoid a ceiling effect. The items were arranged in terms of increasing difficulty based on the notation type included (i.e., the test started with basic Hiragana characters and proceeded to special notations) and the percentage of correct answers for each character or character pair in a national survey (National Institute for Japanese Language and Linguistics, 1972). Children were asked to read the items presented on a sheet of paper as accurately as possible. A child’s score was the number of items correct. Cronbach’s alpha reliability coefficient in our sample was .94. The Hiragana writing test consisted of 15 items: three basic characters, three characters with diacritic markers, three special notations for glides, and six words (two words of 2, 4, or 6 characters each; see Appendix B). Children were required to write on a paper with numbered spaces a sound or a word that was dictated to them. A child’s score was the number of items correct. Cronbach’s alpha reliability in our sample was .75.
Kanji literacy skills
The Kanji character recognition test consisted of 120 Kanji words (20 characters from each grade from 1 to 6). We included Kanji characters that are introduced in higher grades (i.e., Grades 3–6) because pilot data we had collected indicated that (1) most children in Grades 1 and 2 could read most of the Kanji characters that are introduced at their grade, and thus ceiling effects were expected; (2) some children could read Kanji characters from higher grades. The items were arranged in terms of grades in which they are taught. In addition, they were arranged in terms of increasing difficulty within each grade based on the percentage of correct answers for each character in the national survey (Japan Foundation for Educational & Cultural Research, 1998). Children were asked to read aloud the words presented on a sheet of paper as accurately as possible. Testing was discontinued after six consecutive errors. A child’s score was the number of items correct. Cronbach’s alpha reliability in our sample was .97. The Kanji writing test consisted of 120 characters (20 characters from each grade from 1 to 6) that were arranged in terms of increasing difficulty based on the national survey (Japan Foundation for Educational & Cultural Research, 1998). Half of the items were On-reading words and the other half Kun-reading words. The average number of strokes for the Kanji characters was 9.0 (SD = 3.8, range = 1–18). Children were presented with a short sentence written in Hiragana and asked to read the sentence and to write the Kanji character for the word specified by a byline on a paper with numbered spaces. Testing was discontinued after six consecutive errors. A child’s score was the number of items correct. Cronbach’s alpha reliability in our sample was .81.
Parents’ teaching
The frequency of parents’ direct teaching was assessed by asking parents to indicate on a 5-point Likert scale how often they taught their child (a) reading characters/words and (b) writing characters/simple words, such as his/her name. The Likert scale ranged from never (0) to every day (4). The score for parents’ teaching was the sum of the scores of the two items (max = 8). Cronbach’s alpha reliability in our sample was .88.
Parents’ education
We asked parents to provide information on their highest achieved education. The scale had six options ranging from 1 = some high school studies to 6 = completed graduate studies (see Note under Table 1, for the full scales). A composite score for parents’ education was calculated by averaging z-scores of the scores for mother’s and father’s education. The correlation between mothers’ and fathers’ education levels in our sample was .51.
Procedure
The children were assessed on the cognitive-linguistic skills and Hiragana literacy skills at the beginning of Grade 1 (May/June; Time 1) and Kanji literacy skills at the end of Grade 2 (November/December; Time 2). The measures of Kanji literacy skills were not administered at Time 1 because no Kanji characters had been introduced at school by that time and because pilot data we had collected indicated that very few children could read or write any Kanji characters at that time. Their parents were asked to fill out a questionnaire on parental teaching and education level at Time 1. All children were tested individually by trained research assistants in their respective schools. Testing lasted roughly 40 min at Time 1 and 20 min at Time 2.
Statistical analysis
First, to examine the associations between the predictor variables, early Hiragana literacy skills, and later Kanji literacy skills, we constructed a longitudinal path model (Fig. 1). Non-significant paths were eliminated one-at-a-time while monitoring the model fit to estimate a more parsimonious model with fewer paths. The model fit was assessed using the chi-square value, the comparative fit index (CFI), the Tucker-Lewis index (TLI), the root-mean-square error of approximation (RMSEA), and the standardized root-mean-square residual (SRMR). A non-significant chi-square value, CFI and TLI values above .95, an RMSEA value below .06, and an SRMR value below .08 indicate good model fit (Kline, 2015). Next, to examine the indirect effect of the predictor variables on Kanji literacy skills through Hiragana literacy skills, we conducted mediation analysis (Hayes, 2018). To establish confidence intervals (CIs) for the indirect effects, we used a bootstrapping technique with 5,000 resamples (Hayes & Scharkow, 2013). All analyses were conducted using Mplus (Muthén & Muthén, 1998–2017), and missing data were handled by the full information maximum likelihood estimation (Graham, 2009).
Results
Descriptive statistics and correlations
Descriptive statistics for all measures used in the study are shown in Table 1. An initial inspection of the distributional properties of the measures revealed that, as expected on the basis of previous studies (e.g., Ota et al., 2018), the distributions of character recognition and writing in Hiragana were negatively skewed and showed signs of ceiling effects (25% and 24% of the children scored the maximum possible score for Hiragana character recognition and writing, respectively). Reflection plus log transformation was performed to achieve normality (Tabachnick & Fidell, 2012). Because the scores were reflected, the scores were multiplied by -1 to correct for direction. In addition, character recognition and writing in Kanji were positively skewed. Log transformation was used to normalize the distributions. The transformed scores were used in all further analyses.
The correlations among the variables are shown in Table 2. The correlations between the predictor variables and Hiragana literacy skills ranged from .20 to .57, with the strongest correlations observed for phonological awareness. In turn, the correlations between the predictor variables and Kanji literacy skills ranged from .19 to .43, with the strongest correlations observed for morphological awareness. Finally, the correlations between literacy skills in Hiragana and Kanji ranged from .24 to .57, indicating moderate cross-script associations between them.
Path analysis
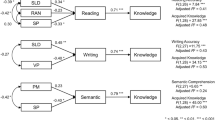
The final path model for the relationship between the predictor variables and literacy skills in Hiragana and Kanji is shown in Fig. 2. The model showed an excellent fit, χ2 = 11.34, df = 17, p = .84, CFI = 1.00, TLI = 1.00, RMSEA = .00, 90% CI [.00, .05], SRMR = .07. The results showed that phonological awareness and RAN at Time 1 were uniquely associated with both character recognition and writing in Hiragana at Time 1 (character recognition: βs were .35 and −.29 for phonological awareness and RAN, respectively; writing: βs were .43 and −.21 for phonological awareness and RAN, respectively). Parents’ education was also associated with Hiragana writing at Time 1 (β = .16). Morphological awareness at Time 1 had a direct effect on the literacy skills in Kanji at Time 2 (βs were .25 and .30 for character recognition and writing, respectively). In addition, Hiragana character recognition and phonological awareness at Time 1 predicted Kanji character recognition at Time 2 (βs were .30 and .18 for Hiragana character recognition and phonological awareness, respectively), while Hiragana writing and parents’ teaching at Time 1 predicted Kanji writing at Time 2 (βs were .33 and .15 for Hiragana writing and parents’ teaching, respectively).

Final Model for the Literacy Skills in Hiragana and Kanji (Standard Solutions). *p < .05. **p < .01. ***p < .001
Finally, the results of mediation analysis are shown in Table 3. Phonological awareness and RAN at Time 1 indirectly predicted character recognition and writing in Kanji at Time 2 through their counterparts in Hiragana at Time 1. Additionally, parents’ education had an indirect effect on Kanji writing at Time 2 through Hiragana writing at Time 1. Taken together, these results indicated that phonological awareness predicted Kanji character recognition both directly and indirectly through Hiragana character recognition, and it predicted Kanji writing only indirectly through Hiragana writing; the effects of RAN on Kanji literacy skills were fully mediated by Hiragana literacy skills; morphological awareness had only direct effects on Kanji literacy skills.
Discussion
We examined the cognitive-linguistic predictors of reading and writing skills in syllabic Hiragana and morphographic Kanji in Japanese. Based on the findings of previous studies in Japanese (e.g., Kobayashi et al., 2005; Koyama et al., 2008; Muroya et al., 2017), we hypothesized that phonological awareness and RAN would be more closely associated with syllabic Hiragana, whereas morphological awareness would play a more important role in Kanji literacy development. Additionally, we expected that Hiragana literacy skills would predict their counterparts in Kanji. The results showed first that, in line with our first hypothesis and the findings of previous studies in Japanese (e.g., Kobayashi et al., 2005; Ogino et al., 2017; Tanji & Inoue, 2021), phonological awareness and RAN were significantly associated with early character recognition and writing in Hiragana after controlling for the effects of parents’ teaching and education levels. Similar findings have been consistently reported in phonologically transparent alphabetic orthographies (e.g., Caravolas et al., 2012; Furnes & Samuelsson, 2011; Georgiou et al., 2012; Moll et al., 2014; Ziegler et al., 2010). Even though Hiragana has highly transparent character-sound mappings, its characteristics as a phonetic (syllabic or moraic) script may lead to an important role the two aspects of phonological processing skills can play in Hiragana literacy acquisition, especially at the early phase of development. As suggested in previous studies in phonologically transparent alphabetic orthographies, phonological awareness may support both decoding and encoding processes in Hiragana in which characters are matched to their corresponding syllables and vice versa, and RAN may support the formation of character-to-syllable and syllable-to-character connections (e.g., Kirby et al., 2010; Melby-Lervåg et al., 2012).
In turn, among the cognitive-linguistic predictors included in the study, morphological awareness had the strongest direct effects on later Kanji character recognition and writing when the effects of early Hiragana literacy skills were controlled. This result is consistent with those of existing studies in Japanese (e.g., Muroya et al., 2017; Tanji & Inoue, 2021). Together with the findings of previous studies in morphosyllabic Chinese (e.g., Li et al., 2012; Lin et al., 2019; McBride-Chang et al., 2008) and Korean Hanja (e.g., Cho & Lee, 2010), this finding provides further evidence for the pivotal role meaning plays in early literacy development in morphographic orthographies where the character-sound correspondences are phonologically opaque. As suggested by the “binding agent” theory (Kirby & Bowers, 2017) as well as the findings of previous studies in Japanese (e.g., Muroya et al., 2017; Tanji & Inoue, 2021), morphological awareness may facilitate Kanji learning by contributing to the establishment of high quality lexical representations of Kanji characters. Arguably, if the underlying cognitive-linguistic foundations for early literacy acquisition vary depending on the characteristics of script children learn, it would be important that the assessments and instruction reflect these differences. Specifically, early instruction of phonological awareness may facilitate early literacy development in Hiragana, while that of morphological awareness would likely be more beneficial to later literacy development in Kanji. In addition, it would be reasonable to expect that the roles word reading in Hiragana and Kanji play in reading comprehension may also be different (for a relevant finding, see Takahashi, 2001).
It should be noted, however, that phonological awareness also predicted Kanji character recognition over and above the effect of morphological awareness, and phonological awareness and RAN had indirect effects on later Kanji literacy skills through early Hiragana literacy skills. There are two explanations for these findings. First, learning Kanji characters may indeed require children to rely on phonological awareness due to its complex, one-to-many orthography-phonology mappings (see Tamaoka & Taft, 2010). Second, the results may reflect the fact that Hiragana is used to help children learn Kanji characters by indicating their pronunciations when new Kanji characters are introduced, which may have resulted in the mediated link between phonological awareness and Kanji literacy skills. In other words, syllabic Hiragana may play a bridging role in learning the opaque orthography-phonology mappings in the Kanji orthography. This is similar to the role the auxiliary phonetic script (Pinyin in mainland China and Zhuyin in Taiwan) plays in Chinese (Hanley, 2005). From a practical point of view, our results emphasize the importance of helping children learn basic reading and writing skills in Hiragana during the first few months of formal literacy instruction (see Inoue et al., 2019).
Interestingly, for both Hiragana and Kanji, the cognitive-linguistic predictors of character recognition and writing were almost identical (see Fig. 2). Moreover, there were significant and moderate residual covariances between character recognition and writing in both scripts even after controlling for the effects of cognitive-linguistic skills and parental factors. An important theoretical implication of these findings is that, as has been suggested in previous studies in alphabetic orthographies (e.g., Ehri, 2000; Georgiou et al., 2020; Vaessen & Blomert, 2013) and Chinese (e.g., Li et al., 2012; Ye et al., 2022), there may be a close developmental link between reading and writing across different types of script, including syllabary and morphography.
Finally, our results showed that Hiragana literacy skills in Grade 1 predicted their counterparts in Kanji in Grade 2, indicating a cross-script transfer of literacy skills in the hybrid orthography of Japanese. In contrast, we did not find evidence for the cross-domain transfer (i.e., the effect of reading on writing and vice versa) between literacy skills in the two scripts. One explanation for these results is that there might be script-universal but domain-specific underlying mechanisms that provide support for the development of each literacy skill across scripts. For example, given the findings of previous studies across writing systems, visual-verbal paired associate learning for reading development (e.g., Georgiou et al., 2017; Liu et al., 2021) and perceptual-motor skills for writing development (e.g., Maldarelli et al., 2015; Xu et al., 2020) may be possible candidates for those mechanisms. However, further studies are clearly needed to clarify the mechanisms responsible for the cross-script associations in Japanese.
Some limitations of our study are worth mentioning. First, our study was correlational and any relations found in the study do not directly imply causation. Second, we did not assess Kanji literacy skills at the beginning of Grade 1 and Hiragana literacy skills at the end of Grade 2. Although this was necessary because of the sequential learning of Hiragana and Kanji set by the national standard curriculum (see Introduction), if we had assessed literacy skills in the two scripts in both testing points, it would have allowed us to examine the bidirectional relationship between literacy skills in Hiragana and Kanji. Finally, our study covered only two years, and especially given the prolonged processes of learning the large number of Kanji characters, a future study should examine the cognitive-linguistic predictors over a longer developmental period.
To conclude, our findings indicated that phonological awareness and RAN were associated with early reading and writing in syllabic Hiragana, which, in turn, predicted their counterparts in morphographic Kanji. Morphological awareness predicted later Kanji literacy skills over and above the effects of Hiragana literacy skills. Taken together, these findings suggest that the cognitive-linguistic foundations for literacy skills are partly different between syllabic Hiragana and morphographic Kanji and developing reading and writing in the two scripts may have a cross-script influence in multiscriptal literacy development in Japanese.
Notes
Transfer is defined as the use of linguistic and cognitive knowledge acquired in language learning (Oldin, 1989).
Although “spelling” has been more commonly used for alphabetic orthographies, we use “writing” for both syllabic Hiragana and morphographic Kanji in this paper for consistency purposes because the sequential phoneme-grapheme encoding is not involved in writing Kanji characters, and thus “spelling” may not be the most appropriate term for Kanji character writing.
References
Akamatsu, N. (2005). Literacy acquisition in Japanese-English bilinguals. In R. M. Joshi & P. G. Aaron (Eds.), Handbook of orthography and literacy (pp. 481–496). Routledge.
Araújo, S., Reis, A., Petersson, K. M., & Faísca, L. (2015). Rapid automatized naming and reading performance: a meta-analysis. Journal of Educational Psychology, 107, 868–883. https://doi.org/10.1037/edu0000006
Caravolas, M., Lervåg, A., Mousikou, P., Efrim, C., Litavsky, M., Onochie-Quintanilla, E., Salas, N., Schöffelová, M., Defior, S., Mikulajová, M., Seidlová-Málková, G., & Hulme, C. (2012). Common patterns of prediction of literacy development in different alphabetic orthographies. Psychological Science, 23, 678–686. https://doi.org/10.1177/0956797611434536
Carlisle, J. F. (1995). Morphological awareness and early reading achievement. In L. B. Feldman (Ed.), Morphological aspects of language processing (pp. 189–209). Lawrence Erlbaum Associates.
Chen, Y.-J.I., Thompson, C. G., Xu, Z., Irey, R. C., & Georgiou, G. K. (2021). Rapid automatized naming and spelling performance in alphabetic languages: a meta-analysis. Reading and Writing, 34, 2559–2580. https://doi.org/10.1007/s11145-021-10160-7
Cheung, H., Chung, K. K. H., Wong, S.W.-L., McBride-Chang, C., Penney, T. B., & Ho, C.S.-H. (2010). Speech perception, metalinguistic awareness, reading, and vocabulary in Chinese-English bilingual children. Journal of Educational Psychology, 102, 367–380. https://doi.org/10.1037/a0017850
Cho, J.-R., & Lee, J.-Y. (2010). Transfer of phonological and morphological awareness to reading in English and logographic Hanja among Korean children. Journal of Cognitive Science, 11, 57–78. https://doi.org/10.17791/jcs.2010.11.1.57
Desrochers, A., Manolitsis, G., Gaudreau, P., & Georgiou, G. K. (2018). Early contribution of morphological awareness to literacy skills across languages varying in orthographic consistency. Reading and Writing, 31, 1695–1719. https://doi.org/10.1007/s11145-017-9772-y
Ehri, L. C. (2000). Learning to read and learning to spell: Two sides of a coin. Topics in Language Disorders, 20, 191–236. https://doi.org/10.1097/00011363-200020030-00005
Ellis, N. C., Natsume, M., Stavropoulou, K., Hoxhallari, L., van Daal, V. H. P., Polyzoe, N., Maria-Louisa, T., & Petalas, M. (2004). The effects of orthographic depth on learning to read alphabetic, syllabic, and logographic scripts. Reading Research Quarterly, 39, 438–468. https://doi.org/10.1598/RRQ.39.4.5
Furnes, B., & Samuelsson, S. (2011). Phonological awareness and rapid automatized naming predicting early development in reading and spelling: Results from a cross-linguistic longitudinal study. Learning and Individual Differences, 21, 85–95. https://doi.org/10.1016/j.lindif.2010.10.005
Georgiou, G. K., Liu, C., & Xu, S. (2017). Examining the direct and indirect effects of visual–verbal paired associate learning on Chinese word reading. Journal of Experimental Child Psychology, 160, 81–91. https://doi.org/10.1016/j.jecp.2017.03.011
Georgiou, G. K., Parrila, R., & Papadopoulos, T. C. (2008). Predictors of word decoding and reading fluency across languages varying in orthographic consistency. Journal of Educational Psychology, 100, 566–580. https://doi.org/10.1037/0022-0663.100.3.566
Georgiou, G. K., Torppa, M., Landerl, K., Desrochers, A., Manolitsis, G., de Jong, P. F., & Parrila, R. (2020). Reading and spelling development across languages varying in orthographic consistency: Do their paths cross? Child Development, 91, e266–e279. https://doi.org/10.1111/cdev.13218
Georgiou, G. K., Torppa, M., Manolitsis, G., Lyytinen, H., & Parrila, R. (2012). Longitudinal predictors of reading and spelling across languages varying in orthographic consistency. Reading and Writing, 25, 321–346. https://doi.org/10.1007/s11145-010-9271-x
Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual Review of Psychology, 60, 549–576. https://doi.org/10.1146/annurev.psych.58.110405.085530
Hamano, T., & Uchida, N. (2012). Cross-cultural study on the process of literacy acquisition and its relationship with environmental factors. Annual Report of Ochanomizu University Research Center for Human Development and Education, 4, 13–26. Retrieved from http://hdl.handle.net/10083/51285 (in Japanese)
Hamilton, L. G., Hayiou-Thomas, M. E., Hulme, C., & Snowling, M. J. (2016). The home literacy environment as a predictor of the early literacy development of children at family-risk of dyslexia. Scientific Studies of Reading, 20, 401–419. https://doi.org/10.1080/10888438.2016.1213266
Hanley, J. R. (2005). Learning to read in Chinese. In M. J. Snowling & C. Hulme (Eds.), The science of reading: a handbook (pp. 316–335). Blackwell.
Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: cooperative division of labor between visual and phonological processes. Psychological Review, 111, 662–720. https://doi.org/10.1037/0033-295X.111.3.662
Hayes, A. F. (2018). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach (2nd ed.). Guilford Press.
Hayes, A. F., & Scharkow, M. (2013). The relative trustworthiness of inferential tests of the indirect effect in statistical mediation analysis. Psychological Science, 24, 1918–1927. https://doi.org/10.1177/0956797613480187
Inoue, T., Georgiou, G, K., Imanaka, H., Oshiro, T., Kitamura, H., Maekawa, H., & Parrila, R. (2019). Cross-script transfer of word reading fluency in a mixed writing system: Evidence from a longitudinal study in Japanese. Applied Psycholinguistics, 40, 235–251. https://doi.org/10.1017/S014271641800054
Inoue, T., Manolitsis, G., de Jong, P. F., Landerl, K., Parrila, R., & Georgiou, G. K. (2020). Home literacy environment and early literacy development across languages varying in orthographic consistency. Frontiers in Psychology, 11, Article 1923. https://doi.org/10.3389/fpsyg.2020.01923
Inoue, T., Georgiou, G. K., Muroya, N., Maekawa, H., & Parrila, R. (2017). Cognitive predictors of literacy acquisition in syllabic Hiragana and morphographic Kanji. Reading and Writing, 30, 1335–1360. https://doi.org/10.1007/s11145-017-9726-4
Inoue, T., Georgiou, G. K., Muroya, N., Maekawa, H., & Parrila, R. (2018). Can earlier literacy skills have a negative impact on future home literacy activities? Evidence from Japanese. Journal of Research in Reading, 41, 159–175. https://doi.org/10.1111/1467-9817.12109
Japan Foundation for Educational and Cultural Research. (1998). Kanji mastery levels for each graders at Japanese elementary school. Retrieved from http://www.jfecr.or.jp/publication/pub-data/kanji/index.html (in Japanese)
Katz, L., & Frost, R. (1992). The reading process is different for different orthographies: the orthographic depth hypothesis. In R. Frost & L. Katz (Eds.), Orthography, phonology, morphology, and meaning (pp. 67–84). Elsevier.
Kirby, J. R., & Bowers, P. N. (2017). Morphological instruction and literacy: binding phonological, orthographic, and semantic features of words. In K. Cain, D. Compton, & R. Parrila (Eds.), Theories of reading development (pp. 437–462). John Benjamins.
Kirby, J. R., Georgiou, G. K., Martinussen, R., & Parrila, R. (2010). Naming speed and reading: from prediction to instruction. Reading Research Quarterly, 45, 341–362. https://doi.org/10.1598/RRQ.45.3.4
Kline, R. B. (2015). Principles and practice of structural equation modeling (4th ed.). Guilford Press.
Kobayashi, M. S., Haynes, C. W., Macaruso, P., Hook, P. E., & Kato, J. (2005). Effects of mora deletion, nonword repetition, rapid naming, and visual search performance on beginning reading in Japanese. Annals of Dyslexia, 55, 105–128. https://doi.org/10.1007/s11881-005-0006-7
Koda, K. (2017). Learning to read Japanese. In L. Verhoeven & C. Perfetti (Eds.), Learning to read across languages and writing systems (pp. 31–56). Cambridge University Press.
Koyama, M. S., Hansen, P. C., & Stein, J. F. (2008). Logographic Kanji versus phonographic Kana in literacy acquisition. Annals of the New York Academy of Sciences, 1145, 41–55. https://doi.org/10.1196/annals.1416.005
Kuo, L.- J., & Anderson, R. C. (2006). Morphological awareness and learning to read: A cross-language perspective. Educational Psychologist, 41, 161–180. https://doi.org/10.1207/s15326985ep4103_3
Landerl, K., Castles, A., & Parrila, R. (2021). Cognitive precursors of reading: a cross-linguistic perspective. Scientific Studies of Reading. https://doi.org/10.1080/10888438.2021.1983820
Landerl, K., Freudenthaler, H. H., Heene, M., de Jong, P. F., Desrochers, A., Manolitsis, G., Parrila, R., & Georgiou, G. K. (2019). Phonological awareness and rapid automatized naming as longitudinal predictors of reading in five alphabetic orthographies with varying degrees of consistency. Scientific Studies of Reading, 23, 220–234. https://doi.org/10.1080/10888438.2018.1510936
Li, L., Wu, X., Cheng, Y., & Nguyen, T. P. (2019). The relationship of character reading and spelling: a longitudinal study in Chinese. Journal of Research in Reading, 42, 18–36. https://doi.org/10.1111/1467-9817.12131
Li, T., McBride-Chang, C., Wong, A., & Shu, H. (2012). Longitudinal predictors of spelling and reading comprehension in Chinese as an L1 and English as an L2 in Hong Kong Chinese children. Journal of Educational Psychology, 104, 286–301. https://doi.org/10.1037/a0026445
Lin, D., Sun, H., & McBride, C. (2019). Morphological awareness predicts the growth rate of Chinese character reading. Developmental Science, 19, Article e12793. https://doi.org/10.1111/desc.12793
Liu, C., Chung, K. K. H., Wang, L.-C., & Liu, D. (2021). The relationship between paired associate learning and Chinese word reading in kindergarten children. Journal of Research in Reading, 44, 264–283. https://doi.org/10.1111/1467-9817.12333
Maldarelli, J. E., Kahrs, B. A., Hunt, S. C., & Lockman, J. J. (2015). Development of early handwriting: visual-motor control during letter copying. Developmental Psychology, 51, 879–888. https://doi.org/10.1037/a0039424
McBride-Chang, C., Tardif, T., Cho, J.-R., Shu, H., Fletcher, P., Stokes, S. F., Wong, A., & Leung, K. (2008). What’s in a word? Morphological awareness and vocabulary knowledge in three languages. Applied Psycholinguistics, 29, 437–462. https://doi.org/10.1017/S014271640808020X
Melby-Lervåg, M., Lyster, S.-A.H., & Hulme, C. (2012). Phonological skills and their role in learning to read: a meta-analytic review. Psychological Bulletin, 138, 322–352. https://doi.org/10.1037/a0026744
Mikami, H., Nohara, Y., & Tanabe, M. (2008). Research on learning letters and reading readiness in early childhood. Bulletin of Nagoya University of Arts, 29, 345–365. (in Japanese).
Ministry of Education, Culture, Sports, Science and Technology (2017). Shogakkou gakushu shidou yoryo [Course of Study]. Retrieved from https://www.mext.go.jp/component/a_menu/education/micro_detail/__icsFiles/afieldfile/2019/03/18/1387017_002.pdf (in Japanese)
Moll, K., Ramus, F., Bartling, J., Bruder, J., Kunze, S., Neuhoff, N., Streiftau, S., Lyytinen, H., Leppänen, P. H. T., Lohvansuu, K., Tóth, D., Honbolygó, F., Csépe, V., Bogliotti, C., Iannuzzi, S., Démonet, J.-F., Longeras, E., Valdois, S., George, F., & Landerl, K. (2014). Cognitive mechanisms underlying reading and spelling development in five European orthographies. Learning and Instruction, 29, 65–77. https://doi.org/10.1016/j.learninstruc.2013.09.003
Muroya, N., Inoue, T., Hosokawa, M., Georgiou, G. K., Maekawa, H., & Parrila, R. (2017). The role of morphological awareness in word reading skills in Japanese: a within-language cross-orthographic perspective. Scientific Studies of Reading, 21, 449–462. https://doi.org/10.1007/s11145-017-9726-4
Muthén, L. K., & Muthén, B. O. (1998–2017). Mplus (Version 8.5). Muthén & Muthén.
Nag, S. (2007). Early reading in Kannada: The pace of acquisition of orthographic knowledge and phonemic awareness. Journal of Research in Reading, 30, 7–22. https://doi.org/10.1111/j.1467-9817.2006.00329.x
O’Brien, B. A., Lim, N. C., Mohamed, M. B. H., & Arshad, N. A. (2020). Cross-lag analysis of early reading and spelling development for bilinguals learning English and Asian scripts. Reading and Writing: An Interdisciplinary Journal, 33, 1859–1891. https://doi.org/10.1007/s11145-019-09999-8
Odlin, T. (1989). Language transfer: Cross-linguistic influence in language learning. Cambridge University Press. https://doi.org/10.1017/CBO9781139524537
Ogino, T., Hanafusa, K., Morooka, T., Takeuchi, A., Oka, M., & Ohtsuka, Y. (2017). Predicting the reading skill of Japanese children. Brain and Development, 39, 112–121. https://doi.org/10.1016/j.braindev.2016.08.006
Ota, S., Uno, A., & Inomata, T. (2018). Attainment level of hiragana reading/spelling in kindergarten children. Japan Journal of Logopedics and Phoniatrics, 59, 9–15. https://doi.org/10.5112/jjlp.59.9(inJapanese)
Pasquarella, A., Chen, X., Gottardo, A., & Geva, E. (2015). Cross-language transfer of word reading accuracy and word reading fluency in Spanish-English and Chinese-English Bilinguals: script-universal and script-specific processes. Journal of Educational Psychology, 107, 96–110. https://doi.org/10.1037/a0036966
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., & Patterson, K. (1996). Understanding normal and impaired word reading: computational principles in quasi-regular domains. Psychological Review, 103, 56–115. https://doi.org/10.1037/0033-295x.103.1.56
Ravid, D. (2012). Spelling morphology: The psycholinguistics of Hebrew spelling. Springer.
National Institute for Japanese Language and Linguistics (1972). Reading and writing ability in pre-school children. Tokyo Shoseki. (in Japanese)
Ruan, Y., Georgiou, G. K., Song, S., Li, Y., & Shu, H. (2018). Does writing system influence the associations between phonological awareness, morphological awareness, and reading? A meta-analysis. Journal of Educational Psychology, 110, 180–202. https://doi.org/10.1037/edu0000216
Seymour, P. H. K., Aro, M., & Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. British Journal of Psychology, 94, 143–174. https://doi.org/10.1348/000712603321661859
Shum, K.K.-M., Ho, C.S.-H., Siegel, L. S., & Au, T.K.-F. (2016). First-language longitudinal predictors of second-language literacy in young L2 learners. Reading Research Quarterly, 51, 323–344. https://doi.org/10.1002/rrq.139
Smith, J. S. (1996). Japanese writing. In P. T. Daniels & W. Bright (Eds.), The world’s writing systems (pp. 209–217). Oxford University Press.
Song, S., Georgiou, G., Su, M.-M., & Shu, H. (2016). How well do phonological awareness and rapid automatized naming correlate with reading accuracy and fluency in Chinese? A meta-analysis. Scientific Studies of Reading, 20, 99–123. https://doi.org/10.1080/10888438.2015.1088543
Sparks, R. L., Patton, J., Ganschow, L., Humbach, N., & Javorsky, J. (2008). Early first-language reading and spelling skills predict later second-language reading and spelling skills. Journal of Educational Psychology, 100, 162–174. https://doi.org/10.1037/0022-0663.100.1.162
Sun, X., Zhang, K., Marks, R. A., Nickerson, N., Eggleston, R. L., Yu, C., Chou, T., Tardif, T., & Kovelman, I. (2022). What’s in a word? Cross-linguistic influences on Spanish-English and Chinese-English bilingual children’s word reading development. Child Development, 93, 84–100. https://doi.org/10.1111/cdev.13666
Tabachnick, B. G., & Fidell, L. S. (2012). Using multivariate statistics (6th ed.). Pearson.
Takahashi, N. (2001). Developmental changes in reading ability: A longitudinal analysis of Japanese children from first to fifth grade. Japanese Journal of Educational Psychology, 49, 1–10. Retrieved from https://www.jstage.jst.go.jp/article/jjep1953/49/1/49_1/_pdf/-char/ja (in Japanese)
Tamaoka, K., & Taft, M. (2010). The sensitivity of native Japanese speakers to On and Kun kanji readings. Reading and Writing, 23, 957–968. https://doi.org/10.1007/s11145-009-9184-8
Tanji, T., & Inoue, T. (2021). Early prediction of reading development in Japanese hiragana and kanji: a longitudinal study from kindergarten to grade 1. Reading and Writing: An Interdisciplinary Journal. https://doi.org/10.1007/s11145-021-10197-8
Taylor, I., & Taylor, M. (2014). Writing and literacy in Chinese, Korean, and Japanese: Studies in written language and literacy 14 (2nd ed.). John Benjamins.
Vaessen, A., & Blomert, L. (2013). The cognitive linkage and divergence of spelling and reading development. Scientific Studies of Reading, 17, 89–107. https://doi.org/10.1080/10888438.2011.614665
Xu, Z., Liu, D., & Joshi, R. M. (2020). The influence of sensory-motor components of handwriting on Chinese character learning in second- and fourth-grade Chinese children. Journal of Educational Psychology, 112, 1353–1366. https://doi.org/10.1037/edu0000443
Yang, J., Shu, H., McCandliss, B. D., & Zevin, J. D. (2013). Orthographic influences on division of labor in learning to read Chinese and English: Insights from computational modeling. Bilingualism: Language and Cognition, 16, 354–366. https://doi.org/10.1017/S1366728912000296
Ye, Y., Yan, M., Ruan, Y., McBride, C., Zheng, M., & Yin, L. (2022). Exploring the underpinnings and longitudinal associations of word reading and word spelling: A 2-year longitudinal study of Hong Kong Chinese children transitioning to primary school. Scientific Studies of Reading, 26, 21–37. https://doi.org/10.1080/10888438.2021.1871909
Zhang, D. (2017). Word reading in L1 and L2 learners of Chinese: Similarities and differences in the functioning of component processes. The Modern Language Journal, 101, 391–411. https://doi.org/10.1111/modl.12392
Ziegler, J. C., Bertrand, D., Toth, D., Csépe, V., Reis, A., Faisca, L., Saine, N., Lyytinen, H., Vaessen, A., & Blomert, L. (2010). Orthographic depth and its impact on universal predictors of reading: a cross-language investigation. Psychological Science, 21, 551–559. https://doi.org/10.1177/0956797610363406
Funding
This research was supported by the Japan Society for the Promotion of Science (JSPS KAKENHI Grant Number 18K13223) to Tomohiro Inoue.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Test Items of the Hiragana Character Recognition Task
No | Item | No | Item | |
|---|---|---|---|---|
1 | し | 26 | べ | |
2 | の | 27 | ぷ | |
3 | ひ | 28 | げ | |
4 | た | 29 | じ | |
5 | う | 30 | ぐ | |
6 | い | 31 | りゃ | |
7 | お | 32 | びゅ | |
8 | こ | 33 | ちょ | |
9 | か | 34 | ぴゅ | |
10 | も | 35 | じゃ | |
11 | ぞ | 36 | ぴょ | |
12 | ほ | 37 | きゅ | |
13 | び | 38 | みゃ | |
14 | ぬ | 39 | にょ | |
15 | づ | 40 | ぎゃ | |
16 | ぽ | 41 | ぴょ | |
17 | ぶ | 42 | びゅ | |
18 | ぴ | 43 | ぎょ | |
19 | ざ | 44 | ちゃ | |
20 | ぺ | 45 | じゅ | |
21 | ぎ | 46 | ぴゃ | |
22 | ば | 47 | しゅ | |
23 | ぜ | 48 | ひゅ | |
24 | ぼ | 49 | ぎゅ | |
25 | ぱ | 50 | きょ |
Appendix B
Test Items of the Hiragana Writing Task
No | Item |
|---|---|
1 | し |
2 | い |
3 | こ |
4 | ぶ |
5 | ぽ |
6 | ぷ |
7 | ちゃ |
8 | しゅ |
9 | しょ |
10 | ゆび |
11 | にわ |
12 | しゃしん |
13 | なっとう |
14 | うんどうかい |
15 | しんかんせん |
Rights and permissions
About this article

Cite this article
Inoue, T., Georgiou, G.K. & Parrila, R. Cross-script effects of cognitive-linguistic skills on Japanese Hiragana and Kanji: Evidence from a longitudinal study. J Cult Cogn Sci 6, 119–134 (2022). https://doi.org/10.1007/s41809-022-00099-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41809-022-00099-8