
Abstract
This paper shows how to compute the standard errors for partial effects of exogenous firm characteristics influencing firm inefficiency under a range of popular stochastic frontier model specifications. We also develop an R2-type measure to summarize the overall explanatory power of the exogenous factors on firm inefficiency. The paper also applies a recently developed model selection procedure to choose among alternative stochastic frontier specifications using data from household maize production in Kenya. The magnitude of estimated partial effects of exogenous household characteristics on inefficiency turns out to be very sensitive to model specification, and the model selection procedure leads to an unambiguous choice of best model. We propose a bootstrapping procedure to evaluate the size and power of the model selection procedure. The empirical application also provides further evidence on how household characteristics influence technical inefficiency in maize production in developing countries.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Stochastic production frontier analysis has been widely used to study technical inefficiency in various settings since its introduction by Aigner et al. (1977), and Meeusen and van den Broeck (1977). The approach has two components: a stochastic production frontier serving as a benchmark against which firm inefficiency is measured, and a one-sided error term which captures technical inefficiency. In early applications the one-sided error was assumed to be identically and independently distributed across firms, but more recent studies have allowed its distribution to be heterogeneous and depend on various firm characteristics (see Battese and Coelli 1995; Caudill et al. 1995; Wang 2002, 2003).
Allowing inefficiency to depend on firm characteristics allows researchers to identify the determinants of inefficiency and to suggest possible policy or behavioral responses which might improve efficiency. However, this approach has been hampered by two problems. First, existing studies have mostly focused on the directions of the influence of the firm characteristics on technical inefficiency while generally overlooking the magnitudes of the partial effects. This makes it difficult to determine which type of policy intervention will have the largest impact on inefficiency. This problem is somewhat surprising given that the magnitudes of the effects of explanatory variables on dependent variables are often the focal point in other types of regression analyses. Second, the relationship between firm characteristics and technical inefficiency is often sensitive to the model used to incorporate firm characteristics, and choosing between competing models is difficult (see Alvarez et al. 2006, hereafter AAOS). This model uncertainty makes policy recommendations quite tenuous.
In this paper we make four contributions to the stochastic frontier literature. First, we take the formulas for estimating the partial effects of exogenous firm characteristics on firm inefficiency that have been proposed by Wang (2002, 2003) and show how to put standard errors around these point estimates. The standard errors are computed using the delta method and will be useful in assessing the precision of estimated partial effects. Second, we propose an R2-type measure to summarize the overall explanatory power of the exogenous factors on inefficiency. To date, there has been no way of assessing the overall power of firm characteristics to explain variations in inefficiency across firms. Our R2-type measure provides an easily computed means of doing this. Third, we propose a bootstrapping procedure to evaluate the power of the recently developed model selection procedure suggested by AAOS to choose among competing models of the influence of firm characteristics on inefficiency. This bootstrapping procedure should prove useful in various applications. Fourth and finally, we apply our procedures to an empirical application of stochastic frontier analysis of maize production in Kenya. In the application we apply the model selection procedures of AAOS and use bootstrapping to evaluate the power of the procedure. We then compute point estimates of partial effects of farm characteristics on inefficiency and their standard errors. We also use our R2-type measure to evaluate the joint explanatory power of the farm characteristics. We find that while alternative models of the relationship between farm household characteristics and technical inefficiency in maize production in Kenya tend to provide the same direction of the influence of household characteristics, the magnitudes of the partial effects on firm inefficiency are quite sensitive to model selection.
In the remainder of the paper, we first review the standard stochastic frontier production model and then extend it to provide: (i) standard errors around point estimates of the effects of firm characteristics on technical inefficiency; and (ii) an R2-type measure of the overall explanatory power of firm characteristics on inefficiency. Next we describe our data and variables used in the empirical application to Kenyan maize production, followed by estimation results from alternative model specifications. Results for the magnitude of partial effects of farm household characteristics on inefficiency are quite sensitive to model specification. Then we carry out AAOS specification tests to choose a final model and use our bootstrapping procedure to examine the reliability of these specification tests in choosing the correct model. The final sections contain an analysis of technical inefficiency in maize production in Kenya based on the final model chosen, and some concluding comments.
1 Stochastic production frontier models
The basic setup and notation follow Wang and Schmidt (2002) and AAOS. Firms are indexed by i = 1,…,N. Let y i be log output; x i be a vector of inputs; and z i be a vector of exogenous variables that exert influence on firm inefficiency. Let y * i be the unobserved frontier which is modeled as
where v i is distributed as N(0, σ 2 v ) and is independent of x i and z i , and β is a parameter vector. The actual log output level y i equals y * i less a one-sided error, u i , whose distribution depends on z i . The full model is written as
where θ is a vector of parameters. It is assumed that u i and v i are independent of one another and that u i is independent of x i (conditional on z i ). The model is usually implemented by assuming u i is distributed as N(μ i , σ 2 i )+ with various specifications (discussed below) used to model μ i and σ i . The frontier function and the inefficiency part are generally estimated in one step using maximum likelihood estimation (MLE) to achieve both efficiency and consistency.Footnote 1
Indexing exogenous factors with k = 1,…,K, we take expectations conditional on x i and z i , and then take partial derivatives with respect to z ik on both sides of Eq. 2,Footnote 2 to get
The term \(\partial{[E(-u_i|x_i, z_i)]}/\partial{z_{ik}}\) can be interpreted as the partial effect of z ik on efficiency and from (3) is also the partial effect on y i . Because y i is log output, \(\partial{[E(-u_i|x_i, z_i)]}/\partial{z_{ik}}\) is the semi-elasticity of output (efficiency) with respect to the exogenous factors (i.e., the percentage change in expected output when z ik increases by one unit). Similarly, taking conditional variances we have
So \(\partial{[V(u_i|x_i, z_i)]}/\partial{z_{ik}}\) is the partial effect of z ik on the variance of both the inefficiency term u i and y i . It can be interpreted as an estimator of the partial effect of z ik on production uncertainty.
The measures \(\partial{[E(u_i|x_i,z_i)]}/\partial{z_{ik}}\) and \(\partial{[V(u_i|x_i, z_i)]}/\partial{z_{ik}}\) were proposed and used in Wang (2002, 2003), but a means for computing their standard errors was not provided. In the Appendix we provide formulas for computing estimates of \(\partial{[E(-u_i|x_i, z_i)]}/\partial{z_{ik}}\) and \( \partial{[V(u_i|x_i, z_i)]}/\partial{z_{ik}},\) along with their standard errors using the delta method for several popular model specifications for μ i and σ i .
It will often be useful to measure how well the vector of exogenous factors, z, explains inefficiency, u, in a data sample. Surprisingly, this has not been addressed in the previous literature. We suggest a statistic, R 2 z , to summarize the explanatory power of z for firm inefficiency. To motivate the measure, the variance of the inefficiency term u i can be decomposed as
where V z [E(u i |z i )] is the variance of the conditional mean function over the distribution of z i , and E z [V(u i |z i )] is the expected variance around the conditional mean of u i . The fraction of variation in u i that is explained by z i is V z [E(u i |z i )]/V(u i ). Thus a natural measure of explanatory power over the sample would be
where \(\hat{E}\) and \(\hat{V}\) indicate sample estimates of the mean and variance of u i conditional on z i . Letting R 1 = μ i /σ i , R 2 = ϕ(R 1)[Φ(R 1)]−1, and R 3 = −R 22 −R 1 R 2, where ϕ(·) and Φ(·) are the density and cumulative density functions for the standard normal, then the mean and variance of u i conditional on z i can be expressed as
So all that remains to compute R 2 z is to estimate \(\hat{\mu_i}\) and \(\hat{\sigma_i}\) for a specific model specification (see the model specification section below) and then substitute these estimators for the population values μ i and σ i in (7) and (8) to get the sample estimates of \(\hat{E}(u_i|z_i)\) and \(\hat{V}(u_i|z_i).\)
Similar to R 2 in an ordinary least squares regression, R 2 z can be called the “goodness of fit” of the efficiency component, and it can be interpreted as the fraction of the sample variation in u that is explained by z.
1.1 Alternative model specifications
In the original specification of stochastic frontier functions, Aigner et al. (1977) and Meeusen and van den Broeck (1977) assumed an identical and independent half-normal distribution for the one-sided error terms u i . Subsequent studies have generalized the model to allow for heterogeneity in the distribution of the inefficiency term while maintaining the assumption of half normality. Kumbhakar et al. (1991), Huang and Liu (1994), and Battese and Coelli (1995) allow the mean of the pre-truncated normal distribution of u i to depend on a set of exogenous factors. Reifschneider and Stevenson (1991), Caudill and Ford (1993), Caudill et al. (1995) and Hadri (1999) allow the variance of the pre-truncated normal distribution of u i to depend on the exogenous factors. Wang (2003) allows both the mean and the variance of the pre-truncated distribution of u i to depend on exogenous factors.
Regardless of whether we allow the mean, the variance, or both the mean and the variance of the pre-truncated normal to depend on exogenous factors, both the mean and the variance of the truncated half normal will always depend on the exogenous factors. These are sometimes called models of heteroscedasticity, but the fact that the mean also changes makes this terminology potentially misleading. Whereas heteroscedasticity affects only the efficiency of estimation in a standard linear model, in a stochastic frontier model with heterogeneity in the distribution of the inefficiency term, failure to model the exogenous factors appropriately leads to biased estimation of the production frontier model and of the level of technical inefficiency, hence leading to poor policy conclusions (see Caudill and Ford 1993; Caudill et al. 1995; Hadri 1999; Wang 2003).
With different specifications available to model heterogeneity, it is unclear which should be used in particular applied settings. The choices made in many past studies seem to be somewhat arbitrary. However, a carefully specified model might help to increase estimation efficiency and remove sources of potential bias and inconsistency (Wang 2003). Moreover, there has been little investigation of how the choice of model specification influences the estimation results. In order to deal with the model specification problem, researchers usually do sensitivity analysis using competing models. But if the competing models give very different results, it is difficult to pick one and discard the others. Wang (2003) treats this problem by specifying a flexible model that nests most of the usual model specifications for μ i and σ i . However, a more flexible model has more parameters, which imposes a higher computational burden and reduces degrees of freedom. Given that large samples are typically difficult to obtain in stochastic frontier estimation, some relevant parameters may be estimated imprecisely in flexible model specifications. Even when large samples are available, finding an appropriate parsimonious model can still improve performance and a more flexible model specification may not always be preferred.
AAOS suggest a procedure for selecting a model for the one-sided error term. First, assume the general model of inefficiency (Wang 2003) in which u i is distributed as N(μ i , σ 2 i )+, with μ i = μ · exp(z ′ i δ) and σ i = σ u · exp(z ′ i γ). This general model nests several simpler models, many of which have been used in previous studies. In particular, the following six models are special cases of the general model, as outline in AAOS.
-
1.
Scaled Stevenson model: let δ = γ. Then the distribution of u i becomes exp(z ′ i δ) · N(μ, σ 2 u )+, which is used in Wang and Schmidt (2002).
-
2.
KGMHLBC model: let γ = 0. Then the distribution of u i becomes N(μ · exp(z ′ i δ), σ 2 u )+, which has been considered in Kumbhakar et al. (1991), Huang and Liu (1994), and Battese and Coelli (1995).
-
3.
RSCFG-μ model: let δ = 0. Then the distribution of u i becomes N(μ, σ 2 u · exp(2z ′ i γ))+.
-
4.
RSCFG model: let μ = 0. Then the distribution of u i becomes exp(z ′ i γ) · N(0, σ 2 u )+, which is considered in Reifschneider and Stevenson (1991), Caudill and Ford (1993), and Caudill et al. (1995).
-
5.
Stevenson model: let δ = γ = 0. Then the distribution of u i becomes N(μ, σ 2 u )+, which is the model of Stevenson (1980).
-
6.
ALS model: let μ = γ = 0. Then the distribution of u i becomes N(0, σ 2 u )+, which is the model of Aigner et al. (1977).
Among the six models, the scaled Stevenson, KGMHLBC and RSCFG-μ models have the same number of parameters. The RSCFG model is nested by the scaled Stevenson model and the RSCFG-μ model. Also notice that the Stevenson model and the ALS model do not contain any variables (z i ) that influence the distribution of inefficiency. AAOS show how to use likelihood ratio (LR) tests, LM tests and Wald tests to test the above restrictions, and hence to choose a plausible model for inefficiency.
2 Empirical application
The empirical application is to maize production in Kenya using detailed household survey data. The problem of hunger in Kenya remains widespread and its economy depends heavily on agriculture with 75% of Kenyans making their living from farming. Maize is the primary staple food and most farmers are engaged in maize production. In recent years, total maize output has not kept pace with growing population and demand, largely due to falling land productivity: average national maize yields have fallen from over 2 tons/ha in the early 1980s to about 1.6 tons/ha recently (Nyoro et al. 2004). The technical efficiency level of Kenya maize production is therefore an important economic and policy issue.
2.1 Data
The data are from a rural household survey of about 1,100 households planting maize in the main season of 2003–2004 in Kenya.Footnote 3 The survey was designed and implemented under the Tegemeo Agricultural Monitoring and Policy Analysis Project, a collaboration among Tegemeo Institute of Egerton University, Michigan State University, and the Kenya Agricultural Research Institute. Figure 1 is a map of Kenya with the round dots representing sampled villages. These villages were chosen randomly from each of eight pre-determined agro-economic zones and then households were sampled randomly from each selected village.

Location of sample villages in Kenya (source: Suri 2005)
Field level data are available for each sampled household and some households planted maize in more than one field. The survey includes not only detailed field production information but also rich demographic and infrastructure characteristics of each household. The production data for each field include size of the field, yield, labor input, fertilizer application, and seed usage. The demographic information includes the age, gender and education level of each household member; how far a household is from a bus stop, a motorable road, a telephone booth, mobile phone service, and extension service; whether a household member has non-farm income; whether a household receives loans; how much land a household owns, and land tenure. Rainfall and soil quality data are also available at the village level.
2.2 Variables in the production frontier
In the production frontier part of the model, the output variable is maize yield per acre, and the input variables are applied fertilizer nutrients, labor, maize seeds and machine usage. Since both the output and inputs are in per acre terms, land is not explicitly included as an input. Most of the maize fields are inter-crop fields where more than one type of crop is planted in the same season. Because most inputs (land, fertilizer and labor) are at the field level and cannot be separately allocated to maize production only, we generate an output index for inter-crop fields using:
where Y i is the output index, P j is the market price of crop j, Y ij is the yield of crop j in field i, and crop 1 is maize. Fields with more than three types of crops are deleted because we want to focus on the fields where maize is the major crop.Footnote 4 Only pre-harvest labor input (LABOR) is included because harvesting and post-harvest activities have little effect, if any, on yield. The unit of labor is person-hours. One person-hour of labor from children younger than 16 is transformed to 0.6 person-hours of adult labor. Nitrogen (FERTILIZER), the most important nutrient in maize growth, is computed from fertilizer application data according to the quantity and composition of each type of fertilizer used.Footnote 5 Maize seeds can be separated into hybrid seeds and local seeds. All fields used either hybrid seeds or local seeds (no combinations in the same field). These seed inputs are captured by two variables, SEED measures the amount of (hybrid or local) seed per acre applied to the field, and HYBRID is a dummy variable measuring one for hybrid seeded fields and zero otherwise. We also use a dummy variable MONO as an indicator for mono-crop fields because these might be expected to have systematically different yields than multi-crop fields. Tractor usage in land preparation is the only machine used for pre-harvest activities. This is captured by a dummy variable TRACTOR with one indicating that a tractor was used and zero otherwise.
Environmental variables are also included on the right hand side of the frontier production function. Failure to control for environmental variables may cause a correlation between some inputs and unobserved factors in the error term (for example, if a farmer makes input decisions based on soil properties that also affect maize yield) and therefore may bias estimates of the production frontier and inefficiency level (Sherlund et al. 2002). In order to control for environmental conditions, we include seven dummy variables indicating the different agro-economic zones. Farms in the same zone share similar terrain and climate conditions. We also include three village level variables: DRAINAGE, DRAINAGE2 and STRESS. DRAINAGE captures the drainage property of the soil. It is a categorical variable ranging from one to ten where one indicates the least and ten the highest drainage. DRAINAGE2 is the square of DRAINAGE. We include a quadratic term because yield is expected to increase in DRAINAGE at lower drainage levels and decrease at higher levels. Rainfall is a very important factor in maize production in Kenya because all of the maize fields are rain-fed and drought is the usual cause of yield loss. We use the variable STRESS to capture the moisture stress in maize growth. STRESS is computed as the total fraction of 20-day periods with less than 40 mm of rain during the 2003–2004 main season. This is a better measure for moisture conditions than total rainfall because total rainfall does not reflect the distribution of rainfall over time, which is very important in maize growth.
Any observations with missing values were discarded. Because of potential measurement errors, we also drop any observation that satisfies one of the following conditions: (1) yield lower than 65 kg per acre or higher than 4,580 kg per acre, (2) seed usage less than 2 kg per acre or more than 20 kg per acre, and (3) labor input less than 40 person-hours per acre or more than 2,200 person-hours per acre. After these filters were applied, there are 815 fields (observations) remaining. The 815 fields were managed by 660 households. Table 1 summarizes the descriptive statistics for the variables included in the frontier production function (excluding zone dummies).
2.3 Exogenous factors affecting efficiency
Previous studies have identified numerous factors that may limit farm productivity and efficiency. Education is arguably an important factor and Kumbhakar et al. (1989) find that education increases the productivity of labor and land on Utah dairy farms while Kumbhakar et al. (1991) also show that education affects production efficiency. Huang and Kalirajan (1997) find that average household education level is positively correlated with technical efficiency levels for both maize and rice production in China. Here we measure education with EDUHIGH, the highest level of education among all household members.Footnote 6 We also investigate gender effects by including a dummy variable for female-headed households (FEMHEAD).
Physical and social infrastructure, such as road conditions, access to telephone and mobile phone service, access to extension service, etc., have also been mentioned for their role in rural development and farm productivity. Jacoby (2000) examines the benefits of rural roads to Nepalese farms and suggests that providing road access to markets would confer substantial benefits through higher farm profits. Karanja et al. (1998) show that distance to the nearest motorable road and access to extension services have positive effects on maize productivity in Kenya. More developed infrastructure helps farmers to obtain more information and thus may improve technical efficiency. Here we use three infrastructure variables to account for these effects on efficiency—DISTBUS, distance of the house from the nearest bus stop;Footnote 7 DISTPHONE, distance of the house from the nearest telephone or mobile phone service; and DISTEXTN, distance from the nearest extension service office.
Land tenure is another element that affects farm performance. Secure tenure may induce more investment (such as soil conservation) and increase farm productivity in the long run. Place and Hazell (1993) suggest land tenure is important to investment and productivity in Rwanda. Puig-Junoy and Argiles (2000) show that farms with a large proportion of rented land have low efficiency in Spain. Here we use a dummy variable (OWNED) with one indicating that the field is owned by the household and zero indicating the field is rented.
Financial constraints, such as limited access to credit, might also affect farm input decisions and efficiency. Ali and Flinn (1989) show that credit non-availability is positively and significantly related to profit inefficiency for rice producers in Pakistan. Parikh et al. (1995) find that farmers with larger loans are more cost efficient in Pakistan. The effects of financial constraints on technical efficiency seem to be unexamined to date but may be important because the timing of input usage can be an important factor influencing yields. When farmers face financial constraints, they may resort to relatives or friends for loans or try to obtain in-kind inputs through governments or other input subsidy programs. These extra efforts may prevent them from applying inputs at the right times to optimize productivity. We attempt to capture this effect using CRDCSTR (a dummy variable with one indicating the household has unsuccessfully pursued credit and zero otherwise), and RNFINC (the proportion of household members that have non-farm income).
The relationship between farm productivity and farm size has been a long-standing empirical puzzle in development economics since Sen (1962) (see Benjamin 1995; Barrett 1996; Lamb 2003). Empirical results on the relationship between efficiency and farm size have been mixed. Kumbahakar et al. (1991) show that large farms are relatively more efficient both technically and allocatively. Ahmad and Bravo-Ureta (1995) find a negative correlation between herd size and technical efficiency, while Alvarez and Arias (2004) find a positive relationship between technical efficiency and size of Spanish Dairy farms. Huang and Kalirajan (1997) show that the size of household arable land is positively related to technical efficiency in maize, rice and wheat production in China. Parikh et al. (1995) find that cost inefficiency increases with farm size. Hazarika and Alwang (2003) show that cost inefficiency in tobacco production is negatively related to tobacco plot size but unrelated to total farm size in Malawi. Here we include farm size (TTACRES) and field size (ACRES) as measures of the size effect. Descriptive statistics for the household survey data used to define the exogenous factors affecting efficiency are summarized in Table 2.
3 Estimation results from competing models
In this section, we report the estimation results under alternative model specifications for the inefficiency component of the model. We use a flexible translog functional form for FERTILIZER, LABOR, and SEED in the frontier production function. We also interact the dummy variable for hybrid maize (HYBRID), and the variable for moisture stress (STRESS), with FERTILIZER, LABOR, and SEED because there may be important interactions between these variables. In order to obtain more precise estimation and simplify computation, we drop jointly insignificant variables based on LR tests and the 10% significance level.Footnote 8 The dropped variables are the second order effects for LABOR and SEED, all interaction effects among FERTILIZER, LABOR, and SEED, interaction effects for SEED and HYBRID, and FERTILIZER and STRESS, two zone dummy variables, DISTPHONE, DISTEXTN, CRDCSTR, and ACRES. Tables 3 and 4 report the MLE estimation results for alternative specifications for the inefficiency part, after dropping the jointly insignificant variables.
The parameter estimates for the frontier part of the model are very similar across alternative models for the inefficiency component (see Table 3). Furthermore, Both the LR test and Wald test reject the null hypothesis that all the exogenous factors have zero effect on inefficiency at the 1% significance level in each of the five models (see Table 4). Hence, it seems clear that the exogenous factors have a statistically significant effect irrespective of the model specification employed to model inefficiency. The Battese and Coelli efficiency estimates are computed for each observation in all the models and their correlations across alternative models are reported in Table 5. The lowest correlation is 0.97. Therefore, all five models yield similar results for the production frontier and for the rankings of inefficiency among households, consistent with previous studies (e.g. Caudill et al. 1995).
The goodness of fit statistics for the inefficiency component, R 2 z , are reported at the bottom of Table 4 for the alternative model specifications. For example, the value of R 2 z for the KGMHLBC model is 0.1035, indicating that 10.35% of the sample variation in inefficiency can be explained by the exogenous factors. The remaining 89.65% of the sample variation is due to other unobserved factors (such as managerial skill). Not surprisingly, the general model provides the best fit at 12.75%.
The coefficients of the exogenous factors reported in Table 4 are not very interesting by themselves because they are the parameters of the pre-truncated distribution of the inefficiency term u i . So these parameters do not tell us how the exogenous factors affect the distribution of u i . In order to quantify the effects of exogenous factors, we compute \(\partial{[E(-u_i|x_i, z_i)]}/\partial{z_i}\) and \(\partial{[V(u_i|x_i,z_i)]}/\partial{z_i}\) for each observation. The formulas for computing these measures and their standard errors for the general model are provided in the Appendix. To obtain the formulas for the nested models, we only need to impose the corresponding restrictions on the parameters.Footnote 9
The partial effects of the exogenous factors evaluated at the sample mean are reported in Table 6 along with their standard errors. The signs of the partial effects are the same for all the models. However, different models give quantitatively different values for the partial effects. For example, the partial effects of TTACRES on the conditional mean of −u range from 0.0023 to 0.0072, and these differences are large relative to the standard errors of the estimates. So conclusions about the semi-elasticity of output with respect to farm size may differ by a factor of more than 100%, depending on which inefficiency model is used.
Table 7 reports the average partial effects of EDUHIGH on E(−u i |x i , z i ) for alternative model specifications over observations within each of the four quartiles of the efficiency levels.Footnote 10 The KGMHLBC model shows an increasing trend of the partial effect of education on efficiency levels from low to high quartiles, while the scaled Stevenson model, RSCFG-μ model and RSCFG model suggest a decreasing trend. So using the KGMHLBC model we would conclude that the households with lower efficiency levels would not benefit as much from increased education as the ones with higher efficiency levels. However, an opposite conclusion would follow if we use the scaled Stevenson model, the RSCFG-μ model or the RSCFG model.Footnote 11
Table 8 reports the correlations of partial effects of EDUHIGH on E(−u i |x i , z i ) among alternative models. Most correlations are very low and some are even negative (see footnote 11). This further confirms that different models yield rather different partial effects. Therefore, if we are only interested in the signs of the yield semi-elasticities with respect to exogenous factors, model specification is not critical. However, if we are interested in the magnitudes of the yield semi-elasticities, it is important to choose the appropriate model specification.
4 Model selection
In this section, we apply the procedure proposed by AAOS to select an appropriate model for our empirical application. A bootstrap analysis then follows to evaluate the performance of the model selection procedure.
4.1 Empirical model selection
We start with the general model, and then use LR tests to find simpler models that the data do not reject. Estimation of the general model yields a log-likelihood value of −616.30. Table 9 reports the log-likelihood values for the six restricted models nested in the general model. Taking the general model as the unrestricted model, we then test the restrictions that would reduce the general model to simpler specifications. LR test statistics with Chi-squared critical values are listed in Table 9 and provide the following results:
-
We reject the scaled Stevenson model (δ = γ), RSCFG-μ model (δ = 0), and RSCFG model (μ = 0) at the 5% significance level.
-
We fail to reject the KGMHLBC model (γ = 0) at any reasonable significance level.
-
We reject the Stevenson model (δ = γ = 0) and ALS model (μ = γ = 0) at any reasonable significance level.
Because both the Stevenson model and ALS model are rejected, we conclude that the exogenous factors do affect efficiency. Among RSCFG, RSCFG-μ, and scaled Stevenson models, the RSCFG model is preferred because we fail to reject the RSCFG model at any reasonable significance level using the RSCFG-μ model or the scaled Stevenson model as the unrestricted model. Moreover, among all the models, the KGMHLBC model is most preferred because it is the only one that we can accept at any reasonable significance level. Therefore, we select the KGMHLBC model as our final model.
4.2 A bootstrap evaluation
The model selection procedure proposed by AAOS leads to one clearly preferred model, the KGMHLBC model, among the set of competing models. However, it is important to ask about the reliability of the model selection criterion, which is a question of the size and power properties of the LR tests. We investigate this question using the bootstrap. That is, we generate data via the bootstrap assuming that the KGMHLBC model is correct, and then we see how reliably the model selection procedure picks the KGMHLBC model. So far as we are aware this approach has not been used previously in the literature. It is useful because we are using the bootstrap to evaluate the probability with which the actual model selection procedure will pick the correct model.
The KGMHLBC model is written as
We take the following steps to conduct the parametric bootstrap:
-
1.
Using the actual sample data {(y i , x i , z i )} n i=1 , estimate the KGMLBC model using MLE to get \(\hat{\theta}=\{\hat{\beta},\hat{\delta},\hat{\mu},\hat{\sigma}_u^2, \hat{\sigma}_v^2\}.\) These results are provided in Tables 3 and 4.
-
2.
Next generate pseudo-data sets based on the parameter estimates from step 1. That is, for i = 1,…,n, draw u * i from \(N[\hat{\mu}\cdot\hbox{exp}(z_i^{\prime}\hat{\delta}), \hat{\sigma}_u^2]^+,\) v * i from \(N(0,\hat{\sigma}_v^2),\) and then compute \(y_i^*=x_i^{\prime}\hat{\beta}+v_i^*-u_i^*.\)
-
3.
Based on the pseudo-data {y * i , x i , z i } n i=1 generated in step 2, estimate all seven inefficiency models using MLE. Take the log-likelihood value (ll *) and parameter estimates (\(\hat{\theta}^*\)) in each of the models, denoted as \(\zeta^*=\{(ll_j^*,\hat{\theta}_j^*)\}_{j=1}^7,\) where j indexes the different models.
-
4.
Repeat steps 2 and 3 1,000 times to obtain \(\fancyscript{B}=\{\zeta_b^*\}_{b=1}^{1000}.\)
We use the log-likelihood statistics in \(\fancyscript{B}\) to conduct the AAOS specification tests for each pseudo-data set, taking the general model as the unrestricted model and conduct LR tests at the 5% significance level. The results are:
-
We reject the true model in 5.7% of the pseudo-data sets, the scaled Stevenson model in 75% of the pseudo-data sets, the RSCFG-μ in 78% of the pseudo-data sets, and the RSCFG in 75% of the pseudo-data sets.
-
We reject both the Stevenson model and the ALS model in 99.9% of the pseudo-data sets. That is, in only one of the 1,000 data sets, we would wrongly conclude that the set of exogenous factors do not affect efficiency.
-
We accept the true model and reject all of the other models in 66.0% of the pseudo-data sets. We reject the true model and accept an alternative one at the same time in only 0.4% of the data sets.
-
In 28.4% of the pseudo-data sets, we simultaneously accept the true model and at least one of the alternative models. And we reject all of the models simultaneously in 5.3% of the data sets.
These results suggest that the AAOS model selection criteria do a good job of discriminating between models. If the KGMHLBC model is correct, the model selection procedure will reject it with small probability (6%), and will pick it unambiguously with relatively high probability (66%).
The bootstrap results also can be used to generate confidence intervals for any of our original estimates. These confidence intervals may be more accurate in finite samples than those generated by first order asymptotic approximations such as the delta method. For example, we can use the parameter estimates of the KGMHLBC model in \(\fancyscript{B}\) to compute the partial effects for every observation in each pseudo-data set. Confidence intervals then follow directly from the set of \(\fancyscript{B}\) estimates. For example, given 1,000 pseudo-data sets a 90% confidence interval for a parameter ranges from the 50th to the 950th largest values of the bootstrap estimates of that parameter. This is called the “percentile bootstrap”. Table 10 reports 90% percentile bootstrap confidence intervals for the partial effects in the KGMHLBC model, evaluated at the sample mean. For purposes of comparison, it also gives the 90% confidence intervals based on the delta method (i.e. using the standard errors computed as in the appendix and reported in Table 6). The confidence intervals given by bootstrap and the delta method are not very different. This confirms the reliability of the delta method.
5 Post-estimation analysis
Post-estimation analysis is based on the results of our selected KGMHLBC model. Table 11 reports output elasticity estimates for local seed users and hybrid seed users calculated at their respective sample means with their standard errors in parentheses.Footnote 12 The sum of the output elasticities with respect to FERTILIZER, LABOR, and SEED is less than 1 (0.80 for local seed users and 0.74 for hybrid seed users). However, this is expected and does not mean the technology is decreasing returns to scale because we are holding land constant (production is measured as yield per acre). Results show that output elasticities with respect to FERTILIZER and SEED are higher for hybrid seed users than local seed users, but the output elasticity with respect to LABOR is higher for local seed users.
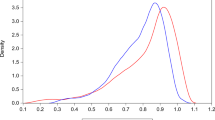
Figure 2 plots the density of the Battese and Coelli technical efficiency estimates. The minimum efficiency level is 18% and the maximum is 98%. The mean of technical efficiency is 71%, while the mode is around 80%. The distribution is left skewed.

Kernel density estimate based on Battese and Coelli technical efficiency estimates
The statistic R 2 z suggests that about 10% of the sample variation in inefficiency can be explained by the set of exogenous factors (see bottom of Table 4). From Table 6, EDUHIGH, RNFINC and TTACRES all have positive partial effects on the mean and negative effects on the variance of efficiency. FEMHEAD, DISTBUS, and OWNED all have negative effects on the mean and positive effects on the variance of efficiency. Therefore, an average household tends to have a higher efficiency level and a lower uncertainty on efficiency if it has a higher education level, more off-farm income, or larger farm size. Alternatively, it tends to have a lower efficiency level and higher uncertainty of efficiency if it has a female head, or is far from a bus-stop.
These results are mostly consistent with a priori reasoning and the previous literature. The effects of education, credit constraints, farm size and infrastructure on efficiency have been discussed extensively in the previous literature. The effect of female head could be due to the fact that females are subject to social discrimination in Kenya. There are generally two situations in which a female can become the head of a household. One is that she is a single mother, and the other is that her husband is dead. Females do not have the same inheritance rights as males in rural Kenya. A widow cannot obtain full rights to the land left by her husband and has to give away a certain proportion of the harvest to her husband’s brothers. This may reduce the incentive to work intensively.
A surprising result is that farmers tend to be more efficient in rented fields than in their own fields. There are possible two reasons: (1) a fixed rent has to be paid at planting time, which provides more incentives for farmers who work in a rented field than in their own fields; (2) farmers rent fields that they know are productive. To the extent the second reason is a factor, the variable OWNED might capture the unobserved land quality not included as a covariate in the production frontier.
As explained earlier, not only the directions but the values of the partial effects on E(−u i |x i , z i ) are of economic interest. According to the KGMHLBC model (see Table 10), one more school year would increase yield per acre by a little over half a percent for an average household, ceteris paribus. Being one kilometer closer to public transportation would increase yield per acre by 3.7%. An increase of one acre in farm size would raise yield per acre by less than one-third of a percent. If the proportion of household members who receive off-farm income increases by 10%, yield per acre would increase by 1.3%. However, using the same amount and the same quality of inputs, a household with a female head tends to produce 14% less maize than a household with a male head, and farmers tend to produce 17% more maize working in rented fields than in their own fields.
6 Conclusion
This paper makes four contributions to the stochastic frontier literature. First, we provide formulas to compute the standard errors for partial effects of exogenous firm characteristics on output levels and inefficiency for alternative model specifications. Second, we develop an R2-type measure that summarizes the overall explanatory power of the exogenous factors that affect inefficiency. Third, we propose a bootstrapping procedure to evaluate the power of the recently developed model selection procedure suggested by AAOS to choose among competing models of the influence of firm characteristics on inefficiency. To our knowledge, bootstrapping has not been used previously to examine the size and power of model selection criteria. Fourth and finally, we apply our procedures and the AAOS model selection approach to an empirical application of stochastic frontier analysis of maize production in Kenya.
The application is to Kenyan maize production and we find that different specifications provide similar efficiency rankings of households and predict the same directions for partial effects of exogenous factors. However, the magnitudes of these estimated partial effects are rather different across model specifications. This finding calls for more attention to model selection in empirical stochastic frontier analysis. The specification tests recently proposed by Alvarez et al. (2006) yield an unambiguous choice of best model using the Kenyan maize data. After evaluating the size and power of the test procedures with our bootstrap analysis we then use the preferred model to identify factors that limit technical efficiency in maize production in Kenya, and quantify their partial effects on maize yields. We examine the effects of education, female head of household, distance from a bus stop, land owned or rented, extent of off-farm income, and farm size on the level of efficiency. Approximately 10% of the variation in efficiency levels is accounted for by these household characteristics, and while education, non-farm income, and farm size increase technical efficiency, female-headed households, distance from a bus stop, and land being owned rather than rented all decrease it.
Notes
Some studies use a two-step procedure where the frontier function is estimated first, and then the inefficiency term is regressed on exogenous variables in the second step. This procedure is biased for two reasons. The first and more obvious reason is the possible correlation between the input variables in the frontier function and the variables in the inefficiency term. The second reason is that the inefficiency term from the first step is measured with error and the error is correlated with the exogenous factors. See Wang and Schmidt (2002) for an extensive discussion and evidence from Monte Carlo experiments.
Here we assume there is no overlap between x and z, i.e., no variable appears in both the frontier component (x) and the inefficiency component (z). It is straightforward to generalize the following equations to allow for overlap between x and z.
See Suri (2005) for a study of the adoption decisions of hybrid seed by maize producers in Kenya using the same data set.
Six hundred and thirty-seven out of the total 1,718 fields are dropped.
More than 20 types of fertilizers were applied. While some of these use nitrogen, phosphorous, and other nutrients in various proportions, nitrogen is usually the major nutrient deficiency and many of the major fertilizers use nitrogen and phosphorous in fixed proportions. Therefore, the level of applied nitrogen should give a reasonably accurate measure of the impact of fertilizer on yields.
EDUHIGH may capture the effects of education on efficiency for a household better than the average education level or the education level of the household head, in that the one who receives the highest education can help the household head and the other household members in making production decisions.
We use DISTBUS instead of how far a household is from a motorable road, because only a very small proportion of the households in Kenya own motorable transportation tools (like tractors), and bus and bicycles are the major transportation tools there.
The LR test results are available from the authors on request.
Wang (2002) gives the expressions for these derivatives but not for the standard errors.
The quartiles were computed using the KGMHLBC model.
Similar patterns are observed for the other exogenous factors but these results are not reported to conserve space.
The means of FERTILIZER, LABOR, and SEED are computed after taking logarithms.
References
Ahmad M, Bravo-Ureta BE (1995) An econometric decomposition of dairy output growth. Am J Agric Econ 77:914–921
Ali M, Flinn JC (1989) Profit efficiency among basmati rice producers in Pakistan Punjab. Am J Agric Econ 71:303–310
Alvarez A, Arias C (2004) Technical efficiency and farm size: a conditional analysis. Agric Econ 30:241–250
Alvarez A, Amsler C, Orea L, Schmidt P (2006) Interpreting and testing the scaling property in models where inefficiency depends on firm characteristics. J Productiv Anal 25: 201–212
Aigner DJ, Lovell CAK, Schmidt P (1977) Formulation and estimation of stochastic frontier production functions. J Econometrics 6:21–37
Barrett C (1996) On price risk and the inverse farm size-productivity relationship. J Dev Econ 51:193–216
Battese GE, Coelli TJ (1995) Frontier production functions, technical efficiency and panel data: with applications to paddy farmers in India. J Productiv Anal 3:153–169
Benjamin D (1995) Can unobserved land quality explain the inverse productivity relationship? J Dev Econ 46:51–84
Caudill SB, Ford JM (1993) Biases in frontier estimation due to Heteroskedasticity. Econ Lett 41:17–20
Caudill SB, Ford JM, Gropper DM (1995) Frontier estimation and firm specific inefficiency measures in the presence of Heteroskedasticity. J Bus Econ Statist 13:105–111
Hadri K (1999) Estimation of a doubly heteroscedastic stochastic frontier cost function. J Bus Econ Statist 17:359–363
Hazarika G, Alwang J (2003) Access to credit, plot size and cost inefficiency among smallholder tobacco cultivators in Malawi. Agric Econ 29:99–109
Huang CJ, Liu JT (1994) Estimation of a non-neutral stochastic frontier production function. J Productiv Anal 5:171–180
Huang Y, Kalirajan K (1997) Potential of China’s grain production: evidence from the household data. Agric Econ 70:474–475
Jacoby H (2000) Access to markets and the benefits of rural roads. Econ J 110:713–737
Karanja D, Jayne T, Strasberg P (1998) Maize productivity and impact of market liberalization in Kenya. Michigan State University International Development, Working Paper
Kumbhakar S, Biswas B, Bailey D (1989) A study of economic efficiency of Utah dairy farmers: a system approach. Rev Econ Statist 71:595–604
Kumbhakar S, Ghosh S, McGuckin J (1991) A generalized production frontier approach for estimating determinants of inefficiency in US dairy farms. J Bus Econ Statist 9:279–286
Lamb R (2003) Inverse productivity: land quality, labor markets, and measurement error. J Dev Econ 71:71–95
Meeusen W, van den Broeck J (1977) Efficiency estimation from Cobb-Douglas production functions with composed error. Int Econ Rev 18:435–44
Nyoro J, Kirimi L, Jayne T (2004) Competitiveness of Kenyan and Ugandan maize production: challenges for the future. Michigan State University, International Development, Working Paper
Parikh A, Ali F, Shah MK (1995) Measurement of economic efficiency in Pakistani agriculture. Am J Agric Econ 77:675–685
Place F, Hazell P (1993) Productivity effects of indigenous land tenure systems in sub-Saharan Africa. Am J Agric Econ 75:10–19
Puig-Junoy J, Argiles J (2000) Measuring and explaining farm inefficiency in a panel data set of mixed farms. Pompeu Fabra University, Working Paper
Reifschneider D, Stevenson R (1991) Systematic departures from the frontier: a framework for the analysis of firm inefficiency. Int Econ Rev 32:715–723
Sen A (1962) An aspect of Indian agriculture. Economics Weekly (February):243–246
Sherlund S, Barrett C, Adesina A (2002) Smallholder technical efficiency controlling for environmental production conditions. J Dev Econ 69:85–101
Stevenson RE (1980) Likelihood functions for generalized stochastic frontier estimation. J Econometrics 13:57–66
Suri T (2005) Selection and comparative advantage in technology adoption. Yale University, Job Market Paper
Wang HJ (2002) Heteroscedasticity and non-monotonic efficiency effects of a stochastic frontier model. J Productiv Anal 18:241–253
Wang HJ (2003) A stochastic frontier analysis of financing constraints on investment: the case of financial liberalization in Taiwan. J Bus Econ Statist 21:406–419
Wang HJ, Schmidt P (2002) One-step and two-step estimation of the effects of exogenous variables on technical efficiency levels. J Productiv Anal 18:129–144
Acknowledgments
The authors would like to thank Peter Schmidt for his suggestions and comments. Thanks also go to Thomas Jayne for generously providing us the data, Elliot Mghenyi, Kirimi Sindi, Tavneet Suri, and Margaret Beaver for comments and suggestions. All remaining errors or omissions are our own.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Estimating partial effects of exogenous factors and their standard errors for the general model
Assume there are K exogenous factors (K 1 continuous variables and K 2 = K − K 1 dummy variables). We deal with the continuous variables first. Let z c i be the K 1 dimensional vector of the continuous variables. We derive the partial effects of z c i on the mean and variance of efficiency via differentiation as
where μ i = μ · exp(z ′ i δ), σ i = σ u · exp(z ′ i γ), δc and γc are the coefficient vectors associated with z c i , R 1, R 2, and R 3 are as defined in the text, and R 4 = R 1(R 2 + R 1 R 3 + 2R 2 R 3).
Next we derive the variances of the partial effects of z c i . Let θ′ = (δ′ γ′), and \(g(\theta)=\partial{[E(-u_i|x_i, z_i)]}/\partial{z_i^c},\) and \(h(\theta)=\partial{[V(u_i|x_i, z_i)]}/\partial{z_i^c},\) where both g(θ) and h(θ) are K 1 × 1 dimensional vectors. Following the delta method,
We derive \(\partial{g(\theta)}/{\partial{\delta^{\prime}}}, \partial{g(\theta)}/{\partial{\gamma^{\prime}}}, \partial{h(\theta)}/{\partial{\delta^{\prime}}}\) and \(\partial{h(\theta)}/{\partial{\gamma^{\prime}}}\) as
where D = [I K1 0 K1 × K2 ] is a K 1 × K dimensional matrix, and
\(\frac{\partial{g(\theta)}}{\partial{\theta^{\prime}}}=\left[\frac{g(\theta)}{\delta^{\prime}}\,\,\frac{g(\theta)}{\gamma^{\prime}}\right]\) and \(\frac{\partial{h(\theta)}}{\partial{\theta^{\prime}}}=\left[\frac{h(\theta)}{\delta^{\prime}}\,\,\frac{h(\theta)}{\gamma^{\prime}}\right]\) are K 1 × 2K dimensional matrices, which depend on the model parameters δ and γ. We can get the estimates of \(\frac{\partial{g(\theta)}}{\partial{\theta^{\prime}}}\) and \(\frac{\partial{h(\theta)}}{\partial{\theta^{\prime}}}\) by substituting the estimates of δ and γ into the above formulas. The variances of the partial effects can be estimated by substituting the estimate of \(\frac{\partial{g(\theta)}}{\partial{\theta^{\prime}}}\) as well as the estimate of the variance–covariance matrix of \(\hat{\theta}\) into the formulas (13) and (14).
Next we compute partial effects of dummy variables. Let z ik be the dummy of concern. The partial effects of z ik on E(−u i |x i ,z i ) and V(u i |x i ,z i ) are
Similarly, following the delta method, we have
We then have \(\partial{d(\theta)}/\partial{\delta^{\prime}}, \partial{d(\theta)}/\partial{\gamma^{\prime}}, \partial{r(\theta)}/\partial{\delta^{\prime}},\) and \(\partial{r(\theta)}/\partial{\gamma^{\prime}}\) as follows
\(\frac{\partial{d(\theta)}}{\partial{\theta^{\prime}}}=\left[\frac{d(\theta)}{\delta^{\prime}}\,\,\frac{d(\theta)}{\gamma^{\prime}}\right]\) and \(\frac{\partial{r(\theta)}}{\partial{\theta^{\prime}}}=\left[\frac{r(\theta)}{\delta^{\prime}}\,\,\frac{r(\theta)}{\gamma^{\prime}}\right]\) are 1 × 2K dimensional matrices. The variances of the partial effects for z ik can be estimated similarly as for the continuous variables described earlier.
Rights and permissions
About this article
Cite this article
Liu, Y., Myers, R. Model selection in stochastic frontier analysis with an application to maize production in Kenya. J Prod Anal 31, 33–46 (2009). https://doi.org/10.1007/s11123-008-0111-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-008-0111-9