
Abstract
Conventional transportation practices typically focus on alleviating traffic congestion affecting motorists during peak travel periods. One of the underlying assumptions is that traffic congestion, particularly during these peak periods, is harmful to a region’s economy. This paper seeks to answer a seemingly straightforward question: is the fear of the negative economic effects of traffic congestion justified, or is congestion merely a nuisance with little economic impact? This research analyzed 30 years of data for 89 US metropolitan statistical areas (MSAs) to evaluate the economic impacts of traffic congestion at the regional level. Employing a two-stage, least squares panel regression model, we controlled for endogeneity using instrumental variables and assessed the association between traffic congestion and per capita gross domestic product (GDP) as well as between traffic congestion and job growth for an 11-year time period. We then investigated the relationship between traffic congestion and per capita income for those same 11 years as well as for the thirty-year time period (1982–2011) when traffic congestion data were available. Controlling for the key variables found to be significant in the existing literature, our results suggest that the potential negative impact of traffic congestion on the economy does not deserve the attention it receives. Economic productivity is not significantly negatively impacted by high levels of traffic congestion. In fact, the results suggest a positive association between traffic congestion and per capita GDP as well as between traffic congestion and job growth at the MSA level. There was a statistically insignificant effect on per capita income. There may be valid reasons to continue the fight against congestion, but the idea that congestion will stifle the economy does not appear to be one of them.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Although not universal, there is a generally established belief that high levels of traffic congestion negatively impact the economy. Figure 1 depicts vehicle miles traveled (VMT) for the US increasing almost linearly with the nation’s gross domestic product (GDP) for most of the last eight decades. Until recently, the positive correlation held reasonably firm, and the seemingly linear relationship between VMT and GDP led policymakers and academics alike to conclude that the relationship is both causal and bi-directional. In other words, anything hindering VMT growth would negatively affect the economy—and vice versa. This mindset often manifests itself as a fear that high levels of traffic congestion are a drain on the economy. For example, the US Department of Transportation (USDOT) stated that:

(Source: created using data collected from BEA and FHWA)
US Real Gross Domestic Product (GDP) and Vehicle Miles Traveled (VMT) from 1929–2017.
Congestion in 498 metropolitan areas caused urban Americans to travel 5.5 billion hours more and to purchase an extra 2.9 billion gallons of fuel for a congestion cost of $121 billion (Federal Highway Administration 2013).
For much of the last century, the approach to solving the perceived traffic congestion problem was to increase highway capacity. Nearly every regional planning agency measures system performance with peak hour congestion, measured in terms of vehicle delay, or its correlate, peak hour level-of-service (NCHRP 2003). Simply put, locations where these measures exceed some threshold value become targets for capacity-expansion projects. Then contemporary transportation practice considers economic factors by aggregating the travel time and fuel savings for all drivers and comparing that sum against the cost of the project. If the estimated value of people’s time and fuel exceeds the proposed cost of the project, the project is typically deemed economically beneficial and worthwhile to the region (Weisbrod et al. 2001).
Despite the widespread prevalence of this transportation planning approach, it is by no means clear that projects focused on eliminating congestion benefit a region’s economy. The research question this paper focuses on, however, is whether too much traffic congestion negatively impacts the economy in the first place. Is our concern for the economic impacts of traffic congestion well founded? In terms of policy implications, should we continue trying to eradicate traffic congestion for the sake of our economic well-being?
We attempt to answer these questions via 30 years of data, from 1982 through 2011, for the largest 100 U.S. metropolitan statistical areas (MSAs). Using a panel regression model with several instrumental variables to control for the endogeneity between traffic congestion and economic productivity, we assess the association between traffic congestion and gross domestic product (GDP) per capita (for the 11 years of available GDP data at the MSA level); jobs (for the same 11 years); and per capita income (PCI) (for the same 11 years as well as for the full 30 years). Controlling for potentially relevant variables—such as education, race/ethnicity, and weather—the goal is to shed light on the relationship between congestion and the economy so that planners, engineers, and policy-makers can make informed decisions when it comes to whether or not congestion alleviation for the sake of the economy deserves its spot as a top transportation priority.
Literature review
Traffic congestion itself has long been a prominent topic, particularly with the popular press with regard to concerns regarding the potential negative impact of congestion on the economy (Copeland 2007; Staley 2012). The research related to traffic congestion tends to be more complicated (Woudsma et al. 2008; Mondschein et al. 2010), with much of the academic work focusing on calculating the various “costs” of congestion (Bilbao-Ubillos 2008; Kriger et al. 2007; Safirova et al. 2007; Weisbrod et al. 2003).
Several studies found congestion to be a drain on the economy (Arnott 2007; Anas and Xu 1999; Weisbrod et al. 2003). For instance, Boarnet investigated California counties from 1977 through 1988 and found that increased congestion was negatively associated with the economy, as measured though a combination of labor inputs and private capital stock (Boarnet 1997). However, Boarnet also found that while congestion reduction is theoretically productive, “the effect of expanding the street and highway stock are more suspect” (Boarnet 1997). In another relevant paper, Hymel studied 85 metropolitan statistical areas (MSAs) with a similar panel model to our study and with employment as the dependent variable (Hymel 2009). Based on his findings suggesting that congestion is a drain on the economy, Hymel called for “expanding road capacity” or implementing “congestion pricing” in order to combat traffic congestion and ensure continued job growth (Hymel 2009).
Another set of papers dispute that idea that traffic congestion is a drain on the economy. Fernald studied the link between congestion and economic output between 1953 and 1989 for the US and found no connection between the variables prior to 1973 and a negative relationship after (Fernald 1999). In a study of London wards, Graham (2007) modeled congestion and density against economic productivity by sector. He found congestion to be positively associated with some business sectors—such as real estate, banking and finance, business services, and personal services—and diminishing returns for others such as manufacturing, construction, distribution, and information technology (Graham 2007). It should be observed that FIRE-based industries (i.e. financial, insurance, and real estate) tend to generate greater revenues than manufacturing, construction, and distribution. The relocation of the latter type of industries to outside of London would appear to be a part of the natural economic functions of cities, where higher-value activities eventually supplant lower-value ones, which in turn relocate to areas with lower land values (Glaeser 2011).
In another pertinent study, Sweet (2014b) examined how traffic congestion impacts job growth and worker productivity (Sweet 2014b). His results suggest that at very high levels of congestion, job growth is expected to be negatively impacted. However, Sweet acknowledges that no MSA in the US has approached the level of congestion at which it would become a negative influence. Of the MSAs with relatively high levels of congestion, only Detroit experienced a negative association between job growth and congestion. At more typical levels of congestion, Sweet’s model found that congestion was positively associated with job growth. However, he downplayed these results as follows:
There is no theoretical reason why congestion would directly act as an input to better economic outcomes, so the effect of congestion at those levels at which it is associated with higher employment growth is perhaps best interpreted as representing the inefficiency of alleviating congestion on uncongested roadways (Sweet 2014b).
Sweet’s secondary model focuses on change in worker productivity instead of jobs and finds congestion to be statistically insignificant. Sweet goes on to say that “economies do not stagnate as a consequence of traffic” and that the best predictors of economic growth in terms of worker productivity have more to do with a dense urban core and regional economic demand (i.e. the quantity, diversity, and types of business and workers within a given region) as opposed to transportation infrastructure (Sweet 2014b).
When considered as a whole, the existing literature is, at best, inconsistent with conventional wisdom that traffic congestion is detrimental to the economy and seemingly dependent upon the framing of the research question and how the data are collected and analyzed. This is particularly true when attempting to account for how traffic congestion might influence land use decisions, infrastructure investments, changes in regional accessibility, and investments in non-automobile modes. For example with the papers investigating how people adapt with location decisions in situations with high traffic congestion, some found more downtown growth (Cervero 1996; Cervero and Duncan 2006; Gordon et al. 1989) while others found increased suburban co-location of both employers and workers (Crane and Chatman 2003; Gordon et al. 1989; Levinson and Wu 2005; Levinson and Kumar 1994). Another paper found evidence of firms moving out due to high levels of regional congestion but saw localized congestion (as measured by a marginal congestion penalty that was calculated using an accessibility index) as an economic benefit in terms of firms being more prone to relocate to areas with relatively high levels of localized congestion (Sweet 2014a). These findings raise the question: is the fear of negative economic impacts due to traffic congestion well founded, or is traffic congestion merely a nuisance with little economic impact? Our paper seeks to shed light on this issue.
Theory
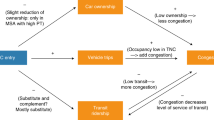
Metropolitan areas help foster social interactions and economic exchanges. These connections typically require people and goods to move within and across regions. When accomplished via driving, we can end up with high levels of vehicular mobility. High levels of driving can positively impact the economy in terms of facilitating these social and economic transactions. At the same time, driving can be costly: for the region in terms of infrastructure and maintenance, land consumption for roads and parking, and the related environmental costs; and for businesses and individuals in terms of vehicle ownership, gas prices, time spent driving, and the related human health costs.
Congestion results from too many people trying to realize these ends at the same time in the same space. If everyone is trying to get to work at the same time on a limited set of infrastructure options, it makes sense that traffic congestion could negatively affect the workers, businesses, and the economic well-being of a region. So on one hand, traffic congestion could constrain mobility and accessibility, limit productivity, and discourage residents and businesses from locating in a region. In light of that, conventional wisdom tells us that high levels of traffic congestion would be associated with decreased economic outputs and the need to compensate workers with higher wages because of higher travel costs. On the other hand, high levels of traffic congestion is suggestive of a region with good economic vitality since a strong economy helps facilitate car ownership and the need for goods movement. Traffic congestion lowers the utility of the car and increases the relative utility of other modes. It could also reduce the attractiveness of suburbs due to a lack of accessibility and increase the relative attractiveness of living in the center city or compact and transit-oriented development. As a result, traffic congestion could lead to potentially positive economic externalities such as infill development, more efficient travel patterns and mode choices, as well as agglomeration benefits.
Thus, the crux of our conceptual model revolves around the potential for endogeneity between traffic congestion and economic productivity as well as between vehicle mobility and economic productivity, which we will test for in our statistical models. In other words, the directionality of these relationships is unknown and could theoretically be bi-directional. The more vehicle mobility there is, for instance, the more traffic congestion there is likely to be. At the same time, the more traffic congestion there is, the less attractive driving a vehicle might be (and the more attractive other modes and/or more accessible locations might be). These relationships can also be moderated by automobile ownership costs, gas prices, and a host of other factors such as the ability to meet daily needs without an automobile. If transit, walking, and bicycling modes can serve social interactions and economic exchanges, then traffic congestion and vehicle mobility may not matter quite as much. If people do not have viable options beyond the automobile, then it is easier to see how traffic congestion could negatively influence our economic outcomes. Measures of urban form and the built environment have long been effective proxies for accessibility, transit use, and active transportation mode shares (Ewing and Cervero 2001). Such measures have also been shown to control for agglomeration benefits (Glaeser et al. 2001).
Economic outputs come down to more than factors related to mobility, traffic congestion, and the built environment. For instance, a highly educated population might lead to better economic outcomes. Regions with more people of working age or a greater percentage of workers in the prime earning years could also improve economic outputs (Andolfatto et al. 2000). Given the gender income gap, regions with relatively higher rates of women in the workforce could play a role (Bobbitt-Zeher 2007). Regrettably, minority populations in the US have also been consistently linked to lower incomes and higher rates of unemployment and poverty than the general population (Wright 1978, Portes and Rumbaut 2014).
Crime levels have long been to be linked economic outcomes (Roman 2013; The Economist 2011; Klaer and Northrup 2014; Glaeser 1994, 1998; Detotto and Otranto 2010). For instance, cities and regions known for high levels of crime, all else being held equal, have been shown to repel workers and businesses (Glaeser 2011). The attractiveness of good weather—particularly in the winter months—has also proven to be a significant factor in residential location decisions as well as in forecasting the economic success of different regions (Glaeser and Kohlhase 2004; Rappaport 2007). Accordingly, both crime and weather seem to be control factors worthy of consideration in our study (Glaeser 2011).
Figure 2 illustrates the theoretical constructs of this discussion and the basis of our statistical models.

Conceptual Model
Data
Dependent variables: economic performance
To assess economic activity, we collected data for the 100 largest metropolitan statistical areas (MSA) from the U.S. Bureau of Economic Analysis (BEA), which is the governmental unit charged with measuring economic statistics. This included: gross domestic product (GDP), for the years 2001 through 2011; and per capita income (PCI), for the years 1982 through 2011. While GDP per capita and PCI are highly correlated (Pearson correlation coefficient = 0.90 for our dataset), there are differences in how the data are collected. GDP measures the value of what an economy produces in terms of goods and services as well as economic outputs such as technology and intellectual property. PCI intends to capture overall economic value via the pre-tax income of those that produced the goods and services. If it were true that traffic congestion has a negative effect on a region’s economic performance, then one would expect regions with higher levels of congestion to have lower levels of per capita GDP and/or PCI, ceteris paribus.
We also collected MSA-level jobs data from the U.S. Bureaus of Labor Statistics. In theory, traffic congestion could have differing impacts on, for instance, PCI and job growth. That is, if firms need to pay their workers more to overcome the costs of congestion, then PCI would increase; yet, job growth could slow because of the lack of additional capital after paying these existing workers higher wages and/or the potentially high costs of starting a business in a congested region where higher wages are needed. For the sake of comprehensiveness, we included per capita GDP, job growth, and PCI as our economic outcomes.
We focus on the regional level because that is primarily where the population and economic capacity for the US is congregated, as the top 100 MSAs consume only 12% of US land but possess more than two-thirds of US population and three-quarters of the national GDP (Katz and Bradley 2013). According to the Census, the general concept behind MSAs is to bring large population centers together with adjacent communities that have a “high degree of economic and social integration with that core” (U.S. Census 1994). In order to meet the standards for a high degree of integration, surrounding areas must achieve a certain level of commuting to the primary population center as well as meet other requirements relating to metropolitan character such as minimum population densities or percentages of the population considered urban. The idea for metropolitan districts dates back to the early 1900s when the Census of Manufacturers realized that it was difficult to assess economic outcomes while being limited to the boundaries of any one city. While MSA boundaries are county-based and include some rural areas, these designations were intended for economic analysis.
Nominal dollar figures were converted to 2017 constant dollars using the Consumer Price Index calculator on the US Bureau of Labor Statistics webpage (BLS 2017). The data sources do not distinguish among different industries or worker classifications.
The intent was to control for as many factors that have been found to be associated with a region’s economic performance as possible, including: socio-demographic composition (Murnane 2008; Ribeiro et al. 2010; Rose and Betts 2004; Sweet 2014b); the physical characteristics of the built environment (Harris and Ioannides 2000; Marrocu et al. 2013; Paci and Usai 2000; Glaeser 2001; Glaeser et al. 1992); and weather and crime rates (Sweet 2011; Glaeser and Kahn 2003; Glaeser 2011).
Measuring congestion
The first step in measuring the economic effects of congestion is to define what, specifically, traffic congestion is and how it differs from vehicle miles traveled (VMT) because there is an important difference between the two measures. Congestion is a measure of the difference between free-flow travel speeds and speeds experienced under congested conditions. This is typically reported in terms of vehicle hours of delay, or else converted into level-of-service, which translates vehicle delay into a scale of A to F, where A = free flow, or unimpeded conditions, and F = forced flow. Traffic congestion, however, is functionally distinct from VMT. A region with a high level of VMT per capita does not necessarily mean that region is congested; on the other hand, much of the VMT in a region with a relatively low total VMT per capita could still be under severely congested conditions. As a result, it is important to distinguish traffic congestion (delay) from vehicular mobility (VMT) as well as understand that overall mobility also includes other modes of transportation and can be moderated by gas prices and a host of other factors. Because congestion and VMT were not highly correlated variables in our dataset (finding a Pearson correlation coefficient of 0.24), we examined the economic effects of congestion while controlling for VMT.
While congestion manifests itself at the micro-scale (i.e. corridor and/or intersection), it remains the macro-scale factors—such as regional land use patterns, modal options, and car ownership trends—that generate traffic congestion outcomes. In terms of measuring congestion, the Urban Mobility Reports published by the Texas Transportation Institute (TTI) have long been the industry standard for understanding such traffic issues in the US. The focus of the congestion metrics in this series of reports has always been at the regional level. These urbanized area boundaries for which the congestion metrics are collected correspond to contiguous areas of populations more than 50,000 and population densities greater than 1000 per square mile (U.S. Census 2010). Measuring congestion at levels of geography larger than the region (such as for a state, nation, or planet) do not mean as much due to the lack of contiguity. Measuring congestion at levels of geography smaller than the region (such as a corridor or intersection) is great for short-term travel decisions, but these metrics do not mean much for strategic planning because of their lack of representative impact and failure to reflect congestion exposure. When issues such as crashes or work zones cause individual transportation links to experience congestion, many road users can re-route to a different link and reach their destination without much hassle. However, peak hour traffic congestion when experienced across a region—instead of along individual corridors—leaves many of those that are driving with little in the way of alternative route options.
Thus, we collected congestion data from the TTI Annual Urban Mobility Scorecard database. While the TTI Urban Mobility Reports have taken their fair share of criticism, the critiques tend to be less about the congestion metrics themselves and more about how those metrics are used and interpreted. For example in his 2014 report, “Congestion Costing Critique,” Litman highlights the Urban Mobility Report’s biases in favor of automobile commuters over other travel modes as well as the exaggerated benefits of congestion reduction related to travel time cost savings and emissions reductions (Litman 2014). Litman goes on to say that the title of the Urban Mobility Report is somewhat misleading because, in reality, it only measures vehicle congestion. In terms of the metrics themselves, the most prominent critique is that TTI bases their congestion benefits off of free-flow speed—which in many cases can be significantly higher than the speed limit and can lead to the overestimated impacts when under congested conditions (Litman 2014). While we acknowledge that the historic TTI Urban Mobility Report traffic congestion metrics are not perfect, few researchers dispute their validity in terms of reflecting regional-scale traffic congestion both within and across regions.
Relevant congestion metrics were available for the period since 1982 included:
Percent of peak VMT under congested conditions;
Percent of lane miles under congested conditions;
Total annual hours of delay and annual hours of delay per automobile commuter;
Travel time index value; and
Roadway congestion index.
Since all of the congestion variables were all highly correlated with one another, we focused on finding the most theoretically relevant congestion variable that would minimize the potential for overestimation as described above. Several studies have investigated the various congestion metrics (Bertini 2006; Grant-Muller and Laird 2007; Lomax et al. 1997; NCHRP 2003). In a survey of transportation professionals conducted by Bertini, for instance, the majority of respondents felt that congestion referred to travel during peak periods (Bertini 2006). Based on this, we wanted our measure of congestion to represent peak hour delay or peak hour level-of-service seeing as these variables are also commonly used in planning decisions regarding congestion mitigation strategies. As peak period traffic congestion also coincides temporally with the majority of work-related commuting travel, it stands to reason that congestion could impact the labor force, business community, and the economic well-being of a region, at least more so than non-peak traffic congestion, which tends to be intermittent and more unpredictable. The “percent of peak VMT under congested conditions” fit these criteria and is also a variable that is easy to understand and relatively stable in terms of TTI procedure over the longitudinal project period (the methods for some congestion metrics changed over the years). TTI calculates this variable in the following manner:
It should be noted that the geography used for measuring congestion (i.e. urbanized area) does not precisely overlap with the geography used to measure economic performance (i.e. MSA). MSAs are based upon the county level of geography. The county containing the urbanized area is the core county, and other counties with a high degree of economic or social integration are added to form the overall MSA (U.S. Census 2010). This geographic difference is an unavoidable result of the manner in which these data are collected. As described above, MSAs were intended for economic analysis (even though they use county boundaries), and most jobs, households, and traffic congestion occur within the urbanized area. Moreover, the research suggests that most economic activity within an MSA emanates from the urbanized portion (Redman and Sai 2012). Thus, many of those that live outside the UZA boundary but inside the MSA boundary are still impacted by UZA traffic congestion because, according to the Census, all MSA counties must meet a minimum commuting rate threshold into the primary city to be included. While this geographic mismatch may influence the results, the effects are likely minor since most of the economic activity and travel in any given MSA is within the UZA. Methods to account for potential endogeneity between congestion and the economy will be detailed in the methods section.
The percent of peak VMT under congested conditions averaged just over 17% for our regions in 1982 and 45% in 2011. This equates to approximately 9 h of annual delay per automobile commuter in 1982 and more than 33 h of annual delay per automobile commuter in 2011. The Los Angeles region experienced the highest levels of traffic congestion over this timespan. With more than 80% of their VMT during the peak period coming under congested conditions, this equates to more than 65 h of delay annually for each automobile commuter. At the other end of the spectrum, the Wichita, Kansas region only has 6% of their VMT taking place under congested conditions with 15 h of annual delay per automobile commuter. While every region experienced traffic congestion and automobile commuter delay, these levels varied by region. The standard deviation of the percent of peak VMT under congested conditions variable was just over 20 and that for delay per automobile commuter was approximately 15 h. These measurable differences in traffic congestion by region form the basis for our study.
Mobility
We collected regional VMT and gas price data from the TTI database for the years since 1982. As discussed in the previous section, the congestion and VMT variables are not highly correlated and are intended to measure different phenomena. Longitudinal motor vehicle operating cost data that varied by region would have been preferable but was not available. With respect to gas prices, nominal dollar figures were converted to 2017 constant dollars using the Consumer Price Index calculator on the US Bureau of Labor Statistics webpage (BLS 2017).
Built environment
To control for the impact of the built environment and possible positive externalities of traffic congestion such as residential location decision-making that could lead to more efficient travel patterns and mode choices, we sought out population density data. Population density has long been used as a measure of urban form and a proxy for active transport and transit alternatives (Ewing and Cervero 2001). For instance in our dataset, population density of the primary city was highly correlated with transit, walking, and biking mode shares as well as overall MSA and UZA populations.
Population density has been shown to be associated with street network and neighborhood characteristics (Tsai 2005; Marshall and Garrick 2010, 2011); walking, bicycling, and transit mode shares to work and school (Ewing and Cervero 2001; McDonald 2007); non-work trip-making and modal choice (Frank and Pivo 1994; Rajamani et al. 2003); as well as regional commute distances and times (Ewing et al. 2003; Zolnik 2011). It has also been shown to be associated with economic inputs such higher consumption (Glaeser et al. 2001). Other built environment variables that we tested were omitted due to high correlation and the resulting potential for multicollinearity and biased estimators.
Measuring population density for a region over a 30-year period presented special challenges given the possibility of changing boundaries. To improve consistency and maintain an emphasis on residential location decision-making of the center city, we downloaded GIS shapefiles at the city-level for the years 1980, 1990, 2000 and 2010 and then used time series population data to calculate population density for the primary city within each MSA for each of those years (Manson et al. 2017).
We also tested MSA and UZA populations in the models in place of population density (since the Pearson correlation coefficients were both greater than 0.73, we could not include both population and population density in the models due to the potential for multicollinearity issues and biased estimators). However, the population variables were insignificant or the resulting models not nearly as strong. The significance and direction of other variables in our models were stable regardless.
Miscellaneous variables
Socio-demographic characteristics
In order to control for socio-demographic differences in age, gender, race/ethnicity, and education, we collected Census data from the National Historical Geographic Information System for the major city within each MSA for the years 1980 through 2010 (Manson et al. 2017). We developed several age-related factors such as the number of workers in each region and the percent of the population that is of working age. We also created variables based on the prime earning years and a variable differentiating the relative percentage of women in each region. While the literature suggests 40–55 as the prime earning years, we used 35–54 to match the Census designations (Andolfatto et al. 2000). Due to high correlation among the various race/ethnicity variables, we aggregated the categories in order to represent the percent of non-white residents as compared to the overall population. Due to similar issues with the disaggregated education data, we focused on the percent of the population 25 years and over with a bachelor’s degree. This education variable is often deemed to be a measure of human capital and hypothesized to be associated with improved economic outcomes (Chatman and Noland 2014). For the Census data, we interpolated between the decennial years using the trend function in Microsoft Excel, which performs a least squares statistical regression. With respect to the final models, this turned out to be limited to just our race and education variables.
Crime
Violent crime data was gathered from the Uniform Crime Reporting Statistics website for both county and city police departments for the years 1985 through 2012 (DOJ & FBI 2014). The count of violent crime consists of four criminal offenses: murder and non-negligent manslaughter, forcible rape, robbery, and aggravated assault. The counts were geocoded based upon the name of the county (or city) and the state. We aggregated the total number of violent crimes in each MSA using a spatial join in GIS and calculated the violent crime rate using the longitudinal population numbers. We then extrapolated the rate of violent crimes in each MSA for the years 1982 through 1984 using the trend function in Microsoft Excel and the subsequent 20 years of data.
Weather
Using data from the PRISM Climate Group based at Oregon State University, we controlled for weather in order to account for the general desire for warmer weather and/or less precipitation when selecting a job (The Prism Climate Group 2014). Glaeser found mean January temperatures and average precipitation rates to be important predictors of metropolitan growth (Glaeser and Kohlhase 2004). For the sake of this study, we developed and tested the same variables. This process began with collecting a raster file containing the average January temperature across the continental US for the 30-year time period. After creating a point layer based upon the raster file, we employed a spatial join to average the data points spread across the major city within each MSA and converted the data from degrees Celsius to degrees Fahrenheit. The same procedure was repeated when calculating the annual inches of precipitation.
Table 1 presents the descriptive data for the analysis. This study initially focused on the largest 100 MSAs in the US. Due to occasional missing data with respect to our variables of interest (e.g. crime statistics) and/or inconsistencies with longitudinal geography definitions (e.g. some regions were not defined as MSAs at the beginning of our longitudinal period), the final statistical analyses included 89 MSAs. Over the course of our 30-year study period, this totaled 2670 observations. We describe the methods used for dealing with endogeneity—and the potentially relevant instrumental variables—in the next section.
Methods
The relationship between congestion and economic productivity is quite complex and possibility bi-directional. A strong economy often engenders automobile ownership and goods movement, which in turn facilitates motor vehicle travel and traffic congestion. At the same time, traffic congestion may impede mobility, limit economically productive activities, and impact the ability for residents and businesses to locate in a region. Then again, traffic congestion could lead to potentially positive economic externalities such as infill development, more efficient travel patterns, or those related to agglomeration benefits.
With regard to statistical modeling, the related methodological problem is called endogeneity (Sweet 2014b). Statistically, this creates a situation where the error term in the statistical model could be correlated with the variable representing traffic congestion, which violates the independence assumption and could bias the model (Chatman and Noland 2014; Duranton and Turner 2011; Baum-Snow 2007, Hymel 2009; Sweet 2011, 2014a).
We used Durbin Wu-Hausman to test traffic congestion, VMT per person per day, and population density for possible endogeneity with our economic outputs and found that while there are logical arguments for all three, instrumentation was only necessary for our traffic congestion variable.Footnote 1 We addressed this concern through the use of instrumental variables. Instrumental variables are predictors of one of the problematic endogenous variables but statistically independent of the other (Chatman and Noland 2014). Accordingly, we sought out variables that would potentially be useful in predicting traffic congestion but not necessarily economic well-being. We then tested these instrumental variables in a two-stage least-squares panel model regression.
Instrumental variables
Finding suitable instrumental variables led us back to the existing literature and researchers that have tackled similar endogeneity problems. For example, Sweet (2013) and Hymel (2009) both relied upon a count of the number of years of service of House of Representatives’ members from each metropolitan statistical area (MSA) on the House Transportation and Infrastructure committee (or prior to 1994, the House Public Works and Transportation Committee) (Sweet 2014b, Hymel 2009). As Hymel suggested, “the relationship between this measure and congestion is clear; members of Congress tend to promote projects and spending that benefit their constituents. One would therefore expect that metropolitan areas with greater historical representation on the Transportation Committee received more funding” and relate to subsequent congestion levels in these metropolitan areas (Hymel 2009). Sciara’s work (2012) suggests that Congressional influence can help redistribute transportation money via earmarks (Sciara 2012). Brown (2003) analyzed federal highway dollars and found them to be most closely related to political representation (Zhu and Brown 2013).
The underlying premise of this instrumental variable, however, is less about funding and more about the idea that regions with high levels of congestion may have a higher level of representation on the House Transportation and Infrastructure Committee. Since the evidence suggests that transportation infrastructure investments do little to help congestion problems anyway (Duranton and Turner 2011; Noland 2001, 2007, Cervero 2002, Cervero and Hansen 2002; Jorgensen 1947; Downs 1992; Downs 2006), then committee membership could be representative of traffic congestion levels whether or not these regions see higher funding levels. Thus, we first collected committee membership data from the C-SPAN website (C-SPAN 2016). We then cross-referenced representative names with Congressional archives to determine the state district number before then geocoding each committee member using historic district boundary GIS files (Lewis et al. 2013). While it would be possible for a Congressional district to overlap with the MSA boundary but not the UZA boundary, this was done intentionally because these outlying counties must meet a minimum commuting rate threshold into the primary city to be included in an MSA. This suggests that many of the constituents of an MSA that do not live within the UZA would still be concerned about traffic congestion into UZA. In turn, traffic congestion would likely be an issue of concern to the Congressional representative and be a valid data point for our instrumental variable. For each year of our study, we summed the number of committee members within each MSA for the previous 5 years.
The existing literature also commonly employed historic infrastructure maps—such as mid-twentieth century planned highway maps or early 1900s major road and railroad maps—to help predict contemporary traffic congestion (Baum-Snow 2007; Hymel 2009; Sweet 2011; Duranton and Turner 2011). The thinking is that the planning of new transportation infrastructure often focuses on areas where there is already significant existing traffic congestion. For example, a 1954 Highway Research Board report on urban traffic congestion discusses the process of justifying highway projects based on existing vehicle delay (Highway Research Board 1954). If existing congestion led to planned highways, and induced demand negated the expected benefits, then it stands to reason that such plans could coincide with future congestion.
The results of Duranton and Turner (2011) also support the hypothesis that roads generally lead to an increase in traffic in urban areas (Duranton and Turner 2011). If adding infrastructure to urban areas does typically lead to increased traffic, then these historic maps do not necessarily need to be a response to pre-existing congestion to be valid. In other words, these historic maps of planned infrastructure could have led, at least in part, to contemporary congestion levels. The same can be said for the private rail companies, presumably looking to make a profit, building their systems along congested travel corridors. Overall, the logic suggests that this sort of historic transportation infrastructure could help predict current congestion levels while remaining orthogonal to economic outcomes, especially given sufficient temporal lag. Thus, we tested instrumental variables representing planned highways published by the Public Works Administration in 1947 as well as maps representing US primary roads in 1902 and US railroads in 1901. We operationalized each of these potential instrumental variables by bringing the maps from Fig. 3 into GIS to calculate the area of each infrastructure type for each region (Roddy 1902; Public Works Administration 1947; Public Works Administration 1957).

With respect to our congestion metric, the Pearson correlation coefficients for our instrumental variables ranged from 0.37 (for the 1901 US Railroads map) to 0.44 (for the 1947 Planned Highways map). Although all were statistically significant, we wanted to dig a bit deeper into how these factors might differentiate contemporary traffic congestion. For instance, the region with the most planned highways based on the 1947 map was Riverside-San Bernardino CA. This turned out to be the region with the second most growth in our congestion metric with the percent of peak VMT under congested conditions increasing from 16 to 82% over the course of our 30-year study period. In terms of our Congressional committee measure, the two regions with the highest level of representation were the New York City and Chicago MSAs. Both of these regions also rank among the regions with the highest levels of traffic congestion. At the other end of the spectrum, the three regions with the lowest levels of congestion (Wichita, KS; Corpus Christi, TX; and Spokane, WA) only had 10 years of Congressional House committee representation among them (adding up the total number of years of service for every member). At the same time, the ten regions with the highest traffic congestion levels averaged more than 100 years of total Congressional representation on the House Transportation and Infrastructure committee each.
Statistical methodology
The literature suggests that a longitudinal study—where we are also interested in cross-locational issues—can best be conducted using a panel data regression model (Ahangari et al. 2014). This methodology is common to studies examining the relationship between the economy and various explanatory variables (Sweet 2011, 2014b). As described above, congestion also has the potential to be endogenous to our dependent economic variables, and a two-stage least-squares panel model regression accounts for the potential bias caused by endogeneity (Katchova 2014; Greene 2012; Sweet 2014a).
Based upon this approach, we tested the following dependent variables:
Model 1: per capita gross domestic product (GDP) at the regional MSA level (2001–2011)
Model 2: jobs at the regional MSA level (2001–2011)
Model 3: per capita income (PCI) at the regional MSA level (2001–2011)
Model 4: per capita income (PCI) at the regional MSA level (1982–2011)
Scatterplots depicting the relationship between traffic congestion and the outcome variables were skewed, suggesting a non-linear relationship. However, we first ran models using unlogged values as our dependent variables, and the results were nearly identical to the logged models presented in this paper. We also tested both fixed and random effects models, and the results of the Hausman test indicate that the random effects model is appropriate. The following log-linear equation example of a random effects panel regression statistical model facilitates the modeling of non-linear relationships (Greene 2012):
with GDP = per capita gross domestic product (constant 2017 dollars), i = MSA identification variable; t = time variable, αi = represents the unobservable random effects, x = endogenous congestion variable, y = exogenous explanatory variables, β, γ = coefficients of x and y, \({{\varepsilon }}_{\text{it}}\) = error term for MSA i at time t.
The first stage of the two-stage least-squares panel model estimates the percent of peak VMT under congested conditions with the instrumental variable and exogenous regressors, which vary by MSA i and time t, as follows.
with C = percent of peak VMT under congested conditions, i = MSA identification variable; t = time variable, X = instrumental variables, Y = exogenous explanatory variables, δ0 = intercept for congestion, δ1, δ2 = coefficients of X and Y, \({\varepsilon }_{\text{it}}\) = error term for MSA i at time t.
To control for this endogeneity of congestion, Eq. 1 is modified to include Eq. 2 in the following manner (Katchova 2014; Greene 2012; Sweet 2014a).
The validity of our instrumental variables was checked with the Durbin-Wu-Hausman tests for endogeneity (Katchova 2014). For the models presented, the instrumentation of the congestion variable was necessary as evidenced by the significance of the test statistics shown in Table 2.
For each model, we also tested our instrumental variables for weak instruments, under-identification, and over-identification. For Models 1 and 4, the following two instrumental variables led to the strongest overall model that also fit the instrumental variable conditions:
Number of years of House of Representatives Transportation and Infrastructure committee members from the previous 5 years
Land consumed by interstate highways planned for each MSA based upon the 1947 highway plan
This combination of instruments led to over-identification in Models 2 and 3. Instead, Models 2 and 3 were successfully instrumented with:
Number of years of House of Representatives Transportation and Infrastructure committee members from the previous 5 years
Land consumed by major roads in each MSA based upon the 1902 major roads map
These instrumental variables were then combined with our other exogenous variables to predict traffic congestion, the result of which was then used to predict our economic outcomes as the MSA level. The results of the two-stage least-squares panel model regression follow in the next section.
Model results
Model overview and fit
Table 2 presents the following four models in order to best illustrate the relationship between traffic congestion and the economy:
Model No. | Dependent variable |
|---|---|
1 | 11 Years (2001–2011) of GDP per capita |
2 | 11 Years (2001–2011) of jobs |
3 | 11 Years (2001–2011) of per capita income (PCI) |
4 | 30 Years (1982–2011) of per capita income (PCI) |
We included Model 4 to provide longer-term context for the other results and to protect against any biases that might be caused by the recent recession. We also decided to include Model 3 for the sake of a more direct comparison with Models 1 and 2 as well as to facilitate a more comprehensive interpretation of Model 4. The dependent variables are all in 2017 constant dollars. The panel data for the first three models includes 11 years of data for 89 MSAs and 979 total observations. The 30 years of data for Model 4 results in 2670 observations.
The non-instrumented OLS panel regression for Model 1 finds an adjusted R2 values of 0.6065 (see “Appendix”). While this suggests a strong goodness-of-fit, the Durbin-Wu-Hausman tests identify an endogeneity issue and the need for instrumental variables.Footnote 2 Accordingly, we predict our model using a two-stage least-squares panel model regression. As shown at the bottom of Table 2, the significance of the weak instruments test indicates that the selected instrumental variables helped remedy the endogeneity bias (p < 0.0001). With the test of over-identifying restrictions, the insignificant p values denote that the instruments do not over-identify and are valid (p = 0.2230). The “Appendix” presents the unlogged models.
We also attempted to lag our economic outcomes dependent variables in order to test, for example, whether last year’s congestion led to this year’s GDP (we tested 1, 2, and 3 years of lag). While lagged endogenous variables can be problematic and lead to estimator bias (MathWorks 2017), lagging could also help reduce endogeneity issues. For instance if traffic congestion inhibits the future expansion or relocation of a firm, then the relationship is less likely to be endogenous. However, our lagged models still had endogeneity issues. For the 11-year models, the lagged results were similar to the unlagged models; the main difference was that the lagged models ended up with very low R2 value for the within-group variance. Model 4, for the 30-year timespan, resulted in nearly identical results whether lagged or unlagged. As a result, the models presented in this paper are unlagged, but the lagged models are all included in the “Appendix”. For the sake of comparison, we also included the fixed effects models in the “Appendix”.
Final variable selection was based upon overall significance and instrumental variable goodness-of-fit using Stata 13.1. Table 3 presents the first stage regression results of the two-stage process, which includes the instruments as well as the other exogenous variables.
Log-linear model elasticities are presented in Table 4. These numbers represent the percent change that one would expect in per capita GDP given a one unit increase in the variable shown. For illustrative purposes, we also calculated the expected difference in per capita GDP based upon changing a single independent variable and holding all other variables at their mean value for the dataset. These results are shown in Table 5. For instance in the top row with Model 1, Table 5 shows that if the congestion metric increased from a reference value of 35% to 50% of peak VMT congested, this would be associated with an expected difference in GDP per capita of 12.8% (from $44,416 to $49,728). This expected difference is mathematically the same as the elasticity value shown in Table 4 but easier to visualize and understand (Noland and Quddus 2004). Please note that these results do not imply causality.
We selected the reference value of each category in Table 5 based upon a logical value close to the mean for the dataset and then tested other values based upon differences close to the standard deviation. The intent was to be able to focus solely on the influence of a single variable while holding all others at their mean value. For instance with the percent of non-white residents, the mean for the dataset was 37.5% and the standard deviation was 17.1. For the sake of Table 5, we estimated the expected economic outcomes differences at the following levels of non-white residents: 20, 37.5, and 55%.
Traffic congestion
Conventional wisdom regarding traffic congestion suggests that higher levels of peak hour delay would be associated with decreases in GDP and jobs as well as higher wages to compensate workers for the increased costs of travel. We did not find this to be the case. For our regions, peak hour delay had a statistically significant and positive effect on both per capita GDP and jobs. This suggests that our current concerns about traffic congestion negatively impacting the economy may not be particularly well founded. In terms of per capita income, the results were statistically insignificant. Thus, regions with more congestion were more economically productive with more jobs, and this took place without traffic congestion manifesting itself with higher labor costs.
Congestion versus VMT
Our results suggest that higher VMT levels per person per day are associated with higher per capita GDP and higher PCI. As detailed in the literature review, this idea that expanding economies associate with more VMT was expected. However, higher VMT levels per person per day are also associated with fewer jobs. This can perhaps be explained by the increased costs associated with more driving reducing the funds able to be allocated for additional workers.
These results should not necessarily be interpreted to say that the average worker gains much economic benefit from this additional driving. For example in Table 5, an increase of 4 miles per person per day would equate to more than 2.9 billion additional miles driven each year for an average-sized MSA in our dataset. We would expect this increase in VMT to be associated with a 3.7% higher per capita GDP and a PCI jump of just over 1.6% in Model 3 and 6.3% in Model 4. Using the more recent estimate from Model 3, this translates to an increase of about $679 of income annually per capita. However, this neglects the associated driving expenditures. Given the standard mileage rate, this additional driving would cost approximately $840, which eats up all of the additional income before even considering the value of time that might be associated with the additional driving.
Also, while graphs such as Fig. 1 might lead us to believe that the dip in VMT was due to the recession, researchers have subsequently shown that the decline in per-capita VMT started in 2004, several years before the recession hit (Dutzik and Baxandall 2013). Moreover, nationwide VMT continued to drop for more than 5 years after the recession was over (Sundquist and McCahill 2015) and has now started to rise again with the help of relatively lower driving costs, among other factors (Manville et al. 2017).
Fuel costs
It is worth noting that gas prices are often associated with reductions in driving and total VMT. As an input into the economy, it is further assumed that higher gas prices have a negative effect on the economy. Interestingly, we did not find this to be the case. The price of gas was positively associated with an increase of our economic outputs in the 11-year models. For instance, an increase of fifty cents per gallon in the cost of gasoline was associated with increases in per capita GDP, jobs, and PCI between 1.4 and 1.8%. Gas prices were not significant in Model 4. Our results cannot be considered causal and thus do not necessarily support the conclusion that increasing gas prices or gas taxes would lead to better economic outputs. However, the 11-year models suggest that we should expect regions with higher gas prices to have better economic outputs, holding all other variables constant.
Built environment
In all three of the 11-year models, the variable we used as a proxy for the built environment—population density of the primary city—was positively associated with improved regional economic output. This suggests that, at least in the more recent models, people in denser environments are more economically productive, and that these regions have more jobs with higher wages. Given the positive association of traffic congestion in the first two models, it also suggests that high levels of traffic congestion may induce more people to move to the center city into areas with higher levels of accessibility and more modal options. The positive association between population density and jobs was the strongest relationship found in any of our models and could be indicative of jobs helping attract in-movers. Population density was insignificant in the 30-year PCI model.
To help make these statistics more relevant to practice, Table 6 includes the corresponding population density values so we can focus on the actual population density numbers standing in for the standardized scores. That is to say, a population density score of 15 is equivalent to an actual population density of approximately 4000 people per square mile (PPSM); this is the realm of cities such as Denver, CO and San Diego, CA. For the sake of discussion, we also included estimated dwelling units per acre (du/ac), which for a city of 4000 PPSM is approximately 2.4 du/ac. With all other variables held at their mean, we would expect the regional per person GDP of cities with 4000 PPSM to be $43,900 (using 2017 constant dollars), as shown at the bottom of Table 5.
When holding all other variables at their mean and only changing population density in the models, we would expect cities with lower primary city population densities to have lower regional economic outcomes. For cities with around 1333 PPSM—such as Kansas City, MO or Salt Lake, UT—we would expect a 3.8% lower regional per capita GDP, 20.6% reduction in jobs, and a 4.4% drop in regional PCI (equating to a reduction of around $1600 of annual income per person), as compared to our baseline cities. Conversely, the first three models suggest that denser cities are associated with better economic outcomes. For instance with cities of roughly 8000 PPSM (4.8 du/ac), our models would expect regional per capita GDP close to $46,650, a 40% increase in jobs, and regional PCIs of more than $45,200, all else being equal. This population density level is approximately where cities such as Baltimore, MD and Los Angeles, CA fall on the spectrum.
As population density continues to increase—and assuming all other variables are held at their mean value—we would expect similar increases. The next level shown is for primary cities with population densities of around 12,000 PPSM (7.1 du/ac)—such as Boston, MA and Chicago, IL—where we would expect a jump in regional per capita GDP of over 13% from the reference value (to over $49,600) and a nearly 100% increase in jobs. The expected increase in regional PCI equates to 14.5% over the reference value to a level of over $48,000. Economic productivity and incomes continue to grow for the next two levels of population density shown in Table 5. For the sake of this discussion, the 16,000 PPSM (9.5 du/ac) is representative of San Francisco, CA while the 26,667 PPSM (15.8 du/ac) characterizes New York City.
Control variables: age, gender, race, crime, education, and weather
The variables describing the percent of the population in the workforce and the percent in their relatively prime earning years (i.e. 35–54) were highly correlated with one another. The results focus on the former, which led to the strongest models overall. The percent of population in the workforce was positively associated with PCI in Models 3 and 4 and insignificant in Models 1 and 2.
In terms of gender, the percent of women in the workforce factor that we developed did not seem to do enough to distinguish our regions from each other and turned out to be insignificant in our models.
The percentage of non-whites residing in the primary city was insignificant in Model 3. However, this variable was negatively associated with regional GDP per capita and jobs in Models 1 and 2 but positively associated with regional per capita income in Model 4. This result may be indicative of differences in the level of gentrification over the short-term (Models 1 and 2) versus the long-term (Model 4) in wealthier regions with respect to the drastic changes in urban residential preference over this timespan.
Education (as measured the percent of residents aged 25 or older in the MSA primary city) was associated with better economic outcomes in all of our models. With 35% of residents aged 25 or older possessing their bachelor’s degree, we would expect a 5.3% increase in per capita GDP, a 9.4% increase in jobs, and a 2.5% increase in PCI. For the 30-year model, this jumps to a 19.8% increase in PCI.
The rate of violent crimes in a region was positively associated with per capita GDP and PCI in Models 1 and 3. In other words, places with higher economic outputs had slightly higher violent crime rates. This supports the strand of literature linking higher crime rates to better economic times (Roman 2013, The Economist 2011, Klaer and Northrup 2014). However, this variable was not significant in Model 4 over the longer timeframe or in the jobs model. Again, these results do not speak to causality.
The weather-related factors (i.e. average January temperature and annual inches of precipitation) were not significant in any model even though these variables have shown to be significant in some of the existing literature (Rappaport 2007, Glaeser and Kohlhase 2004).
Conclusion
This study sought to understand whether traffic congestion in US metropolitan areas should be considered a foe that needs to be jettisoned for the sake of the economy or merely an inconvenience with minimal economic impact. Based on longitudinal data from 89 US regions and controlling for reverse causality, our findings suggest that a region’s economy is not significantly impacted by traffic congestion. In fact, the results even suggest a positive association between traffic congestion and economic productivity as well as jobs. This is unlikely, however, to be a directly causal relationship as growing economies typically result in rising gross domestic product (GDP), more jobs, and income growth. Alternatively, we might also expect declining economies to experience less traffic congestion. In both cases, it stands to reason that traffic congestion could be positively associated with economic outcomes and not the limiting factor it is often considered to be.
With respect to our other variables of interest, population density of the primary city and the education level of residents resulted in the greatest positive associations with economic productivity, jobs, and income. Higher vehicle miles traveled (VMT) was also associated with higher per capita GDP and income but fewer jobs. Although this variable was not highly correlated with our congestion variables nor found to be endogenous with our economic output variables, the relationship among VMT, congestion, and economic well-being is complicated, may depend on context, and deserves additional research. Gas prices were positively associated with better economic outcomes in the 11-year models. The percent of non-white residents in the primary center was associated with lower per capita GDP and fewer jobs in the shorter-term models but higher incomes in the 30-year model. The percent of the population in the workforce was positively associated with higher incomes but not significant with respect to either per capita GDP or jobs. Lastly, the violent crime rate was positively associated with higher per capita GDP and incomes in the 11-year models but insignificant in the other models. Although these results by no means imply causality, they do facilitate a greater understanding economic outcome trends within and between our US regions. Future research should look to further analyze these complex relationships as related to the structural differences among metropolitan areas and attempt to untangle issues related to causality, directionality, and generalizability across regions. This study should also be revisited with improved congestion metrics once companies such as INRIX have enough longitudinal data to do so.
One explanation for the positive association between traffic congestion and economic outcomes might have to do with the positive adaptations that traffic congestion may entice. For instance, traffic congestion could potentially lead to positive economic externalities such as infill development (via improved location efficiency), more efficient travel patterns, and/or agglomeration benefits. People may also adapt to high levels of traffic congestion by switching to other travel modes (Wheaton 2004, Chatman and Noland 2014). Our own regression analysis of driving mode share as the dependent variable and traffic congestion as the independent variable showed higher levels of congestion to be significantly associated (p = 0.0002) with lower driving mode shares. Case in point: of the ten most congested cities in the recent Urban Mobility Report, seven of those cities rank in the top ten for lowest driving mode share. Eight of the top ten congested cities rank in the top ten for highest transit mode share, and four rank in the top ten for highest active transportation mode shares.
It would make sense for individuals and businesses to respond to traffic congestion by changing modes or locations, but there might also be higher-level shifts toward a greater concentration of industries—such as professional service and tech industries—that would be less impacted by traffic congestion than industries such as manufacturing. Such a mix of industries may be more resilient to traffic congestion problems as well as associated with higher GDP and incomes. Future research should look to study the relative impacts of traffic congestion by industry. Businesses in high congestion areas have also been shown to use “email, third-party carriers, consolidated shipments, driver assistance, flexibility in work and meeting schedules, and work at home days” to minimize the impacts of traffic congestion (Hartgen et al. 2012). While it is also worth noting that we cannot observe how these economies might have been different absent traffic congestion, such adaptations illustrate how cities and regions can help maintain accessibility and economic prosperity despite high levels of traffic congestion.
We continually hear that traffic is bad and getting worse. We also keep hearing that this problem costs Americans more than $160 billion annually (Schrank et al. 2015). Civil engineers, in turn, contend that traffic congestion can be solved with more funding and improved infrastructure (ASCE 2017). While increasing roadway capacity helps relieve congestion in the short-term, a growing body of literature demonstrates this new capacity filling far earlier than expected (Duranton and Turner 2011; Noland 2001; Noland 2007; Cervero 2002; Cervero and Hansen 2002; Jorgensen 1947; Downs 1992; Downs 2006). One reason has to do with the downward sloping demand curves with respect to the generalized cost of travel. This shift is also referred to as the principle of induced demand (Levinson et al. 2017). This is not to suggest that we should ignore micro-scale inefficiencies in the system that produce needless congestion such as poorly-configured signal timings, as such improvements allow us to realize the benefits of the system in which we have already invested. However, the larger implication is that, at least in most US metropolitan areas, we should begin to move our focus away from macro-scale congestion relief efforts and towards more salient economic and transportation concerns.
Downs from the Brookings Institute argues that: “congestion should be considered the price Americans and others around the world pay to achieve and sustain high-level economic efficiency and provide millions of households with varied choices of where to live and work and the means to move between them” (Downs 2006). The Urban Mobility Report even acknowledges that “some traffic congestion is indicative of a strong regional economy” (Schrank et al. 2012, Sweet 2011). In fact, many of the cities that perpetually show up on the annual list of the most congested US cities—such as Washington DC, Los Angeles, San Francisco, New York, and Boston—also seem to be considered some of our best and most vibrant (Roads & Bridges 2013). Moreover, cities faced congestion problems long before the advent of the automobile (Morris 2007). There may be valid reasons to continue the fight against traffic congestion in US metropolitan areas– such as improving accessibility, health, and emergency response while reducing road rage, air pollution, and fossil fuel consumption—but a fear that gridlock will stifle the economy does not seem to be one of them.
Notes
The Durbin Wu–Hausman results for our traffic congestion variable are included in Table 2.
With vehicle miles traveled variable: for Model 1, Durbin p = 0.5034 and Wu–Hausman p = 0.5096; for Model 2, Durbin p = 0.2259 and Wu–Hausman p = 0.2322; and for Model 3, Durbin p = 0.2769 and Wu–Hausman p = 0.2844.
With the population density variable: for Model 1, Durbin p = 0.7809 and Wu–Hausman p = 0.7837; for Model 2, Durbin p = 0.4317 and Wu–Hausman p = 0.4375; and for Model 3, Durbin p = 0.2769 and Wu–Hausman p = 0.2844.
With both the VMT and population density variables, these results tell us that instrumentation is not necessary.
The results of the Durbin–Wu–Hausman tests of endogeneity are shown at the bottom of Table 2, and significant p values indicate that the variables in question are endogenous and need to be corrected.
References
Ahangari, H., Outlaw, J., Atkinson-Palombo, C., Garrick, N.W.: An Investigation into the Impact of Fluctuations in Gasoline Prices and Macroeconomic Conditions on Road safEty in Developed Countries. Transportation Reserach Board Annual Meeting, Washington DC (2014)
Anas, A., Xu, R.: Congestion, land use, and job dispersion: A general equilibrium model. J. Urban Econ. 45, 451–473 (1999)
Andolfatto, D., Ferrall, C., Gomme, P.: Human Capital Theory and the Life-Cycle Pattern of Learning and Earning, Income and Wealth. In: University, S.F. (ed.) Burnaby, BC, Canada (2000)
Arnott, R.: Congestion tolling with agglomeration externalities. J. Urban Econ. 62, 187–203 (2007)
ASCE: Infrastructure Report Card. American Society of Civil Engineers, Washington DC (2017)
Baum-Snow, N.: Did highways cause suburbanization? Quart. J. Econ. 122, 775–805 (2007)
Bertini, R.: You Are the Traffic Jam: An Examination of Congestion Measures. Transportation Research Board, Washington DC (2006)
Bilbao-Ubillos, J.: The costs of urban congestion: estimation of welfare losses arising from congestion on cross-town link roads. Transp. Res. A Policy Pract. 42, 1098–1108 (2008)
BLS: CPI Inflation Calculator [Online]. Bureau of Labor Statistics, U.S. Department of Labor, Washington DC. http://www.bls.gov/data/inflation_calculator.htm (2017). Accessed 25 Sept 2017
Boarnet, M.G.: Infrastructure services and the productivity of public capital: The case of streets and highways. Natl. Tax J. 50, 39–57 (1997)
Bobbitt-Zeher, D.: The gender income gap and the role of education. Sociol. Educ. 80, 1–22 (2007)
C-SPAN: House Transportation and Infrastructure Committee [Online]. Cable-Satellite Public Affairs Network. www.c-span.org/organization/?2118&congress=114 (2016). Accessed 9 Aug 2016
Cervero, R.: Jobs-housing balance revisited—trends and impacts in the San Francisco Bay Area. J. Am. Plan. Assoc. 62, 492–511 (1996)
Cervero, R.: Induced travel demand: research design, empirical evidence, and normative policies. J. Plan. Lit. 17, 3–20 (2002)
Cervero, R., Duncan, M.: Which reduces vehicle travel more: jobs-housing balance or retail-housing mixing? J. Am. Plan. Assoc. 72, 475–490 (2006)
Cervero, R., Hansen, M.: Induced travel demand and induced road investment—a simultaneous equation analysis. J. Transp. Econ. Policy 36, 469–490 (2002)
Chatman, D.G., Noland, R.B.: Transit Service, Physical Agglomeration and Productivity in US Metropolitan Areas. Urban Studies 51, 917–937 (2014)
Copeland, L.: Cities Afraid of Death by Congestion. USA Today, March 1 (2007)
Crane, R., Chatman, D.G.: Traffic and sprawl : evidence from U.S. commuting from 1985–1997. Plan. Mark. 6, 14–22 (2003)
Detotto, C., Otranto, E.: Does crime affect economic growth? Kyklos 63, 330–345 (2010)
DOJ & FBI: Uniform Crime Reporting Statistics [Online]. Clarksburg, WV: U.S. Department of Justice, Federal Bureau of Investigation. www.ucrdatatool.gov (2014)
Downs, A.: Stuck in Traffic. Brookings Institute, Washington DC (1992)
Downs, A.: Can Traffic Congestion Be Cured? [Online]. Washington DC. http://www.brookings.edu/research/opinions/2006/06/30transportation-downs (2006)
Duranton, G., Turner, M.A.: The fundamental law of road congestion: evidence from US cities. Am. Econ. Rev. 101, 2616–2652 (2011)
Dutzik, T., Baxandall, P.: A new direction: our changing relationship with driving and the implications for America’s future. U.S. PIRG Education Fund, Washington DC (2013)
Ewing, R. & Cervero, R.: Travel and the built environment—A synthesis. Land Development and Public Involvement in Transportation, pp. 87–114 (2001)
Ewing, R., Pendall, R., Chen, D.: Measuring sprawl and its transportation impacts. Travel Demand Land Use 2003, 175–183 (2003)
Federal Highway Administration.: Focus on Congestion Relief [Online]. U.S. Department of Transportation, Washington DC. http://www.fhwa.dot.gov/congestion/ (2013). Accessed 12 May 2014
Fernald, J.G.: Roads to prosperity? Assessing the link between public capital and productivity. Am. Econ. Rev. 89, 619–638 (1999)
Frank, L.D., Pivo, G.: Impacts of mixed use and density on utilization of three modes of travel: single-occupant vehicle, transit, and walking. Transp. Res. Rec. 1466, 44–52 (1994)
Glaeser, E., Kahn, M.E.: Working Paper No. 9733: Sprawl and Urban Growth. National Bureau of Economic Research, Cambridge (2003)
Glaeser, E.L.: Cities, information, and economic growth. Cityscape 1, 9–47 (1994)
Glaeser, E.L.: Are cities dying? J. Econ. Perspect. 12, 139–160 (1998)
Glaeser, E.L.: Triumph of the City: How Our Greatest Invention Makes Us Richer, Smarter, Greener, Healthier, and Happier. Penguin Press, New York (2011)
Glaeser, E.L., Kallal, H.D., Scheinkman, J.A., Shleifer, A.: Growth in cities. J. Polit. Econ. 100, 1126–1152 (1992)
Glaeser, E.L., Kohlhase, J.E.: Cities, regions and the decline of transport costs. Pap. Reg. Sci. 83, 197–228 (2004)
Glaeser, E.L., Kolko, J., Saiz, A.: Consumer city. J. Econ. Geogr. 1, 27–50 (2001)
Gordon, P., Kumar, A., Richardson, H.W.: Congestion, changing metropolitan structure, and city size in the United-States. Int. Reg. Sci. Rev. 12, 45–56 (1989)
Graham, D.J.: Variable returns to agglomeration and the effect of road traffic congestion. J. Urban Econ. 62, 103–120 (2007)
Grant-Muller, S., Laird, J.: International Literature Review of the Costs of Road Traffic Congestion with the Main Focus on the Different Methods Used to Measure the Costs of Congestion. Institute for Transport Studies, University of Leeds, Leeds, Scotland (2007)
Greene, W.H.: Econometric Analysis. Prentice Hall, Boston (2012)
Harris, T.F., Ioannides, Y.M.: Productivity and Metropolitan Density. Tufts University, Medford, MA (2000)
Hartgen, D.T., Fields, M.G., Layzell, A.L., San Jose, E.: How Employers View Traffic Congestion: Results of National Survey. Transportation Research Record, pp. 56–66 (2012)
Highway Research Board: Urban Traffic Congestion. National Academy of Science, National Research Council, Washington DC (1954)
Hymel, K.: Does traffic congestion reduce employment growth? J. Urban Econ. 65, 127–135 (2009)
Jorgensen, R.E.: Influence of expressways in diverting traffic from alternate routes and in generating new traffic. Highw. Res. Board Proc. 27, 322–330 (1947)
Katchova, A.: Instrumental Variables [Online]. Econometrics Academy, Lexington, KY. https://sites.google.com/site/econometricsacademy/econometrics-models/instrumental-variables (2014). Accessed 25 Jan 2014
Katz, B., Bradley, J.: The Metropolitan Revolution: How Cities and Metros are Fixing Our Broken Politics and Fragile Economy. Brookings Institution Press, Washington DC (2013)
Klaer, J., Northrup, B.: Effects of GDP on Violent Crime. Georgia Tech, Atlanta (2014)
Kriger, D., Miller, C., Baker, M., Joubert, F.: Costs of urban congestion in Canada—A model-based approach. Transp. Res. Record, 94–100 (2007)
Levinson, D., Marshall, W., Axhausen, K.: Elements of Access. Network Design Lab, Sydney (2017)
Levinson, D., Wu, Y.: The rational locator reexamined: are travel times still stable? Transportation 32, 187–202 (2005)
Levinson, D.M., Kumar, A.: The rational locator—why travel-times have remained stable. J. Am. Plan. Assoc. 60, 319–332 (1994)
Lewis, J.B., Devine, B., Pitcher, L., Martis, K.C.: Digital Boundary Definitions of United States Congressional Districts, 1789–2012 [Online]. UCLA. http://cdmaps.polisci.ucla.edu (2013). Accessed 10 Aug 2016
Litman, T.: Congestion Costing Critique. Victoria Transport Policy Institute, Victoria (2014)
Lomax, T., Turner, S., Shunk, G.: NCHRP Report 398: Quantifying Congestion. National Academy Press, Washington DC (1997)
Manson, S., Schroeder, J., Riper, D.V., Ruggles, S.: PUMS National Historical Geographic Information System: Version 12.0. University of Minnesota, Minneapolis (2017)
Manville, M., King, D.A., Smart, M.J.: The driving downturn: a preliminary assessment. J. Am. Plan. Assoc. 83, 14p (2017)
Marrocu, E., Paci, R., Usai, S.: Productivity growth in the old and new europe: the role of agglomeration externalities. J. Reg. Sci. 53, 418–442 (2013)
Marshall, W.E., Garrick, N.W.: Effect of street network design on walking and biking. Transp. Res. Rec., 103–115 (2010)
Marshall, W.E., Garrick, N.W.: Does street network design affect traffic safety? Accid. Anal. Prev. 43, 769–781 (2011)
Mathworks: Time Series Regression VIII: Lagged Variables and Estimator Bias [Online]. www.mathworks.com/help/econ/examples/time-series-regression-viii-lagged-variables-and-estimator-bias.html (2017)
McDonald, N.C.: Active transportation to school—trends among US schoolchildren, 1969–2001. Am. J. Prev. Med. 32, 509–516 (2007)
Mondschein, A., Brumbaugh, S., Taylor, B.D.: Congestion and Accessibility: What’s the Relationship?. Institute of Transport Studies, Los Angeles (2010)
Morris, E.: From horse power to horsepower. Access 30, 2–9 (2007)
Murnane, R.J.: Educating urban children. National Bureau of Economic Research, Cambridge (2008)
NCHRP: Synthesis 311: performance measures of operational effectiveness for highway segments and systems. Transportation Research Board, Washington DC (2003)
Noland, R., Quddus, M.: A spatially disaggregate analysis of road casualties in England. Accid. Anal. Prev. 36, 973–984 (2004)
Noland, R.B.: Relationships between highway capacity and induced vehicle travel. Transp. Res. A Policy Pract. 35, 47–72 (2001)
Noland, R.B.: Transport planning and environmental assessment: implications of induced travel effects. Int. J. Sustain. Transp. 1, 1–28 (2007)
Paci, R., Usai, S.: Externalities, Knowledge, Spillovers and the Spatial Distribution of Innovation. Cagliari, Solter (2000)
Portes, A., Rumbaut, R.N.G.: Immigrant America: a portrait. University of California Press, Berkeley and Los Angeles, California (2014)
Public Works Administration: National System of Interstate Highways. Public Works Administration, Washington DC (1947)
Public Works Administration: Interstate and Defense Highways Map. Public Works Administration, Washington DC (1957)
Rajamani, J., Bhat, C.R., Handy, S., Knaap, G., Song, Y.: Assessing impact of urban form measures on nonwork trip mode choice after controlling for demographic and level-of-service effects. Travel Demand Land Use 2003, 158–165 (2003)
Rappaport, J.: Moving to nice weather. Reg. Sci. Urban Econ. 37, 375–398 (2007)
Redman, A., Sai, A.: Opportunities in an Urbanizing World. Credit Suisse Research Institute, Zurich (2012)
Ribeiro, A., Antunes, A.P., Paez, A.: Road accessibility and cohesion in lagging regions: empirical evidence from Portugal based on spatial econometric models. J. Transp. Geogr. 18, 125–132 (2010)
Roads & Bridges.: Congestion: DC Tops TTI List of Most Congested Cities [Online]. Arlington Heights, IL. Available: www.roadsbridges.com/congestion-dc-tops-tti-list-most-congested-cities (2013). Accessed 25 Sept 2017
Roddy, H.J.: Complete geography, American Book Company, New York, Cincinnati etc (1902)
Roman, J. The Puzzling Relationship Between Crime and the Economy. Citylab (2013)
Rose, H., Betts, J.R.: The effect of high school courses on earnings. Rev. Econ. Stat. 86, 497–513 (2004)
Safirova, E., Gillingham, K., Houde, S.: Measuring marginal congestion costs of urban transportation: Do networks matter? Transp. Res. A Policy Pract. 41, 734–749 (2007)
Schrank, D., Eisele, B., Lomax, T.: Urban Mobility Report. Texas A&M Transportation Institute, College Station (2012)
Schrank, D., Eisele, B., Lomax, T., Bak, J.: Urban Mobility Scorecard. Texas A&M Transportation Institute, College Station (2015)
Sciara, G.-C.: Planning for unplanned pork. J. Am. Plan. Assoc. 78, 17p (2012)
Staley, S.: Traffic Congestion and the Economic Decline of Cities [Online]. Reason Foundation. http://reason.org/news/show/traffic-congestion-and-the-economic (2012). Accessed 6 April 2014
Sundquist, E., Mccahill, C.: For the first time in a decade, U.S. per capita highway travel ticks up. State Smart Transportation Initiative, Madison (2015)
Sweet, M.: Does traffic congestion slow the economy? J. Plan. Lit. 26, 391–404 (2011)
Sweet, M.: Do firms flee traffic congestion? J. Transp. Geogr. 35, 10p (2014a)
Sweet, M.: Traffic congestion’s economic impacts: evidence from US metropolitan regions. Urban Stud. 51, 2088–2110 (2014b)
The Economist.: Falling together: The relationship between crime and GDP in America [Online]. London, England. www.economist.com/blogs/dailychart/2011/09/us-crime-and-gdp (2011). Accessed 25 Sept 2017
The Prism Climate Group: Climate Obsertations [Online]. Corvallis, OR: Oregon State University. http://prism.oregonstate.edu/normals (2014). Accessed 15 Feb 2014
Tsai, Y.H.: Quantifying urban form: compactness versus ‘Sprawl’. Urban Stud. 42, 141–161 (2005)
U. S. Census: Geographic Areas Reference Manual. U.S. Department of Commerce, Washington DC (1994)
U.S. Census: 2010 Census Urban Area FAQs [Online]. Washington, DC. https://www.census.gov/geo/reference/ua/uafaq.html (2010). Accessed 7 March 2014
Weisbrod, G., Vary, D., Treyz, G.: NCHRP Report 463: Economic Implications of Congestion. National Academy Press, Washington DC (2001)
Weisbrod, G., Vary, D., Treyz, G.: Measuring economic costs of urban traffic congestion to business. Transp. Finance Econ. Econ. Dev. 2003, 98–106 (2003)
Wheaton, W.C.: Commuting, congestion, and employment dispersal in cities with mixed land use. J. Urban Econ. 55, 417–438 (2004)
Woudsma, C., Jensen, J.F., Kanaroglou, P., Maoh, H.: Logistics land use and the city: a spatial-temporal modeling approach. Transp. Res. E-Logist. Transp. Rev. 44, 277–297 (2008)
Wright, E.O.: Race, class, and income inequality. Am. J. Sociol. 83, 1368–1397 (1978)
Zhu, P.Y., Brown, J.R.: Donor states and donee states: investigating geographic redistribution of the US federal-aid highway program 1974-2008. Transportation 40, 203–227 (2013)
Zolnik, E.J.: The effects of sprawl on private-vehicle commuting distances and times. Environ. Plan. B-Plan. Des. 38, 1071–1084 (2011)
Acknowledgements
The authors would like to thank Ed Gaviria for his help during our initial discussions surrounding this topic as well as his preliminary data collection efforts. Although we ended up developing our own instrumental variables for this analysis, we appreciate Dr. Matthias Sweet of Ryerson University for generously sharing those used in his impressive papers. Lastly, we would like to thank the anonymous reviewers for their detailed and insightful recommendations.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors that they have no conflict of interest.
Appendix
Appendix
See Tables 7, 8, 9, 10, 11, 12 and 13.
Rights and permissions
About this article

Cite this article
Marshall, W.E., Dumbaugh, E. Revisiting the relationship between traffic congestion and the economy: a longitudinal examination of U.S. metropolitan areas. Transportation 47, 275–314 (2020). https://doi.org/10.1007/s11116-018-9884-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11116-018-9884-5