
Abstract
Discrete choices are often analyzed statically. The limitations of static models become more obvious when employing them in more long-term travel demand forecasting. The research gap lies in a theoretical model which is dynamically formulated, and in readily available longitudinal data sources. To address this, a heterogeneous hidden Markov modeling approach (HMM) is proposed in this paper to model dynamic discrete choices. Both longitudinal and cross-sectional heterogeneity are considered. The approach is demonstrated on a travel mode choice application using ten-wave Puget Sound Transport Panel data coupled with some other supplementary data sources. Results indicate that travelers’ long-term life-cycle stages have an enduring impact when shifted to different mode choice states, wherein sensitivities to travel time and cost vary. Empirical results are put in line with static discrete choice models. The paper demonstrates that the family of HMM models provide the best fitting model. The dynamic model has superior explanatory power in fitting longitudinal data and thus shall provide more accurate estimates for planning and policy analyses. The proposed approach can be generalized to study other short/mid-term travel behavior. The estimated model can be easily calibrated and transferred for applications elsewhere.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Although mode choice is obviously an important dimension in individual decision-making process, it is usually treated as aggregate in many practices and is not part of the individual travel demand models Pendyala (2009). One reason for this treatment is that mode decision is constrained by factors such as vehicle ownership, availability of public transit, and transit fare, all of which are relatively stable and unlikely to change in a short time period. However, as concepts such as transit oriented development (TOD) and multimodal corridor management attract increasing interests from both researchers and policy makers, there is increasing need to internalize mode decisions and build a more comprehensive model to support long-term policy analysis.
A number of time-varying personal/household-level factors would influence travel mode choice. For instance, a person who previously drove to work may have to carpool in the future if she/he gets married and the partner does not own a car. When kids reach school age and can ride school bus on her own, family adults are likely to commute alone more often. These examples illustrate how changes in lifecycle stage may affect individuals’ mode choice preference. In the real world, many other factors may also play their roles, e.g., occupation, salary, health status, immigration, etc. These factors are time-varying and can no longer be accommodated by modeling methods that emphasize only the cross-sectional variability. This research gap in modeling methodology can be filled, when discrete choice data collected over time (e.g., multi-day/week travel diary data, annual panel survey data, etc.) becomes available and provides sufficient empirical evidence. Hence, the authors are motivated to:
-
develop a dynamic modeling approach that is flexible enough to consider cross-sectional observed/unobserved heterogeneity and time-dependent heterogeneity.
-
empirically test the approach using longitudinal data sources and understand its implications and sensitivity.
The organization of the remainder of the paper is as follows. The next section reviews existing literature in modeling mode choice. Attention is paid to dynamic mode choice models and Markov process models. Section “Modeling dynamic mode choice: a hidden markov approach” presents a hidden Markov multinomial logit model and one of its direct extensions, hidden Markov random-parameter error component model. An empirical application on Puget Sound Travel Panel (PSTP) survey data for travel mode decision processes is described in “Data” section, followed by an empirical estimation demonstrating the model’s capability in capturing individual dynamics. Closing remarks on theoretical/practical contributions, as well as directions for future research, are offered at the end of the paper.
Literature review
The majority of travel mode choice studies have been focused on econometric theory of random utility maximization. It assumes that an individual’s choice is determined by the indirect utility of each alternative and the individual can choose the one that maximizes her/his utility level. For example, Koppelman (1983) used a multinomial logit model to predict mode share changes in response to a range of transit service improvements. Later on, a great deal of advances has been done following this line of research. Mixed logit models have been applied to model mode choice and the underlying heterogeneity (McFadden and Train 2000). Random parameters have been adopted to incorporate both observed and unobserved heterogeneity (i.e., taste variation) cross observations using the mean and the variance of random parameters. In addition to the taste variation over travelers, a number of researchers have recognized that tastes can vary across tasks for the same traveler and thus generalized the heterogeneity to intra-personal level (Hess and Train 2011; Cherchi and Guevara 2012). These studies are well suited for analyzing cross-sectional heterogeneity relying on short-term cross-sectional data (Kitamura 1990; Pendyala and Pas 2000). In addition to cross-sectional heterogeneity, the possible time-varying heterogeneity can cause concern in travel choices from the perspective of relatively more long-term horizon (Pendyala 2009). As discussed in the introduction section, various time-varying factors could influence travelers’ decisions such as mode choice. Only recently, increasing amount of research on dynamic models has been available (e.g., Cirillo and Axhausen 2010; Pendyala et al. 2005; Walker 2001). For example, Cirillo and Axhausen (2002) studied short-term mode choice dynamics using discrete choice method and panel data. They further extended the method to include dynamic variables in the systematic utility functions (Cirillo and Axhausen 2010). Srinivasan and Bhargavi investigated long-run commute mode choice dynamics (including exogenous variable change, state-dependence, user sensitivity, and unobserved factors) in India using a 5-year longitudinal dataset (Srinivasan and Bhargavi 2007). Their model captured persistent inertia which would hinder the immediate effects, as predicted by traditional cross-sectional models, of improved LOS in transit services. Studies on short-term within-day (Ramadurai and Srinivasan 2006) and day-to-day (Pas and Koppelman 1987) variability were also seen in literature.
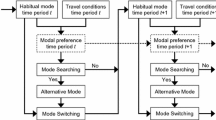
As an alternative, process models switch the focus from what travelers should do (i.e., utility maximization) to what they actually do by assuming behavior process and incorporating constraints, habits, learning, etc. This line of research attracts increasing research attention. Data mining methods and artificial intelligence were typically employed to direct behavioral process. For instance, Pendyala et al. (1998) derived decision rules based on neural network to predict activity scheduling and mode choice. Arentze and Timmermans developed a computational process model (ALBATROSS) to mimic travel decision-making process (Arentze and Timmermans 2004). A number of decision trees based on machine learning and artificial intelligence were employed to model different choices. Xiong and Zhang (2013) developed an agent-based process to imitate travel behavior in terms of information acquisition, learning, adaptation and decision heuristics. Markov chain was another way to model the decision-making process. Goulias reported results within the context of time-use and activity patterns using Markov process model and PSTP dataset (Goulias 1999). Ben-Akiva (2010) proposed a planning-action model where the intrinsic plan of changing modes was modeled as a Markov process. Choudhury et al. (2010) applied the planning-action process to study more short-term dynamic plans of driving and route changing behavior. Xiong and Zhang (2014) proposed a travel mode search-switching process model. It is found that travelers can be classified into different “states” (e.g., car-loving state v.s. transit-loving state). With changes in level-of-service and/or socio-demographic characteristics, travelers may change their preference, which can be identified as the state-switching using Markov chain. Vij (2013) also demonstrated the use of Markov process more specific to mode choice and modality style based on panel data from Santiago, Chile. He further asserted that Markovian state is a dynamic extension to “latent class”. Overall, these action plans, preference states, and modality styles are not directly observable and can only be inferred from empirical data. Thus, this group of models can be categorized as “hidden Markov models” (HMM). HMM has been applied in other fields such as speech recognition, biological sequences analysis, etc. (Netzer et al. 2008; Scott 2002; Smith and Vounatsou 2003). It receives limited research attention in transportation modeling, especially in travel behavior modeling.
In contrast to its limited applications in modeling travel behavior, HMM approach, however, has the potential to uncover factors that contribute to the dynamics of choices. In this paper, an HMM dynamic mode choice model is developed and estimated, wherein hidden states are a finite set of states representing different hidden modal preferences. There are three main contributions related to HMM mode choice modeling. In the modeling part, a nonhomogeneous transition matrix is developed and thus it incorporates time-varying covariates, such as household composition changes, income increase, personal occupation changes, etc., to explain heterogeneity. Secondly, a hierarchical structure under HMM is developed using random parameters and error components to account for unobserved heterogeneity. This is not seen in most existing HMM studies. And our results show that it greatly enhances the model goodness-of-fit. Finally, our empirical results focus on long-term changes in modal preferences. Transitions in lifecycle stages can lead to switching in hidden preferences. After getting married, the couple is likely to coordinate carpooling more often. Parents will do drive-alone more often if their kids reach school age and take school buses. Using the 1989–2002 10-wave panel survey data for the Puget Sound region, we can empirically explain the dynamic influence of life-stage changes on mode choice dynamics. And a number of “hidden” human factors, including inertia, values, attitudes, and preference, can potentially fit in this hierarchical approach in explaining why and how travelers are evolving and adjusting their decisions.
Modeling dynamic mode choice: a hidden Markov approach
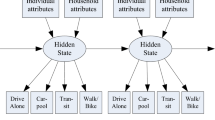
We define \({\mathbf{{Y}}} = \{y_{it}\}\) as a vector of all travel mode choices \(y_{it}\) observed for individual i during the time period t. In our application, t is defined as the time between each two waves of the longitudinal data collection (typically 1 year). \(y_{it}\) can take values from 1 to 5, indicating auto drive alone, carpool, transit, walk, and bike, respectively. Some predefined availability constraints are specified here in order to make the estimation more meaningful (e.g., walk mode is not available for travels with excessively long distance). Heterogeneous choice sets can be a worthy topic for future research.
At certain time period, observed travel mode choices may be governed by unobserved states representing modal preferences, e.g., car-oriented, transit loving, etc. Between time periods, this behavioral predisposition may evolve. And this dynamic portion of behavior is modeled as a Markov process, using transition matrix to describe the transitions between different preference states. The transition matrix is defined as:
In this formulation, \({\varvec{P}}_{i,t-1\rightarrow t}\) is the Markov chain transition matrix expressing, in probabilistic manner, the likelihood that traveler i switches hidden state. In a typical hidden Markov model, the transition probabilities term \(p_{it}^{(a,b)}\) is often defined as a constant transition probability as:
In this paper, this homogeneous Markov transition is further extended with observed heterogeneity. Consider different states of travel mode choice, it highly depends on a number of factors, which is already successfully observed from latent-class approach (Vij 2013) and latent variable approach (Paulssen et al. 2013). This paper explores the specification of a heterogeneous Markov transition by hypothesizing that the transition highly depends on whether changes in personal/household attributes in the previous period were strong enough to transition the traveler from one hidden preference state to another state. For simplicity, we first assume a two-state hidden Markov model with \(p_{it}^{(h_1,h_2)}\) denoting the transition probability from hidden state \(h_1\) to hidden state \(h_2\) for individual i in period t. We introduce the following parameterization for the heterogeneous Markov transitions:
\({{{\varvec{\lambda}}}^{(h_1,h_2)}}\) is the corresponding regression coefficients for the transition probability \(p_{it}^{(h_1,h_2)}\). \({\mathbb{Z}}\) denotes personal/household covariates. This formulation defines a heterogeneous Markov Chain since it allows the transition probabilities of the hidden states to depend on the set of observed covariates (can include travel time, cost, and socio-demographic variables). This extension is general enough to, in the future, incorporate drivers’ latent modal preferences and their unobserved variables including familiarity, inertia, and attitudes into the formulation.
We assume that given individual i’s true state \(H_{it}\) in period t, the observed process of travel mode choices: \(Y_{it}\) are conditionally independent of the hidden state of other time periods. The state-dependent mode choice follows random utility maximization modeling form. Thus, we assume that the state-dependent choice of the alternative mode m has the utility as follows:
where \({\varvec{\beta}}\) and \({\varvec{\gamma}}\) are the vectors of state \(H_{it}\) dependent fixed parameters for personal/household covariates \({\mathbb{Z}}\) and travel mode covariates \({\mathbb{X}}\), respectively. Level-of-service variables (i.e., travel time, cost) and various personal/household characteristics (e.g., gender, income level, number of vehicles) can enter the formulation of utility functions. Therefore, the probability for individual i to choose travel mode m, conditional on the unobserved random state \(H_{it}\) is given by:
where \({{\mathbb{Z}}_{it}}\) is the vector of covariates measured at period t for individual i, \({\varvec{\beta}}_{m|h}\) is the corresponding regression coefficients for choosing mode m given hidden state h. One good feature about this hierarchical modeling structure is that this model can be generalized to allow for various forms of parameter heterogeneity following the well-established line of random utility maximization while still retaining its dynamic nature. For instance, combining random parameters and error components into the modeling structure can account for heterogeneity across observations. This paper extends the HMM function by incorporating error components into state-dependent utility functions:
where \(\sigma _{(m|H_{it})}\) is a scalar parameter specific to travel mode m and state \(H_{it}\). \(\eta _{(im|H_{it})}\) is a random variable hypothesized to be i.i.d. normal (0, 1) across individual i, mode m, and hidden state \(H_{it}\). Conditionally conjugate priors that are commonly used in different Bayesian statistical studies are employed in this paper to sample posterior distributions for the coefficients. In terms of the empirical test in this paper which employs 10-year travel panel survey data, we adopt non-informative conjugate priors and let the massive data determine inferences. This is largely due to the relatively huge sample size over the years and the fact that little evidence is known in terms of any established prior information regarding the estimation parameters.
where \(a_m\) and \(b_m\) are predefined values. An individual’s decision probabilities are correlated through the common underlying path of the hidden states, because of the Markovian properties of the model. Therefore, the joint likelihood function is given as:
where N denotes the total number of periods in the observations. \(H_{i1}\) denotes the initial hidden state of the individual i. Therefore, the joint likelihood can be interpreted as the likelihood of observing a sequence of chosen travel modes. The likelihood is given by the sum over all possible routes that this person could take over periods between the underlying states.
Parameters of the transition matrix and state-dependent searching are estimated using the joint likelihood function in Eq. (7). Estimation and maximization of the likelihood is not easy especially when the transition matrix is covariate-dependent. Here we employ Bayesian estimation and Markov Chain Monte Carlo (MCMC) simulation to sample the parameter distributions. This method follows Bayesian statistical inference. This paper assumes prior distributions for the regression coefficients \({\varvec{\beta}}\) and \({\varvec{\lambda}}^{(h_1,h_2)}\). The Bayesian inference is based on the posterior distribution:
This formulation’s left-hand side represents the posterior distribution of the coefficients. The right-hand side is a multiplication of the joint likelihood function and the prior distribution. To estimate the coefficients, this posterior distribution needs to be sequentially drawn. However, the equation does not have a closed form. In Bayesian theory, if it is possible to express each of the coefficients to be estimated as conditioned on the others, then we can eventually reach the true joint distribution by cycling through these conditional statements (Gill 2002). Thus we use MCMC simulation to sample the posterior. For this paper, standard MCMC technique (i.e., Gibbs sampler) is coded using R and WinBUGS package. Starting from initial values \([{\varvec{\beta}}^{[0]},{\varvec{\lambda}}^{[0]}]\) (the superscript denotes the step), at the jth step, the estimation method draws values from the following conditional distributions:
\(\pi ({\varvec{\beta}},{\varvec{\lambda}})\) denotes the limiting distribution of interest where \({\varvec{\beta}}\) and \({\varvec{\lambda}}\) are the vectors of coefficients whose posterior distributions are what we want to statistically describe. Number of iterations j is incremented and repeated until convergence. By doing this, a Markov chain is constructed to cycle through these conditional statements using Eqs. (9) and (10). It moves forward and then around the true limiting distribution. Once convergence is reached, a sufficient number of samples should be drawn to represent all areas of the target posterior. Gibbs sampling requires a full set of conditional distributions which is often not the case in hierarchical conditional relationships. The Metropolis-Hastings algorithm can be explored in future research when the model is enhanced with a Bayesian hierarchical structure.
Data
The data used for this study is from the Puget Sound Transportation Panel survey data that was collected over a 10-year period from 1989 to 2000. Stratified samples based on usual mode choice and residence county have been contacted via telephone random digit dialing. Recontacting participants from a previous transit survey and bus on-board letter distribution have been adopted to ensure sufficient transit samples. Each wave of the panel included some 1700 household samples and 3400 people in the Puget Sound area. Each member of the households surveyed were asked to record a two-day travel diary along with their personal, household, and vehicle information. Monetary incentive has been used to maintain response rates at 60 % level.
The first wave survey started in 1989 with 1687 households. Approximately 20 % of the samples left the panel between each two waves due to relocation and other issues. This attrition was replaced with new panel members. The panel data is processed in the way that any households that have stayed in the panel for six consecutive waves are included in the data set. All the home-based work trips produced by these households are then collected for analyzing the commute travel mode choice. A total number of 1050 samples have been included in the analysis, which results in 6300 commute trip records in the data set.
In addition to the two-day travel diary, personal and household characteristics have been collected, including gender, age, occupation, education, and household-level life-cycle stages. Meanwhile, information on household vehicles, workplace and employment has also been structured, allowing future analysis on vehicle ownership and land use. Descriptive statistics are summarized by Table 1. Statistics for wave 7, 8, 9, and 10 are omitted.
One uniqueness of this data is that it provides one of the few, if any, longitudinal travel survey datasets within United States. It is rich in long-term travel behavior adjustments. For instance, the commute travel mode shares for the observed 10-wave panel data are plotted in Fig. 1a. We can observe a slight increase in drive-alone percentage while transit and walk shares shrink. On average, 14.9 % of the samples have changed travel modes between each two waves of the survey. And over the entire survey period, 35.9 % of the samples have changed modes at least once.

Commute travel mode split and household life-cycle stage changes during the survey. a Commute travel mode ahare for the 10 wave panel. b % of households in different life-cycle stages
At the same time, more profound life-cycle stage and household composition changes beyond travel behavioral changes can be captured by this dataset. Here we choose to analyze the most representative life-cycle stages. The predefined life-cycle stages (i.e., 1: pre-school kids; 2: school-age kids; 3: 1 adult under 35, no kids; 4: one adult 35–64, no kids; 5: one adult above 65, no kids; 6: two+ adults under 35, no kids; 7: two \(+\) adults 35–64, no kids; 8: two \(+\) adults above 65, no kids) is re-grouped into four categories: (1) households with preschool kids; (2) households with school-age kids; (3) single households no kids; (4) two \(+\) households no kids. During the panel survey period, the proportion changes of these four types of households can be tracked in Fig. 1b. An average of 12.0 % of travelers have experienced changes in lifecycle stages between waves. And for the entire survey period, this percentage for life-stage changes increases to 47.4 %.
Within the over 10 years of the survey, the percentage of households with kids dropped to around 30 %. Significant decrease in the percentage of households with preschool-age kids is observed. On the contrary, the percentage of single households without kids has increased, while the percentage of 2-adult families remain in a stable level. While this paper’s main purpose is to propose and demonstrate the dynamic mode choice model, the changes in household composition and life-cycle stages can be an important factor in explaining the dynamics and thus can introduce interesting empirical finding if we incorporate this in the model.
Figure 2 plots commute travel mode share in different waves for travelers in different life-cycle stages. While the mode share for travelers in life-cycle stage 4 (plotted in Fig. 2d) is generally stable during the plotted six time periods, travelers in other stages tend to behave differently among different time periods. For instance, growing carpool share and diminishing transit share are observed among individuals in lifecycle stage 2.

Commute travel mode share for different lifecycle stages. a Lifecycle stage 1: family with preschool age kids. b Lifecycle stage 2: family with school age kids. c Lifecycle stage 3: single-adult family no kids. d Lifecycle stage 4: double-adult family no kids
Estimation results
The HMM family of models are compared with their benchmarks to reach a conclusion of which model fits the data best. Five alternative model specifications are considered: a standard multinomial logit model (MNL), which has a single homogeneous component and fixed parameters across all observations; a latent classes model; a mixture model of latent classes and error components; a two-state homogeneous-chain hidden Markov multinomial logit model; and a two-state heterogeneous-chain hidden Markov model with error components. Following Vij et al. (2013)’s formulation, we specify our state/class-dependent systematic utility functions as follows:
where t denotes travel time; c denotes travel cost; highinc is a dummy variable for higher income population (with household annual income higher than $50K); numveh denotes the number of vehicles in household; hhsize denotes the household size; buspass is a dummy variable for holding a bus pass; male is a dummy variable for male travelers.
Various performance measures of these five models are compared in Table 2. The estimated parameters from the MNL model are set up as a group of initial values to the Bayesian estimation of the hidden Markov models. The details about the estimation results of the benchmark model are not included in the interest of paper length but can be obtained from the authors. The same utility functions specified in MNL are used in modeling the class-dependent choice (latent classes models) and state-dependent choice (hidden Markov models). From Table 2, it is worth noting that static latent classes models do not fit the data very well. Even with 42 parameters specified in a latent-classes model with error components, the Pseudo \(\rho ^2\) statistic is only improved from 0.673 to 0.737. This is due to the fact that a typical static latent-classes model cannot consider the dependencies between time periods. Hidden Markov models can capture time-varying heterogeneity with the transition probabilities. A homogeneous-chain HMM model (i.e., transition probabilities are not related to personal/household covariates) with 40 parameters outperforms latent-classes model with pseudo \(\rho ^2 = 0.798\). And the extension to a heterogeneous chain (i.e., a transition model rather than probabilities) can further enhance the goodness-of-fit. This demonstrates the superiority of HMM models in modeling dynamic data.
We report the estimation results for the HMM models in Table 3. The standard errors of the estimated parameters are reported in the brackets. Insignificant parameters at the 90 % confidence level are denoted as italic in Table 3.
Once in a specific state, holding certain preferences on different travel modes for commuting travel, travelers exhibit certain levels of inertia in changing the state. This is validated by the negative and significant estimates for the Markov transition probabilities, which also indicates the stickiness of the two states (stickiness indicates that the probability of staying in the state is greater than the probability of switching out). Secondly, the heterogeneous chain estimates suggest significantly negative results for long-term life-cycle stages. This finding indicates that compared to travelers in a 2-adult household, single individuals and individuals with kids in general have higher inertia in switching hidden states (except that single-family individuals are more likely to switch from state 1 to state 2). We found this finding interesting. While further evidence needs to be drawn to validate the true impact from life-cycle stages on transitions between different states, the empirical results suggest that this modeling framework can serve as a useful test-bed wherein various empirical assumptions on choice dynamics, not limited to travel mode choice, can be tested. For instance, more general assumptions on inertia, modal preference, and attitudes can be incorporated in modeling this state transition.
From the empirical test, HMM model finds factors that significantly influence travelers’ commute mode choice. The HMM model with heterogeneous chain and error components (denoted as EC in Table 3) demonstrated a superior goodness-of-fit by accounting for both the cross-sectional unobserved heterogeneity and time-varying observed heterogeneity. The EC effects for different alternatives are all positive and significant, indicating strong alternative-specific taste variation. State-1 individuals tend to have the highest variation in bike utilities, while the variation is high for auto, transit, and bike modes for state-2 individuals. In terms of our posterior estimates, we find that State 1 tends to be a “time/cost-sensitive state” which has the highest elasticity of demand with respect to travel times and costs. In this state, individuals tend to have higher commute value-of-time (reported in Table 6) and evaluate their options mainly based on travel times/costs of each travel mode. Higher numbers of vehicles per person are likely to trigger individuals in this state to choose driving. Possessing a metro card does not necessarily increase the propensity to use transit significantly. On the contrary, State 2 is more likely to be an “auto-loving” state, judging by the alternative specific constant (ASC) statistics. Individuals in this state have strong preferences towards driving-alone mode and their sensitivities to level-of-service variables are less intense when compared with State 1. Marginal disutilities from travel time and costs are estimated one tenth of the scale of the disutilities observed for State 1. Different states are likely to be related to individuals on certain life-cycle stages. Conforming to the findings obtained from the heterogeneous Markov transitions, Individuals on life stage 2 and 3 are more likely to stay in State 2. Especially for life stage 3 individuals (single adult with no kids), the positive estimate on the transition probability from State 1 to State 2 is 1.128, which suggests that they have a much higher possibility to switch state in the short-term if they are currently in State 1. This coefficient for life stage 1 individuals (adults with preschool-age kids) is \(-\)1.674 and \(-\)0.916 for the two transitions, respectively. It indicates that while in general reluctant to any change, preschool kids parents are more likely to stay in “time/cost sensitive state”. Similar interpretation can be done to life stage 3 individuals. If considering the case when an individual makes life-stage change from stage 1 to 2, for example, this individual have a much higher chance to stop being a time/cost sensitive parent and embrace the “car-loving” state.
The model predicts a Markov transition with small transition probabilities (negative coefficients from Table 3). We further test the model’s sensitivities to Markov transition covariates and state-dependent choice covariates. Sensitivity statistics are reported in Tables 4 and 5. Life-stage status significantly influences the share of individuals in different hidden states. In terms of sensitivities to different modes, life stage 2 and 4 individuals exhibit similar patterns in increasing the percentages of carpool and low-speed modes. The marginal effects from one minute increase in different travel times and from one dollar increase in different travel costs are presented in Table 5. For example, one minute increase in car travel time will lead to a 3.93 % decrease in car mode share among State 1 travelers. This number is much smaller for State 2 as State 2 individuals are predicted to be less sensitive to time and costs.
Finally, the estimation with regards to commute value of travel times is presented in Table 6. Value of travel times can be calculated for both states and for both the low-income group and the high-income group. Monetary terms are transferred to dollars in year 2013 using consumer price index in order to make results comparable to findings in most recent research. State-1 individuals all tend to have a higher value of time, compared to State-2 individuals. The difference between low-income and high-income people is found much smaller in State 1, While in State 2, high-income group has a much higher value of time.
Conclusions
The objective of this paper is to explore the dynamic nature of travel mode choice. To accomplish this goal, the choice has been formulated as a hidden Markov model. Bayesian estimation with MCMC sampling procedure has been used to estimate the HMM model and to account for observed heterogeneity. This method is believed to embed time-varying heterogeneity in modeling mode choice. This extension helps relieve the limitation of time-constant assumptions of traditional methods, which can be potentially problematic if models employ longitudinal data. The model further extends the HMM to include hierarchical random parameters and error components in order to better consider unobserved heterogeneity. Most importantly, the model includes a heterogeneous transition matrix to incorporate observable dynamics. This is innovative and can be potentially significant since it provide a hierarchical framework wherein a great deal of empirical assumptions and model formulation can be tested.
Practical highlights of the paper include an empirical experiment conducted using a 10-wave PSTP data. The data for the analysis is limited to the subjects that appear in at least six waves of the survey. In order to obtain supplementary data on alternative modes, Seattle region’s planning model is obtained and executed to collect 24-h origin-destination skimming matrix information. The paper has found that the HMM family of models produces the best data fitting when compared with static discrete choice models such as MNL and latent-classes. Two hidden states have been specified and the model statistics suggest a clear evidence that individuals’ long-term life-cycle changes significantly influence their state switching. Other factors, such as mode-specific level-of-service variables, household characteristics (household size, number of vehicles), and personal characteristics were found to have an effect on commute mode choice in a dynamic context.
This paper remains as a first research effort that uses panel dataset to estimate a model with sensitivity to time/cost changes and various personal/household changes. It is fully acknowledged that limitations are there for us to address in the future. First of all, all travel modes are assumed available to decision-makers. This assumption needs to be relaxed as modality availability is more variant especially in modeling long-term behavior. Another limitation lies in the way we specify the HMM transition matrix. We demonstrate the formulation of transition matrix using two hidden states and the life-cycle stage variables. We may try to capture other modality styles (Vij 2013), e.g., inveterate drivers, car commuters, multimodals, etc. And other socio-demographic variables could influence the state specification, the number of states, and initial state distribution. These aspects can and should be incorporated in a more comprehensive model formulation.
Future work can also focus on the theoretical part, e.g., taking into account the individual unobserved heterogeneity in the HMM model. Random-effect parameters can be incorporated into the transition matrix and estimated with a hierarchical Bayesian structure, allowing for unobserved heterogeneity in the stickiness to different states. Another promising direction can explore practical applications of this model. The authors see a potential integration of the HMM and a one-day traffic simulation model to simulate day-to-day behavior changes (Xiong et al. 2015). Interesting results on multimodal behavior responses can be captured.
References
Arentze, T.A., Timmermans, H.J.: A learning-based transportation oriented simulation system. Transp. Res. Part B 38(7), 613–633 (2004)
Ben-Akiva, M.: Planning and Action in a Model of Choice. Choice Modelling: The State-of-the-Art and the State-of-Practice. Emerald, Bingley (2010)
Cherchi, E., Guevara, C.A.: A monte carlo experiment to analyze the curse of dimensionality in estimating random coefficients models with a full variance-covariance matrix. Transp. Res. Part B 46(2), 321–332 (2012)
Choudhury, C.F., Ben-Akiva, M., Abou-Zeid, M.: Dynamic latent plan models. J. Choice Model. 3(2), 50–70 (2010)
Cirillo, C., Axhausen, K.W.: Mode Choice of Complex Tours: A Panel Analysis. ETH, Eidgenössische Technische Hochschule Zürich, Institut für Verkehrsplanung, Transporttechnik, Strassen-und Eisenbahnbau IVT (2002)
Cirillo, C., Axhausen, K.W.: Dynamic model of activity-type choice and scheduling. Transportation 37(1), 15–38 (2010)
Gill, J.: Bayesian Methods: A Social and Behavioral Sciences Approach. CRC Press, Boca Raton (2002)
Goulias, K.G.: Longitudinal analysis of activity and travel pattern dynamics using generalized mixed markov latent class models. Transp. Res. Part B 33(8), 535–558 (1999)
Hess, S., Train, K.E.: Recovery of inter-and intra-personal heterogeneity using mixed logit models. Transp. Res. Part B 45(7), 973–990 (2011)
Kitamura, R.: Panel analysis in transportation planning: an overview. Transp. Res. Part A 24(6), 401–415 (1990)
Koppelman, F.S.: Predicting transit ridership in response to transit service changes. J. Transp. Eng. 109(4), 548–564 (1983)
McFadden, D., Train, K.: Mixed mnl models for discrete response. J. Appl. Econ. 15(5), 447–470 (2000)
Netzer, O., Lattin, J.M., Srinivasan, V.: A hidden markov model of customer relationship dynamics. Mark. Sci. 27(2), 185–204 (2008)
Pas, E.I., Koppelman, F.S.: An examination of the determinants of day-to-day variability in individuals’ urban travel behavior. Transportation 14(1), 3–20 (1987)
Paulssen, M., Temme, D., Vij, A., Walker, J.L.: Values, attitudes and travel behavior: a hierarchical latent variable mixed logit model of travel mode choice. Transportation 41, 1–16 (2013)
Pendyala, R., Kitamura, R., Prasuna Reddy, D.: Application of an activity-based travel-demand model incorporating a rule-based algorithm. Environ. Plan. B 25, 753–772 (1998)
Pendyala, R., Pas, E.: Multi-day and multi-period data for travel demand analysis and modeling. Technical report (2000)
Pendyala, R. M.: Challenges and opportunities in advancing activity-based approaches for travel demand analysis. In: The Expanding Sphere of Travel Behavior Research: Selected Papers from the 11th Conference of the International Association for Travel Behavior Research: Selected Papers from the 11th Conference of the International Association for Travel Behavior Research, p. 303. Emerald Group Publishing
Pendyala, R.M., Kitamura, R., Kikuchi, A., Yamamoto, T., Fujii, S.: Florida activity mobility simulator: overview and preliminary validation results. Transp. Res. Rec. 1921(1), 123–130 (2005)
Ramadurai, G., Srinivasan, K.K.: Dynamics and variability in within-day mode choice decisions: role of state dependence, habit persistence, and unobserved heterogeneity. Transp. Res. Rec. 1977(1), 43–52 (2006)
Scott, S.L.: Bayesian methods for hidden Markov models. J. Am. Stat. Assoc. 97(457), 337–352 (2002)
Smith, T., Vounatsou, P.: Estimation of infection and recovery rates for highly polymorphic parasites when detectability is imperfect, using hidden markov models. Stat. Med. 22(10), 1709–1724 (2003)
Srinivasan, K.K., Bhargavi, P.: Longer-term changes in mode choice decisions in chennai: a comparison between cross-sectional and dynamic models. Transportation 34(3), 355–374 (2007)
Vij, A.: Incorporating the Influence of Latent Modal Preferences in Travel Demand Models. University of California Transportation, Berkley (2013)
Vij, A., Carrel, A., Walker, J.L.: Incorporating the influence of latent modal preferences on travel mode choice behavior. Transp. Res. Part A 54, 164–178 (2013)
Walker, J.L.: Extended Discrete Choice Models: Integrated Framework, Flexible Error Structures, and Latent Variables. Ph. D. thesis, Massachusetts Institute of Technology (2001)
Xiong, C., Zhang, L.: Positive model of departure time choice under road pricing and uncertainty. Transp. Res. Rec. 2345(1), 117–125 (2013)
Xiong, C., Zhang, L.: Dynamic travel mode searching and switching analysis considering hidden modal preference and behavioral decision processes. In: Transportation Research Board 93rd Annual Meeting, Number 14-4710
Xiong, C., Chen, X., He, X., Lin, X., Zhang, L.: Agent-based en-route diversion: Dynamic behavioral responses and network performance represented by macroscopic fundamental diagrams. Transp. Res. Part C. (2015). doi:10.1016/j.trc.2015.04.008
Acknowledgments
This research is financially supported by a National Science Foundation (NSF) CAREER Award, “Reliability as an Emergent Property of Transportation Networks”, and the U.S. Federal Highway Administration (FHWA) Exploratory Advanced Research Program. The authors are grateful to Neil Kilgren and Carol Naito affiliated with Puget Sound Regional Council for kindly provide Puget Sound Transportation Panel data and supplemented Puget Sound regional planning skimming matrices. The authors would like to thank Chen Dong affiliated with the Department of Mathematics, Univ. of Maryland, for his advice in addressing various hidden Markov model estimation issues. The opinions in this paper do not necessarily reflect the official views of NSF or FHWA. They assume no liability for the content or use of this paper. The authors are solely responsible for all statements in this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Xiong, C., Chen, X., He, X. et al. The analysis of dynamic travel mode choice: a heterogeneous hidden Markov approach. Transportation 42, 985–1002 (2015). https://doi.org/10.1007/s11116-015-9658-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11116-015-9658-2