
Abstract
Recently, Bouafia et al. (J Optim Theory Appl 170:528–545, 2016) investigated a new efficient kernel function that differs from self-regular kernel functions. The kernel function has a trigonometric barrier term. This paper introduces a new efficient twice parametric kernel function that combines the parametric classic function with the parametric kernel function trigonometric barrier term given by Bouafia et al. (J Optim Theory Appl 170:528–545, 2016) to develop primal–dual interior-point algorithms for solving linear programming problems. In addition, we obtain the best complexity bound for large and small-update primal–dual interior point methods. This complexity estimate improves results obtained in Li and Zhang (Oper Res Lett 43(5):471–475, 2015), Peyghami and Hafshejani (Numer Algorithms 67:33–48, 2014) and matches the best bound obtained in Bai et al. (J Glob Optim 54:353–366) and Peng et al. (J Comput Technol 6:61–80, 2001). Finally, our numerical experiments on some test problems confirm that the new kernel function has promising applications compared to the kernel function given by Fathi-Hafshejani (Optimization 67(10):1605–1630, 2018).
Similar content being viewed by others

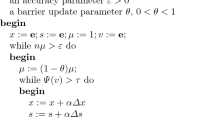

Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we focus on the primal Linear Optimization \({\mathbf { LO}}\) problem as
along with its dual problem as follows:
Where \(A\in {{\mathbb {R}}} ^{m\times n}\), \(rank(A)=m,b\in {{\mathbb {R}}} ^{m}\), and \(c\in {{\mathbb {R}}} ^{n}\).
Karmarkar (1984) proposed a new polynomial-time method for solving linear programs. This method and its variants that followed are now called \({\mathbf {IPMs}}\). In our work, we refer to recent books on the subject as Peng et al. (2002), Bai and Roos (2002), Roos et al. (1997), Ye (1997).
Without loss of generality, we assume that (P) and (D) satisfy the interior-point condition \({\mathbf {IPC,}}\) i.e., there exist \((x^{0}\), \(y^{0}\) , \(s^{0})\) such that
Kernel functions provide a characterization of the central path of the primal and dual problems by using its minima and derivatives. Furthermore, to compute the complexity bound, its derivatives, and the inverse functions of the kernel function with its derivatives.
Peng et al. (2001) and Peng et al. (2002) introduced and proposed new variants of \({\mathbf {IPMs}}\) based on a new nonlogarithmic kernel functions. They obtained the complexity results for large and small-update methods, which have \({\mathbf {O}}\left( \sqrt{n}\left( \log n\right) \log \frac{n}{\epsilon }\right)\) complexity for large-update and \({\mathbf {O}}\left( \sqrt{n} \log \frac{n}{\epsilon }\right)\) complexity for small-update methods.
Bai et al. (2005) proposed a new kernel function with an exponential barrier term. The same paper introduced the first new kernel function to have a trigonometric barrier term.
El Ghami et al. (2012) evaluated the first new kernel function with a trigonometric barrier term given by Bai et al. (2005). They obtained \({\mathbf {O}}\left( n^{\frac{3}{4}}\log \frac{n}{\epsilon }\right)\) iterations bound for large-update methods. Since then, research has focused on developing a new kernel function with a trigonometric barrier term to improve the complexity bound obtained by El Ghami et al. (2012).
Peyghami and Hafshejani (2014) proposed a new kernel function with an exponential trigonometric for \({\mathbf {LO}}\). They obtained \({\mathbf {O}}\left( \sqrt{n}\left( \log n\right) ^{2}\log \frac{n}{\epsilon }\right)\) iterations bound for large-update methods.
Li and Zhang (2015) presented another trigonometric barrier function, which has \({\mathbf {O}}\left( n^{\frac{2}{3}}\log \frac{n}{\epsilon }\right)\) complexity for large-update methods. These results improve the complexity bound obtained by El Ghami et al. (2012).
Bouafia et al. (2016a, b) proposed two parameterized kernel functions. The first has a trigonometric barrier term for interior point methods in \(\mathbf {LO}\). We generalized and improved the complexity bound based on a new kernel function with trigonometric barrier terms obtained in Li and Zhang (2015), Peyghami and Hafshejani (2014), El Ghami et al. (2012) and Peyghami et al. (2014). We obtained the best known complexity results for large and small-update methods. The second function generalizes the kernel function given by Bai et al. (2005).
Bouafia et al. (2018) presented the first parameterized logarithmic kernel function. It is proven to efficiently give the best logarithmic complexity.
Fathi-Hafshejani et al. (2018) presented a large-update primal–dual interior-point algorithm for linear optimization problems based on a new kernel function with a trigonometric growth term. They obtained the best known complexity results for large which has \({\mathbf {O}}\left( \sqrt{n} \log n \log \frac{n}{\epsilon }\right)\) complexity for large-update method. This result improve the complexity bound obtained in Li and Zhang (2015), Peyghami and Hafshejani (2014), El Ghami et al. (2012) and Peyghami et al. (2014).
In this paper, we introduce a new twice parametric kernel function
for the development of primal–dual interior-point algorithms for solving linear programming problems. We investigate the properties of the proposed kernel functions and corresponding parameters, improving the complexity bound obtained by Li and Zhang (2015) for \({\mathbf {LO}}\). More precisely, based on the proposed kernel function, we prove that the corresponding algorithm has \({\mathbf {O}}\left( pn^{\frac{\left( p+2\right) \left( q+1\right) }{2\left( p+1\right) q}}\log \frac{n}{\epsilon }\right)\) complexity bound for the large-update method and \({\mathbf {O}}\left( \left( p+q\right) ^{2}\sqrt{n}\log \frac{n}{\epsilon }\right)\) for the small-update method. In another interesting approach, where p and q is dependent on n, we take \(p = q = logn\), and we obtain the known complexity bound for large-update methods namely \({\mathbf {O}}\left( \sqrt{n} \log n\log \frac{n}{\epsilon }\right)\). This bound improves the complexity results we have obtained so far for the large-update methods based on a trigonometric kernel function given by Li and Zhang (2015), Peyghami and Hafshejani (2014).
The paper is organized as follows. In Sect. 2, we recall the basic concepts of a central path, barrier function, and kernel function. A generic primal–dual \(\mathbf {IPMs}\) based on kernel functions is described in Sect. 3. In Sect. 3, we present some properties of the new kernel function, as well as several properties and the growth behavior of the barrier function based on the kernel function, the estimate of the stepsize, and the decreasing behavior of the new barrier function decrease behavior of new barrier function. In Sect. 4, we derive the inner iteration bound and the total iteration bound of the algorithm. In Sect. 5, we compare our results to those of the algorithm given by Fathi-Hafshejani et al. (2018). Finally, we are finishing the paper with some remarks and a general conclusion showing the added value of our work. We use the following notations throughout the paper. \({{\mathbb {R}}} _{+}^{n}\) and \({{\mathbb {R}}} _{++}^{n}\)denote the set of n-dimensional nonnegative vectors and positive vectors, respectively. For x, s\(\in {{\mathbb {R}}} ^{n}\), \(x_{\min }\) and xs denote the smallest component of the vector x and the componentwise product of the vector x and s, respectively. We denote \(X = diag(x)\) by the n diagonal matrix with the components of the vector \(x\in {{\mathbb {R}}} ^{n}\), the diagonal entries. Finally, e denotes the n-dimensional vector of ones. For \(f\left( x\right) ,g\left( x\right)\) : \({{\mathbb {R}}} _{++}^{n}\rightarrow {{\mathbb {R}}} _{++}^{n},\)\(f\left( x\right) ={\mathbf {O}}\left( g\left( x\right) \right)\) if \(f\left( x\right) \le C_{1}g\left( x\right)\) for some positive constant \(C_{1}\) and \(f\left( x\right) =\varvec{\Theta }\left( g\left( x\right) \right)\) if \(C_{2}g\left( x\right)\)\(\le f\left( x\right) \le C_{3}g\left( x\right)\) for some positive constant \(C_{2}\) and \(C_{3}\). And throughout the paper, || || denotes the 2-norm of a vector.
2 The generic primal–dual interior-point algorithm
In this section, we briefly describe the idea behind the interior point methods based on kernel functions. We also provide the structure of the generic primal–dual \({\mathbf {IPMs}}\) when the kernel functions are used to induce the proximity measure. One knows that for the feasible primal and dual linear optimization problems, i.e.problems (P) and (D), an optimal solution can be found by solving the following system:
The basic idea of primal–dual \({\mathbf {IPMs}}\) is to replace the third equation in (2), the so-called complementarity condition for (P) and (D) , by the parameterized equation \(xs= \mu e,\) with \(\mu >0\). Thus we consider the system
It is shown that, under \({\mathbf {IPC}}\) condition and \(rank(A) = m\), system (4) has a unique solution, for each\(\mu >0\). This solution is denoted by \((x( \mu ),y( \mu ),s( \mu ))\), and we call \(x( \mu )\) the \(\mu\)-center of (P) and \((y( \mu ),s( \mu ))\) the \(\mu\)-center of (D). The set of \(\mu\)-centers (with \(\mu\) running through all positive real numbers) gives a homotype path, which is called the central path of (P) and (D). The relevance of the central path for linear optimization \({\mathbf {LO}}\) was recognized first by Sonnevend (1986) and Megiddo (1989). It is proved that as \(\mu \rightarrow 0\), the limit of the central path exists and converges to an analytic center of the optimal solutions set of (P) and (D).
Let \(\mu >0\) be fixed. A direct application of the Newton method on (4) provides the following system for \(\varDelta x, \varDelta y \,\,{\text{and}}\,\, \varDelta s:\)
This system uniquely defines a search direction \((\varDelta x,\varDelta y,\varDelta s)\). By taking a step along the search direction, with the step size defined by some line search rules, we construct a new triple (x, y, s). If necessary, we repeat the procedure until we find iterates that are “close” to \((x( \mu ),y( \mu ),s( \mu ))\). Then \(\mu\) is again reduced by the factor \(1-\theta\), and we apply Newton’s method targeting the new \(\mu\)-centers, and so on. This process is repeated until \(\mu\) is small enough, say until \(n\mu \le \epsilon\); at this stage we have found an \(\epsilon\)-solution of problems (P) and (D).
The result of a Newton step with step size \(\alpha\) is denoted as
where, the step size \(\alpha\) satisfies (\(0<\alpha \le 1\)).
Now we introduce the scaled vector v and the scaled search directions \(d_{x}\) and \(d_{s}\) as follows:
System (4) can be rewritten as follows:
where \(\overline{A}=\frac{1}{\mu }AV^{-1}X,V=diag(v),X=diag(x)\). Note that \(d_{x} = d_{s} = 0\) if and only \(v^{-1}-v=0\) if and only \(x=e\) if and only \(x=x(\mu ), s=s(\mu )\). A crucial observation in (7) is that the right hand side of the third equation is the minus the negative gradient of the logarithmic barrier function \(\varvec{\Phi }\left( v\right) ,\) i.e., \(d_{x}+d_{s}=-\nabla \varvec{\Phi }\left( v\right)\), then system (7) can be rewritten as follows:
where the barrier function \(\varvec{\Phi }\left( v\right)\)\(: {{\mathbb {R}}} _{++}^{n}\rightarrow {{\mathbb {R}}} _{+}\) is defined as follows:
We use \(\varvec{\Phi }\left( v\right)\) as the proximity function to measure the distance between the current iterate and the \(\mu\)-center for given \(\mu >0\). We also define the norm-based proximity measure, \(\delta (v)\)\(: {{\mathbb {R}}} _{++}^{n}\rightarrow {{\mathbb {R}}} _{+}\), as follows
The new variant of primal–dual \(\text{ IPMs }\) was developed by Peng et al. (2002) in which the proximity function \(\varvec{\Phi }\left( v\right)\) is replaced by a new proximity function \(\varvec{\Phi }_{M}\left( v\right) =\sum _{i=1}^{n}\psi _{M} \left( v_{i}\right) ,\) which will be defined in Sect. 3, where \(\psi _{M} \left( t\right)\) is any strictly differentiable convex barrier function on \({\mathbb {R}}_{++}\) with \(\psi _{M} \left( 1\right) =\psi ' _{M}(1)=0\).
Now, we describe one step of the \(\text{ IPMs }\) based on the kernel function. Starting with the interior point \((x^{0}\), \(y^{0}\), \(s^{0})\), \(\mu >0\), an accuracy \(\epsilon >0\) and the proximity function \(\varvec{\Phi }_{M}\left( v\right)\), let a good approximation of the \(\mu\)-center \((x(\mu ),y(\mu ),s(\mu ))\) be known for \(\mu >0\). Then, the parameter \(\mu\) is decreased by a factor \(1-\theta\), for \(0<\theta <1\), and we apply Newton’s method targeting the new \(\mu\)-centers, and so on. Indeed, we first solve system (8) for \(d_{x} \,\,{\text{and}}\,\, d_{s}\) and then find the Newton directions \(\left( \varDelta x,\varDelta y,\varDelta s\right)\). This procedure is repeated until we get to the point in which \(x^{T}s<\epsilon\) In this case, we say that the current x and (y, s) are \(\epsilon\)-approximate solutions of the primal and dual problems, respectively. Now, we can outline the above procedure in the following primal–dual interior point scheme (Peng et al. 2002). The parameters \(\tau ,\theta\) and the step size \(\alpha\) should be chosen in such a way that the algorithm is optimized in the sense that the number of iterations required by the algorithm is as small as possible. The choice of the so-called barrier update parameter \(\theta\) plays an important role in both theory and practice of \(\text{ IPMs }\). Usually, if \(\theta\) is a constant independent of the dimension n of the problem, for instance, \(\theta = 1/2\), then we call the algorithm a large-update (or long-step) method. If \(\theta\) depends on the dimension of the problem, such as \(\theta =1/n\), then the algorithm is called a small-update (or short-step) method. The generic form of the algorithm is shown in Fig. 1.

Generic algorithm
3 Properties of the new kernel function
Recently, Bouafia et al. (2016a), investigated a new efficient kernel function with trigonometric barrier for \({\text{LO}}\), which differs from the self-regular kernel functions. Motivated by their work, in this paper we introduce a new efficient twice parametric kernel function, which is a combination of the parametric classic function and the parametric kernel function trigonometric barrier term given by Bouafia et al. (2016a), for the development of primal–dual interior-point algorithms for solving linear programming problems, and we present a primal–dual interior-point algorithm for \({\text{LO}}\) based on this kernel function:
3.1 Some technical results
In the analysis of the algorithm based on \(\psi _{M} \left( t\right)\) we need its first three derivatives. These are given by
with
and
We present some of the specificities of the function h that are given in Bouafia et al. (2016a), we need in the following proofs to present:
Lemma 3.1
(Lemma 3.1 in Bouafia et al. (2016a)) For \(h\left( t\right)\) defined in (12) and \(p\ge 2\), we have the following
From (5–14,16,18), Lemma 3.1 and definition of kernel function (Bai et al. 2005), we can easy to check that
which show that \(\psi _{M}\left( t\right)\) is indeed a kernel function.
3.2 Eligibility of the new kernel function
The next lemma serves to prove that the new kernel function (18) is eligible.
Lemma 3.2
Let \(\psi _{M}\left( t\right)\) be as defined in (12) and \(t>0\). Then,
Proof
For (22), the sign of \(\psi _{M}^{\prime \prime \prime }\left( t\right)\), using (15), (16) and (18), we have
which implies that (22).
For (23), we again use (13) and (14),
Form (16) and the positivity of \(-h^{\prime \prime }\left( t\right)\), the right-hand side of the last equality is positive, which proves (23).
For (24), using (13) and (14), we have
and
using (20), the right-hand side of the above equality is positive, which proves (24).
The last property (24) in Lemma 3.2 is equivalent to convexity of composed functions \(t\mapsto \psi _{M}\left( e^{t}\right)\) and this holds if only if \(\psi _{M}\left( \sqrt{t_{1}t_{2}} \right) \le \frac{1}{2}\left( \psi _{M}\left( t_{1}\right) +\psi _{M}\left( t_{2}\right) \right)\) for any \(t_{1}\), \(t_{2}\ge 0\),this property is known in the literature, it was demonstrated by several researchers (see Peng et al. 2002; El Ghami et al. 2012; Bai et al. 2003).
As a preparation for later, we present the some technical results for the new of kernel function
Lemma 3.3
For \(\psi _{M}\left( t\right)\), we have
Proof
For (26), since \(\psi _{M}\left( 1\right) =\psi _{M}^{\prime }\left( 1\right) =0,\psi _{M}^{\prime \prime \prime }\left( t\right) <0,\)\(\psi _{M}^{\prime \prime }\left( 1\right) =\left( 3+q+\frac{\pi }{4}p\right)\), and by using Taylor’s Theorem, we have
for some \(\xi ,\)\(1\le \xi \le t.\) This completes the proof. \(\square\)
Let \(\sigma :[ 0,+\infty [ \rightarrow [ 1,+\infty [\) be the inverse function of \(\psi _{M}\left( t\right)\) for \(t\ge 1\) and \(\rho :[ 0,+\infty [ \rightarrow ] 0,1]\) be the inverse function of \(\frac{-1}{2}\psi _{M}^{\prime }\left( t\right)\) for all \(t\in ] 0,1]\). Then we have the following lemma.
Lemma 3.4
For \(\psi _{M}\left( t\right)\), we have
Proof
For (27), let
By (25), we have
we have
which implies that
For (28), let
By the definition of
By the definition of \(\psi _{M}^{\prime }\left( t\right)\) and \(h^{\prime }\left( t\right)\), we have
this implies
and
which implies that
For (29), we have
which implies that
This completes the proof. \(\square\)
We offer important theorem which is valid for all kernel functions that satisfy (22) and (23) (Lemma 2.4 in Bai et al. 2005)
Theorem 3.1
(Bai et al. 2005) Let \(\sigma :[ 0,+\infty [ \rightarrow [ 1,+\infty [\) be the inverse function of \(\psi _{M}\left( t\right)\) for \(t\ge 1\). Then we have
Lemma 3.5
Let \(0\le \theta <1\), \(v_{+}=\frac{v}{\sqrt{1-\theta }},\) If \(\ \varvec{\Phi }_{M}\left( v\right) \le \tau ,\) then we have
Proof
Since \(\frac{1}{\sqrt{1-\theta }}\ge 1\) and \(\sigma \left( \frac{\varvec{\Phi }_{M}\left( v\right) }{n}\right) \ge 1\), then \(\frac{\sigma \left( \frac{\varvec{\Phi }_{M}\left( v\right) }{n}\right) }{\sqrt{1-\theta }}\ge 1\).
And for \(t\ge 1,\) we have
Using Theorem 3.1 with \(\beta =\frac{1}{\sqrt{1-\theta }}\), and (27) , for \(\varvec{\Phi }_{M}\left( v\right) \le \tau\), we have
This completes the proof. \(\square\)
Denote
then \(\left( \varvec{\Phi }_{M}\right) _{0}\) is an upper bound for \(\mathbf { \Phi }_{M}\left( v_{+}\right)\) during the process of the algorithm.
3.3 Determining a stepsize
In this section, we compute a default, stepsize \(\alpha\) and the resulting decrease of the barrier function. After a damped step we have
Using (6), we have
So we have
Define, for \(\alpha >0\),
Then \(f\left( \alpha \right)\) is the difference of proximities between a new iterate and a current iterate for fixed \(\mu\). By (24), we have
Therefore, we have \(f\left( \alpha \right)\)\(\le\)\(f_{1}\left( \alpha \right)\), where
Obviously, \(f\left( 0\right) = f_{1}\left( 0\right) =0\). Taking the first two derivatives of \(f_{1}\left( \alpha \right)\)with respect to \(\alpha\), we have
For convenience, we denote
Lemma 3.6
Let \(\delta (v)\) be as defined in (11). Then we have
Proof
Using (25), we have
so
This completes the proof. \(\square\)
Remark 3.1
Throughout the paper, we assume that \(\tau\)\(\ge 1\). Using Lemma 3.6 and the assumption that \(\varvec{\Phi }_{M}\left( v\right)\)\(\ge\)\(\tau\), we have
From Lemmas 4.1–4.4 in Bai et al. (2005), we have the following Lemmas \(\mathbf { 3.7-3.10}\).
Lemma 3.7
Let \(f_{1}\left( \alpha \right)\) be as defined in (27) and \(\delta (v)\) be as defined in (11). Then we have
Lemma 3.8
If the stepsize \(\alpha\) satisfies the inequality
we have
Lemma 3.9
let \(\rho :[ 0,+\infty [ \rightarrow ] 0,1]\) be the inverse function of \(\frac{-1}{2}\psi _{M}^{\prime }\left( t\right)\) for all \(t\in ] 0,1]\). Then the largest stepsize \(\overline{\alpha }\) satisfying (33) is given by
Lemma 3.10
Let \(\overline{\alpha }\) be as defined in Lemma 3.9. Then
Lemma 3.11
Let \(\rho\) and \(\overline{\alpha }\) be as defined in Lemma 3.10. If \(\varvec{\Phi }_{M}\left( v\right) \ge\)\(\tau\)\(\ge\) 1, then we have
Proof
Using Lemma 3.10, the definition of \(\psi _{M}^{\prime \prime }\left( t\right)\), and (28) we have
And for \(\rho \left( 2\delta \right) =t\in ] 0,1]\), we have
for \(z=2\delta\) we have \(\tan h\left( t\right) \le \left( 4z+2\right) ^{ \frac{1}{p+1}}\), this implies
using (29) and \(\left( 8\delta +2\right) >1\), we have \(t\ge \left[ \frac{1}{8\delta +2}\right] ^{\frac{1}{q}}\) this implies
we have
This completes the proof. \(\square\)
Denoting
we have that \(\widetilde{\alpha }\) is the default stepsize and that \(\widetilde{\alpha }\le \overline{\alpha }\).
Lemma 3.12
(4.5 in Bai et al. (2005)) If the stepsize \(\alpha\) satisfies \(\alpha\)\(\le \overline{\alpha }\), then
Lemma 3.13
Let \(\widetilde{\alpha }\) be the default stepsize as defined in (34) and let
Then
Proof
Using Lemma 3.12 (4.5 in Bai et al. (2005)) with \(\alpha =\widetilde{\alpha }\) and (34), we have
because
This completes the proof. \(\square\)
4 Iteration bounds of the algorithm
4.1 Inner iteration bound
After the update of \(\mu\) to \(\left( 1-\theta \right) \mu\), we have
We need to count how many inner iterations are required to return to the situation where \(\varvec{\Phi }_{M}\left( v\right) \le \tau\) . We denote the value of \(\varvec{\Phi }_{M}\left( v\right)\) after the \(\mu\) update as \(\left( \varvec{\Phi }_{M}\right) _{0}\); the subsequent values in the same outer iteration are denoted as \(\left( \varvec{\Phi }_{M}\right) _{k}\), \(k=1,2,...,K\), where K denotes the total number of inner iterations in the outer iteration. The decrease in each inner iteration is given by (35). In Bai et al. (2005) we can find the appropriate values of \(\overline{\kappa }\) and \(\gamma \in\) ]0, 1] :
Lemma 4.1
Let K be the total number of inner iterations in the outer iteration. Then we have
Proof
By Lemma 1.3.2 in Peng et al. (2002), we have
This completes the proof. \(\square\)
4.2 Total iteration bound
The number of outer iterations is bounded above by \(\frac{\log \frac{n}{ \epsilon }}{\theta }\) (see Roos et al. 1997, Lemma \(\mathbf {II}\).\(\mathbf {17}\), page \(\mathbf {116}\)). Through multiplying the number of outer iterations by the number of inner iterations, we get an upper bound for the total number of iterations, namely,
For large-update methods with \(\tau ={\mathbf {O}}\left( n\right)\) and \(\theta =\varvec{\Theta }\left( 1\right)\) we have
In case of a small-update methods, we have \(\tau ={\mathbf {O}}\left( 1\right)\) and \(\theta =\varvec{\Theta }\left( \frac{1}{\sqrt{n}}\right) .\) Substitution of these values into (36) does not give the best possible bound. A better bound is obtained as follows.
By (26), with
we have
where we also used that \(1-\sqrt{1-\theta }=\frac{\theta }{1+\sqrt{1-\theta } }\le \theta\) and \(\varvec{\Phi }_{M}\left( v\right) \le \tau\),using this upper bound for \(\left( \varvec{\Phi }_{M}\right) _{0}\), we get the following iteration bound:
note the now \(\left( \varvec{\Phi }_{M}\right) _{0}={\mathbf {O}}\left( p+q\right)\), and the iteration bound becomes
5 Comparison of algorithms
In this section we offer compared of their algorithm given by S. Fathi-Hafshejani et al. in Fathi-Hafshejani et al. (2018) and the result with ours. To prove the effectiveness of our new kernel function and evaluate its effect on the behavior of the algorithm, we offer a comparison between the results of algorithms of \(\text{ IPMs }\), the following two kernel functions.
- 1.
The first kernel function, given by S. Fathi-Hafshejani et al. in Fathi-Hafshejani et al. (2018), is noted kernel function F, defined by
$$\begin{aligned} \psi _{F}\left( t\right) =2\pi \int _{1}^{t}(tan(v(x))-cot^{3p}(v(x)))dx, \ \ \ p>0, v(x)=\frac{\ x \pi }{2+2x}>0. \end{aligned}$$ - 2.
Our new kernel function is noted kernel function M, defined in (12) by
$$\begin{aligned} \psi _{M}\left( t\right) =t^{2}+\frac{t^{1-q}}{q-1}-\frac{q}{q-1}+\frac{4}{ \pi p}\left[ \tan ^{p}h\left( t\right) -1\right] ,\ \left\{ \begin{array}{c} h\left( t\right) =\frac{\pi }{2t+2}, \\ p\ge 2,\ q>1. \end{array} \right. \end{aligned}$$We summarize this results in the Table 1
Comments For the same value of parameter p, for both functions:
If \(q>p\), the complexity results for large-update methods, of the algorithm based of our new kernel function best of the complexity results of the algorithm based of the kernel function given by Fathi-Hafshejani et al. (2018). While always the opposite of The complexity results for small-update methods.
If \(q=p=logn\), the complexity results for large-update methods, of the tow algorithms consolidate of the best known complexity bound for large-update methods namely \({\mathbf {O}}\left( \sqrt{n} \log n\log \frac{n}{\epsilon }\right)\).
5.1 Numerical tests
Recall that the considered problem is
\(c\left( i\right) =-1,\)\(c\left( i+m\right) =0,\)\(b\left( i\right) =2,\) and the interior-point condition \(\mathbf {IPC}\), \(x^{0}(i)=x^{0}(i+m)=1\), \(y^{0}(i)=-2\), \(s^{0}(i)=1, s^{0}(i+m)=2\) for \(i\ =1, \ldots ,m\).
To prove the effectiveness of our new kernel function and evaluate its effect on the behavior of the algorithm, we conducted comparative numerical tests between the following two kernel functions previous.
To be solved, we used the Software Dev Pascal. We have taken \(\epsilon =10^{-4}\), \(\mu ^{0}=1\), \(\theta =\frac{1}{2}\), \(\tau =n\), \(p\in \{4, logn\}\) and \(q\in \{6, log n\}\) for the new kernel function.
We have the step size \(\alpha\), satisfying \(0<\alpha <\overline{\alpha }\) : we take respectively, \(\alpha _{\textit{F}}\) and \(\alpha _{\textit{M}}\), which match with the notation of precedent kernel functions; We choose \(\alpha = min\{\alpha _{\textit{F}},\alpha _{\textit{M}}\}\).
In the table of results, (ex (m, n)): m is the number of constraints and n is the number of variables, \(\left(\textit{Itr A} {\rm and} \textit{Med A}=\frac{{\rm total} {\rm iteration }}{{\rm outer} {\rm iteration}}\right)\) represents the number of outer iteration necessary to obtain the optimal solution and the median value of the number of internal iterations using the function A, Respectively. We summarize this numerical study in Tables 2, 3, 4 and 5.
Comments These tables confirm the theoretical results obtained and show the reduction of the complexity results of the algorithm based of our new kernel function best of the complexity results of the algorithm based of the kernel function given by Fathi-Hafshejani et al. (2018).
6 Concluding remarks
In this work, we propose new efficient parameterized kernel functions with trigonometric barrier terms. We study the properties of the kernel functions and investigate the effects of parameters. Moreover, we improve the algorithmic complexity of the interior points method. We analyze large-update and small-update versions of the primal–dual interior algorithm described in Fig. 1, which is based on the new parameterized kernel functions (12). We prove that the iteration bound of the large-update interior-point method based on the kernel function considered in this paper is \({\mathbf {O}}\left( pn^{\frac{\left( p+2\right) \left( q+1\right) }{2\left( p+1\right) q}}\log \frac{n}{\epsilon }\right)\). Setting the bound to \(p=q\ge 6\) improves the complexity results we obtained so far for large-update methods, the trigonometric kernel function given by Peyghami et al. (2014), i.e., \({\mathbf {O}}\left( n^{\frac{2}{3}}\log \frac{n}{\epsilon }\right)\). When p is dependent on n, it minimizes the iteration bound. In particular, if we take \(p=q=\log n\), we obtain the best known complexity bound for large-update methods, namely \({\mathbf {O}}\left( \sqrt{n}\left( \log n\right) \log \frac{n}{\epsilon }\right)\). This bound improves the complexity results obtained so far for large-update methods, the trigonometric kernel function given by Peyghami and Hafshejani (2014), i.e.,\({\mathbf {O}}\left( \sqrt{n}\left( \log n\right) ^{2}\log \frac{n}{\epsilon }\right)\). For small-update methods, we obtain the best know iteration bound, namely \({\mathbf {O}}\left( \sqrt{n}\log \frac{n}{\epsilon }\right)\), by taking \(\left( p+q\right) ={\mathbf {O}}\left( 1\right)\). These results are an important contribution for improving the computational complexity of the problem under study.
References
Bai YQ, Roos C (2002) A primal–dual interior point method based on a new kernel function with linear growth rate. In: Proceedings of the 9th Australian optimization day, Perth, Australia
Bai YQ, El Ghami M, Roos C (2003) A new efficient large-update primal–dual interior point method based on a finite barrier. SIAM J Optim 13(3):766–782
Bai YQ, El Ghami M, Roos C (2005) A comparative study of kernel functions for primal–dual interior point algorithms in linear optimization. SIAM J Optim 15(1):101–128
Bai YQ, Xie W, Zhang J (2012) New parameterized kernel functions for linear optimization. J Glob Optim 54:353–366
Bouafia M, Benterki D, Yassine A (2016a) An efficient primal–dual interior point method for linear programming problems based on a new kernel function with a trigonometric barrier term. J Optim Theory Appl 170:528–545
Bouafia M, Benterki D, Yassine A (2016b) Complexity analysis of interior point methods for linear programming based on a parameterized kernel function. RAIRO Oper Res 50:935–949
Bouafia M, Benterki D, Yassine A (2018) An efficient parameterized logarithmic kernel function for linear optimization. Optim Lett 12(5):1079–1097
El Ghami M, Guennoun ZA, Bouali S, Steihaug T (2012) Interior point methods for linear optimization based on a kernel function with a trigonometric barrier term. J Comput Appl Math 236:3613–3623
Fathi-Hafshejani S, Mansourib H, Peyghamic MR, Chene S (2018) Primaldual interior-point method for linear optimization based on a kernel function with trigonometric growth term. Optimization 67(10):1605–1630
Karmarkar NK (1984) A new polynomial-time algorithm for linear programming. In: Proceedings of the 16th annual ACM symposium on theory of computing, vol 4, pp 373–395
Li X, Zhang M (2015) Interior-point algorithm for linear optimization based on a new trigonometric kernel function. Oper Res Lett 43(5):471–475
Megiddo N (1989) Pathways to the optimal set in linear programming. In: Megiddo N (ed) Progress in mathematical programming: interior point and related methods. Springer, New York, pp 131–158
Peng J, Roos C, Terlaky T (2001) A new and efficient large-update interior point method for linear optimization. J Comput Technol 6:61–80
Peng J, Roos C, Terlaky T (2002) Self-regularity: a new paradigm for primal–dual interior point algorithms. Princeton University Press, Princeton
Peyghami MR, Hafshejani SF (2014) Complexity analysis of an interior point algorithm for linear optimization based on a new proximity function. Numer Algorithms 67:33–48
Peyghami MR, Hafshejani SF, Shirvani L (2014) Complexity of interior point methods for linear optimization based on a new trigonometric kernel function. J Comput Appl Math 255:74–85
Roos C, Terlaky T, Vial JPh (1997) Theory and algorithms for linear optimization, an interior point approach. Wiley, Chichester
Sonnevend G (1986) An “analytic center” for polyhedrons and new classes of global algorithms for linear (smooth, convex) programming. In: Prekopa A, Szelezsan J, Strazicky B (eds), System modelling and optimization: proceedings of the 12th IFIP-conference, Budapest, Hungary, 1985. Lecture Notes in Control and Inform. Sci, vol 84, pp 866–876. Springer, Berlin
Ye Y (1997) Interior point algorithms, theory and analysis. Wiley, Chichester
Acknowledgements
We thank an anonymous referee for comments that helped us improve the readability of this paper. I dedicate my work to my mother, Fatima Zohra SANSRI, who has been a constant source of love and encouragement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bouafia, M., Yassine, A. An efficient twice parameterized trigonometric kernel function for linear optimization. Optim Eng 21, 651–672 (2020). https://doi.org/10.1007/s11081-019-09467-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11081-019-09467-w