
Abstract
Traditional practices using probabilistic methods resorted in designing hydraulic structures commonly assume that hydro-meteorological time series are stationary over time. The prevailing thought has been challenged due to the deterioration of the natural function of hydrologic cycle. It is an inevitable fact that the estimation of the design parameters under non-stationary conditions could prevent the expected function of the hydraulic structure from being performed successfully. This study was conducted to come up with how the regional frequency distribution behavior of maximum rainfall with 6-, 12-, and 24-h duration in the Euphrates–Tigris river basin would differ under non-stationary conditions. According to the ITA (innovative trend analysis) approach, a statistically significant trend was detected in approximately 89% (61% increasing and 28% decreasing) of the maximum rainfall sequences of the stations in the region. In order to reveal the variability in the regional frequency distribution of the maximum rainfall series, the L-moments algorithm was applied to the full (F) rainfall datasets and the first and second rainfall sub-series (FH and SH) formed by the ITA method. In this comparison process based on the PITA (probabilistic innovative trend analysis) approach, considerable differences were detected in the L-moment statistics of the F, FH, and SH data sets and the quantile estimates for some risk levels. In particular, the findings associated with the SH data series differed markedly when compared to those of the F and FH datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Accurately estimating design rainfall or in other words, probable maximum rainfall, which directly influences the planning, management, and cost of a hydraulic structure, has crucial importance in providing the expected benefit from that structure. Since hydrological variables are under the influence of many factors where they occur, their statistical characteristics are taken into consideration in terms of what their probable amounts in the future may be. In this context, when acquiring the design rainfall value for small or comprehensive water-related structures such as culverts, drainage channels, flood control structures, etc., knowing the statistical properties of the relevant rainfall series is a necessity for reliable estimation. But, the commonly encountered problem with respect to having suitable data is that the at-site data are either short or are not available. On the other hand, global warming, which disrupts the natural functioning of the hydrological cycle and leads to inhomogeneity in the data in question, is also another very important negative effect. Houghton (2012) and Sellers and McGuffie (2012) announced that extreme events such as drought and flood have grown up in many parts of the world as a result of global warming in the last century. Based on the Intergovernmental Panel on Climate Change abbreviated IPCC (2013), on a global scale, a large number of heavy rainfall events have been experienced in many regions. From the perspective of Turkey, Turkes (2012) underscored that Turkey was one of the countries where it is at risk of long- and short-term climate fluctuations due to the impact based on this global threat. IPCC (2007) pointed out that there would be a significant decrease in precipitation amounts toward the end of the twenty-first century in the Mediterranean basin, which includes Turkey. Gao et al. (2006) and Önol and Semazzi (2009) came up with that global climate change would be felt more effectively in the southern, central, and western parts of the country when considered on a regional scale for Turkey. Hemming et al. (2010) foresaw that there would be a decreasing trend in precipitation along the western coasts of Turkey. Kitoh et al. (2008) emphasized that Euphrates River flows would decrease by 30% to 70% based on the decrease in precipitation in the Euphrates Basin in the last period of the twenty-first century. Güventürk (2013) stated that the time to reach peak flow for many rivers in Eastern Anatolia has shifted to earlier periods, and the reason for this was that the melting of the snow cover started earlier than the usual time due to the increase in temperature. Bozkurt and Şen (2012) accentuated that there would be a remarkable decrease in water resources in the Euphrates–Tigris Basin in the future with the effect of global climate change. Bozkurt et al. (2010) underlined that the decrease in snow cover based on the increase in temperature in the Eastern Anatolia Region included in the Euphrates–Tigris basin would considerably lead to seasonal changes in the runoff. Fujihara et al. (2008) pointed out that a meaningful downward would be experienced in the amount of snow and runoff in the Seyhan Basin in Turkey compared to normal conditions due to climate change. Therefore, the occurrence possibility of non-stationarity data originated due to both technical errors made while measuring hydro-meteorological data and the effect of global warming should be adequately scrutinized to estimate a reasonable design value. The presence of upward or downward trends in the rainfall sequences shows that the frequency distribution of the data is inconstant over time. From this perspective, the stationarity of rainfall data should be satisfied to remove possible doubt while performing the frequency analysis of the available data.
In estimating the design value, the intensity–duration–frequency (IDF) curve representing the relationship between intensity, frequency, and duration of rainfall has been a fundamental reference tool in the construction of water structures. In this state, considering the information obtained from the IDF curve as a design criterion is directly related to data quality and frequency analysis (Adamowski and Bougadis 2003). Hosking and Wallis (1997) highlighted that there should be serial independence among the observations to realize successful regional frequency analysis for a given region based on the L-moments approach. Also, they stressed that the assumption associated with having analogous characteristics of frequency distributions belonging to the past observations and the possible future observations would be invalid where there is an upward or downward trend in hydro-meteorological data over time.
As can be seen from the literature review, parametric linear regression (LR), non-parametric Mann–Kendall (MK), and Spearman Rho (SR) approaches were widely applied to determine the change in hydro-meteorological variables for different regions of the world (Jun et al. 2012; Malekinezhad and Garizi 2014; Meddi and Toumi 2015; Xu et al. 2012; Yang et al. 2010; Yurekli 2015, 2021; Hadi and Tombul 2018; Deshpande et al. 2012; Jakop et al. 2003; Jhajharia et al. 2012; Yilmaz and Perera 2015). But the MK and LR approaches require some prerequisites. These are that there should be serial independence between observations for the MK and that the observations should be normally distributed for the LR. Regardless of these assumptions, the innovative trend analysis technique, whose mental structure was first presented by Şen (2012) and then its statistical significance test was formulated in Şen (2017), has recently become a notable tool to reveal variation in the hydro-meteorological dataset. Yurekli (2021) compared the ability of the ITA technique to determine the change in a given data with the MK, LR, and SR approaches. He found that the ITA detected statistically significant trends in approximately 87% of the rainfall datasets and that this rate varied between 7 and 13% in other methods. There are other researches supporting the above study in which the trend-detecting ability of the ITA technique is evaluated (Wang et al. 2020; Zhou et al. 2018; Kişi 2015; Güçlü, 2018). Also, Şen et al. (2019) proposed a new trend analysis method, called innovative polygon trend analysis (IPTA), to perform seasonal trend depiction based on the ITA template. The reason for introducing this method is that all of the above-mentioned methods reveal the trend in a holistic manner, the fact that seasonal trend detection is not considered in trend analysis remains on the agenda as an important shortcoming. Şen (2020) introduced a new approach (PITA), which was based on the comparison of the cumulative distribution function of the equally split two sub-series according to the ITA approach, to the literature. Güçlü (2020) proposed a new methodology to get more detailed information on the trend in a given series by adhering to the ITA template and claimed that this methodology had the capability of objectively defining the variability in the high and low values of the compared sub-series.
Although there are several studies involved in detecting the variation in the climate of Turkey, one of which is the study conducted by Yurekli (2015) which includes a change in seasonal and annual rainfall series of the Euphrates–Tigris river basin. The prevailing view among climate scientists in the southern part of Turkey is that the region is at risk of drought due to global warming. With this human-induced global threat, it would be provided with an undesired contribution to the existing natural conditions of the upper Euphrates and Tigris rivers basins with inherent arid climate characteristics. More importantly, these adverse conditions would cause the failure of the Southeastern Anatolia Project (GAP). In this context, changes in the maximum rainfall for reliable estimation of design criteria should be explored on both site and regional basis. But there has not been detailed research describing the variability in the maximum rainfalls of the Euphrates–Tigris basin selected as a study area yet.
Based on what has been explained above, the reliability of the data to be used in the frequency analysis should be ensured before forming the IDF curve required in the estimation of the design rainfall value. Accordingly, the main objectives of conducting this study are: a—to complete the missing data, b—to statistically analyze the change in the maximum rainfalls with the innovative trend analysis method (ITA), c—to realize regional frequency analysis separately with observations of the equally split two sub-series based on PITA methodology, and d—to perform the probabilistic risk assessment of two sub-series to reveal the influence of variability in climate.
1.1 Basin characteristics and data
The Euphrates and Tigris, two major rivers in the Middle East, are discharged to the Persian Gulf after merging at the Shatt al-Arab in the north of Basra, and the rivers have lengths of 2700 and 1840 km, respectively. The arid and semi-arid climate structures having dominance in the basin of these rivers induce drought to be experienced frequently. In this sense, the Euphrates and Tigris rivers are vital for the region. Precipitation occurring in the basin of these rivers substantially takes place in the winter period from October to April. A quantitatively large part of the precipitation falling during this period occurs in the form of snow. Therefore, snowmelt from the highlands of these riparian countries largely forms the flow of these rivers. (Altınbilek 2004; Beaumont 1998; Ozdogan 2011). In the study, variability in the maximum rainfall data sequences from 18 rainfall gauging stations in the Euphrates–Tigris rivers upper basin which is located approximately between 36° and 41° N latitudes and between 36° and 45° E longitudes was investigated. Some descriptive characteristics of the stations are given in Table 1, and their geographic positions are shown in Fig. 1. As can be seen in Table 1, the annual total rainfall amounts for stations in the basin are quite variable, while this amount is 377 mm in Malatya, it is 1234 mm in Bitlis. The data sets of each station include the maximum rainfall amounts with the duration of 6-, 12-, and 24-h. These rainfall values of the stations missing maximum rainfall data among the 18 stations were completed with the normal-ratio method (Singh 1994).

The geographic position of the stations in the Euphrates–Tigris Basin
1.2 Şen-innovative trend analysis (ITA) approach
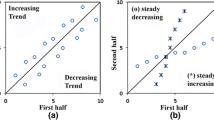
The parametric or nonparametric statistical tests to reveal trends in many hydro-meteorological time series have been commonly used in the literature (Yurekli 2021; Longobardi and Villani 2010; Wickramagamage 2016). But, there is a requirement of following a certain distribution of the considered data while applying the parametric tests. On the contrary, the nonparametric Mann–Kendall (MK) test, which is widely used, is applied without the requirement of fitting to a certain distribution in the analysis of the variability of the data. But the existence of serial dependence between observations is an obstacle to successful evaluation with this method. The advantage of the ITA technique over other methods such as LR, SR, and MK methods is its ability to perform the analysis, regardless of pre-assumptions, such as the necessity for the data to follow a theoretical distribution, the length of the sample size, and a serial dependence between observations. Another distinctive superiority of the ITA is that each observation has scattered in descending or ascending order along the line in which there is a slope of 45°. This characteristic positioning allows for making judgments about all observations. In other words, the clusters formed by low, medium, and high observations provide information about the internal variability of the data. In the application process of this method, considering a hydro-meteorological time series with data length n, defined as x1, x2,…, xn, these full data are divided into two equal sub-series (hereafter the first part of which would be referred to as FH and the second part as SH) and the sub-series are arranged in ascending order. Later on, the FH series (xi: i = 1, 2, 3, …, n/2) are located on the X-axis against the SH series (xj: j = n/2 + 1, n/2 + 2, n/2 + 3, …, n) on the Y-axis in the Cartesian coordinate system. Thus, the ordered series are positioned against each other, and the scatter of the points around the line with a slope of 45° is provided. It is judged on the existence of an increasing, decreasing, or no trend according to the position of the points being above, below, or on the line. Some studies recently realized to reveal variability in a given data by implementing this technique are Alashan (2018), Cui et al. (2017), Wu and Qian (2017), Almazroui et al. (2019), Wang et al. (2020), Dabanlı et al. (2016), Mohorji et al. (2017), Güçlü (2018), Yagbasan et al. (2020) and, Singh et al. (2021). The statistical significance test of the ITA procedure, which was placed in the literature by Şen (2017), is based on the comparison of the means of two sub-series formed by splitting full data. The null hypothesis of the ITA significance test, which corresponds to the absence of the trend, is accepted when the value of the calculated slope (Scal) is less than the critical slope value (Scrit); otherwise, the alternative hypothesis indicating the presence of the trend in the data is approved. In fact, the acceptance of the null hypothesis highlights that the calculated Scal value would remain within the confidence interval obtained by multiplying the Scrit value and the standard deviation value (σs) belonging to the Scal. The Scal value representing a change in data is calculated based on Eq. 1:
where \(\overline{y}_{1}\) and \(\overline{y}_{2}\) are the means of the FH and SH series splitting from a full data sequence having "n" observations. The mathematical expression of the σs is as follows:
The terms in Eq. 2, “\(\rho_{{\overline{y}_{1} \overline{y}_{2} }}\)” and “σ”, correspond to the cross-correlation coefficient and standard deviation of the complete data, respectively. The confidence interval for a 5% (α) significance level is obtained from the following relationship:
The \(S_{{{\text{crit}}}}\) value is picked up as ± 1.960 from the standard normal distribution table for the 5% significance level.
1.3 Regional frequency analysis
In the study, the regionalization algorithm, whose methodology was based on L-moments (Hosking and Wallis 1997), was used to determine the statistical behavior of the maximum rainfall data with different durations (6-, 12-, and 24-h) belonging to 18 rain gauge stations. The L-moments approach introduced by Hosking (1990) have some advantages over the conventional (product) moments and maximum likelihood methods in the estimation of parameters representing the theoretical probability distributions. These include: being less sensitive to outliers; more secure inferences related to a probability distribution can be made even if the sample size is small; they sometimes enable more efficient parameter estimates than the maximum likelihood estimates (Hosking 1990; Park et al. 2001; Gubareva and Gartsman 2010). To define L-moments, let us consider a random variable x and its quantile function to be an x(u). The quantitative description of the L-moments associated with the variable x would be as follows:
where \(P_{r - 1}^{*} \left( u \right)\) denotes the rth shifted Legendre polynomial.
L-moment ratios \(\left( {\tau_{{\text{r}}} } \right)\) have explanatory power on the shape of the probability distribution specify the ratio of the higher-order L-moments \((\lambda_{{\text{r}}} )\) to the scale measure \((\lambda_{2} )\). The relationship is as follows:
The \(\lambda_{1}\) designates the measure of location. The \(\tau_{3}\) and \(\tau_{4} \) L-moment ratios define the coefficient of L-skewness and the coefficient of L-kurtosis. The ratio of \(\lambda_{2}\) to \(\lambda_{1}\) also corresponds to the coefficient of L-variation (\(\tau )\). The sample L-moments ratios, called L-CV (\(\left( \tau \right)\), L-CS (\(\tau_{3}\)), and L-CK (\(\tau_{4}\)), are defined mathematically as follows:
Implementing regional frequency analysis being subject to L-moments is accomplished in mainly three stages. The first stage is the process of assigning sites to the region on which the assumption is made that the frequency distributions of the sites are approximately close to each other. A widely accepted way to initially form a tentative region, that is, assigning sites to it, is cluster analysis, in which some characteristics of the sites are taken into account (Modarres and Sardai 2011). Following this process, the site(s) having discordancy with the sites in the formed region is brought out by the discordancy measure (Di), and it is decided to move the discordant site(s) to another region. The mathematical expression of the discordancy measure for a region with the N-sites is as follows (Rao and Hamed 2000; Šimková 2017):
In Eqs. (6) and (7), \(u_{i} \) is a vector including the \( \tau ,\, \tau_{3}\) and \(\tau_{4} \) dealing with the site i, \(\overline{u}\) is the unweighted group mean, the “A” is the covariance matrix for the example. When Di > Dcritic for any site i in a region, that site is considered discordant. The values of Dcritic based on the number of sites are tabulated in Hosking and Wallis (1997).
The presumption of a region to be homogeneous is based on the presence of not being discordant sites in that region, as well as the fact that the observations of the sites have a similar frequency distribution. In practice, the fulfillment of the conditions for homogeneity is mostly accomplished by removing sites in the studied region to sub-regions. The second stage is on whether or not regional homogeneity is carried out. Acceptance of regional homogeneity for the tentatively formed region having N sites is realized with the heterogeneity measure (H) whose relationship is given below (Hosking and Wallis 1997):
In Eqs. (8) and (9), ni is the data length for site i, τi and τR are the coefficients of L-variation for site i and the relevant region. The μv and σv are the mean and standard deviation associated with the “V” values of the data obtained from the Monte Carlo simulation method. The judgment on the homogeneity of the formed region is made according to the H measure calculated for the region. There are three criteria in this context, which are acceptably homogeneous if H < 1, possibly heterogeneous if 1 ≤ H < 2, and definitely heterogeneous if H ≥ 2.
The final step is to find out the regional distribution that would best fit the observations of the region whose homogeneity has been approved. The decision on regional distribution is performed with the goodness-of-fit test, denominated as ZDIST. The analysis of the ZDIST is fulfilled based on the difference between the L-kurtosis \(\left( {\tau_{4}^{DIST} } \right) \) of the considered distribution and the regional average L-kurtosis \((\tau_{4}^{R}\)) of the sites in the homogenous region. Mathematically, formulation of the ZDIST test is below:
In Eq. (10), DIST represents the candidate probability distribution. β4 and σ4 are the bias and standard deviation belonging to the 500 regions simulated by the four-parameter Kappa distribution. Hosking and Wallis (1997) recommended the use of the four-parameter Kappa distribution for the simulation. They highlighted that the Kappa distribution had the ability to represent as special cases generalized logistic, generalized extreme values, and generalized Pareto distributions. Also, it was underlined that the characteristic structure of this theoretical distribution was therefore capable of encompassing most of the distributions occurring in environmental science. Among the candidate distributions considered in the study, which are generalized logistic (GLOG), generalized extreme values (GEV), generalized normal (GNO), Pearson type III (PIII), and generalized Pareto (GPA) distributions, those that satisfy the condition of the \(\left| {Z^{DIST} } \right| \le 1.64 \) are accepted as regional distributions. But the distribution with the smallest \(\left| {{\text{Z}}^{{{\text{DIST}}}} } \right|\) value for the relevant region should be chosen as the best fit.
Both regional and site quantile estimation at the T return period is performed according to the approach of Dalrymple (1960) which is named the index-flood or index-storm with regard to flood and rainfall data. The basic of the approach is based on the postulation in which the data of the sites in the homogeneous region are identically distributed apart from a site-specific scaling factor (Hosking and Wallis 1997). Its mathematical relationship at site i is as follows:
In Eq. (11), Q(F) and \(\mu_{i}\) are, respectively, the estimated rainfall amounts and index rainfall (a site-specific scaling factor) value for site i, and q(F) is the value corresponding to the growth factor. F is probability level.
2 Results and discussions
The main objective of the study was to reveal how the temporal variability in the maximum rainfall data sequences with the duration of 6-, 12-, and 24-h belonging to 18 precipitation stations would affect their probabilistic behavior. Therefore, first of all, the analysis of variability in the maximum rainfall data sets was realized by the ITA methodology having the possibility of use without any prerequisites. For this purpose, each data set was split into two equal parts (two sub-series) and the slope value (Scal) calculated from Eq. 1 was compared with the critical slope value (Scrit). The ITA results associated with the maximum rainfall data sets of each station are available in Table 1. Statistically insignificant changes were detected in only six of them out of all data sequences with 12-h and 24-h durations, while a statistically significant downward or upward trend was found in all datasets with 6-h duration. Regardless of whether statistically significant, the maximum rainfall series of all three durations showed an increasing trend in 70% of the stations, whereas the remaining stations had a decreasing trend. The findings showed that all maximum rainfall series (excluding the six data sets) in the studied region were subjected to statistically significant variability from the middle of their observation periods. This result made it necessary to take into account the non-stationary conditions in the data in order to carry out the planning, construction, and operation processes of a hydraulic structure in the region reliably. If the design value required for the construction of a hydraulic structure is not estimated under stationary conditions, the structure would face the risk of not providing the expected benefit. In this context, it is a necessity to reveal how the frequency distribution pattern that characterizes the maximum rainfall data sequences in the basin where the study is carried out changes over time and to define the possible risks related to this. In order to establish the study in the Euphrates–Tigris basin on this basis, Şen (2020)'s proposal with station-based was applied regionally and the findings detailed below were obtained.
First of all, before starting the regionalization process, the first L-moment and L-moment ratios dealing with the first and second sub-series (FH and SH) of the full maximum rainfall data sequences (F) of the three durations (6-, 12-, and 24-h) were positioned according to the 1:1 line within the ITA mentality. Thus, the change of these statistics belonging to both sub-series with respect to each other has been tried to be revealed visually (Fig. 2). The change in the λ1, which was specified as the first L-moment or the measure of location, was observed as an increase in the maximum rainfall data series with the 6-h and 12-h durations. The λ1s of the series with the 24-h duration were mostly located on the 1:1 line. Especially for the 6-h and 12-h durations, this finding explains that the maximum rainfall amounts belonging to the FH in the region were smaller than that of the SH. On the other hand, as can be seen from the figure, the L-CV statistics of the rainfall series with the 6-h and 12-h durations deviated less from the 1:1 line, whereas those of the data sets with the 24-h duration were scattered much more than the line. The L-CS among the statistics considered showed the most surprising and obvious finding. This L-moment ratio had a decreasing trend for the rainfall time series of the three durations on a regional basis. The most noticeable downward change was in the time series with the 6-h duration, and then in the time series with the 24-h duration. Compared to the others, the variation in the L-CS values of the series with the 12-h duration was less. Looking at the variation in terms of L-CK statistic, there was an explicit upward trend in the data sets with the 24-h duration. For the data sequences of the 6-h and 12-h durations, the high L-CK values had a decreasing trend, while the medium and small L-CKs generally clustered around the 1:1 line. In the regionalization process, the change in the above-mentioned statistical parameters, which are of great importance in identifying the regional distribution, would allow it to undermine the reliable selection of the most suitable distribution for the region. However, the common opinion is that the estimation of the design values of water-related structures has to be obtained from stationary data. In the context of the studied region, it was understood from the findings that the maximum rainfall data sets took on a non-stationary character. In our globe under the influence of climate change, it is an inevitable fact that researchers or other interested parties who focus on the analysis of hydro-meteorological data would often encounter variability in these data. How the regional frequency analysis process envisaged for a region would be affected under such unstable conditions was explained below on the basis of the studied basin.

Change of the L-moment statistics of the FH and SH datasets with respect to each other
Based on the aforementioned reference regarding Şen (2020)'s proposal, the regional L-moments algorithm was performed for the split FH and SH data series by considering their L-moments and ratios. The first application in the regionalization process of the rainfall series with all three durations was on testing the possibility of evaluating the basin as a single region. In a single-region effort dealing with the maximum rainfall data sets of the 6-h duration belonging to the FH, the value of the discordancy measure for the Mardin station became greater than the critical value (Dcritic = 3 for 18 sites). None of the remaining stations became discordant, provided that this station was removed in order to continue the single-region trial. In this decision condition, it was concluded that the region was acceptably homogeneous according to the heterogeneity measure, called “H” (Table 2). For this region satisfying the homogeneity condition, the acceptable ones among the candidate distributions as regional distributions were determined based on the goodness-of-fit measure (ZDIST). The results are in Table 3. Three distributions (GEV, GNO, and PIII) performed the condition of the \(\left| {Z^{{{\text{DIST}}}} } \right| \le 1.64\). However, the smallest ZDIST value was detected in the GNO distribution. The 17 same stations in the single region approved for the FH were kept constant during the regionalization process of the SH, and the effect of the change in rainfall series with the 6-h duration was investigated. Although the Mardin station was excluded from the operation, two stations (Hakkari ve Tunceli) became discordant. The result of the analysis on the homogeneity of the proposed region is that the region should definitely be evaluated as heterogeneous (Table 2). This finding indicates that the basin should be divided into sub-regions.
All stations were taken into account in establishing homogeneous sub-region conditions for the data sequences with the 6-h duration of the SH. Initially, the focus was on the single region option with 18 stations. The discordancy test results for the SH data sequences with the 6-h-duration showed that only the Tunceli station was discordant. When this station was ignored, although none of the 17 stations were discordant, the homogeneity condition on the single-region preference was not satisfactory. As an alternative option, all phases of regionalization have been accomplished, with the activity of dividing the basin into two sub-divisions (6SH-R1 and 6SH-R2) based on cluster analysis. However, the assumption of homogeneity for the two sub-regions was approved only when the Hakkari station was excluded (Table 4). On the other hand, the smallest ZDIST value for the regional distribution of the 6SH-R1 data sets was estimated in the GEV distribution, and for 6SH-R2 data sets in the PIII distribution (Table 5). These findings underline how different the frequency distribution behavior associated with the first sub-series of the maximum rainfall data sequences with the 6-h duration is from that of the second sub-series. In fact, these results echo the argument of Pettitt (1979). He reported the existence of a change point when parts of a time series had different frequency distributions. The PITA proposal in Şen (2020) is also based on this reference.
In the regionalization process for the first and second sub-series of the maximum rainfall data with the 12-h duration belonging to 18 rainfall gauging stations, it was primarily focused on whether all stations would form a single region. The discordancy test results associated with the two sub-series were that the Mardin station for the FH and the Hakkari station for the SH were discordant. When these stations were disregarded, it was determined from the discordancy analysis that the statistical compatibility between all the remaining stations was acceptable. Despite discordancy results, the findings of the heterogeneity measure dealing with the first and second sub-series of the maximum rainfall data with the 12-h duration became greater than one. Therefore, it was decided that the regionalization analysis could not be completed with a single region preference. The alternative of forming two sub-regions for the maximum rainfall data sequences regarding the FH was focused on. The homogeneity results of the two sub-region trial for the first sub-series are as in Table 2. The heterogeneity measurement results confirmed the acceptable homogeneity of the sub-regions (12FH-R1 and 12FH-R2) for the first sub-series, with the Mardin station excluded due to its discordant. However, this result could not be reached with the data sets of the same stations in the two sub-regions (12SH-R1 and 12SH-R2) for the SH, and one of the two was heterogeneous (Table 2). Related to the maximum rainfall data series with 12-h duration, the PIII and GEV distributions were found as most appropriate regional distributions for the 12FH-R1 and 12FH-R2, respectively, (Table 3). Due to the presence of the 12SH-R2 region exhibiting a heterogeneous character in the two sub-region trial for the rainfall series with the 12-h duration of the SH, the focus was on the re-composition of two sub-region alternatives considering the 18 stations. However, within the scope of this application, considering that Hakkari station caused heterogeneity, discordancy and homogeneity conditions were tried to be established over 17 stations. The results of the heterogeneity and goodness-of-fit measures dealing with the two re-arranged sub-regions (12SH-R1 and 12SH-R2) not having a problem in discordancy are in Table 4 and Table 5. The most appropriate regional distribution for both sub-regions fulfilling the homogeneity condition became the GNO.
In the single region alternative (whole basin) of the maximum rainfall series with the 24-h duration for the FH, only the Hakkari station was discordant. When the Hakkari station was taken out of the region, not all of the remaining stations were discordant. However, in the single-region trial, the heterogeneity measure indicated definitely heterogeneity (3.87). Since the H-measure pointed out heterogeneity, the single region selection was abandoned. Alternatively, in the condition of dividing the basin into two sub-regions (24FH-R1 and 24FH-R2), no discordant stations were found in each sub-region, and the sub-regions appeared acceptably homogeneous according to the heterogeneity criteria (Table 2). The regional distributions to best represent the maximum rainfall of both sub-regions became GEV for the 24FH-R1 and PIII for the 24FH-R2. The regionalization process was applied to the rainfall series with the 24-h duration of the SH for the same stations in the sub-regions approved for the FH, and the heterogeneity measure findings of these regions where there were no discordant stations were given in Table 2. While the two sub-regions satisfied the homogeneity requirement, none of the candidate distributions for one (24FH-R1) of these regions could be carried out the requirement to be less than 1.64 associated with the goodness-of-fit measure.
None of the stations had discordancy when the basin was considered as a single region for the SH of the maximum rainfall data sets with 24-h duration. In addition, the basin was found to be acceptably homogeneous according to the heterogeneity criteria. Despite all these results, none of the candidate distributions passed the goodness-of-fit test in this trial. As another alternative, unlike the two sub-regions conditions formed above, the 18 stations were re-assigned to both sub-regions for the regionalization of the rainfall series with the 24-h duration of the SH. In the attempt to divide the basin into two sub-regions (24SH-R1 and 24SH-R2), no discordant stations were found in all of the sub-regions. But, homogeneity and regional distribution criteria were satisfied in the condition in which the Siirt station was not included in both sub-regions (Tables 4 and 5). The sub-regions became acceptably homogeneous. The ZDIST value of only one candidate distribution (GLOG) for the sub-regions was smaller than the critical test value (1.64). The regionalization applications realized for both sub-series of the maximum rainfall data with 12- and 24-h durations also indicated different frequency distributions. These findings emphasize that the rainfall data sequences of the FH and SH are non-stationary relative to each other, just like in the rainfall data sets with a 6-h duration.
Considering that there was no change in the 6-, 12- and 24-h duration maximum rainfalls of 18 stations in the basin, regional frequency analysis based on these data sets was executed to compare with the results of the first and second sub-series. With the full datasets (F) of all three durations, the single region alternative was focused on, and none of the stations showed discordancy. However, in this preference, it has been determined based on the heterogeneity measure that the basin could not be considered a homogeneous region. This finding revealed the necessity of separating the region into sub-regions. By excluding Hakkari and Mardin stations in two sub-region alternatives, discordancy and homogeneity conditions were achieved for the maximum rainfall series with 6- and 12-h duration. On the other hand, all stages of regionalization were carried out without removing any station in the two sub-region preference of the 24-h duration maximum rainfall series. The relevant results are given in Table 4 and Table 5.
The box plots in Fig. 3 were obtained to provide a visual summary of the variability in the L-moments statistics (λ1, L-CK, L-CS, and L-CK) belonging to the F, FH, and SH rainfall datasets of the three durations (6-, 12-, and 24-h). As can be seen from Fig. 3a, the scattering in the first L-moments corresponding to the averages of the rainfall data sequences is greater in the second sub-series. It was also found that the high mean values dealing with the SH were more than those of the F and FH datasets, due to right skewness. Nevertheless, owing to the more or less equivalence of the lengths of the box plots, it could be concluded that there is no significant difference in terms of the first L-moments. On the other hand, it would not be correct to reach the same conclusion about the range statistic of the means. The variability of the L-CV parameter in the basin for the F, FH, and SH maximum rainfalls with 6-, 12- and 24-h duration is visualized in Fig. 3b. As it is known, this parameter directly influences the decision of regional homogeneity. From this point of view, the difference in the L-CV values of three different data groups (F, FH, and SH) of all three durations would cause the regional frequency analysis to be realized differently. The box plots visually representing L-CV values of the full data sets with the 6- and 12-h duration were quite different with respect to those of the FH and SH. On the other hand, the L-CVs regarding the SH for the 24-h duration were significantly different from those of the F and FH datasets. In the context of L-CS statistics, the box plots of the L-CSs of the rainfall data series with all three durations (6-, 12-, 24-h) for the FH differed markedly from those of the F and SH datasets (Fig. 3c). An inverse boxplot appeared in the L-CSs of the F and SH for the 6- and 12-h duration in terms of the range statistic. However, L-CS values for the F and SH data series with 24-h duration showed a distribution characteristic shifted to the left. The most obvious difference regarding the box plot of the L-CK statistic, which has an important role in determining the regional distribution (especially in performing the goodness-of-fit test), occurred in the full datasets of the 12-h duration. When the L-CK box plots of the remaining data sets were compared with each other, no similarity was found. In fact, this finding confirms the results given above of the regional frequency analysis implemented to the data sequences of the F, FH, and SH.

The variability in L-moments statistics associated with Full (F), first sub-series (FH), and second sub-series (SH) of the three durations
The station-based quantile estimates at the different risk levels were realized with the regional distribution best fitted to the sub-regions formed for the F, FH, and SH rainfall datasets of all three durations. The main goal of this effort was to reveal the difference between the quantiles estimated for the F, FH, and SH data series of the selected station. While choosing the station, the principle that the station in question should be located in the same sub-regions formed for each of the F, FH, and SH data sequences with the same rainfall duration was taken into consideration. In fact, one of the main objectives was to detect the variability between the regional quantiles estimates, but the differences in the stations assigned to the sub-regions formed for the three data groups (F, FH, and SH) prevented reaching the intended target in the mentioned context. For the F, FH, and SH datasets, the variation between the station-based estimated quantities was investigated through the proportional percentage change (SH/F, SH/FH, and FH/F) between the quantities belonging to three data groups. Figure 4 visually explains the variation in the quantiles estimates at different risk levels of the stations selected for the sub-regions. Positive ratios describe how much the numerator is as a percentage than the denominator, while negative ratios are the opposite. As can be seen from the examination of Fig. 4, it has become evident that the proportional changes of the quantiles estimated by the F, FH, and SH rainfall series of the three durations formed very significant differences on the basis of stations. In fact, an important finding based on the graphs of change of quantile symbolized from "a" to "f" in Fig. 4 is that the proportional change amounts of SH-F remain between those of SH-FH and FH-F. In Fig. 4d, the quantile proportional change of the FH-F was quite different from the others. The explanation for this is that the quantiles predicted from the FH dataset are larger than those predicted from the F dataset. In other proportional change graphs (characterized as blue and red) presented in this figure, the opposite is the case. That is, the quantiles associated with the SH data set are smaller than the quantiles estimated from the datasets (F and FH) in the denominator. Another finding based on this figure is that the graph of change in red showed a very different structure than those presented in other figures. The reason for this can be explained by the fact that the maximum rainfall data of the Urfa station have a decreasing variation.

Variation in the quantiles estimates at different risk levels
3 Conclusion
The basic assumption in traditional approaches to the analysis of hydrological time series is that the hydrological variable does not change over time. But, under the threat of global warming, which has affected our globe since the middle of the twentieth century, performing hydrological data analysis with the assumption of stationarity would hinder the fulfillment of the expectations from a hydraulic structure constructed based on this analysis. Estimation of hydrological design value based on the frequency analysis could only be obtained with reliable data. But, climate conditions changing naturally or with human intervention have led to challenging the traditional assumption on frequency analysis of hydrological data. This study, taking the Euphrates–Tigris basin as the case study, was conducted to reveal how changing climatic conditions affect regional frequency analysis of maximum rainfalls with 6-, 12-, and 24-h duration. The L-moments algorithm based on the PITA approach (probabilistic innovative trend analysis) was used to achieve this goal. The major judgments deduced from the study are as follows:
-
1.
The ITA (innovative trend analysis) approach was applied to the maximum rainfall data sequences of all three durations to detect the change in them. In line with this goal, the analysis was carried out by dividing the full data (F) into two equal parts, which are described as the first sub-series (FH) and the second sub-series (SH). Statistically significant trends were found in all datasets (18 series) with the 6-h duration, only five of which had a decreasing trend. Statistically insignificant changes were detected in the rainfall series of only three stations for each duration of 12- and 24-h in the basin. A statistically significant downward trend was observed in five of the remaining maximum rainfall data sequences for each of these durations. In fact, this finding underlines that approximately 89% of the total data (54 series) belonging to the stations in the basin have statistically increasing (61%) and decreasing (about 28%) changes.
-
2.
Considering the PITA approach, the L-moment statistics of maximum rainfall datasets belonging to the F, FH, and SH for all three durations were calculated in order to reveal the change in their regional frequency distribution behavior. Regarding FH and SH data series of all three duration, λ1, L-CV, L-CS, and L-CK statistics, which largely characterize the frequency distribution shape, were compared to each other within the ITA mentality. The most obvious difference between these statistics was observed in the L-CS statistics in the form of a decrease for all maximum rainfall series. In fact, the reverse of this change (as an increase) was detected in the L-CK statistics of the 24-h duration data sequences. The λ1 statistics for the rainfall series with 6- and 12-h duration belonging to the SH became greater than those of the FH. In terms of L-CV statistics, rainfall series of 6- and 12-h duration had more stable scattering than those of 24-h duration. Also, the box plots were formed to provide a visual summary of the variability in the L-moments statistics belonging to the F, FH, and SH rainfall datasets. The most notable one of them happened in the L-CV statistics. This finding associated with the L-CV highlights that the variability in the rainfall data sequences of all three durations would lead to their regional frequency analysis to realize differently. In terms of L-CS statistics, the box plots obtained for the L-CSs of the rainfall series of all three durations for the FH showed greater range statistics. On the other hand, the box plots of the L-CK coefficients, which play a decisive role in statistically approving a regional distribution, for the F, FH, and SH datasets had dissimilar shapes to each other. In fact, all these agreed-upon findings prove that the frequency distributions of the F, FH, and SH data sequences would be characterized differently.
-
3.
For the homogeneous regions formed separately with the F, FH, and SH rainfall data sequences, the regional distributions accepted to be statistically best fit differed. Particularly, the regional distributions determined based on the SH data were not consistent with each other when compared with those of F and FH datasets. However, a partial similarity was found between the regional distributions determined for the F and FH data. The station-based quantile estimates at the different risk levels were performed with the regional distribution best fitted to the sub-regions formed for the F, FH, and SH rainfall series. The purpose of the attempt was to reveal the difference between the quantiles estimated for the rainfall data series of the selected station. Although such an effort was considered among the regional quantile estimates, the difference in stations assigned to homogeneous regions hindered this goal. The inequality between the quantities estimated at different risk levels for the stations was evaluated through the proportional percentage change (SH/F, SH/FH, and FH/F). The proportional changes of the quantiles associated with the F, FH, and SH rainfall series highlighted very marked differences. Under the guidance of all these findings, it is an absolute necessity to estimate the design value by considering the variability of the hydrological data during the construction and operation of a hydraulic structure in the studied region.
As can be noticed from the findings of this study, it is no longer possible to perform the frequency analysis of hydro-meteorological data with the assumption of traditional stationarity under changing climatic conditions. The change point detected at approximately 89% of the total data in this study, caused the regional frequency distribution function to be different, that is, two different portions from the same regional data provided the best fit to different probability distribution functions. As an alternative proposal to be presented based on the findings of this study, apart from dividing the full data into two portions, it is possible to analyze the number of more portions and identify more change points. The most notable conclusion to be drawn from this study is that the existence of variation in the studied data allows for shifts in quantile estimates on both site-based and regional basis, that is, the determination of a value below or above the probable real estimate. The effort required to be applied in these conditions is to perform the frequency analysis process after the stationarity of the data is ensured.
References
Adamowski K, Bougadis J (2003) Detection of trends in annual extreme rainfall. Hydrol Process 17:3547–3560. https://doi.org/10.1002/hyp.1353
Alashan S (2018) An improved version of innovative trend analyses. Arab J Geosci 11:50. https://doi.org/10.1007/s12517-018-3393-x
Almazroui M, Şen Z, Mohorji AM, Islam MN (2019) Impacts of climate change on water engineering structures in arid regions: case studies in Turkey and Saudi Arabia. Earth Syst Environ 3:43–57. https://doi.org/10.1007/s41748-018-0082-6
Altınbilek D (2004) Development and management of the Euphrates-Tigris basin. Int J Water Resour D 20:15–33. https://doi.org/10.1080/07900620310001635584
Beaumont P (1998) Restructuring of water usage in the Tigris-Euphrates basin: the impact of modern water management policies. In: Albert J, Bernhardsson M, Kenna R (eds) Transformations of middle eastern natural environments: legacies and lessons, Yale School of Forestry and Environmental Studies, Bulletin Series No. 103, New Haven, Connecticut, USA, pp. 168–186
Bozkurt D, Sen OL (2012) Climate change impacts in the Euphrates-Tigris basin based on different model and scenario simulations. J Hydrol. https://doi.org/10.1016/j.jhydrol.2012.12.021
Bozkurt D, Şen ÖL, Turunçoğlu UU, Önol B, Kındap T, Dalfes HN, Karaca M (2010) Impacts of climate change on hydrometeorology of the Euphrates and tigris basins. Geophys Res Abstr 12:14278
Cui L, Wang L, Lai Z, Tian Q, Liu W, Li J (2017) Innovative trend analysis of annual and seasonal air temperature and rainfall in the Yangtze river basin, China during 1960–2015. J Atmos Sol-Terr Phy 164:48–59. https://doi.org/10.1016/j.jastp.2017.08.001
Dabanlı İ, Şen Z, Yeleğen MÖ, Şişman E, Selek B, Güçlü YS (2016) Trend assessment by the innovative-Şen method. Water Resour Manag 30:5193–5203. https://doi.org/10.1007/s11269-016-1478-4
Dalrymple T (1960) Flood frequency methods. U.S. geological survey, water supply paper, 1543A, 11–51
Deshpande NR, Kulkarni A, Kumar KK (2012) Characteristic features of hourly rainfall in India. Int J Climatol 32:1730–1744. https://doi.org/10.1002/joc.2375
Fujihara Y, Tanaka K, Watanabe T, Nagano T, Kojiri T (2008) Assessing the impacts of climate change on the water resources of the Seyhan river basin in Turkey: use of dynamically downscaled data for hydrologic simulations. J Hydrol 353:33–48. https://doi.org/10.1016/j.jhydrol.2008.01.024
Gao X, Pal JS, Giorgi F (2006) Projected changes in mean and extreme precipitation over the Mediterranean region from high resolution double nested RCM simulations. Geophys Res Lett 33(L03706):1–4. https://doi.org/10.1029/2005GL024954
Gubareva TS, Gartsman BI (2010) Estimating distribution parameters of extreme hydrometeorological characteristics by L-Moment method. Water Resour 37:437–445
Güçlü YS (2018) Multiple ŞEN-innovative trend analyses and partial Mann–Kendall test. J Hydrol 566:685–704. https://doi.org/10.1016/j.jhydrol.2018.09.034
Guçlü YS (2020) Improved visualization for trend analysis by comparing with classical Mann–Kendall test and ITA. J Hydrol 584:124674. https://doi.org/10.1016/j.jhydrol.2020.124674
Güventürk A (2013) Impacts of climate change on water resources eastern mountainous region of Turkey. Middle East Technical University, Disertation
Hadi SJ, Tombul M (2018) Long-term spatiotemporal trend analysis of precipitation and temperature over Turkey. Meteorol Appl 25:445–455. https://doi.org/10.1002/met.1712
Hemming D, Buontempo C, Burke E, Collins M, Kaye N (2010) How uncertain are climate model projections of water availability indicators across the middle east. Philos Trans R Soc A 368:5117–5135. https://doi.org/10.1098/rsta.2010.0174
Hosking JRM (1990) L-moments: analysis and estimation of distributions using linear combinations of order statistics. J R Stat Soc Ser b 52:105–124
Hosking JRM, Wallis JR (1997) Regional frequency analysis: an approach based on L moments. Cambridge University Press, Cambridge, U.K
Hougton J (2012) Global warming: the complete briefing, 4th edn. Cambridge University Press, New York
IPCC (2007) Climate change 2007: Synthesis report. In: Pachauri RK, Reisinger A (eds) Contribution of working groups I, II and III to the fourth assessment report of the intergovernmental panel on climate change [Core Writing Team], IPCC: Geneva, Switzerland
IPCC (2013) Climate change 2013: The physical science basis. In: Contribution of working group I to the fifth assessment report of the intergovernmental panel on climate change. Cambridge University Press, Cambridge
Jakop M, McKendry I, Lee R (2003) Long-term changes in rainfall intensities in vancouver. Br Columbia Can Water Resour J 28:587–604. https://doi.org/10.4296/cwrj2804587
Jhajharia D, Yadav BK, Maske S, Chattopadhyay S, Kar AK (2012) Identification of trends in rainfall, rainy days and 24 h maximum rainfall over subtropical Assam in Northeast India. Comptes Rendus Geosci 344:1–13. https://doi.org/10.1016/j.crte.2011.11.002
Jun X, Dunxian S, Yongyong Z, Hong D (2012) Spatio-temporal trend and statistical distribution of extreme precipitation events in Huaihe River Basin during 1960–2009. J Geogr Scie 22:195–208. https://doi.org/10.1007/s11442-012-0921-6
Kisi O (2015) An innovative method for trend analysis of monthly pan evaporations. J Hydrol 527:1123–1129. https://doi.org/10.1016/j.jhydrol.2015.06.009
Kitoh A, Yatagai A, Alpert P (2008) First super-high-resolution model projection that the ancient fertile crescent will disappear in this century. Hydrol Res Lett 2:1–4. https://doi.org/10.3178/hrl.2.1
Longobardi A, Villani P (2010) Trend analysis of annual and seasonal rainfall time series in the Mediterranean area. Int J Climatol 30:1538–1546. https://doi.org/10.1002/joc.2001
Malekinezhad H, Garizi AZ (2014) Regional frequency analysis of daily rainfall extremes using L-moments approach. Atmosfera 27:411–427. https://doi.org/10.1016/S0187-6236(14)70039-6
Meddi M, Toumi S (2015) Spatial variability and cartography of maximum annual daily rainfall under different return periods in Northern Algeria. J Mt Sci 12:1403–1421. https://doi.org/10.1007/s11629-014-3084-3
Modarres R, Sarhadi A (2011) Statistically-based regionalization of rainfall climates of Iran. Glob Planet Chang 75:67–75. https://doi.org/10.1016/j.gloplacha.2010.10.009
Mohorji AM, Şen Z, Almazroui M (2017) Trend analyses revision and global monthly temperature innovative multi-duration analysis. Earth Syst Environ 1:1–13. https://doi.org/10.1007/s41748-017-0014-x
Önol B, Semazzi FHM (2009) Regionalization of climate change simulations over eastern mediterranean. J Climatol 22:1944–1961. https://doi.org/10.1175/2008JCLI1807.1
Ozdogan M (2011) Climate change impacts on snow water availability in the Euphrates-Tigris basin. Hydrol Earth Syst Sci Discuss 8:3631–3666
Park JS, Jung HS, Kim RS, Oh JH (2001) Modelling summer extreme rainfall over the Korean Penissula using wakeby distribution. Int J Climatol 21:1371–1384
Pettitt AN (1979) A non-parametric approach to the change-point problem. Appl Stat 28:126–135
Rao AR, Hamed KH (2000) Flood frequency analysis. CRC Press, Boca Raton, FL
Sellers AH, McGuffie K (2012) The future of the word’s climate, 2nd edn. Elsevier, New York
Şen Z (2012) Innovative trend analysis methodology. J Hydrol Eng 17:1042–1046. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000556
Şen Z (2017) Innovative trend significance test and applications. Theor Appl Climatol 127:939–947. https://doi.org/10.1007/s00704-015-1681-x
Şen Z (2020) Probabilistic innovative trend analysis. Int J Glob 20:93–105. https://doi.org/10.1504/IJGW.2020.105387
Şen Z, Şişman E, Dabanli I (2019) Innovative polygon trend analysis (IPTA) and applications. J Hydrol 575:202–210. https://doi.org/10.1016/j.jhydrol.2019.05.028
Šimková T (2017) Homogeneity testing for spatially correlated data in multivariate regional frequency analysis. Water Resour Res 53:7012–7028. https://doi.org/10.1002/2016WR020295
Singh RN, Sah S, Das B, Potekar S, Chaudhary A, Pathak H (2021) Innovative trend analysis of spatio-temporal variations of rainfall in India during 1901–2019. Theor Appl Climatol 145:821–838. https://doi.org/10.1007/s00704-021-03657-2
Singh VP (1994) Elementary hydrology. Prentice Hall of India, New Delhi
Türkes M (2012) Observed and projected climate change, drought and desertification in Turkey. Ankara Univ J Environ Sci 4:1–32
Wang Y, Xu Y, Tabari H, Wang J, Wang Q, Song S, Hu Z (2020) Innovative trend analysis of annual and seasonal rainfall in the Yangtze river delta, eastern China. Atmos Res 231:1–14. https://doi.org/10.1016/j.atmosres.2019.104673
Wickramagamage P (2016) Spatial and temporal variation of rainfall trends of Sri Lanka. Theor Appl Climatol 125:427–438. https://doi.org/10.1007/s00704-015-1492-0
Wu H, Qian H (2017) Innovative trend analysis of annual and seasonal rainfall and extreme values in Shaanxi, China, since the 1950s. Int J Climatol 37:2582–2592. https://doi.org/10.1002/joc.4866
Xu YP, Yu C, Zhang X, Zhang Q, Xu X (2012) Design rainfall depth estimation through two regional frequency analysis methods in Hanjiang river basin. China Theor Appl Climatol 107:563–578. https://doi.org/10.1007/s00704-011-0497-6
Yagbasan O, Demir V, Yazicigil H (2020) Trend analyses of meteorological variables and lake levels for two shallow lakes in central Turkey. Water 12:1–16. https://doi.org/10.3390/w12020414
Yang T, Xu CY, Shao QX, Chen X (2010) Regional flood frequency and spatial patterns analysis in the Pearl river delta region using L-moments approach. Stoch Environ Res Risk Assess 24:165–182. https://doi.org/10.1007/s00477-009-0308-0
Yilmaz AG, Perera BJC (2015) Spatiotemporal trend analysis of extreme rainfall events in Victoria, Australia. Water Resour Manag 29:4465–4480. https://doi.org/10.1007/s11269-015-1070-3
Yurekli K (2015) Impact of climate variability on precipitation in the upper Euphrates-Tigris rivers basin of Southeast Turkey. Atmos Res 154:25–38. https://doi.org/10.1016/j.atmosres.2014.11.002
Yurekli K (2021) Scrutinizing variability in full and partial rainfall time series by different approaches. Nat Hazards 105:2523–2542. https://doi.org/10.1007/s11069-020-04410-0
Zhou Z, Wang L, Lin A, Zhang M, Niu Z (2018) Innovative trend analysis of solar radiation in China during 1962–2015. Renew Energ 119:675–689. https://doi.org/10.1016/j.renene.2017.12.052
Funding
The author declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author has no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yurekli, K. Identification of possible risks to hydrological design under non-stationary climate conditions. Nat Hazards 116, 517–536 (2023). https://doi.org/10.1007/s11069-022-05686-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-022-05686-0