
Abstract
Flood routing is one of the methods of flood forecasting in rivers to manage and control the flood. Today, the new technique of using the intelligent models is widely reported in various fields of science and engineering, particularly water resources. In this research, flood routing was studied using artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS) models. By using the bat algorithm and imperialist competitive algorithm (ICA), the structure of ANN models was optimized. This process was repeated for combining genetic algorithm and particle swarm optimization algorithm with the ANFIS model. Four input patterns were used for network training, which It−7, It−6, Qt−1, Qt−2 pattern was the best pattern for network input according to the evaluation test. Results of routing of 8 flood hydrographs (6 hydrographs for network training and 2 hydrographs for network testing) indicated that the ANN–ICA predicted the hydrograph volume, peak flow and flood time more accurately. The statistical analyses at the training stage were: RMSE = 0.33, MARE = 0.32, SI = 0.05, BIAS = 0.18 and at the testing stage were: RMSE = 0.3, MARE = 0.32, SI = 0.04, BIAS = 0.08. Also, according to the sensitivity analysis, It−6 has the highest impact on flood discharge. Finally, the flood hydrograph was predicted for a return period of 10,000 years.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Any water flow, regardless of its causative factor, is considered as flood when discharge in the river is higher than normal and the flow of water exceeds the natural banks and covers surrounding lands. Floods are one of the most important natural phenomena that cause a lot of damages to the world and countries pay a lot of costs annually. Flood routing is one of the most important engineering techniques for flood control (Wright 2000; Birkland et al. 2003; Brody et al. 2007; Chan 2012; Floater et al. 2014). Rainfall and hydrological characteristics of the basin are important in flood routing problems and factors such as previous rainfall, soil permeability and land gradient play a key role for a rainfall to cause flood occurrence at a certain period (Nguyen and Chua 2012). Today, one of the most vital concerns about rivers is their flood events. Forecasting is possible with ascent and descent of river hydrographs at a certain station. This method can be analyzed by flood routing technique.
Artificial neural network (ANN) has been successfully applied in many fields, including water resources. Recent studies have indicated that ANN can be an alternative to modeling the rainfall-runoff process and prediction of inflow to a dam reservoir (Dawson and Wilby 1998; Maier and Dandy 2000; Govindaraju and Rao 2000; Kisi 2004; Kumar et al. 2005; Mutlu et al. 2008; Zadeh et al. 2010; Kisi et al. 2012).
There are various methods for flood routing. Dynamic wave method is one of the most widely used. Using dynamic wave method requires cross-sectional mapping and hydrometric data. Thus, using this method is costly, time-consuming and sometimes impossible due to the unavailability of enough relevant data. Thus, studying artificial intelligence techniques is felt more than ever.
In recent decades, the meta-heuristic algorithms such as GA, ICA, PSO and Harmony Search (HS) can easily solve optimization problems for approximating the global optimum of a given function (Atashpaz-Gargari and Lucas 2007). Most of the optimization algorithms such as GA, simulated annealing and PSO have been developed based on biological intelligence. But the ICA was based on the human intelligence structure and is more accurate in many issues. The BA is based on the bat’s characteristics and can solve nonlinear problems (Yang 2010).
Kuo et al. (2001) stated in a study that GA provides more accurate results for optimization of the neural network. Aksoy and Dahamshed (2009) applied ARIMAX time-series model and PREVIS model to predict 1–7 days flow in the spring season in Chute-du-Daibale (an area of 9700 km2, located in northern Canada) for reservoir operation. They compared the performance of ARIMAX and PREVIS conceptual models to the ANN model. Results indicated that the ANN model is highly capable of prediction of river flow. Khatibi et al. (2011) compared three artificial intelligence methods [ANN, ANFIS and genetic programming (GP)] for flood routing. They concluded that GP provided better results compared to other methods. Several different networks have been used to predict and analyze rainfall-runoff process (Nourani et al. 2011), to predict flood flow (Dawson et al. 2006) and route the floods (Barati 2018).
Barati et al. (2012) did a comprehensive analysis of flood decomposition using dynamic wave method and sensitivity analysis of the parameters. Results showed that errors in the input parameters (such as low values of Manning roughness coefficient and/or steep bed slopes) are very significant in the characteristics of design hydrograph. Barati et al. (2013) performed flood routing for the Karun River using hourly and daily data and the Muskingum-Cunge method. Then, the results were compared to dynamic wave method.
Bozorg-Haddad et al. (2014) addressed the optimization of reservoir systems using BA and GA and showed that BA performed better in optimizing reservoir systems. Nikoo et al. (2016) studied flood routing in the Karun River using feed forward (FF), multilayer perceptron (MLP) and radial basis function (RBF) models. Input and output data were used to determine the effective delay time. The structure of artificial neural network models was optimized in terms of the number of nodes in the hidden layer using GA.
The aim of present study was to apply different meta-heuristic algorithms such as GA, PSO, BA and ICA as well as combinations (hybrids) of these algorithms with ANN and ANFIS for flood routing and estimation of the flood volume. In addition, flood hydrograph was estimated for 10,000-year return period using the best obtained hybrid algorithm.
2 Methodology
2.1 Case study
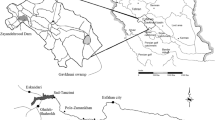
In this study, hydrometric data of two stations of Pir Soleiman and Kaleh Choub were used for routing the floods in Maryam Negar River, Kermanshah province, Iran. Pir Soleiman station is located at latitude of 27°47′ north and longitude of 42°34′ east, and Kaleh Choub station is located at latitude of 27°47′ north and longitude of 35°34′ east. The length of Maryam Negar River between the above stations is 24 km. Figure 1a shows the Maryam Negar River plan. Figure 1b is the location of this river in Iran.

a Location of Maryamnegar River. b Map of study site location
In this study, 8 measured flood hydrographs at Kaleh Choub and Pir Soleiman stations were used.
2.2 Flood hydrograph
Studies conducted on the eight measured flood hydrographs showed that some volume of the inflow hydrograph is lost as transferred from Kaleh Choub to Pir Soleiman stations. Given the geographic location, it is possible to consider the losses to be due to evaporation. But decreasing water volume in downstream and peak discharge can be due to water penetration in the substrate. Comparison of the measured hydrographs between the two stations showed that in most cases, there is a base flow in Kaleh Choub station and there is little base flow in Pir Soleiman station (Fig. 2) .


Flood hydrograph
2.3 Neural network
Artificial neural network (ANN) is one of the smart computing models. It is a unique black-box concept, able to model complex systems with nonlinear pattern. It imitates the human brain’s neural network (Bowden et al. 2005). ANN was first introduced by Rosenblatt as a perceptron computational model (Rosenblatt 1958). Although ANN is not completely comparable to the natural neuronal system, it has features that are unique in some applications such as pattern separation, or wherever there is need for learning with a linear or nonlinear mapping (Coulibaly et al. 2000).
The structure of ANN is introduced by the relationship between nodes, determining the communicational weights as well as activity function. The normal structure of an ANN includes input layer, middle layers and output layer. The input layer is a transmitter layer; in other words, it provides the data. The last layer or output layer includes the values estimated by the network. The middle or hidden layers, which are composed of processor nodes, are data processing layers. The number of hidden layers and the number of nodes in each hidden layer are determined by trial and error method. To train the ANN, the followings are essential: selection and preprocessing steps, network architecture, training and testing the model (Bishop 1995).
2.4 Adaptive neuro-fuzzy inference system (ANFIS)
The ANFIS model is a hybrid model of soft computing and neural networks. Considering an example of this process for a fuzzy inference system (two inputs and one output), the general structure and the five layers of ANFIS are described as follows:
First layer (input nodes): Each node in this layer represents the degree of membership to an input.
where Qt−1 and Qt−2 are the first and second inputs, and μAi and μBi−2 are the membership functions of Ai and Bi of the fuzzy sets. In order to determine the membership degrees, there are different membership functions: triangular, zodiac, Gaussian and bell-shaped. Gaussian function has the advantage of being smooth and nonzero, and it has fewer parameters; therefore, Gaussian function was used in this research.
Second layer (rule nodes): In this layer, the fuzzy operators are used to extract the power of each fuzzy rule to the sum of the powers of calculated membership degrees in the first layer:
Third layer (average nodes): In this layer, the motivational ratio of each fuzzy rule to the sum of the motivating powers of all the rules is determined as follows:
Fourth layer: In this layer, the values of the p, q and r parameters are optimized. In fact, in this layer, all nodes are going compatible with a node function as follows:
where p, q and r are sum of the parameters and w is the output of this layer.
Fifth layer (output node): In this layer, all outputs are calculated as the sum of all input signals as follows:
where p, q and r are sum of the parameters and w is the output of this layer.
2.5 Evolutionary calculations
Each engineering issue may have several different solutions; some of which are possible and some impossible. The task of designers is to find the best possible solution from different solutions. The set of possible answers make the design space in which we look for the best answer. Usually, the classic search technique is used to solve nonlinear equations. But the new optimization methods that are used today to solve many different issues are simulated annealing (SA), ant colony algorithm (ACO), PSO, GA, HS, etc. (Pham et al. 2006; Sivanandam and Deepa 2007; Ramezani and Lotfi 2013; Salimi et al. 2018).
2.6 Bat algorithm (BA)
The BA is inspired by the trapping characteristics of small bats in search of bait. Small bats can fly in absolute darkness, and by emitting sound and receiving it they can hunt their prey. Development of this algorithm is based on three ideal rules:
All bats use sound reflection to detect distances and they know the difference between food and obstacle.
The bats fly randomly at speed νi in distance xi with fixed frequency fmin and different wavelengths of λ and loudness of A0 for hunting. Also, they can automatically set the waves and the rate of their sent pulses (r ∈ [0, 1]) with respect to closeness of the prey.
Given that the volume may vary in many different ways, it is assumed that the loudness of the sound varies between R0 to Rmin.
According to the above-mentioned rules, the xti location and the velocity of vit for each ith virtual bat at t replication as well as the fi frequency are calculated as follows:
where θ ∈ [− 1, 1] is a random vector with uniform distribution and x0 is the best current location, which is selected in each replication after comparison with the position of the virtual bats. Usually, the frequency f is considered with fmin = 0 and fmax = 100. In each replication, in the local search, one of the answers is selected as the best answer, and the new position of each bat is updated locally with random pace as follows:
where e ∈ [− 1,1] is a random number and \( A^{t} \le A_{i}^{t} \) is the average bat loudness at t. In addition, the loudness of Ai and the sent pulse rate r at each replication is updated as follows:
where α and γ are fixed values for each 0 < α > 1 and r > 0. Figure 3 depicts the flowchart of BA.

Bat algorithm flowchart
2.7 Imperialist competitive algorithm (ICA)
Recently, a new algorithm called ICA was presented by Atashpaz-Gargari and Lucas (2007), which is inspired by a social phenomenon instead of the nature. The inventors of this algorithm analyzed the historical phenomenon of imperialism regarding a sociopolitical development of human societies. By mathematical modeling of this process, they proposed a powerful optimization algorithm.
There are a number of countries in the ICA algorithm. In fact, these sets of countries are random points within the search space. Then, a few stronger countries (more powerful) are selected as imperialist. Therefore, powerful countries are considered as imperialist and weak ones are colonies. At the beginning of the implementation of this algorithm, countries are randomly generated and several powerful countries are considered as imperialist. Then, other countries are randomly assigned to one of the imperialists. The number of each imperialist is in accordance with its power.
In this algorithm, the imperialist countries attract colonial countries into their own countries by applying assimilation policy (e.g., language and culture). This is modeled by the random movement of each colonial country toward its imperialist country in the search space. As shown in Fig. 4a, the colonial country movement toward the imperialist country is done at α and an angle of θ, which are determined randomly. In the process of movement of countries during the implementation of the algorithm, a colonial country may become stronger than its colonizer. In this case, the colonial and colonizer countries will be replaced. At each stage of the replication of the algorithm, there is a competition between the imperialist countries. In this process, the weakest colony of the weakest imperialist will randomly join one of the other imperialists. The probability of assigning this new colony to each imperialist is proportional to their power. If an imperialist loses all of its colonies, it will become colonized by another imperialist. The algorithm proceeds similarly so that there is only one imperialist. In this case, all countries are colonies of an imperialist and the algorithm ends. Of course, other stop conditions such as a certain process replication can also be applied (Fig. 4b).

a Imperialism competitive algorithm. b Imperialism competitive algorithm flowchart
2.8 Combining GA and PSO
The GA is very sensitive to the initial population. In fact, the random nature of genetic operators leads to this sensitivity. The dependency on the initial population is so that if the population is not well-chosen, the algorithm cannot get converged at all. However, if the initial population is well-chosen, the algorithm operator will be improved.
On the other hand, the PSO algorithm is sensitive to the initial population, too. One of the characteristics of the PSO is its rapid convergence toward overall optimization at early stages of the search process. The idea behind this research is to combine (hybridize) the GA and PSO so that it performs better than GA and PSO. This means that the speed of getting response increases significantly, while the accuracy is acceptable as well (Kennedy and Eberhart 1995; Shi and Eberhart 1999; Murthy et al. 2010).
2.9 Criteria for evaluation of the accuracy of the models
The following criteria were used to evaluate the models (Sudheer et al. 2002; Barati 2011, 2013).
where Qi is observed flow, \( Q_{i}^{*} \) is calculated flow, and \( \overline{{Q_{i} }} \) is average calculated flow.
2.10 Selection of input and output parameters of the models
In this research, statistical data are used as inputs of the neural network as well as training, testing and validating the neural network and reviewing and comparing them.
Using trial and error procedure, the above 4 patterns were selected for flood routing, where It−7 is the inflow with delay time of t−7, It−6 is inflow with delay time of t−6, Qt−1 is outflow with delay time of t−1, and Qt−2 is outflow with delay time of t−2. Inflow is the measured flow at Kaleh Choub station, and outflow is the flow measured at Pir Soleiman station.
The following formula was used for normalizing the data:
In the next step, the inflow and outflow data are divided into two categories: 6 hydrographs were used or training, and 2 hydrographs were used for testing. The input matrix of our data includes the parameters that each flood event depends on it. The total number of flows was 147; 109 data were used to train the network; and 38 data were used for testing.
2.11 Sensitivity analysis
Over the past years, several methods have been used to analyze the effect or importance of input variables on the output of the proposed neural network. These methods are divided into two sets of analysis based on weight and sensitivity analysis. However, these methods are subject to limitations. The sensitivity analysis using weight was first used for the first time by Garson (1991) and is followed by Goh (1995) and Gervey et al. (2003):
An analysis based on the weight values is exclusively based on the values stored in the static-weight matrix to determine the relative effect of each input data on the output. Different equations for the weight values are provided; all of which are determined by calculating the weight product of wij (the binding weight between input neuron i and hidden neuron j) and νjk (the binding weight between hidden neuron j and output neuron k).
3 Results and discussion
3.1 Flood routing results using ANN
MLP model was applied to predict the outflow hydrograph. Number of nodes in its first layer was 5. TanhAxon transfer function and the momentum network learning algorithm were used. Equation (15) was used to select the best combination of inputs. As seen in Table 1, pattern 4 is the best pattern. In this model, the moment discharge flow depends on the inputs of t − 7 and t − 6 and the discharge flow of the same station depends on the inflow Q − 1 and Q − 2 of Pir Soleiman station.
The statistical profile of the hydrograph calculated by the model is presented in Table 1. Figure 5 presents the calculated hydrographs. In addition, calculations for hydrograph volume at peak flow and peak time and relative error that is obtained by dividing the measured hydrograph values into calculated hydrographs are available in Table 2.

a Calculation hydrograph and observation hydrograph in flood event 1. b Calculation hydrograph and observation hydrograph in flood event 2
3.2 Flood routing results using ANN–ICA
As stated above, six hydrographs were used for training and two hydrographs were used for model testing. The parameters used in the MATLAB software for predicting outflow hydrographs using the ICA are: number of countries = 150, number of imperialists = 10, number of decades = 50 and revolution rate = 0.1.
To select the best input composition from the time delays, data were divided into four different combinations. According to Eq. (15), the best combination was selected using different tests.
The hydrograph profile calculated by the model is presented in Table 3. In addition, Fig. 6a, b presents the calculated hydrographs. Furthermore, calculations for hydrograph volume at peak flow and peak time and relative error that is obtained by dividing the measured hydrograph values by the calculated hydrograph values are presented in Table 4.

a Calculation hydrograph and observation hydrograph in flood event 1. b Calculation hydrograph and observation hydrograph in flood event 2
3.3 Flood routing results using ANN–BA
The parameters used in the MATLAB software for predicting outflow hydrographs using the BA are: walk factor = 0.03, walk rate = 5, Amin = 0.03, A0 = 0.9, fmax = 1 and fmin = 0.
To select the best input composition from the time delays, data were divided into four different combinations. The best combination was selected using different criteria.
The calculated hydrograph profile using the present model is presented in Table 5. Figure 7 presents the calculated hydrographs. Furthermore, calculations for hydrograph volume at peak flow and peak time are presented in Table 6.

a Calculation hydrograph and observation hydrograph in flood event 1. b Calculation hydrograph and observation hydrograph in flood event 2
3.4 Flood routing results using ANFIS (PSO–GA)
The parameters used in the MATLAB software for predicting outflow hydrographs using GA and PSO combination optimization are: population = 50, crossover rate = 0.7, mutation rate = 0.1 and number of iterations= 1000.
To select the best input composition from the time delays, data were divided into four different combinations. The best combination was selected using different tests.
The calculated hydrograph profile using the present model is shown in Table 7. Figure 8 presents the calculated hydrographs. Furthermore, calculations for hydrograph volume at peak flow and peak time are presented in Table 8.

a Calculation hydrograph and observation hydrograph in flood event 1. b Calculation hydrograph and observation hydrograph in flood event 2
3.5 Comparison of the models
There is a general consensus that each model is more appropriate than others for a number of specific issues. Therefore, the disadvantages and advantages of the models should be considered in relation to each other. In this research, the performance of each method has been compared regarding the prediction of outflow hydrographs. In Tables 1, 3, 5 and 7, using the statistical parameters, the success rate of each of the models for fitting the measured hydrographs was evaluated. The results of these tables indicated that for both hydrographs, ANN–ICA performed better in prediction of the outflow hydrographs. Relative error percentage was used to compare the performance of different models in prediction of outflow hydrograph characteristics, including volume of outflow flood hydrograph, peak discharge of the hydrograph and the time of peak flow occurrence. According to Tables 2, 4, 6 and 8, in both flood cases, ANN–ICA performed better for prediction of the peak flow rate and volume of outflow hydrograph and time of occurrence of the peak flow was predicted more precisely by ANFIS. Figure 9 presents the calculated and observed flows using ANN–ICA. It is seen that the results are acceptable, peak flow is calculated accurately and it provided us reasonable results for the baseflow.

a Calculate and observed discharge by using ANN–ICA in training. b Calculate and observed discharge by using ANN–ICA in testing
Figure 10 represents the variations of error in ANN–ICA.

a Network error changed by using ANN–ICA in training. b Network error changed by using ANN–ICA in testing
Given Figs. 9 and 10, statistical criteria, as well as relative errors, it can be concluded that ANN–ICA performed better than other single and hybrid algorithms in terms of peak flows and flood volume. The PSO–GA and ANN–BA ranked next. Ultimately, it is concluded that all three methods were better than ANN. Results showed that combination of intelligent algorithms with ANN leads to an increase in accuracy of the neural networks. Results of the ANN–ICA were used to predict the outflow hydrographs.
3.6 Sensitivity analysis of the input parameters
Sensitivity analysis was used to measure the influence of the four input parameters in the ANN on the output of the model. Results of ANN–ICA sensitivity analysis are presented in Fig. 11.

Sensitivity analysis
According to Fig. 11, the It−6 parameter had the highest effect on the output of the model (with a value of 58.3%) and next were Qt−1, It−7 and Qt−2 (23.2, 11.6 and 6.9%, respectively).
3.7 Overflow flood prediction
Given the results of previous sections and the superiority of ANN–ICA, this hybrid method was used to predict overflow characteristics. Using the prediction of inflow in Kaleh Choub station flood routing information of Maryam Negar River, the outflow discharge with a return period of 10,000 years is calculated (Table 9). The reason for choosing 10,000-year flood is that the dam was considered to be highly at risk.
In this hydrograph, which is shown in Fig. 12 and Table 10, the peak flow is 794 m3/s and the flood volume is 21,435,480 m3. This is the inflow hydrograph which enters the dam reservoir. Since the reservoir is assumed to be full, this volume of flood is released as overflow on the spillway.

Flood hydrograph (10,000 year) calculated by ANN–ICA
Of course, given the limited data, this method should be used with caution to predict a 10,000-year flood.
Given the data in Table 9, the full hydrograph is drawn.
4 Conclusion
In this research, few meta-heuristic algorithms and their combinations with ANN and ANFIS were used for flood routing of Maryam Negar River. Results indicated that considering the river inflow in Kaleh Choub station and transmission losses in the river reach, the ANN model accurately simulated the outflow hydrograph in the Pir Soleiman station. To test the model, the It−6, It−7, Qt−1 and Qt−2 patterns were used. The ICA, BA, PSO and GA were used to optimize ANN and ANFIS. This technique significantly decreased the time needed to determine the optimal structure. Results of the routed inflow hydrograph indicated that ANN–ICA was the best method for flood routing. The error of predicting flood volumes was acceptable, but it is not applicable for peak flow. Then, by using the best prediction model (i.e., ANN–ICA), the 10,000-year peak flood discharge was estimated as 794 m3/s. The outflow hydrograph could be used in design of hydraulic structures such as dam spillway. To determine the effect of each of the input parameters on prediction of flood, sensitivity analysis was carried out by Garson (1991) method using the adjusted weight gain as well as ANN–ICA. The results indicated that It−6, Qt−1, It−7 and Qt−2 were evaluated with 58.3, 23.2, 11.6 and 6.9%, respectively.
References
Aksoy H, Dahamshed A (2009) Artificial neural network models for forecasting monthly precipitation in Jordan. Stoch Environ Res Risk Assess. https://doi.org/10.1007/s00477-008-0267-x
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. IEEE Congr Evol Comput. https://doi.org/10.1109/CEC.2007.4425083
Barati R (2011) Parameter estimation of nonlinear Muskingum models using Nelder-Mead simplex algorithm. J Hydrol Eng 16(11):946–954
Barati R (2013) Application of excel solver for parameter estimation of the nonlinear Muskingum models. KSCE J Civil Eng 17(5):1139–1148
Barati R (2018) Discussion of “Application of Genetic Programming to flow routing in simple and compound channels” by Elahe Fallah-Mehdipour, Omid Bozorg-Haddad, Hossein Orouji, and Miguel A. Mariño. J Irrig Drain Eng 144(5):07018015
Barati R, Rahimi S, Akbari GH (2012) Analysis of dynamic wave model for flood routing in natural rivers. Water Sci Eng 5(3):243–258
Barati R, Akbari GH, Rahimi S (2013) Flood routing of an unmanaged river basin using Muskingum–Cunge model: field application and numerical experiments. Casp J Appl Sci Res 2(6):08
Birkland TA, Burby RJ, Conrad D, Cortner H, Michener WK (2003) River ecology and flood hazard mitigation. Nat Hazards Rev 4(1):46–54. https://doi.org/10.1061/(ASCE)1527-6988(2003)4:1(46)
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Bowden GJ, Maier HR, Dandy GC (2005) Input determination for neural network models in water resources applications. Part 2. Case study: forecasting salinity in a river. J Hydrol 301(1):93–107. https://doi.org/10.1016/j.jhydrol.2004.06.020
Bozorg-Haddad O, Karimirad I, Seifollahi-Aghmiuni S, Loáiciga HA (2014) Development and application of the bat algorithm for optimizing the operation of reservoir systems. J Water Resour Plan Manag 141(8):04014097. https://doi.org/10.1061/(ASCE)WR.1943-5452.0000498
Brody SD, Zahran S, Maghelal P, Grover H, Highfield WE (2007) The rising costs of floods: examining the impact of planning and development decisions on property damage in Florida. J Am Plan As 73(3):330–345. https://doi.org/10.1080/01944360708977981
Chan NW (2012) Impacts of disasters and disasters risk management in Malaysia: the case of floods. In: Sawada Y, Oum S (eds) Economic and welfare impacts of disasters in East Asia and Policy responses. ERIA Research Project Report 2011-8, ERIA, Jakarta, pp 503–551. https://doi.org/10.1007/978-4-431-55022-8_12
Coulibaly P, Anctil F, Bobee B (2000) Daily reservoir inflow forecasting using artificial neural networks with stopped training approach. J Hydrol 230:244–257. https://doi.org/10.1016/S0022-1694(00)00214-6
Dawson CW, Wilby R (1998) An artificial neural network approach to rainfall-runoff modeling. Hydrol Sci J 43(1):47–66
Dawson CW, Abrahart RJ, Shamseldin AY, Wilby RL (2006) Flood estimation at ungauged sites using artificial neural networks. J Hydrol 319(1–4):391–409. https://doi.org/10.1016/j.jhydrol.2005.07.032
Floater G, Bujak A, Hamill G, Lee M (2014) RAMSES Project, WP 5: development of a cost assessment framework for adaptation, D5.1: review of climate change losses and adaptation costs for case studies. Technological Development and Demonstration under Grant Agreement No. 308497 (Project RAMSES), 22 p
Garson GD (1991) Interpreting neural network connection weights. J Artif Intell Expert 6:47–51
Gevrey M, Dimopoulos I, Lek S (2003) Review and comparison of methods to study the contribution of variables in artificial neural network models. J Ecol Model 160:249–264
Goh ATC (1995) Back-propagation neural networks for modeling complex systems. J Artif Intel Eng 9:143–151
Govindaraju RS, Rao AR (2000) Artificial neural networks in hydrology. Kluwer Academic Publisher, Dordrecht
Kennedy J, Eberhart R (1995) Particle swarm optimization. Proc IEEE Int Conf Neural Netw 14:1942–1948
Khatibi R, Ghorbani MA, Kashani MH, Kisi O (2011) Comparison of three artificial intelligence techniques for discharge routing. J Hydrol 403(3–4):201–212. https://doi.org/10.1016/j.jhydrol.2011.03.007
Kisi O (2004) River flow modeling using artificial neural network. ASCE J Hydrol Eng 9(1):60–63. https://doi.org/10.1061/(ASCE)1084-0699(2004)9:1(60)
Kisi O, Nia AM, Gosheh MG, Tajabadi MRJ, Ahmadi A (2012) Intermittent streamflow forecasting by using several data driven techniques. Water Resour Manage 26(2):457–474. https://doi.org/10.1007/s11269-011-9926-7
Kumar APS, Sudheer KP, Jain SK, Agarwal PK (2005) Rainfall-runoff modeling using artificial neural networks: comparison of network types. Hydrol Process 19:1277–1291. https://doi.org/10.1002/hyp.5581
Kuo RJ, Chen CH, Hwang YC (2001) An intelligent stock trading decision support system through integration of genetic algorithm based fuzzy neural network and artificial neural network. Fuzzy Sets Syst 118(1):21–45. https://doi.org/10.1016/S0165-0114(98)00399-6
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modeling issues and applications. Environ Model Softw 15:101–123. https://doi.org/10.1016/S1364-8152(99)00007-9
Murthy KR, Raju MR, Rao GG (2010) Comparison between conventional, GA and PSO with respect to optimal capacitor placement in agricultural distribution system. In: 2010 Annual IEEE India conference (INDICON), pp 1–4. doi:https://doi.org/10.1109/INDCON.2010.5712664
Mutlu E, Chaubey I, Hexmoor H, Bajwa SG (2008) Comparison of artificial neural network models for hydrologic predictions at multiple gauging stations in an agricultural watershed. Hydrol Process 22(26):5097–5106. https://doi.org/10.1002/hyp.7136
Nguyen PKT, Chua LHC (2012) The data-driven approach as an operational real-time flood forecasting model. Hydrol Process 26:2878–2893. https://doi.org/10.1002/hyp.8347
Nikoo M, Ramezani F, Hadzima-Nyarko M, Nyarko EK, Nikoo M (2016) Flood-routing modeling with neural network optimized by social-based algorithm. Nat Hazards 82(1):1–24. https://doi.org/10.1007/s11069-016-2176-5
Nourani V, Kisi O, Komasi M (2011) Two hybrid artificial intelligence approaches for modeling rainfall–runoff process. J Hydrol 402(1):41–59. https://doi.org/10.1016/j.jhydrol.2011.03.002
Pham DT, Koc E, Ghanbarzadeh A, Otri S (2006) Optimization of the weights of multi-layered perceptrons using the bees algorithm. In: Proceedings of 5th international symposium on intelligent manufacturing systems, pp 38–46
Ramezani F, Lotfi S (2013) Social-based algorithm (SBA). Appl Softw Comput 13(5):2837–2856. https://doi.org/10.1016/j.asoc.2012.05.018
Rosenblatt F (1958) The perceptron: a probabilistic model for information storage and organization in the brain. Psychol Rev 65(6):386
Salimi A, Karami H, Farzin S, Hassanvand M, Azad A, Kisi O (2018) Design of water supply system from rivers using artificial intelligence to model water hammer. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1465366
Shi Y, Eberhart RC (1999) Empirical study of particle swarm optimization. In: Proceedings of the 1999 congress evolutionary computation, CEC 99, vol 3, pp 1945–1950. IEEE. doi:https://doi.org/10.1109/CEC.1999.785511
Sivanandam SN, Deepa SN (2007) Introduction to genetic algorithms. Springer, Berlin
Sudheer KP, Gosain AK, Ramasastri KS (2002) A data driven algorithm for constructing artificial neural network rainfall-runoff models. Hydrol Process 16(6):1325–1330. https://doi.org/10.1002/hyp.554
Wright JM (2000) A report by the Association of State Floodplain Managers. The Nation’s responses to flood disasters: a historical account, Association of State Floodplain Managers, Madison
Yang XS (2010) A new metaheuristic bat-inspired algorithm. In: Gonzalez JR et al (eds) Nature inspired cooperative strategies for optimization (NISCO 2010), vol 284. Springer, Berlin, pp 65–74
Zadeh MR, Amin S, Khalili D, Singh VP (2010) Daily outflow prediction by multilayer perceptron with logistic sigmoid and tangent sigmoid activation functions. Water Resour Manag 24(11):2673–2688. https://doi.org/10.1007/s11269-009-9573-4
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Hassanvand, M.R., Karami, H. & Mousavi, SF. Investigation of neural network and fuzzy inference neural network and their optimization using meta-algorithms in river flood routing. Nat Hazards 94, 1057–1080 (2018). https://doi.org/10.1007/s11069-018-3456-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-018-3456-z