
Abstract
A hybrid clustering-fusion methodology is developed in this study that employs genetic algorithm (GA) optimization method, k-means method, and several soft computing (SC) models to better estimate land subsidence. Estimation of land subsidence is important in planning and management of groundwater resources to prevent associated catastrophic damages. Methods such as the Persistent Scatterer Interferometric Synthetic Aperture Radar (PS-InSAR) can be used to estimate the subsidence rate, but PS-InSAR does not offer the required efficiency and accuracy in noisy pixels (obtained from remote sensing). Alternatively, a fusion-based methodology can be used to estimate subsidence rate, which offers a superior accuracy as opposed to the traditionally used methods. In the proposed methodology, five SC methods are employed with hydrogeological forcing of frequency and thickness of fine-grained sediments, groundwater depth, water level decline, transmissivity and storage coefficient, and output of land subsidence rate. Results of individual SC models are then fused to render more accurate land subsidence rate in noisy pixels, for which PS-InSAR cannot be effective. We first extract 14,392 different input–output patterns from PS-InSAR technique for our study area in Tehran province, Iran. Then, k-means method is used to divide the study area into homogenous zones with similar features. The five SC models include adaptive neuro fuzzy inference system, support vector regression, multilayer perceptron neural network and two optimized models, namely radial basis function and generalized regression neural network. To fuse individual SC models, three methods including GA, K-nearest neighbors and ordered weighted average (OWA) based on ORNESS method and ORLIKE method, are developed and evaluated. Results show that the fusion-based method is significantly superior to each of the employed individual methods in predicting land subsidence rate.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Metropolitan and agricultural development increase groundwater resources withdrawal, which in turn poses serious environmental challenges. Unregulated and excessive groundwater extraction for agricultural, domestic and industrial use have resulted in severe drop in groundwater table in several basins in Iran (Motagh et al. 2008; Sadegh et al. 2010; Sadegh and Kerachian 2011). Decline in groundwater level increases the effective stress in the aquifer system that promotes compaction in fine-grained sediments (Budhu and Adiyaman 2010; Dehghani et al. 2013), which in turn prompts land subsidence. In addition to groundwater level decline, other geology and hydrogeology factors can affect subsidence rate, including gas, oil and geothermal water extraction (Gambolati et al. 2005), coal mining (Jung et al. 2007) and sudden hydrogeological changes along faults (Burbey 2002).
Precise estimation of land subsidence provides helpful information to decision makers in their efforts to control and mitigate the impacts of such a grave hazard. Satellites have provided alternative land subsidence monitoring methods complementing in situ observations based on remote sensing techniques. In the previous decades, several studies have performed monitoring and analyzing land subsidence due to groundwater withdrawal based on observations from satellites and radars such as Environmental Satellite Advanced Synthetic Aperture Radar (ENVISAT ASAR) (Osmanoglu et al. 2011; Yue et al. 2011; Ng et al. 2012; Dehghani et al. 2013; Strozzi et al. 2017; Deng et al. 2017; Lu et al. 2018; Du et al. 2018). Interferometry Synthetic Aperture Radar (InSAR) is one such technique that provides accurate measurements of land subsidence (Amelung et al. 1999; Carnec and Fabriol 1999; Nakagawa et al. 2000; Ding et al. 2004; Dehghani et al. 2009; Yue et al. 2011; Calderhead et al. 2011;Cigna et al. 2012; Teatini et al. 2012; Qu et al. 2014; Strozzi et al. 2017; Lu et al. 2018; Du et al. 2018; Nadiri et al. 2018). Another such technique is Persistent Scatterer Interferometric Synthetic Aperture Radar (PS-InSAR) that is recently developed to address the decorrelation problem in land subsidence estimation, and is widely used in the literature (Jung et al. 2007; Osmanoglu et al. 2011; Cigna et al. 2012; Teatini et al. 2012; Dehghani et al. 2013; Strozzi et al. 2013; Wu and Hu 2016; Sun et al. 2017; Deng et al. 2017; Maghsoudi et al. 2018). However, although the remotely sensed techniques offer valuable opportunities and advantages for land subsidence estimation as opposed to traditional in situ observations, a potential drawback associated with remote sensing is lack of accurate and detailed information about subsidence in noisy pixels (Dehghani et al. 2013). In view of the fact that the PS-InSAR technique is based on persistent scatterer points, noisy behavior could be observed in many points of the study area especially in non-urban regions (Gehlot and Hanssen 2008). In such cases, an approach based on soft computing models can be effectively utilized to estimate land subsidence. For example, Artificial Neural Networks (ANNs) have been used to monitor subsidence in various studies. In Table 1, related studies on subsidence analysis using soft computing models are summarized.
In a closely related effort to this study, Dehghani et al. (2013) studied land subsidence due to groundwater extraction in Tehran basin, Iran. They considered six hydrogeological variables as multilayer perceptron (MLP) model’s forcing to estimate subsidence rate. In their study, forcing of the MLP model is not classified, and the subsidence rate is estimated only by one soft computing model (MLP). Hence, the developed model is not sufficiently precise as evidenced by relatively high root-mean square error (RMSE). To improve the accuracy of land subsidence rate estimation one can cluster forcing data and train a separate model for each cluster, and/or employ several soft computing models and fuse their estimations.
In the past years, the increasing demand for enhanced accuracy of soft computing (SC) models has stimulated researchers to develop fusion-based methods. Model fusion is the procedure of gathering data from several models such as different individual SC models’ outputs, aiming to provide more precise and reliable information compared to each individual model (Dasarathy 1997). Fusion-based methods, such as Bayesian Model Averaging, have been recently used in different research areas, namely drought index estimation (Azmi et al. 2016; Alizadeh and Nikoo 2018), river-level forecasting (See and Abrahart 2001) and hydrological engineering (Shu and Burn 2004; Duan et al. 2007; Ajami et al. 2007; Azmi et al. 2010; Ashouri et al. 2015). But to the best of authors knowledge, there is not any study on estimation of land subsidence rate using fusion-based methods. The importance of this phenomenon motivated the authors to develop a fusion model in order to achieve more precision in land subsidence estimation. Therefore, in this study a fusion-based methodology is developed based on five individual soft computing (SC) models, which are subsequently fused using genetic algorithm (GA), K-nearest neighbors (KNN) method and ordered weighted average (OWA) method. Five SC models, namely adaptive neuro fuzzy inference system (ANFIS), support vector regression (SVR), multilayer perceptron (MLP), and two optimized models based on genetic algorithm (GA) including radial basis function (RBF) and generalized regression neural network (GRNN) were employed to estimate subsidence rate. The input variables of all SC models are six effective hydrogeological variables and the output is the subsidence rate derived from PS-InSAR. Then, k-means is utilized for dividing the study area into clusters (homogenous zones) with similar features. 70% and 30% of each cluster’s data are used for training and validating the individual and fusion-based models, respectively. Four fusion methods based on genetic algorithm (GA) optimization method, K-nearest neighbors (KNN) and ordered weighted average (OWA) models are then developed to fuse the outputs of individual SC models. The latter (OWA) consists of two submodels, namely ORNESS and ORLIKE methods. The main novelty of proposed methodology is developing several fusion-based models as well as optimized soft computing (SC) models to achieve the best possible result in land subsidence estimation. In the next sections main parts of proposed methodology, case study and results are presented.
2 Methodology
Flowchart of the fusion-based methodology which proposed for land subsidence rate estimation is presented in Fig. 1. The proposed methodology consists of five main steps. In the first step, the data are prepared and derived from ENVISAT ASAR and PS-InSAR. In the next step, to obtain more precision in subsidence rate estimation, the k-means method is used to classify data. Then, each cluster’s data are randomly separated as train and validation sets. In the third step, five individual Soft Computing (SC) models, namely ANFIS, SVR, MLP and two optimized models, namely RBF and GRNN are developed. In the fourth step, four different methods including KNN, GA and two OWA-based models, namely ORNESS and ORLIKE are utilized as fusion methods for analysis and estimation of land subsidence rate based on PS-InSAR data. Finally, the results of SC models and model fusion methods are assessed and compared through different statistical error indices. In the next sections, the main steps of proposed methodology are briefly described.

Flowchart of fusion-based methodology for land subsidence rate estimation
2.1 k-Means method
This algorithm classifies data into several homogenous clusters with similar features. k-Means method initializes the center of k clusters by random search in each iteration and subsequently measures the distances between data points (xij) and the centers (cj). So, by minimizing the objective function specified in Eq. 1, this algorithm assigns cluster k to data point xij (MacQueen 1967).
In this study, we have tried different number of iterations to avoid converging to local optima by the k-means algorithm, and successively increased the number of iterations until the result not change anymore. We also have repeated the k-mean algorithm several times, each time setting the initial centroid point at the previous optimized points to ensure k-means reached a global optimum.
2.2 Soft computing (SC) models
In order to reach the optimal network architecture of individual SC models, various values of models’ effective parameters (model settings) were optimized with two approaches: (1) Trial-and-error analysis for MLP, SVR and ANFIS, and (2) Genetic algorithm (GA) optimization model for RBF and GRNN. Eventually, SC model structures were selected that provided superior results according to several statistical error indices such as scatter index (SI), root-mean-square error (RMSE), root-mean relative error (RMRE), Nash–Sutcliffe (NS) efficiency, correlation coefficient (CC) and bias:
where ei and oi are respectively ith estimated and observed subsidence rate (SR) and n is the size of dataset. Also, E and O indicate the average estimated and observed SR, respectively. The name of main parameter(s) of each individual SC model and their method of determination are shown in Fig. 2.

Main parameter(s) of individual soft computing (SC) models and their method of determination
2.3 Fusion-based models
Model fusion is a subset of data fusion technique which amalgamates different model simulations with a goal that the result of combining data from different sources becomes more accurate and reliable than the result of each of the primary sources (Hall and Llinas 1997). Key role of the fusion method is to specify weights to individual models. There are various methods available to specify such weights. In this paper, in order to acquire a more precise estimate of land subsidence rate, four fusion methods including genetic algorithm (GA), K-nearest neighbors (KNN), and ordered weighted average (OWA) method based on ORNESS and ORLIKE methods are employed to derive the weights of individual SC models. For estimation purposes, suppose yj(j = 1, 2, …, k) represents observed data, n signifies each individual model, and the estimated value by ith individual model is shown as \(\hat{y}_{ij} (i = 1,\, \ldots ,\,n)\). If weights vector is w = [w1, w2, …, wn]T, the estimated output of fusion model (Yj) can be expressed as below:
Individual model errors are calculated through \(e_{ij} = \hat{y}_{ij} - y_{j}\), while the corresponding error of fusion methods is specified as Ej = Yj − yj.
In order to improve estimation accuracy, the corresponding errors of fusion methods should be minimized. For this purpose, four different fusion methods including GA, KNN and OWA method (ORNESS and ORLIKE methods) are utilized (Fig. 3). A brief explanation of these approaches is given in the next sections.

Schematic representation of the fusion-based methodology
2.3.1 GA fusion method
Genetic algorithm (GA) is one of the optimization methods based on evolutionary process. This method, by iteratively generating a set of possible solutions, tries to achieve a global optimum solution. In the present study, decision variables of the GA optimization model are the weights assigned to each individual SC model. The objective function is to obtain decision variables that minimize Mean Absolute Relative Error (MARE) between the weighted individual models’ output (output of fusion method, \(w_{i} \hat{y}_{ij}\)) and target values of subsidence rate (yj):
where n is the number of individual models and k is the size of dataset.
2.3.2 KNN fusion method
K-nearest neighbor (KNN) obtains the best estimate of a target variable for a specific point based on a weighted average of the target values from its k-nearest samples (Altman 1992). Briefly, Euclidean distance of all available samples to the desired point is calculated according to Eq. 11, and its k-nearest samples are selected to estimate the target value at this point. Neighbors that are closer to the desired point should be weighted more heavily than more distant ones. Hence, reciprocal of squared distance of each data (Eq. 12) is used as weight. Then, using Eq. 13, the target value for the desired point is estimated (Larose 2005):
where xi(i = 1, …, n) are the sample data with known target values Yi, and xx is the desired point, for which the target value, Ynew, is being sought. In this study, the best results of five SC models are applied as inputs of KNN method in order to fuse them. For further information about this method refer to Altman (1992) and Larose (2005).
2.3.3 ORNESS-OWA
The ordered weighted average (OWA) method is a mapping tool F:Rn → R, in which n is the number of individual models. This method allocates weight of each model with the constraint:
Here we first provide some background about the OWA methodology, and then discuss assigning wi values in the subsequent sections. If the predicted subsidence rate of ith individual model is bi, then the vector of the results of n individual models will be B = {b1, b2, …, bn} and the vector of corresponding weights will be w = {w1, w2, …, wn}. Since weighing individual models by the OWA method makes different combinations of weights, Yager (1988) defined the parameter orness and Dispersion to determine the dispersion of weights around the median value of the parameters:
A 0.5 value for orness represents the equality of all weights, meaning weights are normally distributed around the median. Therefore, orness values between 0.5 and 1 indicate that the weight distribution has a positive skewness, so that larger weight is assigned to a better model.
In this approach, the fusion weights for the SC models are estimated using the genetic algorithm (GA) optimization model for different α values between 0 and 1 (Eq. 16). O’Hagan (1988) used the following optimization model to determine the weights so that for the specified values (α) of the orness parameter, the maximum value of Dispersion(w) is calculated:
2.3.4 ORLIKE-OWA
Yager and Filev (1994) present a family of OWA weights named S-OWA, which include two main weighing methods (ORLIKE and ANDLIKEFootnote 1). In this paper, ORLIKE-OWA is used. In this method, similar to ORNESS, the best model gets the highest weight and worst model is penalized in the weighting scheme. This method calculates the weights by solving the following equations. F is the ORLIKE method’s operator as shown in Eq. 20:
In this method, for α = 0, the orness parameter is equal to 0.5 and for α = 1, the value of orness parameter is equal to 1, that means the first model will gain more weight. Since the results of individual models are sorted in the descending order of the best result to the worst one, it is necessary that the model weights are also adjusted in the descending order so that the highest weight is given to the best model output. It is noteworthy that for α values smaller than 0.5, the weights of the models are ascending, and for more than 0.5, the weights of the models are descending. To accommodate weights and variables, α values > 0.5 have been used to implement the optimization and weighting process. For more information about OWA methods, refer to Yager (1988), O’Hagan (1988) and Yager and Filev (1994). In this study, ORNESS and ORLIKE methods are performed for different α values and their best results are determined (Tables 6, 7).
3 Study area
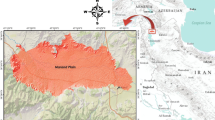
Tehran basin with a total area of 2250 km2 is surrounded by the Alborz and the Fashapouye Mountains (Dehghani et al. 2013). The vast majority of this basin, which is under agricultural activities, is subject to subsidence due to excessive abstraction of groundwater. The study area, depicted in Fig. 4, is in the southwest of the Tehran basin in central north part of Iran.

Location of the study area in Tehran province
The data collected by Dehghani (2010) is used in this study to develop a model fusion methodology for estimating land subsidence using PS-InSAR technique. Dehghani (2010) extracted, with piezometric measurements, the effective parameters on subsidence rate, including water level decline (observed between 1968 and 2003), groundwater depth, storage coefficient, transmissivity, alluvial thickness and frequency of fine-grained sediments. Also, the subsidence rates were inferred from the PS-InSAR technique. As previously mentioned, to achieve more accuracy in land subsidence rate estimation, the dataset were clustered using k-means method. Statistics of hydrogeological variables, including maximum, minimum and average, for each cluster are presented in Table 2.
4 Results
For all Soft Computing (SC) models, available hydrogeology information, which were extracted from piezometric measurements, are utilized as forcing and subsidence rates from PS-InSAR technique is used as output data. Available data is categorized by k-means method into five clusters, and of each cluster’s data, 70% are used for training and 30% for validation. To train the five SC models, namely ANFIS, SVR, MLP, RBF and GRNN, we employed trial-and-error analysis and genetic algorithm (GA) optimization. It should be noted that the GA optimization method is utilized for training two SC models (RBF and GRNN), optimizing ORNESS-OWA and also as one of the fusion methods. Specifications relating to the GA optimization method used in aforementioned models are presented in Table 3. Scattered crossover function with fraction value 0.8 is considered for this approach. The TolFun 1e-10 (tolerance value) for StallGenLimit 80 (generation limits) are defined as stopping criteria for models. The results of each individual model’s parameters and their method of determination are listed in Table 4.
In order to evaluate the accuracy of these models, six statistical error indices including NS, CC, SI, RMSE, RMRE and Bias (Eqs. 2–7) are calculated for all individual models. As an example, the results of all SC models in estimating land subsidence rate in validation stage are presented in Table 5.
Proximity of the NS and CC to 1, and RMSE, RMRE, SI and Bias indices to 0, indicate higher accuracy of the model. Each model result is then ranked based on superior performance and ranked, with 1 representing best model. Minimum summation of ranking in each cluster (Table 5) specifies the more accurate SC model according to all indices (bold values). Since the aim of this study is to improve accuracy of subsidence rate estimation, four fusion-based methods including genetic algorithm (GA) optimization model, K-nearest neighbors (KNN) and two ordered weighted average (OWA) models, namely ORNESS and ORLIKE methods were used to fuse the outputs of individual SC models and were compared with the best individual model in each cluster (Fig. 6). The performance of ORNESS (Eqs. 14–19) for α values from 0.5 to 1 and ORLIKE (Eqs. 20–22) for α values from 0.1 to 1 are determined and compared based on trial-and-error analysis (Tables 6, 7). As noted earlier, in ORNESS and ORLIKE methods, the best model gets the highest weight. Therefore, according to Tables 6 and 7, the results obtained from these two methods are compared based on two statistical error indices (NS and RMSE) for different α values. Best prediction and associated α are shown in bold in Tables 6 and 7 for the ORNESS and ORLIKE methods. In addition to the trial-and-error analysis, α values were also optimized using GA optimization methods, results of which did not significantly change the findings of Tables 6 and 7.
Table 8 presents performance evaluation of four fusion methods of this study in terms of the six statistical error indices mentioned before. Also, in this table, bold values represent the best fusion method for each cluster. Comparing the statistical error indices shown in Tables 5 and 8 shows the superior accuracy of the fusion methods compared to the individual models.
To make the intercomparison of fusion methods more visually appealing, bar charts of fusion models performance with respect to different statistical error indices are presented in Fig. 5. This figure shows that ORNESS-OWA model has a superior performance and is more accurate as opposed to the other fusion methods in most of clusters.

Fusion methods’ performance with respect to several statistical error indices
Figure 6 compares the best fusion method in each cluster with the best individual SC model in the same cluster. The figure confirms that the fusion-based methods are more accurate in estimation of land subsidence rate.

Comparison the results of best fusion method and best individual SC model of each cluster
The average RMSE reported by Dehghani et al. (2013) is 4.055 (mm/year), while in this study, we obtained an RMSE value of 3.89 (mm/year) for the best individual SC model (SVR) in most clusters and 2.55 (mm/year) for the best fusion model (ORNESS-OWA) in most clusters. Comparing the present study results with Dehghani et al. (2013) shows that the presented methodology in this study is more accurate. Moreover, fusion-based methods are more accurate than individual soft computing methods.
5 Summary and conclusion
Land subsidence due to excessive and unsustainable groundwater withdrawal is a paramount hazard to infrastructure safety. Estimating subsidence rate (SR) with sufficient precision is hence of particular interest to sustain human and environmental safety and well-being. In this paper, in order to increase the precision of subsidence rate estimation in the Tehran basin, Iran, a new methodology is developed based on four fusion-based methods, namely genetic algorithm (GA), K-nearest neighbors (KNN) and ordered weighted average (OWA) with two weighting methods (ORNESS and ORLIKE) to fuse five individual Soft Computing (SC) models. The approach initiates with obtaining hydrogeological information and subsidence rates estimated based on PS-InSAR technique, and employing a k-means method to categorize different station data into homogeneous groups. The cluster data are in turn used to train five Soft Computing (SC) models, namely adaptive neuro fuzzy inference system (ANFIS), support vector regression (SVR), multilayer perceptron (MLP) neural network and two optimized models, namely radial basis function (RBF) and generalized regression neural network (GRNN). Fusion methods then create a weighted average of individual SC models to improve land subsidence rate accuracy. To evaluate and compare the results of all models, six statistical error indices, namely scatter index (SI), root-mean-square error (RMSE), root-mean-relative error (RMRE), Nash–Sutcliffe (NS) efficiency, correlation coefficient (CC) and bias, were utilized. The results show that, fusion methods are more accurate than individual SC models. Also, the result of fusion methods, reveals that ORNESS-OWA method is the superior model in most of clusters. Authors’ suggestions for future studies are (i) to consider Subsidence Vulnerability Indices (SVIs) to represent subsidence potential that affect the vulnerable aquifer, and (ii) to employ the proposed methodology to determine these indices more precisely. Also, Fuzzy set theory can be utilized to address uncertainty sources in land subsidence estimation.
Notes
In the ANDLIKE method, the worst model gets the highest weight. Authors considered in this study both models to assign weight in a sequence. Both (ORLIKE and ORNESS) assign the highest weight to the best.
References
Ajami NK, Duan Q, Sorooshian S (2007) Bayesian multimodel combination framework: confronting input, parameter, and model structural uncertainty in hydrologycal prediction. Water Resour Res 43:W01403. https://doi.org/10.1029/2005WR004745
Alizadeh MR, Nikoo MR (2018) A fusion-based methodology for meteorological drought estimation using remote sensing data. Remote Sens Environ 211:229–247
Altman NS (1992) An introduction to kernel and nearest-neighbor nonparametric regression. Am Stat 46(3):175–185
Ambrožič T, Turk G (2003) Prediction of subsidence due to underground mining by artificial neural network. Comput Geosci 29:627–637
Amelung F, Galloway DL, Bell JW, Zebker HA, Laczniak RJ (1999) Sensing ups and downs of Las Vegas: InSAR reveals structural control of land subsidence and aquifer-system deformation. Geology 27(6):483–486
Ashouri H, Hsu KL, Sorooshian S, Braithwaite DK, Knapp KR, Cecil LD, Nelson BR, Prat OP (2015) PERSIAN-CDR: daily precipitation climate data record from multi satellite observations for hydrological and climate studies. Bull Am Meteorol Soc 96(1):69–83
Azmi M, Araghinejad S, Kholghi M (2010) Multi model data fusion for hydrological forecasting using K-nearest neighbor method. Iran J Sci Technol 34(B1):81
Azmi M, Rodiger C, Walker JP (2016) A data fusion-based drought index. Water Resour Res 52(3):2222–2239
Budhu M, Adiyaman IB (2010) Mechanics of land subsidence due to groundwater pumping. Int J Numer Anal Methods Geomech 34(14):1459–1478
Burbey TJ (2002) The influence of faults in basin-fill deposits on land subsidence, Las Vegas, Valley, Nevada, USA. Hydrol J 10(5):525–538
Calderhead AI, Therrien R, Rivera A, Martel R, Garfias J (2011) Simulating pumping-induced regional land subsidence with the use of InSAR and field data in the Toluca Valley, Mexico. Adv Water Resour 34(1):83–97
Carnec C, Fabriol H (1999) Monitoring and Modeling land subsidence at the Cerro Prieto Geothermal field, Baja California, Mexico, using SAR interferometry. Geophys Res Lett 26(9):1211–1214
Cigna F, Osmanoglu B, Cabral-Cano E, Dixon TH, Avila-Olivera JA, Garduno-Monroy VH, DeMets C, Wdowiski S (2012) Monitoring land subsidence and its induced geological hazard with Synthetic Aperture Radar Interferometry: a case study in Morelia, Mexico. Remote Sens Environ 117:146–161
Dasarathy BV (1997) Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc IEEE 85(1):24–38
Dehghani M (2010) Estimation of deformation rate and modeling of land subsidence induced by groundwater exploitation using interferometry. Ph.D. thesis. K. N. Toosi University
Dehghani M, Valadan Zoej MJ, Saatchi S, Biggs J, Parsons B, Wright T (2009) Radar interferometry time series analysis of Mashhad subsidence. J Indian Soc Remote Sens 37(1):147–156
Dehghani M, Valadan Zoej MJ, Entezam I (2013) Neural network modeling of Tehran Land subsidence measured by Persistent Scatterer Interferometry. Photogrammetrie-Fernerkundung-Geoinformation 2013(1):5–17
Deng Z, Ke Y, Gong H, Li X, Li Z (2017) Land subsidence prediction in Beijing based on PS-InSAR technique and improved Grey-Marcov model. GISci Remote Sens 54(6):797–818
Ding XL, Liu GX, Li ZL, Chen YQ (2004) Ground subsidence monitoring in Hong Kong with Satellite SAR Interferometry. Photogramm Eng Remote Sens 10:1151–1156
Du Z, Ge L, Ng AHM, Li X, Li L (2018) Monitoring land deformation in Liulin district, China using InSAR approaches. Int J Dig Earth 11(3):264–283
Duan Q, Ajami NK, Gao X, Sorooshian S (2007) Multi-model ensemble hydrologic prediction using Bayesian model averaging. Adv Water Resour 30(5):1371–1386
Gambolati G, Teatini P, Ferronato M (2005) Anthropogenic land subsidence. Encycl Hydrol Sci 13:158
Gehlot S, Hanssen RF (2008) Monitoring and interpretation of urban land subsidence using radar interferometric time series and multi-source GIS database. In: Nayak S, Zelatanova S (eds) Remote sensing and GIS technologies for monitoring and prediction of disasters. Environmental science and engineering (Environmental Science). Springer, Berlin
Hall DL, Llinas J (1997) An introduction to multisensor data fusion. Proc IEEE 85(1):6–23
Jung HC, Kim SW, Jung HS, Min KD, Won JS (2007) Satellite observation of coal mining subsidence by Persistent Scatterer analysis. Eng Geol 92(1–2):1–13
Kim DK, Lee S, Oh HJ (2009) Prediction of ground subsidence in Samcheok City, Korea using artificial neural network and GIS. Environ Geol 58(1):61–70
Larose DT (2005) Introduction to data mining. In: Discovering knowledge in data. Wiley, New Jersey, pp 1–25
Lee S, Park I, Jk Choi (2012) Spatial prediction of ground subsidence susceptibility using an artificial neural network. Environ Manag 49(2):347–358
Lu Y, Ke CQ, Zhou X, Wang M, Lin H, Chen D, Jiang H (2018) Monitoring land deformation in Changzhou City (China) with multi-band InSAR datasets from 2006 to 2012. Int J Remote Sens 39(4):1151–1174
MacQueen J (1967) June. Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, vol 1(14), pp 281–297
Maghsoudi Y, Meer F, Hecker C, Perissin D, Saepuloh A (2018) Using PS-InSAR to detect surface deformation in geothermal areas of West Java in Indonesia. Int J Appl Earth Obs Geoinf 64:386–396
Motagh M, Walter TR, Sharifi MA, Fielding E, Schenk A, Andeson J, Zschau J (2008) Land subsidence in Iran caused by widespread water reservoir overexploitation. Geophys Res Lett. https://doi.org/10.1029/2008GL033814
Nadiri AA, Taheri Z, Khatibi R, Barzegari G, Dideban K (2018) Introducing a new framework for mapping subsidence vulnerability indices (SVIs): ALPRIFT. Sci Total Environ 628–628:1043–1057
Nakagawa H, Murakami M, Fujiwara S, Tobita M (2000) Land subsidence of the northern Kanto Plains caused by ground water extraction detected by JERS-1 SAR interferometry. Int Geosci Remote Sens Symp 5:2233–2235. https://doi.org/10.1109/IGARSS.2000.858366
Ng AHM, Ge L, Li X, Zhang K (2012) Monitoring ground deformation in Beijing, China with Persistent Scatterer SAR interferometry. J Geodesy 86(6):375–392
Ocak I, Seker SE (2013) Calculation of surface settlements caused by EPBM tunneling using artificial neural network, SVM, and Gaussian processes. Environ Earth Sci 70(3):1263–1276
O’Hagan M (1988) Aggregating template or rule antecedents in real-time expert systems with fuzzy set logic. In: Twenty-second Asilomar conference on signals, systems and computers, 1988, vol 2. IEEE, pp 681–689
Osmanoglu B, Dixon TH, Wdowinski S, Cabral-Cano E, Jiang Y (2011) Mexico City subsidence observed with persistent scatterer InSAR. Int J Appl Earth Obs Geoinf 13(1):1–12
Qu F, Zhang Q, Lu Z, Zhao C, Yang C, Zhang J (2014) Land subsidence and ground fissures in Xi’an, China 2005–2012 revealed by multi-band InSAR time series analysis. Remote Sens Environ 155:366–376
Rafie M, Samimi Namin F (2015) Prediction of subsidence risk by FMEA using artificial neural network and fuzzy inference system. Int J Min Sci Technol 25(4):655–663
Sadegh M, Kerachian R (2011) Water resources allocation using solution concepts of fuzzy cooperative games: fuzzy least core and fuzzy weak least core. Water Resour Manag 25(10):2543–2573
Sadegh M, Mahjouri N, Kerachian R (2010) Optimal inter-basin water allocation using crisp and fuzzy Shapley games. Water Resour Manag 24(10):2291–2310
See L, Abrahart RJ (2001) Multi-model data fusion for hydrological forecasting. Comput Geosci 27(8):987–994
Shu C, Burn DH (2004) Artificial neural network ensembles and their application in pooled flood frequency analysis. Water Resour Res. https://doi.org/10.1029/2003WR002816
Strozzi T, Teatini P, Tosi L, Wegmuller U, Warner C (2013) Land subsidence of natural transitional environments by satellite radar interferometry on artificial reflectors. J Geophys Res Earth Surf 118:1177–1191
Strozzi T, Caduff R, Wegmuller U, Raetzo H, Houser M (2017) Widespread surface subsidence measured with satellite SAR interferometry in the Swiss alpine range associated with the construction of the Gotthard Base Tunnel. Remote Sens Environ 190:1–12
Sun H, Zhang Q, Zhao C, Yang C, Sun Q, Chen W (2017) Monitoring land subsidence in the southern part of the lower Liaohe Plain, China with a multi-track PS-InSAR technique. Remote Sens Environ 188:73–84
Teatini P, Tosi L, Strozzi T, Ceccini G, Rosselli R, Libardo S (2012) Resolving land subsidence within the Venice Lagoon by Persistent Scatterer SAR Interferometry. Phys Chem Earth Parts A/B/C 40–41:72–79
Wu J, Hu F (2016) Monitoring ground subsidence along the Shanghai Maglev Zone using TerraSAR-X Images. IEEE Geosci Remote Sens Soc 14(1):117–121
Yager RR (1988) On ordered weighted averaging aggregation operators in multi criteria decision making. IEEE Trans Syst Man Cybern 18(1):183–190
Yager RR, Filev DP (1994) Parameterized AND-UKE and OR-LIKE OWA operators. Int J General Syst 22(3):297–316
Yue H, Liu G, Guo H, Li X, Kang Z, Wang R, Zhong X (2011) Coal mining induced land subsidence monitoring using multiband spaceborne differential interferometric synthetic aperture radar data. J Appl Remote Sens 5(1):053518. https://doi.org/10.1117/1.3571038
Acknowledgements
The authors would like to thank Dr. Maryam Dehghani for providing the dataset used in this study.
Author information
Authors and Affiliations
Corresponding author
Additional information
The original article has been updated to reflect the correct affiliations for the authors.
Rights and permissions
About this article

Cite this article
Taravatrooy, N., Nikoo, M.R., Sadegh, M. et al. A hybrid clustering-fusion methodology for land subsidence estimation. Nat Hazards 94, 905–926 (2018). https://doi.org/10.1007/s11069-018-3431-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-018-3431-8