
Abstract
Landslides are natural disasters often activated by interaction of different controlling environmental factors, especially in mountainous terrains. In this research, the landslide susceptibility map was developed for the Sarkhoun catchment using Index of Entropy (IoE) and Dempster–Shafer (DS) models. For this purpose, 344 landslides were mapped in GIS environment. 241 (70%) out of the landslides were selected for the modeling and the remaining (30%) were employed for validation of the models. Afterward, 10 landslide conditioning factor layers were prepared including land use, distance to drainage, slope gradient, altitude, lithology, distance to roads, distance to faults, slope aspect, Topography Wetness Index, and Stream Power Index. The relationship between the landslide conditioning factors and landslide inventory maps was determined using the IoE and DS models. In order to verify the models, the results were compared with validation landslide data not employed in training process of the models. Accordingly, Receiver Operating Characteristic (ROC) curves were applied, and Area Under the Curve (AUC) was calculated for the obtained susceptibility maps using the success (training data) and prediction (validation data) rate curves. The land use was found to be the most important factor in the study area. The AUC are 0.82, and 0.81 for success rates of the IoE, and DS models, respectively, while the prediction rates are 0.76 and 0.75. Therefore, the results of the IoE model are more accurate than the DS model. Furthermore, a satisfactory agreement is observed between the generated susceptibility maps by the models and true location of the landslides.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Mass movement and landslide are considered significant potential damaging natural hazards (Lee and Oh 2012). These movements occur under influence of natural and anthropogenic factors and their study is considered significantly important for assessment, prediction and zonation of potential landslides (Chen et al. 2016a, b). Landslide cause damage to various engineering structures, residential areas, vital resources, power lines, forests, rangelands, agricultural lands, mines and in consequence produces sediments and muddy floods resulting in filling of dams. In addition to economic and environmental effects created by occurrence of this phenomenon, social effects such as immigration and unemployment should not also be ignored (Conforti et al. 2014; Nourani et al. 2014; Friedl et al. 2015; Shirani 2017).
Landslide occurs annually in many countries such as Iran (Shirani 2017). Mountainous regions cover extensive parts of Iran and accordingly landslide is considered a natural hazard causing abundant life and property damages (ILWP 2007). Damages caused by mass movements in Iran were studied and expenses were estimated to be 10 billion dollars according to 4900 landslides occurred till September 2007 (ILWP 2007). According to adverse effects of landslides on natural resources, rural/urban residential areas and structures and also erosion of significant volume of soil, thus detection and zonation of potential lands and prediction of landslides are necessary to avoid this geohazard and also to develop controlling and inhibition methods (Tien Bui et al. 2015, 2016). Employing GIS as a principle interpretation tool associated with appropriate statistical models are very effective in landslide susceptibility zonation (van Westen 2000; Dai and Lee 2002). Generation of landslide susceptibility map is one of the main activities during this process (Ngadisih et al. 2016; Pourghasemi and Rossi 2017). Usage of data driven models for landslide susceptibility zonation and prediction with appropriate accuracy require three main basics. These principles are governed by three assumptions as follows (Guzzetti et al. 2005, 2012): (1) Landslide inventory map (according to this fact that past and present events are keys or guides for generalization and prediction of the future) (Varnes 1984; Guzzetti et al. 2005, 2012). (2) Appropriate selection of data or factors affecting the landslide (the data or factors must have significant effect on landslide occurrence and meanwhile, they should be independent of each other without any information overlap. and finally (3) selection of appropriate models for generation of landslide susceptibility zonation map (Cruden and Varnes 1996; Malamud et al. 2004; Gokceoglu and Sezer 2009; Guzzetti et al. 2005, 2012).
Of course, in spite of great progresses made in landslide hazard mapping, there still exist some limitations (van Westen et al. 2006). So far, different data driven approaches have been proposed for landslide susceptibility and hazard zonation. The methods are categorized into definitive (deterministic) and probabilistic (non-deterministic) (Yilmaz 2009). The non-deterministic methods are based on various heuristic, bivariate (Süzen and Doyuran 2004b; Yalcin 2008) and multivariate (Süzen and Doyuran 2004a; Akgun and Bulut 2007) statistical analyses and also probabilistic (Lee and Talib 2005; Lee and Pradhan 2007; Akgun et al. 2008) and knowledge based (Yesilnacar and Topal 2005; Falaschi et al. 2009) methods. Certainty Factor (CF) function (Lan et al. 2004) and Weight of Evidence (WoE) (Bonham-Carter 1994; Lee and Choi 2004; Zhu and Wang 2009; Pradhan et al. 2010; Pourghasemi et al. 2012a) are examples of bivariate methods, while Dempster–Shafer (DS) (governed by Bayesian theory) (Tangestani 2009; Park 2011; Althuwaynee et al. 2012; Mohammady et al. 2012; Pourghasemi et al. 2012b) and also Index of Entropy (IoE) Shanon model (Vlcko et al. 1980; Bednarik et al. 2010; Lee et al. 2012; Pourghasemi et al. 2012a; Sharma et al. 2012) are considered as probabilistic methods.
Nowadays, capability of various bivariate (Chen et al. 2014, 2015, 2017d; Rahmati et al. 2016; Ding et al. 2017; Hong et al. 2016, 2017), multivariate (Youssef et al. 2015; Chen et al. 2017d, f, h, i), probabilistic (Regmi et al. 2014a, b; Chen et al. 2015, 2016b, 2017b, c; Wang et al. 2015, 2016; Youssef et al. 2016), knowledge based (Chen et al. 2017a, e, g), IoE (Wang et al. 2015; Chen et al. 2017b, c; Hong et al. 2017; Naghibi et al. 2015; Tsangaratos et al. 2017) and DS methods (Chen et al. 2016b, 2017f; Hosseinpour et al. 2016; Wang et al. 2016; Jirousek and Shenoy 2017) for generation of landslide susceptibility maps are still assessed and compared with each other by the researchers.
DS and IoE theories are both important for uncertainty quantification of informational systems. DS theory was initially developed by Dempster employing upper and lower probabilistic concepts and then Shafer introduced it as a hypothesis. Existence of uncertainty makes evident differences of assessment and comparison between IoE and DS theories in natural systems. Reason for usage of DS model is its advantage for analysis of uncertainties with respect to conventional theories (Pourghasemi et al. 2012a; Chen et al. 2017f). Moreover, frequent examples of encounter with uncertainties in natural systems and also representation and combination of various evidences obtained from multiple sources are other advantages of this method (Pourghasemi et al. 2012a; Chen et al. 2017f). On the other hand, IoE approach is one of the significant means of uncertainty measurement in finite series of evidences by their probability distribution function. The inconsistency between the possible distribution of evidence sources can be determined through this model (Park 2011; Liu et al. 2015; Wang et al. 2016). According to the mentioned various advantages of the models, comparison between these models still needs to be studied. Assessment and comparison of the models can provide advantageous and valid results for the landslide susceptibility zonation of natural systems.
The Sarkhoon basin located in Chaharmahal and Bakhtiari province and the Zagros structural zone, holds specific environmental and active geological characteristics (Darvishzadeh 1991) make it susceptible to landslide occurrence. Different landslide susceptibility analysis methods examined in Iran have been mainly concentrated in north of the country associated with the Alborz structural zone. Therefore, the Sarkhoon basin was selected for the analysis and comparison of the statistical models according to different environmental and geological characteristics of the Zagros region with respect to the Alborz mountainous area. No zonation of landslides has been carried out for the basin and comparison between DS and IoE models were not also fully examined. Accordingly, the main objectives of this research are development, assessment and validation of landslide susceptibility map for the Sarkhoon basin through DS and IoE models employing landslide conditioning factors. The relative importance of the landslide conditioning factors was also examined.
2 Materials and methods
2.1 Study area
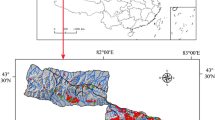
The study area with an approximate areal extent of 3293 km2 is located in the southwest of the Chaharmahal and Bakhtiari Province (N31°37′–31°51′; E50°25′–50°43′), Iran (Fig. 1). The main population center of the basin is Sarkhoun village located in central part of the basin. The area is heterogeneous regarding various climatic regimes and terrain complexity. The rainfall regime is inhomogeneous, with less frequent long periods of heavy rainfalls. The disastrous river flooding and abundant landslides occurring on slopes were resulted from very intense precipitation. The annual precipitation of the catchment is 600 mm, and the distribution of monthly precipitation is homogenous (Shirani 2017). According to 30 years of climatic measurements in the Sarkhoun catchment, February and August are, respectively, the coldest and hottest months with average temperatures of 2.3 and 27.6 °C, respectively (http://www.irimo.ir).

Landslides location on hill shaded map of the study area
The study area structurally occurs in High Zagros structural zone within the Zagros mountain range. The region mainly includes high mountains and deep valleys (with north-northwest and south-southwest trends). Relatively smooth morphology with relatively extensive plains only extend from central to southern part of the basin. Several secondary faults are distributed in the area created by action of the Zagros main thrust fault. The faults are mainly reverse or strike-slip. An irregular and rare folding influenced by the faulting is observed in the area. The basin is considered sub-basin of the Karoon basin with main stream of Sarkhoun river. The river is 35 km long and height of its upstream and downstream are 3383 and 1015 meters, respectively. The river route is northwest-southeast in trend (Shirani 2017).
The basin is relatively a residential (rural and nomadic) area and the main connection road between two important cities (Shahrekord and Ahwaz) also passes through this basin. Landslide occurrence is currently considered the main natural hazard in the basin due to its specific geological, climatological and geomorphological conditions and also human effects.
2.2 Methodology
As indicated in the flowchart (Fig. 2), the research was carried out in 5 stages: (1) collection and preparation of the required data including selection of the landslide conditioning factors (10 factors were selected), preparation of the landslides inventory map and division of the data into two groups (70% for training and 30% for validation) (2) providing a database containing generation and classification of landslide conditioning factor maps, preparation of geodatabase including landslide conditioning factors and the landslide inventory map (3) testing of conditional independence of the landslide conditioning factors by overlay of every landslide conditioning factor map on the landslide inventory map, calculation of CF approach, testing of conditional independence the landslide conditioning factors and multi-collinearity between the data (4) preparation of weighted maps by implementation of the models (DS and IoE) and generation of the landslide susceptibility map based on the models employing the landslide inventory map (70% of the data) (5) validation of the models and their comparison by means of the landside inventory map (30% of the data) and selection of the most appropriate landslide susceptibility map based on the Area Under Curve (AUC) related to curve of the Receiver Operating Characteristic (ROC).

Flowchart of the research methodology
2.2.1 Data collection and interpretation
The required data of the research was partly provided by existing information and maps prepared by organizations and another part was generated according to field investigations. The lithology and distance to fault factor maps were derived from the 1:100,000 geological map prepared by Geological Society of Iran (GSI) (http://www.gsi.ir/). The land use factor was extracted from the land use map prepared by Iranian Soil Conservation and Watershed Management Research Institute (https://www.scwmri.ac.ir). The LANDSAT-7 image archived by USGS with 30 meters spatial resolution for visual and 15 meters for panchromatic bands (https://earthexplorer.usgs.gov/) and also aerial photographs taken by Iranian National Cartographic Center (http://www.ncc.org.ir) were employed to generate precise maps of lithology, fault and land use factors. DEM-SRTM with 30 meters spatial resolution (http://dwtkns.com/srtm30m/) was used to derive altitude, slope gradient, slope aspect, drainage, TWI and SPI factor maps. The road factor map with 1:50,000 scale was obtained from National Geographic Organization of Iran (www.ngo-org.ir). The archive of landslides inventory map of Isfahan Agricultural and Natural Resources, Research and Education Center (http://esfahan.areeo.ac.ir/) associated with the Google Earth satellite images were used to prepare and complete the landslide inventory map. Google Earth pro 7.8, ENVI®5.3, ArcGIS®10.4 and also the ArcHydro®10.4 toolbox were employed to prepare and process the required data of the factors for landslide susceptibility assessment. SPSS®24 and Microsoft Excel®2016 were also used for the exploratory, statistical and validation analyses.
2.2.2 The landslide inventory map
Accuracy of the landslide occurrence data is very important for landslide susceptibility, hazard, and risk assessments. Accordingly, the first step in these analyses is landslide inventory mapping (Chen et al. 2016a, 2017c, d). The landslide inventory map displays characteristics and locations of landslides associated with past movements. Landslides are controlled by geological, topographical and climatic factors. Therefore, location and condition of future landslides can be predicted based on these factors. For this purpose, determination of accurate location and areal extent of landslides is prominent for preparation of landslide susceptibility maps (Yalcin 2008). Variety of sources, instruments and methods have been suggested for landslide mapping (van Westen et al. 2008) and the landslide susceptibility assessment is carried out in various phases as well. Identification and evaluation of landslide prone areas is an initial phase for preparation of an inventory landslide map. Various approaches such as field studies, interpretation of aerial photographs/satellite images, and also historical landslide records are used for landslide inventory mapping. Widespread mass movements occurred in the study area play a significant role in the landslide assessment.
344 landslides were identified and analyzed by field surveys, aerial photographs, and satellite images and then boundaries of the landslides were mapped. The research uses the landslide classification developed by Varnes (1978) and Hungr et al. (2014). Landslide types of the study area include 109 (32%) transitional slides, 99 (29%) rotational slides, 46 (13%) complex, 48 (14%) debris flows, and 41 (12%) surface landslide with a total areal extent of 17,699,977 m2 (Figs. 1 and 3). Transitional and rotational landslides are very common in the study area (Fig. 3a, b). The analysis on sizes of landslides shows that areal extents of the smallest and largest landslides are about 72.58 and 1,064,370 m2, respectively, with an average about 26,572.7 m2. Most landslides are shallow-seated. The areal extent of landslides was used to map the landslide susceptibility.

Photographs of different landslide types occurred in the study area, a the rotational, b the complex, c the surface, d the rockfall, e the debris flow, f the transitional
Geo-environmental features can be used as landslide conditioning factors to predict landslides occurrence in the future (van Westen et al. 2008). The conditioning factors are selected based on study area characteristics, analysis scale and type of landslides. The most common mentioned conditioning factors in the literature were used in the study to assess the landslide susceptibility. The dates of landslide occurrences are almost unknown. 241 landslides (70%) were randomly selected for implementation and 30% (103 landslides) were employed for validation of the model. The non-landslide points were randomly selected using ArcGIS®10.4 software. The number of non-landslide points is equal to that of landslide points, and they were randomly divided into two parts (70/30) for verification of the models. Afterward, the landslide susceptibility map of the Sarkhoun catchment was produced through the IoE and DS models and then it was validated by the ROC curve analysis.
2.2.3 Landslide conditioning factors
Different and various factors are decisive in landslide occurrence and subsequently preparation of landslide susceptibility map (Varnes 1984; Youssef et al. 2015). Some factors have triggering effect. These factors are classified into two major and secondary or subsequent groups (Varnes 1984; Guzzetti et al. 2005). According to the literature, these groups fall into 4 categories of geomorphological, geological, hydrological and anthropogenic (Varnes 1984; Youssef et al. 2015; Pourghasemi and Rossi 2017). Selection of landslide conditioning factors is a fundamental step in zonation and assessment of landslide susceptibility (Hong et al. 2017). In the literature, intrinsic factors of slope, slope aspect and lithology have been usually considered consistent with landslide susceptibility, while selection of other factors such as land use, road and drainage is under debate yet. Selection of landslide conditioning factors for every region depends on type of occurred landslides, geographical characteristics and the analysis techniques (Tien Bui et al. 2015, 2016; Hong et al. 2017). In various landslide susceptibility assessments, number of employed conditioning factors varies from few (Pradhan et al. 2010; Akgun et al. 2012; Tien Bui et al. 2015) to several (Catani et al. 2013; Dou et al. 2015; Meinhardt et al. 2015). Anyhow, consideration of several factors in a landslide susceptibility zonation model will not necessarily lead to high quality prediction results (Pradhan and Lee 2010; Hong et al. 2017). Sometimes, quality of results of models reduces with inclusion of noise factors (Tien Bui et al. 2015; Hong et al. 2017).
10 landslide conditioning factors were selected according to the literature, conditional independence test (Lee and Talib 2005; Xu et al. 2012a, b; Pradhan 2013; Jebur et al. 2014; Tien Bui et al. 2015; Chen et al. 2014, 2015, 2016b, 2017d; Hong et al. 2016, 2017; Kornejady et al. 2017; Pourghasemi and Rossi 2017), analysis of the recorded landslide inventory map and also geographical condition of the study area. The selected conditioning factors are frequently used for landslide susceptibility assessments (Pourghasemi and Rossi 2017). These factors include altitude, lithology, distance to fault, slope aspect, distance to road, distance to drainage, land use, slope gradient, TWI and SPI. The landslide conditioning factors (independent variables) are either categorical or numerical variables. Categorical variables (lithology and land use) were reclassified based on the related thematic information (Calvello and Ciurleo 2016; Chen et al. 2017c). The numerical variables with normal (altitude, slope aspect and TWI) and non-normal (slope gradient, distance to fault, distance to road, distance to drainage and SPI) distributions of pixel frequency were classified based on Natural Breaks and Geometrical Intervals classification methods, respectively (Pourghasemi et al. 2012b; Calvello and Ciurleo 2016; Chen et al. 2017c; Pourghasemi and Rossi 2017; Tsangaratos et al. 2017) through ArcGIS®10.4 environment. Natural Breaks algorithm of pixel frequency was used for the landslide susceptibility map generation because of normal distribution of the data.
Slope instability is directly affected by geomorphometric parameters and geomorphological processes. Therefore, six parameters (altitude, slope aspect, distance to drainage, slope gradient, TWI and SPI) out of all parameters were generated from the DEM map. DEM map of the study area was extracted from SRTM data (http://dwtkns.com/srtm30m) with 30 meters spatial resolution. The maps were prepared in the ArcGIS®10.4 environment.
Altitude is another parameter commonly employed in the landslide susceptibility analysis (Pachauri and Pant 1992). Landslides can situate within a specific relief range and the relative relief can be obtained from the altitude map. The altitude map was categorized into five categories of < 1500, 1500–2000, 2000–2500, 2500–3000 and > 3000 m (Fig. 4A).

The maps of landslide conditioning factors generated for the analysis of landslide susceptibility: A altitude; B lithology; C distance to faults; D slope aspect; E distance to road; F distance to drainage; G land use; H slope gradient; I Topography Wetness Index (TWI); J Stream Power Index (SPI)
Slope aspect is also a significant parameter for landslide susceptibility mapping (Yalcin 2008). This parameter actually implements some microclimatic factors such as sunlight exposure, wet or dry winds and rainfall intensity which all control material properties of slope aspect and cause difference in soil moisture and subsequently prepare suitable condition for slope instability (Yalcin 2008; Pourghasemi et al. 2012a; Pourghasemi and Rossi 2017). The slope aspect map was reclassified into 8 categories (Jebur et al., 2014; Wen and He 2012; Hong et al. 2017) including north (0°–22.5° and 337.5°–360°), northeast (22.5°–67.5°), east (67.5°–112.5°), southeast (112.5°–157.5°), south (157.5°–202.5°), southwest (202.5°–247.5°), west (247.5°–292.5°) and northwest (292.5°–337.5°) (Fig. 4D).
Slope gradient is a highly important factor affecting slope instability (Lee and Min 2001) and this parameter is often employed in assessment of landslide susceptibility (Anbalagan 1992; Yalcin 2008), because whatever slope gradient increases, shear stress increases too (Guillard and Zezere 2012). Slope gradient correlates with gravity. Therefore, landslide occurrence probability basically increases with increase in slope (He et al. 2012; Chen et al. 2015; Youssef et al. 2015). The slope gradient (in percentage) map was reclassified into 5 categories of 0–12, 12–25, 25–40, 40–70 and > 70% (Fig. 4H).
The drainages and rivers have significant role in slope instability especially in mountainous regions due to water flow and consequently outwash of embankments (Yalcin 2008; Pourghasemi et al. 2012b; Devkota et al. 2013; Chen et al. 2017c). Therefore, this factor was extracted from the DEM map through ArcGIS®10.4 environment. The map was reclassified into 5 category including 0–200, 200–500, 500–700, 700–1000 and > 1000 m classes (Fig. 4F).
TWI and SPI are both the most standard indices representing combinational effects of topography and hydrology of watersheds on either erosion or conservation of soils (Moore et al. 1991). The erosive power of running water flow is expressed by SPI index. The discharge is assumed proportional to specific catchment area (\(As\)) based on this index (Moore et al. 1991) and it is calculated as follows:
In equation, \(\sigma\) is slope angle (in degrees). SPI represents gravity force action on sediments and it is accordingly consistent with solid grains motion. It can increase slope instability in direction of the slope (Pourghasemi et al. 2012a; Regmi et al. 2014a). The SPI map was reclassified into 5 categories of 0–100, 100–200, 200–300, 300–400 and > 400 (Fig. 4I) in the ArcGIS®10.4 environment based on Eq. 1.
The Topography Wetness Index (TWI) implements effect of topography on size and location of saturated source areas of runoff initiation (Moore et al. 1991):
Uniform soil properties and steady state conditions are assumed for this index, \(a\) is cumulative upslope area which drains to a point (per unit contour length) and \(\sigma\) is slope angle (in degrees). TWI is function of actions of slope and flow direction. Therefore, this factor can also be significant in slope instability (Pourghasemi et al. 2012a; Regmi et al. 2014a). The TWI map was categorized into 5 classes of < 10, 10–15, 15–20, 20–25 and > 25 based on Eq. 2 in the ArcGIS®10.4 environment (Fig. 4K).
Slope stability is also influenced by changes in land use by human (Van Beek and Van Asch 2004; Lee and Sambath 2006; Yalcin 2008; Pourghasemi and Rossi 2017), hence, this parameter was considered in landslide susceptibility assessment. In order to increase precision of the land use factor map, map of various types of land use was prepared in the ENVI®5.3 environment by means of LANDSAT 7/ETM + image of 2002 and unsupervised classification (IsoData). 11 categories with classification precision of 87.5% were recognized through field visits and employing GPS. The categories include agricultural usage (agri), orchard and agriculture (orch-agri), orchard (orchard), mixing water farming (mix(dryfarming_x), mixing thin forest, mix(lowforest_x), thin forest (lowforest), semi-dense forest (modforest), woodland (woodland), poor rangeland (poorrange), semi-dense rangeland (midrange), rock outcrop (rock) and residential area (urban) (Fig. 4G).
Construction of roads in mountainous areas is another anthropogenic factor and it changes equilibrium of hillslopes. According to mountainous condition of the study area, construction of roads has been considered as another landslide condition factor (Pourghasemi et al. 2012b; Devkota et al. 2013; Chen et al. 2017c). The road map was prepared by means of the 1:50,000 topographic map produced by National Geographic Organization of Iran (www.ngo-org.ir). Geometry of the road layer has initially been line vector. The map was converted to distance to road map and then it was reclassified into 5 categories of 0–700, 700–1500, 1500–3000, 3000–4500 and > 4500 m in the ArcGIS®10.4 environment (Fig. 4E).
Various lithological units have different landslide susceptibility degree and lithology is considered the most significant parameter in landslide susceptibility assessments (Yesilnacar and Topal 2005). Geotechnical characteristics of various lithologies can affect slope instability in mountainous regions due to their mechanical specifications and different erosional actions (Yesilnacar and Topal 2005; Devkota et al. 2013). The lithological map was prepared using geological maps of Ardal and Dehdez in 1:100,000 scale provided by Geological Society of Iran (GSI) (http://www.gsi.ir/). The LANDSAT 7/ETM + image of 2002 was employed to correct boundaries of the lithological units. The required processing on the images including construction of false color composite images (7, 4 and 2 bands) with 2% linear enhancement was performed in ENVI®5.3 environment. The lithological map was reclassified into 11 categories including Jds (Jurassic dolomite and dolomitic limestone of Sormeh formation), Kldf (Cretaceous medium thickness limestone layers of Fahlian-Darian formation), Klk (Cretaceous shale and limestone of Kazhdoumi formation), Kmg (Cretaceous marl and limestone of Gourpi formation), Ksi (Cretaceous limestone with shale intercalations of Sarvak and Ilam formations), Mmm (Tertiary marl of Mishan formation), Mplsma (Tertiary sandstone and marl of Aghajari formation), Plcb (Tertiary conglomerate and sandstone), Edj (Tertiary stratified dolomite of Jahrom formation), Mmg (Tertiary marl and gypsum of Gachsaran formation) and Q (Quaternary alluvial deposits) (Fig. 4B).
Fault as a trigger factor also causes displacement, change of base level and slope instability especially in sloping area due to causing rupture in rock mass (Devkota et al. 2013; Conforti et al. 2014). Accordingly, line vector layer of faults was extracted by means of digital map of active faults of Iran prepared by Geological Society of Iran (GSI) (http://www.gsi.ir/). As geometry of the map was line vector layer, it was converted to the distance to fault map and then it was categorized into 5 classes of 0–500, 500–1500, 1500–2500, 2500–3500 and > 3500 m (Fig. 4C) in the ArcGIS®10.4 environment.
Finally, all the maps including landslide inventory map and layers of the landslide conditioning factors were converted into raster where necessary and then they were saved in a personal geodatabase with 30 × 30 pixel size for later processing. The division thresholds of every class and number of classes in the raster factor maps (distance to fault, distance to road, distance to drainage, altitude, TWI, SPI, slope gradient and slope aspect) are based on previous studies, probability distribution of pixel frequency of every map and considering geographical condition of the study area relative to the distribution of occurred landslides.
2.2.4 The independence analysis of landslide conditioning factors
Before employing landslide conditioning factors and their combination for the landslide susceptibility map preparation based on the models, it is required that the conditional independence between the employed data to be examined. If the data are conditionally independent, they can be used in the models. Various statistical tests are carried out to analyze correlation between landslide conditioning factors. Principal Component Analysis, pairwise comparison and logistic regression are examples of these tests (Lee and Choi 2004; Pradhan et al. 2010; Regmi et al. 2010). As the data or landslide conditioning factors are normally as well as non-normally distributed, therefore non-parametric statistical analyses of pairwise comparison (Chi-square) and multi-collinearity were used (Tsangaratos and Ilia 2016; Tsangaratos et al. 2017).
2.2.4.1 Chi-square test for conditional independence analysis
The non-parametric statistical analysis determines the conditional independence of conditioning factors based on pairwise comparison by Chi-square test (Pradhan et al. 2010; Regmi et al. 2010). For this purpose, all factor maps were initially analyzed and calculated based on the landslide inventory map, engineering judgement and weights calculated by overlay of the landslide inventory map on every map of landslide conditioning factors through CF approach (Lee and Choi 2004; Regmi et al. 2010). The weighted maps resulted from the CF approach were converted to binary maps (with 0 and 1 codes). For generating the binary patterns, code of 1 was assigned to classes of the factor maps containing positive weights representing presence of landslide occurrence and negative weights were assigned code of 0 for absence of landslide. The Chi-square among every pairwise binary factor (with 0 and 1 codes) was calculated with one freedom degree and 99% confidence level for all 10 factors with binary pattern through construction of 2 by 2 contingency tables according to presence (code of 1) and absence (code of 0) of landslide occurrence. The Chi-square values greater than the Chi-square theoretical value (6.64) indicate lack of significant difference. Therefore, the pairwise factors with correlation or absence of conditional independence should not be used with each other for preparation of landslide susceptibility map. The Chi-square values between factors were calculated by Eq. 3.
\({O_i}\) and \({E_i}\) are the observed and expected landslide frequencies in each class of binary factors, respectively (Regmi et al. 2010). For calculation of \({E_i}\), the marginal observed frequencies (horizontal and vertical rows of the contingency table) were multiplied by each other and then divided by the total landslide occurrences.
2.2.4.2 Multi-collinearity analysis
Multi-collinearity analysis estimates correlation between independent variables (Dormann et al. 2013; Tien Bui et al. 2015). Two important indices of Tolerance (TOL) and Variance Inflation Factor (VIF) are used for multi-collinearity analysis during implementation of the model (Marquardt 1970; Weisberg and Fox 2010; Tien Bui et al. 2015; Pourghasemi and Rossi 2017; Tsangaratos et al. 2017).
Although, there is no definite law for thresholds of TOL and VIF values for the analysis and estimation of multi-collinearity of landslide conditioning factors (Tsangaratos et al. 2017), but according to the literature, if VIF < 5 or 10 and TOL > 0.1 or 0.2, then there is no problem of collinearity and the variables are independent (Menard 2002; O’brien 2007; Van Den Eeckhaut et al. 2006, 2010; Guns and Vanacker 2012; Schicker and Moon 2012; Tsangaratos and Ilia 2016; Hong et al. 2017; Pourghasemi and Rossi 2017).
2.2.5 Certainty Factor model
In this research, CF model was used as a bivariate statistical analysis to evaluate correlation between landslides and the different conditioning factors. The calculated weights by this model were also used for preparation and conversion of landslide conditioning factor maps into binary maps (0 and 1 for classes with negative and positive weights, respectively) in order to implement conditional independence analysis.
CF is one of the favorable functions for management of input variables uncertainty in rule based systems and usage of heterogeneous data (Chung and Fabbri 1993; Pourghasemi and Rossi 2017). Among bivariate statistical methods, CF approach performs more precisely (Chung and Fabbri 1993; Binaghi et al. 1998; Luzi and Pergalani 1999). This model resolves combination problem of heterogeneous data layers. The manner of integrating maps into the model is the main difference between this model and other bivariate models. In this method, maps are initially classified and then weight of every pixel is obtained from Eq. 4:
\({\text{PPa}}\) is ratio of number of landslide pixels in a class to total pixels of that class. \({\text{PPs}}\) is ratio of total landslide pixels of the area to total pixels of the map. Each class is quantified between − 1 and +1 by means of this formula. If value of the class is positive, it indicates that landslide occurrence certainty is high while, the value is negative, it means that certainty of landslide occurrence is low. If value of that class is zero, it means that enough information does not exist for the variable and there is uncertainty in landslide occurrence. The 10 factors were weighted as independent variables for analysis of correlation between landslide conditioning factors using the CF approach. Then CF is implemented in the modified linear regression as dependent variable for multi-collinearity test.
2.2.6 Dempster–Shafer model
A discernment frame can be examined according to the DS evidence theory for the landslide susceptibility analysis (Dempster 1967; Shafer 1976; Mohammady et al. 2012):
where \({T_P}\) is the target to be affected by future landslides at pixel \(P\) and \({\bar T_P}\) is opposite target proposition will not be influenced by future landslides at each pixel \(P\) (Park 2011).
This model is a generalized form of Bayesian probabilistic theory (Wang et al. 2016). Advantage of this model is its capability in combining beliefs from several conditioning factors and its relative flexibility in consideration of uncertainty (Bui et al. 2012; Wang et al. 2016).
For landslide susceptibility analysis, the DS theory defines mass functions using relationships between input conditioning factors and the known landslides. In this study, susceptibility analysis and likelihood ratio functions were used to calculate the mass function to distinguish susceptible and non-susceptible regions. The ratio of susceptible and non-susceptible functions can emphasize on their contrast. When multiple spatial data layers exist in the region, each data layer is selected as evidence \({B_i}\) (\(i\) = 1, 2, …, \(l\)) for the proposed target \({T_P}\). The likelihood ratio \(\lambda \left( {T_P} \right){B_{ij}}\) for verification of the proposed positive target is as follows (Park 2011; Pourghasemi et al. 2012b):
where \({B_{ij}}\) is the \(j{\text{th}}\) attribute class of the evidence \({B_i}\) and \(N\left( {A \cap {B_{ij}}} \right)\) is the number of landslide pixels occurred in \({B_{ij}}\), \(N\left( {{B_{ij}}} \right)\) is density of pixels in \({B_{ij}}\), \(N\left( A \right)\) is total number of landslides happened in the study area, and \(N\left( C \right)\) is number of pixels in the whole study area \(C\). The numerator is the ratio of landslides occurred in the attribute \({B_{ij}}\) and the denominator is the ratio of non-susceptible areas in this attribute. Consequently, the likelihood ratio to support proposition of the opposite target is as follow:
The numerator and denominator are ratios of non-susceptible and susceptible regions for the attribute \({B_{ij}}\). All likelihood ratio values of class attributes of the evidence \({B_i}\) divide the likelihood ratios to meet the standardization condition (Eq. 7), and also to consider relative importance within the class attribute (Park 2011):
The belief function for supporting the positive target preposition is obtained from the mass function \(m{\left( {T_P} \right)_{{B_{ij}}}}\) based on Eq. 9. \(1 - m{\left( {T_P} \right)_{{B_{ij}}}}\) can be used to compute the plausibility function. The constraints related to occurrence of landslide are applied separately to define the belief and plausibility functions based on the likelihood ratio functions.
As Dempster–Shafer theory is the basis of evidence function estimation (Liu et al. 2015), therefore this model is a combination of belief, disbelief, uncertainty and plausibility functions and they range from 0 to 1 (Amiri et al. 2014). Upper and lower boundaries of probability are belief (equivalent to mass function, \(m{\left( {{{\bar T}_P}} \right)_{{B_{ij}}}}\)) and plausibility, respectively (Althuwaynee et al. 2012; Wang et al. 2016). Uncertainty function \(m{\left( \theta \right)_{{B_{ij}}}}\) (Eq. 11) is difference between belief and plausibility. Disbelief function (Eq. 10) is belief to lack of correctness based on existing evidences (Awasthi and Chauhan 2011; Althuwaynee et al. 2012; Bui et al. 2012) which results from plausibility difference from 1. Therefore, summation of belief, disbelief and uncertainty function values equals 1 (Wang et al. 2016).
No belief in the proposed target (i.e., \(m{({T_P})_{{B_{ij}}}} = 0\)) is when landslides have not occurred in the attribute \({B_{ij}}\). Anyhow there is uncertainty in the landslide studies and this does not mean disbelief in its complement \(m{\left( {{{\bar T}_P}} \right)_{{B_{ij}}}}\). Therefore, \(m{\left( {{{\bar T}_P}} \right)_{{B_{ij}}}}\) and consequently \(m{\left( \theta \right)_{{B_{ij}}}}\) are set to 0 and 1, respectively. Landslide occurrences are related to the second complementary constraint. In some cases, such as flat areas, the first constraint cannot be directly employed. In this situation, landslides cannot occur (zero slope) and there is no belief in \(m{\left( {T_P} \right)_{{B_{ij}}}}\). The disbelief and \(m{\left( \theta \right)_{{B_{ij}}}}\) are set 0 and 1 based on the first constraint, but the disbelief should be set to 1 based on the second constraint. Therefore, \(m{\left( {T_P} \right)_{{B_{ij}}}}\) and \(m{\left( \theta \right)_{{B_{ij}}}}\) are considered 0, and \(m{\left( {{{\bar T}_P}} \right)_{{B_{ij}}}}\) is 1 in flat areas (Park 2011).
As DS model is generalized form of Bayesian theory, therefore natural logarithm of probability ratio (\(\lambda \left( {T_P} \right){B_{ij}}\)) and its opposite (\(\lambda \left( {T_P} \right){B_{ij}}\)) are equivalent to positive and negative weights, respectively, in Weight of Evidence (WoE) model (another modified method of Bayesian theory) (Bonham-Carter 1994; Park 2011).
Consequently, the sum of logarithms of the likelihood ratio (Eq. 6) and opposite target (Eq. 7) is equivalent to the final weight of the WoE model. Therefore, they can be used as alternatives for verification of weights calculated by this model to prepare and convert the landslide conditioning factor maps into binary maps (negative and positive weighted classes equal with 0 and 1, respectively). We can also use them in order to implement the conditional independence test.
The landslide susceptibility map of the study area was eventually calculated based on implementation of the DS model and weighting of landslide conditioning factors and also algebraic summation of belief function values (Eq. 12). All the landslide conditioning factors were calculated in the ArcGIS®10.4 environment.
where \({\text{LSI}}({\text{DS}})\) is landslide susceptibility index for DS model and \({({\text{Bel}})_{ij}}\) is belief value of class \(i\) in parameter \(j\), and \(n\) is number of variables.
2.2.7 Index of Entropy model
The entropy computed based on Shannon (1948) considers the frequency of various categories of each factor and thereby highly reduces their unevenness and provides a practical and realistic metric of their influence on landslide susceptibility. The entropy based on Shannon (1948) is an uncertainty measure associated with a random variable, representing the system information content. Imbalance, disorder, uncertainty and instability of a system is determined based on entropy (Yufeng and Fengxiang 2009). A one-to-one relationship exists between the disorder degree of a system and the entropy. Thermodynamic status of a system is described based on the Boltzmann principle (Yufeng and Fengxiang 2009). The IoE model for information theory has developed by Shannon (1948) as an improvement upon the Boltzmann principle. The weight index of natural hazards is mostly determined on the basis of the information entropy method for the natural processes analysis (Mon et al. 1994; Yi and Shi 1994). IoE model can be employed to describe and measure landslide, because it is a complex system exchanging energy and materials with the environment (Yang and Qiao 2009). The influence of different factors on development of a landslide is determined by its entropy. Few significant factors create extra entropy in the index system. Objective weights of the index system can be calculated by entropy value (Yang and Qiao 2009). The information coefficient \({W_j}\) (weight of the parameter) is calculated as follows (Bednarik et al. 2010; Constantin et al. 2011):
where \(a\) is the domain percentage and \(b\) is the landslide percentage, \({S_j}\) is number of classes, \({P_{ij}}\) is the probability density.
In Eqs. 15 and 16, \({H_j}\) and \({H_{j\hbox{max} }}\) are the entropy values.
In Eq. 17, \({I_j}\) represents the information coefficient and varies from 0 to 1.
where \({W_j}\) is the resultant weight value of the parameter.
The major advantage of the theory by Shannon (1948) is its non-parametric nature. No assumption is required for distribution of variables or conditioning factors (Chen et al. 2017c). It does not also presume a linear model for relationship between independent and dependent variables. Hence, most landslide conditioning factors are selectable by the model and also their relative prominence can be determined for landslide susceptibility assessment (Pourghasemi et al. 2012a).
The landslide susceptibility map of the study area was calculated based on implementation of the IoE model through weighting of factor classes and algebraic summation of weight values (Eq. 19) of all the landslide conditioning factors in the ArcGIS®10.4 environment.
where \({\text{LSI}}({\text{IoE}})\) is landslide susceptibility index for IoE model; \(i\) is the number of landslide conditioning factor maps; \({\text{RCL}}{{\text{S}}_{ij}}\) is the weight value of class \(i\) in factor \(j\) after reclassification; and \({W_j}\) is the weight of factor \(j\) (Devkota et al. 2013).
2.2.8 Validation of the models
Validation of the employed models is necessary for landslide susceptibility map analysis. The spatial landslide data of training (for implementation of the model and analysis of success rate) and testing (for validation and analysis of prediction rate) are the basis of validation of landslide susceptibility zonation maps (Chung and Fabbri 2003, 2008; Akgun et al. 2012; Ozdemir and Altural 2013; Youssef et al. 2015; Su et al. 2015; Chen et al. 2016a, b; Fabbri and Chung 2016; Tien Bui et al. 2016; Chen et al. 2017c, d, g, h). More landslides are used for implementation and validation, the better results are obtained (Chung and Fabbri 2003, 2008; Fabbri and Chung 2016).
The Relative (Receiver) Operation Characteristic (ROC) Curve is a useful tool for displaying definite and probable identification quality as well as system forecasting (Swets 1998; Maier and Dandy 2000; Fawcett 2006; Akgun et al. 2012; Ozdemir and Altural 2013). The area under the curve (AUC) indicates predictive quality of the system by describing its ability to accurately predict the presence or absence of predetermined events (Youssef et al. 2015b; Tien Bui et al. 2015, 2016). ROC curve represents sensitivity of the model to percentage of cells. Unstable units are correctly predicted by the model versus the percentage of predicted unstable cells relative to the total (Fabbri and Chung 2016; Tien Bui et al. 2016; Chen et al. 2017a, c, d). The values express the model ability to correctly distinguish between positive and negative observations in the validation sample. In the AUC, false (1 − Specificity) (Eq. 20) and true (Sensitivity) (Eq. 21) positive rates are displayed (Komac 2006; Constantin et al. 2011; Youssef et al. 2015).
In Eqs. 20 and 21, TP and TN stand for true positive and negative rates, respectively, while FP and FN represent false positive and negative rates. Qualitative-quantitative correlation between the curve and estimation assessment is as follows: excellent (0.9–1), very good (0.8–0.9), good (0.7–0.8), moderate (0.6–0.7), and poor (0.5–0.6) (Yesilnacar and Topal 2005; Zhu and Wang 2009). The AUC of ROC reliably determines quality of probabilistic model for either presence or absence of landslide (Youssef et al. 2015; Chen et al. 2017c).
241 (70%) out of 344 landslides were randomly selected as training data for implementation of the models and 103 (%30) remaining landslides were used for the validation. In order to calculate the ROC curve, the absence (stable) points were extracted equivalent to presence (unstable) points (testing and training landslides). The extraction has been carried out through Random Points algorithm in the ArcGIS®10.4 environment. The Area Under Curve was calculated for the success and prediction rates by both IoE and DS models.
3 Results and discussion
3.1 Results of independence test and multi-collinearity between landslide conditioning factors
3.1.1 Chi-square test
Pairwise comparison for determination of conditional independence between landslide conditioning factors (independent variables) was examined based on the Chi-square test (Table 1). 45 possible pairs of the landslide conditioning factors were tested for pairwise comparison. The Chi-square values of all pairs (Table 1) are lower than the theoretical Chi-square value (6.64) tabulated in standard Chi-square tables. The conditional independence between every conditioning pair was determined in 0.01 confidence level and one freedom degree. The highest Chi-square pair values are 6.35, 6.01, 4.07, 3.79, 3.78, 2.83 and 2.55 for Alt–Rod, Asp–Lus, Slp–Spi, Lus–Rod, Alt–Lus, Asp–Slp, Alt–Flt, respectively, and the remaining pairs are lower than 2. All values are lower than the theoretical standard Chi-square value (6.64) with one degree of freedom. Therefore, the selected landslide conditioning factors are independent of each other and they can be employed for preparation of landslide susceptibility maps by DS and IoE models.
3.1.2 Multi-collinearity test
Results of the multi-collinearity test between landslide conditioning factors with 99% confidence level are mentioned in Table 2. There is no collinearity between independent factors based on the maximum VIF (1.831) and the minimum of TOL (0.546). All VIF values of the independent factors are lower than the theoretical critical value (5 or 10) and all the TOL values of independent factors were also calculated greater than the theoretical critical value (0.1 or 0.2). The maximum and minimum values of VIF are 1.8 and 1.01, respectively, and subsequently the lowest and highest tolerances are 0.546 and 0.989 pertinent to altitude and TWI factors, respectively.
3.2 Results of CF approach and the spatial correlation between landslides and landslide conditioning factors
Identification of effective factors on landslide occurrence is the most important step in the landslide susceptibility zonation. 10 landslide conditioning factors were used for landslide susceptibility assessment in the study area namely altitude, slope aspect, distance to drainage, distance to fault, distance to road, slope gradient, lithology, land use, TWI and SPI. The spatial correlation between landslide occurrence density and every landslide conditioning factor categories was calculated using CF approach (Table 3 and Fig. 5). According to Table 3 and Fig. 5, CF is 0.37 and 0.04 for the altitude categories of < 1500 and 2000–2500 m based on landslide occurrence density and it is negative for other altitude categories. For slope aspect, the northwest, west, southwest and north with CF values of 0.37, 0.26, 0.21, and 0.08 have positive correlation and subsequently the highest frequency of landslide occurence. While the remaining categories show negative correlation. The analysis of relationship between distance to drainage and landslide density indicates inverse correlation with the CF values. This means that the CF decreases with increase in distance to drainage. The highest CF values for distance to drainage are related to 0–200 m (0.19) and 200–500 m (0.14) categories. Similar to trend of distance to fault, the highest CF value is for < 500 m category. This means that the CF with 0.2 value is positively correlated with < 500 m category of distance to fault and it is negatively correlated with distance to fault for the other classes. For distance to road categories, the highest CF values are for 0–700 and 700–1500 m categories with 0.1 and 0.07 values, respectively. The CF value generally decreases with distance to road and this factor is negatively correlated with the CF values the same as distance to drainage and distance to fault factors. In other words, the landslide frequency decreases with increase in distance to the linear features. For the slope gradient higher then 40%, the CF value is positive (0.17, and 0.41 for 40–70, and > 70% categories, respectively) representing a high probability of landslide occurrence. In contrast, the other classes have negative CF values indicating a lower landslide probability. For lithology, categories of Mmm, Kmg, and Mplasma have Cf values of 0.066, 0.17, and 0.12, respectively, and they have the highest landslide frequency. The remaining categories have lower frequency or negative values. Among the 12 land use categories, the highest CF values are for poorrange (poor rangelands with 0.64 value), agri (water agricultural lands with 0.47 value) and rock (rock outcrops with 0.44 value) and the remaining categories have lower frequency or are negatively correlated. The CF values of hydro-geomorphometric factors (TWI and SPI) are negatively correlated with similar trends. The highest value of CF for TWI factor is for < 10 (0.17) and 10–15 (0.09) categories and they are negatively correlated. The CF value is negative for > 15 category. The CF values of SPI factor for categories lower than 300 (0–100, 100–200 and 200–300) are 0.23, 0.22 and 0.03, respectively, with positive correlation but reversal trend. The CF values are negative for the SPI greater than 300 keeping reversal trend. In general, the altitude categories of < 1500 and 2000–2500 m, geographical azimuthal direction categories of southwest, west, northwest and north, for distance to drainage categories lower than 500 m (0–200 and 200–500 m), < 500 m category of distance to fault, distance to road categories lower than 1500 m (0–700 m, 700–1500 m), slope gradient categories higher than 40% (40–70 and > 70%), lithology categories of Mmm, Kmg, Mplasma, Plcb and Jds, land use categories of poorrange, agri, rock and mix (lowforest-x), TWI categories lower than 15 (0–10, 10–15) and SPI categories lower than 300 (0–100, 100–200 and 200–300) have positive effect on the landslide frequency and remaining categories of the factors have negative effect. The relative importance of landslide conditioning factor categories is also verified after implementation of IoE and DS models (Table 3).

CF values for the landslide conditioning factor classes
3.3 Index of Entropy application
Every class of the landslide conditioning factors was represented by a specific landslide occurrence density (\({P_{ij}}\)) according to the result of the bivariate analysis (Eq. 13 and Table 3). The prominent factors influencing the distribution of landslides were extracted and presented in Table 3. The results of IoE model indicate that land use, and distance to drainage are the most significant landslide conditioning factors.
The landslide susceptibility map has been generated using IoE model (Fig. 6b). As the most important advantage of IoE model is determination of the most effective variables in landslide occurrence, accordingly the relative prominence of landslide conditioning factors was determined through implementation of IoE model. The calculated weights (Wj) (Table 3) indicate that the most significant landslide conditioning factors are land use (0.326) and distance to drainage (0.269). The other influencing factors including slope gradient (0.254), altitude (0.248), SPI (0.225), lithology (0.222), TWI (0.195), distance to road (0.186), distance to fault (0.185) and slope aspect (0.012) are of lower importance, respectively. According to the landslide frequency of every category (Pij), the altitude categories of < 1500 and 2000–2500 m are the most susceptible to landslide, respectively. Slope aspect categories of northwest, west, southwest and north have the most landslide frequency, respectively. According to Table 3, the landslide frequency decreases with getting away from linear features (drainage, fault and road). The highest landslide frequency is for Mmm, Kmg and Mplsma lithologies, respectively. For land use, the poor rangeland is the most susceptible to landslide category (landslide frequency of 3.115) and agricultural land use (2.007) and then rock outcrops (1.85) categories are in the next orders. The landslide frequency increases with slope gradient. Eventually, the susceptibility to landslide decreases with increase in the landslide frequency of TWI and SPI factors. The results of class weights of the landslide conditioning factors produced by the implementation of IoE model are completely consistent with the results of the CF approach.

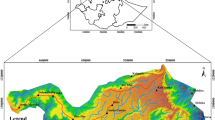
The generated landslide susceptibility maps by a IoE and b DS models
Weighted products of the secondary parametric maps were summed to generate the eventual landslide susceptibility map (Fig. 4). Applying the IoE model, the final landslide susceptibility map was generated using the following equation:
where YIoE is the landslide susceptibility employing the IoE model.
The final calculated LSM of the IoE model ranges from 3.187 to 13.931. These values were normalized between 0 and 1. The interval was reclassified into five classes (very low, low, moderate, high and very high susceptibility classes) by the Natural Breaks classification method and the susceptibility map was generated (Fig. 6a).
3.4 Dempster–Shafer model application
DS model was employed to calculate the Landslide Susceptibility Index (LSI). The occurrence of pixels was used to calculate DS values. The results of DS analysis to examine spatial relationship between landslides and the conditioning factors are presented in Table 3. Mass functions \(m\left( {T_P} \right)\), \(M\left( {{{\bar T}_P}} \right)\) and \(m\left( \varTheta \right)\) were calculated for belief, disbelief, and plausibility functions, respectively, based on Eqs. 9, 10, and 11 (Table 3).
The correlation between landslide conditioning factor categories and landslide occurrence depends on belief function. Whatever the belief function is higher, relationship between categories of landslide conditioning factors with the landslide occurrence is stronger and subsequently probability of the landslide occurrence would be higher too (Wang et al. 2016). The higher belief function in the class results in the lower amounts of disbelief and plausibility functions. As it is observable in Table 3, the altitude factor categories of < 1500 and 2000–2500 m have the highest belief and subsequently the lowest disbelief with respect to other categories. The slope aspect categories of northwest, west, southwest and north have the most belief value and thus the lowest disbelief, respectively. For distance to linear features (drainage, fault and road), the belief function reduces and subsequently the disbelief function increases with increase of distance to these features. The Mmm, Mplsma, and Kmg lithological units have the highest belief (the lowest disbelief), respectively. For land use, the poor rangeland, agricultural land use and then rock outcrops have the highest belief function values (the least disbelief values) among other land use factor categories. If the slope gradient increases, amount of the belief function increases too and the disbelief function conversely decreases. With increase in TWI and SPI, the belief function decreases and the disbelief function increases. In general, the results of weighting functions produced by implementation of the DS model as well as IoE model are completely associated with the theoretical results of correlation between the categories of landslide conditioning factors and also the true landslide occurrences.
Employing the DS model (Table 3), the final landslide susceptibility map was generated using the following equation:
YDS is the landslide susceptibility calculated by the DS model.
The final calculated LSM of the DS model varies from 0.9 to 2.79. These values were normalized between 0 and 1. The interval was reclassified into five classes (very low, low, moderate, high and very high susceptibility classes) by the Natural Breaks classification method and the susceptibility map was generated (Fig. 6b).
3.5 Landslide susceptibility mapping
The estimated landslide susceptibility map relies on scale, completeness and accuracy of the landslide inventory map and also maps of different landslide conditioning factors. The higher accuracy is usually dependent on larger scale (i.e., 1:50,000 scale). The landslide susceptibility maps were produced by the IoE and DS models (Fig. 6a, b) employing limited input conditioning factors such as land use, lithology, altitude, slope gradient, slope aspect, TWI and SPI, and proximity to lineaments (drainage, fault and road). The maps include very low, low, moderate, high, and very high classes. The areal extents of the classes were found to be 12.39, 27.24, 30.32, 23.21 and 6.84% for the IoE model, whereas 8.55% of the study area is very low susceptible to landslide and 24.03, 33.11, 25.54 and 8.77% of the study area are covered by the low, moderate, high, and very high landslide susceptibility zones, respectively, based on the DS model.
The low landslide occurrence areas are located in north to northwest of the basin and its surrounding parts conform with very low to low susceptible zones distinguished by both DS and IoE models (Fig. 6a, b). The zones have very low to low landslide susceptibility despite relatively high slope gradient (15–40%) and high altitude of greater than 2500 m. But the central to southern regions and margin of the main river of the basin (Sarkhoun river) which have high landslide occurrence, relatively low slope gradient (lower than 25%) and also altitude lower than 2500 m, conform with high to very high susceptible zones. The both results can be interpreted according to linear features (drainage, road and fault) density and type of lithological units. Surrounding the basin especially the northern part which adapts with relatively high altitude and slopes gradient, fall into very low to low susceptible to landslide zone because of rocky outcrops and being away to linear features and also occurrence of dense forests and rangelands. The high to very high susceptible zones were developed in central and southern parts which conform with very dense linear features and loose rock units (Mmm, Mplasma and Kmg with marl and shale lithologies).
3.6 The susceptibility maps verification
Models of landslide prediction are not valid without verification of their results (Chung and Fabbri 2003, 2008; Beguería 2006; Chen et al. 2017c). The landslide susceptibility model should be verified using information not employed for construction of the model.
Accordingly, the landslide susceptibility maps generated by IoE and DS models were validated by ROC and SCAI curves (Figs. 7, 8, 9). The success and prediction rates were obtained for the models based on the training (70% of landslides) and testing (30% of landslides) data (Fig. 1). The AUC-ROC curves were calculated as 0.75 and 0.81 for prediction rates of the DS and IoE models, respectively. In addition, they were also calculated as 0.76 and 0.82 for success rates of the models, respectively. The success and prediction rates indicate that both landslide susceptibility zonation models are valid at good and very good levels (Table 4) (Yesilnacar and Topal 2005). The ROC curve of the IoE model indicates a more rapid increase at the initial stages compared to the DS model (Fig. 7). This reveals relatively high sensitivity of the IoE model. The prediction rates (0.01) are slightly lower than success rate values of the models (Table 4). It indicates that probability of the expected is lower than the observed. But effect of landslide frequencies of training and testing datasets should not be ignored (Fabbri and Chung 2003, 2016).

The Receiver Operation Characteristic Curves (ROC) indicating success and prediction rates of the susceptibility maps

Plots of FR of the landslide susceptibility zones

SCAI plots of the landslide susceptibility zones
Other researchers have also concluded higher capability of IoE model with respect to other models such as WoE, logistic regression, Frequency Ratio (FR) and CF (Pourghasemi et al. 2012a; Devkota et al., 2013; Wang et al. 2015; Hong et al. 2016; Youssef et al. 2016; Chen et al. 2017c). Youssef et al. (2016) have calculated success and prediction rates of 0.80 and 0.95, respectively, for their IoE model. While their DS model has success and prediction rates of 0.78 rate of 0.93, respectively. The results of AUC-ROC curve produced from success and prediction rates of both models also agree with investigations by others (Althuwaynee et al. 2012; Mohammady et al. 2012; Regmi et al. 2014a; Wang et al. 2016; Youssef et al. 2016; Chen et al. 2017b, c, d; Hong et al. 2017). Results of the models also show good agreement with the results of Youssef et al. (2016), especially in priority of the success and prediction rates.
The IoE model was evaluated suitable for prediction of landslide susceptibility map because the success and prediction rates of the AUC-ROC are both higher than 0.8 and they are also 0.06 higher than the success and prediction rates of the DS model (Table 4).
In the second stage, the generated susceptibility maps were compared on the basis of the landslide susceptibility zones. FR (Fig. 8; Table 5) and Seed Cell Area Index (SCAI) (Fig. 9; Table 5) analyses (Süzen and Doyuran 2004a, b; Bui et al. 2011a, b) were performed on the classification results (Figs. 8, 9; Table 5).
FR of every class can be obtained through dividing the occurred landslide areal extent in every susceptibility class by landslide susceptibility class area. SCAI is landslide density in every landslide susceptibility class and it is calculated by dividing percentage of every landslide susceptibility class area by seed cell percentage. SCAI and FR of each landslide class can also confirm the ROC results. The FR increases and subsequently SCAI decreases according to the existing logical relationship between landslide area and susceptibility zones from very low to very high susceptibility potentials (Akgun et al. 2012; Pourghasemi et al. 2012a; Sdao et al. 2013; Conforti et al. 2014). In order to evaluate precision of landslide susceptibility classification by the models, the FR was calculated (Table 5; Fig. 8). The FR values of susceptibility classes for the IoE and DS models are very low (0.63 and 0.39), low (2.44 and 2.15), moderate (4.36 and 4.07), high (9.41 and 8.02) and very high (16.41 and 16.31) susceptible zones.
Results of comparison of the models indicate that with increase in landslide susceptibility from very low to very high, the FR shows an increasing trend (Fig. 5). But for the IoE model, gradient of the FR curve is higher than the DS model from the medium to very high susceptibility classes. In fact, separation of landslide susceptibility classes based on the IoE model is better than the DS model. According to Table 5, the SCAI values for IoE and DS models are very low (6.57 and 6.73), low (3.71 and 3.46), moderate (2.31 and 2.52), high (0.82 and 0.99) and very high (0.14 and 0.17) susceptible zones. The results of assessment and comparison of the models indicate that with increase in landslide susceptibility from very low to very high, the SCAI values show decreasing trend (Fig. 9). But in the IoE model, the SCAI values show a specific regular decreasing trend from very low to very high, while for the DS model, they show irregular decreasing trend (between low to high susceptibilities). Accordingly, the SCAI diagram of the IoE model shows more uniform decreasing trend with respect to the DS model. Hence, the landslide susceptibility classification by the IoE model is more reliable (Figs. 9). If trend of the FR curve is only considered for classification of landslide susceptibility, no obvious difference is observed between the models (Table 5; Fig. 8). But separation of the IoE classification was found to be more suitable with respect to the DS model according to the trends of both SCAI and FR curves (Table 5; Figs. 8 and 9). Therefore, it is required to use both SCAI and FR to obtain better separation for the models classification.
4 Conclusion
Nowadays, assessment of landslide susceptibility is highly important for planning and management of potentially susceptible areas. Researchers try to find and apply easy, user friendly and understandable models capable of generating results more compatible with landslide occurrences. The models should provide predictions close to reality for landslide susceptible zones.
In this research, applicability of IoE and DS models were evaluated for landslide susceptibility prediction in the Sarkhoun basin. According to high occurrence of landslides in southwest part of Iran and especially in the study area, generation of landslide susceptibility map by models with the above mentioned capabilities is necessary. For this purpose, 10 landslide conditioning factors were selected for the analysis. The CF approach was employed to analyze correlation of the conditioning factors with landslide occurrences. According to Chi-square test, no pairwise was higher than the standard Chi-square value with 99% confidence level and one degree of freedom. In addition, the landslide conditioning factors were significantly estimated lower than the reported thresholds based on multi-collinearity. Therefore, the selected factors are conditionally independent and applicable as conditioning factors in the IoE and DS models.
344 landslides were identified which 70% out of them were used for the modeling and 30% were selected for the validation procedure. Accuracy of the landslide inventory map is highly important for evaluating the susceptibility maps. Results of the ROC analysis indicate very good agreement of the recorded landslide inventory map with the landslide susceptibility zonation maps generated through IoE and DS models. Similarity in trend and closeness of AUC values of prediction and success rates in the ROC curve indicate that both models have favorably valid. The IoE model shows better capability (higher success and prediction rates) with respect to the DS model. Therefore, application of IoE model is advised for areas with similar characteristics to the study area.
According to the IoE model, prominence of the landslide conditioning factors is in order of land use, distance to drainage, slope gradient, altitude, SPI, lithology, TWI, distance to road, distance to fault, and slope aspect, respectively. In this study, both IoE and DS models have determined priority of classes of landslide conditioning factors with a similar trend. Land use has been found to be the most important landslide conditioning factor in the study area. Every factor (especially anthropogenic and triggering factors) which changes land use in the study area, it will increase landslide occurrence too. According to the geomorphological conditions of the study area, distance to drainage and slope gradient factors which fall into second and third priority of effect on landslide occurrence, have significant influence on landslide occurrence.
The landslide susceptibility maps generated based on the IoE and DS models, divide the study area into five zones with very low to very high susceptibility to landslide. In general, about more than 30% of the study area are high to very high susceptible to landslide. According to the FR and SCAI, the susceptibility map produced by the IoE model benefits from higher separation in comparison to the map by DS model.
References
Akgun A, Bulut F (2007) GIS-based landslide susceptibility for Arsin-Yomra (Trabzon, 381 North Turkey) region. Environ Geol 51:1377–1387
Akgun A, Dag S, Bulut F (2008) Landslide susceptibility mapping for a landslide-prone area (Findikli, NE of Turkey) by likelihood frequency ratio and weighted linear combination models. Environ Geol 54(6):1127–1143
Akgun A, Sezer EA, Nefeslioglu HA, Gokceoglu C, Pradhan B (2012) An easy-to-use MATLAB program (MamLand) for the assessment of landslide susceptibility using a Mamdani fuzzy algorithm. Comput Geosci 38:23–34
Althuwaynee OF, Pradhan B, Lee S (2012) Application of an evidential belief function model in landslide susceptibility mapping. Comput Geosci 44:120–135
Amiri MA, Karimi M, Sarab AA (2014) Hydrocarbon resources potential mapping using the evidential belief functions and GIS, Ahvaz, Khuzestan Province, southwest Iran. Arab J Geosci 8(6):3929–3941
Anbalagan R (1992) Landslide hazard evaluation and zonation mapping in mountainous terrain. Eng Geol 32(4):269–277
Awasthi A, Chauhan SS (2011) Using AHP and Dempster–Shafer theory for evaluating sustainable transport solutions. Environ Model Softw 26(6):787–796
Bednarik M, Magulova B, Matys M, Marschalko M (2010) Landslide susceptibility assessment of the Kraovany–Liptovski Mikulas railway case study. Phys Chem Earth 35(3):162–171
Beguería S (2006) Validation and evaluation of predictive models in hazard assessment and risk management. Nat Hazards 37(3):315–329
Binaghi E, Luzi L, Madella P, Pergalani F, Rampini A (1998) Slope instability zonation: a comparison between certainty factor and fuzzy Dempster–Shafer approaches. Nat Hazards 17(1):77–97
Bonham-Carter GF (1994) Geographic information systems for geoscientists: modelling with GIS. Computer methamphetamine geos, vol 13. Pergamon, New York
Bui DT, Lofman O, Revhaug I, Dick OB (2011a) Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Nat Hazards 59(3):1413–1444
Bui DT, Pradhan B, Lofman O, Revhaung I, Dick OB (2011b) Landslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput Geosci 45:199–211
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): a comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. CATENA 96:28–40
Calvello M, Ciurleo M (2016) Optimal use of thematic maps for landslide susceptibility assessment by means of statistical analyses: case study of shallow landslides in fine grained soils. In: Aversa S, Cascini L, Picarelli L, Scavia C (eds) Landslides and engineered slopes. Experience, theory and practice: proceedings of the 12th international symposium on landslides, Napoli, Italy, 12–19 June 2016. Associazione Geotecnica Italiana, Rome
Catani F, Lagomarsino D, Segoni S, Tofani V (2013) Landslide susceptibility estimation by random forests technique: sensitivity and scaling issues. Nat Hazards Earth Syst Sci 13:2815–2831. https://doi.org/10.5194/nhess-13-2815-2013
Chen W, Li W, Hou E, Zhao Z, Deng N, Bai H, Wang D (2014) Landslide susceptibility mapping based on GIS and information value model for the Chencang District of Baoji, China. Arab J Geosci 7:4499–4511
Chen W, Li W, Hou E, Bai H, Chai H, Wang D, Cui X, Wang Q (2015) Application of frequency ratio, statistical index, and index of entropy models and their comparison in landslide susceptibility mapping for the Baozhong Region of Baoji, China. Arab J Geosci 8:1829–1841
Chen W, Li W, Chai H, Hou E, Li X, Ding X (2016a) GIS-based landslide susceptibility mapping using analytical hierarchy process (AHP) and certainty factor (CF) models for the Baozhong region of Baoji City, China. Environ Earth Sci 75:1–14
Chen W, Pourghasemi HR, Zhao Z (2016b) A GIS-based comparative study of Dempster–Shafer, logistic regression and artificial neural network models for landslide susceptibility mapping. Geocarto Int 11:408–424. https://doi.org/10.1080/10106049.2016.1140824
Chen W, Panahi M, Pourghasemi HR (2017a) Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling. CATENA 157:310–324
Chen W, Pourghasemi HR, Kornejady A, Zhang N (2017b) Landslide spatial modeling: introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 305:314–327
Chen W, Pourghasemi HR, Naghibi SA (2017c) A comparative study of landslide susceptibility maps produced using support vector machine with different kernel functions and entropy data mining models in China. Bull Eng Geol Environ 77:647–664
Chen W, Pourghasemi HR, Naghibi SA (2017d) Prioritization of landslide conditioning factors and its spatial modeling in Shangnan County, China using GIS-based data mining algorithms. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1004-9
Chen W, Pourghasemi HR, Panahi M, Kornejady A, Wang J, Xie X, Cao S (2017e) Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 297:69–85
Chen W, Pourghasemi HR, Zhao Z (2017f) A GIS-based comparative study of Dempster–Shafer, logistic regression and artificial neural network models for landslide susceptibility mapping. Geocarto Int 32(4):367–385
Chen W, Shirzadi A, Shahabi H, Ahmad BB, Zhang S, Hong H, Zhang N (2017g) A novel hybrid artificial intelligence approach based on the rotation forest ensemble and naive Bayes tree classifiers for a landslide susceptibility assessment in Langao County, China. Geomat Nat Hazards Risk. https://doi.org/10.1080/19475705.2017.1401560
Chen W, Xie X, Peng J, Wang J, Duan Z, Hong H (2017h) GIS-based landslide susceptibility modelling: a comparative assessment of kernel logistic regression, naive-Bayes tree, and alternating decision tree models. Geomat Nat Hazards Risk. https://doi.org/10.1080/19475705.2017.1289250
Chen W, Xie X, Wang J, Pradhan B, Hong H, Bui DT, Duan Z, Ma J (2017i) A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. CATENA 151:147–160
Chung CF, Fabbri AG (1993) The representation of geoscience information for data integration. Non Renew Resour 2(2):122–139
Chung CF, Fabbri AG (2003) Validation of spatial prediction models for landslide hazard mapping. Nat Hazards 30(3):451–472
Chung CF, Fabbri AG (2008) predicting future landslides for risk analysis-spatial models and cross-validation of their results. Geomorphology 94(3–4):438–452
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy. CATENA 113(1):236–250
Constantin M, Bednarik M, Jurchescu MC, Vlaicu M (2011) Landslide susceptibility assessment using the bivariate statistical analysis and the index of entropy in the Sibiciu Basin (Romania). Environ Earth Sci 63(2):397–406
Cruden DM, Varnes DJ (1996). Landslide types and processes. In: Turner AK, Schuster RL (eds) Landslides, investigation and mitigation, Special report 247. Transportation Research Board, Washington, pp 36–75. ISSN 0360-859X, ISBN 030906208X
Dai FC, Lee CF (2002) Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 42:213–228
Darvishzadeh A (1991) Geology of Iran. Neda Publication, Tehran, 1-901. (in Persian)
Dempster AP (1967) Upper and lower probabilities induced by a multi valued mapping. Ann Math Stat 38(2):325–339
Devkota KC, Regmi AD, Pourghasemi HR, Yoshida K, Pradhan B, Ryu IC, Dhital MR, Althuwaynee OF (2013) Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat Hazards 65(1):135–165
Ding Q, Chen W, Hong H (2017) Application of frequency ratio, weights of evidence and evidential belief function models in landslide susceptibility mapping. Geocarto Int 32:619–639
Dormann CF, Elith J, Bacher S, Buchmann C, Carl G, Carré G, Marquéz JRG, Gruber B, Lafourcade B, Leitão PJ, Münkemüller T, McClean C, Osborne PE, Reineking B, Schröder B, Skidmore AK, Zurell D, Lautenbach S (2013) Collinearity: a review of methods to deal with it and a simulation study evaluating their performance. Ecography 36:27–46
Dou J, Tien Bui D, Yunus AP, Jia K, Song X, Revhaug I, Xia H, Zhu Z (2015) Optimization of causative factors for landslide susceptibility evaluation using remote sensing and GIS Data in parts of Niigata, Japan. PLoS ONE 10:e0133262. https://doi.org/10.1371/journal.pone.0133262
Fabbri AG, Chung CJ (2016) Blind-testing experiments for interpreting spatial-prediction patterns of landslide hazard. Int J Saf Secur Eng 6(2):193–208
Falaschi F, Giacomelli F, Federici PR, Puccinelli A, D’Amato Avanzi G, Pochini A, Ribolini A (2009) Logistic regression versus artificial neural networks: landslide susceptibility evaluation in a sample area of the Serchio River valley, Italy. Nat Hazards 50(3):551–569
Fawcett T (2006) An introduction to ROC analysis. Pattern Recogn Lett 27(8):861–874
Friedl B, Hölbling D, Eisank C, Blaschke T (2015) Object-based landslide detection in different geographic regions Geophysical research abstracts, vol 17, EGU2015-774, EGU General Assembly
Gokceoglu C, Sezer E (2009) A statistical assessment on international landslide literature (1945–2008). Landslides 6:345–351. https://doi.org/10.1007/s10346-009-0166-3
Guillard C, Zezere J (2012) Landslide susceptibility assessment and validation in the framework of municipal planning in Portugal: the case of Loures municipality. Environ Manag 50(4):721–735
Guns M, Vanacker V (2012) Logistic regression applied to natural hazards: rare event logistic regression with replications. Natur Hazards Earth Syst Sci 12:1937–1947
Guzzetti F, Reichenbach P, Cardinali M, Galli M, Ardizzone F (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72:272–299
Guzzetti F, Mondini AC, Cardinali M, Fiorucci F, Santangelo M, Chang KT (2012) Landslide inventory maps: new tools for an old problem. Earth Sci Rev 112:42–66
He S, Pan P, Dai L, Wang H, Liu J (2012) Application of kernel-based Fisher discriminant analysis to map landslide susceptibility in the Qinggan River delta, three Gorges, China. Geomorphology 171:30–41
Hong H, Pourghasemi HR, Pourtaghi ZS (2016) Landslide susceptibility assessment in Lianhua County (China): a comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 259:105–118
Hong H, Chen W, Xua C, Youssef AM, Pradhan B, Bui DT (2017) Rainfall-induced landslide susceptibility assessment at the Chongren area (China) using frequency ratio, certainty factor, and index of entropy. Geocarto Int 32(2):139–154
Hosseinpour MA, Delavar MR, Chehreghan A (2016) Uncertainty in landslide occurrence prediction using Dempster–Shafer theory. Model Earth Syst Environ 2:188. https://doi.org/10.1007/s40808-016-0240-5
Hungr O, Leroueil S, Picarelli L (2014) The Varnes classification of landslide types, an update. Landslides 11:167–194
Iranian Landslide Working Party (ILWP) (2007) Iranian landslides list. Forest, Rangeland and Watershed Association, Tehran
Jebur MN, Pradhan B, Tehrany MS (2014) Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens Environ 152:150–165
Jirousek R, Shenoy PP (2017) A new definition of entropy of belief functions in the Dempster–Shafer theory. Int J Approx Reason. https://doi.org/10.1016/j.ijar.2017.10.010
Komac M (2006) A landslide susceptibility model using the analytical hierarchy process method and multivariate statistics in perialpine Slovenia. Geomorphology 74(1):17–28
Kornejady A, Ownegh M, Rahmati O, Bahremand AR (2017) Landslide susceptibility assessment using three bivariate models considering the new topohydrological factor: HAND. Geocarto Int. https://doi.org/10.1080/10106049.2017.1334832
Lan HX, Zhou CH, Wang LJ, Zhang HY, Li RH (2004) Landslide hazard spatial analysis and prediction usingGIS in the Xiaojiang watershed, Yunnan, China. Eng Geol 76:109–128
Lee S, Choi J (2004) Landslide susceptibility mapping using GIS and the weight-of-evidence model. Int J Geogr Inf Sci 18(8):789–814
Lee S, Min K (2001) Statistical analysis of landslide susceptibility at Yongin, Korea. Environ Geol 40(9):1095–1113
Lee S, Oh HJ (2012) Ensemble-based landslide susceptibility maps in Jinbu area, Korea. In: Pradhan B, Buchroithner M (eds) Terrigenous mass movements. Springer, Berlin, pp 193–220
Lee S, Pradhan B (2007) Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 4:33–41
Lee S, Sambath T (2006) Landslide susceptibility mapping in the Damrei Romel area, Cambodia using frequency ratio and logistic regression models. Environ Geol 50(6):847–855
Lee S, Talib JA (2005) Probabilistic landslide susceptibility and factor effect analysis. Environ Geol 47:982–990
Lee S, Hwang J, Park I (2012) Application of data-driven evidential belief functions to landslide susceptibility mapping in Jinbu, Korea. CATENA 100:15–30
Liu Y, Cheng Q, Xia Q, Wang X (2015) The use of evidential belief functions for mineral potential mapping in the Nanling belt, South China. Front Earth Sci 9(2):342–354
Luzi L, Pergalani F (1999) Slope instability in static and dynamic conditions for urban planning: the ‘Oltre Po Pavese’ case history (Regione Lombardia-Italy). Nat Hazards 20:57–82
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environ Model Softw 15(1):101–124
Malamud BD, Turcotte DL, Guzzetti F, Reichenbach P (2004) Landslide inventories and their statistical properties. Earth Surf Proc Land 29(6):687–711
Marquardt D (1970) Generalized inverses, ridge regression, biased linear estimation, and nonlinear estimation. Technometrics 12:605–607
Meinhardt M, Fink M, Tunschel H (2015) Landslide susceptibility analysis in central Vietnam based on an incomplete landslide inventory: comparison of a new method to calculate weighting factors by means of bivariate statistics. Geomorphology 234:80–97. https://doi.org/10.1016/j.geomorph.2014.12.042
Menard SW (2002) Applied logistic regression analysis, 2nd edn. Sage, Thousand Oaks, p 111
Mohammady M, Pourghasemi HR, Pradhan B (2012) Landslide susceptibility mapping at Golestan Province, Iran: a comparison between frequency ratio, Dempster–Shafer, and weights-of-evidence models. J Asian Earth Sci 61:221–236
Mon DL, Cheng CH, Lin JC (1994) Evaluating weapon system using fuzzy analytic hierarchy process based on entropy weight. Fuzzy Set Syst 62(2):127–134
Moore ID, Grayson RB, Ladson AR (1991) Digital terrain modelling: a review of hydrological, geomorphological, and biological applications. Hydrol Process 5(1):3–30
Naghibi SA, Pourghasemi HR, Pourtaghi ZS, Rezaei A (2015) Groundwater qanat potential mapping using frequency ratio and Shannon’s entropy models in the Moghan watershed, Iran. Earth Sci Inf 8:171–186
Ngadisih, Bhandary NP, Yatabe R, Dahal RK (eds) (2016) Logistic regression and artificial neural network models for mapping of regional-scale landslide susceptibility in volcanic mountains of West Java (Indonesia). In: AIP conference proceedings. AIP Publishing
Nourani V, Pradhan B, Ghaffari H, Sharifi SS (2014) Landslide susceptibility mapping at Zonouz Plain, Iran using genetic programming and comparison with frequency ratio, logistic regression, and artificial neural network models. Nat Hazards 71(1):523–547
O’Brien RM (2007) A caution regarding rules of thumb for variance inflation factors. Qual Quant 41(5):673–690
Ozdemir A, Altural T (2013) A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J Asian Earth Sci 64:180–197
Pachauri AK, Pant M (1992) Landslide hazard mapping based on geological attributes. Eng Geol 32(1–2):81–100
Park NW (2011) Application of Dempster–Shafer theory of evidence to GIS-based landslide susceptibility analysis. Environ Earth Sci 62(2):367–376
Pourghasemi HR, Rossi M (2017) Landslide susceptibility modeling in a landslide prone area in Mazandarn Province, north of Iran: a comparison between GLM, GAM, MARS, and M-AHP methods. Theor Appl Climatol 130:609–633
Pourghasemi HR, Mohammady M, Pradhan B (2012a) Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: Safarood Basin, Iran. CATENA 97:71–84
Pourghasemi HR, Pradhan B, Gokceoglu C, Deylami Moezzi K (2012b) A comparative assessment of prediction capabilities of Dempster–Shafer and weights-of-evidence models in landslide susceptibility mapping using GIS. Geomat Nat Hazards Risk 4(2):93–118
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51:350–365
Pradhan B, Lee S (2010) Landslide susceptibility assessment and factor effect analysis: backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ Model Softw 25:747–759. https://doi.org/10.1016/j.envsoft.2009.10.016
Pradhan B, Oh HJ, Buchroithner MF (2010) Weights of evidence model applied to landslide susceptibility mapping in a tropical hilly area. Geomat Nat Hazards Risk 1(3):199–223
Rahmati O, Haghizadeh A, Pourghasemi HR, Noormohamadi F (2016) Gully erosion susceptibility mapping: the role of GIS-based bivariate statistical models and their comparison. Nat Hazards 82:1231–1258
Regmi NR, Giardino JR, Vitek JD (2010) Modeling susceptibility to landslides using the weight of evidence approach: Western Colorado, USA. Geomorphology 115:172–187
Regmi AD, Devkota KC, Yoshida K, Pradhan B, Pourghasemi HR, Kumamoto T, Akgun A (2014a) Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab J Geosci 7(2):725–742
Regmi AD, Yoshida K, Pourghasemi HR, Dhita LMR, Pradhan B (2014b) Landslide susceptibility mapping along Bhalubang–Shiwapur area of mid-Western Nepal using frequency ratio and conditional probability models. J Mt Sci 11:1266–1285
Schicker R, Moon V (2012) Comparison of bivariate and multivariate statistical approaches in landslide susceptibility mapping at a regional scale. Geomorphology 161:40–57
Sdao F, Lioi DS, Pascale S, Caniani D, Mancini IM (2013) Landslide susceptibility assessment by using a neuro-fuzzy model: a case study in the Rupestrian heritage rich area of Matera. Nat Hazard Earth Syst Sci 13(2):395–407
Shafer G (1976) A mathematical theory of Evidence. Princeton University Press, Priceton
Shannon CE (1948) A mathematical theory of communication. Bull Syst Technol J 27(3):379–423
Sharma L, Patel N, Ghose M, Debnath P (2012) Influence of Shannon’s entropy on landslide-causing parameters for vulnerability study and zonation—a case study in Sikkim, India. Arab J Geosci 5:421–431
Shirani K (2017) Modelling of landslide susceptibility zonation using Shannon’s entropy index and weight of evidence model (case study: Sarkhoon’s Karoon). JWSS 21(1):51–68 (in Persian)
Su C, Wang LL, Wang XZ, Huang ZC, Zhang XC (2015) Mapping of rainfall-induced landslide susceptibility in Wencheng, China, using support vector machine. Nat Hazards 76:1759–1779
Süzen ML, Doyuran V (2004a) A comparison of the GIS based landslide susceptibility assessment methods: multivariate versus bivariate. Environ Geol 45(5):665–679
Süzen ML, Doyuran V (2004b) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu catchment, Turkey. Eng Geol 71(3–4):303–321
Swets JA (1998) Measuring the accuracy of diagnostic systems. Science 240:1285–1293
Tangestani MH (2009) A comparative study of Dempster–Shafer and fuzzy models for landslide susceptibility mapping using a GIS: an experience from Zagros Mountains, SW Iran. J Asian Earth Sci 35(1):66–73
Tien Bui D, Pradhan B, Revhaug I, Nguyen DB, Pham HV, Bui QN (2015) A novel hybrid evidential belief function-based fuzzy logic model in spatial prediction of rainfall-induced shallow landslides in the Lang Son city area (Vietnam). Geomat Nat Hazards Risk 6:243–271
Tien Bui D, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13(2):361–378
Tsangaratos P, Ilia I (2016) Comparison of a logistic regression and naïve Bayes classifier in landslide susceptibility assessments: the influence of models complexity and training dataset size. CATENA 145(2016):164–179
Tsangaratos P, Ilia I, Hong H, Chen W, Xu C (2017) Applying information theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng County, China. Landslides 14:1091–1111. https://doi.org/10.1007/s10346-016-0769-4
Van Beek LPH, Van Asch T (2004) Regional assessment of the effects of land-use change on landslide hazard by means of physically based modelling. Nat Hazards 31(1):289–304
Van Den Eeckhaut M, Vanwalleghem T, Poesen J, Govers G, Verstraeten G, Vandekerckhove L (2006) Prediction of landslide susceptibility using rare events logistic regression: a case-study in the Flemish Ardennes (Belgium). Geomorphology 76:392–410
Van Den Eeckhaut M, Marre A, Poesen J (2010) Comparison of two landslide susceptibility assessments in the Champagne–Ardenne region (France). Geomorphology 115:141–155
van Westen CJ (2000) The modelling of landslide hazards using GIS. Surv Geophys 21(2–3):241–255
van Westen CJ, van Asch TWJ, Soeters R (2006) Landslide hazard and risk zonation—why is it still so difficult? Bull Eng Geol Env 65(2):167–184
van Westen CJ, Castellanos E, Kuriakose SL (2008) Spatial data for landslide susceptibility, hazard and vulnerability assessment: an overview. Eng Geol 102(3–4):112–131
Varnes DJ (1978) Slope movements, type and processes. In: Schuster RL, Krizek RJ (eds) Landslide analysis and control, Transportation Research Board, Special report 176. National Academy Sciences, Washington, pp 11–33
Varnes DJ (1984) Landslide hazard zonation: a review of principles and practice. Natural Hazards No. 3. Commission on Landslides of the IAEG, UNESCO, Paris
Vlcko J, Wagner P, Rychlikova Z (1980) Evaluation of regional slope stability. Mineralia Slovaca 12(3):275–283
Wang Q, Li W, Chen W, Bai H (2015) GIS-based assessment of landslide susceptibility using certainty factor and index of entropy models for the Qianyang County of Baoji city, China. J Earth Syst Sci 124:1399. https://doi.org/10.1007/s12040-015-0624-3
Wang Q, Li W, Wu Y, Pei Y, Xing M, Yang D (2016) A comparative study on the landslide susceptibility mapping using evidential belief function and weights of evidence models. J Earth Syst Sci 125(3):645–662
Weisberg S, Fox J (2010) An R companion to applied regression. Sage, Los Angeles
Wen BP, He L (2012) Influence of lixiviation by irrigation water on residual shear strength of weathered red mudstone in Northwest China: implication for its role in landslides’ reactivation. Eng Geol 151:56–63
Xu C, Dai FC, Xu X, Lee YH (2012a) GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorph 145–146:70–80
Xu C, Xu XW, Dai FC, Saraf AK (2012b) Comparison of different models for susceptibility mapping of earthquake triggered landslides related with the 2008 Wenchuan earthquake in China. Comput Geosci 46:317–329
Yalcin A (2008) GIS-based landslide susceptibility mapping using analytical hierarchy process and bivariate statistics in Ardesen (Turkey): comparisons of results and confirmations. CATENA 72(1):1–12
Yang Z, Qiao J (2009) Entropy-based hazard degree assessment for typical landslides in the Three Gorges Area, China. In: Wang F, Li T (eds) Landslide disaster mitigation in Three Gorges Reservoir, China. Environmental Science and Engineering. Springer, Berlin, pp 519–529
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79(3–4):251–266
Yi CX, Shi PJ (1994) Entropy production and natural hazard. J Beijing Norm Univ 30(2):276–280
Yilmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat—Turkey). Comput Geosci 35:1125–1138
Youssef AM, Pradhan B, Pourghasemi HR, Abdullahi A (2015) Landslide susceptibility assessment at Wadi Jawrah Basin, Jizan region, Saudi Arabia using two bivariate models in GIS. Geosci J 19:449–469
Youssef AM, Pourghasemi HR, El-Haddad BA, Dhahry BK (2016) Landslide susceptibility maps using different probabilistic and bivariate statistical models and comparison of their performance at Wadi Itwad Basin, Asir Region, Saudi Arabia. Bull Eng Geol Environ 75(1):63–87. https://doi.org/10.1007/s10064-015-0734-9
Yufeng S, Fengxiang J (2009) Landslide stability analysis based on generalized information entropy. In: 2009 international conference on environmental science and information application technology, pp 83–85
Zhu C, Wang X (2009) Landslide susceptibility mapping: a comparison of information and weights-of evidence methods in Three Gorges Area. In: 2009 international conference on environmental science and information application technology, 2009. ESIAT 2009. International conference on IEEE. https://doi.org/10.1109/esiat.2009.187
Acknowledgements
This article is part of the results of a research project entitled “Evaluation of the best important landslide hazard zonation methods” by Isfahan Agricultural and Natural Resources Research and Education Center under Grant Number 79-01-500003000-01. Authors would like to thank the soil conservation and watershed management department of Isfahan Center for Research of Agricultural Science and Natural Resources. Also, the authors would like to thank the editor and anonymous reviewers for their helpful comments for improvement of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shirani, K., Pasandi, M. & Arabameri, A. Landslide susceptibility assessment by Dempster–Shafer and Index of Entropy models, Sarkhoun basin, Southwestern Iran. Nat Hazards 93, 1379–1418 (2018). https://doi.org/10.1007/s11069-018-3356-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-018-3356-2