
Abstract
To improve the air pollution of China fundamentally, effective measures should be proposed based on the thorough understanding of the characteristics of air pollution. Based on spatial econometrics, this paper investigates the characteristics and analyzes the determinants of the spatial concentration of PM2.5 pollution in China. Results show that: (1) PM2.5 pollution is highly concentrated in Central and Eastern China, covering 17 regions which accounts for 75% of the total population and GDP (gross domestic product). (2) The PM2.5 values in China show a significant spatial correlation. Provinces such as Shandong, Henan, Anhui, and Hubei are high in PM2.5 concentration. Meanwhile, these provinces are high in population density, GDP, and coal consumptions and have a large amount of civilian cars. (3) PM2.5 pollution shows spatial spillover effects. A 1% increase in the PM2.5 values of neighboring provinces will lead to a 0.78% increase in that of one province. (4) An upward U-shaped relationship is observed between the density of per capita GDP and PM2.5, and the PM2.5 value is far from the turning point of growth. With the further growth of the density of per capita GDP, the PM2.5 value is expected to increase rapidly and continuously. (5) Based on the characteristics of spatial concentration and spatial spillover, this paper proposes several prevention-control measures for haze pollution, such as stressing on the treatment of air pollution in severely polluted provinces, avoiding moving pollution industries to neighboring areas, performing joint prevention and control nationwide. Air pollution may only be rooted by transforming the pattern of economic growth.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In recent years, large-scale hazy weather has persistently occurred in China. This phenomenon has seriously endangered public health and caused huge economic losses (Chen et al. 2012; Mu and Zhang 2013). In January 2013, haze affected an area of more than 1.4 million km2 in Eastern and Northern China, resulting in over 800 million victims. Non-hazy weather lasted for only 5 days in this January. In February 2014, haze clouded 161 cities in Northern China, among which 51 cities, including Beijing, were polluted and 11 cities were seriously polluted. Haze forced the closure of primary and secondary schools as well as that of highways and airports. In 2012, the economic losses in China caused by PM2.5 and other air pollutants amounted to nearly 2 trillion RMB (Zhang et al. 2013).
The Chinese government is used to taking stopgap measures for haze pollution. One way is to transfer the pollution source to other places to reduce the pollutant discharge. For example, Beijing moves its heavy polluting enterprises such as iron and steel plants to its neighboring regions like Tangshan (Hebei Province). Another way is to shut down pollution sources for some time before and after major events to get clean air temporarily, such as “APEC Blue,” “Youth Olympic Blue,” and “G20 Blue.” However, it turns out to be an expedient which cannot solve haze pollution from the root. The haze in Tangshan floats back to Beijing, resulting in long-lasting hazy weather in Beijing. Once APEC, Youth Olympic Games, and G20 are over, the hazy weather will return. Therefore, effective prevention-control countermeasures should be proposed based on the characteristics of haze pollution. Thus, we need to find out the characteristics of haze pollution. Where does haze concentrate? Is there spillover effect in neighboring areas? What are the impact factors of haze pollution? Is there an inflection point in the development of haze pollution? These questions are crucial for the research of the characteristics of haze pollution. However, the studies on these questions are quite limited, let alone the countermeasures for haze pollution. Thus, this paper attempts to study the characteristics of haze pollution and proposes corresponding measures.
Haze is mainly composed of PM10 (inhalable particles) and PM2.5 (inhalable particles). With more previous researches conducted on the components of PM2.5 and easier access to the observation data of PM2.5, PM2.5 is adopted as the object of this study instead of PM10. PM2.5 is structurally complicated. Most scholars have analyzed the components of PM2.5 from the physical and chemical perspectives (Bates and Sizto 1987; Hussain et al. 2013; Tang et al. 2014; Thurston et al. 1994; Tran et al. 2003; Ma et al. 2012; An et al. 2013; Jansen et al. 2014), but little is known about the contribution of different components from the perspectives of time and space (Dong and Liang 2014; Wu et al. 2013, 2016; Xie et al. 2014; Yang et al. 2010; Zhao et al. 2013). As for its composition, PM2.5 largely consists of industrial waste gas, exhaust of automobiles and machines, smoke of cooking oil, coal dust, and so on. These pollutants are closely related to GDP (gross domestic product), population, energy consumption, and industrial waste gas emission, respectively. We intend to use the density of the above variables as the substitution variables of the components of PM2.5. We collect the data of PM2.5 and variables from 2001 to 2010. Based on the analysis of the spatial spillover effect of PM2.5, the contribution degrees of different components to PM2.5 growth will be discussed via the spatial panel data model. To predict the possible turning point in the PM2.5 growth curve, a Kuznets curve will be built by virtue of PM2.5 values and the density of per capita GDP variables.
The empirical study of this paper is based on the spatial panel data model first proposed by Anselin (1988). Based on panel data model, the dependent variable and error term of spatial lag are introduced into the spatial panel data model. Besides, spatial correlation is included in the spatial panel data model which takes into consideration not only spatial correlation but also temporal factors. Thus, this model makes up for the deficiency of the traditional panel data model and is widely applied in the researches on environmental economics. Based on the provincial panel data in China and via the spatial fixed effect model, Zhu et al. (2010) and Zhang (2014) studied the spatial dependence relationship among industrial pollutants and the environmental Kuznets curve between these pollutants and GDP per capita. After testing the transnational environmental Kuznets curve model according to the spatial lag model, Maddison (2006) found that both the SO2 emission amount per capita and the NOx emission amount per capita are affected by the emission from neighboring countries. Based on the spatial panel model, Hossein and Kaneko (2013) discovered that environmental quality of countries spreads spatially to their neighbors through the flowing of institutional quality of countries. Burnett et al. (2013) explored the relationship among CO2 emission of states in USA., economic activity, and other factors through spatial panel econometric model and found that economic distance plays an important role in interstate CO2 emission. Taking SO2 and CO2 as the research objects, these studies analyzed their spatial effect, spatial dependence, and spatial heterogeneity. Similar to SO2 and CO2, PM2.5 is the product of human life and characterized by spillover-proneness in space. However, rare literature has touched upon the spatial spillover effect of PM2.5 from the perspective of spatial econometrics at present. Therefore, we use spatial panel data model to analyze the spatial concentration of PM2.5 as well as the environmental Kuznets curve of PM2.5.
Similar to the studies by Zhu et al. (2010), Zhang (2014), Maddison (2006), Ma and Zhang (2014), the present study consists of three steps. First, the Moran’s I index proposed by Moran (1950) and (Wu et al. 2016) was used to test global spatial correlation of PM2.5 (Sect. 2). Second, to further study the formation factors of PM2.5 and their influence degrees, variables closely related to PM2.5 values were selected and spatial correlation between these variables and PM2.5 values was explored via spatial econometric model. We found that PGDPD affects PM2.5 most (Sect. 3). According to the above results, we further studied the relationship between PGDPD and PM2.5 by using the Kuznets curve and then summarized the research results and prevention-control measures (Sect. 4).
2 Spatial correlation analysis of PM2.5 concentrations
2.1 Data
China began collecting formal statistical data about PM2.5 in 2012 and has put great effort into data collection since ever. At present, besides observation data [such as Abas et al. (2004); Hossein and Kaneko (2013)], annual average values of PM2.5 from 2001 to 2010 offered by Battelle Memorial Institute and Center for International Earth Science Information Network have also been adopted by many scholars (Ma and Zhang 2014). For example, after studying and preliminarily estimating the concentration of inhalable particulate matter in provinces of China based on satellite data, they came up with a table of “Annual average population-weighted PM2.5 concentrations in provinces, municipalities and autonomous regions of China in 2001–2010” (obtained from Reference Environmental Information Network 2012, and see Table A1). In this table, the PM2.5 concentration index is indicated by the average concentration of exposure to air pollution in each province, and the population is weighted. Namely, each province is divided into certain grid regions (0.1°×0.1°), or approximately 10 km × 10 km at mid-latitudes. Then, with the proportion of residents within a grid region to the total population of each province and municipality as the weight, the average population-weighted concentration of exposure to air pollution in each grid region is calculated. The population-weighted value fully considers different situations in sparsely populated low-polluted areas and densely populated high-polluted areas, pays more attention to the actual effects of fine particulate matter on residents, and is in line with Ma and Zhang (2014), Donkelaar et al. (2010) and Wu et al. (2016).
Therefore, population-weight PM2.5 values in different provinces are adopted in this study, without considering Taiwan, Hong Kong, and Macao, and combining Chongqing and Sichuan as one region due to data availability. Thereby, we use data of PM2.5 in 30 administrative regions in 10 years.
2.2 Present status of PM2.5 concentrations
Haze pollution is quite severe in China. Judging from population-weighted values of PM2.5, the average PM2.5 values vary between 24.475 and 29.975 in China from 2001 to 2010. Fluctuations in PM2.5 values are observed, but only at a modest rate. The value is the largest (29.975) in 2007 and the smallest (24.475) in 2010. Nevertheless, the smallest value is still higher than the air quality standard of 10 set by the WHO (World Health Organization). Only the PM2.5 values of three regions are lower than the air quality standard. They are Hainan, Heilongjiang, and Tibet, which have the lowest values for 10, 8, and 4 years, respectively. The PM2.5 values of other provinces are all higher than the standard, among which Shandong, Henan, Jiangsu, and Hebei have the highest values (approximately being 50, which is five times higher than the air quality standard) for 4, 3, 2, and 1 year respectively. These values indicate severe air pollution. Those provinces are located in Central and Eastern China (Fig. 1). We can observe from the figures in brackets thatFootnote 1 the standard deviations of population-weighted PM2.5 values in provinces from 2001 to 2010 fluctuate slightly. The maximum value and the minimum value are 13.211 (in 2007) and 10.550 (in 2009) respectively.

Boxplots of population-weighted PM2.5 values in provinces of China from 2001 to 2010. Note On the top of each boxplot is the province with the largest population-weighted PM2.5 value in a year, Below each boxplot is the province with the smallest population-weighted PM2.5 value in the same year, The horizontal line in each boxplot represents the mean population-weighted PM2.5 value in this year. Besides, the values in the brackets are the standard deviations of population-weighted PM2.5 values in provinces from 2001 to 2010
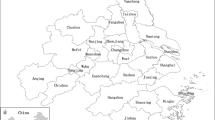
The PM2.5 values exhibit an obvious spatial concentration phenomenon. Han et al. (2014) applied the annual average PM2.5 values from 2001 and 2006 offered by Battelle Memorial Institute and Center for International Earth Science Information Network. They found that the PM2.5 values in 350 prefecture-level cities of China are distributed in two bandsFootnote 2: One starts from the North of Hebei, passes through Beijing, Shaanxi, the Northwest of Henan and the South of Shaanxi, and ends at the Southeast of Sichuan; the other starts from Shanghai and Zhejiang in the East, passes through the South of Anhui, Henan, and Jiangxi and arrives at Guangxi and Guangdong. However, our findings are somewhat different: we found that the PM2.5 values in different regions are distributed in blocks and highly agglomerated geographically. In other words, the regions with high PM2.5 values (larger than the average value) are located in Central and Eastern China to form a large block area. The area covers 14–17 provinces. The population sizes and GDP values in these provinces account for three-fourths of the total amount in China, nearly covering all economically developed provinces of China. At the same time, populations in these provinces are exposed to the threat of haze. The geographic distribution of PM2.5 values in different provinces in 2006 and in 2010 is shown in Fig. 2a, b, respectively.

Distribution maps of PM2.5 values in different provinces of China in 2006 and in 2010
According to the above research, PM2.5 values are obviously distributed in blocks, indicating that PM2.5 concentrations are in a spatial correlation. Then, the spatial correlation degree is measured by spatial econometrics.
2.3 Global spatial correlation
Tobler (1970) proposed the first law of geography, holding that all things are spatially correlated. A shorter distance means a higher correlation degree; meanwhile, a longer distance means a lower correlation degree. The population distribution and economic development in China also exhibit spatial concentration. Accordingly, PM2.5 values may share this feature. In the present study, Moran’s I index proposed by Moran (1950) is adopted to test the global spatial correlation of PM2.5 values. The calculation formula is:
where n is the number of subject provinces, a total of 30 administrative regions, excluding Hong Kong, Macao, and Taiwan and combining Sichuan and Chongqing as a whole; i and j refer to each province; \(A_{i}\) and \(A_{j}\) refer to the population-weighted PM2.5 values in the i th province and the j th province, respectively; I is the index value used to measure the global spatial correlation. I varies between −1 and 1. If I is positive, \(A_{i} {\text{and }}A_{j}\) change in the same direction and the data are positively correlated. A closer value to 1 corresponds to higher positive spatial autocorrelation. The high values (low values) of PM2.5 are adjacent. If I is negative, \(A_{i} {\text{and }}A_{j}\) change in opposite directions and the data are negatively correlated. A closer value to −1 corresponds to higher negative spatial autocorrelation. The high values of PM2.5 are adjacent to the low values, or the low values are adjacent to the high values. If I is close to 0, the data are distributed randomly without correlation.
wij, which refers to the spatial weight matrix, can be calculated as
Adjacency means two regions have a common border or point. When calculating the spatial weight matrix, Sichuan and Chongqing are combined into one region. The global and local spatial correlations are calculated with GeoDA1.4.0.
From 2001 to 2010, the Moran’s I values in regions vary between the relatively stable values of 0.412 and 0.484, indicating that the PM2.5 values in these provinces exhibit a positive spatial autocorrelation. In other words, the higher the PM2.5 value of a province, the higher that of its adjacent province, and vice versa. The concomitant probabilities (p) of Moran’s I are all smaller than 0.05, which suggests statistical significance.
Moran’s I value is the highest (0.484) in 2007 and the lowest (0.412) in 2009, which is basically close to the years with the highest and lowest average PM2.5 values. Thereby, we can infer that these sequences exhibit a certain significant correlation at the level of 10%. PM2.5 and Moran’s I are positive correlation. The years with high average PM2.5 values also have high Moran’s values (0.412–0.484). As Moran’s I is a measure of spatial autocorrelation, in the years with high average PM2.5 values, the spatial correlation is strong. By contrast, in the years with low average values of PM2.5, the spatial correlation is weak (Table 1).
The scatter diagram of Moran’s I values in different regions from 2001 to 2010 can be divided into four quadrants with the average value as the axis. The first and third quadrants indicate high–high and low–low positive correlations, respectively. The second and fourth quadrants indicate low–high and high–low negative correlations, respectively. According to the scatter diagram of 2006 (Fig. 3a), the Moran’s I values in about 15 regions are in the first quadrant every year, indicating large PM2.5 values in spatial concentration. Eleven regions are in the third quadrant, which indicates small PM2.5 values in spatial concentration. Four regions are in the second and fourth quadrants, showing negatively correlated PM2.5 values not in any spatial concentration. Overall, the PM2.5 values in most regions are in spatial concentration. In other words, the regions with high (or low) PM2.5 values are adjacent (See Fig. 3a, b for details).

Moran’s I scatter diagrams of PM2.5 values in different regions in 2006 and in 2010. Note The vertical axis is used for the spatially averaged neighboring values and the horizontal for the value for the area at the center of the spatial average
2.4 Local spatial correlation
A Moran’s I scatter diagram can test overall agglomeration through local spatial autocorrelation, but it cannot test whether PM2.5 values in some local regions exhibit agglomeration or not. Accordingly, a local indicator of spatial association (LISA) proposed by Anselin (1995) is adopted to test the local spatial autocorrelation of PM2.5 values in different regions. The calculation formula of LISA of the area i is:
where n, i, and j mean the same mentioned above;\(S^{2}\) refers to the variance of population-weighted PM2.5 values in 30 provinces; \(I_{i}\) is the index value used to measure the spatial correlation of Area i. If \(I_{i} > 0\), the high PM2.5 values (or low values) in different parts of Area i are adjacent. In other words, regions with high or low PM2.5 values are agglomerated spatially. The spatial concentration diagrams of local PM2.5 values in 2006 and in 2010 are shown below (Fig. 4a, b). Each diagram passes the test of significance level of 5% and is obtained after Monte Carlo simulations.

Local agglomeration diagrams of the PM2.5 values in different regions of China in 2006 and 2010
According to the above diagrams and the LISA diagram of other years, the PM2.5 values in most regions of China exhibit obvious high–high or low–low spatial concentration. The provinces with high values are mostly concentrated in Central and Eastern China, including Shandong, Henan, Anhui, and Hubei. The regions with low values are mostly concentrated in northwestern, north and northeastern of China. These regions include Xinjiang, Inner Mongolia, Heilongjiang, and Jilin. Table 2 lists the regions with high–high or low–low PM2.5 agglomeration from 2001 to 2010. The results pass the test of significance level of 5% and are obtained after Monte Carlo simulations.
The PM2.5 values show obvious spatial concentration considering the following points. First, the provinces in Central and Eastern China are located in the East Asian summer monsoon area with meteorological conditions of precipitation and wind speed/direction. In January 2013, hazy weather occurred in Eastern China (Anhui, and Shandong, Henan, Hubei) with strong intensity, great duration, and large scope. The meteorological factor can explain the variance of diurnal variation of more than two-thirds of hazy weather, and the variance contribution reaches 0.68 (Zhang et al. 2014). Second, Central and Eastern China has a dense population and a well-developed economy, leading to large waste gas emission, automobile exhaust, and coal consumption, which explains high PM2.5 values (Table 3). Shandong, Henan, Hubei, and Anhui with high PM2.5 values are considered as examples in the discussion below. The population sizes per km2 in these provinces are many times larger than the average value of the country (obtained through dividing the sum of the total by the country’s total area, the same below): Shandong (623 per km2), Henan (563 per km2), Anhui (426 per km2), and Hubei (308 per km2). The GDPs per km2 are also more than two times larger than the average value of the country: Shandong (2546.809 ten thousand yuan per km2), Henan (1382.776 ten thousand yuan per km2), Anhui (884.705 ten thousand yuan per km2), and Hubei (858.935 ten thousand yuan per km2). In addition, the numbers of civilian cars per km2 of these four provinces are in the top 50% of the country: Shandong (45.896 per km2), Henan (23.936 per km2), Anhui (15.019 per km2), and Hubei (11.162 per km2). Coal consumptions per km2 are two times larger than the average value of the country (455.486 tons per km2): Shandong (2427.041 tons per km2), Henan (1559.880 tons per km2), Anhui (957.459 tons per km2), and Hubei (724.598 tons per km2). Third, Jilin has a low PM2.5 value in 2010, a population density of 147 per km2, a GDP of 462.520 ten thousand yuan per km2, a car number of 8.158 per km2, and a coal consumption of 511.348 tons per km2. These values are close to the national average and less than half of those of Anhui. Fourth, Zhang (2014) believed that haze in China is agglomerated in Central and Eastern China, which is related closely to their similar industrial structure. Arguably, it is difficult to obtain a clean-type, high-quality innovation-driven industry in the short term. Therefore, under the strong GDP examination by the central government, these provinces have to prioritize the manufacturing industry characterized by three highs (i.e., high pollution, high emission, and high consumption). Moreover, investors tend to choose central and eastern provinces with rich resources, large population, and convenient transport for survival. To attract investors, the local governments dominantly or recessively race to relax the restrictions on the environment, which further intensifies the agglomeration of haze in these provinces.
3 Analysis of spatial influential factors of PM2.5 concentrations
To further study the factors that contribute to PM2.5 concentrations and the degrees of influence of different factors, the variables closely related to PM2.5 concentrations are selected based on the previous analysis for the empirical analysis of the correlation between these variables and the PM2.5 value.
3.1 Data
We perform a quantitative analysis of the data in the 30 regions from 2001 to 2010. As mentioned previously, the major sources of PM2.5 include industrial waste gas (dust), life waste gas (dust), vehicle exhaust (dust), and coal dust. The number of vehicles is difficult to obtain. On the one hand, the number of public cars cannot be obtained. On the other hand, though the number of civilian cars since 2005 is available for Chinese people, the short data sequence is not representative. As a result, this variable is not included in the analysis. In this study, population size, per capital GDP, coal consumption, and industrial waste gas emission are considered as the source variables of PM2.5. The data of PM2.5 values are obtained from Battelle Memorial Institute and CIESIN (2013). Those of population size, per capita GDP, and industrial waste gas emission are obtained from China Statistical Yearbook, and those of coal consumption are obtained from China Energy Statistical Yearbook. To reduce the heteroscedasticity with logarithmic values of variables, the logarithmic values of independent variables and dependent variables are adopted. The regression of the spatial panel data is calculated by MATLAB 2010a.
In addition, with the values in 2000 as the base year, the density of per capita GDP (PGDPD) in different provinces is deflated according to the inflation rate with yuan per km2 as the unit; the density of population size (POPD) is measured in per km2; the density of industrial waste gas emission in different provinces (GWASD) is measured in ten thousand normal m3 per km2; and the density of coal consumption (COACD) is measured in ton per km2.
3.2 Model setting
The POPD, PGDPD, GWASD, and COACD in these provinces in the past years may have multi-collinearity, which leads to information redundancy, and the multi-index multi-collinearity of the spatial panel data has not been solved by Lesage and Pace (2014). Thus, regression is conducted between the above variables and the PM2.5 value to identify the relationship between them.
-
1.
Traditional panel data model. The basic model is.
$$ln{\text{PM}}2.5_{it} = \alpha_{0} + \alpha_{1} lnX_{it} + \mu_{it}$$(4)where i refers to the province, i=1,2,…,29, t refers to the year, t=1,2,…,10, \(lnPM2.5_{it}\) refers to the PM2.5 values in different provinces from 2001 to 2010, \(lnX_{it}\) refers to \(ln{\text{POP}}_{\text{it}}^{\text{D}}\), \(ln{\text{PGDP}}_{\text{it}}^{\text{D}}\), \(ln{\text{COAC}}_{\text{it}}^{\text{D}} , ln{\text{GWAS}}_{\text{it}}^{\text{D}}\), \(\alpha_{0 }\) refers to the intercept term; \(\alpha_{1}\) refers to the coefficients of independent variables, and \(\mu_{it}\) refers to the random error term, which could be decomposed as follows:
$$\mu_{it} = \delta_{it} + \vartheta_{it} + \varepsilon_{it}$$(5)where \(\delta_{it} {\text{and }}\vartheta_{it}\) refer to the random perturbations of time effect and individual effect, respectively, and \(\varepsilon_{it}\) refers to the random error term. OLS (ordinary least squares) can be used for parameter estimation.
-
2.
Spatial lag panel data model. After introducing the spatial variable, the spatial error model assumes that the random error term \(\varepsilon_{it}\) follows a normal distribution. Equation (4) can be rewritten as the spatial lag panel data model.
$$ln{\text{PM}}2.5_{it} = \alpha_{0} + \alpha_{1} lnX_{it} + \rho \sum Wln{\text{PM}}2.5_{it} + \delta_{it} + \vartheta_{it} + \varepsilon_{it} \,(\varepsilon_{it} \sim{\text{N}}\left( {0,\sigma_{it}^{2} } \right))$$(6)where W refers to the spatial weight vector matrix, \(\varSigma Wln{\text{PM}}_{2.5it}\) refers to the overall situation of PM2.5 in the areas around Province i in Year t, \(\rho\) is the degree of the spatial spillover effect, indicating the correlation coefficient of PM2.5 in the areas around Province i with that in Province i in Year t, \(\sigma_{it}^{2}\) is the variance of \(\varepsilon_{it}\)
-
3.
Spatial error panel data model. If the disturbance term shows spatial correlation, \(\varepsilon_{it}\) does not necessarily follow a normal distribution. Equation (6) can be rewritten as the spatial error panel data model.
$$ln{\text{PM}}2.5_{it} = \alpha_{0} + \alpha_{1} lnX_{it} + \delta_{it} + \vartheta_{it} + \varepsilon_{it} ,\,\varepsilon_{it} = \lambda \sum W\varepsilon_{it} + \varphi_{it,} \varphi_{it} \sim{\text{N}}0,\sigma_{it}^{2}$$(7)where \(\varphi_{it}\) refers to the random error term of \(\varepsilon_{it}\), which follows a normal distribution, and \(\lambda\) is the spatial autocorrelation coefficient of \(\varepsilon_{it}.\)
GMM or ML (Anselin and Getis 1992) is used in estimating Eqs. (6) and (7). The empirical results are given and explained below.
3.3 Results of empirical analysis
To analyze the influence of different independent variables on the PM2.5 value and their contributions, five variables in 30 regions of China (excluding Hong Kong, Macao, Taiwan, and combining Chongqing and Sichuan) from 2001 to 2010 are selected to establish the spatial panel regression model. The dependent variable is \(ln{\text{PM}}2.5_{it}\), and the independent variables are \(ln{\text{POP}}_{\text{it}}^{\text{D}}\), \(ln{\text{PGDP}}_{\text{it}}^{\text{D}}\), \(ln{\text{COAC}}_{\text{it}}^{\text{D}} , ln{\text{GWAS}}_{\text{it}}^{\text{D}}\). On the basis of Models (4), (6), and (7), the ML method is adopted. The results calculated by MATLAB 2010a are shown in Table 4.
When setting the threshold value of selecting the random effect or the fixed effect by Hausman test with Matlab2010a, p > 0.05 implies the rejection of spatial fixed effect (Table 4). The Hausman test values of Equations (a) and (c) show that the random effect model is desirable. The Hausman test values of Equations (b) and (d) show that the fixed effect model is recommendable.
According to the equations in Table 4, both \(\rho\) and \(\lambda\) are positive, which indicates that PM2.5 has spatial spillover effect. In Equations (a) and (c), \(\rho\) are 0.776 and 0.781, respectively, which indicates that every 1% increase in the PM2.5 value in the surrounding areas will cause the PM2.5 value in the local place to increase by 0.776 and 0.781%, respectively. In Equations (b) and (d), \(\lambda\) is 0.793 and 0.801, which indicates that the residual error term of PM2.5 in the surrounding areas significantly affects that in the local place, with the residual error term referred to the factors except independent variables (\(ln{\text{GWAS}}_{\text{it}}^{\text{D}} ,{\text{lnPGDP}}_{\text{it}}^{\text{D}}\)) that determine dependent variables; \(\alpha_{1}\) shows that the factors such as the density of population size and per capita GDP are positive spatially correlated with PM2.5 value. Meanwhile, the density of coal consumption and waste gas emission has no significant impact on the PM2.5 value.
According to Equations (a) and (b), every 1% increase in the logarithmic values of the density of population size and per capita GDP will cause the logarithmic value of PM2.5 to increase by 0.072 and 0.180%, respectively. Among these variables, the density of per capita GDP has significant influence on PM2.5. Thus, a higher density of per capital GDP in a region corresponds to a larger PM2.5 value. However, according to Equations (c) and (d), the influence of the density of coal consumption and waste gas emission on PM2.5 is not significant. This shows the following implications. First, the PM2.5 value is affected by the density of the total amount rather than the economic structural factor. For example, the coefficients of the indicators (POPD, PGDPD) that represent the density of total amount are large and significant, whereas those of the indicators (GWASD and COACD) that represent the density of structural factors are not significant. This suggests that per capita GDP composition, production mode, and people’s consumption and lifestyles be adjusted and systematically designed to realize the change in the mode of economic growth. Second, the effect of the direct sources (waste gas emission and coal consumption) on PM2.5 becomes insignificant because of the spatial spillover effect. According to Equation (c), the density of coal consumption is not a significant source indicator of PM2.5 due to the spatial spillover effect of PM2.5 in surrounding areas. According to Equation (d), the coefficient of another important source indicator of PM2.5 (i.e., the density of waste gas emission) is also not significant because of the spatial spillover effect of society, economy, technology, and other error elements in different regions.
Considering that the density of per capita GDP shows the greatest influence on PM2.5, we use Kuznets curve to further study the relationship between PGDPD and PM2.5. The steps and test are the same as earlier. Equations (4), (6), and (7) are consistent, but the independent variables are changed to \(ln{\text{PGDP}}_{\text{it}}^{\text{D}}\) and \((ln{\text{PGDP}}_{\text{it}}^{\text{D}} )^{2}\). The parameter test shows that the spatial lag panel data model with the fixed effect should be adopted. The results are as follows:
The values in brackets are the concomitant probability of the parameter. R2 = 0.992; Log likelihood = 415.323; LR-test = 984.505 (p value = 0).
Thus, without considering the spatial lag term \(\mathop \sum \nolimits \varvec{W}ln{\text{PM}}2.5_{it}\) of the dependent variable \(ln{\text{PM}}2.5_{\text{it}}\), a quadratic equation of one unknown between \(ln{\text{PM}}_{2.5}\) and \(lnGDP\) in the positive U shape is formulated. The PM2.5 value in the surrounding significantly influences that in the local place with the coefficient of 0.789, implying that every 1% increase in the logarithmic value of PM2.5 in the surrounding will increase that in the local region by 0.789%.From the curve, the slope equation of \(ln{\text{PM}}2.5_{\text{it}}\) to \(lnGDP_{it}^{D}\) is:
From the above formula, the PM2.5 value is the lowest when the logarithmic value of the PGDPD is 5.221 (the PGDPD value is 185.043 yuan per km2). From 2001 to 2010, the regions reaching the lowest point of the curve are Guangxi (from 2001 to 2004) and Guizhou (2007, 2009). In Fig. 4a, b these regions have low \(ln{\text{PM}}_{2.5}\) values and their spatial correlations are insignificant, which implicitly implies to some degree that social structure, industrial structure, and consumption trends in these provinces are relatively logistically structured and of help in reducing the emission of PM2.5.
The part between 3.578 and 10.809 in Fig. 5 shows that the curve section of \(ln{\text{PM}}2.5_{\text{it}}\) and \(ln{\text{PGDP}}_{\text{it}}^{\text{D}}\) is in different areas from 2001 to 2010. Therefore, if current trends continue, with the steady growth of the \({\text{PGDP}}^{\text{D}}\) in different areas, the PM2.5 value will also rapidly increase. The so-called inverted U-shape inflection point does not appear. Hence, the rapid growth trend of PM2.5 will be difficult to curb if the existing mode of economic growth is not changed fundamentally and the environmental pollution is not effectively controlled. In fact, the haze pollution with PM2.5 as the representative continuously occurred at a large scale in different parts of China from 2011 and 2014 (Sun et al. 2016). The pollution is particularly serious in Northern, Central, and Eastern China, which further verifies the conclusions of the present study.

Curve relationship between \(ln{\text{PM}}_{2.5}\) and \(ln{\text{PGDP}}^{D}\)
4 Concluding remarks
In recent years, the air pollution in China has not been improved fundamentally. The main reason lies in that there lack adequate researches on the characteristics and impact factors of spatial concentration and spatial spillover. Thus, effective prevention-control plans cannot be made in time. This study has facilitated the overall and local spatial correlation analyses between PM2.5 values in different provinces of China and variables indicating the sources of PM2.5. These variables consist of the density of population size, per capita GDP, coal consumption, and industrial waste gas emission. Afterward, the spatial panel data model has been built. We have the following concluding remarks:
-
1.
PM2.5 pollution in China is increasingly grave. The PM2.5 value each year is two to three times greater than the air quality standard of the WHO. The pollution concentrates in Central and Eastern China in blocks, covering 17 regions which accounts for 75% of the total population size and GDP of China.
-
2.
The PM2.5 values in China show a significant spatial correlation. The regions with high PM2.5 are agglomerated in masses with severe pollution, such as Hubei, Henan, Shandong, and Anhui. These regions had large population size, GDP, coal consumption, and number of civilian cars among all the provinces in China. The regions with low PM2.5 are also agglomerated in masses. These provinces include Xinjiang, Jilin, Heilongjiang, and Inner Mongolia. The indicator values in these provinces are small.
-
3.
There shows spatial spillover effect in PM2.5 pollution. A 1% increase in the PM2.5 values of neighboring provinces will lead to a 0.78% increase in that of one province.
-
4.
The PM2.5 value is affected by the total amount indicators. The density of the total amount indicators per capita GDP and population size significantly influences the PM2.5 value, in which every 1% increase in the logarithmic values of POPD and PGDPD causes the logarithmic value of PM2.5 to increase by 0.072 and 0.180%, respectively. Both people’s lifestyle and mode of per capita GDP growth influence PM2.5.
-
5.
An upward U-shaped relationship is observed between \(ln{\text{PM}}_{2.5}\) and \(ln{\text{PGDP}}^{\text{D}}\). The PM2.5 value is far from the turning point of growth. With the further growth of \({\text{PGDP}}^{D}\), the PM2.5 value is expected to increase rapidly and continuously. The observation during 2011 and 2013 also verifies such a prediction. The values of \(ln{\text{PGDP}}^{\text{D}}\) in regions including Guangxi (from 2001 to 2004) and Guizhou (2007, 2009) are closest to the lower portion of the Kuznets curve, and to some extent, this implies that in these provinces, social structure, industrial structure, and consumption trends are relatively logistically structured, thus reducing the emission of PM2.5. The deeper reason of such a phenomenon is worth of further studies in the future.
Thus, haze in China with PM2.5 and PM10 as representatives is typically distributed in blocks and exhibits significant spatial spillover effect. Thus, a province or region cannot fundamentally control PM2.5 concentrations solely by transferring the polluting industries to adjacent provinces or strictly implementing the one-side PM2.5 concentration control action. According to the characteristics of air pollution, prevention-control measures should be taken in the following ways. First, the central government of China shall focus on the haze pollution of severely polluted provinces. Only by changing the structure of energy consumption and transforming the pattern of economic growth can these provinces prevent air pollution from its source as well as bring the inflection point of air pollution growth forward. Second, local government shall stop transferring heavily polluted industries to its neighboring areas. According to data analysis and empirical fact, there is special spillover effect in air pollution. It will only make situations worse for all involved by moving polluted sources to neighboring regions. Third, haze pollution shall be prevented and controlled with joint efforts. The “whole nation system” can be adopted in handling haze pollution (Zhang and Zhong 2014). For example, to set up a special group led by the State Council and assisted by local government for the comprehensive treatment of haze pollution or implement “grid” management in pollution highly concentrated and severely polluted areas (She and Cao 2012). Therefore, the advantages of Chinese government in public administration and “whole nation system” can be maximized to prevent and control pollution. Taxation and environmental regulation with laws and economic means are also applicable. Fourth, all individuals should be encouraged to practice an environmentally friendly way of living and participate in PM2.5 concentration control. Only through the effective implementation of the above-mentioned measures can we reduce the threat of haze pollution and realize sustainable development.
Notes
The values in the brackets are the standard deviations of population-weighted PM2.5 values of provinces from 2001 to 2010.
Though PM2.5 concentrations in 350 prefecture-level cities can be obtained, the social and economic data of these 350 cities are not available. Thus, the data of prefecture-level cities are not adopted in this paper.
References
Abas MRB, Rahman NA, Omar NYMJ, Maah MJ, Samah AA, Oros DR, Otto A, Simoneit BRT (2004) Organic composition of aerosol particulate matter during a haze episode in Kuala Lumpur, Malaysia. Atmos Environ 38:4223–4241
An JL, Li Y, Chen Y, Li J, Qu Y, Tang YJ (2013) Enhancements of major aerosol components due to additional HONO sources in the North China Plain and implications for visibility and haze. Adv Atmos Sci 30:57–66
Anselin L (1988) Spatial econometrics: methods and models. Kluwer, Dordrech, p 10
Anselin L (1995) Local indicators of spatial association—LISA. Geogr Anal 27:93–115
Anselin L, Getis A (1992) Spatial statistical analysis and geographic information system. Ann Reg Sci 26:19–33
Bates DV, Sizto R (1987) Air pollution and hospital admissions in Southern Ontario: the acid summer haze effect. Environ Res 43:317–331
Burnett JW, Bergstrom JC, Dorfman JH (2013) A spatial panel data approach to estimating U.S. state-level energy emissions. Energy Econ 40:396–404
Chen RJ, Kan HD, Chen BH, Huang W, Bai ZP, Song GX, Pan GW (2012) Association of particulate air pollution with daily mortality: the China Air pollution and health effects study. Am J Epidemiol 175:1173–1181
Dong L, Liang HW (2014) Spatial analysis on regional air pollutions and CO2 emissions in China: emission pattern and regional disparity. Atmos Environ 92:280–291
Donkelaar A, Martin RV, Brauer M (2010) Global estimates of ambient fine particulate matter concentrations from satellite-based aerosol optical depth: development and application. Environ Health Prospect 118:847–855
Environmental Information Network (2012) A panorama of air pollution in China seen from space. Available online: http://www.12369.com.cn/news/detail?id=1403. Accessed 21 Feb 2012
Han LJ, Zhou WQ, Li WF, Li L (2014) Impact of urbanization level on urban air quality: a case of fine particles (PM2.5) in Chinese cities. Environ Pollut 194:163–170
Hossein HM, Kaneko S (2013) Can environmental quality spread through institutions? Energy Policy 56:312–321
Hussain SQ, Ahn SY, Park H, Kwon G, Raja J, Lee Y, Balaji N, Le AHT, Yi J (2013) Light trapping scheme of ICP-RIE glass texturing by SF6/Ar plasma for high haze ratio. Vacuum 94:87–91
Jansen RC, Shi Y, Chen JM, Hu WJ, Xu C, Hong SM, Li J, Zhang M (2014) Using hourly measurements to explore the role of secondary inorganic aerosol in PM2.5 during haze and fog in Hangzhou, China. Adv Atmos Sci 31:1427–1434
Lesage J, Pace RL (2014) Introduction to spatial econometrics. Peking University Press, Beijing, pp 99–100
Ma LM, Zhang X (2014) The spatial effect of haze pollution in China and the impact from economic change and energy structure. China Ind Econ 4:19–31
Ma JZ, Xu XB, Zhao CS, Yan P (2012) A review of atmospheric chemistry research in China: photochemical smog, haze pollution, and gas-aerosol interactions. Adv Atmos Sci 29:1006–1026
Maddison D (2006) Environmental Kuznets Curves: a Spatial Econometric Approach. J Enviro Econ Manag 51:218–230
Moran PAP (1950) Notes on continuous stochastic phenomena. Biometrika 37(1-2):17–23
Mu Q, Zhang SQ (2013) An evaluation of the economic loss due to the heavy haze during January 2013 in China. China Environ Sci 33:2087–2094
She L, Cao XX (2012) Reflections on the disaster emergency response capacity of China. Manag W 7:176–177
Sun J, Wang JN, Wei YQ, Li YR, Liu M (2016) The haze nightmare following the economic boom in china: dilemma and tradeoffs. Int J Environ Res Public Health 13:402–414
Tang LL, Zhang YJ, Sun YL, Yu HX, Zhou HC, Wang Z, Qin W, Chen P, Zhang HL, Chen Y, Jiang RX (2014) Components and optical properties of submicron aerosol during the lasting haze period in Nanjing. Chin Sci Bull 59:1955–1966
Thurston GD, Iot K, Hayes CG, Bates DV, Lippmann M (1994) Respiratory hospital admissions and summertime haze air pollution in Toronto, Ontario: consideration of the role of acid aerosols. Environ Res 65:271–290
Tobler W (1970) A computer movies simulating urban growth in the Detroit region. Econ Geogr 46:234–240
Tran BN, Ferris JP, Chera JJ (2003) The photochemical formation of a titan haze analog. Structural analysis by x-ray photoelectron and infrared spectroscopy. Icarus 162:114–124
Wu JN, Zhang P, Yi HT, Zhao Q (2013) What Causes Haze Pollution? An Empirical Study of PM2.5 Concentrations in Chinese Cities. Sustainability 8:132–146
Wu XH, Tan L, Guo J, Wang YY, Liu H, Zhu WW (2016) A study of allocative efficiency of PM2.5 emission rights based on a zero sum gains data envelopment model. J Clean Prod 113:1024–1031
Xie YB, Chen J, Li W (2014) An assessment of PM2.5 related health risks and impaired values in Beijing residents in a consecutive high-level exposure during heavy haze days. Environ Sci 35:1–8
Yang J, Niu ZQ, Shi CE, Liu DY, Li ZH (2010) Microphysics of atmospheric aerosols during winter haze/fog events in Nanjing. Environ Sci 31:1425–1431
Zhang HB (2014) ‘Robust’ Influence Factors of Environment Pollution in China: An Empirical Analysis Based on Spatial Panel Data EBA Model. Master Thesis, Hefei University of Technology, Anhui, China
Zhang W, Zhong NS (2014) “Whole-nation system” for haze control and treatment. China High-tech Industry Herald 10th March:004
Zhang XY, Zhang XY, Sun JY, Wang YQ, Li WJ, Zhang Q, Wang WG, Quan JN, Cao GL, Wang JZ, Yang YQ, Zhang YM (2013) Factors contributing to haze and fog in China. Chin Sci Bull 58:1178–1187
Zhang RH, Li Q, Zhang RN (2014) Meteorological conditions for the persistent severe fog and haze event over eastern China in January 2013. Sci China 57:26–35
Zhao XJ, Pu WW, Meng W, Ma ZQ, Dong F, He D (2013) PM2.5 pollution and aerosol optical properties in fog and haze days during autumn and winter in Beijing area. Environ Sci 34:416–423
Zhu PH, Yuan JJ, Zeng WY (2010) Analysis of Chinese Industry Environmental Kuznets Curve Empirical Study Based on Spatial Panel Model. China Ind Econ 6:65–74
Acknowledgements
This research was supported by The Natural Science Foundation of China (71373131, 41501555, 91546117), National Social and Scientific Fund Program (11CGL100), National Soft Scientific Fund Program (15BTJ019), National Industry-specific Topics (GYHY 201506051), and The Ministry of Education Scientific Research Foundation for the returned overseas students (No. 2013-693, Ji Guo). This research was also supported by the Priority Academic Program Development of Jiangsu Higher Education Institutions and the Flagship Major Development of Jiangsu Higher Education Institutions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, X., Chen, Y., Guo, J. et al. Spatial concentration, impact factors and prevention-control measures of PM2.5 pollution in China. Nat Hazards 86, 393–410 (2017). https://doi.org/10.1007/s11069-016-2697-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-016-2697-y