
Abstract
Landslide susceptibility assessment is a major research topic in geo-disaster management. In recent days, various landslide susceptibility and landslide hazard assessment methodologies have been introduced with diverse thoughts of assessment and validation method. Fundamentally, in landslide susceptibility zonation mapping, the susceptibility predictions are generally made in terms of likelihoods and probabilities. An overview of landslide susceptibility zoning practices in the last few years reveals that susceptibility maps have been prepared to have different accuracies and reliabilities. To address this issue, the work in this paper focuses on extreme event-based landslide susceptibility zonation mapping and its evaluation. An ideal terrain of northern Shikoku, Japan, was selected in this study for modeling and event-based landslide susceptibility mapping. Both bivariate and multivariate approaches were considered for the zonation mapping. Two event-based landslide databases were used for the susceptibility analysis, while a relatively new third event landslide database was used in validation. Different event-based susceptibility zonation maps were merged and rectified to prepare a final susceptibility zonation map, which was found to have an accuracy of more than 77 %. The multivariate approach was ascertained to yield a better prediction rate. From this study, it is understood that rectification of susceptibility zonation map is appropriate and reliable when multiple event-based landslide database is available for the same area. The analytical results lead to a significant understanding of improvement in bivariate and multivariate approaches as well as the success rate and prediction rate of the susceptibility maps.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Landslides triggered by rainfall are common problems in tropical and subtropical regions of the world. Repeatedly occurred landslides year after year and month after month have led to heavy damages to property and lives throughout the world. To reduce and manage landslide-related disasters, it is important to assess areas susceptible to landslides during extreme rainfall events. Hence, in recent years, the assessment of landslide susceptibility, landslide hazard, and related disaster risk has become one of the major topics of research.
In the last few decades, various landslide susceptibility and landslide hazard assessment methodologies have been introduced with versatile thoughts of analysis. In the growing research efforts, basically, intrinsic (e.g., geology, geomorphology, soil depth, soil type, slope gradient, slope aspect, slope curvature, elevation, land use pattern, drainage patterns, and so on) and extrinsic variables (heavy rainfall, earthquakes, and volcanoes) are used to describe landslide susceptibility and hazard assessment (Siddle et al. 1991; Wu and Siddle 1995; Atkitson and Massari 1998; Dai et al. 2001; Cevik and Topal 2003; van Westen et al. 2003; Regmi et al. 2010; Ghimire 2011; Dahal et al. 2008a, b, 2012; Bednarik et al. 2012; Kayastha et al. 2012; Pourghasemi et al. 2012). In landslide hazard assessment practice, the term “landslide susceptibility mapping” is addressed without considering the extrinsic variables in determining the probability of occurrence of a landslide event (Dai et al. 2001; Dahal et al. 2008a, b; Ghosh et al. 2012). In 2008, JTC-1 (Joint International Society of Soil Mechanics and Geotechnical Engineering (ISSMGE), International Society of Rock Mechanics (ISRM), and International Association of Engineering Geology (IAEG) Technical Committee on Landslides and Engineered Slopes) prepared the guidelines and defined landslide susceptibility and hazard in the prospect of interaction between intrinsic and extrinsic variables as well as frequency of occurrence of the events (Fell et al. 2008). According to JTC-1 definition, landslide susceptibility is a quantitative or qualitative assessment of the classification, volume (or area), and spatial distribution of landslides which exist or may potentially occur in an area. Landslide susceptibility zoning requires an inventory map of landslides occurred in the past together with the assessment of the areas with the potential of landslide occurrence in future but with no assessment of frequency (annual probability) of occurrence (Cascini 2008). Landslide susceptibility map includes landslides which have their source in the area or may have their source outside the area but may travel through the area or return into the area (Fell et al. 2008; Cascini 2008; Frattini et al. 2010).
Landslide susceptibility is often defined as the propensity of an area to generate landslides (Guzzetti et al. 2006) with susceptibility represented by a relative value in a given area. In general, landslide susceptibility can be depicted as the physical potential of the process to produce landslides and associated damage. Fundamentally, landslide susceptibility can be characterized by statements beginning with “what,” “where,” and “when.” Unfortunately, the ability to predict landslide susceptibility precisely is always limited; as a consequence, the susceptibility predictions are generally made in terms of likelihoods and probabilities. In many landslide susceptibility zonation techniques, probabilities of failure are classified as per the distribution of susceptibility index for preparing landslide susceptibility zonation maps. In general, however, a landslide susceptibility zonation technique should be able to demonstrate spatial (i.e., what will occur? and where will it occur?) and temporal occurrence (i.e., when will it occur?) of future landslides in terms of probability.
In landslide susceptibility assessment, landslide inventory is always necessary, but most previous studies have considered only a single-event landslide database to assess landslide susceptibility as well as to evaluate the accuracy of the susceptibility zonation map. With wide development of GIS and statistical data processing techniques, many different statistical or quantitative methods have been applied so far in various studies of landslide susceptibility zonation. Such studies can be identified on the basis of the technique used, such as probabilistic methods (Lee and Choi 2004; Guzzetti 2005, Dahal et al. 2008a, b; Regmi et al. 2010; Ozdemir 2011), logistic regression methods (Atkitson and Massari 1998; Dai et al. 2001; Nefeslioglu and Gokceoglu 2011; Dahal et al. 2012), and artificial neural network methods (Ermini et al. 2005; Lee et al. 2003; Gómez and Kavzoglu 2005; Melchiorre et al. 2008; Poudyal et al. 2010).
The available literature highlights an extensive development in the landslide susceptibility and hazard zoning techniques. The JTC1 has also well described the methodology for landslide susceptibility and hazard (Cascini 2008). However, it still lacks information about standardization of landslide susceptibility map for all regions. Following the JTC1 definition of landslide hazard, it is difficult to prepare an extreme weather-based landslide hazard zonation map, particularly because annual probability cannot be interpreted in terms of extreme events such as typhoon, hurricane, or cyclone. The same problem arises in case of landslide susceptibility zonation for extreme monsoon events.
Most available scientific works have evaluated landslide susceptibility in terms of good accuracy of landslide prediction in their study area. However, even in the same region and similar geological and geomorphological settings, there is remarkable lack of uniformity in methodology and accuracy of the landslide susceptibility zonation maps. An overview of landslide susceptibility zoning practices in the last few years reveals that susceptibility maps have been prepared to have different accuracies and reliabilities. To address this issue, the work in this paper focuses on extreme event-based landslide susceptibility zonation mapping and its evaluation.
The main objective of this study is to prepare a validated landslide susceptibility map of the study area by rectifying landslide susceptibility zonation maps developed out of multiple landslide events. Unlike other statistical methods and validation procedures, this study incorporates two separate event-based landslide data for the zonation mapping and validates the obtained results using new landslide information. This work also attempts to represent a good compromise between comprehensibility, accuracy, and efficiency of landslide susceptibility zonation maps. The study specifically focuses at: (1) preparing InfoVal and logistic regression models and apply them in the study area for the assessment of landslide hazard index (LHI), (2) verifying the accuracy of bivariate and multivariate approaches for event-based landslide susceptibility analysis, (3) evaluating the rectification procedure of landslide susceptibility mapping, and (4) preparing a validated landslide susceptibility zonation map of the area.
2 Study area
2.1 General features
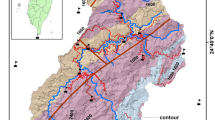
The study area, as shown in Fig. 1, lies in central north part of Shikoku Island of Japan. It covers a little more than 30 km2 forested hilly area of Niihama city in the eastern part of Ehime prefecture, which is the second populous city in the prefecture with more than 125,000 residents.

a Location map of the study area and b simplified geological map of Shikoku, Japan (MTL—Median Tectonic Line and BTL—Butsuzo Tectonic Line, the geological map is modified after Geological Survey of Japan (2002)
The geographical location of the study area is 33°55′48.57″N to 34°00′37.06″N in latitude and 133°17′55.16″E to 133°25′23.15″E in longitude. Surrounded by mountains and hills on the south and east and facing Seto Inland Sea on the north, Niihama city is well known for its Besshi copper mine in the southern mountainous region. The copper deposits were discovered in 1690, and the mining began in the following year and was closed in 1973. As the hills of the study area are mainly composed of sedimentary rocks, base areas of the hills are composed of debris flow deposits. Before World War II (1939–1945), the study area was sparsely populated, and traces of old terraced farming and a few abandoned houses are still found in the hill slopes. At present, there are no settlements on the slopes, but hillbases are highly populated. The elevation of the study area varies from 3 to 285 m from mean sea level, and it is surrounded by river flood plains in all directions except for the northeast corner, where the hills have coastal cliffs facing the Seto Inland Sea.
The Niihama plain is characterized by the alluvial fan of two rivers, Kawahigashi river and Kawanishi river, while the study area consists of well-forested hills on the eastern part of the plain. As shown in Fig. 1, the hills are divided into two regions: Kita-yama and Nishi-no-yama. The forest vegetation mainly consists of evergreen broad leaf and deciduous broad leaf types of plants. For example, Japanese red pine (Pinus deniflora), camphor (Cinanamomum camphora), and Japanese oak (Quercus serrata and Quercus variabilis) can be found as well-grown species, while Baby rosa (Rosa multiflora) and China root (Smilax china) can be found as shrubs in the study area.
2.2 Geological setting
Geologically, the study area is composed of Miocene sandstone, shale, conglomerate, and tuff deposits, which belong to the Izumi Group of Ryoke Belt (Fig. 1). The Ryoke Belt is a well-known paired-metamorphic belt of high temperature-low pressure type and exhibits a sharp contrast to the high pressure-low temperature type Sambagawa metamorphic belt on the south separated by the Median Tectonic Line (MTL). It is composed of metamorphic rocks (e.g., pelitic, psammitic and siliceous schists, and gneisses), sedimentary rocks, and a series of granitic plutons called the Ryoke granites. The metamorphic rocks in the Ryoke Belt occupy only 20–30 % of the belt area. This belt occupies an important area of the outermost part of inner zone of southwest Japan, and in Shikoku Island, it is represented by three rock units, namely late Cretaceous granitic rocks, late Cretaceous sedimentary rocks (Izumi Group), and Miocene volcanic rocks (Sanuki Group). Particularly, the Cretaceous granite is widely distributed in the north of Seto Inland Sea (Fig. 1).
On the northern side of the MTL, mainly in Shikoku region, a narrow belt of thick piles of intercalated sandstone and shale together with a few thin beds of acidic tuff runs east–west. These sediment piles are of late Cretaceous age and are collectively known as the Izumi Group. The sediment strata generally dip at 30°–50° toward the east and form a synclinal structure. The northern wing of the Izumi Group lies unconformably over rocks of the Ryoke Belt, and the southern wing is in fault contact with the Sambagawa Belt. A large part of the Izumi Group is marine, yielding fossil shells. The basal conglomerate of the northern wing contains pebbles of granite, quartz porphyry, and mica schist, which were all derived from the Ryoke Belt on the north. The geological unit of the study area consists of 84 % alternating bands of sandstone and shale of the Izumi Group.
2.3 Rainfall and weather
Japan has a very diverse climate. In global climatic environment, Japan belongs to a temperate environment with cold winter and hot summer. This may be partially accounted for by the presence of a cold current, which extends farther south in winter than in summer on both sides of the Japan islands, and by their position in the path of the monsoon winds. Within the Japan islands, differences in latitude produce marked differences in climate and the great variation in altitude produces much local diversity irrespective of latitude.
Shikoku region has a mild climate but it comparatively receives heavy precipitation. The mean annual precipitations in different parts of Shikoku range from 1,000 and 3,500 mm, which are nearly 20 % greater than the mean precipitation of whole Japan, where a maximum mean precipitation of around 1,950 mm in Hokuriku (northern) region and a minimum mean precipitation of around 950 mm in Hokkaido region have been recorded. Shikoku Island usually receives extensive typhoon rainfalls in southern part rather than in northern part; as a result, rainfall-related slope failure phenomena are common in central and southern Shikoku.
A lower value of mean annual precipitation in Shikoku is represented by northeast area while in contrast, the southern Shikoku Mountain Range is usually hit by an annual rainfall of 3,500 mm, which is significantly high in the whole country. Orographic effect of the Shikoku Mountain Range is the main cause of extreme rainfall in the southern part of Shikoku (Fig. 2). The prevailing winds (moisture-laden vapor) from the Pacific Ocean get intercepted by the mountains and cause extreme rainfall on the south of the mountains. The northern part of Shikoku including the study area, however, has Mediterranean type of climate and is in the rain shadow zone if the Pacific Ocean side moisture-laden vapors are supposed to cause rainfall in Shikoku. Although nearly 30 % days in a year are rainy, the period of comparatively heavy precipitation in Shikoku is June–September. The causes of rainfall, in an order of importance, are typhoons, low atmospheric pressures, seasonal rain fronts, and thunderstorms. In particular, the heavy precipitations exceeding an hourly value of as high as 100 mm are caused by typhoons in July to September.

Geomorphological map and isohyets of the Shikoku Island. The isohyets of the study area show that the mean annual precipitation of the study area is about 1,500 mm
3 Methodology
Both bivariate and multivariate statistical approaches have been considered for assessing the landslide susceptibility indexes. In the bivariate approach, the InfoVal model was used, while in the multivariate approach, the logistic regression model was used. Both these are well-established models and have been used in different parts of the world (such as Guzzetti et al. 1999; Dai and Lee 2002; Ohlmacher and Davis 2003; Zhu and Huang 2006; Chen and Wang 2007; Akgün and Bulut 2007; Chauhan et al. 2010; Dahal et al. 2012). The models and the data preparation details are described in the following subsections.
3.1 InfoVal model
Proposed by van Westen (1997), the Information Value (InfoVal) method for landslide susceptibility analysis only considers probability of landslide occurrence within a certain area of each class of a landslide causative factor. This method is also regarded as a simplified version of the method applied in Yin and Yan (1988), which determines the weight of a particular class in a causative factor using the following equation.
where W i is the weight given to all classes of a particular landslide causative factor layer, D clas is the landslide density within the landslide causative factor class, and D map is the sum of the landslide density within the entire landslide causative factor class layer. InfoVal method is one of the very familiar statistical methods of landslide susceptibility study, well practiced in different parts of the world (e.g., Yin and Yan 1988; Jade and Sarkar 1993; van Westen 1997; Cevik and Topal 2003; Oztekin and Topal 2005; Pantha et al. 2008; Saha et al. 2005; Dahal et al. 2010).
3.2 Logistic regression model
Logistic regression model is used to determine the relationship between landslide occurrence and related factors (Guzzetti et al. 1999; Dai and Lee 2002; Ohlmacher and Davis 2003; Ayalew and Yamagishi 2005; Lee 2005; Zhu and Huang 2006; Chen and Wang 2007; Akgün and Bulut 2007; Chauhan et al. 2010; Bui et al. 2011; Dahal et al. 2012). This model is useful when the outcome variable or dependent variable is binary or dichotomous. The dependent variable in this analysis is the absence or presence of a landslide.
Considering n number of independent variables, x 1, x 2, x 3, …, x n , that affect landslide occurrences, the vector X = (x 1, x 2, x 3, ……, x n ) is defined. In logistic regression analysis, the logit y is assumed as a linear combination of independent variables and is given as follows.
where b 0 is a constant of the equation, and b 1, b 2, …, b n are the coefficients of independent variables, x 1, x 2, x 3, …, x n . For landslide hazard assessment, the dependent variable is a binary variable, with values of 1 or 0, representing the presence or absence of landslides. Quantitatively, the relationship between the occurrence and its dependency on several variables can be expressed as follows (Hosmer and Lemeshow 2000).
where P is the estimated conditional probability of landslide occurrence. From Eqs. 2 and 3, the natural logarithm of the odds, log{P/(1 − P)}, is obtained to have a linear relationship with the independent variables as in Eq. 4.
The goodness of fit of the model was evaluated by Hosmer–Lemeshow test (Hosmer and Lemeshow 2000). The sign of estimated coefficient of a dependent variable determines the effect of that variable on the probability of landslide occurrence. So, these values were utilized to decide the final landslide susceptibility indexes (LSI) of the study area.
There are three main types of sampling practices in logistic regression modeling. First, use of all data from the whole study area, which undoubtedly creates a situation that the comparison is not the same for landslide and non-landslide pixels (Guzzetti et al. 1999; Ohlmacher and Davis 2003). Second, all landslide pixels and an equal number of non-landslide pixels are selected for regression analysis to obtain a regression equation. This method minimizes the bias in the data (Zhu and Huang 2006; Das et al. 2010; Ramani et al. 2011). Non-landslide pixels from landslide-free area can be obtained by random sampling (Chang et al. 2007; Das et al. 2010) or buffering landslide boundary at some distance (Ramani et al. 2011). The third practice involves dividing the data as training and validating according to variation in datasets. There are two cases in this method: unequal pixels (Atkitson and Massari 1998; Van Den Eeckhaut et al. 2006) and equal proportion of landslide and non-landslide pixels (Dai and Lee 2002; Bai et al. 2010). In this study, we have used all landslide pixels and an equal number of non-landslide pixels to obtain logistic regression equations based on the two landslide events. Finally, the regression equations were used to obtain landslide susceptibility indexes for the first and second landslide events separately.
3.3 Data collection
Data collection and preparation of a spatial database are an essential first step for the landslide susceptibility zonation, which help extract relevant causative parameters. This is followed by the assessment of landslide susceptibility using the relationship between landslides and causative factors in bivariate and multivariate models, and the subsequent validation of the results. For modeling in InfoVal and logistic regression, a number of thematic data of the causative factors were considered. They include (1) slope, (2) slope aspect, (3) distance to drainage, (4) sediment transport index, (6) relief, (7) drainage density, (8) geology, and (9) soil type. Field surveys were also conducted for data collection and preparation of data layers of various factors. These data sources were then used to generate various thematic layers using GIS. Methodological descriptions of preparing the data layers are given in the subsequent subheadings and the prepared data layers are presented in Fig. 3.

Various data layers used in the susceptibility assessment
3.3.1 Landslide characteristics and inventory maps
A landslide inventory is the simplest map of observable landslides in a target area. For this study, depending on the landslide events, three landslide inventory maps were prepared. The study area was hit by one extreme seasonal rain front in 2000 and by two typhoon events in 2004. In September 2000, the seasonal rain front-related extreme rainfall triggered a total of 53 landslides in the study area with greater failure concentration in Kitayama area than Nishi-no-yama area. In 2004, the whole Japanese archipelago was hit by a total of 10 typhoons, while the Shikoku Island suffered extensive damage in nine of them. Typhoon 0423 and Typhoon 0421 mostly affected Ehime, Kochi, and Kagawa prefectures while Typhoons 0404, 0406, 0410, 0411, 0415, 0416, and 0418 caused an extensive damage including fatal loss in Kochi, Tokushima, and Ehime prefectures (Hiura et al. 2005; Dahal et al. 2008b, c, 2011).
Niihama area was also badly affected by the typhoon rainfalls of September–October 2004, which triggered a large number of landslides and caused a great loss of life and property. Rather, Niihama was the most affected area in Ehime Prefecture in 2004 typhoons. It was later understood that hourly rainfalls exceeding 50 mm and total 24-h rainfalls exceeding 300 mm were the main causes of slope failures at the selected hilly area (Dahal et al. 2006). It was interesting to note that more landslides occurred in October than September. A total of 424 landslides were identified in September, while this number was 1,396 in October. In this paper, for an easy reference, the September 2000 landslides are referred to as first event landslides, the September 2004 landslides are referred to as second event landslides, and the October 2004 landslides are referred to as third event landslides. The event rainfall of each landslide event and rainfall pattern of the study area are illustrated in Fig. 4. Rainfall data of last 38 years suggested that maximum value of annual rainfall, one-day rainfall, and 1-h rainfall achieved in 2004.

Rainfall in the study area, a event rainfall in September 2000, b event rainfall in September 2004, c event rainfall in October 2004, d annual rainfall pattern of Niihama area, (SD standard deviation), e maximum 1-h rainfall of Niihama area in the period of 1976–2012, f maximum one-day rainfall of Niihama area in the period of 1976–2012
In the inventory map, only primary failures were considered in delineating the landslides. Aerial survey data availed by Ehime Prefecture Sabo Division were the primary source of landslide delineation for all three events. However, the landslide scars mapped in the field as well as referred from the database of Ehime Prefecture Sabo Division were revised over Google Earth images before the final landslide inventory maps for all three events were prepared.
The first and second event landslides were used to assess landslide susceptibility index (LSI) of the study area through both InfoVal and logistic regression modeling and to prepare the zonation maps. A total of four zonation maps were prepared (two through InfoVal model and two through logistic regression model). Each LSI map was then divided into 100 classes of susceptibility levels, and two classified LSI maps were rectified by merging the same susceptibility level. Finally, predictability of the rectified susceptibility zonation maps of each model was evaluated by prediction rate and success rate (Chung and Fabbri 2003) estimated from area under the ROC (receiver operating characteristic) curve method.
3.3.2 DEM-based causative parameter
A digital elevation model (DEM) of the terrain is a key to generate various geomorphological parameters that control landslide activities in an area. For the study area, a 10-m DEM is available, which was used to derive geomorphology-related thematic data layers such as slope, aspect, relative relief, distance to drainage, drainage density, and sediment transport index.
Field measurements revealed that most landslides occurred on slopes of 20° to 30°. So, in this particular study, the slope data layer is comprised of five classes as <10°, 10° to 20°, 20° to 30°, 30° to 40°, and >40° (Fig. 3). Likewise, as a frequently considered terrain dataset, the direction of maximum slope of the terrain surface, referred to as slope aspect, of the study area was divided into nine classes of N, NE, E, SE, S, SW, W, NW, and Flat (Fig. 3). Both the slope and aspect maps were prepared in ILWIS 3.7 platform. These classified slope and aspect maps were then used to calculate LSI through InfoVal method, while the same pixel values of slope and aspect were also used in logistic regression modeling.
Relative relief is another DEM-derived parameter, which is defined as the maximum height dispersion of a terrain normalized by its length or area. In this study, it was computed as the difference between maximum and minimum elevations within a given relief class, and a relief map with a total of five classes at an interval of 50 m was prepared (Fig. 3). This relief map was used in InfoVal modeling, while for the logistic regression modeling, the elevation values from the DEM dataset were directly used.
As most of the landslides in the study area were found to have occurred along the streams, the relative location of a landslide with respect to stream was considered to be one of the important geomorphology-related causal factors. So, a distance-to-drainage map was also prepared on the basis of field observations as well as a general understanding that landslides are more frequent along the streams due to groundwater movement toward the streams, toe cutting, and upslope erosion. In order to prepare the distance-to-drainage map, the drainage segment map was first rasterized and the distance to drainage was calculated in meters. The resultant map was then divided into 7 classes as <10, 10–20, 20–30, 30–50, 50–70, 70–100, and >100 m. The prepared raster map was used in InfoVal modeling, while for the logistic regression modeling, the pixel values were directly considered (Fig. 3).
During and after rainfall events, the surface water generally flows from convex terrains and accumulates in concave terrains. This process is known as flow accumulation, which is a measure of terrain that contributes to the accumulation of surface water. Since the flow accumulation also governs sediment transportation index (STI) of topographic hollows, STI was also considered to be a relevant parameter in this study, which accounts for the effect of topography on erosion process. As per the histogram information of sediment transport index values in the study area and equal area distribution, the STI values were classified into six categories as <10, 10–20, 20–30, 30–50, 50–100, and >100 m, and an STI map was prepared (Fig. 3) for the InfoVal model analysis. In logistic regression analysis, however, the pixel values were directly used to obtain the regression equations.
3.3.3 Drainage density
Drainage density is a ratio of total length of streams in a drainage basin to the total projected area of the basin. In this study, however, the drainage density was not computed in the basin scale; it was rather calculated in 1-km grid scale of the study area and classified into five categories as very low drainage density (<0.001 km−1), low drainage density (0.001–0.003 km−1), medium drainage density (0.003–0.005 km−1), high drainage density (0.005–0.008 km−1), and very high drainage density (>0.008 km−1). The classified drainage density map was then used in InfoVal modeling, but in the logistic regression modeling, pixel values of the drainage density were used instead.
3.3.4 Geological map
Previous studies have revealed that geology plays a major role in susceptibility of a slope to landsliding. Different geological units are found to have different susceptibilities for landslide occurrence. In this study, two geological parameters, that is, lithology and proximity to fault–fold, were considered for the analysis. Sandstone, mudstone, tuff, and conglomerate are the main lithological units of the study area. The geological map by Miyahisa et al. (1976) was referred for the preparation of lithological map and fault–fold proximity map (Fig. 3).
3.3.5 Soil map
Surface soil type greatly influences the occurrence of shallow landslides which is also true in northern Shikoku (Dahal et al. 2006, 2008b, 2011). The soil map prepared by Simizu and Tanbara (1976) was used in this study (Fig. 3). They have classified the top soil of the study area into five formations, namely Otani 1, Teranoo, Tsunatsukeyama 1, Tsunatsukeyama 2, and Tsunatsukeyama 3. Otani 1 is the Pleistocene sandy soil, which is basically found in topographic hollows. Teranoo is a thin-layered residual soil developed basically on sandstones of the Izumi Group. It consists of strongly acidic fine sandy soil and is usually found on steep slopes. Shallow failures and top layer erosion are very common in Teranoo soil slopes. Tsunatsukeyama 1 formation is developed in topographic hollows as well as ridge areas. It consists of brownish, relatively dry residual soil deposited over sandstone and shale of the Izumi Group. Likewise, Tsunatsukeyama 2 formation is found just below Tsunatsukeyama 1 formation. It is widely distributed in the study area and many landslides can be found in this formation. It also consists of many angular fragments of bedrock and the soil is sandy in nature in many places. Tsunatsukeyama 3 is another forest soil formation, but it has volcanic ash in lower part. This soil mass is particularly supportive to enhanced growth of Japanese cedar and cypress.
4 Analysis and results
4.1 Landslide characteristics
Most of the landslides in the study area can be classified as shallow debris slides (based on Varnes 1984). The main features of the 2004 September and October landslides (i.e., second and third event landslides) are as follows.
-
In general, they can be identified as translational slides, rotational slides, and a combination of both on the basis of the shape of the failure surface (Fig. 5). The translational slides were the most dominant failure types (more than 90 %) (Dahal et al. 2006, 2008c).
Fig. 5 
Schematic representation of failure pattern observed in study area after 2004 typhoon. a Longitudinal section, b transverse section
-
The volume of failed mass was generally in a range of a few tens to a few hundreds of cubic meters.
-
In most cases, majority of the debris slides and flows were found to be shallow with a failure depth of less than 2 m.
-
Bedrocks were well exposed after the slide.
-
Many of the landslides could be identified as translational debris slides occurring first on a steep zero-order valley or topographic hollow and then flowing through a first-order stream channel. Generally, the slides were found to measure several meter wide and tens of meter long. All of these initial soil slides were found to have been mobilized completely to transform into debris flows, which continued to erode the soil mass en route resulting in either huge debris pile-up near the mouth of the streams or continuous travel through the second-order streams up to a considerable distance.
-
In some cases, the down-to-top failure was also noticed, and it was exactly like head ward erosion of the first-order stream onto the topographic hollow at an extremely high rate of erosion.
-
Finally, the field observations also revealed that the most landslides occurred in natural as well as man-made slopes with thick residual or colluvial deposits and strongly weathered bedrock of sedimentary origin.

The inventory map prepared out of all events of landslides considered in this study is shown in Fig. 6.

Landslide inventory map of the study area showing distribution of all landslide events
4.2 Data analysis
4.2.1 InfoVal model
To evaluate the contribution of each causative factor to landslide susceptibility, both first and second event landslide inventory data layers were separately compared with various thematic data layers. For this purpose, the basic equation of InfoVal method (i.e., Eq. 1) is converted into Eq. (5) in terms of numbers of pixels.
where W i is weight given to a certain parameter class (such as soil formation or slope class), Npix a is the number of landslide pixels in a certain parameter class, and Npix b is the total number of pixels in a certain class of causative factor. The natural logarithm is used to take care of large variation in the weights.
All thematic maps of the considered causative factors were rasterized in a pixel size of 10 m × 10 m and were combined with the landslide inventory map for calculating the LSI. The calculation was basically carried out through a script file written in ILWIS 3.7 and consisting of a series of GIS command to support Eq. (5). The calculated weight values are either positive or negative. If a positive weight value is obtained, the causative factor is considered to favor the occurrence of landslides, but if it is negative, the factor is considered to be ineffective. The obtained weight values were assigned to the classes of each thematic layer, and the resultant weighted thematic maps were overlaid and numerically added to produce an LSI map. The weight integration approach used for each landslide event is as follows.
where W iSlope , W iAspect , W iDrnDen , W iDisDrain , W iDisLinea , W iGeology , W iSoil , W iRelief , W iSTI , respectively are distribution-derived weights of slope, slope aspect, drainage density, distance to drainages, distance to lineaments, geology, soil formations, relief, and sediment transport index factor maps, for InfoVal method. The suffix “j” in Eq. (6) represents a particular class in the causative factors.
Finally, the calculated probability was crosschecked for reliability by ROC (receiver operating characteristics) curve method. The landslide susceptibility probability index based on the first event landslides resulted in an ROC value of 0.826, while the second event landslide yielded an ROC value of 0.772 (Table 1).
4.2.2 Logistic regression model
As also mentioned in previous section, all landslide pixels and an equal number of non-landslide pixels were used to obtain logistic regression equations for two landslide events. As the dependent variable is dichotomous and the relationship between the dependent variables and independent variables is nonlinear, logistic regression model was used on the causative factors. In this study, geology and soil formation thematic maps were categorized into various formations. As each parameter was a nominal variable, it was converted into a numeric variable by coding. For this purpose, landslide density (Carrara 1983) was used because it avoids the creation of an excessively high number of dummy variables. The following equation was used for the calculation of landslide normalize densities in each class of causative factors.
where L D is landslide density, a i is the area of ith class of a causative factor (such as slope class of 10° to 20°), l i is landslide area within ith class of the factor (such as slope of 10° to 20°), and n is the total number of classes of a particular causative factor. All parameter maps were then overlaid with the landslide inventory map so as to calculate landslide densities for each causal factor based on Eq. (7). Moreover, all classes of causative factors were converted into numerical variable of landslide density. The landslide inventory map domain was also changed from landslide presence and landslide absence to numerical variables as 1 and 0, respectively. All spatial databases of causative parameters and landslide inventory were exported to a statistical package (SPSS in this study) for logistic regression analysis of first and second landslide events. Finally, the following logistic regression equations were extracted out of the regression analyses.
The data used in the logistic regression modeling and overall model statistics of the regression analysis conducted for both landslide events are presented in Table 1. Hosmer–Lemeshow test shows that the goodness of fit of the equation can be well accepted because the significance of chi-square is 0.156 for the first event landslides and 0.126 for the second event landslides. In Hosmer–Lemeshow test, if the significance of chi-square value is less than 0.05, the logistic regression model cannot be accepted (Zhu and Huang 2006; Chen and Wang 2007; Dahal et al. 2012). The Cox and Snell R2 values and Nagelkerke R2 show that the independent variables can explain the dependent variables in an acceptable way for both the landslide events. Likewise, the ROC values of probability obtained from the first and second event landslides are 0.797 and 0.726, respectively (Table 1). For a valid regression model, the ROC value must be greater than 0.5 (Hosmer and Lemeshow 2000). So, the logistic regression models for both the landslide events in this study are valid and are in well acceptable range.
4.3 Bivariate versus multivariate and zonation maps
From the ROC of the InfoVal and logistic regression models for landslide susceptibility assessment, it is understood that the InfoVal model has a slightly better accuracy than the logistic regression model. It led to a difficulty to decide precisely which model better predicts new landslides (i.e., the third event landslides). Therefore, the LSIs obtained from both the logistic regression and InfoVal models were considered for preparing landslide susceptibility zonation maps of the study area. Considering the InfoVal model based on the first and second event landslides, LSI-1 and LSI-2 maps were prepared, while considering the logistic regression model based on the same event landslides, LSI-3 and LSI-4 maps were prepared, as indicated in Fig. 7. LSI-1 and LSI-3 suggest that the southern part of the study area has higher susceptibility index, whereas LSI-2 and LSI-4 indicate that northern part of the study area is highly susceptible to landslides.

Landslide susceptibility index maps by InfoVal model and susceptibility probability maps by logistic regression model. a LSI-1 was prepared through InfoVal modeling using the first event landslides, b LSI-2 was prepared through InfoVal modeling using the second event landslides, c LSI-3 was prepared through logistic regression modeling using the first event landslides, and d LSI-4 was prepared through logistic regression modeling using the second event landslides
4.4 Rectification of zonation maps
When LSI-1, LSI-2, LSI-3, and LSI-4 are compared with the third event landslides, the ROC value is obtained to be <0.65, which infers that the prediction rate is weak for all susceptibility maps. So, any of these maps cannot be considered as the best suitable susceptibility maps for the study area. According to the definition, after the landslide susceptibility assessment, a zonation map should accurately indicate potential zone of occurrence of future landslides. In most cases, previous studies on statistical landslide hazard assessment, in most cases, indicate that the accuracy of susceptibility maps ranges from 65 to 85 %. Many comparative studies also suggest that the accuracy of a landslide susceptibility map relies more on good data rather than the model approaches, and in general, the multivariate approaches yield better prediction rates than the bivariate approaches.
If LSI-1, LSI-2, LSI-3, and LSI-4 are visually analyzed for spatial distribution of the susceptibility zones, it is understood that many pixels of lesser susceptibility zones of LSI-1 or LSI-3 are higher susceptibility zones of LSI-2 or LSI-4. The same problem can be noticed in medium and higher susceptible zones too. So, LSI-1 and LSI-3 need to be combined with LSI-2 and LSI-4, respectively, in such a way that the higher susceptible zones are accommodated and preserved well in the zonation map. For this purpose, a rectification process was done, in which, all LSI maps of the two events (i.e., LSI-1 and LSI-2 based on the InfoVal model and LSI-3 and LSI-4 based on the logistic regression model) were first divided into 100 classes of low to high LSI values as per the cumulative distribution percentage of the values. By using “raster mask” operation in ILWIS, each class was extracted from LSI-1, LSI-2, LSI-3, and LSI-4 maps. As a result, a total of 400 maps were prepared; each map has hazard zonation class of 1, 2, 3…100 %. The zonation class maps were denoted by LSI-1-1 %, LSI-1-2 %, LSI-1-3 %,…, LSI-1-100 % for maps generated from LSI-1 and LSI-2-1 % and LSI-2-2 %, LSI-2-3 %… LSI-2-100 % for maps generated from LSI-2. The same procedure was considered for other maps. Then, the maps of the same classes and generated with the same model, such as LSI-1-1 % and LSI-2-1 %, were merged to obtain a combined map of only 1 % class of low to high LSI values in LSI-1 and LSI-2 maps. Following this procedure, a total of 200 merged maps were generated out of the 400 maps. To obtain a single zonation map having zonation from 1 to 100 % classes of low to high LSI values of LSI-1 and LSI-2 maps, all 100 maps of each model were again merged, and a single raster map was prepared. When joining 100 maps of combined 1–100 % classes of low to high LSI values estimated from the InfoVal model, many overlapping zonation class pixels were identified, but they were replaced by higher zonation class pixels. For example, if 1 % zonation class of LSI-1 map and 2 % zonation class of LSI-2 map were in the same pixels after the merge, the priority was given to the 2 % zonation class of LSI-2 map. Following the same rule of prioritizing, a single raster map (LS1) having 1–100 % classes of low to high LSI values of LSI-1 and LSI-2 maps was prepared. The same procedure was followed to merge LSI-3 and LSI-4 maps and to generate LS2. A diagrammatical flow of the rectification procedure is given in Fig. 8. The merging procedure was written as a script consisting of a number of commands in Ilwis 3.7, and the same script was used for merging LSI-1 and LSI-2, and subsequently for LSI-3 and LSI-4.

Rectification procedure and preparation of final landslide susceptibility map, details are in text
4.5 Validation of susceptibility map
The classified raster maps obtained with 1–100 % classes of low to high LSI values were compared with the third event landslides for the estimation of prediction rate. As indicated in Fig. 9, the prediction rate as interpreted from the area under the ROC curve for LS1 map as obtained from the InfoVal modeling is 0.757, while that for LS2 map as obtained from the logistic regression modeling is 0.778. It indicates that in the LS1 map, if 30 % of the classes have high landslide susceptibility value for future landslides, 70 % of the landslides can be correctly fit. For LS2 map too, the same is true. For this level of accuracy, the logistic regression model was considered more suitable for the study area. Then, the final classified landslide susceptibility map through multivariate modeling was prepared, as presented in Fig. 10. To prepare the final zonation map, five susceptibility classes as very low (<20 % class of low to high LSI value), low (20–40 % class of low to high LSI value), moderate (40–60 % class of low to high LSI value), high (60–80 % class of low to high LSI value), and very high (>80 % class of low to high LSI value) were considered (Fig. 10). Figure 11 demonstrates the distribution of the third event landslides in the final susceptibility zonation map, which is evident that the results are very promising. The high susceptibility (HS) and very high susceptibility (VHS) classes cover a total of about 84 % of the third event landslides.

Prediction rate curves for the InfoVal and logistic regression models after the rectification of zonation map

Final landslide susceptibility zonation map of the study area obtained through the logistic regression modeling

Distribution of the third event landslides in shallow landslide susceptibility zonation map prepared through the logistic regression modeling. The concentration of the third event landslides in the susceptibility map indicates 83.66 % of landslide coverage in very high and high susceptibility levels based on the logistic regression modeling, and <1 % new landslides return in very low zone
5 Summary and discussion
In this study, we have tried an integrated methodology for reliable landslide susceptibility zonation mapping. We have used bivariate and multivariate approaches for the same instability factor database to generate the landslide susceptibility maps. The JTC-1 guidelines suggest a tool for landslide susceptibility zonation taking into account the frequency of landslide events. However, an annual value of landslide frequency is not always available, particularly in areas of monsoon- or typhoon-related rainfall. This study has addressed this problem by preparing an event-based landslide susceptibility zonation map.
The study also emphasizes the importance of collecting event-based landslide data. The ancillary data sources, such as Google Earth images and field visit, have also largely helped to revise the existing event-based landslide data. In the estimation of temporal probability of landslides, the landslide databases of three extreme events have certainly enhanced the quality of the probability maps. Up until now, most research studies have considered only a single-event-based landslide database for both modeling and validation. Some researchers have also used old landslides for modeling and new landslides for validation. In this study, however, we have used two event-based landslide databases to come out with a number of zonation maps, which are then rectified to yield the final susceptibility zonation map for the study area. This process has drastically enhanced the quality and accuracy of the zonation map.
In the initial stage of this work, the susceptibility indexes obtained from the first event landslide-based bivariate and multivariate models were evaluated for the predictability by using the second and third event landslide database. At this stage, the prediction rate was below 0.65. Even when the second event landslides were used to estimate the probability and the third event landslides were used to evaluate the predictability, the prediction rate was still below 65 %. This clearly suggests that a single-event-based landslide susceptibility zonation cannot adequately express the future probability, although it often results in a good success rate. To overcome this drawback with the statistical methods of landslide susceptibility zonation, multiple event-based landslide databases may be taken into account. To estimate the probability of future landslide occurrences, event-based probability zonation maps should be combined together to generate a reasonably accurate landslide susceptibility zonation map.
The validation results show that the multivariate model is more accurate than the bivariate model for the area considered in this work. Other researchers have also found the similar results when performing susceptibility analysis in different part of the world (Suzen and Doyuran 2004; Lee and Touch 2006; Lee and Pradhan 2007; Nandi and Shakoor 2009; Yilmaz 2010; Van Den Eeckhaut et al. 2010; Dahal et al. 2012; Schicker and Moon 2012). In this study, significant improvement on available method of probability modeling has been accomplished by incorporating an event-based landslide database. Altogether, nine landslide causative factors were used for the probability evaluation, while it is also considered that incorporation of hydrological and hydrogeological parameters (e.g., micro watershed, depth to groundwater table, and rainfall and so on) will further increase the reliability of zonation maps.
6 Concluding remarks
Preparing a landslide susceptibility map is an essential step in landslide hazard mitigation. In this study, an ideal terrain in the northern part of Shikoku of Japan was selected for bivariate and logistic regression analyses to define spatial distribution of landslide susceptibilities in a scale of 1:10,000. Two event-based landslide databases were used for the susceptibility analysis in 10 m × 10 m pixel size, while a third event landslide database was used in accuracy evaluation of the zonation map.
From this work, we conclude that rectification of susceptibility zonation maps is appropriate and reliable when multiple event-based landslide database is available for the same study area. The results of this work lead to a significant understanding of improvement in bivariate and multivariate approaches as well as the success rate and prediction rate of the susceptibility maps. The methodology described in this paper for event-based landslide susceptibility map is expected to consolidate an understanding that the integration of bivariate and multivariate approaches and rectification of the obtained susceptibility zonation maps lead to drastically enhanced predictability of the landslide susceptibility zonation map for a place where multi-event-based landslide database is available.
References
Akgün A, Bulut F (2007) GIS-based landslide susceptibility for Arsin-Yomra (Trabzon, North Turkey) region. Environ Geol 51:1377–1387
Atkitson PM, Massari R (1998) Generalized linear modeling of susceptibility to landsliding in the Central Apennines, Italy. Comput Geosci 24:373–385
Ayalew L, Yamagishi H (2005) The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda–Yahiko Mountains, Central Japan. Geomorphology 65:15–31
Bai S-B, Wong J, Lu G-N, Zhou P, Hou S–S, Xu S-N (2010) GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the three Gorges area, China. Geomorphology 115:23–31
Bednarik M, Yilmaz I, Marschalko M (2012) Landslide hazard and risk assessment: a case study from the Hlohovec–Sered’ landslide area in south-west, Slovakia. Nat Hazards. doi:10.1007/s11069-012-0257-7 (online first)
Bui DT, Lofman O, Revhaug I, Dick O (2011) Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Nat Hazards 59:1413–1444
Carrara A (1983) Uncertainty in evaluating landslide hazard and risk. In: Nemec J, Nigs JM, Siccardi F (eds) Prediction and perception of natural hazards. Kluwer, Dordrecht, pp 101–111
Cascini L (2008) Applicability of landslide susceptibility and hazard zoning at different scales. Eng Geol 102:164–177
Cevik E, Topal T (2003) GIS-based landslide susceptibility mapping for a problematic segment of the natural gas pipeline, Hendek (Turkey). Environ Geol 44(8):949–962. doi:10.1007/s00254-003-0838-6
Chang K-T, Chiang S-H, Hsu M-L (2007) Modeling typhoon and earthquake-induced landslides in a mountainous watershed using logistic regression. Geomorphology 89:335–347
Chauhan S, Sharma M, Arora MK (2010) Landslide susceptibility zonation of the Chamoli region, Garhwal Himalayas, using logistic regression model. Landslides 7:411–423
Chen Z, Wang J (2007) Landslide hazard mapping using logistic regression model in Mackenzie Valley Canada. Nat Hazards 42:75–89
Chung CJF, Fabbri AG (2003) Validation of spatial prediction models for landslide hazard mapping. Nat Hazards 30(3):451–472
Dahal RK, Hasegawa S, Yamanaka M, Nishino K (2006) Rainfall triggered flow-like landslides: understanding from southern hills of Kathmandu, Nepal and northern Shikoku, Japan. In: Proceedings of 10th International Congress of IAEG, The Geological Society of London, IAEG2006 Paper number 819, pp 1–14 (CD-ROM)
Dahal RK, Hasegawa S, Nonomura A, Yamanaka M, Dhakal S, Paudyal P (2008a) Predictive modelling of rainfall-induced landslide hazard in the Lesser Himalaya of Nepal based on weights-of-evidence. Geomorphology 102(3–4):496–510. doi:10.1016/j.geomorph.2008.05.041
Dahal RK, Hasegawa S, Nonomura A, Yamanaka M, Masuda T, Nishino K (2008b) GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ Geol 54(2):314–324. doi:10.1007/s00254-007-0818-3
Dahal RK, Hasegawa S, Nonomura A, Yamanaka M, Nishino K (2008c) Failure characteristics of rainfall-induced shallow landslides in granitic terrains of Shikoku Island of Japan. Environ Geol 56(7):1295–1310. doi:10.1007/s00254-008-1228-x
Dahal RK, Hasegawa S, Yamanaka M, Bhandary NP, Yatabe R (2010) Statistical and deterministic landslide hazard assessment in the Himalayas of Nepal. In: Williams et al. (eds) IAEG 2010 conference, Geologically active. Taylor & Francis Group, London, pp 1053–1060
Dahal RK, Hasegawa S, Yamanaka M, Bhandary NP, Yatabe R (2011) Rainfall-induced landslides in the residual soil of andesitic terrain, western Japan. J Nepal Geol Soc 42:127–142
Dahal RK, Hasegawa S, Bhandary NP, Poudel PP, Nonomura A, Yatabe R (2012) A replication of landslide hazard mapping at catchment scale. Geomat Nat Hazards Risk 3(2):161–192. doi:10.1080/19475705.2011.629007
Dai FC, Lee CF (2002) Landslide Characteristics and slope instability modeling using GIS, Lantau Island Hongkong. Geomorphology 42:213–228
Dai FC, Lee CF, Li J, Xu ZW (2001) Assessment of landslide susceptibility on the natural terrain in Lantau Island, Hong Kong. Environ Geol 40:381–391
Das I, Sahoo S, van Westen C, Stein A, Hack R (2010) Landslide susceptibility assessment using logistic regression and its comparison with a rock mass classification system, along a road section in the Northern Himalaya (India). Geomorphology 114:627–637
Ermini L, Catani F, Casagli N (2005) Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 66:327–343
Fell R, Corominas J, Bonard C, Cascini L, Leroi E, Savage WZ (2008) Commentary guidelines for landslide susceptibility, hazard and risk zoning for land use planning. Eng Geol 102(3–4):85–98
Frattini P, Crosta G, Carrara A (2010) Techniques for evaluating the performance of landslide susceptibility models. Eng Geol 111:62–72
Geological Survey of Japan (2002) Computer graphics geology of Japanese Islands CD-ROM version
Ghimire M (2011) Landslide occurrence and its relation with terrain factors in the Siwalik Hills, Nepal: case study of susceptibility assessment in three basins. Nat Hazards 56:299–320
Ghosh S, van Westen CJ, Carranza EJM, Jetten VG, Cardinali M, Rossi M, Guzzetti F (2012) Generating event-based landslide maps in a data-scarce Himalayan environment for estimating temporal and magnitude probabilities. Eng Geol 128:49–62. doi:10.1016/j.enggeo.2011.03.016
Gómez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Guzzetti F (2005) Landslide hazard and risk assessment, PhD thesis, Rheinischen Friedrich-Wilhelms-Univestität Bonn, Germany, p 373 (unpublished)
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 31(1–4):181–216
Guzzetti F, Reichenbach P, Ardizzone F, Cardinali M, Galli M (2006) Estimating the quality of landslide susceptibility models. Geomorphology 81(1–2):166–184
Hiura H, Kaibori M, Suemine A, Yokoyama S, Murai M (2005) Sediment related disasters generated by typhoons in 2004. In: Senneset K, Flaate K, Larsen JO (eds) Landslides and avalanches ICFL2005 Norway, pp 157–163
Hosmer DW, Lemeshow S (2000) Applied logistic regression. Wiley, p 375
Jade S, Sarkar S (1993) Statistical model for slope instability classifications. Eng Geol 36:71–98
Kayastha P, Dhital MR, Smedt FD (2012) Landslide susceptibility mapping using the weight of evidence method in the Tinau watershed, Nepal. Nat Hazards. doi:10.1007/s11069-012-0163-z. Online version, 8 April 2012
Lee S (2005) Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data journals. Int J Remote Sens 26(7):1477–1491. doi:10.1080/01431160412331331012
Lee S, Choi J (2004) Landslide susceptibility mapping using GIS and the weight-of-evidence model. Int J Geogr Inf Sci 18:789–814
Lee S, Pradhan B (2007) Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 4:33–41
Lee S, Touch S (2006) Landslide susceptibility mapping in the Damrei Romel area, Cambodia using frequency ratio and logistic regression models. Environ Geol 50(6):847–855
Lee S, Ryu JH, Min K, Won JS (2003) Landslide susceptibility analysis using GIS and artificial neural network. Earth Surf Proc Land 28:1361–1376
Melchiorre C, Matteucci M, Azzoni A, Zanchi A (2008) Artificial neural networks and cluster analysis in landslide susceptibility zonation. Geomorphology 94(3–4):379–400
Miyahisa M, Inami U, Kondo M, Nagai K (1976) Subsurface geological map of Niihama area. Ehime Prefectural Office, Matsuyama, Ehime, Japan
Nandi A, Shakoor A (2009) A GIS-based landslide susceptibility evaluation using bivariate and multivariate statistical analyses. Eng Geol 110:11–20. doi:10.1016/j.enggeo.2009.10.001
Nefeslioglu HA, Gokceoglu C (2011) Probabilistic risk assessment in medium scale for rainfall induced earthflows: Catakli catchment area (Cayeli, Rize, Turkey). Math Prob Eng. doi:10.1155/2011/280431 (Article ID 280431)
Ohlmacher GO, Davis JC (2003) Using multiple logistic regression and GIS technology to predict landslide hazard in northeast Kansas, USA. Eng Geol 69:331–343
Ozdemir A (2011) Landslide susceptibility mapping using Bayesian approach in the Sultan Mountains (Aks¸ehir, Turkey). Nat Hazards 59(3):1573–1607. doi:10.1007/s11069-011-9853-1
Oztekin B, Topal T (2005) GIS-based detachment susceptibility analyses of a cut slope in limestone, Ankara-Turkey. Environ Geol 49(1):124–132. doi:10.1007/s00254-005-0071-6
Pantha BR, Yatabe R, Bhandary NP (2008) GIS-based landslide susceptibility zonation for roadside slope repair and maintenance in the Himalayan region. Episodes 31(4):384–391
Poudyal CP, Chang C, Oh H-J, Lee S (2010) Landslide susceptibility maps comparing frequency ratio and artificial neural networks: a case study from the Nepal Himalaya. Environ Earth Sci 61:1049–1064
Pourghasemi HR, Pradhan B, Gokceoglu C (2012) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat Hazards. doi:10.1007/s11069-012-0217-2 (online first)
Ramani SE, Pitchaimani K, Gnanamanickam VR (2011) GIS based-landslide susceptibility mapping of Tevankarai Ar Sub-watershed, Kodaikhanal, India using binary logistic regression analysis. Mt Sci 8:505–517
Regmi NR, Giardino JR, Vitek JD (2010) Modeling susceptibility to landslides using the weight of evidence approach: Western Colorado, USA. Geomorphology 115:172–187
Saha AK, Gupta RP, Sarkar I, Arora MK, Csaplovics E (2005) An approach for GIS-based statistical landslide susceptibility zonation—with a case study in the Himalayas. Landslides 2:61–69
Schicker R, Moon V (2012) Comparison of bivariate and multivariate statistical approaches in landslide susceptibility mapping at a regional scale. Geomorphology 161–162:10–57
Siddle HJ, Jones DB, Payne HR (1991) Development of a methodology for landslip potential mapping in the Rhondda Valley. In: Chandler RJ (ed) Slope stability engineering. Thomas Telford, London, pp 137–142
Simizu T, Tanbara K (1976) Soil map of Niihama area. Ehime Prefectural Office, Matsuyama, Ehime, Japan
Suzen ML, Doyuran V (2004) A comparison of the GIS based landslide susceptibility assessment methods: multivariate versus bivariate. Environ Geol 45(5):665–679. doi:10.1007/s00254-003-0917-8
Van Den Eeckhaut M, Vanwalleghem T, Poesen J, Govers G, Verstraeten G, Vandekerckhove L (2006) Prediction of landslide susceptibility using rare events logistic regression: a case-study in the Flemish Ardennes (Belgium). Geomorphology 76(3–4):392–410. doi:10.1016/j.geomorph.2005.12.003
Van Den Eeckhaut M, Marre A, Poesen J (2010) Comparison of two landslide susceptibility assessment in the Champagne-Ardenne region (France). Geomorphology 115:141–255
van Westen CJ (1997) Statistical landslide hazard analysis. ILWIS 2.1 for Windows application guide. ITC Publication, Enschede, pp 73–84
van Westen CJ, Rengers N, Soeters R (2003) Use of geomorphological information in indirect landslide susceptibility assessment. Nat Hazards 30:399–419
Varnes DJ (1984) International association of engineering geology commission on landslides and other mass movements on slopes: landslide hazard zonation: a review of principles and practice. UNESCO, Paris 63 pp
Wu W, Siddle RC (1995) A distributed slope stability model for steep forested basins. Water Resour Res 31:2097–2110
Yilmaz I (2010) Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ Earth Sci 61(4):821–836
Yin KI, Yan TZ (1988) Statistical prediction models for slope instability of metamorphosed rocks. In: Proceedings of the 5th international symposium on landslides, Lausanne, vol 2, pp 1269–1272
Zhu L, Huang J (2006) GIS-based logistic regression method for landslide susceptibility mapping in regional scale. Zhejiang Univ Sci A 7(12):2007–2017
Acknowledgments
The GIS data, particularly the details of landslide spots, obtained from Asia Air Survey Co. Ltd. through Prof. Hiromitsu Yamagishi of Ehime University are sincerely acknowledged. Authors are also thankful to Mr. Masatoshi Anakura and Kiran Prasad Acharya for technical support during preparation of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Bhandary, N.P., Dahal, R.K., Timilsina, M. et al. Rainfall event-based landslide susceptibility zonation mapping. Nat Hazards 69, 365–388 (2013). https://doi.org/10.1007/s11069-013-0715-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-013-0715-x