
Abstract
The landslide studies can be categorized as pre- and postdisaster studies. The predisaster studies include spatial prediction of potential landslide zones known as landslide susceptibility zonation (LSZ) mapping to identify the areas/locales susceptible to landslide hazard. The LSZ maps provide an assessment of the safety of existing habitations and infrastructural/functional elements and help plan further developmental activities in the hilly regions. Landslides are one of the natural geohazards that affect at least 15% of land area of India. Different types of landslides occur frequently in geodynamical active domains of the Himalayas. In India, various techniques have been developed and adopted for LSZ mapping of different regions. However, the technique for LSZ mapping is not yet standardized. The present research is an attempt in this direction only. In our earlier work (Kanungo et al. 2006), a detailed study on conventional, artificial neural network (ANN)- black box-, fuzzy set-based and combined neural and fuzzy weighting techniques for LSZ mapping in Darjeeling Himalayas has been documented. In this paper, other techniques such as combined neural and certainty factor concept along with combined neural and likelihood ratio techniques have been assessed in comparison with combined neural and fuzzy technique for the preparation of LSZ maps of the same study area in parts of Darjeeling Himalayas. It is observed from the present study that the LSZ map produced using combined neural and fuzzy approach appears to be the most accurate one as in this case only 2.3% of the total area is found to be categorized as very high susceptibility zone and contains 30.1% of the existing landslide area. This approach can serve as one of the key objective approaches for spatial prediction of landslide hazards in hilly terrain.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Disasters caused by landslides are common in mountainous regions such as the Himalayas. Landslides are one of the most widespread and damaging natural hazards in the hilly regions of India. The landslide incidences in a region have been of serious concern to the society due to the loss of life, natural resources, infrastructural facilities, and also posing problem for future urban development. The landslide disaster situation is further compounded by increased vulnerabilities related to rapidly growing population, unplanned urbanization, fast-paced industrialization, rapid development in high-risk areas, environmental degradation, and climatic change. These are the reasons for which the study of landslides has drawn global attention. It is further observed that the impact of landslide disaster is felt more severely by socio-economically weaker sections of the people because their habitats in vulnerable areas are not designed to withstand the impact of such a disaster. Hence, landslide hazard studies are essential for an assessment of the safety of existing habitations and infrastructural/functional elements and can help safer strategic plans for further development activities in the hilly regions.
Landslide susceptibility zonation (LSZ) studies in the Himalayas have conventionally been carried out based on the manual interpretation of a variety of thematic maps and their superimposition (Anbalagan 1992; Pachauri and Pant 1992; Gupta et al. 1993; Sarkar et al. 1995; Mehrotra et al. 1996; Virdi et al. 1997). However, this approach is time consuming, laborious, and uneconomical with data collected over long time intervals. In recent times, due to the availability of a wide range of remote sensing data together with the data from other sources in digital form and their analysis using Geographic Information System (GIS), it has now become easy to prepare different thematic layers corresponding to the causative factors that are responsible for the occurrence of landslides (Gupta and Joshi 1990; van Westen 1994; Nagarajan et al. 1998; Gupta 2003). The integration of these thematic layers with weights assigned according to their relative importance in a GIS environment leads to the generation of an LSZ map (Gupta et al. 1999; Saha et al. 2002, 2005; Sarkar and Kanungo 2004). However, in the studies cited above, the weights were assigned on the basis of the experience of the experts about the subject and the area. The weighting system in this condition is thus highly subjective and might therefore contain some implicit biases toward the assumptions made.
For minimizing the subjectivity and bias in the weight assignment process, quantitative methods such as statistical analysis, deterministic analysis, probabilistic models, distribution-free approaches, and landslide frequency analysis may be utilized. During the last 5 years, bivariate statistical models (e.g., Lin and Tung 2003; He et al. 2003; Suzen and Doyuran 2004; Saha et al. 2005), multivariate methods (e.g., Dhakal et al. 2000; Clerici et al. 2002), and probabilistic prediction models (e.g., Lee et al. 2002a, b; Chi et al. 2002a; Lan et al. 2004) have been implemented for LSZ studies. Apart from these methods, some work on distribution-free approaches such as fuzzy set-based methods (Chi et al. 2002b; Gorsevski et al. 2003; Tangestani 2003; Metternicht and Gonzalez 2005; Ercanoglu and Gokceoglu 2004), artificial neural network (ANN) models (Arora et al. 2004; Gomez and Kavzoglu 2005; Yesilnacar and Topal 2005), and neuro-fuzzy models (Elias and Bandis 2000; Lee et al. 2004; Kanungo et al. 2006) have recently been attempted for LSZ studies. In the present study, an attempt has been made to implement an objective (quantitative) technique for landslide hazard zonation mapping in the selected area of Darjeeling Himalayas.
2 Study area and data
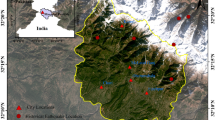
The landslide incidences in Darjeeling Himalaya (parts of West Bengal State in India) have been of serious concern to the preservation of natural landscape of the area, maintenance of infrastructural facilities, and future urban development. Therefore, an area in the Darjeeling Himalaya, which covers a part of Darjeeling district, has been selected for this study. This study focused on Darjeeling hill, which lies within the latitudes 26°56′–27°8′N and longitudes 88°10′–88°25′E and covers an area of about 254 km2 (Fig. 1). The main localities are Darjeeling, Sonada, and Sukhiapokhri. Darjeeling is located almost at the center of the study area. The Darjeeling Himalaya lies within the Lesser and Sub-Himalayan belts. The valleys of Darjeeling hills are mainly drained by the Tista River and its tributaries. The southerly flowing Tista River is on the eastern side of the study area, but not falling within it. The hill portion is like a labyrinth of ridge and narrow valleys. Most of the ridges are forest clad, and in the lower slopes, tea plantation and crop cultivation are done. The main land use practice in the study area is tea plantation. The agriculture lands are mostly present around the habited areas. The area is dominated by thick forest particularly in the eastern part.

Location map of the study area
Data from different sources such as (a) remote sensing images from IRS-1C LISS-III multi-spectral (acquired on March 22, 2000) and IRS-1D-PAN (acquired on April 3, 2000); (b) Survey of India (SOI) topographic maps at 1:50,000 scale and 1:25,000 scale; (c) published geological map; and (d) extensive field data on landslides and land use/land cover have been collected to generate various thematic data layers.
The digital elevation model (DEM), which is an excellent source to derive topographic attributes responsible for the landslide activity in the region, was generated by digitization of contours on SOI topographic maps. The slope and aspect data layers were derived from the DEM. The lithology data layer pertaining different rock types was derived from the published geological map of Sikkim–Darjeeling area. The varied composition and structure of different rock types contribute to the strength of the material and in turn contribute to the slope instability. Lineaments were interpreted from the PAN and LISS-III images. There is no major thrust/fault reported in the study area, but major lineaments were identified. A distance buffer map was generated to deduce the influence of lineaments on the occurrence of landslide. Many landslides in hilly areas occur due to the erosional activity associated with drainage. Therefore, a drainage data layer was prepared using the topographic maps and LISS-III image. A distance buffer map with 25 m buffer zone around 1st and 2nd order drainages only was generated for further analysis. Land use land cover is also a key factor to be considered in landslide studies, as the incidence of landslide is inversely related to the vegetation density. The four spectral bands of LISS-III image, DEM, and Normalized Difference Vegetation Index (NDVI) image were digitally analyzed to prepare a land use land cover map by a multisource classification process using the most widely adopted maximum likelihood classifier. The mapping of existing landslides is essential to study the relationship between the actual landslide distribution in the area and the causative factors. High spatial resolution IRS-1C-PAN and PAN-sharpened LISS-III images were used to produce an existing landslide distribution map, which was verified from field surveys. A total of 101 landslides showing areas occupied by sliding activity were identified. The majority of landslides have areal extent of 500–2,000 m2. Most of the observed landslides fall in the category of rockslides. However, at some places, complex types of failure were also observed.
These thematic data layers pertaining to causative factors for landslide occurrence form the input layers for spatial modeling of landslide potential zones. The detailed description of these is already available in Kanungo et al. (2009).
3 Methodology
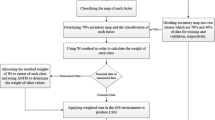
In this study, spatial modeling of potential landslides (popularly known as landslide susceptibility zonation mapping) has been carried out using varied importance of causative factors (i.e., weight) and their categories (i.e., rating) for landslide occurrences under the domain of GIS. The weights for different causative factors have been determined using ANN approach, and the ratings for different categories within each factor have been determined using certainty factor, likelihood ratio, and fuzzy similarity concepts. Then, by combining the ANN-derived weights with the ratings derived from each of the above mentioned approaches, landslide susceptibility maps for the study area have been prepared. A comparative evaluation of these LSZ maps has also been carried out. The overall methodology of the present research is given in Fig. 2. The methodologies for weight and rating determination are described below.

Flow diagram showing an overview of the methodology adopted in this study
3.1 Weight determination using ANN approach
The ANN architectures with one input layer, two hidden layers, and one output layer have been considered. The input layer contains six neurons corresponding to six different causative factors, and the output layer contains a single neuron corresponding to the presence or absence of existing landslide. Three independent training, testing, and validation datasets are formed. Each dataset consists of 226 mutually exclusive pixels, which correspond to 113 existing landslide pixels and remaining 113 landslide-free pixels. The pixels in all the three datasets were mutually exclusive. The validation dataset has been used to control the overtraining/overfitting of the networks.
Data from input neurons are processed through hidden neurons to generate an output in the output neuron. In this process, a feed-forward multilayer network is generally used. Generally, the input that a single neuron j in the 1st hidden layer (HA) receives from the neurons (i) in its preceding input layer (I) can be expressed as:
where c ij represents the connection weight between input neuron i and hidden neuron j, p i is the output from the input neuron i, and t is the number of input neurons (i.e., six different thematic data layers in the present case). The output value produced by the hidden neuron j, p j , is the transfer function, f, evaluated as the sum produced within neuron j, net j . Hence, the transfer function f can be expressed as:
The function f is usually a nonlinear function that is applied to the weighted sum of the inputs, and then, the combined effect proceeds to the next layer. Any differentiable nonlinear function can be used as a transfer function, but a sigmoid function is generally used (Schalkoff 1997). The sigmoid function constrains the outputs of a network between 0 and 1. As in this case of LSZ mapping, the desired output (d o) is represented by the presence/absence (1 or 0) of landslides the sigmoid transfer function has been used for input-hidden, hidden-hidden, and hidden-output layers. The sigmoid function in case of LSZ mapping can be expressed as:
In this feed-forward process of neural network, the network output value for the output neuron o, p o is obtained. The error is calculated as the difference between the desired output (d o) and the network output (p o). The error function, e, is a measure of network’s performance for the processing elements in the output layer and can be expressed as follows:
where d o is the desired output vector, p o is the network output vector, and s is the number of training samples (Arora et al. 2004).
The error gets backpropagated through the neural network and is minimized by changing the connection weights between neurons of different layers. This can be executed through a number of learning algorithms based on backpropagation learning (Ripley 1996; Haykin 1999; Zhou 1999; Arora et al. 2004; Lee et al. 2004; Gomez and Kavzoglu 2005; Yesilnacar and Topal 2005). The most widely used backpropagation algorithms are gradient descent and gradient descent with momentum. These are often too slow for the solution of practical problems. The faster algorithms use standard numerical optimizers such as conjugate gradient, quasi-Newton, and Levenberg–Marquardt approaches. Levenberg–Marquardt algorithm was designed to approach the second-order training speed like quasi-Newton methods without having to compute the Hessian matrix (i.e., the second derivatives of the performance index of weights). This algorithm uses an approximation to the Hessian matrix in the following manner:
where c ij is a vector of current connection weights, J is the Jacobian matrix, which contains the first derivatives of the network errors with respect to connection weights, e is a vector of network errors, and μ is a scalar. Unlike gradient descent algorithms, the Levenberg–Marquardt algorithm does not consider learning rate and momentum factor as its parameters. It takes into account important training parameters such as mu (μ), mu_dec, and mu_inc. The parameter mu(μ) is decreased by multiplying it with mu_dec after each successful step (reduction in error) and is increased only when the error is increased. The main scalar parameter mu (μ) is modified in an adaptive fashion after giving an initial random value. In this study, Levenberg–Marquardt algorithm (implemented as TRAINLM in MATLAB software) has been used for training the neural network. The details of this algorithm can be found in Hagan and Mehnaj (1994) and Hagan et al. (1996). The training process is initiated by assigning arbitrary initial connection weights, which are constantly updated until an acceptable training accuracy is reached. The adjusted weights obtained from the trained network have been subsequently used to process the testing data to evaluate the generalization capability and accuracy of the network. A total of 100 network architectures were designed, trained, and tested to evaluate their generalization capabilities and accuracies in the present case. The overall training accuracies observed for all the 100 networks are of the order of 75% to 90%, whereas the testing accuracies are of the order of 60–70%. The connection weights thus captured for each of the 100 networks are further analyzed to determine the weights for the causative factors.
The connection weights of the neurons from input-hidden, hidden-hidden, and hidden-output layers for each of the 100 networks are further analyzed to determine the weights of the causative factors for each neural network. Thus, three different weight matrices are obtained for the connection weights from input-hidden, hidden-hidden, and hidden-output layers of each network. Simple matrix multiplication has been performed on these weight matrices to obtain a final 6 × 1 weight matrix for each network, which represents the weights of six causative factors in this study. These causative factors are ranked according to the corresponding absolute weights for each network, which means higher is the value of absolute weight of a factor, more crucial is that factor for the occurrence of landslide. Considering all the 100 networks, the rank of a factor is decided based on the rank observed by maximum number of networks (majority rule). Out of 100 networks, 41 networks categorize lithology as rank 1 (most important), 31 networks for lineament as rank 2, 30 networks for slope as rank 3, 27 networks for aspect as rank 4, 33 networks for land use land cover as rank 5, and 49 networks for drainage as rank 6 (least important). Subsequently, the normalized average of the weights of these networks at a scale of 0–10 for a particular factor is calculated and assigned as the weight of that factor (W l ) for the preparation of LSZ map. The weights thus obtained through ANN connection weight approach for all the factors are listed in Table 1. It can be observed from Table 1 that lithology is the most important (weight = 4.8), while drainage buffer is the least important (weight = 0.2) causative factors for landslide occurrences in the area. The details of ANN-based weight determination procedure are given in Kanungo et al. (2006).
3.2 Rating determination
The ratings for different categories under various causative factors were determined using certainty factor-, likelihood ratio-, and fuzzy logic-based concepts, which are described in the following section.
3.2.1 Certainty factor concept
The certainty factor (CF) concept is one of the possible approaches to handle the problem of combination of different data layers and the heterogeneity and uncertainty of the input data. The CF, defined as a function of probability, was originally proposed by Shortliffe and Buchanan (1975) and later modified by Heckerman (1986):
where pp a is the conditional probability of having a number of landslide event occurring in category a and pp s is the prior probability of having the total number of landslide events occurring in the study area. The range of variation of the CF is [−1.1]: positive value means an increasing certainty in landslide occurrence, while negative value corresponds to a decreasing certainty in landslide occurrence. A value close to 0 means that the prior probability is very similar to the conditional one, so it is difficult to give any indication about the certainty of the landslide occurrence.
The favorability values (pp a, pp s) are derived from overlaying each data layer with the existing landslide distribution layer in GIS and calculating the landslide occurrence frequency. CF values are then calculated for each layer. For example, the ratio of the area of landslide falling in a particular category and the total area of this category gives the favorability value pp a. Likely, the value of pp s can be calculated by dividing the total area of landslide with the total study area. Inputting the pp a and pp s into expression (6), the CF value of the particular category can be finally calculated.
The landslide distribution and different categories of thematic layers taken one at a time have been considered as two datasets for the computation of certainty factor (rating). The number of pixels and the number of landslide pixels in each category of thematic data layers (Table 2) have been determined using these layers. With the help of these data, ratings for all the 35 categories (Table 2) have been calculated using the Eq. 6. The graphical representation of these ratings is given in Fig. 3.

Graphical representation of ratings determined through different techniques
It can be observed from Table 2 that the highest certainty factor rating (0.797) has been attributed to the barren land category of land use land cover and the lowest (−.749) to the lineament buffer category given as >500 m. The categories namely water bodies, river sand, and flat areas have rating −1.0. This is true also since usually landslides will not occur in these areas. This also proves the performance of certainty factor-based approach. The 25 m buffers along 1st and 2nd order drainage categories have ratings of 0.053 and 0.477, respectively. Within the lineament buffer categories, 0–125 m buffer has the highest rating of 0.498 and >500 m buffer has the lowest rating of −0.749. This indicates that the probability of landslide occurrences is high at locations that are closer to lineaments.
Further, within the slope categories, 35°–45° slopes have the highest rating of 0.28 and 0°–15° slopes have the lowest rating of −0.462. This indicates that steeper slopes are more prone to landslide occurrences in the area. Among the lithology categories, Paro quartzites have the highest rating of 0.785 and Paro gneiss has the lowest rating of −0.232. In this case, quartzitic rocks have higher ratings than other rocks as they are highly jointed and fractured and more prone to landslide occurrences. Within the land use land cover categories, barren land has the highest rating of 0.797, and thick and sparse forests have the lowest ratings of −0.371 and −0.404. This reflects that the incidence of landslide is inversely related to the vegetation density. Hence, barren slopes are more prone to landslide activity as compared to the forest areas. Among the aspect categories, southeast (SE)-facing slopes have the highest rating of 0.507 and north (N)-facing slopes have the lowest rating of −0.558. It is observed from the ratings of aspect categories that the south-facing slopes have higher ratings than the north-facing slopes. This also supports the fact that the south-facing slopes have lesser vegetation density as compared to the north-facing slopes; hence, the landslide activity is relatively more in former case (Sinha et al. 1975).
3.2.2 Likelihood ratio concept
A probability method known as likelihood ratio (LR) approach (Lee and Min 2001) has been used as one of the approaches for the determination of the observed relationship (i.e., rating) between the causative factors and landslide occurrences. Likelihood ratio for a particular category within a particular factor is defined as the ratio between the percent landslide occurrence and percent landslide nonoccurrence in that category.
The number of pixels and the number of landslide pixels in each category of the causative factors (Table 2) have been determined using the thematic data layers and the landslide distribution layer. With the help of these data, likelihood ratios (i.e., ratings) for all the 35 categories (Table 2) have been calculated. The graphical representation of these ratings is given in Fig. 3.
It can be observed from Table 2 that the highest likelihood ratio (4.926) has been attributed to the barren land category of land use land cover and the lowest (0.250) to the lineament buffer category given as >500 m. The categories namely water bodies, river sand, and flat areas have likelihood ratios of 0.0. This is true also since usually landslides will not occur in these areas. The 25 m buffers along 1st and 2nd order drainage categories have ratings of 0.865 and 1.567, respectively. Within the lineament buffer categories, 0–125 m buffer has the highest rating of 1.993 and >500 m buffer has the lowest rating of 0.250. This indicates that the probability of landslide occurrences is high at locations that are closer to lineaments.
Further, within the slope categories, 35°–45° slopes have the highest rating of 1.388 and 0°–15° slopes have the lowest rating of 0.538. This indicates that steeper slopes are more prone to landslide occurrences in the area. Among the lithology categories, Reyang quartzites have the highest rating of 2.083 and Paro gneiss has the lowest rating of 0.768. In this case, quartzitic rocks have higher ratings than other rocks as they are highly jointed and fractured and more prone to landslide occurrences. Within the land use land cover categories, barren land has the highest rating of 4.926, and thick and sparse forests have the lowest ratings of 0.630 and 0.597. This reflects that the incidence of landslide is inversely related to the vegetation density. Hence, barren slopes are more prone to landslide activity as compared to the forest areas. Among the aspect categories, southeast (SE)-facing slopes have the highest rating of 2.027 and north (N)-facing slopes have the lowest rating of 0.441. It is observed from the ratings of aspect categories that the south-facing slopes have higher ratings than the north-facing slopes. This also supports the fact that the south-facing slopes have lesser vegetation density as compared to the north-facing slopes; hence, the landslide activity is relatively more in former case (Sinha et al. 1975).
It is also observed that the likelihood ratios for different categories of the factors have a similar trend as of certainty factor ratings.
3.2.3 Fuzzy similarity concept
In this research, one of the well-known fuzzy similarity methods, cosine amplitude method, has been used to determine the relationship between the landslide occurrence and the factors responsible for such activity. The membership values (ratings) of the categories of each factor are calculated by the strength of the relationship (r ij ) between the existing landslides and the factors and can be computed by the following equation with its values ranging from 0 to 1 (0 ≤ r ij ≤ 1).
where x i represents a category of a thematic layer (i.e., layer corresponding to a causative factor), x j represents the existing landslide distribution layer, k is a particular pixel in the study area, and p is the total number of pixels in the area.
The landslide distribution and different categories of thematic layers taken one at a time have been considered as two datasets for the computation of rating or strength of relationship (r ij ). The pixels in the landslide areas are assigned a value of 1, whereas rest of the pixels are assigned a value of 0 in the landslide distribution layer. Similarly, a value of 1 is assigned to a particular category of a thematic layer and a value of 0 to rest of the pixels. The number of pixels and the number of landslide pixels in each category of thematic data layers are listed in Table 2. With the help of these data, ratings for all the 35 categories (Table 2) have been calculated. The graphical representation of these ratings is given in Fig. 3.
It can be observed from Table 4 that the highest fuzzy rating (0.064) has been attributed to the barren land category of land use land cover and the lowest (0.014) to the lineament buffer category given as >500 m. The categories namely water bodies, river sand, and flat areas have zero fuzzy rating zero. This is true also since usually landslides will not occur in these areas. The 25 m buffers along 1st and 2nd order drainage categories have fuzzy ratings of 0.030 and 0.040, respectively. Within the lineament buffer categories, 0–125 m buffer has the highest rating of 0.041 and >500 m buffer has the lowest rating of 0.014. This indicates that the probability of landslide occurrences is high at locations that are closer to lineaments. Further, within the slope categories, 35°–45° slopes have the highest rating of 0.034 and 0°–15° slopes have the lowest rating of 0.021. This indicates that steeper slopes are more prone to landslide occurrences in the area. Among the lithology categories, Reyang quartzites have the highest rating of 0.042 and Paro gneiss has the lowest rating of 0.025. In this case, quartzitic rocks have higher ratings than other rocks as they are highly jointed and fractures and more prone to landslide occurrences. Within the land use land cover categories, barren land has the highest rating of 0.064, and thick and sparse forests have the lowest ratings of 0.023 and 0.022. This reflects that the incidence of landslide is inversely related to the vegetation density. Hence, barren slopes are more prone to landslide activity as compared to the forest areas. Among the aspect categories, southeast (SE)-facing slopes have the highest rating of 0.041 and north (N)-facing slopes have the lowest rating of 0.019. It is observed from the ratings of aspect categories that the south-facing slopes have higher ratings than the north-facing slopes. This also supports the fact that the south-facing slopes have less vegetation density as compared to the north-facing slopes; hence, the landslide activity is relatively more in former case (Sinha et al. 1975).
4 Landslide susceptibility mapping
The weights for the causative factors determined through ANN approach and the ratings for the categories determined through three different approaches have been integrated separately to produce the LSZ maps.
4.1 Combined neural and CF approach
In this approach, the weights for factors determined through ANN and the ratings for the categories determined through certainty factor approach have been considered in the integration process to prepare the LSZ map. The integration of six thematic data layers representing the ratings for the categories (R l ) of the factors and weights for the factors (W l ) has been performed by using simple arithmetic overlay operation in GIS. The landslide susceptibility index (LSI) for each pixel of the study area is obtained by using the following equation:
where t is the number of thematic data layers (i.e., six causative factors in this case).
The LSI values have been found to lie in the range from −4.553 to 6.128. This range of LSI values has been divided into five different susceptibility zones (i.e., VHS, HS, MS, LS, and VLS) with boundaries located at (μo − 1.5 mσo), (μo − 0.5 mσo), (μo + 0.5 mσo), and (μo + 1.5 mσo) values, where observed mean (μo) is −0.775, standard deviation (σo) is 1.754, and m is a positive, nonzero value (Saha et al. 2005; Kanungo et al. 2006). This classification is adopted to fix the boundaries of classes statistically and to avoid the subjectivity in arbitrarily selecting the boundaries of classes. Several LSZ maps have been prepared, and different success rate curves have been plotted for various values of m. The suitability of any LSZ map can be judged by the fact that more percentage of landslides must occur in VHS zone as compared to other zones. Therefore, the cumulative percentage of landslide occurrences in various susceptibility zones ordered from very high susceptibility (VHS) to very low susceptibility (VLS) have been plotted against the cumulative percentage of area of the susceptibility zones for LSZ maps with different values of m. These curves have been defined as the success rate curves (Chung and Fabbri 1999; Lu and An 1999; Lee et al. 2002b) and have been used to select the appropriate value of m to decide the suitability of an LSZ map. Five representative success rate curves corresponding to m = 1.0, 1.1, 1.2, 1.3, and 1.4 are shown in Fig. 4. It can be observed from Fig. 4 that for 10% of the area in very high susceptibility zone, the curves corresponding to m = 1.0, 1.1, 1.2, 1.3, and 1.4 show the landslide occurrences of 39.0, 39.9, 42.0, 41.6, and 40.0%, respectively. Hence, for the first 10% area, the curve corresponding to m = 1.2 shows the highest success rate, and the corresponding LSZ map appears to be the most appropriate one. Accordingly, putting the values of μo as −0.775, σo as 1.754, and m as 1.2, the landslide susceptibility zone boundaries have been fixed at LSI values of −3.932 (μo − 1.5 mσo), −1.827 (μo − 0.5 mσo), 0.277 (μo + 0.5 mσo), and 2.382 (μo + 1.5 mσo), and five different susceptibility zones have been categorized. The LSZ map thus produced is shown in Fig. 5.

Success rate curves for choosing the best segmentation in LSI values for LSZ classification in combined neural and CF approach

LSZ map produced from combined neural and CF approach
The area covered by different landslide susceptibility zones, the area of landslides occupied per class, and the landslide densities of different zones have been determined and listed in Table 3. It is observed from Table 3 that 5.9% of the total area have been occupied by VHS zone, while 17.7, 42.8, 33.4, and 0.2% area have been occupied by HS, MS, LS, and VLS zones, respectively. This shows that the area wise coverage of different susceptibility zones is normally distributed, which should be the case. The distribution of landslides in different susceptibility zones has been compared. It has been found that 33.9% of landslide area is predicted over VHS zone, while 23.3, 28.0, 14.8, and 0.0% of landslide area are predicted over HS, MS, LS, and VLS zones, respectively. These results show that 23.6% area of VHS and HS zones could predict 57.2% landslide area.
4.2 Combined neural and LR approach
In this approach, the weights for factors determined through ANN and the ratings for the categories determined through likelihood ratio approach have been integrated to prepare the LSZ map. The integration of the ratings for the categories of the factors and weights for the factors has been performed by using simple arithmetic overlay operation in GIS as per the Eq. 8. The LSI values have been found to lie in the range from 0.530 to 20.652. The range of LSI values has been categorized into five susceptible zones such as VHS, HS, MS, LS and VLS with boundaries fixed by using success rate curves method. The observed mean (μo) and standard deviation (σo) from the probability distribution curve of these LSI values are 9.857 and 2.314 respectively. Using these values, several LSZ maps of the study area have been prepared for different values of m. Five representative success rate curves corresponding to m = 1.1, 1.2, 1.3, 1.4 and 1.5 are shown in Fig. 6. It can be seen that for 10% of the area in VHS zone the curves corresponding to m = 1.1, 1.2, 1.3, 1.4 and 1.5 show the landslide occurrences of 41.6, 43.4, 45.2, 45.15 and 44.1% respectively. Hence, for the first 10% area, the curve corresponding to m = 1.3 has the highest success rate. Based on this analysis, the LSZ map corresponding to m = 1.3 appears to be the most appropriate one for the study area. Accordingly, putting the values of μo as 9.857, σo as 2.314 and m as 1.3, the landslide susceptibility zone boundaries have been fixed at LSI values of 5.345 (μo − 1.5 mσo), 8.352 (μo − 0.5 mσo), 11.360 (μo + 0.5 mσo) and 14.368 (μo + 1.5 mσo) and the five different susceptibility zones have been categorized. The LSZ map thus produced is shown in Fig. 7.

Success rate curves for choosing the best segmentation in LSI values for LSZ classification in combined neural and LR approach

LSZ map produced from combined neural and LR approach
The area covered by different landslide susceptibility zones, the area of landslides occupied per class and the landslide densities of different zones have been determined and listed in Table 3. It is observed from Table 3 that 3.6% of the total area have been occupied by VHS zone while 19.8, 45.1, 31.3 and 0.2% area have been occupied by HS, MS, LS and VLS zones respectively. This shows that the area wise coverage of different susceptibility zones is normally distributed, which should be the case. The distribution of landslides in different susceptibility zones has been compared. It has been found that 31.3% of landslide area is predicted over VHS zone while 30.7, 24.2, 13.8 and 0.0% of landslide area are predicted over HS, MS, LS and VLS zones respectively. These results show that 23.4% area of VHS and HS zones could predict 62.0% landslide area. Further, the distribution of landslides over VHS to VLS zones is skewed toward the higher susceptibility zones, which should in fact be the case.
4.3 Combined neural and fuzzy approach
In this approach, the weights for factors determined through ANN and the ratings for the categories determined through fuzzy approach have been integrated to prepare the LSZ map. The integration of the ratings for the categories of the factors and weights for the factors has been performed by using simple arithmetic overlay operation in GIS as per the Eq. 8. The LSI values have been found to lie in the range from 0.030 to 0.408. The range of LSI values has been categorized into five susceptible zones such as VHS, HS, MS, LS, and VLS with boundaries fixed by using success rate curves method (see Sect. 4.1). The observed mean (μo) and standard deviation (σo) from the probability distribution curve of these LSI values are 0.276 and 0.032, respectively. Using these values, several LSZ maps of the study area have been prepared for different values of m. Five representative success rate curves corresponding to m = 1.2, 1.3, 1.4, 1.5, and 1.6 are shown in Fig. 8. It can be seen that for 10% of the area in VHS zone, the curves corresponding to m = 1.2, 1.3, 1.4, 1.5, and 1.6 show the landslide occurrences of 43.9, 45.6, 46.7, 43.3, and 43.9%, respectively. Hence, for the first 10% area, the curve corresponding to m = 1.4 has the highest success rate. Based on this analysis, the LSZ map corresponding to m = 1.4 appears to be the most appropriate one for the study area. Accordingly, putting the values of μo as 0.276, σo as 0.032, and m as 1.4, the landslide susceptibility zone boundaries have been fixed at LSI values of 0.208 (μo − 1.5 mσo), 0.253 (μo − 0.5 mσo), 0.299 (μo + 0.5 mσo), and 0.344 (μo + 1.5 mσo), and the five different susceptibility zones have been categorized. The LSZ map thus produced is shown in Fig. 9.

Success rate curves for choosing the best segmentation in LSI values for LSZ classification in combined neural and fuzzy approach

LSZ map produced from combined neural and fuzzy approach
The area covered by different landslide susceptibility zones, the area of landslides occupied per class, and the landslide densities of different zones have been determined (Table 3). It is observed from Table 3 that 2.3% of the total area have been occupied by VHS zone, while 20.2, 48.4, 28.8, and 0.3% area have been occupied by HS, MS, LS, and VLS zones, respectively. This shows that the area wise coverage of different susceptibility zones is normally distributed, which should be the case. The distribution of landslides in different susceptibility zones has been compared. It has been found that 30.1% of landslide area is predicted over VHS zone, while 31.9, 26.5, 11.5, and 0.0% of landslide area are predicted over HS, MS, LS, and VLS zones, respectively. These results show that 22.5% area of VHS and HS zones could predict 62.0% landslide area. Further, the distribution of landslides over VHS to VLS zones is skewed toward the higher susceptibility zones, which should in fact be the case.
5 Interpretations and evaluation of approaches
The interpretations and comparative evaluation of three different LSZ maps prepared using combined neural and CF, combined neural and LR, and combined neural and fuzzy approaches throw interesting light on their relative efficacy. This has now been discussed using three different approaches:
-
(a)
Visual Interpretation.
-
(b)
Landslide Density Analysis.
-
(c)
Success Rate Curves Method.
5.1 Visual interpretation
Visual inspection of LSZ maps prepared using three different approaches reflected a preferential distribution of higher landslide susceptibility zones along structural discontinuities (lineaments), which should indeed be the case. The buffer zones of lineaments have clearly indicated the VHS and HS zones in the north and southeast parts of the area. Therefore, it indicates the “ghost-effect” of lineaments on LSZ maps as stated by Saha et al. (2005). Also, the Darjeeling gneiss rock type in south-eastern part, feldspathic graywacke and Reyang quartzite in the northern part of the study area indicated moderate to very high susceptibility zones. However, in case of the LSZ map prepared using combined neural and CF approach, Paro quartzites in the south-western and north-eastern part of the study area indicated mostly very high susceptible zones in comparison with other LSZ maps.
5.2 Landslide density analysis
Landslide density is defined as the ratio of the existing landslide area in percent to the area of each landslide susceptibility zone in percent and is computed here on the basis of the number of pixels in the image. Landslide density values for each susceptibility zone for different LSZ maps have been computed separately (Table 4). Usually, an ideal LSZ map should have the highest landslide density for VHS zone, as compared to other zones and there ought to be a decreasing trend of landslide density values successively from VHS to VLS zone.
It is observed from Table 4 that the landslide densities for VHS zone of all the three LSZ maps are significantly higher than those obtained for other susceptibility zones. There is also a decreasing trend of landslide density values from VHS zone to VLS zone for all the LSZ maps. As far as the landslide density in VHS zone is concerned, it is observed that the LSZ map prepared using combined neural and fuzzy approach has a markedly higher landslide density (i.e., 13.09) for this zone than that observed in other LSZ maps (5.74 for combined neural and CF approach and 8.69 for combined neural and LR approach). This may be due to more efficient rating determination process through fuzzy set-based approach. Thus, based on the landslide density values of different landslide susceptibility zones and their trend from VHS to VLS zones for all the LSZ maps, it can be inferred that the combined neural and fuzzy approach developed and implemented for LSZ mapping appears to be significantly better than other approaches used here, and the corresponding LSZ map may be considered as the best LSZ map of the area.
5.3 Success rate curves method
The success rate curves for different LSZ maps prepared using three different approaches are given in Fig. 10. It can be seen from the figure that for 10% of the area in VHS zone, the curve corresponding to the LSZ map prepared using combined neural and fuzzy approach shows the maximum landslide occurrences of 46.6% in comparison with 45.2% and 42.0% of landslide occurrences for the LSZ maps prepared using combined neural and LR approach and combined neural and CF approach, respectively. Hence, for the first 10% area, the curve corresponding to the LSZ map prepared using combined neural and fuzzy approach has the highest success rate, and this LSZ map appears to be the most appropriate one for the study area.

Success rate curves for choosing the most appropriate LSZ map among those prepared using combined neural and CF, combined neural and LR, and combined neural and fuzzy approaches
6 Conclusions
In this study, two different weighting and rating approaches, viz. combined neural and certainty factor and combined neural and likelihood ratio along with one already developed combined neural and fuzzy approach (Kanungo et al. 2006), were applied for LSZ mapping in the part of Darjeeling Himalayas. A comparative evaluation of these approaches was also carried out. The combined neural and fuzzy weighting integration produced the most accurate LSZ map. Previous comparative evaluation of combined neural and fuzzy weighting approach with subjective weighting-, ANN black box-, and fuzzy logic-based approaches (Kanungo et al. 2006) also witnessed the similar result of the LSZ map prepared using the combined neural and fuzzy approach being the most accurate one. This LSZ map delineates a relatively small area (only 2.3% of total area) for VHS zone, which can be more meaningful for practical applications. Therefore, the integration of different factors in GIS environment using the combined neural and fuzzy weighting procedure may serve as one of the key objective approaches in this direction because of the fact that it can narrow down the potential susceptibility zones in a meaningful way for planning future developmental activities and the implementation of disaster management programmes in hilly terrains.
References
Anbalagan R (1992) Landslide hazard evaluation and zonation mapping in mountainous terrain. Eng Geol 32:269–277
Arora MK, Das Gupta AS, Gupta RP (2004) An artificial neural network approach for landslide hazard zonation in the Bhagirathi (Ganga) Valley, Himalayas. Int J Remote Sens 25(3):559–572
Chi K-H, Park N-W, Lee K (2002a) Identification of landslide area using remote sensing data and quantitative assessment of landslide hazard. In: Proceedings of IEEE international geosciences and remote sensing symposium, 19 July, Toronto, Canada
Chi K-H, Park N-W, Chung C-J (2002b) Fuzzy Logic Integration for landslide hazard mapping using spatial data from Boeun, Korea. In: Proceedings of symposium on geospatial theory, processing and applications, Ottawa
Chung C-JF, Fabbri AG (1999) Probabilistic prediction models for landslide hazard mapping. Photogramm Eng Remote Sens 65(12):1389–1399
Clerici A, Perego S, Tellini C, Vescovi P (2002) A procedure for landslide susceptibility zonation by the conditional analysis method. Geomorphology 48:349–364
Dhakal AS, Amada T, Aniya M (2000) Landslide hazard mapping and its evaluation using GIS: an investigation of sampling schemes for a grid-cell based quantitative method. Photogramm Eng Remote Sens 66(8):981–989
Elias PB, Bandis SC (2000) Neurofuzzy systems in landslide hazard assessment. In: Proceedings of 4th international symposium on spatial accuracy assessment in natural resources and environmental sciences, July 2000, pp 199–202
Ercanoglu M, Gokceoglu C (2004) Use of fuzzy relations to produce landslide susceptibility map of a landslide pron area (West Black Sea Region, Turkey). Eng Geol 75(3&4):229–250
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78(1–2):11–27
Gorsevski PV, Gessler PE, Jankowski P (2003) Integrating a fuzzy k-means classification and a Bayesian approach for spatial prediction of landslide hazard. J Geograph Syst 5:223–251
Gupta RP (2003) Remote sensing geology, 2nd edn. Springer, Berlin
Gupta RP, Joshi BC (1990) Landslide hazard zonation using the GIS approach—a case study from the Ramganga Catchment, Himalayas. Eng Geol 28:119–131
Gupta V, Sah MP, Virdi NS, Bartarya SK (1993) Landslide hazard zonation in the Upper Satlej Valley, District Kinnaur, Himachal Pradesh. J Himal Geol 4:81–93
Gupta RP, Saha AK, Arora MK, Kumar A (1999) Landslide hazard zonation in a part of Bhagirathy Valley, Garhwal Himalayas, using integrated remote sensing–GIS. J Himal Geol 20(2):71–85
Hagan MT, Mehnaj M (1994) Training feedforward networks with the Marquardt algorithm. IEEE Trans Neural Netw 5(6):989–993
Hagan MT, Demuth HB, Beale MH (1996) Neural network design. PWS Publishing, Boston
Haykin S (1999) Neural networks: a comprehensive foundation, 2nd edn. Prentice Hall, New Jersey
He YP, Xie H, Cui P, Wei FQ, Zhong DL, Gardner JS (2003) GIS-based hazard mapping and zonation of debris flows in Xiaojiang Basin, Southwestern China. Env Geol 45:286–293
Heckerman D (1986) Probabilistic interpretation of MYCIN’s certainty factors. In: Kanal LN, Lemmer JF (eds) Uncertainty in artificial intelligence. Elsevier, New York, pp 298–311
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng Geol 85:347–366
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2009) A fuzzy set based approach for integration of thematic maps for landslide susceptibility zonation. Georisk: Assess Manage Risk Eng Syst Geohazards 3(1):30–43
Lan HX, Zhou CH, Wang LJ, Zhang HY, Li RH (2004) Landslide hazard spatial analysis and prediction using GIS in the Xiaojiang Watershed, Yunnan, China. Eng Geol 76:109–128
Lee S, Min KD (2001) Statistical analysis of landslide susceptibility at Yongin, Korea. Env Geol 40(9):1095–1113
Lee S, Choi J, Chwae U, Chang B (2002a) Landslide susceptibility analysis using weight of evidence. In: Proceedings of IEEE international geosciences and remote sensing symposium, 19 July, Toronto, Canada
Lee S, Choi J, Min KD (2002b) Landslide susceptibility analysis and verification using the Bayesian probability model. Env Geol 43:120–131
Lee S, Ryu J, Won J, Park H (2004) Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng Geol 71:289–302
Lin M-L, Tung C-C (2003) A GIS-based potential analysis of the landslides induced by the Chi-Chi earthquake. Eng Geol 71:63–77
Lu PF, An P (1999) A metric for spatial data layers in favorability mapping for geological events. IEEE Trans Geosci Remote Sens 37:1194–1198
Mehrotra GS, Sarkar S, Kanungo DP, Mahadevaiah K (1996) Terrain analysis and spatial assessment of landslide hazards in parts of Sikkim Himalaya. Geol Soc India 47:491–498
Metternicht G, Gonzalez S (2005) FUERO: foundations of a fuzzy exploratory model for soil erosion hazard prediction. Environ Model Softw 20(6):715–728
Nagarajan R, Mukherjee A, Roy A, Khire MV (1998) Temporal remote sensing data and GIS application in landslide hazard zonation of part of Western Ghat, India. Int J Remote Sens 19(4):573–585
Pachauri AK, Pant M (1992) Landslide hazard mapping based on geological attributes. Eng Geol 32:81–100
Ripley B (1996) Pattern recognition and neural networks. Cambridge University Press, Cambridge
Saha AK, Gupta RP, Arora MK (2002) GIS-based landslide hazard zonation in a part of the Himalayas. Int J Remote Sens 23:357–369
Saha AK, Gupta RP, Sarkar I, Arora MK, Csaplovics E (2005) An approach for GIS-based statistical landslide susceptibility zonation—with a case study in the Himalayas. Landslides 2:61–69
Sarkar S, Kanungo DP (2004) An integrated approach for landslide susceptibility mapping using remote sensing and GIS. Photogram Eng Remote Sens 70(5):617–625
Sarkar S, Kanungo DP, Mehrotra GS (1995) Landslide hazard zonation: a case study in Garhwal Himalaya, India. Mountain Res Dev 15(4):301–309
Schalkoff RJ (1997) Artificial neural networks. Wiley, New York
Shortliffe EH, Buchanan GG (1975) A model of inexact reasoning in medicine. Math Biosci 23:351–379
Sinha BN, Varma RS, Paul DK (1975) Landslides in Darjeeling District (West Bengal) and adjacent areas. Bull Geol Survey India Series B, no. 36:1–45
Suzen ML, Doyuran V (2004) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu Catchment, Turkey. Eng Geol 71:303–321
Tangestani MH (2003) Landslide susceptibility mapping using the fuzzy gamma operation in a GIS, Kakan Catchment Area, Iran. In: Proceeding of map India conference 2003
van Westen CJ (1994) GIS in landslide hazard zonation: a review, with examples from the Andes of Colombia. In: Price M, Heywood I (eds) Mountain environments and geographic information system. Taylor & Francis, Basingstoke, pp 135–165
Virdi NS, Sah MP, Bartarya SK (1997) Mass wasting, its manifestations, causes and control: some case histories from Himachal Himalaya. In: Agarwal DK, Krishna AP, Joshi V, Kumar K, Palni MS (eds) Perspectives of mountain risk engineering in the Himalayan Region. Gyanodaya Prakashan, Nainital, pp 111–130
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a Medium Scale Study, Hendek region (Turkey). Eng Geol 79:251–266
Zhou W (1999) Verification of the nonparametric characteristics of backpropagation neural networks for image classification. IEEE Trans Geosci Remote Sens 37:771–779
Acknowledgments
The authors are grateful to the Director, CSIR-Central Building Research Institute, Roorkee for granting permission to publish this paper. The suggestions made by the referees to improve the quality of the paper are greatly acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kanungo, D.P., Sarkar, S. & Sharma, S. Combining neural network with fuzzy, certainty factor and likelihood ratio concepts for spatial prediction of landslides. Nat Hazards 59, 1491–1512 (2011). https://doi.org/10.1007/s11069-011-9847-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-011-9847-z