
Abstract
Innovation efforts in developing soft computing models (SCMs) of researchers and scholars are significant in recent years, especially for problems in the mining industry. So far, many SCMs have been proposed and applied to practical engineering to predict ground vibration intensity (BIGV) induced by mine blasting with high accuracy and reliability. These models significantly contributed to mitigate the adverse effects of blasting operations in mines. Despite the fact that many SCMs have been introduced with promising results, but ambitious goals of researchers are still novel SCMs with the accuracy improved. They aim to prevent the damages caused by blasting operations to the surrounding environment. This study, therefore, proposed a novel SCM based on a robust meta-heuristic algorithm, namely Hunger Games Search (HGS) and artificial neural network (ANN), abbreviated as HGS–ANN model, for predicting BIGV. Three benchmark models based on three other meta-heuristic algorithms (i.e., particle swarm optimization (PSO), firefly algorithm (FFA), and grasshopper optimization algorithm (GOA)) and ANN, named as PSO–ANN, FFA–ANN, and GOA–ANN, were also examined to have a comprehensive evaluation of the HGS–ANN model. A set of data with 252 blasting operations was collected to evaluate the effects of BIGV through the mentioned models. The data were then preprocessed and normalized before splitting into individual parts for training and validating the models. In the training phase, the HGS algorithm with the optimal parameters was fine-tuned to train the ANN model to optimize the ANN model's weights. Based on the statistical criteria, the HGS–ANN model showed its best performance with an MAE of 1.153, RMSE of 1.761, R2 of 0.922, and MAPE of 0.156, followed by the GOA–ANN, FFA–ANN and PSO–ANN models with the lower performances (i.e., MAE = 1.186, 1.528, 1.505; RMSE = 1.772, 2.085, 2.153; R2 = 0.921, 0.899, 0.893; MAPE = 0.231, 0.215, 0.225, respectively). Based on the outstanding performance, the HGS–ANN model should be applied broadly and across a swath of open-pit mines to predict BIGV, aiming to optimize blast patterns and reduce the environmental effects.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Sustainable and responsible in mining is the explicit goals of researchers in recent years since the negative impacts on environments of mining practices, especially surface mining (Bakhtavar et al., 2021; Bui and Ho 2020; Patra et al., 2016; Poudyal et al., 2019; Schueler et al., 2011; Tiwary, 2001; Zeng et al., 2020). Among the operations in open-pit mines, blasting is the most sensitive to the environment (Ainalis et al., 2017; Katsabanis, 2020). It contributes a large amount of dust and toxic gas to the air environment. Not only that, but blasting activities are even more dangerous when generating harmful waves to the surrounding environment, such as shock waves and air over-pressure (Faramarzi et al., 2014). At a gradual distance from the center of the explosion, the shock wave turned into blast-induced ground vibration (BIGV) (Nguyen et al., 2020a, b, c). Furthermore, the structures may be broken, vibration, benches may be instability and fail at a high intensity of BIGV (Bui et al., 2019). Therefore, accurate prediction of BIGV has a vital role in mitigating the damages of structures, buildings, and benches/slopes.
For predicting BIGV, many researchers proposed and applied different approaches, and they can be categorized into two groups: empirical equations and soft computing models. Whereas empirical equations are considered the “white box” mathematics, most soft computing models are taken into account as the “black box” mathematics (Le and Dang 2020; Nguyen 2020). However, the accuracy and reliability of the “black box” mathematics were recommended as better as the “white box” mathematics in predicting BIGV (Ghoraba et al., 2016; Saadat et al., 2014). As a matter of fact, many artificial intelligence (AI) models were proposed with promising results. The proposed AI models (in the previous papers) and their results are listed in Table 1.
From a comprehensive review in Table 1, it is conspicuous that many state-of-the-art techniques based on AI have been introduced to predict BIGV with different results reported. Indeed, various meta-heuristic algorithms have been applied to enhance the accuracy of the classic models, such as PSO, GWO, GA, ICA, CSO, to name a few. They worked based on the swarm, evolutionary, and social behaviors to generate many solutions for predicting BIGV. Each solution corresponds to a fitness of the model, and finally, the best solution was selected based on the best performance of the benchmark models. Based on the recommendations of previous researchers, hybrid models based on meta-heuristic algorithms often providing better performance over the conventional models. Thus, current models' trend is often integrated between optimization algorithms and other powerful machine learning algorithms. This study introduces a novel and robust hybrid model for predicting BIGV based on the Hunger Games Search optimization algorithm (HGS) and ANN, named as HGS–ANN model. It is worth noting that the HGS algorithm was just introduced by Yang et al. (2021) on March 04, 2021. Yet, it has not been considered and combined with the ANN or other models for any problems. Therefore, the HGS–ANN model was proposed the first time in this study and applied for predicting BIGV. Note that it can be widely applied to other problems in real life. Besides, three other hybrid models, such as PSO–ANN, FFA–ANN, and GOA–ANN, were also developed and compared to the proposed HGS–ANN model to emphasize the robustness of the proposed HGS–ANN model.
Methodology
As introduced in the above section, this study considered and developed different ANN models based on various meta-heuristic algorithms (i.e., HGS, PSO, FFA, and GOA). Due to the FFA–ANN, PSO–ANN, and GOA–ANN models have been introduced in many published papers (Hasanipanah et al., 2016; Heidari et al., 2019; Le et al., 2019; Shang et al., 2019; Moayedi et al., 2020; C. Xie et al., 2021), they have not been mentioned in this section. This section only focuses on proposing the framework of the novel HGS–ANN model for predicting BIGV.
Artificial Neural Network (ANN)
ANN is incredibly famous for its applications in real life. It was developed based on the biological neuron’s functionality of the human brain (Basheer & Hajmeer, 2000; Falahian et al., 2015). There are many types of ANN, such as feedforward, regulatory feedback, physical, recurrent, convolutional, radial basis function, and dynamic neural networks, to name a few (Aggarwal & Song, 1998; T. Xie et al., 2011; Suzuki, 2013; Tsantekidis et al., 2017; Al Kheraif et al., 2019; Yazdinejad et al., 2020). In this work, the multiple layers perceptron (MLP), which is a class of feedforward neural networks, was used to predict BIGV.
Theoretically, the network topology of an MLP model includes an input layer, one or multiple hidden layers, and one output layer (Fig. 1). Accordingly, the information is moved from the input layer through the hidden layers and finally summaries the results to the output layer in one direction. In each layer of an MLP (except the input layer), neurons (nodes) are the computational units that can help the MLP model achieves the expected results. In order to implement the computation, ANN uses a training algorithm, such as backpropagation, feedforward, and Levenberg–Marquardt. It can compute the connections between nodes through their weights and biases. Besides, activation functions are also the critical components of an MLP neural network. They are nonlinear functions (e.g., relu, edlu, tanh, sigmoid) applied to the outputs of hidden layers in an MLP, and they are then used as the inputs for the next layer. In this way, MLP can detect and explain complex relationships of the dataset. In other words, without activation functions, the predictive power of the MLP will be limited and significantly reduced. The combination of activation functions between hidden layers is to help the model learn complex nonlinear relationships latent in the data. Due to the principle of MLP has been introduced in many published papers and books (Basheer & Hajmeer, 2000; Ertuğrul, 2018); therefore, this section only briefly introduces the principle of MLP neural network. Further details of MLP neural networks can be found in the following materials (Alanis et al., 2019; Bre et al., 2018; Hassoun, 1995; Livingstone, 2008; Suzuki, 2013). In this study, MLP neural network was simply called ANN for predicting BIGV, and its architecture is illustrated in Figure 1.

General architecture of an ANN for predicting BIGV
Hunger Games Search (HGS) Optimization Algorithm
HGS is a new meta-heuristic algorithm introduced and proposed by Yang et al. (2021). It is designed inspired by the cooperative behavior of the animal and their hunger-driven activities. The mathematical model of HGS was proposed based on a simple structure, but the performance is very competitive. It includes two stages: (1) approach food; and (2) hunger role.
In the first stage, the cooperative communication and foraging behavior of individuals are described as:
where \(\sigma _{1} \;{\text{and}}\;\sigma _{2}\) are random numbers \(\left( {0 \le \sigma _{1} ,\,\sigma _{2} \le 1} \right)\); \({\text{rand}}\left( {} \right)\) is also a random number but it must be satisfied a normal distribution; \(t\) is the current iteration; \(\overrightarrow {{W_{1} }} \;{\text{and}}\;\overrightarrow {{W_{2} }}\) stand for the weights of hunger behavior; \(\overrightarrow {{G_{{\text{b}}} }}\) stands for the best position of the best individual; \(l\) is a constant; S is a variation control, which is determined as:
where \({\text{hyp}}.\;{\text{func}}\) is a hyperbolic function; \(\overrightarrow {R}\) is a number in the range of [− a, a] and it is used to control the range of activity:
where \(\beta\) is a random number interval [0,1]; \(\alpha\) is the shrink of iterations, thus:
where T is the maximum number of iterations.
In the second stage, the characteristics of hunger-driven activities are simulated. Accordingly, the weights of hunger behavior are represented in Eqs. 5 and 6:
where \(\delta\) represents the hunger of each population; \(N_{{{\text{pop}}}}\) is the number of populations;
where \(\sigma _{3} ,\,\sigma _{4} ,\;{\text{and}}\;\sigma _{5}\) denote the random numbers \(\left( {0 \le \sigma _{3} ,\,\sigma _{4} ,\sigma _{5} \le 1} \right)\). \(\delta\) can be provided by the following function:
where \({\text{fitness}}_{i}\) is the fitness of each individual at the ith iteration; \({\text{fitness}}_{{{\text{best}}}}\) is the best fitness obtained at the current iteration; \(\delta _{{{\text{new}}}}\) is a new hunger, and it is calculated based on Eqs. 8 and 9:
where \({\text{bound}}_{{{\text{upper}}}}\) and \({\text{bound}}_{{{\text{lower}}}}\) stand for the feature space bounds; \(\sigma _{6}\) is a random number \(\left( {0 \le \sigma _{6} \le 1} \right)\).
The pseudo-code of the HGS algorithm is shown in Figure 2.

[modified from Yang et al. (2021)]
Pseudo-code of the HGS algorithm
Hybrid HGS–ANN Model
Like other meta-heuristic algorithms, the primary role of the HGS algorithm in this study is the optimization of weights of the ANN model for predicting BIGV. To do this, an initial ANN model was developed first. Next, the initial weights were transferred to the optimization procedure of the HGS algorithm to re-calculate and update the weights to the ANN model, called the HGS–ANN model. During optimizing the HGS–ANN model, the stopping conditions, such as RMSE and the maximum number of iterations, were used to evaluate the fitness of the proposed HGS–ANN model. If the accuracy of the HGS–ANN model is satisfied (i.e., with the lowest RMSE), the optimization process will stop, and the optimal HGS–ANN model will be selected for predicting BIGV. Otherwise, the optimization procedure will continuously be searching, calculating, and updating the weights of the ANN model in the subsequent iterations. Once the optimization procedure was repeated with the maximum of iterations, the lowest RMSE was selected, and the corresponding model will be assigned as the best model for predicting BIGV. The framework of the HGS–ANN model for predicting BIGV is proposed in Figure 3.

Introduction of the HGS–ANN model for predicting BIGV
Performance Metrics for Model Evaluation
As is known, model evaluation is mandatory after the predictive models were developed, aiming to not only understanding the performance of the models (e.g., over-fitting or under-fitting) but also have a comprehensive assessment and comparison of individual models in terms of BIGV prediction. Herein, four performance metrics were used to evaluate the predictive models, including MAE, RMSE, R2, and MAPE. Whereas the MAE and RMSE metrics show the models' errors, the MAPE metric shows the percentage of the error, and R2 metric helps to understand the suitability of the dataset used for each model. They are calculated using the following equations:
where \(n_{{{\text{blast}}}}\) is the number of blasting events used in the evaluation; \(y_{{i\_{\text{BIGV}}}}\) is the measured BIGV value at ith blasting event; \(\hat{y}_{{i\_{\text{BIGV}}}}\) stands for the predicted BIGV value at ith blasting event; \(\bar{y}_{{{\text{BIGV}}}}\) denotes the mean of measured BIGV values.
Data and Statistical Analysis
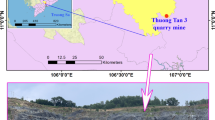
To realize this study, 252 blasting operations were performed at an open-pit coal mine located in the Northern Vietnam (Fig. 4). Accordingly, BIGV values were monitored at the sensitivity locations, and the corresponding parameters of blasts were collected. It is a fact that this mine applied the non-electric millisecond delay blasting method to reduce BIGV (Guan et al., 2019; Nateghi et al., 2009). Nevertheless, several recorded results indicated that the BIGVs measured are high, and they may damage the surrounding environment, especially the benches and slopes of the surrounding open-pit mines, as shown in Figure 4. Thus, monitoring and predicting BIGV in this mine is necessary to control and mitigate the adverse effects of BIGV.

Location and an aerial view of the study area
Before measuring BIGVs, blast patterns of 252 blasting events were collected first with the blasting parameters, such as hole length (HL), maximum explosive charge per delay (W), the number of blasting groups (NG), time delay for each group (TL), burden (B), powder factor (PF), spacing (S), and stemming (T). For each blasting event, the position(s) of the seismograph was/were determined, and a GPS receiver was then used to measure the distance from the blasting face to the position(s) of the seismograph (abbreviated as D). Finally, the blasts were detonated, and BIGVs were recoded by the Micromate devices (seismographs). The statistical analysis of the dataset collected is shown in Table 2. In addition, the visualization of this dataset is shown in Figure 5.

Visualizations of the dataset used: (a) histograms; (b) box plots; (c) variable correlations
In Figure 5, the details of the dataset used were illustrated. Accordingly, the distribution of the variables is illustrated by the histogram (Fig. 5a), the statistics and outliers of the dataset are illustrated by box plots (Fig. 5b), and the correlation between independent variables (inputs) and dependent variable (output, i.e., BIGV) is illustrated in Figure 5c. The correlation results show that all the input variables in this dataset should be used to evaluate their effects on BIGV since its correlation is not high (< 0.75). Therefore, we used the whole dataset with nine input variables to predict BIGV based on the introduced models, HGS–ANN, FFA–ANN, GOA–ANN, and PSO–ANN.
Results and Discussion
As introduced earlier, this work aims at proposing the novel HGS–ANN model for predicting BIGV in mine blasting. Three other hybrid models, namely PSO–ANN, FFA–ANN, and GOA–ANN, were also taken into consideration to predict BIGV and compared with the proposed HGS–ANN model.
Prior to developing these models, the blasting dataset was preprocessed using the MinMax scaling method with the interval [− 1,1] to normalize the dataset. Subsequently, the dataset was divided into two partitions that can be managed, developed and tested separately (70% for training and 30% for testing). Finally, the proposed HGS–ANN framework was applied, as shown in Figure 3. Similar approaches were applied for the PSO–ANN, FFA–ANN, and GOA–ANN models. Before training the ANN model by the optimization algorithms (i.e., HGS, PSO, FFA, and GOA), an initial ANN model and the algorithms’ parameters were established sufficiency. For the initial ANN model, a network topology with two hidden layers (e.g., ten neurons in the first layer, five neurons in the second layer) was selected to predict BIGV through the trial-and-error procedure, and the initial weights were computed. The parameters of the HGS, PSO, FFA, and GOA were set up as follows:
-
Numbers of hungers, swarms, fireflies, and grasshoppers (populations): 50, 100, 150, 200, 250, 300, 350, 400, 450, 500.
-
Maximum number of iterations: 1000.
-
PSO’s parameters: \(c_{1} = c_{2} = 1.2\); \(w_{{\min }} = 0.4\); \(w_{{\max }} = 0.9\).
-
GOA’s parameters: \(c_{{\min }} = 0.00004\); \(c_{{\max }} = 1\).
-
HGS’s parameters: \(L = 0.03\); \({\text{LH}} = 1000\).
-
FFA’s parameters: \(\gamma = 1\); \(\beta = 1\); \(\alpha = 0.2\); \(\alpha _{{{\text{damp}}}} = 0.99\); \(\delta = 0.05\); \(m_{{{\text{exponent}}}} = 2\).
Finally, the meta-heuristic algorithms were applied to optimize the initial weights of the initial ANN model. RMSE was used as the predictive models' objective function to evaluate the training error of the swarm-based ANN models during 1000 iterations. The results are shown in Figure 6.


Performance of the optimal predictive models under various population sizes: (a) HGS–ANN; (b) FFA–ANN; (c) GOA–ANN; (d) PSO–ANN
As shown in Figure 6, the best hybrid models (optimal models) for predicting BIGV were defined with the following parameters:
-
HGS–ANN model: 400 populations, 684 iterations;
-
FFA–ANN model: 450 populations; 727 iterations;
-
GOA–ANN model: 300 populations; 992 iterations;
-
PSO–ANN model: 300 populations; 969 iterations.
Once the models were optimized, the testing dataset was imported to calculate their performance as unseen data in practice. The statistical analysis of the performances is given in Table 3. As indicated in the statistical indexes, it is possible to see that all four models are acceptable for predicting BIGV. However, the HGS–ANN and GOA–ANN models provided better performances than the other models (i.e., FFA–ANN and PSO–ANN). Nevertheless, it is difficult to evaluate which model is better among the HGS–ANN and GOA–ANN models. However, the training phase provides a better performance for the GOA–ANN model, and the testing phase provides a better performance for the HGS–ANN model. Therefore, we used the ranking method to sort the models based on their performances and rankings, as given in Table 4.
From the results in Table 4, it is easy to recognize which model is the best based on the ranking of the models. Accordingly, the HGS–ANN model yielded the highest ranking, with a total ranking of 28. Meanwhile, the GOA–ANN model only provided a total ranking of 26. The other models, i.e., FFA–ANN and PSO–ANN, provided the same ranking with a total ranking of 13. Furthermore, based on the parameters of the meta-heuristic algorithms used and the training time of the models in Figure 6, it can be seen that the HGS is an outstanding algorithm and the HGS–ANN model is the most superior model in the training dataset. Whereas the HGS’s parameters are most of the number of populations and maximum iterations (except L and LH are coefficients), the other algorithms required additional parameters during training. Moreover, considering the training time of the hybrid models (Fig. 6), the PSO–ANN model provided the lowest training time with 1944.472 s. Following are the HGS–ANN model (i.e., 2121.498 s), GOA–ANN model (i.e., 6350.216 s), and FFA–ANN model (i.e., 7033.281 s). However, the training error of the HGS–ANN model is the lowest, and the training time is slightly higher than the PSO–ANN model. Overall, the HGS–ANN model is the most superior model in terms of development and modeling. For further assessment of the models, the relative error (RE), correlation of observed and predicted values, and a comparison of them are shown in Figure 7.


Evaluation of the BIGV prediction models based on the relative error, performance prediction, and linear relationship: (a) HGS–ANN; (b) FFA–ANN; (c) GOA–ANN; (d) PSO–ANN
From Figure 7, it can be seen that the accuracy of the predictions obtained by individual models is high, and the convergence on the regression lines is very good. Nevertheless, taking a closer look at Figure 7, it is taken into consideration that the accuracy and convergence on the HGS–ANN model are superior to the other models. In particular, considering the models' RE graphics, we can see a peak point on the graphics at sample #32. Taking a closer look at this peak point in the developed models, it is no doubt that the RE in the HGS–ANN model is the lowest (~ − 550%), whereas it is ~ − 1300% for the GOA–ANN model, ~ − 800% for the PSO–ANN model, and ~ − 7100% for the FFA–ANN model. Hence, it can claim that the HGS–ANN model provided an excellent performance in this study for predicting BIGV. In other words, the HGS algorithm is more robust than the other algorithms (i.e., GOA, PSO, FFA) when combined with the ANN model for BIGV estimation in this work.
Sensitivity Analysis
In order to determine the robustness of the proposed HGS–ANN model, a sensitivity analysis was adopted to examine the extent to which the results are affected by changes in values of the input variables. In other words, this step aims to identify the important variables on which the results depend most. The sensitivity criteria (Dimopoulos et al., 1995) were calculated and evaluated, as shown in Figure 8. As illustrated in this figure, B, W, NG, S, D, and PF are the variables that have high effects on the BIGV. In contrast, the HL and T variables have low influences on BIGV, especially the T variable.

Sensitivity analysis results of the variables used through the proposed HGS–ANN model
Conclusion
Blasting is an indispensable method in open-pit mines; however, its negative impacts on the environment are inevitable, especially BIGV. This study proposed a novel AI model with the accuracy improved for predicting BIGV, namely the HGS–ANN model. The optimization role of the HGS algorithm was thoroughly interpreted in this study when combined with the ANN model for predicting BIGV, and it is a robust optimization algorithm for engineering problems. The HGS–ANN model was proved as a robust soft computing model for predicting BIGV with the outstanding obtained results compared to the benchmark hybrid models (i.e., GOA–ANN, FFA–ANN, and PSO–ANN). As a recommendation, this model should be used in practical engineering to control and mitigate the adverse effects of BIGV in mine blasting.
References
Aggarwal, R., & Song, Y. (1998). Artificial neural networks in power systems. II. Types of artificial neural networks. Power Engineering Journal, 12(1), 41–47.
Ainalis, D., Kaufmann, O., Tshibangu, J.-P., Verlinden, O., & Kouroussis, G. (2017). Modelling the source of blasting for the numerical simulation of blast-induced ground vibrations: A review. Rock Mechanics and Rock Engineering, 50(1), 171–193.
Al Kheraif, A. A., Alshahrani, O. A., Al Esawy, M. S. S., & Fouad, H. (2019). Evolutionary and Ruzzo-Tompa optimized regulatory feedback neural network based evaluating tooth decay and acid erosion from 5 years old children. Measurement, 141, 345–355.
Alanis, A. Y., Arana-Daniel, N., & Lopez-Franco, C. (2019). Artificial neural networks for engineering applications. Academic Press.
Amiri, M., Amnieh, H. B., Hasanipanah, M., & Khanli, L. M. (2016). A new combination of artificial neural network and K-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Engineering with Computers, 32(4), 631–644.
Armaghani, D. J., Hasanipanah, M., Amnieh, H. B., & Mohamad, E. T. (2018). Feasibility of ICA in approximating ground vibration resulting from mine blasting. Neural Computing and Applications, 29(9), 457–465.
Armaghani, D. J., Momeni, E., Abad, S. V. A. N. K., & Khandelwal, M. (2015). Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environmental Earth Sciences, 74(4), 2845–2860.
Arthur, C. K., Temeng, V. A., & Ziggah, Y. Y. (2020). Multivariate adaptive regression splines (MARS) approach to blast-induced ground vibration prediction. International Journal of Mining, Reclamation and Environment, 34(3), 198–222.
Bakhtavar, E., Hosseini, S., Hewage, K., & Sadiq, R. (2021). Air pollution risk assessment using a hybrid fuzzy intelligent probability-based approach: Mine blasting dust impacts. Natural Resources Research, 30, 1–21.
Basheer, I. A., & Hajmeer, M. (2000). Artificial neural networks: Fundamentals, computing, design, and application. Journal of Microbiological Methods, 43(1), 3–31.
Bre, F., Gimenez, J. M., & Fachinotti, V. D. (2018). Prediction of wind pressure coefficients on building surfaces using artificial neural networks. Energy and Buildings, 158, 1429–1441.
Bui, N. X., & Ho, G. S. (2020). Vietnamese Surface Mining - Training and scientific research for integrating the Fourth Industrial Revolution. Journal of Mining and Earth Sciences, 61(5), 1–15. https://doi.org/10.46326/JMES.KTLT2020.01
Bui, X.-N., Nguyen, H., Le, H.-A., Bui, H.-B., & Do, N.-H. (2019). Prediction of blast-induced air over-pressure in open-pit mine: Assessment of different artificial intelligence techniques. Natural Resources Research, 29(2), 571–591.
Bui, X.-N., Nguyen, H., Tran, Q.-H., Nguyen, D.-A., & Bui, H.-B. (2021). Predicting ground vibrations due to mine blasting using a novel artificial neural network-based cuckoo search optimization. Natural Resources Research. https://doi.org/10.1007/s11053-021-09823-7
Chen, W., Hasanipanah, M., Rad, H. N., Armaghani, D. J., & Tahir, M. (2019). A new design of evolutionary hybrid optimization of SVR model in predicting the blast-induced ground vibration. Engineering with Computers, 37, 1–17.
Dimopoulos, Y., Bourret, P., & Lek, S. (1995). Use of some sensitivity criteria for choosing networks with good generalization ability. Neural Processing Letters, 2(6), 1–4.
Ertuğrul, Ö. F. (2018). A novel type of activation function in artificial neural networks: Trained activation function. Neural Networks, 99, 148–157.
Falahian, R., Dastjerdi, M. M., Molaie, M., Jafari, S., & Gharibzadeh, S. (2015). Artificial neural network-based modeling of brain response to flicker light. Nonlinear Dynamics, 81(4), 1951–1967.
Faradonbeh, R. S., Armaghani, D. J., Abd Majid, M., Tahir, M. M., Murlidhar, B. R., Monjezi, M., et al. (2016). Prediction of ground vibration due to quarry blasting based on gene expression programming: A new model for peak particle velocity prediction. International Journal of Environmental Science and Technology, 13(6), 1453–1464.
Faramarzi, F., Farsangi, M. A. E., & Mansouri, H. (2014). Simultaneous investigation of blast induced ground vibration and airblast effects on safety level of structures and human in surface blasting. International Journal of Mining Science and Technology, 24(5), 663–669.
Fattahi, H., & Hasanipanah, M. (2021). Prediction of blast-induced ground vibration in a mine using relevance vector regression optimized by metaheuristic algorithms. Natural Resources Research, 30(2), 1849–1863.
Fişne, A., Kuzu, C., & Hüdaverdi, T. (2011). Prediction of environmental impacts of quarry blasting operation using fuzzy logic. Environmental Monitoring and Assessment, 174(1–4), 461–470.
Fouladgar, N., Hasanipanah, M., & Amnieh, H. B. (2017). Application of cuckoo search algorithm to estimate peak particle velocity in mine blasting. Engineering with Computers, 33(2), 181–189.
Ghoraba, S., Monjezi, M., Talebi, N., Armaghani, D. J., & Moghaddam, M. (2016). Estimation of ground vibration produced by blasting operations through intelligent and empirical models. Environmental Earth Sciences, 75(15), 1–9.
Guan, X., Guo, C., Mou, B., & Shi, L. (2019). Tunnel millisecond-delay controlled blasting based on the delay time calculation method and digital electronic detonators to reduce structure vibration effects. PLoS ONE, 14(3), e0212745.
Hajihassani, M., Armaghani, D. J., Marto, A., & Mohamad, E. T. (2015a). Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bulletin of Engineering Geology and the Environment, 74(3), 873–886.
Hajihassani, M., Armaghani, D. J., Monjezi, M., Mohamad, E. T., & Marto, A. (2015b). Blast-induced air and ground vibration prediction: A particle swarm optimization-based artificial neural network approach. Environmental Earth Sciences, 74(4), 2799–2817.
Hasanipanah, M., Amnieh, H. B., Khamesi, H., Armaghani, D. J., Golzar, S. B., & Shahnazar, A. (2018). Prediction of an environmental issue of mine blasting: An imperialistic competitive algorithm-based fuzzy system. International Journal of Environmental Science and Technology, 15(3), 551–560.
Hasanipanah, M., Faradonbeh, R. S., Amnieh, H. B., Armaghani, D. J., & Monjezi, M. (2017a). Forecasting blast-induced ground vibration developing a CART model. Engineering with Computers, 33(2), 307–316.
Hasanipanah, M., Naderi, R., Kashir, J., Noorani, S. A., & Qaleh, A. Z. A. (2017b). Prediction of blast-produced ground vibration using particle swarm optimization. Engineering with Computers, 33(2), 173–179.
Hasanipanah, M., Noorian-Bidgoli, M., Armaghani, D. J., & Khamesi, H. (2016). Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Engineering with Computers, 32(4), 705–715.
Hassoun, M. H. (1995). Fundamentals of artificial neural networks. MIT Press.
Heidari, A. A., Faris, H., Aljarah, I., & Mirjalili, S. (2019). An efficient hybrid multilayer perceptron neural network with grasshopper optimization. Soft Computing, 23(17), 7941–7958.
Katsabanis, P. D. (2020). Analysis of the effects of blasting on comminution using experimental results and numerical modelling. Rock Mechanics and Rock Engineering, 53(7), 3093–3109.
Khandelwal, M., Kankar, P., & Harsha, S. (2010). Evaluation and prediction of blast induced ground vibration using support vector machine. Mining Science and Technology (china), 20(1), 64–70.
Lawal, A. I., Kwon, S., Hammed, O. S., & Idris, M. A. (2021). Blast-induced ground vibration prediction in granite quarries: An application of gene expression programming, ANFIS, and sine cosine algorithm optimized ANN. International Journal of Mining Science and Technology, 31(2), 265–277.
Le, D. N., & Dang, C. V. (2020). Application of fuzzy-logic to design fuzzy compensation controller for speed control system to reduce vibration of CBШ-250T drilling machine in mining industry. Journal of Mining and Earth Sciences, 61(6), 90–96. https://doi.org/10.46326/JMES.2020.61(6).10
Le, L. T., Nguyen, H., Dou, J., & Zhou, J. (2019). A comparative study of PSO-ANN, GA-ANN, ICA-ANN, and ABC-ANN in estimating the heating load of buildings’ energy efficiency for smart city planning. Applied Sciences, 9(13), 2630.
Livingstone, D. J. (2008). Artificial neural networks: Methods and applications. Springer.
Moayedi, H., Gör, M., Lyu, Z., & Bui, D. T. (2020). Herding behaviors of grasshopper and Harris hawk for hybridizing the neural network in predicting the soil compression coefficient. Measurement, 152, 107389.
Monjezi, M., Hasanipanah, M., & Khandelwal, M. (2013). Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Computing and Applications, 22(7), 1637–1643.
Nateghi, R., Kiany, M., & Gholipouri, O. (2009). Control negative effects of blasting waves on concrete of the structures by analyzing of parameters of ground vibration. Tunnelling and Underground Space Technology, 24(6), 608–616.
Nguyen, H. (2020). Application of the k - nearest neighbors algorithm for predicting blast - induced ground vibration in open - pit coal mines: A case study. Journal of Mining and Earth Sciences, 61(6), 22–29. https://doi.org/10.46326/JMES.2020.61(6).03
Nguyen, A. D., Nhu, B. V., Tran, B. D., Pham, H. V., & Nguyen, T. A. (2020a). Definition of amount explosive per blast for spillway at the Nui Mot lake - Binh Dinh province. Journal of Mining and Earth Sciences, 61(5), 117–124. https://doi.org/10.46326/JMES.KTLT2020.10
Nguyen, A. D., Tran, H. Q., Tran, B. D., & Soukhanouvong, P. (2020b). Prediction of the peak velocity of blasting vibration based on various models at Ninh Dan quarry Thanh Ba district Phu Tho province. Journal of Mining and Earth Sciences, 61(4), 102–109. https://doi.org/10.46326/JMES.2020.61(4).11
Nguyen, H., Bui, N. X., Tran, H. Q., & Le, G. H. T. (2020c). A novel soft computing model for predicting blast - induced ground vibration in open - pit mines using gene expression programming. Journal of Mining and Earth Sciences, 61(5), 107–116. https://doi.org/10.46326/JMES.KTLT2020.09
Nguyen, H., Bui, X.-N., Tran, Q.-H., & Mai, N.-L. (2019). A new soft computing model for estimating and controlling blast-produced ground vibration based on hierarchical K-means clustering and cubist algorithms. Applied Soft Computing, 77, 376–386. https://doi.org/10.1016/j.asoc.2019.01.042
Nguyen, H., Bui, X.-N., Tran, Q.-H., Nguyen, H. A., Nguyen, D.-A., & Le, Q.-T. (2021). Prediction of ground vibration intensity in mine blasting using the novel hybrid MARS–PSO–MLP model. Engineering with Computers, 37, 1–19.
Nguyen, H., Drebenstedt, C., Bui, X.-N., & Bui, D. T. (2020d). Prediction of blast-induced ground vibration in an open-pit mine by a novel hybrid model based on clustering and artificial neural network. Natural Resources Research, 29(2), 691–709.
Patra, A. K., Gautam, S., & Kumar, P. (2016). Emissions and human health impact of particulate matter from surface mining operation—A review. Environmental Technology & Innovation, 5, 233–249.
Poudyal, N. C., Gyawali, B. R., & Simon, M. (2019). Local residents’ views of surface mining: Perceived impacts, subjective well-being, and support for regulations in southern Appalachia. Journal of Cleaner Production, 217, 530–540.
Saadat, M., Khandelwal, M., & Monjezi, M. (2014). An ANN-based approach to predict blast-induced ground vibration of Gol-E-Gohar iron ore mine, Iran. Journal of Rock Mechanics and Geotechnical Engineering, 6(1), 67–76.
Schueler, V., Kuemmerle, T., & Schröder, H. (2011). Impacts of surface gold mining on land use systems in Western Ghana. Ambio, 40(5), 528–539.
Shahnazar, A., Rad, H. N., Hasanipanah, M., Tahir, M., Armaghani, D. J., & Ghoroqi, M. (2017). A new developed approach for the prediction of ground vibration using a hybrid PSO-optimized ANFIS-based model. Environmental Earth Sciences, 76(15), 1–17.
Shang, Y., Nguyen, H., Bui, X.-N., Tran, Q.-H., & Moayedi, H. (2019). A novel artificial intelligence approach to predict blast-induced ground vibration in open-pit mines based on the firefly algorithm and artificial neural network. Natural Resources Research, 28, 1–15.
Suzuki, K. (2013). Artificial neural networks: Architectures and applications. BoD—Books on Demand.
Taheri, K., Hasanipanah, M., Golzar, S. B., & Abd Majid, M. Z. (2017). A hybrid artificial bee colony algorithm-artificial neural network for forecasting the blast-produced ground vibration. Engineering with Computers, 33(3), 689–700.
Tiwary, R. (2001). Environmental impact of coal mining on water regime and its management. Water, Air, and Soil Pollution, 132(1), 185–199.
Tsantekidis, A., Passalis, N., Tefas, A., Kanniainen, J., Gabbouj, M., & Iosifidis, A. (2017). Forecasting stock prices from the limit order book using convolutional neural networks. In 2017 IEEE 19th conference on business informatics (CBI), 2017 (vol. 1, pp. 7–12). IEEE.
Verma, A. K., & Singh, T. N. (2011). Intelligent systems for ground vibration measurement: A comparative study. Engineering with Computers, 27(3), 225–233.
Xie, C., Nguyen, H., Bui, X.-N., Choi, Y., Zhou, J., & Nguyen-Trang, T. (2021). Predicting rock size distribution in mine blasting using various novel soft computing models based on meta-heuristics and machine learning algorithms. Geoscience Frontiers, 12(3), 101108.
Xie, T., Yu, H., & Wilamowski, B. (2011). Comparison between traditional neural networks and radial basis function networks. In 2011 IEEE international symposium on industrial electronics, 2011 (pp. 1194–1199). IEEE.
Yang, Y., Chen, H., Asghar Heidari, A., & Gandomi, A. H. (2021). Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Systems with Applications. https://doi.org/10.1016/j.eswa.2021.114864
Yazdinejad, A., HaddadPajouh, H., Dehghantanha, A., Parizi, R. M., Srivastava, G., & Chen, M.-Y. (2020). Cryptocurrency malware hunting: A deep recurrent neural network approach. Applied Soft Computing, 96, 106630.
Yu, Z., Shi, X., Zhou, J., Chen, X., & Qiu, X. (2020). Effective assessment of blast-induced ground vibration using an optimized random forest model based on a Harris hawks optimization algorithm. Applied Sciences, 10(4), 1403.
Zeng, Q., Shen, L., & Yang, J. (2020). Potential impacts of mining of super-thick coal seam on the local environment in arid Eastern Junggar coalfield, Xinjiang region, China. Environmental Earth Sciences, 79(4), 1–15.
Zhou, J., Asteris, P. G., Armaghani, D. J., & Pham, B. T. (2020). Prediction of ground vibration induced by blasting operations through the use of the Bayesian network and random forest models. Soil Dynamics and Earthquake Engineering, 139, 106390.
Zhu, W., Rad, H. N., & Hasanipanah, M. (2021). A chaos recurrent ANFIS optimized by PSO to predict ground vibration generated in rock blasting. Applied Soft Computing, 108, 107434.
Acknowledgments
This paper was supported by the Ministry of Education and Training (MOET) in Viet Nam under Grant Number B2020-MDA-16.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nguyen, H., Bui, XN. A Novel Hunger Games Search Optimization-Based Artificial Neural Network for Predicting Ground Vibration Intensity Induced by Mine Blasting. Nat Resour Res 30, 3865–3880 (2021). https://doi.org/10.1007/s11053-021-09903-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11053-021-09903-8