
Abstract
Geochemical anomalies are commonly separated into different geochemical anomaly levels based on one or more thresholds. However, this practice may cause some important geochemical anomaly information to be lost and subsequently draw wrong decisions for mineral exploration. In addition, previous studies indicate that sparse geochemical sampling always entails uncertainty resulting from conventional geochemical interpolation methods because of smoothing effect. Uncertainty can propagate through the various steps of geochemical data analysis that may lead to significant impact on the final results (e.g., anomaly interpretation and mineral exploration). For geochemical anomaly identification, quantifying the probability of unsampled locations and characterizing the spatial uncertainty of geochemical anomaly based on (not) exceeding a key threshold is very important for practical demands such as exploration risk assessment. Considering the limitations of deterministic modeling method and geochemical anomaly assessment, this study proposes a new method of geochemical anomaly uncertainty assessment by combining geostatistical simulation and singularity analysis. A case study for Au anomaly uncertainty assessment is presented in the west Tianshan region (China) so as to verify the feasibility and effectiveness of the proposed method. The sequential Gaussian simulation was adopted to generate a set of equiprobable realizations that were subsequently employed to produce a series of corresponding singularity index realizations by means of singularity analysis. Critical thresholds of E-type singularity index (α) were determined by the method of singularity-quantile plot analysis, which were used to simulate the spatial uncertainty of Au anomaly in the study area. The results show that the risk probability of Au anomaly characterized by (not) exceedance of a critical threshold can be considered as an important reference for exploration decision-making and risk management.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Singularity analysis has proven to be an important tool for identifying geochemical anomalies and characterizing element distribution patterns (Cheng 2007, 2012; Chen et al. 2007; Zuo et al. 2009; Agterberg 2012a; Liu et al. 2013, 2014; Wang et al. 2013; Zhang et al. 2017a; Lark et al. 2018; Wang and Zuo 2018). For singularity mapping, conventional interpolation methods, such as inverse distance weighted (IDW) interpolation and kriging, are commonly used to produce a continuous geochemical field from point data of element concentrations (Carranza 2010). However, any interpolation method inevitably leads to smoothing out of element concentrations (also called smoothing effect) as indicated by lower variations in estimated values compared to those in original values, because most interpolation techniques result in small values being overestimated and large values being underestimated (Juang et al. 2004; Goovaerts 2006; Yuan et al. 2015). In particular, kriging-based algorithms (e.g., simple kriging and ordinary kriging) only describe the spatial variation of observed data at each sampled location, whereas the variation of the estimated values at each unsampled location is ignored (Afrasiab and Delbari 2013), and the IDW interpolation is a pure mathematical method that is sensitive to extreme values. Unlike IDW and kriging-based algorithms, the multifractal IDW takes into account local singularities in the data (Cheng 2008) although it remains a moving average method that is not devoid of smoothing effect. Therefore, the results obtained from any interpolation method may not reflect to some degree the inherent geochemical spatial pattern and thus can undermine geochemical anomaly identification through singularity analysis.
Questions regarding accuracy of characterizing spatial variability of element concentrations, producing simulated maps (also called realizations) from sparse sampling data, and quantifying uncertainties in maps are critical concerns in earth and environmental sciences. However, every geostatistical simulation technique (Goovaerts 1997, 1999; Deutsch and Journel 1998; Juang et al. 2004; Deutsch 2006; Emery and Ortiz 2012; Emery 2012), such as sequential Gaussian simulation (SGS), provides powerful means of addressing the above-mentioned and related questions, because they can produce a series of equiprobable realizations of target attribute values and each realization honors sample data at their original locations. Therefore, a stochastic simulation map is a realistic representation of the spatial distribution of the target attribute. Compared to other techniques, SGS is the most straightforward and analytically simple algorithm for determining conditional cumulative distribution functions (Deutsch and Journel 1998).
Geostatistical simulation algorithms are designed to overcome limitations (e.g., smoothing effect and inability to consider variation in estimations at unsampled locations) of conventional interpolation methods. In recent years, geostatistical simulation has been widely used in the field of environmental and exploration geochemistry and ore grade simulation (Zhao et al. 2005; Afzal et al. 2015; Soltani et al. 2014; Olea and Luppens 2015; Sadeghi et al. 2015; Mery et al. 2017; Qu et al. 2013; Qu and Deutsch 2018; Paithankar and Chatterjee 2017; Rahimi et al. 2018) because of its several advantages including unbiased predictions and uncertainty estimates of model outputs, evaluation of uncertainty propagation and estimation of probability by exceedance of a critical threshold (Goovaerts 1997; Deutsch and Journel 1998). A method by combining singularity analysis and sequential indicator simulation (SIS) has been presented to evaluate geochemical anomaly uncertainty related to gold exploration in the west Junggar belt, China (Liu and Zhou 2018).
Uncertainty associated with geochemical anomaly maps can impact the whole geochemistry exploration decision-making process. In view of the foregoing discussion, the present study focuses on methodological issues of assessing uncertainty of geochemical anomaly maps. We attempted to develop a new method by means of integrating geostatistical simulation and singularity analysis to assess potential risk in geochemical exploration activities. The proposed method takes spatial uncertainty analysis into account to quantify the influence of geochemical anomaly uncertainty on mineral exploration. For demonstration purposes, a case study for spatial prediction and uncertainty assessment of Au anomaly was carried out by SGS and singularity analysis to support risk management of Au anomaly based on stream sediment geochemical data in the west Tianshan region, China.
Methods
Procedures for Geochemical Anomaly Uncertainty Assessment
The workflow, consisting of several steps, for the proposed geochemical anomaly uncertainty assessment is shown in Figure 1. First, geostatistical simulation algorithms (Deutsch and Journel 1998), such as SGS, were used to simulate geochemical spatial patterns by generating a set of equiprobability realizations of original element concentrations. Second, singularity analysis (Cheng 2007) was performed on realizations to calculate corresponding singularity index realizations (SIRs). Variations in the SIRs allow a measure of geochemical anomaly uncertainty defined by singularity indices (SI). Third, the map of conditional average estimation of SIRs, termed as E-type singularity index (α), was generated from a set of SIRs, which was used to determine geochemical anomaly thresholds by means of singularity-quantile (S-Q) method (Liu et al. 2017). Finally, uncertainty algorithms including local uncertainty analysis and spatial uncertainty analysis were used to quantify the uncertainties among the SIRs through characterization of the probability of (not) exceeding a critical threshold derived from the S-Q method.

Workflow of uncertainty propagation in geochemical anomaly analysis
Sequential Gaussian Simulation
The SGS is on the base of multi-Gaussian assumption of a random function model; thus, a normal score transformation of original sampling data is necessary so that the data could follow the normal distribution assumption at unsampled locations (Deutsch and Journel 1998). The SGS procedures consist of designing a regularly spaced grid, selecting a study area and establishing a random path through each grid node, so that all the nodes can be visited only once in each sequence.
A general workflow for SGS involves normal score transformation of the original data, creating the realizations, and back transforming the results into original units. The sequential steps shown in Figure 2 carry out only the first realization. To produce the remaining realizations, the sequential steps are repeated with different random paths by passing through all nodes for each realization.

A general workflow for sequential Gaussian simulation
Singularity Analysis
The method of singularity analysis was developed for geochemical anomaly identification based on inherent fractal/multifractal properties (Cheng 2007; Cheng and Agterberg 2009; Agterberg 2012b). The window-based method is frequently used to calculate singularity indices (α) in a 2-dimensional space (Cheng 1999). The average concentration ρ within an area A of window size ε can be obtained based on the following power-law relationship:
where c is the fractal density (Cheng 2016; Liu et al. 2018a), α is the singularity index of the power-law relationship, and the μ[A(ε)] is the total concentration within an area A of window size ε. On a log–log plot, the relationship between ρ[A(ε)] and ε can be fitted by least squares method, and the α is determined by the slope (α − 2).
According to Cheng (2007) and Cheng and Agterberg (2009), most singularity indices with α ≈ 2 obey a normal or lognormal distribution, while the remaining singularity indices with α > 2 and α < 2 might follow fractal/multifractal distributions. For geochemical anomaly identification, α < 2 indicates element concentration enrichment, while α > 2 indicates element concentration depletion. Based on the concept of singularity analysis, the S-Q method was developed to separate multiple geochemical populations in frequency domain by plotting singularity index quantiles vs. standard normal quantiles (Liu et al. 2017, 2018a). The critical point of the S-Q method is how to extract these singularity indices with α ≈ 2. This problem can be addressed by setting a confidence interval (e.g., 99%) of singularity indices and selecting suitable percentile intervals, such as 15th and 85th, to determine normal reference line and residual fitting curves. Then, a polynomial curve is fitted by total singularity indices. Using these three curves, two intersection points or thresholds can be solved; these are located above and below the normal reference line, respectively. Thus, hybrid geochemical distribution patterns of singularity indices can be separated into three populations in frequency domain, corresponding to element enrichment, element average and element depletion. Finally, frequency-distributed singularity indices are converted back to spatial domain for visual representation of different patterns. From the fractal/multifractal and statistical points of view, the S-Q method provides insight into the nature of the geochemical anomaly according to Cheng (2007) and Cheng and Agterberg (2009), and S-Q method has been successfully used for chromitite prospectivity analysis based on stream sediment geochemical data in the west Junggar region, China (Liu et al. 2017). Recently, the S-Q method was applied to explore geochemical distribution patterns of minor and major elements in the west Tianshan region based on fractal density model, and it provided excellent performance for characterizing normal/lognormal, power-law and multifractal distributions (Liu et al. 2018a).
Uncertainty Assessment Based on Probability Representation
Uncertainty of a target attribute at a specific location can be expressed by a series of probability values (Goovaerts 1997; Juang et al. 2004; Zhao et al. 2005). For geochemical data at a specific location x’, the local uncertainty can be expressed by a quantified probability z(x) involved in the exceedance of a critical geochemical anomaly threshold z(c), defined by the following equation:
where N is the number of grid nodes across the whole study area, the integer L is the total number of realizations, and n(xi) is the number of realizations that have all simulated values at location xi being larger than the zc in the L realizations.
The reliability of delineating geochemical anomalous areas is described by the spatial uncertainty, which is defined by the joint probability of L realizations across each node:
Case Study
Study Area
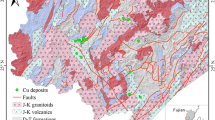
The west Tianshan region along the southern margin of the Central Asian Orogenic Belt (CAOB) was formed during the Paleozoic closure of the Northern Tianshan and Southern Tianshan oceans between the Junggar block and Tarim craton (Fig. 3a; Charvet et al. 2011; Xiao et al. 2008; Zhang et al. 2015; Chen et al. 2018). The study area is a significant part of the Chinese Tianshan, consisting dominantly of Proterozoic basement and Paleozoic magmatic and sedimentary rocks, and structurally comprises a series of approximately E–W-trending faults (Fig. 3b). The basement is mainly comprised of Proterozoic metamorphic rocks that are unconformably overlain by upper Paleozoic granites and a series of sedimentary rocks (Xia et al. 2004; Long et al. 2011; Xu et al. 2013). Two large-scale Paleozoic granitic belts distributed in the middle and northern parts of the study area are considered to be associated with southward and northward subduction of the northern Tianshan ocean, respectively (Gao et al. 2009; Tang et al. 2010). The northern granitic belt was dated at 390–287 Ma by means of the zircon U–Pb method, while the middle granitic belt was dated at 497–296 Ma by means of the SHRIMP method (Han et al. 2011; Xu et al. 2013; Yin et al. 2016). Some metamorphic rocks (e.g., metasedimentary and basic metavolcanic rocks) due to high to ultrahigh pressure have been recognized within Paleozoic ophiolitic mélanges at the southern part of the west Tianshan region (Fig. 3b; Gao et al. 2009; Zhang et al. 2013).

(a) Schematic map showing the position of west Tianshan region; (b) sampling sites of geochemical data overlain on geological map
In recent years, several researches on gold deposits have been conducted in the west Tianshan region (e.g., Chen et al. 2012; Xue et al. 2014, 2015; Yu et al. 2017; Zhang et al. 2017b; Dong et al. 2018). Gold deposits in this region, which occurred mainly during Variscan-Indosinian period, are spatially controlled by geological structures and surrounding strata (Wang et al. 2004; Yang et al. 2015). Gold mineralization in the northern parts of study area is associated with volcanic rocks of the Paleozoic strata, whereas in the southern parts of study area, gold deposits are mainly hosted by slightly metamorphosed clastic rocks and obviously controlled by the ductile shear or fault zone. The ore-forming fluid in these deposits was mainly originated from deep-derived fluid in the early stage of ore formation but combined with meteoric water in the late stage (Sha et al., 2003; Yang et al. 2015). Therefore, Xue et al. (2014) considered that two types of gold systems can be identified in the west Tianshan region, namely orogenic gold and porphyry gold systems. On the one hand, the orogenic Au deposits are hosted in the Paleozoic subduction-related accretionary zone and the collisional orogenic environment, and they are closely associated with Precambrian crust, structure deformation and overprinting of magma hydrothermal fluid. On the other hand, the porphyry gold deposits are mainly hosted in Carboniferous intermediate-acidic pyroclastic rocks and intermediate-basic lavas and are closely related to matured arc, deep-source magma and long-lived mineralization.
Dataset
The study area is chiefly composed of high mountains and a series of catchment systems. The dense drainage and snow water in the area contribute to the transportation of stream sediments that led to dispersion of geochemical elements in each catchment system. Stream sediment samples were commonly collected at the bottom of riverbeds, near waterlines, at dried-up riverbeds, or near the paleo-channels (Fig. 3b). Geostatistical analysis of stream sediment geochemical data is based on 1731 samples, which were analyzed for a total of 39 trace and major elements. Details of the chemical analytical methods employed can be found in Wang et al. (2007) and Liu et al. (2016, 2018b). Because the study area is an important gold belt where several gold deposits/occurrences have been discovered (Feng et al. 2014; Xue et al. 2014; Wang 2016), data for Au were selected in this study to demonstrate the application of the proposed method for assessing uncertainty of Au anomaly and identifying gold target areas.
Uncertainty Assessment of Au Anomaly
Spatial Autocorrelation Analysis Based on Variogram Model
Variogram analysis was performed after normal scores transformation. The fitting parameters of the semivariogram (Fig. 4) show that the distributions of normal scores of Au concentrations are spatially dependent. The exponential model was chosen to construct the variogram model because the squared correlation coefficient for the curve fitting was highest (R2 = 0.96), while it possesses the lowest residual sums of squares (RSS = 8E−04). The nugget variance represents the experimental error and field variation within the minimum sample spacing (Chang et al. 1998), showing that C0 is 0.51 when the distance is close to 0. The sill variance C is 0.2 when the fitting line is close to horizontal at a distance of ~ 36 km considered as the autocorrelation range. There is no significant spatial correlation beyond 36 km; hence, no significant spatial autodependence. The proportion C0/(C0 + C) is the coefficient of variation (CV), which can be used to investigate the spatial dependence of geochemical distribution. Cambardella et al. (1994) suggested that CV < 25% indicates strong spatial dependence, 25% ≤ CV ≤ 75% indicates moderate spatial dependence, and CV > 75% indicates weak spatial dependence. In this study, CV = 71.8% indicates moderate spatial autodependence for the Au normal scores.

Experimental variogram and the fitted exponent model, where C0 is nugget variance, C is Sill variance, R2 is the squared correlation coefficient, and RSS is residual sum of squares
Spatial Distribution Pattern of Au Realizations and SIRs
Following the assumption of Gaussian normal distribution, Au concentration values were first subjected to normal score transformation so that the dataset approximates a normal distribution. According to the workflow for geochemical anomaly uncertainty assessment (Fig. 1), the SGS was used to generate 200 equiprobable realizations with 1 km × 1 km grid cells aided by simple kriging and the semivariogram model. Then, the realizations were back-transformed to Au concentration values for processing later by singularity analysis. Figure 5 shows four randomly selected Au realizations in original unit (#32, #79, #115 and #164). Each realization is a realistic spatial distribution of Au concentrations because of the elimination of smoothing effect. The small discrepancies among these realizations are called ergodic fluctuations, which can be attributed to several factors, such as the stochastic simulation algorithm that was used, and the semivariogram parameters (Goovaerts 1997).

Four out of 200 equiprobable realizations of Au concentrations: (a) realization #32, (b) realization #79, (c) realization #115, and (d) realization #164
The uncertainty of geochemical information at unsampled locations can propagate into the final geochemical anomaly identification and could seriously impact gold exploration in the study area. The 200 realizations of Au concentrations were further processed by singularity analysis to obtain 200 corresponding SIRs, as described in the workflow for geochemical anomaly uncertainty assessment. Fluctuations among the SIRs provide a measure of Au anomaly uncertainty and exhibit equiprobable spatial distributions of Au singularity indices across the study area. Four SIRs, each corresponding to the four selected realizations (#32, #79, #115 and #164), are shown in Figure 6. The E-type α map provides the spatial representations of average of Au singularity indices as each SIR is equiprobable (Fig. 7a). The spatial distribution of E-type α is obviously smoother than the four randomly selected SIRs. The results show that the degree of Au anomalies is inversely proportional to the singularity indices. In addition, the approximate numerical interval of singularity indices can be detected from the SIRs map and E-type α map (Figs. 6 and 7a), implying that the E-type α not only avoids smoothing effect caused by interpolation methods, but also preserve the spatial variability of Au concentrations. The E-type α variance map is presented in Figure 7b. The largest predictive variance implies the largest uncertainty, and vice versa. The results indicate that higher uncertainty occurred at the northeastern and southwestern parts of the west Tianshan region, mainly developed on Paleozoic strata as indicated by Figure 3b.

Four singularity index realizations calculated from the corresponding realizations of Au concentration: (a) SIR #32, (b) SIR #79, (c) SIR #115, and (d) SIR #164

E-type estimates of singularity index realizations: (a) E-type α, and (b) α variance
Probabilistic Modeling of Au Anomaly
One of the most important steps in geochemical exploration is to determine one or more critical thresholds for certain elements, so as to delineate anomalous areas where mineralization is likely present. Here, the S-Q method was used to identify critical thresholds based on inherent multifractal properties, as described in section of singularity analysis. A 99% confidence interval of E-type Au singularity indices was selected to determine normal reference line and residual fitting curves based on passing through the 15th and 85th quartiles. As shown in Figure 8a, two critical thresholds of singularity indices corresponding to 1.961 and 2.108 were determined. Therefore, the spatial distribution patterns of E-type Au singularity indices can be classified into three groups (Fig. 8b): element enrichment with α < 1.961, element average with 1.961 ≤ α ≤ 2.108 and element depletion with α > 2.108.

Geochemical anomaly separation of E-type α map by means of S-Q method in (a) frequency domain, and (b) spatial domain
Based on the two thresholds, uncertainty assessment for Au anomaly can be achieved in order to determine gold exploration risk. The SIRs were used to simulate uncertainty associated with Au anomaly by generating probability maps of (not) exceeding a critical threshold. As shown in Figure 9a and b, the probability maps of α < 1.961 and α > 2.108 are represented by colored scale values, which depict the reliability of delineating Au anomalous areas. Uncertainty is related to the actual Au anomaly at any location, the probabilities of α < 1.961 and α > 2.108 are very low nearly everywhere with blue color, and there are only isolated areas with red and yellow colors where the probabilities of α < 1.961 and α > 2.108 are high as shown in Figure 9a and b. For geochemical exploration, we are interested in Figure 9a because it is characterized by small singularity indices with α < 1.961, indicating element enrichment or possible gold mineralization as described in the section of singularity analysis. As shown in Figure 9a, areas with possible gold mineralization indicated by high probability values imply low risk for gold exploration. For example, the probability values are greater than 0.813, implying that there are areas in which the Au singularity indices may not always exceed 1.961 as justified by 200 SIRs. However, the low probability values mean that the risk of gold exploration will be highly uncertain and more information is needed to mitigate risk of gold exploration.

Probability maps of geochemical anomaly with (a) α < 1.961, and (b) α > 2.108
Summary and Conclusions
-
1.
The new method of integrated geostatistical simulation technique and local singularity analysis proposed in the present study for geochemical anomaly uncertainty assessment allows generation of a series of singularity index realizations (SIRs). Compared to deterministic modeling methods (e.g., kriging and IDW), this new method overcomes the smoothing effect and ensures that extreme values are not downgraded, making them highly conducive to geochemical anomaly identification. By means of spatial uncertainty analysis, the probability distribution pattern of SIRs can be determined and this provides an opportunity for risk evaluation and uncertainty quantification of geochemical anomaly.
-
2.
The case study for Au anomaly uncertainty assessment based on stream sediment geochemical data in the west Tianshan region (China) was used to demonstrate the proposed method. Two hundred equiprobable Au SIRs were generated to enable quantification of spatial uncertainty of Au anomalies across the study area. Two critical thresholds of Au E-type α were determined in frequency domain by means of the singularity-quantile method, and the estimate of Au anomaly uncertainty at unsampled locations was performed by mapping the probabilities of α < 1.961 and α > 2.108. The results indicate that areas delineated by high probability pattern with α < 1.961 have significant spatial correlation with known gold locations, implying that the proposed method can be helpful to evaluate exploration risk and to delineate areas that more likely contain gold mineralization.
References
Afrasiab, P., & Delbari, M. (2013). Assessing the risk of soil vulnerability to wind erosion through conditional simulation of soil water content in Sistan plain, Iran. Environmental Earth Sciences, 70(6), 2895–2905.
Afzal, P., Madani, N., Shahbeik, S., & Yasrebi, A. B. (2015). Multi-Gaussian kriging: A practice to enhance delineation of mineralized zones by Concentration-Volume fractal model in Dardevey iron ore deposit, SE Iran. Journal of Geochemical Exploration, 158, 10–21.
Agterberg, F. P. (2012a). Sampling and analysis of chemical element concentration distribution in rock units and orebodies. Nonlinear Processes in Geophysics, 19(1), 23–44.
Agterberg, F. P. (2012b). Multifractals and geostatistics. Journal of Geochemical Exploration, 122, 113–122.
Cambardella, C. A., Moorman, T. B., Parkin, T. B., Karlen, D. L., Novak, J. M., Turco, R. F., et al. (1994). Field-scale variability of soil properties in central Iowa soils. Soil Science Society of America Journal, 58(5), 1501–1511.
Carranza, E. J. M. (2010). Mapping of anomalies in continuous and discrete fields of stream sediment geochemical landscapes. Geochemistry: Exploration, Environment, Analysis, 10(2), 171–187.
Chang, Y. H., Scrimshaw, M. D., Emmerson, R. H. C., & Lester, J. N. (1998). Geostatistical analysis of sampling uncertainty at the Tollesbury Managed Retreat site in Blackwater Estuary, Essex, UK: Kriging and cokriging approach to minimise sampling density. Science of the Total Environment, 221(1), 43–57.
Charvet, J., Shu, L., Laurent-Charvet, S., Bo, W., Faure, M., & Cluzel, D. (2011). Palaeozoic tectonic evolution of the Tianshan belt, NW China. Science China Earth Sciences, 54(2), 166–184.
Chen, H., Chen, Y., & Baker, M. J. (2012). Evolution of ore-forming fluids in the Sawayaerdun gold deposit in the Southwestern Chinese Tianshan metallogenic belt, Northwest China. Journal of Asian Earth Sciences, 49, 131–144.
Chen, Z., Cheng, Q., Chen, J., & Xie, S. (2007). A novel iterative approach for mapping local singularities from geochemical data. Nonlinear processes in Geophysics, 14(3), 317–324.
Chen, H., Wan, B., Pirajno, F., Chen, Y., & Xiao, B. (2018). Metallogenesis of the Xinjiang orogens, NW China—New discoveries and ore genesis. Ore Geology Reviews. https://doi.org/10.1016/j.oregeorev.2018.02.035.
Cheng, Q. (1999). Spatial and scaling modelling for geochemical anomaly separation. Journal of Geochemical Exploration, 65(3), 175–194.
Cheng, Q. (2007). Mapping singularities with stream sediment geochemical data for prediction of undiscovered mineral deposits in Gejiu, Yunnan Province, China. Ore Geology Reviews, 32(1), 314–324.
Cheng, Q. (2008). Modeling local scaling properties for multiscale mapping. Vadose Zone Journal, 7(2), 525–532.
Cheng, Q. (2012). Singularity theory and methods for mapping geochemical anomalies caused by buried sources and for predicting undiscovered mineral deposits in covered areas. Journal of Geochemical Exploration, 122, 55–70.
Cheng, Q. (2016). Fractal density and singularity analysis of heat flow over ocean ridges. Scientific Reports, 6, 19167.
Cheng, Q., & Agterberg, F. P. (2009). Singularity analysis of ore-mineral and toxic trace elements in stream sediments. Computers & Geosciences, 35(2), 234–244.
Deutsch, C. V. (2006). A sequential indicator simulation program for categorical variables with point and block data: BlockSIS. Computers & Geosciences, 32(10), 1669–1681.
Deutsch, C. V., & Journel, A. G. (1998). Geostatistical software library and user’s guide. New York: Oxford University Press.
Dong, L., Wan, B., Deng, C., Cai, K., & Xiao, W. (2018). An Early Permian epithermal gold system in the Tulasu Basin in North Xinjiang, NW China: Constraints from in situ oxygen-sulfur isotopes and geochronology. Journal of Asian Earth Sciences, 153, 412–424.
Emery, X. (2012). Co-simulating total and soluble copper grades in an oxide ore deposit. Mathematical Geosciences, 44, 27–46.
Emery, X., & Ortiz, J. M. (2012). Enhanced coregionalization analysis for simulating vector Gaussian random fields. Computers & Geosciences, 42, 126–135.
Feng, B., Xue, C., Zhao, X., Ding, Z., Zhang, Q., Zu, B., et al. (2014). Petrology, geochemistry and zircon U–Pb isotope chronology of monzogranite of the Katbasu Au–Cu deposit, western Tianshan, Xinjiang Province. Earth Science Frontiers, 21(5), 187–195. (in Chinese with English abstract).
Gao, J., Long, L., Klemd, R., Qian, Q., Liu, D., Xiong, X., et al. (2009). Tectonic evolution of the South Tianshan orogen and adjacent regions, NW China: Geochemical and age constraints of granitoid rocks. International Journal of Earth Sciences, 98(6), 1221–1238.
Goovaerts, P. (1997). Geostatistics for natural resources evaluation. New York: Oxford University Press.
Goovaerts, P. (1999). Geostatistics in soil science: State-of-the-art and perspectives. Geoderma, 89(1), 1–45.
Goovaerts, P. (2006). Geostatistical analysis of disease data: Visualization and propagation of spatial uncertainty in cancer mortality risk using Poisson kriging and p-field simulation. International Journal of Health Geographics, 5(1), 7.
Han, B., He, G., Wang, X., & Guo, Z. (2011). Late Carboniferous collision between the Tarim and Kazakhstan-Yili terranes in the western segment of the South Tian Shan Orogen, Central Asia, and implications for the Northern Xinjiang, western China. Earth-Science Reviews, 109(3), 74–93.
Juang, K. W., Chen, Y. S., & Lee, D. Y. (2004). Using sequential indicator simulation to assess the uncertainty of delineating heavy-metal contaminated soils. Environmental Pollution, 127(2), 229–238.
Lark, R. M., Patton, M., Ander, E. L., & Reay, D. M. (2018). The singularity index for soil geochemical variables, and a mixture model for its interpretation. Geoderma, 323, 83–106.
Liu, Y., Cheng, Q., Xia, Q., & Wang, X. (2013). Application of singularity analysis for mineral potential identification using geochemical data—A case study: Nanling W–Sn–Mo polymetallic metallogenic belt, South China. Journal of Geochemical Exploration, 134, 61–72.
Liu, Y., Cheng, Q., Xia, Q., & Wang, X. (2014). Identification of REE mineralization-related geochemical anomalies using fractal/multifractal methods in the Nanling belt, South China. Environmental Earth Sciences, 72(12), 5159–5169.
Liu, Y., Cheng, Q., & Zhou, K. (2018a). New insights into element distribution patterns in geochemistry: A perspective from fractal density. Natural Resources Research. https://doi.org/10.1007/s11053-018-9374-7.
Liu, Y., Cheng, Q., Zhou, K., Xia, Q., & Wang, X. (2016). Multivariate analysis for geochemical process identification using stream sediment geochemical data: A perspective from compositional data. Geochemical Journal, 50(4), 293–314.
Liu, Y., & Zhou, K. (2018). Gold anomaly identification and its uncertainty analysis in the west Junggar belt, Xinjiang. Earth Science (in press) (in Chinese with English abstract).
Liu, Y., Zhou, K., & Carranza, E. J. M. (2018b). Compositional balance analysis for geochemical pattern recognition and anomaly mapping in the western Junggar region, China. Geochemistry: Exploration, Environment, Analysis. https://doi.org/10.1144/geochem2017-050.
Liu, Y., Zhou, K., & Cheng, Q. (2017). A new method for geochemical anomaly separation based on the distribution patterns of singularity indices. Computers & Geosciences, 105, 139–147.
Long, L., Gao, J., Klemd, R., Beier, C., Qian, Q., Zhang, X., et al. (2011). Geochemical and geochronological studies of granitoid rocks from the Western Tianshan Orogen: Implications for continental growth in the southwestern Central Asian Orogenic Belt. Lithos, 126, 321–340.
Mery, N., Emery, X., Cáceres, A., Ribeiro, D., & Cunha, E. (2017). Geostatistical modeling of the geological uncertainty in an iron ore deposit. Ore Geology Reviews, 88, 336–351.
Olea, R. A., & Luppens, J. A. (2015). Mapping of coal quality using stochastic simulation and isometric logratio transformation with an application to a Texas lignite. International Journal of Coal Geology, 152, 80–93.
Paithankar, A., & Chatterjee, S. (2017). Grade and tonnage uncertainty analysis of an African copper deposit using multiple-point geostatistics and sequential gaussian simulation. Natural Resources Research. https://doi.org/10.1007/s11053-017-9364-1.
Qu, J., & Deutsch, C. V. (2018). Geostatistical simulation with a trend using Gaussian mixture models. Natural Resources Research, 27(3), 347–363.
Qu, M., Li, W., & Zhang, C. (2013). Assessing the risk costs in delineating soil nickel contamination using sequential Gaussian simulation and transfer functions. Ecological Informatics, 13, 99–105.
Rahimi, H., Asghari, O., & Hajizadeh, F. (2018). Selection of optimal thresholds for estimation and simulation based on indicator values of highly skewed distributions of ore data. Natural Resources Research. https://doi.org/10.1007/s11053-017-9366-z.
Sadeghi, B., Madani, N., & Carranza, E. J. M. (2015). Combination of geostatistical simulation and fractal modeling for mineral resource classification. Journal of Geochemical Exploration, 149, 59–73.
Sha, D., Dong, L., Bao, Q., Wang, H., Hu, X., Zhang, J., et al. (2003). The genetic types of gold deposits and their prospecting in west Tianshan mountains. Xinjiang Geology, 21(4), 419–425. (in Chinese with English abstract).
Soltani, F., Afzal, P., & Asghari, O. (2014). Delineation of alteration zones based on sequential Gaussian simulation and concentration–volume fractal modeling in the hypogene zone of Sungun copper deposit, NW Iran. Journal of Geochemical Exploration, 140, 64–76.
Tang, G., Wang, Q., Wyman, D. A., Sun, M., Li, Z., Zhao, Z., et al. (2010). Geochronology and geochemistry of Late Paleozoic magmatic rocks in the Lamasu-Dabate area, northwestern Tianshan (west China): Evidence for a tectonic transition from arc to post-collisional setting. Lithos, 119, 393–411.
Wang, Y. (2016). Metallogenic features and resource potential of the west Tianshan Fe–Pb–Zn–Au–CU metallogenic belt. Acta Geologica Sinica, 90(7), 1377–1391. (in Chinese with English abstract).
Wang, Z., Mao, J., Zhang, Z., Zuo, G., & Wang, L. (2004). Types, characteristics and metallogenic geodynamic evolution of the Paleozoic polymetallic copper-gold deposits in the Western Tianshan mountains. Acta Geologica Sinica, 78(6), 836–847. (in Chinese with English abstract).
Wang, X., Zhang, Q., & Zhou, G. (2007). National-scale geochemical mapping projects in China. Geostandards and Geoanalytical Research, 31(4), 311–320.
Wang, W., Zhao, J., & Cheng, Q. (2013). Fault trace-oriented singularity mapping technique to characterize anisotropic geochemical signatures in Gejiu mineral district, China. Journal of Geochemical Exploration, 134, 27–37.
Wang, J., & Zuo, R. (2018). Identification of geochemical anomalies through combined sequential Gaussian simulation and grid-based local singularity analysis. Computers & Geosciences, 118, 52–64.
Xia, L., Xu, X., Xia, Z., Li, X., Ma, Z., & Wang, L. (2004). Petrogenesis of Carboniferous rift-related volcanic rocks in the Tianshan, northwestern China. Geological Society of America Bulletin, 116(3–4), 419–433.
Xiao, W., Han, C., Yuan, C., Sun, M., Lin, S., Chen, H., et al. (2008). Middle Cambrian to Permian subduction-related accretionary orogenesis of Northern Xinjiang, NW China: Implications for the tectonic evolution of central Asia. Journal of Asian Earth Sciences, 32, 102–117.
Xu, X., Wang, H., Li, P., Chen, J., Ma, Z., Zhu, T., et al. (2013). Geochemistry and geochronology of Paleozoic intrusions in the Nalati (Narati) area in western Tianshan, Xinjiang, China: Implications for Paleozoic tectonic evolution. Journal of Asian Earth Sciences, 72, 33–62.
Xue, C., Zhao, X., Mo, X., Dong, L., Gu, X., Bakhtiar, N., et al. (2014). Asian Gold Belt in western Tianshan and its dynamic setting, metallogenic control and exploration. Earth Science Frontiers, 21(5), 128–155. (in Chinese with English abstract).
Xue, C., Zhao, X., Zhang, G., Mo, X., Gu, X., Dong, L., et al. (2015). Metallogenic environments, ore- forming types and prospecting potential of Au–Cu–Zn–Pb resources in western Tianshan Mountains. Geology in China, 42(3), 381–410. (in Chinese with English abstract).
Yang, X., Yu, X., Wang, Z., Xiao, W., & Zhou, X. (2015). Comparative study on ore-forming conditions and sources of the hydrothermal gold deposits in the Chinese western Tianshan. Geotectonica et Metallogenia, 39(4), 633–646. (in Chinese with English abstract).
Yin, J., Chen, W., Xiao, W., Yuan, C., Long, X., Cai, K., et al. (2016). Late Carboniferous adakitic granodiorites in the Qiongkusitai area, western Tianshan, NW China: Implications for partial melting of lower crust in the southern Central Asian Orogenic Belt. Journal of Asian Earth Sciences, 124, 42–54.
Yu, J., Li, N., Shu, S. P., Zhang, B., Guo, J. P., & Chen, Y. J. (2017). Geology, fluid inclusion and HOS isotopes of the Kuruer Cu–Au deposit in Western Tianshan, Xinjiang, China. Ore Geology Reviews. https://doi.org/10.1016/j.oregeorev.2017.07.016.
Yuan, F., Li, X., Zhou, T., Deng, Y., Zhang, D., Xu, C., et al. (2015). Multifractal modelling-based mapping and identification of geochemical anomalies associated with Cu and Au mineralisation in the NW Junggar area of northern Xinjiang Province, China. Journal of Geochemical Exploration, 154, 252–264.
Zhang, L., Chen, H., Liu, C., & Zheng, Y. (2017a). Ore genesis of the Saridala gold deposit, Western Tianshan, NW China: Constraints from fluid inclusion, S–Pb isotopes and 40Ar/39Ar dating. Ore Geology Reviews. https://doi.org/10.1016/j.oregeorev.2017.06.011.
Zhang, D., Cheng, Q., & Agterberg, F. (2017b). Application of spatially weighted technology for mapping intermediate and felsic igneous rocks in Fujian Province, China. Journal of Geochemical Exploration, 178, 55–66.
Zhang, L., Du, J., Lü, Z., Yang, X., Gou, L., Xia, B., et al. (2013). A huge oceanic-type UHP metamorphic belt in southwestern Tianshan, China: Peak metamorphic age and PT path. Chinese Science Bulletin, 58(35), 4378–4383.
Zhang, X., Zhao, G., Eizenhöfer, P. R., Sun, M., Han, Y., Hou, W., et al. (2015). Latest Carboniferous closure of the Junggar Ocean constrained by geochemical and zircon U–Pb–Hf isotopic data of granitic gneisses from the Central Tianshan block, NW China. Lithos, 238, 26–36.
Zhao, Y., Shi, X., Yu, D., Wang, H., & Sun, W. (2005). Uncertainty assessment of spatial patterns of soil organic carbon density using sequential indicator simulation, a case study of Hebei province, China. Chemosphere, 59(11), 1527–1535.
Zuo, R., Cheng, Q., Agterberg, F. P., & Xia, Q. (2009). Application of singularity mapping technique to identify local anomalies using stream sediment geochemical data, a case study from Gangdese, Tibet, western China. Journal of Geochemical Exploration, 101(3), 225–235.
Acknowledgments
We greatly appreciate the valuable comments of Associate Editor Dr. Renguang Zuo and two anonymous reviewers, which helped us improve the paper. This work was funded jointly by the project of CAS “Light of West China” program (No. 2015-XBQN-B-23), the project of China Postdoctoral Science Foundation (Nos. 2016M590992, 2018T111123), and the National Natural Science Foundation of China (Nos. 41702356, U1503291, 41430320).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, Y., Cheng, Q., Carranza, E.J.M. et al. Assessment of Geochemical Anomaly Uncertainty Through Geostatistical Simulation and Singularity Analysis. Nat Resour Res 28, 199–212 (2019). https://doi.org/10.1007/s11053-018-9388-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11053-018-9388-1