
Abstract
Relevance feedback (RF) has long been an important approach for multi-media retrieval because of the semantic gap in image content, where SVM based methods are widely applied to RF of content-based image retrieval. However, RF based on SVM still has some limitations: (1) the high dimension of image features always make the RF time-consuming; (2) the model of SVM is not discriminative, because labels of image features are not sufficiently exploited. To solve above problems, we proposed robust discriminative extreme learning machine (RDELM) in this paper. RDELM involved both robust within-class and between-class scatter matrices to enhance the discrimination capacity of ELM for RF. Furthermore, an angle criterion dimensionality reduction method is utilized to extract the discriminative information for RDELM. Experimental results on four benchmark datasets (Corel-1K, Corel-5K, Corel-10K and MSRC) illustrate that our proposed RF method in this paper achieves better performance than several state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image retrieval is an effective approach to search the special images for queries, and has many emerging applications. There are a significant number of methods for extracting image features which play an important role in CBIR (Swain and Ballard 1991; Liu et al. 2011; Ojala et al. 2002). Image representation methods mainly fall into three categories: color, texture and shape feature. Liu et al. (2011) propose Micro-structure Descriptor (MSD) which used edge orientation to extract micro-structures of images. It depends on the similarity of underlying colors and structure element correlation, then a 72-length feature vector can be obtained for describing an image. Ojala et al. (2002) propose local binary patterns (LBP) as texture descriptor of an image, which is widely applied to face recognition (Tan and Triggs 2007), image retrieval (Murala and Wu 2014), etc.
The extracting methods of image feature have improved the image retrieval results, but do not always describe the semantic of images. Consequently, RF becomes an essential technique to deal with the semantic gap (see Fig. 1) (Feng et al. 2015). Yong et al. first involved the RF concept into a CBIR system. Then, many methods of RF have been proposed to enhance image retrieval results achieved by Non-RF based methods while semantic gap existed. He (2004) proposed a semi-supervised learning approach to keep the local space information of the query image by calculating the local data basis of the query image from RF. Moreover, by utilizing Locality Preserving Projections (LPP) algorithm (He and Niyogi 2003), the local visual features were extracted and the graph of LPP were reconstructed with RF. Kundu et al. (2015) proposed graph-based relevance feedback mechanism for image retrieval task. Zhang et al. (2015) proposed query special rank fusion to solve the ranking problem in image retrieval which could also help RF to improve the retrieval results. Besides, many SVM active learning (Hoi et al. 2008; Anitha and Rinesh 2013; Lu et al. 2006; Hoi and Lyu 2005; Wang et al. 2011) algorithms have been applied in RF-CBIR. However, SVM based algorithms are difficult to obtain exciting classification results, for the labeled sample size is generally small in RF-CBIR. Hoi et al. (2008) proposed a semi-supervised SVM batch mode active learning algorithm. The supervised SVM classifier is trained by constructing a kernel function learned from the Laplacian graph which represents the global geometry structure of the samples. And then the supervised SVM classifier is used to label samples containing most information. By using the integrated SVM learner in RF-CBIR, Wang et al. (2011) handled the unbalance problem between positive and negative samples with the asymmetric bagging SVM and avoided the outfitting problem with subspace random chosen.

Semantic gap in image retrieval
ELM is an efficient classification method. There are many ELM-based modified versions in recent years (Huang et al. 2006, 2012; Huang and Chen 2007; Horata et al. 2012; Deng et al. 2009; Liu et al. 2014; Tang and Han 2009; Zhang and Yang 2015; Huang 2015; Cao and Lin 2015; Cao et al. 2015a, b, 2012). Huang et al. proved that by adding activation functions as nodes randomly, SLFNs can approximate any continuous target function, such as, RBF. On this basis, they proposed incremental ELM algorithm (Huang et al. 2006) and convex incremental ELM algorithm (Huang and Chen 2007). Outliers of the training datasets have a great impact on the precision of ELM (Zhang and Luo 2015). Considering this, Horata et al. (2012) proposed the Robust ELM algorithm, which gets the output weights by constructing an Extended Complete Orthogonal Decomposition. The final output weights are computed by iterating the initial output weights. Besides, the time complexity of Robust ELM is equal to that output weights computed by Singular Value Decomposition (SVD). Its main reason is that the empirical risk of ELM is lowered by the Robust ELM algorithm through the reasonable numerical computation. Hence, we can conclude that the robustness of ELM is closely related to the empirical risk. Deng et al. (2009) proposed a weighted Regular ELM (RELM) algorithm. This algorithm enhances the robustness of RELM to outliers and by lowering the empirical risk weights of outliers. Even if the methods introduced above have done a lot of improvements on ELM, but there are always few labeled samples in real-world datasets. In order to take full advantage of unlabeled samples and improve the generalization capability of ELM, Liu et al. (2014) proposed a semi-supervised ELM, which extends the ELM algorithm to a semi-supervised version based on the graph theory. In addition to the above theoretical improvements on ELM, some applications of ELM-related methods also have been proposed. For instance, Iosifidis et al. proposed (Tang and Han 2009) minimum class variance extreme learning machine method for human action recognition [also see related papers (Iosifidis et al. 2013, 2014; Mohammed et al. 2011)]. Akusok et al. utilized optimally pruned ELM to analysis web content (Minhas et al. 2010). Jin et al. (2015) proposed an Ensemble based extreme learning machine method for face matching.
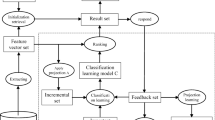
There are few image retrieval researches related to ELM and discriminative methods. From previous works, we know that the data distribution in ELM feature space plays an important role on clustering (Akusok et al. 2015) and classification (Tang and Han 2009). Motivated by this idea, in this paper, we exploit a novel ELM-based method called RDELM for RF in CBIR system (see Fig. 2). The main contributions of RDELM are as follows:
-
(1)
RDELM utilizes within and between scatters in hidden layer to detect a discriminative classification model.
-
(2)
The model of RDELM can balance the within and between scatters of feature space by using cosine metric.
-
(3)
RDELM involves supervised reduction with angle criterion in ELM feature space, which makes the proposed classification method stable and robust in image retrieval task.

RDELM for relevance feedback in CBIR system
The rest of the paper is organized as follows. ELM classification method is reviewed in Sect. 2. Section 3 analyzes the scatters in ELM feature space, and proposes a supervised dimensionality reduction method. In Sect. 4, we introduce the RDELM method for RF in CBIR system. Experimental results are shown in Sect. 5. The last section is the conclusion of this paper.
2 Brief of ELM
Given D dimensional dataset \(X = \left[ {x_1, x_2 ,\ldots , x_N} \right] ^T \in {R}^{D\times N}\) with N samples , and corresponding labels \(t_i = \left[ {t_{i1} ,t_{t2} ,\ldots ,t_{im} } \right] ^T \in {R}^m\), with \(\tilde{N}\) hidden neurons in network, then the output of the network can be obtained by the following equation
where \(j = 1,\ldots ,N,\,g(a_i x_j + b_j )\) denotes activation function in Neural Networks (NN), \(a_i = \left[ {a_{i1} ,a_{i2} ,\ldots ,a_{iN} } \right] ^T\) is the weight vector connecting input neurons and the ith hidden node, \(b_i\) is bias of the ith hidden node.
For hidden neurons \(\tilde{N}\), Eq. (1) can be rewritten as a matrix format: \(H\beta = T\), where network hidden layer output matrix can be expressed as \(H = \left[ \begin{array}{lll} g(a_1 ,x_1 ,b_1 ) &{}\quad \cdots &{}\quad g(a_{\tilde{N}} ,x_{1} ,b_{\tilde{N}}) \\ \vdots &{}\quad \cdots &{}\quad \vdots \\ g(a_1 ,x_N ,b_1 ) &{}\quad \cdots &{}\quad g(a_{\tilde{N}} ,x_{N} ,b_{\tilde{N}} ) \\ \end{array} \right] _{N\times \tilde{N}} = \left[ \begin{array}{ccc} h_{1} \\ \vdots \\ h_{N} \\ \end{array}\right] , \beta = \left[ \begin{array}{lll} \beta _{1}^{T} \\ \vdots \\ \beta _{\tilde{N}}^{T} \\ \end{array} \right] _{\tilde{N}\times m} \quad \hbox {and}\quad T = \left[ \begin{array}{lll} t_{1}^{T} \\ \vdots \\ t_{N}^{T} \\ \end{array} \right] _{N\times m} , h_{i} = \left[ g(a_{1} ,x_{i}, b_{1} ), \ldots ,g(a_{\tilde{N}}, x_{i}, b_{\tilde{N}}) \right] ,\quad i = 1, 2, \ldots ,N.\) The standard single hidden feedforward neural networks (SLFNs) is to compute appropriate \(\hat{a}_i ,\,\hat{b}_i \) and \(\hat{\beta }(i = 1,\ldots ,\tilde{N})\) to satisfy:
Equation (2) can be solved by gradient-based methods. Liu et al. (2011) have proved that the weights between input layer and the biases need no adjustment compared with the standard SLFNs. The input weight \(a_i \) and the biases \(b_i\) of hidden layer in ELM can be selected randomly, if the activation function of network is continuously differentiable. From Eq. (2), it is clear that the solution of SLFNs’ network can be get by the least-squares methods of the linear system \(H\beta = T\).
If the number of hidden neurons \(\tilde{N}\) is equivalent to the number of training samples N, that is \(\tilde{N} = N\), the matrix H is invertible directly. However, in most cases \(\tilde{N} \ne N\), the solution of \(H\beta = T\) can be written as
where \(H^\dag \) denotes the generalized inverse matrix of H. \(H^\dag \) can be calculated by SVD or least-squares. Meanwhile, in order to avoid outfitting, we hope to keep the weights as small as possible. Thus, the optimization model of ELM can be modeled as follows:
where C is a penalty factor, which can balance the empirical risk and structural risk. The optimization model in Eq. (4) can be transformed to an unconstrained optimization problem of solving \(\beta \) with Lagrange method.
ELM can be simply implemented as follows:
-
(1)
Assign arbitrary input weights \(a_i \) and bias \(b_i,\,i = 1, \ldots ,\tilde{N}\);
-
(2)
Calculate the hidden layer output matrix H by active function;
-
(3)
Compute the output weight \(\hat{\beta } = H^\dag T\), where \(T = \left[ {t_1 ,\ldots ,t_N } \right] ^T\).
3 Robust supervised dimensionality reduction for discriminative extreme learning machine
In this section, we give a theoretical analysis of the within and between scatter in ELM hidden layer matrix \(H = \left[ {h_1 , \ldots ,h_N } \right] ^T\). Then, we introduce supervised dimensionality reduction in ELM feature space if \(\tilde{N} < N\), otherwise \(\tilde{N} \ge N\), a dimensionality reduction free method will be proposed in Sect. 4.
Supposed that matrix H is grouped as \(H = [H_1 ,H_2 ,\ldots ,H_m ]^T\), where \(H_i \in \mathrm{R}^{\tilde{N}\times N_i }\) is the data matrix consisting of data from the ith class with a sample size of \(N_i \) satisfying \(N = \sum \nolimits _{i = 1}^m {N_i } \). The mean vector of the ith class can be defined as \(\mu _h^i = \frac{1}{N_i }\sum \nolimits _{j = 1}^{N_i } {h_j^i } \), and the mean vector of H can be calculated as \(\mu _h = \frac{1}{N}\sum \nolimits _{i = 1}^N {h_i } \).
In linear discriminant analysis (LDA), the minimization of within-class scatter corresponding subspace is \(W_{ opt }^{ LDA } = \arg \min \sum \nolimits _{i,j} {\left\| { WW ^T\left( {h_j^i - \mu _h^i } \right) } \right\| _2^2 } \), where \( WW ^T( \cdot )\) is the orthogonal projection of \(( \cdot )\). \(\left( \cdot \right) _e \) denotes the unit vector of \(( \cdot )\). Then we can compute the cosine value of \(\alpha _j^i = \left\langle { WW ^T\left( {h_j^i - \mu _i^h } \right) ,h_j^i - \mu _i^h } \right\rangle \) as follows:
From formula (5) we can see that minimization of within-class scatter equals to \(\min \nolimits _W \sum \nolimits _{i,j} {\cos ^2\alpha _j^i }\) in geometry. Similarly, the maximization of between-class scatter equals to \(\max \nolimits _W \sum \nolimits _{i,j} {\cos ^2\beta _h^i }\) in geometry, where \(\beta _h^i = \left\langle { WW ^T\left( {h_i - \mu _h } \right) ,h_i - \mu _h } \right\rangle \).
where \({S}'_w = \frac{1}{N}\sum \nolimits _{i = 1}^m {\sum \nolimits _{j = 1}^{N_i } {\left( {h_j^i - \mu _h^i } \right) _e^T \left( {h_j^i - \mu _h^i } \right) _e } } = H_{we}^T H_{we}\), \(H_{we} = \frac{1}{\sqrt{N} }\left[ {\left( {h_1^1 - \mu _h^1 } \right) _e , \ldots ,\left( {h_1^{N_1 } - \mu _h^1 } \right) _e, \ldots ,\left( {h_m^1 - \mu _h^m } \right) _e , \ldots ,\left( {h_m^{N_m } - \mu _h^m } \right) _e } \right] ^T\).
The between-class scatter can be written as:
where \({S}'_b = \frac{1}{N}\sum \nolimits _{i = 1}^m {N_i \left( {\mu _h^i - \mu _h } \right) _e^T \left( {\mu _h^i - \mu _h } \right) _e } = H_{be}^T H_{be}\), \(H_{be} = \frac{1}{\sqrt{N} }\left[ {\sqrt{N_1 } \left( {\mu _h^1 - \mu _h } \right) _e , \ldots ,\sqrt{N_m } \left( {\mu _h^m - \mu _h } \right) _e } \right] ^T\).
Then, the supervised dimensionality reduction function based on angle criterion can be expressed as follows:
The constraint of Eq. (8) is \(W^TW = I\), where I is an identity matrix.
\({S}'_w \) and \({S}'_b \) can balance the scatter of within and between class. This conclusion is shown in Fig. 3. There are three classes features in Fig. 3a, b. In Fig. 3a, LDA can obtain an appropriate subspace, but fails in Fig. 3b. Comparing with LDA, our angle criterion approach is suitable in the two feature spaces because of the scatter balance. The conclusion is detailed in reference Liu et al. (2015).

Comparing our robust scatter method to LDA in ELM hyperplane selection. a Feature space data1, b feature space data2
4 Robust discriminative extreme learning machine for RF
In this section, we will propose the RDELM model for classification, and give a RDELM-based relevance feedback method for CBIR system. RDELM is introduced in Sect. 4.1, and both dimensionality reduction based RDELM and non-dimensionality reduction based RDELM methods are included. In Sect. 4.2, the RDELM-based retrieval method is utilized on relevance feedback technique for CBIR system.
4.1 Robust discriminative extreme learning machine
We know that the original ELM utilizes H to compute the output weights \(\beta \) directly. Actually, there are some important structures in hidden layer feature space of ELM. For example, He et al. (2014) proposed clustering method in ELM feature space. When training samples containing outliers, over-fitting problem is important to the classifier (see Fig. 4b).

Comparison of hyper plane on different versions ELM. a MCVELM and ELM, b RDELM, MCVELM and ELM
As shown in Fig. 4, original ELM and MCVELM can get appropriate decision spaces when there is no outlier involved in feature space (Fig. 4a). But if outliers exist because of over-fitting in the feature space, the original ELM and MCVELM may generate unsuitable decision spaces (Fig. 4b). Consequently, we can involve the robust class structure to construct an ELM-based classifier.
4.1.1 Dimensionality reduction free based version of RDELM
Considering the minimization of within-class scatter, the maximization of between-class scatter and the algorithm robustness, RDELM method can be modeled by solving an optimization problem as follows:
In (9), \(\left\| {H_{we} \beta } \right\| _2^2 \) and \(\left\| {H_{be} \beta } \right\| _2^2 \) aim to balance the class structure of the feature space in ELM, \(\lambda \left\| \beta \right\| _2^2 \) is to avoid over-fitting problem, and the \(C\sum \nolimits _{i = 1}^N {\left\| {\xi _i } \right\| _2^2 } \) term can minimize the error which is generated by the constraint. RDELM is robust which is analyzed in Sect. 3. The solution of (9) can be calculated by Lagrange multiplier method. \(\beta \) can be expressed by
From (10), the output function of RDELM classifier can be written as:
4.1.2 Dimensionality reduction based version of RDELM
When \(\tilde{N} < N,\,P = \frac{1}{C}\left( {{S}'_w - {S}'_b } \right) + \frac{1}{C\lambda }I + H^TH\) may not be invertible. To keep the discriminative information and make P invertible, the dimensionality reduction method in Eq. (8) can be applied to the basis RDELM classifier. Then, the within-class and between scatter matrices are rewritten by \(\hat{S}_w = W^T{S}'_w W\) and \(\hat{S}_b = W^T{S}'_b W\), respectively. So, the final solution of dimensionality reduction based version of RDELM can be got by
where W has been calculated by Eq. (8) in Sect. 3. We illustrate that \(\tilde{N}\) is chosen by users. Then, we will know whether \(\tilde{N} < N\) or not, and select the method in Sects. 4.1.1 or 4.1.2.
4.2 The RF algorithm using RDELM
The scheme of relevance feedback based on SVM has been exploited in CBIR system. However, an unsatisfied performance may be occurred because of the over-fitting problem when the large number of feature dimensions need to be calculated in SVM. Furthermore, SVM has to generate a lot of support vectors which leads to classification a time-consuming work. In order to solve the above problems, a RDELM-based relevance feedback method is proposed in CBIR system (see Fig. 5).

Comparison of ELM-based and SVM-based RF image retrieval
According to the above introduction, the retrieved images in the previous step can be marked by users themselves. Take the retrieved images as training data, a two classes learning algorithm can be carried out by ELM, based on which a classifier can be constructed. Given an arbitrarily distinct sample set \((x_i ,t_i ),\,x_i \in \mathrm{R}^D\), where \(x_i \) represents feature vector of an image containing the information of color, texture and shape, and \(t_i \) is the label of \(x_i ,\,t_i \in \{(1, - 1)^T,( - 1,1)^T\}\). Then constructing a classifier by ELM algorithm, and classifying rest images into relevant class or irrelevant class. On this basis, we can obtain a better result after several feedbacks after sorting images according to their relevance to the query. The process of our algorithm is summarized in Algorithm 1:

Sigmoid function is selected for ELM-based classification methods. The above process of the algorithm is obviously similar to the relevant feedback scheme based on SVM (Wang et al. 2011). However, this algorithm can be thousands times faster than the SVM based relevant feedback scheme and performs better while completing the same task. Its main reason is the utilizing of the ELM classifier, and our experiments illustrate the validity and time complexity of the algorithm.
5 Experimental results
In this section, we utilize four image retrieval datasets and three RF methods (SVM, ELM, MCVELM, RDELM and the RDELM-DRfree version methods) to evaluate the effect of our proposed RF image retrieval method. The four dataset are listed as follows: Corel-1K, Corel-5K, Corel-10K and MSRC image databases (see Figs. 6, 7, 8, 9, respectively). In following experiments, we re-write RDELM-DRfree method as DRfree for short.

Some samples of Corel-1K images

Some samples of Corel-5K images

Some samples of Corel-10K images

Some samples of MSRC images
In the following experiments, we assign \(C = 0.05,\,\lambda = 1\). There are four RF times in our experiments, which are denoted by RF1, RF2, RF3 and RF4. The original image retrieval results mark as “Init”. “FE method” represents feature extraction method. “STY1” indicates a feature extraction method, and includes global color histogram, LBP feature, and basis shape feature.
5.1 Image retrieval results
Corel-1K contains 10 categories and total 1000 images, includes bus, drag, food and so on. The size of each image is \(256\times 384\) or \(384\times 256\) (Fig. 6). The results of Corel-1K images are listed in Tables 1, 2, 3 and 4.
Corel-5K contains 50 categories and total 5000 images. The size of each image is \(192\times 128\) or \(128\times 192\) (Fig. 7). The results of Corel-5K images are listed in Tables 5, 6, 7 and 8.
The Corel-10K contains 100 categories and total 10000 images. The size of each image is \(126\times 187\) or \(187\times 126\) (Fig. 8). The results of Corel-10K images are listed in Tables 9, 10, 11 and 12.
We select a sub-dataset which includes 30 images for each of the 19 classes from MSRC dataset (as shown in Fig. 9). The size of each image is about \(320\times 240\). The results of MSRC images are listed in Tables 13, 14 and 15.
5.2 Parameters analysis
In this subsection, we discuss the influence of parameters in Eq. (9). Three parameters \(\lambda ,\,C\) and \(\tilde{N}\) are illustrated as follows. The parameter C is used to balance the Structural risk and empiric risk in Eq. (9). In image retrieval task, structural risk is more important than empiric risk because of small size of labeled samples. In our paper, we set \(C=0.05\) in all experiments and data sets. We involved \(\lambda \) to avoid the optimization matrix irreversible in Eq. (10). We set \(\lambda =1\) in our method. In fact, \(\lambda \) can be set by \(\lambda =tr(S'_{w}-S'_{b})\) in any cases. In ELM, the parameter \(\tilde{N}\) is also important, more details can be seen in references Huang et al. (2006) and Huang and Chen (2007). We set \(\tilde{N}=200\) in all ELM versions and experiments.
5.3 Results analysis
RDELM and the DRfree version achieve better performance than SVM, MCVELM and ELM in most cases, especially in Corel-1K dataset (see Tables 1, 2, 3, 4). This is mainly because the classes of images keep good structures in RDELM space. There is also an interesting result that retrieval results of MSD are always better than that of STY1 (see Tables 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12). It illustrates that a good feature is very important, and needs fewer times in RF. However, In MSRC dataset, SVM, ELM, MCVELM and RDELM achieved the similar results which illustrate the classes in ELM space and original sample space are not distinguishable. This can be also explained by the similar results using STY1 or MSD features (see Tables 13, 14, 15).
RDELM and the DRfree version get better performance than SVM, MCVELM and ELM in Corel-1K dataset, which can be also attributed to the robust discriminative structure of RDELM. Corel-1K is more difficult to retrieve than other datasets. For example, the classes of beach and mountain share some similar features in Corel-1K dataset. From the above experimental results in four datasets, we claim that a good descriptor of image may be discriminative which can also help RF and the discriminative structure in score model.
The efficiency of RDELM is similar to MCVELM because both the two methods need dimensionality reduction with the similar process and dimension. The time complexity of dimensionality reduction in RDELM needs \(O(D^3)\). This is an extra time consuming to ELM. Therefore, RDELM need more time to get the feedback function. However, it makes little influence while the feature dimensions of image are not very high (more than 500).
6 Conclusion
In this paper, we deeply analyzed the class structures in ELM feature space, and propose a robust ELM version for RF in CBIR system (RDELM). RDELM can select whether the dimensionality reduction method need to be involved or not, and is suitable for image retrieval application. Experimental results on benchmark datasets show that ELM-related methods are more efficient than SVM-based method. Furthermore, the results of RF1 illustrate image feature extraction plays an important role in image retrieval process.
References
Akusok, A., Miche, Y., Karhunen, J., et al. (2015). Arbitrary category classification of websites based on image content. IEEE on Computational Intelligence Magazine, 10(2), 30–41.
Anitha, S., & Rinesh, S. (2013). Semi-supervised biased maximum margin analysis for interactive image retrieval. Research Journal of Computer Systems Engineering, 4, 532–536.
Cao, J., Huang, W., Zhao, T., Wang, J., & Wang, R. (2015a). An enhance excavation equipments classification algorithm based on acoustic spectrum dynamic feature. Multidimensional Systems and Signal Processing. doi:10.1007/s11045-015-0374-z.
Cao, J., & Lin, Z. (2015). Extreme learning machine on high dimensional and large data applications: A survey. Mathematical Problems in Engineering. doi:10.1155/2015/103796.
Cao, J., Lin, Z., Huang, G.-B., & Liu, N. (2012). Voting based extreme learning machine. Information Sciences, 185(1), 66–77.
Cao, J., Zhao, Y., Lai, X., Ong, M., Yin, C., Koh, Z., et al. (2015b). Landmark recognition with sparse representation classification and extreme learning machine. Journal of The Franklin Institute, 352(10), 4528–4545.
Deng, W., Zheng, Q., & Chen, L. (2009). Regularized extreme learning machine. In Computational intelligence and data mining, CIDM’09 (pp. 389–395).
Feng, L., Liu, S., Xiao, Y., et al. (2015). A novel CBIR system with WLLTSA and ULRGA. Neurocomputing, 147, 509–522.
He, X. (2004). Incremental semi-supervised subspace learning for image retrieval. In Proceedings of the 12th annual ACM international conference on multimedia (pp. 2–8).
He, X., & Niyogi, P. (2003). Locality preserving projections. In Advances in neural information processing systems 16. Vancouver, Canada.
He, Q., Jin, X., Du, C., et al. (2014). Clustering in extreme learning machine feature space. Neurocomputing, 128, 88–95.
Hoi, S. C. H., Jin, R., Zhu, J., et al. (2008) Semi-supervised SVM batch mode active learning for image retrieval. In IEEE Conference on Computer Vision and Pattern Recognition (pp. 1–7).
Hoi, S. C. H., & Lyu, M. R. (2005). A semi-supervised active learning framework for image retrieval. Computer Vision and Pattern Recognition, 2, 302–309.
Horata, P., Chiewchanwattana, S., & Sunat, K. (2013). Robust extreme learning machine. Neurocomputing, 102, 31–44.
Huang, G.-B. (2015). What are extreme learning machines? Filling the gap between Frank Rosenblatt’s Dream and John von Neumann’s Puzzle. Cognitive Computation, 7, 263–278.
Huang, G., & Chen, L. (2007). Convex incremental extreme learning machine. Neurocomputing, 70(16–18), 3056–3062.
Huang, G., Chen, L., & Siew, C.-K. (2006). Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Transactions on Neural Networks, 17(4), 879–892.
Huang, G. B., Zhou, H., Ding, X., et al. (2012). Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 42(2), 513–529.
Iosifidis, A., Tefas, A., & Pitas, I. (2013). Minimum class variance extreme learning machine for human action recognition. IEEE Transactions on Circuits and Systems for Video Technology, 23(11), 1968–1979.
Iosifidis, A., Tefas, A., & Pitas, I. (2014). Regularized extreme learning machine for multi-view semi-supervised action recognition. Neurocomputing, 145, 250–262.
Jin, Y., Cao, J., Wang, Y., et al. (2015). Ensemble based extreme learning machine for cross-modality face matching. Multimedia Tools and Applications, 1–16.
Kundu, M. K., Chowdhury, M., & Bulò, S. R. (2015). A graph-based relevance feedback mechanism in content-based image retrieval. Knowledge-Based Systems, 73, 254–264.
Liu, S., Feng, L., & Qiao, H. (2015). Scatter Balance: An angle-based supervised dimensionality reduction. IEEE Transactions on Neural Networks and Learning Systems, 26(2), 277–289.
Liu, S., Feng, L., Xiao, Y., et al. (2014). Robust activation function and its application: Semi-supervised kernel extreme learning method. Neurocomputing, 144, 318–328.
Liu, G. H., Li, Z. Y., Zhang, L., et al. (2011). Image retrieval based on micro-structure descriptor. Pattern Recognition, 44(9), 2123–2133.
Lu, K., Zhao, J., & Cai, D. (2006). An algorithm for semi-supervised learning in image retrieval. Pattern Recogition, 39(4), 717–720.
Minhas, R., Baradarani, A., Seifzadeh, S., et al. (2010). Human action recognition using extreme learning machine based on visual vocabularies. Neurocomputing, 73(10), 1906–1917.
Mohammed, A. A., Minhas, R., Wu, Q. M. J., et al. (2011). Human face recognition based on multidimensional PCA and extreme learning machine. Pattern Recognition, 44(10), 2588–2597.
Murala, S., & Wu, Q. M. (2014). Local mesh patterns versus local binary patterns: Biomedical image indexing and retrieval. IEEE Journal of Biomedical and Health Informatics, 18(3), 929–938.
Ojala, T., Pietikainen, M., & Maenpaa, T. (2002). Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(7), 971–987.
Swain, M. J., & Ballard, D. H. (1991). Color indexing. International Journal of Computer Vision, 7(1), 11–32.
Tan, X., & Triggs, B. (2007). Enhanced local texture feature sets for face recognition under difficult lighting conditions. In Analysis and modeling of faces and gestures (pp. 168–182). Berlin: Springer.
Tang, X., & Han, M. (2009). Partial Lanczos extreme learning machine for single-output regression problems. Neurocomputing, 72(13–15), 3066–3076.
Tang, X., & Han, M. (2009). Partial Lanczos extreme learning machine for single-output regression problems. Neurocomputing, 72(13–15), 3066–3076.
Zhang, P., & Yang, Z. (2015). A robust AdaBoost.RT based ensemble extreme learning machine. Mathematical Problems in Engineering, 2015, 260970. http://www.hindawi.com/journals/mpe/2015/260970/cta/.
Zhang, K., & Luo, M. (2015). Outlier-robust extreme learning machine for regression problems. Neurocomputing, 151, 1519–1527.
Zhang, S., Yang, M., Cour, T., et al. (2015). Query specific rank fusion for image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(4), 803–815.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by National Natural Science Foundation of P. R. China (61173163, 61370200) and China Postdoctoral Science Foundation (ZX20150629).
Rights and permissions
About this article

Cite this article
Liu, S., Feng, L., Liu, Y. et al. Robust discriminative extreme learning machine for relevance feedback in image retrieval. Multidim Syst Sign Process 28, 1071–1089 (2017). https://doi.org/10.1007/s11045-016-0386-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11045-016-0386-3