
Abstract
With the development of advanced multimedia editing tools, numerous unauthorized manipulations are easily doable to surveillance systems video files. Thus, video tamper detection is revealed as a big challenge for multimedia security field researchers. Indeed, we propose herein a singular value decomposition (SVD) and discrete wavelet transform (DWT) based semi fragile watermarking scheme for video content authentication. A content-based authentication signature is firstly generated by extracting reliable features from regions of interest. QR code generation technique as well as Arnold transform are used to boost the security aspect of the watermark. This latter is efficiently hidden in the wavelet middle frequency sub bands through an additive embedding algorithm and then extracted via a blind detection method. Simulation results demonstrate that the proposed scheme jointly achieves a good perceptual quality and a high watermark capacity. In addition, it is capable of distinguishing intentional attacks from incidental modifications. Indeed, the proposed watermarking scheme is very fragile to malicious tampering while allowing non-malicious processing.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Nowadays, video surveillance is broadly deployed in several sectors. In fact, surveillance cameras are increasingly installed in public places as well as private ones for instance, in street corners, commercial stores, residential areas, airports, train stations etc. Indeed, 245 million security cameras were active around the world in 2014 [22]. According to Information Handling Services (IHS), there were less than 10 million professionally installed video surveillance cameras globally in 2006 [20]. This number rises quickly to beyond 100 million in 2016. Moreover, over than130 million cameras are shipped in 2018. The main reasons for this burgeoning deployment are the public safety improvement against the crime threat growing and the property security in the society [13]. In addition, the hardware low cost in comparison to the human surveillance further enhances the video surveillance systems ubiquity [13, 18]. Furthermore, videos recorded by a video surveillance system are the subject of many analytical functions such as objects classification and identification, objects tracking and activities and behaviors analysis [7,8,9]. Besides, they play an important role in police and judicial investigations as legal evidences.
In the other hand, the recent revolution in computer technology field is leading to several problems for the multimedia industry in general and the video surveillance one in particular. In fact, this improvement comes across with the development of sophisticated signal and image processing software, which are able to maliciously manipulate the stored videos content without deteriorating of the visual quality. For instance, surveillance sequences can be simply doctored in such way to exculpate or incriminate an individual. Thereby, the stored videos lose their trustworthiness and credibility as legal proof in front of court low. Hence, it is a critical need that video surveillance systems integrate authentication procedures in order to guarantee data integrity and prove their true origin [66].
To overcome this challenge, a broad range of authentication techniques has already been introduced. Cryptography with different protocols is one of the most used solution to protect videos authenticity and integrity [1, 40, 56]. Nonetheless, this video authentication mechanism has some shortcomings such as computation and storage requirements. Likewise, after encrypting the digital video any visualization, analysis or visual data search requires its decryption. To deal with these weaknesses, video watermarking is introduced as a promising cryptography alternative [35, 36, 45, 46]. It is the procedure of embedding a signature called watermark in the video frames. The embedded watermark can be an image, a logo or any particular kind of information content. A video watermarking system is consisting of two processes as shown in Fig. 1. The first one is the embedding, which refers to the watermark combination with the host video. The information to be used as a watermark can be an image or a binary sequence. In addition, it can be constructed through exploiting video frames features. The watermark extraction is the second process consisting a video watermarking system. It is the process of extracting the hidden information from the eventually tampered watermarked video that will be used to ascertain the video content authenticity.

Video watermarking general framework
Watermarking based authentication approaches were first introduced as fragile watermarking systems. In this case, any modification of the watermarked video readily generates a mark detection failure. Thus, the watermark loss is considered as an evidence of content tampering. The main benefit of fragile watermarking is the ability of tampering localization but it is so difficult to discriminate between malicious video processing which aims to alter the video semantic content and some non-intentional processing [3, 12]. Another popular used approach is the robust watermarking. It is aptly named due to its resilience against any attacks form. Indeed, the hidden information can be recovered from tremendously attacked watermarked video [19, 43]. To exploit the advantages of both the fragile approach and the robust one, another paradigm is introduced. It is referred as semi fragile [17, 44]. This watermarking method type is designed to be robust against intentional tampering distortion and to tolerate only unintentional manipulations. A semi-fragile watermarking system has provide its efficiency for applications that require a trade-off between robustness and fragility namely for video surveillance application. Thus, we propose in this work a blind semi fragile watermarking scheme for video authentication in video surveillance context using Discrete Wavelet Transform (DWT), Singular Value Decomposition (SVD), Quick Response code (QR code) and Arnold Transform.
This paper remainder is organized as follows. Section 2 provides an overview of video watermarking field. The review of state of the art of video watermarking based authentication techniques is given in Section 3. Section 4 presents the proposed semi fragile watermarking scheme. Performances results and a comparison with existing techniques are reported in Section 5. Finally, conclusions are drawn and perspectives are open in the last section.
2 Overview of video watermarking
In this section, an overview of video watermarking and its main terminologies is given. First, we define the video watermarking applications. Next, we key out the requirements in this field. Finally, we present various video watermarking techniques classifications.
2.1 Video watermarking applications
Digital watermarking has become into vogue from the late 1980s. This research area has quickly witnessed a great growth due to its important applications. Broadcast monitoring is one of the common used video watermarking applications. It enables advertising agencies to verify whether their commercial contents are broadcasted as contracted by hiding a watermark in advertisements contents. In fact, extracting the embedded watermark enables to check that commercials have been aired during all the payed for time [28, 47]. Moreover, watermarking can be used for fingerprinting. This application allows finding illegal copies source. Indeed, the owner can embed a different watermark in each content media copy. Thus, this mark enables the intellectual property owner to identify the buyer for each legal distribution and check who has broken his license by providing the content to third parties [38, 70]. Copyright protection is a fundamental video watermarking application. In this case, specific owner information are used as a watermark in order to identify the copyright ownership as well as prevent video fraud and misappropriation. Indeed, watermark retrieving from the watermarked video allows the rightful owner to prove the video ownership when someone alleges it [14, 61]. Besides, data authentication is another popular watermarking application, which aims to confirm the watermarked video integrity and to detect the attempted altering of the original video content. The watermark, which is concealed in the host video, is designed to be affected by signal manipulations and then be used to indicate whether the watermarked video content is authentic or not [30, 63].
2.2 Video watermarking requirements
As we previously mentioned, video watermarking is exploited in wide range of applications. Consequently, every watermarking system should have its own specific properties with respect to the considered application. Mostly, three requirements are basically given for most video watermarking systems. The first one is imperceptibility or transparency, which refers to the watermarked video perceptual quality. Obviously, it depends on the embedding process. Indeed, the distortion caused by the algorithm used for watermarking should add a minor degradation to the host video perceptual quality. Therefore, the watermarked video should not be distinguishable from the original one by human eyes. The second property is robustness. It means the ability of the watermark to survive under distortions. These attacks are mainly divided into two types; unintentional and intentional ones. Unintentional attacks are processing that do not have the goal to impair or remove the watermark. Intentional attacks attempt mischievously to damage the embedded data in the watermarked video. Capacity denotes the third requirement for video watermarking system. It defines the maximum amount of information that can be hidden in the host video as a watermark. The embedded information size varies according to the targeted watermarking application. For instance, for security purpose, a big capacity is required. In contrast, for copy protection purpose one-bit capacity is generally sufficient. Imperceptibility, robustness and capacity are mutually dependent to each other. In fact, increasing the capacity leads to decrease the robustness and degrade the visual quality. Therefore, a good trade-off among all the properties listed above should be maintained when designing a watermarking system [5, 64, 65]
2.3 Video watermarking techniques classification
Video watermarking techniques can be classified based on distinct criteria. According to human perception, video watermarking techniques are divided into two classes: visible watermarking techniques and invisible ones. For the first class, the watermark is embedded in such way to be noticeable when viewing the watermarked video. For the second class, the watermark is concealed in the host video in order to be perceptively unidentifiable by human eyes. Based on watermark detection criterion video watermarking techniques are classified as non blind, semi blind and blind. In non blind techniques, both the original video and the watermark are required during the extraction process. On the other hand, in semi blind techniques the information used as a watermark can be successfully extracted from the watermarked video without using the original video. In blind detection neither the embedded watermark nor the original host video are required for watermark extraction [5, 6].
Another criterion, which is frequently used to classify video watermarking schemes, is the working domain. Indeed, depending upon this criterion video watermarking techniques are usually divided into two categories. The first one is the spatial domain watermarking. In this type, the embedding process is achieved by directly modifying or replacing the original video frame pixel values. Spread spectrum, Least Significant Bit, correlation based technique present the most used technique in this domain [54, 55, 69]. Spatial domain based watermarking approaches are characterized by a simple implementation and a low computational complexity. However, it is denoted that these techniques have several drawbacks namely low embedding capacity and weak robustness against several attacks specially compression. The frequency domain which also referred as transform domain is the spatial domain alternative. Video watermarking technique in this case starts by converting the host frame to a new appropriate working domain. Then transform coefficients are adjusted by the watermark to obtain a watermarked frame. The common domain transformation techniques are the singular value decomposition (SVD), the Discrete Cosine Transform DCT, the Discrete Wavelet Transform (DWT) and the Lifting Wavelet Transform (LWT)[26, 49, 53]. Frequency domain based approaches have gained a tremendous exposure as compared to spatial domain based ones since they are more resilient to geometrical and compression attacks. Subsequently, they yield large capacity and better imperceptibility by respecting more advanced human visual system properties. Therefore, transform domain based approaches allow to efficiently meet the trade-off between the different watermarking system requirements [6, 11, 68].
3 Related work
Video authentication through video watermarking scheme is an appealing field, which motivates several researchers. In the literature, there is a variety of existing approaches relevant to this research area. As already noted in Section 2.3, video watermarking techniques are commonly classified, based on the embedding domain criterion, to two categories, i.e., spatial domain watermarking techniques and frequency domain ones. In the present section, we will only investigate frequency domain based watermarking schemes since this domain allows better attaining the compromise between the different watermarking requirements. Regarding the number of the used domain transformations, existing approaches dedicated to frequency domain can be mono frequency or multi frequency.
The mono-frequency based watermarking systems involve only one transform to embed the mark. In [4], Alenizi et al. propose a new DWT based video watermarking scheme for authentication purpose. The luminance Y component undergoes a DWT decomposition via randomly generated filters to increase the algorithm security. The watermark is inserted in the middle frequency sub band using an additive method with a pseudo-random sequence P, which is generated using a secret key and a constant magnitude factor α to control the watermark robustness. The simulation results show that this scheme has good performances under different well-known attacks. However, it gives lower performance in terms of correlation when the scenes have a smooth nature and a few motions. In [25], a DCT based video watermarking is introduced. In this scheme, the watermark is concealed in the low frequency sub-band resulting of the DCT application to the changed scene specific frames. Farfoura et al. present a semi-fragile watermarking scheme for content-based authentication [15]. The authentication codes used in this scheme are composed of frames index timing information and invariant features, which are extracted from intra macroblocks. The watermark is inserted into Quantized DCT (QDCT) coefficients in a set of random chosen Group of Pictures (GOP). The advantages of this watermarking scheme are the resilience against semantic content preserving attacks as well as the sensitivity to content altering attacks. In addition, the technique shows a low computational complexity and a good imperceptibility level. Furthermore, Bhardwaj et al. introduced a robust video watermarking technique operating in the mono frequency domain [10]. In this scheme, the to-be-watermarked frames are chosen via a frame selection procedure based on the mathematical relationship between the non-watermarked video frames index, the embedding capacity and the coefficient block size. The watermark bits are hidden in the quantified LH3 sub-band coefficients resulting from the lifting wavelet transform (LWT). Experimental results demonstrate that this technique is robust to various image processing attacks with a good level of imperceptibility. Khosravi et al. propose several efficient interpolation based-watermarking schemes operating in the mono frequency domain for data management transmission in remote sensing video surveillance by video synthetic aperture radar (ViSAR). In fact, this latter provides several principal, control and managerial data which should be compressed before been transmitted. Hence, authors adopt watermarking systems based on interpolators and domain transformations such as Fast Fourier Transform (FFT), (DCT) and (DWT) to aggregate and reduce the ViSAR information size [32,33,34].
Conversely, multi-frequency based video watermarking techniques operate combining several transformations in the embedding process. A DWT and SVD based watermarking technique is developed in [59]. In this methodology, Fibonacci sequence is used to identify key frames which will be used for the watermarking. The watermark singular values are embedded in LH mid frequency sub band coefficients of selected frames. Based on simulation results, this technique is immune to video processing attacks and it ensures a good quality of watermarked videos. Another multi-frequency based video watermarking combining the (DWT) with the principal component analysis (PCA) is proposed by Yassin et al. in [67]. In this work, two levels DWT is used to transform the Y component to the frequency domain. The maximum coefficients of the maximum entropy principal component analysis (PCA) blocks are identified as the optimal watermarking locations. The watermark is hidden in the selected suitable coefficients quantified values. According to the experimental results, this watermarking methodology proves its robustness against different distortions specially contrast adjustment, Gaussian noise addition and JPEG coding.
In [51], Nouioua et al. introduce a novel digital video watermarking technique based on SVD which performs in the Multi-resolution Singular Value Decomposition domain. The watermark is encrypted through a Logistic Map Encryption and then hosted only in the fast motion frames in each video shot. The embedding is done following a blind Quantization Index Modulation algorithm. Authors claimed that this scheme is secure and robust to a variety of manipulations like compression, image processing and frame synchronization. Another multi-frequency based video watermarking technique is developed by Panyavarapornto for both copyright protection and content authentication purposes [52]. In this scheme, discrete wavelet transform is used as a combination with discrete cosine transform. Indeed, the watermarking is achieved by applying DWT on the Y component of the video sequence frames then performing the DCT on the middle frequency sub bands and finally the watermark is inserted in mid-band DCT coefficients. The proposed algorithm has proven its robustness especially against compression attacks and has shown visually acceptable quality. Similarly, an enhanced watermarking approach using DWT, DCT and interpolation is proposed in [29]. In this algorithm, interpolation technique is applied, after the watermark extraction, to zoom the host frame and to get the concealed and improved information hidden in the host watermarked frame.
According to the above existing video watermarking approaches overview, it is clear that the combination of transformation domain techniques offers better resilience to different attacks than the technique involving one single transform. Consequently, in the proposed work the watermark embedding is carried out in the multi frequency domain.
4 Proposed approach
The proposed system is a blind and semi fragile video watermarking in the frequency domain based on DWT, SVD, QR code and Arnold transform for video authentication in video surveillance context.
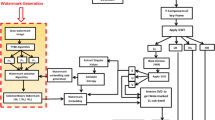
As illustrated in Fig. 2, it involves 3 processes namely: the watermark generation, the watermark embedding and the detection process. The design of each process will be explained in the following subsections.

The proposed approach general framework
The main contributions in this work are:
-
1)
The selection of proper invariant features to construct a content-based watermark that exhibits semi fragility property and allows to fulfill the task of discrimination between malicious processing actions and non-malicious ones.
-
2)
The adoption of QR code technique and Arnold transform to deal with the watermark security and computational complexity challenges. Before being embedded in the host video frame, the watermark is processed by a QR code generator and then encrypted by Arnold transform. Therefore, the hidden information cannot be recovered in its original form even if the attacker successfully decodes the extraction algorithm.
-
3)
The hybridization of two transformation domain techniques, namely the DWT and the SVD, and the exploitation of their complementary characteristics to enhance the watermarking system performance. In fact, The DWT sub bands properties as well as the relation between the SVD coefficients are jointly used to embed the watermark into the host video and to guarantee a blind detection during the extraction process.
4.1 Preliminaries
To better understand the details of the proposed approach, a brief overview of YUV space color, discrete wavelet transform, singular value decomposition, QR code technique and Arnold transform is provided in this section.
4.1.1 YUV color space
The YUV color spaces consists of luminance (intensity) and chrominance (color) components.YUV components are less correlated than the RGB color space ones that makes it more suitable for image and video processing applications and for watermarking in particular. The conversion from RGB to YUV and the transformation from YUV to RGB are done using formulas (1) and (2) respectively.
4.1.2 Singular value decomposition
SVD is a numerical transform which decomposes an mxn real matrix A into a factorization of three matrices:
Where:
U and V, that are orthogonal matrices of size mxm and nxn respectively, present the singular vectors of matrix A. S is mxn diagonal matrix and its non-zero elements arranged in descending order define the singular values of matrix A. The singular values matrix S ensures higher invisibility and more robustness against attacks as compared to U and V matrices thereby it suits the watermarking requirements. Generally, SVD is gaining more popularity in image and video processing area thanks to it attractive properties namely its conceptual stability and its maximum energy packing [39, 57].
4.1.3 Discrete wavelet transform
DWT is a mathematical tool used to hierarchically decompose an image and video frames. This tool allows separate an image into 4 frequency sub-bands i.e. low-frequency sub-band (LL) as well as high-frequency sub-band (HH) and mid frequency sub-bands (HL and LH). The process can be repeated to compute multiple levels wavelet decomposition. DWT is well known for its resilience to noise addition and compression. Also, it better modulates the Human Visual System aspects than the other domain transformation techniques. Hence, it was adopted for many practical applications in image and video processing such as image restoration and image zooming as well as transmission and compression [23, 24, 48, 50]. It is often used in watermarking schemes due to its spatial localization, frequency spread and multi-resolution modelling [2].
Figure 3 illustrates the sub-bands obtained after two decomposition levels.

a Original image b 1 level DWT decomposition c 2 level DWT decomposition
4.1.4 Quick response code
Quick response code is a two dimensional matrix symbols introduced in 1994 by Denson-Wave and it is standardized by the international organization for standardization as ISO/IEC 18004:2015 [21].
A QR code is a set of black square blocks arranged in a white background. Version information, separators, timing patterns, format information, data and error correction, quiet zone, alignment patterns and position detection are the QR code basic structure elements as shown in Fig. 4. It is used in a wide range of multimedia applications especially when a great information size should be transmit in a compact format. In fact, a QR code can carry up to 7089 numeric characters and up to 4296 alphanumeric characters [27]. Likewise, providing a good damage resilience and a high storage capacity are the main reasons for the QR code adoption in the watermarking field.

Quick Response code basic structure
4.1.5 Arnold transform
Arnold transform is an invertible and iterative mapping, which permits to randomize the original pixels positions in an image. The considered iterations number is called as the Arnold’s period and it depends on the original image size. The main purpose of the Arnold transform is to warp the original image semantic, which become unreadable in the scrambled version. The Arnold Transform of an nxn image is described by the following equation:
Where (x, y) and (\(x^{\prime }, y^{\prime }\)) are the original pixel coordinate and the scrambled one respectively and N is the image size.
Arnold transform is recognized as one of the most used image scrambling technique. It has various applications, particularly in watermarking field; it is often utilized to encrypt the watermark in order to ensure the confidentiality and to improve the security level of the watermarking scheme [58]. Indeed the watermark cannot be extracted without an accurate knowledge of the particular Arnold period K.
Figure 5 depicts an example of Arnold transform applied to an image with different periods K.

a original image Lena b Arnold transform with period = 1 c Arnold transform with period = 3 d Arnold transform with period = 7
4.2 Watermark generation process
A well-designed watermark is a prominent requirement for the watermarking scheme efficiency. In the proposed watermarking system, the host video is divided into sequences of N successive frames. For every video sequence, a watermark is generated from its first frame based on Algorithm 1 and then it is repeatedly inserted in each frame of the given sequence.

In order to cater to the security need, N, which defines the number of frames in each sequences. In fact, a large value of N means embedding the same watermark into a large number of consecutive frames. Conversely, small value of N denotes the watermarking of few number of frames with the same watermark. Hence, its value should be properly fixed to avoid making the watermark vulnerable to unintentional manipulations.
As illustrated in Fig. 6, the watermark generation process implies two main steps: Regions Of Interest (ROI) extraction and watermark construction. Since we focus on captured videos for surveillance purpose in public places, moving objects for instance pedestrians and vehicles are the required regions. Indeed, they are the most targeted regions by malicious attacks in a video frame and each intentionally forgery on their content should be detectable. A technique based on adaptive improved version of Gaussian Mixture Model (GMM) [62] is used to detect ROI. In order to remove noising information, morphological filtering operations such as closing and opening are achieved as explained in [7].

The proposed watermark generation process flow chart
Then the extracted regions are exploited for the watermark construction strategy. First, the ROI extern contours are extracted. We select only salient points from moving objects edges in order to keep relevant information as well as to significantly minimize the computation time and enhance the watermark robustness. Indeed, salient points selection is done through Shi-Tomasi corner detector [60], which is resilient to several attacks. In our algorithm, the detected corner positions are considered as features. In fact, a cartographic map is constructed with the selected salient points coordinates. To provide additional security level to our system, the constructed map is processed as an input to a QR code generator. This contributes not only to enhance the security side of the system but also to conceal a large amount of information during a less embedding time. To further strengthen the security of the secret information to be hidden, the obtained QR code is encrypted using Arnold transform with a period K. Hence, this image scrambling technique ensures that the watermark extraction cannot be done without an accurate knowledge of the particular Arnold period K, which represents the second watermarking secret key in our approach. Finally, the scrambled version of the QR code is used as a watermark and hosted into the video frames.
4.3 Embedding process
As mentioned before, the host video is processed initially to be segregated into sequences of N gathered frames. All frames in each sequence are watermarked by a unique scrambled watermark, which is intrinsic to the given video sequence. The embedding process flow chart is shown in Fig. 7 and described in Algorithm 2. The RGB frame is first converted into YUV format as its components are less correlated than the RGB color space [16]. By virtue of the fact that it is better harmonized with human visual system (HVS), the luminance component Y is selected for the embedding process to strengthen the watermark imperceptibility. More precisely, the human eye is less sensitive to the luminance component Y compared to the chrominance components U and V [16].

The proposed watermark embedding process flow chart
The selected component is divided into several non-overlapping blocks of 4*4 size. The block size is chosen to maximize the number of bit to be inserted i.e., to guarantee a large capacity. Indeed, in every resulting block one bit will be concealed. Thereafter, each block is subjected to a single level discrete wavelet transform DWT. The DWT is solicited as a domain transformation technique thanks to its efficient resilience to noise addition. Moreover, it allows to more faithfully modeling the Human Visual System aspects than the other domain transformation techniques. Among the produced sub bands, only the mid frequency sub bands (LH1 and HL1) are selected as the best watermarking locus because they strike the correct trade-off between the imperceptibility and the robustness requirements. In fact, involving the low frequency sub-band (LL), which represents the most significant video frame parts, in the embedding process can increase the watermark robustness at the cost of the perceptual quality. Conversely, inserting the watermark within the high frequency sub-band (HH) guarantees a good imperceptibility but the secret embedded information risks to be lost during the compression processing since it refers to the least important information in the given video frame [41, 42].

Afterwards, the singular value decomposition is performed to the selected sub-bands. This operation yields 3 independent matrices namely U, S and V. Since S provides higher invisibility and more robustness against attacks as compared to the two obtained matrices U and V, it is particularly taken as the one to be watermarked. The watermark insertion is carried out by modifying the singular values of S matrices relative to the mid frequency sub-band HL1 and LH1 according to the bellow equations:
If Wembedding = 0
Else
Where Wembedding is the watermark bit, Soriginal and Swatermarked are respectively the original version of the singular value matrix and the watermarked one. Factα and Factβ are two scaling factors used for controlling the watermarked video visual quality as well as the watermark robustness. Their values, which depend on the coefficients of the original matrix S, are calculated using the following formulas.
Where α and β are two integer values.
Next, both singular value decomposition inverse and discrete wavelet transform inverse are applied to yield the watermarked luminance component Y. This latter is combined with the non watermarked chrominance components to obtain the watermarked RGB frame after re-converting the color space from YUV to RGB using (2).
The watermarked video is the result of the repetition of the above-described process to each frame in every sequence.
4.4 Detection process
Figure 8 illustrates the watermark detection general scheme that involves two processes: the regeneration process and the extraction one.

The proposed watermark detection process flow chart
It claims that the detection is blind since only the watermarked video and the two secret keys N and K are required as the scheme inputs. The regeneration process is composed of the same steps used in the watermark generation process. The regenerated watermark is denoted by Wregenerated. In the other hand, the extraction process starts operating in analogy with the watermark embedding process as described in Algorithm 3. In fact, the watermarked video is subdivided into video sequences using the secret key N and a watermark is further extracted from each sequence. At first, a conversion from RGB to YUV color space is performed. Then the luminance component Y is decomposed to 4x4 non-overlapping blocks. After performing a single level DWT to each block, the singular value decomposition SVD is applied to the middle frequency sub bands LH1 and HL1. Finally, the hidden signature is extracted from the singular values matrices coefficients based on the following rules:
Where Sextracted is the extracted singular value matrix, Wextracted is the extracted watermark bit, Factα and Factβ are the two scaling factors computed using (7) and (8) respectively.

For tampering detection, the extracted watermark Wextracted and the regenerated one Wregenerated are compared. In fact,a mismatch between these two watermarks denotes an occurred alteration.
5 Experimental results
The proposed scheme is tested on various videos. The selected videos include at least one moving object and low to high movement activities amount. Details of videos for testing are indicated in Table 1. As depicted in this latter, these videos are test.avi, camera2.avi, video1.avi, foreman.avi, tempete.avi, table.avi and mobile.avi. The first three sequences belong to PETS benchmark datasets. However, the others videos are often used to evaluate previous existing works. The used videos, which hold on a different frames number, are distinguished by frame size as well as the frame per second (FPS) metric.
The performance of the proposed watermarking system is assessed by analyzing its watermark capacity, imperceptibility and robustness. In the following, evaluation metrics used to measure these properties will be introduced and the obtained results will be displayed, discussed and compared to other existing approaches results.
5.1 Metrics
The watermark capacity is mostly quantified by the maximum number of bits that could be embedded in a given frame. According to our embedding algorithm, the watermark capacity Cmax per frame is equal to the number of blocks resulting from the Y subdivision into 4×4-block size. Thus, it can be computed via the following equation:
Where h and w are respectively the height and the width of corresponding Y component and Bsize presents the block size that is 4×4 in our work. The imperceptibility property is quantitatively scrutinized using Peak Signal to Noise Ratio (PSNR) as well as Structural Similarity index (SSIM) [31, 37]. While the robustness requirement is examined computing two metrics which are Normalized Correlation (NC) and Bit Error Ratio (BER) [16]. The PSNR allows checking the perceptual quality degradation of the watermarked video after the embedding process with references to the non-watermarked one. It is calculated by:
Where F and F’ are the original host frame and the watermarked one respectively with radiometric accuracy of d pixel and c channels. For RGB frame with 256 different gray levels, d and c values are 8 and 3 respectively. h and w are respectively the height and the width of corresponding frame.
The structural similarity index (SSIM) is used to find out the similarity between two images. This metric is based on neighboring pixel dependencies and it is computed using the following equation:
Where SSIMchannel is structural similarity index per channel. It is defined as:
Where μx and μy are the average of intensities corresponding respectively to the original frame channel and the watermarked one, \({\sigma _{x}^{2}}\) and \({\sigma _{y}^{2}}\) are the variance of the intensities corresponding respectively to the original frame and the watermarked one and σxy is the covariance of original and watermarked frame, c1 and c2 are two factors used as division stabilizers.
Normalized Correlation (NC) measures the similarity between the original and the extracted watermarks. The NC value is derived by utilizing (14) given below:
Where m and n are the watermark size. Woriginal and Wextracted are the original watermark and the extracted one respectively.
The bit error ratio evaluates the accuracy of watermark quantitatively. Hence, it refers to the number of bits received in error during the extraction process to the total number of bits in the extracted watermark. The BER value is calculated via the following formula:
Where, mxn is the total number of pixels of the watermark, Woriginal and Wextracted represent the original and the extracted watermark respectively and ⊕ is the exclusive OR operation.
For video, the PSNR, the SSIM as well as the NC and the BER values are computed as the average of their values in every video frame. For instance, the NC value of a video composed by frames is defined as:
Where NF is the total number of frames in the video. \(NC_{F_{i}}\) is the normalized correlation corresponding to the frame number i in the video.
5.2 Configuration of parameters used for experimentation
In our system, we have three parameters to be fixed. The first one is the frames number held in each video sequence, yielded after the host video split, already denoted by N and used as a first secret key. As highlighted before, this parameter value should be properly adjusted to ensure the watermark resilience to non malicious attacks. In order to avoid watermarking a large frames number with the same watermark, N is experimentally tuned to be as:
Where FPS denotes the frame per second metric.
Indeed, Table 2 provides resulting NC for different N values obtained in case of compression attack, which is the most important non-malicious manipulation, applied to several videos. It is clear that (17) allows obtaining the suitable N value that ensures the greater NC.
The two other factors are α and β, used in (7) and (8), which allow controlling the compromise between the watermark robustness and imperceptibility. Therefore, their suitable adjustment is crucial for the system efficiency. To this end, the PSNR is computed for different (α,β) values. According to the obtained results tabulated in Table 3, it is quite evident that the couple (2, 4) exhibits the best PSNR values. Consequently, α = 2 and β = 4 are the considered values for the watermarking process.
5.3 Capacity results
For each video, the capacity per frame Cmax is calculated using the (10) and then the capacity per video is deduced by multiplying Cmax by the number of frames in the given video. According to the obtained values represented in Table 4, it is noticeable that the proposed scheme proves its proficiency in terms of capacity. In fact, the subdivision of the luminance component Y to 4×4 non-overlapping blocks during the embedding process allows scatting a watermark with a large size in each frame.
5.4 Imperceptibility results
The proposed scheme perceptual quality is assessed through subjective and objective measures. For the subjective evaluation, non watermarked frames from some tested videos and their corresponding watermarked versions are shown in Fig. 9. It is clear that no visual artifacts can be observed between the original frames and the watermarked ones.

Up: original frames a test.avi b foreman.avi c camera2.avi, Down: watermarked frames: d test.avi e foreman.avi f camera2.avi
Concerning the objective evaluation, the different watermarked videos PSNR values are calculated and presented in Fig. 10. The resulting PSNR values exceeds 37 (dB) and reaches 47 (dB), which demonstrates that the proposed scheme preserves the watermarked video visual quality. For videos with different textures, the PSNR cannot be a compatible metric that faithfully reflects the visual quality. So, the SSIM is also employed as another objective metric since it is more accurate and consistent than PSNR. The Fig. 11 exhibits the resulting SSIM values that are approximately equal to 1. This confirms that both the host video and the watermarked one are entirely identical. Hence, based on the subjective as well as the objective evaluation, the watermark is visually transparent. Hence, the proposed scheme meets the watermarking system imperceptibility requirement. This high imperceptibility level is reached due to the selection of singular value matrix coefficients as watermark embedding holders.

Obtained PSNR values of various watermarked videos

Obtained SSIM values of various watermarked videos
5.5 Robustness and fragility results
The proposed scheme effectiveness is evaluated against two attacks categories. The first group focuses on intentional tampering that seeks to change the video frame semantic content. The second set contains incidental attacks that preserve the frame semantics. The distinction between intentional and non-intentional modifications is achieved using a threshold. Since the robustness investigation is performed based on two metrics the NC and the BER, two different thresholds are considered and denoted by TNC and TBER. In this work, TNC and TBER are set to 0.9 and 0.1 respectively.
The set of incidental attacks holds the compression, additional noise attacks and finally brightness and contrast changing with moderate ratios. Experimental results presented in Tables 5 and 6 demonstrate that the detector is able to successfully retrieve the hidden watermark from the compressed watermarked videos. Indeed, the obtained NC values reach 0.9975 and BER values are close to 0. Obviously, the resulting NC and BER values are respectively above and below their thresholds, which indicates that no malicious distortion has occurred. This high resilience level is provided thanks to the selection of the mid frequency sub bands of the discrete wavelet transform as locations for the watermark embedding. This choice allows avoiding a potential information loss during compression process.
Furthermore, the proposed watermarking system robustness is investigated in the presence of Gaussian noise and salt and pepper attacks. As well seen from simulation results tabulated in Table 5, the minimum obtained NC is 0.92471 after adding white Gaussian noise of mean zero and standard variances and 0.95386 after conducting salt and peppers attack. As shown in Table 6, the maximum BER is below 0.1. The above results indicate that the procured NC values are superior to the relative threshold TNC and the BER values do not exceed the TBER. Hence, the watermark can be correctly extracted after applying white Gaussian noise and salt and pepper to all the watermarked video frames. Using the discrete wavelet transform that is immune to noise adding, improves the robustness of the scheme against these two manipulations. Analyzing the results presented in Table 7, it can be noticed that the proposed technique efficiently survives the adjustment of both brightness and contrast since the obtained NC and BER values are respectively above and below their predefined thresholds. In fact, using moderate ratios does not affect the frame semantic content.
The effectiveness of the proposed watermarking scheme is assessed against intentional manipulations namely: rotation, cropping, filtering, object removing, object insertion and high variation of brightness and contrast level.
First, each frame is rotated by different angles. It is observed from Tables 8 and 9 that BER varies between 0.46031 and 0.51988 and NC is ranged between 0.65343 and 0.71645 for all tested videos when varying the rotation degree from 5 to 90 with a step of 5. From these results, it is clear that NC is inferior than 0.9 and BER is superior than 0.1. Hence, we conclude that the watermarked video is deliberately tampered.
In addition to rotation, the tested videos are subjected to cropping with different window sizes. Results are depicted in Table 10. In this case, the maximum NC and the minimum BER are 0.70400 and 0.46938 respectively. From these results, it is noticed that the detector fails in recovering the embedded watermark since the achieved BER values are extremely above the threshold 0.1 and NC values are below the relative threshold 0.9. Afterward, sensitivity to frame filtering is tested. Therefore, watermarked video frames are subjected to median filter with median radius of 2×2 and 3×3. The NC and BER values corresponding to these manipulations are given in Figs. 12 and 13. It is observed that the BER values are greater than 0.4 and attain 0.51528. In addition, NC values lie between 0.68971 and 0.72964. By comparing these results to the preset thresholds TNC = 0.9 and TBER = 0.1, it is evident that the watermarked videos are regarded as non-authentic.

NC values obtained for the used videos after median filtering attack

BER values obtained for the used videos after median filtering attack
The next considered malicious attacks are object deletion and insertion. These two attacks are among the common tampering that must be detectable by an efficient semi-fragile watermarking scheme notably in video surveillance context. Therefore, an object is intentionally removed from watermarked frames of randomly selected sequences of the test videos. To provide a better illustration, Fig. 14 depicts an example of a watermarked frame and its maliciously tampered version from a used video. The resulting values of the two authentication metrics BER and NC relative to the test.avi and camera2.avi videos are respectively presented in Tables 11 and 12. As we can see from these results, the minimum BER is higher than the threshold 0.1, and the maximum NC is lower than the preset threshold 0.9 for the two considered videos. Therefore, the watermarking scheme proves its ability to successfully detect these malicious tampering attacks. Likewise, to test object insertion attack, watermarked frames of arbitrarily chosen sequences are corrupted by introducing an external object to their visual content as shown in Fig. 14. The obtained BER values show high values contrary to NC that exhibit low values as we can see from Tables 13 and 14, which summarizes the resulting measurements values relative to the two previously used videos. Thus, the watermarked videos are deemed as maliciously attacked.

test.avi video: a watermarked frame b attacked frame after object insertion c attacked frame after object deletion
Finally, the fragility of the proposed scheme to brightness change and contrast adjustment with high variation ratios is checked. Unlike brightness and contrast varying with moderate ratios, these types of modifications are identified as malicious because they permit the attacker to hide several semantic details from frames. Figure 15 displays example of watermarked frames after being attacked by strongly increasing and decreasing the luminance and the contrast levels. The BER and NC values tabulated in Table 15 indicate that the videos are unauthentic for the different ratios. Again, the detector properly identifies the intentional tampering.

test.avi: video a watermarked frame b attacked frame after brightness increasing c attacked frame after brightness decreasing
5.6 Comparison of our proposed scheme with existing authentication approaches
The proposed technique performances are compared to the existing works presented in [10, 15, 25, 51, 59, 67] with respect to watermark capacity, imperceptibility and robustness. As previously described in Section 3, [10, 15, 25] are mono frequency domain approaches involving DCT, QDCT and LWT respectively. Nonetheless, our proposed scheme as well as the ones presented in [51, 59, 67] carry out in the multi frequency domain. In fact, our technique and [59] jointly involve the SVD and the DWT for the watermarking. However, [51, 67] use the combinations (DWT,PCA) and (SVD, MR-SVD) respectively. The comparative comparison between the proposed method and [15] is provided in Tables 16 and 17. This latter demonstrates a comparison in terms of robustness while Table 16 depicts a comparison in terms of capacity and imperceptibility requirements. Referring to Table 17, it can be seen that our scheme, which exhibits the lowest BER values, performs better than the method in [15] under Gaussian noise, salt and pepper, compression and brightness variation attacks. Similarly, the values of the quality measure PSNR illustrated in Table 16 indicate that our technique noticeably outperforms the watermarking technique [15] with respect to capacity and imperceptibility requirements. Indeed, the proposed scheme provides a PSNR average equals to 47.727 db while offering a watermarking capacity 4 times greater than the aforementioned method one. This demonstrates that the watermark embedding holders in our work are selected correctly and ensure a good watermarked video quality despite the high capacity.
The comparison between our scheme and those in [10, 25, 51, 59, 67] is given in Tables 18 and 19. Analyzing this latter, it can be seen that our scheme robustness against Gaussian noise attack is superior to those in [10, 25, 51, 67]. However, the method in [59] provides a NC value which is slightly better than our approach. From Table 19, it is well proven that our technique and the ones [10, 25, 51, 59] are resilient to salt and pepper attack. Both our method and the scheme presented in [51] ensure the best performance. Regarding the compression, the scheme introduced in [10] and the proposed one show a comparable robustness level. However, the methods presented in [51, 67] provide a poor resilience to this attack. From the same table, it can be inferred that our technique is more robust to contrast adjustment than the methods in [59, 67].
As far as imperceptibility is concerned, the watermarking approaches in [10, 25, 51, 67] are more imperceptible than the proposed one because the capacity in the present scheme is noticeably high in comparison with the methods [10] and [51] as shown in Table 18. Besides, the two previously cited approaches and the ones introduced in [25, 67] use a watermark holders selection strategies. Consequently, the video perceptual quality is slightly affected since very few frames or blocks are chosen for the watermark embedding process and remaining frames and blocks are unused. Moreover, the proposed method exhibits a better imperceptibility level compared to [59] as shown in Table 18.
6 Conclusion and future works
In this paper, a blind semi fragile watermarking scheme for video content authentication in the multi SVD-DWT domain was proposed. The scheme starts operating with a watermark generation process that is built based on extracted features from regions of interest and QR code technique. After being encrypted by Arnold transform, the authentication watermark is embedded into the singular value matrix coefficients relative to the mid frequency sub-bands of the discrete wavelet transform. Involving these sub-bands in the watermarking allows lessening the visual degradation effect while ensuring a high resilience to common image processing attacks. On the verification side, a blind detection is performed for extracting the hidden watermark that is compared to the regenerated one in order to detect occurred forgeries. Results of simulation experiments, which are conducted on various surveillance videos as well as standard ones, show that the proposed semi-fragile watermarking scheme has the ability to differentiate intentional attacks from non-intentional ones. In fact, achieved NC and BER values, which are above 0.9 and below and 0.1 respectively, prove that our detector withstands moderate content preserving modifications such as common image processing. However, it exhibits a high fragility to semantic content changing alterations such as cropping and objects manipulations by providing NC and BER values extremely inferior and superior to 0.9 and 0.1 respectively. Moreover, the proposed scheme successfully satisfies the trade-off between the capacity and the imperceptibility by achieving a large capacity within a negligible perceptual quality compromising as shown by the obtained PSNR and SSIM high values. The future work may focus on tampering localization and self-recovery, which consists in recovering the original content within the tampered areas. In addition, the proposed watermarking scheme fragility to spatio-temporal attacks can be improved by exploiting other pertinent features during the watermark generation process.
Abbreviations
- Acronym/Symbol :
-
Definition
- BER:
-
Bit Error Rate
- Cmax:
-
Maximum Capacity
- DCT:
-
Discrete Cosine Transform
- DWT:
-
Discrete Wavelet Transform
- F a c t α :
-
Scaling factor
- F a c t β :
-
Scaling factor
- FFT:
-
Fast Fourier Transform
- FPS:
-
Frame per second
- GMM:
-
Gaussian Mixture Model
- GOP:
-
Group Of Pictures
- HH:
-
High Frequency sub-band
- HL:
-
Middle Frequency sub-band
- LH:
-
Middle Frequency sub-band
- LL:
-
Low Frequency sub-band
- LWT:
-
Lifting Wavelet Transform
- NC:
-
Normalized Correlation
- PCA:
-
Principal Component Analysis
- PSNR:
-
Peak Signal to Noise Ratio
- QDCT:
-
Quantized Discrete Cosine Transform
- QR code:
-
Quick Response code
- ROI:
-
Regions Of Interest
- S e x t r a c t e d :
-
Extracted singular value matrix
- S o r i g i n a l :
-
Original version of the singular value matrix
- SSIM:
-
Structural SIMilarity index
- S w a t e r m a r k e d :
-
Watermarked version of the singular value matrix
- T B E R :
-
Threshold for BER values
- T N C :
-
Threshold for NC values
- ViSAR:
-
Video Synthetic Aperture Radar
- W e m b e d d i n g :
-
Watermark bit
- W e x t r a c t e d :
-
Extracted watermark bit
- W r e g e n e r a t e d :
-
Regenerated watermark bit
- ⊕:
-
Exclusive OR operation
References
Abood OG, Guirguis SK (2018) A survey on cryptography algorithms. Int J Sci Res Publ 8(7):495–512
Agarwal P, Choudhary A (2014) Protecting video data through watermarking: a comprehensive study. In: 5th international conference-confluence the next generation information technology summit, pp 657–662
Ait Sadi K, Guessoum A, Bouridane A, Khelifi F (2016) Content fragile watermarking for H.264/AVC video authentication. Int J Electron 104 (4):673–691
Alenizi F, Kurdahi F, Eltawil A, Aljumah A (2015) DWT-Based watermarking technique for video authentication. In: International conference on electronics, circuits, and systems (ICECS), pp 41–44
Asikuzzaman M, Pickering MR (2018) An overview of digital video watermarking. IEEE Trans Circ Sys Video Technol 28(9):2131–2153
Bartolini F, Tefas A, Barni M, Pitas I (2001) Image authentication techniques for surveillance applications. Proc IEEE 89(10):1403–1418
Ben Hamida A, Koubaa M, Nicolas H, Ben Amar C (2013) Video pre-analyzing and coding in the context of video surveillance applications. In: International conference on multimedia and expo workshops (ICMEW), pp 1–4
Ben Hamida A, Koubaa M, Nicolas H, Ben Amar C (2014) Toward scalable application-oriented video surveillance systems. In: Science and information conference, pp 384–388
Ben Hamida A, Koubaa M, Nicolas H, Ben Amar C (2016) Video surveillance system based on a scalable application-oriented architecture. Multimed Tools Appl 75(24):17187–17213
Bhardwaj A, Verma VS, Jha RK (2018) Robust video watermarking using significant frame selection based on coefficient difference of lifting wavelet transform. Multimed Tools Appl 77(15):19659–19678
Boreiry M, Keyvanpour MR (2017) Classification of watermarking methods based on watermarking approaches. In: Artificial intelligence and robotics (IRANOPEN), pp 73–76
Chang Y-C, Wang J-T, Chang Y-T, Yu S-S (2016) An error-detecting code based fragile watermarking scheme in spherical coordinate system. In: International symposium on computer, consumer and control (IS3C), pp 287–290
Chaudhary S, Berki E, Nykanen P, Zolotavkin Y, Helenius M, Kela J (2016) Towards a conceptual framework for privacy protection in the use of interactive 360 video surveillance. In: 22nd international conference on virtual system & multimedia (VSMM), pp 1–10
Deljavan Amiri D, Amiri A, Meghdadi M (2019) HVS-Based scalable video watermarking. Multimedia Systems 25(3):1–19
Farfoura ME, Horng S-J, Guo JM (2016) Low complexity semi-fragile watermarking scheme for H.264/AVC authentication. Multimed Tools Appl 75(13):7465
Hammami A, Ben Hamida A, Ben Amar C (2019) A robust blind video watermarking scheme based on discrete wavelet transform and singular value decomposition. In: International joint conference on computer vision, imaging and computer graphics theory and application, pp 597–604
Hammami A, Ben Hamida A, Ben Amar C, Nicolas H (2020) Regions based semi-fragile watermarking scheme for video authentication. In: International conference in Central Europe on computer graphics, visualization and computer vision, pp 96–104
Hasnaoui M, Mitrea M (2012) Semi-fragile watermarking for video surveillance applications. In: 20th European signal processing conference (EUSIPCO), pp 1782–1786
Himeur Y, Boukabou A (2018) A robust and secure key-frame based video watermarking system using chaotic encryption. Multimed Tools Appl 77 (7):8603–8627
IHS Web page. [Online]. Available: https://technology.ihs.com
ISO 18004 Web page. [Online]. Available: https://www.iso.org/standard/62021.html
Jenkins N (2015) 245 million video surveillance cameras installed globally in 2014 [Online]. Available: https://technology.ihs.com/532501/245-million-video-surveillance-cameras-installed-globally-in-2014
Jindal H, Kasana SS, Saxena S (2016) A novel image zooming technique using wavelet coefficients. In: Proceedings of the international conference on recent cognizance in wireless communication and image processing, pp 1–7
Jindal H, Kasana SS, Saxena S (2018) Underwater pipelines panoramic image transmission and refinement using acoustic sensors. International Journal of Wavelets, Multiresolution and Information Processing 16(01):1850013
Joshi AM, Mishra V, Patrikar RM (2016) FPGA prototyping of video watermarking for ownership verification based on H.264/AVC. Multimed Tools Appl 75(6):3121
Joshi AM, Gupta S, Girdhar M, Agarwal P, Sarker R (2017) Combined DWT-DCT-based video watermarking algorithm using arnold transform technique. In: International conference on data engineering and communication technology, pp 455–463
Jumana W, Huang Dong J, Sarah S, Saad H, Hiyam H (2015) An immune secret QR-code sharing based on a twofold zero watermarking scheme. International Journal of Multimedia and Ubiquitous Engineering 1(4):399–412
Kalker T, Depovere G, Haitsma J, Maes MJ (1999) Video watermarking system for broadcast monitoring. In: The international society for optical engineering, pp 103–112
Kaur S, Jindal H (2017) Enhanced image watermarking technique using wavelets and interpolation. Int J Image Graph Signal Process 9(7):23–35
Kaur G, Kasana SS, Sharma MK (2019) An efficient authentication scheme for high efficiency video coding/H.265. Multimed Tools Appl 78 (15):21245–21271
Khosravi MR, Yazdi M (2018) A lossless data hiding scheme for medical images using a hybrid solution based on IBRW error histogram computation and quartered interpolation with greedy weights. Neural Comput Appli 30:2017–2028
Khosravi MR, Samadi S (2019) Reliable data aggregation in internet of ViSAR vehicles using chained dual-phase adaptive interpolation and data embedding. IEEE Internet of Things Journal 7(4):2603–2610
Khosravi MR, Samadi S (2019) Efficient payload communications for IoT-enabled ViSAR vehicles using discrete cosine transform-based quasi-sparse bit injection. EURASIP J Wirel Commun Netw 2019:262
Khosravi MR, Samadi S (2019) Modified data aggregation for aerial viSAR sensor networks in transform domain. In: 25th international conference on parallel and distributed processing techniques and applications (PDPTA), pp 87–90
Kim C, Shin D, Leng L, Yang C-N (2018) Separable reversible data hiding in encrypted halftone image. Displays 55:71–79
Kim C, Shin D, Leng L, Yang CN (2018) Lossless data hiding for absolute moment block truncation coding using histogram modification. J Real-Time Image Proc 14(1):101–114
Kim C, Yang CN, Leng L (2020) High-capacity data hiding for ABTC-EQ based compressed image. Electronics 9:644
Kirovski D, Malvar H, Yacobi Y (2002) Multimedia content screening using a dual watermarking and fingerprinting system. In: ACM international conference on multimedia, pp 372–381
Koohpayeh T, Abd A, Kohpayeh S (2018) A secure blind discrete wavelet transform based watermarking scheme using two-level singular value decomposition. Expert Syst Appl 112(1):208–228
Kumar S, Kumar M, Budhiraja R, Das MK, Singh S (2018) A cryptographic model for better information security. J Inf Secur Appl 43:123–138
Leng L, Zhang JS, Khan MK, Chen X, Alghathbar K (2010) Dynamic weighted discrimination power analysis: a novel approach for face and palmprint recognition in DCT domain. Int J Phys Sci 5(17):2543–2554
Leng L, Li M, Kim C, Bi K (2017) Dual-source discrimination power analysis for multi-instance contactless palmprint recognition. Multimed Tools Appl 76:333–354
Li L, Li X, Qiao T, Xu X, Zhang S, Chang CC (2018) A novel framework of robust video watermarking based on statistical model. In: International conference cloud computing and security (ICCCS), pp 160–172
Li J, Li X, Guo Y, Xu X, Liu S (2018) Semi-fragile video watermarking algorithm based on energy relation. In: International conference on virtual reality (ICVR), pp 95–101
Liao X, Li K, Yin J (2017) Separable data hiding in encrypted image based on compressive sensing and discrete fourier transform. Multimed Tools Appl 76:20739–20753
Liao X, Qin Z, Ding L (2017) Data embedding in digital images using critical functions. Signal Process Image Commun 58:146–156
Liu L, Li X (2010) Watermarking protocol for broadcast monitoring. In: International conference on E-business and E-government, pp 1634–1637
Mander K, Jindal H (2017) An improved image compression decompression technique using block truncation and wavelets. Int J Image Graph Signal Proc 9(8):17–29
Mishra A, Agarwal C, Chetty G (2018) Lifting wavelet transform based fast watermarking of video summaries using extreme learning machine. In: International joint conference on neural networks, pp 1–7
Mittal A, Jindal H (2017) Novelty in image reconstruction using dwt and clahe. Int J Image Graph Signal Proc 9(5):28–34
Nouioua I, Amardjia N, Belilita S (2018) A novel blind and robust video watermarking technique in fast motion frames based on SVD and MR-SVD. Security and Communication Networks 2018(10):1–17
Panyavaraporn J (2017) DWT/DCT watermarking techniques with chaotic map for video authentication. In: Ninth international conference on digital image processing (ICDIP
Ponnisathya S, Ramakrishnan S, Dhinakaran S, Ashwanth PS, Dhamodharan P (2017) CHAOTIC map based video watermarking using DWT and SVD. In: International conference on inventive communication and computational technologies, pp 45–49
Preda RO, Vizireanu N (2011) New robust watermarking scheme for video copyright protection in the spatial domain. UPB Sci Bull 73(1):93–104
Priya P, Tanvi G, Nikita P, Ankita T (2014) Digital video watermarking using modified LSB and DCT technique. Int J Res Eng Technol 4(3):630–634
Rafik H (2017) A novel pseudo random sequence generator for image-cryptographic applications. J Inf Secur Appl 35:119–127
Sadek RA (2012) SVD based image processing applications: state of the art, contributions and research challenges. Int J Adv Comput Sci Appl 3 (7):26–34
Saikrishna N, Resmipriya MG (2016) An invisible logo watermarking using arnold transform. In: International conference on advances in computing & communications (ICACC), pp 808–815
Sathya SPA, Ramakrishnan S (2018) Fibonacci based key frame selection and scrambling for video watermarking in DWT-SVD domain. Wirel Pers Commun 102:2011–2031
Shi J, Tomasi C (1994) Good features to track. In: Conference on computer vision and pattern recognition, pp 593–600
Shukla D, Sharma M (2018) A novel scene-based video watermarking scheme for copyright protection. J Intell Syst 27(1):47–66
Stauffer C, Grimson WEL (1999) Adaptive background mixture models for real-time tracking. In: Computer society conference on computer vision and pattern recognition, pp 246–252
Sujatha CN, Sathyanarayana P (2019) DWT-based blind video watermarking using image scrambling technique. In: Information and communication technology for intelligent systems, pp 621–628
Swaraja K, Karuna G, Kora P, Meenakshi K (2019) Video watermarking fundamentals and overview. In: International conference on intelligent computing and communication technologies (ICICCT), pp 379–385
Tyagi S, Singh HV, Agarwal R, Gangwar SK (2016) Digital watermarking techniques for security applications. In: International conference on emerging trends in electrical electronics & sustainable energy systems (ICETEESES), pp 379–382
Upadhy S, Singh SK (2011) Video authentication- an overview. Int J Comput Sci Eng Surv 2(4):75–96
Yassin NI, Salem NM, Adawy MIE (2014) QIM Blind video watermarking scheme based on wavelet transform and principal component analysis. Alex Eng J 53(4):833–842
Yu X-Y, Wang C-Y, Zhou X (2018) A survey on robust video watermarking algorithms for copyright protection. Appl Sci 8(10):1891
Zhang D, Li Y (2010) A non-blind watermarking on 3D model in spatial domain. In: International conference on computer application and system modeling, pp 267–269
Zebbiche K, Ghouti L, Khelifi F, Bouridane A (2006) Protecting fingerprint data using watermarking. In: NASA/ESA conference on adaptive hardware and systems, pp 451–456
Acknowledgments
The research leading to these results received funding from the Ministry of Higher Education and Scientific Research of Tunisia under the grant agreement number LR11ES48.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hammami, A., Ben Hamida, A. & Ben Amar, C. Blind semi-fragile watermarking scheme for video authentication in video surveillance context. Multimed Tools Appl 80, 7479–7513 (2021). https://doi.org/10.1007/s11042-020-09982-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-09982-4