
Abstract
In self-similarity digital image features, nonlocal means (NLM) exploits the major aspects when it comes to noise removal methods. Despite the high performance characteristics that NLM has proven, computational complexity yet to be highly achieved especially in case of complicated texture patches. In this regard, this study uses the clustered batches of noisy images and hidden Markov models (HMMs) in order to achieve noiseless images where the dependency between additive noise model pixels and its neighbors on stationary wavelet transform is found using HMMs. This paper is helpful and significant in order to develop a speedy and efficient plant recognition system computer-based to identify the plant species. The pivotal significant of the use of NLM and HMMs in this study is to ensure the statistical properties of the wavelet transform such as multiscale dependency among the wavelet coefficients, local correlation in neighbourhood coefficients. Practically, the experimental results present that the proposed algorithm has depicts high visual quality images in the experiments that are conducted in this study, apart from the objective analysis of the proposed algorithm, the execution time and its complexity show a competitive performance with state of the art noise removal methods in low and high noise levels.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Several noise removal techniques work in either spatial domain or frequency domain [25]. Spatial denoising methods have the advantages of simple algorithm structure and high image quality in low noise levels. However, their performances decayed in sever noise models and complex textures of tested images especially the digital images with repeated patterns [7]. From theoretical point of view, most of transform domain methods does not show an adequate results particularly in real-time applications due to the loopholes in hardware limitation and manufacturing issues.
In this regard, NLM filters [2] utilizes the original characteristics which are mostly appear in the repeated textures of the digital images and then shows an output images which have very clear details both in its presence and visual quality. The pivotal difference between NLM and the bilateral and spatial domain filters is that NLM exploits merits of statistical structures that represented by mean and local correlation in the contaminated patches, instead of using only a few samples in specific area of the noisy images like what local filters do [26]. In addition, recent studies highlighted on the way of increasing speed of NLM technique in terms of its calculation processes such as matching and searching procedures due to the long consuming time that NLM is taken. As a result, many techniques are developed to eliminate the different patches before weighted averaging process carries out. In recent study by [13], the visual quality of a natural digital image deteriorates by the noise model of impulse type during the record or transmission situation. Their experimental results concluded that the proposed technique can efficiently remove salt-and-pepper noise from noisy images for several noise levels and the denoised image is freed from the blurred and Gibbs phenomenon. Another study by [17] combined adaptive vector median filter (VMF) and weighted mean filter in order to remove high-density impulse noise from colored digital images. They found that their method outperformed (~1.5 to 6.2 dB improvement) some of the recent techniques not only at low noise levels but at high-density impulse noise as well. On the same regard, Chen and Qian in [3] have reached to an algorithm that suppressed the noise from hyperspectral digital images where they utilized stationary wavelet approach principle component analysis to reduce the dimensionalities. Despite the high quality noise removal results, execution time of this method was the real burden. Support vector machine (SVM) was exploited in study that represented by [5]. An empirical model has been created in order to remove the noise from hyperspectral images. Yet to get rid of the cost in the time execution which is their technique showed. In order to improve the boundary discriminative noise detection, filter that proposed in [6] was used and uncorrupted pixels are calculated within the processing window in order to scan the while entire noisy image. A novel adaptive iterative fuzzy filter for denoising images corrupted by impulse noise was proposed by [1]. They used two stages-detection approach for noisy pixels with an adaptive fuzzy detector and then applied denoising processes using a weighted mean filter. Experimental results demonstrated high image quality compared to best standard image denoising techniques where it showed robustness performance even in high noise levels. A switching median filter is proposed to be applied on a fuzzy-set framework. Schulte et al. in [16] proposed two-stage nonlinear noise removal method worked according to fuzzy logic procedure. Whereas multiclass SVM based adaptive filter (MSVMAF) has been introduced for removal of multiplicative noise from RGB images. Furthermore, PCA shows its high performance when it comes to the reduction dimensionality issues. On the other hand, over-complete approach which utilizes shift spinning technique was used in this study in order to enhance the denoised image quality especially in high noise levels and sharp edges in the image textures and other delicate parts [9, 10] where in [10] there was no any NLM filters or any classification approaches to classify the corrupted pixels from the noise free ones.
In study that was proposed by Li et al. in [12], an image block-based noise detection rectification method was introduced in order to estimate the contaminated density of a tested image. The experimental results have depicted that their technique could dramatically improve the denoising and blur effects. Moreover, another study proposed by in [11] it utilized the local statistics for additive white Gaussian noise in order to estimate additive Guassian noise. In their study, the approach included selecting low-rank sub-image with removing high-frequency components from the contaminated image. The results were efficiently outperformed state of the art noise estimation methods in a wide range of visual contents and noise conditions. In MRI image type, Nayak et al. presented an automatic classification system for segregating pathological brain from normal brains in magnetic resonance imaging scanning [15]. In the same regard, Zhang et al. utilized SWT in order to extract the features instead of DWT, their experimental results on a normal brain MRI demonstrate that wavelet coefficients via SWT is superior compared to the traditional wavelet transformation DWT [27].
In the current study, an algorithm based on the NLM procedure and utilize the coefficient correlation in different levels is proposed. In addition, to minimize the interference of the AWGN in the preclassification step, stationary wavelet semi-soft thresholding approach is firstly utilized in classification of the contaminated patches. Afterward, the HMM filter is adopted to capture the dependencies among the coefficients in the transform domain, as well as smooth the image and reduce the noise prior to thresholding. The experimental results show that this method outperforms several up-to-date denoising methods in terms of both peak signal-to-noise ratio (PSNR) and image appearance. The paper contains number of contributions. Firstly, it presents an HMM-based invariant similarity quantity to catch the dependency of contaminated coefficients with AWGN and increase the number of candidates for nonlocal mean filtering. The other contribution is that the suggested algorithm shows a high performance in comparison with ordinary NLM and up-to-date denoising methods at several noise levels.
2 Related work
In terms of the original NLM method and its updated filters, the main idea of NLM is according to the fact that sub-images in a whole image mostly contain a self-similarity pixels, where the image patches share the same structure and textures as line squares and geometric shapes [21]. Given a contaminated image, the resulted intensity of the investigated pixel NL(u)(i) computed as a weighted average of the whole intensity amount within the same location I. [2]:
u(j) being the pixel intensity at the location j, and w(i, j) being the weight of u(j) in order to measure the connection among the investigated pixels i and j, L is the number of elements in each cluster. The specific weights are computed using the following expression.
N i is the patch with stationary size and it is located at pixel i. In this case, the similarity can be calculated as a shrinking model that utilizes the weighted Euclidean distance. The case where a > 0 is known by the standard deviation of the kernel of Gaussian function, and Z(i) is a constant and represents the normalization amount where\( Z(i)=\sum \limits_jw\left(i,j\right) \), and h represents the parameter function of the filter.
In order to find the set of consistent candidates which are similar to the patch under testing from a complete digital image, three main classes of techniques are used, Preclassification step, and to find the updated similarity groups and finally to apply applying HMMs to catch the dependencies among similar patches.
Preclassification process was previously utilized to deal with only the part of the patch searching rather than the full testing of the whole image in order to attain high efficiency of NLM. However, most of modified versions of NLM contribute only in few margins of improvements when it comes to noise removal results. In [14], a study exploited the mean quantity and local average gradient vectors as well in order to ignore unrelated sub-images. On the other hand, the criterion might only be used when the gradient magnitudes of the main patches are lasted in a value of threshold more than the desired amount, which can be very easy to be adjusted by additive white Gaussian noise. A preclassification approach based on sub-image variance was similarly proposed in [4].
The main disadvantage of the earlier mentioned techniques is that their entire structure is very complicated, despite it is not built according to any statistical models, such as correlation among coefficients in the same neighborhood. In [20], SVD was implemented in order to utilize some statistical properties to keep its gradient structure to be used in k-means clustering. Consequently, the gradient structure of the image shows a sever sensitivity to the noise level amount. Additionally, there is one more loophole in the traditional NLM; this disadvantage is that there are no enough candidates for each patch to be used in weighted averaging when an image lacks repetitive patterns. This deficiency will radically show its impact on the visual appearance of the images that resulted from NLM.
In order to conquer this effect, a study in [8, 23] developed a rotated matching technique that utilize the block procedure to achieve more similar sub-images, though the scheme is basically restricted to specific number of rotation angles and images with simple textures. Finding out updated similarity methods is another manner to guarantee reliable group of candidates using wavelet transforms.
In [19], block matching based on moment invariants were introduced, which is invariant under rotation processes, blurring, and noise. In order to attain the main objective of finding further reliable groups of candidates, the proposed technique utilizes both preclassification and definition of the updated similarity model. However, the chance of finding candidates for non-repetitive patterns [20] is needed to be implemented. Therefore, preclassification step is exploited to provide suitable candidate sets which can be built form the whole parts of the tested image. In addition, in [25] a method utilized clustering according to NLM using invariants of specific moments to be as classification step was introduced. Furthermore, they have adopted a technique that uses the rotationally of each block matching in sub-images in order to increase the matching rate. High PSNR values and good image quality have been achieved but their method was time consuming due to matching processes. Markov models can also be considered in each state corresponding to a deterministically observable experience. Hidden Markov models (HMMs) are essentially first-order discrete time series with some hidden information. In other words, the time series states are not the observed information but are connected through an abstraction to the observation. Consequently, the result of such sources in any given state is not random. This model is somehow considered a restrictive technique that is applicable to many problems of interest [10]. As a result, the notion of Markov models should be extended to contain the case in which the reflection is a probabilistic model of the state. That is, the resulting concept (called an HMM) is a doubly embedded stochastic procedure with a fundamental stochastic process, which is not observed directly. On the contrary, the process is observed only throughout the stochastic process of another set that yields the structure of observations. Specifically, the state sequence is one whose states are not uniquely determined according to the observation of sequence of the output and the knowledge of the original state [7].
Defining a new similarity term that can evaluate the noisy coefficients and suppress the noise in the contaminated image is thus essential.
3 NLM based on stationary wavelet transformation and HMMs
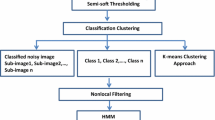
The pipeline processing of the proposed technique is shown in Fig. 1. Given a contaminated image, the main aim is to result a noise removal image in which the noise is eliminated and most of the fine structures are reserved. The image is corrupted by additive noise n i, j and one observes the noisy image as y i, j , such that:

Block diagram of the proposed natural image denoising algorithm
Similar to (1) and (2), the suggested NLM can be expressed as follows:
v is the noisy image, w R (i, j) is depended on the updated distance quantity d R (i, j) and Z R = \( \sum \limits_j{w}_R\left(i,j\right) \). The weighted averaging is accomplished in each bunch. In addition, L reflects the number of components in every cluster. The impact of clustering is shown in Fig. 2. Furthermore, the filtering issue thus changes into how the updated weights [w R (i, j)] can be calculated, which is elaborated in coming Subsections.

(a) Noisy image with Gaussian noise σ = 25. (b) Filtered image with semi-soft thresholding
The proposed NLM has the following features:
-
Filtering process using semi-soft thresholding in stationary wavelet domain provides the pre-processing for preclassification. The main impact is depicted in Fig. 2.
-
Clustering of K-means on moment invariants of the distorted contaminated image assists as a preclassification model for the proposed noise removal technique. In the traditional NLM, most investigated sub-images have a stable size of candidate groups which either take the entire signal or the only a sub-group of neighborhood which is located at selected patch.
-
HMM on the wavelet domain is the main step to design the proposed algorithm. The relationship between noise-free image, AWGN, and corrupted image can be represented by (5).
3.1 Preprocessing stage
In this step, the main classification process is applied basically on the structural information of the tested image. Thus, patch-based preclassification in a contaminated image will show inaccurate evaluation [23]. As a result, a pre-filter approach will be considered to smooth the image and thus avoid dealing with the incorrect patches, especially in sever noise cases.
In practice, estimating the standard deviation σ of the noise is an essential task in the proposed algorithm, and it should be performed from the image rather than assumed as given. The noise level can be estimated empirically from the finest scale HH1. Moreover, the coefficients of stationary wavelet transform are stated as a correlated group of data and are linked with few patches in the same neighborhood. The large wavelet coefficients mostly will reflect large coefficients in the same neighborhood. As a result, the suggested thresholding is found up from the coefficients that last in the same investigated zone of the contaminated image. In this regard, presume B i,j is wavelet coefficient that lies in the target noisy image. Then:
In the Equation, U 2 i, j represents the summation of the square of the terms which is centered at the same side of the coefficient under the thresholding process, while (i,j) shows the coefficients which lie in the contaminated image. The following situation is considered if:
3.2 Clustering procedure
In several fields, moment invariants are utilized, such as skin detection, image registration, image deblurring, and shape recognition, to name a few. Previous studies showed that it is robust to be used as image descriptors under different applications such as shifting, changing in its value, and applying spin processes. In [19], the moments that have greater invariants were shown their performance to be more susceptible when the noise of Gaussian mode takes place. As a result, in the proposed technique that exploits Hu’s moment invariants [19], which have peak order of 2, are used as feature descriptors with size of (1 × 5 vector) for the clustering of K- means. In this regard, consider a N × N size of digital whole-image and a n × n sub-image that is located at i (i = 1, 2, …, N × N), the moment-invariants of the sub-group is presented by the vector of size of 1 × 5. As a result, regarding to the entire image; the tested image with size of N × N vectors that works as the initial signal of the clustering of K-means.
Then the tested coefficients B i,j substituted by zero; else, it will be shrunk based on the following formula:
where σ w is the standard deviation of the corrupted image, and M j depicts the size of coefficients in a sub-band under investigation at the analysis edge j. Equation (10) summarizes the semi-soft thresholding approach.
After the semi-soft thresholding is utilized on the contaminated image, the hazy image assists as the contribution of grouping. This input is demonstrated clearly in Fig. 2.
In the above mentioned equation, Gb(i) denotes the Gaussian blurred sub-image which is located at i. H(.) represents the output the moment invariants of an input sub-image. In addition, μ k is considered as the mean vector for the kth cluster Hm k … Afterwards, K clusters Hm 1, Hm 2, Hm k , …, Hm K can be achieved. Every single cluster Hm k is composed of L vectors and Hm k1 (k = 1, …, K, l = 1, 2, …L). In the same issue, the high efficient technique which adopts an iterative refinement procedure is utilized [21]. Furthermore, clustering technique which utilizes K-means offers the pre-selected candidates for the selected weighted averaging. The resulted data of the desired classification (the matches of the center of sub-image) is located at form of a look-up table. Weighted averaging structure is performed inside every single cluster throughout the next step.
3.3 HMMs-based Non-local mean method
In this step, the parameters of the HMM template can be obtained in each block using\( \kern0.5em \prod \limits_{k,d}=\left\{{p}_{s_{k,d}}(m),{\sigma}_{k,d,m}^2\right\} \), where p is the number of states in the independent mixture model, and the label in the each position i can be represented by D i . In denoising-based wavelet transform, the aim is to minimize the MSE between the estimated and the original image. This step can be done by calculating the minimizing MSE between the estimated wavelet coefficients of the denoised and the original image. As a result, the image denoising process can be considered as process of estimating wavelet coefficients of the original image from coefficients of the wavelet signal of the noise and the contaminated image. Given that the distribution of each coefficient in the wavelet realm of the noisy image W i is stated as a Gaussian mixture model (GMM), and the probability density function PDF of W i is given by
In terms of the relationship among the specific coefficients of the noise, the relationship of the noisy image and the original image is as follows:
where w i, k , x i, k , and n i, k refer to the wavelet coefficients of the contaminated input image, the image, and the noise; n i, k is AWGN; and iid with variance \( {\sigma}_n^2 \) . Thus, the distribution of the original image x i, k is GMM as well, and if the value of the hidden state S k is determined, then the estimation issue can be considered as estimating a Gaussian signal in the AWGN in order to reduce the MSE. The following Eq. (14) is used to achieve the Gaussian estimation:
X i, k and W i, k are random variables of x i, k and w i, k respectively, \( {P}_{S_k} \) is the probability mass function (PMF) of the hidden state S i, k , and \( {\sigma}_{k,m}^2 \)is the variance of the component X i, k .
Therefore, by applying the transition criteria and adding the hidden states to Eq. (14), the estimation criteria become
The independent mixture model is used to join the PDF of the coefficients in the wavelet domain at the same block. Hence, Eq. (15) is utilized to evaluate and estimate the coefficients of the noise-free image in the block under study. With the block label stated, the formula can be modified as
where X i, k , D i, k , and W i, k are the random variables of x i, k , the block label, and w i, k , respectively; and \( {P}_{S_k} \) is the PMF of the hidden states S i, k , whose block label is d. In addition, \( {\sigma}_{k,m}^2 \) is considered as the variance of the component X i, k , which has the same block label d.
As the variance of X i, k cannot be derived directly from the estimation, the denoised image variance can be obtained from the noisy image, and then the redundant variance resulted from the noise can be subtracted.
4 Experimental results
In the experiment part, the images used in the experimental purposes are all standard grayscale and natural testing images. The benchmark tested images are selected from a popular image database, the USC-SIPI Database Images (University of Southern California). For performance evaluation, the proposed method will be compared to the conventional NLM and the recent related techniques [8, 24] according to the specific dataset. The evaluation metrics adopted in the experiments are structural similarity index (SSIM) and peak signal to noise ratio (PSNR). PSNR is exploited in order to provide objective evaluations of the noise removal image results. It is expressed by the following formula:
As eq. (17) shows, MAX is representing the dynamic size of the tested image, MSE is the mean squared error between the tested and the noise removal images. For instance, if the noisy image contains 8 bits per pixel, it can be formed with a pixel scale range of 0 to 255. A higher PSNR value shows higher-quality image and noise reduction results. On the other hand, SSIM [22] is a metric that has a kind of consistency with human visual perception. Regarding to this, SSIM is expressed by [8]:
Note that α > 0, β > 0, and γ > 0, whose parameters are used to arrange the modules.
where \( {\mu}_x=\sum \limits_{i=1}^N{w}_i{x}_i \), μ x represents the mean of the original image; \( {\sigma}_x={\left(\sum \limits_{i=1}^N{w}_i\left({x}_i-{\mu}_x\right)\right)}^{\frac{1}{2}} \); σ x represents the standard deviation of the original image; \( {\sigma}_{xy}=\sum \limits_{i-1}^N{w}_i\left({x}_i-{\mu}_x\right)\left({y}_i-{\mu}_y\right);{\sigma}_{xy} \) represents the cross standard deviation through the tested image and the noisy one; w represents the circular symmetric Gaussian weighting function; and C 1, C 1, and C 3 are the three constants to prevent instability.
4.1 Parameters of clustering
The proposed clustering method is implemented based on moment invariants. Several parameters need to be decided for standard K-means clustering, such as type of distance used, quantity of clusters assigned, and length of vector parameters utilized in the suggested NLM-based framework. In practice, the Euclidean distance is exploited to measure the distance between two significant feature vectors as [14] showed. Based on study in [18], the sub-image size chosen is 7 × 7. In order to examine how the effect of the technique fluctuates with several values of K, we tuned K in the range of 350 and 4200. The results of PSNR and SSIM of the investigated images (noise level σ is 20) with different cluster numbers are depicted in Fig. 3. The main fluctuating trends of both scales PSNR and SSIM are mostly compatible. By other words, when K increases, the number of current clusters which are represented from different types of image fine structure increases as well. Thus, in the case where K becomes particularly high, then there will not be enough clusters candidates. Consequently, the measured PSNR and SSIM decrease next to the climax. Furthermore, if the complexity of the algorithm is not the main target, the optimal amount of K can be chosen according to the input size of the contaminated image. In the current experiments, all the images have the size of 256 × 256. Hence, K = 3200 (when K = 3200, it consumes a time more than the time as K = 1600 consumes) is chosen to give enough candidate choices to every single patch regarding to the variation of appearance results when the K values is changed. The visual effect of the clustering of K-means on one of the benchmark images under testing (Lena) is depicted in Fig. 5. As shown in the figure, the proposed algorithm shows high performance in high frequency component of the tested image, such as the edges, ridges, and fine textures. With comparison to the method in [20], the proposed method very clear distinguishes the grayscale components, which gives more adaptively behavior to the proposed classifications manner (Fig. 4).

PSNR and SSIM values fluctuate with K in noise level σ =20

Performances of the clustering analysis of the proposed technique when K is 256
4.2 Noise removal quality and assessments
In the practical part the chosen tested benchmark images have been contaminated with AWGN with several noise levels σ= [10, 20, 35, 45, 55, and 70]. Most of recent studies started their noise levels from 10 and above. In addition, in high noise levels many denoising techniques are always prone to have over-smoothing and extra blurring in the crucial image features as well as introducing artifacts. By stating the block label, The PSNR and SSIM several results are shown in Tables 1 and 2. The qualitative findings reveal that the high noise levels yields an image with low visual quality and it causes intensity difference in the patches with the same structures. As can be seen in Fig. 5e, the resulted image which is acquired by the proposed method showed high visual quality especially in Lena hat and hair textures. Additionally, Figs. 6 and 7 shows benchmark images with complicated textures, Boat and Man. The denoised images by the proposed algorithm still kept the fine details such as Boat’s mast and Man’s hair and cap’s feathers textures. Furthermore, Figs. 8 and 9 show benchmark images of Peppers and Straw, both images carry lines curves and complex details. Despite most of state of the art noise removal methods under investigation failed to keep the core details of the figures as can see in the straw edges and Peppers ridges, the proposed method showed the best performance among the rest techniques. Finally, Fig. 10 shows zoomed in part of Baboon benchmark image. In this figure, the nose and eyes and eyelashes are kept in the proposed technique while most of noise removal methods added some blurring artifacts to their resulted images. Practically, the technique in [25] employs a spatial filter method but is applied to neighborhoods, a practice that may result in a few of correct candidates especially in the case where the variation of the fine details is robust. Therefore, specific patches still contaminated with noise. The proposed technique overcomes this problem by gaining adequate reliable candidates from the clustering of K-means. Figure 8 depicts the subjective results for a benchmark image in the case where the noise level of Gaussian noise is 55. It is worthy to notice that the conventional NLM is mostly ineffective. However, in high noise levels the intensity matching among several patches is very sensitive to noise. The suggested technique adopted wavelet filter as preprocessing step to conquer the additive noise and thus the moment invariants give robustness to the proposed algorithm. The method in [19] dealt with rough image configuration but still not enough to keep the fine details of the tested image. The proposed algorithm also preserves the small textures much better in comparison with other methods under investigation. This finding proves that the use of clustering model just before the weighted averaging process can guarantee the reliable candidates and its sub-images. In order to present the execution time of the proposed algorithm and compare it with state of the art noise removal methods, the average run-time of each noise removal method is shown in Table 3. The proposed technique is effectively retaining the main details of the tested image and simultaneously introducing small artifacts in comparison with other techniques. Thus, K-means clustering which is used in the proposed algorithm is a time-consuming method. As future study, it needed to find a clustering approach with fast processing in matching of patch candidates and also to speed up the preclassification process.






5 Conclusion
This study presented a noise removal method that exploited NLM approach in order to suppress the AWGN in natural images. In this regard, moment invariants which represented by K-means clustering and stationary wavelet transformation filtering is used to classify the noisy coefficinets from the original and noise free ones. Hidden Markov models is likewise used in order to add some similar sub-images that have been exploited by specific angles to be more strength to the target sub-images and catch the dependencies among similar classes. Experimental results show that moment invariant in the patch clustering has an effective performance in preclassification procedure. The suggested method is successfully retaining the fine details of the investigated image and simultaneously produced small artifacts in comparison with state of the art noise removal techniques. Thus, K-means clustering which is exploited in the proposed algorithm is a time-consuming technique. As future study, it needed to find a clustering method with fast processing in the processing of matching to find out patch candidates as fast as possible to speed up speed up the preclassification step.
References
Ahmed F, Das S (2014) Removal of High-Density Salt-and-Pepper Noise in Images With an Iterative Adaptive Fuzzy Filter Using Alpha-Trimmed Mean. IEEE Trans Fuzzy Syst 22(5):1352–1358
Buades A, Coll B, Morel J-M (2005) A non-local algorithm for image denoising. IEEE Conf Comput Vis Pattern Recognit 2:60–65
Chen G, Qian S-E (2011) Denoising of hyperspectral imagery using principal component analysis and wavelet shrinkage. IEEE Trans Geosci Remote Sens 49(3):973–980
Coupé P, Yger P, Prima S, Hellier P, Kervrann C, Barillot C (2008) An optimized blockwise nonlocal means denoising filter for 3-D magnetic resonance images. IEEE Trans Med Imaging 27(4):425–441
Demir B, Erturk S, Gullu M (2011) Hyperspectral image classification using denoising of intrinsic mode functions. IEEE Geosci Remote Sens Lett 8(2):220–224
Jafar IF, AlNa'mneh RA, Darabkh KA (2013) Efficient improvements on the BDND filtering algorithm for the removal of high-density impulse noise. IEEE Trans Image Process 22(3):1223–1232
Khmag A, Ramli R, Al-haddad SAR, Kamarudin NHA, Mohammad OA (2015) Robust Natural Image Denoising in Wavelet Domain using Hidden Markov Models. Indian J Sci Technol 8(32):1–9
Khmag A, Ramli AR, Al-Haddad SAR, Hashim SJ, Noh ZM, Najih AA (2015) Design of natural image denoising filter based on second-generation wavelet transformation and principle component analysis. J Med Imaging Health Inform 5(6):1261–1266
Khmag A, Ramli AR, Al-haddad SAR, Yusoff S, Kamarudin NH (2016) Denoising of natural images through robust wavelet thresholding and genetic programming. Vis Comput 33(9):1141–1154
Khmag A, Ramli AR, Hashim SJ, Al-Haddad SAR (2016) Additive noise reduction in natural images using second-generation wavelet transform hidden Markov models. IEEJ Trans Electr Electron Eng 11(3):339–347
Khmag A, Ramli AR, Al-haddad SAR, Kamarudin N (2017) Natural image noise level estimation based on local statistics for blind noise reduction. Vis Comput 34(2):141–154
Li Z, Cheng Y, Tang K, Xu Y, Zhang D (2015) A salt & pepper noise filter based on local and global image information. Neurocomputing 159:172–185
Lu C-T, Chen Y-Y, Wang L-L, Chang C-F (2016) Removal of salt-and-pepper noise in corrupted image using three-values-weighted approach with variable-size window. Pattern Recogn Lett 80(1):188–199
Mahmoudi M, Sapiro G (2005) Fast image and video denoising via nonlocal means of similar neighborhoods. IEEE Signal Process Lett 12(12):839–842
Nayak DR, Dash R, Majhi B (2017) Stationary Wavelet Transform and AdaBoost with SVM Based Pathological Brain Detection in MRI Scanning. CNS Neurol Disord Drug Targets 16(2):137–149
Roy A, Laskar RH (2016) Multiclass SVM based adaptive filter for removal of high density impulse noise from color images. Appl Soft Comput 46:816–826
Roy A, Singha J, Manam L, Laskar RH (2017) Combination of adaptive vector median filter and weighted mean filter for removal of high-density impulse noise from color images. IET Image Process 11(6):352–361
Salmon J (2010) On two parameters for denoising with non-local means. IEEE Signal Process Lett 17(3):269–272
Sven G, Sebastian Z, Joachim W (2011) Rotationally invariant similarity measures for nonlocal image denoising. J Vis Commun Image Represent 22(2):117–130
Thaipanich T, Oh BT, Wu PH, Xu D, Kuo CCJ (2010) Improved image denoising with adaptive nonlocal means (ANL-means) algorithm. IEEE Trans Consum Electron 56(4):2623–2630
Tomasi C, Manduchi R (1998) Bilateral filtering for gray and color images. In: Sixth IEEE International Conference on Computer Vision, Bombay, India, pp 839–846
Wang Z, Bovik AC, Sheikh HR, Simoncelli E (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Wang J, Guo Y, Ying Y, Liu Y, Peng Q (2006) Fast non-local algorithm for image denoising. In: IEEE International Conference on Image Processing, p 1429–1432
Yan R (2014) Adaptive Representations for Image Restoration. PhD Thesis, University of Sheffield, UK
Yan R, Shao L, Cvetkovic SD, Klijn J (2012) Improved Nonlocal Means Based on Pre-Classification and Invariant Block Matching. IEEE/OSA J Disp Technol 8(4):212–218
Zhang P, Li F (2014) A new adaptive weighted mean filter for removing salt-and-pepper noise. IEEE Signal Process Lett 21(10):1280–1283
Zhang Y, Wang S, Huo Y, Wu L, Liu A (2010) Feature extraction of brain MRI by stationary wavelet transform and its applications. Int Conf Biomed Eng Comput Sci (ICBECS) 18:115–132
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Khmag, A., Al Haddad, S.A.R., Ramlee, R.A. et al. Natural image noise removal using non local means and hidden Markov models in stationary wavelet transform domain. Multimed Tools Appl 77, 20065–20086 (2018). https://doi.org/10.1007/s11042-017-5425-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-5425-z