
Abstract
Diterpene trilactone ginkgolides, one of the major constituents of Ginkgo biloba extract, have shown interesting bioactivities including platelet-activating factor antagonistic activity. 1-Hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate synthase (HDS), converting 2-C-methyl-d-erythritol-2,4-cyclodiphosphate into 1-hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate, is the penultimate enzyme of the seven-step 2-C-methyl-d-erythritol 4-phosphate pathway that supplies building blocks for plant isoprenoids of plastid origin such as ginkgolides and carotenoids. Here, we report on the isolation and characterization of the full-length cDNA encoding HDS (GbHDS, GenBank accession number: DQ251630) from G. biloba. Full-length cDNA of GbHDS, 2,763 bp long, contained an ORF of 2,226 bp encoding a protein composed of 741 amino acids. The theoretical molecular weight and pI of the deduced mature GbHDS of 679 amino acid residues are 75.6 kDa and 5.5, respectively. From 2 weeks after initiation of the culture onward, transcription level of this gene in the ginkgo embryo roots increased to about two times higher than that in the leaves. GbHDS was predicted to possess chloroplast transit peptide of 62 amino acid residues, suggesting its putative localization in the plastids. The transient gene expression in Arabidopsis protoplasts confirmed that the transit peptide was capable of delivering the GbHDS protein from the cytosol into the chloroplasts. The isolation and characterization of GbHDS gene enabled us to further understand the role of GbHDS in the terpenoid biosynthesis in G. biloba.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
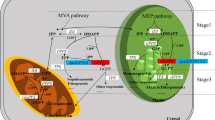
Terpenoids in living organisms are an extremely diverse group of compounds taking roles ranging from pigments and fragrances to vitamins and precursors of the sex hormones [1]. Though found in all organisms, terpenoids are especially abundant and diverse in plants [2, 3]. Surprisingly, the structural diversity of terpenoids is derived from the simple five-carbon building units of the isoprene carbon skeleton, isopentenyl diphosphate (IPP) and its isomer dimethylallyl diphosphate (DMAPP) [4]. Terpenoids are thus also known as isoprenoids. In plants, two pathways for the synthesis of the isoprene building blocks are in operation: cytosolic mevalonate (MVA) pathway starting from 3 acetyl-CoA to finally yield IPP through six-step reactions and plastidial 2-C-methyl-d-erythritol 4-phosphate (MEP) pathway simultaneously producing IPP and DMAPP from pyruvate and d-glyceraldehyde 3-phosphate (G-3-P) through seven serial reactions (Fig. 1) [5]. Though both pathways produce the same isoprenoid building blocks, the channeling of the isoprene units to the end products in plants is known to be specific: mono-, di-, and tetra-terpenoids originate from the MEP pathway, whereas sesqui- and triterpenoids are from the mevalonate pathway. However, evidences of cross-talks between the pathways have been reported [6, 7].

2-C-Methyl-D-erythritol 4-phosphate (MEP) pathway in the isoprenoid biosynthesis of G. biloba. DXS, 1-deoxy-D-xylulose 5-phosphate synthase; DXR, 1-deoxy-D-xylulose 5-phosphate reductoisomerase; MECT, 2-C-methyl-D-erythritol 4-phosphate cytidyltransferase; CMEK, 4-(cytidine 5′-diphospho)-2-C-methyl-D-erythritol 4-phosphate kinase; MECS, 2-C-methyl-D-erythritol 2,4-cyclodiphosphate synthase; HDS, 1-hydroxy-2-methyl-2-(E)-butenyl 4-diphosphate synthase; IDS, 1-hydroxy-2-methyl-2-(E)-butenyl 4-diphosphate reductase; IDI, isopentenyl diphosphate isomerase; LPS, levopimaradiene synthase
Ginkgolides, highly modified diterpene lactones found uniquely in Ginkgo biloba, have many pharmacological activities such as the anti-platelet-activating factor (PAF) activity [8] and the selective glycine receptor antagonism [9]. Though ginkgolides accumulate in the Ginkgo leaves, they are known to be synthesized in the roots and subsequently translocated to the leaves [10]. Studies have demonstrated that building blocks for the ginkgolides are derived through the MEP pathway [11]. Despite the impressive progress on the structural determination and biosynthetic pathway of ginkgolides, much work still remains on the enzymology and molecular biology involved in the ginkgolide biosynthesis. Nevertheless, some achievement has been reported. Geranylgeranyl diphosphate (GGPP) synthase gene was cloned from G. biloba [12], and levopimaradiene synthase (LPS) gene that encodes enzyme converting GGPP into levopimaradiene, the precursor of ginkgolide, was cloned and functionally characterized [13]. Our group isolated all MEP pathway genes from G. biloba except for HDS, demonstrated their functional activities, and determined the temporal and spatial transcription patterns of each gene [14–19]. These works showed that there are two additional multi-copy genes in the MEP pathway of Ginkgo besides DXS, which is the well-known multi-copy gene in higher plants [18, 20]. GbCMEK and GbIDS each have two and three copies of the isogene, respectively [16, 19]. The IDS gene is also present in multi-copy in other gymnosperm plants such as Pinus [16, 20, 21] and Cycas [16], whereas two-copy GbCMEK is unique in the plant EST database [19].
1-Hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate synthase (HDS), the penultimate enzyme in the MEP pathway sequence, converts 2-C-methyl-d-erythritol-2,4-cyclodiphosphate (MEcPP) into 1-hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate (HMBPP). Up until now, except for a few examples including tomato [22], Arabidopsis [23], and Hevea brasiliensis [24], HDSs from plants have not been fully characterized. The HDS gene in tomato showed no significant change in the transcript number at different stages of the fruit development, although a huge supply of the isoprenoid precursors through the MEP pathway is required during the development. Furthermore, little difference was found in the transcript levels of HDS in both the wild-type and carotenoid-depleted mutant fruits, an indication that in tomato fruit this gene is not regulated by the end product carotenoids [22]. Arabidopsis clb4 mutant, a defective HDS mutant, showed the arrested chloroplast development at the proplastid stage, indicating this gene is required for the early chloroplast development in Arabidopsis. The non-cell autonomous nature of the clb4 mutant suggests a movement of the isoprene building blocks from cytoplasm to the chloroplasts [23]. Recent work demonstrated that CSB3 Arabidopsis mutant, a recessive partial loss-of-function mutant of the HDS gene, showed a high level of resistance to the biotrophic pathogens Pseudomonas syringae and Plectosphaerella cucumerina due to the activation of the plant defenses [25].
In the present work, we report the cloning and characterization of the HDS gene (GbHDS, GenBank accession number: DQ251630) from G. biloba. Intracellular localization of GbHDS and the transcription pattern of the gene with respect to the ginkgolide biosynthesis were also evaluated.
Materials and methods
Plant materials
Dehulled seeds of ginkgo, purchased from Sillim Market, Seoul, Korea, were sterilized in 4% NaOCl solution for 20 min. After extensive washing in distilled water, the embryos were separated from the cotyledons. The embryos were then placed on the hormone-free MS medium and incubated in a controlled-growth chamber (23°C under 16 h/8 h light and dark regimen). Roots and leaves from the seedling were harvested every week for the transcription analysis. For the Arabidopsis protoplast isolation, the plants were grown in the same controlled-growth chamber for 4 weeks.
RNA isolation and cDNA synthesis
Total RNA and mRNA were isolated from the roots of 1-month-old embryo culture through the CTAB method [26]. For the full-length single strand cDNA synthesis, GeneRacer Kit (Invitrogen, http://www.invitrogen.com) was used with 1 μg of the isolated mRNA following the manufacturer’s protocol. In reverse transcription PCR (Qiagen Omniscript Reverse Transcription kit), 2 μg of total RNA from each plant sample was used to synthesize the single strand cDNAs, which were then used in quantitative real-time polymerase chain reaction (QRT-PCR).
Isolation of full-length cDNA of GbHDS by RACE
All primers used in this research are listed in Table 1. A degenerate primer pair, GcpE-F and GcpE-B, was designed based on the conserved regions of the previously known plant HDS genes and used to amplify the core cDNA fragment. The PCR fragment was cloned into the pGEM-T easy vector (Promega) and sequenced. For the full-length cDNA isolation, rapid amplification of cDNA end (RACE) PCR method was used. The primer pair of GeneRacer 5′-nested and HDS-5B1 was used for 5′-RACE, whereas the primer pair of GeneRacer 3′-nested and HDS-3F1 was used for 3′-RACE. Each RACE product was cloned and sequenced as mentioned above. Based on each RACE sequences, a full-length cDNA sequence of HDS was assembled and amplified with its respective primer pair, HDS-TE-START and HDS-TE-STOP.
Multiple alignment and bioinformatic analyses
The deduced amino acid sequence of GbHDS was aligned with the sequences of other known plant HDSs from GenBank using the Multalin program (http://prodes.toulouse.inra.fr/multalin/). Prediction of the chloroplast-targeting peptides was made using ChloroP program (http://www.cbs.dtu.dk/services/ChloroP/). TreeTop program (http://www.genebee.msu.su/services/phtree_reduced.html) was used for the phylogenetic tree construction at a default setting using the cluster algorithm. The reliability of the tree was measured by bootstrap value with 100 replicates. Partial HDS sequences of Picea abies and Pinus taeda were collected from the DFCI Gene index database (http://compbio.dfci.harvard.edu/tgi/cgi-bin/tgi/Blast/index.cgi). Putative molecular weight and pI values were calculated using the Compute pI/Mw tool (http://ca.expasy.org/tools/pi_tool.html). The SIM program (http://www.expasy.org/tools/sim-prot.html) was used for the comparison of each HDS protein sequence from GenBank.
Transcript profile analysis by QRT-PCR
Total RNA was separately extracted from the roots and leaves of Ginkgo embryo culture harvested every week for 4 weeks. The sampling was done in triplicate with three plants per sample. Single strand cDNA was synthesized from 2 μg of each isolated total RNA with oligo(dT)17 primer as described previously [18]. The tissue-specific expression of GbHDS gene was examined with the gene-specific primer pair (HDS-F and HDS-B) by QRT-PCR. The PCR reaction was carried out in triplicates for 45 cycles on the Rotor-Gene 2000 Real Time Amplification System (Corbett Research, http://www.corbettresearch.com) using the Qiagen Quantitect SYBR Green PCR system [18].
Protein targeting analysis
The fragments encoding the full-length protein and the N-terminal 100 amino acid residues, were separately amplified, respectively with each primer pair (for full-length protein, HDS-TE-START and -STOP; for N-terminal, HDS-TE-START and -STOP2) and fused to the psmGFP vector in frame. Arabidopsis protoplasts were prepared from the leaves of 4-week-old seedling. The constructed plasmids were transformed into the Arabidopsis protoplasts using a polyethylene glycol method [27]. In brief, 20 μg each plasmid DNA (1 μg/μl) was transfected into 300 μl protoplast suspension (106/ml), and the transfected protoplasts were incubated for 12–15 h at 22°C in darkness. The images were captured with the MRC-1024 Confocal Laser Scanning Microscope system (Bio-Rad). Fluorescence images of the protoplasts were taken on a confocal laser scanning microscope at 500–530 nm for GFP (green) and 600–660 nm for chlorophyll autofluorescence (red). Data were processed using the CAS program (Bio-Rad) and the Adobe Photoshop v7.0 software.
Results and discussion
Full-length cDNA isolation and sequence analyses of GbHDS
For the cloning of GbHDS, a pair of primer, designed based on the conserved region of HDS genes from different plants, was used for the amplification of the core sequence of GbHDS. A DNA fragment of 1,351 bp was amplified with this degenerate primer pair and was identified as a putative HDS by BlastX analysis. Based on this sequence information, two gene-specific primer pairs were designed and used in 5′- and 3′-RACE PCRs, respectively to obtain 1,070- and 681-bp fragments. Sequence analysis indicated that the full-length cDNA of GbHDS was 2,763 bp containing 164 bp 5′-untranslated region (UTR) and 193 bp 3′-UTR. This cDNA contained an open reading frame (ORF) of 2,226 bp encoding a protein consisting of 741 amino acids. ChloroP program predicted that GbHDS had the N-terminal chloroplast transit peptide consisting of 62 residues that is absent in the E. coli counterpart [28] and was similar in length to the transit peptides of the putative HDSs from other plants such as Catharanthus roseus (CrHDS), Oryza sativa (OsHDS), Lycopersicon esculentum (LeHDS), and A. thaliana (AtHDS) (on-line supplementary Fig. S1). The deduced amino acid sequence of the mature GbHDS consisted of 679 residues, and the theoretical molecular weight and pI were 75.6 kDa and 5.5, respectively. At the protein level, mature GbHDS without the predicted plastid signal peptide had about 85–86% sequence identities with the putative CrHDS, AtHDS, and OsHDS.
HDS is an iron–sulfur protein, which has a [4Fe–4S] cluster for catalysis [28]. The CXXC motif, the common binding motif for [4Fe–4S] cluster in all plant HDSs, was also present in GbHDS. Amino acid alignment showed the presence of a large additional domain of 268 residues (ca. 30 kDa) in the plant HDS protein [22] not present in the bacterial proteins (on-line supplementary Fig. S1). Querol et al. [29] reported that this additional domain, showing no significant homology with any other known proteins, did not affect the complementation assay with the E. coli HDR disruptant. Mature GbHDS, however, could not rescue the E. coli disruptant, NMW18 (pTMV20KM) [30] (data not shown). H. brasiliensis HDS (HbHDS) also could not complement the same E. coli HDS mutant [24]. Possibly the extra domain composed of 268 residues in plant HDS, putatively responsible in the interaction with the electron shuttle system, could be incompatible with the bacterial electron shuttle flavodoxin/flavodoxin reductase system in E. coli [31]. Another possibility is the difference in the codon usage between plant and E. coli. In particular, abundant arginine residues in the N-terminal regions of the mature GbHDS were encoded by the AGA codon rare in E. coli [29].
Molecular evolution analysis
A phylogenetic tree was constructed using the deduced amino acid sequences of the plant HDSs retrieved from GenBank and DFCI Gene index database to trace the evolutionary relationship among the HDSs of different species (Fig. 2). The results clearly demonstrated that plant HDSs formed one large cluster separated from the bacterial HDSs. Within the plant group, GbHDS and Pinus taeda HDS, being of gymnosperm origin, formed a clade separated from an angiosperm clade. However, HDS from P. abies (PaHDS) was an outlier from gymnosperm clade, presumably because the partial sequence of PaHDS was used to construct the tree.

Phylogenetic tree of HDSs. Bootstrap values are expressed in percentages and placed at the nodes in the tree. The bar on the tree represents the branch length equivalent to 0.1 amino acid changes per residue. Plant origin: AtHDS (Arabidopsis thaliana, accession no. AF434673), LeHDS (Lycopersicon esculentum, AAO15447), OsHDS (Oryza sativa, BAD19354), GbHDS (Ginkgo biloba, DQ251630), ZmHDS (Zea mays, AAT70081), CrHDS (Catharanthus roseus, AAO24774), SrHDS (Stevia rebaudiana, ABG75916), HbHDS (Hevea brasiliensis, AB294707), PaHDS (Picea abies, TC48506), PtHDS (Pinus taeda, TC91039). Bacterial origin: EcHDS (E. coli, AAC75568), StHDS (Salmonella typhimurium LT2, NP_461458), SpHDS (Serratia proteamaculans 568, YP_001479833)
Profiles of HDS gene transcript levels among organs
The copy number of GbHDS transcripts in the 1-week-old embryo roots was slightly lower than that of the leaves (Fig. 3). However, the level in the roots was consistently higher than that in the leaves from the week 2 onward, and reached two times higher level at week 3. Interestingly, Ginkgo possesses multiple MEP pathway genes at three different steps at DXS [18], CMEK [19], and IDS [16] stages along the pathway. At least one copy from each of these genes, generically labeled as type 2 or class 2, was differentially transcribed in the roots in a much higher copy number than type 1 or class 1 isogene. On the other hand, the type 1 gene transcription was not specifically targeted—the type 1 gene appeared at comparable levels both in roots and leaves. This observation together with other evidences was interpreted as that the type 2 enzymes have correlation with the ginkgolide biosynthesis [16, 18, 19], whereas the class 1 enzymes are performing the household function. The transcription pattern of the single-copy genes such as GbDXR [18] and GbMECS [15], except for GbMECT [17], appeared as hybrid between type 1 and 2 isogenes; they are transcribed at noticeably higher expression levels, but not in such a distinctive way as the type 2 enzymes, in the roots, suggesting a dual role in the primary and the secondary metabolisms. In fact, the pattern of transcription level of GbHDS during the culture period followed those of GbDXR and GbMECS, again indicating the dual role [15, 17, 18].

Transcript levels of GbHDS in the Ginkgo embryos grown on the hormone-free MS medium for 4 weeks. White bar, root; black bar, leaf; Y axis, mRNA copy number (×103) per ng total RNA
Intracellular targeting analysis of HDSs
Chloroplast transit peptide signals the delivery of premature protein synthesized in the cytosol into the chloroplast. At the target location, the transit peptide is removed to generate a fully functional mature protein [32]. Ginkgo HDS was predicted by the ChloroP program to have a chloroplast transit peptide consisting of 62 amino acid residues. All other MEP pathway proteins in the plant are known to have transit peptide. Length of the chloroplast transit peptide of the Ginkgo HDS was similar to those predicted for the other plant HDSs, even though its sequence similarities were very low in this region. To determine whether this putative transit peptide was functional, we constructed two plasmids that expressed GFP-fused proteins with the N-terminal 100 amino acids and a full-length sequence of GbHDS (Fig. 4a). Transient expression of the fused proteins in the Arabidopsis protoplasts showed that both the full-length HDS- and N-terminal 100 residue-fused GFPs appeared in the chloroplasts (Fig. 4b, c), indicating that HDS was imported into the chloroplast, in agreement with the proposed primary role of HDS in the MEP pathway for the biosynthesis of plastidic isoprenoids. The present finding suggests the possibility that the product of HDS, 1-hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate (HMBPP) could occur in the cytosol, since one isozyme of the terminal MEP pathway enzyme IDS was suggested to occur in cytosol [16]. Because HDS was found to be localized only in the chloroplast, the putative occurrence of HMBPP in the cytosol would be a result of transport from chloroplast to cytosol. However, the transportation of HMBPP across the chloroplast membrane at a discernable level has not been demonstrated [6, 7]. Furthermore, the presence of GbCMEK1 in the cytosol was also indicated [19]. These findings alluded the possible occurrences of the whole later phase of MEP pathway in cytosol, which, however, is negated since GbMECS [15] and GbHDS were not found in the cytosol. Therefore, the presence of the MEP pathway intermediates and the enzymes in the cytosol need be vigorously verified through a more sensitive method.

Subcellular localization of the fusion constructs of N-terminal residues and full-length protein of GbHDS with GFP. a plasmid construction; b localization of GFP fused with full-length GbHDS; c localization of GFP fused with N-terminal 100 residues of GbHDS. 35S, 35S promoter; CTP, chloroplast transit peptide; NOS, NOS terminator
References
Eisenreich W, Bacher A, Arigoni D, Rohdich F (2004) Biosynthesis of isoprenoids via the non-mevalonate pathway. Cell Mol Life Sci 61:1401–1426
Chappell J (1995) Biochemistry and molecular biology of the isoprenoid biosynthetic pathway in plants. Ann Rev Plant Physiol Plant Mol Biol 46:521–547
McGravey DJ, Croteau T (1995) Terpene metabolism. Plant cell 7:1015–1026
Kuzuyama T, Seto H (2003) Diversity of the biosynthesis of the isoprene units. Nat Prod Rep 20:171–183
Dubey VS, Bhalla R, Luthra R (2003) An overview of the non-mevalonate pathway for terpenoid biosynthesis in plants. J Biosci 28:637–646
Bick JA, Lange BM (2003) Metabolic cross talk between cytosolic and plastidial pathways of isoprenoid biosynthesis: unidirectional transport of intermediates across the chloroplast envelope membrane. Arch Biochem Biophys 415:146–154
Flugge UI, Gao W (2005) Transport of isoprenoid intermediates across chloroplast envelope membranes. Plant Biol 7:91–97
Braquet P, Spinnewyn B, Braquet M, Bourgain RH, Taylor JE, Etienne A, Drieu K (1985) BN 52021 and related compounds: a new series of highly specific PAF-acether antagonists isolated from Ginkgo biloba. Blood Vessels 16:559–572
Jaracz S, Nakanishi K, Jensen AA, Strømgaard K (2004) Ginkgolides and glycine receptors: a structure–activity relationship study. Chemistry 10:1507–1518
Cartayrade A, Neau E, Sohier C, Balz JP, Carde JP, Walter J (1997) Ginkgolide and bilobalide biosynthesis in Ginkgo biloba. I: Sites of synthesis, translocation and accumulation of ginkgolides and bilobalide. Plant Physiol Biochem 35:859–868
Schwarz M, Arigoni D (1999) Ginkgolide biosynthesis. In: Cane D (ed) Comprehensive natural products chemistry, vol 2. Oxford, Pergamon, pp 367–400
Liao Z, Chen M, Gong Y, Guo L, Tan Q, Feng X, Sun X, Tan F, Tang K (2004) A new geranylgeranyl diphosphate synthase gene from Ginkgo biloba, which intermediates the biosynthesis of the key precursor for ginkgolides. DNA Seq 15:153–158
Schepmann HG, Pang J, Matsuda SPT (2001) Cloning and characterization of Ginkgo biloba levopimaradiene synthase, which catalyzed the first committed step in the ginkgolide biosynthesis. Arch Biochem Biophys 392:263–269
Kim SM, Kuzuyama T, Chang YJ, Kim SU (2005) Functional identification of Ginkgo biloba 1-Deoxy-d-xylulose 5-phosphate synthase (DXS) gene by using Escherichia coli disruptants defective in DXS gene. Agric Chem Biotechnol 48:101–104
Kim SM, Kuzuyama T, Chang YJ, Kim SU (2006) Cloning and characterization of 2-C-methyl-d-erythritol 2,4-cyclodiphosphate synthase (MECS) gene from Ginkgo biloba. Plant Cell Rep 25:829–835
Kim SM, Kuzuyama T, Chang YJ, Kobayashi A, Sando T, Kim SU (2008) 1-Hydroxy-2-methyl-2-(E)-butenyl 4-diphosphate reductase (IDS) is encoded by multicopy genes in gymnosperms Ginkgo biloba and Pinus taeda. Planta 227:287–298
Kim SM, Kuzuyama T, Chang YJ, Kwon HJ, Kim SU (2006) Cloning and functional characterization of 2-C-methyl-d-erythritol 4-phosphate cytidyltransferase (GbMECT) gene from Ginkgo biloba. Phytochemistry 67:1435–1441
Kim SM, Kuzuyama T, Chang YJ, Song KS, Kim SU (2006) Identification of class 2 1-deoxy-d-xylulose 5-phosphate synthase and 1-deoxy-d-xylulose 5-phosphate reductoisomerase genes from Ginkgo biloba and their transcription in embryo culture with respect to ginkgolide biosynthesis. Planta Med 72:234–240
Kim SM, Kim YB, Kuzuyama T, Chang YJ, Kim SU (2008) Two copies of 4-(cytidine 5′-diphospho)-2-C-methyl-d-erythritol kinase (CMK) gene in Ginkgo biloba: molecular cloning and functional characterization. Planta 228:941–950
Walter MH, Hans J, Strack D (2002) Two distantly related genes encoding 1-deoxy-d-xylulose 5-phosphate synthases: differential regulation in shoots and apocarotenoid-accumulating mycorrhizal roots. Plant J 31:243–254
Kim YB, Kim SM, Kang MK, Kuzuyama T, Lee JK, Park SC, Shin SC, Kim SU (2009) Regulation of resin acid synthesis in Pinus densiflora by differential transcription of multiple 1-deoxy-d-xylulose 5-phosphate synthase (PdDXS) and 1-hydroxy-2-methyl-2-(E)-butenyl 4-diphosphate reductase (PdHDR) genes. Tree Physiol 29:737–749
Rodríguez-Concepción M, Querol J, Lois LM, Imperial S, Boronat A (2003) Bioinformatic and molecular analysis of hydroxymethylbutenyl diphosphate synthase (GCPE) gene expression during carotenoid accumulation in ripening tomato fruit. Planta 217:476–482
Guttiérrez-Nava ML, Gillmor CS, Jiménez LF, Guevara-García A, León P (2004) Chloroplast biogenesis genes act cell and noncell autonomously in early chloroplast development. Plant Physiol 135:471–482
Sando T, Takeno S, Watanabe W, Okumoto H, Kuzuyama T, Yamashita A, Hattori M, Ogasawara N, Fukusaki E, Kobayashi A (2008) Cloning and characterization of 2-C-methyl-d-erythritol 4-phosphate (MEP) pathway genes of a natural-rubber producing plant, Hevea brasiliensis. Biosci Biotechnol Biochem 72:2903–2917
Gil MJ, Coego A, Mauch-Mani B, Jordá L, Vera P (2005) The Arabidopsis csb3 mutant reveals a regulatory link between salicylic acid-mediated disease resistance and the methyl-erythritol 4-phosphate pathway. Plant J 44:155–166
Chang S, Puryear J, Cairney J (1993) A simple and efficient method for isolating RNA from pine tree. Plant Mol Biol Rep 11:113–116
Abel S, Theologis A (1994) Transient transformation of Arabidopsis leaf protoplasts: a versatile experimental system to study gene expression. Plant J 5:421–427
Brandt W, Dessoy MA, Fulhorst M, Gao W, Zenk MH, Wessjohann LA (2004) A proposed mechanism for the reductive ring opening of the cyclodiphosphate MEcPP, a crucial transformation in the new DXP/MEP pathway to isoprenoids based on modeling studies and feeding experiments. Chembiochem 5:311–323
Querol J, Campos N, Imperial S, Boronat A, Rodríguez-Concepción M (2004) Functional analysis of the Arabidopsis thaliana GCPE protein involved in plastid isoprenoid biosynthesis. FEBS Lett 514:343–346
Puan KJ, Jin C, Wang H, Sarikonda G, Raker AM, Lee HK, Samuelson MI, Märker-Hermann E, Pasa-Tolic L, Nieves E, Giner JL, Kuzuyama T, Morita CT (2007) Preferential recognition of a microbial metabolite by human Vγ2Vδ2 T cells. Int Immunol 19:657–673
Seemann M, Wegner P, Schünemann V, Tse Sum Bui B, Wolff M, Marquet A, Trautwein AX, Rohmer M (2005) Isoprenoid biosynthesis in chloroplasts via the methylerythritol phosphate pathway: the (E)-4-hydroxy-3-methylbut-2-enyl diphosphate synthase (GcpE) from Arabidopsis thaliana is a [4Fe–4S] protein. J Biol Inorg Chem 10:131–137
Bruce BD (2001) The paradox of plastid transit peptide: conservation of function despite divergence in primary structure. Biochim Biophys Acta 1541:2–21
Acknowledgments
The authors appreciate support from the Korea Science and Engineering Foundation (KOSEF 981-0608-040-2) through PMRC, and Ministry of Food, Agriculture, Forestry and Fisheries through Agricultural R&D Promotion Center (Grant No. 09-0116), Korea.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article
Cite this article
Kim, SM., Kim, SU. Characterization of 1-hydroxy-2-methyl-2-(E)-butenyl-4-diphosphate synthase (HDS) gene from Ginkgo biloba . Mol Biol Rep 37, 973–979 (2010). https://doi.org/10.1007/s11033-009-9771-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11033-009-9771-4