
Abstract
A geostatistics-based methodology is proposed to evaluate existing groundwater quality monitoring networks by considering the spatial correlation of various physicochemical parameters and the aquifer vulnerability index simultaneously, using the weighted normalized estimate error variance of all variables as the optimization criterion to be minimized. The DRASTIC method was chosen to determine the vulnerability index. The methodology requires a covariance matrix for each variable that is obtained from a geostatistical analysis of the corresponding data. Each matrix is normalized to give the same initial weight to each parameter, whereas different weights can be specified later during the optimization process, depending on the monitoring goals. The vulnerability index is used in the evaluation to include areas within the aquifer that are highly susceptible to contamination. Two optimization strategies are presented. In the first strategy, the vulnerability index is included as an additional variable during the optimization process and more weight is assigned to this variable than to the others. In the second strategy, the optimization process seeks to minimize the total weighted variance, prioritizing the areas with the highest vulnerability index values. For the estimation, the static Kalman filter, which requires an initial estimate, was chosen and its error covariance matrix for each variable is involved in the evaluation. Employing successive-inclusions optimization, the contribution of each monitoring well in reducing the estimate error variance for all parameters at predefined estimation points is evaluated and those that reduce the variance the most are retained in the optimal monitoring network.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Groundwater monitoring serves a highly important role in supporting management strategies and operational conservation policies for aquifers. The implementation of programs for monitoring groundwater quantity and quality helps to improve the planning, development, protection and management of groundwater, by anticipating or controlling contamination and overexploitation problems. Understanding water quality and its evolution, owing to either natural processes or human activities, requires the acquisition of long-term, reliable data. In Mexico, following the guidelines of the National Water Commission, groundwater quality is systematically monitored at only 1179 sites within the 653 administrative aquifers defined for the entire country (CONAGUA 2013), mainly because of the high costs associated with this activity. Since this issue has acquired worldwide interest within organizations responsible for groundwater administration, methodologies have been developed for the optimal design of monitoring networks. The aim of these methodologies is to avoid sampling in wells that, relative to the monitoring goals, provide redundant information. Usually, an objective function that represents these goals mathematically is chosen and an optimization method is used to select an optimal set of wells.
There are several examples that report the use of geostatistics in the design of optimal groundwater quality monitoring networks in the specialized literature. These studies often consider one and sometimes various physicochemical parameters of the water. Chadalavada et al. (2011) and Li et al. (2011) used spatial correlations between concentrations of a single solute. Lin and Rouhani (2001) designed a different groundwater quality monitoring network for each of the two analyzed contaminants: trichloroethylene and tetrachloroethylene. Yeh et al. (2006) employed multivariate analysis and factorial kriging to design a spatial monitoring network for nine water quality parameters. Furthermore, as well as using current solute concentrations, hydrogeological aspects and contamination risks of aquifers have been incorporated in the design by means of a vulnerability index or by conditioning the optimization procedure. Dutta et al. (1998) employed the vulnerability index (calculated with the DRASTIC method proposed by Aller et al. 1987), industry and stream network coverage, and data of some sampled water quality parameters to suggest different monitoring alternatives, but considered only the parameter with the largest variance in the optimization process. Narany et al. (2013) presented a methodology that combines, through a geographic information system, a risk map (calculated from the vulnerability index and land use) and a map of the groundwater nitrate thresholds exceedance probability (obtained with indicator kriging); the highest combined index represents areas in which there is a very strong probability of elevated nitrate concentrations and therefore a higher risk of contamination. The monitoring network was proposed by a visual procedure; the authors concluded that a monitoring network design should consider both the risks and the current state of contamination. It is noteworthy that, to date, there is no geostatistical method that incorporates several water quality parameters and a vulnerability index simultaneously in the objective function of an automated process that selects the wells to include in an optimal monitoring network.
Herrera (1998) presented a methodology that uses a successive-inclusions optimization method in combination with a Kalman filter to assign a priority order to sampling wells for a single groundwater quality parameter. This methodology requires, among other inputs, a prior covariance matrix, the elements of which are derived from a numerical transport model, of the water quality parameter considered in the design of a monitoring network. Priority is assigned to each well according to its contribution to minimizing the total variance (the sum of the diagonal elements of the covariance matrix). In more recent studies, Herrera et al. (2004), Júnez (2005) and Hergt (2009) modified the methodology for the design of an optimal monitoring network to include a range of water quality parameters, deriving the covariance matrices of the water quality parameters from geostatistical analyses. In the optimization procedure, all water quality parameters carry the same weight, and a joint normalized variance is minimized to assign a priority order to the wells.
In the present study, the geostatistical methodology proposed by Júnez (2005) is modified to evaluate an existing groundwater quality monitoring network in Mexico through a consideration of various physicochemical parameters simultaneously in a weighted manner. Furthermore, the hydrogeological aspects are incorporated via the aquifer vulnerability index. Two different applications of the aquifer vulnerability index are considered within the evaluation.
This paper is structured as follows. The study area is presented in Sect. 2. Section 3 introduces the proposed methodology. The data used in this research are described in Sect. 4. The results of the evaluation are presented in Sect. 5. The paper concludes in Sect. 6.
2 Study Area
The proposed methodology was used to evaluate a pilot monitoring network (PMN) for the Calera aquifer, Mexico. The Calera aquifer is located in the central part of the Mexican state of Zacatecas, where the most populous cities of the state that account for a quarter of the state’s population are located (Fig. 1). The study area has a total population of 319,440 inhabitants distributed throughout 12 urban centers, and the cities of Zacatecas, Calera and Fresnillo are home to 88.49 % of the total population INEGI (2013). The Zacatecas–Fresnillo industrial corridor accounts for 74.5 % of the personal income base and 17 % of the employment in Zacatecas state (COTAS 2008). The main economic activities within the region are agriculture, livestock farming and industry.

Calera aquifer geological framework, location of the pilot monitoring network (PMN), and groundwater flow directions
2.1 Hydrogeological Setting
The Calera aquifer has a horizontal extent of about 2087 km\(^{2}\) and is defined as unconfined in a granular medium that fills a regional graben with a thickness that varies from 38 m in the north to 570 m in the central and southern zones. The reported representative specific yield of the Calera aquifer is 0.13, and the hydraulic conductivity ranges from 10\(^{-5}\) to 10\(^{-8}\) m/s (Núñez 2003). The preferential flow direction is from south to north. Groundwater represents the only practical source of water to meet domestic, industrial and agricultural needs in the region. Within the aquifer there are 2035 pumping wells, which extract a total of 185.51 \(\times \) 10\(^{6}\) m\(^{3}\) of groundwater annually. Of the total abstracted groundwater, 67 % is used for agricultural activities. Rainfall is scarce in the study zone; the mean annual precipitation is 425 mm. The mean annual temperature is 16.3 \(^{\circ }\)C and the potential evapotranspiration is 1990 mm/year (CONAGUA 2009). Recharge into the aquifer originates mainly from intermittent streams that form during rainfall events in the northern-central part of the aquifer. These streams are produced by rainfall through the Sierra of Zacatecas and Fresnillo that are located in the southeast and west of the aquifer, respectively. Irrigation returns are an additional important source of recharge. Discharge occurs mainly through groundwater pumping, with a small proportion discharged as springs (CONAGUA 2009). Water budget calculations report a deficit of 60.68 \(\times \) 10\(^{6}\) m\(^{3}\)/year for the Calera aquifer (CONAGUA 2009). Inadequate management policies have led to a sustained average decrease in water levels of 1 m/year. Additionally, the excessive abstraction has resulted in subsidence, fracturing and deterioration of the groundwater quality.
Because of the importance of the Calera aquifer as a source of domestic, agricultural and industrial water, the contamination of the aquifer would be catastrophic. It is therefore imperative that the groundwater quality monitoring network is able to anticipate adverse natural changes in groundwater by allowing early detection of anthropogenic contaminants entering the aquifer. The methodology proposed in this paper seeks to incorporate aspects of both the design and evaluation of monitoring networks by simultaneously considering the actual groundwater concentrations of indicator parameters and the zones of the aquifer where there is a higher risk of contamination.
3 Methods
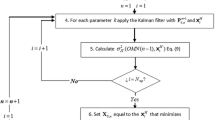
In this study, the performance of the groundwater quality PMN is evaluated by assessing the contribution that each monitoring well makes in minimizing the estimate error variance of the sampled indicator parameters at predefined estimation points. Two optimization strategies that include the vulnerability index in the performance evaluation are presented. In the first scenario, the vulnerability index is included as an additional variable during the optimization process and more weight is assigned to this variable than to the others, while in the second scenario, the optimization process seeks to minimize the total weighted variance by prioritizing the areas with the highest vulnerability index values, through a refinement of the estimation grid in those areas. The estimate error variance is minimized using a Kalman filter and an optimization method. The successive-inclusions optimization procedure seeks to reduce the estimate error variance over an area of interest. (The area of interest may include contaminated areas, highly vulnerable zones, pollution sources, drinking water exploitation zones, recharge zones or the entire area that defines an aquifer.) To achieve this, a spatial set of locations for which estimates are required must be obtained (the estimation grid). An alternative to assigning more weight to areas with higher priority in the optimization process is to use a denser set of estimation nodes in such areas. To design a monitoring network for several variables, the Kalman filter (as used here) requires a prior spatial covariance matrix (calculated here from geostatistics) for each of them.
3.1 Kalman Filter
The spatial approach of the static Kalman filter formulae presented in Júnez-Ferreira and Herrera (2013) was applied in this paper for each analyzed water quality indicator parameter (WQIP) and the vulnerability index (when this variable is used during the optimization). The linear measurement equation of the discrete Kalman filter, which links the state vector of the variable q in positions of interest, with sampled data z is
where \(\{\mathbf{z}_j,\; j=1,2,\ldots \}\) is a sequence of measurements for a single variable. The jth sampling matrix H \(_{j}\) is a \(1\times N\) matrix that is nonzero only at the position corresponding to the entry of q where the jth sample is taken, and N is the dimension of the vector \(\mathbf{q}\cdot \mathbf{q}=\{\mathbf{q}_i \}\) is the spatial vector with the variable values in the positions of interest (q \(_{i}\) is the variable estimate in position x \(_{i}\), where x \(_{i}\) is an estimation point or the position of a sampling well). The vector \(\{ \mathbf{v}_j,\;j=1,2,\ldots \}\) represents measurement errors, namely a white Gaussian sequence, with a mean of zero and a covariance of r \(_{j}\). The measurement error sequence {v \(_{j}\)} and the vector q are independent. In the case study, the measurement error variances included in the Kalman filter formulations were very small because the measurement error was considered negligible. The estimate error covariance matrix is
where \({\hat{\mathbf{q}}}^n=E\{ ( \mathbf{q}/\mathbf{z}_{1}, \mathbf{z}_{2},\ldots ,\mathbf{z}_n)^\mathrm{T} \}\) is the expected value of q, given the measurements \(\mathbf{z}_{1}, \mathbf{z}_{2} ,\ldots , \mathbf{z}_{n}\).
To implement the filter, prior estimates of q (denoted \({\hat{\mathbf{q}}}^0\) ) and of the error covariance matrix (P \(^{0}\)) are required. Note that P \(^{0}\) is a spatial covariance matrix. Given these prior estimates, the minimum-variance linear estimate for q can be obtained sequentially according to
There are many ways to estimate \({\hat{\mathbf{q}}}^0\) . In this study, the prior estimate of each variable is the mean value of its sampled data. The prior estimate error covariance matrix (P \(^{0}\)) for each variable is obtained through geostatistical analysis by fitting a spatial variogram model to the sample variogram. Once the variogram model is selected, the elements of the spatial covariance matrix for each variable are calculated according to
where C(0) is the variance of the analyzed variable, which is equal to the sill of the variogram, and \(\gamma (h)\) is the variogram model function. Equation (6) assumes that the variogram is bounded. The number of rows and columns of P \(^{0}\) for each variable is the sum of the nodes of the estimation grid (positions where estimates are required) and the number of monitoring positions (wells that can be monitored). If a spatial position is considered for both monitoring and estimation, it only needs a row (and a column) of the matrix.
The Kalman filter provides a minimum-variance unbiased linear estimate for the state of a system given noisy data (Jazwinski 1970). An important advantage of the optimization with the Kalman filter is that a set of simplified equivalent equations can be employed, as shown by Herrera and Pinder (2005). Once each monitoring position is selected, Eqs. (3)–(5) are solved only once to update the state vector and the covariance matrix in all estimation positions. Kriging could also be used as the estimation method, but would require greater computational effort during the optimization procedure (Webster and Oliver 2007).
3.2 Monitoring Network Optimization
The set of all possible monitoring positions is considered using \(M=\{\mathbf{x}_{i}^{M},\;i=1,\ldots ,Nmp\},\) where Nmp is the number of possible monitoring positions and \(\mathbf{x}=(x,y)\in D\), where D is the Euclidean plane. From this set, the points that minimize the estimate error variance on the set of estimation points, \(E=\{\mathbf{x}_j^{E},\;j=1,\ldots ,Nep\}\) where Nep is the number of estimation points, are chosen. If the optimization procedure used the sum of the variances of each variable over the estimation grid, as obtained directly from the geostatistical analysis, more weight would be given to variables that have a large variance than to variables with a small variance during the optimization procedure, and low-variance variables would therefore be inadequately monitored in the resulting monitoring network. To control the weight of each variable during the optimization procedure, the covariance matrix from the geostatistical analysis for each variable was normalized to obtain a correlation matrix. Each covariance matrix is normalized by dividing all its elements by the variance of the variable (the sill of its corresponding variogram model), and in this way, the principal diagonal for each prior correlation matrix will be entirely composed of values of 1; that is
where \(\mathbf{CM}_{k}^{0}\) is the correlation matrix for variable k, \(\mathbf{C}_{k}^{0}\) is the covariance matrix obtained from the geostatistical analysis for variable k, and \(C(0)_{k}\) is the sill of the variogram model for variable k. This matrix is used as P \(^{0}\) in the Kalman filter formulae.
The problem is optimized sequentially using a successive-inclusions method (Samper and Carrera 1990). For each \(n=1,\ldots ,{ Nmp}\), the point X \(_{o,n}\) in M that minimizes the function
is chosen, where \(\sigma _\mathrm{TW}^2 \) is referred to as the total weighted variance, \(W_{k}\) is the weight for variable k, Nv is the number of variables considered in the performance evaluation and \(\sigma _{k,j}^2 ({ OMN}(n-1), \mathbf{x})\) is the element in the diagonal of the updated correlation matrix of variable k corresponding to the estimation point \((\mathbf{x}_j^E)\) obtained from the Kalman filter using the \(n-1\) optimal monitoring network \({ OMN}(n-1)=\{\mathbf{X}_{o,1}, \mathbf{X}_{o,2},\ldots ,\mathbf{X}_{o,n-1}\}\) previously chosen and the spatial point x. It is important to note that OMN(0) is an empty set. Let \(\mathbf{P}_{k,o}^{n-1} \) be the matrix of variable k obtained after applying Eqs. (4) and (5) of the Kalman filter to the set OMN(\(n-1\)). Then, to find X \(_{o,n}\), for each possible monitoring point that has not been chosen before, calculate the updated variance for each variable using, instead of Eqs. (4) and (5) of the Kalman filter with the matrix \(\mathbf{P}_{k,o}^{n-1}\) and the possible monitoring point, the simplified equivalent equations given by Herrera and Pinder (2005) and then select the point that gives the minimum \(\sigma _\mathrm{TW}^{2} ({ OMN}(n-1), \mathbf{x})\) . The selected point is then added to the set of optimal monitoring points and the matrix \(\mathbf{P}_{k,o}^{n-1} \) for each parameter is calculated again using Eqs. (4) and (5) of the Kalman filter. The process is started by assigning \(\mathbf{P}_{k,o}^{0} = \mathbf{CM}_{k}^{0}\). A good approach for determining the high-priority monitoring wells (HPWs) is to consider the spatial locations where 90 % of the maximum possible reduction (mpr) is achieved (Júnez-Ferreira and Herrera 2013)
where \(\sigma _{TN}^2 (n) \sum \nolimits _{k=1}^{Nv} \sum \nolimits _{j=1}^{Nep} \sigma _{j,k}^2 ({ OMN}(n))\) is the total normalized variance obtained with the set of n optimal wells.
3.3 Vulnerability Index
In hydrogeology, vulnerability can be defined as the susceptibility of groundwater to contamination by the infiltration of contaminants from the ground surface. Nowadays, a quantitative approach is applied using the emerging definitions and methodologies of a vulnerability index (Andreo 2004). The DRASTIC method (Aller et al. 1987) was chosen to determine the vulnerability index, because it is one of the most popular methods for assessing the potential contamination of aquifers. The method is based on the assignment of indexes that relate to the features of an individual well. The parameters considered in the DRASTIC method relate to the depth to groundwater (D), net recharge (R), aquifer media (A), soil type (S), topography slope (T), impact of the vadose zone (I) and hydraulic conductivity of the aquifer (C). The parameters are evaluated with ratings ranging from 1 (low vulnerability) to 10 (maximum vulnerability), and different weights are assigned to each vulnerability parameter, as shown in Table 1. Additionally, each parameter is quantified with a ranking that reflects the likelihood of groundwater pollution; for example, in the case of soil type, the rating for gravel is 10, whereas the rating for non-shrinking and non-aggregated clay is 1. The vulnerability index is calculated by multiplying the weight and rating of each vulnerability parameter; these results are summed to obtain a final value of the vulnerability index for each analyzed position as follows
where subscripts r and w indicate the rating and weight assigned to each parameter, respectively. Finally, the value of the vulnerability index is compared with the vulnerability categories in Table 2. There are various assumptions associated with this method, as outlined in Aller et al. (1987). It is assumed that (1) the contaminant is introduced at the ground surface, (2) the contaminant is flushed into the groundwater by precipitation, (3) the contaminant has the mobility of water and (4) the area evaluated using DRASTIC is 100 acres (45.5 ha) or larger.
4 Data
Information about the arsenic, calcium, sodium, sulfate and chloride concentrations was obtained at 43 wells in a sampling campaign conducted in 2007 in the Calera region. Of these wells, 36 constituted the PMN and had locations that corresponded to the Calera aquifer. The wells were distributed across the horizontal extent of the aquifer in an approximately uniform manner (Fig. 1). The vulnerability index was calculated by applying the DRASTIC method to the positions of the PMN. Summary statistics of data (for the WQIPs) and calculations of the vulnerability index are given in Table 3.
A geostatistical analysis of the same data has been previously reported in Júnez-Ferreira et al. (2013). Therefore, this paper only conducts a geostatistical analysis of the vulnerability data; in this case, regression analysis was used to remove the detected trend. Parameters of selected variogram models and cross-validation results for all the variables considered in the performance evaluation of the PMN are given in Table 4. In both cases, the cross-validation procedure was conducted using the “leave one out” method that establishes if the selected variogram model is representative of the spatial variability of sampled data (Samper and Carrera 1990). The model parameters given in Table 4 indicate, in general, large correlation distances (ranges) for all WQIPs. They also show that the nugget-to-sill ratio has a strong spatial dependence (lower than 25 %) for ln sodium and ln sulfate, and moderate spatial dependence (between 25 and 75 %) for the other WQIPs (Okeyo et al. 2006). Cross-validation results were considered satisfactory for the selected models; values of the squared mean standardized error fall between 1 and 1.314, indicating consistency between the estimated and observed variances (Delhomme 1978).
The Kalman filter was used to obtain estimates and the associated estimate error variances for all the variables within the limits of the Calera aquifer. Figures 2 and 3, respectively, present estimates and error variances for arsenic and the vulnerability index. The relative values for the vulnerability index were highest in the central and northern parts of the aquifer, which means that those zones are more vulnerable to contamination. An analysis carried out by Reyes (2014) relates these relative high vulnerability values to the presence of nitrates, which gives confidence that the calculated values of the vulnerability index can help to evaluate how well the monitoring network detects anthropogenic contamination.

Maps of a estimates and b estimate error variances for arsenic in the Calera aquifer obtained using the PMN

Maps of a estimates and b estimate error variances for the vulnerability index in the Calera aquifer obtained using the PMN
5 Evaluation of the Performance of the PMN
The effectiveness of the PMN for the Calera aquifer according to an analysis of redundancy in the information collected from the wells is evaluated in this study. There were two main objectives for the optimal monitoring network of the Calera aquifer. First, it was expected that the selected wells should provide a level of uncertainty in estimates of WQIPs that was approximately the same as that achieved using the PMN (i.e., wells that provide redundant information should be avoided). Second, the monitoring network must permit early detection of contaminant entry into the aquifer. Therefore, the performance was evaluated by assessing whether or not these objectives were achieved for the two optimization strategies evaluated in this paper. In the first strategy, the variables, one of which is the vulnerability index, in the optimization process are assigned different weightings. In the second strategy, the estimation grid is refined for zones with the highest values of the vulnerability index and only the physicochemical parameters are included in the optimization procedure. The refinement of the estimation grid in some areas implies that wells located near or inside these areas will lower the variance over a larger number of estimation points, and, therefore, these wells will have a greater possibility of selection. In this way, priority zones to be monitored can be considered through the refinement of the estimation grid.
5.1 Strategy 1: Weights Assigned to the Physicochemical Parameters and the Vulnerability Index
The methodology proposed in this study allows the weights for each variable involved in the evaluation process to be considered; in this way, it is possible to evaluate the monitoring preferences established in the objectives of the monitoring network. The objectives of the case study were twofold: the monitoring network should have the same probability of detecting adverse changes in WQIPs (therefore, low uncertainty estimates of actual solute concentration must be obtained with the monitoring network) and contaminants entry into the aquifer should be detected early. To this end, in the optimization procedure, a 50 % weight was assigned to the combined WQIPs and the other 50 % was assigned to the vulnerability index. Five WQIPs were considered in the performance evaluation, and as there was no preference for one parameter over the others, a 10 % weight was assigned to each WQIP. These weights can change according to the monitoring goals.
Because the largest estimate error variances of the vulnerability index coincide with the highest estimate values for this variable (Fig. 3b), the way this variable was used in the proposed optimization procedure meant that a high priority could be assigned to wells located inside or near zones known to be highly susceptible to anthropogenic contamination. The estimation grid (nodes where estimates are required) was defined with square elements having side lengths of 1 km; this grid encompassed the existing PMN (Fig. 4a). The estimation grid was composed of 1,084 nodes.

Estimation grid and labeling of the priority order of the high-priority wells (HPWs): a Strategy 1 and b Strategy 2
Once the optimization method is applied, the order in which the spatial locations are selected in a natural way represents a priority order, because in each round the location that reduces the most variance (i.e., the location that gives maximum information) is selected. In this way, the selection order is an indicator of how important the data obtained at those locations are in reducing the total weighted variance; if the selection order is small, the priority is high. This is shown clearly in Fig. 5, where the total normalized variance is greatly reduced when the first spatial locations are chosen; however, as the number of selected locations increases, the reduction of the total normalized variance decreases. Following this optimization strategy, the initial total normalized variance is equal to 6504 square units, obtained by multiplying 1084 (unit variance values in estimate positions of each correlation matrix) by six (the number of variables considered in the optimization). The results show that 90 % of the maximum possible reduction was achieved when 16 wells of the PMN were used. These wells were deemed HPWs, while the remaining 20 wells were considered to provide redundant information and were therefore identified as low-priority wells (Fig. 4a). Four of the eight wells with the highest priority were selected near the zones with the highest vulnerability.

Total normalized variance versus the number of spatial monitoring points for Strategies 1 and 2
Finally, estimates and the associated estimate error variances obtained using the HPWs were obtained for all variables. Figures 6 and 7 present estimates for arsenic and the vulnerability index. Spatial configurations of estimates and error variances for the vulnerability index using the HPWs (Fig. 7) are very similar to those obtained with the PMN (Fig. 3), because more weight was assigned to this variable during the optimization. In the case of arsenic, there are larger differences (Figs. 2, 6), but the largest difference occurs at the extreme south of the estimation grid, because the well with the highest arsenic value was not selected as an HPW. This is a problem associated with the shape of the estimation grid because, compared with the other sampling positions, that well only affects a minor number of estimation points (Fig. 4a).

Maps of a estimates and b estimate error variances for arsenic in the Calera aquifer obtained using the HPWs (Strategy 1)

Maps of a estimates and b estimate error variances for the vulnerability index in the Calera aquifer obtained using the HPWs (Strategy 1)
To compare the estimates obtained with the PMN (36 wells) and the HPWs (16 wells), statistics of differences between estimates and estimate error variances obtained with the Kalman filter are presented in Table 5. The column labeled “PMN minus HPWs estimates” gives the mean absolute differences; differences between estimates can be considered acceptable according to the range of values measured for each variable. The square-root-mean variance (SRMV) is a measure of the average uncertainty in the estimation grid when employing the PMN or the HPWs. The comparison shows greater average uncertainty when the HPWs are used rather than the PMN; when the HPWs are used, there is only a marginal loss of certainty, compared with the case for the PMN (a maximum of 9.4 % for chloride).
5.2 Strategy 2: Weights Assigned to the Physicochemical Parameters and Estimation Grid Refinement
In the second optimization strategy, the aquifer vulnerability was incorporated by refining the estimation grid in zones where the largest values of the vulnerability index were estimated, after the DRASTIC methodology was applied. This was done to reduce the estimate uncertainty in those zones when using the monitoring network. The estimation grid (nodes where estimates are required) was defined with square elements with side lengths of 1 km. This grid encompasses the existing PMN. For the refinement, a separation between nodes of 500 m was chosen in the zone that was most vulnerable to contamination. Finally, the estimation grid was composed of 1498 nodes (Fig. 4b). During the optimization, a weight of 20 % was assigned to each of the five WQIPs. Once the optimization method was applied, the sampling positions with the higher priority were selected; in this optimization strategy, 90 % of the maximum possible reduction is achieved when 14 wells of the PMN are used (Fig. 5). In this case, the initial total normalized variance is equal to 7490 square units, i.e., the result of multiplying 1498 (unit variance values in estimation positions of each correlation matrix) by 5 (the number of variables considered in the optimization). The difference in the reduction in the number of selected wells between this strategy and Strategy 1 is due to the reduction in the number of variables involved in the optimization. When the second strategy is chosen, four of the first five selected wells are within the zone with the highest vulnerability index values. This result shows that the selected refinement of the grid has a greater influence than assigning a 50 % weight to the vulnerability variance values in the prioritization process that considers the areas highly susceptible to contamination. This is because, in the latter approach, much larger weights are assigned to wells within the priority zones than to the other wells, and additionally these weights are kept constant during the optimization procedure; in contrast, in the former approach, the weight assigned to each well is smoothly distributed (depending on the variance of the variable) and is reduced any time a new sampling position is added to the set of HPWs.
Arsenic estimates and error variances obtained when using the HPWs of Strategy 2 (Fig. 8) are very similar to those obtained in Strategy 1 (Fig. 6), with a large estimate difference (compared with the estimation using the PMN) at the southern part of the estimation grid due to the shape of the estimation grid as explained in the analysis of Strategy 1. Vulnerability estimates and error variances are not presented for this strategy, since this variable was only used in the optimization for the definition of the estimation grid. Statistics presented in Table 5 show no appreciable changes, in terms of absolute values, between mean absolute difference estimates for Strategies 1 and 2. The maximum increase in the average uncertainty for Strategy 2 when the PMN and the HPWs used are 11.9 % for chloride.

Maps of a estimates and b estimate error variances for arsenic in the Calera aquifer obtained using the HPWs (Strategy 2)
6 Conclusions
The proposed methodology considers various water quality parameters and the vulnerability index simultaneously in this evaluation of the performance of an existing monitoring network. Furthermore, this method could be used in the optimal design or redesign of monitoring networks for tracking the evolution of groundwater quality, considering at the same time areas vulnerable to contamination and the current state of solute concentrations in groundwater. The methodology is based on the spatial correlation between each variable and uses spatial covariance models derived from geostatistical analyses.
To define the nodes of the estimation grid within the aquifer, the wells at the periphery should have a minimum number of estimation nodes to avoid their exclusion from the set of HPWs. The design of a monitoring network may involve the inclusion of priority wells defined using previous hydrogeological knowledge of the aquifer before applying the optimization procedure. This methodology is versatile in terms of including practical hydrogeological criteria because it allows weights to be assigned to variables involved in the evaluation or design of a monitoring network.
In this study, the zones with the highest vulnerability were considered in the performance evaluation in two ways: (1) by means of spatial correlation and (2) through a refinement of the estimation grid. Both optimization strategies in the proposed methodology are successful because HPWs were chosen inside or near to vulnerable zones. Strategy 2 assigns a higher priority to those wells located inside or close to the zones with the highest vulnerability values, while, although the selection is more relaxed in Strategy 1, it is prompted to assign a higher priority to wells located in zones where the highest relative estimate uncertainty vulnerability index values are calculated each time a new sampling position is selected. The first optimization strategy seems to balance the selection of monitoring wells to reduce uncertainty within priority zones and at other nodes where estimates are required. Strategy 2 seems to be more appropriate when a monitoring network biased to mainly reduce estimate uncertainties of a variable within its priority zones is required.
The performance evaluation in the case study showed that 16 of the 36 wells of the PMN provide 90 % of the maximum possible reduction of the total normalized variance for the selected variables on a regular grid when a 50 % weight is assigned to all WQIPs and a 50 % weight is assigned to the vulnerability index in the optimization. A maximum increase of 9.4 % in the SRMV for all nodes of the estimation grid was obtained for the 16 selected HPWs, compared with the SRMV calculated for the PMN of 36 wells. When, in the optimization, the same weight was assigned to all WQIPs (20 % each) and the vulnerability index was considered by means of an estimation grid refinement in zones with the highest values, 14 of the 36 wells of the PMN provided 90 % of the maximum possible reduction of the total weighted variance. A maximum increase of 11.9 % in the SRMV values for all nodes of the estimation grid was obtained for the 14 selected HPWs, compared with the SRMV calculated with the PMN of 36 wells. When the 14 wells with the highest priority in each of the two optimization strategies are compared, only two positions did not coincide. The performance assessment for both optimization strategies implies more than a 50 % cost reduction with a marginal increase in uncertainty in terms of achieving the monitoring goals. Areas with large values of total variance after measurements at the monitoring locations indicate that the spatial distribution of the parameter is not represented with certainty in certain zones. This means that new wells should be added to the optimal monitoring network in those zones. To propose the locations of the new wells, potential pollution sources and hydrogeological criteria should also be considered.
References
Aller L, Bennett T, Lehr JH, Petty R, Hackett G (1987) DRASTIC: a standardized system to evaluate groundwater pollution using hydrogeologic settings. US environmental protection agency report 600/2-87/035. http://nepis.epa.gov/Exe/ZyPURL.cgi?Dockey=20007KU4.TXT. Accessed 15 June 2015
Andreo B (2004) Cartografía de vulnerabilidad a la contaminación de acuíferos. In: Fernández L, Ruiz L, Fernández JA, López JA (eds) Protección de las aguas subterráneas frente a vertidos directos e indirectos, 13th edn. Publicaciones del instituto geológico y minero de España, Serie: Hidrogeología y aguas subterráneas No 13. Granada, España, pp 55-78
Chadalavada S, Datta B, Naidu R (2011) Uncertainty based optimal monitoring network design for a chlorinated hydrocarbon contaminated site. Environ Monit Assess 173:929–940. doi:10.1007/s10661-010-1435-2
CONAGUA. Comisión nacional del agua (2009) Actualización de la disponibilidad media anual de agua subterránea del acuífero (3225) Calera. Diario oficial de la federación. México. http://www.conagua.gob.mx/Conagua07/Aguasubterranea/pdf/DR_3225.pdf. Accessed 15 June 2015
CONAGUA. Comisión nacional del agua (2013) Estadísticas del agua en México. Secretaría de medio ambiente y recursos naturales. México. http://www.conagua.gob.mx/CONAGUA07/Noticias/SGP-2-14Web.pdf. Accessed 15 June 2015
COTAS. Comités técnicos de aguas subterráneas acuíferos Aguanaval, Calera y Chupaderos, (2008) Plan hídrico de los acuíferos Aguanaval. Calera y Chupaderos en el Estado de Zacatecas, México
Delhomme JP (1978) Kriging in the hydrosciences. Adv Water Resour 1(5):251–266. doi:10.1016/0309-1708(78)90039-8
Dutta D, Das Gupta A, Ramnarong V (1998) Design and optimization of a ground water monitoring system using GIS and multicriteria decision analysis. Ground Water Monit R 18(1):139–147. doi:10.1111/j.1745-6592.1998.tb00610.x
Hergt T (2009) Diseño optimizado de redes de monitoreo de la calidad del agua de los sistemas de flujo subterráneo en el acuífero 2411 “San Luis Potosí”: Hacia un manejo sustentable. Universidad Autónoma de San Luis Potosí, Tesis de doctorado
Herrera GS (1998) Cost effective groundwater quality sampling network design. Ph. D. Dissertation, University of Vermont. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.383.9759&rep=rep1&type=pdf. Accessed 15 June 2015
Herrera GS, Júnez-Ferreira HE, González L, Cardona A (2004) Diseño de una red de monitoreo de la calidad del agua para el acuífero Irapuato-Valle. Memorias del XVIII congreso nacional de hidráulica, AMH. SLP, México, Guanajuato
Herrera GS, Pinder GF (2005) Space-time optimization of groundwater quality sampling networks. Water Resour Res 41(12):W12407. doi:10.1029/2004WR003626, http://onlinelibrary.wiley.com/doi/10.1029/2004WR003626/full. Accessed 15 June 2015
INEGI. Instituto nacional de estadística y geografía, (2013) Proyecto de información básica. Mapa digital para escritorio, México
Jazwinski AH (1970) Stochastic processes and filtering theory. Academic Press, London
Júnez HE (2005) Diseño de una red de monitoreo de la calidad del agua para el acuífero Irapuato-Valle, Guanajuato. Tesis de maestría, UNAM, México. http://132.248.9.195/ptd2012/anteriores/0339152/Index.html. Accessed 15 June 2015
Júnez-Ferreira HE, Bautista-Capetillo CF, González J (2013) Análisis geoestadístico espacial de cuatro iones mayoritarios y arsénico en el acuífero Calera, Zacatecas. Tecnología y Ciencias del Agua 4:175-181
Júnez-Ferreira HE, Herrera GS (2013) A geostatistical methodology for the optimal design of space-time hydraulic-head monitoring-networks and its application to the Valle de Querétaro aquifer. Environ Monit Assess 185(4):3527–3549. doi:10.1007/s10661-012-2808-5
Li J, Bárdossy A, Guenni L, Liu M (2011) A Copula based observation network design approach. Environ Modell Softw 26:1349–1357. doi:10.1016/j.envsoft.2011.05.001
Lin Y, Rouhani S (2001) Multiple-Point variance analysis for optimal adjustment of a monitoring network. Environ Monit Assess 69:239–266. doi:10.1023/A:1010767022936
Narany T, Ramli M, Aris A, Sulaiman W, Fakharian K (2013) Spatial assessment of groundwater quality monitoring wells using indicator kriging and risk mapping, Amol-Babol plain, Iran. Water 6:68–85. doi:10.3390/w6010068
Núñez EP (2003) El acuífero de Ca2003lera, Zacatecas, situación actual y perspectivas para un desarrollo sustentable. Universidad autónoma de Nuevo León, Tesis de maestría
Okeyo JM, Shepherd KD, Wamicha W, Shisanya C (2006) Spatial variation in soil organic carbon within smallholder farms in western Kenya: a geostatistical approach. Afr Crop Sci J 14(1): 27–36. http://www.bioline.org.br/pdf?cs06003. Accessed 15 June 2015
Reyes JE (2014) Metodología geoestadística que involucra la vulnerabilidad en el diseño de redes de monitoreo de la calidad del agua subterránea: Aplicación Calera, Zacatecas. Orientación en recursos hidráulicos, Zacatecas, México, Tesis de maestría, Maestría en ingeniería aplicada
Samper FJ, Carrera J (1990) Geoestadística, aplicaciones a la hidrogeología subterránea. Centro internacional de métodos numéricos en ingeniería, Universidad politécnica de Cataluña, Barcelona
Webster R, Oliver M (2007) Geostatistics for environmental scientists. Wiley, UK
Yeh M, Lin Y, Chang L (2006) Designing an optimal multivariate geostatistical groundwater quality monitoring network using factorial kriging and genetic algorithms. Environ Geol 50:101–121. doi:10.1007/s00254-006-0190-8
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Júnez-Ferreira, H., González, J., Reyes, E. et al. A Geostatistical Methodology to Evaluate the Performance of Groundwater Quality Monitoring Networks Using a Vulnerability Index. Math Geosci 48, 25–44 (2016). https://doi.org/10.1007/s11004-015-9613-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-015-9613-y