
Abstract
Uncertainty pervades most aspects of life. From selecting a new technology to choosing a career, decision makers rarely know in advance the exact outcomes of their decisions. Whereas the consequences of decisions in standard decision theory are explicitly described (the decision from description (DFD) paradigm), the consequences of decisions in the recent decision from experience (DFE) paradigm are learned from experience. In DFD, decision makers typically overrespond to rare events. That is, rare events have more impact on decisions than their objective probabilities warrant (overweighting). In DFE, decision makers typically exhibit the opposite pattern, underresponding to rare events. That is, rare events may have less impact on decisions than their objective probabilities warrant (underweighting). In extreme cases, rare events are completely neglected, a pattern known as the “Black Swan effect.” This contrast between DFD and DFE is known as a description–experience gap. In this paper, we discuss several tentative interpretations arising from our interdisciplinary examination of this gap. First, while a source of underweighting of rare events in DFE may be sampling error, we observe that a robust description–experience gap remains when these factors are not at play. Second, the residual description–experience gap is not only about experience per se but also about the way in which information concerning the probability distribution over the outcomes is learned in DFE. Econometric error theories may reveal that different assumed error structures in DFD and DFE also contribute to the gap.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the standard (decision from description (DFD)) approach to studying decision under uncertainty, participants are presented with choices between prospects that are described as event-contingent outcomes (e.g., lose $50 with probability 0.5, and nothing otherwise; gain $100 if the home team wins and nothing otherwise). The decision maker is either provided with precise objective probabilities (risk) or natural events for which vague subjective probabilities may be assigned (ambiguity). Most of the accumulated empirical findings can be summarized with the assertion of a robust tendency for people to overweight low probabilities and unlikely events and to underweight moderate to high probabilities and likely events (Tversky and Kahneman 1992; Tversky and Fox 1995; Fox and Tversky 1998; Wakker 2010).
In the last decade, behavioral decision researchers introduced a new decision from experience (DFE) paradigm in which characteristics of prospects are learned from experience rather than explicitly described. In this case, both probabilities and outcomes are learned through sequential sampling, that is, through repeated draws with replacement from a probability distribution over outcomes that are unknown to the decision maker (Hertwig et al. 2004). The dominant finding then is that decision makers underrespond to rare events, contrary to the typical pattern observed in DFD (Barron and Erev 2003; Hertwig et al. 2004). Taleb (2007) refers to an extreme case, in which the possibility of rare events is ignored (due to an inaccurate mental model of the uncertain environment) as the “Black Swan effect.” The contrast between decisions from description and decisions from experience is usually referred to as the “description–experience gap” (Hertwig and Erev 2009).
This paper critically examines the description–experience gap. We first take stock of prior contributions in the literature. Second, we propose econometric tools to analyze errors and heterogeneity, which can shed light on the DFD-DFE gap. Third, we link the literature on DFE with recent empirical literature on DFD under ambiguity (Dimmock et al. 2013).
2 Risk and ambiguity in prospect theory
In standard decision under uncertainty, an alternative, or prospect, is described by a list of event-contingent outcomes. To illustrate, let x E y denote the prospect that pays $x if event E obtains, and $y otherwise. For instance, setting x = 10, y = 1, and E = “rain tomorrow,” 10 E 1 denotes a prospect yielding $10 if there is rain tomorrow and $1 otherwise. The evaluation of such alternatives requires an assessment not only of the desirability of outcomes (utilities) but also of the likelihoods of the events (probabilities or their generalizations). For risk, with p = P(E), we often write x p y instead of x E y. In this case, standard decision theory recommends evaluating a prospect using expected utility (EU), i.e., probability-weighted average utility. Thus, the EU of 10 E 1 is P(E)u(10) + (1 − P(E))u(1) (probability (P); utility (u)). Risk aversion (valuing a risky prospect less than its expected value) is commonly assumed to hold. EU explains risk aversion using a concave utility function over outcomes—for example, if gaining $100 increases utility by more than half as much as does gaining $200 (assuming u(0) = 0), then a decision maker should prefer receiving $100 for sure to a prospect that offers a 50-50 chance of receiving $200 or else receiving nothing.
Several empirical findings have challenged the descriptive validity of EU. Allais’ (1953) famous violation of the independence axiom suggests that people do not weight the utilities by their probabilities. More generally, the assumption of risk aversion is violated by the commonly observed fourfold pattern of risk preferences: risk aversion for moderate to high-probability gains and low-probability losses, coupled with risk seeking for low-probability gains and moderate to high-probability losses (Tversky and Kahneman 1992). Rabin (2000) showed that moderate risk aversion for small-stake mixed (gain-loss) gambles at all levels of wealth (assuming a strictly increasing and concave utility function) implies an implausible level of risk aversion for large-stake gambles under EU.
Such violations of EU are accommodated by prospect theory (PT), the leading descriptive model of decision under uncertainty (Kahneman and Tversky 1979; Tversky and Kahneman 1992). Under PT, outcomes are evaluated with respect to a reference point. We assume for simplicity that the reference point is 0. Utility u is strictly increasing and u(0) = 0. Utility further exhibits diminishing sensitivity: marginal utility diminishes with distance from the reference point, leading to concavity for gains but convexity for losses. Diminishing sensitivity thus contributes to risk aversion for gains and risk seeking for losses. The latter goes against conventional wisdom but has been confirmed empirically. Furthermore, utility u is characterized by loss aversion in which the function is steeper for losses than gains—typically, this is modeled by multiplying utility for losses by a coefficient λ > 1 (Fig. 1). Loss aversion enhances risk aversion for mixed prospects that offer the possibility of both gains and losses. Probabilities are transformed by a weighting function w + for gains and w − for losses, both normalized so that w(0) = 0 and w(1) = 1, and strictly increasing (Fig. 2). Hence, under PT, x p y is evaluated by the following: w +(p)u(x) + [1 − w +(p)]u(y), if x ≥ y ≥ 0; w −(p)λu(x) + [1 − w −(p)]λu(y), if x ≤ y ≤ 0; w +(p)u(x) + w −(1 − p)λu(y), if x > 0 > y.

Prospect theory utility function

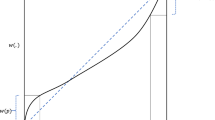
Probability weighting function
Figure 2 illustrates an inverse S-shaped probability weighting function. Probability intervals at the extremes, [0, q] and [1 − q, 1], have more impact than equivalent probability intervals in the middle, [p, p + q], that are bounded away from the lower and upper endpoints. The underweighting of moderate to large probabilities reinforces the tendency implied by the S-shaped utility function toward risk aversion for gains and risk seeking for losses of moderate to high probabilities, but reverses this pattern for very low probabilities, which are overweighted.
Numerous studies surveyed by Wakker (2010) have confirmed the above qualitative empirical properties, using choices among simple risky prospects.
3 The description–experience gap
Studies of “decisions from experience” (DFE) employ paradigms in which decision makers learn characteristics of prospects through sequential sampling of independent identically distributed realizations (outcomes). Three experimental paradigms (see Hertwig and Erev 2009) and variants thereof have been used. All involve a choice between two or more prospects. In the most popular sampling paradigm, people first sample from the distributions as long as they wish without costs. Once search is terminated, they decide from which distribution to make a single incentivized draw. In the full-feedback paradigm, each draw adds to a person’s income, and the decision maker receives draw-by-draw feedback about both the actual payoff and the forgone payoff. Finally, the partial-feedback paradigm is identical to the full-feedback paradigm except that it restricts feedback to the actual payoff.
Comparisons of DFE with DFD under risk reveal a description–experience gap for rare events (Hertwig and Erev 2009). Figure 3 illustrates this gap using six representative decision problems. In DFE, people afford rare events less impact than they deserve according to their objective (but unknown) probabilities, whereas in DFD, people afford rare events more impact than they deserve according to their objective (and known) probabilities.

The description–experience gap
Choice patterns in all three experience-based paradigms are surprisingly similar in the tendency to “underweight” rare events. It should be noted that when all possible payoffs are identified explicitly (whether or not they are experienced), this reduces the underweighting of rare events in the sampling paradigm (see Erev et al. 2008; Hadar and Fox 2009) though perhaps not in the full-feedback paradigm (see Yechiam et al. 2005).
3.1 What causes the description–experience gap?
Researchers have thus far identified five broad mechanisms that contribute to the description–experience gap. The first three relate to DFE and choices consistent with underweighting and neglect of rare events; the final two relate to both DFD and DFE.
3.1.1 Sampling error and sheer unawareness of the rare events’ existence
A world in which all risks are transparent and elicit an appropriate response is unrealistic given inherent limits to our information, attention, and memory. Thus, we often cannot help but be unaware of possible rare outcomes that we have forgotten or not attended to. Similarly, we may sometimes rely on an inaccurate model of a decision environment as when we estimate financial risks using tools that assume a normal distribution in non-Gaussian environments (Taleb 2007). Unawareness of rare events can occur in the DFE sampling paradigm when decision makers rely on small samples in which they never experience rare events. Such lack of awareness that an outcome is possible is one mechanism that has been found to contribute to the description–experience gap in studies using the original sampling paradigm (Hertwig et al. 2004; Hadar and Fox 2009). Fox and Hadar (2006) argued that when one accounts for sampling error in Hertwig et al. (2004) so that decisions are analyzed with respect to sampled probability distributions over outcomes (i.e., what participants actually experienced) rather than the “objective” probability distributions from which outcomes were sampled (that were unknown to participants), then choices accord well with PT. This said, a diminished description–experience gap has been shown to persist when participants have ample exposure to rare events or when participants are forced to sample all possible outcomes in proportion to their objective probabilities (Barron and Erev 2003; Ungemach et al. 2009). This suggests that additional mechanisms may contribute to observations of the decision–experience gap (see Gonzalez and Gutt 2011, on instance-based learning).
3.1.2 Selective reliance on past experiences
In many settings, people behave as if they rely on small samples drawn from their past experiences, possibly due to limitations of memory (e.g., outcomes that were more recently experienced; see Hertwig et al. 2004). Thus, decision makers may choose as if they underweight rare events that they have, in fact, experienced. The importance of this mechanism emerged in two choice prediction competitions focusing on the full- and the partial-feedback paradigms (Erev et al. 2010a, b): the winning models in both competitions implied reliance on small set of past experiences.
3.1.3 Tallying
A factor amplifying the gap concerns the way people search in the sampling paradigm. Hills and Hertwig (2010) found that participants who frequently switch between sampling each prospect (rather than sampling several times from each prospect before switching) are likely to choose options that win most of the time in round-wise comparisons. Such comparisons ignore the magnitude of the win (defeat), thus affording little weight to rare extreme outcomes. In contrast, participants who sample several times from each prospect before switching are more sensitive to rare extreme outcomes. Frequent switchers therefore tend to exhibit a pronounced description–experience gap, whereas infrequent switchers tend to behave more consistently across these paradigms.
3.1.4 The mere-presentation effect: analogical versus propositional representations
Erev et al. (2008) argued that a mere-presentation effect may contribute to overweighting in DFD but not in DFE. Specifically, DFD involves propositional representations—e.g., “32 with probability 0.1; 0 otherwise”—thus putting a more equal emphasis on outcomes than their objective probabilities warrant. If attention translates into decision weights, rare and common events’ weights will regress toward the mean. DFE, in contrast, invoke an analogical representation: for instance, draws from the aforementioned option could lead to this sequence {0, 0, 0, 0, 0, 32, 0, 0, 0, 0}. More attention is allocated to the processing of the frequent than of the rare events.
3.1.5 Unpacking and repacking
As mentioned previously, even when participants sample an entire distribution of outcomes without replacement so that there is no sampling error and therefore no unawareness, they tend to exhibit a diminished but significant description–experience gap. Moreover, selective reliance on past experiences may not play a role, as explicit judgments of sampled outcome probabilities tend to be quite accurate (see Ungemach et al. 2009). Fox et al. (2013) validated the robustness of this finding and argued that description–experience gap was due to the fact that DFE using the sampling paradigm “unpack” occurrence of outcomes (and therefore attention afforded to them) in proportion to their objective probabilities (similar to Erev et al. 2008 cited above). Fox et al. (2013) show that DFD can also be made to resemble decisions from experience if described outcomes are explicitly unpacked. For example, describing the outcome of a game of chance in a “packed” manner (e.g., “get $150 if a 12-sided die lands 1–2; get $0 otherwise”) leads to PT-like preferences. In contrast, “unpacking” the same description using a table of outcomes listed by die roll (e.g., “$150 if the die rolls 1; $150 if the die rolls 2; $0 if the die rolls 3; $0 if the die rolls 4; etc.”) leads to the opposite pattern of risk preferences, much like DFE.
Moreover, Fox et al. (2013) show that prompting decision makers to mentally “repack” events that are sampled from experience (by having participants sample colored cards and identifying outcomes associated with each color only after sampling is completed) leads to choices that accord with PT. This result accords with the aforementioned observation of Hills and Hertwig (2010) that participants who sample each distribution separately tend toward more PT-like behavior—one presumes that such sampling facilitates a spontaneous “repacking” of probabilities (i.e., consideration of overall impressions of the probability of each outcome). One interpretation of these results could be that the description–experience gap is not about experience per se but rather about the way in which information is presented or attended to.
4 Decision under described ambiguity
Evidence for the description–experience gap has relied almost exclusively on comparisons between DFE paradigms involving sampled experience to DFD paradigms involving precisely described probability distributions over outcomes (i.e., decisions under risk). However, because outcome probabilities are generally ambiguous to decision makers in DFE, it is instructive to compare DFE with DFD under ambiguity. The presence of ambiguity introduces two complications to decision weighting under PT. First, decision makers must judge for themselves the likelihood of events on which each outcome depends. Several studies suggest that to a first approximation, choices accord well with a two-stage model (Tversky and Fox 1995; Fox and Tversky 1998; Fox and See 2003) in which the probability weighting function from PT is applied to judged probabilities of events, consistent with support theory (Tversky and Koehler 1994; Rottenstreich and Tversky 1997). Generally, people tend to overestimate the likelihood of rare events and underestimate the likelihood of very common events, which amplifies the characteristic pattern of overweighting and underweighting in PT. However, studies using the standard sampling paradigm have typically yielded judged probabilities that are quite accurate (Fox and Hadar 2006; Ungemach et al. 2009), perhaps due to people’s natural facility in encoding frequency information (Hasher and Zachs 1984).
Second, the shape of the weighting function can vary with the source of uncertainty, which is defined as a group of events whose realization is determined by a similar mechanism and that therefore have similar characteristics (see Tversky and Fox 1995; Tversky and Wakker 1995; Abdellaoui et al. 2011a). Experimental evidence suggests that the probability weighting function is systematically affected by specific characteristics of the decision situation, whereas the curvature of the utility function is not (Fehr-Duda and Epper 2012). For example, departures from linear weighting are more pronounced for more emotional consequences such as an electric shock than for less emotional consequences such as a financial payment (Rottenstreich and Hsee 2001), and high-stake prospects are evaluated less optimistically than low-stake prospects (Fehr-Duda et al. 2010). People typically exhibit aversion to betting on ambiguous events (Ellsberg 1961), particularly when they feel relatively ignorant or incompetent assessing those events (Heath and Tversky 1991; Fox and Tversky 1995; Fox and Weber 2002) although ambiguity seeking is occasionally observed, especially for losses (Camerer and Weber 1992).
If ambiguous probabilities are weighted more pessimistically than chance (risky) probabilities, then it stands to reason that prospects will be more attractive when their probability distributions are precisely known than when they are sampled from experience. Abdellaoui et al. (2011b) observe such a difference in elevation of probability weighting functions between DFD under risk and DFE.
5 Calibration and estimation
Different assumptions on error structures between DFE and DFD can also contribute to the description–experience gap. Econometric studies (Ben-Akiva et al. 2012; Wilcox 2008) consider such choice errors. We assume observed preferences between J pairs of prospects x p y and x q ′y ′. The PT value of x p y, PT δ (x p y), depends on δ, which denotes the vector of subjective parameters determining (w,u,λ). Here, we assume only gains and write w = w +. This general notation facilitates applications of a number of techniques to decision models other than PT.
One way to estimate δ is by minimizing some distance function between, say, observed certainty equivalents and those theoretically predicted by δ. We may also minimize the number of observed choices mispredicted by δ. This will usually give a region of optimal δs.
In a stochastic choice model, an error process is assumed and maximum likelihood (ML) estimation can be used to estimate δ. One example of error process is the trembling hand model that assumes that decision makers can get confused, say with probability π, and choose randomly. The probability of a “wrong” choice then is π/2. Likelihood is maximized by maximizing the number of correctly predicted choices agreeing with an aforementioned criterion.
An alternative error process entails that a random and independent, continuously distributed noise term ε is added to each PT value or that each PT value is multiplied by a random positive factor. This yields the well-known logit model when ε has an extreme value distribution. In the additive error case, the decision maker now chooses x p y over x q ′y ′ with probability
where σ > 0 denotes the scale parameter of the extreme value distribution. The bigger σ, the closer we are to random, 50-50, choice. For σ tending to 0, we approximate deterministic choice. The parameters σ and δ can again be estimated using maximum likelihood.
Some error models assume that in each choice situation a new PT model is chosen according to some probability distribution over δ (de Palma et al. 2011). For example, the exponent in the power (CRRA) utility function may be determined randomly for each choice. Unlike the foregoing trembling hand or logit models, models directly estimating the probability distribution over δ do not allow for violations of stochastic dominance in the data. The resulting likelihood functions are usually more complex, and estimation requires simulation methods (Train 2009; de Palma and Picard 2010).
Although the aforementioned models focus on parameters at the individual level, the techniques can also be used to estimate population or group-level parameters. Heterogeneity of δ can either systematically vary across the population or randomly vary, as in the random parameter or latent class model (Ben-Akiva et al. 2012). The random parameter distribution is assumed to be a distribution across a population rather than across decision instances of a single individual. The random distribution can be either continuous or discrete. The discrete case (a latent class choice model) allows one to estimate segments of the population that have distinctly different decision behaviors. The resulting model describes both who is likely to be in the segment as well as the segment-specific behavior (Walker and Ben-Akiva 2011). This could be useful in capturing different probability weighting functions and loss aversion characteristics as influenced by the experimental design.
Fox et al. (2013) provide an early econometric estimation of DFE. A common utility function parameter and error parameter are assumed to apply to DFE and DFD, but a (single) weighting function parameter could vary across paradigms. Their data accord well with a stochastic PT model with an inverse S-shaped weighting function for DFD and a linear weighting function for DFE.
Extending the above error theories from risk to ambiguity is especially desirable for examining the gap between DFD and DFE. Error theories are yet to be developed for beliefs in the two-stage model described above, where those beliefs should also capture learning processes. We consider this to be a promising direction for future research.
6 Conclusions
Several tentative conclusions can be drawn from our interdisciplinary discussion of the description–experience gap in decision under uncertainty. First, a substantial part of the gap can be explained by sampling error (which can cause sheer unawareness that rare events could occur) and misplaced faith in Gaussian distributions (which can give rise to misplaced confidence that rare events are highly unlikely to occur). Second, the way in which the probability distribution over possible outcomes is learned by a decision maker matters, and an error theory to characterize this process would help advance our understanding. Thus, elicitation methods that facilitate allocation of decision makers’ attention to possible outcomes in proportion to respective probabilities of occurrence (in any sort of analogical fashion) may lead decision makers to weigh probabilities in a more linear fashion. Third, it is instructive to compare DFE to DFD under ambiguity (rather than risk), and ambiguity aversion may contribute to the putative description–experience gap.
References
Abdellaoui, M., Baillon, A., Placido, L., & Wakker, P. P. (2011a). The rich domain of uncertainty: source functions and their experimental implementation. American Economic Review, 101, 699–727.
Abdellaoui, M., l’Haridon, O., & Paraschiv, C. (2011b). Experienced vs. described uncertainty: do we need two prospect theory specifications? Management Science, 57, 1879–1895.
Allais, M. (1953). Le comportement de l’homme rationnel devant le risque: critique des postulats et axiomes de l’école américaine. Econometrica, 21, 503–546.
Barron, G., & Erev, I. (2003). Small feedback-based decisions and their limited correspondence to description-based decisions. Journal of Behavioral Decision Making, 16, 215–233.
Ben-Akiva, M., de Palma, A., McFadden, D., Abou-Zeid, M., Chiappori, P. A., de Lapparent, M., et al. (2012). Process and context in choice models. Marketing Letters, 23, 439–456.
Camerer, C., & Weber, M. (1992). Recent development in modeling preferences: uncertainty and ambiguity. Journal of Risk and Uncertainty, 5, 325–370.
de Palma, A., & Picard, N. (2010). Measuring individual-specific risk aversion, loss aversion and probability weighting. Unpublished manuscript, Paris Ecole Polytechnique.
de Palma, A., Picard, N., & Ziegelmeyer, A. (2011). Individual and couple decision behavior under risk: evidence on the dynamics of power balance. Theory and Decision, 70, 45–64.
Dimmock, S. G., Kouwenberg, R., Mitchell, O. S., & Peijnenburg, K. (2013). Ambiguity aversion and household portfolio choice: empirical evidence. Unpublished manuscript, NBER.
Ellsberg, D. (1961). Risk, ambiguity and the Savage axioms. Quarterly Journal of Economics, 75, 643–669.
Erev, I., Glozman, I., & Hertwig, R. (2008). What impacts the impact of rare events. Journal of Risk and Uncertainty, 36, 153–177.
Erev, I., Ert, E., & Roth, A. E. (2010a). A choice prediction competition for market entry games: an introduction. Games, 1, 117–136.
Erev, I., Ert, E., Roth, A. E., Haruvy, E., Herzog, S. M., Hau, R., et al. (2010b). A choice prediction competition: choices from experience and from description. Journal of Behavioral Decision Making, 23, 15–47.
Fehr-Duda, H., & Epper, T. (2012). Probability and risk: foundations and economic implications of probability-dependent risk preferences. Annual Review of Economics, 4, 567–593.
Fehr-Duda, H., Bruhin, A., Epper, T., & Schubert, R. (2010). Rationality on the rise: why relative risk aversion increases with stake size. Journal of Risk and Uncertainty, 40, 147–180.
Fox, C. R., & Hadar, L. (2006). “Decisions from experience” = sampling error plus prospect theory: reconsidering Hertwig, Barron, Weber & Erev (2004). Judgment and Decision Making, 2, 159–161.
Fox, C. R., & See, K. E. (2003). Belief and preference in decision under uncertainty. In D. Hardman & L. Macchi (Eds.), Thinking: current perspectives on reasoning, judgment, and decision making (pp. 273–314). Hoboken: Wiley.
Fox, C. R., & Tversky, A. (1995). Ambiguity aversion and comparative ignorance. Quarterly Journal of Economics, 110, 585–603.
Fox, C. R., & Tversky, A. (1998). A belief-based account of decision under uncertainty. Management Science, 44, 879–895.
Fox, C. R., & Weber, M. (2002). Ambiguity aversion, comparative ignorance and decision context. Organizational Behavior and Human Decision Processes, 88, 476–498.
Fox, C. R., Long, A., Hadar, L., & Erner, C. (2013). Unpacking decisions from description and experience. Unpublished manuscript, UCLA Anderson School of Management.
Gonzalez, C., & Gutt, V. (2011). Instance-based learning: integrating sampling and repeated decisions form experience. Psychological Review, 118, 523–551.
Hadar, L., & Fox, C. R. (2009). Information asymmetry in decisions from description versus decisions from experience. Judgment and Decision Making, 4, 317–325.
Hasher, L., & Zachs, L. T. (1984). Automatic processing of fundamental information: the case of frequency of occurrence. American Psychologist, 39, 1372–1388.
Heath, C., & Tversky, A. (1991). Preference and belief: ambiguity and competence in choice under uncertainty. Journal of Risk and Uncertainty, 4, 5–28.
Hertwig, R., & Erev, I. (2009). The description-experience gap in risky choice. Trends in Cognitive Science, 13, 517–523.
Hertwig, R., Barron, G., Weber, E. U., & Erev, I. (2004). Decisions from experience and the effect of rare events in risky choice. Psychological Science, 15, 534–539.
Hills, T., & Hertwig, R. (2010). Information search and decisions from experience: do our patterns of sampling foreshadow our decisions? Psychological Science, 21, 1787–1792.
Kahneman, D., & Tversky, A. (1979). Prospect theory: an analysis of decision under risk. Econometrica, 47, 263–291.
Rabin, M. (2000). Risk aversion and expected-utility theory: a calibration theorem. Econometrica, 68, 1281–1292.
Rottenstreich, Y., & Hsee, C. (2001). Money, kisses, and electric shocks: on the affective psychology of risk. Psychological Science, 12, 185–190.
Rottenstreich, Y., & Tversky, A. (1997). Unpacking, repacking, and anchoring: advances in support theory. Psychological Review, 104, 406–415.
Taleb, N. N. (2007). The black swan: The impact of the highly improbable. New York: Random House.
Train, K. (2009). Discrete choice methods with simulation. Cambridge: Cambridge University Press.
Tversky, A., & Fox, C. R. (1995). Weighing risk and uncertainty. Psychological Review, 102, 269–283.
Tversky, A., & Kahneman, D. (1992). Advances in prospect theory: cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5, 297–323.
Tversky, A., & Koehler, D. J. (1994). Support theory: a nonextensional representation of subjective probability. Psychological Review, 101, 547–567.
Tversky, A., & Wakker, P. P. (1995). Risk attitudes and decision weights. Econometrica, 63, 1255–1280.
Ungemach, C., Chater, N., & Stewart, N. (2009). Are probabilities overweighted or underweighted, when rare outcomes are experienced (rarely)? Psychological Science, 20, 473–479.
Wakker, P. P. (2010). Prospect theory: For risk and ambiguity. Cambridge: Cambridge University Press.
Walker, J. L., & Ben-Akiva, M. (2011). Advances in discrete choice: mixtures models. In A. de Palma, R. Lindsey, E. Quinet, & R. Vickerman (Eds.), Handbook in transport economics (pp. 160–187). Cheltenham: Edward Elgar.
Wilcox, N. T. (2008). Stochastic models for binary discrete choice under risk: a critical primer and econometric comparison. In J. C. Cox & G. W. Harrison (Eds.), Risk aversion in experiments (research in experimental economics 12) (pp. 197–292). Bingley: Emerald.
Yechiam, E., Barron, G., & Erev, I. (2005). The role of personal experience in contributing to different patterns of response to rare terrorist attacks. Journal of Conflict Resolution, 49, 430–439.
Acknowledgments
We thank two anonymous referees and an associate editor for their useful comments and suggestions. We also thank Benedict Dellaert and Bas Donkers for organizing this successful 9th Invitational Choice Symposium.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
de Palma, A., Abdellaoui, M., Attanasi, G. et al. Beware of black swans: Taking stock of the description–experience gap in decision under uncertainty. Mark Lett 25, 269–280 (2014). https://doi.org/10.1007/s11002-014-9316-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11002-014-9316-z