
Abstract
Representation learning is one of the most important aspects of multi-label learning because of the intricate nature of multi-label data. Current research on representation learning either fails to consider label knowledge or is affected by the lack of labeled data. Moreover, most of them learn the representations and incorporate the label information in a two-step manner. In this paper, due to the success of representation learning by deep learning we propose a novel framework based on neural networks named SERL to learn global feature representation by jointly considering all labels in an effective supervised manner. At its core, a two-encoding-layer autoencoder, which can utilize labeled and unlabeled data, is adopted to learn feature representation in the supervision of softmax regression. Specifically, the softmax regression incorporates label knowledge to improve the performance of both representation learning and multi-label learning by being jointly optimized with the autoencoder. Moreover, the autoencoder is expanded into two encoding layers to share knowledge with the softmax regression by sharing the second encoding weight matrix. We conduct extensive experiments on five real-world datasets to demonstrate the superiority of SERL over other state-of-the-art multi-label learning approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Multi-label learning, which deals with the problem where one object may be associated with one or more labels, has attracted extensive researches in the past decades (Tsoumakas and Katakis 2006). Different from single-label problem where binary class and multi-class classification hold, multi-label learning could model the world more exactly. Besides, multi-label learning has widespread applications such as news classification and image processing (Boutell et al. 2004). For example, one news may belong to multiple topics such as politics and economy because it reports new policies on bank rate. A scenery picture, as a more familiar example, may contain sky, road, cornfield and so on, where they can be viewed as with multiple labels.
Traditionally in multi-label learning, the problem transformation method transformed the multi-label dataset to a series of single label datasets (Zhang and Zhou 2014), such as the binary relevance method (Tsoumakas et al. 2009) and the label powerset method (Tsoumakas et al. 2011). This kind of methods neglect the fact that some labels are more likely to co-exist in one instance, which is the main focus of many recent multi-label works. Therefore, in order to parameterize the label correlations, Ghamrawi and McCallum (2005) proposed a multi-label classifier in conditional random field by modeling the label co-occurrences explicitly. Zhang and Zhang (2010) utilized a Bayesian network structure to encode the conditional dependencies of the labels and the feature set. Nguyen et al. (2016) proposed a Bayesian nonparametric approach to automatically learn the number of label-feature correlation patterns. However, most existing multi-label methods utilized the raw instance data to formalize the model, which might contain non-helpful feature attributes from the input space prior to training. Hence, learning better feature representation is important for the multi-label learning.
There exist some related works on multi-label learning classifiers based on representative features (Zhang and Zhou 2008; Read and Perezcruz 2014; Zhang and Wu 2015). MMDM (Zhang and Zhou 2008) discovers a low-dimension feature space which maximizes the dependence between the original features and the corresponding labels. LIFT (Zhang and Wu 2015) uses clustering techniques to construct label-specific features for each label and then solves binary classification problems based on the transformed features. MLFE (Zhang et al. 2018) utilizes the structural information in feature space to enrich the labeling information. However, these works either learn representative features without considering label knowledge or suffer from the lack of labeled data. Recently, deep learning has proven to be able to learn good representation in natural language processing, image classification, and so on. And some effort has been devoted to handling multi-label learning problem to improve the performance. Read and Perezcruz (2014) used restricted Boltzmann machine (RBM) to get a better representation of the original features, and then applied the supervised learning algorithms to training classification models. However, they performed the optimization framework in a two-step manner, while we try to learn the representation and incorporate label knowledge in a joint optimization framework.
To address these issues, we propose a novel framework named SERL (SupErvised Representation Learning for multi-label classification) in this paper. SERL adopts a two-encoding-layer autoencoder to learn better representation of the original features in the supervision of softmax regression. Specially, the softmax regression incorporates label knowledge to improve the performance of both representation learning and multi-label learning by being jointly optimized with the autoencoder, where the autoencoder can sufficiently utilize labeled and unlabeled data to learn nonlinear representation of the original features. In addition, the autoencoder is expanded into two encoding layers to share knowledge with the softmax regression by sharing the second encoding weight matrix. We evaluate the proposed approach on five real-world datasets and observe the effectiveness of SERL that it can outperform the compared state-of-the-art algorithms significantly. The contribution of this paper is summarized as follows.
-
We propose an autoencoder based framework (SERL) to discover latent knowledge of the original features by jointly considering all labels in an effective supervised manner.
-
The autoencoder learns representation from labeled and unlabeled data in the supervision of the softmax regression. Moreover, the autoencoder shares knowledge with softmax regression by sharing the second encoding weight matrix.
-
We conduct extensive experiments on five real-world datasets to demonstrate the superiority of the proposed method over other state-of-the-art algorithms.
The remainder of this paper is organized as follows. Section 2 introduces the preliminary knowledge. The framework and its solution are detailed in Sect. 3. The experimental results are reported in Sect. 4. Section 5 discusses the related work and finally Sect. 6 concludes.
2 Preliminaries
2.1 Softmax regression
Softmax regression which is often used to solve the problem of multi-class classification can be regarded as the generalization of the logistic regression. When given a test input x, softmax regression estimates the probability of each label (label space \(y \in \{1,2,\ldots ,k\}\)) by the hypothesis function as follows,
The objective function of softmax regression can be described as follows,
where the indicator function \(1\{\varvec{\cdot }\}\) equals 1 when \(x_i\) holds label j and equals 0 otherwise. Given training dataset \(\{\varvec{x_i,~y_i}\}_{i=1}^n\) (\(y_i \in \{1,2,\ldots ,k\}\)), the model parameter \(\varvec{\theta }\) can be derived by minimizing Eq. (2). After training, the probability of each label can be computed using Eq. (1), then the predicted label can be assigned as follows,
2.2 Autoencoder
Autoencoder, which is a neural network, uses unsupervised learning method to learn compressed features from original features. A multi-layer autoencoder comprises one input layer, one output layer, and several hidden layers. The aim of the autoencoder is to reconstruct the input signal in the output layer with the least amount of distortion. A simple autoencoder consists of two parts, that is, an encoder including the input layer and hidden layer and a decoder including the hidden layer and output layer. Given an input \(\varvec{x_i} \in \mathbb {R}^{d\times 1}\), weight matrix \(\varvec{W}_1\in \mathbb {R}^{k\times d}\), \(\varvec{W}_1^{'}\in \mathbb {R}^{d\times k}\), and bias vector \(\varvec{b}_1\in \mathbb {R}^{k\times 1}\), \(\varvec{b}_1^{'}\in \mathbb {R}^{d\times 1}\), a single hidden layer autoencoder encodes it into the hidden layer \(\varvec{{\xi }_i} \in \mathbb {R}^{k \times 1}\) and decodes the hidden layer into the output layer \({\hat{\varvec{x_i}}}\) which is as same as possible with the input layer. This process can be described as,
Here we use the sigmoid function as the activation function f. Given a set of inputs \(\{\varvec{x}_i\}_{i=1}^n\), the goal of autoencoder is to minimize the reconstruction error using L2 regularization as follows,
3 The SERL framework
In this section, we present our proposed framework in detail and the symbols used are listed in Table 1.

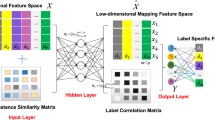
The framework of SERL
3.1 Problem formalization
The proposed framework is composed of a two-encoding-layer autoencoder and softmax regression as shown in Fig. 1. The two components are jointly optimized and they share the second encoding weight matrix \(\varvec{W}_2\). Given multi-label training dataset \({D_r}=\{(x_i^{(r)},Y_i^{(r)})|1\le i \le n_r\}\) and test dataset \({D_s}=\{(x_i^{(s)},Y_i^{(s)})|1\le i \le n_s\}\), where \(x_i^{(r)},x_i^{(s)} \in \mathbb {R}^{d \times 1}\) and \(Y_i^{(r)},Y_i^{(s)} \subseteq \mathcal {Y}\) (\(\mathcal {Y} = \{1,2\ldots ,c\}\)) are sets of relevant labels associated with \({x_i^{(r)}},{x_i^{(s)}}\) respectively. The objective function can be described as follows,
where J is the loss of autoencoder, \(\mathcal {L}\) is the loss of softmax regression, \(\varOmega \) is the regularization term, \( \alpha \) and \( \beta \) are trade-off parameters for the whole framework. \(\varvec{W}, \varvec{b}\) include all the parameters for encoding, and \(\varvec{W}^{'}, \varvec{b}{'}\) represent the ones for decoding.
There are three terms in Eq. (6). In the first term \(J(\varvec{x}^{(t)},{\hat{\varvec{x}}}^{(t)})\), the reconstruction error is calculated for both training and test datasets, and it is defined as follows,
where
There are three hidden layers in our framework. The first one called the embedding layer has k nodes (\(k \le d\)) with output \(\varvec{\xi }^{(t)}_{i} \in \mathbb {R}^{k\times 1}\), weight matrix \(\varvec{W}_1\in \mathbb {R}^{k\times d}\), and bias vector \(\varvec{b}_1\in \mathbb {R}^{k\times 1}\). The second one called the label layer has c nodes (equals to the number of labels) with output \(\varvec{z}^{(t)}_{i} \in \mathbb {R}^{c\times 1}\), weight matrix \(\varvec{W}_2\in \mathbb {R}^{c\times k}\) and bias vector \(\varvec{b}_2\in \mathbb {R}^{c\times 1}\). The input of the label layer is also the input of the softmax regression which incorporates label knowledge. The third one is the reconstruction of the embedding layer with output \({\hat{\varvec{\xi }}}^{(t)}_{i} \), weight matrix \(\varvec{W}_2^{'} \in \mathbb {R}^{k \times c}\) and bias vector \(\varvec{b}_2^{'}\in \mathbb {R}^{k\times 1}\). The output layer is the reconstruction of input \(\varvec{x}^{(t)}_{i} \) with output \(\varvec{\hat{\varvec{x}}}^{(t)}_{i} \in \mathbb {R}^{d \times 1}\), weight matrix \(\varvec{W}_1^{'} \in \mathbb {R}^{d \times k}\) and bias vector \(\varvec{b}_1^{'} \in \mathbb {R}^{d \times 1}\).
The second term in the objective Eq. (6) is the optimization of softmax regression, which incorporates the label knowledge from training data. Note here that the autoencoder is expanded into two encoding layers to share the second encoding weight matrix \(W_2\) with the softmax regression, which aims to share knowledge with the softmax regression.
Here we try to use the softmax regression to handle multi-label data. The basic idea is to transform the multi-label data to multi-class data. Let \(\sigma : (x_i,Y_i) \rightarrow \{(x_i, y_j)|y_j \in Y_i\}\) be the function which converts a (instance, labels) pair into a set of (instance, label) pair where each (instance, label) pair contains only one label. For example, suppose we have one instance \(x_i\) with labels \(y_1\), \(y_2\), \(y_4\). \(\sigma \) converts \((x_1, \{y_1, y_2, y_4\})\) to \((x_1, y_1)\), \((x_1, y_2)\), \((x_1, y_4)\). In the training phase, we firstly converts the original multi-label training dataset \(D_r\) into the following multi-class training dataset \(D_r^{\dag }\) by \(\sigma \) as follows,
After that, softmax regression \(\mathcal {M}\) is utilized to induce multi-class classifier \(g^{\dag }:\mathcal {X} \rightarrow \mathcal {Y}, i.e., g^{\dag } \leftarrow \mathcal {M}(D_r^{\dag })\) (\(\mathcal {X} \in \mathbb {R}^{d\times 1}\), \(\mathcal {Y} = \{1,2,\ldots ,c\}\)). The objective function of softmax regression can be formalized as follows,
In this term, \(\varvec{\xi }^{(r)}_i\) is the output of the embedding layer and \(\varvec{\theta }_j^{\top } (j \in \{1,\ldots ,c\})\) is the j-th row of \(\varvec{W}_2\) which is also the second encoding weight matrix of autoencoder.
Finally, the last term in the objective Eq. (6) is the regularization on model parameters which controls the complexity of the framework to improve its generalization ability. The last term is defined as follows,
3.2 Solution of the proposed framework
The optimization problem of our proposed framework is to minimize \(\mathcal {J}\) (seen in Eq. (6)) as a function of \(\varvec{W}_1\), \(\varvec{b}_1\), \(\varvec{W}_2\), \(\varvec{b}_2\), \(\varvec{W}_2^{'}\), \(\varvec{b}_2^{'}\), \(\varvec{W}_1^{'}\) and \(\varvec{b}_1^{'}\). This is an unconstrained optimization problem and therefore we can adopt the gradient descent method to solve it.
We first introduce some intermediate variables for simplicity as follows,
The partial derivatives of \(\varvec{W}_1\), \(\varvec{W}_2\), \(\varvec{W}_2^{'}\), \(\varvec{W}_1^{'}\) are as follows respectively,
where \(\varvec{W}_{2j}\) is the j-th row of \(\varvec{W}_2\) and \(n_{rj}\) is the number of instance associated with label j in training dataset. According to the above partial derivatives, we update the parameters by alternatively iterating following those rules,
where \(\eta \) is step length controlling the learning rate. Finally, the whole algorithm is summarized in “Algorithm 1”.

Although the optimization of the objective function is not convex, we can get a better local optimal solution through appropriate initialization of the weights and biases. Specifically, we use the stacked denosing autoEncoder (SDAE) to initialize the values of \(\varvec{W}\) and \(\varvec{b}\).
3.3 Prediction
After training, we use the softmax regression to predict the label set of each test instance. Specifically, we can estimate the probability \(P(y_i^{(s)}=j| \varvec{x}_i^{(s)})\) of one certain test instance belonging to each label. Then we sort all the label probabilities in descending order and compute the difference between two adjacent label probabilities in this order. Finally we assign the labels, which are in the front of the position of the max difference, as the predicted labels of the instance. This process can be described by Fig. 2, where \(P_i\) is the probability of one certain test instance belonging to label i and \(\triangle P_j\) is the probability difference between adjacent labels in the ordered list.

The prediction strategy
4 Experimental evaluation
In this section, we conduct extensive experiments on five benchmark multi-label datasets to evaluate the performance of the proposed framework.
4.1 Datasets and preprocessing
These five datasets include slashdot, corel5k, bibtex, corel16k01 (sample 1) and corel16k02 (sample 2) from MULAN (Tsoumakas et al. 2011) and MEKA (Read et al. 2016) multi-label learning libraries. These datasets can evaluate the proposed framework in different cases including text and image. For all the datasets, we randomly sample \(50\%\) of examples without replacement to construct training dataset and the remaining \(50\%\) to construct test dataset. We sample each dataset for five times and calculate the average accuracies. The information of all the datasets is detailed in Table 2, #instances represents the number of instances, #features represents the feature dimension, #labels represents the number of labels, and #domains represents the domains of the datasets.
4.2 Comparison methods
We compare our proposed model with seven multi-label algorithms as follows.
-
Binary relevance (BR) (Boutell et al. 2004) This algorithm learns c independent binary classifiers for each label and queries all the classifiers for prediction.
-
Calibrated label ranking (CLR) (Fürnkranz et al. 2008) This algorithm uses pairwise comparison to decompose the multi-label learning problem into the label ranking problem with calibrated scenario.
-
Random k-Labelsets (RAkEL) (Tsoumakas and Vlahavas 2007) This algorithm applies Label Powerset techniques, which transforms the multi-label learning problem into the multi-class classification problems, on an ensemble of k random label subsets.
-
Ensemble of classifier chains (ECC) (Read et al. 2011) This algorithm is an ensemble of classifier chain algorithm which considers high-order relations among labels represented in an ordered chain and then trains c binary classifiers according to the chain.
-
Multi-label learning with Label specIfic FeaTures (LIFT) (Zhang and Wu 2015) This algorithm conducts clustering analysis on positive and negative instances of each label to construct its specific features, then applies binary relevance algorithm on label-specific features of each label.
-
Multi-label learning with stacked denoising autoencoders (SDAE) (Vincent et al. 2010) Here we use SDAE in a two-step manner to compare with our joint optimization framework. Specially, we first train the autoencoder alone to learn feature representation and then combine the new features with the labels to construct new training dataset. Finally, we use Bayesian Multinomial Regression(BMR) to learn the classifier on the new training dataset.
-
Multi-label learning with feature-induced labeling information enrichment (MLFE) (Zhang et al. 2018) In MLFE, the structural information in feature space is utilized to enrich the labeling information. The sparse reconstruction among the training examples is conducted to characterize the underlying structure of feature space. Then the reconstruction information is conveyed from feature space to label space so as to enrich the labeling information.
4.3 Experimental settings
There are three factors in our proposed framework including trading-off parameters \(\alpha \), \(\beta \) and the number of nodes k of the embedding layer. After cross-validations on training dataset, we set \(\alpha = 15\), \(\beta = 0.005\), \(k = 100\) for all datasets. LIBSVM with linear kernel (Chang and Lin 2011) is employed as the base classifier for all baselines except SDAE. Bayesian multinomial regression (BMR) (Madigan et al. 2005) is employed as the base classifier for SDAE. Specifically, for RAkEL, the size of label subset k is set as 3 and the size of ensemble is set as 2c (c is the number of labels) as a rule-of-thumb setting. For ECC, the size of ensemble is set 100 to cover the high-order relations among labels sufficiently. For LIFT, the ratio is set to 0.1 as reported in their original paper (Zhang and Wu 2015). For MLFE, the penalty parameters \(\beta _1\), \(\beta _2\) and \(\beta _3\) are set as 2, 10, 1, respectively according to Zhang et al. (2018).
4.4 Results and discussion
To compare our proposed model with baselines in a more comprehensive way, we adopt two types of evaluation metrics, i.e., ranking metrics and classification metrics. Further more, both types of metrics can be subdivided into example-based and label-based ones. Tables 3 and 4 summarizes the results on all five datasets, and the best results are marked in bold. Next, we analyze the results on all these metrics in detail as follows.
4.4.1 Results on ranking evaluation metrics
Among all ranking evaluation metrics, OneError, Coverage, RankingLoss and AvgPrecision are example-based, while MacroAUC is label-based.
-
We can see that SERL performs the best in all five datasets on Coverage and RankingLoss. Even on the metric of OneError, SERL achieves the best performance on datasets corel5k and corel16k01, and gets an comparable performance to CLR and MLFE, which obtain best results on some corresponding datasets.
-
For label-based ranking metric MacroAUC, SERL also achieves the best performance in most datasets. According to Table 2, we can see that corel5k has the most labels up to 374 and slashdot has the least labels of 22. The results in all the five datasets show the outstanding performance of SERL in probability estimation over the datasets with high-diversity of label size.
4.4.2 Results on classification evaluation metrics
Among classification evaluation metrics, Accuracy and F1 are example-based and MacroF1 is label-based.
-
It is obvious that SERL achieves better performance than the baselines in terms of Accuracy and F1. We can get the following two observations from the results. The first one is that our model performs well for each example, which contributes to high accuracy and F1. And the other one is that some baselines such as BR and RAkEL output empty sets for some examples, failing to predict label information, which makes no sense for classification and leads to unsatisfying results.
-
For MacroF1, SERL achieves the best in all data sets, which proves good performance of SERL in classifying the positive and negative examples of each label. The fact that SERL does well in both example-based and label-based classification metrics shows the superior classification performance of our model.
Overall, all the results validate the effectiveness of our framework.
4.5 Parameter sensitivity
For analyzing the influence of the parameters \(\alpha \), \(\beta \), k, we do a series of sensitivity experiments. We choose RankingLoss as the criterion of sensitivity experiments. All the results are shown in Fig. 3.
-
For \(\alpha \), RankingLoss has a obvious inflection point when \(\alpha \) changes from 0 to 15. Specially, RankingLoss achieves the best value when \(\alpha \) gets 15 and 30. In general, the trend of RankingLoss is gentle when \(\alpha \) changes, which shows that our proposed framework is not sensitive to \(\alpha \) when its value is not too small.
-
For \(\beta \), RankingLoss gets the best value when \(\beta \) is 0.005 and 0.01. When \(\beta \) increases after 0.01, RankingLoss gets worse obviously.
-
For the number of nodes k of the embedding layer, RankingLoss reduces firstly and then increases slightly. It is interesting that RankingLoss gets its best value when k is relatively small, which guarantees that we can speed up the construction of our model because of the low dimension. Moreover, the trend of RankingLoss is gentle when k changes, which is helpful for the tuning process of k.
As a whole, we set \(\alpha = 15\), \(\beta = 0.005\), \(k = 100\) for all datasets according to the parameter sensitivity experiments.

The parameter affects
4.6 Effects on supervision information
To study the effectiveness of the proposed model in the case there are different numbers of labeled instances are available, we do a series of experiments in variable ratios of labeled instances. Specifically, the ratio of labeled instances increases from \(5\%\) to \(50\%\) and the step size is \(5\%\). The results are shown in Fig. 4. It is obvious that SERL achieves the best performance in all ratios, which demonstrates the effectiveness of SERL. Moreover, compared to the baselines, the superiority of SERL is higher in small ratios than high ratios, which shows that SERL can make full use of labeled and unlabeled data sufficiently.

The performance in variable ratios of labeled instances
5 Related work
Multi-label learning has attracted a lot of interest in recent years. There are two kinds of multi-label algorithms, problem transformation and algorithm adaptation methods.
Problem transformation methods transform multi-label learning problem into other problems which have solid theories and well-established solutions. For example, Binary Relevance (Boutell et al. 2004), AdaBoost.MH (Schapire and Singer 2000), Stacked Aggregation (Godbole and Sarawagi 2004) and Classifier Chains (Read et al. 2011) transform multi-label learning problem into binary classification problems. Calibrated Label Ranking transforms multi-label learning problem into label ranking problems with calibrated scenario by pairwise comparison (Fürnkranz et al. 2008). Random k-Labelsets (Tsoumakas and Vlahavas 2007) transforms multi-label learning problem into multi-class classification problems on an ensemble of k random label subsets.
Algorithm adaptation methods adapt traditional algorithms to multi-label data (Zhang and Zhou 2014). For example, ML-kNN (Zhang and Zhou 2005) adapts traditional k-nearest neighbor algorithm to multi-label data and uses maximum a posteriori(MAP) principle to predict labels for the new instance. ML-DT (Clare and King 2002) calculates information gain based on multi-label entropy. Rank-SVM (Elisseeff and Weston 2002) fits the maximum margin to differentiate the relevant and irrelevant labels of one instance. BP-MLL (Zhang and Zhou 2006) uses feedforward neural network to hold multi-label data where a error function capturing ranking correlation between relevant and irrelevant labels is calculated through backpropagation algorithm. CML (Ghamrawi and McCallum 2005) utilizes conditional random field to model label co-occurrences in multi-label data. Nguyen et al. (2016) proposed a Bayesian nonparametric approach to learn the number of label-feature correlation pat- terns automatically. MLFE (Zhang et al. 2018) utilized the structural information in feature space to enrich the labeling information.
Except these algorithms, representation learning is also one of the most important aspects of multi-label learning (Zhang and Zhou 2008; Read and Perezcruz 2014; Zhang and Wu 2015; Yu et al. 2005; Chen et al. 2008; Sun et al. 2008; Qian and Davidson 2010; Ji et al. 2010; Karalas et al. 2015; Zhou et al. 2017). For example, Read and Perezcruz (2014) utilized restricted Boltzmann machine (RBM) to achieve better representation of the original features to train the classifier. BILC (Zhou et al. 2017) mapped the label relationship into a binary embedded space instead of real-valued to achieve better performance. However, current works about representation learning neglect label knowledge, or suffer from the lack of labeled data, or are limited to linear projection. The most related work (Li and Guo 2014), which proposed a bi-directional representation model for multi-label classification, in which the mid-level representation layer is constructed from both input and output spaces. In essence, their network structure is different from ours. Their framework contained two basic autoencoders, i.e., one for the input features and the other one for output labels, and had to compute the additional parameters of encoding weights from low-dimensional representation of the input features to output labels and prediction model from input features to the low-dimensional representation of the output labels. In this paper, we propose a framework named SERL, which adopts a two-encoding-layer autoencoder to learn feature representation in a supervised manner. The autoencoder can sufficiently utilize labeled and unlabeled data simultaneously under the supervision of softmax regression. The softmax regression incorporates label knowledge to improve the performance of both representation learning and multi-label learning by being jointly optimized with the autoencoder. Extensive experiments on five data sets demonstrate the good performance of our framework.
6 Conclusion
In this paper, we proposed a framework named SERL, which adopts autoencoder to learn feature representation in a supervised manner. In this framework, labeled and unlabeled data can be handled by the autoencoder, meanwhile the softmax regression incorporates label knowledge by being jointly optimized with autoencoder. Moreover, the autoencoder is expanded into two encoding layers to share knowledge with softmax regression by sharing the second encoding weight matrix. Extensive experiments on five real-world datasets demonstrate the superiority of SERL over other state-of-the-art multi-label learning algorithms.
References
Boutell, M. R., Luo, J., Shen, X., & Brown, C. M. (2004). Learning multi-label scene classification. Pattern Recognition, 37(9), 1757–1771.
Chang, C. C., & Lin, C. J. (2011). Libsvm: A library for support vector machines. ACM Transactions on Intelligent Systems & Technology, 2(3), 27.
Chen, G., Song, Y., Wang, F., & Zhang, C. (2008). Semi-supervised multi-label learning by solving a sylvester equation. In SIAM international conference on data mining, SDM 2008, April 24–26, 2008, Atlanta, Georgia, USA (pp. 410–419).
Clare, A., & King, R. D. (2002). Knowledge discovery in multi-label phenotype data. Lecture Notes in Computer Science, 2168(2168), 42–53.
Elisseeff, A. E., & Weston, J. (2002). A kernel method for multi-labelled classification. Advances in Neural Information Processing Systems, 14, 681–687.
Fürnkranz, J., Hüllermeier, E., Mencía, E. L., & Brinker, K. (2008). Multilabel classification via calibrated label ranking. Machine Learning, 73(2), 133–153.
Ghamrawi, N., & McCallum, A. (2005). Collective multi-label classification. In Proceedings of the 14th ACM international conference on information and knowledge management (pp. 195–200). ACM.
Godbole, S., & Sarawagi, S. (2004). Discriminative methods for multi-labeled classification. In Pacific-Asia conference on knowledge discovery and data mining (pp. 22–30). Springer.
Ji, S., Tang, L., Yu, S., & Ye, J. (2010). A shared-subspace learning framework for multi-label classification. Acm Transactions on Knowledge Discovery from Data, 4(2), 1–29.
Karalas, K., Tsagkatakis, G., Zervakis, M., & Tsakalides, P. (2015). Deep learning for multi-label land cover classification. In SPIE remote sensing (pp. 96430Q–96430Q). International Society for Optics and Photonics.
Li, X., & Guo, Y. (2014). Bi-directional representation learning for multi-label classification. In Joint European conference on machine learning and knowledge discovery in databases (pp. 209–224). Springer.
Madigan, D., Genkin, A., Lewis, D. D., Argamon, S., Fradkin, D., Li, Y., & Consulting, D. D. L. (2005). Author identification on the large scale. Proceedings of the meeting of the classification society of North America.
Nguyen, V., Gupta, S., Rana, S., Li, C., & Venkatesh, S. (2016). A Bayesian nonparametric approach for multi-label classification. In Asian conference on machine learning (pp. 254–269).
Qian, B., & Davidson, I. (2010). Semi-supervised dimension reduction for multi-label classification. In AAAI (Vol. 10, pp. 569–574).
Read, J., & Perezcruz, F. (2014). Deep learning for multi-label classification. Machine Learning, 85(3), 333–359.
Read, J., Pfahringer, B., Holmes, G., & Frank, E. (2011). Classifier chains for multi-label classification. Machine Learning, 85(3), 333.
Read, J., Reutemann, P., Pfahringer, B., & Holmes, G. (2016). Meka: A multi-label/multi-target extension to weka. Journal of Machine Learning Research, 17(21), 1–5.
Schapire, R. E., & Singer, Y. (2000). Boostexter: A boosting-based system for text categorization. Machine Learning, 39(2–3), 135–168.
Sun, L., Ji, S., & Ye, J. (2008). Hypergraph spectral learning for multi-label classification. In ACM SIGKDD international conference on knowledge discovery and data mining, Las Vegas, Nevada, USA (pp. 668–676).
Tsoumakas, G., & Katakis, I. (2006). Multi-label classification: An overview. International Journal of Data Warehousing and Mining, 3(3), 1–13.
Tsoumakas, G., Katakis, I., & Vlahavas, I. (2009). Mining multi-label data. Data mining and knowledge discovery handbook (pp. 667–685). Boston, MA: Springer.
Tsoumakas, G., Katakis, I., & Vlahavas, I. (2011). Random k-labelsets for multilabel classification. IEEE Transactions on Knowledge and Data Engineering, 23(7), 1079–1089.
Tsoumakas, G., Spyromitros-Xioufis, E., Vilcek, J., & Vlahavas, I. (2011). Mulan: A java library for multi-label learning. Journal of Machine Learning Research, 12, 2411–2414.
Tsoumakas, G., & Vlahavas, I. (2007). Random k-labelsets: An ensemble method for multilabel classification. In European conference on machine learning (pp. 406–417). Springer.
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., & Manzagol, P.-A. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11, 3371–3408.
Yu, K., Yu, S., & Tresp, V. (2005). Multi-label informed latent semantic indexing. In International ACM SIGIR conference on research and development in information retrieval (pp. 258–265).
Zhang, M.-L., & Wu, L. (2015). Lift: Multi-label learning with label-specific features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(1), 107–120.
Zhang, M. -L., & Zhang, K. (2010). Multi-label learning by exploiting label dependency. In Proceedings of the 16th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 999–1008). ACM.
Zhang, M. L., & Zhou, Z. H. (2005). A k-nearest neighbor based algorithm for multi-label classification. In IEEE international conference on granular computing (Vol. 2, pp. 718–721).
Zhang, M. L., & Zhou, Z. H. (2006). Multilabel neural networks with applications to functional genomics and text categorization. IEEE Transactions on Knowledge & Data Engineering, 18(10), 1338–1351.
Zhang, M.-L., & Zhou, Z.-H. (2014). A review on multi-label learning algorithms. IEEE Transactions on Knowledge and Data Engineering, 26(8), 1819–1837.
Zhang, Q.-W., Zhong, Y., & Zhang, M.-L. (2018). Feature-induced labeling information enrichment for multi-label learning. In Thirty-Second AAAI Conference on Artificial Intelligence.
Zhang, Y., & Zhou, Z. H. (2008). Multi-label dimensionality reduction via dependence maximization. In AAAI conference on artificial intelligence, AAAI 2008, Chicago, Illinois, USA (pp. 1503–1505).
Zhou, W.-J., Yu, Y., & Zhang, M.-L. (2017). Binary linear compression for multi-label classification. In Proceedings of the 26th international joint conference on artificial intelligence (pp. 3546–3552). AAAI Press.
Acknowledgements
The research work is supported by the National Key Research and Development Program of China under Grant No. 2018YFB1004300, the National Natural Science Foundation of China under Grant Nos. 61773361, U1836206, U1811461, the Project of Youth Innovation Promotion Association CAS under Grant No. 2017146.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Editors: Masashi Sugiyama, Yung-Kyun Noh.
Rights and permissions
About this article

Cite this article
Huang, M., Zhuang, F., Zhang, X. et al. Supervised representation learning for multi-label classification. Mach Learn 108, 747–763 (2019). https://doi.org/10.1007/s10994-019-05783-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-019-05783-5