
Abstract
In the present research, an artificial neural network model was developed to predict the pool boiling heat transfer coefficient (HTC) of refrigerant-based nanofluids based on a large number of experimental data (1342) extracted from the literature. Diverse training algorithms, e.g., Bayesian regulation backpropagation, Levenberg–Marquardt (LM), Resilient backpropagation and scaled conjugate gradient were utilized. Besides, several transfer functions like log-sigmoid (logsig), radial basis (radbas), soft max transfer function (softmax), hard-limit (hardlim), tan-sigmoid (tansig) and triangular basis (tribas) were applied for the hidden layer, and their influences on model correctness were surveyed. The effects of heat flux, saturation pressure, nanoparticle thermal conductivity, base fluid thermal conductivity, nanoparticle concentration (mass%), nanoparticles size and lubricant concentration (mass%) on the pool boiling HTC of refrigerant-based nanofluids were determined over wide ranges of operating conditions. A network possessing one hidden layer with 19 neurons using tansig and purelin as transfer functions in hidden and output layers in a row was introduced as a model having the best performance. In addition, LM was known as a much more efficient train algorithm in comparison with others resulting in extremely precise prediction. The outcomes indicated the present model could accurately estimate the pool boiling HTC of refrigerant-based nanofluids with a correlation coefficient (R2) of 0.9948 and overall mean square error of 0.01529.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The process of surface heat transfer into a large body of stagnant liquid is called pool boiling. In fact, pool boiling is a type of boiling process in which the temperature of the surface is slightly hotter than the saturated temperature of the fluid. This process is specified by the nucleation and subsequent growth of vapor bubbles of the fluid on the surface and then rising from the surface. Generally, bubbles growth in pool boiling is highly related to temperature, surface type, thermodynamics properties of the fluid and surface tension of the fluid. Pool boiling as an important way of heat transfer is applied in heat transfer equipment in the process and refrigeration industries [1]. In refrigeration industries, this heat transfer route is used in flooded refrigerant evaporators, where refrigerants boil on external zone of a tube bundle, thereby cooling the tube side fluid. The value of HTC on the shell side is a well-known parameter for evaluating the applicability of these evaporators [2,3,4,5]. In a refrigeration operation, optimal layout of the evaporator entails the exact estimation of the pool boiling HTC of the refrigerant [6].
As mentioned before, according to massive ability of boiling heat transfer in heat removal, it has been appointed as building air-conditioning equipment capacity. During recent decades, many types of research were performed to further enhance the boiling HTCs [7]. Recently, environmental interests about the CFC application have contributed to the growth of appropriate fluids to substitute CFC refrigerants [8]. Accordingly, various nanofluids mainly containing Cu and Al nanoparticles were developed. From the theoretical point of view, these particles possessing high thermal conductivity ought to enhance the overall heat transfer by turbulence near the laminar sublayer [7, 9]. Furthermore, refrigerant-based nanofluids are among the nanofluids, in which the base fluid is a conventional refrigerant. Experiments illustrated that thermal conductivity of the refrigerant-based nanofluids is larger than that of the pure refrigerant [10], and the refrigeration system exerting refrigerant-based nanofluid possesses a higher efficiency compared with those using conventional refrigerants [11,12,13,14].
Indeed, an innovative method to increase heat transfer is the dispersion of the nanoparticles in a base fluid known as “nanofluid” introduced by Choi for the first time [15,16,17,18,19,20]. Primitive announced essays on this topic reported the pivotal thermal conductivity enhancement. On account of the fact that nanofluids possess a larger thermal conductivity compared with base fluids, their heat transfer characteristics are anticipated to be greater than those of the base fluids leading to much more efficient alternatives for heat transfer purposes, including pool boiling heat transfer [8, 21].
Das et al. [22, 23] conducted an experimental study for evaluating pool boiling heat transfer employing a horizontal heater tube with nanofluids containing 1, 2 and 4% vol%. Al2O3 nanoparticles were dispersed into water. The outcomes were stunning: nanofluids were foreseen to promote the heat transfer features during pool boiling; nonetheless, the nanofluids boiling curves revealed that the water boiling heat transfer had diminished through the adding of nanoparticles. This was attributed to the tube roughness and the increment in particle vol%. Moreover, the reduction in pool boiling heat transfer of Al2O3–water nanofluid was reported in the study of Bang and Chang [24]. Controversial outcomes were published [25] related to usage of electrostatic stabilizers as surfactant. Pool boiling heat transfer of Al2O3–water nanofluids on a horizontal flat surface developed up to 40% at the mass percent of 1.25% mass% [8]. Investigations on the pool boiling of nanofluids which made by dispersion of 47 and 150 nm Al2O3 nanoparticles in water as base fluid, on a smooth tube (average surface roughness was 48 nm) proved that the fewer number of large particles is in the scale of the average surface roughness, and the nanofluid having larger particles gives higher HTC [26, 27].
In fact, a few researches were based on the heat transfer features of refrigerant-based nanofluids [8, 28, 29]. Nanoparticles addition to pure refrigerants has known as a unique heat transfer augmentation method to advance the performance of refrigeration systems [12,13,14]. As far as the working fluid in the most vapor compression refrigeration systems is combined with lubricating oil, nanoparticles could be dispersed in the mentioned fluid to form the nanoparticles/oil suspensions [30]. The existence of nanoparticles/oil suspension might influence significantly the efficiency of the refrigeration operation since nanoparticle/oil suspensions alter thermophysical characteristics of refrigerants such as thermal conductivity, density, viscosity. So as to evaluate the impact of nanoparticles/oil suspensions on the efficiency of the refrigeration operation, the boiling heat transfer features of refrigerant/oil mixtures including nanoparticles must be investigated [31]. Lately, Park and Jung [7, 32] surveyed pool boiling heat transfer utilizing a CNT-halocarbon refrigerant nanofluid. The experiment was conducted at just 1 vol% of nanoparticle and 7 °C pool temperature, and notable pool boiling heat transfer augmentation was obtained. Data on the pool boiling properties of refrigerant-based nanofluids are yet restricted. Further, there are opportunities for additional examination in particular on the position at which the existence of nanoparticles could increase or decline heat transfer and how the nanoparticle content influence pool boiling heat transfer at diverse saturation pressures [8]. Researches that are relevant to the pool boiling heat transfer of blend of R113/oil containing diamond nanopowder depicted that nanopowder contributed to heat transfer promotion as the augmentation of diamond nanopowder on pool boiling heat transfer is greater than that of CuO nanopowder at similar conditions [31]. Experiment on pool boiling heat transfer of R141b–TiO2 nanofluid revealed that the pool boiling heat transfer plunged by nanopowder concentration raising, chiefly at high heat fluxes [8]. Nanopowder type is an important factor on the pool boiling heat transfer of refrigerant-based nanofluids. Pool boiling heat transfer characteristics of refrigerant/oil mixtures with nanoparticles are reported by Kedzierski and Gong [30] for CuO–R134a/oil nanofluids, and the outcomes indicated that CuO-oil suspensions enhance the heat transfer. For pool boiling heat transfer characteristics of refrigerant-CNTs nanofluids, the experimental outcomes revealed CNTs could increase the pool boiling HTCs of pure refrigerants (R22, R123 and R134a) by a 36.6% enhancement at the CNTs volume percent of 1% [7, 32, 33]. Henderson et al. [34] studied the heat transfer characteristics of pure R134a and R134a/polyolester contained nanopowder in a horizontal tube during boiling flow conditions. The R134a/SiO2 nano-refrigerants with 0.5 vol% and 0.05 vol% were examined to estimate the influence of nanopowder on boiling heat transfer. At both concentrations, the convective boiling HTC plummeted in comparison with pure R134a due to weak scattering. Additionally, they carried out tests with R134a/POE blends possessing CuO nanopowder with 0.02, 0.04 and 0.08 vol%. It had been seen that R134a/CuO/POE nano-refrigerant at a 0.02 vol% particle concentration depicted a minor growth in the heat transfer characteristics. CuO with 0.04 vol% and 0.08 vol% led to an average heat transfer augmentation of 52% and 76% in a row. Next studies endorsed that this enhancement was not merely because of thermal property alterations, but also surface modifications caused by CuO particles. Sun and Yang [35] investigated Cu–R141b, Al–R141b, Al2O3–R141b and CuO–R141b as nano-refrigerants for 0.1 mass%, 0.2 mass% and 0.3 mass% in a test section to examine the impacts of material nature and vapor quality on the flow boiling heat transfer in a flat tube. At the similar mass fraction, Cu–R141b nano-refrigerant owned the greatest average HTC, more than Al–R141b which was the next on the list. Besides, Al2O3–R141b had the minimum HTC. Tang et al. [36] studied impacts of nanopowder and surfactant volume fraction on pool boiling of R141b/δ-Al2O3. The results revealed that R141b/δ-Al2O3 with SDBS enhanced the pool boiling heat transfer in comparison with pure R141b. [37]. For evaluation of the pool boiling HTC of refrigerant/oil blend with nanopowder, Peng et al. [31] suggested a correlation, in which the impacts of nanopowder kinds (CuO and diamond) and base fluids (R134a/RL68H and R113/VG68 blends) were displayed. Nevertheless, the influence of nanopowder average size is ignored in the aforementioned correlation [26]. Moreover, a small amount of lubricating oil is necessary to seal the compressor as well as lubricating the sliding parts [33].
Lately, artificial intelligent-like ANN has grabbed attention more and more as a foreseen means because of their individual merits. ANNs are nonparametric models that could manage the enormous number of data sets and are qualified to do nonlinear regression [38]. ANN model could be easily assembled without the requirement for complete information of the fundamental system. These particular characteristics have presented it appropriate in various disciplines of science [39,40,41]. Indeed, a number of pure refrigerants properties have been modeled accurately using ANN so far. Chouai et al. [42] investigated the applicability of ANN to estimate the compressibility factor of diverse pure refrigerants in the 240–340 K temperature range. Furthermore, ANN was used for PVT representations of refrigerants at various pressures up to 20 MPa. Results on three refrigerants (R134a, R32 and R143a) were presented. The outcomes revealed that multilayer perceptron (MLP) network would be a proper model to anticipate compressibility factor depended to pressure and temperature. Laugier and Richon [43] proposed an ANN model to evaluate PVT data of refrigerants from 240 up to 340 K and up to 20 MPa. Outcomes of six refrigerants were presented (R134a, R32, R125, R290, R143a and R227ea). Furthermore, Sozen et al. [44] proposed the ANN to estimate the thermodynamic features (specific volume, enthalpy and entropy) of an alternative refrigerant (R508b) in both saturation and superheated regions. The most appropriate algorithm with suitable number of neurons in the hidden layer was obtained as LM algorithm. The outcomes obtained the value of R2 in the 0.93–0.97 range, whereas they altered in the range of 0.97–0.99 where ANN was used. A novel method for the auto-design of a neural network dependent upon genetic algorithm (GA) was applied by Mohebbi et al. [45] for calculation of 19 pure and 6 mixed refrigerants’ saturated liquid density. The experimental data including reduced temperature, reduced saturated liquid density and Pitzer’s acentric factor were applied to make a GA-ANN model. A generalized correlation based on neural network for boiling HTC of R22 and R407C, R410A and R134a considered as its alternative refrigerants within horizontal smooth tubes was developed by Wang et al. [46]. They selected four dimensionless parameter using existing correlations as the input of neural networks, while Nusselt number was considered as the target. The average, mean and root-mean square deviations of the trained neural network were 2.5, 13.0 and 20.3%, respectively. Balcilar et al. [47] investigated pool boiling heat transfer performance of TiO2 nanofluids to estimate the effect of various factors on heat transfer. They chose nanofluids with different contents of nanopowder such as 0.0001, 0.0005, 0.005 and 0.01 vol%. The ANN training data sets originated from the results of pool boiling experiments, such as the difference between the average temperature of surface of the heater and the liquid saturation temperature from 5.8 up to 25.21 K as well as heat fluxes from 28.14 up to 948.03 kW m−2. Pool boiling HTC was estimated by applying the values of current, voltage and temperatures. Input of the ANNs is 8 dimensionless and dimensional values of test section, including physical properties of the fluid, particle size, thermal conductivity, concentration rate of nanoparticles, surface roughness and wall superheating, where the outputs are experimental pool boiling HTC and heat flux. Pool boiling heat transfer of TiO2 nanofluids was modeled to select the most practical approach, using different ANN methods such as generalized regression neural network (GRNN), radial basis networks (RBF) and multilayer perceptron (MLP). Recently, Zendehboudi et al. [6] have used radial basis function (RBF) neural network to anticipate nucleate pool boiling heat transfer properties of refrigerant blends in which mixture of R113 and ester oil VG68 had been chosen as base fluid, whereas CuO and diamond were selected as various nano-additives. Despite this study, in their study, only 360 experimental data had been gathered restricted to particular materials.
In this study, according to the importance and necessity of investigation of pool boiling heat transfer process for different industrial applications, a FFANN model with different learning algorithms is analyzed and optimized for the first time to estimate the relative pool boiling HTC of different refrigerant-based nanofluids. Moreover, data sets used in this work not only include abundant nano-refrigerant experiments but also contain data of diverse nanoparticles and base fluids (1342 experimental data). The outcomes of this study could play an important role on the understanding and usage of nano-refrigerant for HTC enhancement in pool boiling heat transfer processes. Furthermore, based on the “relative importance” calculation in this study, the effective operating conditions on HTC including heat flux, saturation pressure, nanoparticle thermal conductivity, base fluid thermal conductivity, nanoparticle concentration (mass%), nanoparticles size and lubricant concentration (mass%) were compared to each other and the most important feature of the nanofluid was introduced for practical application of nanofluids.
Acquiring experimental data sets
The chief purpose of this work is to introduce a convenient, efficient and agile model, for first time that can calculate a large range of nano-refrigerant and dispel previous model problem. As mentioned in this study, for the first time a FFANN model with different learning algorithms is designed and optimized for calculation of the relative pool boiling HTC of different refrigerant-based nanofluids as a function of the saturation pressure, thermal conductivity of nanoparticle, heat flux, thermal conductivity of the base fluid, nanoparticle concentration (mass%), nanoparticle size and lubricant concentration (mass%) based on a large number of experimental data (1342) extracted from the literature. The major objectives of the current study were to propose a model to minimize the MRE for both predicted and experimental data. Some salient researches on the pool boiling HTC of different refrigerant-based nanofluids applied in this study and conditions of the experiments are given in Table 1. Reviewing the mentioned reports showed that thermophysical properties of various nanoparticles suspended in various pure refrigerants were investigated in diverse research studies.
Implementation of ANN model
The novel standpoint on neural networks according to brain administration arose in the 1940s. The earliest attainable utilization of neural networks appeared in the late 1950s by the introduction of perceptron network [48]. Recently, tons of papers have been relevant to neural networks and its wide application in various fields. A neural network using a backpropagation learning algorithm called multilayer feed-forward neural network (MLFNN) is the most trustworthy among several types of ANN. These sorts of ANN formations have hidden layer(s) and computational junctions called hidden neurons. In these ANNs structures, data progress is done in a progressive trend.
The interconnection design linking diverse neurons in ANN has nominated the network “architecture.” One of the most prevalent and functional architectures of ANN is multilayer perceptron (MLP) network [49, 50]. The input data in MLP network are given to the input layer to bring forward inputs to the network and then moved about to hidden layer(s) to be followed out. Ultimately, the terminal hidden layer forwards prepared information to the output layer and the outcomes are attained. The output and hidden layer(s)’ neurons are joined to each previous layer neuron via different masses expressing the relevant importance of the different neuron inputs to different neurons. The weighted summation of the inputs is shifted to the hidden neurons, where it is converted by applying an activation function [51, 52]. So as to develop the network performance to obtain a greater degree of exactness, one or extra hidden layers would be combined. This could result in an additional collection of synaptic contacts and neural cooperation improved consequently [53,54,55]. The below equation expresses the output MLP neural network:
where Y refers to the output, the bias mass for jth neuron is shown by b, while xij represents the input signals of the ith neuron to the jth neuron, n is the number of neurons linked to the jth neuron and the mass quantifying the magnitude of the relationship within the ith neuron in the former layer and the jth neuron in the current layer is denoted by wij [56].
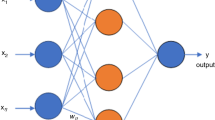
The training algorithm, the transfer function, the number of neurons per layer as well as the number of layers could determine the structure of each ANN model [53, 57]. In this investigation, many transfer functions including radbas, tansig, logsig, hardlim, tribas and softmax were examined within hidden layer and their consequences on network accuracy were studied. In addition, several training algorithms such as LM, RP, BR and scaled conjugate gradient (SCG) were utilized in this research The topology of the MLFNN and the interconnection among layers are depicted in Fig. 1.

Schematic topology of the most suitable ANN model
Results and discussion
In order to examine the accuracy of the ANN studies, regression and error analysis are the most prevalent factors. Owing to determination of the ANN performance, error analysis must be implemented.
Pre-processing
In the majority of cases that the ranges of input variables are excessively distinct, variables ought to normalize to possess similar order for calculation and training process [58]. Furthermore, normalized input data strengthen swiftness and rapidity of learning and performing data processing much easier [6]. The whole data were normalized into the range of (− 1, 1) using Eq. (2):
in which, Xmin and Xmax are the least and the greatest values of Xi related to training, validation and testing steps.
Accuracy investigation using regression and error analysis
For appraising the model accuracy and prediction capability of the relative pool boiling HTC of refrigerant-based nanofluids, regression analysis was employed. Besides, the correlation coefficient (R2) was employed to specify whether network outputs were in acceptable agreement with the real data considering Eq. (3) or not. As remarked former, the kind of both transfer function and training algorithm and further the excellent number of neurons inside the hidden layer is crucial circumstances in precision and efficiency of the model. For this purpose, to specify the accuracy, error analysis was implemented. Numerous sorts of error exist to examine ANN model, among which MSE and MRE are much more reputable options to ascertain the ANN exactitude expressed according to:
where \( \overline{h} \) depicts the average of experimental data for relative pool boiling HTC, \( h_{\text{i}}^{\text{ANN}} \) shows predicted value for ith as ANN model outcomes, \( h_{\text{i}}^{\text{Exp}} \) is the ith real value of relative pool boiling HTC, and N illustrates the number of real data.
The training step of ANN
In this paper, the Neural Network Toolbox™ of MathWorks MATLAB® [59] was applied to obtain the proper MLFNN model. Besides, among various accessible learning algorithms LM, RP, BR, and SCG were tried to acquire the relations between inputs and outputs. In fact for training, the Levenberg–Marquardt backpropagation (trainlm) is one of the most reliable and agile algorithms [60, 61]. So as to attain a reliable network upon training using trainlm, ANN variables were set with the intention of decreasing MSE as well as progressing of R2 up to 1.
Transfer function
Selection of each layer transfer function is the next step. Tan-sigmoid, softmax, Log-sigmoid, Hard-limit, Triangular basis and Radial basis are known as instances of diverse transfer functions. According to main aim of present research, the suitable transfer function (f) for hidden layer of the present investigation was selected as hyperbolic tangent sigmoid function expressed as Eq. (6) and linear function for output layer.
It should be noted that x refers to weighted sum presented in expressions of masses (w), bias (b) and output (y) with regard to Eq. (1).
The most appropriate ANN arrangement
As shown in Fig. 1, one hidden layer just was investigated in existing article. Tentatively, the number of neurons was altered from 9 up to 29 in the first hidden layer, iteratively and attitude of the network was checked by means of MSE, MRE and R2. Optimal ANN was network with the minimal MSE and MRE and maximal correlation coefficient (R2) for all data. Table 2 shows the MSE, MRE and R2 quantity for the network possessing diverse neuron number. It can be comprehended that the best condition was in the network with a hidden layer contained 19 neurons using LM training algorithm as displayed in table. Figure 2 shows the trends of R2 and overall MSE per the number of neurons within hidden layer. As illustrated, when the number of neurons in hidden layer was 19, the MSE and R2 for all data sets in a row were attained to the least and the highest values. Moreover, it could be determined that growing the hidden layers number might not be beneficial undoubtedly. The optimal configuration of network structure possesses MSE, MRE and R2 of 0.01529, 5.37E−09 and 0.9948, respectively.

R2 variation and overall MSE versus variation of neurons number within hidden layer
In the next stage, transfer function was appointed by examination. The transfer functions applied and considered in this work to attain appropriate transfer function for the neural network consisting of Hard-limit, softmax, Log-sigmoid, Tan-sigmoid, Radial basis and Triangular basis. Table 3 exhibits error contrasting of ANN employing diverse transfer functions. Table 3 depicts that Tan-sigmoid is more efficient in comparison with other transfer functions.
The iteration progress and the iteration at which the validation achievement reaches the smallest value are represented in Fig. 3. As seen, when epochs of training are progressed, the error is diminished. When the test curve soared suddenly, whereas the validation curve did not, the possibility of remarkable overfitting exists. Nevertheless, in Fig. 3, the test and validation curves have had substantially identical tendency, so it could be realized that there was no overfitting.

Error trend and performance of the excellent neural network
The recommended network that is capable of anticipating meticulously the refrigerant-based nanofluids relative pool boiling HTC could be reused by mass, and bias values have been shown in Table 4.
The outcomes gained via the proposed network versus the real data are exposed in Fig. 4a–d. The solid line exhibits a suppositive precise fit of the experimental and the predicted values. The fine agreement between real and calculated values was noticed, and it depicted that the ANN was trained successfully. It must be declared that 70% of data sets were allocated to the training procedure. With the purpose of test and validate the perfect network, 50% of whole data were designated to the testing section and the residual data were dedicated to validation section. Testing and validation data sets are of the notable importance, and they were discrete from training data sets. The connection between calculated and real data of validation step is given in Fig. 4b. MSE, MRE and R2 values for validation data sets were 0.01967, 3.02375E−05 and 0.99362 in a row. The outcomes disclose that the calculated values were in rational agreement with the real experimental values. Figure 4 part (c) depicts the connection between the calculated and real data of test step. MSE, MRE and R2 are 0.01504051225, 2.16884E−06 and 0.99528 in a row. The connection between the calculated and real data of all steps is illustrated in Fig. 4d. MSE, MRE and R2 are 0.01528921041, 5.36863E−09 and 0.9948, respectively.

Correlation plot of relative pool boiling HTC data vs calculated values through introduced ANN for a train, b validation, c test and d all data sets
Contribution analyses
There are numerous methods to ascertain the impact of all input variables and their contribution on model output. In the current study, the method for partitioning the joint masses was supposed to estimate the relative importance (RI) [62,63,64]. This approach was proposed by Garson [65], and afterward it was applied by Goh [66]. The particularity of the RI algorithm is expressed as:
In this equation, nH and nν represent the numbers of neurons in the hidden layer and the input layer, Oj is the absolute amount of connection masses between the hidden and the output layers and ij depicts the absolute amount of connection masses between the input and the hidden layers. Alteration of variables with greater RI would have a much more significant influence on the outcomes of the network than changing the variables of less RI [53, 62, 64]. As shown in Fig. 5, the thermal conductivity and size of nanoparticles which have a slight difference are known as the most effective factor influencing the outcomes of the proposed ANN model.

Contribution analysis of the input parameters on the model results
Comparison of the results of model in this study and Peng correlation
As previously discussed, there is just one approach for the prediction of the pool boiling HTC. Peng et al. [31] developed a new correlation for predicting the pool boiling HTC of refrigerant/oil blend with nanopowders based on Rohsenow equation [67]. As can be recognized, the suggested ANN in this study possesses a much more reliable performance compared with Peng correlation and consequently it could be suitably applied to evaluate pool boiling HTC of nano-refrigerants with the higher degree of precision. The analogous trend of the calculated and real pool boiling HTC of nano-refrigerants illustrates the ability of the recommended model not only to anticipate the pool boiling HTC of nano-refrigerant with great exactness but also to predict precisely the tendency of pool boiling HTC variations with heat flux values (Fig. 6).

Calculated and real pool boiling HTC for some pure refrigerants and nano-refrigerants with various heat fluxes
Conclusions
This research was performed to examine the strength of feed-forward back-propagation network in the prediction of the pool boiling HTC for different refrigerant-based nanofluids in an ample range of experimental conditions. 1342 experimental data sets were collected from different references, in current work. In order to training, evaluation and attaining the optimal network architecture data were separated to train, test and validation sets.
Firstly, roughly 70% of data sets were employed for training the network and adjust the effective network variables, such as the much more efficient transfer functions of hidden and output layers and the number of neurons in the hidden layer.
Next, test and validation data points (approximately 30% of experimental data sets divided equally for both steps) were utilized to investigate and confirm the optimized artificial neural network and for approximating the anticipating capability of the ANN. The outcomes of this research pointed out the obtained neural network with 19 hidden neurons can properly model nano-refrigerants pool boiling HTC (MSE and R2 are 0.0145 and 0.995004 in a row).
Abbreviations
- ANN:
-
Artificial neural network
- MLFNN:
-
Multilayer feed-forward neural network
- MLP:
-
Multilayer perceptron
- FFANN:
-
Feed-forward artificial neural network
- BP:
-
Backpropagation
- R 2 :
-
Correlation coefficient
- MRE:
-
Mean relative error
- MSE:
-
Mean square error
- N :
-
Number of experimental data points
- Epoch:
-
Number of iteration in training process
- h :
-
Relative pool boiling heat transfer coefficient (HTC) (W m−2 K−1)
- P :
-
Pressure (kPa)
- q :
-
Heat flux (kW m−2)
- d p :
-
Particle size (nm)
- k :
-
Thermal conductivity of nanoparticles (w m−1 k−1)
- X :
-
Input variable
- CNT:
-
Carbon nanotube
- RI:
-
Relative importance (%)
- Exp:
-
Experimental
- min:
-
Minimum
- max:
-
Maximum
- N:
-
Number of experimental data points
- p:
-
Nanoparticle
- bf:
-
Base fluid
- sat:
-
Saturation
- φ p :
-
Particle concentration (mass%)
- φ lub :
-
Lubricant concentration (mass%)
References
Bayareh M, Mohammadi M. Multi-objective optimization of a triple shaft gas compressor station using imperialist competitive algorithm. Appl Therm Eng. 2016;109:384–400.
Webb RL, Pais C. Nucleate pool boiling data for five refrigerants on plain, integral-fin and enhanced tube geometries. Int J Heat Mass Transf. 1992;35(8):1893–904.
Salehi H, Hormozi F. Prediction of Al2O3–water nanofluids pool boiling heat transfer coefficient at low heat fluxes by using response surface methodology. J Therm Anal Calorim. 2019;137(3):1069–82.
Nazari A, Saedodin S. An experimental study of the nanofluid pool boiling on the aluminium surface. J Therm Anal Calorim. 2019;135(3):1753–62.
Akbari A, Fazel SAA, Maghsoodi S, Kootenaei AS. Pool boiling heat transfer characteristics of graphene-based aqueous nanofluids. J Therm Anal Calorim. 2019;135(1):697–711.
Zendehboudi A, Tatar A. Utilization of the RBF network to model the nucleate pool boiling heat transfer properties of refrigerant–oil mixtures with nanoparticles. J Mol Liq. 2017;247:304–12.
Park K-J, Jung D. Boiling heat transfer enhancement with carbon nanotubes for refrigerants used in building air-conditioning. Energy Build. 2007;39(9):1061–4.
Trisaksri V, Wongwises S. Nucleate pool boiling heat transfer of TiO2–R141b nanofluids. Int J Heat Mass Transf. 2009;52(5):1582–8.
Jahanbakhshi A, Nadooshan AA, Bayareh M. Magnetic field effects on natural convection flow of a non-Newtonian fluid in an L-shaped enclosure. J Therm Anal Calorim. 2018;133(3):1407–16.
Jiang W, Ding G, Peng H, Gao Y, Wang K. Experimental and model research on nanorefrigerant thermal conductivity. HVAC&R Res. 2009;15(3):651–69.
Peng H, Ding G, Hu H. Effect of surfactant additives on nucleate pool boiling heat transfer of refrigerant-based nanofluid. Exp Therm Fluid Sci. 2011;35(6):960–70.
Wang R, Hao B, Xie G, Li H, editors. A refrigerating system using HFC134a and mineral lubricant appended with n-TiO2 (R) as working fluids. In: Proceedings of the 4th international symposium on HAVC. Tsinghua University Press, Beijing, China; 2003.
Wang K, Shiromoto K, Mizogami T, editors. Experiment study on the effect of nano-scale particle on the condensation process. In: Proceedings of the 22nd international congress of refrigeration, Beijing, China, Paper no; 2007.
Bi S-S, Shi L, Zhang L-L. Application of nanoparticles in domestic refrigerators. Appl Therm Eng. 2008;28(14):1834–43.
Chol S. Enhancing thermal conductivity of fluids with nanoparticles. ASME-Publ Fed. 1995;231:99–106.
Zarei M, Keshavarz P, Zerafat M. Dynamic viscosity of triethylene glycol–water–CuO nanofluids as a gas dehydration desiccant. J Nanofluids. 2017;6(3):395–402.
Zarei M, Gholizadeh F, Sabbaghi S, Keshavarz P. Estimation of CO2 mass transfer rate into various types of nanofluids in hollow fiber membrane and packed bed column using adaptive neuro-fuzzy inference system. Int Commun Heat Mass Transf. 2018;96:90–7.
Hashemi M, Noie SH. Study of flow boiling heat transfer characteristics of critical heat flux using carbon nanotubes and water nanofluid. J Therm Anal Calorim. 2017;130(3):2199–209.
Bayareh M, Kianfar A, Kasaeipoor A. Mixed convection heat transfer of water-alumina nanofluid in an inclined and baffled c-shaped enclosure. J Heat Mass Transf Res. 2018;5(2):129–38.
Sepyani M, Shateri A, Bayareh M. Investigating the mixed convection heat transfer of a nanofluid in a square chamber with a rotating blade. J Therm Anal Calorim. 2019;135(1):609–23.
Shirazi M, Shateri A, Bayareh M. Numerical investigation of mixed convection heat transfer of a nanofluid in a circular enclosure with a rotating inner cylinder. J Therm Anal Calorim. 2018;133(2):1061–73.
Das SK, Putra N, Roetzel W. Pool boiling characteristics of nano-fluids. Int J Heat Mass Transf. 2003;46(5):851–62.
Das SK, Putra N, Roetzel W. Pool boiling of nano-fluids on horizontal narrow tubes. Int J Multiph Flow. 2003;29(8):1237–47.
Bang IC, Chang SH. Boiling heat transfer performance and phenomena of Al2O3–water nano-fluids from a plain surface in a pool. Int J Heat Mass Transf. 2005;48(12):2407–19.
Wen D, Ding Y. Experimental investigation into the pool boiling heat transfer of aqueous based γ-alumina nanofluids. J Nanopart Res. 2005;7(2):265–74.
Peng H, Ding G, Hu H, Jiang W. Effect of nanoparticle size on nucleate pool boiling heat transfer of refrigerant/oil mixture with nanoparticles. Int J Heat Mass Transf. 2011;54(9):1839–50.
Narayan GP, Anoop K, Sateesh G, Das SK. Effect of surface orientation on pool boiling heat transfer of nanoparticle suspensions. Int J Multiph Flow. 2008;34(2):145–60.
Alawi OA, Sidik NAC. Applications of nanorefrigerant and nanolubricants in refrigeration, air-conditioning and heat pump systems: a review. Int Commun Heat Mass Transf. 2015;68:91–7.
Redhwan A, Azmi W, Sharif M, Mamat R. Development of nanorefrigerants for various types of refrigerant based: a comprehensive review on performance. Int Commun Heat Mass Transf. 2016;76:285–93.
Kedzierski MA, Gong M. Effect of CuO nanolubricant on R134a pool boiling heat transfer. Int J Refrig. 2009;32(5):791–9.
Peng H, Ding G, Hu H, Jiang W, Zhuang D, Wang K. Nucleate pool boiling heat transfer characteristics of refrigerant/oil mixture with diamond nanoparticles. Int J Refrig. 2010;33(2):347–58.
Park K-J, Jung D. Enhancement of nucleate boiling heat transfer using carbon nanotubes. Int J Heat Mass Transf. 2007;50(21):4499–502.
Peng H, Ding G, Hu H, Jiang W. Influence of carbon nanotubes on nucleate pool boiling heat transfer characteristics of refrigerant–oil mixture. Int J Therm Sci. 2010;49(12):2428–38.
Henderson K, Park Y-G, Liu L, Jacobi AM. Flow-boiling heat transfer of R-134a-based nanofluids in a horizontal tube. Int J Heat Mass Transf. 2010;53(5):944–51.
Sun B, Yang D. Experimental study on the heat transfer characteristics of nanorefrigerants in an internal thread copper tube. Int J Heat Mass Transf. 2013;64:559–66.
Tang X, Zhao Y-H, Diao Y-H. Experimental investigation of the nucleate pool boiling heat transfer characteristics of δ-Al2O3–R141b nanofluids on a horizontal plate. Exp Therm Fluid Sci. 2014;52:88–96.
Celen A, Çebi A, Aktas M, Mahian O, Dalkilic AS, Wongwises S. A review of nanorefrigerants: flow characteristics and applications. Int J Refrig. 2014;44:125–40.
Hagan MT, Demuth HB, Beale MH. Neural network design. Boston: PWS Pub. Co; 1996. p. 3632.
Ansari H, Zarei M, Sabbaghi S, Keshavarz P. A new comprehensive model for relative viscosity of various nanofluids using feed-forward back-propagation MLP neural networks. Int Commun Heat Mass Transf. 2018;91:158–64.
Hekayati J, Rahimpour MR. Estimation of the saturation pressure of pure ionic liquids using MLP artificial neural networks and the revised isofugacity criterion. J Mol Liq. 2017;230:85–95.
Esfe MH, Saedodin S, Sina N, Afrand M, Rostami S. Designing an artificial neural network to predict thermal conductivity and dynamic viscosity of ferromagnetic nanofluid. Int Commun Heat Mass Transf. 2015;68:50–7.
Chouai A, Laugier S, Richon D. Modeling of thermodynamic properties using neural networks: application to refrigerants. Fluid Phase Equilib. 2002;199(1):53–62.
Laugier S, Richon D. Use of artificial neural networks for calculating derived thermodynamic quantities from volumetric property data. Fluid Phase Equilib. 2003;210(2):247–55.
Sözen A, Özalp M, Arcaklioğlu E. Calculation for the thermodynamic properties of an alternative refrigerant (R508b) using artificial neural network. Appl Therm Eng. 2007;27(2):551–9.
Mohebbi A, Taheri M, Soltani A. A neural network for predicting saturated liquid density using genetic algorithm for pure and mixed refrigerants. Int J Refrig. 2008;31(8):1317–27.
Wang W-J, Zhao L-X, Zhang C-L. Generalized neural network correlation for flow boiling heat transfer of R22 and its alternative refrigerants inside horizontal smooth tubes. Int J Heat Mass Transf. 2006;49(15):2458–65.
Balcilar M, Dalkilic A, Suriyawong A, Yiamsawas T, Wongwises S. Investigation of pool boiling of nanofluids using artificial neural networks and correlation development techniques. Int Commun Heat Mass Transf. 2012;39(3):424–31.
Esfe MH, Ahangar MRH, Rejvani M, Toghraie D, Hajmohammad MH. Designing an artificial neural network to predict dynamic viscosity of aqueous nanofluid of TiO2 using experimental data. Int Commun Heat Mass Transf. 2016;75:192–6.
Moghadassi A, Parvizian F, Hosseini S. A new approach based on artificial neural networks for prediction of high pressure vapor–liquid equilibrium. Aust J Basic Appl Sci. 2009;3(3):1851–62.
Heidari E, Sobati MA, Movahedirad S. Accurate prediction of nanofluid viscosity using a multilayer perceptron artificial neural network (MLP-ANN). Chemom Intell Lab Syst. 2016;155:73–85.
Eslamloueyan R, Khademi MH, Mazinani S. Using a multilayer perceptron network for thermal conductivity prediction of aqueous electrolyte solutions. Ind Eng Chem Res. 2011;50(7):4050–6.
Hamzehie M, Fattahi M, Najibi H, Van der Bruggen B, Mazinani S. Application of artificial neural networks for estimation of solubility of acid gases (H2S and CO2) in 32 commonly ionic liquid and amine solutions. J Nat Gas Sci Eng. 2015;24:106–14.
Nabipour M, Keshavarz P. Modeling surface tension of pure refrigerants using feed-forward back-propagation neural networks. Int J Refrig. 2017;75:217–27.
Nabipour M. Prediction of surface tension of binary refrigerant mixtures using artificial neural networks. Fluid Phase Equilib. 2018;456:151–60.
Gholizadeh F, Sabzi F. Prediction of CO2 sorption in poly (ionic liquid) s using ANN-GC and ANFIS-GC models. Int J Greenh Gas Control. 2017;63:95–106.
Hekayati J, Rahimpour MR. Estimation of the saturation pressure of pure ionic liquids using MLP artificial neural networks and the revised isofugacity criterion. J Mol Liquids. 2017;230:85–95.
Fatehi M-R, Raeissi S, Mowla D. Estimation of viscosities of pure ionic liquids using an artificial neural network based on only structural characteristics. J Mol Liq. 2017;227:309–17.
Haykin S, Network N. A comprehensive foundation. Neural Netw. 2004;2004(2):41.
Beale MH, Hagan MT, Demuth HB. Neural network toolbox™ user’s guide. Natick: The MathWorks, Inc.; 2012.
Lashkarbolooki M, Shafipour ZS, Hezave AZ. Trainable cascade-forward back-propagation network modeling of spearmint oil extraction in a packed bed using SC-CO2. J Supercrit Fluids. 2013;73:108–15.
Levenberg K. A method for the solution of certain non-linear problems in least squares. Q Appl Math. 1944;2(2):164–8.
Rezakazemi M, Razavi S, Mohammadi T, Nazari AG. Simulation and determination of optimum conditions of pervaporative dehydration of isopropanol process using synthesized PVA–APTEOS/TEOS nanocomposite membranes by means of expert systems. J Membr Sci. 2011;379(1):224–32.
Shabanzadeh P, Yusof R, Shameli K. Artificial neural network for modeling the size of silver nanoparticles’ prepared in montmorillonite/starch bionanocomposites. J Ind Eng Chem. 2015;24:42–50.
Vatankhah E, Semnani D, Prabhakaran MP, Tadayon M, Razavi S, Ramakrishna S. Artificial neural network for modeling the elastic modulus of electrospun polycaprolactone/gelatin scaffolds. Acta Biomater. 2014;10(2):709–21.
Garson DG. Interpreting neural network connection weights. Al Expert. 1991;6:46.
Goh A. Back-propagation neural networks for modeling complex systems. Artif Intell Eng. 1995;9(3):143–51.
Rohsenow WM. A method of correlating heat transfer data for surface boiling of liquids. Cambridge: MIT Division of Industrial Cooporation; 1951.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zarei, M.J., Ansari, H.R., Keshavarz, P. et al. Prediction of pool boiling heat transfer coefficient for various nano-refrigerants utilizing artificial neural networks. J Therm Anal Calorim 139, 3757–3768 (2020). https://doi.org/10.1007/s10973-019-08746-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10973-019-08746-z