
Abstract
Prior research has identified a vast number of correlates for delinquent behavior during adolescence, yet a considerable number of errors in prediction remain. These errors suggest that behavioral development among a portion of youths is not well understood, with some exhibiting resilience and others a heightened vulnerability to risks. Examining cases that do not confirm prediction outcomes provides an opportunity to achieve a greater understanding of the relationships between risk factors and delinquency, which can be used to improve theoretical explanations of behavior. This study explores the contribution of genetic and environmental factors to differences in individual responses to cumulative risk for delinquency among a sample of adolescent twins (N = 784 pairs, 49 % female) in the National Longitudinal Study of Adolescent Health. The results indicate that additive genetic and unique environmental factors significantly contribute to variation in responses to cumulative risk across 14 risk factors spanning individual, familial, and environmental domains. When analyzed separately, the majority of the difference between vulnerable youths and the overall population was attributed to genetic influences, while differences between resilient youths and the population were primarily attributed to environmental influences. The findings illustrate the importance of examining both genetic and environmental influences in order to enhance explanations of adolescent offending.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Developmental research has long emphasized the importance of identifying the correlates and causes of various behavioral outcomes. In addition to allowing for early identification and intervention with high-risk youths, prediction research can also be used to construct or reformulate theories relevant to antisocial behavior (Loeber and Dishion 1983). Indeed, if constructs within a given theory fail to explain outcomes as expected, it may be necessary to falsify or revise the theory or consider alternative explanations (Weisburd and Piquero 2008). In the pursuit of a better understanding of the etiology of delinquency specifically, researchers have uncovered a vast array of risk factors across individual, familial, and environmental domains. Although researchers have investigated the impact of a large spectrum of risk factors fairly extensively, considerable errors in prediction remain. For example, Herrenkohl et al. (2000) examined risk factors for violent behavior at age 18 that were present at ages 10, 14, and 16. Up to 18 % of youths that were not predicted to be violent and up to 3 % that were predicted to be violent were incorrectly classified. In a well-known study of persistent serious delinquency by Stouthamer-Loeber et al. (2002), up to 28 % of youths were incorrectly classified. A more recent study by Van der Laan et al. (2010) showed a similar pattern, identifying one group of youths who were not considered to be at-risk exhibiting serious delinquent behavior, and another group of nondelinquent youths who were able to overcome their heightened risk. These studies suggest that as many as a quarter of adolescents do not confirm predicted outcomes, and that many of these errors are false negatives, or antisocial youths that were not considered at-risk. In short, even when a host of risk factors are considered, the behavior of a proportion of the population is still not well understood.
At the same time, studies have begun to explore the genetic factors that contribute to variation in antisocial behavior and the factors underlying those behaviors (Baker et al. 2006). The available research indicates that approximately 50 % of the variation in antisocial behavior is due to genetic influences (Moffitt 2005; Rhee and Waldman 2002). Genetic variation between individuals also accounts for some of the heterogeneity in intelligence (Deary et al. 2006), low self-control (Beaver et al. 2008, 2009), impulsivity (Bezdjian et al. 2011), and personality (Eysenck 1990), indicating that there may be multiple paths by which such genetic differences might impact antisocial behavior. Despite clear advances, there are still limitations in understanding the processes by which risk factors might affect antisocial behavior outcomes. Furthermore, some have argued that future growth in knowledge about behavior will only come through research and theory that improves our understanding of how risk factors may contribute to behavioral outcomes as opposed to merely identifying correlates (see Hedström 2005; Rutter 1988; Wikström 2008).
A portion of the error in prediction and limitations in explanatory power can be attributed to various methodological restrictions present within any given study and also across areas of research writ large. The characteristics of the sample, measurement error, the omission of key variables in the model, or the statistical techniques employed by the researcher can all compromise predictive efficacy (Farrington and Tarling 1985). Undoubtedly, even the best efforts to predict behavioral outcomes are not immune from imperfections. There is, however, evidence to suggest that some of these errors may connote substantively-relevant groups, and that errors should not necessarily be dismissed on the assumption that they are random or unimportant (Stein et al. 1970). Moreover, careful inspection of these cases can be a useful strategy for improving prediction and advancing our understanding of the development of antisocial behavior (Marks 1964; Sullivan 2011).
Resilience and Vulnerability
An area of developmental research that has specifically focused on cases whose outcome deviates from that which is expected characterizes these individuals as uniquely resilient or vulnerable (Luthar and Zelazo 2003). Although these terms are often used broadly, it is beneficial to consider errors in the prediction and explanation of delinquency within this framework. Adolescents who remain prosocial when faced with risk factors for delinquency and other problem behaviors (i.e., false positives) display resilience. Conversely, vulnerable youths may experience minimal or no exposure to known risk factors, yet still choose to engage in such behaviors (i.e., false negatives). Examining these cases in more depth can help extend our understanding and explanations of the variation in antisocial outcomes relative to exposure to risk. Understanding the process by which antisocial behavioral patterns emerge and are sustained is also likely the better course of action for the field—given limitations in prospective prediction (Sampson and Laub 2005).
Since the 1970s, there has been a growing interest in the study of resilience (Masten and Powell 2003). Similar to research on risk factors, investigations into the origins of resilience have focused on individual characteristics, the family environment, and other social factors. In fact, many variables associated with resiliency represent the opposite extreme of known risk factors, and are sometimes included as “promotive” or “protective” factors (Farrington and Welsh 2007). Research on vulnerable youths is not as abundant, but may nevertheless be relevant to understanding the development of problem behavior. Again, these cases are defined by their inability to avoid maladaptive outcomes when faced with few or no outward signs of risk relative to similarly situated individuals (Ingram and Price 2010), which creates a dilemma for those seeking a more complete understanding of delinquency and analogous behaviors. Specifically, if known risk factors are not relevant in these cases, scholars may have to expand existing explanations to account for their behavior or offer some plausible demarcation for theories (Sullivan 2011). In this way, efforts to better understand individual differences in the response to risk can prove useful, not only in terms of enhancing the understanding of resilience and vulnerability, but also in advancing theory and improving intervention strategies (Wikström 2008).
Theoretical Explanations for Differences in Sensitivity
An underlying theme that unifies both the risk-factor approach and research on resilience and vulnerability is the acknowledgment that adolescents vary in their exposure to risk factors and the manner in which they respond to them. One explanation for this differential response to risk is that individuals vary in sensitivity to the risks that they encounter (Belsky 1997, 2005; Boyce and Ellis 2005). According to this perspective, some people are hardier than others and will thrive in a variety of conditions. Though applied more often in the study of resilience, this theoretical framework could contribute to the understanding of those vulnerable youths for whom even minimal exposure to risk factors could generate an antisocial response.
Differential susceptibility theory (DST; Belsky 1997, 2005) and biological sensitivity to context theory (BSCT; Boyce and Ellis 2005) are founded on an evolutionary perspective, which assumes that all living things share the goal of dispersing their genetic material into future generations. Meeting this goal requires that natural selection favor traits that promote survival and reproduction; however, the future can be somewhat unpredictable, making it difficult to identify the most advantageous traits. Both theories contend that natural selection has likely preserved a method for ensuring survival and reproduction under a variety of conditions (Boyce and Ellis 2005).
Boyce and Ellis (2005) hypothesize that the reactivity of the stress response system differs between individuals, which in turn accounts for multifinality in developmental outcomes. When the stress response system, which is housed in the central and peripheral nervous systems, is activated, physiological changes take place in the body such as the release of neurotransmitters in various parts of the brain, redirection of energy to vital organs, and increase in heart rate and breathing (Boyce and Ellis 2005). Genetic differences between people generate differences in reactivity, with some being predisposed toward high reactivity and others low reactivity.
According to the context sensitivity perspective, the social environment also plays a salient role in this process (Boyce and Ellis 2005). When situated in a harsh environment, individuals who are more sensitive will develop even greater awareness and sensitivity to threats, but are also more likely to experience negative psychological and physiological outcomes as a result of their extensive reactivity. Conversely, when environmental conditions are highly supportive, youths with greater reactivity are more likely to use that to their benefit (Boyce and Ellis 2005). Under adverse conditions, those with low reactivity avoid experiencing negative outcomes, and will experience more positive health and behavioral outcomes than their more sensitive counterparts. The benefits associated with low reactivity are lost, however, in supportive environments, as these children would be less likely to take advantage of the beneficial aspects of their environment.
Belsky’s (1997, 2005) DST also maintains that individuals vary in their degree of sensitivity to the conditions under which they develop. Children with high susceptibility are likely to experience outcomes that reflect the rearing environment, whether those environments are positive or negative. On the other hand, children who are less malleable will resist parental efforts to shape development. Under this differential susceptibility framework, genetic differences are largely responsible for variation in sensitivity (Belsky 1997, 2005). Those who possess a sensitive genotype are under greater environmental influence, while those that are less sensitive will be more heavily influenced by their genetic predispositions. In short, individuals differ in the amount of influence genes and the environment has on their development. This will produce variation in behavioral outcomes, even if different individuals shared the exact same environments and experiences.
Investigating the origins of resilience and vulnerability within the framework of DST and BSCT may help in better explaining the development of antisocial behavior. Previous research, though limited, provides evidence indicating that researchers may gain a more in-depth understanding of developmental outcomes by considering the effects of genes and the environment—particularly in the context of resilience and vulnerability. Kim-Cohen and her colleagues (Kim-Cohen et al. 2004) examined resilience and vulnerability to socioeconomic deprivation with respect to aggressive and delinquent outcomes. The results indicated that 70.5 % of the variation in responses to socioeconomic deprivation was due to genetic factors and the remaining variation was due to unique environmental factors. Group heritability estimates for the most vulnerable and most resilient youths were 71 and 72 %, respectively. Waaktaar and Torgersen (2012) found the heritability of resilience as a personality trait to be largely influenced by additive genetic effects (70–77 %). Boardman et al. (2008) investigated the origins of psychological resilience to stressors and obtained heritability estimates between 38 and 52 %. These studies provide evidence of genetic influences on resilience and vulnerability, and demonstrate the value of considering the role of both genes and environment in extending our understanding of the relationships between risks and outcomes.
Current Study
Two limitations in the available research are addressed in the current investigation. First, despite extensive effort, the risk factor approach is limited in its ability to fully account for variation in the ways individuals respond to personal liabilities or adverse conditions; therefore, it falls short in explicating the development of adolescent delinquent behavior in distinguishing between outcomes that might be anticipated and those that actually occur (Cicchetti and Rogosch 1996). Second, although some scholars have begun to consider the importance of biological influences, many fail to examine their significance in the relationship between exposure to risk and behavioral outcomes. In light of these considerations, the current study extends the previous literature in two important respects. First, the differential susceptibility perspective is employed as a framework for investigating individual differences in the response to risks by examining differences in outcomes for youths with similar predicted levels of delinquency. This represents a shift from previous studies that emphasize one’s circumstances rather than one’s capacity to manage those circumstances, providing some insight into the processes that might move a youth from initial risk (or lack thereof) to a particular behavioral outcome. We hypothesize that genetic influences will partially account for variation in responses to risk for delinquency. Second, both vulnerable and resilient cases are identified and examined independently, as it is possible that these two groups are influenced by different factors. Based on prior research, we hypothesize that genetic factors will account for a significant portion of the difference between youths who exhibit resilience or vulnerability and the overall population (Boardman et al. 2008; Kim-Cohen et al. 2004; Waaktaar and Torgersen 2012).
Methodology
Sample
Subjects are participants in the National Longitudinal Study of Adolescent Health (Add Health). The Add Health study was initiated in 1994 and has included four waves of data collection, with the most recent efforts conducted in 2007–2008. During Wave I, more than 90,000 adolescents in grades 7 through 12 across 132 schools in the United States completed an in-school questionnaire on a wide range of topics (Harris et al. 2006). A subsample of youths enrolled in participating schools was then randomly selected to take part in an in-home interview.
A number of special subsamples were also selected, one of which included pairs of siblings residing in the same household (Harris et al. 2006). During the in-school questionnaire, youths were asked if they had a biological or genetically unrelated sibling (e.g., step-sibling, adoptive sibling) who was also in grades 7–12. Identified siblings were automatically asked to participate in the in-home interviews as part of the genetic subsample. Following a classical twin design, the current study includes only the twin siblings (N = 1,568).
Two methods were employed to ascertain the zygosity of the twins (Harris et al. 2006). First, opposite sex twin pairs were automatically classified as dizygotic, but same-sex twins were asked four questions to assess their degree of physical similarity and the frequency that family members, teachers, and strangers confuse one twin with the other (Rowe and Jacobson 1998). An average confusability score, which was created with responses from both twins, was used to classify the majority of twin pairs. Some pairs, however, produced a confusability score greater than the cutoff for dizygotic (DZ) twins but less than the cutoff for monozygotic (MZ) classification. The undetermined pairs were classified using DNA analysis during Wave III. Twins that were 100 % concordant on 11 genetic markers and a sex-determining gene were classified as MZ. The use of DNA analysis resulted in the correct zygosity classification in 16 pairs that had initially been incorrectly assigned and 18 pairs that were formerly classified as unknown zygosity (Harris et al. 2006). The information from both confusability scores and DNA analysis resulted in a final analytic sample of 307 MZ pairs, 452 DZ pairs, and 25 pairs with unknown zygosity. Pairs with unknown zygosity were classified as DZ, which is considered a conservative method from the standpoint of variance decomposition because it increases the likelihood of overestimating environmental influences (Rowe and Jacobson 1998).
Measures
Examining the overall contribution of genetic and environmental factors to differential response to risk for delinquency requires a single measure that captures varying levels of both risk and delinquency. In light of this, measures of cumulative risk and delinquency were developed and used to capture differential response to risk by regressing delinquency on cumulative risk and saving the standardized residuals. Each of the measures is described here and a complete list of items included in variables comprised of multiple items is provided in the “Appendix”.
Cumulative Risk
Prior research suggests that individuals are impacted by influences across domains (Bronfenbrenner 1979; Tolan and Guerra 1994), and that exposure to a greater number of risk factors is associated with increases in adverse outcomes during adolescence, including internalizing and externalizing behaviors (Appleyard et al. 2005; Buehler and Gerard 2013; Deković 1999), conduct problems (Gerard and Buehler 2004), and serious delinquency (Stoddard et al. 2012; Stouthamer-Loeber et al. 2002; Van der Laan et al. 2010). The use of a cumulative measure of risk in this study is based on the premise that as one accumulates risks, the mental and physiological demands of dealing with multiple challenges can compromise normal psychological, cognitive, and social development (Evans 2003; Evans et al. 2007). Reactivity or sensitivity to stressors may be heightened during adolescence, which may contribute to an elevated vulnerability during this stage of development (Spear 2009). Moreover, the use of a comprehensive measure of risk recognizes that there is equifinality in developmental trajectories, which may be unaccounted for in studies that focus on particular risk factors (Cicchetti and Rogosch 1996).
The measure of cumulative risk used in this study includes 14 items spanning individual, family, and broader social/environmental domains during Wave I. Following previous research, each measure was dichotomized so that those individuals deemed at-risk received a score of “1” and all others received a score of “0” (Buehler and Gerard 2013; Stouthamer-Loeber et al. 2002). Cutoffs were typically at or above the 75th percentile, or at or below the 25th percentile if the lower end of the distribution was indicative of a greater risk. Descriptive statistics and cutoff criteria for all risk measures and the final cumulative risk measure are presented in Table 1. Initially, each case was required to have a valid score on all 14 risk factors, resulting in a loss of approximately 200 cases. This criterion was relaxed so that cases were required to have a valid score on at least 10 of the 14 risk items to preserve the size of the sample. The main analytic models were estimated using measures based on both criteria, and the results in each case were nearly identical.
Individual Risk Items
Seven measures were created to assess risk at the individual level including school performance, attachment to school, intelligence, problem-solving, coping skills, marijuana use, and cigarette use. All individual-level items are based on the youths’ self-reports at Wave I.
School Performance: School performance was created by averaging self-reported grades received in English, mathematics, history, and science during the most recent grading period (1 = A, 2 = B, 3 = C, 4 = D or lower). If the individual did not take all of these subjects, or if a course was not graded using traditional letter grades, the average of available grades was used. The average score on this measure was 2.19 (SD = .76; α = .79).
Attachment to School: Attachment to school is comprised of nine items asking the individual how often he or she had trouble at school (0 = never, 4 = every day) and the degree to which he or she felt connected to the school (1 = strongly agree, 5 = strongly disagree). Factor analysis using principle components extraction indicated that a two factor model fit the data well [Kaiser–Meyer–Olkin (KMO) = .799; two eigenvalues greater than 1]; however, further inspection of factor loadings suggested a single factor may provide a good fit. Because all but one of the items produced a higher loading on the first factor, a second factor analysis was conducted in which the number of factors extracted was fixed to one. The results of this analysis were virtually identical to the first model, with factor loadings ranging from .52 to .71. Additionally, the reliability analysis indicated that removing any item from the scale would reduce Cronbach’s alpha (α = .78). Therefore, all items were standardized and summed to create a single measure of attachment to school.
Intelligence: Intelligence was measured using scores from the Add Health Peabody Picture Vocabulary Test (PPVT), an abridged version of the PPVT-Revised. During testing, an interviewer would read a word to the participant who would then select an illustration from four choices that best reflects the meaning of the word. Scores ranged from 0 to 87, and youths scoring at or below the 25th percentile (57) were considered at-risk.
Problem Solving Skills: At Wave I, participants were asked to report the degree to which they agreed with seven statements relating to how they respond to problems using a 5-point Likert scale (1 = strongly agree, 5 = strongly disagree). Factor analysis revealed that a two factor model fit the data (KMO = .74, two eigenvalues greater than 1). Inspection of the factor loadings suggested that the first factor was tapping into problem solving skills. This factor comprised four items that related to one’s strategy or approach to solving a problem (factor loadings ranged from .71 to .78).
Coping Skills: The second factor extracted in the factor analysis of items related to problem solving included three items reflecting how one deals with problems emotionally. These items asked youths to indicate whether they avoid dealing with problems, if they are upset by problems, or if they make decisions based on “gut feelings” rather than thinking about the consequences of the alternatives. The factor loadings for these three items ranged from .65 to .71 (α = .44). The items were summed to create a measure of coping skills.
Marijuana Use: Participants were also asked two questions about their personal substance use. Individuals that confirmed using marijuana at least once in their lifetime were asked, “During the past 30 days, how many times did you use marijuana?” Individuals that reported using marijuana at least once in the past 30 days (13 %) were considered at-risk.
Cigarette Use: Adolescents were asked to report the number of days in the past 30 days that they had used cigarettes. Responses ranged from 0 to 30 days. Individuals that reported smoking at least 1 day were classified as at-risk.
Family Level Risk Items
Four risk factors were included at the family level during Wave I. For each of the measures, items relating to both the mother and father were included as opposed to constructing these variables separately for each parent. When the father was missing from the home, a score of “0” was entered for each of the paternal items. This approach has been used previously by Gerard and Buehler (2004) and offers three potential benefits. First, many studies tend to emphasize the importance of maternal influence on the development of a child, but this strategy accounts for the importance of both parents. Second, this approach provides a more accurate reflection of the parental environment. Adolescents with only one parent in the household will have lower scores on all items, while those with two parents will have higher scores indicating greater interaction with parents. Third, this approach assists in addressing the issue of missing data when the father is not present in the household (approximately 30 % of households sampled).
Attachment to Parents: The level of a youth’s attachment to his or her parents was measured by asking youths to report how close they were to each parent and how much they felt each parent cared about them (1 = not at all, 5 = very much). Scores across all four items were summed, and a factor analysis confirmed that each of the items loaded adequately on the factor, with loadings ranging from .59 to .83.
Parental Involvement: The extent to which parents were involved with their youth was measured by asking adolescents whether or not they had participated in ten different activities with their mothers or fathers in the past 4 weeks. A score of “1” was given for each activity a youth reported doing with a parent. Scores across all 20 items were then summed to create an overall measure of parental involvement. The average score for parental involvement was 5.69 (SD = 3.38), and any youth scoring 3 or less was classified as at-risk for this measure.
Parental Engagement: Youths were also asked to report how much they agreed with eight statements regarding their relationship with their parents (1 = strongly agree, 5 = strongly disagree). A single factor model fit the data (KMO = .84) with loadings ranging from .53 to .89 (α = .88). The eight items were summed to create a measure of parental engagement, with higher scores indicating less engagement.
Parental Supervision: The measure of supervision provided by parents was created by summing responses to four questions in which youths reported the frequency that their mother or father are home before and after school (1 = always, 5 = never). Factor analysis indicated that a single factor provided an adequate fit (KMO = .66) with loadings ranging from .35 to .76. Youths with a score of 20 or greater were considered at-risk.
Environmental Risk Items
Three different measures were included in the cumulative risk index to assess risk beyond the family environment during Wave I. These include delinquent peers, social support, and neighborhood safety.
Delinquent Peers: Adolescents were asked to report how many of their three closest friends use cigarettes, alcohol, or marijuana. Responses to these three questions were summed, creating an index ranging from 0 to 9 with a mean of 2.46 (α = .76). Youths scoring at or above 4 were classified as at-risk.
Social Support: A measure of social support was operationalized by summing responses to seven items that asked youths to report how much they felt others care about, understand, and pay attention to them (1 = not at all, 5 = very much). Factor analysis confirmed that a single factor fit the data (KMO = .84), and factor loadings ranged from .47 to .78. The average score of social support was 28.34 (SD = 4.05), and youths with a score at or below 26 were considered at-risk.
Neighborhood Safety: The final risk measure, neighborhood safety, is based on each participant’s response to the question, “Do you usually feel safe in your neighborhood?” (0 = yes, 1 = no). If the youth responded negatively, he or she was classified as at-risk for this measure.
Delinquency
Previous research using the Add Health data has measured overall delinquency using 14-items from the in-home questionnaire at Wave I (Boisvert et al. 2012; Haynie 2001, 2002). Questions asked participants to report the frequency with which they engaged in various behaviors, such as stealing, fighting, or selling drugs over the past 12 months. These items were summed to create an overall delinquency scale (α = .84). Because the measure was skewed (\( \bar{x}=2.46 \), SD = 4.19), it was log transformed (ln(x + 1)) prior to analysis. Transformed scores for overall delinquency range from 0 to 3.71 (\( \bar{x}=.80 \), SD = .87).
Differential Response to Risk
The operationalization of differential response to risk was guided by research on resilience and vulnerability, since some of the errors in predicting delinquency may stem from these processes. The conceptualization and operationalization of resilience has varied across previous studies (Luthar et al. 2000; Luthar and Cushing 1999), but their operational definitions typically include two constructs: (1) exposure to some adverse or risky condition(s) and (2) evidence of positive adjustment (Luthar and Cushing 1999). These constructs reflect “false positives,” and this logic is extended to account for “false negatives,” or those cases that are exposed to relatively little risk but nevertheless engage in delinquency, on the same continuum.
Researchers have previously operationalized resilience and vulnerability in a single measure using residual scores (Boardman et al. 2008; Kim-Cohen et al. 2004). The use of residual scores is particularly useful in measuring variation in response to risks for delinquency because it captures the full range of delinquent outcomes across the full range of cumulative risk. This approach was used here by regressing delinquency on cumulative risk (b = .14, SE = .01, p < .001, R 2 = .16). The standardized residual values were then regarded as a measure of differential response to risk, with scores ranging from −2.41 to 3.09. The distribution represents a continuum with negative values reflecting resilience (i.e., less delinquent than predicted) and positive values reflecting vulnerability (i.e., more delinquent than predicted). A closer inspection of the cases at the extremes of this distribution indicates that this interpretation of the standardized residuals has validity. Among the more extreme cases of resilience, or those with scores below −1, the average cumulative risk score (\( \bar{x}=5.65 \), SD = 1.68) exceeds that of the full sample (\( \bar{x} =3.79\), SD = 2.56). The average delinquency score (pre-transformation) for the resilient end of the distribution (\( \bar{x}=.03 \), SD = .16), however, is less than that of the full sample (\( \bar{x} =2.46\), SD = 4.19). Among the more vulnerable youths (those with residual scores greater than 1), the average cumulative risk score is 4.23 (SD = 2.43) and the average delinquency score is 8.53 (SD = 6.06). These youths are exposed to a similar number of risks, yet are involved in more delinquent acts.
Analytic Process
Univariate Decomposition of Variance
Using a classical twin design, a univariate model that decomposes the variance in differential response to risk is estimated. The design compares the degree of phenotypic, or observed behavioral, resemblance between MZ twins reared together to that of DZ twins reared together (Neale and Cardon 1992). Variance in a phenotype can be attributed to four types of influences; two environmental and two genetic. Environmental influences can be classified as either common (those experienced by both twins in a pair) or unique (those experienced by only one twin). Common environmental influences (C) are perfectly correlated between twin siblings in all pairs, and unique environmental factors (E) are, by definition, not correlated. Genetic effects can be additive or dominant (Neale and Cardon 1992). Additive effects (A) occur when alleles at a single gene share a combined effect. Genetic dominance (D), in contrast, exists if the effects of one allele are stronger than that of another, masking its effects (Carey 2003). The correlation between both additive and dominant genetic effects is 1.00 for MZ twins and .50 and .25, respectively, for DZ twins.
After calculating the overall variance in a trait and specifying the expected covariances between relatives, it is possible to derive estimates of genetic and environmental influences using structural equation modeling. All four parameters (i.e., A, D, C, and E) cannot be estimated simultaneously, however, because there are only three observed statistics (Neale and Cardon 1992). To avoid a non-identified model, the cross-twin correlations are inspected to determine whether the dominant genetic or shared environmental parameter should be omitted. If the correlation between MZ twins is less than twice the DZ correlation, shared environmental effects are estimated (i.e., an ACE model). On the other hand, if the correlation between MZ twins is more than double the correlation between DZ twins, dominant genetic effects are estimated (i.e., an ADE model; Grayson 1989).
After selecting the appropriate model, a fully saturated model is estimated in which each of the genetic and environmental components of variance are free to vary. The means and variances for the phenotype are assumed to be equal across members of a twin pair and between MZ and DZ pairs. These assumptions are tested by fitting two submodels, one where the means and variances are equated across members of a pair (twin one and twin two within MZ and DZ pairs) and a second in which these values are equated across zygosity (twin one and twin two across both MZ and DZ pairs). The goodness of fit across these models is determined by examining Chi square (χ2) and Akaike Information Criterion (AIC) values (Akaike 1987). If placing these constraints on the model does not significantly reduce the fit as indicated by a non-significant p value, it can be concluded that the assumptions have not been violated. Additionally, the significance of the additive genetic, dominance or shared environment, and their combined effects can be tested by fixing these parameters to zero in a series of nested models (e.g., AE, CE, E) and assessing the change in model fit. It should be noted that the unique environmental effect parameter is never fixed to zero because it also captures any residual error in the model. The best-fitting model is that which produces a non-significant p value on a χ2 test and the lowest AIC value.
Extremes Analysis
In this study, differential response to risk for delinquency was operationalized as a continuous measure ranging from resilience at one end to vulnerability at the other, reflecting differences in how individuals respond to cumulative risk. It is possible, however, that a proportion of the difference between the vulnerable and resilient groups and the overall population may be due to genetic factors. This has been termed group heritability (h 2 g ), and it can be estimated directly using DeFries–Fulker (DF) extremes analysis.
The DF analysis involves regressing the score of one twin on their co-twin, and is based on the proposition that if a trait is influenced by genetic factors, the mean score of MZ twins will regress less toward the population mean than the mean score of DZ twins (DeFries and Fulker 1985, 1988). Given that MZ twins share greater genetic similarity than DZ twins, increased phenotypic similarity would be observed if genetic factors are at work. If shared environmental factors are influential, the mean scores of MZ and DZ twins will be similar to each other and will regress toward the population mean because both types of twins are assumed to share these experiences with their co-twin to the same extent. In the event that a trait is influenced entirely by unique environmental experiences, the mean scores of MZ and DZ twins will not correlate with their co-twin and their means will regress to the population mean (DeFries and Fulker 1985, 1988).
The DF regression model is based on the following equation:
where Y 1 is the score of one twin, Y 2 is the score for his or her sibling, and R represents the degree of genetic relatedness between the twins (MZ = 1, DZ = .5). There are multiple methods of determining which twin will be entered as the co-twin (Y 1) and which the proband (Y 2; a twin selected due to a deviant or extreme score). To provide both twins the opportunity to be selected as a proband, the double entry method is used in this study. Each pair is entered as a case twice, once in which a twin is assigned to be the first twin and once in which the assignments are reversed (LaBuda et al. 1986; Rodgers and McGue 1994). Once the data are double-entered, extreme cases can be selected using a specified cutoff criterion (DeFries and Fulker 1985, 1988). Pairs in which one twin meets the criteria are entered into the analysis once, pairs in which both twins meet the criteria are entered twice, and pairs in which neither meets the criteria are omitted. Though the double-entry method will not bias the estimates, it may increase the value of N resulting in biased standard errors (Cherny et al. 1992). Implementing the Huber–White correction is commonly used to adjusting the standard errors, and is the approach taken in the current study (Kohler and Rodgers 2001).
After selecting probands, individual scores can be transformed so that b 2 from the regression equation will estimate (h 2 g ) directly using the following formula:
where \( \bar{x}_{0} \) is the mean of the population and \( \bar{x}_{1} \) is the mean of the probands (DeFries and Fulker 1988; LaBuda et al. 1986; Purcell and Sham 2003). To account for any differences that may exist between MZ and DZ proband means, the transformation should incorporate zygosity-specific means. Transforming the data in this way results in a proband mean of one, a population mean of zero, and a co-twin mean between zero and one. The regression can then be conducted using the transformed data, and the statistical significance of h 2 g evaluated accordingly.
Results
Univariate Results
Inspection of the cross-twin correlations reveals that the correlation for MZ twins (.47) is larger than that for DZ twin pairs (.25), and that an ACE model should be estimated. Table 2 presents the model fit statistics and parameter estimates for each of the specified models. The first model shown is a saturated model in which the means and variances across twin order and zygosity are free to vary. The second model constrains the mean and variance between twin one and twin two to be equal, and the third model (ACE) equates these values across twin order and zygosity. The non-significant p values and decrease in AIC indicates that the assumptions of equal means and variances have been met. The remaining specifications are then nested under the ACE model.
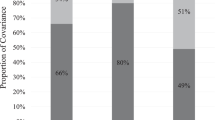
The fourth model (AE) in Table 2 tests the significance of the C parameter by fixing it to zero. Placing this constraint on the model did not result in a significant change in fit (p = .40, AIC = 1,144.70), and the AIC value showed a very slight decrease relative to the ACE model (AIC = 1,145.99). The CE model tests the significance of additive genetic effects, and provides a significantly worse fit than the ACE model (p = .00, AIC = 1,152.32). Additionally, constraining both the A and C parameters in the final model (E) did not improve the fit of the model (p = .00, AIC = 1,239.60). Therefore, the AE model is determined to be the best-fitting. The standardized path estimates indicate that additive genetic factors contribute moderately (46 %) to the variance in differential response to risk for delinquency. Unique environmental influences and any residual error are accounted for in the remaining 54 % of the variance.
Extremes Analysis
The final stage of the analysis seeks to determine whether genetic factors account for a portion of the difference between resilient and vulnerable groups and the overall population. Proband and co-twin means pre- and post-transformation are shown in Table 3. The transformed means for vulnerability, displayed in the first row in Table 3, indicate that the mean for MZ co-twins is closer to the proband mean than the mean of DZ co-twins (\( \bar{x}_{\rm proband}=1 \); \( \bar{x}_{\rm MZ Co-twin}=.52 \); \( \bar{x}_{\rm DZ Co-twin}=.25 \)). The same pattern is observed across all four selected samples, and suggests that genetic factors contribute to explaining membership in each of the four extreme groups.
The results for each DF regression are shown in Table 4. In transformed data, the coefficient for the proband score captures everything that makes twins alike independent of genetic similarity, and the coefficient associated with genetic relatedness is a direct estimate of group heritability. In the first model, the estimate of group heritability of .53 is significant (p < .05). This indicates that the genetic contribution to the difference between vulnerable cases and the population is 53 %. The second model was estimated among cases where the proband exhibits a more extreme case of vulnerability, and pairs in which the proband score is less than one are removed. The heritability estimate for this group was .55 (p < .05), revealing significant genetic influences on the difference between the extreme group and the population. Both models indicate the importance of genetic influences on involvement in overall delinquency–beyond that which is predicted by cumulative risk.
The third and fourth models investigate the group heritability of resilient and extremely resilient youth. In the third model, the estimate of group heritability was .38 and significant (p < .05). This suggests that the difference between resilient youth and the population is moderately influenced by genetic factors. The last model presented in Table 4 estimates the group heritability for extremely resilient youth, or those in which the proband score is less than negative one. The heritability estimate among this group is not significant, and genetic factors do not appear to contribute to differences between the group of extremely resilient youths and the overall population.
Discussion
Scholars have identified numerous risk factors for adolescent antisocial behavior; nevertheless, the remaining errors in prediction and shortcomings in explanation signal the importance of continuing to investigate how risks and protective factors impact behavior. Although it is unrealistic to expect perfection in predicting and explaining delinquency, closely examining those individual cases that are not well-explained in commonly-used models offers potential benefits for expanding the understanding of adolescent behavior. This approach provides one avenue for improving prediction, advancing theory, and developing appropriate interventions, despite the fact that there will continue to be false positive and false negative cases (Marks 1964; Sullivan 2011).
One means of moving beyond the risk factor perspective is to recognize that while some youths engage in less delinquency than would be expected based on their level of risk, others exhibit more. That can then be used as a starting point for understanding the process by which risk may serve as a precursor to behavior. Differential susceptibility theory asserts that individuals may respond differently to their circumstances, and that these contrasting reactions may be due to genetic variation between people (Ellis et al. 2011). Several studies have examined the relationships between specific genes and risk factors such as participation in the prevention program Strong African American Families and DRD4 (Beach et al. 2010) and 5-HTTLPR genotypes (Brody et al. 2009); religiosity and DRD2 (Beaver et al. 2009); adverse social environment and DRD4, 5-HTTLPR, and MAOA (Simons et al. 2011; Simons et al. 2012); and MAOA and maltreatment (Caspi et al. 2002; Kim-Cohen et al. 2006); and neglect (Widom and Brzustowicz 2006). This is the first study, however, to investigate the overall extent to which genetic and environmental factors contribute to differential responses to cumulative risk for delinquency.
The results indicate that there is variation in how individuals respond to cumulative risk, and that the variation is partially influenced by genetic factors. Some leading theories explaining antisocial behavior omit the importance of heredity, and those that accept it as a possibility often dismiss or minimize the relevance of genetic factors on the grounds that it is not possible to change one’s DNA (Beaver 2008). Failing to consider genotypic differences, however, may limit the capacity for scholars to accurately assess the impact of risk factors as they affect development and antisocial behavior. Several studies have demonstrated the moderating effects of genotype on the relationship between a given risk factor and antisocial outcomes, suggesting that risk factors do not have an equal impact on all youths. Rather than seeking out more risk factors for consideration, it may be worthwhile to ask, how and for whom does a particular factor increase risk?
The current study also examined vulnerable and resilient cases separately. More than half of the difference between vulnerable and extremely vulnerable youth and the population is due to genetic factors (h 2 g = 53–55 %). In light of these findings, investigating genetic influences on vulnerability may be particularly useful in future efforts to understand delinquency in the absence of earlier risk. The strength of genetic effects weakened in moving across the continuum from extreme vulnerability to extreme resilience. Group heritability on resilience dropped to 38 %, and no significant genetic effects were observed among extremely resilient youths. This pattern of findings is consistent with the social push perspective (Raine 2002). According to this perspective, psychophysiological factors may be more prominent among individuals that do not encounter the typical risk factors for antisocial behavior. At the same time, those that are exposed to risk factors for maladaptive outcomes may also possess the same underlying biological risk factors, but the role of those factors in development may be masked by the presence of social factors. This further illustrates the need to examine cases that do not confirm predicted outcomes. As the results of this study show, investigating the role of biological factors among these cases can provide important insights that can guide future research, particularly among adolescents that display vulnerability. At the same time, identifying the environmental factors that promote resilience could serve as a useful means of fostering the understanding of how risk and resilience unfold and interact in terms of their impact on adolescent behavior (Schoon and Bynner 2003).
Importantly, the strength of the genetic influences among vulnerable and extremely vulnerable cases should not be interpreted as a genetic predisposition towards delinquency. Rather, these findings reflect differences in how individuals respond to risks, which may be indicative of a heightened sensitivity to environmental influences as hypothesized by the differential susceptibility perspective (Belsky 1997, 2005; Boyce and Ellis 2005; Ellis et al. 2011). Although it was not directly tested in this study, recognizing the importance of genotypic differences in the relationships between risks and behavior could have important implications for understanding responsivity to particular environmental conditions. For example, in a randomized controlled trial, Bakermans-Kranenburg et al. (2008) found that toddlers in families that participated in the Video-feedback Intervention to promote Positive Parenting (VIPP) program showed reductions in externalizing behaviors, but only among children that possessed the 7-repeat DRD4 allele (see also, Beach et al. 2010). These findings suggest that considering how biological and socialization influences might affect developmental trajectories and, eventually, antisocial behavior may provide valuable insight into why some individuals appear to be affected by various risk factors or experiences and others do not. In turn, it is probably unrealistic to assume that similar risk or protective factors will have homogeneous effects on individual behavior.
Understanding variability in developmental pathways, as far as where individuals start on the spectrum of risk and their subsequent outcomes, as well as the parallel question of the different tracks by which youth might reach a similar end state in the life course, are essential endeavors (Cicchetti and Rogosch 1996). To that end, it is important to get a further grasp on patterns in how individual factors interact with those in the environment to generate such pathways (Elder and Caspi 1990). Although risk and protective factors have long been a part of the lexicon of researchers interested in the development of antisocial behavior (e.g., Hawkins et al. 1998; Stouthamer-Loeber et al. 2002), an expansion of understanding of constructs like resiliency and vulnerability to capture their biosocial dimension offers an opportunity to blend the two areas of knowledge to get a better sense of important aspects of development that foster or restrain such behavior in adolescence. In general, these analyses suggest that consideration of both genes and environment will be important in first understanding the individual response to risk exposure and then developing a sense of how to intervene effectively to promote positive development and minimize maladaptive outcomes.
The findings of this study are based on sample of adolescent twins, and although the Add Health research team employed a strong sampling technique in an effort to select a nationally representative sample of twins, it has been argued that important differences may exist between twins and singletons (Rutter and Redshaw 1991; Rutter et al. 1993). Barnes and Boutwell (2013) recently examined this issue among participants of the Add Health study and found that the effects of several predictors of delinquent and analogous behaviors did not differ between twins and non-twin subjects. This suggests that evidence obtained in studies of the Add Health twins is generalizable to the larger population of adolescents selected in the initial design.
This study does not distinguish different types of offenders in a developmental fashion. Moffitt’s (1993) developmental taxonomy theorizes that there are two classes of offenders that have contrasting developmental trajectories and etiologies: Life-course persistent (LCP) offenders and Adolescence-limited (AL) offenders. It could be argued that the vulnerability and extreme vulnerability observed in this study may be capturing some AL offending, particularly when youths are situated in prosocial environments and do not appear to be at risk for delinquency. Another possibility is that AL offenders may exhibit vulnerability only during the maturity gap, but display resiliency before and after as a result of the promotive environmental conditions they encounter. Future research that examines differential response to risk using a longitudinal design could offer several advantages. Observing youths beginning earlier in the life course could broaden the understanding of development in light of the type and number of risks one encounters, the accumulation of risks across developmental periods, the duration of exposure to risks, and factors that foster vulnerability and resilience in different types of offenders across life stages.
Strategies for measuring resilience and vulnerability have been heavily debated, as well, but scholars agree that consideration of both exposure to risk and the resulting outcome is required (Luthar and Cushing 1999; Luthar et al. 2000). Beyond this basic premise, there is no widely accepted method to evaluate these aspects of development (Olsson et al. 2003). Researchers interested in the study of resilience have identified such individuals as those who demonstrate positive adjustment despite exposure to risk, and often examine the moderating effects of factors (or groups of factors) that are hypothesized to have a promotive effect (Luthar et al. 2000). Studies seeking to identify factors that increase vulnerability take a similar approach. While prior studies that have used these strategies can be useful in developing a richer understanding of the particular factors that contribute to a given outcome, they are often restricted to one end of the outcome distribution—either individuals who display resilience or those who display vulnerability.
The operationalization of resilience and vulnerability with residuals permits the investigation of influences across the entire range of possible outcomes, but faces potential limitations of its own. The operationalization of differences in response to risk through residuals may capture error in addition to individual differences in responses to risk. When used previously, Kim-Cohen et al. (2004) found that the standardized residuals were not heavily compromised by measurement error. As an added means of ensuring additional error was reduced as much as possible in this study, several ancillary analyses were conducted to assess whether the model would be better specified using an alternative regression specification. The analyses revealed that the OLS linear regression was most appropriate. Moreover, when regressions were estimated separately for MZ and DZ twins the results were very similar. This suggests that any error that was unaccounted for affected MZ and DZ twin pairs to the same extent. Because the error applies equally across zygosity, it is likely that the difference (though not the size) in cross-twin correlations was unaffected and the results of the analyses are not strongly affected by any differential in predictive power. Despite efforts to obtain the purest measure of resilience and vulnerability in response to risk, it is likely that the measure is at least minimally compromised as it was not possible to include all relevant risk factors. Vulnerability may have been overestimated, resilience underestimated, or both if relevant risk factors were not included. To reduce this bias, future research should seek to include more thorough assessments of risk.
Relatedly, studies that employ a measure of cumulative risk face a number of potential limitations that have not been fully investigated. One possibility is that the accumulation of risks may only be problematic once a particular threshold has been exceeded (Appleyard et al. 2005). Another possibility is that encountering risks in multiple domains could place one at the greatest risk for delinquency (Gerard and Buehler 2004). Further still, the influence of some risk factors or risk domains may exceed that of others (Ribeaud and Eisner 2010). Researchers have only recently begun to examine these issues, and the evidence to date indicates that youths who are subjected to multiple risk factors are more likely to experience adverse outcomes (Sameroff et al. 1998). As more empirical research related to these issues becomes available, it will be important to reexamine the results of the current study.
Conclusion
The association between risk and behavior is complex, and a closer examination of cases whose outcomes deviate from that which is predicted can provide valuable insights into the development of antisocial behavior. This study is useful in illustrating how developmental, life-course explanations might further consider the role of genetic influences in their pursuit of better understanding the etiology of antisocial behavior. The results of this study provide evidence for genetic influences on the ways adolescents respond to risks, particularly those who display vulnerability. By exploring the possibility that individuals respond to risk differently, and that this differential response may in part be genetically-influenced, we can move toward further elaboration of the relationships between risk and protective factors and relevant outcomes. It is important that we are thorough in evaluating available empirical evidence using a variety of approaches while also maintaining a focus on the processes underlying the development of antisocial behavior. The results of this study emphasize the importance of examining cases whose behaviors deviate from outcomes anticipated by their risk profiles and considering both genetic and environmental factors in investigations of risk and resilience; both of which have important implications for enhancing the understanding of antisocial behavior in adolescence.
References
Akaike, H. (1987). Factor analysis and AIC. Psychometrika, 52, 317–332.
Appleyard, K., Egeland, B., van Dulmen, M. H. M., & Sroufe, L. A. (2005). When more is not better: The role of cumulative risk in child behavior outcomes. Journal of Child Psychology and Psychiatry, 46, 235–245.
Baker, L. A., Bezdjian, S., & Raine, R. (2006). Behavioral genetics: The science of antisocial behavior. Law and Contemporary Problems, 69, 7–46.
Bakermans-Kranenburg, M. J., van Ijzendoorn, M. H., Pijlman, F. T. A., Mesman, J., & Juffer, F. (2008). Experimental evidence for differential susceptibility: Dopamine D4 receptor polymorphism (DRD4 VNTR) moderates intervention effects on toddlers’ externalizing behavior in a randomized controlled trial. Developmental Psychology, 44, 293–300.
Barnes, J. C., & Boutwell, B. B. (2013). A demonstration of the generalizability of twin-based research on antisocial behavior. Behavioral Genetics, 43, 120–131.
Beach, S. R. H., Brody, G. H., Philibert, R. A., & Lei, M. (2010). Differential susceptibility to parenting among African American youths: Testing the DRD4 hypothesis. Journal of Family Psychology, 24, 513–521.
Beaver, K. M. (2008). Biosocial criminology: A primer. Dubuque, IA: Kendall/Hunt Publishing Company.
Beaver, K. M., Eagle Schutt, J., Boutwell, B. B., Ratchford, M., Roberts, K., & Barnes, J. C. (2009). Genetic and environmental influences on levels of self-control and delinquent peer affiliation: Results from a longitudinal sample of adolescent twins. Criminal Justice and Behavior, 36, 41–60.
Beaver, K. M., Wright, J. P., DeLisi, M., & Vaughn, M. G. (2008). Genetic influences on the stability of low self-control: Results from a longitudinal sample of twins. Journal of Criminal Justice, 36, 478–485.
Belsky, J. (1997). Theory testing, effect-size evaluation, and differential susceptibility to rearing influence: The case of mothering and attachment. Child Development, 64, 598–600.
Belsky, J. (2005). Differential susceptibility to rearing influence: An evolutionary hypothesis and some evidence. In B. Ellis & D. Bjorklund (Eds.), Origins of the social mind: Evolutionary psychology and child development (pp. 139–163). New York, NY: Guilford Press.
Bezdjian, S., Baker, L. A., & Tuvblad, C. (2011). Genetic and environmental influences on impulsivity: A meta-analysis of twin, family and adoption studies. Clinical Psychology Review, 31, 1209–1233.
Boardman, J. D., Blalock, C. L., & Button, T. M. (2008). Sex differences in heritability of resilience. Twin Research and Human Genetics, 11, 12–27.
Boisvert, D., Wright, J. P., Knopik, V., & Vaske, J. (2012). Genetic and environmental overlap between low self-control and delinquency. Journal of Quantitative Criminology, 28, 477–507.
Boyce, W. T., & Ellis, B. J. (2005). Biological sensitivity to context: I. An evolutionary–developmental theory of the origins and functions of stress reactivity. Development and Psychopathology, 17, 271–301.
Brody, G. H., Beach, S. R., Philibert, R. A., Chen, Y., & McBride Murry, V. (2009). Prevention effects moderate the association of 5-HTTLPR and youth risk behavior initiation: Gene × environment hypotheses tested via a randomized prevention design. Child Development, 80, 645–661.
Bronfenbrenner, U. (1979). Ecology of human development. Cambridge, MA: Harvard University Press.
Buehler, C., & Gerard, J. M. (2013). Cumulative family risk predicts increases in adjustment difficulties across early adolescence. Journal of Youth and Adolescence, 42, 905–920.
Carey, G. (2003). Human genetics for the social sciences. Thousand Oaks, CA: Sage.
Caspi, A., McClay, J., Moffitt, T. E., Mill, J., Martin, J., Craig, I. W., et al. (2002). Role of genotype in the cycle of violence in maltreated children. Science, 297, 851–854.
Cherny, S. S., DeFries, J. C., & Fulker, D. W. (1992). Multiple regression analysis of twin data: A model-fitting approach. Behavior Genetics, 22, 489–497.
Cicchetti, D., & Rogosch, F. A. (1996). Equifinality and multifinality in developmental psychopathology. Development and Psychopathology, 8, 597–600.
Deary, I. J., Spinath, F. M., & Bates, T. C. (2006). Genetics of intelligence. European Journal of Human Genetics, 14, 690–700.
DeFries, J. C., & Fulker, D. W. (1985). Multiple regression analysis of twin data. Behavior Genetics, 15, 467–473.
DeFries, J. C., & Fulker, D. W. (1988). Multiple regression analysis of twin data: Etiology of deviant scores versus individual differences. Acta Geneticae Medicae et Gemellologiae, 37, 205–216.
Deković, M. (1999). Risk and protective factors in the development of problem behavior during adolescence. Journal of Youth and Adolescence, 28, 667–685.
Elder, G. H., & Caspi, A. (1990). Studying lives in a changing society: Sociological and personological explorations. In A. I. Rabin, R. A. Zucker, & S. Frank (Eds.), Studying persons and lives (pp. 201–247). New York, NY: Springer.
Ellis, B. J., Boyce, W. T., Belsky, J., Bakermans-Kranenburg, M. J., & van Ijzendoorn, M. H. (2011). Differential susceptibility to the environment: An evolutionary–neurodevelopmental theory. Development and Psychopathology, 23, 7–28.
Evans, G. W. (2003). A multimethodological analysis of cumulative risk and allostatic load among rural children. Developmental Psychology, 39, 924–933.
Evans, G. W., Kim, P., Ting, A. H., Tesher, H. B., & Shannis, D. (2007). Cumulative risk, maternal responsiveness, and allostatic load among young adolescents. Developmental Psychology, 43, 341–351.
Eysenck, H. J. (1990). Genetic and environmental contributions to individual differences: The three major dimensions of personality. Journal of Personality, 58, 245–261.
Farrington, D. P., & Tarling, R. (1985). Criminological prediction: An introduction. In D. P. Farrington & R. Tarling (Eds.), Prediction in criminology (pp. 2–33). Albany, NY: State University of New York Press.
Farrington, D. P., & Welsh, B. C. (2007). Saving children from a life of crime: Early risk factors and effective interventions. Oxford: Oxford University Press.
Gerard, J. M., & Buehler, C. (2004). Cumulative environmental risk and youth problem behavior. Journal of Marriage and Family, 66, 702–720.
Grayson, D. A. (1989). Twins reared together: Minimizing shared environmental effects. Behavior Genetics, 19, 593–604.
Harris, K. M., Halpern, C. T., Smolen, A., & Haberstick, B. C. (2006). The national longitudinal study of adolescent health (add health) twin data. Twin Research and Human Genetics, 9, 988–997.
Hawkins, J. D., Herrenkohl, T. I., Farrington, D. P., Brewer, D., Catalano, R. F., & Harachi, T. W. (1998). A review of predictors of youth violence. In R. Loeber & D. P. Farrington (Eds.), Serious and violent juvenile offenders: Risk factors and successful interventions (pp. 106–146). Thousand Oaks, CA: Sage.
Haynie, D. L. (2001). Delinquent peers revisited: Does network structure matter. American Journal of Sociology, 106, 1013–1057.
Haynie, D. L. (2002). Friendship networks and delinquency: The relative nature of peer delinquency. Journal of Quantitative Criminology, 18, 99–134.
Hedström, P. (2005). Dissecting the social: On the principles of analytical sociology. Cambridge: Cambridge University Press.
Herrenkohl, T. I., Maguin, E., Hill, K. G., Hawkins, J. D., Abbott, R. D., & Catalano, R. F. (2000). Developmental risk factors for youth violence. Journal of Adolescent Health, 26, 176–186.
Ingram, R. E., & Price, J. M. (2010). Understanding psychopathology: The role of vulnerability. In R. E. Ingram & J. M. Price (Eds.), Vulnerability to psychopathology (2nd ed., pp. 3–17). New York, NY: Guilford Press.
Kim-Cohen, J., Caspi, A., Taylor, A., Williams, B., Newcombe, R., Craig, I. W., et al. (2006). MAOA, maltreatment, and gene–environment interaction predicting children’s mental health new evidence and a meta-analysis. Molecular Psychiatry, 11, 903–913.
Kim-Cohen, J., Moffitt, T. E., Caspi, A., & Taylor, A. (2004). Genetic and environmental processes in young children’s resilience and vulnerability to socioeconomic deprivation. Child Development, 75, 651–668.
Kohler, H., & Rodgers, J. L. (2001). DF-analyses of heritability with double-entry twin data: Asymptotic standard errors and efficient estimation. Behavior Genetics, 31, 179–191.
Labuda, M. C., DeFries, J. C., & Fulker, D. W. (1986). Multiple regression analysis of twin data obtained from selected samples. Genetic Epidemiology, 3, 425–433.
Loeber, R., & Dishion, T. (1983). Early predictors of male delinquency: A review. Psychological Bulletin, 94, 68–99.
Luthar, S. S., Cicchetti, D., & Becker, B. (2000). The construct of resilience: A critical evaluation and guidelines for future work. Child Development, 7, 543–562.
Luthar, S. S., & Cushing, G. (1999). Measurement issues in the empirical study of resilience: An overview. In M. D. Glantz & J. L. Johnson (Eds.), Resilience and development: Positive life adaptations (pp. 129–160). New York, NY: Kluwer Academic/Plenum.
Luthar, S. S., & Zelazo, L. B. (2003). Research on resilience: An integrative review. In S. S. Luthar (Ed.), Resilience and vulnerability: Adaptation in the context of child adversities (pp. 510–549). New York, NY: Cambridge University Press.
Marks, M. R. (1964). How to build better theories, tests, and therapies: The off-quadrant approach. American Psychologist, 19, 793–795.
Masten, A. S., & Powell, J. L. (2003). A resilience framework for research, policy, and practice. In S. S. Luthar (Ed.), Resilience and vulnerability: Adaptation in the context of child adversities (pp. 1–25). New York, NY: Cambridge University Press.
Moffitt, T. E. (1993). Adolescence-limited and life-course-persistent antisocial behavior: A developmental taxonomy. Psychological Review, 100, 674–701.
Moffitt, T. E. (2005). The new look of behavioral genetics in developmental psychopathology: Gene–environment interplay in antisocial behavior. Psychological Bulletin, 111, 533–554.
Neale, M. C., & Cardon, L. R. (1992). Methodology for genetic studies of twins and families. Dordrecht: Kluwer Academic.
Olsson, C. A., Bond, L., Burns, J. M., Vella-Brodrick, D. A., & Sawyer, S. M. (2003). Adolescent resilience: A concept analysis. Journal of Adolescence, 26, 1–11.
Purcell, S., & Sham, P. C. (2003). A model-fitting implementation of the DeFries–Fulker model for selected twin data. Behavior Genetics, 33, 271–278.
Raine, A. (2002). Biosocial studies of antisocial and violent behavior in children and adults: A review. Journal of Abnormal Child Psychology, 30, 311–326.
Rhee, S. H., & Waldman, I. D. (2002). Genetic and environmental influences on antisocial behavior: A meta-analysis of twin and adoption studies. Psychological Bulletin, 128, 490–529.
Ribeaud, D., & Eisner, M. (2010). Risk factors for aggression in pre-adolescence: Risk domains, cumulative risk and gender differences–Results from a prospective longitudinal study in a multi-ethnic urban sample. European Journal of Criminology, 7, 460–498.
Rodgers, J. L., & McGue, M. (1994). A simple algebraic demonstration of the validity of DeFries–Fulker analysis in unselected samples with multiple kinship levels. Behavior Genetics, 24, 259–262.
Rowe, D. C., & Jacobson, K. C. (1998). National longitudinal study of adolescent health: Pairs code book. Chapel Hill, NC: Carolina Population Center, University of North Carolina at Chapel Hill.
Rutter, M. (1988). Longitudinal data in the study of causal processes: Some uses and some pitfalls. In M. Rutter (Ed.), Studies of psychosocial risk: The power of longitudinal data (pp. 1–28). New York, NY: Cambridge University Press.
Rutter, M., & Redshaw, J. (1991). Annotation: Growing up as a twin. Journal of Child Psychology and Psychiatry, 32, 885–895.
Rutter, M., Simonoff, E., & Silberg, J. (1993). How informative are twin studies of child psychopathology? In T. J. Bouchard & P. Propping (Eds.), Twins as a tool of behavioral genetics (pp. 179–194). Chichester, NY: Wiley.
Sameroff, A. J., Bartko, W. T., Baldwin, C., & Siefer, R. (1998). Family and social influences on the development of child competence. In M. Lewis & C. Feiring (Eds.), Families, risk, and competence (pp. 161–185). Mahwah, NJ: Erlbaum.
Sampson, R. J., & Laub, J. H. (2005). A life-course view of the development of crime. The Annals of the American Academy, 602, 12–45.
Schoon, I., & Bynner, J. (2003). Risk and resilience in the life course: Implications for interventions and social policies. Journal of Youth Studies, 6, 21–31.
Simons, R. L., Lei, M. K., Beach, S. R., Brody, G. H., Philibert, R. A., & Gibbons, F. X. (2011). Social environment, genes, and aggression: Evidence supporting the differential susceptibility perspective. American Sociological Review, 76, 883–912.
Simons, R. L., Lei, M. K., Stewart, E. A., Beach, S. R., Brody, G. H., Philibert, R. A., et al. (2012). Social adversity, genetic variation, street code, and aggression: A genetically informed model of violent behavior. Youth Violence and Juvenile Justice, 10, 3–24.
Spear, L. (2009). Heightened stress responsivity and emotional reactivity during pubertal maturation: Implications for psychopathology. Development and Psychopathology, 21, 87–97.
Stein, K. B., Vadum, A. C., & Sarbin, T. R. (1970). Socialization and delinquency: A study of false negatives and false positives in prediction. The Psychological Record, 20, 353–364.
Stoddard, S. A., Zimmerman, M. A., & Bauermeister, J. A. (2012). A longitudinal analysis of cumulative risks, cumulative promotive factors, and adolescent behavior. Journal of Research on Adolescence, 22, 542–555.
Stouthamer-Loeber, M., Loeber, R., Farrington, D. P., Wikström, P. H., & Wei, E. (2002). Risk and promotive effects in the explanation of persistent serious delinquency in boys. Journal of Consulting and Clinical Psychology, 70, 111–123.
Sullivan, C. J. (2011). The utility of the deviant case in the development of criminological theory. Criminology, 49, 905–920.
Tolan, P., & Guerra, N. (1994). What works in deducing adolescent violence: An empirical review of the field. Boulder, CO: Institute of Behavioral Science.
Van der Laan, A. M., Veenstra, R., Bogaerts, S., Verhulst, F. C., & Ormel, J. (2010). Serious, minor, and non-delinquents in early adolescents: The impact of cumulative risk and promotive factors. The TRAILS study. Journal of Abnormal Child Psychology, 38, 339–351.
Waaktaar, T., & Torgersen, S. (2012). Genetic and environmental causes of variation in trait resilience in young people. Behavior Genetics, 42, 366–377.
Weisburd, D., & Piquero, A. R. (2008). How well do criminologists explain crime? Statistical modeling in published studies. Crime and Justice, 37, 453–502.
Widom, C. S., & Brzustowicz, L. M. (2006). MAOA and the “cycle of violence”: Childhood abuse and neglect, MAOA genotype, and risk for violent and antisocial behavior. Biological Psychology, 60, 684–689.
Wikström, P. H. (2008). In search of cause and explanations of crime. In R. King & E. Wincup (Eds.), Doing research on crime and justice (2nd ed., pp. 117–139). New York: Oxford University Press.
Acknowledgments
This research uses data from Add Health, a program project directed by Kathleen Mullan Harris and designed by J. Richard Udry, Peter S. Bearman, and Kathleen Mullan Harris at the University of North Carolina at Chapel Hill, and funded by Grant P01-HD31921 from the Eunice Kennedy Shriver National Institute of Child Health and Human Development, with cooperative funding from 23 other federal agencies and foundations. Special acknowledgment is due Ronald R. Rindfuss and Barbara Entwisle for assistance in the original design. Information on how to obtain the Add Health Data Files is available on the Add Health website (http://www.cpc.unc.edu/addhealth). No direct support was received from Grant P01-HD31921 for this analysis.
Author Contributions
J.N. conceived of the study, participated in developing the research design, analyzed the data, and was involved in the preparation of the manuscript. C.S. participated in the development of the measures, the interpretation of the results, and assisted in preparing the manuscript. Both authors have read and approved the final manuscript.
Author information
Authors and Affiliations
Corresponding author
Appendix: Description of Risk and Delinquency Measures
Appendix: Description of Risk and Delinquency Measures
School Performance
-
1.
At the most recent grading period, what was your grade in English or language arts?
-
2.
And what was your grade in mathematics?
-
3.
And what was your grade in history or social studies?
-
4.
And what was your grade in science?
Attachment to School
Since the school year started, how often did you have trouble:
-
1.
Getting along with your teachers?
-
2.
Paying attention in school?
-
3.
Getting your homework done?
-
4.
Getting along with other students?
How much do you agree or disagree with the following statements:
-
5.
You feel close to people at your school.
-
6.
You feel like you are part of your school.
-
7.
You are happy to be at your school.
-
8.
The teachers at your school treat students fairly.
-
9.
You feel safe in your school.
Problem Solving Skills
-
1.
When you have a problem to solve, one of the first things you do is get as many facts about the problem as possible.
-
2.
When you are attempting to find a solution to a problem, you usually try to think of as many different ways to approach the problem as possible.
-
3.
When making decisions, you generally use a systematic method for judging and comparing alternatives.
-
4.
After carrying out a solution to a problem, you usually try to analyze what went right and what went wrong.
Coping Skills
-
1.
You usually go out of your way to avoid having to deal with problems in your life.
-
2.
Difficult problems make you very upset.
-
3.
When making decisions, you usually go with your “gut feelings” without thinking too much about the consequences of each alternative.
Attachment to Parents
-
1.
How close do you feel to your mother?
-
2.
How much do you think she cares about you?
-
3.
How close do you feel to your father?
-
4.
How much do you think he cares about you?
Parental Involvement
Which of the following have you done with your mother/father in the past 4 weeks?
-
1.
Gone shopping
-
2.
Played a sport?
-
3.
Gone to religious or church-related event?
-
4.
Talked about someone you’re dating or a party you went to?
-
5.
Gone to a movie, play, museum, concert, or sports event?
-
6.
Had a talk about a personal problem you were having?
-
7.
Had a serious argument about your behavior?
-
8.
Talked about your school work or grades?
-
9.
Worked on a project for school?
-
10.
Talked about other things you’re doing in school?
Parental Engagement
-
1.
Most of the time, your mother is warm and loving toward you.
-
2.
Your mother encourages you to be independent.
-
3.
When you do something wrong that is important, your mother talks about it with you and helps you understand why it is wrong.
-
4.
You are satisfied with the way you and your mother communicate with each other.
-
5.
Overall, you are satisfied with your relationship with your mother.
-
6.
Most of the time, your father is warm and loving toward you.
-
7.
You are satisfied with the way you and your father communicate with each other.
-
8.
Overall, you are satisfied with your relationship with your father.
Parental Supervision
-
1.
How often is she [mother] home when you leave for school?
-
2.
How often is she home when you return from school?
-
3.
How often is he [father] home when you leave for school?
-
4.
How often is he home when you return from school?
Delinquent Peers
-
1.
Of your 3 best friends, how many smoke at least 1 cigarette a day?
-
2.
Of your 3 best friends, how many drink alcohol at least once a month?
-
3.
Of your 3 best friends, how many use marijuana at least once a month?
Social Support
-
1.
How much do you feel that adults care about you?
-
2.
How much do you feel that your teachers care about you?
-
3.
How much do you feel that your parents care about you?
-
4.
How much do you feel that your friends care about you?
-
5.
How much do you feel that people in your family understand you?
-
6.
How much do you feel that you and your family have fun together?
-
7.
How much do you feel that your family pays attention to you?
Delinquency
In the past 12 months, how often did you:
-
1.
Paint graffiti or signs on someone else’s property or in a public place?
-
2.
Deliberately damage property that did not belong to you?
-
3.
Take something from a store without paying for it?
-
4.
Get into a serious physical fight?
-
5.
Hurt someone badly enough to need bandages or care from a doctor or nurse?
-
6.
Drive a car without its owner’s permission?
-
7.
Steal something worth more than $50?
-
8.
Go into a house or building to steal something?
-
9.
Use or threaten to use a weapon to get something from someone?
-
10.
Sell marijuana or other drugs?
-
11.
Steal something worth less than $50?
-
12.
Take part in a fight where a group of your friends was against another group?
During the past 12 months, how often did each of the following things happen?
-
1.
You pulled a gun or knife on someone.
-
2.
You shot or stabbed someone.
Rights and permissions
About this article
Cite this article
Newsome, J., Sullivan, C.J. Resilience and Vulnerability in Adolescents: Genetic Influences on Differential Response to Risk for Delinquency. J Youth Adolescence 43, 1080–1095 (2014). https://doi.org/10.1007/s10964-014-0108-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10964-014-0108-9