
Abstract
The problem of calculating the rate of mutual information between two coarse-grained variables that together specify a continuous time Markov process is addressed. As a main obstacle, the coarse-grained variables are in general non-Markovian, therefore, an expression for their Shannon entropy rates in terms of the stationary probability distribution is not known. A numerical method to estimate the Shannon entropy rate of continuous time hidden-Markov processes from a single time series is developed. With this method the rate of mutual information can be determined numerically. Moreover, an analytical upper bound on the rate of mutual information is calculated for a class of Markov processes for which the transition rates have a bipartite character. Our general results are illustrated with explicit calculations for four-state networks.
Similar content being viewed by others
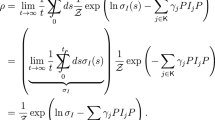

Avoid common mistakes on your manuscript.
1 Introduction
Mutual information [1, 2] is a quantity of central importance in information theory. It is a nonlinear correlation function [3] between two random variables that measures how much information about one random variable is encoded in the other. In other words, it measures the reduction of the uncertainty of a random variable resulting from knowing the other one. Since the Shannon entropy quantifies the randomness of a random variable, mutual information is a difference between Shannon entropies. More generally, given two stochastic time series the information per unit of time between them is quantified by the rate of mutual information, which is a difference between Shannon entropy rates. Whereas the Shannon entropy rate of Markovian time series can be expressed in terms of the stationary probability distribution [2], no general formula is known for non-Markovian processes.
Recently, we have obtained an analytical upper bound on the rate of mutual information and calculated it numerically for a class of Markov processes [4]. This class is formed by bipartite networks where the full state of the systems is determined by two coarse-grained variables: one corresponding to an external Markovian process and the other to an internal non-Markovian process. In this paper we generalize the results obtained in [4] by calculating an upper bound on the rate of mutual information for a more general class of Markov processes, where both coarse-grained processes can be non-Markovian. Moreover, we develop a numerical method to estimate the Shannon entropy rate of a continuous time coarse-grained non-Markovian process by adapting an extant numerical method for discrete time [5–7].
Apart from the quite challenging mathematical problem of determining the rate of mutual information, there are physical motivations for our study. First, within stochastic thermodynamics [8], which is a framework for far from equilibrium systems, a central quantity is the thermodynamic entropy production. In a nonequilibrium steady state, it characterizes the rate at which heat is dissipated. On the other hand, the rate of mutual information is an information theoretic entropy rate that characterizes the correlations between the two coarse-grained processes. The study of the relation between both quantities for specific models should improve our understanding of the relation between thermodynamics and information.
More specifically, a considerable amount of work on the role of information in the stochastic thermodynamics of feedback driven systems, for which a controller acts at periodic time intervals, has emerged recently [9–22]. In such periodic steady states the rate of mutual information between system and controller is just the average mutual information due to each new measurement divided by the length of the period [13]. The second law of thermodynamics bounding the maximum extractable work has then to be modified in order to include the mutual information between system and controller, linking directly thermodynamic and information theoretic entropy productions. On the other hand, if a Maxwell’s demon is described as an autonomous system [23–25], calculating the rate of mutual information in such a genuine nonequilibrium steady states shows that in this case there is no such relation between the rate of mutual information and the thermodynamic entropy production [4].
Second, the study of the energetic costs of sensing in biochemical networks is a field emerging at this interface between thermodynamics and information theory [26, 27]. For example, an intriguing relation between the energy costs of dissipation, quantified by the thermodynamic entropy production, and the adaptation error has been found in a model for the E. coli sensory system [26]. In these papers, the observables characterizing the quality of sensing are the adaptation error [26] and the uncertainty in the external ligand concentration [27]. Alternatively, a natural quantity that should be discussed in this context with the same dimension of the thermodynamic entropy production is the rate of mutual information. Hence, the study of the relation between these two quantities in biochemical sensory networks could contribute to an understanding of the thermodynamics of such systems [4].
This paper is organized as follows. In Sect. 2, we discuss a one spin system with a fluctuating magnetic field as a simple introductory example. We define the bipartite network and the quantities of interest in Sect. 3. In Sect. 4, we derive our first main result, which is the analytical upper bound on the rate of mutual information. Our second main result, namely, the continuous time numerical method, is explained in Sect. 5, where we also discuss the discrete time case. In Sect. 6, we calculate the rate of mutual information explicitly for four-state systems considering cases where the rate of mutual information admits a simple interpretation. We conclude in Sect. 7.
2 One Spin Out of Equilibrium
For a simple illustration let us start with the four-state model represented in Fig. 1. One spin is subjected to a time varying magnetic field while in contact with a thermal reservoir inducing flips. The magnetic field is controlled by some external device that randomly changes it. More precisely, the field is a Poisson process with rate γ, fluctuating between the values B 1 and B 2. The transition rates for the spin flip are denoted by \(w^{\alpha}_{mm'}\) (from m to m′), where α=1,2 represents the state of the magnetic field and m,m′=−,+ the orientation of the spin. These transition rates are given by the local detailed balance assumption, i.e.,
where we set Boltzmann constant multiplied by temperature to 1.

One spin system in a time varying magnetic field. The transition rules for the model are shown in the left panel. The vertical transitions correspond to a spin flip due to thermal fluctuations and fulfill local detailed balance. The horizontal transitions at rate γ, controlled by an external device, correspond to a change in the magnetic field between the values B 1 (full blue line) and B 2 (dashed red line). The right panel shows the corresponding time series
Now consider the three time series shown in Fig. 1. The first time series \(\{(B(t),m(t))\}_{0}^{T}\) represents a stochastic trajectory of the full four-state Markov process. The time series \(\{B(t)\}_{0}^{T}\) is also Markovian, because if we integrate out the spin variable we get a two-state Markov process. The physical reason for the Markov character of this process is that the magnetic field is controlled by an external device that does not care about the internal state (the spin orientation). The spin time series \(\{m(t)\}_{0}^{T}\) is non-Markovian and contains information about the magnetic field time series \(\{B(t)\}_{0}^{T}\), i.e., both are correlated.
The rate of mutual information \(\mathcal{I}\) (see definition below) quantifies how much information about the time series \(\{B(t)\}_{0}^{T}\) is encoded in the time series \(\{m(t)\}_{0}^{T}\). In other words, it gives a (non-linear) measure of how correlated both time series are, being zero in the case where they are independent and positive otherwise. Within the present model, both time series become independent only for B 1=B 2. For this choice of parameters, we obtain a two-state Markov process for the spin by integrating out the magnetic field, i.e., for B 1=B 2 the processes \(\{B(t)\}_{0}^{T}\) and \(\{m(t)\}_{0}^{T}\) become two independent Markov processes.
Moreover, the model is in equilibrium, i.e., detailed balance is fulfilled if and only if B 1=B 2. The thermodynamic entropy production σ (see definition below) is a signature of nonequilibrium since it is zero when detailed balance is fulfilled and strictly positive for nonequilibrium stationary states. For this one-spin system, σ is the rate at which the system dissipates heat to the thermal reservoir.
As cited in the introduction, for feedback driven systems the second law of thermodynamics has to be adapted in order to include the rate of mutual information between the system and the controller. For these systems it is possible to rectify fluctuations in order to extract work from a single heat bath, where the rate of the extracted work is bounded by the rate of mutual information. A complementary question, considering the model of Fig. 1, is whether the rate of mutual information between m(t) and B(t), which is non-zero only when the system is out of equilibrium, is bounded by the dissipation rate required to sustain the nonequilibrium stationary state. In [4] we have shown that, in general, there is no such bound. In Fig. 2, we compare the thermodynamic entropy production σ with the rate of mutual information \(\mathcal{I}\) for the one-spin system of Fig. 1 using the results derived further below.

Comparison of the thermodynamic entropy production σ (20) and the rate of mutual information \(\mathcal{I}\) for the model of Fig. 1 as a function of k, where γ=1, B 1=0 and B 2=ln(10). The abbreviation (disc.) indicates the mutual information obtained with the extrapolation for τ→0 in discrete time explained in Sect. 5.1 and (cont.) is related to the continuous time numerical method explained Sect. 5.2. \(\mathcal{I}^{(u)}\) shows the analytical upper bound (34)
3 Bipartite Network
We now define the class of bipartite Markov processes studied in this paper and the rate of mutual information, for discrete and continuous time.
3.1 Shannon Entropy Rates for Discrete Time
First we consider a discrete time Markov process where the states are labeled by the pair of variables (α,i), where α=1,…,Ω x and i=1,…,Ω y . The Markov chain is defined by the following transition probabilities,
where τ is the time spacing. Transitions where both variables change are not allowed, which means that the network of states is bipartite.
We denote a discrete time series of the full Markov process with N jumps by \(\{Z_{n}\}_{0}^{N}= (Z_{0},Z_{1},\ldots,Z_{N})\), where Z n =(X n ,Y n )∈{1,…,Ω x }×{1,…,Ω y }. The Shannon entropy rate of the Markov chain (2) is defined by [2]
where the sum is over all possible stochastic trajectories \(\{Z_{n}\}_{0}^{N}\). Since the full process is Markovian, it is well known that this entropy rate can be expressed in terms of the stationary probability distribution \(P_{i}^{\alpha}\) in the form [2]
Moreover, the Shannon entropy rates of the coarse-grained processes \(\{X_{n}\}_{0}^{N}\) and \(\{Y_{n}\}_{0}^{N}\) are defined as
These two coarse-grained processes are in general non-Markovian. More precisely, they are hidden Markov processes [28]. The quantity we wish to calculate is the rate of mutual information between the two coarse-grained variables, which is defined as
Therefore, in order to obtain the rate of mutual information we have to calculate the Shannon entropy rates of the two coarse-grained variables X and Y. Using the definitions of the Shannon entropy rates (3), (5), and (6), we can rewrite I in the form
where the Kullback-Leibler distance is defined as [2]
With this formula it becomes explicit that the rate of mutual information measures how correlated the two processes are.
In [4] we have studied the particular case where X is an external process independent of the internal states, i.e., \(w^{\alpha\beta}_{i}\equiv w^{\alpha\beta}\) for all i=1,…,Ω y . In this case, the external process is also Markovian and H X becomes
where
For later convenience we also define
In this paper we are mostly interested in the continuous time limit τ→0. For the calculation of an analytical upper bound on the continuous time rate of mutual information, it is useful to consider the discrete time Markov chain and then take the limit τ→0. In this limit, the Shannon entropy rates diverge as lnτ [29, 30], however, the rate of mutual information is a well defined finite quantity: it is a difference between Shannon entropy rates for which the term proportional to lnτ cancels.
It is possible to calculate the rate of mutual information numerically for the discrete time case as a function of τ and then extrapolate to the limit τ→0. Alternatively, we develop a more efficient numerical method to directly estimate the entropy rate of a continuous time series. We now define the Shannon entropy rates and the rate of mutual information for the continuous time case.
3.2 Shannon Entropy Rates for Continuous Time
The continuous time Markov process is defined by the transition rates (transition probability per time)
The stochastic trajectory for a fixed time interval T is written as \(\{Z(t)\}_{0}^{T}\) (in this case the time interval is fixed and the number of jumps N is a random variable). Similarly, the definition of the Shannon entropy rate of the full Markov process is
where \(\mathcal{P}[\{Z(t)\}_{0}^{T}]\) is the probability density of the trajectory \(\{Z(t)\}_{0}^{T}\) and the integral is over all possible stochastic trajectories. Since the Z process is Markovian the continuous time Shannon entropy rate can also be written in terms of the stationary probability distribution, and it is given by [31]
Since the transition rates can take any positive value, it is clear that this Shannon entropy rate can be negative. This is a well known fact for continuous random variables [2]. The Shannon entropy rates of the X and Y processes are defined in the same way,
Moreover, the definition of the continuous time rate of mutual information is
where the relation between \(\mathcal{I}\) and the discrete time rate of mutual information (7) is \(\mathcal{I}= \lim_{\tau\to 0}I \). Even though the Shannon entropy rates \(\mathcal{H}_{X}\), \(\mathcal{H}_{Y}\), and \(\mathcal{H}_{Z}\) may be negative, the rate of mutual information \(\mathcal{I}\), the quantity of central interest in this paper, fulfills \(\mathcal{I}\ge0\). In order to show this we write the rate of mutual information as a Kullback-Leibler distance,
3.3 Thermodynamic Entropy Production
A central quantity in stochastic thermodynamics is the thermodynamic entropy production [8, 32], which for the rates (13) reads
Analogously to the rate of mutual information, the thermodynamic entropy production can also be expressed as [33]
where \(\{\tilde{Z}(t)\}_{0}^{T}\) denotes the time-reversed trajectory, i.e., \(\tilde{Z}(t)= Z(T-t)\). Depending on the physical interpretation of the transition rates, the entropy rate σ may characterize the dissipation associated with the full network of states, being zero only if detailed balance is fulfilled. As discussed above, for the one spin system of Fig. 1 it is proportional to the heat that flows from the system to the thermal reservoir. On the other hand, \(\mathcal{I}\) is the information theoretic entropy rate that quantifies the correlation between the X and Y processes. No closed formula like equation (20) is known for the rate of mutual information. However, as we show next, it is still possible to calculate it numerically and to obtain an analytical upper bound.
4 Analytical Upper Bound
Let us take the Y process in the discrete time case and in the stationary regime. The conditional Shannon entropy is defined as
where P(Y N+1|Y N ,…,Y 1)=P(Y N+1,Y N ,…,Y 1)/P(Y N ,…,Y 1) is a conditional probability. The knowledge of one extra random variable can only decrease the uncertainty about Y N+1, which means that H(Y N+1|Y N ,…,Y 2,Y 1)≤H(Y N+1|Y N ,…,Y 2). Therefore, as the Y process is stationary, we obtain that this conditional entropy is a decreasing function of N, i.e.,
Moreover, in the limit N→∞, we have [2]
which means that the conditional entropy (22) bounds the Shannon entropy rate H Y from above. Furthermore, it can be shown that H Y is bounded from below by [2]
leading to
where the bounds become tighter for increasing N.
As we show in the appendix, for any finite N,
and, analogously,
From (4) we obtain the following formula for the entropy rate H Z ,
For convenience we define the average transition rates
The N-th upper bound on the rate of mutual information is then
From Eqs. (27), (28), and (29), it is given by
Taking the continuous time limit τ→0, the rate of mutual information is hence bounded from above by
Two remarks are important. First, it is interesting to note the formal similarity between this expression and the one for the thermodynamic entropy production (20). Substituting in the latter inside the logarithm the rate of a reversed transition by the respective average forwards rates (30) and (31), we get the former. Second, to calculate the true rate of mutual information we would have to take the limit N→∞ with fixed τ. This would give an expression for the rate of mutual information that would be valid for any time spacing τ and should become the continuous time rate of mutual information by taking the limit τ→0 afterwards.
A similar calculation for the lower bounds in Eq. (26) shows that in the continuous time limit they all go to zero. This is illustrated in Fig. 3, where we plot upper and lower bounds obtained from (26) as a function of the time spacing τ for the discrete time version of the one spin model of Fig. 1. This discrete time version is defined by the transition probabilities given by (2) obtained from the transition rates represented in Fig. 1.

Finally, one limiting case for which the rate of mutual information saturates the upper bound is the following. We take the X process to be Markovian, i.e., \(w^{\alpha\beta}_{i}\equiv w^{\alpha\beta}\) for all i=1,…,Ω y . From Eq. (10), it follows
Furthermore, if the X transitions are much faster than the Y transitions (\(w^{\alpha\beta}\gg w^{\alpha}_{ij}\)), the Y process becomes approximately Markovian, with transition rates \(\overline{w_{ij}}\) [34, 35]. Therefore, in this limit we expect
The continuous time rate of mutual information \(\mathcal{I}\) obtained from (29), (35) and (36) is then precisely the upper bound (34). Therefore, in the case where the X process is Markovian and much faster then the Y process, the rate of mutual information saturates the upper bound (34). In Sect. 6, we illustrate this fact explicitly for four-state models.
5 Estimating Shannon Entropy Rate from a Single Time Series
5.1 Discrete Time
For discrete time, the probability of a stochastic trajectory of the Y process can be written as
where P(X 0,Y 0) denotes the initial probability distribution and P[X n ,Y n |X n−1,Y n−1] is the conditional probability. Explicitly, for (X n−1,Y n−1)=(α,i) and (X n ,Y n )=(β,j) we have \(P[X_{n},Y_{n}|X_{n-1},Y_{n-1}]=W^{\alpha\beta}_{ij}\).
Let the random matrix T(Y n ,Y n−1) be defined by
This is a Ω x ×Ω x matrix, where the variables (Y n ,Y n−1) make it random. Using this matrix, Eq. (37) can be rewritten as
where V is a row vector with all Ω x components equal to one and \(\mathbf{P}_{Y_{0}}\) is a column vector with components P(Y 0,X 0), with X 0=1,…,Ω x . The Shannon entropy rate (6) can then be written as
Moreover, in the large N limit, where boundary terms become irrelevant, we can replace the product of matrices (39) in Eq. (40) with \(\lVert \prod_{n=1}^{N}\boldsymbol{T}(Y_{n},Y_{n-1}) \rVert\), where ∥⋅∥ is any matrix norm [5]. Therefore, in order to estimate the entropy rate H Y we generate a long time series \(\{Y^{*}_{n}\}_{0}^{N}\) with a numerical simulation and calculate
Such a numerical method to calculate the Shannon entropy rate has been used in [5–7]. The appropriate way to calculate this product, avoiding numerical precision problems for large N, is to normalize the product every L steps and repeat the procedure M times, so that N=ML [36]. More precisely, for m=1,…,M we calculate the vector
and the normalization factor
where u m is the normalized vector
and the initial vector u 0 is any random vector with an unitary norm. By calculating the normalization factors iteratively we obtain the Shannon entropy rate with the formula
The present method is based on the fact that the probability of an Y stochastic trajectory can be written as a product of random matrices (39). Since this is true for any coarse-grained non-Markovian variable we can also apply the same method to calculate H X . Explicitly, if we define the Ω y ×Ω y random matrix
then we can estimate the Shannon entropy rate from the numerically generated time series \(\{X^{*}_{n}\}_{0}^{N}\) from
Moreover, we can also apply the same procedure of normalizing the product after some steps and keep track of the normalization factor to calculate this product numerically. Finally, with the Shannon entropy rates (41) and (47) we obtain the rate of mutual information from (4) and (7).
In Fig. 3, we show the numerically obtained rate of mutual information for two sets of the kinetic parameters of the discrete time version of the one spin system of Fig. 1 as a function of the time spacing τ. For small τ, the rate of mutual information shows a linear behavior, which we can extrapolate in order to obtain the continuous time rate of mutual information \(\mathcal{I}\). The result has been shown in Fig. 2. A more efficient numerical method to obtain \(\mathcal{I}\), which generalizes the above discussion to the continuous time case, is introduced next.
5.2 Continuous Time
We consider the continuous time trajectory \(\{Z(t)\}_{0}^{T}\) that stays in state Z n during the waiting time τ n . The number of jumps N is a random functional of the trajectory and the time interval \(T=\sum_{n=0}^{N}\tau_{n}\) is fixed. The main difference, in relation to the discrete time case, is the presence of the exponentially distributed waiting times in the probability density of the continuous time trajectory, which is written as
where P(Z 0) is the initial probability distribution. For Z n =(α,i), the escape rate is
Furthermore for Z n+1=(β,j) the transition rates are \(w_{Z_{n}Z_{n+1}}= w_{ij}^{\alpha\beta}\).
As illustrated in Fig. 4, the path \(\{Z(t)\}_{0}^{T}\) has N x jumps for which the variable X changes and N y jumps for which the variable Y changes. Due to the bipartite form of the network of states, there are no jumps where both variables change, which implies N=N x +N y . We denote the time intervals between jumps for the trajectory \(\{X(t)\}_{0}^{T}\) by \(\tau^{x}_{n}\), with n=0,…,N x . Similarly, for the trajectory \(\{Y(t)\}_{0}^{T}\) we have \(\tau^{y}_{n}\), with n=0,…,N y . In Fig. 4, an example of a trajectory with N=6 jumps is shown.

Example of continuous time-series where the Z process jumps 6 times and the X and Y process each jumps 3 times, i.e., N x =N y =3
The random matrix \(\boldsymbol{\mathcal{T}}(Y_{n},Y_{n-1})\) is defined by its elements \(\boldsymbol{\mathcal{T}}(Y_{n},Y_{n-1})_{X_{n},X_{n-1}}\), which are the transition rate \(w_{Z_{n-1}Z_{n}}\) if Z n−1≠Z n and \(-\lambda_{Z_{n}}\) otherwise. More precisely, we can define \(\boldsymbol{\mathcal{T}}(Y_{n},Y_{n-1})\) using its relation with the matrix T(Y n ,Y n−1), defined in (38), which is
where \(\mathbb{I}_{x}\) is the Ω x ×Ω x identity matrix and \(\delta_{Y_{n-1}Y_{n}}\) is the Kronecker delta. In addition, we define the matrix
Similarly to the discrete time case, for which Eq. (39) holds, from the master equation, we obtain
Moreover, the same expression is valid for the probability density of the X time-series, i.e.,
The matrix \(\boldsymbol{\mathcal{T}}(X_{n},X_{n-1})_{Y_{n},Y_{n-1}}\) is now defined as
where T(X n ,X n−1) is given by (46) and \(\mathbb{I}_{y}\) is the Ω y ×Ω y identity matrix. The matrix \(\boldsymbol{\mathcal{F}}_{X_{n}}(\tau)\) is defined as
In order to calculate the Shannon entropy rates a procedure similar to the discrete time case method can be used: we generate a long continuous time series, with the waiting times, \(\{Z^{*}(t)\}_{0}^{T}\), with \(N^{*}=N^{*}_{x}+N^{*}_{y}\) jumps, and estimate the non-Markovian Shannon entropy rates through the expressions
We are assuming that \(N_{x}^{*}\) and \(N_{y}^{*}\) are large, so that boundary terms can be neglected and we can use any matrix norm. These products are also numerically calculated by normalizing after a certain number of steps and keeping track of the normalization factors. The result obtained with the continuous time method for the one spin system of Fig. 1 can be seen in Fig. 2. This method is more direct because for discrete time we have to obtain the result as a function of τ and then extrapolate for τ→0. Moreover, when the probabilities of not jumping in discrete time are large, the continuous time method is computationally cheaper.
The continuous time method we presented above is not restricted to the bipartite networks we consider in this paper: it could be applied for other kinds of coarse-graining. The method only depends on the fact that we can write the probability density of a trajectory as a product of random matrices.
6 Four-State System
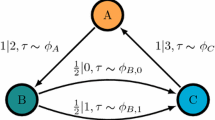
We now illustrate the main results of this paper, namely, the analytical upper bound and the continuous time numerical method, by considering the general four-state network shown in Fig. 5, for which the one spin system of Fig. 1 is a particular example. Since Ω x =Ω y =2, there are four \(\boldsymbol{\mathcal{T}}(Y_{n},Y_{n-1})\) and four \(\boldsymbol{\mathcal{T}}(X_{n},X_{n-1})\) matrices, each of which is a two by two matrix. For the sake of clarity, let us write these matrices explicitly. Using the superscript (y) for the \(\boldsymbol{\mathcal{T}}(Y_{n},Y_{n-1})\) matrices and (x) for the \(\boldsymbol{\mathcal{T}}(X_{n},X_{n-1})\) matrices, they are given by:
In the following we treat two simple cases for which the rate of mutual information acquires a simple form in some limit.

General four-state model
6.1 Y Following X
Here we consider k 1=k 4=0. For this choice of rates a jump in the Y process can happen only after a jump in the X process. In this sense, Y follows X. Calculating the stationary probability distribution, we obtain for the upper bound on the rate of mutual information (34) the expression
where γ 1=γ 2=γ 3=γ 4=γ. If we further assume k 2=k 3=k and k≫γ, the rate of mutual information can be obtained with the following heuristic argument. A typical time series of the full process is an alternating sequence of long time intervals of size 1/γ with short time intervals of size 1/k. If we know the X time series, we can predict in which of the k/γ intervals of size 1/k the Y jumps will take place. Since this information amounting to lnk/γ occurs at the rate γ of the X jumps, we obtain that for k≫γ
More generally, for k 1≠k 3, from the same kind of argument, we obtain
This expression is in agreement with the upper bound (61) in the limit k 2,k 3≫γ.
Moreover, we can also understand the rate of mutual information in the limit γ≫k 2,k 3. This corresponds to the case where the X process becomes Markovian and much faster than the Y process, therefore, as discussed in Sect. 4 the rate of mutual information should saturate the upper bound. Suppose that we know the Y time series. In the time interval between two Y jumps there are many X jumps and we have no information about the X state during this time interval. When a Y jump takes place, we know the state X with absolute precision, i.e., if the Y jump is 1→2 (2→1) then the X state is 2 (1). Furthermore, since the X jumps are fast compared to k 2,k 3, the time interval between two Y jumps is long enough for the X process to decorrelate, so that the information obtained with an Y jump is completely new. The complete knowledge of a binary random variable accounts for ln2 of mutual information. The average rate of Y transitions is given by k 3 P III +k 2 P II =k 2 k 3/(k 2+k 3), where P II and P III denote the stationary probabilities of the states II and III defined in Fig. 5. This leads to the expression
valid for γ≫k 2,k 3. As expected, this form is also in agreement with the upper bound (61) in the respective limit. Figure 6, where we compare the analytical upper bound with the numerical result, demonstrates that in the limits k 2 k 3≫γ and γ≫k 2,k 3 the upper bound and the numerical result indeed tend to the same value.

Numerically obtained rate of mutual information \(\mathcal{I}\) compared to the upper bound \(\mathcal{I}^{(u)}\) (61) as a function of γ −1 for γ 1=γ 2=γ 3=γ 4=γ, k 1=k 4=0, k 3=4, and k 2=1
6.2 Equilibrium Model
As a second example, we consider a network in equilibrium for which the rate of mutual information is nevertheless non-zero. In Fig. 5, we set γ 1=γ 2=γ 3=γ 4=γ, k 3=k 1, and k 4=k 2. For this choice of rates detailed balance is fulfilled because the product of the transition rates for the clockwise cycle equals the product of the transition rates for the counterclockwise cycle. Moreover, in the stationary state all states are equally probable. The upper bound on the rate of mutual information (34) is independent of γ and given by
where ϵ≡k 1/(k 1+k 2) and H(ϵ)≡−ϵlnϵ−(1−ϵ)ln(1−ϵ). As we show in Fig. 7, the rate of mutual information tends to the upper bound in the limit γ≫k 1,k 2. This is again in agreement with the discussion at the end of Sect. 4, since the X process is Markovian and, in the limit γ≫k 1,k 2, much faster than the Y process. Moreover, similarly to the way we obtained the result (64) for the previous model, the rate of mutual information can be easily explained in this limit. The difference in relation to the previous explanation is that when an Y jump occurs the mutual information about the X state is ln2−H(ϵ). This happens because if a Y jump occurs, then the probability of X being in state 1 is ϵ and in state 2 is 1−ϵ. As the average rate of a Y jump is simply (k 1+k 2)/2, we obtain
which is equal to the upper bound (65).

Numerically obtained rate of mutual information \(\mathcal{I}\) compared to the upper bound \(\mathcal{I}^{(u)}\) (65) as a function of γ 1=γ 2=γ 3=γ 4=γ. The other parameters are k 3=k 1=1 and k 4=k 2, thus enforcing equilibrium
More generally, if the only restrictions are γ 1=γ 2=γ 3=γ 4=γ and γ≫k 1,k 2,k 3,k 4, then from the same kind of argument we obtain
where ϵ 1=k 1/(k 1+k 2) and ϵ 2=k 3/(k 3+k 4). This more general expression accounts for the results (64) and (66).
7 Summary
In this paper we have addressed the problem of calculating the rate of mutual information between two coarse-grained processes that together fully specify a continuous time Markov process. To this end, we have developed a numerical method to estimate the Shannon entropy rate of hidden Markov processes from a continuous time series, generalizing the numerical method used in the discrete time case [5–7]. Moreover, for the class of bipartite Markov processes we considered in this paper, we have obtained an expression for an upper bound on the rate of mutual information in terms of the stationary probability distribution. While this expression has some formal similarity with the one for the rate of thermodynamic entropy production, it has become clear that these two rates, in general, are not related through a simple inequality.
As applications of the theory developed here we have studied three four-state systems each of which can serve as illustrating, inter alia, the apparent independence of the rate of mutual information from the rate of thermodynamic entropy production. First, the one spin system with time-varying magnetic field is arguably the simplest case which shows that in an non-equilibrium steady state the rate of mutual information is not bounded by the dissipation rate. Second, for a four state network for which some transition rates are zero, the rate of mutual information is still well defined whereas the thermodynamic entropy production is not since the latter requires that each backward transition is possible with a finite rate as well. Third, a four state system in equilibrium with zero thermodynamic entropy production can still have non-zero rate of mutual information. Moreover, in these four-state systems it is typically possible to find, and to understand in simple terms, a limiting case for the rates such that the analytical upper bound on the rate of mutual information becomes saturated.
On the mathematical side, finding a general expression for the rate of mutual information at least for the bipartite case on which we focused is most likely as hard a problem as finding one for the Shannon entropy rate of a non-Markovian process. For interesting physical perspectives, the rate of mutual information could become particularly relevant for the emerging theories of both autonomous information machines and cellular sensing systems. In both cases, one could suspect that even though there is no simple bound between the information-theoretic and the thermodynamic rate of entropy production in general, in more specific settings these two quantities might obey relations still to be uncovered. The algorithm described here to calculate the former will help in generating the necessary data for any specific model network efficiently.
References
Shannon, C.E.: Bell Syst. Tech. J. 27, 379–423 (1948)
Cover, T.M., Thomas, J.A.: Elements of Information Theory, 2nd edn. Wiley, Hoboken (2006)
Li, W.: J. Stat. Phys. 60, 823 (1990)
Barato, A.C., Hartich, D., Seifert, U.: Phys. Rev. E 87, 042104 (2013)
Holliday, T., Goldsmith, A., Glynn, P.: IEEE Trans. Inf. Theory 52, 3509 (2006)
Jacquet, P., Seroussi, G., Szpankowski, W.: Theor. Comput. Sci. 395, 203 (2008)
Roldan, E., Parrondo, J.M.R.: Phys. Rev. E 85, 031129 (2012)
Seifert, U.: Rep. Prog. Phys. 75, 126001 (2012)
Touchette, H., Lloyd, S.: Phys. Rev. Lett. 84, 1156 (2000)
Cao, F.J., Feito, M.: Phys. Rev. E 79, 041118 (2009)
Sagawa, T., Ueda, M.: Phys. Rev. Lett. 104, 090602 (2010)
Sagawa, T., Ueda, M.: Phys. Rev. Lett. 109, 180602 (2012)
Sagawa, T., Ueda, M.: Phys. Rev. E 85, 021104 (2012)
Horowitz, J.M., Vaikuntanathan, S.: Phys. Rev. E 82, 061120 (2010)
Horowitz, J.M., Parrondo, J.M.R.: Europhys. Lett. 95(1), 10005 (2011)
Granger, L., Kantz, H.: Phys. Rev. E 84, 061110 (2011)
Abreu, D., Seifert, U.: Phys. Rev. Lett. 108, 030601 (2012)
Abreu, D., Seifert, U.: Europhys. Lett. 94, 10001 (2011)
Bauer, M., Abreu, D., Seifert, U.: J. Phys. A, Math. Theor. 45, 162001 (2012)
Ito, S., Sano, M.: Phys. Rev. E 84, 021123 (2011)
Crisanti, A., Puglisi, A., Villamaina, D.: Phys. Rev. E 85, 061127 (2012)
Mandal, D., Jarzynski, C.: Proc. Natl. Acad. Sci. USA 109, 11641 (2012)
Esposito, M., Schaller, G.: Europhys. Lett. 99, 30003 (2012)
Strasberg, P., Schaller, G., Brandes, T., Esposito, M.: Phys. Rev. Lett. 110, 040601 (2013)
Barato, A.C., Seifert, U.: Europhys. Lett. 101, 60001 (2013)
Lan, G., Sartori, P., Neumann, S., Sourjik, V., Tu, Y.: Nat. Phys. 8, 422 (2012)
Mehta, P., Schwab, D.J.: Proc. Natl. Acad. Sci. USA 109, 17978 (2012)
Ephraim, Y., Merhav, N.: IEEE Trans. Inf. Theory 48, 1518 (2002)
Gaspard, P.: J. Stat. Phys. 117, 599 (2004)
Lecomte, V., Appert-Rolland, C., Wijland, F.: J. Stat. Phys. 127, 51 (2007)
Dumitrescu, M.B.: Čas. Pěst. Mat. 113, 429 (1988)
Schnakenberg, J.: Rev. Mod. Phys. 48, 571 (1976)
Kawai, R., Parrondo, J.M.R., van den Broeck, C.: Phys. Rev. Lett. 98, 080602 (2007)
Rahav, S., Jarzynski, C.: J. Stat. Mech., Theor. Exp. P09012 (2007)
Esposito, M.: Phys. Rev. E 85, 041125 (2012)
Crisanti, A., Paladin, G., Vulpiani, A.: Products of Random Matrices in Statistical Physics. Springer Series in Solid State Sciences (1993)
Acknowledgements
Support by the ESF through the network EPSD is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Appendix: Detailed Derivation of the Analytical Upper Bound
Appendix: Detailed Derivation of the Analytical Upper Bound
The first upper bound H(Y 2|Y 1) can be easily calculated by using the conditional probability
where Y 2≠Y 1. We here performed the substitutions X 1→α, Y 1→i, and Y 2→j. Using this formula in (22) we obtain
Moreover, H(Y N+1|Y N ,…,Y 1) up to order τ is given by the above formula for any finite N. In order to demonstrate this we first rewrite (22) as
where P(Y N ,Y N ,…,Y 1) denotes the probability of having a sequence for which Y N+1=Y N . For Y N+1≠Y N , the expression of the conditional probability P(Y N+1|Y N ,…,Y 1) has at least one transition probability term of order τ. Therefore, as P(Y N+1|Y N ,…,Y 1) is at least a term of order τ, it is convenient to further rewrite the above expression as
where in the first line we summed over the variables Y 1,…,Y N−1. The three following relations are important for the subsequent derivation. First, for Y N+1≠Y N ,
Moreover,
where η≥1 is an integer and A is a constant independent of τ. Finally, the conditional probability distribution fulfills
where ν≥1 is an integer and B is a constant independent of τ. With these three relations, the term in the second line in Eq. (71) becomes
where we used τ ν+η−1lnτ ν−1∈O(τ). For the term in the third line in Eq. (71) we need the relations,
and
which lead to
Inserting (75) and (78) in (71) we obtain
Therefore, since the Y process is stationary, from (69), we obtain for any finite N
Applying the same method to the X process we get,
Rights and permissions
About this article
Cite this article
Barato, A.C., Hartich, D. & Seifert, U. Rate of Mutual Information Between Coarse-Grained Non-Markovian Variables. J Stat Phys 153, 460–478 (2013). https://doi.org/10.1007/s10955-013-0834-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10955-013-0834-5