
Abstract
Various direct and indirect sensing methods for machine condition monitoring have been reported in the literature. Among these methods, acoustic emission technique is one of the effective means of monitoring rolling element bearings during industrial processes. Today, many machines use computerized classification in a wide range of applications. Further, recent developments indicate the drive towards integration of diagnosis and prognosis algorithms in future integrated machine health management systems. With this in mind, this paper concentrates on the estimation of the remaining useful life for bearings whilst in operation. To implement this, a linear regression classifier and multilayer artificial neural network model have been proposed to correlate the selected AE features with corresponding bearing wear throughout laboratory experiments. Results showed that the proposed models exhibit good prediction performance. This paper also presents the use of a new representative fault indicator, signal intensity estimator, employed for AE signals originating from natural degradation of slow speed rolling element bearings. It is concluded that the obtained results were promising and selecting this appropriate signal processing technique can significantly affect the defect identification.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The useful operating life of a rolling element bearing is influenced by a number of factors. Some of the factors are controlled by the designer while others are controlled by the user. Most of the research related to condition based maintenance is mainly focused on fault diagnostic. A tremendous amount of work has been undertaken over the last 30-years in developing of the application of the condition monitoring techniques for bearing health monitoring [1]. Although a lot of work has been undertaken in the area of bearing fault diagnosis, there is still an on-going need for the area of bearing prognosis. Most of the techniques that are widely used for health monitoring and prediction of remaining useful life (RUL) are divided into two models [2]. The first model is the model based (or physics-based) method, which predicts the RUL based on the propagation of the damage mechanism. The second approach involves the data driven methods. In this model, data acquired by sensors are further processed in relevant models (parametric/non-parametric) to estimate the RUL [3]. To use the data driven models, sufficient failure data should be provided to train the prediction models such as Neural Networks, Bayesian Networks and Markova Processes. Over a number of recent years, attempts to estimate the remaining useful life of bearings have been addressed in number of publications. Nathan et al. [4], for instance, undertook experimental bearing tests to predict the RUL of an aircraft engine bearing. In this study a model based on the steps of developing the spall propagation mechanism was used. To validate the results of the developed RUL prediction method, a full-scale bearing test was performed. It was postulated that the developed model could accurately predict the spall propagation and the corresponding RUL. Shao et al. [5] proposed progression prediction of remaining life (PPRL) of bearing. In this model, different prediction methods were applied to different bearing running stages. Another model, Neural Network based, for predicting bearing failures was developed by Gebraeel et al. [6]. Gebraeel et al. came up with a conclusion that best estimation of bearing failure times can be obtained by weighted average of the exponential parameters. In his PhD study, Ghafari [7] extracted vibration signals features that were used as the input of the diagnostic model. Adaptive neuro-fuzzy inference system (ANFIS) was used to evaluate the efficiency of bearing prognosis. It was reported that the trained ANFIS could successfully capture the damage propagation behaviour and predict the future states of the same series of bearings at different speed and load conditions. Comparative investigation of the accuracy between three different techniques to estimate the bearing RUL was done by Sutrisno et al. [8]. Moving average spectral Kurtosis and Bayesian Monte Carlo, support vector regression and anomaly detection have been applied to an experimental data set from seventeen ball bearings provided by the FEMTO-ST Institute. Sutrisno et al. reported that anomaly detection method was found to be the most accurate method overall. Goebel et al. [9] undertook another comparative results between relevance vector machine (RVM), Gaussian process regression (GPR), and a neural network model. Obtained results showed that each algorithm produced a significant different estimation of RUL from the others. A machine prognostics model based on health state estimation using support vector machines (SVM) has been proposed in an undertaken investigation by Kim et al. [10]. Data from faulty bearing cases in pumps, used for high pressure liquefied natural gas (LNG), were analysed. Results were used to identify the failure degradation process and further validate the feasibility of the proposed model for accurate assessment of RUL.
An artificial neural network (ANN) based method was developed by Tian [11]. Features such as age and multiple condition monitoring measurements at the present and previous inspection points were employed as inputs for the proposed model. Based on these inputs the ANN model will produce the bearing life percentage as the output. Tian reported that achieving accurate useful life prediction using the proposed method was observed. Another ANN model based on the data driven prognostic method was proposed by Ben Ali et al. [12]. In this proposed model, Weibull distribution (WD) along with the Simplified Fuzzy Adaptive Resonance Theory Map (SFAM) neural network was employed to estimate the bearings RUL. To fit and avoid the fluctuation in the measured time domain data, a modified Weibull Distribution function was selected. Features at present and previous inspection time points were first extracted from the time domain signals and then fitted using the selected WD. Fitted RMS, kurtosis and root mean square entropy estimator (RMSEE), a fault indicator that was proposed by the authors, were used to train the SFAM. It is worth mentioning that for the accuracy assessment the proposed model was also applied to unfitted data. It was postulated that the proposed technique could reliably predict the RUL and can be expanded to include the prognosis of the other mechanical components. Mejia et al. [13] utilized wavelet packet decomposition (WPD) and Gaussians hidden Markov models (MoG-HMM) to estimate the bearing RUL. WPD was used to extract the relevant information from the vibration bearing signals. These features are then used to train several behaviour models MoG-HMM at different initial states and operating conditions of the bearing. Comparative results between the estimation of RUL using the extracted time domain features and the extracted time-frequency domain features was also presented. Mejia et al. came up with a conclusion that is the extracted features from time-frequency domain are more precise in achieving the RUL. In another investigation, Loutas et al. [14] has presented another approach for condition assessment and life prediction. This method is mainly based on nonlinear support vector regression (SVR) where a set of multiple statistical vibration features from the time-domain, frequency domain, and time-scale domain through a wavelet transform features were extracted. Further, the authors also utilized Wiener Entropy for the condition monitoring of rolling bearings. Prior to testing, the SVR model was trained and tuned off-line using the extracted features. Unseen data was then employed to online RUL prediction. The authors claimed that the results obtained by the proposed model showed a significant consistency with the corresponding actual bearing degradation level.

Test rig layout
It can be concluded that off the shelf, most of the published attempts, for earlier bearing prognosis, have made use of vibration analysis, in which the current and previous vibration data was used to predict the RUL of bearings. Keeping this in mind, there are potentially unlimited opportunities for a wide scope to develop methods, tools and applications for effective prognostic systems. This can be implemented by expanding the area of research to assess the feasibility of the use of the other condition monitoring techniques, such as Acoustic Emission, for the RUL estimation. The high sensitivity of AE in detecting the loss of mechanical integrity at early stages has become one of the significant advantages over the well-established vibration monitoring technique [15] and [16]. To date most published work on the application of the AE to monitoring bearing mechanical integrity have been conducted on artificially (‘seeded’) damage or ground metal debris that were introduced gradually into Bearings. However, Elforjani el al. [17] undertook an investigation to assess the potential of the acoustic emission (AE) technology for detecting natural cracks in operational slow speed shafts. In addition to that, this work presented experimental results on accelerated bearing fatigue under starved lubricating conditions. Elforjani el al. concluded that AE technology successfully detected natural cracks induced on slow speed rotating machinery.
Price et al. [18] also showed the applicability of AE to monitor naturally generated scuffing and pitting defects in a four ball lubricant test machine. The work undertaken by Yoshioka [19] also identified the onset of natural degradation in bearings with AE. It is worth noting that Yoshioka employed a bearing with only three rolling elements which is not representative of a typical operational bearing. Moreover, Yoshioka terminated AE tests once AE activity increased as such the propagation of identified subsurface defects to surface defects was not monitored. To date the only published work by Elforjani et al [15–17] and [20] could be considered the first that directly addressed not only the identification of the initiation of cracks, but also its propagation to spalls or surface defects on a conventional slow speed bearing with the complete set of rolling elements. This work builds further on the work of Elforjani by estimating the remaining useful life for slow speed bearings using acoustic emission signals.
2 Experimental Procedure and Equipment
One of the challenges was to enhance the crack signatures at the early stage of defect development. To implement this, bearing run to failure tests were performed under natural damage conditions on a specially designed test rig. To accelerate crack initiation, a combination of a thrust ball bearing and a thrust roller bearing was selected. One race of ball bearing (SKF 51210) was replaced with a flat race taken from the roller bearing (SKF 81210 TN) of the same size. Consequently, the rolling ball elements on a flat track caused very high contact pressure in excess of 6,000MPa. The test rig rotational speed was 72 rpm and an axial load of 50 kN was employed for this particular investigation. A commercially available piezoelectric sensor (physical acoustic corporation type “PICO”) with an operating range of 200–1000 kHz was used. Four acoustic sensors, together with two thermocouples were attached to the back of the flat raceway using superglue. The acoustic sensors were connected to a data acquisition system via preamplifiers, set at 40 db gain. The system was continuously set to acquire AE waveforms at a sampling rate of 2 MHz. The software (signal processing package “AEWIN”) was incorporated within the PC to monitor AE parameters such as counts, RMS, amplitude, ASL and energy (recorded at a time constant of 10 ms and sampling rate of 100 Hz). Schematic of the test rig layout is shown in Fig. 1. The presented experimental cases in this work reflect the general observations associated with over a dozen experimental tests. High AE signal levels were noted during the final stages of bearing life. It is also worth mentioning that bearing tests were terminated after 16 hours testing. Figure 2 shows the surface damage observed on the termination of the tests (16-h). Further detailed description, experimental setup, observations, analysis and discussions can be found in [15–17] and [20].

Surface damage on flat bearing race, see ‘circle’ section

Schematic of constructing the proposed model
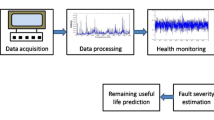
3 Estimation of Remaining Useful Life (RUL)
In this section the methodology, used for estimation the RUL of the test bearings, is presented. The feature extraction, classification, and prediction are also discussed. Figure 3 summarises in sufficient details the steps followed from the basic extraction of AE features till the interpretation of RUL results.
3.1 Extraction and Reduction of AE Features
In the application of the condition monitoring, signals are information provider. Hence, it is global acceptance that more failure histories will lead to accurate results. The acquired data normally tend to be high dimensional noisy data, such as the case of AE data, and therefore it is necessarily needed to be cleaned, reduced and pre-processed prior to further processing. However, excess in cleaning, reduction and pre-processing the acquired data may lead to lose the significance of the carrying information. Operators are, very often, careful in selecting representative fault index tools to interpret the signal trend. One of the widely used indicators is the kurtosis (KU), which is employed as a measure of the peakness of the signals. In this particular investigation, attempts were made to extract the features from time domain AE signals, originating from test bearings, using the Kurtosis. For individual event (x), sample size (N) sample mean (\(\mu \)) and sample standard deviation (\(\sigma \)), kurtosis can be calculated as [20]:
Results showed that as the tests progressed with time, KU showed a noisy trend to the variation in bearing signals, see Fig. 4; reinforcing the observations that although the kurtosis becomes very sensitive indicator as the presence of the defects is pronounced, its values may become noisy and come down to the level of undamaged bearings when the damage is well advanced [20] and [21]. Hence the continuous monitoring of bearings employing techniques such as the kurtosis may not offer the operator a relatively sensitive tool for observing high transient type activity (e.g. AE signals).

Kurtosis trend
With this in mind, it was thought prudent to ascertain which other processing techniques could employ the transient characteristics noted thus far in determining the bearing mechanical condition. Based on the assumption that a feature that monotonically increases over time is the ideal degradation signal [8], the author proposed a new dimensionless fault indicator technique; signal intensity estimator (SIE).
-
Signal intensity estimator (SIE)
Whilst the root mean square (RMS) is one of the widely used statistical parameters for condition monitoring measurements, it is typically recorded over a predefined time constant. As such the RMS values, for the case of denser data such as AE data, are not necessarily sensitive to transient changes, which typically are of a few micro-seconds. However, this is not the case for the cumulative sums where they not only display the total at any given time but also they can chart statistic that involves current and previous data values from the process. This helps to track how the sample values deviate from a target value and also improves the ability to detect micro-changes. Processing several samples from failure histories using cumulative sums will result in greater sensitivity for detecting shifts or variation in trends over time. The relative slopes from point to point will indicate greater or lesser increases. A sharp slope, for instance, means a greater increase than a steady slope. Thus, the author believes that the use of cumulative sums would make it easy for the operator to predict or pre-plan in advance. To overcome the inadequacy in the use of the RMS, a relatively more sensitive and robust technique based on the cumulative sums has been proposed; the SIE. SIE can be defined as the ratio of the sum of cumulative sum of a defined segment, window, (SCS\(_{\mathrm {segment}})\) in a given signal to the overall sum of cumulative sum (SCS\(_{\mathrm {overall}})\) of the same signal. This ratio is then multiplied by a magnification factor (MAGF). The advantage of the dimensionless SIE is that it can reduce the complexity of the problem as its result is numerical values without physical dimensions. This in turn will allow the user to perform any analysis for any condition monitoring data (e.g. vibration, AE, etc.) irrespective of their physical units. Besides it resolves the problem in the cases of small values of the calculated SIE, the MAGF also plays a vital role to overcome the problem of selecting the size of a given window. The author assumed that there is a direct proportionality between the MAGF and the selected number of the windows (W). This means the higher number of W the higher MAGF and vice versa. This proportionality produced a constant (k) that is highly dependent on the type of the data. For high dimensionality data, such as the case of AE data, high W and small k are preferred whilst small W and high k are better for low dimensionality measurements. Mathematical expressions that are required to perform the SIE analysis are explained as following:

Results of SIE analysis
-
(a)
To obtain optimal SIE value, signal should be rectified as the first step.
-
(b)
The SIE is calculated using the following equation:
$$\begin{aligned} { SIE}\, =\, \frac{{ SCS}_{{ segment}} }{{ SCS}_{{ overall}} }. ~{ MAGF} \end{aligned}$$(2) -
(c)
With the knowledge of the size of a given signal (N) and the size of each segment (n), the MAGF can be derived as:
$$\begin{aligned} { MAGF}\, \alpha W, \quad { where}\;W=\, \frac{N_{{ overall}} }{n_{{ segment}}} \end{aligned}$$(3) -
(d)
With the use of the proportionality constant (k), the MAGF can simply calculated as:
$$\begin{aligned} k=\left\{ {2,3,4,5,6} \right\} \end{aligned}$$(4)$$\begin{aligned} {} { MAGF}= & {} k.W, \quad { where} \; \nonumber \\&\left\{ { \begin{array}{l} k=2\; { for}\; { very~high}\; W\; { and}\; { high}\; { dimentionality}\; { data} \\ 2\prec k\le 4\; { for~high}\; W\; { and}\; { high}\; { dimentionality}\; { data} \\ 4\le k\le 6\; { for}\; { low}\; W\; { and}\; { low}\; { dimentionality}\; { data} \\ \end{array}} \right\} \nonumber \\ \end{aligned}$$(5)
It is worth mentioning that the above values of k have been selected based on the results of the iterative process, undertaken, to achieve the optimal values. In application, SIE value of one, between two adjacent segments, is associated with non-transient type signals and greater than one where transient characteristics are present. For this particular investigation AE signals, recorded throughout the bearing tests, were split into several windows each of which contains one hundred segments and the optimal value of k was found to be 4. This allowed to smoothen the high dimensional AE data without losing the carrying information. It was noted that after about 8-hrs relatively rise in SIE value was recorded. After running of 10-hrs, SIE values started to grow steadily with time. On termination of the tests (16-hrs), the SIE raised to the maximum values. It is also interestingly to note that the trend of SIE was completely consistent with the general trend of AE noted by Elforjani et al. [15–17] and [20]. This confirms the author’s belief that the SIE is reliable, robust and sensitive to the detection of incipient cracks and surface spalls and can successfully be employed for condition monitoring of rotating machines. Results of SIE analysis are presented in Fig. 5.
-
Correlation Coefficient
Thus far the observations have shown SIE can monitor the degradation of an accelerated bearing test; the next phase of this investigation involved the ascertainment of how strong the monotonic relationship is between the SIE with the time duration of the tests. To implement this, what-so-called correlation coefficient was calculated using Pearson’s product-moment correlation. Correlation can be defined as a class of statistical relationship between variables. From the results presented in Table 1, it can be seen that true correlation between SIE with time is not equal to 0. From p-value that is less 0.05 and the positive sign of the correlation coefficient, it can be concluded that SIE is strongly correlated with time; association between these two parameters are strong (strong monotonic relationship).
3.2 Fitting of AE Signal Features
As mentioned in the previous section that the acquired data is accompanied with an external noise that significantly influences the final interpretation of the general trend. Although it was observed in the previous sections that the bearing failure, throughout 16 hours testing, was relatively a monotonic process, the acquired data cannot be directly fed to the prediction models. This is because that any noise in the acquired data will significantly disturb the performance of the model and subsequently its capability to accurately predict the health condition of the bearings; prediction models in such a case will follow the randomness. To overcome this issue, the raw data have to be fitted using appropriate mathematical functions. To represent trends in the degradation signals, originating from bearings, linear or exponential models were widely employed. In this research work, several linear and exponential function have been applied to the acquired data. Finally, the author proposed the following exponential model to fit the extracted features first, and then use the fitted values as inputs to the prediction model.
This function could fit the different bearing cases that used for constructing, training, validation and testing the prediction model. In the above function f is the magnitude of the signal feature; here is the value of SIE,a is the model constant, and t is the time. The constant \(y_{0}\) is used here to indicate the value when the degradation time is equal to zero. To find the optimal values for the above function constants a and \(y_{0}\) that can fit all the tested measurement series, the popular least-square method was applied to four bearing cases; Fig. 6 shows the fitted bearing cases. These cases will be used for constructing, training and validating the prediction model, see the following sections. Table 2 also summarizes the general optimal estimated constants for the exponential model. For a technical and economical estimation of RUL, it is very important to predefine a threshold. This threshold represents an early warning of the onset of the degrading bearing. Further, it discriminates the onset of the degradation region from the healthy region.

Actual and Fitted SIE
Predefining a threshold is not an easy task and it is entirely up to the operator experience and/or it can very often be found experimentally. Failure in accurately selecting this threshold may lead to false estimation of RUL and untimely downtime of the system. Sophisticated and classification algorithms are usually used for such situations to find the optimal border between the healthy and degrading regions.
In this particular investigation, a simple and quick method to set the threshold was suggested. This method is based on the fitting of the bearing cases, that are selected to use for construction, training and validation the prediction model, together and the output \(y_{0} \)value of the general fitting was used to set the threshold.
Having established that, the \(y_{0} \)value for the general fitting was found to be (28.5). With this in mind and considering the general trend of the four cases, the threshold was set at (SIE \(=\) 35) and its corresponding time (\(t =\) 8 h). This threshold will help to avoid any false alarms that may trigger before the degradation zone. For a quick diagnosis purpose, this also suggested dividing the monitoring process into two status; healthy and degradation regions; Class H denotes the former whilst Class D is assigned to the latter, see Fig. 7. Any values fall in the area before the onset of the predefined threshold the bearing will be considered as a healthy bearing. This classification was used to train the linear regression classifier (LRC), see the following section, which can be considered as an early alarm to start the process of RUL estimation.
Another issue that was addressed in the most published work is the selection of the final threshold [6, 8, 12] and [22]. The corresponding time (\(t_{f})\) to this threshold is normally defined as the time at which the component is considered to be out of the service and accordingly used for further RUL estimation. It is worth noting that in the application of real world machines the time of the fully mature failure is estimated by the analyst, experimentally, and/or provided by the manufacturer. However, several attempts including experimental work, were made in the literature to set an appropriate \(t_{f}\) [6, 8, 12] and [22]. This also included attempts to use sophisticated classifiers and/or assumptions that suggested the value of \(t_{f}\) to be the time at which experimental tests were terminated.
For this particular investigation, the threshold corresponding to the time of fully developed failure, based on the conclusion made by Elforjani et al. [15–17, 20] was set at 16-h of testing.
3.3 Linear Regression Classifier (LRC)
Machine learning is the field that gives the computers the ability to learn without being explicitly programmed [23]. Machine learning can be divided into two types; supervised learning and unsupervised learning. In supervised learning, inputs and outputs are known; for the purpose of learning, an answer is given to the algorithm. Regression, support vector machine and neural networks are some techniques used for supervised learning type. In the second type, unsupervised learning, only the inputs are known and the used technique must predict the right answer [23]. The common techniques are widely used for this type of learning include clustering and k-means. As mentioned, linear regression analysis is one of the techniques employed for the supervised learning type and it is a common technique that is mainly focusing on finding a relationship between one dependent variable and one or more independent variables [24]. The coefficient explains the impact of changes of an independent variable on the dependent variable. A line is fitted through the group of plotted data, such as scattered plots [24, 25] and [26]. The distance of the plotted points from the line gives the residual value. The residual value is a discrepancy between the actual and the predicted values. The procedure to find the best fit is called the least-squares method [24, 25] and [26]. The equation that represents how an independent variable (x) is related to a dependent variable (y) is called a regression model [24, 25] and [26].
where \(\upbeta _{\mathrm {0}}\) and \(\upbeta _{\mathrm {1}}\) are called the parameters of the model, and \(\upvarepsilon \) is a random variable called error term. Getting the estimation of \(\upbeta _{\mathrm {0}}\) and \(\upbeta _{\mathrm {1}}\) means finding the best straight line that can be drawn through the scatter plot between y and x. Fitting of linear regression model requires several assumptions being made to get the best fit. This includes that the predictor variable x must not be a random; there is no variance in the measurements of x. The error term \(\upvarepsilon \) is random and it follows the normal distribution and the standard deviation and therefore error is independent of x. Also the data being used to estimate the parameters should be independent of each other. If any of the mentioned assumptions are violated the modelling procedures must be modified. In linear regression analysis, a coefficient of determination R\(^{\mathrm {2}}\) is used to measure the goodness of fit. For negative relationship the value of (R\(^{\mathrm {2\, }}=-\)1), and (R\(^{\mathrm {2}}=0\)) denotes that there is no relationship. In the case of (R\(^{\mathrm {2}}= +\)1), a positive relationship exists. Hence, one can explain how well the model based on R\(^{\mathrm {2\,}}\)value. The difference between observations that are not explained by the model is the error term or residual [24, 25] and [26].

Generalized optimal exponential model
In this research work, a LRC was proposed. This model is used to classify the acquired data for bearing tests into two classes based on the threshold obtained from the general fitting of the bearing tests, see the previous section.
Prior to the training of LRC, two categorical values were used to classify the training data; Class H for healthy bearing and Class D for degrading bearing. As the regression model would only accept the numerical values, the next step involved the conversion of these categorical values into numerical values using binary classification; zero denotes a Class H (healthy bearing) whereas one is assigned to Class D (degrading bearing). Following to this, the categorized data was passed to the LRC model for training. In this LRC model, the dependent variable is the class type whereas SIE and its corresponding time represent the independent variables. The obtained R\(^{\mathrm {2\, }}\)value is 0.7674 and the Residual standard error is 0.2426. This shows that the goodness of fit is good and there is a strong relationship between the variables in the model. Hence, the proposed model was accepted and no further modifications were made.
In machine learning field, available data is very often divided into two sets. 70–80 % of the data is employed for training models while the remaining 20–30 % is used for validation. Suggestions also include dividing data into 50 % for training and 50 % for validating. For this investigation data from six bearing cases that reflect the general observations of bearing tests were used. It was planned to divide the data into three equal portions. Two cases, Case 1 and Case 2, are devoted to the process of constructing and training the proposed model while Case 3 and Case 4 will be used for validating the model. The last two case will be held for the real tests. This strategy was also followed in the prediction model in the later sections of this work. The cases used for constructing, training, and validating the proposed models are presented in Fig. 6. Figure 8 shows the cases, Case 5 and case 6, that are used for the final tests.
Prior to the training process, SIE is calculated and the resulting data is fitted and categorized, see the previous section. The resulting data is then used to feed the LRC and training process is terminated once the miss-classification rate (MCR) achieved zero value using a predefined threshold. To assess the accuracy of the selected threshold, the LRC is fed with Case 3 and Case 4 and the process is repeated several times until the optimal threshold, which satisfies the four cases, is obtained, see Fig. 9. The MCR was calculated with the help of a confusion matrix. This matrix also helped to assess the overall performance of the proposed model.

Bearing cases used for testing the LRC

Schematic of the proposed LRC model
The MCR was determined using the following steps:

Confusion matrix for the proposed LRC model
-
(a)
Tabulate the results using a specific confusion matrix format [23, 27] and [28], shown in Fig. 10:
-
(b)
Using the following equations, false class H rate (FCHR), false class D rate (FCDR) and MCR were determined:
In this section the method that employed to select the threshold is discussed. As mentioned above, during the training process iterative analysis is repeated until the MCR reached a zero value and the corresponding classification probability threshold (CPT) is selected. In a probability regression classification for a two-class problem, the CPT is normally set to be 0.5 (50 %). However, this is not always the case as the CPT is very sensitive indicator and should carefully be selected. Thus, in this research work, it was decided that the best CPT value is the value where the above three error rates traverse with each other; the error value for the three error indicators is equal to zero then the LCR model employed this threshold to estimate the class of the bearing case. Results of MCR, FCHR and FCDR analysis, for the four bearing cases, are presented in Fig. 11. Analysis revealed that a different CPT for each bearing case was noted as expected. For instance whilst CPT is 0.57 for Case 1 it has values 0.51, 0.49 and 0.41 for Case 2, Case 3 and Case 4 respectively. To optimize the performance of the LRC and select a generalized CPT, the mean square error (MSE) was calculated for every CPT value, see Table 3.

Results of error analysis
It should be noted that the difference between the data used for validating the model and the data selected for the real test is that the validation data is categorized. The reason behind that is to tune the model to achieve the best generalized CPT. Based on the above results, the best (CPT \(=\) 0.49 \(\approx \) 0.5) was selected. Having established the best CPT, another two uncategorized cases, not used for training and validating LRC (Case 5 and Case 6), were employed to run the final test, see Fig. 10 and Table 4 for the test results. From Table 4, it can be observed that the proposed model could accurately classify 248 readings from Case 5 out of a total of 257 were fed to the model. Also was noted that only 14 readings out of 257 in the second case, Case 6, were false classified. The model performed a good prediction as this can clearly be seen from the low values of MCR, FCHR and FCDR. This suggested that employing the proposed LRC can successfully lead to discriminate the onset of the degrading bearing from the healthy bearing and accordingly
manipulating the data of degrading signals for both precaution steps and RUL estimation.

Structure of the proposed ANN model

Schematic of the proposed ANN model
3.4 Multilayer Artificial Neural Network (ANN)
Artificial neural networks (ANN) are a supervised machine learning type. They are inspired by biological neural networks and each neuron is represented by a node [23]. It is basically a directed graph where each edge has a weight. These neural networks are capable of learning by changing the weights of their connections [29] and [30]. Components of ANN involve input neurons, output neurons, hidden neurons, and bias neurons. The input neurons has no processing and are used to provide input signals. On the other hand, output neurons process the units and are used to get the output. The task of the hidden neurons is to add additional processing for the units to achiev6 e a converged solution. The bias neurons are employed to avoid zero results even if the inputs are zero. It is worth mentioning that the bias neurons are not connected to the input neurons and normally their values set to one. Neurons are connected with each other through a connection weights (synaptic weights) that are used to signify the strength of the connection and therefore, the higher the weight the higher strength of that connection [31]. This will also lead to higher of the effect of the processing. The edge weights have a random value at the beginning and they are updated accordingly. The connection between the neurons is directional, namely, connection from, for instance n\(_{\mathrm {1}}\) to n\(_{\mathrm {2}}\) is different from the connection from n\(_{\mathrm {2}}\) to n\(_{\mathrm {1\, }}\) [31]. In general there are two kinds of neural networks; Hopfield Neural Network and Feedforward Neural Network. In the former each neuron is connected to every other neurons whilst there are directed edges from input layer to hidden layer and from hidden layer to output layer in the latter [31]. In the ANN structure, activation functions, for example linear function, hyperbolic tangent and/or sigmoid functions, are extensively also used. These functions take some weights of the input signals and perform some actions. The model in ANN is defined as the neural network architecture and it contains [30] and [31]:

Validation results for the proposed ANN model
-
The neurons (inputs, outputs, hidden and biases) where inputs and outputs are mandatory,
-
Structure which means how these neurons are attached to each other,
-
Activation functions, and
-
Weights.
The model is called a trained model when the weights were adjusted for minimum error (E). In general, there are two types of errors; local error and global or network error. The local error is the difference between the ideal value and the actual value whereas the global error is a cumulative effect of all local errors. In the training process, interconnection weights are adjusted so that the global error is less than some predefined level (PL). This predefined limit is very sensitive as in the case of a high limit the model will be under trained whilst low limit will lead to over trained model. For the training purpose, different algorithms with different rules to update weights; different calculation methods for global errors and different flow charts, are used. The most common training algorithms include Back-Propagation algorithm, resilient-propagation algorithm, Quick-Propagation algorithm and LMA algorithm [31] and [32]. The algorithm terminates the training process when the network error rate is small. To select an appropriate training algorithm, accuracy, required computational resources and training time must be considered.

Test results for the proposed ANN model
In this research work, an ANN model was proposed to estimate the RUL for slow speed bearings. The model is a Feedforward ANN model with three layers at beginning that were used for constructing the ANN model; one input layer, one output layer and one hidden layer with changeable number of neurons in the hidden layer. The model parameters such as the number of hidden layers, algorithm type and learning rate were kept changing until the best performance was achieved. The best results eventually were obtained by an ANN model containing one input layer,; represents the SIE value, one output layer; represents estimated RUL, and two hidden layers with five neurons in the first layer and eight neurons in the second layer. For the best training, the resilient back-propagation algorithm and the activation sigmoid function (logistic) were selected. Figure 12 shows the final structure of the proposed ANN model that used to estimate the bearing RUL. The strategy followed in LRC model was also used for constructing, training, validating and testing the ANN model. Data from the presented four bearing cases in Fig. 6 were held for constructing, training and validating themodel whereas the other two cases, shown in Fig. 8, were used for the final testing process. The SIE was calculated from the acquired AE data and further fitted prior to the training process. The fitted data was passed to the model, and the selected algorithm in turn started to train the model. Several runs accompanied with adjusting and tuning the ANN parameters such as weights, number of hidden layers etc. were made to minimize the global error. Eventually, the used algorithm terminated the training process once the error approached zero value (it recorded the minimum value). The next phase involved validating the trained model. This was implemented by passing the fitted data from Case 3 and Case 4 to the trained model. The steps followed from the training of the proposed ANN model until the estimation of the RUL are presented in Fig. 13. Interestingly observations from the validation results, showed the feasibility of the ANN model to accurately predicting the RUL; although small difference between the estimated RUL values and the actual RUL values was noted in Case 4, the estimated RUL values in Case 3 are concentrated around the line of the actual RUL, see Fig. 14. It worth mentioning that the RUL, the error and some of square error (ESS) were calculated using the Eqs. 12, 13 and 14 respectively.

Error analysis for the proposed ANN model
where t\(_{\mathrm {f}}\)is the time at which the fully mature failure is formed, and (tc) is the current time at which the RUL is estimated.
Analysis of the results obtained from the real test using Case 5 and Case 6 present almost consistent trends to that noted earlier in Case 3 and Case 4. By visually inspecting the plots, it can obviously be observed that the predictions made by the ANN model for Case 5 and Case 6 are almost concentrated around the actual RUL line (a perfect alignment with the line would indicate a low Some Square Error (ESS) and thus an ideal perfect prediction), see Fig. 15 and Table 5. Also was noted that Case 5 registered the lowest error values in the real test. Interestingly, some negative error values were recorded by Case 3 and Case 6, shown in Fig. 16. These negative values imply that the ANN model has overestimated the RUL.
The lowest error values showed by Case 3 and Case 5 could also be ascertained by the ESS analysis, see Table 5. Highest ESS value of 4184.31 was recorded by Case 4.
4 Conclusion
Estimation of RUL for slow speed bearing under natural damage conditions were successfully performed using supervised machine learning techniques. At the rotational speed on which bearing tests were employed, this is the first known attempt at employing the LRC and ANN models to estimate the RUL using acoustic emission signals. The six cases presented are representative of other tests performed in this study. The results demonstrated the applicability of the proposed LRC in discriminating and locating the onset of the degrading bearings from healthy bearings. It was also shown that the proposed ANN model with back-propagation learning could accurately estimate the RUL for slow speed bearings. It can be concluded that the use of LRC and ANN as early alarm tools not only minimizes the wasteful machine downtime but also the untimely replacement of components. The study also showed that SIE is reliable, robust and sensitive to the detection of incipient cracks and surface spalls in slow speed bearing and show that there is a clear correlation between increasing SIE levels and the natural propagation and formation of bearing defects. Finally, this study can be considered as the first investigative step since it concerns a single application of the proposed models (LRC and ANN) to a specific test rig and to unique specimens and therefore its effectiveness, both technically and economically, has to be proved with further investigations.
References
Jammu, N.S., Kankar, P.K.: A review on prognosis of rolling element bearings. Int. J. Eng. Sci. Technol. (IJEST) 3(10), 7497–7503 (2011)
Zhigang, T.: An artificial neural network method for remaining useful life prediction of equipment subject to condition monitoring. J. Intell. Manuf. ISSN 23(2), 0956–5515 (2012)
Medjaher, K., Tobon-Mejia, D.A., Zerhouni, N.: Remaining useful life estimation of critical components with application to bearings. IEEE Trans. Reliab. Inst. Electr. Electron. Eng. (2012) doi:10.1109/TR.2012.2194175
Nathan, B., Hai, Q., Neil, E., Ed, H., Taylor, R.: Physics-based remaining useful life prediction for aircraft engine bearing prognosis. In: Annual Conference of the Prognostics and Health Management Society (2009)
Shao, Y., Nezu, K.: Prognosis of remaining bearing life using neural networks. Proc. Inst. Mech. Eng. Part I 214(3), 217–230 (2000)
Gebraeel, N., Lawley, M., Liu, R., Parmeshwaran, V.: Residual life predictions from vibration-based degradation signals: a neural network approach. IEEE Trans. Ind. Electron. 51(3), 694–700 (2004)
Ghafari, S.H.: A fault diagnosis system for rotary machinery supported by rolling element bearings. PhD Thesis, University of Waterloo, Ontario (2007)
Sutrisno, E., Oh, H., Vasan, A.S.S., Pecht, M.: Estimation of remaining useful life of ball bearings using data driven methodologies. In: IEEE Conference on Prognostics and Health Management (PHM) (2012) doi:10.1109/ICPHM.2012.6299548
Goebel, K., Saha, B., Saxena, A.: A comparison of three data-driven techniques for prognostics. In: 62nd Meeting of the Society for Machinery Failure Prevention Technology (2008)
Kim, H.E., Tan, A.C., Mathew, J., Kim, E.Y., Choi, B.K.: Machine prognostics based on health state estimation using SVM. In: Proceedings of 3rd World Congress on Engineering Asset Management and Intelligent Maintenance Systems Conference, Vol. 199 (2008)
Tian, Z.: An artificial neural network method for remaining useful life prediction of equipment subject to condition monitoring. J. Intell. Manuf. 23(2), 227–237 (2009)
Ali, J.B., Chebel-Morello, B., Saidi, L., Malinowski, S., Fnaiech, F.: Accurate bearing remaining useful life prediction based on weibull distribution and artificial neural network. Mech. Syst. Signal Process. 56—-57, 150–172 (2015)
Tobon-Mejia, D.A., Medjaher, K., Zerhouni, N.: Tripot, G., Estimation of the remaining useful life by using Wavelet Packet Decomposition and HMMs. In: IEEE, Aerospace Conference. (2011) doi:10.1109/AERO.2011.5747561
Loutas, T.H., Roulias, D., Georgoulas, G.: Remaining useful life estimation in rolling bearings utilizing data-driven probabilistic e-support vectors regression. IEEE Trans. Reliab. 62(4), 821–832 (2013)
Elforjani, M., Mba, D.: Monitoring the onset and propagation of natural degradation process in a slow speed rolling element bearing with acoustic emission. J. Vib. Acoust. (2008) doi:10.1115/1.2948413
Elforjani, M., Mba, D.: Detecting the onset, propagation and location of non-artificial defects in a slow rotating thrust bearing with acoustic emission. Insight Non-Destruct. Test. Cond. Monit. (2008). doi:10.1784/insi.2008.50.5.264
Elforjani, M., Mba, D.: Condition monitoring of slow speed shafts and bearings with acoustic emission. Strain (2011) doi:10.1111/j.1475-1305.2010.00776.x
Price, E.D., Lees, A.W., Friswell, M.I.: Detection of severe sliding and pitting fatigue wear regimes through the use of broadband acoustic emission. IMechE J. Eng. Tribol. (2005) doi:10.1243/135065005X9817
Yoshioka, T.: Detection of rolling contact subsurface fatigue cracks using acoustic emission technique. J. Soc. Tribol. Lubr. Eng. 49(4), 303–308 (1993)
Elforjani, M., Mba, D.: Accelerated natural fault diagnosis in slow speed bearings with acoustic emission. Eng. Fract. Mech. 77(1), 112–127 (2010)
Norton, M.P., Karczub, D.G.: Fundamentals of Noise and Vibration Analysis for Engineers, 2nd edn. Cambridge University Press, Cambridge (2003)
Liu, Z., Zuo, M.J., Zhang, L.: Remaining useful life prediction of rolling element bearings based on health state assessment. In: Annual Conference of the Prognostics and Health Management Society, Vol. 5 (2014)
Murphy P.K.: Machine Learning A Probabilistic Perspective. MIT Press, Cambridge (2012)
Seber, G.E., Lee, A.: Linear Regression Analysis, 2nd edn. Wiley, Hoboken (2003)
Hocking, R.R.: Methods and Applications of Linear Models: Regression and the Analysis of Variance, 3rd edn. Wiley, New York (2013)
Chatterjee, S., Simonoff, S.J.: Handbook of Regression Analysis, 1st edn. Wiley, New York (2012)
Wikipedia https://en.wikipedia.org/wiki/Confusion_matrix, Accessed Date (2016)
Kubat, M.: An Introduction to Machine Learning. Springer, New York (2015)
Livingstone, J.D.: Artificial Neural Networks: Methods and Applications, 2009 Edition. Humana Press, Heidelberg (2008)
Hopgood, A.A.: Intelligent Systems for Engineers and Scientists, 2nd edn. CRC Press, Boca Raton (2001)
Heaton, J.: Artificial Intelligence for Humans, Volume 3: Deep Learning and Neural Networks. CreateSpace Independent Publishing Platform (2015)
Apolloni, B., Bassis, S., Marinaro, M., Apolloni, B.: New Directions in Neural Networks. In: 18th Italian Workshop on Neural Networks, WIRN, Frontiers in Artificial Intelligence and Applications, Vol. 193 (2009)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Elforjani, M. Estimation of Remaining Useful Life of Slow Speed Bearings Using Acoustic Emission Signals. J Nondestruct Eval 35, 62 (2016). https://doi.org/10.1007/s10921-016-0378-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10921-016-0378-0