
Abstract
Computer Vision has provided immense support to medical diagnostics over the past two decades. Analogous to Non Destructive Testing of mechanical parts, advances in medical imaging has enabled surgeons to determine root cause of an illness by consulting medical images particularly 3-D imaging. 3-D modeling in medical imaging has been pursued using surface rendering, volume rendering and regularization based methods. Tomographic reconstruction in 3D is different from camera based scene reconstruction which has been achieved using various techniques including minimal surfaces, level sets, snakes, graph cuts, silhouettes, multi-scale approach, patchwork etc. In tomography limitations of image aquisition method i-e CT Scan, X Rays and MRI as well as non availability of camera parameters for calibration restrict the quality of final reconstruction. In this work, a comprehensive study of related approaches has been carried out with a view to provide a summary of state of the art 3D modeling algorithms developed over the past four decades and also to provide a foundation study for our future work which will include precise 3D reconstruction of human spine.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
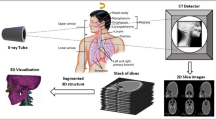
Medical imaging has provided doctors an insight of human anatomy with no need of prior surgery. This technology is evolving with a great pace in order to meet ever increasing demand of better and reliable medical diagnostics. Tomographic reconstruction of X Ray, CT Scan has been around over past few decades. Johann Radon laid mathematical (Fig. 1) foundation for 3D tomography [1]. Inverse Radon transform has been in use for reconstruction of tomograhic images [2].

CT Scan [5]
CT Scan and MRI are widely used as a tool for (Fig. 2) medical diagnosis. Magnetic Resonance Imaging (MRI) unlike CT Scan, does not utilize direct exposure of human body to X Rays.

MRI [3]
Instead MRI exploits the fact that human body is made of 70 percent H2O. Application of magnetic field realigns the protons [3]. Upon removal of the field, protons of different tissues return to their orignal state at varying rate, the process is termed as precession which produces radio waves. These radio waves are unique for different tissues thereby providing immense details in the gray scale image intensities. Variation of intensities in the MRI provide valuable information about different tissues. The MRI has black, gray and white portions which are low, medium and high amplitude signals.
CT Scan are equispaced X Ray images stalked approximately 5 mm apart on average [4] that takes 360 degrees view of human organ of interest. Radon transform is used for obtaining 3d models from CT Scan images. CT Scan technology has improved over a period of last three decades from axial scanning to helical scanning and with increased number of slices per scan [5].
In the next sections few most popular tomographic 3D reconstruction algorithms have been elaborated. Section “Consistency based volumetric rendering” deals with consistency based volume rendering techniques including Maximum Intensity projection in “MIP: Maximum intensity projection”, Curved Plannar Reformation in “??”, Ray Tracing in “Ray tracing” and Shaded Surface Display in “SSD: Surface shaded display”. Section “Direct volume rendering” deals with direct volume rendering techniques including Ray Casting in “Ray casting”, Spatting in “Splatting”, Shear Warp in “Shear warp”, Texture Mapping in “Texture mapping”. Section “4” discusses regularization based surface reconstruction techniques including Convolutional Network 3D reconstruction in “3D reconstruction using convolutional network”, Point Spread Function Reconstruction in “Point spread function based 3D reconstruction” and Hierarchial Deformable Model based Reconstruction in “Hierarchial deformable model based reconstruction”. Section “Contemporary 3D reconstruction technology” discusses two latest 3D medical imaging platforms i-e Syngo and Mimics. 3D medical image reconstruction is moving towards development of accurate models which has been briefly mentioned in Section “Moving towards measured tomography”. Section “Conclusion and future work” elaborates our future research endeavours.
Consistency based volumetric rendering
Volumetric rendering techniques are fairly simple to understand and implement however at the cost of accuracy of final 3-D model. Some of the popular algorithms developed and used for tomographic reconstruction include Maximum Intensity Projection , Shaded Surface Display , Volume Rendering , Curved planar reformation. All these techniques focus on pixels property thresholding in relation to voxels.
MIP: Maximum intensity projection
MIP utilizes the fact that intensities of vascular structures in an MRI have higher pixel intensities with respect to the surrounding tissues. However, thresholding of pixel intensities also results in (Fig. 3) loss of valuable information [6].

Maximum intensity projection [7]
CPR : Curved planar reformation
In curved plannar reformation, the vessel which needs to be projected in 3D is focused. A line of interest is drawn parallel to the vessel and all voxels which touch the line of interest or fall (Fig. 4) in near vicinity are taken as volume of interest [8].

CPR [9]
Ray tracing
The algorithm was proposed in late 1970s. In ray tracing, a ray is cast from the viewer to the object and all the points hit by the ray are collected. Out of these points the closest point is selected and then colored using phong shading algorithm. An improved model of the algorithm was presented by [10] in which three unresolved problems at the time were addressed which included definition of shadows, reflection and refraction. Simplest implementation of the ray tracing algorithm involved casting a ray on a sphere and registering the point as a hit if the distance of the point is less than the radius of sphere.
SSD: Surface shaded display
Taking the lead from Ray Tracing, Surface Shaded Display produces depth perception by shading the surface in a way that surfaces nearer to the screen appear brighter [11], [12]. The algorithm segments the surfaces in background and foreground. Calculates the gradients at surfaces and surface normals which are compared with a threshold to identify the desired surface. Phong shading (Fig. 5) algorithm is then used for shading purposes.

SSD [13]
Direct volume rendering
Direct Volume Rendering methods comprise of three main steps including sampling, classification and composing [14]. Sampling of the volume is carried out piecewise for further integration, classification is the assignment of color and opacity and composing step is the arrangement of samples duly classified in 3D volume.
Ray casting
Raycasting sometimes also known as raytracing is a popular algorithm developed in 1980s - 90s. Owing to the huge computation requirement parallel computation approaches for the algorithm have been sought over the time initially using pipelined approaches and then using GPUs. The main difference between ray casting and ray tracing is that ray casting is a volume rendering algorithm while ray tracing is surface rendering with in built iteration. In raycasting the closest point is not selected, rather the ray bisects the volume and at evenly located points the color and opacity are interpolated. These interpolated values are then merged to produce the color at the pixel on the image plane. The algorithm presented by Blinn and Kajiya in their papers [15] and [16] derives an equation for intensity of light. The equation is rewritten as
where, D(x(t), y(t), z(t)) or D(t) is the local density which expresses the fact that few bright pixels will scatter less light compared to a number of less bright pixels. I(x, y, z) or I(t) is the illumination from the source. R is the ray of light penetrating the density D(t) and P is the illumination function describing scattered intensity along the ray to the eye. 𝜃 is the angle between ray of light R and source of light L. τ is a constant that converts density to attenuation. The complete equation for illumination can be divided into two parts i-e attenuation of intensity due to density \({\int }_{\tau _{1}}^{\tau _{2}} [exp [- \tau {{\int }_{\tau _{1}}^{\tau _{2}} D(s) ds}]\) and illumination scatter along the ray R as it travels a distance t which is the second part i-e I(t)D(t)P(Cos𝜃)]dt. Attenuation of intensity affects shading (Fig. 6) whereas scatter of light defines the opacity of voxels.

A. Relationship of Voxels and Pixels B. Accumulation of intensity along the ray [18]
For computer graphics a popular practical implementation for raycasting algorithm has been provided by Marc Levoy [17]. In his work Marc Levoy has introduced adaptive solution for calculating opacity and shading of voxels using a pipelined approach. Both opacity and shading are then merged to provide realistic 3D tomography. In order to acquire surface shading surface gradient is used to obtain surface normal which is fed in Phong’s shading model to get intensities.
Since completely homogeneous regions provide unreliable shading therefore opacity values obtained for such regions are multiplied with the surface gradient. The product obtained is zero for completely homogeneous regions which makes such regions transparent thus avoiding ill effects of inconsistency due to such regions.
Opacity of voxels is obtained using simple formula analogous to central difference of current and neigbouring voxels. Triangulation of intensity values from neigbouring pixels produce opacity for the voxel under consideration.
Splatting
Splatting algorithm was first introduced by [19] as a feed forward method, which reconstructs a volume after processing tuples through four steps i-e Transfomation, CRIO (Classification, Reflection, Illumination and Opacity), Reconstruction and Visibility. [19] distinguishes the feed forward method from the feed backward in terms of number of accesses to input and output samples. In feed forward techniques the output terms are accessed many times where as the input terms are accessed once and it is vice versa for feed backward technique. In their work the authors dwell upon the idea of interpolation and its relation with band pass (Fig. 7) filtering in frequency domain.

Splatting [20]
Reconstruction or volume rendering is carried out using input sample images via interpolation. Therefore, different interpolation functions have been viewed in frequency domain and their shortcomings have been highlighted. Linear interpolation is a triangular pulsed filter which produces false edges. Nearest Neighbour interpolation is a rectangular filter in spatial domain. It is a poor low pass filter as viewed in frequency domain since it limits the pass band due to its curved edges and it also produces ringing in stop band allowing undesireable stop band frequencies to leak out. Cubic interpolation produces reconstruction artifacts. Gaussian filter retains its shape approximately in spatial and frequency domains. It produces lesser ringing in stop band and attenuates asymptotically towards pass band edges thereby producing blurring effects in the output.
Splatting technique initializes with a registration process in which sample images are registered by rotation and translation, followed by surface shading through CRIO process. Surface shading is a process in which four tables are used for surface shading. The four tables are for calculating emitted color, opacity, reflected color and opacity enhancement. After eliminating voids in the input image sample by shading process, reconstruction or interpolation between the samples is carried out. Reconstruction of the volume is carried out by convolution of sample images with a Kernel Function along spatial length, width and depth. It is equivalent to interpolating between the sample images which have already been aligned using registration process. Convolution sum is reduced to the product of image sample with the foot print function which is the sum of Kernel function along depth direction. To avoid computational cost involved in the integral evaluation of the Kernel Function for each sample image two approaches are envisaged. In the first approach, a look up table is build by estimating Kernel function size. The size of Kernel function is dependent upon the number of pixels occupied by the sample i-e sample size. Bigger sample size means that the samples are distinctly located. The table is built by oversampling well above the Nyquist rate to avoid artifacts. Another approach is modeling the Kernel Integral with a Gaussian function since, integral of Gaussian function is also a Gaussian.
Shear warp
Shear Warp technique [21] considers an image as a perspective projection of a volume slice. The object is viewed from the axis parallel to the depth i-e z axis. Available tomographic images which belong to a particular volume are transformed by using perspective transformation i-e translation and scaling of slices. After obtaining a set of perspective transformed images being viewed from a perpendicular axis along the depth direction, composite of the transformed images is used to produce an intermediate image. Due to perspective transformation the obtained image doesnot provide a realistic 3D view. Therefore the perspective projection of the obtained 3D image is restored (Fig. 8) using a warp matrix.

Alignment of CT Scan images to produce intermediate depth image which is warped and resampled to produce reconstruction [21]
Where P is called the “permutation matrix” which transforms the coordinate matrix in order to transform the z-axis as the principle viewing axis. S represents the sheared space and Mwarp is the object to image transformation matrix.
In a generalized shear map algorithm, volume reconstruction of the object is carried out in three steps:-
- ∙:
-
Shearing volumetric slices by translating and scaling
- ∙:
-
Occluding voxel slices using over operator thus producing an intermediate image
- ∙:
-
Transformation of 3D image using Warp matrix
Three types of shear warp techniques have been introduced by [21]. The first method focuses on the concept of scan line. CT images of the object of interest are the translated and scaled versions of the same object. Considering two CT images at a time and following a scan line from top of CT images to the bottom only translation of pixels can be considered. Using Over Operator concept and a lookup table for opacity of pixels based on viewing direction, three types of pixel regions are identified during line scan i-e opaque, translucent and transparent. Resampling, composing and shading are performed for translucent pixel regions only by using offset in the scan line which searches only for the desired regions. Two scan lines are traversed at a time and by shading, composing translucent pixels only an intermediate image is formulated. The formed intermediate image is corrected for distortion using affine filter, also called warping intermediate image.
Texture mapping
Complexity in 3D reconstruction by using mathematical modeling approaches has been reduced by [22] using texture tracing technique. The method has been explained in [23] by first analysing 2D reconstruction (Fig. 9) using rectangles and then extrapolating the technique to 3D reconstruction using cubes.

Marching Cube: Texture Mapping [24]
In [22] a 3D object is assumed to be made of cubes. If the 3D space in which the object of interest lies is considered to be made of a number of cubes of which the object is also a part but with different color only, then it can be easily perceived that there will be three types of cubes. The first type will be ones which lie within the surface completely. The second type of cubes will be the ones that lie completely outside the object whereas the third type will be those cubes which make part of both the object and the surrounding space. Third type of cubes will be intersected by the object surface. These three types of cubes have 8 vertices each which either lie inside the surface or are outliers. Therefore the vertices have two states at a time. The surface intersects the cube in 28, 256 ways which are reduced to 14 cases keeping in view topology, rotation and reflection of thus formed triangles. These 14 cases are indexed using a binary code represented by 8 vertices, thus forming a look up table. Pattern of the binary code indicates one of the 14 cases for surface construction.
Once the surface-cube interaction is known then comes the question of shading the surface. Unit normals to the triangulated surface are used for Gouraud shading.
Regularization based surface reconstruction
In this technique the base line idea is to design a model which accepts a priori information as an input from the available dataset of 2 D images and produces posterior probabilities of pixel properties based on which 3 D image reconstruction can be carried out. Regularization term is generally incorporated in the energy function to penalize tendencies of over fitting.
3D reconstruction using convolutional network
3D reconstruction using CNN for tomographic imaging is still in its adolescence stages. However, immense work using CNN has been carried out on camera images. CNN has been mainly used for segmentation and classification of images which are then registered using different techniques , mainly requiring camera calibration parameters and finally stiched together to form a 3D surface. Same methodolgoy can be replicated for tomographic imaging with an alternate for image to world coordinates transformation.
In an interesting work carried out for 3D reconstruction of human models [25] only sketches have been used to produce an output shape. The method utilizes powerful features of CNN and introduce different loss functions for network parameter optimization. In the training step, sketches of an object from multiple views are fed along with 3D model to produce surface normals and depth information. Human sketches are obtained synthetically using combination of well known algorithms like silhouettes, contours, ridges, valleys and edge preserving filtering. Different viewpoint sketches (C number of sketches ) of 256 x 256 size are fed in an encoder decoder configuration of CNN to obtain 256 x 256 x 5 channel output image. 5 channels represent the depth, 3 normals and the foreground probability index (50 percent threshold ). To optimize the parameters of CNN, a loss function is minimized which is formulated using differences between estimated and ground truth depth, normals, foreground labeling and structural variations.
In the reconstruction step, all points classified as foreground as per the index, with image space coordinates ρx and ρy and depth map dp,v for the particular view point v are projected from image coordinates to 3D point qp,v using camera parameters of rotation Rp,v and translation ev. Alignment of 3D points is carried out using iterative closest point (ICP) algorithm.
Rejection of outlier qp,v points is carried out as an iterative process involving removal of depth map dp,v inconsistencies by minimizing a combination of loss functions and using the obtained optimized depth for 3D point recalculation. The loss functions used for depth optimization are based on three criterias i-e requiring the depth to be closest to the approximate depth produced by network, their first order derivates produce tangents which are approximately orthognal to the surface normals and the depth is consistent with depth and normal of corresponding 3D points.
As a final step mesh is generated from the point cloud image using Poisson Surface Reconstruction algorithm. Training of 10K training meshes and 40K sketches have been carried out on Titan X GPU which took 2 days time. Output shape is claimed to be produced within 10 seconds.
Point spread function based 3D reconstruction
Point spread function is another mapping technique used for producing 3D volume from individual slices. The idea is to use sifting property of PSF for reconstruction of volume from individual images. The technique has been developed over the last decade. In one of the latest works by [26] MRI slices and [27] super pixel segmented patches have been reconstructed in a 3D volume. In their work, authors have introduced methods for reconstruction while catering for motion artifacts due to fetal movements. Volumetric model of the object is related to the image using PSF. Slices Y k obtained from the image are mapped to the volume X by PSF matrix Mk as
In [26] PSF has been approximated by 3D Gaussian matrix. For each slice from the volume Y k voxels are represented by yj,k. Motion artifacts in the MRI scan are catered for by introducing spatial and temporal scaling of the input voxel yj,k in order to produce corrected voxel \(y^{*}_{j},_{k}\). Spatial scaling is carried out using a bias field bj,k whereas temporal scaling by sk.
to change Y k to \(Y^{*}_{k}\). Therefore, using bias field, PSF, spatial alignment and scaling factors, standardized slices are obtained from the volume X. Where initially the volume X is thick MRI slices stacked together. A recursive algorithm is introduced to cater for motion artifacts which iteratively updates the bias field bj,k, temporal scaling factor sk using Expectation Maximization algorithm. Thereby updating the difference \(e_{i},_{j} = y^{*}_{j},_{k} - {\sum }_{i} {m^{k}_{i}},_{j} x_{i}\). Using the error ei thus obtained along with PSF matrix approximated as Gaussian and probability of corrected voxels p the volume X is recalculated recursively to be used to update the error e.
Improvement in the proposed technique presented by [26] has been claimed by [27] by incorporating two changes i-e using super resolution segmented patches instead of slices of equal size and using Tailor series approximation for PSF.
Hierarchial deformable model based reconstruction
As a next step in 3D reconstruction, HDM has been used for segmentation, detection, orientation and modeling of human spine [28]. Underlying idea is simple yet powerful. Reconstruction is carried out in three main steps (Fig. 10) landmark detection, global shape registration and local orientation.

Spine Modelling Using HDM [28]
Human spine is composed of vertebras, discs, spinal cord and ligaments as surrounding muscles [29]. Vertebras are the main constituents with a peculiar shape. Spinal column is divided into 5 main sections including cervical (7 vertebras), thoracic (12 vertebras), lumbar (5 vertebras), sacral (5 vertebras), coccyx(1 vertebra). Each column has its characteristic degrees of movement. Vertebras are joined together via discs which are tubular structure composed of fibers to avoid vertebral bones contact. Spine structure visible in MRI and CT scans is the vertebra weaved together with the discs via spinal cord. Vertebras are visibile in an MRI along Sagittal (side wise), Coronal (front) and transverse (top down) planes. A template of vertebra from each view is used for the detection of vertebra in MRI CT images. A triplanar vertebra model is built using the template vertebra from each view. Pose adjustment is then carried out to adjust vertebra which are further connected using shape registration between detected landmarks and built in vertebra models.
Modular approach used in this study uses three main modules including local appearance module, local geometry module and global geometry module. Purpose of local appearance module is to detect vertebra location in CT and MRI. 24 x 24 size patches from MRI and CT images are obtained and learned separately using Convolutional Restricted Boltzman Machine (CRBM). MRI and CT learned features are fed to the Restricted Boltzman Machine (RBM) to obtain a composite descriptor vector. 24 templates are obtained for the 4 sections of spine (Lumbar, thoracic, cervical, sacrum), 2 types of images (MR and CT ) and 3 views (saggital, coronal and axial). These templates are obtained after part based image registration and taking the mean. To obtain the landmark vertebra locations a comparison is drawn between the current image and corresponding templates using L2 distances between the two.
After obtaining the templates and landmarks, it is required to warp each template to the landmarks which can be later stitched to form a 3D model. Template T and landmark Ip are related by the affine matrix Gp. However, the exact affine matrix which will align the template with landmark cannot be calculated explicitly. Therefore, a minimization model is used in which difference between the template and input image is minimized alongside neighbourhood smoothing to obtain optimum estimates of Gp.
After the local pose adjustment, a 3D pose adjustment algorithm has also been suggested which reprojects the 3D template to 2D landmark. The 3D corners of template ps are reprojected to 2D landmark using a projection matrix Ps and rotation, translation matrix R.
After obtaining the building blocks in the shape of verterbra, global spine model is constructed in three steps including unification of triplannar model, outlier removal, shape deformation for registration.
Tomographic 3D reconstruction techniques can be classified as surface or volume rendering as in Table 1.
Contemporary 3D reconstruction technology
In [30] two latest 3D modeling softwares have been compared for accuracy and computational efficiency. The softwares used for comparison are Syngo and Mimics. Both softwares have been compared using CT Scan images in DICOM format by comparing segmentation accuracy, anatomical measurements, cost and computational time as baseline. The authors claim that Mimics software outperforms Syngo considering semi-automated segmentation and cost of equipment. However, Syngo software proves superior to Mimics in terms of computational efficiency.
In the study vessels have been physically (Figs. 11 and 12) measured by dissection of cadaver. CT images slice thickness of 0.5 mm has been used due to which vessels of lesser diameter have been neglected.

Mimics [31]

Syngo [32]
Moving towards measured tomography
Boileau et al. [33] measures the reliability and accuracy of Glenoid Version and Inclination angle measurements in Arthritic Shoulders. For automated measurements of the two parameters commercially available softwares have been used including Amira Software and Imascap software. Sample size is chosen using MedCalc Software. Result of measurements were compared with manual and semi automated methods including Friedman version angle on 2D CTs, Friedman method on 3D multiplanar reconstructions, Ganapathi-Iannotti and Lewis- Armstrong methods on 3D volumetric reconstructions (for glenoid version), and Maurer method (for glenoid inclination).The Sample size calculation allowed 55 patients where as 60 patients have been selected in actual. The Glenoid version measurements have been performed in 2D and 3D using Osiri X software in a semiautiomated fashion whereas same measurements were taken using Imscap Software - Glenosys in fully automated manner.
Comparison of results have revealed that difference between 2D and 3D measurements is not signficant with P value greater than 0.05 (obtained P value at 0.45).With obtained results reliabilty and validity of automated software based 3D tomographic measurement has been justified. ln order to prove clinical relevance of these softwares, two orthopadic surgeons separately analyzed the images for interobserver consistency, whereas one the surgeon undertook the measurements twice for intraobserver reliability analysis. With the aid of 3D automated measurement softwares, interobserver and intraobserver discrepancies can be safely eliminated. [34] compares the accuracy of measurement of consistency based techniques including MPI (2.1), MPR(2.2) and SSD (2.3) with direct volume rendering (3.1). Aneurysm has been simulated by an experimetal setup in which a scaled baloon is inserted in a tube and CT scans of the apparatus has been obtained. Mentioned algorithms are used for generation of 3D models. Dimensions of the obtained 3D models are then compared with the orignal apparatus. Mean differences for each algoriithm is calculated and one way ANOVA (Analysis of Variance) is used to obtain P value for the differences which proved significant (with P value less than 0.05). Obtained results prove that direct volume rendering technique (Ray casting) provides accurate results compared to MPI, MPR and SSD methods.
Conclusion and future work
Tomographic imaging has developed tremendously with a pace matching advancements in the field of computer vision. Although latest 3D reconstruction software packages available provide high quality visualization of human anatomy, however, there still exists room for improvement specially in terms of calibration and accurate modelling. We intend to develop a scaled 3d model for human spine. Due to the non availability of annotated and scaled vertebra test cases, we will calibrate our reconstructed model based on average vertebra size for cervical, thoracic, lumbar, sacral and cocyx sections. We intend to follow the foot steps of [28] for 3D modelling. During the process powerful segmentation feature of convolutional neural nets as used by [25] will also be studied and implemented.
References
Dhawan, A.: Radon transform wiley encyclopedia of biomedical engineering, 2006
Weisstein, E.W.: Radon Transform – from Wolfram MathWorld, Mathworld.wolfram.com. [Online]. Available: http://mathworld.wolfram.com/RadonTransform.html. [Accessed: 20- Oct- 2017], 2018
Physics.stackexchange.com, Why Fields? Why do nuclei precess in magnetic fields? [online] Available at: https://physics.stackexchange.com/questions/386863/why-donucleiprecess-in-magnetic-fields [Accessed 3- Jan- 2018], 2018
Mulay, C., AV, Patient Specific Bone Modeling for Minimum Invasive Spine Surgery. Journal of Spine 04:04, 2015.
Garutti, E.: Index of / garutti/LECTURES/BioMedical. [online] Desy.de. Available at: http://www.desy.de/garutti/LECTURES/BioMedical/ [Accessed 3 Feb. 2018], 2014
Sato, Y., Shiraga, N., Nakajima, S., Tamura, S., and Kikinis, R., Local maximum intensity projection (LMIP. J. Comput. Assist. Tomogr. 22(6):912–917, 1998.
Creedy, M.: [Online]. Available: https://mipav.cit.nih.gov/pubwiki/index.php/Maximum-Intensity-Projection. [Accessed: 02- Jan- 2018], 2012
Kanitsar, A., Fleischmann, D., Wegenkittl, R., Felkel, P., and Groller, E.: CPR - Curved planar reformation, IEEE Visualization. VIS 2002, 2002
Kanitsar, A., Fleischmann, D., Wegenkittl, R., Felkel, P., and Groller, E.: CPR - curved planar reformation. IEEE Visualization. VIS 2002. [Accessed: 02- Jan- 2018], 2002
Whitted, T., An improved illumination model for shaded display. Commun. of the ACM 23(6):343–349, 1980.
Naiwen, l.: Shaded Surface Display Technique, Csee.umbc.edu. [Online]. Available: https://www.csee.umbc.edu/ebert/693/NLiao/node5.html. [Accessed: 23- Nov- 2017], 1996
Heffernan, P., and Robb, R., A new method for shaded surface display of biological and medical images. IEEE Trans. Med. Imaging 4(1):26–38, 1985.
Radiology Imaging: Shaded surface displays of ct scan abdominal, Radiology Imaging. [Online]. Available: http://radiology-information.blogspot.com/2013/03/shaded-surface-displays-of-ct-scan.html. [Accessed: 11- Dec- 2017], 2015
Callahan, S., Callahan, J., Scheidegger, C., and Silva, C., Direct Volume Rendering: A 3D Plotting Technique for Scientific Data. Comput. Sci. Eng. 10(1):88–92, 2008.
Blinn, J.F.: Models of light reflection for computer synthesized pictures. In: Proceedings of the 4th annual conference on Computer graphics and interactive techniques - SIGGRAPH 77, 1977.
Kajiya, J.T.: New techniques for ray tracing procedurally defined objects. In: Proceedings of the 10th annual conference on Computer graphics and interactive techniques - SIGGRAPH 83, 1983.
Levoy, M., A hybrid ray tracer for rendering polygon and volume data. IEEE Comput. Graph. Appl. 10(2): 33–40, 1990.
Li, G., Xie, H., Ning, H., Citrin, D., Capala, J., Maass-Moreno, R., Guion, P., Arora, B., Coleman, N., Camphausen, K., and Miller, R., Accuracy of 3D volumetric image registration based on CT, MR and PET/CT phantom experiments. J. Appl. Clin. Med. Phys. 9(4):17–36, 2008.
Westover, L.A., Splatting: a parallel, feed-forward volume rendering algorithm. Chapel Hill: University of North Carolina at Chapel Hill, 1992.
Celebi Tutorial, Volume Rendering, Byclb.com. [Online]. Available: https://www.byclb.com/TR/Tutorials/volume-rendering/ch1-1.htm. [Accessed: 11- Dec- 2017], 2014
Lacroute, P., and Levoy, M.: Fast volume rendering using a shear-warp factorization of the viewing transformation. In: Proceedings of the 21st annual conference on Computer graphics and interactive techniques - SIGGRAPH 94, 1994.
Lorensen, W.E., and Cline, H.E., Marching cubes: a high resolution 3D surface construction algorithm. ACM SIGGRAPH Comput. Graph. 21(4):163–169, 1987.
Naiwen, L.: Shaded surface display technique. [Online]. Available: https://www.csee.umbc.edu/ebert/693/NLiao/node5.html. [Accessed: 15-Nov-2017], 1996
Anderson, B.: Marching Cubes, Cs.carleton.edu. [Online]. Available: http://www.cs.carleton.edu/cs-comps/0405/shape/marching-cubes.html. [Accessed: 07- Nov- 2017]
Lun, Z., Gadelha, M., Kalogerakis, E., Maji, S., and Wang, R.: 3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks. In: Proceedings of the International Conference on 3D Vision (3DV) 2017, 2017.
Kuklisova-Murgasova, M., Quaghebeur, G., Rutherford, M.A., Hajnal, J.V., and Schnabel, J.A., Reconstruction of fetal brain MRI with intensity matching and complete outlier removal. Med. Image Anal. 16(8): 1550–1564, 2012.
Alansary, A., Rajchl, M., Mcdonagh, S.G., Murgasova, M., Damodaram, M., Lloyd, D.F.A., Davidson, A., Rutherford, M., Hajnal, J.V., Rueckert, D., and Kainz, B., PVR: Patch-to-volume reconstruction for large area motion correction of fetal MRI. IEEE Trans. Med. Imaging 36(10):2031–2044, 2017.
Cai, Y., Osman, S., Sharma, M., Landis, M., and Li, S., Multi-Modality Vertebra recognition in arbitrary views using 3D deformable hierarchical model. IEEE Trans. Med. Imaging 34(8):1676–1693, 2015.
Hines, T.: Spine Anatomy, Anatomy of the Human Spine. [online] Available at: https://www.mayfieldclinic.com [Accessed 15 Jan. 2018], 2016
An, G., Hong, L., Zhou, X. -B., Yang, Q., Li, M. -Q., and Tang, X. -Y., Accuracy and efficiency of computer-aided anatomical analysis using 3D visualization software based on semi-automated and automated segmentations. Ann. Anat. Anat. Anz. 210:76–83, 2017.
Mimics 5 Edit Mask in 3D pt2, YouTube. [Online]. Available: https://www.youtube.com/watch?v=xxw2klImERM. [Accessed: 10- Jan- 2018]
Syngo.via for Cardiovascular Care - Siemens Healthineers Global, Healthcare.siemens.com. [Online]. Available: https://www.healthcare.siemens.com/medical-imaging-it/syngoviaspecialtopics/syngo-via-for-sustainable-cardiovascular-care/coronary-artery-disease. [Accessed: 09- Jan- 2018]
Boileau, P., Cheval, D., Gauci, M., Holzer, N., Chaoui, J., and Walch, G., Automated Three-Dimensional measurement of glenoid version and inclination in arthritic shoulders. J. Bone Joint Surg. 100 (1):57–65, 2018.
Lee, S., Kim, H., Kim, H., Choi, J., and Cho, J., Comparison of image enlargement according to 3D reconstruction in a CT scan: Using an aneurysm phantom. J. Korean Phys. Soc. 72(7):805–810, 2018.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
All authors declare that they have no conflict of interest
Additional information
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
This article is part of the Topical Collection on Image & Signal Processing
Rights and permissions
About this article

Cite this article
Khan, U., Yasin, A., Abid, M. et al. A Methodological Review of 3D Reconstruction Techniques in Tomographic Imaging. J Med Syst 42, 190 (2018). https://doi.org/10.1007/s10916-018-1042-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10916-018-1042-2