
Abstract
This paper aims to develop new and fast algorithms for recovering a sparse vector from a small number of measurements, which is a fundamental problem in the field of compressive sensing (CS). Currently, CS favors incoherent systems, in which any two measurements are as little correlated as possible. In reality, however, many problems are coherent, and conventional methods such as \(L_1\) minimization do not work well. Recently, the difference of the \(L_1\) and \(L_2\) norms, denoted as \(L_1\)–\(L_2\), is shown to have superior performance over the classic \(L_1\) method, but it is computationally expensive. We derive an analytical solution for the proximal operator of the \(L_1\)–\(L_2\) metric, and it makes some fast \(L_1\) solvers such as forward–backward splitting (FBS) and alternating direction method of multipliers (ADMM) applicable for \(L_1\)–\(L_2\). We describe in details how to incorporate the proximal operator into FBS and ADMM and show that the resulting algorithms are convergent under mild conditions. Both algorithms are shown to be much more efficient than the original implementation of \(L_1\)–\(L_2\) based on a difference-of-convex approach in the numerical experiments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recent developments in science and technology have caused a revolution in data processing, as large datasets are becoming increasingly available and important. To meet the need in “big data” era, the field of compressive sensing (CS) [3, 8] is rapidly blooming. The process of CS consists of encoding and decoding. The process of encoding involves taking a set of (linear) measurements, \(b = Ax\), where A is a matrix of size \(M\times N\). If \(M<N\), we say the signal \(x\in \mathbb {R}^N\) can be compressed. The process of decoding is to recover x from b with an additional assumption that x is sparse. It can be expressed as an optimization problem,
with \(\Vert \cdot \Vert _0\) being the \(L_0\) “norm”. Since \(L_0\) counts the number of non-zero elements, minimizing the \(L_0\) “norm” is equivalent to finding the sparsest solution.
One of the biggest obstacles in CS is solving the decoding problem, Eq. (1), as \(L_0\) minimization is NP-hard [23]. A popular approach is to replace \(L_0\) by a convex norm \(L_1\), which often gives a satisfactory sparse solution. This \(L_1\) heuristic has been applied in many different fields such as geology and geophysics [29], spectroscopy [22], and ultrasound imaging [24]. A revolutionary breakthrough in CS was the derivation of the restricted isometry property (RIP) [3], which gives a sufficient condition of \(L_1\) minimization to recover the sparse solution exactly. It was proved in [3] that random matrices satisfy the RIP with high probabilities, which makes RIP seemingly applicable. However, it is NP-hard to verify the RIP for a given matrix. A deterministic result in [7, 11] says that exact sparse recovery using \(L_1\) minimization is possible if
where \(\mu \) is the mutual coherence of a matrix A, defined as
The inequality (2) suggests that \(L_1\) may not perform well for highly coherent matrices. When the matrix is highly coherent, we have \(\mu \sim 1\), then the sufficient condition \(\Vert x\Vert _0\le 1\) means that x has at most one non-zero element.
Recently, there has been an increase in applying nonconvex metrics as alternative approaches to \(L_1\). In particular, the nonconvex metric \(L_p\) for \(p\in (0,1)\) in [4, 5, 13, 33] can be regarded as a continuation strategy to approximate \(L_0\) as \(p\rightarrow 0\). The optimization strategies include iterative reweighting [4, 5, 14] and half thresholding [31,32,33]. The scale-invariant \(L_1\), formulated as the ratio of \(L_1\) and \(L_2\), was discussed in [9, 26]. Other nonconvex \(L_1\) variants include transformed \(L_1\) [35], sorted \(L_1\) [12], and capped \(L_1\) [21]. It is demonstrated in a series of papers [19, 20, 34] that the difference of the \(L_1\) and \(L_2\) norms, denoted as \(L_1\)–\(L_2\), outperforms \(L_1\) and \(L_p\) in terms of promoting sparsity when sensing matrix A is highly coherent. Theoretically, a RIP-type sufficient condition is given in [34] to guarantee that \(L_1\)–\(L_2\) can exactly recover a sparse vector.
In this paper, we generalize the \(L_1\)–\(L_2\) formalism by considering the \(L_1-\alpha L_2\) metric for \(\alpha \ge 0\). Define
We consider an unconstrained minimization problem to allow the presence of noise in the data, i.e.,
where l(x) has a Lipschitz continuous gradient with Lipschitz constant L. Computationally, it is natural to apply difference-of-convex algorithm (DCA) [25] to minimize the \(L_1\)–\(L_2\) functional. The DCA decomposes the objective function as the difference of two convex functions, i.e., \(E(x) = G(x)-H(x)\), where
Then, giving an initial \(x^0\ne \mathbf {0}\), we obtain the next iteration by linearing H(x) at the current iteration, i.e.,
It is an \(L_1\) minimization problem, which may not have analytical solutions and usually requires to apply iterative algorithms. It was proven in [34] that the iterating sequence (4) converges to a stationary point of the unconstrained problem (3). Note that the DCA for \(L_1\)–\(L_2\) is equivalent to alternating mininization for the following optimization problem:
because \(q=-{x\over \Vert x\Vert _2}\) for any fixed x. Since DCA for \(L_1\)–\(L_2\) amounts to solving an \(L_1\) minimization problem iteratively as a subproblem, it is much slower than \(L_1\) minimization. This motivates fast approaches proposed in this work.
We propose fast approaches for minimizing (3), which are approximately of the same computational complexity as \(L_1\). The main idea is based on a proximal operator corresponding to \(L_1\)–\(\alpha L_2\). We then consider two numerical algorithms: forward–backward splitting (FBS) and alternating direction method of multipliers (ADMM), both of which are proven to be convergent under mild conditions. The contributions of this paper are:
-
We derive analytical solutions for the proximal mapping of \(r_\alpha (x)\) in Lemma 1.
-
We propose a fast algorithm—FBS with this proximal mapping—and show its convergence in Theorem 1. Then, we analyze the properties of fixed points of FBS and show that FBS iterations are not trapped at stationary points near \(\mathbf {0}\) if the number of non-zeros is greater than one. It explains that FBS tends to converge to sparser stationary points when the \(L_2\) norm of the stationary point is relatively small; see Lemma 3 and Example 1.
-
We propose another fast algorithm based on ADMM and show its convergence in Theorem 2. This theorem applies to a general problem–minimizing the sum of two (possibly nonconvex) functions where one function has a Lipschitz continuous gradient and the other has an analytical proximal mapping or the mapping can be computed easily.
The rest of the paper is organized as follows. We detail the proximal operator in Sect. 2. The numerical algorithms (FBS and ADMM) are described in Sects. 3 and 4, respectively, each with convergence analysis. In Sect. 5, we numerically compare the proposed methods with the DCA on different types of sensing matrices. During experiments, we observe a need to apply a continuation strategy of \(\alpha \) to improve sparse recovery results. Finally, Sect. 6 concludes the paper.
2 Proximal Operator
In this section, we present a closed-form solution of the proximal operator for \(L_1\)–\(\alpha L_2\), defined as follows,
for a positive parameter \(\lambda >0\). Proximal operator is particularly useful in convex optimization [27]. For example, the proximal operator for \(L_1\) is called soft shrinkage, defined as
The soft shrinkage operator is a key for rendering many efficient \(L_1\) algorithms. By replacing the soft shrinkage with \({\mathbf{prox}}_{\lambda r_\alpha }\), most fast \(L_1\) solvers such as FBS and ADMM are applicable for \(L_1\)–\(\alpha L_2\), which will be detailed in Sects. 3 and 4. The closed-form solution of \({\mathbf{prox}}_{\lambda r_\alpha }\) is characterized in Lemma 1, while Lemma 2 gives an important inequality to prove the convergence of FBS and ADMM when combined with the proximal operator.
Lemma 1
Given \(y\in \mathbb R^N\), \(\lambda >0\), and \(\alpha \ge 0\), we have the following statements about the optimal solution \(x^*\) to the optimization problem in (5):
-
1)
When \(\Vert y\Vert _\infty >\lambda \), \(x^*= z(\Vert z\Vert _2+\alpha \lambda )/\Vert z\Vert _2\) for \(z = \mathcal S_1(y,\lambda )\).
-
2)
When \(\Vert y\Vert _\infty =\lambda \), \(x^*\) is an optimal solution if and only if it satisfies \(x^*_i=0\) if \(|y_i|<\lambda \), \(\Vert x^*\Vert _2=\alpha \lambda \), and \(x^*_iy_i\ge 0\) for all i. When there are more than one components having the maximum absolute value \(\lambda \), the optimal solution is not unique; in fact, there are infinite many optimal solutions.
-
3)
When \((1-\alpha )\lambda<\Vert y\Vert _\infty <\lambda \), \(x^*\) is an optimal solution if and only if it is a 1-sparse vector satisfying \(x^*_i=0\) if \(|y_i|<\Vert y\Vert _\infty \), \(\Vert x^*\Vert _2=\Vert y\Vert _\infty +(\alpha -1)\lambda \), and \(x^*_iy_i\ge 0\) for all i. The number of optimal solutions is the same as the number of components having the maximum absolute value \(\Vert y\Vert _\infty \).
-
4)
When \(\Vert y\Vert _\infty \le (1-\alpha )\lambda \), \(x^*=0\).
Proof
It is straightforward to obtain the following relations about the sign and order of the absolute values for the components in \(x^*\), i.e.,
and
Otherwise, we can always change the sign of \(x^*_i\) or swap the absolute values of \(x^*_i\) and \(x^*_j\) and obtain a smaller objective value. Therefore, we can assume without loss of generality that y is a non-negative non-increasing vector, i.e., \(y_1\ge y_2\ge \cdots \ge y_N\ge 0\).
Denote \(F(x)=\Vert x\Vert _1-\alpha \Vert x\Vert _2 + \frac{1}{2\lambda } \Vert x-y\Vert _2^2\) and the first-order optimality condition of minimizing F(x) is expressed as
where \(p\in \partial \Vert x\Vert _1\) is a subgradient of the \(L_1\) norm. When \(x=0\), we have the first order optimality condition \(\Vert y-\lambda p\Vert _2=\alpha \lambda \). Simple calculations show that for any \(x\ne 0\) satisfying (7), we have
Therefore, we have to find the \(x^*\) with the largest norm among all x satisfying (7). Now we are ready to discuss the four items listed in order,
-
1)
If \(y_1 >\lambda \), then \(y_1-\lambda p_1>0\). For the case of \(x^*\ne 0\), we have \(x^*_1>0\) and \(1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}>0\). For any i such that \(y_i\le \lambda \), we have \(x_i=0\); otherwise for this i, the left-hand side (LHS) of (7) is positive, while the right-hand side (RHS) is nonpositive. For any i such that \(y_i>\lambda \), we have that \(p_i=1\). Therefore, \(y-\lambda p=\mathcal {S}_1(y,\lambda )\). Let \(z = \mathcal S_1(y,\lambda )\), and we have \(x^*= z(\Vert z\Vert _2+\alpha \lambda )/\Vert z\Vert _2\). Therefore, \(x^*\ne 0\) is the optimal solution.
-
2)
If \(y_1 = \lambda \), then \(y_1-\lambda p_1\ge 0\). Let \(j=\min \{i: y_i<\lambda \}\), and we have \(x^*_i=0\) for \(i\ge j\); otherwise for this i, RHS of (7) is negative, and hence \(1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}<0\). It implies that \(x_1^*=0\) and \(x^*\) is not a global optimal solution because of (6). For the case of \(x^*\ne 0\), we have \(1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}=0\). Therefore, any optimal solution \(x^*\) satisfy that \(x^*_i=0\) for \(i\ge j\), \(\Vert x^*\Vert _2=\alpha \lambda \), and \(x^*_iy_i\ge 0\) for all i. When there are multiple components of y having the same absolute value \(\lambda \), there exist infinite many solutions.
-
3)
Assume \((1-\alpha )\lambda<y_1 <\lambda \). Let \(j=\min \{i: y_i<\Vert y\Vert _\infty \}\), and we have \(x^*_i=0\) for \(i\ge j\); otherwise for this i, RHS of (7) is negative, thus \(1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}<0\) and \(y_1-\lambda p_1=\left( 1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}\right) x^*_1\le \left( 1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}\right) x^*_i=y_i-\lambda p_i\), which is a contradiction to \(y_1>y_i\). For the case of \(x^*\ne 0\), we have \(1-\frac{\alpha \lambda }{\Vert x^*\Vert _2}<0\). From (7), we know that \(\alpha \lambda -\Vert x^*\Vert _2 =\Vert y-\lambda p\Vert _2\). Finding \(x^*\) with the largest norm is equivalent to finding \(p\in \partial \Vert x^*\Vert _1\) such that \(\Vert y-\lambda p\Vert _2\) is smallest and \(x^*\ne 0\). So we choose \(x^*\) to be a 1-sparse vector, and \(\Vert x^*\Vert _2=\alpha \lambda -\Vert y-\lambda p\Vert _2=\alpha \lambda -(\lambda -y_1)=y_1-(1-\alpha )\lambda \).
-
4)
Assume that \(y_1\le (1-\alpha )\lambda \). If there exists an \(x^*\ne 0\), we have \(\Vert y-\lambda p\Vert _2\ge |y_1-\lambda |\ge \alpha \lambda \), while (7) implies \(\Vert y-\lambda p\Vert _2=\alpha \lambda -\Vert x^*\Vert _2 < \alpha \lambda \). Thus we can not find \(x^*\ne 0\). However, we can find \(p\in \partial \Vert 0\Vert _1\) such that \(\Vert y-\lambda p\Vert _2=\alpha \lambda \). Thus \(x^*=0\) is the optimal solution.
\(\square \)
Remark 1
When \(\alpha =0\), \(r_\alpha \) reduces to the \(L_1\) norm and the proximal operator \({\mathbf{prox}}_{\lambda r_\alpha }\) is equivalent to the soft shrinkage \(\mathcal {S}_1(y,\lambda )\). When \(\alpha >1\), items 3) and 4) show that the optimal solution can not be 0 for any y and positive \(\lambda \).
Remark 2
During the preparation of this manuscript, Liu and Pong also provided an analytic solution for the proximal operator for the cases \(0\le \alpha \le 1\) using a different approach [17]. In Lemma 1, we provide all the solutions for the proximal operator for any \(\alpha \ge 0\).
Lemma 2
Given \(y\in \mathbb R^N\), \(\lambda >0\), and \(\alpha \ge 0\). Let \(F(x)=(\Vert x\Vert _1-\alpha \Vert x\Vert _2) + \frac{1}{2\lambda } \Vert x-y\Vert _2^2\) and \(x^*\in {\mathbf{prox}}_{\lambda r_\alpha }(y)\). Then, we have for any \(x\in \mathbb R^N\),
Here, we define \({\alpha \over 0}\) be 0 when \(\alpha =0\) and \(+\infty \) for \(\alpha >0\).
Proof
When \(\Vert y\Vert _\infty >(1-\alpha )\lambda \), Lemma 1 guarantees that \({\mathbf{prox}}_{\lambda r_\alpha }(y)\ne 0\), i.e., \(x^*\ne 0\). The optimality condition of \(x^*\) reads \(p={1\over \lambda }y-\left( {1\over \lambda }-\frac{\alpha }{\Vert x^*\Vert _2}\right) x^*\in \partial \Vert x^*\Vert _1,\) then we have
Here, the first inequality comes from \(p\in \partial \Vert x^*\Vert _1\), and the last inequality comes from the Cauchy-Schwartz inequality.
When \(\Vert y\Vert _\infty \le (1-\alpha )\lambda \), Lemma 1 shows that \(x^*= {\mathbf{prox}}_{\lambda r_\alpha }(y)= 0\) and \(F(x^*)-F(x)\le 0\). Furthermore, if \(\alpha =0\), we have
where the last inequality holds because \(\Vert y\Vert _\infty \le \lambda \). \(\square \)
3 Forward–Backward Splitting
Each iteration of forward–backward splitting applies the gradient descent of l(x) followed by a proximal operator. It can be expressed as follows:
where \(\lambda >0\) is the stepsize. To prove the convergence, we make the following assumptions, which are standard in compressive sensing and image processing.
Assumption 1
l(x) has a Lipschitz continuous gradient, i.e., there exists \(L>0\) such that
Assumption 2
The objective function \(r_\alpha (x)+l(x)\) is coercive, i.e., \(r_\alpha (x)+l(x)\rightarrow +\infty \) when \(\Vert x\Vert _2\rightarrow +\infty \).
The next theorem establishes the convergence of the FBS algorithm based on these two assumptions together with appropriately chosen stepsizes.
Theorem 1
If Assumptions 1 and 2 are satisfied and \(\lambda <1/L\), then the objective value is decreasing and there exists a subsequence that converges to a stationary point. In addition, any limit point is a stationary point of E(x) defined in (3).
Proof
Simple calculations give that
The first inequality comes from Assumption 1, and the second inequality comes from Lemma 2 with y replaced by \(x^k-\lambda \nabla l(x^k)\) and x replaced by \(x^{k}\). Therefore, the function value \(r_\alpha (x)+l(x)\) is decreasing; in fact, we have
Due to the coerciveness of the objective function (Assumption 2), we have that the sequence \(\{x^k\}_{k=1}^\infty \) is bounded. In addition, we have \(\sum _{k=0}^{+\infty }\Vert x^{k+1}-x^k\Vert _2^2<+\infty \), which implies \(x^{k+1}-x^k\rightarrow 0\). Therefore, there exists a convergent subsequence \(x^{k_i}\). Let \(x^{k_i}\rightarrow x^*\), then we have \(x^{k_i+1}\rightarrow x^*\) and \(x^*= {\mathbf{prox}}_{\lambda r_\alpha }(x^*-\lambda \nabla l(x^*))\), i.e., \(x^*\) is a stationary point. \(\square \)
Remark 3
When \(\alpha =0\), the algorithm is identical to the iterative soft thresholding algorithm (ISTA) [1], and the stepsize can be chosen as \(\lambda <2/L\) since (9) becomes
When \(\alpha >0\), if we know a lower bound of \(\Vert x^k\Vert _2\), we may choose a larger stepsize to speed up the convergence based on the inequality (8).
Remark 4
The result in Theorem 1 holds for any regularization r(x), and the proof follows from replacing \(\min \left( {\alpha \over 2\Vert x^{k+1}\Vert _2}-{1\over 2\lambda } ,0\right) \) in (8) by 0 [2, Proposition 2.1].
Since the main problem (3) is nonconvex, there exist many stationary points. We are interested in those stationary points that are also fixed points of the FBS operator because a global solution is a fixed point of the operator and FBS converges to a fixed point. In fact, we have the following property for global minimizers to be fixed points of the FBS algorithm for all parameters \(\lambda <1/L\).
Lemma 3
(Necessary conditions for global minimizers) Each global minimizer \(x^*\) of (3) satisfies:
-
1)
\(x^{*}\in {\mathbf{prox}}_{\lambda r_\alpha }(x^*-\lambda \nabla l(x^*))\) for all positive \(\lambda <1/L\).
-
2)
If \(x^*=0\), then we have \(\Vert \nabla l(0)\Vert _\infty \le 1-\alpha \). In addition, we have \(\nabla l(0)=0\) for \(\alpha =1\) and \(x^*=0\) does not exist for \(\alpha >1\).
-
3)
If \(\Vert x^*\Vert _2\ge \alpha /L\),let \({\varLambda }=\{i,x^*_i\ne 0\}\). Then \(x^*_{\varLambda }\) is in the same direction of \(\nabla _{\varLambda }l(x^*)+\text{ sign }(x^*_{\varLambda })\) and \(\Vert \nabla _{\varLambda }l(x^*)+\text{ sign }(x^*_{\varLambda })\Vert _2 = \alpha \).
-
4)
If \(0<\Vert x^*\Vert _2<\alpha /L\), then \(x^*\) is 1-sparse, i.e., the number of nonzero components is 1. In addition, we have \(\nabla _i l(x^*)=(\alpha -1)\text{ sign }(x^*_i)\) for \(x^*_i\ne 0\) and \(|\nabla _i l(x^*)|< 1-\alpha +\Vert x^*\Vert _\infty L\) for \(x^*_i= 0\).
Proof
Item 1) follows from (9) by replacing \(x^k\) with \(x^*\). The function value can not decrease because \(x^*\) is a global minimizer. Thus \(x^{k+1}=x^*\), and \(x^*\) is a fixed point of the forward–backward operator. Let \(x^*=0\), then item 1) and Lemma 1 together give us item 2).
For items 3) and 4), we denote \(y(\lambda )=x^*-\lambda \nabla l(x^*)\) and have \(\Vert y(\lambda )\Vert _\infty >\lambda \) for small positive \(\lambda \) because \(x^*\ne 0\). If \(\Vert x^*\Vert _2\ge \alpha /L\), then from Lemma 1, we have that \(\Vert x^*\Vert _2\ge \alpha \lambda \) and \(\Vert y(\lambda )\Vert _\infty \ge \lambda \) for all \(\lambda <1/L\). Therefore, we have \(x^*=S_1(y,\lambda )(\Vert S_1(y,\lambda )\Vert _2+\alpha \lambda )/\Vert S_1(y,\lambda )\Vert _2\) for all \(\lambda <1/L\) from Lemma 1. \(S_1(y,\lambda )\) is in the same direction of \(x^*\), and thus \(x^*_{\varLambda }\) is in the same direction of \(\nabla _{\varLambda }l(x^*)+\text{ sign }(x^*_{\varLambda })\). In addition, \(\Vert \nabla _{\varLambda }l(x^*)+\text{ sign }(x^*_{\varLambda })\Vert _2 = \alpha \). If \(0<\Vert x^*\Vert _2<\alpha /L\) then from Lemma 1, we have that \(x^*\) is 1-sparse. We also have \(\nabla _i l(x^*)=(\alpha -1)\text{ sign }(x^*_i)\) for \(x^*_i\ne 0\), which is obtained similarly as Item 3). For \(x^*_i=0\), we have \(|\lambda \nabla _i l(x^*)|\le \Vert x^*\Vert _\infty -\lambda (\alpha -1)\) for all \(\lambda < 1/L\). Thus \(|\nabla _il(x^*)|\le \Vert x^*\Vert _\infty /\lambda -(\alpha -1)\) for all \(\lambda <1/L\). Let \(\lambda \rightarrow 1/L\), and we have \(| \nabla _i l(x^*)|< 1-\alpha +\Vert x^*\Vert _\infty L\). \(\square \)
The following example shows that FBS tends to select a sparser solution, i.e., the fixed points of the forward–backward operator may be sparser than other stationary points.
Example 1
Let \(N=3\) and the objective function be
We can verify that \(\left( 0,1.2-{1/\sqrt{2}},0\right) \) is a global minimizer. In addition, we get (0.2, 0, 0.2), \(\left( 1.2-{1/\sqrt{2}},0,0\right) \), \(\left( 0,0,1.2-{1/\sqrt{2}}\right) \), and \((4/5-2/9-\sqrt{2}/3,2/5-1/9-\sqrt{2}/6,4/5-2/9-\sqrt{2}/3)\) are stationary points. Let \(x^0=(0,0,0)\), we have that \(x^*=\left( 0,1.2-{1/\sqrt{2}},0\right) \). If we let \(x^0=(0.2,0,0.2)\), we will have that \(x^*=\left( 1.2-{1/\sqrt{2}},0,0\right) \) (or \(\left( 0,0,1.2-{1/\sqrt{2}}\right) \)), for stepsize \(\lambda > 0.2\sqrt{2}\approx 0.2828\). Similarly, if we let \(x^0=(4/5-2/9-\sqrt{2}/3,2/5-1/9-\sqrt{2}/6,4/5-2/9-\sqrt{2}/3)\), we will have that \(x^*=\left( 0,1.2-{1/\sqrt{2}},0\right) \) for \(\lambda >6/5-1/3-\sqrt{2}/2\approx 0.1596\). For both stationary points that are not 1-sparse, we can verify that their \(L_2\) norms are less than \(1/L=1/3\). Therefore, Lemma 3 shows that they are not fixed points of FBS for all \(\lambda <1/L\) and hence they are not global solutions.
We further consider an accelerated proximal gradient method [16] to speed up the convergence of FBS. In particular, the algorithm goes as follows,
It was shown in [16] that the algorithm converges to a critical point if \(\lambda <1/L\). We call this algorithm FBS throughout the numerical section.
4 Alternating Direction Method of Multipliers
In this section, we consider a general regularization r(x) with an assumption that it is coercive; it includes \(r_\alpha (x)\) as a special case. We apply the ADMM to solve the unconstrained problem (3). In order to do this, we introduce an auxiliary variable y such that (3) is equivalent to the following constrained minimization problem:
Then the augmented Lagrangian is
and the ADMM iteration is:
Note that the optimality condition of (12b) guarantees that \(0= \nabla l(y^{k+1})+\delta (y^{k+1}-x^{k+1}-u^k)\) and \(\delta u^{k+1}=\nabla l(y^{k+1})\).
Lemma 4
Let \((x^k,y^k,u^k)\) be the sequence generated by ADMM. We have the following statements:
-
1)
If l(x) satisfies Assumption 1, then we have
$$\begin{aligned} \textstyle L_\delta (x^{k+1},y^{k+1},u^{k+1}) - L_\delta (x^{k},y^k,u^k) \le \left( {3L\over 2} +{L^2\over \delta } -{\delta \over 2}\right) \Vert y^{k+1}-y^k\Vert _2^2, \end{aligned}$$(13)and, in addition, if l(x) is convex,
$$\begin{aligned} \textstyle L_\delta (x^{k+1},y^{k+1},u^{k+1}) - L_\delta (x^{k},y^k,u^k) \le \left( {L^2\over \delta }-{\delta \over 2}\right) \Vert y^{k+1}-y^k\Vert _2^2. \end{aligned}$$(14) -
2)
If l(x) satisfies Assumption 1, then there exists \(p\in \partial _x L_\delta (x^{k+1},y^{k+1},u^{k+1})\), where \(\partial _x L_\delta \) is the set of general subgradients of L with respect to x for fixed y and u [28, Denition 8.3] such that
$$\begin{aligned}&\Vert p\Vert _2+\Vert \nabla _y L_\delta (x^{k+1},y^{k+1},u^{k+1})\Vert _2+\Vert \nabla _u L_\delta (x^{k+1},y^{k+1},u^{k+1})\Vert _2 \nonumber \\&\quad \le (3L+\delta )\Vert y^{k+1}-y^k\Vert _2. \end{aligned}$$(15)
Proof
1): From (12a), we have
From (12b) and (12c), we derive
Assumption 1 gives us
and, by Young’s inequality, we have
for any positive c (we will decide c later). Therefore we have
Let \(c={\delta /(2L)}\), and we obtain:
Combining (16) and (18), we get (13). If, in addition, l(x) is convex, we have, from (17), that
Thus (14) is obtained by combining (16) and (19).
2) It follows from the optimality condition of (12a) that there exists \(q\in \partial r(x^{k+1})\) such that
Let \(p=q+\delta (u^{k+1}+x^{k+1}-y^{k+1})\in \partial _x L_\delta (x^{k+1},y^{k+1},u^{k+1})\), then we have
The optimality condition of (12b) and the update of u in (12c) give that
Thus (15) is obtained by combining (20), (21), and (22). \(\square \)
Theorem 2
Let Assumptions 1 and 2 be satisfied and \(\delta > (3+\sqrt{17})L/2\) (\(\delta > \sqrt{2}L\) if l(x) is convex), then
-
1)
the sequence \((x^k,y^k,u^k)\) generated by ADMM is bounded and has at least one limit point.
-
2)
\(x^{k+1}-x^k\rightarrow 0\), \(y^{k+1}-y^k\rightarrow 0\), and \(u^{k+1}-u^k\rightarrow 0\).
-
3)
each limit point \((x^*,y^*,u^*)\) is a stationary point of \(L_\delta (x,y,u)\), and \(x^*\) is a stationary point of \(r(x)+l(x)\).
Proof
1) When \(\delta >(3+\sqrt{17})L/2\), we have \({3L\over 2} +{L^2\over \delta } -{\delta \over 2}<0\). In addition, for the case l(x) being convex, we have \({L^2\over \delta }-{\delta \over 2}<0\) if \(\delta >\sqrt{2}L\). There exists a positive constant \(C_1\) that depends only on L and \(\delta \) such that
Next, we show that the augmented Lagrangian \(L_\delta \) has a global lower bound during the iteration. From Assumption 1, we have
Thus \(L_\delta (x^k,y^k,u^k)\) has a global lower bound because of the coercivity of \(r(x)+l(x)\) and \(\delta >L\). It follows from (24) that \(x^k, y^k, r(x^k)+l(x^k),\) and \(\Vert x^k-y^k\Vert _2\) are all bounded. Therefore, \(u^k\) is bounded because of Assumption 1.
Due to the boundedness of \((x^k,y^k,u^k)\), there exists a convergent subsequence \((x^{k_i},y^{k_i},u^{k_i})\), i.e., \((x^{k_i},y^{k_i},u^{k_i})\rightarrow (x^*,y^*,u^*)\).
2) Since the sequence \(L_\delta (x^k,y^k,u^k)\) is bounded below, (23) implies that \(\sum _{k=1}^\infty \Vert y^{k+1}-y^k\Vert _2^2<\infty \) and \(\Vert y^{k+1}-y^k\Vert _2^2\rightarrow 0\), i.e., \(y^{k+1}-y^k\rightarrow 0\). In addition, we have \(u^{k+1}-u^{k}\rightarrow 0\) and \(x^{k+1}-x^{k}\rightarrow 0\) due to Assumption 1 and (12c) respectively.
3) Part 2 of Lemma 4 and \(y^{k+1}-y^k\rightarrow 0\) suggest that \((x^*,y^*,u^*)\) is a stationary point of \(L_\delta (x,y,u)\). Since \((x^*,y^*,u^*)\) is a stationary point, we have \(x^*=y^*\) from (22), then (20) implies that \(\delta u^*=\nabla l(y^*)\) and \(0\in \partial _x r(x^*)+ \nabla l(x^*)\), i.e., \(x^*\) is a stationary point of \(r(x)+l(x)\). \(\square \)
Remark 5
In [15], the authors show the convergence of the same ADMM algorithm when \(l(y)=\Vert Ay-b\Vert _2^2\) and \(\delta >\sqrt{2}L\), other choices of l(x) are not considered in [15]. The proof of Theorem 2 is inspired from [30]. Early versions of [30] on arXiv.org require that r(x) is restricted prox-regular, while our r(x) does not satisfy because it is positive homogeneous and nonconvex. However, we would like to mention that later versions of [30] after our paper cover our result.
The following example shows that both FBS and ADMM may converge to a stationary point that is not a local minimizer.
Example 2
Let \(n=2\) and the objective function be
We can verify that (1, 0) and (0, 1) are two global minimizers with objective function value 0. There is another stationary point \(x^*=({1\over 2\sqrt{2}},{1\over 2\sqrt{2}})\) for this function. Assume that we assign the initial \(x^0=(c^0,c^0)\) with \(c^0> 0\), FBS generates \(x^k=(c^k,c^k)\) where \(c^{k+1}=(1-2\lambda )c^k+\lambda /\sqrt{2}\) for all \(\lambda <1/L=1/2\). For ADMM, let \(y^0=(d^0,d^0)\) and \(u^0=(e^0,e^0)\) such that \(e^0>0\) and \(d^0>e^0+1/\delta \), then ADMM generates \(x^k=(c^k,c^k)\), \(y^k=(d^k,d^k)\), and \(u^k=(e^k,e^k)\) with
5 Numerical Experiments
In this section, we compare our proposed algorithms with DCA on three types of matrices: random Gaussian, random partial DCT, and random over-sampled DCT matrices. Both random Gaussian and partial DCT matrices satisfy the RIP with high probabilities [3]. The size of these two types of matrices is \(64\times 256\). Each entry of random Gaussian matrices follows the standard normal distribution, i.e., zero-mean with standard deviation of one, while we randomly select rows from the full DCT matrix to form partial DCT matrices. The over-sampled DCT matrices are highly coherent, and they are derived from the problem of spectral estimation [10] in signal processing. An over-sampled DCT matrix is defined as \(A=[\mathbf {a}_1, \ldots , \mathbf {a}_N]\in \mathbb {R}^{M\times N}\) with
where \(\mathbf {w}\) is a random vector of length M and F is the parameter used to decide how coherent the matrix is. The larger F is, the higher the coherence is. We consider two over-sampled DCT matrices of size \(100\times 1500\) with \(F=5\) and \(F=20\). All the testing matrices are normalized to have unit (spectral) norm.
As for the (ground-truth) sparse vector, we generate the random index set and draw non-zero elements following the standard normal distribution. We compare the performance and efficiency of all algorithms in recovering the sparse vectors for both the noisy and noise-free cases. For the noisy case, we may also construct the noise such that the sparse vectors are stationary points. The initial value for all the implementations is chosen to be an approximated solution of the \(L_1\) minimization, i.e.,
The approximated solution is obtained after 2N ADMM iterations. The stopping condition for the proposed FBS and ADMM is either \(\Vert x^{k+1}-x^k\Vert _2/\Vert x^k\Vert _2<1e^{-8}\) or \(k>10N\).
We examine the overall performance in terms of recovering exact sparse solutions for the noise-free case. In particular, we look at success rates with 100 random realizations. A trial is considered to be successful if the relative error of the reconstructed solution \(x_r\) by an algorithm to the ground truth \(x_g\) is less than .001, i.e., \(\frac{\Vert x_r-x_g\Vert }{\Vert x_g\Vert }<.001\). For the noisy case, we compare the mean-square-error of the reconstructed solutions. All experiments are performed using Matlab 2016a on a desktop (Windows 7, 3.6GHz CPU, 24GB RAM). The Matlab source codes can be downloaded at https://github.com/mingyan08/ProxL1-L2.
5.1 Constructed Stationary Points
We construct the data term b such that a given sparse vector \(x^*\) is a stationary point of the unconstrained \(L_1\)–\(L_2\) problem,
for a given positive parameter \(\gamma \). This can be done using a similar procedure as for the \(L_1\) problem [18]. In particular, any non-zero stationary point satisfies the following first-order optimality condition:
where \(p^*\in \partial \Vert x^*\Vert _1\). Denote Sign(x) as the multi-valued sign, i.e.,
Given \(A,~\gamma \), and \(x^*\), we want to find \(w\in \text{ Sign }(x^*)\) and \(w-\frac{x^*}{\Vert x^*\Vert _2} \in \text{ Range }(A^\top )\). If y satisfies \(A^\top y=w-\frac{x^*}{\Vert x^*\Vert _2} \) and b is defined by \(b=\gamma y+Ax^*\), then \(x^*\) is a stationary point to (25). To find \(w\in \mathbb R^N\), we consider the projection onto convex sets (POCS) [6] by alternatively projecting onto two convex sets: \(w\in \text{ Sign }(x^*)\) and \(w-\frac{x^*}{\Vert x^*\Vert _2} \in \text{ Range }(A^\top )\). In particular, we compute the orthogonal basis of \(A^\top \), denoted as U, for the sake of projecting onto the set \(\text{ Range }(A^\top )\). The iteration starts with \(w^0\in \text{ Sign }(x^*)\) and proceeds
until a stopping criterion is reached. The stopping condition for POCS is ether \(\Vert w^{k+1}-w^k\Vert _2<1e^{-10}\) or \(k>10N\). Note that POCS may not converge and w may not exist, especially when A is highly coherent.
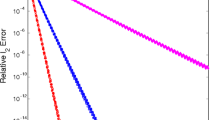
For constructed test casesFootnote 1 with giving \(A,~\gamma ,~x^*,\) and b, we study the convergence of three \(L_1\)–\(L_2\) implementations (DCA, FBS, and ADMM). We consider the sparse vector x with sparsity 10. We fix \(\lambda = 1\) (FBS stepsize), and \(\delta = 0.1\) (ADMM stepsize). We only consider incoherent matrices (random Gaussian and partial DCT) of size \(64\times 256\), as it is hard to find an optimal solution to (26) for over-sampled DCT matrices. Figure 1 shows that FBS and ADMM are much faster than the DCA in finding the stationary point \(x^*\). Here we give a justification of the speed by complexity analysis. For each iteration, FBS requires to compute the matrix-vector multiplication of complexity O(MN) and shrinkage operator of complexity O(N), while ADMM requires a matrix inversion of \(O(M^3)\). As for DCA, it requires to solve an \(L_1\) minimization problem iteratively; at each iteration, the complexity is equivalent to FBS or ADMM, whichever we use to solve the subproblem. As a result, the DCA is much slower than FBS and ADMM.

Computational efficiency. Problem setting: a matrix A is of size \(64\times 256\) (random Gaussian or partial DCT) and \(x_g\) has 10 non-zero elements drawn from standard Gaussian distribution; b is constructed such that \(x_g\) is a stationary point of the unconstructed \(L_1\)–\(L_2\) minimization. In each case, we plot the error to the ground-truth solution versus iteration numbers for three \(L_1\)–\(L_2\) minimization methods: DCA, FBS, and ADMM; FBS and ADMM are much faster than DCA. a Gaussian, \(\gamma =0.01\), b DCT, \(\gamma = 0.01\), c Gaussian, \(\gamma =0.1\) and d Gaussian, \(\gamma = 0.001\)
5.2 Noise-Free Case
In this section, we look at the success rates of finding a sparse solution while satisfying the linear constraint \(Ax=b\). We consider an unconstrained formulation with a small regularizing parameter in order to enforce the linear constraint. In particular, we choose \(\gamma =1e^{-6}\) for random Gaussian matrices and \(\gamma =1e^{-7}\) for oversampled DCT matrices, which are shown to have good recovery results. As for algorithmic parameters, we choose \(\delta =10\gamma \) for ADMM and DCA. FBS does not work well with a very small regularization parameter \(\gamma \), while a common practice is gradually decreasing its value. We decide not to compare with FBS in the noise-free case. Figure 2 shows that both DCA and ADMM often yield the same solutions when sensing matrix is incoherent, e.g., random Gaussian and over-sampled DCT with F=5; while DCA is better than ADMM for highly coherent matrices (bottom right plot of Fig. 2.) We suspect the reason to be that DCA is less prone to parameters and numerical errors than ADMM, as each DCA subproblem is convex; we will examine extensively in the future work. This hypothesis motivates us to design a continuation strategy of updating \(\alpha \) in the weighted model of \(L_1\)–\(\alpha L_2\). Particularly for incoherent matrices, we want \(\alpha \) to approach to 1 very quickly, so we consider a linear update of \(\alpha \) capped at 1 with a large slope. If the matrix is coherent, we want to impose a smooth transition of \(\alpha \) going from zero to one, and we choose a sigmoid function to change \(\alpha \) at every iteration k, i.e.,
where a and r are parameters. We plot the evolution of \(\alpha \) for over-sampled DCT when \(K=5\) (incoherent) and \(K=20\) (coherent) on the top right plot of Fig. 2. Note that the iteration may stop before \(\alpha \) reaches to one. We call this updating scheme a weighted model. In Fig. 2, we show that the weighted model is better than DCA and ADMM when the matrix is highly coherent.

Success rates of random Gaussian matrices and over-sampled DCT matrices for \(F=5\) and \(F=20\). The ADMM approach yields almost the same results compared to the DCA for incoherent matrices (random Gaussian and over-sampled DCT with \(F=5\)), and the weighted model with a specific update of \(\alpha \) (see top right plot) achieves the best results in the highly coherent case (over-sampled DCT with \(F=20\))
Although the DCA gives better results for coherent matrices, it is much slower than ADMM in the run time. The computational time averaged over 100 realizations for each method is reported in Table 1. DCA is almost one order of magnitude slower than ADMM and weighted model. The time for the \(L_1\) minimization via ADMM is also provided. Table 1 shows that \(L_1\)–\(L_2\) via ADMM and weighted model are comparable to the \(L_1\) approach in efficiency. The weighted model achieves the best recovery results in terms of both success rates and computational time.
5.3 Noisy Data
Finally we provide a series of simulations to demonstrate sparse recovery with noise, following an experimental setup in [33]. We consider a signal x of length \(N=512\) with \(K=130\) non-zero elements. We try to recover it from M measurements b determined by a normal distribution matrix A (then each column is normalized with zero-mean and unit norm), with white Gaussian noise of standard deviation \(\sigma = 0.1\). To compensate the noise, we use the mean-square-error (MSE) to quantify the recovery performance. If the support of the ground-truth solution x is known, denoted as \({\varLambda }=\text{ supp }(x)\), we can compute the MSE of an oracle solution, given by the formula \(\sigma ^2\text{ tr }(A_{{\varLambda }}^TA_{{\varLambda }})^{-1}\), as benchmark.

MSE of sparse recovery under the presence of additive Gaussian white noise. The sensing matrix is of size \(M\times N\), where M ranges from 230 to 330 and \(N = 512\). The ground-truth sparse vector contains 130 non-zero elements. The MSE values are averaged over 100 random realizations
We want to compare \(L_1\)–\(L_2\) with \(L_{1/2}\) via the half-thresholding methodFootnote 2 [33], which uses an updating scheme for \(\gamma \). We observe all the \(L_1\)–\(L_2\) implementations with a fixed parameter \(\gamma \) almost have the same recovery performance. In addition, we heuristically consider to choose \(\gamma \) adaptively based on the sigmoid function (27) with \(a=-1, r = 0.02\), along with the FBS framework. Therefore, we record the MSE of two \(L_1\)–\(L_2\) implementations: ADMM with fixed \(\gamma = 0.8\) and FBS with updating \(\gamma \). The \(L_1\) minimization via ADMM with updating \(\gamma \) is also included. Each number in Fig. 3 is based on the average of 100 random realizations of the same setup. \(L_1\)–\(L_2\) is better than \(L_{1/2}\) when M is small, but it is the other way around for large M. It is consistent with the observation in [34] that \(L_p\) \((0<p<1)\) is better than \(L_1\)–\(L_2\) for incoherent sensing matrices. When M is small, the sensing matrix becomes coherent, and \(L_1\)–\(L_2\) seems to show advantages and/or robustness over \(L_p\).
In Table 2, we present the mean and standard deviation of MSE and computational time at four particular M values: 238, 250, 276, 300, which were considered in [33]. Although the half-thresholding achieves the best results for large M, it is much more slower than other competing methods. We hypothesize that the convergence of \(L_{1/2}\) via half-threshdoling is slower than the \(L_1\)–\(L_2\) approach.
6 Conclusions
We derived a proximal operator for \(L_1\)–\(\alpha L_2\), as analogue to the soft shrinkage for \(L_1\). This makes some fast \(L_1\) solvers such as FBS and ADMM applicable to minimize \(L_1\)–\(\alpha L_2\). We discussed these two algorithms in details with convergence analysis. We demonstrated numerically that FBS and ADMM together with this proximal operator are much more efficient than the DCA approach. In addition, we observed DCA gives better recovery results than ADMM for coherent matrices, which motivated us to consider a continuation strategy in terms of \(\alpha \).
Notes
If POCS does not converge, we discard this trial in the analysis.
We use the author’s Matlab implementation with default parameter settings and the same stopping condition adopted as \(L_1\)–\(L_2\) in the comparsion.
References
Beck, A., Teboulle, M.: A fast iterative shrinkage–thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009)
Bredies, K., Lorenz, D.A., Reiterer, S.: Minimization of non-smooth, non-convex functionals by iterative thresholding. J. Optim. Theory Appl. 165(1), 78–112 (2015)
Candès, E.J., Romberg, J., Tao, T.: Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 59, 1207–1223 (2006)
Chartrand, R.: Exact reconstruction of sparse signals via nonconvex minimization. IEEE Signal Process. Lett. 10(14), 707–710 (2007)
Chartrand, R., Yin, W.: Iteratively reweighted algorithms for compressive sensing. In: International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 3869–3872 (2008)
Cheney, W., Goldstein, A.A.: Proximity maps for convex sets. Proc. Am. Math. Soc. 10(3), 448–450 (1959)
Donoho, D., Elad, M.: Optimally sparse representation in general (nonorthogonal) dictionaries via l1 minimization. Proc. Natl. Acad. Sci. U.S.A. 100, 2197–2202 (2003)
Donoho, D.L.: Compressed sensing. IEEE Trans. Inf. Theory 52(4), 1289–1306 (2006)
Esser, E., Lou, Y., Xin, J.: A method for finding structured sparse solutions to non-negative least squares problems with applications. SIAM J. Imaging Sci. 6(4), 2010–2046 (2013)
Fannjiang, A., Liao, W.: Coherence pattern-guided compressive sensing with unresolved grids. SIAM J. Imaging Sci. 5(1), 179–202 (2012)
Gribonval, R., Nielsen, M.: Sparse representations in unions of bases. IEEE Trans. Inf. Theory 49(12), 3320–3325 (2003)
Huang, X., Shi, L., Yan, M.: Nonconvex sorted l1 minimization for sparse approximation. J. Oper. Res. Soc. China 3, 207–229 (2015)
Krishnan, D., Fergus, R.: Fast image deconvolution using hyper-Laplacian priors. In: Advances in Neural Information Processing Systems (NIPS), pp. 1033–1041 (2009)
Lai, M.J., Xu, Y., Yin, W.: Improved iteratively reweighted least squares for unconstrained smoothed lq minimization. SIAM J. Numer. Anal. 5(2), 927–957 (2013)
Li, G., Pong, T.K.: Global convergence of splitting methods for nonconvex composite optimization. SIAM J. Optim. 25, 2434–2460 (2015)
Li, H., Lin, Z.: Accelerated proximal gradient methods for nonconvex programming. In: Advances in Neural Information Processing Systems, pp. 379–387 (2015)
Liu, T., Pong, T.K.: Further properties of the forward-backward envelope with applications to difference-of-convex programming. Comput. Optim. Appl. 67(3), 489–520 (2017)
Lorenz, D.A.: Constructing test instances for basis pursuit denoising. Trans. Signal Process. 61(5), 1210–1214 (2013)
Lou, Y., Osher, S., Xin, J.: Computational aspects of l1-l2 minimization for compressive sensing. In: Le Thi, H., Pham Dinh, T., Nguyen, N. (eds.) Modelling, Computation and Optimization in Information Systems and Management Sciences. Advances in Intelligent Systems and Computing, vol. 359, pp. 169–180. Springer, Cham (2015)
Lou, Y., Yin, P., He, Q., Xin, J.: Computing sparse representation in a highly coherent dictionary based on difference of l1 and l2. J. Sci. Comput. 64(1), 178–196 (2015)
Lou, Y., Yin, P., Xin, J.: Point source super-resolution via non-convex l1 based methods. J. Sci. Comput. 68(3), 1082–1100 (2016)
Mammone, R.J.: Spectral extrapolation of constrained signals. J. Opt. Soc. Am. 73(11), 1476–1480 (1983)
Natarajan, B.K.: Sparse approximate solutions to linear systems. SIAM J. Comput. 24, 227–234 (1995)
Papoulis, A., Chamzas, C.: Improvement of range resolution by spectral extrapolation. Ultrason. Imaging 1(2), 121–135 (1979)
Pham-Dinh, T., Le-Thi, H.A.: A DC optimization algorithm for solving the trust-region subproblem. SIAM J. Optim. 8(2), 476–505 (1998)
Repetti, A., Pham, M.Q., Duval, L., Chouzenoux, E., Pesquet, J.C.: Euclid in a taxicab: sparse blind deconvolution with smoothed regularization. IEEE Signal Process. Lett. 22(5), 539–543 (2015)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1997)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Springer, Dordrecht (2009)
Santosa, F., Symes, W.W.: Linear inversion of band-limited reflection seismograms. SIAM J. Sci. Stat. Comput. 7(4), 1307–1330 (1986)
Wang, Y., Yin, W., Zeng, J.: Global convergence of ADMM in nonconvex nonsmooth optimization. arXiv:1511.06324 [cs, math] (2015)
Woodworth, J., Chartrand, R.: Compressed sensing recovery via nonconvex shrinkage penalties. Inverse Probl. 32(7), 075,004 (2016)
Wu, L., Sun, Z., Li, D.H.: A Barzilai–Borwein-like iterative half thresholding algorithm for the \(l_{1/2}\) regularized problem. J. Sci. Comput. 67, 581–601 (2016)
Xu, Z., Chang, X., Xu, F., Zhang, H.: \(l_{1/2}\) regularization: a thresholding representation theory and a fast solver. IEEE Trans. Neural Netw. Learn. Syst. 23, 1013–1027 (2012)
Yin, P., Lou, Y., He, Q., Xin, J.: Minimization of \(l_1\)– \(l_2\) for compressed sensing. SIAM J. Sci. Comput. 37, A536–A563 (2015)
Zhang, S., Xin, J.: Minimization of transformed \(l_1\) penalty: Theory, difference of convex function algorithm, and robust application in compressed sensing. arXiv preprint arXiv:1411.5735 (2014)
Acknowledgements
The authors would like to thank Zhi Li and the anonymous reviewers for valuable comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was partially supported by the NSF grants DMS-1522786 and DMS-1621798.
Rights and permissions
About this article

Cite this article
Lou, Y., Yan, M. Fast L1–L2 Minimization via a Proximal Operator. J Sci Comput 74, 767–785 (2018). https://doi.org/10.1007/s10915-017-0463-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10915-017-0463-2
Keywords
- Compressive sensing
- Proximal operator
- Forward–backward splitting
- Alternating direction method of multipliers
- Difference-of-convex