
Abstract
The reconstruction of a 3D object or a scene is a classical inverse problem in Computer Vision. In the case of a single image this is called the Shape-from-Shading (SfS) problem and it is known to be ill-posed even in a simplified version like the vertical light source case. A huge number of works deals with the orthographic SfS problem based on the Lambertian reflectance model, the most common and simplest model which leads to an eikonal-type equation when the light source is on the vertical axis. In this paper, we want to study non-Lambertian models since they are more realistic and suitable whenever one has to deal with different kind of surfaces, rough or specular. We will present a unified mathematical formulation of some popular orthographic non-Lambertian models, considering vertical and oblique light directions as well as different viewer positions. These models lead to more complex stationary non-linear partial differential equations of Hamilton–Jacobi type which can be regarded as the generalization of the classical eikonal equation corresponding to the Lambertian case. However, all the equations corresponding to the models considered here (Oren–Nayar and Phong) have a similar structure so we can look for weak solutions to this class in the viscosity solution framework. Via this unified approach, we are able to develop a semi-Lagrangian approximation scheme for the Oren–Nayar and the Phong model and to prove a general convergence result. Numerical simulations on synthetic and real images will illustrate the effectiveness of this approach and the main features of the scheme, also comparing the results with previous results in the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The 3D reconstruction of an object starting from one or more images is a very interesting inverse problem with many applications. In fact, this problem appears in various fields which range from the digitization of curved documents [15] to the reconstruction of archaeological artifacts [24]. More recently, other applications have been considered in astronomy to obtain a characterization of properties of planets and other astronomical entities [27, 41, 66] and in security where the same problem has been applied to the facial recognition of individuals.
In real applications, several light sources can appear in the environment and the object surfaces represented in the scene can have different reflection properties because they are made by different materials, so it would be hard to imagine a scene which can satisfy the classical assumptions of the 3D reconstruction models. In particular, the typical Lambertian assumption often used in the literature has to be weakened. Moreover, despite the fact that the formulation of the Shape-from-Shading problem is rather simple for a single light source and under Lambertian assumptions, its solution is hard and requires rather technical mathematical tools as the use of weak solutions to non-linear partial differential equations (PDEs). From the numerical point of view, the accurate approximation of non-regular solutions to these non-linear PDEs is still a challenging problem. In this paper, we want to make a step forward in the direction of a mathematical formulation of non-Lambertian models in the case of orthographic projection with a single light source located far from the surface. In this simplified framework, we present a unified approach to two popular models for non-Lambertian surfaces proposed by Oren–Nayar [47–50] and by Phong [51]. We will consider light sources placed in oblique directions with respect to the surface and we will use that unified formulation to develop a general numerical approximation scheme which is able to solve the corresponding non-linear partial differential equations arising in the mathematical description of these models.
To better understand the contribution of this paper, let us start from the classical SfS problem where the goal is to reconstruct the surface from a single image. In mathematical terms, given the shading informations contained in a single two-dimensional gray level digital image \( I(\mathbf {x})\), where \(\mathbf {x}:= (x,y)\), we look for a surface \(z = u(\mathbf {x})\) that corresponds to its shape (hence the name Shape from Shading). This problem is described in general by the image irradiance equation introduced by Bruss [8]
where the normalized brightness of the given gray-value image \(I(\mathbf {x})\) is put in relation with the function \(R(\mathbf {N}(\mathbf {x}))\) that represents the reflectance map giving the value of the light reflection on the surface as a function of its orientation (i.e., of the normal \(\mathbf {N}(\mathbf {x})\)) at each point \((\mathbf {x},u(\mathbf {x}))\). Depending on how we describe the function R, different reflection models are determined. In the literature, the most common representation of R is based on the Lambertian model (the L-model in the sequel) which takes into account only the angle between the outgoing normal to the surface \(\mathbf {N}(\mathbf {x})\) and the light source \(\varvec{\omega }\), that is
where \(\cdot \) denotes the standard scalar product between vectors and \(\gamma _D(\mathbf {x})\) indicates the diffuse albedo, i.e., the diffuse reflectivity or reflecting power of a surface. It is the ratio of reflected radiation from the surface to incident radiance upon it. Its dimensionless nature is expressed as a percentage and it is measured on a scale from zero for no reflection of a perfectly black surface to 1 for perfect reflection of a white surface. The data are the gray-value image \(I(\mathbf {x})\), the direction of the light source represented by the unit vector \(\varvec{\omega }\) and the albedo \(\gamma _D(\mathbf {x})\). The light source \(\varvec{\omega }\) is a unit vector, hence \(|\varvec{\omega }| = 1\). In the simple case of a vertical light source, that is when the light source is in the direction of the vertical axis, this gives rise to an eikonal equation. Several questions arise, even in the simple case: Is a single image sufficient to determine the surface? If not, which set of additional informations is necessary to have uniqueness? How can we compute an approximate solution? Is the approximation accurate? It is well known that for Lambertian surfaces there is no uniqueness and other informations are necessary to select a unique surface (e.g., the height at each point of local maximum for \(I(\mathbf {x})\)). However, rather accurate schemes for the classical eikonal equation are now available for the approximation. Despite its simplicity, the Lambertian assumption is very strong and does not match with many real situations that is why we consider in this paper some non-Lambertian models trying to give a unified mathematical formulation for these models.
In order to set this paper into a mathematical perspective, we should mention that the pioneering work of Horn [28, 29] and his activity with his collaborators at MIT [30, 31] produced the first formulation of the SfS problem via a PDE and a variational problem. These works have inspired many other contributions in this research area as one can see looking at the extensive list of references in the two surveys [19, 85]. Several approaches have been proposed, we can group them in two big classes (see the surveys [19, 85]): methods based on the resolution of PDEs and optimization methods based on a variational approximation. In the first group the unknown is directly the height of the surface \(z=u(\mathbf {x})\), one can find here rather old papers based on the method of characteristics [6, 17, 29, 38, 45, 46, 60] where one typically looks for classical solutions. More recently, other contributions were developed in the framework of weak solutions in the viscosity sense starting from the seminal paper by Rouy and Tourin [61] and, one year later, by Lions–Rouy and Tourin [40] (see e.g., [4, 9–11, 22, 23, 33, 36, 53, 56, 62]). The second group contains the contribution based on minimization methods for the variational problem where the unknown are the partial derivatives of the surface, \(p=u_x\) and \(q=u_y\) (the so-called normal vector field. See e.g., [7, 16, 26, 30, 32, 67, 68, 82]). It is important to note that in this approach one has to couple the minimization step to compute the normal field with a local reconstruction for u which is based usually on a path integration. This necessary step has also been addressed by several authors (see [18] and references therein). We should also mention that a continuous effort has been made by the scientific community to take into account more realistic reflectance models [2, 3, 59, 76, 77], different scenarios including perspective camera projection [1, 14, 44, 54, 70, 75] and/or multiple images of the same object [83, 84]. The images can be taken from the same point of view but with different light sources as in the photometric stereo method [37, 42, 43, 69, 81] or from different points of view but with the same light source as in stereo vision [13]. Recent works have considered more complicated scenarios, e.g., the case when light source is not at the optical center under perspective camera projection [35]. It is possible to consider in addition other supplementary issues, as the estimation of the albedo [5, 64, 65, 86] or of the direction of the light source that are usually considered known quantities for the model but in practice are hardly available for real images. The role of boundary conditions which have to be coupled with the PDE is also a hard task. Depending on what we know, the model has to be adapted leading to a calibrated or uncalibrated problem (see [25, 57, 83, 84] for more details). In this work we will assume that the albedo and the light source direction are given.
Regarding the modeling of non-Lambertian surfaces we also want to mention the important contribution of Ahmed and Farag [1]. These authors have adopted the modeling for SfS proposed by Prados and Faugeras [52, 55] using a perspective projection where the light source is assumed to be located at the optical center of the camera instead at infinity and the light illumination is attenuated by a term \(1/r^2\) (r represents here the distance between the light source and the surface). They have derived the Hamilton–Jacobi (HJ) equation corresponding to the Oren–Nayar model, and developed an approximation via the Lax–Friedrichs sweeping method. They gave there an experimental evidence that the non-Lambertian model seems to resolve the classical concave/convex ambiguity in the perspective case if one includes the attenuation term \(1/r^2\). In [2] they extended their approach for various image conditions under orthographic and perspective projection, comparing their results for the orthographic L-model shown in [63, 85]. Finally, we also want to mention the paper by Ragheb and Hancock [58] where they treat a non-Lambertian model via a variational approach, investigating the reflectance models described by Wolff and by Oren and Nayar [50, 79, 80].
1.1 Our Contribution
In this paper we will adopt the PDE approach in the framework of weak solutions for Hamilton–Jacobi equations. As we said, we will focus our attention on a couple of non-Lambertian reflectance models: the Oren–Nayar and the Phong models [47–51]. Both models are considered for an orthographic projection and a single light source at infinity, so no attenuation term is considered here. We are able to write the Hamilton–Jacobi equations in the same fixed point form useful for their analysis and approximation and, using the exponential change of variable introduced by Kružkov in [39], we obtain natural upper bound for the solution. Moreover, we propose a semi-Lagrangian approximation scheme which can be applied to both the models, prove a convergence result for our scheme that can be applied to this class of Hamilton–Jacobi equations, hence to both non-Lambertian models. Numerical comparisons will show that our approach is more accurate also for the 3D reconstructions of non-smooth surfaces.
A similar formulation for the Lambertian SfS problem with oblique light direction has been studied in [23] and here is extended to non-Lambertian models. We have reported some preliminary results just for the Oren–Nayar model in [72].
1.2 Organization of the Paper
The paper is organized as follows. After a formulation of the general model presented in Sect. 2, we present the SfS models starting from the classical Lambertian model (Sect. 3). In Sects. 4 and 5, we will give details on the construction of the non-linear PDE which corresponds, respectively, to the Oren–Nayar and the Phong models. Despite the differences appearing in these non-Lambertian models, we will be able to present them in a unified framework showing that the Hamilton–Jacobi equations for all the above models share a common structure. Moreover, the Hamiltonian appearing in these equations will always be convex in the gradient \(\nabla u\). Then, in Sect. 6, we will introduce our general approximation scheme which can be applied to solve this class of problems. In Sect. 7, we will apply our approximation to a series of benchmarks based on synthetic and real images. We will discuss some issues like accuracy, efficiency, and the capability to obtain the maximal solution showing that the semi-Lagrangian approximation is rather effective even for real images where several parameters are unknown. Finally, in the last section we will give a summary of the contributions of this work with some final comments and future research directions.
2 Formulation of the General Model
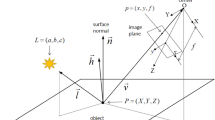
We fix a camera in a three-dimensional coordinate system (Oxyz) in such a way that Oxy coincides with the image plane and Oz with the optical axis. Let \(\varvec{\omega } = (\omega _1,\omega _2,\omega _3) = (\varvec{\tilde{\omega }},\omega _3)\in \mathbb {R}^3\) (with \(\omega _3 > 0\)) be the unit vector that represents the direction of the light source (the vector points from the object surface to the light source); let \(I(\mathbf {x})\) be the function that measures the gray level of the input image at the point \(\mathbf {x}:= (x,y)\). \(I(\mathbf {x})\) is the datum in the model since it is measured at each pixel of the image, for example in terms of a gray level (from 0 to 255). In order to construct a continuous model, we will assume that \(I(\mathbf {x})\) takes real values in the interval [0, 1], defined in a compact domain \(\overline{\varOmega }\) called “reconstruction domain” (with \(\varOmega \subset \mathbb {R}^2\) open set), \(I:\overline{\varOmega }\rightarrow [0,1]\), where the points with a value of 0 are the dark point (blacks), while those with a value of 1 correspond to a complete reflection of the light (white dots, with a maximum reflection).
We consider the following assumptions:
-
A1
There is a single light source placed at infinity in the direction \(\varvec{\omega }\) (the light rays are, therefore, parallel to each other);
-
A2
The observer’s eye is placed at an infinite distance from the object you are looking at (i.e., there is no perspective deformation);
-
A3
There are no autoreflections on the surface.
In addition to these assumptions, there are other hypothesis that depend on the different reflectance models (we will see them in the description of the individual models).

An object on a flat background. \(\varOmega \) indicates the region inside the silhouette, \(\partial \varOmega \) the boundary of it
Being valid the assumption (A2) of orthographic projection, the visible part of the scene is a graph \(z = u(\mathbf {x})\) and the unit normal to the regular surface at the point corresponding to \(\mathbf {x}\) is given by
where \(\mathbf {n}(\mathbf {x})\) is the outgoing normal vector.
We assume that the surface is standing on a flat background so the height function, which is the unknown of the problem, will be non-negative, \(u:\varOmega \rightarrow [0,\infty )\). We will denote by \(\varOmega \) the region inside the silhouette and we will assume (just for technical reasons) that \(\varOmega \) is an open and bounded subset of \(\mathbb {R}^2\) (see Fig. 1). It is well known that the SfS problem is described by the image irradiance Eq. (1) and depending on how we describe the function R different reflection models are determined. We describe below some of them. To this end, it would be useful to introduce a representation of the brightness function \(I(\mathbf {x})\) where we can distinguish different terms representing the contribution of ambient, diffuse reflected, and specular reflected light. We will write then
where \(I_A(\mathbf {x})\), \(I_D(\mathbf {x})\), and \(I_S(\mathbf {x})\) are, respectively, the above-mentioned components and \(k_A\), \(k_D\), and \(k_S\) indicate the percentages of these components such that their sum is equal to 1 (we do not consider absorption phenomena). Note that the diffuse or specular albedo is inside the definition of \(I_D(\mathbf {x})\) or \(I_S(\mathbf {x})\), respectively. In the sequel, we will always consider \(I(\mathbf {x})\) normalized in [0, 1]. This will allow to switch on and off the different contributions depending on the model. Let us note that the ambient light term \(I_A(\mathbf {x})\) represents light everywhere in a given scene. In the whole paper, we will consider it as a constant and we will neglect its contribution fixing \(k_A = 0\). Moreover, for all the models presented below we will suppose uniform diffuse and/or specular albedo and we will put them equal to 1, that is all the points of the surface reflect completely the light that hits them. We will omit them in what follows. As we will see in the following sections, the intensity of diffusely reflected light in each direction is proportional to the cosine of the angle \(\theta _i\) between surface normal and light source direction, without taking into account the point of view of the observer, but another diffuse model (the Oren–Nayar model) will consider it in addition. The amount of specular reflected light towards the viewer is proportional to \((\cos \theta _s)^\alpha \), where \(\theta _s\) is the angle between the ideal (mirror) reflection direction of the incoming light and the viewer direction, \(\alpha \) being a constant modeling the specularity of the material. In this way, we have a more general model and, dropping the ambient and specular component, we retrieve the Lambertian reflection as a special case.
3 The Lambertian Model (L-model)
For a Lambertian surface, which generates a purely diffuse model, the specular component does not exist, then in (4) we have just the diffuse component \(I_D\) on the right side. Lambertian shading is view independent, hence the irradiance Eq. (1) becomes
Under these assumptions, the orthographic SfS problem consists in determining the function \(u:\overline{\varOmega }\rightarrow \mathbb {R}\) that satisfies Eq. (5). The unit vector \(\varvec{\omega }\) and the function \(I(\mathbf {x})\) are the only quantities known.
For Lambertian surfaces [30, 31], just considering an orthographic projection of the scene, it is possible to model the SfS problem via a non-linear PDE of the first order which describes the relation between the surface \(u(\mathbf {x})\) (our unknown) and the brightness function \(I(\mathbf {x})\). In fact, recalling the definition of the unit normal to a graph given in (3), we can write (5) as
where \({\widetilde{\varvec{\omega }}} = (\omega _1,\omega _2)\). This is an Hamilton–Jacobi type equation which does not admit in general a regular solution. It is known that the mathematical framework to describe its weak solutions is the theory of viscosity solutions as in [40].
The Vertical Light Case
If we choose \( \varvec{\omega } = (0,0,1)\), Eq. (6) becomes the so-called “eikonal equation”:
where
The points \(\mathbf {x}\in \varOmega \) where \(I(\mathbf {x})\) assumes maximum value correspond to the case in which \(\varvec{\omega }\) and \(\mathbf {N}(\mathbf {x})\) have the same direction: these points are usually called “singular points.”
In order to make the problem well-posed, we need to add boundary conditions to the Eqs. (6) or (7): they can require the value of the solution u (Dirichlet boundary conditions type), or the value of its normal derivative (Neumann boundary conditions), or an equation that must be satisfied on the boundary (the so-called boundary conditions “state constraint”). In this paper, we consider Dirichlet boundary conditions equal to zero assuming a surface on a flat background
but a second possibility of the same type occurs when it is known the value of u on the boundary, which leads to the more general condition
Unfortunately, adding a boundary condition to the PDE that describes the SfS model is not enough to obtain a unique solution because of the concave/convex ambiguity. In fact, the Dirichlet problem (6)–(10) can have several weak solutions in the viscosity sense and also several classical solutions due to this ambiguity (see [29]). As an example, all the surfaces represented in Fig. 2 are viscosity solutions of the same problem (7)–(9) which is a particular case of (6)–(10) (in fact the equation is \(|u'|=-2x\) with homogenous Dirichlet boundary condition). The solution represented in Fig. 2a is the maximal solution and is smooth. All the non-smooth a.e. solutions, which can be obtained by a reflection with respect to a horizontal axis, are still admissible weak solutions (see Fig. 2b). In this example, the lack of uniqueness of the viscosity solution is due to the existence of a singular point where the right-hand side of (7) vanishes. An additional effort is then needed to define which is the preferable solution since the lack of uniqueness is also a big drawback when trying to compute a numerical solution. In order to circumvent these difficulties, the problem is usually solved by adding some information such as height at each singular point [40].

Illustration of the concave/convex ambiguity. a maximal solution and b a.e. solutions giving the same image. Figure adapted from [19]
For analytical and numerical reasons it is useful to introduce the exponential Kružkov change of variable [39] \(\mu v(\mathbf {x}) = 1- \mathrm{e}^{-\mu u(\mathbf {x})}\). In fact, setting the problem in the new variable v we will have values in \([0, 1/\mu ]\) instead of \([0,\infty )\) as the original variable u so an upper bound will be easy to find. Note that \(\mu \) is a free positive parameter which does not have a specific physical meaning in the SfS problem. However, it can play an important role also in our convergence proof as we will see later (see the remark following the end of Theorem 1). Assuming that the surface is standing on a flat background and following [23], we can write (6) and (9) in a fixed point form in the new variable v. To this end let us define \(\mathbf {b}^L:\varOmega \times \partial B_3(0,1)\rightarrow \mathbb {R}^2\) and \(f^L:\varOmega \times \partial B_3(0,1)\times [0,1] \rightarrow \mathbb {R}\) as
and let \(B_3\) denote the unit ball in \(\mathbb {R}^3\). We obtain

It is important to note for the sequel that the structure of the above first-order Hamilton–Jacobi equation is similar to that related to the dynamic programming approach in control theory, where \(\mathbf {b}\) is a vector field describing the dynamics of the system and f is a running cost. In that framework the meaning of v is that of a value function which allows to characterize the optimal trajectories (here they play the role of characteristic curves). The interested reader can find more details on this interpretation in [21].
4 The Oren–Nayar Model (ON-model)
The diffuse reflectance ON-model [47–50] is an extension of the previous L-model which explicitly allows to handle rough surfaces. The idea of this model is to represent a rough surface as an aggregation of V-shaped cavities, each with Lambertian reflectance properties (see Fig. 3).
In [48] and, with more details, in [50], Oren and Nayar derive a reflectance model for several type of surfaces with different slope-area distributions. In this paper we will refer to the model called by the authors the “Qualitative Model,” a simpler version obtained by ignoring interreflections (see Sect. 4.4 of [48] for more details).

Facet model for surface patch dA consisting of many V-shaped Lambertian cavities. Figure adapted from [34]
Assuming that there is a linear relation between the irradiance of the image and the image intensity, the \(I_D\) brightness equation for the ON-model is given by
Note that A and B are two non-negative constants depending on the statistics of the cavities via the roughness parameter \(\sigma \). We set \(\sigma \in [0,\pi /2)\), interpreting \(\sigma \) as the slope of the cavities. In this model (see Fig. 4), \(\theta _{i}\) represents the angle between the unit normal to the surface \(\mathbf {N}(\mathbf {x})\) and the light source direction \(\varvec{\omega }\), \(\theta _{r}\) stands for the angle between \(\mathbf {N}(\mathbf {x})\) and the observer direction \(\mathbf {V}\), \(\varphi _{i}\) is the angle between the projection of the light source direction \(\varvec{\omega }\) and the \(x_1\) axis onto the \((x_1, x_2)\)-plane, \(\varphi _{\mathrm r}\) denotes the angle between the projection of the observer direction \(\mathbf {V}\) and the \(x_1\) axis onto the \((x_1, x_2)\)-plane, and the two variables \(\alpha \) and \(\beta \) are given by
Since the vectors \(\varvec{\omega }\) and \(\mathbf {V}\) are fixed and given, their projection on the incident plane is obtained considering their first two components over three (see Eq. (21)). In this way, the quantity \(\max \{0,\cos (\varphi _r - \varphi _i)\}\) is computed only once for a whole image.

Diffuse reflectance for the ON-model. Figure adapted from [34]
We define (see Fig. 4):
where
For smooth surfaces, we have \(\sigma =0\) and in this case the ON-model reduces to the L-model. In the particular case \(\varvec{\omega }= \mathbf {V}= (0,0,1)\), or, more precisely, when \(\cos (\varphi _r - \varphi _i) \le 0\) (e.g., the case when the unit vectors \(\varvec{\omega }\) and \(\mathbf {V}\) are perpendicular we get \(\cos (\varphi _r - \varphi _i) = -1\)) the Eq. (14) simplifies and reduces to a L-model scaled by the coefficient A. This means that the model is more general and flexible than the L-model. This happens when only one of the two unit vectors is zero or, more in general, when the dot product between the normalized projections onto the \((x_1, x_2)\)-plane of \(\varvec{\omega }\) and \(\mathbf {V}\) is equal to zero.
Also for this diffuse model we neglect the ambient component, setting \(k_D = 1\). As a consequence, in the general Eq. (4) the total light intensity \(I(\mathbf {x})\) is equal to the diffuse component \(I_D(\mathbf {x})\) (described by Eq. (14)). This is why we write \(I(\mathbf {x})\) instead of \(I_D(\mathbf {x})\) in what follows.
To deal with this equation one has to compute the \(\min \) and \(\max \) operators which appear in (14) and (18). Hence, we must consider several cases described in detail in what follows. For each case we will derive a partial differential equation that is always a first-order non-linear HJ equation:
Case 1 \(\theta _i \ge \theta _r\) and \((\varphi _r - \varphi _i) \in [0, \frac{\pi }{2}) \cup (\frac{3}{2}\pi , 2 \pi ]\)
The brightness Eq. (14) becomes
and by using the formulas (19)–(23) we arrive to the following HJ equation
where \({\widetilde{\varvec{\omega }}} := (\omega _1,\omega _2)\) and \(\widetilde{\mathbf {v}} := (v_1, v_2)\).
Case 2 \(\theta _i < \theta _r\) and \((\varphi _r - \varphi _i) \in [0, \frac{\pi }{2}) \cup (\frac{3}{2}\pi , 2 \pi ]\)
In this case the brightness Eq. (14) becomes
and by using again the formulas (19)–(23) we get
Case 3 \(\forall \, \theta _i, \theta _r\) and \((\varphi _r - \varphi _i) \in [\frac{\pi }{2}, \frac{3}{2}\pi ]\)
In this case we have the implication \(\max \{0, \cos (\varphi _r - \varphi _i)\} = 0\). The brightness Eq. (14) simplifies in
and the HJ equation associated to it becomes consequentially
that is equal to the L-model scaled by the coefficient A.
Case 4 \(\theta _i = \theta _r\) and \(\varphi _r = \varphi _i\)
This is a particular case when the position of the light source \(\varvec{\omega }\) coincides with the observer direction \(\mathbf {V}\) but it is not on the vertical axis. This choice implies \(\max \{0,\cos (\varphi _i - \varphi _r)\} = 1\), then defining \(\theta := \theta _i = \theta _r = \alpha = \beta \), Eq. (14) simplifies to
and we arrive to the following HJ equation
Note that this four cases are exactly the same cases reported and analyzed in [35]. This is not surprising since the reflectance model used there is always the same one proposed by Oren and Nayar. However, here we get different HJ equations since we consider an orthographic camera projection and cartesian coordinates, whereas in [35] the HJ equations are derived in spherical coordinates under a generalized perspective camera projection. Another major difference is that in that paper the light source is close to the camera but is not located at the optical center of the camera.
The Vertical Light Case
If \(\varvec{\omega }= (0,0,1)\), independently of the position of \(\mathbf {V}\), the analysis is more simple. In fact, the first three cases considered above reduce to a single case corresponding to the following simplified PDE for the brightness Eq. (14)
In this way we can put it in the following eikonal-type equation, analogous to the Lambertian eikonal Eq. (7):
where
Following [72], we write the surface as \(S(\mathbf {x},z) = z - u(\mathbf {x})=0\), for \(\mathbf {x}\in \varOmega \), \(z\in \mathbb {R}\), and \(\nabla S(\mathbf {x},z) = (-\nabla u(\mathbf {x}),1)\), so (31) becomes
Defining
and
using the equivalence
we get
Let us define the vector field for the ON-model
and
Then, introducing the exponential Kružkov change of variable \(\mu v(\mathbf {x}) = 1- \mathrm{e}^{-\mu u(\mathbf {x})}\) as already done for the L-model, we can finally write the fixed point problem in the new variable v obtaining the

Note that the simple homogeneous Dirichlet boundary condition is due to the flat background behind the object but a condition like \(u(\mathbf {x}) = g(\mathbf {x})\) can also be considered if necessary. Moreover, the structure is similar to the previous Lambertian model although the definition of the vector field and of the cost are different.
In the particular case when \(\cos (\varphi _r - \varphi _i) = 0\), Eq. (14) simply reduces to
and, as a consequence, the Dirichlet problem in the variable v is equal to (42) with \(c(\mathbf {x},z) = I(\mathbf {x})\).
5 The Phong Model (PH-model)
The PH-model is an empirical model that was developed by Phong [51] in 1975. This model introduces a specular component to the brightness function \(I(\mathbf {x})\), representing the diffuse component \(I_D(\mathbf {x})\) in (4) as the Lambertian reflectance model.
A simple specular model is obtained putting the incidence angle equal to the reflection one and \(\varvec{\omega }\), \(\mathbf {N}(\mathbf {x})\) and \(\mathbf {R}(\mathbf {x})\) belong to the same plane.
This model describes the specular light component \(I_S(\mathbf {x})\) as a power of the cosine of the angle between the unit vectors \(\mathbf {V}\) and \(\mathbf {R}(\mathbf {x})\) (it is the vector representing the reflection of the light \(\varvec{\omega }\) on the surface). Hence, the brightness equation for the PH-model is
where the parameter \(\alpha \in [1,10]\) is used to express the specular reflection properties of a material and \(k_D\) and \(k_S\) indicate the percentages of diffuse and specular components, respectively. Note that the contribution of the specular part decreases as the value of \(\alpha \) increases.

Geometry of the Phong reflection model
Starting to see in details the PH-model in the case of oblique light source \(\varvec{\omega }\) and oblique observer \(\mathbf {V}\).
Assuming that \(\mathbf {N}(\mathbf {x})\) is the bisector of the angle between \(\varvec{\omega }\) and \(\mathbf {R}(\mathbf {x})\) (see Fig. 5), we obtain
which implies
From the parallelogram law, taking into account that \(\varvec{\omega }, \mathbf {R}(\mathbf {x})\) and \(\mathbf {N}(\mathbf {x})\) are unit vectors, we can write \(||\varvec{\omega }+ \mathbf {R}(\mathbf {x})|| = 2(\mathbf {N}(\mathbf {x}) \cdot \varvec{\omega })\), then we can derive the unit vector \(\mathbf {R}(\mathbf {x})\) as follows:
With this definition of the unit vector \(\mathbf {R}(\mathbf {x})\) we have
Then, setting \(\alpha =1\), that represents the worst case, Eq. (44) becomes
to which we add a Dirichlet boundary condition equal to zero, assuming that the surface is standing on a flat blackground. Note that the cosine in the specular term is usually replaced by zero if \(\mathbf {R}(\mathbf {x})\cdot \mathbf {V}< 0\) (and in that case we get back to the L-model).
As we have done for the previous models, we write the surface as \(S(\mathbf {x},z) = z - u(\mathbf {x})=0\), for \(\mathbf {x}\in \varOmega \), \(z\in \mathbb {R}\), and \(\nabla S(\mathbf {x},z) = (-\nabla u(\mathbf {x}),1)\), so (49) will be written as
Dividing by \(|\nabla S(\mathbf {x},z)|\), defining \(\mathbf {d}(\mathbf {x},z)\) as in (36) and \(c(\mathbf {x}) := I(\mathbf {x}) + k_S (\varvec{\omega }\cdot \mathbf {V})\), we get
By the equivalence \( \displaystyle |\nabla S(\mathbf {x},z)| \equiv \max _{a\in \partial B_3} \{a\cdot \nabla S(\mathbf {x},z)\}\) we obtain
Let us define the vector field
where
and
Let us also define
Again, using the exponential Kružkov change of variable \(\mu v(\mathbf {x}) = 1- \mathrm{e}^{-\mu u(\mathbf {x})}\) as done for the previous models, we can finally write the non-linear fixed point problem

A. Oblique Light Source and Vertical Position of the Observer
In the case of oblique light source \(\varvec{\omega }\) and vertical observer \(\mathbf {V}= (0,0,1)\), the dot product \(\mathbf {R}(\mathbf {x}) \cdot \mathbf {V}\) becomes
The fixed point problem in v will be equal to (57) with the following choices
B. Vertical Light Source and Oblique Position of the Observer
When \(\varvec{\omega }= (0,0,1)\) the definition of the vector \(\mathbf {R}(\mathbf {x})\) reported in (47) becomes
and, as a consequence, the dot product \(\mathbf {R}(\mathbf {x}) \cdot \mathbf {V}\) with general \(\mathbf {V}\) is
Hence, the fixed point problem in v is equal to (57) with
C. Vertical Light Source and Vertical Position of the Observer
If we choose \(\varvec{\omega }\equiv \mathbf {V}= (0,0,1)\), Eq. (49) simplifies in
Working on this equation one can put it in the following eikonal-type form, which is analogous to the Lambertian eikonal Eq. (7):
where now
with
Remark on the control interpretation The above analysis has shown that all the cases corresponding to the models proposed by Oren–Nayar and by Phong lead to a stationary Hamilton–Jacobi equation of the same form, namely
where the vector field \(\mathbf{b}\) and the cost f can vary according to the model and to the case. This gives to these models a control theoretical interpretation which can be seen as a generalization of the control interpretation for the original Lambertian model (which was related to the minimum time problem). In this framework, v is the value function of a rescaled (by the Kružkov change of variable) control problem in which one wants to drive the controlled system governed by
(\(a(\cdot )\) here is the control function taking values in \(\partial B_3\)) from the initial position \(\mathbf{x}\) to the target (the silhouette of the object) minimizing the cost associated to the trajectory. The running cost associated to the position and the choice of the control will be given by f. More informations on this interpretation, which is not crucial to understand the application to the SfS problem presented in this paper, can be found in [21].
6 Semi-Lagrangian Approximation
Now, let us state a general convergence theorem suitable for the class of differential operators appearing in the models described in the previous sections. As we noticed, the unified approach presented in this paper has the big advantage to give a unique formulation for the three models in the form of a fixed point problem
where M indicates the model, i.e., \(M=L, ON, PH\).
We will see that the discrete operators of the ON-model and the PH-model described in the previous sections satisfy the properties listed here. In order to obtain the fully discrete approximation we will adopt the semi-Lagrangian approach described in the book by Falcone and Ferretti [21]. The reader can also refer to [12] for a similar approach to various image processing problems (including non-linear diffusions models and segmentation).
Let \(W_i=w(x_i)\) so that W will be the vector solution giving the approximation of the height u at every node \(x_i\) of the grid. Note that in one dimension the index i is an integer number, in two dimensions i denotes a multi-index, \(i=(i_1,i_2)\). We consider a semi-Lagrangian scheme written in a fixed point form, so we will write the fully discrete scheme as
Denoting by G the global number of nodes in the grid, the operator corresponding to the oblique light source is \({\widehat{T}}:\mathbb {R}^G\rightarrow \mathbb {R}^G\) that is defined componentwise by
where I[W] represents an interpolation operator based on the values at the grid nodes and
Since \(w(x_i + h b(x_i,a))\) is approximated via I[W] by interpolation on W (which is defined on the grid G), it is important to use a monotone interpolation in order to preserve the properties of the continuous operator T in the discretization. To this end, the typical choice is to apply a piecewise linear (or bilinear) interpolation operator \(I_1 [W]: \varOmega \rightarrow \mathbb {R}\) which allows to define a function defined for every \(x\in \varOmega \) (and not only on the nodes)
where
A simple explanation for (76)–(77) is that the coefficients \(\lambda _{ij}(a)\) represent the local coordinates of the point x with respect to the grid nodes (see [21] for more details and other choices of interpolation operators). Clearly, in (71) we will apply the interpolation operator to the point \(x^+_i=x_i + h b(x_i,a)\) and we will denote by w the function defined by \(I_1[W]\).
Comparing (71) with its analogue for the vertical light case we can immediately note that the former has the additional term \(\tau F(x_i,z,a)\) which requires analysis.
Theorem 1
Let \({\widehat{T}}_i(W)\) the i-th component of the operator defined as in (71). Then, the following properties hold true:
-
1.
Let \(\overline{a}_3 \equiv arg \min \limits _{a\in \partial B_3} \big \{ \mathrm{e}^{-\mu h} w\big (x_i + h b(x_i,a)\big ) - \tau F(x_i,z,a) \big \}\) and assume
$$\begin{aligned} P(x_i,z) \overline{a}_3 \le 1. \end{aligned}$$(78)Then \(0\le W\le \frac{1}{\mu }\) implies \(0\le {\widehat{T}}(W)\le \frac{1}{\mu }\).
-
2.
\({\widehat{T}}\) is a monotone operator, i.e., \(W\le \overline{W}\) implies \({\widehat{T}}(W)\le {\widehat{T}}(\overline{W})\).
-
3.
\({\widehat{T}}\) is a contraction mapping in \(L^{\infty }([0,1/\mu )^G)\) if \(P(x_i,z) \,\overline{a}_3 < \mu \).
Proof
-
1.
To prove that \(W\le \frac{1}{\mu }\) implies \(T(W)\le \frac{1}{\mu }\) we just note that
$$\begin{aligned} {\widehat{T}}(W) \le \frac{\mathrm{e}^{-\mu h}}{\mu } + \tau = \frac{1}{\mu }. \end{aligned}$$(79)Let \(W \ge 0\); then
$$\begin{aligned} \begin{aligned} {\widehat{T}}(W)&\ge - \tau P(x_i,z) \,\overline{a}_3 \big (1-\mu W_i\big ) + \tau \\&= \tau \big ( 1 - P(x_i,z) \,\overline{a}_3 \big (1-\mu W_i\big ) \big ). \end{aligned} \end{aligned}$$(80)This implies that \({\widehat{T}}(W) \ge 0\) if \( P(x_i,z) \,\overline{a}_3 \le 1\) since \(0 \le 1-\mu W_i\le 1\).
-
2.
In order to prove that \({\widehat{T}}\) is monotone, let us observe first that for each couple of functions \(w_1\) and \(w_2\) such that \(w_1(x)\le w_2(x)\) for every \(x\in \varOmega \) implies
$$\begin{aligned}&\mathrm{e}^{-\mu h} \Big [ w_1\big (x + h b(x,a^*)\big ) - w_2\big (x + h b(x,\overline{a})\big ) \Big ] \nonumber \\&\quad - \,\tau P(x,z) ( a^*_3 (1-\mu w_1(x)) - \overline{a}_3 (1-\mu w_2(x)) ) \nonumber \\&\le \mathrm{e}^{-\mu h} \Big [ w_1\big (x + h b(x,\overline{a})\big ) - w_2\big (x + h b(x,\overline{a})\big ) \Big ] \nonumber \\&\quad + \,\tau P(x,z) \overline{a}_3 \big (w_1(x) - w_2(x)\big ), \end{aligned}$$(81)where \(a^*\) and \(\overline{a}\) are the two arguments corresponding to the minimum on a of the expression
$$\begin{aligned} \mathrm{e}^{-\mu h} w\big (x + h b(x,a)\big ) - \tau P(x,z) a_3 \big (1-\mu w(x)\big ) \end{aligned}$$(82)respectively, for \(w=w_1,w_2\). Hence, if we take now two vectors W and \(\overline{W}\) such that \(W\le \overline{W}\) and we denote, respectively, by w and \(\overline{w}\) the corresponding functions defined by interpolation, we will have \(w(x)=I_1[W](x)\le I_1[\overline{W}](x)=\overline{w}(x)\), for every \(x\in \varOmega \), because the linear interpolation operator \(I_1\) is monotone. Then, by (71), setting \(x_i^+=x_i + h b(x_i,\overline{a})\) we get
$$\begin{aligned}&{\widehat{T}}_i(W) - {\widehat{T}}_i(\overline{W}) \le \mathrm{e}^{-\mu h} \big [ I_1[W](x_i^+)) - I_1\big [\overline{W}\big ]\big (x_i^+)\big ) \nonumber \big ]\\&\quad + \, \tau P\big (x_i,z\big ) \overline{a}_3 \big (W_i - \overline{W}_i\big )\le 0, \end{aligned}$$(83)where the last inequality follows from \(P\ge 0\). So we can conclude that \({\widehat{T}}(W)-{\widehat{T}}(\overline{W})\le 0\). Note that this property does not require condition (78) to be satisfied.
-
3.
Let us consider now two vectors W and \(\overline{W}\) (dropping the condition \(W\le \overline{W}\)) and assuming
$$\begin{aligned} P(x_i,z) \overline{a}_3 < \mu . \end{aligned}$$(84)To prove that T is a contraction mapping note that following the same argument used to prove the second statement we can obtain (83). Then, by applying the definition of \(I_1\), we get
$$\begin{aligned} {\widehat{T}}(W) -{\widehat{T}}(\overline{W}) \le \left( \mathrm{e}^{-\mu h} + \tau P\big (x_i,z\big ) \overline{a}_3 \right) ||W- \overline{W} ||_{\infty }. \end{aligned}$$Reversing the role of W and \(\overline{W}\), one can also obtain
$$\begin{aligned} {\widehat{T}}(\overline{W}) - {\widehat{T}}(W) \le \left( \mathrm{e}^{-\mu h} + \tau P\big (x_i,z\big ) \overline{a}_3 \right) ||W- \overline{W}||_{\infty } \end{aligned}$$and conclude then that \({\widehat{T}}\) is a contraction mapping in \(L^\infty \) if and only if
$$\begin{aligned} \mathrm{e}^{-\mu h} + \tau P\big (x_i,z\big ) \overline{a}_3 < 1 \end{aligned}$$(85)and this holds true if the bound (84) is satisfied.
\(\square \)
Remark on the role of \(\mu \) The parameter \(\mu \) can be tuned to satisfy the inequality which guarantees the contraction map property for \({\widehat{T}}\). This parameter adds a degree of freedom in the Kružkov change of variable and modifies the slope of v. However, in the practical applications we have done in our tests, this parameter has been always set to 1 so in our experience this parameter does not seem to require a fine tuning.
Remark on the choice of the interpolation operator Although \( I_1\) can be replaced by a high-order interpolation operator (e.g., a cubic local Lagrange interpolation), the monotonicity of the interpolation operator plays a crucial role in the proof because we have to guarantee that the extrema of interpolation polynomial stay bounded by the minimum and maximum of the values at the nodes. This property is not satisfied by quadratic or cubic local interpolation operators and the result is that this choice introduces spurious oscillations in the numerical approximation. A cure could be to adopt Essentially Non-Oscillatory (ENO) interpolations. A detailed discussion on this point is contained in [21].
Remark on the minimization. In the definition of the fixed point operator \({\widehat{T}}\) there is a minimization over \(a\in \partial B_3\). A simple way to solve it is to build a discretization of \(\partial B_3\) based on a finite number of points and get the minimum by comparison. One way to do it is to discretize the unit sphere by spherical coordinates, even a small number of nodes will be sufficient to get convergence. A detailed discussion on other methods to solve the minimization problem is contained in [21].
Let us consider now the algorithm based on the fixed point iteration

We can state the following convergence result
Theorem 2
Let \(W^k\) be the sequence generated by (86). Then the following results hold:
-
1.
Let \(W^0\in \mathcal {S}=\{W\in \mathbb {R}^G: W\ge {\widehat{T}}(W)\}\), then the \(W^k\) converges monotonically decreasing to a fixed point \(W^*\) of the \({\widehat{T}}\) operator;
-
2.
Let us choose \(\mu >0\) so that the condition \(P(x_i,z) \overline{a}_3 \le \mu \) is satisfied. Then, \(W^k\) converges to the unique fixed point \(W^*\) of the \({\widehat{T}}\). Moreover, if \(W^0\in \mathcal {S}\) the convergence is monotone decreasing.
Proof
-
1.
Starting from a point in the set of super-solutions \(\mathcal {S}\), the sequence is non-increasing and lives in \(\mathcal {S}\) which is a closed set bounded from below (by 0). Then, \(W^k\) converges and the limit is necessarily a fixed point for \({\widehat{T}}\).
-
2.
The assumptions guaranteed by Theorem 1 are satisfied and \({\widehat{T}}\) is a contraction mapping in \([0,1/\mu ]\), so the fixed point is unique. The monotonicity of \({\widehat{T}}\) implies that starting from \(W^0\in \mathcal {S}\) the convergence is monotone decreasing.
\(\square \)
It is important to note that the change of variable allows for an easy choice of the initial guess \(W^0\in \mathcal {S}\) for which we have the natural choice \(W^0=(1/\mu , 1/\mu , \dots , 1/\mu )\) and monotonicity can be rather useful to accelerate convergence as shown in [20]. A different way to improve convergence is to apply Fast Sweeping or Fast Marching methods as illustrated in [71, 73]. A crucial role is played by boundary conditions on the boundary of \(\varOmega \), where usually we impose the homogeneous Dirichlet boundary condition, \(v=0\). This condition implies that the shadows must not cross the boundary of \(\varOmega \), so the choice \(\omega _3 = 0\) corresponding to an infinite shadow behind the surface is not admissible. However, other choices are possible: to impose the height of the surface on \(\partial \varOmega \) we can set \(v=g\) or to use a more neutral boundary condition we can impose \(v=1\) (state constraint boundary condition). More informations on the use of boundary conditions for these type of problems can be found in [21].
6.1 Properties of the Discrete Operators \({\widehat{T}}^{ON}\) and \({\widehat{T}}^{PH}\)
We consider a semi-Lagrangian (SL) discretization of (42) written in a fixed point form, so we will write the SL fully discrete scheme for the ON-model as
where ON is the acronym identifying the ON-model. Using the same notations of the previous section, the operator corresponding to the oblique light source is \({\widehat{T}}^{ON}:\mathbb {R}^G\rightarrow \mathbb {R}^G\) that with linear interpolation can be written as
where
Note that, in general, \(P^{ON}\) will not be positive but that condition can be obtained tuning the parameter \(\sigma \) since the coefficients A and B depend on \(\sigma \). This explains why in some tests we will not be able to get convergence for every value of \(\sigma \in [0, \pi /2)\). Once the non-negativity of \(P^{ON}\) is guaranteed, we can follow the same arguments of Theorem 1 to check that the discrete operator \({\widehat{T}}^{ON}\) satisfies the three properties which are necessary to guarantee convergence as in Theorem 2 provided we set \(P=P^{ON}\) in that statement.
For the Phong model, the semi-Lagrangian discretization of (57) written in a fixed point form gives
where \({\widehat{T}}^{PH}:\mathbb {R}^G\rightarrow \mathbb {R}^G\), that is defined componentwise by
where, in the case of oblique light source and vertical position of the observer,
Here the model has less parameters and \(P^{PH}\) will always be non-negative. Again, following the same arguments of Theorem 1, we can check that the discrete operator \({\widehat{T}}^{PH}\) satisfies the three properties which are necessary to guarantee convergence as in Theorem 2 provided we set \(P=P^{PH}\) in that statement.
7 Numerical Simulations
In this section, we show some numerical experiments on synthetic and real images in order to analyze the behavior of the parameters involved in the ON-model and the PH-model and to compare the performances of these models with respect to the classical L-model and with other numerical methods too. All the numerical tests in this section have been implemented in language C++. The computer used for the simulations is a MacBook Pro \(13^\prime \) Intel Core 2 Duo with speed of 2.66 GHz and 4 GB of RAM (so the CPU times in the tables refer to this specific architecture).
We denote by \(\mathcal {G}\) the discrete grid in the plane getting back to the double index notation \(x_{ij}\), \(G:=card(\mathcal {G})=n\times m\). We define \(G_{in} := \{x_{ij} : x_{ij} \in \varOmega \}\) as the set of grid points inside \(\varOmega \); \(G_{out} := G\setminus G_{in}\). The boundary \(\partial \varOmega \) will be then approximated by the nodes such that at least one of the neighboring points belongs to \(G_{in}\). For each image we define a map, called mask, representing the pixels \(x_{ij} \in G_{in}\) in white and the pixels \(x_{ij} \in G_{out}\) in black. In this way it is easy to distinguish the nodes that we have to use for the reconstruction (the nodes inside \(\varOmega \)) and the nodes on the boundary \(\partial \varOmega \) (see e.g., Fig. 6b).
Regarding the minimization over \(a\in \partial B_3\) that appears in the definition of the fixed point operators associated to the models, in all the tests we discretize the unit sphere by spherical coordinates, considering 12 steps in \(\theta \) and 8 in \(\phi \), where \(\theta \) is the zenith angle and \(\phi \) is the azimuth angle.
7.1 Synthetic Tests
If not otherwise specified, all the synthetic images are defined on the same rectangular domain containing the support of the image, \(\varOmega \equiv [-1,1]\times [-1,1]\). We can easily modify the number of the pixels choosing different values for the steps in space \(\varDelta \,x\) and \(\varDelta \,y\). The size used for the synthetic images is \(256\times 256\) pixels, unless otherwise specified. X and Y represent the real size (e.g., for \(\varOmega \equiv [-1,1]\times [-1,1]\), \(X=2, Y=2\)). For all the synthetic tests, since we know the algebraic expression of the surfaces, the input image rendering in gray levels is obtained using the corresponding reflectance model. This means that for each model and each value of parameter involved in it, the reconstruction will start from a different input image. Clearly, this is not possible for real images, so for these tests the input image will be always the same for all the models, independently of the values of the parameters. Moreover, we fix \(\mu = 1\) and we choose the value of the tolerance \(\eta \) for the iterative process equal to \(10^{-8}\) for the tests on synthetic images, using as stopping rule \(|W^{k+1} - W^k|_{max} \le \eta \), where \(k+1\) denotes the current iteration. We will see that dealing with real images, sometimes we will need to increase \(\eta \).
Test 1: Sphere For this first test we will use the semisphere defined as
where
and \(\tilde{\delta } := \max \lbrace \varDelta {}x,\varDelta {}y\rbrace \).

Sphere via the L-model. a Input image; b mask; c surface
As example, we can see in Fig. 6 the input image, the corresponding mask and the surface reconstructed by the L-model. The values of the parameters used in the simulations are indicated in Table 1. Note (in Table 2) that when the specular component is zero for the PH-model, we just have the contribution of the diffuse component so we have exactly the same error values of the L-model, as expected. By increasing the value of the coefficient \(k_S\) and, as a consequence, decreasing the value of \(k_D\), in the PH-model the \(L^2(I)\) and \(L^\infty (I)\) errors on the image grow albeit slightly and still remain of the same order of magnitude, whereas the errors on the surface decrease. For the ON-model, the same phenomenon appears when we set the roughness parameter \(\sigma \) to zero: we bring back to the L-model and, hence, we obtain the same errors on the image and the surface. Note that the errors in \(L^2(I)\) and \(L^\infty (I)\) norm for the image and the surface, decrease by increasing the value of \(\sigma \). This seem to imply that the model and the approximation work better for increasing roughness values.
We point out that the errors computed on the images I in the different norms are over integer between the input image and the image computed a posteriori using the value of u just obtained by the methods. This is why small errors become bigger since can jump from an integer to the other one, as for the Phong case.
In Table 3, we reported the number of iterations and the CPU time (in seconds) referred to the three models with the parameter indicated in Table 1. For all the models, also varying the parameters involved, the number of iterations is always about 2000 e the CPU time slightly greater than 2 seconds, so the computation is really fast.
Test 2: Ridge tent In tests on synthetic images, the relevance of the choice of a model depends on which model was used to compute the images. In the previous test, the parameters that are used for the 3D reconstruction are identical to those used to compute the synthetic sphere input images, so there is a perfect match. However, for real applications, it is relevant to examine the influence of an error in the parameter values. To this end we can produce an input image with the Oren–Nayar model using \(\sigma = 0.1\) and then process this image with the same model using a different value of \(\sigma \) to see how the results are affected by this error. This is what we are going to do for the ridge tent. Let us consider the ridge tent defined by the following equation

where
In Fig. 7 we can see an example of reconstruction obtained by using the ON-model with \(\sigma = 0.3\), under a vertical light source \(\varvec{\omega }= (0,0,1)\). A first remark is that the surface reconstruction is good even if in this case the surface is not differentiable. Moreover, note that there are no oscillations near the kinks where there is jump in the gradient direction. Let us examine the stability with respect to the parameters. We have produced seven input images for the ridge tent, all of size \(256\times {}256\), with the following combinations of models and parameters:
-
LAM Lambertian model;
-
ON1 Oren–Nayar model with \(\sigma =0.1\);
-
ON3 Oren–Nayar model with \(\sigma =0.3\);
-
ON5 Oren–Nayar model with \(\sigma =0.5\);
-
PH1 Phong model with \(\alpha =1\) and \(k_S=0.1\);
-
PH3 Phong model with \(\alpha =1\) and \(k_S=0.3\);
-
PH5 Phong model with \(\alpha =1\) and \(k_S=0.5\).
Then we have computed the surfaces corresponding to all the parameter choices (i.e., matching and not matching the first choice). The results obtained in this way have been compared in terms of \(L^2\) and \(L^\infty \) norm errors with respect to the original surface. The errors obtained by the ON-model are shown in Tables 4 and 5 for the PH-model.

Tent via the ON-model with \(\sigma = 0.3\): a Input image; b 3D reconstruction
Analyzing the errors in Tables 4 and 5, we can observe that using the same model to generate the input image and to reconstruct the surface is clearly the optimal choice. The errors on the surface grow more as we consider a parameter \(\sigma \) other than the one used to generate the input image as data for the 3D reconstruction. For the ON-model we loose one or two order of magnitude, depending on the “distance” of the parameter from the source model. For the PH-model we can observe that the \(L^2\) and \(L^\infty \) errors grow more as we consider a different \(k_S\) for the generation of the image and for the reconstruction, loosing one or two order of magnitude. However, the two models seem to be rather stable with respect to a variation of the parameters since the errors do not increase dramatically varying the parameters.

Example of concave/convex ambiguity for the ON-model with \(\sigma = 0.5\) and \(\varvec{\omega }= (0,0,1)\). a Original Surface, b maximal solution, c approximated surface with value in the origin equal to zero
Test 3: Concave/convex ambiguity for the ON-model We consider this test in order to show that the ON-model is not able to overcome the concave/convex ambiguity typical of the SfS problem although it is a model more realistic than the classical L-model. Let us consider the following function

We discretize the domain \(\varOmega = [-1.5,1.5]\times [-1.5,1.5]\) with \(151\times 151\) nodes. The fixed point has been computed with an accuracy of \(\eta = 10^{-4}\) and the stopping rule for the algorithm based on the fixed point iteration defined in (86) is \(|W^{k+1} - W^k|_{max} \le \eta \), where \(k+1\) denotes the current iteration. The iterative process starts with \(W^0 = 0\) on the boundary and \(W^0=1\) inside in order to proceed from the boundary to the internal constructing a monotone sequence (see [7, 23] for details on the approximation of maximal solutions).
Looking at Fig. 8 we can note that the scheme chooses the maximal viscosity solution stopping after 105 iterations, which does not coincide with the original surface. In order to obtain a reconstruction closer to the original surface, we fix the value in the origin at zero. In this way we forced the scheme to converge to a solution different from the maximal solution (see Fig. 8c). We obtained this different solution shown in Fig. 8c after 82 iterations.
Test 4: Concave/convex ambiguity for the PH-model The fourth synthetic numerical experiment is related to the sinusoidal function defined as follows:
With this test we want to show that also the PH-model is not able to overcome the concave/convex ambiguity typical of the SfS problem.

Synthetic sinusoidal function: example of concave/convex ambiguity for the PH-model with \(k_S = 0,0.5,0.8\) for each row from the top to the bottom, respectively
Figure 9 shows the results related to the PH-model with \(k_S = 0, 0.5, 0.8\). In the first column one can see the input images generated by the PH-model using the values of the parameter before mentioned. In the second column we can see the output images computed a posteriori using the depth just computed and approximating the gradient via finite difference solver. What we can note is that even if the reconstructed a posteriori images match with the corresponding input images, the SL method always chooses the maximal solution even varying the parameters \(k_D\) and \(k_S\). By adding some informations as shown in the previous test it is possible to achieve a better result, but these additional informations are not available for real images.
Test 5: Role of the boundary conditions With this fifth test we want to point out the role of the boundary condition (BC), showing how good BC can significantly improve the results on the 3D reconstruction. We will use the synthetic vase defined as follows:
where \(\bar{y} := y/Y\),
and
In Fig. 10, one can see on the first row the input images (size \(256\times 256\)) generated by the L-model, ON-model, and the PH-model, from left to right, respectively. On the second row we reported the 3D reconstruction with homogeneous Dirichlet BC (\(g(x,y)=0\)). As we can see, there is a concave/convex ambiguity in the reconstruction of the surface. If we consider the correct boundary condition, that is the height of the surface at the boundary of the silhouette that we can easily derive in this case being the object a solid of rotation, what we obtain is visible in the third row of the same Fig. 10.

Synthetic vase under vertical light source [\(\varvec{\omega }=(0,0,1)\)]: example of concave/convex ambiguity solved by using correct Dirichlet BC. On the first row from left to right: input images generated by L-model, ON-model with \(\sigma = 0.2\) and PH-model with \(k_S = 0.4\). On the second row: 3D reconstruction with homogeneous Dirichlet BC. On the last row: 3D reconstruction with Dirichlet BC \(u(x,y)= g(x,y)\)
In Tables 6 and 7 we can see the number of iterations, the CPU time and the error measures in \(L^2\) and \(L^{\infty }\) norm for the method used with homogeneous and non-homogeneous Dirichlet BC, respectively. Looking at these errors we can note that in each table the values are almost the same for the different models. Comparing the values of the two tables one can see that we earn an order of magnitude using good BC, that confirms what we noted looking at Fig. 10.
Test 6: Comparison with other numerical approximations In this sixth and last test of this subsection dedicated to synthetic tests we will compare the performance of our semi-Lagrangian approach with other methods used in the literature. For this reason, we will use a very common image used in the literature, that is the vase, defined in the previous test through the (95). More in detail, we will compare the performance of our semi-Lagrangian method with the Lax–Friedrichs Sweeping (LFS) scheme adopted by Ahmed and Farag [2] under vertical and oblique light source. Also these authors derive some similar HJ equations for the L-model in [1], and generalize this approach for various image conditions in [2], comparing their results on the only L-model with the results shown in [63] and the algorithms reported in [85]. Unfortunately, we cannot compare our semi-Lagrangian approximation for the PH-model with no other schemes since, to our knowledge, there are no table of errors for the PH-model under orthographic projection in the literature. In order to do the comparison, we will consider the vase image of size \(128\times 128\) as used in the other papers. We start to remind the error estimations used: given a vector \(\mathbf {A}\) representing the reference depth map on the grid and a vector \({\widetilde{\mathbf {A}}}\) representing its approximation, we define the error vector as \(\mathbf {e}=\mathbf {A}-{\widetilde{\mathbf {A}}}\) and
where N is the total number of grid points used for the computation, i.e., the grid points belonging to \(G_{in}\). These estimators are called mean and standard deviation of the absolute error. In Table 8, we compare the error measures for the different SfS algorithms under the L-model with \(\varvec{\omega }= (0,0,1)\). What we can note is that our semi-Lagrangian method is better than the other ones also if we consider Dirichlet boundary condition equal to zero (as used by Ahmed and Farag in their work [2]), but the better result is with correct BC, shown in bold in the last row. In Table 9, we can see the same methods applied to the L-model but under a different light source, that is (1, 0, 1). Also in this case, our approach obtains always the smallest errors and the best is with non-homogeneous Dirichlet BC, as noted before.
Only with respect to the LFS used by Ahmed and Farag, we can compare the performance of our semi-Lagrangian scheme under the ON-model as well, since the other authors only consider the L-model. In this context, we show in Table 10 the error measures for the two SfS algorithms with \(\sigma = 0.2\), under vertical position of light source and viewer [\(\varvec{\omega }= (0,0,1), \mathbf {V}= (0,0,1)\)]. As before, the best result is obtained using the semi-Lagrangian scheme with non-homogeneous Dirichlet BC. The reconstructions corresponding to the error measures shown in the three last Tables 8, 9, and 10 obtained applying our scheme and compared to [2] are shown in Fig. 11. The reconstruction obtained by the two methods are comparable. In particular, in the second column regarding the oblique light source case we can note that our scheme reconstructs a surface that incorporates the black shadow part (see [23] for more details on this technique), avoiding the effects of “dent” present in the reconstruction obtained by Ahmed and Farag visible in the last row, second column.

Synthetic vase: from top to bottom, Input images, recovered shapes by our approach with homogeneous Dirichlet BC and with non-homogeneous BC, recovered shape by [2]. First column: L-model with vertical light source (0,0,1). Second column: L-model with oblique light source (1,0,1). Third column: ON-model with \(\sigma = 0.2\), \(\varvec{\omega }= (0,0,1)\), \(\mathbf {V}= (0,0,1)\). Input images size: \(128\times 128\)
Finally, in Table 11 we reported the number of iterations and the CPU time in seconds with the comparison with respect to [2]. This shows that the SL-scheme is competitive also in terms of CPU time. Of course, in the case of oblique light source the number of iterations, and hence the CPU time needed is much more bigger. Just think that for the reconstruction under the L-model with oblique light source (1, 0, 1) and \(BC \not = 0\) visible in the second column of the third row of Fig. 11, we need 15513 iterations (CPU time: 147.40 seconds). If we double the size of the input image, considering the vase \(256\times 256\) visible in Fig. 10, for the reconstruction visible in the third row, first column of the same Fig. 10, we need 30458 iterations to get convergence, that we obtain in 1163 seconds.
Since it is difficult to compare the performance of our approach based on the PH-model with other schemes based on the same reflectance model under orthographic projection for the consideration made before, we report in Fig. 12 the performances obtained by our method based on the PH-model compared to the approximate Ward’s method on the vase test (Cf. Fig. 7 in [2]). What we can see is that both the two methods reconstruct the surface in a quite good way, without particular distinctions in the goodness of the reconstructions. In order to analyze the results not only in a qualitative way but also in a quantitative one, we report the mean and the standard deviation of the absolute errors in Table 12. Looking at this table, we can note that our approach seems to be superior, obtaining the reconstruction with errors smaller of one order with respect to the other model.

Synthetic vase: The first row shows the input image and the recovered shape by our approach with non-homogeneous BC based on the PH-model with \(k_S = 0.2\), \(\varvec{\omega }= (0,0,1)\) and \(\mathbf {V}= (0,0,1)\). The second row shows the input image and the recovered shape by the approximate Ward’s method illustrated in [2] with \(\sigma = 0.2\), \(\rho _d = 0.67\), \(\rho _s = 0.075\), \(\varvec{\omega }= (0,0,1)\), \(\mathbf {V}= (0,0,1)\). Input images size: \(128\times 128\)
7.2 Real Tests
In this subsection we consider real input images. We start considering the golden mask of Agamemnon taken from [78] and then modified in order to get a picture in gray tones. The size of the modified image really used is \(507\times 512\). The input image is visible in Fig. 13a, the associated mask used for the 3D reconstruction in Fig. 13b. The second real test is concerning the real vase (RV in the following) visible in Fig. 16, taken from [19]. The size of the input image shown in Fig. 16a is \(256\times 256\). The reconstruction domain \(\varOmega _{RV}\), shown in Fig. 16b, is constituted by the pixels situated on the vase. For the real cases, the input image is the same for all the models and we can compute only errors on the images since we do not know the height of the original surface. For the real tests we will use the same stopping criterion for the iterative method before defined for the synthetic tests, i.e., \(|W^{k+1} - W^k|_{max} \le \eta \).

Agamemnon images (size \(507\times 512\)). a Input image, b mask
Test 7: Agamennon mask For this test we will compare the results regarding 3D reconstruction of the surface obtained with a vertical light source \(\varvec{\omega }_{vert} = (0,0,1)\) and an oblique light source \(\varvec{\omega }_{obl} = (0, 0.0995, 0.9950)\). The values of the parameters used in this test are reported in Table 13. For a vertical light source, we refer to Table 14 for the number of iterations and the CPU time (in seconds) and to Table 15 for the errors obtained with a tolerance \(\eta =10^{-8}\) for the stopping rule of the iterative process. Clearly, the number of iteration and the errors of the two non-Lambertian models are the same of the classical Lambertian model when \(\sigma \) for the ON-model and \(k_S\) for the PH-model are equal to zero (and for this reason we do not report them in the tables). In all the other cases, the non-Lambertian models are faster in terms of CPU time and need a lower number of iterations with respect to the L-model.
In Table 15 we can observe that the \(L^2\) errors produced by the ON-model increase by increasing the value of \(\sigma \). However, the \(L^{\infty }\) errors are lower than the error obtained with the Lambertian model. With respect to the PH-model, all the errors increase by increasing the value of the parameter \(k_S\), as observed for synthetic images.

Agamennon mask: results with vertical light source. On the first row the output images, on the second row the 3D reconstruction with vertical view, on the third row the 3D reconstruction with oblique view
In Fig. 14, we can see the output image and the 3D reconstruction in a single case for each models. What we can note is that no big improvements we can obtain visually.
For the oblique light case, we consider the values for the parameters reported in Table 16.
Looking at Table 17 we can note that the oblique cases require higher CPU time with respect to the vertical cases due to the fact that the equations are more complex because of additional terms involved. Because of these additional terms involved in the oblique case, in Table 18 we have reported the results obtained using the parameters shown in Table 16 with a value of the tolerance \(\eta \) for the stopping rule of the iterative method equal to \(10^{-3}\). This is the maximum accuracy achieved by the non-Lambertian models since roundoff errors coming from several terms occur and limit the accuracy.
In Fig. 15, we can see the output image and the 3D reconstruction in a single case for each models. What we can note is that also using more realistic illumination models as the two non-Lambertian considered, we do not obtain a so better approximation of the ground truth solution. This is due to the missing important informations (e.g., the correct oblique light source direction, the values of the parameter involved that are known for the models but not available in the real cases) and also due to the fact that we are using a first-order method of approximation.

Agamennon mask: results with oblique light source \(\varvec{\omega }_{obl} = (0, 0.0995, 0.9950)\). On the first row the output images, on the second row the 3D reconstruction with vertical view, on the third row the 3D reconstruction with oblique view

Real vase images (size \(256\times 256\)). a Input image, b mask

Real vase: Output images and 3D reconstructions. On the first row the L-model, on the second row the ON-model with \(\sigma = 0.2\), on the third row the PH-model with \(k_S = 0.2\)
Test 8: Real vase With this test we want to investigate the stability of our method with respect to the presence of noise. In fact, looking at Fig. 16a we can consider that RV is a noisy version of the synthetic vase used in the Tests 5 and 6. The test was performed using a vertical light source \(\omega = (0,0,1)\). The output images, computed a posteriori by using the gradient of u approximated via centered finite differences starting from the values of u just computed by the numerical scheme, are visible in Fig. 17, first column. The reconstruction obtained with the three models are visible in the same Fig. 17, second column. What we can note is that all the reconstructions, obtained using homogeneous Dirichlet BC, suffer for a concave/convex ambiguity, as already noted for the synthetic vase (SV in the following). Since it is visible looking at the SV and the RV tests that we obtain results with errors of the same order of magnitude around \(10^{-2}\), considering that RV is a noisy version of SV, Table 19 shows that the method is stable in the presence of noise in the image.
Finally, in Fig. 18 one can note the behavior of the ON-model by varying the value of the parameter \(\sigma \). Since in real situations we do not know it (as other parameters like the light source direction) we can only vary it in order to see the one which gives the best fit with the image. Looking at Fig. 18 what we can observe is that increasing the value of \(\sigma \) the reconstruction shows a wider concave/convex ambiguity, which affects more pixels. But this holds only in this specific case, not in general for all the real images as a rule.

Real vase: 3D reconstructions related to the ON-model, varying \(\sigma \). From left to right \(\sigma = 0.2, 0.4, 0.6\)
Test 9: Corridor As an illustrative example, let us consider a real image of a corridor (see Fig. 19) as a typical example of a scene which can be useful for a robot navigation problem. The test has been added as an illustrative example to show that even for a real scene which does not satisfy all the assumptions and for which several informations are missing (e.g., boundary conditions) the method is able to compute a reasonable accurate reconstruction in the central part of the corridor (clearly the boundaries are wrong due to a lack of information). The size of this image is \(600\times 383\). Note that for this picture we do not know the parameters and the light direction in the scene. It seems that there is a diffused light and more than one light source. So this picture does not satisfy many assumptions we used in the theoretical part. In order to apply our numerical scheme we considered a Dirichlet boundary condition equal to zero at the wall located at the bottom of the corridor. In this way, we have a better perception of the depth of the scene. In Fig. 20 we can see the output images (on the first column) and the 3D reconstructions (on the second column) obtained by L-model, ON-model with \(\sigma = 0.1\) and PH-model with \(k_S = 0.2\). In this example, the PH-model seems to recognize the scene better than the ON-model. In some sense this is probably due to the fact that it has less parameters so it is easier to tune to a real situation where the information on the parameters is not available. We point out that this test is just an illustration of the fact that coupling SfS with additional informations (e.g., coming from distance sensors to fix boundary conditions) can be useful to describe a scene.

Image of a real scene (size \(600\times 383\))

Output images and 3D reconstructions of a scene for a robot path planning application. On the first row the L-model, on the second row the ON-model with \(\sigma = 0.1\), on the third row the PH-model with \(k_S = 0.2\)
Test 10: Other tests on real images In order to demonstrate the applicability of our proposed approach for real data, we added here other experiments conducted on a real urn, real rabbit, and real Beethoven’s bust. The input images and the related recovered shapes obtained by the three models studied under different light directions and parameters are shown in Fig. 21. As visible from Fig. 21, the results are quite good, even for pictures like the rabbit or the bust of Beethoven, which have many details, even if they still suffer for the concave/convex ambiguity typical of the SfS problem.

Experiments on real images: input images and the recovered shapes obtained by our approach. On the first row: urn reconstructed by the L-model with \(\varvec{\omega }= (0,0,1)\). On the second row: rabbit reconstructed by the ON-model with \(\sigma = 0.2\), \(\varvec{\omega }= (0,0,1)\), \(\mathbf {V}= (0,0,1)\). On the third row: Beethoven reconstructed by the PH-model with \(\varvec{\omega }= (0.0168, 0.198, 0.9801)\), \(k_S = 0.2\)
8 Conclusions
In this paper, we derived non-linear PDEs of first order, i.e., Hamilton–Jacobi equations, associated to the non-Lambertian reflectance models ON-model and PH-model. We have obtained the model equations for all the possible cases, coupling vertical or oblique light source with vertical or oblique position of the observer. This exhaustive description has shown that these models lead to stationary Hamilton–Jacobi equations with a same structure and this allows for a unified mathematical formulation in terms of fixed point problem. This general formulation is interesting because we can switch on and off the different terms related to ambient, diffuse, and specular reflection in a very simple way. As a result, this general model is very flexible to treat the various situations with vertical and oblique light sources. Unfortunately, we have observed that none of these models is able to overcome the typical concave/convex ambiguity known for the classical Lambertian model. Despite these limitations, the approach presented in this paper is able to improve the Lambertian model that is not suitable to deal with realistic images coming from medical or security application. The numerical methods presented here can be applied to solve the equations corresponding to the ON-model and the PH-model in all the situations although they suffer for the presence of several parameters related to the roughness or to the specular effect. Nonetheless, looking at the comparisons with other methods or models shown in this paper, one can see that the semi-Lagrangian approach is competitive with respect to other techniques used, both in terms of CPU time and accuracy. As we have seen, in the complex non-linear PDEs associated to non-Lambertian models the parameters play a crucial role to obtain accurate results. In fact, varying the value of the parameters it is possible to improve the approximation with respect to the classical L-model. We can also say that for real images the PH-model seems easier to tune, perhaps because we need to manage less parameters.
Focusing the attention on the tests performed with an oblique light source, we have to do some comments that are common to the PH-model and the ON-model. Several terms appear in these models and each of them gives a contribution to the roundoff error. Note that the accumulation of these roundoff errors makes difficult in the oblique case to obtain a great accuracy. A possible improvement could be the use of second order schemes, that release the link between the space and the time steps which characterizes and limits the accuracy for first-order schemes. Another interesting direction would be to extend this formulation to other reflectance models (like e.g., the Ward’s model) and/or to consider perspective projection also including an attenuation term which can help to resolve the concave/convex ambiguity or considering more than one input image with non-Lambertian models, that solves the well-known ambiguity (see [74] for a first step in this last direction considering the Blinn–Phong model). These directions will be explored in future works.
References
Ahmed, A., Farag, A.: A new formulation for shape from shading for non-Lambertian surfaces. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1817–1824 (2006)
Ahmed, A.H., Farag, A.A.: Shape from Shading under various imaging conditions. In: IEEE International Conference on Computer Vision and Pattern Recognition CVPR’07, pp. X1–X8. Minneapolis (2007)
Bakshi, S., Yang, Y.H.: Shape-from-Shading for non-Lambertian surfaces. In: Proceedings of IEEE International Conference on Image Processing (ICIP), pp. 130–134 (1994)
Barles, G.: Solutions de viscosité des équations de Hamilton-Jacobi. Springer, Berlin (1994)
Biswas, S., Aggarwal, G., Chellappa, R.: Robust estimation of albedo for illumination-invariant matching and shape recovery. IEEE Trans. Pattern Anal. Mach. Intell. 31(5), 884–899 (2009)
Brooks, M., Chojnacki, W., Kozera, R.: Impossible and ambiguous shading patterns. Int. J. Comput. Vis. 7(2), 119–126 (1992)
Brooks, M., Horn, B.: Shape and source from shading. In: Proceedings of the Ninth International Joint Conference on Artificial Intelligence (vol. II), pp. 932–936. Los Angeles (1985)
Bruss, A.: The image irradiance equation: Its solution and application. Technical report ai-tr-623, Massachusetts Institute of Technology (1981)
Camilli, F., Falcone, M.: An approximation scheme for the maximal solution of the shape from shading model. In: Proceedings of the IEEE International Conference on Image Processing (vol. I), vol. 1, pp. 49–52. Lausanne (1996). doi:10.1109/ICIP.1996.559430
Camilli, F., Grüne, L.: Numerical approximation of the maximal solutions for a class of degenerate Hamilton-Jacobi equations. SIAM J. Numer. Anal. 38(5), 1540–1560 (2000)
Camilli, F., Siconolfi, A.: Maximal subsolutions of a class of degenerate Hamilton-Jacobi problems. Indiana Univ. Math. J. 48(3), 1111–1131 (1999)
Carlini, E., Falcone, M., Festa, A.: A brief survey on semi-lagrangian schemes for image processing. In: M. Breuss, A. Bruckstein, P. Maragos (eds.) Innovations for Shape Analysis: Models and Algorithms, pp. 191–218. Springer (2013). ISBN: 978-3-642-34140-3
Chambolle, A.: A uniqueness result in the theory of stereo vision: coupling shape from shading and binocular information allows unambiguous depth reconstruction. Ann. l’Ist. Henri Poincarè 11(1), 1–16 (1994)
Courteille, F., Crouzil, A., Durou, J.D., Gurdjos, P.: Towards shape from Shading under realistic photographic conditions. In: Proceedings of the 17th International Conference on Pattern Recognition, vol. 2, pp. 277–280. Cambridge (2004)
Courteille, F., Crouzil, A., Durou, J.D., Gurdjos, P.: Shape from shading for the digitization of curved documents. Mach. Vis. Appl. 18(5), 301–316 (2007)
Daniel, P., Durou, J.D.: From deterministic to stochastic methods for shape from shading. In: Proceedings of the Fourth Asian Conference on Computer Vision, pp. 187–192. Taipei, Taiwan (2000)
Diggelen, J.V.: A photometric investigation of the slopes and heights of the ranges of hills in the maria of the moon. Bull. Astron. Inst. Neth. 11(423), 283–290 (1951)
Durou, J.D., Aujol, J.F., Courteille, F.: Integrating the normal field of a surface in the presence of discontinuities. Energy Minim. Methods Comput. Vis. Pattern Recogn. (EMMCVPR) 5681, 261–273 (2009)
Durou, J.D., Falcone, M., Sagona, M.: Numerical methods for shape from shading: a new survey with benchmarks. Comput. Vis. Image Underst. 109(1), 22–43 (2008)
Falcone, M.: Numerical solution of dynamic programming equations. In Bardi, M., Dolcetta, I.C., Optimal Control and Viscosity Solutions of Hamilton-Jacobi-Bellman Equations, pp. 471–504 (1997)
Falcone, M., Ferretti, R.: Semi-Lagrangian approximation schemes for linear and hamilton-jacobi equations. SIAM (2014)
Falcone, M., Sagona, M.: An algorithm for the global solution of the shape from shading model. In: Proceedings of the Ninth International Conference on Image Analysis and Processing (vol. I), vol. 1310 of Lecture Notes in Computer Science, pp. 596–603. Florence (1997)
Falcone, M., Sagona, M., Seghini, A.: A scheme for the shape–from–shading model with “black shadows”. Numer. Math. Adv. Appl. 503–512 (2003)
Fassold, H., Danzl, R., Schindler, K., Bischof, H.: Reconstruction of archaeological finds using shape from stereo and shape from shading. In: Proceedings of the 9th Computer Vision Winter Workshop. Piran, pp. 21–30 (2004)
Favaro, P., Papadhimitri, T.: A closed-form solution to uncalibrated photometric stereo via diffuse maxima. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 821–828 (2012)
Frankot, R., Chellappa, R.: A method for enforcing integrability in shape from shading algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 10(4), 439–451 (1988)
Grumpe, A., Belkhir, F., Wöhler, C.: Construction of lunar DEMs based on reflectance modelling. Adv. Sp. Res. 53(12), 1735–1767 (2014)
Horn, B.: Shape from shading: a method for obtaining the shape of a smooth opaque object from one view. Ph.D. Thesis, Massachusetts Institute of Technology (1970)
Horn, B.: Obtaining shape from shading information. In: Winston, P.H. (ed.) The Psychology of Computer Vision, vol. 4, pp. 115–155. McGraw-Hill, New York (1975)
Horn, B., Brooks, M.: The variational approach to shape from shading. Comput. Vis. Graph. Image Process. 33(2), 174–208 (1986)
Horn, B., Brooks, M.: Shape from Shading (Artificial Intelligence). The MIT Press, Cambridge (1989)
Ikeuchi, K., Horn, B.K.: Numerical shape from shading and occluding boundaries. Artif. Intell. 17(1–3), 141–184 (1981)
Ishii, H., Ramaswamy, M.: Uniqueness results for a class of Hamilton–Jacobi equations with singular coefficients. Commun. Partial Differ. Equ. 20, 2187–2213 (1995)
Ju, Y., Breuß, M., Bruhn, A., Galliani, S.: Shape from shading for rough surfaces: analysis of the Oren-Nayar model. In: Proceedings of the British Machine Vision Conference (BMVC), pp. 104.1–104.11. BMVA Press (2012). doi:10.5244/C.26.104
Ju, Y., Tozza, S., Breuß, M., Bruhn, A., Kleefeld, A.: Generalised perspective shape from shading with Oren-Nayar reflectance. In: Proceedings of the 24th British Machine Vision Conference (BMVC 2013), pp. 42.1–42.11. BMVA Press, Bristol (2013)
Kain, J., Ostrov, D.: Numerical shape from shading for discontinuous photographic images. Int. J. Comput. Vis. 44(3), 163–173 (2001)
Kozera, R.: Existence and uniqueness in photometric stereo. Appl. Math. Comput. 44(1), 103 (1991)
Kozera, R.: Uniqueness in shape from shading revisited. J. Math. Imaging Vis. 7(2), 123–138 (1997)
Kruzkov, S.N.: The generalized solution of the hamilton-jacobi equations of eikonal type i. Math. USSR Sbornik 27, 406–446 (1975)
Lions, P., Rouy, E., Tourin, A.: Shape-from-shading, viscosity solutions and edges. Numer. Math. 64(3), 323–353 (1993)
Lohse, V., Heipke, C., Kirk, R.L.: Derivation of planetary topography using multi-image shape-from-shading. Planetary Sp. Sci. 54(7), 661–674 (2006)
Mecca, R., Falcone, M.: Uniqueness and approximation of a photometric shape-from-shading model. SIAM J. Imaging Sci. 6(1), 616–659 (2013)
Mecca, R., Tozza, S.: Shape reconstruction of symmetric surfaces using photometric stereo. In: M. Breuss, A. Bruckstein, P. Maragos (eds.) Innovations for Shape Analysis: Models and Algorithms, pp. 219–243. Springer (2013). ISBN: 978-3-642-34140-3
Okatani, T., Deguchi, K.: Shape reconstruction from an endoscope image by shape from shading technique for a point light source at the projection center. Comput. Vis. Image Underst. 66(2), 119–131 (1997)
Oliensis, J.: Shape from shading as a partially well-constrained problem. Comput. Vis. Graph. Image Process. 54(2), 163–183 (1991)
Oliensis, J.: Uniqueness in shape from shading. Int. J. Comput. Vis. 6(2), 75–104 (1991)
Oren, M., Nayar, S.: Diffuse reflectance from rough surfaces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 763–764 (1993)
Oren, M., Nayar, S.: Generalization of Lambert’s reflectance model. In: Proceedings of the International Conference and Exhibition on Computer Graphics and Interactive Techniques (SIGGRAPH), pp. 239–246 (1994)
Oren, M., Nayar, S.: Seeing beyond Lambert’s law. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 269–280 (1994)
Oren, M., Nayar, S.: Generalization of the Lambertian model and implications for machine vision. Int. J. Comput. Vis. 14(3), 227–251 (1995)
Phong, B.T.: Illumination for computer generated pictures. Commun. ACM 18(6), 311–317 (1975)
Prados, E., Camilli, F., Faugeras, O.: A viscosity solution method for shape-from-shading without image boundary data. ESAIM Math. Model. Numer. Anal. 40(2), 393–412 (2006)
Prados, E., Faugeras, O.: A mathematical and algorithmic study of the lambertian sfs problem for orthographic and pinhole cameras. Rapport de recherche 5005, Institut National de Recherche en Informatique et en Automatique, Sophia Antipolis (2003)
Prados, E., Faugeras, O.: Perspective shape from shading and viscosity solutions. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 826–831 (2003)
Prados, E., Faugeras, O.: Shape from shading: a well-posed problem? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, pp. 870–877 (2005)
Prados, E., Faugeras, O., Rouy, E.: Shape from shading andviscosity solutions. In: A. Heyden, G. Sparr, M. Nielsen,P. Johansen (eds.) Computer Vision, ECCV 2002, Lecture Notes in Computer Science, vol. 2351, pp. 790–804. Springer, Berlin/Heidelberg (2002)
Quéau, Y., Lauze, F., Durou, J.: Solving uncalibrated photometric stereo using total variation. J. Math. Imaging Vis. 52(1), 87–107 (2015)
Ragheb, H., Hancock, E.: Surface normals and height from non-lambertian image data. In: Proceedings of the International Symposium on 3D Data Processing, Visualization and Transmission (3DPVT), pp. 18–25 (2004)
Ragheb, H., Hancock, E.: Surface radiance correction for shape from shading. Pattern Recogn. 38(10), 1574–1595 (2005)
Rindfleisch, T.: Photometric method for lunar topography. Photogramm. Eng. 32(2), 262–277 (1966)
Rouy, E., Tourin, A.: A viscosity solutions approach to shape-from-shading. SIAM J. Numer. Anal. 29(3), 867–884 (1992)
Sagona, M.: Numerical methods for degenerate eikonal type equations and applications. Ph.D. thesis, Dipartimento di Matematica dell‘Università di Napoli Federico II, Napoli (2001)
Samaras, D., Metaxas, D.: Incorporating illumination constraints in deformable models for shape from shading and light direction estimation. IEEE Trans. Pattern Anal. Mach. Intell. 25(2), 247–264 (2003)
Smith, W., Hancock, E.: Recovering facial shape and albedo using a statistical model of surface normal direction. In: 10th IEEE International Conference on Computer Vision (ICCV 2005), 2005, Beijing, pp. 588–595 (2005)
Smith, W., Hancock, E.: Estimating facial albedo from a single image. IJPRAI 20(6), 955–970 (2006)
Steffen, W., Koning, N., Wenger, S., Morisset, C., Magnor, M.: Shape: a 3d modeling tool for astrophysics. IEEE Trans. Visual. Comput. Graph. 17(4), 454–465 (2011)
Strat, T.: A numerical method for shape from shading from a single image. Master’s thesis, Department of Electrical Engineering and Computer Science, Massachussetts Institute of Technology, Cambridge (1979)
Szeliski, R.: Fast shape from shading. Comput. Vis. Graph. Image Process. 53(2), 129–153 (1991)
Tankus, A., Kiryati, N.: Photometric stereo under perspective projection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), vol. 1, pp. 611–616 (2005)
Tankus, A., Sochen, N., Yeshurun, Y.: Shape-from-shading under perspective projection. Int. J. Comput. Vis. 63(1), 21–43 (2005)
Tozza, S.: Analysis and approximation of non-Lambertian shape-from-shading models. Ph.D. thesis, Dipartimento di Matematica, Sapienza - Universitá di Roma, Rome (2015)
Tozza, S., Falcone, M.: A semi-Lagrangian approximation of the Oren-Nayar PDE for the orthographic shape-from-shading problem. In: S. Battiato, J. Braz (eds.) Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP), vol. 3, pp. 711–716. SciTePress (2014)
Tozza, S., Falcone, M.: A comparison of non-lambertian models for the shape-from-shading problem. In: M. Breuss, A. Bruckstein, P. Maragos, S. Wuhrer (eds.) New Perspectives in Shape Analysis. Springer (2015)
Tozza, S., Mecca, R., Duocastella, M., Bue, A.D.: Direct differential photometric-stereo shape recovery of diffuse and specular surfaces. J. Math. Imaging Vis. (JMIV) (2016). doi:10.1007/s10851-016-0633-0
Vogel, O., Breuß, M., Leichtweis, T., Weickert, J.: Fast shape from shading for phong-type surfaces. In: X.C. Tai, K. Mørken, M. Lysaker, K.A. Lie (eds.) Scale Space and Variational Methods in Computer Vision, Lecture Notes in Computer Science, vol. 5567, pp. 733–744. Springer (2009)
Vogel, O., Breuß, M., Weickert, J.: Perspective shape from shading with non-Lambertian reflectance. In: Proceedings of the DAGM Symposium on Pattern Recognition, pp. 517–526 (2008)
Vogel, O., Valgaerts, L., Breuß, M., Weickert, J.: Making shape from shading work for real-world images. In: J. Denzler, G. Notni,H. Süße (eds.) Pattern Recognition, Lecture Notes in Computer Science, vol. 5748, pp. 191–200. Springer, Berlin/Heidelberg (2009)
Wikipedia: Mask of Agamemnon. http://en.wikipedia.org/wiki/Mask_of_Agamemnon
Wolff, L.: Diffuse-reflectance model for smooth dielectric surfaces. J. Opt. Soc. Am. A 11(11), 2956–2968 (1994)
Wolff, L.B., Nayar, S.K., Oren, M.: Improved diffuse reflection models for computer vision. Int. J. Comput. Vis. 30(1), 55–71 (1998)
Woodham, R.J.: Photometric method for determining surface orientation from multiple images. Opt. Eng. 19(1), 134–144 (1980)
Worthington, P., Hancock, E.: New constraints on data-closeness and needle map consistency for shape-from-shading. IEEE Trans. Pattern Anal. Mach. Intell. 21(12), 1250–1267 (1999)
Wu, C., Narasimhan, S., Jaramaz, B.: A multi-image shape-from-shading framework for near-lighting perspective endoscopes. Int. J. Comput. Vis. 86, 211–228 (2010)
Yoon, K.J., Prados, E., Sturm, P.: Joint estimation of shape and reflectance using multiple images with known illumination conditions. Int. J. Comput. Vis. 86, 192–210 (2010)
Zhang, R., Tsai, P.S., Cryer, J., Shah, M.: Shape from shading: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 21(8), 690–706 (1999)
Zheng, Q., Chellappa, R.: Estimation of illuminant direction, albedo, and shape from shading. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1991. Proceedings CVPR ’91. pp. 540–545 (1991)
Acknowledgments
The first author wishes to acknowledge the support obtained by the INDAM under the GNCS research project “Metodi ad alta risoluzione per problemi evolutivi fortemente nonlineari” and the hospitality obtained by Prof. Edwin Hancock of the University of York, Department of Computer Science, during her scholarship “Borsa di perfezionamento all’estero” paid by Sapienza—Università di Roma.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Tozza, S., Falcone, M. Analysis and Approximation of Some Shape-from-Shading Models for Non-Lambertian Surfaces. J Math Imaging Vis 55, 153–178 (2016). https://doi.org/10.1007/s10851-016-0636-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-016-0636-x