
Abstract
In this paper we establish the convergence of a general primal–dual method for nonsmooth convex optimization problems whose structure is typical in the imaging framework, as, for example, in the Total Variation image restoration problems. When the steplength parameters are a priori selected sequences, the convergence of the scheme is proved by showing that it can be considered as an ε-subgradient method on the primal formulation of the variational problem. Our scheme includes as special case the method recently proposed by Zhu and Chan for Total Variation image restoration from data degraded by Gaussian noise. Furthermore, the convergence hypotheses enable us to apply the same scheme also to other restoration problems, as the denoising and deblurring of images corrupted by Poisson noise, where the data fidelity function is defined as the generalized Kullback–Leibler divergence or the edge preserving removal of impulse noise. The numerical experience shows that the proposed scheme with a suitable choice of the steplength sequences performs well with respect to state-of-the-art methods, especially for Poisson denoising problems, and it exhibits fast initial and asymptotic convergence.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Image restoration is an inverse problem that consists in finding an approximation of the original object \(\tilde{x}\in R^{n}\) from a set g∈R m of detected data. In a discrete framework, we assume that each component of the data g i is the realization of a random variable whose mean is \((H\tilde{x} + b)_{i}\), where H∈R m×n represents the distortion due to the acquisition system and b∈ℝm is a nonnegative constant background term. We assume that H is known and, in particular, when H=I we have a denoising problem while, in the other cases, we deal with a deblurring problem.
In the Bayesian framework [17, 27], an approximation of the original object \(\tilde{x}\) is obtained by solving a minimization problem where the objective function is the combination of two terms: the first one is a nonnegative functional measuring the data discrepancy, to be chosen according to the noise statistics, while the second one is a regularization term weighted by a positive parameter balancing the two terms. Some physical constraint can be added, such as non negativity and flux conservation. When the goal is preserving sharp discontinuities while removing noise and blur, we can use as regularization term the Total Variation (TV) functional (introduced first in [25]), which, in the discrete framework, is defined as
where (∇x) k denotes a discrete approximation of the gradient of x at the pixel k.
For Gaussian noise, the fit-to-data term is given by the following quadratic function
and the variational model combining (2) and (1) has been extensively studied; its primal and dual formulations have been deeply investigated in order to design algorithms specifically tailored for image processing applications. The large size of these problems requires schemes with a low computational cost per iteration (typically only a matrix–vector product per iteration) and a fast initial convergence that enables to obtain medium accurate and visually satisfactory results in a short time. In the class of first order methods, requiring only function and gradient evaluations, popular methods for TV minimization include the time-marching method [25], split Bregman [19, 22], Chambolle’s [4, 8, 9], gradient projection [29, 32], Nesterov-type methods [2, 14]. For the most part of these algorithms, Matlab codes are available in the public domain (see [14] for references).
We mention also second-order methods proposed in [11, 18]. These can be quadratically convergent, but they require the solution of a system at each iteration and information about the Hessian matrix.
Another approach is based on the primal–dual formulation of (3) as saddle point problem. In [31], Zhu and Chan propose a first-order method named Primal–Dual Hybrid Gradient (PDHG) method, where at any iteration both primal and dual variables are updated by descent and ascent gradient projection steps respectively. Furthermore, the authors propose to let the steplength parameters varying trough the iterations and to choose them as prefixed sequences. The twofold aim is to avoid the difficulties that arise when working only on the primal or dual formulation and to obtain a very efficient scheme, well suited also for large scale problems.
The convergence of PDHG has been investigated in [16], where the algorithm with variable stepsizes is interpreted as a projected averaged gradient method on the dual formulation, while in [10] the convergence of PDHG with fixed stepsizes is discussed (see also [2]). Numerical experiments [10, 16, 31] show that the method exhibits fast convergence for some special choices of the steplength sequences, but, at the best of our knowledge, a theoretical justification of the convergence of the PDHG scheme with these a priori choices is still missing.
A recent development on the primal–dual methods can be found also in [10] as a special case of a primal–dual algorithm for the minimization of a convex relaxation of the Mumford-Shah functional. This last algorithm generalizes the classical Arrow-Hurwicz algorithm [1] and converges for constant steplength parameters. Furthermore, for uniformly convex objective functions, a convenient strategy to devise adaptive step sizes is theoretically obtained and it seems to be numerically effective.
The aim of this paper is to define a robust convergence framework for primal–dual methods with variable steplength parameters which apply to optimization problems of the form
where f 0 and f 1 are convex proper lower semicontinuous functions, over ℝn and ℝm respectively, not necessarily differentiable, A∈ℝm×n and X represents the domain of the objective function or a subset of it expressing physical features. The key point of our analysis is to consider the primal–dual method as an ε-subgradient method [13, 20, 23] on the primal formulation (3). Then, the two main contributions of this paper are the following:
-
we establish the convergence proof of a primal–dual method where the steplength are chosen as a priori sequences; this analysis provides also, as a special case, the convergence proof of the PDHG method [31] with the steplength choices suggested by the authors as the best performing one on the variational problem (2)–(1);
-
we design a general algorithm which can be applied to general TV restoration problems such as
-
the denoising or deblurring of images corrupted by Poisson noise, where the data discrepancy is expressed by the generalized Kullback–Leibler (KL) divergence:
$$f_0(x) = \sum_{k} \biggl \{g_k\ln\frac{g_k}{{(Hx+b)}_k} + {(Hx+b)}_k -g_k\biggr\} $$(4)with g k lng k =0 if g k =0;
-
the edge preserving removal of impulse noise, where a suitable fit-to-data term is the ℓ 1 norm
$$f_0(x) = \|x-g\|_1$$
-
The paper is organized as follows: in Sect. 2 some basic definitions and results about ε-subgradient and ε-subgradient methods are restated. In Sect. 3 we introduce the primal–dual scheme and the connections with ε-subgradient methods are investigated. In particular, we provide the convergence analysis for primal-explicit and primal-implicit schemes. In Sect. 4 some applications of our results are described. The numerical experiments in Sect. 5 show that the proposed scheme, with a suitable choice of the steplength sequences, can be a very effective tool for TV image restoration also in presence of Poisson and impulse noise.
2 Definitions and Preliminary Results
We denote by ℝn the usual n-dimensional Euclidean space, by 〈x,y〉=x T y the inner product of two vectors of ℝn and by ∥⋅∥ the l 2 norm.
The domain of a function f:ℝn→ ] −∞,+∞] is dom (f)={x∈ℝn:f(x)<+∞}. A function f is said proper if dom (f)≠∅. The diameter of a set X is defined as diam (X)=max x,z∈X ∥x−z∥.
Let P Ω (z) denote the orthogonal projection of the point z∈ℝn onto the nonempty, close, convex set Ω⊆ℝn, \(P_{\varOmega}(z) = \arg\min_{u\in\varOmega}\frac{1}{2} \|u-z\|^{2}\).
We recall that for a convex function f, the resolvent operator (I+θ∂f)−1 is defined as
where ∂f is the subdifferential mapping and θ is a positive parameter.
Definition 1
[24, Sect. 23]
Let f a proper convex function on ℝn.
The ε-subdifferential of f at x∈dom (f), defined for ε∈ℝ, ε≥0, is the set
For ε=0 the definition of subdifferential is recovered while for ε>0 we have a larger set; furthermore, for ε 1>ε 2>0, we have \(\partial_{\varepsilon_{1}} f(x)\supseteq \partial_{\varepsilon_{2}} f(x)\supseteq\partial f(x)\). Every element of ∂ ε f(x) is an ε-subgradient of f at x. In the following we will make use of the linearity property of the ε-subgradient, which, for sake of completeness, is restated below.
Property 1
If \(f(x) = \sum_{i=1}^{n} \alpha_{i}f_{i}(x)\), where α i ≥0, \(w_{i}\in\partial_{\varepsilon_{i}}f_{i}(x)\) and \(x\in\bigcap_{i=1}^{n}\operatorname{dom}(f_{i})\), then \(\sum_{i=1}^{n} \alpha_{i}w_{i}\in\partial_{\varepsilon}f(x)\), where \(\varepsilon= \sum_{i=1}^{n} \varepsilon_{i}\).
Proof
By Definition 1, we have
Then, the claim follows by multiplying the previous inequalities by α i and summing up for i=1,…,n. □
Definition 2
[24, Sect. 12]
The conjugate of a convex function f is the function f ∗ defined by
If f(x) is lower semicontinuous and proper, then f ∗ is lower semicontinuous and f ∗∗=f.
Proposition 1
Let f(x) a proper lower semicontinuous convex function. Then, for every x∈dom (f) and y∈dom (f ∗) we have y∈∂ ε f(x), with ε=f(x)−(〈y,x〉−f ∗(y)).
Proof
Let x,z∈ℝn and y∈dom (f ∗). Then, we can write

Since f(x)=sup x 〈y,x〉−f ∗(y), then ε≥0; thus, Definition 1 is fulfilled. □
We remark that ε=0 (that is y∈∂f(x)) if and only if f(x)=〈y,x〉−f ∗(y). Now we state the following corollary, which is useful for the subsequent analysis; its proof can be carried out by employing similar arguments as in the previous proposition.
Corollary 1
Let f a proper lower semicontinuous convex function and let A be a linear operator. Consider the composition (f∘A)(x)=f(Ax): then, for every x∈dom (f∘A) and y∈dom (f ∗) we have A T y∈∂ ε (f∘A)(x), with ε=f(Ax)−(〈y,Ax〉−f ∗(y)).
An important property of the ε-subgradients is their boundedness over compactly contained subsets of int dom (f), as we prove in the following proposition.
Proposition 2
Assume that S is a compactly contained bounded subset of int dom (f). Then, the set ⋃ x∈S ∂ ε f(x) is nonempty, closed and bounded.
Proof
Let λ>0 be such that S+B λ⊆int dom (f), where B λ is the ball of ℝn with radius λ and S+B λ={u∈ℝn:∥u−x∥≤λ,x∈S}. By Theorem 6.2 in [15] it follows that \(\bigcup_{x\in S}\partial_{\varepsilon}f(x)\subseteq\bigcup_{x\in S+B^{\lambda}}\partial f(x) + B^{\frac{\varepsilon}{\lambda}}\). The last term in the previous inclusion is nonempty, closed and bounded (see [24, Theorem 24.7]); thus the theorem follows. □
Proposition 3
Let \(x,\bar{x}\in\operatorname{dom}f\) and g∈∂f(x); then, \(g\in\partial_{\varepsilon}f(\bar{x})\) with \(\varepsilon= D_{f}(\bar{x},x)\), where \(D_{f}(\bar{x},x)=f(\bar{x})-f(x)-\langle g, \bar{x}-x\rangle\) is the Bregman divergence associated with f at x.
Proof
Since g∈∂f(x), for all z we have

where ε≥0 by the hypothesis on g. □
2.1 The ε-Subgradient Projection Method
Consider the constrained minimization problem
where f is a convex, proper, lower semicontinuous function; the ε-subgradient projection method is defined as follows
given the steplength sequence {θ k } and subgradient residuals {ε k} (see for example [13, 20, 23] and reference therein).
The convergence properties of a subgradient method strongly depends on the steplength choice, and different selection strategies can be devised in the literature (see [5, Chap. 6.8] for a recent review). In this paper we focus on the diminishing divergent series stepsize rule, that consists in choosing any sequence of positive steplength θ k >0 such that

The convergence of the ε-subgradient projection method can be stated as in [20, Theorem 3]. For sake of completeness we report the statement below.
Theorem 1
Let {x (k)} be the sequence generated by the method (6) and assume that the set X ∗ of the solutions of (5) is bounded. Under the Assumptions A1–A2, if w (k) is bounded and lim k ε k=0, then {f(x (k))} converges to a minimum of f(x) over X and dist (x (k),X ∗)→0.
Remark
When problem (5) has a unique solution x ∗, the previous theorem assures the convergence of the sequence {x (k)} to the minimum point x ∗.
3 The Primal–Dual Scheme
We consider the minimization of
where f 0(x) and f 1(x) are convex, proper, lower semicontinuous functions, not necessarily differentiable, and such that
We consider problems of the form (5) where the constraint set X is a closed convex subset X of dom (f); otherwise, for the unconstrained case, we set X=dom (f). We assume also that the set of the minimum points X ∗ is bounded.
We remark that, the boundedness of X ∗ together with (7), ensures that the min–max theorem [24, p. 397] holds. As a consequence of this, the minimization problem (5) is equivalent to the saddle point problem
Indeed, by definition, the pair (x ∗,y ∗) is a saddle point of (8) when
and (9) holds if and only if A T y ∗∈∂f 1(x ∗) and x ∗∈X ∗.
3.1 Primal-Explicit Scheme
We consider the following algorithm.

Primal-explicit scheme
In order to prove the convergence of Algorithm 1, we make the following assumptions on the parameters τ k and δ k :

Lemma 1
Let x (k) any sequence in dom (f) and assume that (7) holds. Under the Assumptions A1 and A3, we have that \(A^{T}y^{(k+1)}\in\partial_{\varepsilon^{k}}(f_{1}\circ A)(x^{(k)})\) with lim k→∞ ε k=0.
Proof
Corollary 1 guarantees that
with \(\varepsilon^{k} = f_{1}(Ax^{(k)}) + f_{1}^{*}(y^{(k+1)})-\langle y^{(k+1)},Ax^{(k)}\rangle\).
By (10) it follows that

We have

which results in

Since τ k →+∞ and ε k≥0 ∀k, then ε k→0. □
We are now ready to state the following convergence result for Algorithm 1, which directly follows from Theorem 1 and Lemma 1.
Theorem 2
We assume X ∗ bounded. Let {x (k)} be the sequence generated by Algorithm 1. Under the Assumptions A1–A4, if {g (k)} is bounded, then {f(x (k))} converges to a minimum of f(x) over X and dist (x (k),X ∗)→0.
One of the main advantages of Algorithm 1 is its generality, and different algorithms can be defined according to the strategy chosen to compute the approximate subgradient g (k).
In particular, when the function f 0(x) is differentiable, we may set
so that we have δ k =0 for all k.
3.2 Primal-Implicit Scheme
We observe that the constrained problem (5) can be formulated also as
where \(f_{0}^{X}(x) = f_{0}(x) + \iota_{X}(x)\) and ι X (x) is the indicator function of the set X, defined as
We consider the following implicit version of Algorithm 1.

Primal-implicit scheme
Then, the new point x (k+1) is defined also as
and, thus, the updating step (13) implies that
In particular, we have that \(x^{(k+1)}\in\operatorname{dom}(f_{0}^{X})\) and
where \(g^{(k)}\in\partial f_{0}^{X}(x^{(k+1)})\). From Proposition 3, it follows that
with
Thus, Algorithm 2 can be considered an ε-subgradient method and the convergence analysis previously developed still applies, as we show in the following. However, this semi-implicit version has stronger convergence properties: in particular, we are able to prove the boundedness of the iterates {x (k)}.
Lemma 2
Assume that
Then, the sequence {x (k)} generated by Algorithm 2 is bounded.
Proof
Let (x ∗,y ∗) a saddle point of (8). From (14) and from the definition of the subgradient, we obtain

where

which gives

Similarly, from (13) we obtain

We observe that, if we define
we have

where the last inequality follows from the saddle point property (9) of the pair (x ∗,y ∗).
The last term can be further estimated as in [10, Sect. 3.2], by observing that for any t∈(0,1] we have
which yields

where L=∥A∥. Thus, summing up (19) and (18) yields

In particular, recalling (7), the inequality (20) results in
By multiplying both sides of the previous inequality by 2θ k and summing up for k=0,…,N−1 we obtain
Then, the boundedness of {x (k)} is ensured by the hypothesis (17). □
Thanks to the previous lemma, the boundedness of the subgradients g (k) is assured.
Theorem 3
Assume that f 0(x) is locally Lipschitz in its domain. If the steplength sequences {θ k } and {τ k } satisfy the conditions A1–A3 and (17), then {f(x (k))} converges to a minimum of f(x) over X and dist (x (k),X ∗) converges to zero.
Proof
From the previous lemma and by Proposition 2, the sequence of subgradients g (k) is bounded, thus, from (15) and A1, we have ∥x (k)−x (k+1)∥→0 as k→∞. If f 0(x) is locally Lipschitz continuous, then for every compact subset \(K\subset\operatorname{dom}(f_{0}^{X})\), there exists a positive constant M K such that ∥f 0(z)−f 0(x)∥≤M K ∥z−x∥ for all x,z∈K. Thus, since all the iterates are contained in a suitable compact subset of \(\operatorname{dom}(f_{0}^{X})\), we have \(|f_{0}^{X}(x^{(k)})-f_{0}^{X}(x^{(k+1)})|\rightarrow0\) as k→∞. As consequence, the sequence {δ k} defined in (16) converges to zero as k diverges. Then, we can invoke Theorem 2 to conclude that {f(x (k))} converges to a minimum of f(x) over X and, furthermore, lim k→∞dist (x (k),X ∗)=0. □
Remark
If X ∗={x ∗}, Theorems 2 and 3 state the convergence of the sequences {x (k)} generated by the Algorithms 1 and 2 to the unique solution x ∗ of the problem (5).
In the following section we discuss the implementation of Algorithms 1 and 2 for the TV restoration of images.
4 Applications to Total Variation Image Restoration Problems
In this section we consider problem (5) where the objective function is the combination of a convex, proper, lower semicontinuous function measuring the data fidelity with the discrete TV function (1).
In this case we define the function f 1 on ℝ2n such that
where β>0 is the regularization parameter. We denote by A i ∈R 2×n the discrete approximation of the gradient of x at the pixel i and by A∈ℝ2n×n the following block matrix

Then, we have
The conjugate of f 1 is \(f_{1}^{*}(y) = \iota_{Y}(y)\), namely the indicator function of the set Y⊂ℝ2n defined as follows

As a consequence of this, \(\operatorname{dom}(f^{*}_{1})=Y\) satisfies (7) and we can write
We remark that the updating rules (10) and (12) for the variable y reduce to the orthogonal projection onto the set Y, which is defined by the following closed formula
4.1 Gaussian Noise
We notice that the PDHG algorithms proposed in [31] are special cases of Algorithm 2 for \(f_{0}(x) = \frac{1}{2}\|Hx-g\|^{2}\), X=ℝn. In this case, denoting by \({\mathcal{N}}(A)\) and \({\mathcal{N}}(H)\) the null spaces of A and H, under the usual assumption that
the solution of the minimization problem (3) is unique. Thus, Theorem 3 establishes the convergence to this unique solution.
In particular, we stress that the steplength choices indicated by the authors in [31] and employed for the numerical experiments also in [10, 16] guarantee the convergence, according to Theorem 3. Indeed, the proposed steplength choices are

for denoising problems, while
for deblurring problems. Both these choices satisfy the hypotheses of Theorem 3, which provides the theoretical foundation to the convergence that, so far, was experimentally observed.
An explicit variant of PDHG can be derived from Algorithm 1, by setting g (k)=H T(Hx (k)+b−g). For denoising problems, in order to define a bounded set X containing the solution x ∗, we recall the following result.
Lemma 3
Let x ∗ be the unique minimum point of f(x)≡f 0(x)+f 1(Ax), where \(f_{0}(x)=\frac{1}{2}\|x-g\|^{2}\) and f 1(Ax) is the TV function (21). Then we have
Proof
See for example [7]. □
We observe that the previous result can be adapted also for constrained problems of the form min x≥η f(x). In this case, the lower bound of the solution becomes max{η,g min}, where the maximum is intended componentwise. In summary, if we define
Algorithm 1 with g (k)=x (k)−g is convergent to the unique solution x ∗ of min x≥η f(x), thanks to Theorem 1.
For general deblurring problems, convergence of Algorithm 1 is ensured under the hypothesis that the generated sequence is bounded.
4.2 Poisson Noise
Algorithms 1 and 2 can be applied to the denoising or deblurring of images corrupted by Poisson noise, where the data discrepancy is expressed by the generalized KL divergence (4) and X is a subset of the domain of f 0(x). It is well known that f 0(x) is a proper, convex and lower semicontinuous function. Under the hypothesis (24), the solution of the minimization problem (3) on X exists and it is unique. Since f 0(x) is a differentiable function, an explicit version of Algorithm 1 can be implemented by setting g (k)=∇f 0(x (k))=H T e−H T Z(x (k))−1 g, where e is the n-vector with all entries equal to one and Z(x)=diag (Hx+b).
For deblurring problems, in order to state the convergence of Algorithm 1 using Theorem 1, we need to assume that the sequence of the iterates stays bounded.
In case of a denoising problem (H=I), the convergence of Algorithm 1 is ensured by defining X as a suitable bounded set containing the unique solution, as suggested in the following Lemma.
Lemma 4
Let x ∗ be the unique solution of the problem
where \(f_{0}(x)=\sum_{i} g_{i}\log\frac{g_{i}}{x_{i}}+x_{i}-g_{i}\), with g i logg i =0 if g i =0, and f 1(Ax) is the TV function (21). Then, for all i such that g i >0 we have
Proof
See [6]. □
Consequently, for denoising problems from data corrupted by Poisson noise, if we define

then, the unique solution x ∗ of (27) belongs to X and the sequence generated by Algorithm 1 converges to x ∗.
Furthermore, it is easy to see that the i-th component of (I+θ∂f 0)−1(p) is given by
which can be exploited for the computation of the step (13) in Algorithm 2.
For the deblurring problems, a closed form formula for (13) is not available, thus Algorithm 2 can be difficult to implement in this case.
4.3 Impulse Noise
When the noise affecting the data contains strong outliers (e.g. impulse or salt & pepper noise), a well suited data discrepancy function is the non-smooth L 1 norm:
The resolvent operator of f 0 is given by the pointwise shrinkage operations:
This closed-form representation of the resolvent operator (I+θ∂f 0)−1 enables us to apply Algorithm 2 to the minimization of the L 1-TV model (28)–(21).
4.4 Smoothed Total Variation
In many papers (see, for example, [2, 3, 11, 30]), the discrete TV (21) is replaced by the following smoothed approximation
where ρ is a small positive parameter. This variant has been considered also in a general edge-preserving regularization framework as Hypersurface (HS) potential [12]. When the smoothed TV regularization (30) is used, if f 0(x) is a differentiable function, the minimization of f(x) can be obtained by efficient differentiable optimization methods. In this section we show that Algorithms 1 and 2 can also be applied with minor modifications.
In this case the conjugate is the indicator function of the following set

In particular, setting  , with y
i
∈ℝ2, Algorithms 1 and 2 can be adapted to the smoothed TV model by modifying the projection at the steps (10) and (12), detailed in (23), as follows:
, with y
i
∈ℝ2, Algorithms 1 and 2 can be adapted to the smoothed TV model by modifying the projection at the steps (10) and (12), detailed in (23), as follows:
for i=1,…,n, where
As observed in [6], numerical methods which are not based on the differentiability of (30) can be convenient for the smoothed TV minimization, especially when the smoothing parameter ρ is very small.
5 Numerical Experience
The steplength selection is a crucial issue for the practical performance of many algorithms. In particular, as pointed out in [31], some choices yield a fast initial convergence, but they are less suited to achieve fast asymptotic convergence and vice versa. One of the main strength of the proposed method is that variable steplength parameters are allowed, and this can help to achieve both fast initial and asymptotic convergence. In the case of the quadratic data fidelity function (2), Algorithm 2 with the choices (25)–(26) is equivalent to the PDHG method and its performances has been experimentally evaluated in [10, 16, 31], showing that convenient steplength sequences lead to a very appealing efficiency with respect to the state-of-the-art methods.
This section is devoted to numerically evaluate the effectiveness of Algorithm 1 for TV restoration of images corrupted by Poisson noise. Algorithm 1 and 2 can be used also for other imaging problems. At the end of the section, we show as Algorithm 2 can be applied for solving an image denoising problem with impulse noise.
The numerical experiments described in this section have been performed in MATLAB environment, on a server with a dual Intel Xeon QuadCore E5620 processor at 2.40 GHz, 12 Mb cache and 18 Gb of RAM.
5.1 Poisson Noise
We compare Algorithm 1 with two methods, especially tailored for the TV restoration in presence of data corrupted by Poisson noise. The first one is the PIDSplit+ algorithm [26], based on a very efficient alternating split Bregman technique. The algorithm guarantees that the approximate solution satisfies the constraints and it depends only on a positive parameter γ. The second one is the Alternating Extragradient Method (AEM) [6], that solves the primal–dual formulation of the problem (3) by a successive updating of dual and primal iterates in an alternating, or Gauss-Seidel, way. Algorithm 1 and AEM are very similar, but AEM requires an additional ascent (extragradient) step at any iteration and it employs the same adaptively computed steplength in the three steps. Furthermore, in the denoising experiments, we include in the comparison also the algorithm in [10, Algorithm 1, p. 122], with θ=1, that in the following is denoted by CP. This general primal–dual algorithm requires that the resolvent operators of f 0 and \(f_{1}^{*}\) have a closed-form representation. As observed in Sect. 4.2, the resolvent of the Kullback–Leibler divergence is easy to compute only for the denoising case. The CP method depends on two parameters σ,τ, which should be chosen such that στL 2=1, where β∥A∥≤L.
In the experiments we consider a set of test problems, where the Poisson noise has been simulated by the imnoise function in the Matlab Image Processing Toolbox. The considered test problems are described in the following.
Denoising Test Problems
-
LCR phantom: the original image is the phantom described in [21]; it is an array 256×256, consisting in concentric circles of intensities 70, 135 and 200, enclosed by a square frame of intensity 10, all on a background of intensity 5 (LCR-1). We can simulate a different noise level by multiplying the LCR phantom by a factor 10 (LCR-10) and 0.2 (LCR-0.2) and generating the corresponding noisy images. The relative difference in l 2 norm between the noisy and the original images is 0.095318, 0.030266, 0.21273 respectively.
-
Airplane (AIR): the original image is an array 256×256 (downloadable from http://sipi.usc.edu/database/), with values in the range [0,232]; the relative difference in l 2 norm between the noisy and noise-free images is 0.070668.
-
Dental Radiography (DR): the original image [30] is an array 512×512, with values in the range [0,255]; for this test problem, simulating a radiographic image obtained by a lower dose, the relative difference in l 2 norm between the noisy and the noise-free images is 0.17866.
Deblurring Test Problems
-
micro: the original image is the confocal microscopy phantom of size 128×128 described in [28]; its values are in the range [0,70] and the total flux is 2.9461×105; the background term b in (4) is set to zero.
-
cameraman: following [26], the simulated data are obtained by convolving the image 256×256 with a Gaussian psf with standard deviation σ=1.3, then adding Poisson noise; the values of the original image are in the range [0,1000]; the background term b in (4) is set to zero.
In the first set of experiments we compare the numerical behavior of Algorithm 1, AEM, PIDSplit+ and CP on the denoising test problems described above. In order to compare the convergence rate from the optimization point of view, we compute the ideal solution x ∗ of the minimization problem, by running 100000 iterations of AEM. Then, we evaluate the progress toward the ideal solution at each iteration in terms of the l 2 relative error
It is noticed that computing the ideal solution with AEM makes a small bias in favour of AEM itself. However the obtained results are sufficiently convincing to forget this bias.
In Table 1 for any test problem we report the number of iterations it and, in brackets, the computational time in seconds needed to satisfy the inequality
for different values of the tolerance μ. We report also the l 2 relative reconstruction error
where \(\tilde{x}\) is the original image and x μ is the reconstruction corresponding to the tolerance μ. The symbol ∗ denotes that 3000 iterations have been performed without satisfying the inequality (31). All methods have been initialized with x (0)=max{η,g}, where the maximum is intended componentwise and η i =0 for g i =0, η i =g min otherwise, and the constraint set X is defined as in Sect. 4.2. In Algorithm 1, AEM and CP, the initial guess for the dual variable y (0) has been set to zero. For the initial setting of the others variables involved in PIDSplit+ see [26]; the value of γ used for the different runs of PIDSplit+ is detailed in Table 1. The value of γ suggested by the authors in [26] is \(\frac{50}{\beta}\). In Table 1 we report also the value of τ used for the different runs of CP. In Table 2 we report the sequences chosen for the steplength parameters in Algorithm 1, which have been optimized for the different test problems.
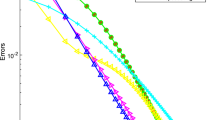
Figure 1 shows the convergence speed of the considered methods for each test problem: we plot, in log-scale, the l 2 relative error e k with respect to the computational time. In Tables 3 and 4 we report some results obtained by running each method for 3000 iterations. In particular, Table 3 shows the l 2 norm of the relative error and corresponding computational time after 3000 iterations. We report also, for any test-problem, the relative reconstruction error and the value of the objective function f(x (3000)). In order to show the quality of the restored images, in Fig. 2 we report the superposition of the row 128 of the original image LCR-0.2 and the related noisy image; besides, we show the same row of the reconstruction corresponding to μ=10−4, obtained by Algorithm 1.

Denoising problems: convergence speed of Algorithm 1, AEM, PIDSplit+ (with different values of γ) and CP (with τ=10 in all test problems except (a) where τ=5): plot of l 2 norm of the relative error e k with respect to the ideal solution of the minimization problem versus the computational time. All the methods run for 3000 iterations

Reconstructions at the level μ=10−4: lineouts of row 128 of the image LCR-0.2. Left panel: superposition of the row 128 of the original image and of the noisy image. Right panel: reconstruction by Algorithm 1 (706 it and time=20.2 seconds)
In Figs. 3 and 4 we report the original, noisy and reconstructed images related to test problems AIR and DR. Since at the tolerance μ=10−4 all the restored images are visually the same, we report only the one provided by the two fastest algorithms.

Test problem AIR, β=0.05, μ=10−4. Upper left panel: original image. Upper right panel: noisy image. Bottom left panel: Algorithm 1 reconstruction. Bottom right panel: PIDSplit+ reconstruction with \(\gamma=\frac {5}{\beta}\)

Test problem DR β=0.27, μ=10−4. Upper left panel: original image. Upper right panel: noisy image. Bottom left panel: Algorithm 1 reconstruction. Bottom right panel: PIDSplit+ reconstruction, \(\gamma=\frac {0.5}{\beta}\)
The results of this numerical experimentation on denoising problems suggests the following considerations.
-
For denoising problems, Algorithm 1 performs well with respect to the other methods; indeed for careful choices of the steplength parameters, the method exhibits a fast initial convergence and this good behavior is preserved also asymptotically; furthermore a single iteration is faster than in the other methods.
-
About PIDSplit+, depending on the value of the parameter γ, we can observe either an initial or an asymptotic fast convergence, but we unlikely obtain both the behaviors. Furthermore, any iteration involves the solution of a linear system. Although this operation is performed by fast transforms, the computational complexity of each iteration of PIDSplit+ is greater than in the other methods, where only matrix–vector products and simple projections are performed.
-
The choice of the steplength sequences is crucial for the effectiveness of Algorithm 1, as well as the choice of γ for PIDSplit+ and of τ for CP. The numerical experience shows that Algorithm 1 is more sensible to the choice of the sequence {θ k } rather than {τ k }; this can be explained by observing that the projection over the domain Y, due to its special structure (22), may overcome the effect of a too large steplength. Furthermore, about the choice of θ k , if we set \(\theta_{k}=\frac{1}{a k+b}\), we observe that b affects the initial rate of convergence while the asymptotic behavior of the method is governed by the value of a.
The second set of experiments concerns the deblurring test problems micro and cameraman. We compare Algorithm 1, AEM and PIDSplit+, considering as ideal solution x ∗ the image obtained by running 100000 iterations of AEM. We consider the same initial setting used for the denoising test problems, except for the primal variable: since for deblurring the constraints are x≥0, then we set x (0)=max{0,g}. In Table 4 for each method we report the computational time and the relative error e 3000 with respect to the ideal solution after 3000 iterations. We report also the minimum value f(x (3000)) and the l 2 norm of relative reconstruction error e rec (since all methods produce the same optimal values, we report them only once). In Fig. 5 we compare the convergence rate of the considered methods for each test problem, by plotting in log-scale the l 2 relative error e k with respect to the computational time. In Figs. 6 and 7 we show the restored images obtained after 3000 iterations by Algorithm 1 and PIDSplit+ with the more effective choice of γ.

Deblurring problems: convergence speed of Algorithm PDHG, AEM, PIDSplit+ (with different value of γ): plot of l 2 norm of the relative error e k with respect to the ideal solution of the minimization problem versus the computational time. All the methods run for 3000 iterations

Test problem micro, β=0.09, 3000 iterations. Upper left panel: original image. Upper right panel: noisy blurred image. Bottom left panel: Algorithm 1 reconstruction. (time=51.1 seconds). Bottom right panel: PIDSplit+ reconstruction, \(\gamma=\frac{50}{\beta}\) (time=85.5 seconds)

Test problem cameraman, β=0.005, 3000 iterations. Upper left panel: original image. Upper right noisy blurred image. Bottom left panel: Algorithm 1 reconstruction (time=177.7 seconds). Bottom right panel: PIDSplit+ reconstruction, \(\gamma=\frac{5}{\beta}\) (time=306.3 seconds)
For deblurring problems, the PIDSplit+ method exhibits a very fast convergence. Indeed, the operator H could be severely ill conditioned, and in this case the implicit step in PIDSplit+ may help to improve the convergence rate. We observe also that for deblurring problems, the complexity of a single iteration of the three methods is similar, since the matrix–vector products involving the matrix H require the same fast transforms employed to compute the implicit step in PIDSplit+.
5.2 Impulse Noise
In this section we apply Algorithm 2 to the L 1-TV problem described in Sect. 4.3. The 512×512 original image boat (downloadable from http://sipi.usc.edu/database/) has been corrupted by 25% salt&pepper noise (after adding noise, the image was rescaled so that its value are between 0 and 1). The original and the noisy images are shown in Fig. 8, together with the restoration provided by Algorithm 2 after 2000 iterations. For this test problem we set β=0.65 and the sequences for the steplength parameters are τ k =0.1+0.1k and \(\theta_{k}=\frac{1}{0.05k+0.1}\). Table 5 shows the results of a comparison between Algorithm 2 and CP (θ=1,τ=0.02). Since the solution of the minimization problem (28)–(21) is in general not unique, we evaluate the normalized error on the primal objective function \(E^{k}=\frac{f(x^{(k)})-f(x^{*})}{f(x^{*})}\), where x ∗ is computed by running 100000 iterations of CP. In Table 5 we report the number of iterations it and the CPU time in seconds needed to drop the normalized error E k below the tolerance μ. Figure 9 shows the convergence speed of Algorithm 2 and CP for the test problem boat: we plot in log-scale the normalized error E k with respect to the computational time.

Image denoising in the case of impulse noise: test problem boat, β=0.65, 2000 iterations. Left panel: original image. Central panel: noisy image. Left panel: Algorithm 2 reconstruction (time=193 seconds)

Image denoising in the case of impulse noise: test problem boat. Convergence speed of Algorithm 2 and PC (τ=0.02): plot of normalized error E k versus the computational time. All the methods run for 2000 iterations
6 Conclusions
The main contribution of this paper is the analysis of a class primal–dual algorithms for convex optimization problems, providing the related convergence proof based on the ε-subgradient techniques. The developed analysis applies, as a special case, to the PDHG method [31], but allows further generalizations. Indeed, as immediate consequence, new methods for solving TV denoising and deblurring problems can be derived from the basic scheme. These methods can be applied also to other imaging problems based on convex regularization terms and data discrepancy functions with simple resolvent operator (see [10] for some examples of applications).
The crucial point to obtain fast convergence is the selection of a priori steplength sequences: numerical experiments show that there exists clever choices leading to very appealing performances (at the initial iterations and also asymptotically), comparable to other state-of-the-art methods.
The numerical experimentation highlights also the importance of the parameters choice for the convergence behaviour of all the considered methods.
For image denoising problems, where the relationship between image and object is simpler, the proposed scheme seems very efficient in terms of accuracy and computational complexity, although the choice of convenient steplength sequences is a difficult problem.
Future work will concern the design of an adaptive rule for generating the steplength sequences, following a strategy similar to that suggested in [5] for the subgradient method.
References
Arrow, K.J., Hurwicz, L., Uzawa, H.: Studies in Linear and Non-Linear Programming, vol. II. Stanford University Press, Stanford (1958)
Aujol, J.F.: Some first-order algorithms for total variation based image restoration. J. Math. Imaging Vis. 34(3), 307–327 (2009)
Bardsley, J.M., Luttman, A.: Total variation-penalized Poisson likelihood estimation for ill-posed problems. Adv. Comput. Math. 31(1–3), 35–59 (2009)
Beck, A., Teboulle, M.: Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 18, 2419–2434 (2009)
Bertsekas, D.: Convex Optimization Theory. Scientific, Athena (2009)
Bonettini, S., Ruggiero, V.: An alternating extragradient method for total variation based image restoration from Poisson data. Inverse Probl. 27, 095001 (2011)
Brune, C., Sawatzky, A., Wübbeling, F., Kösters, T., Burger, M.: Forward–Backward EM-TV methods for inverse problems with Poisson noise. http://wwwmath.uni-muenster.de/num/publications/2009/BBSKW09/ (2009)
Chambolle, A.: An algorithm for total variation minimization and applications. J. Math. Imaging Vis. 20, 89–97 (2004)
Chambolle, A.: Total variation minimization and a class of binary MRF models. In: EMMCVPR 05. Lecture Notes in Computer Sciences, vol. 3757, pp. 136–152 (2005)
Chambolle, A., Pock, T.: A first-order primal–dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40, 120–145 (2011)
Chan, T.F., Golub, G.H., Mulet, P.: A nonlinear primal–dual method for total variation based image restoration. SIAM J. Sci. Comput. 20, 1964–1977 (1999)
Charbonnier, P., Blanc-Féraud, L., Aubert, G., Barlaud, A.: Deterministic edge-preserving regularization in computed imaging. IEEE Trans. Image Process. 6, 298–311 (1997)
Correa, R., Lemaréchal, C.: Convergence of some algorithms for convex minimization. Math. Program. 62, 261–275 (1993)
Dahl, J., Hansen, P.C., Jensen, S.H., Jensen, T.L.: Algorithms and software for total variation image reconstruction via first-order methods. Numer. Algorithms 53, 67–92 (2010)
Ekeland, I., Témam, R.: Convex Analysis and Variational Problems. SIAM, Philadelphia (1999)
Esser, E., Zhang, X., Chan, T.: A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science. SIAM J. Imaging Sci. 3(4), 1015–1046 (2010)
Geman, S., Geman, D.: Stochastic relaxation, Gibbs distribution and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 6, 721–741 (1984)
Goldfarb, D., Yin, W.: Second-order cone programming methods for total variation based image restoration. SIAM J. Sci. Comput. 27(2), 622–645 (2005)
Goldstein, T., Osher, S.: The split Bregman method for L1 regularized problems. SIAM J. Imaging Sci. 2, 323–343 (2009)
Larsson, T., Patriksson, M., Strömberg, A.B.: On the convergence of conditional ε-subgradient methods for convex programs and convex–concave saddle-point problems. Eur. J. Oper. Res. 151, 461–473 (2003)
Le, T., Chartrand, R., Asaki, T.J.: A variational approach to reconstructing images corrupted by Poisson noise. J. Math. Imaging Vis. 27, 257–263 (2007)
Osher, S., Burger, M., Goldfarb, D., Xu, J., Yin, W.: An iterative regularization method for total variation-based image restoration. SIAM J. Multiscale Model. Simul. 4(2), 460–489 (2005)
Robinson, S.M.: Linear convergence of epsilon-subgradient descent methods for a class of convex functions. Math. Program., Ser. A 86, 41–50 (1999)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1970)
Rudin, L., Osher, S., Fatemi, E.: Nonlinear total variation based noise removal algorithms. Physica D 60, 259–268 (1992)
Setzer, S., Steidl, G., Teuber, T.: Deblurring Poissonian images by split Bregman techniques. J. Vis. Commun. Image Represent. 21, 193–199 (2010)
Shepp, L.A., Vardi, Y.: Maximum likelihood reconstruction for emission tomography. IEEE Trans. Med. Imaging 1, 113–122 (1982)
Willett, R.M., Nowak, R.D.: Platelets: a multiscale approach for recovering edges and surfaces in photon limited medical imaging. IEEE Trans. Med. Imaging 22, 332–350 (2003)
Yu, G., Qi, L., Dai, Y.: On nonmonotone Chambolle gradient projection algorithms for total variation image restoration. J. Math. Imaging Vis. 35, 143–154 (2009)
Zanella, R., Boccacci, P., Zanni, L., Bertero, M.: Efficient gradient projection methods for edge-preserving removal of Poisson noise. Inverse Probl. 25, 045010 (2009)
Zhu, M., Chan, T.F.: An efficient primal–dual hybrid gradient algorithm for Total Variation image restoration. CAM Report 08-34, UCLA (2008)
Zhu, M., Wright, S.J., Chan, T.F.: Duality-based algorithms for total-variation-regularized image restoration. Comput. Optim. Appl. 47, 377–400 (2008)
Acknowledgements
We are grateful to the anonymous referees for their comments, which stimulated us to greatly improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is supported by the PRIN2008 Project of the Italian Ministry of University and Research, grant 2008T5KA4L, Optimization Methods and Software for Inverse Problems, http://www.unife.it/prisma.
Rights and permissions
About this article
Cite this article
Bonettini, S., Ruggiero, V. On the Convergence of Primal–Dual Hybrid Gradient Algorithms for Total Variation Image Restoration. J Math Imaging Vis 44, 236–253 (2012). https://doi.org/10.1007/s10851-011-0324-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-011-0324-9