
Abstract
We give an explicit graded cellular basis of the \({\mathfrak {sl}}_3\)-web algebra \(K_S\). In order to do this, we identify Kuperberg’s basis for the \({\mathfrak {sl}}_3\)-web space \(W_S\) with a version of Leclerc–Toffin’s intermediate crystal basis and we identify Brundan, Kleshchev and Wang’s degree of tableaux with the weight of flows on webs and the \(q\)-degree of foams. We use these observations to give a “foamy” version of Hu and Mathas graded cellular basis of the cyclotomic Hecke algebra which turns out to be a graded cellular basis of the \({\mathfrak {sl}}_3\)-web algebra. We restrict ourselves to the \({\mathfrak {sl}}_3\) case over \(\mathbb {C}\) here, but our approach should, up to the combinatorics of \({\mathfrak {sl}}_N\)-webs, work for all \(N>1\) or over \(\mathbb {Z}\).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
After Khovanov published his groundbreaking work [30] on the so-called arc algebra \(H_n\), which was inspired by his categorification of the Jones polynomial [29], researchers started to study these diagrammatic algebras and generalizations of it from different viewpoints and it turns out that these algebras have a beautiful combinatorial structure and representation theory. Moreover, they are related to algebraic geometry and knot theory.
The literature about this subject is wide nowadays and many results are known. To list a few of them, the generalizations of the arc algebra in type \(A_1\) are for example studied in [8–12, 15, 31, 54] and [55], in type \(A_2\) for example in [44] and [48] or [49], in type \(A_N\) case for example in [43] and [47]. There is also an arc algebra in type \(D\) studied in [17, 18] and [19] and one in the \(\mathfrak {gl}(1|1)\) case studied in [53].
These algebras in type \(A\) can be seen as a categorification of the underlying \(\mathfrak {sl}_N\)-web space. In the \(\mathfrak {sl}_2\) case (if one ignores orientations) one has the so-called Temperley-Lieb category, which gives a diagrammatic presentation of the representation theory of \(\mathbf{U}_q(\mathfrak {sl}_2)\) (an interesting historical remark is that a first diagrammatic approach already arose in a paper of Rumer, Teller, and Weyl [51]). In the \(\mathfrak {sl}_3\) case the underlying space consists of Kuperberg’s \(\mathfrak {sl}_3\)-webs, introduced in [38]. They give a diagrammatic presentation of the representation theory of \(\mathbf{U}_q(\mathfrak {sl}_3)\). In the \(\mathfrak {sl}_N\) case the underlying space consists of \(\mathfrak {sl}_N\)-webs. They give a diagrammatic presentation of the representation theory of \(\mathbf{U}_q(\mathfrak {sl}_N)\), as was recently proven by Cautis, Kamnitzer and Morrison [13].
In this paper we continue the study of the so-called \(\mathfrak {sl}_3\)-web algebras introduced in [44]. We denote them by \(K_S\), where \(S\) is a sign string (string of \(+\) and \(-\) signs). To be more precise, we show that \(K_S\) is a graded cellular algebra in the sense of [23] Graham and Lehrer (who introduced the notion in the ungraded setting) and Hu and Mathas [25] (who extended Graham and Lehrer’s notion to the graded setting) by giving an explicit graded cellular basis for the \(\mathfrak {sl}_3\)-web algebra \(K_S\). We follow a different approach than Brundan and Stroppel used in the \(\mathfrak {sl}_2\) case [8], since their arguments does not seem to generalize in a straightforward way to \(N>2\). In fact, we claim that our approach in this paper will, up to some combinatorics of \(\mathfrak {sl}_N\)-webs, generalize to all \(N>1\).
It should be noted that it was known before, as the author showed together with Mackaay and Pan in [44] in the \(\mathfrak {sl}_3\) case and Mackaay and Yonezawa [47] showed in the \(\mathfrak {sl}_N\) case, that all the \(\mathfrak {sl}_N\)-web algebras are graded cellular algebras. The way this was proven is by an abstract Morita equivalence—no other proof is known at the moment. An explicit cellular basis in only known in the \(\mathfrak {sl}_2\) case. As mentioned, the construction is due to Brundan and Stroppel [8].
Our approach in this paper is as follows. One main ingredient is the usage of categorified, diagrammatic quantum skew Howe duality studied recently independently by varies authors in this framework [13, 39] and [44] to cite a few (the first appearance in the context of \(\mathfrak {sl}_2\)-webs seems to be the paper of Huerfano and Khovanov [27], although they never used the notion of skew Howe duality). In the \(\mathfrak {sl}_3\) case this means that there is a strong \(2\)-representation \(\psi :{\mathcal {U}}({\mathfrak {sl}}_n)\rightarrow \mathbf{Foam}_{3}\), called foamation, of Khovanov and Lauda’s [35] categorification of \(\dot{\mathbf{U}}_q(\mathfrak {sl}_n)\), denoted by \({\mathcal {U}}({\mathfrak {sl}}_n)\), to the category of \(\mathfrak {sl}_3\)-foams \(\mathbf{Foam}_{3}\). This foamation functor was used in [44] to show that \(K_S\) is Morita equivalent to a certain block of \(R_{\Lambda }\), where \(R_{\Lambda }\) denotes Khovanov-Lauda’s [33] and [34] and Rouquier’s [50] cyclotomic quotient, called the cyclotomic KL-R algebra.
In a remarkable paper [4] Brundan and Kleshchev showed that the cyclotomic KL-R algebra is isomorphic to the so-called cyclotomic Hecke algebra. Their isomorphism was used by them to define a non-trivial grading on the cyclotomic Hecke algebra. Using this isomorphism, Hu and Mathas gave in [25] a graded cellular basis for the cyclotomic KL-R algebra based on earlier work of Dipper, James and Mathas [16] who gave a (ungraded) cellular basis of the cyclotomic Hecke algebra and Brundan and Kleshchev’s (and Wang’s) work on graded Specht modules for these algebras, see [5–7].
The approach we follow here is that we give a “foamy” version of the Hu and Mathas basis (short HM-basis) using foamation and quantum skew Howe duality. It turns out that the combinatorial structure can be easier seen within the cyclotomic Hecke algebra, while the topological structure can be easier seen within the foam setting.
We note that the explicit construction is a non-trivial task, since bases behave really badly under Morita equivalence and some non-trivial translation from the cyclotomic Hecke algebra to the foam framework was needed, that is, even the answers to basic questions were unknown before. It turns out, as we explain below, that this non-trivial combinatorics is in fact quite nice itself, since it gives a new perspective on the \(\mathfrak {sl}_3\)-web spaces.
The second main ingredient is that we use a special basis for our underlying \(\mathfrak {sl}_3\)-web space \(W_S\), the so-called intermediate crystal basis \(B_{\Lambda }\) of Leclerc–Toffin [40] (short LT-basis) of the highest weight \(\mathbf{U}_q(\mathfrak {sl}_n)\)-module \(V_{\Lambda }\), which can be translated to the \(\mathfrak {sl}_3\)-web setting using quantum skew Howe duality. It turns out the the LT-basis is easy to work with if one wants to categorify the results from the level of \(\mathfrak {sl}_N\)-webs.
To be a little bit more precise, we “categorify” the LT-algorithm for \(\mathfrak {sl}_3\)-webs by giving a growth algorithm for foams producing a graded cellular basis.
That is, the LT-algorithm, under \(q\)-skew Howe duality, turns given semi-standard tableaux into \(\mathfrak {sl}_3\)-webs by applying a sequence of so-called \(\mathfrak {sl}_3\)-ladder operators obtained from an algorithm on semi-standard tableaux to a certain highest weight vector. On the other hand, the growth algorithm for foams, under categorified \(q\)-skew Howe duality, turns standard \(3\)-multitableaux into \(\mathfrak {sl}_3\)-foams by applying a sequence of certain \(\mathfrak {sl}_3\)-foams (that categorify the ladder operators) obtained from an algorithm on standard \(3\)-multitableaux to a certain highest weight object.
It should be noted that, in order to formulate the growth algorithm for foams, we relate standard \(3\)-multitableaux to Khovanov–Kuperberg flows (see [32]) on \(\mathfrak {sl}_3\)-webs. Recall that these flows are a combinatorial way to answer the important question what a web, seen as an invariant tensor \(\mathrm{Inv}_{\mathbf{U}_q(\mathfrak {sl}_3)}(\bigotimes _kV_{s_k})\), is explicitly in terms of the elementary tensors of \(\bigotimes _kV_{s_k}\).
In order to prove both observations highly non-trivial combinatorics on the \(\mathfrak {sl}_3\)-webs is needed (in fact this seems to be the only problem for generalizing everything to \(N>3\)). But this combinatorics turns out to be quite beautiful itself, i.e. we identify Kuperberg’s basis of non-elliptic webs as an intermediate crystal basis (which shows “immediately” that it is related by an unitriangular change-of-base matrix to the dual canonical and again demonstrates that it is somehow “the” basis of the \(\mathfrak {sl}_3\)-web space), we give a growth algorithm for \(\mathfrak {sl}_3\)-webs with flows and we relate webs with flows to standard fillings of \(3\)-multitableaux. We use latter to identify Brundan, Kleshchev and Wang’s notion of degree [7] in a very natural way, i.e. as the weight of flows on webs [32] and the \(q\)-degree of foams, where latter is just a slight modification of the geometrical Euler characteristic (hence, Brundan, Kleshchev and Wang’s degree is an isotopy invariant).
The reason why we think this approach should “easily” (up to combinatorics of \(\mathfrak {sl}_N\)-webs) generalize is that both of our main ingredients are known in general for \(N>1\), see [43] and [47] (and conjecturally \(\mathfrak {sl}_N\)-foams [45]). Note that the results from Sect. 3.1 can be easily generalized to \(\mathfrak {sl}_N\)-webs to give a growth algorithm for such \(\mathfrak {sl}_N\)-webs. In fact, we tend to argue that this basis forms somehow a “natural” basis of the \(\mathfrak {sl}_N\)-web space, which is neither the Satake basis nor Fontaine’s basis. For details about the Satake basis and about Fontaine’s basis see [20] and [21].
This paper is organized as follows.
-
(1)
We start by giving our notation for \(3\)-multipartitions in Sect. 2.1. Most notions from this section can be done in more generality, but we only need the case of \(3\)-multipartitions in this paper.
-
(2)
In Sect. 2.2 we recall Leclerc–Toffin’s basis and its relation to Kashiwara-Lusztig’s crystal bases, Khovanov-Lauda’s categorification \({\mathcal {U}}({\mathfrak {sl}}_n)\), the cyclotomic KL-R algebra and the HM-basis for it.
-
(3)
We recall \(\mathfrak {sl}_3\)-webs/foams and their connection to \(\mathbf{U}_q(\mathfrak {sl}_3)\) in Sect. 2.3.
-
(4)
In Sect. 2.4 we recall the \(\mathfrak {sl}_3\)-web algebra \(K_S\) (note that we use the conventions from [44]) and the foamation functor \(\psi :{\mathcal {U}}({\mathfrak {sl}}_n)\rightarrow \mathbf{Foam}_{3}\).
-
(5)
In the Sect. 3.1 we show that Kuperberg’s basis is indeed a monomial basis, that is, we show that it is an intermediate crystal basis in the sense of Leclerc and Toffin [40]. This includes that there is an unitriangular algorithm to compute the dual canonical basis of the web space \(W_S\) using Kuperberg’s \(\mathfrak {sl}_3\)-web basis and the Kuperberg bracket.
-
(6)
We show how one can relate flows on \(\mathfrak {sl}_3\)-webs to fillings of \(3\)-multipartitions. This gives rise to a growth algorithm for \(\mathfrak {sl}_3\)-webs with flows in the two Sects. 3.2 and 3.3. These two combinatorial sections are crucial for the rest of the paper.
-
(7)
In Sect. 3.4 we show that Brundan, Kleshchev and Wang’s degree of a tableaux [7] has a very natural interpretation as the weight of flows on \(\mathfrak {sl}_3\)-webs.
-
(8)
We give in Sect. 4.1 a growth algorithm for foams that produces a homogeneous basis of the foam space based on a categorified version of Leclerc–Toffin’s algorithm to compute the intermediate crystal basis.
-
(9)
We show that the growth algorithm for foams gives a homogeneous basis of the foam space by showing that it can be seen as a “foamy” version of Hu and Mathas graded cellular basis. Note that this includes that Brundan, Kleshchev and Wang’s degree has a very natural interpretation as the \(q\)-degree of foams (which is just a slightly modified Euler characteristic). This is done in Sect. 4.2.
-
(10)
And finally, in Sect. 4.3, we show that the growth algorithm for foams produces a graded cellular basis of \(K_S\).
-
(11)
It follows (almost) as a direct application (see Remark 4.25) that the set of simple heads of the cell (or Specht) modules \(\mathcal S\) of \(K_S\), denoted by \({\mathcal {D}}\), and the set of their indecomposable, projective covers of, denoted by \({\mathcal {P}}\), give rise to the canonical and dual canonical bases of the \(\mathfrak {sl}_3\)-web space \(W^{(*)}_S\).
It is worth noting that we give lots of examples in each section to show that everything can be done explicitly.
2 Basic notions
2.1 Combinatoric, partitions and tableaux
In this section we define/recall some combinatorial notions that we use in this paper. Note that we recall most notions only for the \(\mathfrak {sl}_3\) case, although they can be done in more generality without difficulties, see for example [25].
Choose arbitrary but fixed non-negative integers \(n\ge 2\) and \(k\le n\). Let
be the set of compositions of \(d\) of length \(n\). By \(\Lambda ^+(n,d)\subset \Lambda (n,d)\) we denote the subset of partitions, i.e. all \(\lambda \in \Lambda (n,d)\) such that
Let \(\Lambda ^{+}(n,d)_{1,2}\subset \Lambda ^{+}(n,d)\) be the subset of partitions whose entries are all \(1\) or \(2\). We use similar notions for \(\Lambda ^{+}(n,d)_{N}\) for some \(N\in {\mathbb {N}}\), that is
Recall that we can associate to each \(\lambda \in \Lambda ^+(n,d)\) a diagram for \(\lambda \)
which we, by a slight abuse of notion, denote by the same symbol \(\lambda \). The elements of a diagram are called nodes \(N\). For example, if \(\lambda =(3,2,1)\), that is \(d=6,n=3\), then

Hence, we use the English notation to denote our partitions/diagrams.
A tableau \(T\) of shape \(\lambda \) is a filling of \(\lambda \) with (possible repeating) numbers from a chosen, fixed set \(\{1,\dots ,k\}\). Such a tableau \(T\) is said to be semi-standard, if its entries increase along its rows (weekly) and columns (strictly), and column-strict, if its entries increase along its columns (no restriction on rows). For example

the tableau \(T_1\) is semi-standard, but \(T_2\) is only column-strict. We denote the set of all semi-standard tableau of shape \(\lambda \) by \(\mathrm{Std}^s(\lambda )\) and the set of all column-strict tableau of shape \(\lambda \) by \(\mathrm{Col}(\lambda )\).
Moreover, we stress that we do not assume that our tableaux have only non-repeating entries. In fact, we only assume that the number of times that an entry appears is between \(0\) and \(3\). For our \(3\)-multitableaux \(\vec {\lambda }\) (see below) we assume the same with the extra restriction that repeating entries are never in the same vector entry of \(\vec {\lambda }\) and all repeating entries are of the same residue. We note that this strange looking condition is due to the fact that we use divided powers which do not appear in the language of cyclotomic Hecke or KL-R algebras.
In the same vein, a 3-multipartition \(\vec {\lambda }\in \Lambda ^+(n,d,3)\) of \(d\) with length \(n\) is a triple of partitions \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\) with \(\lambda ^l=(\lambda ^l_1,\dots ,\lambda ^l_{n_l})\) such that their total length is \(n\) and their total sum is \(d\). As before, we can associate to each \(\vec {\lambda }\in \Lambda ^+(n,d,3)\) a diagram for \(\vec {\lambda }\)
which we, by a slight abuse of notion, denote by the same symbol \(\vec {\lambda }\). For example, if we have \(\vec {\lambda }=((3,2,1),(0),(4))\), that is \(d=10\), \(n=4\), \(\lambda ^1=(3,2,1)\), \(\lambda ^2=(0)\) and \(\lambda ^3=(4)\), then

At this point it is worthwhile to say that since both notations appear repeatedly in the literature: To distinguish between the notion of partition \(\lambda \) and components of multipartition \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\), we write latter using superscripts (and similar for multitableaux).
As before, a \(3\)-multitableau \(\vec {T}\) of shape \(\vec {\lambda }\) is a filling of \(\vec {\lambda }\) with (possible repeating) numbers from a chosen, fixed set \(\{1,\dots ,k\}\). Such a tableau \(\vec {T}\) is said to be standard, if its entries increase along its rows and columns (both strictly).
We denote the set of all standard tableau \(\vec {T}\) of shape \(\vec {\lambda }\) by \(\mathrm{Std}(\vec {\lambda })\).
As we mentioned above, we are mostly interested in \(3\)-multipartitions \(\Lambda ^+(n,d,3)\) here. But under skew Howe-duality it is necessary to consider them as \(l\)-partitions, where the \(l>0\) depends on the context. There are two natural embeddings \(\iota ^l_3,\kappa ^l_3:\Lambda ^+(n,d,3)\rightarrow \Lambda ^+(n,d,l)\) for \(l>2\), i.e.
We always use the first one \(\iota ^l_3\), since the first one fits to our other conventions. But, with a slight abuse of notation, we always think of \(\iota _3^l(\vec {\lambda })\) as a \(3\)-multipartition \(\vec {\lambda }\).
Definition 2.1
Let \(\lambda \in \Lambda ^+(n,d)\) be a partition. Then we associate to each node \(N=(r,c)\in \lambda \) of \(\lambda \) a residue \(r(N)\) by the rule \(r(N)=r-c+m\) where \(m\) is the number of non-zero entries of \(\lambda \). It should be noted that we see \(m\) as being fixed by \(\lambda \), even if we speak about addable or removable nodes.
If \(\vec {\lambda }=\{(r,c,l)\mid 0\le c\le \lambda ^l_r, 1\le r\le n_l, l=1,2,3\}\) is a \(3\)-multipartition, then we can use the same notions for each of its nodes \(N=(r,n,l)\in \vec {\lambda }\). This time \(m\) is the maximal number of non-zero entries of the components of \(\vec {\lambda }\).
An addable node \(N\) of residue \(r(N)=k\) is a node \(N\) that can be added to the diagram of \(\lambda \) such that the new diagram is still the diagram of a partition and the residue is \(r(N)=k\). We denote the set of addable nodes of residue \(k\) of \(\lambda \) by \({\mathsf {A}}^{k}(\lambda )\).
Similar, a removable node \(N\) of residue \(r(N)=k\) is a node that can be removed from the diagram of \(\lambda \) such that the new diagram is still the diagram of a partition and the residue of \(N\) is \(r(N)=k\). We denote the set of removable nodes of residue \(k\) of \(\lambda \) by \(\mathsf {R}^{k}(\lambda )\).
Again, we can use the same notions for a \(3\)-multipartition \(\vec {\lambda }\in \Lambda ^+(n,d,3)\).
Moreover, we say a node \(N=(r,c,l)\) of \(\vec {\lambda }=(\lambda ^l)_{l=1}^3\) comes before (or after) another node \(N^{\prime }=(r^{\prime },c^{\prime },l^{\prime })\) of \(\vec {\lambda }\), denoted by \(N\preceq N^{\prime }\) (or \(N\succeq N^{\prime }\)), iff \(l<l^{\prime }\) or \(l=l^{\prime }\) and \(r\le r^{\prime }\) (or \(l>l^{\prime }\) or \(l=l^{\prime }\) and \(r\ge r^{\prime }\)). We use the obvious definitions for the notions strictly before \(\prec \) and strictly after \(\succ \).
For a fixed node \(N\), we denote the set of addable nodes of \(\lambda \) before \(N\) with the same residue \(r(N)=k\) by \({\mathsf {A}}^{k\prec N}(\lambda )\) and we denote the set of addable nodes of \(\lambda \) after \(N\) with the same residue \(r(N)=k\) by \({\mathsf {A}}^{k\succ N}(\lambda )\). In the same vein, for a fixed node \(N\), we denote the set of removable nodes of \(\lambda \) before \(N\) with the same residue \(r(N)=k\) by \(\mathsf {R}^{k\prec N}(\lambda )\) and we denote the set of removable nodes of \(\lambda \) after \(N\) with the same residue \(r(N)=k\) by \(\mathsf {R}^{k\succ N}(\lambda )\).
We are mostly interested in the nodes after a given node \(N\). One would have to use the nodes before if one wants to construct a “dual” basis of the HM-basis, see [25].
Example 2.2
Let \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\) be the following \(3\)-multipartition (we have \(m=3\)).

We have filled the nodes of \(\lambda ^{1,2,3}\) with the corresponding residues. Note that the residue is constant along the diagonals.
The set of addable nodes of residue \(4\) for \(\vec {\lambda }\) and the set of removable nodes of residue \(2\) for \(\vec {\lambda }\) are given by

where we have indicated the addable nodes with a \(\cdot \) and the removable with a \(\times \). The removable node is after the first addable and before the second addable node. Moreover, in the following we demonstrate all nodes strictly before \(\prec \) and strictly after \(\succ \) a fixed node marked \(-\).

Definition 2.3
Let \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\) and \(\vec {\mu }=(\mu ^1,\mu ^2,\mu ^3)\) be two \(3\)-multipartitions in \(\Lambda ^+(n,d,3)\). Recall that \(\lambda _l=(\lambda ^l_1,\lambda ^l_2,\dots )\) and \(\mu _l=(\mu ^l_1,\mu ^l_2,\dots )\) for \(l\in \{1,2,3\}\).
We say \(\vec {\lambda }\) dominates \(\vec {\mu }\), denoted by \(\vec {\mu }\trianglelefteq \vec {\lambda }\), if
for all \(1\le l\le 3\) and \(1\le s\). We write \(\vec {\mu }\lhd \vec {\lambda }\), if \(\vec {\mu }\unlhd \vec {\lambda }\) and \(\vec {\mu }\ne \vec {\lambda }\). It is easy to check that \(\unlhd \) is a partial ordering of the set of all \(3\)-multipartitions \(\Lambda ^+(n,d,3)\), called the dominance order.
This order can be extended to \(3\)-multitableaux in the following way. Suppose we have two standard \(3\)-multitableaux \(\vec {T}_1\in \mathrm{Std}(\vec {\lambda })\) and \(\vec {T}_2\in \mathrm{Std}(\vec {\mu })\) with \(k\) nodes filled with numbers from \(\{1,\dots ,k\}\) (no repetitions). As in Definition 3.16, we denote the corresponding \(3\)-multipartitions after removing all nodes with entries higher than \(j\in \{1,\dots ,k\}\) by \(\vec {\mu }^j\) and \(\vec {\lambda }^j\). Then
To extend it to all, i.e. allowing repetitions, \(3\)-multitableaux we use a special \(3\)-multitableaux \(\vec {T}^{\prime }\) associated to \(\vec {T}\) by inductively replacing repeating entries from left to right, e.g.

Then we can use the same rules as before.
Given \(\vec {\lambda }\in \Lambda ^+(n,d,3)\) we can associate to it a unique standard \(3\)-multitableau \(T_{\vec {\lambda }}\in \mathrm{Std}(\vec {\lambda })\) with the property
Note that \(T_{\vec {\lambda }}\) is easily seen to be the tableau with all entries in order from top to bottom and left to right.
Example 2.4
Given the same \(3\)-multipartition as later in Example 3.14 part (b), i.e.

we see that

It will dominate all \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\). For example

will be dominated, since

Definition 2.5
Let \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) be a \(3\)-multitableau. The residue sequence of \(\vec {T}\), denoted by \(r(\vec {T})\) is the \(k\)-tuple whose \(j\in \{1,\dots ,k\}\) entry is the residues of the node with number \(j\). Moreover, the residue sequence of a \(3\)-multitableau \(\vec {\lambda }\), denoted by \(r(\vec {\lambda })\), is defined to be \(r(\vec {\lambda })=r(T_{\vec {\lambda }})\). Note that, since we only use \(3\)-multitableaux whose repeating numbers are of the same residue, the notion makes sense for or notion of \(3\)-multitableaux.
2.2 Intermediate crystal bases and categorified quantum algebras
In this section we shortly recall Leclerc–Toffin’s definition of an intermediate crystal basis, of which we think as a basis sitting in between the lower global (in the sense of Kashiwara) crystal bases \(b_T\) (also called canonical basis in the sense of Lusztig) and the standard basis \(e_{T^{\prime }}\). Then we recall the notion of Khovanov and Lauda’s categorification of \(\dot{{\mathbf{U}}}_q(\mathfrak {sl}_n)\) (recall that this is Beilinson, Lusztig and MacPherson idempotented form [2]), denoted by \({\mathcal {U}}({\mathfrak {sl}}_n)\), and the notion of Khovanov-Lauda and Rouquier algebras (KL-R for short) and Hu–Mathas graded cellular basis for latter.
We stress that we really only recall everything very briefly. Much more details can be found for example in the references we give below.
Moreover, we do not recall \(q\)-skew Howe duality or the representation theory of \({\mathbf{U}}_q(\mathfrak {gl}_n)\) and \({\mathbf{U}}_q(\mathfrak {sl}_n)\)-tensors, because we want to keep the length of this paper in a reasonable boundary. Details concerning \(q\)-skew Howe duality (or even more, i.e. a nice survey about it) can for example be found in the paper by Cautis, Kamnitzer and Morrison [13] and, for example in Mackaay’s paper [43], the reader can find a good discussion how tensor products and certain bases behave under \(q\)-skew Howe duality. We note that we use the conventions of [44] (with \(E_{-i}=F_i\)) and we hope that the reader does not get confused, since some authors use different conventions, e.g. a different quantum parameter \(v=-q^{-1}\).
2.2.1 Intermediate crystal bases
Note that a similar section can be found in [43], since Mackaay also uses in his paper [43] the intermediate crystal basis under \(q\)-skew Howe duality.
Let us denote by \(V_{\Lambda }\) the irreducible \(\dot{\mathbf{U}}_q(\mathfrak {sl}_n)\)-representation of highest weight \(\Lambda =(3^\ell )\). There is a particular nice basis of \(V_{\Lambda }\) called the lower global crystal basis (or canonical basis). Since we do not need it explicitly here, we do not recall the definition. Details can be found in [24] or [42] for example. We denote the canonical basis of \(V_{\Lambda }\), which is parametrized by \(\mathrm{Std}^s(3^{\ell })\) Footnote 1, by
In contrast to the standard basis \(\{e_{T^{\prime }}\in \Lambda _q^{\ell }(\mathbb {C}_q^n)^{\otimes 3}\mid T^{\prime }\in \mathrm{Col}(3^{\ell })\}\), which is easy to write down, but has not a very good behavior under the action, the lower global crystal basis is very hard to find, but has a very good behavior. Note that, as pointed out in [43], \(q\)-skew Howe duality turns \(b_T\mapsto b^*_T\) and vice versa, that is, the canonical basis of \(V_{\Lambda }\) turns under \(q\)-skew Howe duality to the \(\dot{{\mathbf{U}}}_q(\mathfrak {sl}_3)\)-dual canonical basis \(\mathrm{dcan}(W_{\Lambda })=\{b^*_T\mid T\in \mathrm{Std}^s(3^{\ell })\}\) of the \(\mathfrak {sl}_3\)-web space \(W_{\Lambda }\).
Leclerc and Toffin [40] defined a different basis of \(V_{\Lambda }\), denoted by \(B_{\Lambda }\), parametrized by the elements in \(\mathrm{Std}^s(3^{\ell })\) (as Kashiwara-Lusztig’s lower global crystal basis). It is also called the intermediate crystal basis. It is much easier to write down than the lower global crystal basis and Leclerc and Toffin [40] gave an inductive algorithm how to compute \(\mathrm{can}(V_{\Lambda })\) from \(B_{\Lambda }\). We recall their definition of \(B_{\Lambda }\) now very briefly (we should admit that we do not recall the details about the notation here, but they are not important for us in this paper. A good discussion can be found in [43]).
Given \(T\in \mathrm{Std}^s(3^{\ell })\), let us recall how to obtain the Leclerc–Toffin (or short LT Footnote 2) basis element \(A_T\in B_{\Lambda }\). Let \(1\le i_1\le \ell \) be the smallest number such that the rows of \(T=T_1\) with row number \(\le i_1\) (where we number the rows starting with \(1\) from top to bottom in our convention) contain numbers equal to \(i_1+1\). We denote the total number of such entries by \(j_1>0\). Lower these entries to \(i_1\) and denote the new tableau by \(T_2\in \mathrm{Std}^s(3^{\ell })\) (this tableau will still be semi-standard). Continue until one obtains after \(s\)-steps a tableau \(T_s\) whose entries are exactly the row numbers. The element \(A_T\) is defined by (\(F_{b}^{(a)}=\frac{F^a_b}{[a]!}\) is the divided power with the quantum integer \([a]=\frac{q^{a}+q^{-a}}{q+q^{-1}}\))
These basis elements are fixed under the bar involution.
One can easily work out the expansion of \(A_T\) on the standard basis \(e_{T^{\prime }}\) of \(\Lambda _q^{\ell }(\mathbb {C}_q^n)^{\otimes 3}\) (the quantum exterior power—details can be found in [13] or [43]). Leclerc and Toffin showed (i.e. Lemma 9 in [40]) that
with \(T^{\prime }\in \mathrm{Col}(3^{\ell })\) and certain \(\alpha _{T^{\prime }}(v)\in {\mathbb {N}}[v,v^{-1}]\) (with \(v=-q^{-1}\)). Here \(\prec \) denotes the lexicographical ordering on column-strict tableaux: For a column-strict tableaux \(T\) we define the column-word \(co(T)=(c_1,\dots ,c_{3\ell })\) to be a sequence of the entries of the columns of \(T\) read from top to bottom and then from left to right. Note that this sequence has length \(m\ell \). Then the set \(\mathrm{Col}(3^{\ell })\) is partial order by
Since we tend to use \(3\)-multipartitions and \(3\)-multitableaux instead let us state what this means in our notation. A column-strict tableaux \(T\) of shape \((3^{\ell })\) corresponds to a \(3\)-multipartition \(\vec {\lambda }\) by subtracting from each row its number and obtain a new column-strict tableaux \(\tilde{T}\). Read the \(k\)-th column from bottom to top to obtain in this way the \(k\)-th partition \(\lambda ^k\) of \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\). It is easy to see that this process is in fact invertible.
Write \(\vec {\lambda }_T\) for the corresponding \(3\)-multipartition. Then \(T\le T^{\prime }\) iff \(\vec {\lambda }_{T}\trianglelefteq \vec {\lambda }_{T^{\prime }}\), where \(\trianglelefteq \) is the dominance order from Definition 2.3. As a small example consider the following.

Moreover, there is an algorithm to obtain the canonical basis \(\mathrm{can}(V_{\Lambda })\) which uses \(B_{\Lambda }\) as an intermediate basis. Leclerc and Toffin showed (i.e. Sect. 4.2 in [40]) that
with \(T^{\prime \prime }\in \mathrm{Std}^s(3^{\ell })\) for certain bar-invariant (!) coefficients \(\beta _{T^{\prime \prime }T}(v)\in \mathbb {Z}[v,v^{-1}]\).
It is worth noting that a slight change in the definition of \(B_{\Lambda }\), i.e. changing the rules which entries are to replaced, one get similar results as above. In fact, in this paper we use such a slight change. We call such these basis, by a slight abuse of notation, still LT-bases or of LT-type. Under \(q\)-skew Howe duality, as explained in Sect. 3.1, this basis turns out to be Kuperberg’s basis of \(\mathfrak {sl}_3\)-webs. Moreover, it changes the underlying space \(\Lambda _q^{\ell }(\mathbb {C}_q^n)^{\otimes 3}\) to \(\Lambda _q^{\bullet }(\mathbb {C}_q^3)^{\otimes n}\).
2.2.2 The special quantum 2-algebras
Khovanov and Lauda (Rouquier introduced independently similar notions [50]) introduced diagrammatic \(2\)-categories \({\mathcal {U}}(\mathfrak {g})\) which categorify the integral version of the corresponding idempotented quantum groups [35].
Cautis and Lauda [14] defined diagrammatic \(2\)-categories \({\mathcal {U}}_Q(\mathfrak {g})\) with implicit scalers \(Q\) consisting of \(t_{ij}\), \(r_i\) and \(s_{ij}^{pq}\) which determine certain signs in the definition of the categorified quantum groups.
In this section, we very briefly recall \({\mathcal {U}}(\mathfrak {sl}_n)={\mathcal {U}}_Q(\mathfrak {sl}_n)\). Much more can be found in the papers cited above. The scalars \(Q\) are given by \(t_{ij}=-1\) if \(j=i+1\), \(t_{ij}=1\) otherwise, \(r_i=1\) and \(s_{ij}^{pq}=0\). This corresponds precisely to the signed version in [35, 36]. For simplicity we work with \(\mathbb {C}\) as an underlying field.
Definition 2.6
(Khovanov–Lauda) The \(2\)-category \({\mathcal {U}}({\mathfrak {sl}}_n)\) is defined as follows.
-
The objects in \({\mathcal {U}}({\mathfrak {sl}}_n)\) are the weights \(\lambda \in \mathbb {Z}^{m-1} \).
For any pair of objects \(\lambda \) and \(\lambda ^{\prime }\) in \({\mathcal {U}}({\mathfrak {sl}}_n)\), the hom category \({\mathcal {U}}({\mathfrak {sl}}_n)(\lambda ,\lambda ^{\prime })\) is the \(\mathbb {Z}\)-graded, additive \(\mathbb {C}\)-linear category consisting of the following data.
-
Objects (or \(1\)-morphisms in \({\mathcal {U}}({\mathfrak {sl}}_n)\)), that is finite formal sums of the form \(\mathcal {E}_{{\underline{i}}}{\mathbf{1}}_{\lambda }\{t\}\) where \(t\in \mathbb {Z}\) is the grading shift and \({\underline{i}}\) is a signed sequence such that \(\lambda ^{\prime }=\lambda +\sum _{a=1}^{l}\epsilon _ai_{a}^{\prime }\).
-
The morphisms or \(2\)-cells are graded, \(\mathbb {C}\)-vector spaces generated by compositions of diagrams shown below. Here \(\{k\}\) denotes a degree shift by \(k\). Moreover, we use the two shorthand notations \(\alpha ^{ij}=(\alpha _i,\alpha _j)\) and \(\alpha ^{\lambda i}=2\frac{(\lambda ,\alpha _i)}{(\alpha _i,\alpha _i)}\).

with \(\phi _1=\mathrm{id}_{{\mathcal {E}}_{i}\mathbf{1}_{\lambda }}\), \(\phi _2:{\mathcal {E}}_{i}\mathbf{1}_{\lambda }\Rightarrow {\mathcal {E}}_{i}\mathbf{1}_{\lambda }\{\alpha ^{ii}\}\), \(\phi _3:{\mathcal {E}}_{i}{\mathcal {E}}_{j}\mathbf{1}_{\lambda }\Rightarrow {\mathcal {E}}_{j}{\mathcal {E}}_{i}\mathbf{1}_{\lambda }\{\alpha ^{ij}\}\) and cups and caps \(\phi _4:\mathbf{1}_{\lambda }\{\frac{1}{2}\alpha ^{ii}+\alpha ^{\lambda i}\}\Rightarrow {\mathcal {E}}_{i}{\mathcal {F}}_{i}\mathbf{1}_{\lambda }\) and \(\phi _5:\mathbf{1}_{\lambda }\{\frac{1}{2}\alpha ^{ii}-\alpha ^{\lambda i}\}\Rightarrow {\mathcal {F}}_{i}{\mathcal {E}}_{i}\mathbf{1}_{\lambda }\). Moreover, we have diagrams of the form

with \(\psi _1=\mathrm{id}_{{\mathcal {F}}_{i}\mathbf{1}_{\lambda }}\), \(\psi _2:{\mathcal {F}}_{i}\mathbf{1}_{\lambda }\Rightarrow {\mathcal {F}}_{i}\mathbf{1}_{\lambda }\{\alpha ^{ii}\}\), \(\psi _3:{\mathcal {F}}_{i}{\mathcal {F}}_{j}\mathbf{1}_{\lambda }\Rightarrow {\mathcal {F}}_{j}{\mathcal {F}}_{i}\mathbf{1}_{\lambda }\{\alpha ^{ij}\}\) and cups and caps \(\psi _4:{\mathcal {F}}_{i}{\mathcal {E}}_{i}\mathbf{1}_{\lambda }\Rightarrow \mathbf{1}_{\lambda }\{\frac{1}{2}\alpha ^{ii}+\alpha ^{\lambda i}\}\) and \(\psi _5:{\mathcal {E}}_{i}{\mathcal {F}}_{i}\mathbf{1}_{\lambda }\Rightarrow \mathbf{1}_{\lambda }\{\frac{1}{2}\alpha ^{ii}-\alpha ^{\lambda i}\}\).


The relations on the \(2\)-morphisms are those of the signed version in [35, 36]. The convention for reading these diagrams is from right to left and bottom to top. The \(2\)-cells should satisfy several relation which we will not recall here. Details can be for example found in Cautis and Lauda’s paper [14].
2.2.3 The cyclotomic KL-R algebras
In this subsection, we recall the definition of the cyclotomic KL-R algebras, due to Khovanov and Lauda [33, 34] and, independently, to Rouquier [50]. We also very shortly recall Hu and Mathas graded cellular basis [25] for these algebras of type \(A\).
Let \(\Lambda \) be a dominant \(\mathfrak {sl}_n\)-weight, \(V_{\Lambda }\) the irreducible \(\dot{\mathbf{U}}_q(\mathfrak {sl}_n)\)-module of highest weight \(\Lambda \) and \(P_{\Lambda }\) the set of weights in \(V_{\Lambda }\).
Definition 2.7
(Khovanov–Lauda, Rouquier) The cyclotomic KL-R algebra \(R_{\Lambda }\) is the subquotient of \({\mathcal {U}}({\mathfrak {sl}}_n)\) defined by the subalgebra of all diagrams with only downward oriented strands and right-most region labeled \(\Lambda \) and modded out by the ideal generated by all diagrams of the form

This relation is known as the cyclotomic relation.
Note that
where \(R_{\Lambda }(\mu )\) is the subalgebra generated by all diagrams whose left-most region is labeled \(\mu \). It is not clear from the definition what the dimension of \(R_{\Lambda }\) is. Moreover, it is not clear that \(R_{\Lambda }\) is finite dimensional, but Brundan and Kleshchev proved that \(R_{\Lambda }\) is indeed finite dimensional [4].
Note that we mod out by relations involving dots on the last strand, rather than the first strand as in [33] to make it consistent with our other conventions in this paper.
It is worth noting that if we draw pictures for the KL-R algebra, then we do not need orientations anymore, that is pictures will look like

In [25] Hu and Mathas gave a graded cellular basis of the KL-R algebra \(R_{\Lambda }\) (or \(R^n_{c(S)}\) in their notation). We do not recall their definition here, since it is not short and we give an alternative definition using foams later. The reader is encouraged to take a look in their great paper. We call their basis HM-basis. We only mention that their basis is parametrized by \(\vec {\lambda }\in \Lambda ^+(n,c(S),l)\), i.e. all \(l\)-multipartitions of \(c(S)\) for all suitable \(n,l\), and \(\vec {T},\vec {T}^{\prime }\in \mathrm{Std}(\vec {\lambda })\), i.e. standard \(l\)-multitableaux in the KL-R sense without repeating entries. They denote their basis by
where \(\mathfrak {P}_{c(S)}\) is the set of all multipartitions of \(c(S)\). Moreover, it is graded by
where the degree is Brundan et al. degree given in [7], which we recall in 3.28. We note that \(n\) in our context will be the number of strands of a given web (see next section) and \(c(S)\) is as in 2.11. It is worth noting that we restrict to the easiest case, i.e. the linear quiver over \(\mathbb {C}\), but much more is known about HM-basis, see for example [26] or [41] for a version over \(\mathbb {Z}\).
2.3 Webs and foams
We are going to recall the notions of \(\mathfrak {sl}_3\)-webs and foams in this section. Nothing here is new, i.e. the whole section is literally copied from [44] (up to some small changes) and the results are mostly from either [32] or [38] in the case of webs or [28] and [46] for the foams. As before, we only briefly recall the different notions and much more can be found in the papers mentioned above.
In [38], Kuperberg describes the representation theory of \({\mathbf{U}}_q(\mathfrak {sl}_3)\) using oriented trivalent graphs, possibly with boundary, called webs or \(\mathfrak {sl}_3\)-webs. Boundaries of webs consist of univalent vertices (the ends of oriented edges), which we will usually put on a horizontal line (or various horizontal lines), called the cut-line, and that we usually picture by a dotted line, e.g. such a web is shown below.

We say that a web has \(n\) free strands if the number of non-trivalent vertices is exactly \(n\). In this way, the boundary of a web can be identified with a sign string \(S=(s_1,\ldots ,s_n)\), with \(s_i=\pm \), such that upward oriented boundary edges get a “\(+\)” and downward oriented boundary edges a “\(-\)” sign. Webs without boundary are called closed webs.
Fixing a boundary \(S\), we can form the \({\mathbb {C}}(q)\)-vector space \(W_S\), spanned by all webs with boundary \(S\), modulo the following set of local relations or Kuperberg relations [38].



Here
denotes the quantum integer. Note that we sometimes do not orient our webs. In all those cases the orientation does not matter and is therefore not pictured.
By abuse of notation, we will call all elements of \(W_S\) webs. From relations (2.6), (2.7) and (2.8) it follows that any element in \(W_S\) is a linear combination of webs with the same boundary and without circles, digons or squares. These are called non-elliptic webs. As a matter of fact, the non-elliptic webs form a basis of \(W_S\), which we call \(B_S\). Therefore, we will simply call them basis webs or Kuperberg’s basis webs or LT-basis webs (we explain the name in Sect. 3.1).
Following Brundan and Stroppel’s [8] notation for arc diagrams, we will write \(w^*\) to denote the web obtained by reflecting a given web \(w\) horizontally and reversing all orientations. Moreover, by \(uv^*\), we mean the planar diagram containing the disjoint union of \(u\) and \(v^*\), where \(u\) lies vertically above \(v^*\). By \(v^*u\), we shall mean the closed web obtained by glueing \(v^*\) on top of \(u\), when such a construction is possible (i.e. the number of free strands and orientations on the strands match).

It should be noted that we usually use the symbol \(w\) for any web, closed or with boundary, while we use the symbols \(u,v\) for half-webs, that is \(w=u^*v\) for suitable webs \(u,v\in B_S\).
To make the connection with the representation theory of \({\mathbf{U}}_q(\mathfrak {sl}_3)\), we recall that a sign string \(S=(s_1,\ldots ,s_n)\) corresponds to
where \(V_{+}\) is the fundamental representation and \(V_{-}\) its dual. Both \(V_+\) and \(V_-\) have dimension three. In this interpretation, webs correspond to intertwiners and
Therefore, the elements of \(B_S\) give a basis of \(\mathrm{Inv}_{{\mathbf{U}}_q(\mathfrak {sl}_3)}(V_S)\). However, this basis is not equal to the usual tensor basis nor to the dual canonical basis, see [32]. Moreover, in [44] it was proved that Kuperberg’s web basis and the dual canonical basis are related by a unitriangular change of basis matrix. The proof follows from categorification. We will reproduce this result without using categorification in Corollary 3.7.
Kuperberg showed in [38] (see also [32]) that basis webs are indexed by closed weight lattice paths in the dominant Weyl chamber of \(\mathfrak {sl}_3\). It is well-known that any path in the \(\mathfrak {sl}_3\)-weight lattice can be presented by a pair consisting of a sign string \(S=(s_1,\ldots ,s_n)\) and a state string \(J=(j_1,\ldots ,j_n)\), with \(j_i\in \{-1,0,1\}\) for all \(1\le i\le n\). Given a pair \((S,J)\) representing a closed dominant path, a unique basis web (up to isotopy) is determined by a set of inductive rules called the growth algorithm. We do not need it here explicitly, but it should be noted that Khovanov and Kuperberg showed in [32], that the growth algorithm is independent of the involved choices. A result that we need later in Sect. 3.1. The growth algorithm gives the basis \(B_S\).
Following Khovanov and Kuperberg in [32], we define a flow or flow line \(f\) on a web \(w\) to be an oriented subgraph that contains exactly two of the three edges incident to each trivalent vertex. At the boundary, the flow lines can be represented by a state string \(J\). By convention, at the \(i\)-th boundary edge, we set \(j_i=+1\) if the flow line is oriented downward, \(j_i=-1\) if the flow line is oriented upward and \(j_i=0\) there is no flow line. The same convention determines a state for each edge of \(w\). We will also say that any flow \(f\) that is compatible with a given state string \(J\) on the boundary of \(w\) extends \(J\).
Given a web with a flow, denoted \(w_f\), Khovanov and Kuperberg [32] attribute a weight to each trivalent vertex and each arc in \(w_f\), as in Figures 2.9 and 2.10. The total weight of \(w_f\) is by definition the sum of the weights at all trivalent vertices and arcs.


For example, the following web has weight \(-4\).

We will show later in Sect. 3.4 that Brundan, Kleshchev and Wang’s degree of a multitableau has, after translating it using \(q\)-skew Howe duality, a very natural interpretation as (minus) the weight of a flow \(f\) on a fixed web \(w\).
We choose arbitrary but fixed non-negative integers \(n\ge 2\) and \(\ell \le n\), such that \(d=3\ell \ge n\). Recall \(\Lambda (n,d)=\left\{ \lambda \in \mathbb {N}^n\mid \sum _{i=1}^n\lambda _i=d\right\} \).
Recall that a flow on the line on the boundary of a web, i.e. a pair of a sign string \(S\) and a state string \(J\), can be encoded using column-strict tableaux \(\mathrm{Col}(\lambda )\). Here \(\lambda =(3^{\ell })\in \Lambda (n,d)\) and for any sign string \(S=(s_1,\dots ,s_n)\) the number \(s_k\) appears with multiplicity one or two depending on the sign string \(S\), see [44]. To be precise, in [44] we showed the following. We note that the restriction to the canonical flow gives semi-standard tableaux. Therefore, non-elliptic webs can be associated \(1:1\) with semi-standard tableaux, a fact that was already known before (we note that some authors, e.g. Russell [52], use different reading conventions).
Proposition 2.8
There is a bijection between \(\mathrm{Col}(\lambda )\) and the set of state strings \(J\) such that there exists a web \(w\in B_S\) and a flow \(f\) on \(w\) which extends \(J\).
Example 2.9
All of the three webs with flow

belong to the same tableau, i.e. the unique one for the sign string and state string pair \((S,J)\) with \(S=(+,-,+,-,+,-)\) and \(J=(0,0,0,0,0,0)\), that is

We need the following constant. For each \(S=(s_1,\dots ,s_n)\) with \(3\ell =n_++2n_-\) define
Moreover, Khovanov and Kuperberg defined a special flow on basis webs, called the canonical flow. See [32]. We do not need it here in much detail, but it is important to note that the pair of a sign string and state string \((S,J)\) for a web \(w\) under the identification with its corresponding tableau gives a semi-standard tableau. See [44] for more details. We denote usually a web \(w\) with its unique canonical flow by \(w_c\).
For another connection to representation theory, recall the following. Let \(e^{\pm }_{-1,0,+1}\) be the standard basis of \(V_{\pm }.\) Given \((S,J)\), let
be the elementary tensor. Khovanov and Kuperberg proved the following result (Theorem 2 in [32]) which we will reprove later. Note that we work with \(q\) instead of \(v=-q^{-1}\) as in [32].
Theorem 2.10
(Khovanov–Kuperberg) Given \((S,J)\), we have
for some coefficients \(c(S,J,J^{\prime })\in \mathbb {N}[v,v^{-1}]\), where the state strings \(J\) and \(J^{\prime }\) are ordered lexicographically.
We shortly review the category called \(\mathbf{Foam}_{3}\) of \(\mathfrak {sl}_3\)-foams introduced by Khovanov in [28] (these can be seen as a \(\mathfrak {sl}_3\) version of Bar-Natan’s \(\mathfrak {sl}_2\)-cobordism [1]). It is worth noting that Blanchet has proposed in [3] a slightly different foam category and it seems to be easier to work out the signs following his approach (as for example in [39]). But we, old-school as we are, do not use his setting here. Moreover, we only need the graded version in this paper. So we do not recall for example Gornik’s filtered version here. For more details see [22].
We recall the following definitions as they appear in [46]. We note that the diagrams accompanying these definitions are taken, also, from [46].
A pre-foam is a cobordism with singular arcs between two webs. A singular arc in a pre-foam \(U\) is the set of points of \(U\) which have a neighborhood homeomorphic to the letter Y times an interval. Note that singular arcs are disjoint. Interpreted as morphisms, we read pre-foams from bottom to top by convention. Thus, pre-foam composition consists of placing one pre-foam on top of the other. The orientation of the singular arcs is, by convention, as in the diagrams below (called the zip and the unzip respectively).

We allow pre-foams to have dots that can move freely about the facet on which they belong, but we do not allow a dot to cross singular arcs.
By a foam, we mean a formal \({\mathbb {C}}\)-linear combination of isotopy classes of pre-foams modulo the ideal generated by the set of relations \(\ell =(3D,NC,S,\Theta )\) and the closure relation, as described below.

The closure relation, i.e. any \({\mathbb {C}}\)-linear combination of foams with the same boundary, is equal to zero iff any way of capping off these foams with a common foam yields a \({\mathbb {C}}\)-linear combination of closed foams whose evaluation is zero.
The relations in \(\ell \) imply some identities (for detailed proofs see [28]). We only recall a few here that we need later on. More can be found in [28].

Definition 2.11
Let \(\mathbf{Foam}_{3}\) be the category whose objects are webs \(\Gamma \) lying inside a horizontal strip in \(\mathbb {R}^2\), which is bounded by the lines \(y=0,1\) containing the boundary points of \(\Gamma \). The morphisms of \(\mathbf{Foam}_{3}\) are \({\mathbb {C}}\)-linear combinations of foams lying inside the horizontal strip bounded by \(y=0,1\) times the unit interval. We require that the vertical boundary of each foam is a set (possibly empty) of vertical lines.
The \(q\)-degree of a foam \(F\) is defined as
where \(\chi \) denotes the Euler characteristic, \(d\) is the number of dots and \(b\) is the number of vertical boundary components. This makes \(\mathbf{Foam}_{3}\) into a graded category. We show later, using \(q\)-skew Howe duality, that the \(q\)-degree \(\mathrm{deg}_q\) is Brundan, Kleshchev and Wang’s degree \(\mathrm{deg}_{BKW}\).
Definition 2.12
(Foam homology) Given a web \(w\) the foam homology of \(w\) is the complex vector space, \(\mathcal {F}(w)\), spanned by all foams
in \(\mathbf{Foam}_{3}\).
Remark 2.13
The complex vector space \(\mathcal {F}(w)\) is graded by the \(q\)-degree on foams and has \(q\)-rank \(\langle w\rangle \), where \(\langle w\rangle \) is the Kuperberg bracket. See [28] or [46] for details.
2.4 The \(\mathfrak {sl}_3\)-web algebra
We are going to recall the definition of the \(\mathfrak {sl}_3\)-web algebra \(K_S\) as given in [44]. For the rest of the section let \(S\) denote a fixed sign string of length \(n\).
Definition 2.14
(\(\mathfrak {sl}_3\)-web algebra) For \(u,v\in B_S\), we define
where \(\{n\}\) denotes a grading shift upwards in degree by \(n\).
The \(\mathfrak {sl}_3\)-web algebra \(K_S\) is defined by
The multiplication on \(K_S\) is defined by taking
to be zero, if \(v_1\ne v_2\), and by the map to be defined as in [44] if \(v_1=v_2=v\).
We use the following lemma throughout the whole paper.
Lemma 2.15
For any \(u,v\in B_S\), we have a grading preserving isomorphism
Using this isomorphism, the multiplication
corresponds to the composition
if \(v=v^{\prime }\), and is zero otherwise.
Proof
See [44]. \(\square \)
Remark 2.16
Lemma 2.15 shows that \(K_S\) is an associative, unital algebra. Moreover, completely similar as in [44], the algebra \(K_S\) is a graded Frobenius algebra of Gorenstein parameter \(n\). We do not need this fact in this paper, so the interested reader can find the details in [44].
Note that for any \(u\in B_S\), the identity \(1_u\in \mathbf{Foam}_{3}(u,u)\) defines an idempotent. We have
Alternatively, one can see \(K_S\) as a category whose objects are the elements in \(B_S\) such that the module of morphisms between \(u\in B_S\) and \(v\in B_S\) is given by \(\mathbf{Foam}_{3}(u,v)\).
Moreover, there is a graded, linear involution on \(K_S\) denoted
that reflects the foams along the xy-plane and reorient the edges afterwards. For example

Remark 2.17
The algebra has a basis given by the so-called face removing algorithm as explained in [56]. We do not know much about this basis except that it is easy to compute. We do not need it here and do not recall it, but it is worth noting that it is possible to prove Theorem 4.18 “by hand”, i.e. use induction on the number of faces and show that the corresponding moves are “almost” face removing moves.
We will now briefly recall an instance of \(q\)-skew Howe duality, the so-called foamation functor. We will refer to the application of this functor on the level of webs and foams, depending on the context, by saying “using foamation” or by abuse of language “by q-skew Howe duality”. The hope that the reader does not get confused.
We note that such a functor was independently studied by Lauda, Queffelec and Rose [39] with a slightly different convention than the one we recall from [44].
Let us denote by \(K_S\text {-}\mathrm{(p)\mathbf{Mod}}_{\mathrm{gr}}\) the category of all finite dimensional, (projective), unitary, graded \(K_S\)-modules. Recall that we need a slightly generalization of a sign string called enhanced sign string. With a slight abuse of notation, we use \(S\) for enhanced sign strings. Fix \(d=3\ell \).
Definition 2.18
An enhanced sign string is a sequence denoted by \(S=(s_1,\ldots , s_n)\) with entries \(s_i\in \{\circ ,-1,+1,\times \}\), for all \(i=1,\ldots n\). The corresponding weight \(\mu =\mu _S\in \Lambda (n,d)\) is given by the rules
Let \(\Lambda (n,d)_3\subset \Lambda (n,d)\) be again the subset of weights with entries between \(0\) and \(3\).
Define
and
Recall that there exists a categorical \({\mathcal {U}}({\mathfrak {sl}}_n)\)-action on \({\mathcal W}^{(p)}_{(3^{\ell })}\), called foamation.
Definition 2.19
(\(\mathfrak {sl}_3\)-foamation) We define a \(2\)-functor
called foamation, in the following way. Recall that we read \({\mathcal {U}}({\mathfrak {sl}}_n)\) diagrams from right to left—this will correspond to reading webs from bottom to top.
On objects: The functor is defined by sending an \(\mathfrak {sl}_n\)-weight \(\lambda =(\lambda _1,\dots ,\lambda _{n-1})\) to an object \(\psi (\lambda )\) of \({\mathcal W}_{(3^{\ell })}\) by
and to zero if no such enhanced sign string \(S\) exists. Note that, if such an \(S\) exists, then it is unique.
On morphisms: The functor on morphisms is defined to be the algebra homomorphism of \(\mathbb {C}\)-algebras defined by glueing the following webs on top of the \(\mathfrak {sl}_3\)-webs in \(W_{(3^{\ell })}\).

If the boundary values \(a_i\) are \(a_i\notin \{0,1,2,3\}\), then we send the morphism to zero. We use the convention that vertical edges labeled 1 are oriented upwards, vertical edges labeled 2 are oriented downwards and edges labeled 0 or 3 are erased. Note that the orientation of the horizontal edges is uniquely determined by the orientation of the vertical edges, e.g. a H-move from an \(E\) is always orientated from right to left and a H-move from a \(F\) from left to right.
On \(2\)-cells: Note our conventions. We only draw the most important part of the foams, omitting partial identity foams. We only mention the most important ones here. See [44] for the full list. Note that our drawing conventions in this paper are slightly different from those in [44], i.e. we have rotated the foams by \(\frac{\pi }{2}\) clockwise around the y-axis.
-
(1)
The bottom (top) part of the string diagram in \({\mathcal {U}}({\mathfrak {sl}}_n)\) is represented by the web at the bottom (top) of the foam.
-
(2)
Glueing a \({\mathcal {U}}({\mathfrak {sl}}_n)\) diagram on top of another corresponds to gluing a foam on top of the other.
-
(3)
In our string diagram conventions an upwards pointing arrow represents an \(E\). Hence, on the level of webs, such H-moves have to point to the bottom left.
-
(4)
We only draw some of the orientations in the pictures. The rest are fixed by the ones drawn following the conventions in [44]. They are not so important here, so we will not recall them.
-
(5)
A facet is labeled 0 or 3 if and only if its boundary has edges labeled 0 or 3.
-
(6)
All facets labeled 0 or 3 in the images below have to be erased, in order to get real foams.
-
(7)
For any \(\lambda >(3^{\ell })\), the image of the elementary morphisms below is taken to be zero, by convention.
In the list below, we always assume that \(i<j\).

Proposition 2.20
The foamation
is a well-defined strong \(2\)-representation in the sense of [14].
Proof
See [44] or with a slightly different setting [39]. \(\square \)
It is worth noting that the foamation functor descends to the KL-R algebra by taking only downwards pointing arrows in a good way, see Cautis and Lauda [14] or Lauda, Queffelec and Rose [39] for more details. There is also a version for the extended graphical calculus from [37] and we conjecture that using it could make some of the later arguments easier.
Moreover, for \(N>3\) Mackaay and Yonezawa give a version of the foamation using matrix factorizations [47]. Conjecturally, there should also be a foamation using \(N>3\)-foams (see [45]).
3 The uncategorified picture
3.1 Web bases and intermediate crystal bases
We are going to show in this section that Kuperberg’s web basis \(B_S\) is in fact an intermediate crystal basis, i.e. we show that it can be obtained from a Leclerc–Toffin likeFootnote 3 algorithm using \(q\)-skew Howe duality, i.e. use the foamation \(2\)-functor \(\psi \) from Definition 2.19 on the level of webs and let the divided powers act on the highest weight vector \(v_{3^{\ell }}\).
Throughout the whole section we assume that all partitions \(\lambda \) are partitions of \(3\ell \) for some \(\ell \), i.e. \(\lambda \in \Lambda ^+(n,3\ell )\), and \(S\) denotes a sign string of length \(n\) such that \(n_++2n_-=3\ell \), where \(n_+,n_-\) denote the number of \(+,-\) of \(S\).
Definition 3.1
Let \(T\in \mathrm{Std}^s(\lambda )\subset \mathrm{Col}(\lambda )\) denote a semi-standard tableau. We associate to each such \(T\) a string of divided powers of \(F\) which we call the LT-generators of \(T\) and we denote it by
The rule to obtain the string is as follows. We have two different kinds of rules, i.e. the usual and the extraordinary rules. We generate the string of \(F\)’s inductively using these rules.
Start with the empty product \(\mathrm{LT}(T)_0=1\) and set \(T_0=T\). Assume that we are in the \(k\)-th step. Search for the lowest entry of \(T_k\) which is below its own row and not in a forbidden position, i.e. a position such that lowering this entry by one does not lead to a semi-standard tableau any more.
Note that we use for simplicity \(2\) for this entry in the following definition and we only picture the important parts of the tableau. As long as the tableau \(T_k\) is not of the form

where the \(3^{\prime }\) should indicate that there is at least one \(3\) in the first column, we use the usual rules, that is, replace all \(j_k\) occurrences of \(2\) below its own row by \(1\) and obtain a new tableau
and a longer string \(\mathrm{LT}(T)_{k+1}=\mathrm{LT}(T)_kF_{1_k}^{(j_k)}\). Otherwise, and this is the extraordinary step, search for the next higher, that is \(>2\), value that appears below its own row and that is not only in the first column or in the first and second column and repeat this step with it instead of \(2\).
We denote the length of
by \(\ell (\mathrm{LT}(T))\) and the total length by \(\ell _{\mathrm{t}}(\mathrm{LT}(T))=\sum _k j_k\).
Note that, since we do not allow infinite tableaux, there can not be an infinite string of extraordinary cases, i.e. a tableau like

does not appear. Hence, the inductive process terminates.
Definition 3.2
(LT-algorithm for webs) Let \(T\in \mathrm{Std}^s(\lambda )\subset \mathrm{Col}(\lambda )\) denote a semi-standard tableau. The Leclerc–Toffin algorithm for \(\mathfrak {sl}_3\)-webs is defined by applying the LT-generators to the highest weight vector \(v_{3^{\ell }}\) using \(q\)-skew Howe duality, that is
We use the notions length and total length of non-elliptic webs \(\ell _{\mathrm{t}}(u)\) under the identification with their semi-standard tableaux (recall that each non-elliptic web \(u\) can be identified with a semi-standard tableau \(T_u\) using its unique canonical flow. See [44] for more details).
Example 3.3
The only non-elliptic webs whose total length \(\ell _{\mathrm{t}}(u)\le 3\) are either arcs

with LT-generators \(F_1\) and \(F_1^{(2)}\), or theta webs

with LT-generators \(F_1F_2^{(2)}\) and \(F_1F_2F_1\) respectively. Moreover, the first three are also the only examples of length \(\ell (u)\le 2\). The corresponding procedure under \(q\)-skew Howe duality for the third web is

Note that we read form bottom to top when we apply \(F_1F_2^{(2)}\) to the highest weight vector \(v_{3^2}\) and we label the boundary points from left to right, i.e. an \(F_i\) acts between the boundary point number \(i\) and \(i+1\).
Proposition 3.4
For any \(T\in \mathrm{Std}^s(3^{\ell })\) we have that Khovanov and Kuperberg’s growth algorithm and Leclerc and Toffin’s algorithm give the same non-elliptic \(\mathfrak {sl}_3\)-web.
Proof
In the growth algorithm there are often cases in which one can choose between several steps. Khovanov and Kuperberg show in Lemma 1 in [32] that the final web does not depend on these choices. We are going to show that the Leclerc–Toffin algorithm makes a particular choice for each step in the growth algorithm, which proves the proposition.
Suppose we are given a semi-standard tableau and that we have already done some steps in the Leclerc–Toffin algorithm. The list below gives all possibilities for the next step. All cases in which one of the entries appears three times are similar, so we have only given one such example at the bottom of our list. To simplify matters we have called the entries \(0,1,2\) and \(3\) etc., instead of \(k-1,k,k+1\) and \(k+2\) etc., and we have only drawn the relevant part of the tableau. The nodes whose contents is not relevant for our argument are left empty. Moreover, if a number \(3\) appears, then we only assume for simplicity that this number has to appear with the same multiplicity in the same columns, but is allowed to be above the shown row.
The usual cases are (beware that in the following pictures we use the numbers \(+1,0,-1\) from Khovanov–Kuperberg’s growth algorithm, that is they do not indicate the orientation of the webs)

In the first extraordinary case, that is

the Leclerc–Toffin algorithm gives the “wrong” answer. That is why we had to add an extra rule for this case. One easily checks that the extra rule works out as claimed.
To be more precise, the first extraordinary case, i.e. at least one three in the first column, is related to the question of nested components of webs. The rules in Definition 3.1 for this case can be read as “outside first”. In fact, choosing the smallest entry that is not only in the first column or in the first and second columns ensures that this entry does not have flow \(1\), while its left neighbour has flow \(1\). In this case, no matter what the orientation of the web is, it is always possible to perform a step in the growth algorithm, i.e. either a Y-move, if the flow is \(1\) and \(0\) or \(1\) and \(-1\) and the orientation is the same, a H-move, if the orientation is different and the flow is \(1\) and \(0\) or an arc-move otherwise.
In the second extraordinary case (where \(3\) is the next to be replaced) we can easily see that the rules forces us to use \(F_2\) which is precisely the answer of the growth algorithm, that is

We should note that the other two cases, where the LT-algorithm gives the “wrong” answer, i.e.

work out up to isotopies. To see this note that in the first case we get first \(F_1\) and then \(F_2\), while we get \(F_2^{(2)}\) after \(F_1\) in the second case. Hence, the LT-algorithm gives us

while the growth algorithm gives us

It is worth noting that, under the assumption that the next step in the Leclerc–Toffin algorithm is a step after \(i-1\), tableaux of the form

can not appear, since, if we assume that the \(1\) does not change in this step, one has to create a tower of non-allowed pairs as illustrated below.

That is the reason why we do not have to take these case in account, since they will never lead to legal tableaux constructions. \(\square \)
Example 3.5
It should be noted that the Leclerc–Toffin algorithm makes a choice of how to apply Khovanov and Kuperberg’s growth algorithm that avoid doing H-move with an horizontal arrow pointing to the left, since they would correspond to \(E\)’s and not \(F\)’s. For example, instead of doing a move like

the Leclerc–Toffin algorithm makes the following move.

The dots between \(F_1\) and \(F_2\) should indicate that there could be \(F_i\) in between, but for all those \(F_i\) one has \(i<1\).
We obtain directly from Proposition 3.4 that the LT-algorithm gives the \(\mathfrak {sl}_3\)-web basis \(B_S\), since the set of semi-standard tableaux enumerates the web basis.
Corollary 3.6
The LT-algorithm gives the full \(\mathfrak {sl}_3\)-web basis \(B_S\).
We note that this gives another proof of Khovanov and Kuperberg’s result.
Proof
(Theorem 2.10) This follows from the LT-algorithm, i.e. an equation like 2.4 can be verified (by using the “LT-like” algorithm from above) as in [40], Proposition 3.4 and the substitution \(v=-q^{-1}\). Note that the underlying space is changed under \(q\)-skew Howe duality (and therefore the corresponding elementary tensors). \(\square \)
Corollary 3.7
Kuperberg’s web basis \(B_S\) and the dual canonical basis are related by a change of base matrix which is unitriangular.
Proof
Note again that our small change of the rules does not affect the arguments in [40].
By Proposition 3.4 the LT-algorithm gives the basis \(B_S\). Moreover, since Leclerc and Toffin showed [40] that their basis is related to the canonical basis by an unitriangular change of base matrix, see 2.4, and since \(q\)-skew Howe duality turns the canonical into the dual canonical basis (as for example explained in [43]), we obtain the statement. \(\square \)
To conclude this section, we note the following simple, but nevertheless important observation that we need repeatedly.
Lemma 3.8
Let \(u,v\in B_S\) be two non-elliptic webs with the same boundary and let \(\mathrm{LT}(u),\mathrm{LT}(v)\) denote their LT-generators. Then \(\ell _{\mathrm{t}}(\mathrm{LT}(u))=\ell _{\mathrm{t}}(\mathrm{LT}(v))\).
Proof
Note that the multiplicities of all the entries in the associated semi-standard tableaux \(T_u,T_v\) for \(u,v\) are equal. Therefore, since the LT-generators are obtained by reducing these semi-standard tableaux \(T_u,T_v\) to the one associated to the highest weight vector, the total length is the same. \(\square \)
It should be noted that the length can be different in general, that is \(\ell (\mathrm{LT}(u))\ne \ell (\mathrm{LT}(v))\), due to Serre relations like
3.2 Multipartitions and webs with flow
We are going to show in this and the next section that non-elliptic webs with flows \(u_f\) can be obtained from fillings of \(3\)-multitableaux via an extended growth algorithm. In this section we discuss how we can turn a web with flow into a filling of a \(3\)-multipartition, while we give the extended growth algorithm in the next section.
The main observation is that there are way more ways to fill a \(3\)-multipartition than there are webs with flows, because, roughly speaking, a filling of a \(3\)-multipartition does not see isotopies. This corresponds to the fact that two Morita equivalent algebras can have different dimensions, e.g. the \(\mathfrak {sl}_3\)-web algebra has a way smaller dimension than the corresponding cyclotomic Hecke algebra. Very roughly, the cyclotomic Hecke algebra does not see isotopies. We therefore stress that, if we work in \(B^J_S\) or \(W^J_S\) as defined below, then we do not take isotopies into account.
The way we show that the extended growth algorithm is really an algorithm to obtain every flow on any web is that we construct an injection \(\iota \) from webs with flow to fillings of \(3\)-multipartitions and we show that \(\iota \) is a left-inverse of the extended growth algorithm (which we discuss in the next section).
We start by extending the Proposition 2.8, that is we give another bijection to a set of so-called \(3\)-multipartitions \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\) from Definition 2.1. Recall that \(\mathrm{Col}(\lambda )\) below means that the entry \(k\) in the column-strict tableaux of \(\mathrm{Col}(\lambda )\) appears with multiplicity \(\lambda _k\).
Proposition 3.9
There is a bijection between \(\mathrm{Col}(\lambda )\), the set of state strings \(J\) such that there exists a web \(w\in B_S\) and a flow \(f\) on \(w\) which extends \(J\), denoted by \(B_S^J\), and \(\Lambda ^+(n,d,3)\), i.e. the set of \(3\)-multipartitions of \(d=3\ell \).
Proof
The first bijection was proven in Proposition 2.8.
We give the bijection from \(\mathrm{Col}(\lambda )\) to \(3\)-multipartitions \(\Lambda ^+(n,d,3)\) with \(d=3\ell \). First we define a standard filling of a diagram with \(i\)-rows and \(j\)-columns, denoted by \(T^i_j\), by filling all nodes in the \(i^{\prime }\)-row with \(i^{\prime }\) for all \(1\le i^{\prime }\le i\), e.g.

Now, given a \(T\in \mathrm{Col}(\lambda )\), the tableau \(T-T^i_j\) (for suitable \(i,j\)) has non-negative entries due to the column-strictness of \(T\). We can now associate for each column \(1\le j^{\prime }\le j\) the column word \(c_{j^{\prime }}\) by reading the entries of \(T-T^i_j\) from bottom to top. This gives a partition \(\lambda _{j^{\prime }}\). The reader can easily verify that this is a bijection. \(\square \)
Note that the second bijection of Proposition 3.9 is not restricted to tableaux with only three columns. In fact the whole bijection is not new, i.e. it is well-known. See [6] for example.
Example 3.10
We have the following correspondence.

Seeing a column-strict tableau \(T\) as a \(3\)-multipartition \(\vec {\lambda }\) has some advantages. For example we can fill such a \(3\)-multipartition \(\vec {\lambda }\) with non-negative numbers. As in Definition 2.1, we denote the set of all \(3\)-multitableaux \(\vec {T}\) of \(\vec {\lambda }\) with a standard fillings by \(\mathrm{Std}(\vec {\lambda })\). For example the following tableau is in \(\mathrm{Std}(\vec {\lambda }=((3,2,1),(2,1),(3,2,1)))\).

In order to give a growth algorithm for webs with flow lines \(u_f\in B_S^J\) (that is the set of all non-elliptic webs \(\partial u=S\) with a fixed flow \(f\) that extends \(J\)), we first define an injection of the set of all non-elliptic webs with flows associated to a certain pair \((S,J)\) (or equivalent a column-strict tableau or a \(3\)-multipartition \(\vec {\lambda }\)) into \(\mathrm{Std}(\vec {\lambda })\). Moreover, we denote the set all webs with boundary datum \((S,J)\) and a chosen flow by \(W_S^J\).
Note again that there are in general much more elements in \(\mathrm{Std}(\vec {\lambda })\) than in \(B_S^J\). After that we give a method to obtain from an element of \(\mathrm{Std}(\vec {\lambda })\) a web with flow and we show that this map is in fact the left-inverse of the embedding \(\iota :B_S^J\rightarrow \mathrm{Std}(\vec {\lambda })\). Hence, we can call this process an extended growth algorithm.
Definition 3.11
Given a partition \(\lambda \) which is partially filled with numbers and a fixed number \(j\). Then the highest not filled node \(N\) of residue \(j\) is the unique (if it exists), highest node of \(\lambda \) without filling to the north east such that a filling of this node still gives a legal tableau and \(r(N)=j\).
Example 3.12
Assume that \(\lambda \) is the following partition (note that \(m=3\), i.e. the residue of the nodes is shifted by \(3\)) with the following partially filling.

We have marked the highest node \(N_{\times }\) with residue \(r(N_{\times })=3\) by \(\times \) and the highest node \(N_{\circ }\) with residue \(r(N_{\circ })=1\) by \(\circ \). Moreover, there is no possible node of residue \(2\) to be filled.
We start now by defining the map \(\iota \). We give it inductively using an inductive algorithm.
It should be noted that the following algorithm looks very complicated, since it has many different rules one has to follow. But the main idea is simple and straightforward, i.e. look at the corresponding pictures and read of the tableau “locally” at the top and the bottom. Then the \(k\)-th step in the algorithm should add nodes labeled \(k\), whose number depends on the divided power of the \(F^{(j_k)}_{i_k}\)’s, at the corresponding given positions with residue \(i_k\).
Definition 3.13
(Flows to fillings) Given a pair of a sign string and a state string \((S,J)\) and a web \(u_f\in B_S^J\), we associate to it a standard filling \(\iota (u_f)\in \mathrm{Std}(\vec {\lambda })\) inductively by going backwards the LT-growth algorithm from Proposition 3.5, i.e. use the canonical flow on \(w\) to determine the LT-generators \(LT(w)=F^{(j_n)}_{i_n}\cdots F^{(j_1)}_{i_1}\) for \(u\) (note that we read backwards now).
-
(1)
At the initial stage set \(\vec {T}_0=(\emptyset ,\emptyset ,\emptyset )\).
-
(2)
At the \(k\)-th step use \(F^{(j_{k})}_{i_{k}}\) to determine the type and color of the operation performed on \(\vec {T}_{k-1}\). We give a full list of all possible types and colors below together with the operation
$$\begin{aligned} \mathbf{k}:\vec {T}_{k-1}\mapsto \vec {T}_{k}. \end{aligned}$$ -
(3)
Repeat until \(k=n\). Then set \(\iota (u_f)=\vec {T}_n\).
The full list of possible types (depending on the orientation of the web) and colors (depending on the flow line) is the following.
-
Arc moves come in two different types, called arc-type a and b, each with three different colors, called \(1,0,-1\). Note that type a corresponds to an \(F^{(2)}\), while type b corresponds to an \(F^{(1)}\).

-
Y-moves come in two different types, called a and b, with six different colors, called \(1,1^{\prime },0,0^{\prime }\) and \(-1,-1^{\prime }\). Note that all Y-moves belong to a \(F^{(1)}\). The Y-moves of type a are

and the Y-moves of type b are

-
H-moves only have one type, since the other type does not appear in the LT-algorithm (it would use a \(E^{(1)}\) instead of a \(F^{(1)}\)). But to make the argument later more convenient, we use two types, again a and b, for them again with six different colors, again \(1,1^{\prime },0,0^{\prime }\) and \(-1,-1^{\prime }\). The H-moves of type a are

while the H-moves of type b are

-
Right shifts come again in two types a and b with three colors, again \(1,0,-1\). Note that type a corresponds to \(F^{(1)}\), while type b corresponds to \(F^{(2)}\).

-
Left shifts come again in two types a and b with three colors, again \(1,0,-1\). Note that type a corresponds to \(F^{(2)}\), while type b corresponds to \(F^{(1)}\).
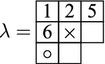
-
The unique empty shift. Note that type a corresponds to \(F^{(3)}\).









Note that the pair \((S,J)\) gives rise to a 3-multipartition \(\vec {\lambda }=(\lambda ^1,\lambda ^2,\lambda ^3)\). The tableau \(\vec {T}_n\) should be a \(3\)-multitableau of shape \(\vec {\lambda }\). We build it inductively.
The following list of operators should add the corresponding nodes at the highest free place of the tableau \(T^{1,2,3}\) of residue \(i_k\) (if the step is for \(F_{i_k}^{(j_k)}\)) (as in in Definition 3.11). We use the symbol \(+\) for this procedure and denote the tableaux of \(\vec {T}_{k-1}\) by \(T_{k-1}^{1,2,3}\). The operators for the \(k\)-th step are the following.
-
For the arc-moves of type a we use

and for the arc-moves of type b we use

-
For the Y-moves of type a and colors \(1,1^{\prime }\) we use

and or the Y-moves of type a and colors \(0,0^{\prime }\) we use

and or the Y-moves of type a and colors \(-1,-1^{\prime }\) we use

-
For the Y-moves of type b and colors \(1,1^{\prime }\) we use similar rules, i.e.

and or the Y-moves of type b and colors \(0,0^{\prime }\) we use

and or the Y-moves of type b and colors \(-1,-1^{\prime }\) we use

-
For the H-moves of type a and colors \(1,1^{\prime }\) we use

and or the H-moves of type a and colors \(0,0^{\prime }\) we use

and or the H-moves of type a and colors \(-1,-1^{\prime }\) we use

-
For the H-moves of type b and colors \(1,1^{\prime }\) we use

and or the H-moves of type b and colors \(0,0^{\prime }\) we use

and or the H-moves of type b and colors \(-1,-1^{\prime }\) we use

-
For the right shifts of type a and colors \(1,0,-1\) we use

and for right shifts of type b and colors \(1,0,-1\) we use

-
And finally, for the left shifts of type a and colors \(1,0,-1\) we use

and for left shifts of type b and colors \(1,0,-1\) we use

-
For the unique empty shift we use




















Thus, we have a map
We have to show that the algorithm is well-defined, i.e. a priori we could run into ambiguities if the nodes in one of the three tableaux are already filled with numbers or that there are no suitable free nodes of residue \(i_k\). But the following lemma ensures that this will never happen. Moreover, the lemma shows that the map \(\iota \) is an injection. But we give an example before we state and prove the lemma.
Example 3.14
-
(a)
For example for \(S=(-,-,-)\) and \(J=(1,-1,0)\) we have the half-theta web with the following flow and tableau, \(3\)-multipartition and LT-generators.

Hence, the algorithm from Definition 3.13 has three steps, i.e. the initial and two “honest” steps. One gets the following sequence

which can be easily verified from the following picture
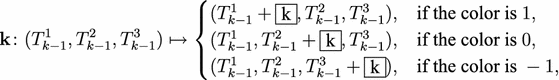
-
(b)
We have two webs with flows for the pair \(S=(+,-,+,-)\) and \(J=(0,0,0,0)\), i.e. two either nested or non-nested circles without flow

In this case the tableaux and the \(3\)-multipartitions are the same, but the LT-generators are different, that is

For the left case one gets the following sequence

while in the right case we get

which can be easily verified from the following picture

It is worth noting that the residues of the nodes match exactly with the corresponding positions.








Lemma 3.15
The algorithm in Definition 3.13 is well-defined and two webs with flow \(u_f,v_{f^{\prime }}\) satisfy
Proof
To show that the algorithm is well-defined observe that Lemma 3.8 ensures that the total number of nodes of the \(3\)-multipartition \(\vec {\lambda }_u\) associated to \(u\) is exactly the number of nodes added in total by the algorithm from Definition 3.13. Hence, we only need to ensure that the placement of the nodes works as claimed, that is, we fill the nodes without running into a step where there are either no nodes to fill at the corresponding position or the tableau can not be filled in a suitable standard way any more.
To show this we use induction on the total length \(\ell _{\mathrm{t}}(u)\). One can easily verify that the placement works for all cases with \(\ell _{\mathrm{t}}(u)\le 3\), i.e. the arcs and theta webs from Example 3.3 with all possible flows.
By induction, given a web with a flow \(u_f\) and LT-generators
we know that the placement works for the web with flow \(u^{<}_{f^<}\) that is obtained from \(u_f\) by removing the last step. Note that \(u^{<}_{f^<}\) has in general a different pair of sign string \(S\) and state string \(J\) than \(u_f\). Moreover, the total length can drop by maximal three.
A case-by-case check considering all possible steps from Definition 3.13 (since all of them could be the last step) then shows the statement. They all work the same so we only illustrate two here, i.e. first an H-move of type a with color 0

where we have illustrated the change for the tableau going from \(u^{<}_{f^<}\) (bottom) to \(u_f\) (top). Note that we for simplicity use the entries \(1,2\) again, but this does not affect the argument.
Hence, the difference between the associated bottom and top \(3\)-multipartition is that latter has one extra node in the last entry. The rules from Definition 3.13 now tell us to perform the following move for the H of type a and color \(0\).

with \(k=\ell (u)\). That the residue of this extra node is exactly \(1\) is due to induction, since in one of the steps before (that is for the web \(u^{<}_{f^<}\)) we see that the \(2\) in the middle was filled with a node that, by the map from Proposition 3.9, has the same residue as the new node.
Second, we consider an right shift of type b and color 0, that is

where we have again illustrated the change for the tableau going from \(u^{<}_{f^<}\) (bottom) to \(u_f\) (top). Thus, the top has two more nodes in the first and third partition. The rules tell us to put two nodes exactly in these partitions, that is

with \(k=\ell (u)\). That these two nodes have the right residue follows by induction again and the fact that this move corresponds to a \(F_1^{(2)}\) and the two extra nodes will be in a row that starts with residue \(1\) (by our shift in the residue from Definition 2.1) and was empty for \(u^{<}_{f^<}\) (again by Proposition 3.9).
Hence, the placement works out as claimed. Moreover, it follows directly that the corresponding tableau is still standard.
To show the second statement we use induction on the total length again. First we consider the case \(u=v\) and \(f\ne f^{\prime }\). Moreover, we can freely assume that the sign and state string pair is the same for both flows, since otherwise the shape of the corresponding \(3\)-multitableaux \(\vec {T}_{u_f},\vec {T}_{u_{f^{\prime }}}\) is already different.
One can check the statement again by hand for the four webs from Example 3.3. As before, we consider the difference between \(u^<_f\) and \(u^<_{f^{\prime }}\) by removing the last step of the LT-algorithm and do a case-by-case check.
It should be noted that the number of cases we have to check is small, since the assumption \(u=v\) fixes the type of the last performed move, i.e. only the color could be different, and the assumption that they have the same state string reduces the question to H-moves of type a. To be more precise, we need to ensure that the H-moves of type a and colors \(1/0\), \(1^{\prime }/-1\) and \(0^{\prime }/-1^{\prime }\) perform a different last step, which is indeed the case. Hence, using induction, we see that
The case \(u\ne v\) works in a slightly different vein, i.e. we are going to show that the two tableaux \(\iota (u_f)\) and \(\iota (v_{f^{\prime }})\) already differ at the first step, following the LT-algorithm for both webs, where the two webs differ.
In order to show this, we note that Proposition 2.8 shows that different webs \(u\) and \(v\) with different sign string \(S\) or state string \(J\) have different column-strict tableaux and therefore we see that the shapes of \(\iota (u_f)\) and \(\iota (v_{f^{\prime }})\) are different.
So let us consider the first step in the LT-algorithm of \(u\) that is different form the one from \(v\). Denote the \(F\) obtained in this step for \(u\) by \(F^{(j_k)}_{i_k}\) and the one for \(v\) by \(F^{(j^{\prime }_k)}_{i^{\prime }_k}\).
Since we assume that they differ at this position, we see that \(i_k\ne i^{\prime }_k\) or \(j_k\ne j^{\prime }_k\). In the first case the residue of the new node with entry \(k\) is different by our construction, since the residue corresponds to the \(i_k\) and the \(i^{\prime }_k\). In the second case the total number of new boxes with entry \(k\) are different, since by our construction they correspond to \(j_k\) and the \(j^{\prime }_k\). In both case we see that the tableaux are different.
Hence, we see that
This proves the lemma. \(\square \)
3.3 Extended growth algorithm
In this section we give the extended growth algorithm
i.e. we give a method to obtain from an element of \(\mathrm{Std}(\vec {\lambda })\) a web with a flow \(u_f\in W_S^J\) (recall that \(W_S^J\) means the set of all possible webs with boundary pair \((S,J)\)). In general, this web can be elliptic. We start with some preliminary combinatorial definitions. It is worth noting that the following definitions can be seen as an extended version of the definitions in the \(\mathfrak {sl}_2\) case, i.e. the case of the level two Hecke algebras, see for example [8, 9] and [10].
Definition 3.16
Let \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) be a \(3\)-multitableau \(\vec {T}=(T^1,T^2,T^3)\) such that \(T^i\) is a standard tableau and the numbers are from a fixed set \(\{1,\dots ,k\}\). Then we associate to \(\vec {T}\) a sequence of \(3\)-multitableaux \((\vec {T}^j)\) for each \(j\in \{0,1,\dots ,k\}\) where \(\vec {T}^j=(T_j^1,T_j^2,T_j^3)\) and \(T_j^{1,2,3}\) is obtained from \(T^{1,2,3}\) by deleting all nodes with numbers strictly bigger than \(j\).
Moreover, we associate to it a sequence of \(3\)-multipartitions \((\vec {\lambda }^j)\) by removing the entries of the nodes of \((\vec {T}^j)\).
Example 3.17
Given the following \(3\)-multitableau

one obtains the following sequence. First note that, by definition, \(\vec {T}^0=(\emptyset ,\emptyset ,\emptyset )\) and the rest is

In order to make connection to webs with flows recall that a flow can be seen as either \(+1\), if it is pointing downwards, \(-1\), if it is pointing upwards or \(0\), if there is no flow at all. We use two extra symbols \(\circ ,\times \) to illustrate the case when there is no web at all.
Definition 3.18
A \(\mathfrak {sl}_3\)-weight diagram \(\Lambda \) is a \(\mathbb {Z}\)-graded tuple with entries \(\Lambda _i\) of symbols from the set \(\{\circ ,-1,0,+1,\times \}\).
A \(\mathfrak {sl}_3\)-weight diagram \(\Lambda \) is said to be trivial, if \(\Lambda _{{\mathbb {N}}_{\le 0}}\in \{\times \}\) and \(\Lambda _{{\mathbb {N}}_{>0}}\in \{\circ \}\).
Example 3.19
An example of a \(\mathfrak {sl}_3\)-weight diagram \(\Lambda \) is the following.

Note that the \(\bullet \) indicates the position of \(\Lambda _0\). And the entries \(\Lambda _i\) with \(i>0\) are right of \(\Lambda _0\), while the entries \(\Lambda _i\) with \(i<0\) are left of \(\Lambda _0\).
Definition 3.20
A tower of \(\mathfrak {sl}_3\)-weight diagrams \((\Lambda ^i)_{i\in I}\) is a sequence of \(\mathbb {Z}\)-graded tuples with entries \(\Lambda _i\) of symbols from the set \(\{\circ ,-1,0,+1,\times \}\) for a finite index set \(I=\{0,1,\dots ,k\}\).
We draw the sequence as a tower starting from the bottom with \(\Lambda ^0\).
Example 3.21
An example of such a tower is the following.

Definition 3.22
Let \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) be a \(3\)-multitableau and let \((\vec {\lambda }^j)\) denote its associated sequence of \(3\)-multipartitions. We denote the number of nodes in the \(1,2,3\)-th entry and the \(l\)-th row of \(T_j^{1,2,3}\) by \(|T_j^{1,2,3}|_l\). We can associate to it a tower of \(\mathfrak {sl}_3\)-weight diagrams \((\Lambda ^i)_{i\in I}\) with \(I=\{0,\dots ,k\}\), where \(k\) is the maximal entry of \(\vec {T}\) in the following way.
-
First define for each \((\vec {\lambda }^j)\) three \({\mathbb {N}}\)-graded tuples \(\vec {k}^j_{1,2,3}\) by
$$\begin{aligned} \vec {k}^j_{1,2,3}=\left( |T_j^{1,2,3}|_1,|T_j^{1,2,3}|_2-1,|T_j^{1,2,3}|_3-2,\dots \right) . \end{aligned}$$ -
Set \(\Lambda ^0\) to be the trivial \(\mathfrak {sl}_3\)-weight diagram.
-
For \(i=1,\dots ,k\) we use the convention
$$\begin{aligned} \Lambda ^i_l={\left\{ \begin{array}{ll} \times , &{} \text {if }l\text { is an entry of } \vec {k}^j_{1,2,3},\\ +1, &{} \text {if }l\text { is only an entry of } \vec {k}^j_{1,2}\text { or only of } \vec {k}^j_{1},\\ 0, &{} \text {if }l\text { is only an entry of } \vec {k}^j_{1,3}\text { or only of } \vec {k}^j_{2},\\ -1, &{} \text {if }l\text { is only an entry of } \vec {k}^j_{2,3}\text { or only of } \vec {k}^j_{3},\\ \circ , &{} \text {otherwise}. \end{array}\right. } \end{aligned}$$
It should be noted that the convention agrees with the initial convention to set \(\Lambda ^0\) to be the trivial, since the corresponding \(3\)-multitableau \(\vec {T}^0\) will only contain empty sets.
Example 3.23
Suppose one has the following filling of a \(3\)-multipartition \(\vec {\lambda }\), which is the one from Example 3.14 part (a),

Then we only have to consider three steps, i.e. the initial plus two non-trivial steps. We illustrate the resulting vectors \(\vec {k}^j_{1,2,3}\) below with \(j\) increasing from left to right and \(\vec {k}^j_{1}\) in the top row, \(\vec {k}^j_{2}\) in the middle and \(\vec {k}^j_{3}\) at the bottom.

The associated tower is illustrated below. Note that it is no coincidence that we need exactly as many steps as in the LT-algorithm for the half-theta web. In fact, the reader is encourage to draw the half-theta web with the flow from Example 3.14 (a) inside.

Remark 3.24
Usually it is more convenient to extend the notions from Definition 3.22 slightly by allowing the entries \(+1,0,-1\) to be marked with a \(*\). For the webs this has the advantage that the tower constructed in 3.22 suffices to recover the web completely by the convention that a \(*\)-marked entry is a downwards pointing arrow of the web and an entry \(+1,0,-1\) without such a marked is a upwards pointing arrow. We use these notions in the following.
In order to define \(\Lambda ^i_l\) with \(*\)-markers one just have to refine the convention and also count the number of occurrences in the vectors \(\vec {k}^j_{1,2,3}\), i.e. use a \(*\)-marker iff the corresponding entry appears twice. Then the example from above would be

We are now ready to define the extended growth algorithm for \(\mathfrak {sl}_3\)-webs.
Definition 3.25
(Extended growth algorithm) The extended growth algorithm is a map
i.e. it assigns to every \(3\)-multitableau \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) a (possible elliptic) web with a flow \(\mathrm{g}(\vec {T})\).
The \(\mathrm{g}(\vec {T})\) is defined to be the web that one obtains by connecting the entries of the tower \((\Lambda ^i)_{i\in I}\) of Definition 3.22 in the way explained in Remark 3.24.
Theorem 3.26
The extended growth algorithm is well-defined. Moreover, we have
that is the extended growth algorithm can be used to obtain any non-elliptic web with any flow and if one start with the unique \(3\)-multitableau \(\iota (\cdot )\), then the resulting web is also unique.
Example 3.27
Before we prove the theorem, let us give an more sophisticated example. We take the web \(u_f\) with one internal hexagon and with the following flow.

As one can easily check (see also Example 2.9) the corresponding column-strict tableau is

and the corresponding \(3\)-multipartition is

Moreover, one easily checks that the sequence of LT-generators is
which can be verified as we explained above in Sect. 3.1.
Everything is of course also the same for the web

since the data on the boundary is the same in both cases.
We have to fill the \(3\)-multitableaux with numbers \(\{1,\dots ,11\}\) to distinguish the two and the algorithm given in Definition 3.13 for the first makes the following twelve steps.

It is worth noting that the node in the seventh step, due to our convention for the residue, is placed the way it is. The reader is encourage to try to do the example

that has the same boundary datum as before (and the same LT-generators). The resulting filling in this case after the last step is

Following the extended growth algorithm one obtains the original web with flow back. Again we encourage the reader to do it for the case with the reversed flow.

Proof
The main part of this proof is the Lemma 3.15, i.e. \(\iota :B^J_S\rightarrow \mathrm{Std}(\vec {\lambda })\) is a well-defined inclusion of webs with flows \(u_f\) to filled \(3\)-multitableaux \(\iota (u_f)\). In fact the only thing we have to see is that the process which we described in Definition 3.25 is given by reading the process from Definition 3.13 backwards and place the web with flow \(u_f\) on a suitable chosen grid.
That the algorithm is well-defined follows by its deterministic nature.
To see that the extended growth algorithm is a left-inverse for the embedding \(\iota :B^J_S\rightarrow \mathrm{Std}(\vec {\lambda })\), we note that, by Proposition 3.4, we only have to consider non-elliptic webs. That the process of Definition 3.13 is literally undone by the process of Definition 3.25 follows by comparing the two procedures as follows.
We prove the statement again by induction on the total length. It is easy to verify all the small cases from Example 3.3, so assume that for all \(1\le i\le j\) the statement is true and consider a web whose total length is \(j=\ell _{\mathrm{t}}(u)\).
Hence, we have to check all the possible last moves. Since they all work in the same fashion, we only do two here and leave the rest to the reader. The first move we discuss is a Y-move of type b and color \(0^{\prime }\), i.e.

We assume that this is the \(j\)-th step. The rules from Definition 3.13 tells us to add one extra node labeled \(j\) to the first tableau \(T^1\), say in the \(l\)-th row. Looking at the information at the bottom, we see that the \({\mathbb {N}}\)-graded tuples \(\vec {k}^{j-1}_{1,2,3}\) are of the form

where we have only illustrated the important parts of the tuples. Here \(l^{\prime }=|T^{1}_{j-1}|_l-l+1\).
This is true, because we can use the induction hypothesis and an easy calculation checking the corresponding residues. It should be noted that the grid is chosen in such a way that for \(d=3\ell \) a \(F_{\ell }^{(j_{\ell })}\) acts between the \(0\)-entry and the \(1\)-entry of the tower.
To see that the step from \(j-1\) to \(j\) happens as indicated above, we note that adding a node only in the first tableau \(T^1\) only effects the tuple \(\vec {k}^{j-1}_1\). Moreover, since we assume to add the node in the \(l\)-row, the only change is as indicated above because \(|T^{1}_{j}|_l=|T^{1}_{j-1}|_l+1\).
The second move we discuss is an arc-move of type a and color \(-1\), i.e.

We use the same notation as before. Again, looking at the information at the bottom, we see that the \({\mathbb {N}}\)-graded tuples \(\vec {k}^{j-1}_{1,2,3}\) are of the form

Here \(l^{\prime }=|T^{1,2}_{j-1}|_{l_{1,2}}-l_{1,2}+1\) by the same argument as above. Note that this time the rules from Definition 3.13 tell us to add a \(j\) labeled node to the first \(T^{1}\) and second \(T^{2}\) tableau. Note that both nodes will be added in different rows \(l_{1,2}\), but since they have the same residue, we see that \(l^{\prime }=l^{\prime }_1=l^{\prime }_2\). Therefore the corresponding numbers for the LT-algorithm have to be in the same row, because their nodes were filled with the highest appearing numbers at the beginning. Hence, the change is as indicated above because \(|T^{1,2}_{j}|_{l_{1,2}}=|T^{1,2}_{j-1}|_{l_{1,2}}+1\).
All other case work similar, hence this proves the statement. \(\square \)
3.4 Degree of tableaux and weight of flows
We are going to recall Brundan, Kleshchev and Wang’s definition of the degree of a tableau given in [7] in this section. We show that the embedding \(\iota :B_S^J\rightarrow \mathrm{Std}(\vec {\lambda })\) is a degree preserving map, where we consider minus the weight of a web with flow \(u_f\in B_S^J\) as the degree \(\mathrm{deg}_{\mathrm{wt}}\) for \(B_S^J\) and Brundan, Kleshchev and Wang’s degree \(\mathrm{deg}_{\mathrm{BKW}}\) as the degree for a \(3\)-multitableau \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\).
Note that this shows that \(\mathrm{deg}_{\mathrm{BKW}}\) is an isotopy invariant and that Brundan, Kleshchev and Wang’s degree has a very natural interpretation on the level of webs, i.e. it is minus the weight of a flow line and is therefore directly connected (to be more precise: to the slightly changed version) to the LT-coefficients in 2.3, since Khovanov and Kuperberg showed in Sect. 4 of [32] that the weight of flows gives the coefficients of the web basis \(B_S\) with respect to the elementary tensors and we showed in Proposition 3.4 that \(B_S\) is in fact an intermediate crystal basis.
Recall the following combinatorial definitions. We only recall the case of a \(3\)-multitableaux, since we do not need the more general case here.
The reader should be careful that we use a slightly different definition than Brundan, Kleshchev and Wang, since we are working with divided powers (and therefore we have in general more than one node with entry \(j\in \{1,\dots ,k\}\)). This is the reason why we have some shifts in our definition. For example, an arc-move created by a divided power differs from the one without the divided power by a digon

and the empty-shift differs from the one without divided powers by a theta web

Definition 3.28
(Brundan, Kleshchev and Wang: Degree of a tableau) Let \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) be a (filled with numbers from \(\{1,\dots ,k\}\)) \(3\)-multitableau \(\vec {T}=(T^1,T^2,T^3)\) as in Definition 3.16. For \(j\in \{1,\dots ,k\}\) let \(N^j\) denote the set of all nodes that are filled with the number \(j\) and let \(\vec {T}^j\) denote the \(3\)-multitableau obtained from \(\vec {T}\) by removing all nodes with entries \(>j\).
The degree of \(\vec {T}^j\), denoted by \(\mathrm{deg}(\vec {T}^j)\), is defined to be
where we use the convention to count all nodes with the same number step by step starting from the leftmost.
The degree of the \(3\)-multitableau \(\vec {T}=(T^1,T^2,T^3)\), denoted by \(\mathrm{deg}_{\mathrm{BKW}}(\vec {T})\), is then defined by
Example 3.29
The following three standard \(3\)-multitableaux have all degree zero.

To see this, we note that in the first case there is no node after \(\succ \) the unique node \(N^1\). Hence, \(\mathrm{deg}(\vec {T}_1)=0\). In the second case we have to calculate two steps. In the first step, i.e.

we count one addable node of the same residue which we have marked with a \(\cdot \), but the second step there is again no node after \(\succ \) the last node anymore. Hence, \(\mathrm{deg}(\vec {T}_2)=0\), since we have to take the divided power into account. For the last case we have to calculate three steps, i.e. the first and the second are

where we have again indicated the addable nodes of the same residue with a \(\cdot \). The third step is again as before. Hence, \(\mathrm{deg}(\vec {T}_3)=0\), because the divided power is \(3\).
It should be noted that it is possible that the degree (total or local) is negative. For example the last step of

has no addable nodes after \(\succ \) the node \(N^{11}\) with the same residue, but one removable, namely the left node filled with the entry \(7\). Hence, \(\mathrm{deg}(\vec {T}_4^{11})=-1\). The total degree in this case is
Example 3.30
Given a column-strict tableau \(T\), a string of LT-generators \(\mathrm{LT}(T)\) and a filling, i.e. flow, for its corresponding \(3\)-multitableau \(\vec {T}\) like

one can easily draw a web with flow \(u_f\) from this data

with total degree \(\mathrm{deg}_{\mathrm{wt}}(u_f)=-\mathrm{wt}(u_f)=2\) and local degrees as indicated in the figure. The degree \(\mathrm{deg}_{\mathrm{BKW}}(\vec {T})\) of \(\vec {T}\) is given inductively by \((\vec {T}^j)^5_{j=1}\) with

Hence, we get
Therefore we see that the total degree is
and the local degrees are exactly the ones we have seen in the figure above.
Recall that the sets \(B_S^J\) and \(W_S^J\) are graded with \(\mathrm{deg}_{\mathrm{wt}}(u_f)=-\mathrm{wt}(u_f)\), while the set \(\mathrm{Std}(\vec {\lambda })\) is graded with the degree from Definition 3.28. In fact the observation from Example 3.30 that the degree of a web with flow \(u_f\in B^J_S\) is exactly the degree of \(\iota (u_f)\in \mathrm{Std}(\vec {\lambda })\) is no coincidence, i.e. we note that following interesting Proposition.
Proposition 3.31
The map \(\iota :B^J_S\rightarrow \mathrm{Std}(\vec {\lambda })\) and \(g:\mathrm{Std}(\vec {\lambda })\rightarrow W^J_S\) are of degree \(0\).
Proof
The proof is again an inductive case-by-case check. It is easy to verify the statement for the case where the total length \(\ell _{\mathrm{t}}(u)\le 3\), i.e. for the four webs given in Example 3.3.
So assume that \(\ell _{\mathrm{t}}(u)> 3\) and that the statement is true for all \(i<\ell _{\mathrm{t}}(u)=k\), i.e. after removing the last LT-generator from \(u_f\), which results in a web with flow denoted by \(u^<_{<f}\), we have
Thus, we only have to show that the local changes of minus weight and \(\mathrm{deg}_{\mathrm{BKW}}(\iota (u_f)^k)\) coincide.
We have to check all the possible cases again. We skip most of them and leave them to the reader, since they all work in the same vein. We do three as an example, i.e. an H-move of type a and color \(1\), an H-move of type a and color \(-1^{\prime }\), and a right shift of type b and color \(0\).
The two H-moves of type a are almost the same, i.e. we have

That is the H-move of type a and color \(1\) lowers the degree by one, while the H-move of type a and color \(-1^{\prime }\) raises the degree by \(1\), but both have the same rule to place the node.
To see why the degree is still different we note that they have a different state string at the top. In fact, if we use \(1\) and \(2\) for simplicity again, we have

Hence, the H-move of color \(1\) has a removable node of the same residue above the new node iff the H-move of color \(-1^{\prime }\) has an addable node of the same residue above the new node. To see that such a removable (or addable) node exists and is unique note that this follows from the fact that there will be a last move before the H-moves that gives rise to the flow at the left side of the H-moves. The node that corresponds to this move will be, by construction, the removable (or addable) node.
The shift of type b and color \(0\), that is

can be done in a similar vein. Again we have to take the state string in account. We have

Thus, the local change in degree is zero, since, by construction, the left new node will have exactly one addable node of the same residue and the second none. Since this shift corresponds to a divided power we have to subtract \(1\) from the degree. Hence, the local change is zero.
We leave the verification that the map \(g\) is also of degree \(0\) to the reader, since it follows by similar arguments as given above. \(\square \)
Example 3.32
For the filled \(3\)-multitableau \(\vec {T}_4\) from Example 3.29 we see that the corresponding web with flow \(u_f\) is

where we have indicated the local degree changes in the figure above (the weight of the flow has a different sign). This corresponds exactly to the calculation from Example 3.29.
Since Khovanov and Kuperberg [32] showed that the weight is invariant under isotopies, we get the following two corollaries.
Corollary 3.33
Let \(u_f\in B^J_S\) be a web with flow. Then \(\mathrm{deg}_{\mathrm{BKW}}(\iota (u_f))\) is invariant under isotopies of the web \(u_f\).
Corollary 3.34
Let \(\vec {T}_1,\vec {T}_2\in \mathrm{Std}(\vec {\lambda })\) such that \(\mathrm{g}(\vec {T}_1)\) and \(\mathrm{g}(\vec {T}_2)\) differ only by isotopies. Then we have \(\mathrm{deg}_{\mathrm{BKW}}(\vec {T}_1)=\mathrm{deg}_{\mathrm{BKW}}(\vec {T}_2)\).
Moreover, we have the following natural interpretation of Brundan, Kleshchev and Wang’s degree on the level of webs. Note that, by our more general construction, the proposition works not just for non-elliptic webs \(u\in B_S\), but for all webs.
Proposition 3.35
Let \(u\in B_S\) be a non-elliptic web. Moreover, let \(F_J\) denote the possible empty set of all flows on \(u\) with boundary \(J\). Denote by \(e^S_J=e^{s_1}_{j_1}\otimes \cdots \otimes e^{s_n}_{j_n}\) the corresponding element in the tensor basis. Then
where the coefficients \(c(S,J)\) (recall \(v=-q^{-1}\)) are given by
Proof
This is a direct consequence of Khovanov and Kuperberg’s results from Sect. 4 of [32] together with the two Propositions 3.4 and 3.31. \(\square \)
4 The categorified picture
4.1 A growth algorithm for foams
In this section we are going to categorify the results from before. That is, we explain how the extended growth algorithm can be used as a growth algorithm for foams.
It should be noted that we freely use the results from the uncategorified framework that we discussed in the sections before, e.g. we identify the flows on webs with their \(3\)-multitableaux.
The main idea can be explained as follows. To define a foam \({\mathcal {F}}:u\rightarrow v\) with \(u,v\in B_S\) we use the two different types of data, i.e. the pair \((S,J)\) of the sign and state string on the line and the two flows on \(u,v\). The first completely determines the dot placement, while the second gives rise to the topology. It should be noted that the dot placement, i.e. the combinatorics, is rather mysterious in the foam framework, but rather “straightforward” in the cyclotomic Hecke algebra framework. The topology on the other hand is in the foam framework only given by zipping certain edges away. Recall that we have \({\mathcal {F}}(u,v)\cong {\mathcal {F}}(u^*v)\). We tend to use the former in the following.
We start and give the definition of the basic idempotent, denoted by \(e(\vec {\lambda })\). It is worth noting that \(e(\vec {\lambda })\) will in general be a foam between elliptic webs, since we do not use divided powers.
Definition 4.1
(Idempotent associated to \(\vec {\lambda }\)) Given a \(3\)-multipartition \(\vec {\lambda }\) with \(k\) nodes, we can associate to it a certain idempotent foam, denoted by \(e(\vec {\lambda })\), using the following rules. Define a sequence of LT-generators for \(\vec {\lambda }\) by (with \(r(\vec {\lambda })\) as in Definition 2.5)
Define a web \(w(\vec {\lambda })\) to be the web generated by applying \(\mathrm{LT}(\vec {\lambda })\) to a highest weight vector \(v_{3^{\ell }}\) and use \(q\)-skew Howe duality. Then
that is the identity foam \(\mathrm{Id}:w(\vec {\lambda })\rightarrow w(\vec {\lambda })\).
Recall that there is an \(\mathbb {C}\)-linear involution \({}^*:{\mathcal {F}}\rightarrow {\mathcal {F}}\) of the foam space
that turns the foams around (and changes some internal boundary orientations). For example

Lemma 4.2
The idempotent \(e(\vec {\lambda })\) is well-defined, that is it is not zero and an idempotent. Moreover, for all \(3\)-multipartitions \(\vec {\lambda },\vec {\mu }\) we have
Moreover, we have
that is \(e(\vec {\lambda })\) is fixed by the involution \({}^*\).
Proof
To see that it is well-defined, i.e. that \(\mathrm{LT}(\vec {\lambda })\) does not kill the highest weight vector, we have to use Theorem 3.26. That is the Theorem 3.26 ensures that there is a web with a flow that has exactly the corresponding multitableaux \(T_{\vec {\lambda }}\). Thus, the idempotent can not be zero.
That the element is an idempotent follows from the fact that it is just the identity foam on a certain web \(w(\vec {\lambda })\).
The other statements follow directly from the definition of the multiplication, that is different \(3\)-multipartition \(\vec {\lambda },\vec {\mu }\) give rise to different webs \(w(\vec {\lambda })\) and \(w(\vec {\mu })\) iff \(r(\vec {\lambda })\ne r(\vec {\mu })\), since the convention to obtain the webs from the multitableaux only depends on the residue sequence, see 4.1. Moreover, the composition is zero if the webs are not the same. by convention.
That the idempotents are fixed by the involution is clear by the definition of \({}^*\), i.e. it just turns the foams around (and inverts some arrows). \(\square \)
Example 4.3
If the \(3\)-multipartition is the one from Example 3.14 part (b), that is

then we get \(\mathrm{LT}(\vec {\lambda })=F_1F_3F_2F_2F_1F_3F_2\) and therefore \(w(\vec {\lambda })\) will be

Hence, the idempotent (we have skipped the orientations below) for \(\vec {\lambda }\) is

An important property of this idempotent is the square (if we ignore the digon) in the back, since it allows use to change to both webs that can be associated to \(\vec {\lambda }\) for “free”, i.e. without changing the degree.
Definition 4.4
(Dot placement associated to \(\vec {\lambda }\)) Given a \(3\)-multipartition \(\vec {\lambda }\) as in Definition 4.1 together with its associated idempotent \(e(\vec {\lambda })\) and its LT-generators
Recall that each of the \(F_{r(\vec {\lambda })_k}\) corresponds to a ladder-move (with some possible deleted edges) on the level of webs. Therefore, each \(F_{r(\vec {\lambda })_k}\) corresponds to a

for the foam \(e(\vec {\lambda })\). We place \(m_k\) dots on \(F_{r(\vec {\lambda })_k}\) on the middle facet

where \(m_k={\mathsf {A}}^{^{k\succ N}}(T_{\vec {\lambda }^k})\), i.e. is the number of addable nodes after the node \(N\) with entry \(k\) in \(T_{\vec {\lambda }^k}\) with the same residue as the node \(N\). We denote the dotted idempotent associated to \(\vec {\lambda }\) by \(e(\vec {\lambda })d(\vec {\lambda })\), where
should indicate the number of dots on the different facets.
It should be noted that it is not clear that \(e(\vec {\lambda })d(\vec {\lambda })\) is well-defined. We show this fact in a lemma below, but first we give an example.
Example 4.5
We consider the \(3\)-multipartition from Example 3.14 part (b) again, i.e.

As before, we have \(\mathrm{LT}(\vec {\lambda })=F_1F_3F_2F_2F_1F_3F_2\) (that is \(k=1,\dots ,7=c((+,-,+,-))\)) and

Thus, we see that \(m_k=0\) unless \(k=1\) or \(k=4\), where \(m_1=2\) and \(m_4=1\). Therefore, we have

Lemma 4.6
The dot placement of Definition 4.4 is well-defined. Moreover, we have
Proof
To see that the dot placement is well-defined it suffices to show that the middle facet always exists, i.e. it is not removed because its corresponding number is \(0\) or \(3\). That this is indeed the case follows from the fact that all possible ladder-moves in our convention from Definition 3.13.
The second statement follows directly from the definition of the involution \({}^*\), the Lemma 4.2 and the fact that the corresponding foams are just identity foams. \(\square \)
It should be noted that \(S_{k-1}\) acts on the set of strings of \(F\)’s of length \(k\) with a fixed number of occurrences of the \(F\)’s by defining the action of the \(j\)-th transposition \(\tau _j\) by exchanging the neighboring entries \(j-1\) and \(j\) reading from right to left. We denote a transposition \(\tau _j\) that exchanges a \(F_{a}\) and a \(F_{b}\) by \(\tau _j(a,b)\), i.e.
Definition 4.7
(Foam between LT-generators) Given two strings of LT-generators
such that \(\mathrm{LT}_1\) and \(\mathrm{LT}_2\) differ only by a permutation \(\sigma \in S_{k-1}\) of their \(F\)’s. Let \(w_1=\mathrm{LT}_1v_{3^{\ell }}\) and \(w_2=\mathrm{LT}_2v_{3^{\ell }}\) be the corresponding webs obtained by \(q\)-skew Howe duality. We assume that \(\sigma \in S_{k-1}\) is already decomposed into a string of transpositions
such that \(\sigma \mathrm{LT}_1=\mathrm{LT}_2\). Then we associate to \(\mathrm{LT}_1\), \(\mathrm{LT}_2\) and \(\sigma \) a foam
by composing the identity \(\mathrm{Id}_{w_1}\) on \(w_1\) from the bottom with the foams

and

where the not pictured parts should be the identity and we use the usual rules to read these foams and the usual signs \(\varepsilon \in \{+,-\}\), i.e. the ones given by categorified \(q\)-skew Howe duality. Note that, by our conventions, this procedure really gives a foam from \(w_1\) to \(w_2\).
The action defined above can be stated in a different way just on the level of tableaux without multiple entries. That is, the group \(S_{k-1}\) acts on the set of all \(3\)-multitableaux \(\mathrm{Std}(\vec {\lambda })\cup \{*\}\) by defining the action of the transposition \(\tau _j\) by
Finally, for a fixed \(3\)-multipartition \(\vec {\lambda }\) and a corresponding \(3\)-multitableau \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\) we choose a fixed permutation \(\sigma \in S_{k-1}\) such that
by searching for the lowest \(j\in \{1,\dots ,k\}\) such that the node \(N\) with entry \(k\) in \(\vec {T}\) is not the same as the node \(N^{\prime }\) with entry \(k\) in \(T_{\vec {\lambda }}\). Apply a minimal sequence of transpositions until they match and repeat the process until \(\sigma ^{-1}(\vec {T})=T_{\vec {\lambda }}\). By construction, the permutation \(\sigma \in S_{k-1}\) will be of minimal length with respect to the property \(\sigma ^{-1}(\vec {T})=T_{\vec {\lambda }}\).
It is worth noting that we put a \(\sigma ^{-1}\) here because we usually want a foam with a web associated to \(T_{\vec {\lambda }}\) at the top. One easily verifies that
We denote the foam associated to this permutation \(\sigma \) by \({\mathcal {F}}_{\sigma }\).
Lemma 4.8
The definition of the foam \({\mathcal {F}}_{\sigma }(\mathrm{LT}_1,\mathrm{LT}_2)\) is well-defined, i.e. one does not run into ambiguities and the resulting foam is a foam between \(w_1\) and \(w_2\). Moreover, the definition via the LT-generators and via actions on \(3\)-multitableaux agree.
Proof
To see that the definition is well-defined, note that, using Lemma 3.8 and the observation that, without divided powers, the total length and the length agree, each step of the action of \({\mathcal {F}}_{\sigma }(\mathrm{LT}_1,\mathrm{LT}_2)\) on the top web changes the boundary of the web to the bottom boundary as indicated in the pictures above. Thus, each step is a legal move between a web at the top and a web at the bottom. That is, starting from \(w_1\) at the top, one builds inductively a foam going stepwise from \(w_1\) to \(w_2\), i.e.
where each step is well-defined and one of the foams pictured above. Hence, we get a well-defined foam
To see that the two actions agree we note again that the residue \(r(N)\) of the node \(N\) with entry \(k\) is exactly the \(F_{r(N)}\). Thus, reading the two residue sequences for \(\vec {T}\) and \(T_{\vec {\lambda }}\), we see that they give rise to a web on the bottom and the top and the action on \(3\)-multitableaux is exactly defined such that the result of the action of \(\tau _j\) depends in the same way on the residue of the two nodes \(N_j\) and \(N_{j+1}\) as the action via foams depends on the difference \(a_i-b_i\). Then one repeats the inductive argument from before, that is, a direct comparison of the LT-generators in each step shows that each step is a legal permutation and the end result are exactly the LT-generators associated to \(w_2\).
It should be noted that this also shows that our rules to define \(\sigma \) ensure that the action of the transpositions of \(\sigma \) on the tableaux never produce a non-standard tableau. \(\square \)
Definition 4.9
(Foam for \(u_f\in B^J_S\)) Given a non-elliptic web with a flow \(u_f\in B^J_S\), we associate to it a foam
where \(\vec {\lambda }\) is the corresponding boundary datum and \(w(\vec {\lambda })\) is as in Definition 4.1, in the following way. Change the \(3\)-multitableau \(\iota (u_f)\) associated to \(u_f\) by replacing the lowest multiple entry \(j\) of multiplicity \(j^{\prime }\) of \(\iota (u_f)\) decreasing from left to right with consecutive numbers \(j,\dots ,j+j^{\prime }\) and shift all other entries by \(j^{\prime }\). Repeat until no multiple entries occur and obtain \(\iota (u_f)^{\prime }\), see 2.1. Set
with \({\mathcal {F}}_{\sigma }(\iota (u_f)^{\prime },T_{\vec {\lambda }})\) for the LT-generators \(\mathrm{LT}_{1,2}\) corresponding to \(\iota (u_f)^{\prime }\) and \(T_{\vec {\lambda }}\) respectively. The foam \({\mathcal {F}}_{\mathrm{R}}\) is given by removing the generated internal digons (pictured below 2.12) with a dot-free digon removal and the internal theta-foams with a dot-free identity. It should be noted that these are the only possible differences for the webs associated to \(g(\iota (u_f))\) and \(g(\iota (u_f)^{\prime })\).
Example 4.10
If we consider Example 3.14 part (b) again, that is

and consider the right example \(u_f\), then we have

Therefore, \(\sigma \in S_6\) is given by \(\sigma =\tau _4\tau _5\tau _3\tau _4\tau _5\tau _2\), since

This can be reinterpreted as an action on the two LT-strings, that is (reading backwards now)
When we re-read the strings of \(F\)’s using \(q\)-skew Howe duality as webs, then we see how this procedure gives rise to a foam between the web associated to \(\mathrm{LT}(T_{\vec {\lambda }})\) (as shown in Example 4.3) and the web associated to \(\mathrm{LT}(\iota (u_f)^{\prime })\) as shown below. Each of the \(\tau _j\) corresponds to one of the basic generators pictured in Definition 4.7—depending on the difference of the residues of the exchanged nodes. For example, the foam associated to the last step \(\tau _2\) is locally

that is a zip, and the identity outside of this local picture. The bottom of this local picture is the part of the web associated to \(w_f\) marked with a square on the left and the top is shown on the right

and unzips the marked edge. The foam \({\mathcal {F}}_{\mathrm{R}}\) then just removes the three digons and we obtain the original web from Example 3.14 part (b) back.
We are now able go give a growth algorithm for foams. We will see later that this gives rise to a graded cellular basis in the sense of Hu and Mathas [25]. Hence, in the spirit of Proposition 3.4, we can call this a categorification of the intermediate crystal bases.
Definition 4.11
(Growth algorithm for foams) Given a pair of a sign string and a state string \((S,J)\), the corresponding \(3\)-multipartition \(\vec {\lambda }\) and two Kuperberg webs \(u,v\in B_S\) that extend \(J\) to \(u_f\) and \(v_{f^\prime }\) receptively.
We define a foam following Definition 4.9
by
Example 4.12
Let us consider t he following example. The web is the right theta-foam from Example 3.3. Note that the Kuperberg bracket gives \([2][3]=q^{-3}+2q^{-1}+2q+q^3\). All the six different flows are indicated below.

To illustrate why the growth algorithm for foams gives (up to a sign) the result above, let us do the top left \(u_c\) in more detail. We have

Thus, the foam \(e(\vec {\lambda })d(\vec {\lambda })\) will be a dotted (the dot comes from the node labeled \(1\)) identity for the web \(F_2F_1F_1v_{3^1}\), which is a theta-foam with an extra digon. It is worth noting that this dot is unexpected from the foam framework. But the permutation from \(\iota (u_c)\) to \(T_{\vec {\lambda }}\) is given by \(\sigma =\tau _2\tau _1\) and thus we see that
where \(u=F_1F_2F_1v_{3^1}\). The corresponding foam \({\mathcal {F}}_{u_c}\) will be a composite of the top left foam from Definition 4.7 and an unzip. Therefore, the final foam \({\mathcal {F}}^{\vec {\lambda }}_{\iota (u_c),\iota (u_c)}:u\rightarrow u\) contains a so-called singular bubble with a dot. As Khovanov explains in [28], this bubble can be bursted which removes the bubble and the dot. The reader is encouraged to do the other five, but we note that two of them will also create “two many” dots, which will be bursted.
Note that it is no coincidence that there are always two basis elements that are “dual” to each other, i.e. cupping them of with its “dual” gives \(\pm 1\) while cupping it of with all the others gives \(0\). This is related to the “dual” cellular basis given in [25]. We note that this could be useful to evaluate “foams” for \(N>3\).
Lemma 4.13
The growth algorithm for foams from Definition 4.11 is well-defined.
Proof
That the algorithm is well-defined follows from the Lemmata 4.2, 4.6 and 4.8 above. \(\square \)
4.2 Foam basis
We are going to show in this section that the growth algorithm for foams given in Definition 4.11 suffices to produce all foams, i.e. it can be used to generate a basis of the foam space. Moreover, we show that this basis is homogeneous. We show in the next section that it is indeed a graded cellular basis in the sense of Hu and Mathas [25].
The main observation is that the foams \({\mathcal {F}}(\tau _{i}(a_{i},b_{i}))\) defined in Definition 4.7 are either zip or unzip foams (in the case \(|a_i-b_i|=1\)), two digon removals (in the case \(a_i=b_i\)) or just shifts (all the other cases). Since this is not trivial, we state it as a lemma. Recall that \(\mathrm{deg}_q\) denotes the \(q\)-degree of the foam space.
We start with some useful Lemmata.
Lemma 4.14
Given the same data as in Definition 4.7, we have that for all \(\tau _{i}\in S_{k-1}\) the foams \({\mathcal {F}}(\tau _{i}(a_{i},b_{i}))\) split into three disjoint cases.
-
(a)
\({\mathcal {F}}(\tau _{i}(a_{i},b_{i})):w_1\rightarrow w_2\) is a zip or a unzip iff \(|a_i-b_i|=1\). We have \(\mathrm{deg}_q({\mathcal {F}}(\tau _{i}(a_{i},b_{i})))=1\) in this case.
-
(b)
\({\mathcal {F}}(\tau _{i}(a_{i},b_{i})):w_1\rightarrow w_2\) removes two digons iff \(a_i=b_i\). We have \(\mathrm{deg}_q({\mathcal {F}}(\tau _{i}(a_{i},b_{i})))=-2\) in this case.
-
(c)
\({\mathcal {F}}(\tau _{i}(a_{i},b_{i})):w_1\rightarrow w_2\) is just a shift iff \(|a_i-b_i|>1\). We have \(\mathrm{deg}_q({\mathcal {F}}(\tau _{i}(a_{i},b_{i})))=0\) in this case.
Proof
(a): A case by case check of all the possibilities how the local picture of the webs \(w_1\) at the top and \(w_2\) at the bottom could look like. Note that both webs are generated by a sequence of LT-generators, thus not all combinations are possible. Since all cases work in the same vein we only illustrate four here. So five in total, i.e. counting the one from Example 4.10. In fact the Example 4.10 is a blueprint of all cases. The four other cases are the following.

and

We have indicated the important face for our argument with color in all the pictures. To be more precise, the foam in the top left is a unzip between a Y-move and a flipped Y-move at the top and two H-moves at the bottom, the foam in the bottom left is between two shifts and a Y-move and a flipped Y-move, the foam in the top right is between a Y-move and arc pair and a H-move and a flipped Y-move at the bottom and the lower right is between two H-moves and a Y-move and a flipped Y-move.
All other cases are similar. It should be noted that the number of case-by-case checks reduces if one takes rotational symmetries into account, e.g. the foam in the top left picture and the one in the right bottom are essentially the same.
Moreover, it is worth noting that the ambiguous case, i.e. two similar moves at the bottom and top, does not occur by construction, since the action of \(F_iF_{i+1}\) will be different than the action of \(F_{i+1}F_i\) and will therefore always give two different local webs.
(b): As before a case-by-case check. In fact the number of cases is small, that is only two can occur, since a H-move after a H-move is not possible because at least one of the H-moves would correspond to an \(E\). Thus, we only the following two cases.

We have smoothen the first picture a little bit to make it more visible. We have indicated the important face with color again.
(c): This is clear by the definition of the local changes of the foam pictured in Definition 4.7, because it will be the identity foam up to isotopy.
Since the \(q\)-degree of a zip or unzip is \(1\), the \(q\)-degree of a digon removal is \(-1\) and the \(q\)-degree of the identity is zero, we conclude that the degrees work out as stated which finishes the proof. \(\square \)
Lemma 4.15
Let the foam
be as in Definition 4.11. Then
Proof
We only have to show the first equality, since the second already follows as a consequence of the Proposition 3.31.
We start by noting that
where \(n_d\) is the number of dots. This is true, because both are topological just the identity and a dot has \(q\)-degree \(2\). This implies, since we spread dots using a convention of adding dots per addable nodes and \(T_{\vec {\lambda }}\) does not have removable nodes, that
It should be noted that the extra removing of the internal faces from Definition 4.9 corresponds exactly to the change in degree from \(\iota (u_f)\) to \(\iota (u_f)^{\prime }\). So to simplify our notation, we can freely assume that \(\iota (u_f)=\iota (u_f)^{\prime }\) and \(\iota (v_{f^{\prime }})=\iota (v_{f^{\prime }})^{\prime }\).
Hence, the results of the two Lemmata 4.8 and 4.14 imply now that we only have to check that the degree works out on the level of actions on tableaux, because the action defined via foams agrees with the one on the tableaux (part two of Lemma 4.8) and, as a consequence of Lemma 4.14, we see that it has exactly the same degree as the action defined on tableaux.
Thus, we can use a result from the side of the cyclotomic Hecke algebra, i.e. Corollary 3.14 of Brundan et al. [7], and we get
Hence, we have
which proves the statement. \(\square \)
Lemma 4.16
Let the foam
be as in Definition 4.11 and let \({}^*\) denote the involution on the foam space. Then
Proof
This is a direct consequence of Lemma 4.2, because we have
where the second equality is due to the definition of the involution \({}^*\). \(\square \)
The next proposition shows that the growth algorithm for foams is a “foamy” version of Hu and Mathas graded cellular basis [25].
Proposition 4.17
Let \(S\) be any sign string and let
and let
Then \((S,J,u_{f},v_{f^{\prime }})\) with \(J\in J_S\) and \(u_{f},v_{f^{\prime }}\in B_S^J\) gives rise to a foam \({\mathcal {F}}^{\vec {\lambda }}_{\iota (u_f),\iota (v_{f^{\prime }})}\in K_S\).
This foam is obtained from the application of the foamation functor to the HM-basis element with the datum (the multipartition \(\vec {\lambda }\) is the one associated to \((S,J)\))
and removing the internal faces using digon removals or theta removals.
Proof
The first statement is just a collection of the results of the sections before, i.e. that a pair \((S,J)\) gives rise to a \(3\)-multitableau \(\vec {\lambda }\) is proven in Theorem 3.26, that the webs with flows \(u_{f},v_{f^{\prime }}\) give rise to a unique filling \(\iota (u_f),\iota (v_{f^{\prime }})\in \mathrm{Std}(\vec {\lambda })\) of the \(3\)-multitableau \(\vec {\lambda }\) is proven in Lemma 3.15 and finally the definition of the foam \({\mathcal {F}}^{\vec {\lambda }}_{\iota (u_f),\iota (v_{f^{\prime }})}\) is given in Definition 4.11.
To see that the second statement is true, we observe that the Sect. 3.1 and \(q\)-skew Howe duality imply that we can read the HM-basis elements as foams in the following way. Given a \(3\)-multipartition \(\vec {\lambda }\) with residue sequence \(r(\vec {\lambda })=(r_1,r_2,\dots )\), we can read it as a \(2\)-morphism in \({\mathcal {U}}({\mathfrak {sl}}_n)\) as indicated below

reading from right to left and all arrows pointing downwards. This can be translated to a web for the top and bottom string of residues by applying the corresponding sequence of \(F\) to the highest weight vector \(v_{3^{\ell }}\) as explained in the Sect. 3.1 and reading the residues \(r_i\) as \(F_{r_i}\) as explained in and around the Definition 3.25.
Then the second statement follows now from the sequence of Lemmata 4.6, 4.8 and 4.14, i.e. the Lemma 4.6 shows that the dotted HM-idempotent, after applying the foamation functor, is essentially the same as the dotted idempotent from Definition 4.4, since in both pictures the idempotent \(e(\vec {\lambda })\) is obtained from the residue sequence \(r(\vec {\lambda })\) and the dots are obtained from the set of addable nodes explained in Definition 4.4. Moreover, the Lemmata 4.8 and 4.14 show that the HM-element \(\psi _{\iota (u_f)^{\prime }}\), after applying the foamation functor, is the same as the foam \({\mathcal {F}}_{u_{f}}\) (plus the extra internal face removals while passing from \(\iota (u_f)^{\prime }\) to \(\iota (u_f)\)), since we have the correspondence

by Lemma 4.14 and the different local pictures are spread in essentially the same way in both cases by Lemma 4.8. Hence, we conclude that the HM-basis element with the datum
corresponds to the foam \({\mathcal {F}}^{\vec {\lambda }}_{\iota (u_f),\iota (v_{f^{\prime }})}\in K_S\) (plus the relevant internal face removals). \(\square \)
We are now able to proof that the growth algorithm for foams given in Definition 4.11 gives a basis of the \(\mathfrak {sl}_3\)-web algebra \(K_S\).
Theorem 4.18
The growth algorithm for foams gives a homogeneous basis of \(K_S\).
Proof
We will show that the growth algorithm gives a linear independent set of foams denoted by
By a counting argument we see that this set forms a basis, since we know that every triple
corresponds exactly to one closed web \(w=u^*v\) with a fixed flow by Theorem 3.26. Thus, because \(K_S\) has a basis indexed by closed webs with flows as we have recalled in Remark 2.13, we conclude that the linear independence of \({\mathfrak {F}}\) suffices to show that the set \({\mathfrak {F}}\) forms a basis.
To see linear independence we use Proposition 4.17 and pull \({\mathfrak {F}}\) back to the cyclotomic Hecke algebra. We denote the pullback (by not removing the internal faces) restricted to the datum
by \(\psi ^{-1}({\mathfrak {F}})\).
Since Hu and Mathas showed that their definition gives rise to a basis, we conclude that the corresponding set \(\psi ^{-1}({\mathfrak {F}})\) is linear independent.
In 4.3.3. of [39] Lauda, Queffelec and Rose showed that all the foam relations in \(\mathcal {F}(w)\) follow from certain relations in \({\mathcal {U}}({\mathfrak {sl}}_n)\). Moreover, they argue that the \(\mathfrak {sl}_3\)-foam category can be obtained from \({\mathcal {U}}({\mathfrak {sl}}_n)\) by modding out certain relations involving bubbles of weight \(3\). But our convention to only use \(3\)-multitableaux ensures that the elements of \(\psi ^{-1}({\mathfrak {F}})\) do not contain any of these relations, while all the other relevant relations are true independent of \(n\). Hence, a possible linear independence of \({\mathfrak {F}}\) can not be created by the foamation functor \(\psi \) (which is an additive functor) nor by modding out by the cyclotomic relation 2.2.
Thus, the set \({\mathfrak {F}}\) must be linear independent, since, as Khovanov showed in Proposition 7 and 8 of [28], the internal face removals give rise to a isomorphism of graded vector spaces and the foams without the internal face removals form a linear independent set for a version of the \(\mathfrak {sl}_3\)-web algebra between the webs without the face removals.
That \({\mathfrak {F}}\) is homogeneous follows from Lemma 4.15. \(\square \)
Remark 4.19
Hu and Mathas proof that their set is linear independent relies on the connection to another basis that is known for the cyclotomic Hecke algebra, the so-called Dipper, James and Mathas standard basis which can be seen as a “higher version” of the classical construction of the basis for Specht modules. The proof that this standard basis is in fact a basis is non-trivial, see Dipper, James and Mathas [16].
In our framework, since everything is inductively build from small cases, it is possible to proof most statements by an inductive case-by-case check. In fact, there is such an alternative proof of Theorem 4.18 in our framework.
The alternative “by hand” proof of the statement 4.18 is roughly as follows. One does induction on the number of faces of \(u^*v\) to conclude that the restriction of \({\mathfrak {F}}\) to \({}_uK_v\) gives a basis of latter. The small cases can all be verified easily and the induction step is similar to the induction that shows that the basis from Remark 2.17 is in fact a basis. To be more precise, all the three basic moves, called circle removal, digon removal and square removal, have a local inverse. One then verifies “by hand” all possible cases how a face in \(u^*v\) with flow can look like. If one does so, then one realizes that the growth algorithm for foams has a summand that looks like one of these face removals and all the other summands are killed by the inverse. To see this one does a case-by-case check. It should be noted that Lemma 4.14 ensures that the growth algorithm “almost” remove faces anyway, since the face removing foams are just local zips. One just have to be careful that sometimes not the right edges will be unziped. But one can always use the relations DR, SqR and Dot Migration to show that at least one of the summands is exactly the desired face removal (and the other is killed by the inverse).
Hence, one can conclude that the set \({\mathfrak {F}}\) is related by a non-singular change of base matrix to the basis from Remark 2.17. But since there are a lot of cases to check, we do not do it here.
We can reprove Brundan and Kleshchev’s graded dimension formula, i.e. Theorem 4.20 in [5], as a direct consequence of Theorem 4.18 in a very simple fashion for our framework. Note that we see \({}_{g(T_{\vec {\lambda }})}K{}_{g(T_{\vec {\mu }})}\) in the following theorem by abuse of notation as an analogue of the \(\mathfrak {sl}_3\)-web algebra between the possible non-elliptic \(\mathfrak {sl}_3\)-web given by the extended growth algorithm from Definition 3.25.
Theorem 4.20
(Brundan and Kleshchev: Graded dimension formula) For \(3\)-multipartitions \(\vec {\lambda },\vec {\mu }\) of \(c(S)\), we have (where \(\{n\}\) is the shift by the number of strands)
Proof
The second equality follows from the fact that Brundan, Kleshchev and Wang’s degree is given by minus the weight of the corresponding flow, i.e. Proposition 3.31, and the fact that the \(q\)-degree of the \(\mathfrak {sl}_3\)-web algebra is given by the Kuperberg bracket (up to the shift \(\{n\}\))—even if the underlying web space consists of non-elliptic \(\mathfrak {sl}_3\)-webs.
The first equality follows from Proposition 4.17 and Theorem 4.18 if we regard \({}_{g(T_{\vec {\lambda }})}K{}_{g(T_{\vec {\mu }})}\) as an analogue of the usual \(K_S\) with a possible different underlying \(\mathfrak {sl}_3\)-web space. The details of this slightly modified version of the \(\mathfrak {sl}_3\)-web algebra can be verified as in the usual case demonstrated in [44]. \(\square \)
4.3 Cellularity
We are able to show now that \({\mathfrak {F}}\) is a cellular basis of \(K_S\). First we recall the definition of a graded cellular algebra due to Graham and Lehrer [23] in the ungraded setting and Hu and Mathas [25] in the graded setting. Note that graded always means \(\mathbb {Z}\)-graded.
Definition 4.21
(Graham–Lehrer, Hu–Mathas) Suppose \(A\) is a graded free algebra over some field \(K\) of finite rank. A graded cell datum is an ordered quintuple \((\mathfrak {P},{\mathcal {T}},C,\mathrm{i},\mathrm{deg})\), where \(({\mathfrak {P}},\rhd )\) is the weight poset, \({\mathcal {T}}(\lambda )\) is a finite set for all \(\lambda \in {\mathfrak {P}}\), \(\mathrm{i}\) is an involution of \(A\) and \(C\) is an injection
Moreover, the degree function deg is given by
The whole data should be such that the \(c^{\lambda }_{st}\) form a homogeneous \(K\)-basis of \(A\) with \(\mathrm{i}(c^{\lambda }_{st})=c^{\lambda }_{ts}\) and \(\mathrm{deg}(c^{\lambda }_{st})=\mathrm{deg}(s)+\mathrm{deg}(t)\) for all \(\lambda \in \mathfrak {P}\) and \(s,t\in {\mathcal {T}}(\lambda )\). Moreover, for all \(a\in A\)
Here \(A^{\rhd \lambda }\) is the \(K\)-submodule of \(A\) spanned by the set \(\{c^{\mu }_{st}\mid \mu \rhd \lambda \text { and }s,t\in {\mathcal {T}}(\mu )\}\).
An algebra \(A\) with such a quintuple is called a graded cellular algebra and the \(c^{\lambda }_{st}\) are called a graded cellular basis of \(A\) (with respect to the involution \(\mathrm{i}\)).
We are now able to show that
is a graded cellular basis.
Theorem 4.22
(Graded cellular basis) The algebra \(K_S\) is a graded cellular algebra in the sense of Definition 4.21 with the cell datum
where \(\mathfrak {P}_{c(S)}^3\) is the set of all multipartitions of \(c(S)\) with at most three non-zero entries that all are gathered in the last three entries ordered by the dominance order \(\vartriangleright \) from Definition 2.3, \(\iota (B_S^J)\) is the image of the set of all webs given by the LT-algorithm together with flows, the involution \({}^*\) on the foam space and the degree \(\mathrm{deg}_{\mathrm{BKW}}\) on the tableaux in \(\iota (B_S^J)\) Footnote 4.
Proof
We have to prove four statements. To shorten our notation in the following equations, we write \(u_f=\iota (u_f)\), \(v_{f^{\prime }}=\iota (v_{f^{\prime }})\) and \(B_S^J=\iota (B_S^J)\) as a shorthand and hope the reader does not get confused since the left hand side is a flow on a web and the right hand side is a multitableau. Moreover, the scalars below should all only depend on the element on the left side of the multiplication.
-
(a)
Each \({\mathcal {F}}^{\vec {\lambda }}_{u_f,v_{f^{\prime }}}\) is homogeneous of degree
$$\begin{aligned} \mathrm{deg}_q({\mathcal {F}}^{\vec {\lambda }}_{u_f,v_{f^{\prime }}})=\mathrm{deg}_{\mathrm{BKW}}(u_f)+\mathrm{deg}_{\mathrm{BKW}}(v_{f^{\prime }}). \end{aligned}$$ -
(b)
The set \({\mathfrak {F}}\) is a basis of the graded \(\mathbb {C}\)-algebra \(K_S\).
-
(c)
The involution satisfies
$$\begin{aligned} ({\mathcal {F}}^{\vec {\lambda }}_{u_f,v_{f^{\prime }}})^*={\mathcal {F}}^{\vec {\lambda }}_{v_{f^{\prime }},u_f}. \end{aligned}$$ -
(d)
Given \(\vec {\lambda },\vec {\mu }\in \mathfrak {P}_{c(S)}^3\), \(u_f,v_{f^{\prime }}\in \mathrm{Std}(\vec {\lambda })\) and \(\tilde{u}_{\tilde{f}},\tilde{v}_{\tilde{f}^{\prime }}\in \mathrm{Std}(\vec {\mu })\), then there exist scalars \(r_{u_f,w_{f^{\prime \prime }}}\) which do not depend on \(v_{f^{\prime }}\), such that
$$\begin{aligned} {\mathcal {F}}^{\vec {\mu }}_{\tilde{u}_{\tilde{f}},\tilde{v}_{\tilde{f}^{\prime }}}{\mathcal {F}}^{\vec {\lambda }}_{u_f,v_{f^{\prime }}}=\sum _{w_{f^{\prime \prime }}\in B_S^J}r_{u_f,w_{f^{\prime \prime }}}{\mathcal {F}}^{\vec {\lambda }}_{w_{f^{\prime \prime }},v_{f^{\prime }}}\;(\mathrm{mod}\;K^{\vartriangleright \lambda }_S). \end{aligned}$$(4.4)
In fact most of the statements follow directly from the work we have already done in the sections before. To be more precise, points (a)+(b) are true because of Lemma 4.15 and Theorem 4.18, while the statement (c) is just Lemma 4.16. Hence, we only have to verify (d), i.e. Eq. 4.4 (it is worth noting that, by linearity, it is sufficient to show Eq. 4.4 to get Eq. 4.3).
We want to use the foamation functor \(\psi \) again together with Proposition 4.17 and the fact that Hu and Mathas proved [25] that their basis is cellular with almost the same poset.
In fact, the difference between the poset Hu and Mathas use is that they consider all multipartitions of \(c(S)\) instead of only the \(3\)-multipartitions. But our convention how we see the \(3\)-multipartitions \(\vec {\lambda }\) as such multipartitions, i.e. embed into the last three entries, ensures that all multipartitions \(\vec {\nu }\) with a node left to the last three entries are bigger in the dominance order, i.e. \(\vec {\nu }\vartriangleright \vec {\lambda }\), than all \(3\)-multipartitions. On the same side the foamation functor and our conventions how to place dots kills all those multipartitions \(\vec {\nu }\), since the first (that is leftmost) node in \(T_{\vec {\nu }}\) will have three or more addable nodes of the same residue. Thus, the corresponding foam \(e(\vec {\nu })d(\vec {\nu })\) will have a face with three or more dots and is therefore killed anyway. Hence, we do not need to consider them in order to prove Eq. 4.4.
Another difference is the fact that we have to use additional face removals, because otherwise, as explained before, we would not have the Kuperberg basis as an underlying web basis. But since the corresponding removals are just digon and theta foam removals, it is quite easy to handle them and the crucial case (where we need the underlying combinatorics of the cyclotomic Hecke framework) is in fact the cases \(\iota (u_f)=\iota (u_f)^{\prime }\) and \(\iota (\tilde{v}_{\tilde{f}^{\prime }})=\iota (\tilde{v}_{\tilde{f}^{\prime }})^{\prime }\) and we can prove the rest by induction on the number \(n(\mathrm{face})\) of extra needed face removals in the multiplication of the middle part \({\mathcal {F}}_{\tilde{v}_{\tilde{f}^{\prime }}}^*{\mathcal {F}}_{u_f}\). Moreover, from now on we consider the case \(u=\tilde{v}\), since the other case is, by our multiplication convention, zero anyway.
Case \(n(\mathrm{face})=0\): So given the two elements \({\mathcal {F}}^{\vec {\mu }}_{\tilde{u}_{\tilde{f}},\tilde{v}_{\tilde{f}^{\prime }}},{\mathcal {F}}^{\vec {\lambda }}_{u_f,v_{f^{\prime }}}\in \mathfrak {F}\), we can pull them back to the HM-basis. We denote the pullbacks by \(\psi ^{\vec {\mu }}_{\tilde{u}_{\tilde{f}},\tilde{v}_{\tilde{f}^{\prime }}}\) and \(\psi ^{\vec {\lambda }}_{u_f,v_{f^{\prime }}}\) (and in a similar way all the other HM-basis elements). By Hu and Mathas results we almost obtain the result we want, i.e.
Moreover, by Proposition 3.9, we can be sure that all possible \(3\)-multipartitions \(\vec {\lambda }\) have an interpretation as some web \(w\) with boundary \(S\) together with some flow \(f\). Those, by Lemma 4.13 and Theorem 4.18, give always rise to a non-zero foam in our basis \({\mathfrak {F}}\) given by applying the foamation to a HM-basis element with the same \(\vec {\lambda }\) by Proposition 4.17. That is, there can not be any gaps in the partial ordering \(\vartriangleright \) on the side of the foams, i.e. we can restrict our attention to the part of Eq. 4.4 and 4.5 with \(\vec {\lambda }\) as the underlying \(3\)-multipartition.
In fact the only problem is the appearance of the full set \(\mathrm{Std}(\vec {\lambda })\), because not all of them give rise to a web \(w_f\in B_S^J\), since there are in general much more fillings for such tableaux than flows on webs. But it turns out, by locality of the construction, that this can only happen on intermediate layers of the foams (where this is allowed by construction), but not at the top or bottom. To be more precise, after translating Eq. 4.5 to the foam picture, we obtain almost Eq. 4.4, i.e. we have
But the \(\vec {T}\in \mathrm{Std}(\vec {\lambda })\), which in general does not correspond to a flow on a web in the LT-basis, certainly, by the extended growth algorithm from Definition 3.25 and the result of Theorem 3.26, corresponds to a web with flow \(w_f\) and boundary pair \((S,J)\). But, due to the definition of the multiplication of \(K_S\), this web has to be \(\tilde{u}\), since we have
and \({}_{\tilde{u}}K_{v}\) is closed under addition. Hence, we have
where the scalar \(\tilde{r}_{u_f}\) is a certain (we have no further control here) sum of scalars \(r_{u_f,\tilde{w}_{f^{\prime \prime }}}\) for some webs \(\tilde{w}\), but, and that is the crucial observation, all the webs \(\tilde{w}\) are non-elliptic.
To summarise, we see that Eq. 4.6 can be restricted to
which proves the point (d).
Case \(n(\mathrm{face})\ne 0\): Since internal theta removals are completely independent from the rest, we can freely ignore them, since they do not affect point (d) at all.
First note that the digon removal all commute with each other because they exists as digons in the web \(\tilde{v}=u\) and are therefore not neighbors) as we see below.

Note that the case where a certain digon removal on the left side corresponds to a mirror digon removal on the right side follows easy from induction since we would get a local picture as pictured in Eq. 4.2.
With the observation diplayed in 4.3 above, we can then slide such a pair to the right side (or the left) such that all other digon removals are left to the fixed pair. This local pair can then be regarded as a legal move for some other flow on the middle web \(\tilde{v}=u\) by Lemma 4.14. Therefore, we get the requirement (d) without difficulties by induction.
Note that, by construction, all digon removals are always mirrored on the other side, since we assume that \(\tilde{v}=u\). Thus, we obtain the statement by induction.
It should be noted that the scalars are in general, due to our case-by-case argumentation from above, not the same for the cyclotomic Hecke algebra and \(K_S\). \(\square \)
Remark 4.23
It is worth noting that Theorem 4.22 can also be verified (at least in theory) “by hand” again, i.e. without using the fact that HM-basis is cellular. Latter relies on the highly non-trivial fact that the standard basis of Dipper, James and Mathas [16] is cellular. Thus, on “higher” Specht theory.
The cellularity proof “by hand” can be done in a similar vein as Brundan and Stroppel did for the \(\mathfrak {sl}_2\) case [8]. Of course the number of case one has to check is bigger in our context.
To be slightly more precise, one can check how the local behaviour of the composition
changes the \(3\)-multipartition \(\vec {\lambda }\). Due to the locality of the construction, we only have to consider compositions of the five cases from Lemma 4.14 and see that the either increase the number of dots (which corresponds to a higher or equal order in the dominance order \(\lhd \)). Hence, one only has to check that the one of the same order do not depend on \(\tilde{u}_{\tilde{f}}\). But this follows again from the locality of the construction, since we can pull the middle, i.e. \({\mathcal {F}}_{\tilde{v}_{\tilde{f}^{\prime }}}^*{\mathcal {F}}_{u_f}\), of
by shifting it to the left side using
This will, by construction, in the end correspond to a linear combination of foams as in 4.6, since we do not affect the right side at all and due to the fact that each each such summand will correspond as a consequence of Theorem 3.26 to a basis element.
As a direct consequence of the cellularity Theorem 4.22 we construct a complete set of pairwise non-isomorphic, graded, simple \(K_S\)-modules and a complete set of pairwise non-isomorphic, graded, projective indecomposable \(K_S\)-modules.
Let us denote the graded cell modules Footnote 5 (also called Specht modules in our context), whose existence is guaranteed by Theorem 4.22, for \(\vec {\lambda }\in \mathfrak {P}_{c(S)}^3\) by \(S^{\vec {\lambda }}\) and their heads or tops by
and the projective cover of the \(D^{\vec {\lambda }}\) by \(P^{\vec {\lambda }}\). Moreover, define \(\mathfrak {P}_0^3=\{\vec {\lambda }\in \mathfrak {P}_{c(S)}^3\mid D^{\vec {\lambda }}\ne 0\}\).
By an abstract theorem about graded cellular algebras, due to Graham and Lehrer [23] in the ungraded stetting and Hu and Mathas [25] is the graded setting, we get the following theorem.
Theorem 4.24
The sets
form a complete set of pairwise non-isomorphic, graded, simple \(K_S\)-modules and pairwise non-isomorphic, graded, projective indecomposable \(K_S\)-modules respectively.
It is worth noting that a direct consequence of Theorem 4.24 is that the set \(\mathfrak {P}_0^3\) is noting else than the set of all semi-standard tableau \(\mathrm{Std}^s(3^{\ell })\) by Corollary 2.11 in [25], since it is well-known that the elements of \(B_S\), which can be identified with the elements of \(\mathrm{Std}^s(3^{\ell })\), enumerate the set \(\underline{{\mathcal {P}}}\), i.e. forgetting the grading. These multipartitions are sometimes called Kleshchev multipartitions and it is in general highly non-trivial to give an explicit characterization which multipartitions are Kleshchev multipartitions, see [25].
Remark 4.25
We note that one can closely follow the approach indicated in [43], i.e. using the strong \(2\)-representation (in the sense of Cautis and Lauda [14]) on the abelian category \(\mathcal {W}_{(3^{\ell })}\) (which can be restricted to the additive category \(\mathcal {W}_{(3^{\ell })}^p\)) defined in [44], where \(\mathcal {W}_{(3^{\ell })}\) and \(\mathcal {W}_{(3^{\ell })}^p\) are the categories of all finite dimensional, graded, unital \(K_{3^{\ell }}\)-modules and of all finite dimensional, graded, unital, projective \(K_{3^{\ell }}\)-modules respectively, to show that the bases \({\mathcal {D}}\) and \({\mathcal {P}}\) (note that \(K_{3^{\ell }}\), as a direct sum of graded cellular algebras, is itself a graded cellular algebra) of the (split) Grothendieck groups
corresponds to the canonical basis of the co-standard form of the \(\mathfrak {sl}_3\)-web space \(W^*_{(3^{\ell })}\) and to the dual canonical basis of the \(\mathfrak {sl}_3\)-web space \(W_{(3^{\ell })}\) respectively (up to shifts as explained by Mackaay in [43]). This can be verified almost similar to the approach of Mackaay in [43], since his arguments are based on Brundan and Kleshchev [5] proof about the graded Specht modules \(S_{T}\) of
where \(R_{\Lambda }\) is the cyclotomic KL-R algebra from Definition 2.7, which can be identified with the corresponding ones coming from Hu and Mathas graded cellular basis, due to Corollary 5.10 in [25].
Notes
Note that we write \(3^{\ell }\) as a shorthand for the partition \((3^{\ell })\).
We always mean Toffin and not Thibon. We thank Catharina Stroppel for recognizing this confusing point.
The reader should compare our definition with the one of Leclerc–Toffin explained in Sect. 2.2.
Note that the formulation can be done alternatively using \(\mathfrak {sl}_3\)-web notions as described in the sections of 3.
References
Bar-Natan, D. : Khovanov’s homology for tangles and cobordisms, Geom. Topol. 9, 1443–1499 (2005). arXiv:math/0410495
Beilinson, A., Lusztig, G., MacPherson, R.: A geometric setting for the quantum deformation of \(\mathfrak{gl}_n\). Duke Math. J. 61–2, 655–77 (1990)
Blanchet, C.: An oriented model for Khovanov homology. J. Knot Theory Ramif. 19–2, 291–312 (2010)
Brundan, J., Kleshchev, A.: Blocks of cyclotomic Hecke algebras and Khovanov-Lauda algebras. Invent. Math. 178, 451–484 (2009). arXiv:0808.2032
Brundan, J., Kleshchev, A.: Graded decomposition numbers for cyclotomic Hecke algebras. Adv. Math. 222, 1883–1942 (2009). arXiv:0901.4450
Brundan, J., Kleshchev, A.: The degenerate analogue of Ariki’s categorification theorem. Math. Z. 266, 877–919 (2010). arXiv:0901.0057
Brundan, J., Kleshchev, A., Wang, W.: Graded Specht modules. J. Reine und Angew. Math. 655, 61–87 (2011). arXiv:0901.0218
Brundan, J., Stroppel, C.: Highest weight categories arising from Khovanov’s diagram algebra I: cellularity. Mosc. Math. J. 11(4), 685–722 (2011). arXiv:0806.1532
Brundan, J., Stroppel, C.: Highest weight categories arising from Khovanov’s diagram algebra II: Koszulity. Transform. Groups 15, 1–45 (2010). arXiv:0806.3472
Brundan, J., Stroppel, C.: Highest weight categories arising from Khovanov’s diagram algebra III: category \({\cal O}\). Represent. Theory 15, 170–243 (2011). arXiv:0812.1090
Brundan, J., Stroppel, C.: Highest weight categories arising from Khovanov’s diagram algebra IV: the general linear supergroup. J. Eur. Math. Soc. 14, 373–419 (2012). arXiv:0907.2543
Brundan, J., Stroppel, C.: Gradings on walled Brauer algebras and Khovanov’s arc algebra. Adv. Math. 231, 709–773 (2012). arXiv:1107.0999
Cautis, S., Kamnitzer, J., Morrison, S. : Webs and quantum skew Howe duality, to appear in Math. Ann. arXiv:1210.6437
Cautis, S., Lauda, A.D.: Implicit structure in 2-representations of quantum groups. arXiv:1111.1431
Chen, Y., Khovanov, M.: An invariant of tangle cobordisms via subquotients of arc rings. arXiv:math/0610054
Dipper, R., James, G., Mathas, A.: Cyclotomic q-schur algebras. Math. Z. 229, 385–416 (1999)
Ehrig, M., Stroppel, C.: 2-row Springer fibres and Khovanov diagram algebras for type D. arXiv:1209.4998
Ehrig, M., Stroppel, C.: Diagrams for perverse sheaves on isotropic Grassmannians and the supergroup \(SOSP(m|2n)\). arXiv:1306.4043
Ehrig, M., Stroppel, C.: Nazarov-Wenzl algebras, coideal subalgebras and categorified skew Howe duality. arXiv:1310.1972
Fontaine, B.: Generating basis webs for \({\mathfrak{sl}}_n\). Adv. Math. 229, 2792–2817 (2012). arXiv:1108.4616
Fontaine, B., Kamnitzer, J., Kuperberg, G.: Buildings, spiders, and geometric Satake. Compos. Math. 149, 1871–1912 (2013). arXiv:1103.3519
Gornik, B.: Note on Khovanov link cohomology. arXiv:math/0402266
Graham, J.J., Lehrer, G.I.: Cellular algebras. Invent. Math. 123, 1–34 (1996)
Hong, J., Kang, S.-J.: Introduction to Quantum Groups and Crystal Bases. Graduate Studies in Mathematics, vol. 42, 307 pp. American Mathematical Society (2002)
Hu, J., Mathas, A.: Graded cellular bases for the cyclotomic Khovanov-Lauda-Rouquier algebras of type A. Adv. Math. 225–2, 598–642 (2010). arXiv:0907.2985
Hu, J., Mathas, A.: Quiver Schur algebras I: linear quivers. arXiv:1110.1699
Huerfano, R.S., Khovanov, M.: Categorification of some level two representations of \(sl(n)\). J. Knot Theor. Ramif. 15–6, 695–713 (2006). arXiv:math/0204333
Khovanov, M.: \({\mathfrak{sl}}_3\) link homology. Algebr. Geom. Topol. 4, 1045–1081 (2004). arXiv:math/0304375
Khovanov, M.: A categorification of the Jones polynomial. Duke Math. J. 101, 359–426 (2000). arXiv:math/9908171
Khovanov, M.: A functor-valued invariant of tangles. Algebr. Geom. Topol. 2, 665–741 (2002). Electronic, arXiv:math/0103190
Khovanov, M.: Crossingless matchings and the cohomology of \((n, n)\) Springer varieties. Comm. Contemp. Math. 6–2, 561–577 (2004). arXiv:math/0202110
Khovanov, M., Kuperberg, G.: Web bases for \({\mathfrak{sl}}_3\) are not dual canonical. Pacific J. Math. 188:1, 129–153 (1999). arXiv:q-alg/9712046
Khovanov, M., Lauda, A.D.: A diagrammatic approach to categorification of quantum groups I. Represent. Theory. 13, 309–347 (2009). arXiv:0803.4121
Khovanov, M., Lauda, A.D.: A diagrammatic approach to categorification of quantum groups II. Trans. Am. Math. Soc. 363, 2685–2700 (2011). arXiv:0804.2080
Khovanov, M., Lauda, A.D.: A categorification of quantum \({\mathfrak{sl}}_n\). Quantum Topol. 2–1, 1–92 (2010). arXiv:0807.3250
Khovanov, M., Lauda, A.D.: Erratum: “A categorification of quantum \({\mathfrak{sl}}_n\)”. Quantum Topol. 2–1, 97–9 (2011)
M. Khovanov, A.D. Lauda, M. Mackaay and M. Stošić, Extended Graphical Calculus for Categorified Quantum \({\mathfrak{sl}}_2\), Mem. Am. Math. Soc. 219 (2012). arXiv:1006.2866
Kuperberg, G.: Spiders for rank 2 Lie algebras. Comm. Math. Phys. 180, 109–151 (1996). arXiv:q-alg/9712003
Lauda, A.D., Queffelec, H., Rose, D.E.V.: Khovanov homology is a skew Howe 2-representation of categorified quantum sl(m). arXiv:1212.6076
Leclerc, B., Toffin, P.: A simple algorithm for computing the global crystal basis of an irreducible \(U_q({\mathfrak{sl}}_n)\)-module. Int. J. Algebr. Comput. 10, 191–208 (2000)
Li, G.: Integral basis theorem of cyclotomic Khovanov-Lauda-Rouquier algebras of type A, Ph.D. thesis, published online by University Sydney, Sydney digital thesis, 2012. hdl.handle.net/2123/8844
Lusztig, G.: Introduction to Quantum Groups. Progress in Mathematics, Birkhäuser (1993)
Mackaay, M. : The sl(N)-web algebras and dual canonical bases. arXiv:1308.0566
Mackaay, M., Pan, W., Tubbenhauer, D.: The \({\mathfrak{sl}}_3\)-web algebra, to appear in Math. Z. arXiv:1206.2118
Mackaay, M., Stošić, M., Vaz, P.: Sl(N) link homology using foams and the Kapustin-Li formula. Geom. Topol. 13–2, 1075–1128 (2009). arXiv:0708.2228
Mackaay, M., Vaz, P.: The universal \({\mathfrak{sl}}_3\)-link homology. Algebr. Geom. Topol. 7, 1135–1169 (2007). Electronic, arXiv:math/0603307
Mackaay, M., Yonezawa, Y.: The sl(N) web categories and categorified skew Howe duality. arXiv:1306.6242
Robert, L.-H. : A characterisation of indecomposable web-modules over Khovanov-Kuperberg Algebras. arXiv:1309.2793
Robert, L.-H.: A large family of indecomposable projective modules for the Khovanov-Kuperberg algebra of \({\mathfrak{sl}}_3\) webs. J. Knot Theor. Ramif. 22, 25 (2013). Electronic, arXiv:1207.6287
Rouquier, R.: 2-Kac-Moody algebras. arXiv:0812.5023
Rumer, G., Teller, E., Weyl, H.: Eine für die Valenztheorie geeignete Basis der binären Vektorinvarianten, Nachrichten von der Ges. der Wiss. Zu Göttingen. Math.-Phys. Klasse, 498–504, 1932.
Russell, H.: An explicit bijection between semistandard tableaux and non-elliptic \({\mathfrak{s}l}_3\) webs. J. Algebr. Comb. (2013). Electronic, arXiv:1204.1037
Sartori, A.: Categorification of tensor powers of the vector representation of \(U_q(gl(1|1))\). arXiv:1305.6162
Stroppel, C.: Parabolic category \(\cal O\), perverse sheaves on Grassmannians, Springer fibres and Khovanov homology. Compos. Math. 145, 945–992 (2009). arXiv:math/0608234
Stroppel, C., Webster, B.: 2-Block Springer fibers: convolution algebras and coherent sheaves. Comment. Math. Helv. 87, 477–520 (2012). arXiv:0802.1943
Tubbenhauer, D.: Categorification and applications in topology and representation theory, Ph.D. thesis, published online by Universität Gttingen, Univ., Diss., 2013, DISS 2013 B 9481. arXiv:1307.1011
Acknowledgments
I like to thank Bernard Leclerc, Lukas Lewark, Marco Mackaay, Weiwei Pan, Hoel Queffelec, A Referee, Louis-Hadrien Robert, Antonio Sartori and Catharina Stroppel for helpful discussions and comments about (intermediate) crystal bases, \(q\)-skew Howe duality, cyclotomic Hecke/KL-R algebras, \({\mathfrak {sl}}_N\)-web algebras and HM-bases. Special thanks to Marco Mackaay for a lot of helpful discussions. The author thanks the FCT–Fundaç ao para a Ciência e a Tecnologia, through project number PTDC/MAT/101503/2008, New Geometry and Topology for sponsoring one research visit during this project.
Author information
Authors and Affiliations
Corresponding author
Additional information
The author was supported by the Courant Research Center “Higher Order Structures” in Göttingen, the Graduiertenkolleg 1493 in Göttingen and the Mathematisches Institut, Georg-August-Universität Göttingen.
Rights and permissions
About this article
Cite this article
Tubbenhauer, D. \({\mathfrak {sl}}_3\)-Web bases, intermediate crystal bases and categorification. J Algebr Comb 40, 1001–1076 (2014). https://doi.org/10.1007/s10801-014-0518-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10801-014-0518-5