
Abstract
In target node localization problem, conventional methods based on received signal strength indicator (RSSI) assume a prior knowledge of a channel model and values of its parameters specific for an environment. This limits the conventional localization system to be set up quickly and effectively due to a necessary pre-measurement step to determine both the channel model and the values of its parameters. To address the limitation, a two-stage iterative algorithm which allows to localize a target node without any prior knowledge of the parameter values has been propose. Each stage of the algorithm can be implemented using different estimation methods, such as maximum likelihood (ML) and least square (LS) estimation which provides four different combinations. To determine the best combination, the location estimation performance for all four combinations is evaluated using experimental data collected in measurement campaigns on various indoor locations. The results reveal that the combination of ML estimation method implemented in both stages provides the best location estimation accuracy and the fastest convergence rate.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Localization systems utilizing wireless sensor networks (WSNs) have been proposed as one of the solutions for indoor localization [1]. In indoor environments, the absolute location of an object, called “the target node”, is estimated through wireless sensor network nodes whose locations are known, called “the anchor nodes”.
To localize a target node, a location estimation system exploits measurement which indicates location or distance, such as time of arrival (TOA) [2, 3], time difference of arrival (TDOA) [4], angle of arrival (AOA) [3, 5] and received signal strength indicator (RSSI) [3]. The TOA technique provides an accurate measurement, however, it requires a precise time synchronization among the nodes and an additional hardware, such as an ultrasound transceiver, which further increases the system cost. The TDOA eliminates the requirement of time synchronization, however, an additional hardware, such as an ultrasound transceiver, is still required. The AOA technique requires nodes equipped with an antenna array and does not perform well in indoor environments due to multi-path propagation. Finally, the RSSI technique does not provide as accurate measurement as TOA and TDOA techniques due to signal fading caused by multi-path propagation, however, the system implementation is simple and inexpensive.
Since the cost of a single wireless sensor node is an important constraint in a system of a large number of nodes, many researchers have decided to focus on the localization techniques utilizing RSSI measurement. In addition, many IEEE 802.x wireless communications standards support RSSI measurement to evaluate link quality such as the IEEE 802.15.4 standard for low-rate wireless personal are network (LR-WPAN) [6].
In the RSSI-based localization, several estimation methods have been proposed, such as multilateration [7, 8], fingerprinting [9–11] and probability based, namely maximum likelihood (ML) estimation [4, 12, 13]. The multilateration method is a very simple one which justifies its poor accuracy. The fingerprinting method is a deterministic method which requires an intensive measurement campaign for its database construction before the localization system is used. In addition, an update of the database may be required whenever the environment changes. Finally, the ML estimation method is more precise than the multilateration method [14] and does not require as intensive measurement campaign as the fingerprinting method.
A localization system based on RSSI measurement utilizes the fact that the power of a transmitted radio frequency (RF) signal attenuates with distance. The relationship between the RF signal power and the distance is expressed by a path loss model [15], which is characterized by several parameters. The path loss model and its parameters are specific to the area where a target node is localized. Hence, a pre-measurement campaign is required to determine them. This prohibits a conventional RSSI-based localization system to be set up quickly. In addition, pre-measurement campaigns are sometimes impossible, e.g. when anchor nodes are installed in harsh environments.
To overcome the limitation, joint target node locations and channel model parameters estimation algorithms have been proposed [16, 17]. The authors of both the papers propose iterative localization algorithms which require no prior knowledge of the channel model parameter values, although a channel model have been assumed valid. Both of the algorithms are structured into two stages; target node locations are estimated in stage one, and channel model parameters are estimated in stage two. The authors of both the papers use ML estimation in stage one, however, they use different estimation methods in stage two, namely, least square (LS) [16] and ML estimation methods [17].
As the experimental setup and equipment are different between the two papers, and one of the papers discusses the estimation accuracy only for three different target node locations in a room, it is difficult to determine which estimation method can potentially provide the best performance. Therefore, we evaluate the two different estimation methods in the stage two using identical experimental setup and equipment. In addition, we also compare different estimation methods in the stage one, namely, LS and ML estimation methods. This provides the opportunity to compare four different combinations of estimation methods used in the stage one–stage two, such as LS–LS, LS–ML, ML–LS and ML–ML.
The rest of the paper is organized as follows. A channel model is described in Sect. 2. The iterative localization estimation algorithms are presented in Sect. 3. Section 4 presents the results and discussion. Finally, Sect. 5 draws the conclusions.
2 Channel Model and Conventional Location Estimation Method
Localization systems based on RSSI measurements exploit the property of RF signal power attenuation with traveled distance. The average received signal power \(\overline{P}(d)\) received at distance d can be expressed as [15]:
where α is a parameter proportional to the received signal power at a reference distance from the transmitter, and parameter β is a path loss exponent [15]. The values of the parameters is particular to an environment and condition [15, 17–19].
LS location estimation method utilizes only the transmitted signal power attenuation with the near–far principle expressed by Eq. 1. However, received signal power fluctuates due to multi-path propagation and does not uniquely correspond to distance d. On the other hand, ML estimation utilizes not only Eq. 1, but also a channel model which is represented by a conditional probability density function (PDF) p(P|d) expressing the probability of receiving a signal with measured power P when a distance d is given.
To be able to use the localization based on ML estimation, a channel model which describes well the RF signal propagation characteristics is required. Based on experiments conducted in various environments a two-layered channel model is expressed as [20]:
The first layer of the model corresponds to Eq. 1, and the second layer of the model is given by Eq. 2 which expresses the fading characteristics of the received signal power. An example of power attenuation and fading characteristics can be found elsewhere [17, 20].
Although, a channel model is known, conventional LS and ML location estimation methods still require a prior knowledge of channel model parameter values α and β since these parameters are particular to an environment. The values of parameters are typically obtained by a pre-measurement campaign which prohibits quick and effective system set up.
3 Two-Stage Algorithm
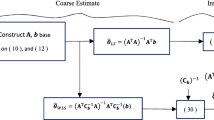
Estimating target node locations without a knowledge of the channel model parameters is based on a joint target nodes locations and channel model parameters estimation where not only the unknown locations of O target nodes but also the values of α and β parameters are estimated. The joint target node locations and channel model parameters estimation is separated into two stages. Namely, target node locations are estimated in stage one using tentatively-decided common values of α and β parameters, whereas the values of the channel model parameters are estimated in stage two using tentatively-estimated target node locations. This two-stage algorithm is iteratively processed by alternating between the two stages. Figure 1 shows the flowchart of the algorithm.

Algorithm’s flowchart
Different estimation methods can be implemented in both of the stages and in the following we consider using different combination of LS and ML estimation methods as is listed in Table 1. The four combinations are referred to as LS–LS, LS–ML, ML–LS and ML–ML.
A localization scenario with O target nodes located within a WSN area is assumed. Every anchor node measures M RSSIs for each of the target node locations forming a vector P = [P (1)11 , P (2)11 ,…, P (M)11 , P (1)12 , P (2)12 ,…, P (M)12 ,…, P (1)1N , P (2)1N ,…, P (M)1N , P (1)2N , P (2)2N ,…, P (M)2N ,…, P (1) ON , P (2) ON ,…,P (M) ON ] composed of k-th RSSI measured at j-th anchor node corresponding to i-th target node location, P (k) ij , and N is the total number of anchor nodes. In addition to this, vector d = [d 11, d 12,…, d 1N , d 21, d 22,…, d 2N ,…, d O1, d O2,…, d ON ] is composed of distances d ij between i-th unknown target node location [X i , Y i , Z i ] and j-th known anchor node location [x j , y j , z j ] defined as:
For the sake of simplicity, we assume that the height Z i of the target node is known and constant for all O target node locations, hence the target node locations are estimated in a plane. In addition, all anchor nodes are placed at the same height z, therefore (Z i − z j ) = (Z − z) = h.
3.1 Stage One: Target Node Locations Estimation
The target node locations are estimated in stage one which implementation is similar to a conventional algorithm. However, in the joint target node locations and channel model parameters estimation algorithm, the values of channel model parameters are unknown and are being estimated. Therefore, in the initial iteration, n = 0, arbitrary α0 and β0 initialization values are used to estimate target nodes locations. In the following iterations, \(n =1, 2, \ldots, \hat{\alpha}_{n}\) and \(\hat{\beta}_{n}\) estimated in stage two are used.
3.1.1 Realization by LS Location Estimation Method
The target node locations [X i , Y i ] are estimated using LS estimation by minimizing the sum of the squared error e ij :
The error e ij is defined as:
where r ij is the measured distance between i-th target node and j-th anchor node locations. Minimizing the error e ij separately for each unknown target node location [X i , Y i ] produces the same result when minimizing Eq. 4.
Considering an ideal case when the error e ij is equal to zero and rearranging Eq. 5 results in:
To generate a set of linear equations, Eq. 6 for the N-th anchor node is subtracted from the rest:
This leads to a system of N − 1 linear equations expressed as:
where A T denotes the transposition of A,
and
The solution to b i is the estimated i-th target node location \([\hat{X}_{i}, \hat{Y}_{i}]^{T}\) .
3.2 Realization by ML Location Estimation Method
The target node locations [X i , Y i ] are estimated using ML estimation by maximizing the joint conditional PDF p(P|d n ). Assuming received signal powers P (k) ij are temporally and spatially independent and target nodes locations [X i , Y i , Z i ] are independent too, the conditional joint PDF is written as:
To obtain the target nodes location estimates \([\hat{X}_{i}, \hat{Y}_{i}]\) , the log-likelihood function \(L_{1}({\mathbf{d}}_{n}) = \log p({\mathbf{P}} | {\mathbf{d}}_{n}, \alpha_{n}, \beta_{n})\) is maximized with respect to the target node locations [X i , Y i ] written as:
Because the target nodes locations [X i , Y i ] are independent of each other, their locations can be estimated separately.
3.3 Stage Two: Channel Model Parameters Estimation
Channel model parameters α n+1 and β n+1 are estimated in stage two. To estimate these parameters, the estimated target node locations, or precisely the distances \(\hat{{\mathbf{d}}}_{n}\) , estimated in stage one are used.
3.3.1 Realization by LS Channel Model Parameters Estimation Method
To estimate the values of α n+1 and β n+1 parameters using LS estimation, the problem is considered as minimizing the sum of the squared error \( {{\epsilon}_{ij}} \):
The error \( {{\epsilon}_{ij}} \) is defined as:
where αdBmn+1 is defined as:
and \(\overline{P}_{{\rm dBm} ij}\) is defined as:
The transformation from watt units to decibel units allows linear LS estimation written in a matrix form as:
where
and
The estimated values \(\hat{\alpha}_{{\rm dBm} n+1}\) and \(\hat{\beta}_{n+1}\) are then used in stage one of the following iteration cycle n = n + 1. Note that the estimated \(\hat{\alpha}_{{\rm dBm} n+1}\) is in decibel units, however, watts units are used in stage one, therefore:
3.3.2 Realization by ML Channel Model Parameters Estimation Method
The same channel model used for estimating target node location can be used in this stage providing that the channel model describing propagation characteristic of a signal defined by the IEEE 802.15.4 standard is valid, which was confirmed in [17].
The ML estimates \(\hat{\alpha}_{n+1}\) and \(\hat{\beta}_{n+1}\) are obtained when the log-likelihood function of stage two L 2(α n+1, β n+1) = logp(P | d n , α n+1, β n+1) is maximized with respect to the two channel model parameters α n+1 and β n+1:
Maximizing the log-likelihood function L 2(α n+1, β n+1) yields the parameter estimates \(\hat{\alpha}_{n+1}\) and \(\hat{\beta}_{n+1}\) common to the desired location estimation area.
After the channel model parameters are estimated, the target node locations are reestimated using the updated values of the channel model parameters \(\hat{\alpha}_{n+1}\) and \(\hat{\beta}_{n+1}\) in the following iteration n = n + 1.
3.4 Termination of the Algorithm
The iterative algorithm terminates when:
where toleranceα and toleranceβ are the required accuracies of the estimated parameters. The recommended values are toleranceα = 1 · 10−8 and toleranceβ = 1 · 10−3 [17]. Smaller values do not improve target node location estimation accuracy.
4 Results and Discussion
To evaluate the various combination of LS and ML estimation methods used in the two stages of the joint target node locations and channel model parameters estimation algorithm, we used RSSI measurements collected during measurement campaigns conducted in four different environments. The environments were a corridor of a shopping center, an office room, a meeting room and a classroom. Detailed descriptions of the environments, measurement campaign and WSN node specification are reported elsewhere [17, 21]. The experiments were conducted when people were present in the environments which represent a practical scenario.
Various α0 and β0 initialization values were used to evaluate the performance of the four different combination, namely LS–LS, LS–ML, ML–LS and ML–ML estimation methods used in the two stages of the algorithm. In addition, we measured the true values of the α and β parameters for each of the environment to compare the location estimation accuracy using the conventional and proposed estimation methods. The total number or RSSI measurements M was equal to 10.
Figures 2–9 show the average location estimation error in meters against the number of iteration n for LS–LS, LS–ML, ML–LS and ML–ML combinations. Each curve in the figure represents different α0 and β0 initialization values. For brevity, figures for only two different environments are presented; the figures for other two environments are very similar.

Average location estimation error of LS–LS combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the office room

Average location estimation error of LS–ML combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the office room

Average location estimation error of ML–LS combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the office room

Average location estimation error of ML–ML combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the office room

Average location estimation error of LS–LS combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the meeting room

Average location estimation error of LS–ML combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the meeting room

Average location estimation error of ML–LS combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the meeting room

Average location estimation error of ML–ML combination versus number of iteration and various α0 and β0 initialization values for the experiment conducted in the meeting room
We can observe in Figs. 2 and 6 that the combination of LS–LS estimation methods is not as precise as other combinations. This is due to the fact that the neither stage one nor stage two utilize the channel model. LS location estimation method in stage one performs a simple multilateration which does not utilize the propagation properties of RF signal on contrary to ML location estimation method. Therefore, the LS location estimation method is less accurate than ML location estimation method [14]. Moreover, LS channel model parameters estimation does not utilizes the channel model in stage two, and the channel model parameters are estimated considering only average received signal power and distance as expressed by Eq. 1.
The LS–ML combination performs better than the LS–LS one, as Figs. 3 and 7 show. The ML channel model parameters estimation in stage two utilizes not only the RSSI measurements but as well a probability of obtaining such measurements employing the channel model, and it can be explained as follows. Because the LS location estimation in stage one does not utilize the channel model, the target node location estimation accuracy is low. However, ML parameters estimation in stage two utilize the channel model and provides for better channel model parameters estimation. Consequently, target node location estimation is improved. The effect can be well observed in Fig. 3 where the target node location estimation accuracy improves every time the channel model parameters are reestimated until the iteration n = 6.
Figures 4 and 8 indicate that the accuracy of ML–LS combination is superior or equal to any of the two previous combinations. This is due to the fact that ML location estimation method in stage one is superior to LS location estimation method [14]. However, using LS channel model parameters estimation in stage two leads to slower convergence rate which is well observed by comparing results of ML–LS combination to ML–ML combination results depicted in Figs. 5 and 9. The slow convergence rate is caused by the fact that LS channel model parameters estimation does not utilize the channel model in stage two, but only path loss model expressed by Eq. 1. The accuracy of ML–ML combination is comparable to ML–LS estimation; however, the convergence rate is faster than of the ML–LS combination. This means that less number of iterations is needed for the algorithm to converge which is advantageous in dynamically changing environments.
To conclude, the ML–ML combination is the preferred one. This is due to the fact that the LS location estimation does not perform as well as the ML location estimation in stage one. In addition, the convergence rate of the ML channel model parameters estimation in the stage two is faster than of the LS channel model parameters estimation. Table 2 summarizes the accuracy of the various combinations after 10 iterations. In addition, Table 2 shows the location estimation accuracy of the conventional location estimation method when the values of α and β parameters are known, obtained by a pre-measurement campaign. We can observe that the accuracy is superior or equal to the conventional localization methods even without a prior knowledge of α and β parameter values.
The algorithm assumes that channel model parameters are the same at any place of an environment (at any target node location). Unfortunately, this is true only for a homogeneous environments and such assumption can lead to inaccuracy. Therefore, a future work can extend the algorithm to situations where channel model parameters are assumed unique for different areas of an environment or for a set of target node locations.
5 Conclusions
Two-stage joint target node locations and channel model parameters estimation algorithm overcomes the drawback of RSSI-based conventional target node location estimation methods which require a prior knowledge of channel model parameter values. The two stages of the algorithm can be implemented using different estimation methods, and we have evaluated four combination of LS and ML estimation methods.
The ML–ML combination is superior to any other combinations due to the fact that ML location estimation method performs better than LS method in stage one. Moreover, ML channel model parameters estimation method converges faster than LS estimation method in stage two. This is advantageous for highly-dynamic environments where the channel model parameter values constantly fluctuate.
References
S. Capkun, M. Hamdi, and J.-P. Hubaux, GPS-free positioning in mobile ad-hoc networks. In Proceedings of the 34th Annual Hawaii International Conference on System Sciences, 3–6 January 2001.
N. Patwari and A. O. Hero III, Location estimation accuracy in wireless sensor networks. In Conference Record of the Thirty-Sixth Asilomar Conference on Signals, Systems and Computers, Vol. 2, pp. 1523–1527, November 2002.
N. Patwari, J. N. Ash, S. Kyperountas, A. O. Hero III, R. L. Moses, and N. S. Correal, Locating the nodes: cooperative localization in wireless sensor networks, IEEE Signal Processing Magazine, Vol. 22, No. 4, pp. 54–69, 2005.
T. Ajdler, I. Kozintsev, R. Lienhart, and M. Vetterli, Acoustic source localization in distributed sensor networks. In Conference Record of the Thirty-Eighth Asilomar Conference on Signals, Systems and Computers, 7–10 Nov. 2004, Vol. 2, pp. 1328–1332, November 2004.
C. Liu, K. Wu, and T. He, Sensor localization with ring overlapping based on comparison of received signal strength indicator. In Proc. of 2004 IEEE International Conference on Mobile Ad-hoc and Sensor Systems, Venice, Italy, pp. 516–518, October 2001.
IEEE standard for information technology - telecommunications and information exchange between systems - local and metropolitan area networks specific requirements part 15.4: wireless medium access control (MAC) and physical layer (PHY) specifications for low-rate wireless personal area networks (LRWPANs), IEEE Std 802.15.4-2003, 2003.
C. Savarese, J. M. Rabaey, and J. Beutel, Locationing in distributed ad-hoc wireless sensor networks. In Proc. of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’01), Vol. 4, Salt Lake City, USA, pp. 2037–2040, May 2001.
J. Hightower and G. Borriello, Location systems for ubiquitous computing, IEEE Computer, Vol. 34, No. 8, pp. 57–66, 2001.
I. Guvenc, C. T. Abdallah, R. Jordan, and O. Dedeoglu, Enhancements to RSS based indoor tracking system using Kalman filters. In International Signal Processing Conference (ISPC) and Global Signal Processing Expo (GSPx), 31 March–3 April, Dallas, USA, March–April 2003.
E. Elnahrawy, X. Li, and R. P. Martin, The limits of localization using signal strength: a comparative study. In IEEE SECON 2004. 2004 First Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, Santa Clara, USA, pp. 406–414, 4–7 October 2004.
P. Bahl and V. N. Padmanabhan, RADAR: an in-building rf-based user location and tracking system. In Proc. of IEEE INFOCOM 2000, Vol. 2, Tel Aviv, Israel, pp. 775–784, March 2000.
N. Patwari, R. J. O’Dea, and Y. Wang, Relative location in wireless networks. In Proc. of IEEE VTC 2001 Spring, Vol. 2, pp. 1149–1153, May 2001.
R. Mino, K. Iwamoto, M. Takashima, R. Zemek, K. Yanagihara, S. Hara, and K. Kitayama, A belief propagation-based iterative location estimation method for wireless sensor networks. In PIMRC 2006, Helsinki, Finland, September 2006.
M. Takashima, D. Zhao, K. Yanagihara, K. Fukui, S. Fukunaga, S. Hara, and K. Kitayama, Location estimation using received signal power and maximum likelihood estimation method in wireless sensor network, IEICE Transation on Communication (Japanese edition), Vol. J89-B, No. 5, pp. 742–750, 2006
H. Hashemi, The indoor radio propagation channel, Proceedings of the IEEE, Vol. 81, No. 7, pp. 943–968, 1993.
I. Yamada and T. Ohtsuki, An indoor location estimation method by maximum likelihood using RSSI. In 3rd Sensor Network Conference, SN2006-43, Tokyo, Japan, pp. 37–41, December 2006.
R. Zemek, S. Hara, K. Yanagihara, and K. Kitayama, A joint estimation of target location and channel model parameters in an IEEE 802.15.4-based wireless sensor network. In 18th IEEE PIMRC 2007, Athens, Greece, pp. in CD–ROM, September 2007.
J. B. Andersen, T. S. Rappaport, and S. Yoshida, Propagation measurements and models for wireless communications channels, IEEE Communications Magazine, Vol. 33, No. 1, pp. 42–49, 1995.
B. Sklar, Rayleigh fading channels in mobile digital communication systems part I: characterization. IEEE Communications Magazine, Vol. 35, No. 7, pp. 90–100, 1997.
S. Hara, D. Zhao, K. Yanagihara, J. Taketsugu, K. Fukui, S. Fukunaga, and K. Kitayama, Propagation characteristics of IEEE 802.15.4 radio signal and their application for location estimation. In Proc. IEEE VTC 2005 Spring, Vol. 1, Stockholm, Sweden, pp. 97–101, May 2005.
R. Zemek, S. Hara, K. Yanagihara, and K. Kitayama, A traffic reduction method for centralized RSSI-based location estimation in wireless sensor network, IEICE Transactions on Communications, Vol. E91-B, No. 6, pp. 1842–1851, 2008.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Zemek, R., Anzai, D., Hara, S. et al. RSSI-based Localization without a Prior Knowledge of Channel Model Parameters. Int J Wireless Inf Networks 15, 128–136 (2008). https://doi.org/10.1007/s10776-008-0085-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10776-008-0085-6