
Abstract
A novel approach to color image segmentation (CIS) in scanned archival topographic maps of the 19th century is presented. Archival maps provide unique information for GIS-based change detection and are the only spatially contiguous data sources prior to the establishment of remote sensing. Processing such documents is challenging due to their very low graphical quality caused by ageing, manual production and scanning. Typical artifacts are high degrees of mixed and false coloring, as well as blurring in the images. Existing approaches for segmentation in cartographic documents are normally presented using well-conditioned maps. The CIS approach presented here uses information from the local image plane, the frequency domain and color space. As a first step, iterative clustering is based on local homogeneity, frequency of homogeneity-tested pixels and similarity. By defining a peak-finding rule, “hidden” color layer prototypes can be identified without prior knowledge. Based on these prototypes a constrained seeded region growing (SRG) process is carried out to find connected regions of color layers using color similarity and spatial connectivity. The method was tested on map pages with different graphical properties with robust results as derived from an accuracy assessment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Color image segmentation is a crucial preliminary process for most image analysis and pattern recognition tasks [8]. For this reason intense research has been carried out on image segmentation in general [17, 31], and on color image segmentation in particular [7, 26]. The aim of segmentation is to divide an image into different regions such that each region is homogeneous, but the union of any two neighboring regions is not [10].
Image segmentation also plays a key role as a pre-processing step in feature extraction and recognition of cartographic documents for GIS data capture [4, 24, 35, 37, 39]. This can be subjected to color image segmentation since thematic layers in maps, such as hydrography, elevation contours, and vegetation, are normally represented by distinct color classes. Map extraction tasks are complex processes [18, 20, 34] because poor data quality and complex map documents tend to be found in combination [12, 25, 38], especially with historical maps [24]. Such maps are unique data sources for GIS-based analysis of land cover changes over long time periods [22], and typically the only spatially contiguous data sources prior to the establishment of remote sensing. Large amounts of historical maps are currently collected in archives and become available as scanned data sources. To make use of these maps in a GIS, automatic approaches for spatial feature extraction and recognition are urgently required. This represents one research challenge at the intersection of GIS and image processing.
Several research efforts e.g., [2, 13], or [35] have been dedicated to the segmentation of digital cartographic documents with high spatial quality constraints. In general the aim is to reduce the scanned color values to the original set of map color layers by regrouping the pixels based on their color information which is a typical classification problem. At the same time the spatial context, connectedness and shape of map objects have to be preserved. Frequently, segmentation in well-conditioned maps aims at the extraction of particular layers from the document such as elevation contours [6, 20, 21, 34]. Existing approaches to color image segmentation developed for image understanding, e.g., [5, 9, 10, 14], or [36], frequently result in significant over-segmentation and distorted shapes if the image is of poor quality. Some interesting recent attempts include combining color with spatial features [7], texture [3], space and texture [30], connectivity and homogeneity [27] or using fuzzy integrals as distance measures [32]. However, none of these approaches allows for identifying initially hidden distinct color layer prototypes in map documents that suffer from noise, false and mixed colors without prior knowledge. In summary, there are no satisfying approaches for reliable color image segmentation of inferior cartographic documents.
In this paper we present a promising automatic approach to the color image segmentation of scanned archival topographic maps of low graphical quality. Typical problems, which are mainly due to ageing and scanning, are noise in colors, blurring, mixed coloring (layer intersections), and false coloring. Variations in color rendition within each color layer as well as between different map pages of one map series also pose problems. The scanning process resulted in digital images of 256 colors, which were assumed to sufficiently account for the observed variability in the color layer values and still allow efficient processing of the images. The proposed method relies on an iterative clustering procedure to identify pixels that represent color layer prototypes without prior knowledge, using information from three different domains: the image plane, histogram and color space. Prototypes and seeds of the different color layers are defined by an iterative peak-finding process that uses local homogeneity measures [8, 9], frequency of homogeneity-tested pixels and color similarity. A constrained seeded region growing (SRG) process [14, 36] is based on color similarity and connectivity. Constrained SRG allows the expansion of connected regions of pixels belonging to the individual map color layers, as well as the discrimination of non-allocated pixels, which are subject to post-processing. The method uses information directly derived from color space [5, 28, 36]. It thus overcomes the drawback of intensity-based approaches where the steps are applied to each component of the color space and the results are combined [7, 19].
In the next section the considered historical map we studied is described. In section three the methods are outlined. In section four the results are reported and discussed in the light of an accuracy assessment, and finally at the end we draw some conclusions.
The historical map studied and associated problems
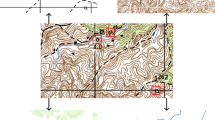
The Siegfried Map series (Fig. 1) was manually produced using copperplate and stone engraving on the scale of 1:25,000 in the Swiss Plateau and 1:50,000 in the mountainous regions. The series consists of thousands of map pages produced between 1868 and the 1930s. Different color layers were used, such as blue for hydrography and wetlands, red for contour lines and white for the background. The black layer includes forest, road networks as solid, double or dashed lines, political boundaries, rocky outcrops and cliffs, vineyards, buildings, as well as written text.

The Siegfried Map with color layers. The subsections, taken from different map pages, illustrate specific problems of graphical image quality, such as noise, color variation, false colors, mixed colors at intersections and blurring at transitions
The main problems concerning the extraction of spatial information stem from the low graphical quality of the complex historical map. This is due to some noise in color rendition, distorted shapes and the varying sizes of symbols (as they were drawn by hand), as well as a high degree of overlap and intersection between objects of the same and different color layers. Scanning these documents results in images that suffer from mixed and false colors, blurring and color variations in the color layers and between different map pages (Fig. 1). Aging of paper archived for long periods causes additional random color variations through bleaching effects. The lines in the scanned documents have varying dimensions, depending on the meaning and graphical quality, which range from one to six pixels.
Methods
Overview of the method
The aim of color image segmentation of scanned cartographic documents is to reduce the color values to fit the original set of printing colors. The segmentation approach presented here involves four main stages (Fig. 2): First, a clustering algorithm is presented which relies on local homogeneity of pixel colors, histogram analysis of homogeneity-tested pixels and color similarity to carry out an iterative peak-finding procedure. This key step allows the automatic determination of the pixels, which represent color layer prototypes, by combining three domains of information: the local image domain, the histogram analysis and color space. Second, pixels are defined as layer-specific seeds based on the distances in color space to the color points of the computed layer prototypes and local homogeneity (seeding). These seeds are the starting points to carry out constrained seeded region growing (SRG), the third main stage. Constrained SRG is based on spatial connectivity between pixels and seeds, as well as similarity in color vectors between them. SRG expands the seeds to identify connected regions of pixels belonging to one of the color layers, and thus to discriminate step-by-step any pixels that could not be allocated. These unallocated pixels typically suffer from false and mixed coloring. As a fourth stage these pixels are further examined in a post-processing step using filtering and spatial neighborhood tests. A method to assess the accuracy of the segmentation, which is part of the inherent uncertainty in the historical map [23], is presented at the end of this section.

Overview of the color image segmentation procedure
In contrast to other research studies on CIS such as [8, 36] the RGB color space is directly used without further transformation as colors in topographic maps are usually represented by values close to the RGB extremes. Despite the known correlation of RGB channels, it offers still the best discrimination space. In contrast to common full-color images, typical color space conversions that focus on color perception are not feasible for cartographic maps. This is because lightness and saturation are only influenced by artifacts and ageing. For this reason such color transformations would not bring any significant advantage to the approach. However, choosing the optimal color space for a specific problem is one of the major challenges in CIS, to date [7, 8].
Finding the prototypes: an iterative clustering approach
A prototype of a color layer is a pixel characterized by a color vector, which occurs very frequently in the histogram and is sufficiently distinct from color properties of the other color layer prototypes. Color properties of pixels within the local neighborhood of prototypes are characterized by random, but low variation which means prototypes are normally located within homogenous local environments although certain variation in colors will occur due to scanning and ageing. To identify these prototypes, the following steps are required:
-
1.
Computing local homogeneity using image plane and color space;
-
2.
Peak-finding based on the frequency of homogeneous pixels in the histogram and color dissimilarity in color space;
-
3.
Iterative processing to find “hidden” prototypes. Hidden means that the color vectors of the remaining layer prototypes cannot be discovered in the histogram as peaks, immediately. The reason is that colors similar to the already identified prototype colors occur very frequent and thus hide or overlay the colors of the next color layer prototypes.
Computing local homogeneity
Homogeneity of color within the considered local neighborhood of a pixel often plays the key role in color image segmentation [27]. In this context, Euclidean distance measures are applied for intensity-based approaches that treat color space components separately [8, 10]. Similarly, Euclidean distances can be used to e.g., derive belief values [5] or similarity values [36].
In the approach presented here, for each pixel j in the image, a local color homogeneity measure is computed from its 3 × 3 neighborhood (Fig. 3). This computation is based on the distances d m,j in color space between the color point of j and the color points of its neighbors m. Distances d m,j are defined as (Eq. 1):
where m indicates the pixel in the 3 × 3 neighborhood, j indicates the central pixel, and r, g and b represent the color components red, green and blue, respectively. Here, and also in the following steps described below, the local 3 × 3 neighborhood is used according to the resolution in the map, which depends on scanning parameters, and in relation to the size of elements represented. This minimum window size is the most appropriate one to investigate the map since the map objects have dimensions between one and many pixels. Neighborhoods of larger size can be used for documents of higher resolution where objects would have a minimum dimension of several pixels.

Derivation of fuzzy homogeneity vectors based on Euclidean distances in the color space between the pixel in question (black) and its 3 × 3 neighbors (white)
Local homogeneity h j describes, for each pixel j in the image, the level of homogeneity between the observation of interest of j and the observations of a given number of neighboring pixels m (m = 1,…,n with n = 8). This measure is weighted by the number of neighbors and ranges between 0 and 1 on a continuous scale. The greater h j is, the more homogeneous is the local environment of j with regard to the observation of interest, which is color in this case. The equation for h j is (Eq. 2):
where n is the number of the local neighbors m (n = 8 for 3 × 3 neighborhood) and δ Z is a fuzzy membership function represented as a Z-function. This function characterizes a fuzzy set F in a universe U by associating with each element u in U a real number in the interval [0,1] such that F: U→ [0,1]. The elements u in U are represented by the neighboring pixels m of j each of which is attributed by distance measure d m,j in color space (Eq. 1). Thus the value of δ Z at element m denotes the degree of membership of m in F based on d m,j This can be interpreted as the degree of homogeneity between pixel j and its neighbor m instead of using a rigid threshold value to determine homogeneity. The smaller d m,j is the higher is δ Z and the higher is the color homogeneity between j and m. The Z-function δ Z (Fig. 4) has the form (Eq. 3):
where d max and d min represent the maximum and minimum Euclidean Distances in color space (d min = 0 and \(d_{{\text{max}}} = \left( {255^2 + 255^2 + 255^2 } \right)^{{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 2}}\right.\kern-\nulldelimiterspace}\!\lower0.7ex\hbox{$2$}}} = 441\) if the whole color space is considered), respectively. The Z-function is appropriate for discriminating artificial color graphics that suffer from noise and blurring because it shows a flattened graph for δ Z close to 1 over a range of small distances and a steeper slope of the graph for decreasing values of δ Z where distances increase (Fig. 4). The described steps (Eqs. 1–3) can be used to derive estimates of local color homogeneity between each pixel j in the image and its neighborhood. We also tested whether we could better address very thin line features in the image by computing h j using only the t (where t < n) 3 × 3 neighbors with the highest memberships δ Z in F. This modification had little effect on the performance of the process except that homogeneity became overestimated in some cases.

Illustration of the Z-Function which characterizes a fuzzy set F. Its value at element m denotes the degree of membership of m in F based on the distances between neighbor m and pixel j in color space
Peak-finding based on frequency and similarity of homogeneous pixels
As mentioned, each prototype is found by examining the homogeneity-tested pixels in two subsequent steps that have to be iteratively repeated:
-
(a)
Deriving frequency of color vectors of homogeneity-tested pixels in a homogeneity histogram (peak finding);
-
(b)
Similarity tests in color space to identify colors that are similar to the color of the layer prototype. These colors are eliminated from the histogram to uncover the next “hidden” prototypes in subsequent iterations.
Frequency
The frequency measure is derived as follows. For each color vector i in the image (i = 1,...,I with I as the total number of colors in the image), we count for how many pixels j the computed local homogeneities h j (see Eq. 2 in Section 3.2.1) exceed a threshold value h crit. This involves a counter C h,i being incremented each time a homogeneous pixel j with color vector i and h j > h crit is found resulting in frequency values of homogeneous pixels. The value h crit indicates the minimum level of homogeneity h j required between pixel j and its local neighbors m to be admitted as a homogeneity-tested pixel. The greater h crit is, the stricter is the requirement that the color layers of the map have to contain some homogeneous subsets. We tested different values of h crit between 0.95 and 1 to examine the sensitivity of the procedure to a change of this parameter. The values of C h,i are presented over the color vector indices i (Fig. 5) in a full color homogeneous histogram. In this case the indices, which indicate existing combinations of color components, range between 0 and 255 as a result of the scanning process. Thus the homogeneous histogram includes information from all color space components since local homogeneity is based on distances in the 3D color space.

Illustration of the clustering process to identify the color layer prototypes. a Peak-finding to search for the most frequent homogeneity-tested color vector index (blue triangle in the histogram, blue circle in the 3D space). Color points with distances less than d crit to the point of this prototype in color space (red triangles and red circles, respectively) are removed from the histogram before the next iteration. b–d The “hidden” maxima, and thus all remaining prototypes, are found iteratively in the same way. Notice the broken range for frequency in the histogram
A peak-finding rule is formulated to identify the color vector of each prototype P k of color map layer k (k = 1,...,K with K as the total number of color map layers). The following condition has to be fulfilled (Eq. 4):
where ii represents the set of color vectors with ii = 1,...,I except i, and C h,i and C h,ii indicate the frequency of homogeneity-tested pixels with color vectors i and ii, respectively. The other variables have been explained earlier. In other words, the color vector i, which is counted most frequently in the homogeneous histogram—the global maximum—represents the color property of the first prototype P k of color map layer k. The values R(P k ), G(P k ) and B(P k ) are registered to locate the corresponding point in the color space (Fig. 5a). All pixels, which are characterized by this color vector and which were tested as homogeneous pixels before, represent prototypes P k of color map layer k.
Similarity
To identify color vectors that are similar to the one of prototype P k , a sphere in color space with a pre-defined radius d crit and centre R(P k ); G(P k ); B(P k ) is defined. The color point of P k is indicated as blue triangle in the histograms and as blue circle in the color space diagrams in Fig. 5. The value d crit is used as a threshold to determine similarity. All color points whose Euclidean distances to the point R(P k ); G(P k ); B(P k ) in color space are smaller than d crit (Fig. 5a) are removed from the homogeneous histogram, regardless of their frequency C h,i , for the following reason: These color vectors are considered too similar to the one of P k but still could have high frequencies in the histogram. If so the color vector of the prototype of the next color layer, R(P k + 1); G(P k + 1 ); B(P k + 1), could not be discovered by searching for a global frequency maximum in the histogram if this would be “hidden” by the frequency of colors similar to R(P k ); G(P k ); B(P k ). Typical examples are documents with large areas of background where normally few similar colors occur with high frequency and the colors of the prototypes of the color map layers have a much lower count than each of these background values. Thus before the next iteration the color points classified as being similar to R(P k ); G(P k ); B(P k ) are removed from the histogram (Fig. 5b). Changing the value of d crit will modify the level of color distinction between the clusters of similar colors in color space. Since color layers in the RGB color space of cartographic documents are represented by well-distinguished colors, a single high value can be set for d crit and considered valid for any map page. For maps where for some reason color layers are more similar this value can be changed to adjust the prototype search, accordingly.
Iterative processing and parameterization
The color points of the remaining color layer prototypes are found by uncovering the next “hidden” maxima in the homogeneous histogram and by carrying out the steps described in Section 3.2.2 (Fig. 5b–d) using Eq. 4. The prototype search terminates if no further global maximum in the histogram is found, i.e., if no more color vectors i exist for which C h,i > C crit. C crit indicates the minimum frequency of homogeneity-tested pixels with the same color vector i required to be admitted as a layer prototype. The larger C crit is, the more homogeneity-tested pixels with the same color vector i have to be found to indicate the existence of a color layer prototype. This demands a higher degree of homogeneity within the color layers of the map. Similar to d crit the value of parameter C crit was defined as a constant valid for any map page if the area of investigation was sufficiently large. It can be assumed that for a whole map page of size 7,000 × 4,800 pixels a sufficient amount (e.g. >100, or >0.0003%) of homogeneous pixels can be found for each of the truly existing color layers even for very strict constraints given by h crit and d crit.
The steps described in Section 3.2 provide the color layer prototypes P k with k = 1,...,K and their color points R(P k ), G(P k ) and B(P k ) (Fig. 6b). The peak-finding method is expected to be robust since, in most cartographic documents, print colors are chosen by the publisher to be as visually distinct as possible. The color layer prototypes should, then, be very distinct from each other in the color space, even in very old documents or those where the colors vary greatly.

Illustration of the single segmentation steps. a Original map. b Homogeneous color prototypes (beige background, blue hydrography, red elevation contours, black black layer, grey non-allocated pixels). c Layer-specific seeds. d Result of constrained SRG. e Inclusion of remaining color patches in constrained SRG. Note the differences between (d) and (e), where smaller regions inside forest symbols and in elevation dashes are additionally segmented. f Final result after post-processing of the non-allocated pixels
The parameters h crit, d crit and C crit mentioned here were all used as constant values for different map pages. Adjusting them did not influence the performance of the procedure, significantly. This is one important presumption to develop a procedure that does not require prior knowledge of the data source. Nevertheless, where needed these parameters could be used to adjust the computation to the level of intra-layer noise (C crit) and overall noise (h crit), as well as to the level of similarity between the color layers in the map (d crit). It could be observed that too small or too high values of C crit result in the definition of too many or too few prototypes, respectively. The value h crit affects the number of homogeneous pixels that can be found in the map in general. Finally, too small or too large values of d crit result in an overestimation or underestimation of the number of color layer prototypes, respectively, by determining the level of similarity between prototype colors.
Seeding, constrained Seeded Region Growing (SRG) and final classification
SRG segments an image into homogeneous regions starting with an initial set of seeds [1]. In each step one additional neighboring pixel is allocated to one of the seed sets whereby the seeds are replaced by the centroids of the homogeneous regions in each iteration [7, 15]. Normally, SRG is repeated until all pixels have been allocated to one of the homogeneous regions. In this paper, the allocation of pixels is based on iterative tests for color similarity and connectivity to one of the homogeneous seeds S k in the map (Fig. 6c), which are derived from the color layer prototypes P k (see Section 3.2). Thus the procedure described is a constrained SRG in that pixels are left unallocated if one of the tests for similarity or homogeneity cannot be approved. To prevent oversegmentation the segmented subregions are immediately classified to one of the color layers whose number is indicated by the number of the derived prototypes (Fig. 6d). This step takes into account that color map layers consist of spatially separated regions.
The unallocated pixels are subject to further examination since they are not located within homogeneous regions. It should be recalled that these parts of the maps are the main reason for the inherent poor graphical quality due to mixed and false colors as well as noise. The following steps identify the connected regions of the color layers (Fig. 6d) and include some post-processing to allocate the unallocated pixels (Fig. 6e):
-
1.
Computing color similarity between pixels in the image and prototypes;
-
2.
Defining initial seeds (Fig. 6c);
-
3.
Performing constrained SRG based on similarity and connectivity (Fig. 6d);
-
4.
Including small unallocated color layer patches in SRG (Fig. 6e); and
-
5.
Post-processing and filtering to allocate remaining pixels.
Computing color similarity with prototypes
For each pixel j in the image, similarity \(s_{P_k ,j} \) with each of the color layer prototypes P k (Section 3.2) with k = 1,...,K, is computed. The values \(s_{P_k ,j} \) are the inverse normalized Euclidean distances d k,j in the color space between the color points of the prototypes P k of layer k and the one of pixel j (Eq. 5):
with
where r, g and b indicate the color values of red, green and blue, respectively, and d max is the maximum Euclidean distance in color space. As can be seen the computation of \(s_{P_k ,j} \) is based on minimum-distance rules in color space. For each pixel j the highest value out of the color similarities \(s_{P_k ,j} \) and the layer index k of this maximum are determined. The value k is registered for pixel j to indicate the color layer to which j shows the highest level of color similarity.
Defining initial seeds
This step has to ensure a sufficient number of seeds such that SRG can be initialized even within smaller isolated layer segments where no prototype could be identified. The seeds, which serve as initial points for layer-specific SRG, are defined based on color similarity \(s_{P_k ,j} \) (see Section 3.3.1) and on homogeneity criteria using weaker homogeneity conditions than when defining prototypes. The prototypes P k (Section 3.2) are immediately defined as seeds since they were already examined for homogeneity.
To test if pixel j is embedded within a homogeneous local environment (Fig. 6c) the 3 × 3 neighborhood is examined using median filtering. If the majority of the neighbors of j shows the highest similarity \(s_{P_k ,j} \)to the same prototype P k , j is registered as a homogeneous seed S k of color layer k and represents one starting point for SRG. Using this weaker homogeneity test means accepting some layer specific color variation to define a sufficient number of homogeneous seeds also in smaller isolated parts of the map color layers.
Constrained SRG based on similarity and connectivity
The constrained SRG process works as an iterative layer-specific expansion procedure, starting at the initial seeds S k of each color layer k (Section 3.3.2) and testing the connected neighbors for similarity. Connectivity is defined as a strict 4-connected neighborhood relationship in order to prevent wrong connections between parts of different color layers that intersect or overlap each other. This condition is included in response to the resulting level of mixed and false colors at these intersections. Each pixel that is a connected or adjacent neighbor m to a seed S k of color layer k is registered as a new seed of the same color layer k if the following condition is fulfilled (Eq. 6):
where \(s_{P_k ,m} \) and \(s_{P_l ,m} \) indicate the similarity of the 4-connected neighbor m to color layer k (Eq. 5) and to all other color layers l, respectively. If pixel m shows the highest similarity to color layer k which S k represents a seed for, m is registered as a new seed S k for the next iteration of SRG (Fig. 6d). Otherwise this pixel is subject to further examination as described below. This step segments the connected subregions of all color layers in the map that have their origin in one of the initial homogeneous seeds, S k of color layer k. Thus the immediate classification of these subregions to one of the color map layers is strictly enforced. Before constrained SRG terminates, one more step is carried out (see Section 3.3.4). After this, SRG runs iteratively until no more pixels in the image can be classified as belonging to one of the color layers.
Including deviating small layer patches in SRG
Small patches of color layers with unexpectedly high deviations in color values sometimes occur where the conditions for seed definition (see Section 3.3.2) cannot be fulfilled. They are not connected to larger regions and are mainly caused by manual updating and bleaching of the archival documents. To include such cases in the segmentation, one further step before completing constrained SRG is required. The image is searched for pixels j that have not yet been allocated. A simplified homogeneity test based on similarity \(s_{P_k ,j} \) (see Eq. 5) within the local 3 × 3 neighborhood is carried out using median filtering techniques (Eq. 7):
where S k indicates a seed of color layer k, l with l = 1,...,K represents all color layers except layer k and m with m = 1,...,M indicates the 3 × 3 neighbors of pixel j being considered. Pixel j is registered as seed S k of color layer k if the majority of the neighboring pixels shows highest similarity to the same color layer prototype P k as j. These new seeds are included in the constrained SRG process (see Section 3.3.3 and Fig. 6e), which runs until no new seed is determined even within the smaller deviating patches of color layers. This step includes the weakest condition to identify the pixels that—based on similarity and homogeneity—belong to one of the color layers in the map. It accepts higher layer-specific variation in color over one map page than in Section 3.3.2 while still enforcing local homogeneity.
Postprocessing of the distribution of unallocated pixels
After the constrained SRG is completed, the final step is to examine the pixels that remain unallocated after the described steps (see Sections 3.3.1–3.3.4). Most of the unallocated pixels can be found adjacent to or form part of an object in the black layer (Fig. 6e), which is very subject to false and mixed coloring. Median filtering rules are used to examine which class dominates within the local 3 × 3 neighborhood of pixel j. At this point it should be recalled that the 3 × 3 neighborhood has been evaluated as the optimal local environment with regard to the resolution of the scanned map and the size of the objects in the map (see Section 3.2.1). Pixel j obtains the same layer index as the dominating class within the neighborhood if the median value is greater than or equal to a predefined number (= 8 in Fig. 6f). Most of the unallocated pixels inside river lines, elevation contours, background or forest symbols can be merged using this filtering step. Some single pixels or small groups of pixels, which are only adjacent to a segmented color layer region, still remain unallocated. They mainly belong to parts of the black layer, which are represented by very thin line-work such as forest symbols. Consequently these pixels are allocated to the black color layer (Fig. 6f). Pixels, which would be misclassified after this step, can be straightforwardly filtered in subsequent stages of image processing based on the size and morphological properties of connected components in the image.
Assessing the accuracy of segmentation results
A method for objectively assessing the accuracy of segmentation results where area, line and symbol regions occur at the same time is presented below. Accuracy assessments must be conducted with care but are rarely done according to the literature [6] or they are focused on line segmentation taking into account the line length as evaluation measure [6, 20]. The developed assessment tool (Fig. 7) allows for an efficient sample-based visual inspection of the original map and the computed segmentation, at the same time. According to well-established techniques in Remote Sensing both the segmentation outputs and the inspection results are used for confusion matrix based assessment of the overall and layer-specific classification accuracy.

Accuracy assessment. a Systematic sampling for test pixels over the set of map pages processed. b Detail of the accuracy assessment. The sample plots in both the original and the segmented map (red dashed rectangle) are dynamically linked and decisions about the central pixel of the rectangle are registered in the database
The first step is the conduction of a systematic sampling over the set of processed map documents (Fig. 7a). The coordinates of each sample pixel and its color layer index after segmentation are registered in the entry rows of a database. Each entry row is dynamically linked to the display representations of the corresponding locations in the original and the segmented map (Fig. 7b). The visual inspection is done by a group of experienced cartographic interpreters, who decide for each sample point in the original map which color layer it belongs to. The dynamic visualization of the segmented image at the same time makes it possible to immediately compare the original and the result. These two sets of layer indices are then input to the confusion matrix. Measures derived from the confusion matrix are recall and precision [33] for each color layer, as well as global measures such as accuracy (ACC) [29], Kappa coefficient of agreement (K) [11] and normalized mutual information criterion (NMI) [16]. NMI is described as the most conservative measure and meets all the requirements of a global accuracy measure, making full use of the information contained in the confusion matrix. Furthermore NMI remains robust against the occurrence of classes whose size far exceeds the sizes of other classes, which has to be expected if area and line features are evaluated by systematic sampling. The evaluation has been done on 1870 sample points selected from eleven maps with 7,000 × 4,800 pixels each. A sample of this size represents a representative set for the whole amount of pixels to be examined and provides a first objective estimation of the accuracy of the procedure.
In addition, the segmentation results—in particular the segmented black layer—were tested as input for cartographic feature extraction as described in [24]. The aim was to examine whether the segmentation remains robust for a large number of maps that show a high degree of variation in color values and graphical properties.
Performance
In this section the results of the color image segmentation are presented and some critical aspects concerning parameter sensitivity and observed segmentation errors are discussed. The results are illustrated for three test images, shown in Figs. 8, 9 and 10. In each of the figures a large subsection of the original map is shown on the top left (a), and the segmentation results on the top right (b). Below the original (c, e, g) and the segmented (d, f, h) sub-images of the larger sections are presented to illustrate specific problems in performance and parameter settings. Reference to a sub-image is given as “figure(sub-image)”, e.g. 8(c) for Fig. 8, sub-image (c).

Results of the color image segmentation presented on a subsection of map page 149. a Original. b Segmented map. c–h Enlarged sub-images showing critical aspects in the original on the left (c, e, g) and in the segmented map on the right (d, f, h)

Results of the color image segmentation presented on a subsection of map page 068. a Original. b Segmented map. c–h Enlarged sub-images showing critical aspects in the original on the left (c, e, g) and in the segmented map on the right (d, f, h)

Results of the color image segmentation presented on a subsection of map page 236. a Original. b Segmented map. c–h Enlarged sub-images showing critical aspects in the original on the left (c, e, g) and in the segmented map on the right (d, f, h)
The global accuracy measures (Table 1) indicate a robust performance of the segmentation procedure (ACC = 0.96, K = 0.93, NMI = 0.81). The accuracy assessment described is strict in nature because it is based on the pixel-level, whereas the aim of the segmentation is to preserve the shapes and spatial properties of the color features on the region level. Nevertheless this is the most objective kind of evaluation to check the overall robustness of the approach. Moreover, the segmentation errors reported do not impede subsequent recognition processes because the geometrical and structural properties of the regions are preserved (Figs. 8, 9 and 10). This could be verified by including the segmentation results in the feature extraction process of forest cover as described in [24], where segmentation as a first step still relied on map-specific parameter settings. The extraction results were comparable to the outcomes in [24] demonstrating a high level of robustness of the segmentation process. Nevertheless, some shortcomings and minor segmentation errors occurred that can be ordered according to categories of graphical quality. These aspects and possible solutions such as adjusting one of the parameters, which are constant values otherwise, are discussed chronologically below.
False colors
Where red elevation contours are drawn extremely dense (Figs. 8c, 9c, 10g), adjacent black objects frequently contain red shadows (Figs. 8d, 9d, 10h) as a consequence of false coloring. In such cases the falsely colored regions fulfill the similarity criterion during SRG and cause a decrease in recall of the black layer as well as a decrease in precision of the red layer. In some instances the shapes of small objects, such as forest symbols, are interrupted (Figs. 8f, 10d, h). Similar effects occasionally occur where false coloring generates small isolated homogeneous regions adjacent to objects of the black layer, e.g., in blue (Fig. 8h). However, such problems can be solved by filtering according to region size and through overshoot analysis in subsequent processing stages.
Mixed colors
Mixed colors at layer intersections, e.g., between the red and the blue layer (Figs. 8e, 9g, 10e), are a frequently observed problem, resulting in decreasing layer-specific precision and recall, depending on the class the region is added to. Normally, these patches remain unallocated and are added to the black layer after the post-processing (Figs. 8f, 9h, 10f). In very few instances such mixed color patches generate an additional layer prototype (e.g., greenish or brownish as a mixture of red and blue or of red and black, respectively). This problem is solved by adjusting the parameters for color distinctness and the minimum frequency of homogeneity-tested pixels required for prototyping. However, filtering in subsequent processing stages will be necessary to eliminate these regions.
Color variations within one layer
As a result of color variations within one color layer (Figs. 8 and 9) some small patches remained unallocated, and were thus falsely added to black. This caused a decrease in precision of the black layer and a decrease in recall of the corresponding color layer. The main reasons for this minor problem are a lack of homogeneity between the pixel values of such small and thin patches, as well as an unexpectedly high deviation of the color values from the prototype. Examples are dashes of elevation contours (Figs. 8d, 9h) or thin isolated line-work indicating elevation (Fig. 10f) or hydrography (Fig. 9f). This error can be corrected by adjusting the homogeneity conditions for seed definition.
Color variations between map pages
In some map pages, a part of the colors used for hydrography or elevation are not very distinct from the black layer values (Fig. 10), leading to misclassifications of single pixels or pixel groups as black (Fig. 10f, h). This can be partially circumvented by adjusting the parameter d crit for color layer distinctness. However, such small pixel groups can be identified in later processing stages using neighborhood analysis and filtering such as median filtering techniques to find small black regions embedded within blue or red local environments.
Manual production and noise
Since the Siegfried Map was manually produced, it is difficult to process the scanned documents, automatically. Transitions between objects and background are usually blurred. Thus, depending on the parameter set, the segmentation tends to thicken black objects (Figs. 8d, h, 10d). In general this has no impact on subsequent line detection except where objects are erroneously connected. Another effect of manual production is the variation in size and shape of objects, e.g., text or forest cover symbols. If a circle-like forest cover symbol is very small and drawn as a closed circle, the background pixels inside the circle do not always fulfill the homogeneity condition. Consequently they remain unclassified and are added to black since the final filtering step will not provide enough background pixels in the neighborhood (Figs. 8h, 9d, 10d, e). This is, however, a minor problem because the recognition of a forest area is not affected.
A similar effect was observed if several parallel hydrography lines are drawn very close to each other (Fig. 10e, g). In some instances thin stripes of background between them could not satisfy the homogeneity criterion and thus remained unclassified. They then appeared as black after the final step (Fig. 10f, h). Such errors can be corrected in subsequent image processing steps using neighborhood analysis and filtering, as described in Section 3.3.5. These manual production problems result in a decreased recall of the background layer and decreased precision of the black layer. Other problems occur where thin line-work of the red and blue layer degenerates and forms bleached and broken partitions (Fig. 9e) which do not fulfill the homogeneity condition. The classification of such parts as black (Fig. 9f) also resulted in a decreased recall of the color layer and decreased precision of the black layer.
Conclusions
In this paper a method for automatically segmenting the color images of archival topographic maps is presented which solves the problem of color layer discrimination in cartographic documents of low graphical quality. The procedure was tested on the so-called Siegfried Map–a manually produced topographic map series of the 19th century. The series suffers from noise and mixed colors, resulting in variations in color and blurring effects.
This method was shown to be robust in solving these discrimination problems and to prevent over-segmentation of the image. The clustering process—the central methodological step—ensures the identification of color layer prototypes without prior knowledge. The iterative clustering method combines different domains of information: local image plane, frequency and color space. Peak-finding in the homogeneous histogram—the histogram showing the homogeneity-tested color values - provided the color vectors of the color layer prototypes. Color similarity tests in color space allowed for identifying the colors similar to the identified prototype that had to be eliminated from the histogram. Thus the colors of the next prototypes, which represent “hidden” maxima in the initial homogeneous histogram, could be uncovered for the next iterations. After the initial seeds are derived from color layer prototypes, constrained SRG, based on similarity and connectivity tests, successfully expands the connected regions of the different color layers. After including some postprocessing steps and filtering rules for unallocated pixels the final segmentation could be derived.
The segmentation results demonstrate how our method allows the simultaneous segmentation of line-work, symbols and area regions that belong to different color layers. The accuracy assessment identified some minor classification errors, many of which can be corrected in later processing steps. Such errors did not, however, impede subsequent feature extraction processes since the shape and size features of map objects could be preserved.
The main advantage of this segmentation approach is that only a few preliminary assumptions are required. These assumptions are derived from rules for producing cartographic documents such as: printing layers should be visually distinct and the typical layer colors should occur frequently, with little color variation in their local environment. The clustering process then automatically derives the color vectors of the layer prototypes and thus the number of color layers in the map. The parameters described allow adjustments of the segmentation process to varying levels of map quality, homogeneity conditions, noise, and color distinctness, as well as to color variation over a set of different map pages. However, for the map pages processed here these parameters are globally defined without severely impeding the robustness of the segmentation.
Future research activities will be dedicated to the further development of the segmentation process in connection to feature extraction and recognition tasks. More advanced cartographic rules and aspects of the spatial context between objects and their neighborhood will be integrated, and ways of including processes for gap filling, filtering and overshoot analysis explored. The procedure will also be tested on other families of historic map documents which suffer from similar or different quality problems. Applying this method as the first processing step will facilitate feature extraction processes in maps and thus help to derive information about the historical landscape for land change detection.
References
Adams R, Bischof L (1994) Seeded region growing. IEEE Trans Pattern Anal Mach Intell 16(6):641–647. doi:10.1109/34.295913
Centeno J (1998) Segmentation of thematic maps using colour and spatial attributes. In: Tombre K, Chhabra AK (eds) Proc the Second IAPR Workshop on Graphics Recognition, Lecture Notes in Computer Science, vol 1389. Springer, Berlin, pp 221–230
Chen J, Pappas TN, Mojsilovic A, Rogowitz B (2002) Adaptive image segmentation based on color and texture. Proc Int’l Conference on Image Processing 3:777–780
Chen L, Liao H, Wang J, Fan K (1999) Automatic data capture for geographic information systems. IEEE Trans Syst Man Cybern C 5(2):205–215
Chen TQ, Lu Y (2002) Color image segmentation - an innovative approach. Pattern Recognit 35(2):395–405. doi:10.1016/S0031-3203(01)00050-4
Chen Y, Wang R, Qian J (2006) Extracting contour lines from common-conditioned topographic maps. IEEE Trans Geosci Rem Sens 44(4):1048–1057. doi:10.1109/TGRS.2005.861478
Cheng HD, Jiang XH, Sun Y, Wang J (2001) Color image segmentation: advances and prospects. Pattern Recognit 34:2259–2281. doi:10.1016/S0031-3203(00)00149-7
Cheng HD, Jiang XH, Wang J (2002) Color image segmentation based on homogram thresholding and region merging. Pattern Recognit 35:373–393. doi:10.1016/S0031-3203(01)00054-1
Cheng HD, Li J (2003) Fuzzy homogeneity and scale-space approach to color image segmentation. Pattern Recognit 36:1545–1562. doi:10.1016/S0031-3203(02)00293-5
Cheng HD, Sun Y (2000) A hierarchical approach to color image segmentation using homogeneity. IEEE Trans Image Process 9(12):2071–2082. doi:10.1109/83.887974
Cohen J (1960) A coefficient of agreement for nominal scales. Educ Psychol Meas 20:37–46. doi:10.1177/001316446002000104
Cordella L, Vento M (2000) Symbol recognition in documents: a collection of techniques? Int’l J Doc Anal Recognit 3:73–88. doi:10.1007/s100320000036
den Hartog J, ten Kate T, Gebrands J (1996) Knowledge based segmentation for automatic map interpretation. In: Kasturi R, Tombre K (eds) Proc first IAPR workshop on graphics recognition, lecture notes in computer science, vol 1072. Springer, Berlin, pp 159–178
Fan J, Yau DKY, Elmagarmid AK, Aref WG (2001) Automatic image segmentation by integrating color-edge extraction and seeded region growing. IEEE Trans Image Process 10(10):1454–1466. doi:10.1109/83.951532
Fan J, Zeng G, Body M, Hacid M-S (2005) Seeded region growing: an extensive and comparative study. Pattern Recognit Lett 26:1139–1156. doi:10.1016/j.patrec.2004.10.010
Forbes AD (1995) Classification algorithm evaluation: five performance measures based on confusion matrices. J Clin Monit 11:189–206. doi:10.1007/BF01617722
Fu KS, Mui JK (1981) A Survey on image segmentation. Pattern Recognit 13:3–16. doi:10.1016/0031-3203(81)90028-5
Gamba P, Mecocci A (1999) Perceptual grouping for symbol chain tracking in digitized topographic maps. Pattern Recognit Lett 20:355–365. doi:10.1016/S0167-8655(99)00003-3
Horiuchi T (2006) Grayscale image segmentation using color space. IEICE Trans Inform Syst E 89-D(3):1231–1237
Khotanzad A, Zink E (2003) Contour line and geographic feature extraction from USGS color topographical paper maps. IEEE Trans Pattern Anal Mach Intell 25(1):8–31. doi:10.1109/TPAMI.2003.1159943
Levachkine S, Torres M, Moreno M, Quintero R (2003) Simultaneous segmentation-recognition-vectorization of meaningful geographical objects in geo-images. Progress in pattern recognition, speech and image analysis, lecture notes in computer Science, vol 2905. Springer, Berlin, pp 635–642
Leyk S, Zimmermann N (2007) Improving land change detection based on uncertain survey maps using fuzzy sets. Landscape Ecol 22:257–272. doi:10.1007/s10980-006-9021-2
Leyk S, Boesch R, Weibel R (2005) A conceptual framework for uncertainty investigation in map-based land cover change modeling. Trans GIS 9(3):291–322. doi:10.1111/j.1467-9671.2005.00220.x
Leyk S, Boesch R, Weibel R (2006) Saliency and semantic processing—extracting forest cover from historical topographic maps. Pattern Recognit 39(5):953–968. doi:10.1016/j.patcog.2005.10.018
Llados J, Valveny E, Sanchez G, Marti E (2002) Symbol recognition: current advances and perspectives. In: Blostein D, Kwon Y-B (eds) Fourth IAPR workshop on graphics recognition, lecture notes in computer science, vol 2390. Springer, Berlin, pp 104–128
Lucchese L, Mitra SK (2001) Color image segmentation: a state-of-the-art survey. Image processing, vision, and pattern recognition, Proc. of the Indian National Science Academy (INSA-A), New Delhi, India, vol 67 A(2), pp 207–221
Macaire L, Vandenbroucke N, Postaire J-G (2006) Color image segmentation by analysis of subset connectedness and color homogeneity properties. Comput Vis Image Underst 102(1):105–116. doi:10.1016/j.cviu.2005.12.001
Makrogiannis S, Economou G, Fotopoulos S (2005) A region dissimilarity relation that combines feature-space and spatial information for color image segmentation. IEEE Trans Syst Man Cybern vol B 35(1):44–53
Michie D, Spiegelhalter D, Taylor C (1994) Machine learning, neural and statistical classification. Ellis Horwood
Ozdena M, Polat E (2007) A color image segmentation approach for content-based image retrieval. Pattern Recognit 40(4):1318–1325. doi:10.1016/j.patcog.2006.08.013
Pal NR, Pal SK (1993) A review on image segmentation techniques. Pattern Recognit 29:1277–1294. doi:10.1016/0031-3203(93)90135-J
Pham TD, Yan H (1999) Color image segmentation using fuzzy integral and mountain clustering. Fuzzy Sets Syst 107(2):121–130. doi:10.1016/S0165-0114(97)00318-7
Salton G (1989) Automatic text processing- the transformation, analysis and retrieval of information by computer. Addison-Wesley Publishing Company
San LM, Yatim SM, Md Sheriff NA N.I. bin Nik Ismail (2004) Extracting contour lines from scanned topographic maps. Proc Int’l Conference CGIV’04, IEEE, pp 187–192
Santos R, Ohashi T, Yoshida T, Ejima T (1998) Filtering and segmentation of digitized land use map images. Int’l J Doc Anal Recognit 1:167–174. doi:10.1007/s100320050015
Shih FY, Cheng S (2005) Automatic seeded region growing for color image segmentation. Image Vis Comput 23:877–886. doi:10.1016/j.imavis.2005.05.015
Velazquez A, Levachkine S (2004) Text/graphics separation and recognition in raster-scanned color cartographic maps. Graph Recognit Recent Adv Perspect Lect Notes Comput Sci 3088:63–74
Watanabe T (2000) Recognition in maps and geographic documents: features and approach. In: Chhabra AK, Dori D (eds) Third IAPR workshop on graphics recognition, lecture notes in computer science, vol 1941. Springer, Berlin, pp 39–49
Yamada H, Yamamoto K, Hosokawa K (1993) Directional mathematical morphology and reformalized Hough transformation for the analysis of topographic maps. IEEE Trans Pattern Anal Mach Intell 15(4):380–387. doi:10.1109/34.206957
Acknowledgments
This study has been partly funded by the Swiss Federal Research Institute for Forest, Snow, and Landscape. We would like to thank Sylvia Dingwal for proof-reading.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Leyk, S., Boesch, R. Colors of the past: color image segmentation in historical topographic maps based on homogeneity. Geoinformatica 14, 1–21 (2010). https://doi.org/10.1007/s10707-008-0074-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10707-008-0074-z