
Abstract
In offshore platforms, the suction caisson is a critical component of the foundation system. A single suction caisson failure could lead to the failure of the system. As a result, correctly predicting the pullout capability of suction caisson is crucial to platform operation. This paper investigates the use of two new models for the prediction of pullout capability of suction caisson. To this end, group method of data handling (GMDH) neural network and Monte Carlo Markov chain (MCMC) simulation are developed. In these models, Teta (inclined angle), L /d (L: embedded length and d: diameter of caisson), Tk (load rate parameter), Su (undrained shear strength of soil) and D/L (D: depth) were utilized as the inputs of models. The proposed models were then tested by using statistical functions such as the coefficient of determination (R2). Results showed the acceptability of two proposed models to predict pullout capability of suction caisson, however, the GMDH neural network method with R2 = 0.9483 performed the best than the MCMC simulation model. Accordingly, the GMDH neural network model could be used to estimate goals in other fields of rock mechanics and geotechnical engineering.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Suction caissons are one of the most strong anchors for deep water offshore installations. Suction caissons have a cylinder as their basic structure. The bottom portion is uncovered and top portion of the cylindrical unit is closed. Under its own weight, it can penetrate into the soil partially. It's sometimes utilized as an anchor. It can sense the pullout displacement caused by wave power and wind. The most significant benefit of a suction caisson is that it can adequately manage pullout loads. The explanation for this is because near the caisson’s tip, suction pore pressure develops in the soils. Due to loop current and wind, the caisson base is intended to withstand both cyclic and static stresses. Pullout load transmitted to caisson anchors due to inclined or horizontal loads. The caisson's overall pullout capability is determined by self-weight of caisson, passive suction under caisson sealed cap and pullout soil bearing pressure (Samui et al. 2011). laboratory model, upper bound analysis (Clukey et al. 1995), prototype model tests (Chou and Bobet 2002; Dyvik et al. 1993), finite element method (FEM) and centrifuge model (Clukey and Morrison 1993) have been tried to consider the lateral and axial load capability of suction caissons for cyclic and static stresses, as well as under various soil conditions. While field tests are costly, they have been carried out to assess the viability of suction caisson in different soil types (Cho et al. 2002; Samui et al. 2011). The FEM and upper bound method, as well as centrifuge and laboratory experiments, are the maximum commonly used approaches for forecasting suction anchor pullout capacity. Nevertheless, there are still a variety of problems and uncertainties around capacity prediction and failure mechanisms.
While previous efforts have been valuable, the aforementioned models are frequently unable of distinguishing the complex patterns found in datasets. These are the key reasons for wanting to discover the relationship between pullout capacity of suction caissons and other effective parameters and to suggest a more accurate and certain model for pullout capacity estimation.
For achieving the goal, using existing techniques, such as artificial intelligence techniques, which can accurately simulate both the linear and nonlinear behaviour of data, is helpful. These techniques are workable, efficient, and optimistic instruments for addressing engineering issues, especially when the nature of the interactions between independent and dependent variables is unclear. Artificial intelligence approaches have been used in certain efforts to predict the pullout capacity of suction caissons (Cheng et al. 2014; Muduli et al. 2013; Samui et al. 2011; Shahr-Babak et al. 2016). A three-layered back-propagation artificial neural network (ANN) was used by Rahman et al. (2001) to forecast the pullout capacity of suction caissons. In other study, Pai (2005) introduced the neuro-genetic network (NGN) hybrid technique, which combines ANN and genetic algorithm (GA) to evaluate the pullout capability. A novel prediction model for the pullout capacity was proposed by Alavi et al. (2010) utilizing a hybrid method that couples genetic programming (GP) with simulated annealing (SA). It has been demonstrated that this hybrid GP and SA technique outperforms regular GP in terms of results. The pullout capacity of suction caissons was recently calculated by Gandomi et al. (2011) utilizing a novel branch of GP called multi expression programming.
The present study presents two artificial intelligence methods including group method of data handling (GMDH) neural network and Monte Carlo Markov chain (MCMC) simulation to predict pullout capacity. The remainder of this research is structured as follows. In Sect. 2, the background of the aforementioned artificial intelligence techniques is briefly presented. Then, the modeling of them in forecasting the pullout capacity are presented in Sect. 3. Lastly, the conclusions and comparison of the models is provided in Sect. 4.
2 Artificial Intelligence Techniques Methodology
2.1 GMDH Neural Network
Ivakhnenko (1971) first proposed a GMDH neural network. The GMDH neural network is used for forecasting and optimization in a wide range of applications, including soil/ rock mechanics. It is now feasible to train the GMDH neural network for any given input values, \(X = \left( {x_{i1} ,x_{i2} ,x_{i3} , \ldots ,x_{in} } \right)\) to estimate output (\(\hat{y}_{i}\)) (M experimental data including one output and n inputs) that is:
The network should be able to reduce the error sum of squares between the estimated and measured values:
The relationship between inputs and output can be defined as follows:
The quadratic form and two variables are used in the following applications:
By regression methods, the \(a_{i}\) in Eq. (4) are determined.
All neurons in the GMDH neural network are made up of n input variables, So:
In the second layer, neurons are built as follows:
A variant of the function stated in Eq. (4) is used for each M triple row. The following is a description of these equations:
where A is the equation's unknown coefficients vector.
The observation vector is the outputs values. So:
and,
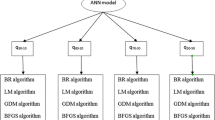
The structure of GMDH neural network is showed in Fig. 1.

Structure of GMDH neural network
In (Anton and Rorres 2013; Jekabsons 2009; Yanai et al. 2011) provide thorough descriptions of the GMDH neural network. This approach has been employed by many researchers in the field of geosciences. For example, Chen et al. (2020) proposed the GMDH neural network approach for rock cohesion estimation. Also, the performance of a tunnel boring machine was predicted using the GMDH neural network approach by Koopialipoor et al. (2019). Mohammadi et al. (2019) made use of the GMDH neural network approach to estimate chain saw machines for dimensional stones. In this research, the characteristics of 98 laboratory experiments on seven carbonate rocks are carefully examined, and the production rate of each test is calculated. The input data includes three important mechanical and physical characteristics such as Los Angeles abrasion test, Schmidt hammer and uniaxial compressive strength, as well as machine operational characteristics such as chain speed, machine speed, and arm angle. The output dataset includes another machine operational characteristic, namely production rate. In another research, Mokfi et al. (2018) proposed the GMDH neural network approach for estimation of peak particle velocity induced by blasting. In this model, maximum charge per delay, powder factor, blast-hole depth, burden to spacing ratio, distance from the blast-face, and the stemming length were used as the inputs of model. Also, MolaAbasi et al. (2019) suggested the GMDH neural network approach for prediction of the soil tensile strength of sands stabilized with cement and zeolite. For this purpose, a program of STT considering four cement contents, three distinct porosity ratios, and six different percent of cement replacement is performed. Finally, the results show that the estimated values by the GMDH neural network are in agreement with the actual data. In addition, Gao et al. (2020) proposed the GMDH neural network approach for estimation of of air overpressure resulting from mine blasting. In this model, rock mass rating, distance between the monitoring station and blasting point, powder factor and maximum charge per delay were used as the inputs of model.
The mentioned studies displayed the capability of GMDH neural network technique for estimation purposes.
2.2 MCMC Simulation
Typical statistical issues include calculating a parameters vector (θ) from the data collected. The standard method suggests that the variables are defined, but that their values are unknown and must be calculated. In general, classical likelihood offer a point predict of the interest parameter. According to the Bayesian technique, the variables have an uncertain distribution. This procedure is based on the premise that the experimenter starts with certain preconceived ideas about the process, and changes them based on new knowledge (Gimenez et al. 2009).
The Bayesian method accomplishes this by combining data using the MCMC simulation. The posterior density's high dimensional integral is calculated using suitable Monte Carlo simulation, which entails building a Markov chain with a stationary distribution identical to the interest posterior distribution (Fattahi and Zandy Ilghani 2019a, b, 2020; Gimenez et al. 2009). The realizations can then be considered a dependent sample from this distribution until the chain has converged. WinBUGS incorporates efficient methods for assembling these chains, adjusting to a wide variety of target distributions and thereby enabling the fitting of a large number of models. Brooks et al. (2011) provide more information on Bayesian modeling with MCMC algorithms.
Bayesian analysis using Bayesian MCMC simulation may be done using a variety of software, both free source and proprietary. WinBUGS is a Windows-based interactive program that performs Bayesian analysis on complex statistical models (Herath 2018). The posterior distributions in this paper are determined using the WinBUGS software. This software is now available for free download at https://www.mrc-bsu.cam.ac.uk/software/bugs/the-bugs-project-winbugs/.
3 Modeling
3.1 Experimental Database
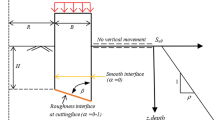
The primary aim of this paper is to apply the above methodologies for estimation of pullout capacity of suction caissons. In this study, 62 datasets from open source literature were used to determine the relationship between a set of inputs and output parameters (Rahman et al. 2001). The database includes the several variables measurements such as the Teta (inclined angle), L/d (L: embedded length and d: diameter of caisson), Tk (load rate parameter), D/L (D: depth) and Su (undrained shear strength of soil) and P (pullout capacity). The database's detailed information can be found in Sect. 2.1 of (Rahman et al. 2001). In this paper, all of the data was split into two subsets at random: 80% (training data) for model construction and 20% (testing data) for assess the accuracy of the model. Figure 2 illustrates a standard suction caisson sketch. Table 1 provides a statistical overview of the datasets utilized in this paper. The probability distribution functions of the variables used in the modelling are also shown in Fig. 3 for a clearer understanding.

A typical drawing of suction caisson (Alavi et al. 2010)

Continuous probability distribution of variables used in modeling
3.2 Data Preparation and Model Performance Evaluation
In order to remove any outliers, inaccurate data, or missing values, several pre-processing techniques are often utilized in data-driven system modelling methodologies before any computations. This method makes sure that the raw data in the database is appropriate for modeling (Babanouri and Fattahi 2018; Fattahi 2016a, b, 2017, 2018; Fattahi and Babanouri 2017; Fattahi and Bazdar 2017). The data samples are normalised to adapt to the interval [0, 1] using the following linear mapping function in order to facilitate training and improve prediction accuracy:
where xM stands for the mapped value, x represents the initial value, and xmin (xmax)stands for the minimum (maximum) raw input values, respectively.
Also, the root mean squared error (RMSE) and squared R2 were chosen as the accuracy measures to assess the models' performance (GMDH neural network and MCMC simulation). The definitions of RMSE and R2 are as follows:
where \(\hat{t}_{k}\) and tk are estimated and measured values, respectively, and n is the sample size.
3.3 Modeling Using GMDH Neural Network Method
In this research, professional neural network software was used to perform GMDH neural network, called GMDH Shell, in order to estimate P (pullout capacity of suction caissons). This software eliminates the need for initial data normalization, resulting in a significant reduction in processing time. A total of 62 data points were utilized in the study, with 80 percent of the data points being used for training (approximate equation) and the remaining data points being used to calculate the accuracy degree. Table 2 shows the supplied equation via the GMDH shell program after modeling. Table 3 and Fig. 4 also show the error measurement provided by the GMDH shell, as well as a comparison of actual and estimated data.

Comparison of estimated values (using GMDH neural network method) with those measured
In addition, Fig. 5 showed an association between the GMDH neural network's estimated values of P (suction caisson pullout capacity) and measured values for data sets during the training and testing phases.

association between the GMDH neural network's estimated values of P (suction caisson pullout capacity) and measured for a) training dataset, b) testing dataset
3.4 Modeling Using MCMC Simulation Method
To begin, the database, which included 62 datasets, was separated into two sections. The first part, which represented 80% of the overall datasets, was utilized to construct the model, while the other part was used to evaluate the model's performance. On the basis of the training database, a Bayesian prediction model was presented. To begin, a preliminary correlation study was conducted to look at the types of relationships that may exist between each of the independent variables (Teta, Su, D/L, Tk, and L/d) and the P (dependent) in order to identify potential candidate words for generating the P correlation. Candidates are chosen from the following list:
In this paper, the undefined variables of the various candidate models are treated as random variables. As previously stated, the goal of this research is to determine the best models that match the P datasets using a Bayesian system in which model parameters are estimated using Bayesian MCMC approaches in WinBUGS software.
Lognormal or normal (or other distributions) were chosen for, Teta, Su, D/L, Tk, and L/d, respectively, at the stochastic nodes after defining the models in WinBUGS language. The first set of datasets was then loaded, the models were built, and the model parameters were calculated using the MCMC sampler. To find the best modeling settings, researchers used a trial-and-error method. The mean values of the uncertain parameters b1, b2,…, b5 and a1, a2,…, a7 for Model #4 \(P = \frac{{a_{1} (L/d)^{{b_{1} }} + a_{2} (Su)^{{b_{2} }} + a_{3} (Teta)^{{b_{3} }} + a_{6} }}{{a_{4} (Tk)^{{b_{4} }} + a_{5} (D/L)^{{b_{5} }} + a_{7} }}\) are 6.056, − 59.27, 5.524, 26.56, − 12.06, 36.77, 0.07215, − 0.05011, − 0.1842, 0.08812, 0.6167, and 14.25, respectively. These values are the most likely values for the model parameters to take for the estimated P to achieve optimum accuracy, as shown in Fig. 6. They correspond to the peak of the posterior distributions, as shown in Fig. 6. Table 4 provides the summaries of the various models.

Model #4's posterior distributions of model parameters (b1, b2, …, b5 and a1,a2,…, a7)
The model has converged when the trace plots wander around the mode of the distribution and don't show a pattern in the sample space, as seen in Fig. 7. Figure 7 provides an illustration of the dynamic traces of the Model #4-corresponding model parameters, illustrating convergence.

Dynamic trace of Model #4's model parameters (b1, b2, …, b5 and a1,a2,…, a7)
The sample values versus iteration dynamic trace plots indicated that the simulation had reached a point of stability.
The datasets (testing and training datasets) were utilized to determine the ideal model for assessing the model's prediction performance. Table 5 and Fig. 8 display the efficiency of eight models for training and research datasets.

A summary of model outcomes for a) training and b) testing
Overall, the results showed that the suggested model (Model #4) could be utilized to forecast the P (pullout capacity of suction caissons). Finally, based on the training and testing datasets, Model #4 is the best candidate for predicting the P, whereas Model #8 is the worst choice.
4 Conclusions
The ability to reliably determine caisson pullout capacity in cohesive soils is a key concern for design engineers. This study suggests two approaches for the formulation of suction caisson pullout capacity using GMDH neural network and MCMC simulation methods. The following conclusions can be drawn:
-
In this study, a new Bayesian inference-based approach was used to identify the most suitable models for predicting the pullout capacity of suction caissons from a collection of candidate models evaluated with the WinBUGS.
-
The inputs of the estimative model included the Teta, Su, D/L, Tk, and L/d. Overall, the findings show that the proposed models for suction caisson pullout capacity are significantly predictive. The Model #4 was the best suitable model which was in agreement with performance indices based on the R2 and RMSE.
-
According to the results, the suggested models provided good estimation of the pullout capacity of suction caissons. Nevertheless, the GMDH neural network method (with R2 = 0.9483 and RMSE = 0.1379 for testing and R2 = 0.9949 and RMSE = 0.0607 for traning) produced better results than MCMC simulation method.
-
As a conclusion, the ability of GMDH neural network method and Bayesian MCMC method to generalize in other rock mechanic fields can be confirmed.
-
In this study, the authors focused on the prediction of pullout capability of suction caissons in clay. It is important to mention that other factors such as friction force between soil and suction caisson or soil cohesion are also worth to investigate and predict in the future studies.
Data Availability
Enquiries about data availability should be directed to the authors.
References
Alavi AH, Gandomi AH, Mousavi M, Mollahasani A (2010) High-precision modeling of uplift capacity of suction caissons using a hybrid computational method. Geomech Eng 2:253–280
Anton H, Rorres C (2013) Elementary linear algebra: applications version. John Wiley & Sons, New York
Babanouri N, Fattahi H (2018) Constitutive modeling of rock fractures by improved support vector regression. Environ Earth Sci 77:243
Brooks S, Gelman A, Jones G, Meng X-L (2011) Handbook of markov chain monte carlo. CRC Press, Boca Raton
Chen W, Khandelwal M, Murlidhar BR, Bui DT, Tahir M, Katebi J (2020) Assessing cohesion of the rocks proposing a new intelligent technique namely group method of data handling. Eng Comput 36:783–793
Cheng M-Y, Cao M-T, Tran D-H (2014) A hybrid fuzzy inference model based on RBFNN and artificial bee colony for predicting the uplift capacity of suction caissons. Automat Constr 41:60–69
Cho Y, Lee T, Park J, Kwag D, Chung E, Bang S (2002) Field tests on suction pile installation in sand. In: International conference on offshore mechanics and arctic engineering, pp 765–771
Chou W-I, Bobet A (2002) Predictions of ground deformations in shallow tunnels in clay. Tunn Undergr Sp Tech 17:3–19
Clukey E, Morrison M, Gamier J, Corté J (1995) The response of suction caissons in normally consolidated TLP loading conditions. In: Offshore Technology Conference. Offshore Technology Conference
Clukey EC, Morrison MJ (1993) A centrifuge and analytical study to evaluate suction caissons for TLP applications in the Gulf of Mexico. In: Nelson PP, Smith TD, Clukey EC (eds) Design and performance of deep foundations: piles and piers in soil and soft rock. ASCE, Reston, pp 141–156
Dyvik R, Andersen KH, Hansen SB, Christophersen HP (1993) Field tests of anchors in clay. I: description. J Geotech Eng 119:1515–1531
Fattahi H (2016a) Application of improved support vector regression model for prediction of deformation modulus of a rock mass. Eng Comp. https://doi.org/10.1007/s00366-016-0433-6
Fattahi H (2016b) Indirect estimation of deformation modulus of an in situ rock mass: an ANFIS model based on grid partitioning, fuzzy c-means clustering and subtractive clustering. J Geosci 5:681–690
Fattahi H (2017) Applying soft computing methods to predict the uniaxial compressive strength of rocks from schmidt hammer rebound values. Comput Geosci 21:665–681
Fattahi H (2018) Applying rock engineering systems to evaluate shaft resistance of a pile embedded in rock. Geotech Geol Eng. https://doi.org/10.1007/s10706-018-0536-5
Fattahi H, Babanouri N (2017) Applying optimized support vector regression models for prediction of tunnel boring machine performance. Geotech Geol Eng 35:2205–2217
Fattahi H, Bazdar H (2017) Applying improved artificial neural network models to evaluate drilling rate index. Tunn Undergr Space Technol 70:114–124
Fattahi H, Zandy Ilghani N (2019a) Applying Bayesian models to forecast rock mass modulus. Geotech Geol Eng 37:4337–4349
Fattahi H, Zandy Ilghani N (2019b) Bayesian prediction of rotational torque to operate horizontal drilling. J Min Environ 10:507–515
Fattahi H, Zandy Ilghani N (2020) Slope stability analysis using Bayesian Markov Chain Monte Carlo method. Geotech Geol Eng 38:2609–2618. https://doi.org/10.1007/s10706-019-01172-w
Gandomi AH, Alavi AH, Yun GJ (2011) Formulation of uplift capacity of suction caissons using multi expression programming. KSCE J Civ Eng 15:363
Gao W, Alqahtani AS, Mubarakali A, Mavaluru D, Khalafi S (2020) Developing an innovative soft computing scheme for prediction of air overpressure resulting from mine blasting using GMDH optimized by GA. Eng Comput 36:647–654. https://doi.org/10.1007/s00366-019-00720-5
Gimenez O et al (2009) WinBUGS for population ecologists: Bayesian modeling using Markov Chain Monte Carlo methods. In: Thomson DL, Cooch EG, Conroy MJ (eds) Modeling demographic processes in marked populations. Springer, Berlin, pp 883–915
Herath HS (2018) Post-auditing and cost estimation applications: an illustration of MCMC simulation for Bayesian regression analysis. Eng Econ 300:1–33
Ivakhnenko AG (1971) Polynomial theory of complex systems. IEEE Trans Syst Man Cybern. https://doi.org/10.1109/TSMC.1971.4308320
Jekabsons G (2009) GMDH-type polynomial neural network toolbox for Matlab/Octave
Koopialipoor M, Nikouei SS, Marto A, Fahimifar A, Armaghani DJ, Mohamad ET (2019) Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull Eng Geol Env 78:3799–3813
Mohammadi J, Ataei M, Kakaie R, Mikaeil R, Shaffiee Haghshenas S (2019) Performance evaluation of chain saw machines for dimensional stones using feasibility of neural network models. J Min Environ 10:1105–1119
Mokfi T, Shahnazar A, Bakhshayeshi I, Derakhsh AM, Tabrizi O (2018) Proposing of a new soft computing-based model to predict peak particle velocity induced by blasting. Eng Comput 34:881–888
MolaAbasi H, Khajeh A, Semsani SN, Kordnaeij A (2019) Prediction of zeolite-cemented sand tensile strength by GMDH type neural network. J Adhes Sci Technol 33:1611–1625
Muduli PK, Das MR, Samui P, Kumar Das S (2013) Uplift capacity of suction caisson in clay using artificial intelligence techniques. Mar Georesour Geotechnol 31:375–390
Pai GV (2005) Prediction of uplift capacity of suction caissons using a neuro-genetic network. Eng Comput 21:129–139
Rahman M, Wang J, Deng W, Carter J (2001) A neural network model for the uplift capacity of suction caissons. Comput Geotech 28:269–287
Samui P, Das S, Kim D (2011) Uplift capacity of suction caisson in clay using multivariate adaptive regression spline. Ocean Eng 38:2123–2127
Shahr-Babak MM, Khanjani MJ, Qaderi K (2016) Uplift capacity prediction of suction caisson in clay using a hybrid intelligence method (GMDH-HS). Appl Ocean Res 59:408–416
Yanai H, Takeuchi K, Takane Y (2011) Projection matrices. In: Yanai H, Takeuchi K, Takane Y (eds) Projection matrices, generalized inverse matrices, and singular value decomposition. Springer, New York, pp 25–54
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest
Insofar as the authors are concerned, they declare that they have no conflicting interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fattahi, H., Zandy Ilghani, N. Application of Monte Carlo Markov Chain and GMDH Neural Network for Estimating the Behavior of Suction Caissons in Clay. Geotech Geol Eng 41, 3305–3319 (2023). https://doi.org/10.1007/s10706-023-02455-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10706-023-02455-z