
Abstract
Grain yield is a result of the combined effects of genotype, environment and their interaction. The importance of the genotype × environment interaction is that it causes different reactions of maize hybrids when they are grown in different environments. This study was performed to analyse discriminativeness, representativeness and relationships of test locations for a grain yield of nine maize hybrids grown at nine locations in a 5 year period 2007–2011 in the South Pannonian Basin, a part of central and south European corn belt. A three-way mixed model revealed the highly significant (P < 0.01) REML variance components for year × location, year × location × hybrid and residuals. The grain yield was also significantly (P < 0.05) affected by the year × hybrid and location × hybrid interaction effect. The sites regression (SREG) model was used to determine whether mega-environments exist, and/or whether the test locations used are suitable for maize hybrids zoning. To determine which environmental factors mostly affect the hybrid × location interaction, the partial least squares regression approach was applied. The “which-won-where” pattern of the SREG biplot confirmed a rank change interaction between the locations, indicating the presence of strong and unpredictable rank-change location-by-year interactions. The main characteristic of the grouping pattern was poor repeatability, since most of the locations that made one mega-environment tended to change from year to year. Therefore, it is preferable to develop hybrids with high yielding potentials, wide adaptability and stability, rather than to develop hybrids specially designed for narrow agro-ecological regions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The term “zoning a variety” means determining optimal growing regions for a variety or hybrid on the basis of multi-environment yield trials (MET). The biological background of zoning is based on the genotype × environment interaction. Thanks to this phenomenon, different genotypes are ranked differently in different environments (Kang 2004). While the genotype of a variety is fixed, environmental conditions are more or less variable, changing with year and location. Plant breeders, geneticists and statisticians have been engaged for many years in the study of genotypes and their relationship with the environment, all aimed at developing superior genotypes (Casanoves et al. 2005; Kang et al. 2005). Correct selection of varieties, i.e., correct zoning, and the grouping of environments based on yielding potential can be made by using the results of a large number of long-term trials and statistical procedures (Yan and Kang 2003; Casanoves et al. 2005; Yan and Tinker 2006; Navabi et al. 2006; Rozeboom et al. 2008). There are several possible approaches to location classification which can be based on criterion of the agro-ecologic, agro-climatic, soil or precipitation pattern informations. All of these approaches are based on data that is important, but not critical for proper location classification since they do not account for the information about the hybrid response to the unpredictable location conditions. The results may not be relevant for plant breeding and hybrid zoning. A more realistic approach should be based on the grain yield response of the specific set of the hybrids for the particular set of the locations and should have (or not) logical background in the above mentioned types of information. Within an extensive production area in which a particular crop is grown, the locations in which a genotype consistently, year after year, performs better than in another location is referred to as a mega-environment (Yan and Rajcan 2002; Gauch 2013). For purposes of wheat breeding at the global level, CIMMYT defined the mega-environment as a part of a broader, not necessarily compact area which covers several countries and sometimes several continents and which is characterized by uniform biotic and abiotic stresses, uniform growing conditions and uniform consumer demands (Braun et al. 1996).
In the last decade, SREG (GGE biplot) analysis proved to be a very useful method for the purpose of genotype analysis, mega-environment investigation and test location analysis. This method combines sites regression (SREG) analysis and biplot technique in displaying both genotype (G) and genotype by environment interaction (GE) which are the two sources of variation that are relevant to cultivar evaluation (Yan et al. 2000). The “which-won-where” pattern of the SREG model can serve as a very effective visual tool for mega-environment identification but only if it is based on multilocation trials from multiple years (Yan et al. 2007). When the “which-won-where” or “crossover” pattern is repeatable across years, a target region can be reliably divided into subregions. This methodology also allows the evaluation of test locations in order to identify superior genotypes on the most effective way. The two most important aspects in terms of test location evaluation are the ability of test location to represent target mega-environment and its ability to discriminate genotypes. Representativeness and discriminating ability of test locations must be assessed using the multi-year data and should be repeatable across years (Yan 2014).
The length of the maize growing season is determined by the length of the frost-free period, from the last spring frost to the first frost in the fall. According to the experience of domestic and international breeders and growers, correct selection of hybrids is the most effective and the least expensive measure in maize production that brings increased yields. The zoning, i.e., determining optimal growing regions for a variety based on the knowledge of its genetic characteristics and agro-ecological conditions was the subject of numerous previous studies (Stojaković et al. 2006; Ivanović et al. 2007; Anley et al. 2013; Nzuve et al. 2013).
The South Pannonian Basin is situated between 44° and 46° northern latitude and 18° and 21° eastern longitude. Due to its geographical location and relief, this area has a continental climate. Therefore, it has a high potential for crop production due to quality agricultural soils, mild climate and long tradition. According to the distribution of soil types, 60 % of the arable lands are chernozems which are considered as ideal for crop production on the basis of their physico-chemical properties. The main crop is maize, which is annually grown at 35–40 % of total arable land. In the last 4 years (2010–2013), maize was grown at about 700,000 ha of a total of 1.763 million ha of arable land (Statistical Office of the Republic of Serbia 2013).
The selection for specific environmental conditions increases the adaptability of maize hybrids, but they are nevertheless tested for performance in different environments in order to make a precise ranking list. The objective of this research was to determine, on the basis of the SREG analysis of multi-location maize trials, whether the production area of the South Pannonian Basin is a uniform region or it can be divided into smaller units (mega-environments). The term mega-environment is used as defined by Gauch and Zobel (1997).
Materials and methods
Genetic material and field trials
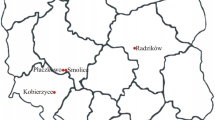
In order to select the best locations for maize hybrid testing, multi-location trials were performed in a 5-year period from 2007 to 2011 using a single set of nine hybrids of different FAO groups: NS 3014 (FAO 300), NS 4015 (FAO 400), NS 5043 and NS 540 (FAO 500), NS 6010, NS 6030 and NS 640 (FAO 600), ZENIT and NS 770 (FAO 700). These hybrids are annually grown at about 45 % of the maize acreage in the region. The multi-location trials were established in nine locations that were fairly evenly distributed (Table 1; Fig. 1). The experiments were conducted in a randomized block design with two replications. The experimental unit area was 9.75 m2 per hybrid. The unit included two rows, each measuring 6.5 m, 0.75 m between rows and 0.22 cm between plants in the row, providing stand density of 60.606 plants ha−1. The experiments were sown in April (15–25) with planting machines and harvested in October (10–20) with combine. Conventional cultivation technology was applied, which was adapted to the ecological conditions of the location. At harvest, grain weight and moisture content were recorded for each experimental plot. Grain yield (t ha−1 at 14 % moisture) was determined by the following formula: weight of sample (kg) × (100 − moisture content % × 86−1) × (10,000 × plot area−1). Meteorological records were taken for minimum temperature in June (mn6), July (mn7) and August (mn8); maximum temperature in June (mx6), July (mx7) and August (mx8); total precipitations in June (pr6), July (pr7) and August (pr8). Temperature variations were calculated as a difference between maximum and minimum temperature for each of 3 months; June (tv6), July (tv7) and August (tv8). Climatic data was obtained from the official meteorological stations of Hydrometeorological Service of the Republic of Serbia (http://www.hidmet.sr.gov.rs) which were located nearby field experiments (Online Resource 1).

Maize test locations and their location codes in the South Pannonian Basin
Statistical analyses
Grain yield data from the individual years was analysed by the following Gausian linear mixed model: \(y_{ijk} = \mu + e_{jk} + h_{i} + l_{j} + (hl)_{ij} + \varepsilon_{ijk} ,\) where y ijk (i = 1,…, I; j = 1,…, J; k = 1,…, K) is the grain yield of hybrid i, in location j, replication k; μ is the overall mean; e jk is the random effect of replication k within location j; \(h_{i}\) is the main fixed effect of hybrid i; \(l_{j}\) is the random main effect of location j; \((hl)_{ij}\) is the random effect of the interaction of hybrid i with location j and \(\varepsilon_{ijk}\) is the random error term associated with grain yield i.e., \(y_{ijk}\). Following the mentioned equation, separate models for individual years were fitted assuming the homogeneous residual error variances (i.e., \(\varepsilon_{ijk} \sim N(0,\sigma^{2} )\)) across locations (similar to classical fixed two-way analysis of variance) and model assuming the heterogeneous residual variances (\(\varepsilon_{ijk} \sim N(0,\sigma^{2} )\) and \(\sigma_{1}^{2} ,\sigma_{j}^{2} , \ldots ,\sigma_{J}^{2}\)) across locations. The choice among the homogeneous versus heterogeneous model was made in accordance to Akaike’s information criterion (AIC) which is calculated as follows: AIC = −2LL + 2q, where LL denotes the log of restricted maximum likelihood (REML) value of the related model and q is the number of estimated variance–covariance parameters. The suitable model is the one with the lowest AIC value. In addition, the three-way model was used to estimate the variance of components of the main effects (year, location and hybrid) and corresponding first and second order interactions by REML algorithm. Throughout the analysis, hybrid effect was considered as fixed and all other model terms were treated as random. The results are reported as REML variance component ± standard error of estimates. The Mixed procedure of the SAS software version 9.1 (SAS Institute Inc. 2003) was used for all mixed model computations.
To study the hybrid plus hybrid × location patterns, the least squares means of the hybrids per location were used as input matrix for the SREG model (Crossa and Cornelius 1997). The SREG model is: \(\overline{{y_{{ij}} }} = \mu + \beta _{j} + \sum\nolimits_{{k = 1}}^{t} {\lambda _{k} a_{{ik}} } \gamma _{{jk}} + \overline{{\varepsilon _{{ij}} }} ,\) where \(\overline{{y_{ij} }}\) is the cell-mean of the ith hybrid in the jth location; \(\mu\) is the intercept term; \(\beta_{j}\) is the main effect of jth location; \(\lambda_{k} (\lambda_{1} \ge \lambda_{2} \ge \cdots \ge \lambda_{k} )\) are scaling constants or singular values that allow the imposition of orthonormality constraints of the singular vectors for hybrids \(a_{k} = (a_{1k} , \ldots ,a_{ik} )\) and locations \(\gamma_{k} = (\gamma_{1k} , \ldots ,\gamma_{jk} )^{\prime}\) such that \(\sum\nolimits_{i} {a_{ik}^{2} = \sum\nolimits_{j} \gamma_{jk}^{2} = 1}\) and \(\sum\nolimits_{i} {a_{ik}^{\prime} = } \sum\nolimits_{j} {\gamma_{jk} \gamma_{jk'} = 0}\) for k ≠ k′; \(\overline{{\varepsilon_{ij} }}\) is the residual of unexplained variation associated with ith hybrid in jth location. In the SREG model, the bilinear terms model that mainly effects hybrids plus the H × L interaction. The maximum number of multiplicative terms is t = min(h, e − 1) for the full SREG model. Graphical visualization of the relationships among test locations was performed using the environment-centered H × L table without scaling and with environment focused singular value portioning (Yan and Rajcan 2002). The SREG model was applied on both individual year dataset and combined dataset.
In order to identify the most important environmental variables that affect the year × hybrid × location interaction for the combined dataset, the partial least squares (PLS) regression approach was applied (Aastveit and Martens 1986; Vargas et al. 1998). As a independent data (Z) matrix a set of 12 environmental scaled variables was related to the double-centered hybrid by location dependent (Y) matrix. Data matrices were expressed as: Y = TQ′ + F and Z = TP′ + E, were matrix T contains the Z scores, P matrix contains the Z loadings, matrix Q contains the Y loadings and F and E are the residuals of the unexplained variation. The relationship among the Y and Z matrices was transmitted through the latent variable T. The number of T variables that are requested to optimally approximate the dimensionality was determined by cross-validation procedure (Stone 1974).
The SREG and PLS analyses and data visualizations were completed using R software (R Development Team 2014).
Results
Maize grain yield variation
In the observed 5-year period, maize grain yield of the tested hybrids across test locations ranged from 7.33 in VS to 10.17 t ha−1 in VB. When comparing individual years, the variation in yield level was also present and ranged from 8.07 to 9.84 t ha−1 (Table 2). The yield level of individual hybrids varied from location to location and from year to year indicating the presence of strong and complex “crossover” interactions. Besides fixed environmental factors such as soil type, altitude, latitude, seeding date, “crossover” interaction can be also influenced by variable environmental factors which vary from year to year such as rainfall, temperature, disease pressure, etc. The main feature of the climatic characteristics (especially rainfall) in the observed region is poor temporal and spatial distribution. The amount of rainfall in the vegetation period (April–October) ranged from 285.2 mm in 2009 to 566.2 mm 2010 (Table 1). Keeping in mind that the maize requirements for water in the vegetation period exceeded 450 mm (460–520 mm, Bošnjak 1982), a lack of water was present in 4 of the 5 observed years. All this led to the fact that certain areas within the South Pannonian Basin in different years are more suitable for maize production than others.
Mixed model analysis of grain yield data
When comparing the results of the homogeneous versus heterogeneous model fitting (Table 3) in the terms of AIC value, the homogeneous model was prefered in 2010 and 2011, while the heterogeneous model was more suitable in 2007 and 2008. In 2009 both models were equally good as indicated by their similar AIC value (416.8 vs. 416.9). In addition to highly significant (P < 0.01) fixed effects of hybrids in each year, highly significant (P < 0.01) REML variance components of the hybrid × location interaction and residuals with significant (P < 0.05) location effects are obtained (results not presented). Three-way mixed model (Table 4) revealed the highly significant (P < 0.01) REML variance components for year × location, year × location × hybrid and residuals. The grain yield was also significantly (P < 0.05) affected by the year × hybrid and location × hybrid interaction effect.
Biplot analysis of location grouping
Graphic presentation of results of long-term trials conducted in several locations using the “which-won-where” model provided an opportunity to identify mega-environments (Gauch and Zobel 1997; Yan et al. 2000) within the region of the South Pannonian Basin. When a line is drawn between the points indicating the position of the most distant hybrids in the biplot, a polygon is made. The lines which start from the coordinate origin are perpendicular to the sides of the polygon dividing the polygon into sectors. All of the locations are found within one or several sectors. The locations that share a single sector have the same hybrid as the best one and they may be considered as a mega-environment. The graphs in this paper show the biplot (“which-won-where” pattern) for nine hybrids tested in nine locations and in 5 years, separately for each year and for combined dataset (Fig. 2a–f). The points indicating the position of locations in the biplot are arranged in several clusters each year. The clustering pattern changed from year to year, indicating that different hybrids were the leading ones in different locations, the overall situation indicating the presence of the strong “crossover” interaction pattern. Each year, the locations were divided into clusters, from two in 2009 to four in 2007 and 2008 (Table 5; Fig. 2a–e). Also, each year (the exception being in 2008) the locations were grouped in a single large cluster (six locations in 2009, 2010 and 2011, four locations in 2007) and two to three clusters that included 1–2 location. In most cases, the composed clusters did not match the traditional maize-growing regions in the South Pannonian Basin; nevertheless, some likelihood did exist. The most productive part of this area for maize growing includes SO, VB, RU and SM locations. When considering individual years, only SO and SM or RU clustered together in four (2008, 2009, 2010 and 2011) out of the 5 years. The location VB, which also belongs to this region, tends to form a separate cluster. The tendency towards separate clustering was also observed for some locations from the traditionally poor regions for maize growing. The location VS clustered with KI in 3 out of the 5 years (2007, 2010 and 2011) to make a separate group. Discriminative ability and representativeness of test locations were estimated based on the length of the vectors formed by each location and the position of the vectors in relation to the “ideal” location (Table 5; Fig. 3a–f). Longer vectors means larger standard deviation and therefore better discriminative ability of the test location. On the other hand, shorter vector length shows less discriminative ability of location, which means that all genotypes performed similarly in it (Yan et al. 2007). Such location gives little or no information about genotype differences. Representativeness of test location can be estimated based on the angle which location vector form with the average environment axis (AEA). The AEA passes through the biplot origin and the point defined by the average coordinates of all test locations (Yan 2014). The location vectors that form small angles with AEA are more representative of the mega-environment than those that form large angles with it. An “ideal” test location is the location that has the longest vector of all test locations (most discriminating) and is located on the AEA (most representative). Such a location probably never exists in reality but it can be used as a reference to assess suitability of the test locations (Yan et al. 2007). Of the nine examined locations, RU (2009 and 2011), SU (2007), KI (2008) and VB (2010) showed to be the most representative ones while SM, SU, VS, KI and RU (in individual years) showed to be the most informative locations (Table 5; Fig. 3a–e). In order to lower the cost of testing of new hybrids, the test locations that overlap and those that does not provide additional information about hybrids than those provided by previous locations (insufficiently informative) may be excluded from a network of test locations. However, such a decision should be made only if this pattern repeats across years.

Polygon view of SREG biplot showing “which-won-where” pattern: a 2007, b 2008, c 2009, d 2010, e 2011, f 2007–2011; H1-NS 3014, H2-NS 4015, H3-NS 5043, H4-NS 540, H5-NS 6010, H6-NS 6030, H7-NS 640, H8-ZENIT, H9-NS 770

Vector view of SREG biplot showing relationships among test locations: a 2007, b 2008, c 2009, d 2010, e 2011, f 2007–2011; H1-NS 3014, H2-NS 4015, H3-NS 5043, H4-NS 540, H5-NS 6010, H6-NS 6030, H7-NS 640, H8-ZENIT, H9-NS 770
Taking into account the 5-year data of nine hybrids grown in nine locations a combined biplot was constructed (Figs. 2f, 3f). On the basis of the location positions on the biplot it can be seen that there is no logical grouping pattern, and that the same locations in different years of testing had both positive and negative PC1 scores, which indicates a strong “crossover” GE interaction. A similar situation was observed in terms of representativeness and discriminating ability of locations. The same locations in different years had a different length of vectors and the position of the vectors in relation to the “ideal” location, which indicates its differences in representativeness and discriminating ability.
Effect of the environmental variables on hybrid by location grouping
With the purpose of the identification of the most important environmental factors that affects the year × hybrid × location interaction as well as location grouping the multivariate dimension reduction PLS regression approach was employed. In according to the cross-validation procedure (results not shown), the only first one latent dimension was found to be highly significant (P < 0.01) for prediction and explained 56.5 % of the total interaction variance. The second one dimension explained an additional 10.3 % of the interaction variance and not to be important for increasing the overall prediction accuracy of the model. When considering the absolute values of the Z-loadings (Fig. 4), the first dimension clearly separate the temperature variations throught the June (tv6), July (tv7) and August (tv8) with positive and minimum temperature in July (mn7) and August (mn8) with negative values of the Z-loadings as the most important environmental variables for overall year × hybrid × location interaction. In addition, maximum temperature in June (mx6) and precipitation through June (pr6) were also identified as important.

Plot of the Z-loading with the first dimension of the PLS regression approach
Discussion
The Pannonian Basin region of the south-eastern and central Europe (Hungary, North Serbia, Eastern Croatia and Western Romania) is the main corn production region in Europe, and second one in the world after the US Corn Belt. The main characteristic of this region is a temperate continental climate with high fluctuations in the amount and distribution of precipitation and air temperature over the year. In the northern part of Serbia, the average annual values (1964–2007) of precipitation and air temperature were 587.7 mm and 11.2 °C respectively. The average values for growing season period (April–September) reach 328 mm for precipitations, and 17.8 °C for air temperature (Pejić et al. 2010). Years with less than 300 mm of precipitation can be classified as very unfavorable years for corn production (Videnović et al. 2013). Corn is most sensitive to lack of water during flowering and pollination (June, July and August), and at the time of intense growth and grain maturing (Pejić et al. 2011). In the observed 5 year period (2007–2011) the highest yield was achieved in 2010, which was the year with the largest amount of precipitation (9.84 t ha−1 yield and 566.2 mm precipitation). While the year 2010 can be considered favorable in terms of precipitation, the years of 2007, 2008, 2009 and 2011 are more or less stressful due to lack of water, and therefore can be considered as unfavorable. Due to differences in grain yield in drought-unfavorable years, it may be assumed that the corn grain yield is under the influence of some other climatic factors besides the total precipitation over the year. The results of the PLS regression approach revealed temperature variations in critical period of vegetation (June, July and August) as a factor that contributed most to differences observed among environments. Differences between maximum and minimum temperatures, especially in the critical period, greatly affects the metabolic processes in maize plants and are manifested differently depending on genotype (hybrid). However, this requires additional studies in physiology which are beyond the scope of the existing ones. Besides that, minimum temperatures during July and August, as well as the maximum temperature and precipitation in June were also significant factors. In addition to temperature variations, maximum and minimum temperatures are the most common limiting factor for maize production (Malvar et al. 2005), while most other authors also includes the water regime, mean daily temperature and humidity (Argillier et al. 1994; Butron et al. 2004). In its reproductive stage, maize is especially sensitive to high daily air temperature which, if exceeding 32.5 °C can lead to decay of pollen and inactivation of certain enzymes.
When examining polygenic traits, which include the grain yield, the interaction between variety and environmental conditions occurs almost regularly. In relation to this, it may be expected that each broad production region includes locations in which one or more hybrids, each year, maintain the same order regarding yield performance. Yan and Tinker (2006) referred to such environments as mega-environment. Disregarding a group or groups of locations that do not cause significant changes in the ranking of hybrids within the group, can be of great importance for both hybrids zoning and the reduction of the number of test location and costs of breeding programs (Stojaković et al. 2010). Under the influence of the genotype × environment interaction, the ranking of varieties according to yield level varies from location to location and from year to year, so that in each environment (location/year) another variety is the leading one. The largest variance component estimate was for the year and location factors which accounted for 56.8 % of the total variance. Variance estimates involving genotype related interactions were significantly smaller than for the location and years (Table 4). A similar pattern regarding the relative magnitude of the entire set of variance components were obtained by Rozeboom et al. (2008) for wheat in the Central Great Plains in the USA. Such pattern of the interaction variance component estimates indicated that the greatest proportion of variability in maize multi-location trials belongs to location, year and their interaction. Highly significant (P < 0.01) or significant (P < 0.05) values of variance components of all types of interactions among years, locations and hybrids indicates low stability of the hybrids, i.e., yield variation among years and locations.
Maize breeders are always concerned whether to select maize hybrids specifically adapted to a certain environment to exploit specific adaptation, or to select hybrids with broader adaptability (Atlin et al. 2000). In this research, the “which-won-where” pattern clearly indicated a “crossover” pattern of location clustering, namely, several groups of locations could be distinguished each year within the maize production area in the South Pannonian Basin. The main feature of the clustering pattern was poor repeatability, which means that most (but not all) locations that made a group changes from year to year. The main cause of such unrepeatability according to Navabi et al. (2006) is the random nature of the year-dependent factors which causes yearly variations in the pattern of environmental factors to be generally unpredictable. Yan (2014) defines this as a type IV classification of target region. This type of classification means that the observed GE interaction is dominated by GLY interaction and that the target region cannot be meaningfully divided into mega-environments (Yan 2014). The target environment represents single but complex mega-environment in which, for reliable evaluation of genotypes, multi-year and multi-location tests are necessary. This can be an important piece of information for maize breeders and growers. Therefore, the selection of maize for the production region of the South Pannonian Basin should focus on hybrids with high genetic yield potential, wide adaptability and yield stability rather than on hybrids adapted to a narrow agro-ecological area. Also, to properly assess the agronomic values of hybrids, it is not sufficient to run tests in a single, “ideal” location, because such a location does not exist, but rather in a number of locations so as to cover the whole region. Our findings were in accordance with the results obtained by Navabi et al. (2006) in classification of spring wheat growing areas in Alberta. The authors concluded that due to the lack of repeatability of the GEI patterns over years, this region should be regarded as a single mega-environment with unpredictable “crossover” interaction which is not in correspondence with traditional wheat growing area divisions in Alberta. Results of our study are also opposite from the previous zoning of the South Pannonian Basin (Stojković 1972; Stojaković et al. 2006) based only on the empirical knowledge and agroecological characteristics of the regions. The subdivision of a target population of environments has been also the subject of numerous studies in Africa (Setimela et al. 2005; Badu-Apraku et al. 2012; Windhausen et al. 2012). Windhausen et al. (2012) pointed out that maize hybrids are broadly adapted to different agroecological conditions of Eastern and Southern Africa, and subdivision based on climate, altitude and soil conditions into subregions contributed little to specific adaptation of maize hybrids. Considering highly variable and unpredictable year effect, maize hybrids recommended for the production region of the South Pannonian Basin should have high grain yield and above-average yield stability (Ivanović et al. 2007; Stojaković et al. 2009). In addition, yield reduction caused by unfavourable environmental conditions can also be avoided by growing a number of hybrids of different FAO maturity groups. The specific environmental conditions of this region allow production of late maturity maize hybrids up to FAO group 800 (Troyer 2001). However, although high yielding, these hybrids are susceptible to drought and heat stress due to longer growing season. On the other hand, earlier hybrids can avoid adverse effects of drought by completing the flowering and fertilisation before the critical period occurs during June, July and August. Growing earlier and later maturity hybrids simultaneously, the stability of maize production can be ensured in contrasting years.
Based on the production area, maize is the most important crop in Serbia with its northern part, the South Pannonian Basin, as the main maize production region. Since average grain yield in this part of Serbia accounts for approximately 5.8 t ha−1 (Statistical Office of the Republic of Serbia 2013) and yield of newly developed hybrids in pre-official, official and macro trials can reach over 11 t ha−1 (Stojaković et al. 2012; Mitrović et al. 2012), it seems that maize produced in this region express just above 50 % of its genetic grain yield potential. This can be due to inadequate cropping practices and an improper hybrid zoning based on the traditional approach only. To address this issue further research in this area would be essential with particular attention to the increase of the number of testing locations, as well as the inclusion of the latest hybrids in the analyses. Besides, in the breeding process, the testing network should include locations outside this region, which are constantly exposed to the drought and heat stress (i.e., a part of the South-Eastern Serbia). This would help assessing genotypes more accurately to drought and heat stress, which occurrence is becoming more frequent in the South Pannonian Basin.
References
Aastveit H, Martens H (1986) ANOVA interactions interpreted by partial least squares regression. Biometrics 42:829–844
Anley W, Zeleke H, Dessalegn Y (2013) Genotype × environment interaction on maize (Zea mays L.) across north western Ethiopia. J Plant Breed Crop Sci 5(9):171–181
Argillier O, Hebert Y, Barriere Y (1994) Statistical analysis and interpretation of line × environment interaction for biomass grain yield in maize. Agronomie 14:661–672
Atlin GN, Baker RJ, McRae KB, Lu X (2000) Selection response in subdivided target regions. Crop Sci 40:7–13
Badu-Apraku B, Oyekunle M, Obeng-Antwi K, Osuman AS, Ado SG, Coulibay N, Yallou CG, Abdulai M, Boakyewaa GA (2012) Performance of extra-early maize cultivars based on GGE biplot and AMMI analysis. J Agric Sci 150:473–483
Bošnjak DJ (1982) Evaporacija sa slobodne vodene površine kao osnova zalivnog režima i njen odnos prema ETP kukuruza i soje. Dissertation, University of Novi Sad (in Serbian)
Braun HJ, Rajaram S, Van Ginel M (1996) CIMMYT’s approach to breeding for wide adaptation. Euphytica 92:175–183
Butron A, Velasco P, Ordas A, Malvar RA (2004) Yield evaluation of maize cultivars across environments with different levels of pink stem borer infestation. Crop Sci 44:741–747
Casanoves F, Baldessari J, Balzarini M (2005) Evaluation of multienvironment trials of peanut cultivars. Crop Sci 45:18–26
Crossa J, Cornelius PL (1997) Sites regression and shifted multiplicative model clustering of cultivar trials sites under heterogeneity of variances. Crop Sci 37:406–415
Gauch HG (2013) A simple protocol for AMMI analysis of yield trials. Crop Sci 53:1860–1869
Gauch HG, Zobel RW (1997) Identifying mega-environments and targeting genotypes. Crop Sci 37:311–326
Ivanović M, Nastasić A, Stojaković M, Jocković Đ (2007) Regional distribution NS Maize Hybrids. A periodical of scientific research on field and vegetable crops, vol 43. Institute of Field and Vegetable Crops, Novi Sad, pp 89–93
Kang MS (2004) Breeding: genotype by environment interaction. In: Goodman RM (ed) Encyclopedia of plant and crop science. Marcel Dekker, New York, pp 218–221
Kang MS, Aggarwal VD, Chirwa RM (2005) Adaptability and stability of bean cultivars as determined via yield-stability statistic and GGE biplot analysis. J Crop Improv 15:97–120
Malvar RA, Revilla P, Butron A, Gouesnard B, Boyat A, Soengas P, Alvarez A, Ordas A (2005) Performance of crosses among French and Spanish maize populations across environments. Crop Sci 45:1052–1057
Mitrović B, Stanisavljević D, Treskić S, Stojaković M, Ivanović M, Bekavac G, Rajković M (2012) Evaluation of experimental maize hybrids tested in multi-location trials using AMMI and GGE biplot analyses. Turk J Field Crop 17(1):35–40
Navabi A, Yang R, Helm J, Spaner DM (2006) Can spring wheat-growing megaenvironments in the northern great plains be dissected for representative locations or niche-adapted genotypes? Crop Sci 46:1107–1116
Nzuve F, Githiri S, Mukunya DM, Gethy J (2013) Analysis of genotype × environment interaction for grain yield in maize hybrids. J Agric Sci 5(11):75–85
Pejić B, Maksimović L, Milić S, Simić D, Miletaški B (2010) Effect of redily available water deficit in soil on maize yield and evapotranspiration. Ratar Povrt 47(1):115–121
Pejić B, Maheshwari B, Šeremešić S, Stričevič R, Pacureuanu-Joita M, Rajić M, Ćupina B (2011) Water-yield relations of maize (Zea mays L.) in temperate climatic conditions. Maydica 56:315–321
R Development Core Team (2014) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, ISBN 3-900051-07-0. http://www.r-project.org
Rozeboom KL, Schapaugh WT, Tuinstra MR, Vanderlip RL, Miliken GA (2008) Testing wheat in variable environments: genotype, environment, interaction effects, and grouping test locations. Crop Sci 48:317–330
SAS Institute (2003) SAS for Windows: release 9.1. SAS Institute, Cary
Setimela P, Chitalu Z, Jonazi J, Mambo A, Hodson D, Bänziger M (2005) Environmental classification of maize testing sites in the SADC region and its implication for collaborative maize breeding strategies in the subcontinent. Euphytica 145:123–132
Statistical Office of the Republic of Serbia (2013) http://www.webrzs.stat.gov.rs/WebSite/Public/PageView.aspx?pKey=82. Accessed 15 June 2014
Stojaković M, Jocković Đ, Ivanović M, Vasić N, Simić D, Boćanski J (2006) NS maize hybrids in trials in 2005. A periodical of scientific research on field and vegetable crops, vol 42. Institute of Field and Vegetable Crops, Novi Sad, pp 3–14
Stojaković M, Jocković Đ, Ivanović M, Bekavac G, Nastasić A, Purar B, Stanisavljević D, Popov R, Capelja V, Laišić R, Dolapcev S, Stojakovic Z (2009) Specific reaction of maize hybrids in different agroecological conditions. A periodical of scientific research on field and vegetable crops, vol 46. Institute of Field and Vegetable Crops, Novi Sad, pp 335–344
Stojaković M, Ivanović M, Jocković Đ, Bekavac G, Purar B, Nastasić A, Stanisavljević D, Mitrović B, Treskić S, Laišić R (2010) NS maize hybrids in production regions of Serbia. Ratar Povrt 47(1):93–102
Stojaković M, Ivanović M, Bekavac G, Nastasić A, Purar B, Mitrović B, Stanisavljević D (2012) Evaluation of new NS maize hybrids using biplot analysis. Genetika 44(1):1–12
Stojković L (1972) Production regions in Vojvodina. In: Živković B (ed) Soils of Vojvodina. Institute for Agricultural Research, Novi Sad, pp 513–571
Stone M (1974) Cross-validatory choice and assessment of statistical predictions. J R Stat Soc B 36:111–147
Troyer AF (2001) Temperate corn. In: Hallauer A (ed) Specialty Corns. CRC Press, Boca Raton, pp 393–466
Vargas M, Crossa J, Sayre K, Reynolds M, Ramírez ME, Talbot M (1998) Interpreting genotype × environment interaction in wheat using partial least squares regression. Crop Sci 38:679–689
Videnović Ž, Dumanović Z, Simić M, Srdić J, Babić M, Dragičević V (2013) Genetic potential and maize production in Serbia. Genetika 45(3):667–677
Windhausen VS, Wagener S, Magorokosho C, Makumbi D, Vivek B, Piepho H, Melchinger AE, Atlin GN (2012) Strategies to subdivide a target population of environments: results from the CYMMIT-led maize hybrid testing programs in Africa. Crop Sci 52:2143–2152
Yan W (2002) Singular-value partitioning in biplot analysis of multienvironment trial data. Agron J 94:990–996
Yan W (2014) Crop variety trials: data management and analysis. Wiley-Blackwell, New York
Yan W, Kang MS (2003) GGE biplot analysis: a graphical tool for breeders, geneticists, and agronomists. CRC Press, Boca Raton
Yan W, Rajcan I (2002) Biplot analysis of test sites and trait relations of soybean in Ontario. Crop Sci 42:11–20
Yan W, Tinker NA (2006) Biplot analysis of multi-environment trial data: principles and aplications. Can J Plant Sci 86:623–645
Yan W, Hunt LA, Sheng Q, Szlavnics Z (2000) Cultivar evaluation and mega-environment investigation based on GGE biplot. Crop Sci 40:596–605
Yan W, Kang MS, Ma B, Woods S, Cornelius PL (2007) GGE Biplot vs. AMMI analysis of genotype-by-environment data. Crop Sci 47:643–655
Acknowledgments
The authors are immensely grateful to two anonymus reviewers whose comments and suggestions led to improvement of our manuscript. This work was supported by Ministry of Education, Science and Technological Development, Republic of Serbia, through the Project TR31073 “Improvement of maize and sorghum production under stress conditions”.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Stojaković, M., Mitrović, B., Zorić, M. et al. Grouping pattern of maize test locations and its impact on hybrid zoning. Euphytica 204, 419–431 (2015). https://doi.org/10.1007/s10681-015-1358-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10681-015-1358-7