
Abstract
The selection of a set of requirements between all the requirements previously defined by customers is an important process, repeated at the beginning of each development step when an incremental or agile software development approach is adopted. The set of selected requirements will be developed during the actual iteration. This selection problem can be reformulated as a search problem, allowing its treatment with metaheuristic optimization techniques. This paper studies how to apply Ant Colony Optimization algorithms to select requirements. First, we describe this problem formally extending an earlier version of the problem, and introduce a method based on Ant Colony System to find a variety of efficient solutions. The performance achieved by the Ant Colony System is compared with that of Greedy Randomized Adaptive Search Procedure and Non-dominated Sorting Genetic Algorithm, by means of computational experiments carried out on two instances of the problem constructed from data provided by the experts.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Software development organizations fail many times to deliver its products within schedule and budget. Statistical studies, and CHAOS Reports (Johnson 2003) published since 1994, reveal that, frequently, tasks related to requirements lead software project to the disaster. As Kotonya and Sommerville (1998) suggest, one of the major problems we face when developing large and complex software systems is the one related with requirements. The concept of requirement, in its broadest sense, must be understood as a logical unit of behaviour that is specified by including functional and quality aspects; other authors as Ruhe and Saliu (2005) use instead the concept of feature. Stakeholders propose some desired functionalities that software managers must filter in order to define the set of requirements or features to include in the final software product.
Usually, during the lifetime of a software product, we are faced with the problem of selecting a subset of requirements from the whole set of candidate requirements (e.g. when a new release is being planned). Enhancements to include into the next software release cannot be randomly selected since there are many factors involved. Within this scenario, customers demand their own software enhancements, but all of them cannot be included in the software product, mainly due to the existence limited resources (e.g. availability of man-month in a given software project). In most cases, it is not feasible to develop all the new functionalities suggested. Hence each new feature competes against each other to be included in the next release.
This task of selecting a set of requirements, which until now only appeared when defining new versions of widely distributed software products, becomes important within the incremental approaches of software development, and specially in the agile approaches. Agile methods promote a disciplined project management process that encourages frequent inspection and adaption. These software development methodologies are based on iterative development, advocating for frequent “releases” in short development cycles, called timeboxes, in order to improve productivity and introduce checkpoints. Each iteration works through a full cycle, generating a software release that has to be shown to stakeholders. These approaches focus on the quick adaptation of software to the changing realities.
Within this prospective, the challenge of Software Engineering consists on defining specific techniques or methods that improve the way requirements are selected. The problem of choosing a set of requirements fulfilling certain criteria, such as minimal cost or maximal client satisfaction, is a good candidate for the application of metaheuristics. Specifically, this paper shows how Ant Colony Optimization (ACO) systems can be applied to problems of requirements selection. Our solution offers to developers and stakeholders a set of possibilities satisfying several objectives, i.e. the Pareto front. The idea is to help people to take a decision about which set of requirements has to be included in the next release during the software development applying both, agile or classical software development approaches. The proposed ACO system is evaluated by means of a compared analysis with Non-dominated Sorting Genetic Algorithm (NSGA-II) (Deb 2001; Deb et al. 2002) and Greedy Randomized Adaptive Search Procedure (GRASP) (Feo and Resende 1989; Pitsoulis and Resende 2003; Resende and Ribeiro 2003); both adapted to the problem of requirements selection.
The rest of the paper is organized in six sections. Section 2 summarizes the basic Requirements Engineering concepts, focusing in requirement selection process, together with the description and definition of the problem of selection of requirements to be included in the next software release, known as Next Release Problem (NRP) (Bagnall et al. 2001), and related works. Section 3 describes the metaheuristic technique applied in this work, Ant Colony Optimization. Specifically, we focus on its application in multi-objective optimization problems, on the study of how multi-objective ACO can be used to find a set of non-dominated solutions to NRP. In Section 4, the experimental evaluation is carried out by comparing ACO with GRASP and NSGA-II approaches. The analysis of the results is presented in Section 5. Section 6 considers threats to the validity of the findings in the study. Finally, in Section 7 we give some conclusions and the future works that can extend this study.
2 Requirements Selection
Requirements related tasks are inherently difficult Software Engineering activities. Descriptions of requirements are supposedly written in terms of the domain, describing how this environment is going to be affected by the new software product. In contrast, other software processes and artifacts are written in terms of the internal software entities and properties (Cheng and Atlee 2007).
The problem of selecting the subset of requirements among a whole set of candidate requirements proposed by a group of customers is not a straightforward problem, since there are many factors involved. Customers, seeking their own interest, demand the set of enhancements they consider important, but not all customers’ needs can be satisfied. On the one hand, each requirement means a cost in effort terms that the company must assume, but company resources are limited. On the other hand, neither all the customers are equally important for the company, nor the requirements are equally important for the customers. Market factors can also drive this selection process; the company may be interested on satisfying the newest customers’ needs, or they may consider desirable to guarantee that every customer sees fulfilled at least one of their proposed requirements. Also, requirements show interactions that impose a certain development order or either conflicts between them, limiting the alternatives to be chosen.
During the software development process many interaction types between two or more requirements can be identified. Karlsson et al. (1997) were the first in proposing a list of interaction types. Later, Carlshamre et al. (2001) propose a set of interaction types as result of an in-depth study of interactions in distinct sets of requirements coming from different software development projects. Although interaction types are semantically different, in practice they can be grouped into:
-
Implication or precedence. \(r_i\Rightarrow r_j\). A requirement r i cannot be selected if a requirement r j has not been implemented yet.
-
Combination or coupling. r i ⊙ r j . A requirement r i cannot be included separately from a requirement r j .
-
Exclusion. r i ⊕ r j . A requirement r i can not be included together with a requirement r j .
-
Revenue-based. The development of a requirement r i implies that some others requirements will increase or decrease their value.
-
Cost-based. The development of a requirement r i implies that some others requirements will increase or decrease their implementation cost.
These interactions must be considered as constraints in the requirements selection problem. So, two main goals are usually considered: maximize the customers satisfaction and minimize the required software development effort satisfying the given constraints. Therefore, optimization techniques can be used to find optimal or near optimal solutions in a reasonable amount of time. Our aim is to define the requirements selection problem as a science (Ruhe and Saliu 2005), formalizing the problem and applying computational algorithms to generate good solutions.
2.1 Previous and Related Works
The Search-Based Software Engineering (SBSE) area is the research field which proposes the application of search-based optimization algorithms to tackle problems in Software Engineering (Harman and Jones 2001; Harman 2007). In this section we provide a comprehensive review of different approaches that can be found in the literature to tackle with the requirements selection problem (an earlier review can be found in del Sagrado et al. 2010b).
As a problem in which is necessary to evaluate multiple conflicting objectives, its solution requires to find the best compromise between the different objectives. In order to achieve this, we can proceed in two ways. The first approach consists in transforming the multi-objective problem into a single objective problem. To do that, we need to combine the different objectives into a single one by means of an aggregation function (e.g. a weighted sum or product). This is the approach chosen by Bagnall et al. (2001), they formulate the problem of selecting a subset of requirements (i.e. Next Release Problem-NRP) having as goal meet the customer’s needs, minimizing development effort and maximizing customers satisfaction and apply hill climbing, greedy algorithms and simulated annealing. Later, Baker et al. (2006) demonstrate that these metaheuristics techniques can be applied to a real-world NRP out-performing expert judgment. Greer and Ruhe (2004) study the generation of feasible assignments of requirements to increments taking into account different stakeholders’ perspectives and resources constraints. The optimization method they used is iterative and essentially based on a genetic algorithm.
With respect to the application of ACO to tackle the single-objective version of NRP, the first approach can be found in the works of del Sagrado and del Águila (2009) and del Sagrado et al. (2010a) where an Ant Colony System (ACS) is proposed. Jiang et al. (2010) incorporate into ACO a local search for improving the quality of solution found. Nonetheless, all of these approaches do not take into account the existence of interactions between requirements. The problem of requirements selection, including interactions between requirements, is introduced in the works of del Sagrado et al. (2011) and de Souza et al. (2011) by adapting the ACS algorithm.
The second approach to multi-objective optimization builds a set with all the solutions found that are not dominated by any other (this is known as the set of efficient solutions or Pareto-optimal set). The decision maker will select a solution from this set according to personal criteria. The works of Saliu and Ruhe (2007), Zhang et al. (2007), Finkelstein et al. (2008, 2009) and Durillo et al. (2009), study the NRP problem from the multi-objective point of view, either as an interplay between requirements and implementation constraints (Saliu and Ruhe 2007) or considering multiple objectives as cost-value (Zhang et al. 2007) or different measures of fairness (Finkelstein et al. 2008, 2009), or applying several algorithms based on genetic inspiration as NSGA-II, MOCell and PAES (Durillo et al. 2009, 2011).
We introduce a new multi-objective search-based approach based on ACO to the problem of selecting requirements to be included in the next software release, in the presence of several stakeholders (with their own importance perception of requirements) and different types of interactions between requirements. The proposed approach automates the search for optimal or near-optimal sets of requirements, within a given effort bound, that balance stakeholders’ priorities while keeping requirements interactions. It is worth to note that, to date, no ACO approach has been applied to multi-objective NRP and that having more than one valid solution, as in the multi-objective approach, constitute a valuable aid for experts who must decide what is the set of requirements that has to be considered in the next software release. Requirements managers analyze these alternatives and their data (e.g. number of customer covered, additional information about risky requirements), before selecting a solution (i.e. the set of requirements to be developed) according to business strategies. Thus, it is considerably helpful, for any software developer, to have these techniques available either embedded in a CASE (Computer-Aided Software Engineering) tool (del Sagrado et al. 2012), or within a decision support tool for release planning (Carlshamre 2002; Momoh and Ruhe 2006).
2.2 NRP Formulation
Let R = {r 1, r 2, ..., r n } be the set of requirements that are still to be implemented. These requirements represent enhancements to the current system that are suggested by a set of m customers and are candidates to be included in the next software release. Customers are not equally important. So, each customer i will have an associated weight w i , which measures its importance. Let W = {w 1, w 2, ..., w m } be the set of customers’ weights.
Each requirement r j in R has an associated development cost e j , which represents the effort needed for its development. Let E = {e 1, e 2, ..., e n } be the set of requirements efforts. On many occasions, the same requirement is suggested by several customers. However, its importance or priority may be different for each customer. Thus, the importance that a requirement r j has for customer i is given by a value v ij . The higher the v ij value, the higher is the priority of the requirement r j for customer i. A zero value for v ij represents that customer i has not suggested requirement r j . All these importance values v ij can be arranged under the form of an m × n matrix.
The global satisfaction, s j , or the added value given by the inclusion of a requirement r j in the next software release, is measured as a weighted sum of its importance values for all the customers and can be formalized as:
The set of requirements satisfaction computed in this way is denoted as S = {s 1, s 2, ..., s n }. Requirements interactions can be divided into two groups. The first consists of the functional interactions: implication, combination and exclusion. The second one includes those interactions that imply changes in the amount of resources needed or the benefit related to each requirement: revenue-based and cost-based. Functional interactions can be explicitly represented as a graph \(\emph{G}=(\mathbf{R, I, J, X}) \) where:
-
R (the set of requirements) is the set of nodes
-
\(\mathbf I=\{ (r_i, r_j)\mid r_i \Rightarrow r_j \}\) each pair (r i , r j ) ∈ I is an implication interaction and will be represented as a directed link r i → r j
-
J = {(r i , r j ) | r i ⊙ r j } each pair (r i , r j ) ∈ J is a combination interaction and will be represented as a double directed link \(r_i \leftrightarrow r_j\)
-
X = {(r i , r j ) | r i ⊕ r j } each pair (r i , r j ) ∈ X is an exclusion interaction and will be represented as a crossed undirected link
For example, consider the set of requirements R = {r 1, r 2, ..., r 10} and the following functional dependencies \(\mathbf I\!=\!\{(r_1, r_3), (r_1, r_6), (r_2, r_4), (r_2, r_5), (r_4, r_6), (r_5, r_7), (r_7, r_8),\) (r 7, r 9), (r 8, r 10), (r 9, r 10)}, J = {(r 3, r 4)}, X = {(r 4, r 8)}. We can represent all of these sets as the graph showed in Fig. 1.

Functional interactions represented as a graph \(\emph{G}=(\mathbf{R, I, J, X})\)
The second group of interactions represents changes in satisfaction and effort values of individual requirements. These two interaction types can be modelled as a pair of n × n symmetric matrices:
-
ΔS where each element Δs ij of this matrix represents the increment or decrement of s j when r i and r j are implemented in the same release,
-
ΔE where each element Δe ij of this matrix represents the increment or decrement of e j when r i and r j are implemented simultaneously,
in which the elements in the diagonal are equal to zero.
In order to define the next software release, we have to select a subset of requirements \({\hat{\mathbf{R}}}\) included in R, which maximize satisfaction and minimize development effort. The satisfaction and development effort of the next release can be obtained, respectively, as:
where j is an abbreviation for requirement r j . For a given release there is a cost bound B, that cannot be overrun. Under this set of circumstances the requirements selection problem for the next software release can be formulated as an optimization problem:
subject to the restriction \(\sum_{j\in {\hat{\mathbf{R}}}}e_j \leq B\) due to the particular effort bound \(\emph B\) applied, where \({\hat{\mathbf{R}}}\) also fulfills functional requirements interactions. Thus, two conflicting objectives, such as maximizing customer satisfaction and minimizing software development effort, are optimized at the same time within a given software development effort bound. The solution to this problem consists of a set of solutions known as Pareto-optimal set (Coello et al. 2007; Deb 2001; Srinivas and Deb 1994).
2.3 Basic Instance of NRP
Bagnall et al. (2001) defines a basic NRP as an NRP where no requirement has any prerequisites. So, following Bagnall formulation, any NRP can be transformed into a basic NRP simply by grouping together each requirement and its ancestors in the graph of precedence interactions (i.e. requirements for which there is a path in the graph ending in the requirement that is being considered). However, there are also other types of interactions besides implication (i.e. combination, exclusion, revenue-based and cost-based interactions) that also have to be taken into account when solving an NRP. Therefore, we are going to extend the work of Bagnall et al. (2001), defining a process for transforming an NRP into a basic NRP, before applying metaheuristics optimization techniques.
The process to transform an NRP into a basic NRP is made on three steps:
-
1.
Each pair (r i , r j ) ∈ J is transformed into a new requirement r i + j , with s i + j = s i + s j + Δs ij and e i + j = e i + e j + Δe ij . The ancestors set of r i + j is defined as the union of the ancestors of r i and r j , anc(r i + j ) = anc(r i ) + anc(r j ). The same applies to descendant set (i.e. requirements for which there is a path in the graph starting in the requirement that is being considered) of r i + j , that is, des(r i + j ) = des(r i ) + des(r j ). In this way, the set I of implication interactions is modified. Finally, all occurences of r i and r j in the set of X of exclusion interactions are replaced by r i + j . This produces a new functional interactions graph \(\emph{G}'=(\mathbf{R, I, J, X}) \) in which J = ∅.
-
2.
A pair (r i , r j ) ∈ X requires the alternative deletion of each requirement together with its descendants from \(\emph{G}'\), resulting two new functional interactions graphs \(\emph{G}_i'\) and \(\emph{G}_j'\). This process is repeated from these new graphs until there are no exclusion interactions.
-
3.
For each interactions graph \(\emph{G}_i'\) obtained in step 2, a basic NRP is built by grouping together implication interactions (i.e. each requirement and its ancestors in the graph), \( r_j^+=\{r_j\} \cup anc(r_j)\), which causes that \(s_j^+=\sum_{r_k \in r_j^+}s_k+ \sum_{r_k,r_l \in r_j^+, k<l} \Delta s_{kl}\) and \(e_j^+=\sum_{r_k \in r_j^+}e_k+ \sum_{r_k,r_l \in r_j^+, k<l} \Delta e_{kl}\).
Revenue-based and cost-based interactions are updated taking into account these graphs and the values of the original NRP:
-
1.
Each pair (r i , r j ) ∈ J implies that, starting from ΔS′ = ΔS, Δs ik ′ = Δs ik + Δs jk and Δs ki ′ = Δs ik ′, for i ≠ k, and Δs ii ′ = 0. After that, the row and column associated to r j are deleted from ΔS′. The same process applies to cost-based interactions. As result, we obtain new revenue-based, ΔS′, and cost-based, ΔE′, matrices.
-
2.
A pair (r i , r j ) ∈ X requires the alternative deletion of the rows and columns associated to each requirement and its descendants in \(\emph{G}'\) from ΔS and ΔE. Thus, the deletion of the rows and columns associated to {r i } ∪ des(r i ) produces ΔS i ′ and ΔE i ′, whereas that of {r j } ∪ des(r j ) produces ΔS j ′ and ΔE j ′. This process is repeated from these new matrices and the graphs \(\emph{G}_i'\) and \(\emph{G}_j'\) until there are no exclusion interactions.
-
3.
For each \(r_j^+\) in the basic NRP built from an interactions graph G i ′ together with its pair of associated matrices ΔS i ′ and ΔE i ′, we define the elements of revenue-based, ΔS + , and cost-based, ΔE + matrices as the sum of the values associated to unshared requirements,
$$ \Delta s_{ij}^+ = \left\{ \begin{array}{ll} \sum_{\stackrel{r_k \in r_i^+ }{\scriptscriptstyle r_l \in r_j^+ }} \Delta s_{kl}', & \mbox{if $r_k, r_l \notin r_i^+ \cap r_j^+$},\\ \par 0, & \mbox{otherwise} \end{array} \right. $$(5)$$ \Delta e_{ij}^+ = \left\{ \begin{array}{ll} \sum_{\stackrel{r_k \in r_i^+ }{\scriptscriptstyle r_l \in r_j^+ }} \Delta e_{kl}', & \mbox{if $r_k, r_l \notin r_i^+ \cap r_j^+$},\\ \par 0, & \mbox{otherwise} \end{array} \right. $$(6)
For example, if we consider the NRP depicted in Fig. 1 as a functional interactions graph, then during the first stage of the process, combination interactions are erased and the graph shown in Fig. 2a is obtained. The second stage takes this functional interactions graph and proceeds to eliminate exclusion dependences. Thus, requirement r 3 + 4 and its descendants are deleted which produces the graph G 3 + 4′ (see Fig. 2b) and the elimination of requirement r 8 along with its descendants, produces the graph G 8′ (see Fig. 2c). Last two graphs contain only implication interactions and define the basic NRP.

Transformation of an NRP into a basic NRP
Once we get the set of functional interactions graphs, containing only implication interactions, the transformation ends simply by grouping together each requirement and its ancestors in each graph, obtaining several basic NRPs. For example, if we consider the graph G 3 + 4′ in Fig. 2b we get \(r_1^+ = \{r_1\}\), \(r_2^+ = \{r_2\}\), \(r_5^+ = \{r_2, r_5\}\), \(r_7^+ = \{r_2, r_5, r_7\}\), \(r_8^+ = \{r_2, r_5, r_7, r_8\}\), \(r_9^+ = \{r_2, r_5, r_7, r_9\}\) and \(r_{10}^+ = \{r_2, r_5, r_7, r_8, r_9, r_{10}\}\).
After executing these processes of eliminating combination and exclusion interactions, we obtain a set of graphs, containing only implication interactions. Observe that the presence of exclusion interactions causes an alternative consideration of requirements and the appearance of a greater number of interactions graphs. This is due to the inner nature of exclusion. If there is an exclusion interaction between two requirements, (r i , r j ) ∈ X, by definition these requirements are incompatible software features that cannot be included in the same software product at the same time. Requirements Engineering faces this problem as a negotiation problem. Project developers must obtain an agreement by the elimination of one of them (i.e. discarding one of the requirements) or by generating two different software applications. For example, consider the exclusive requirements r i : “all users should be able to search for data about both products and customers” and r j : “only personnel with a high security level should be able to search for customers classified as military related”. Each one of them leads to a different software product and we need to perform different search processes defining different alternatives for the next software release.
Note that a more restrictive special case arises when requirements are basic and independent: for all \(r_i \in \mathbf R, r_i^+ = \{r_i\}\). Bagnall et al. (2001) has shown that NRP is an instance of 0/1 knapsack problem, which is NP-hard (Garey and Johnson 1990). This result means that large instances of the problem cannot be solved efficiently by exact optimization techniques. Nonetheless, in this situation the use of metaheuristics is suitable because they can find near-optimal solutions to NRP spending a reasonable amount of time.
3 Multi-Objective Ant Colony Optimization for the NRP
Ant Colony Optimization (ACO) has been applied to multi-objective optimization problems (Iredi et al. 2001; Doerner et al. 2004; Häckel et al. 2008) using a multi-colony strategy, extending the Ant Colony System (ACS) (Dorigo et al. 2006; Dorigo and Stützle 2004). Iredi et al. (2001) and Häckel et al. (2008) propose a multi-colony method to solve multi-objective optimization problems when the objectives cannot be ordered by importance, in which each colony searches for a solution in a different region of the Pareto-front. Whereas Doerner et al. (2004) propose the use of a single colony in which each ant searches in a different direction of the Pareto front, and apply it specifically to a portfolio optimization problem. This last approach enables us to extend in a natural way the ACS for NRP, described in del Sagrado et al. (2010a; del Sagrado et al. (2011), to the multi-objective case by searching in different directions on the Pareto front.
In ACO algorithms, each ant builds its solution from an initial node (requirement) which is selected randomly. At each stage, an ant locates a set of neighbouring nodes to visit (these requirements must satisfy the restrictions of the problem). Among all of them it selects one in a probabilistic way, taking into account the pheromone level and heuristic information. The level of pheromone deposited in an arc from node r i to node r j , τ ij , is stored in a matrix τ, whereas the heuristic information about the problem is represented as the value η ij and have to be defined based on the problem itself.
Many authors Brooks (1995), Boehm (1981) and Albrecht and Gaffney (1983) have proposed several metrics for software projects and products, e.g. man-moths (Brooks 1995), number of lines of code (Boehm 1981) and function points (Albrecht and Gaffney 1983), are only some of them. These metrics help in the assessment of the quality of a software product when its development has finished (i.e. quality metrics) and also in the estimation of the effort of a new software project, either using productivity metrics (e.g. time to delivered a feature or requirement to the final product, total number of units of production, or amount of units produced during a given period of time) or financial metrics (e.g. investment, operating expense that includes salaries, money amount of software sold minus the cost, return of investment, or cost of development effort per feature produced). Since we have to select requirements and the data available are related to requirements, we should consider a metric that measure the productivity in terms of the customers’ benefit and development effort (sets S and E). This concept has been applied in the selection and triage of the requirements (Davis 2003; Simmons 2004). In NRP we can define a productivity metric associated to a requirement r j , as, s j /e j which is the level of satisfaction obtained by the customers when including this requirement in an increment based on the effort applied in its development. Hence, we define:
where ξ is a normalization constant.
Let \(\mathbf{R}^k\subseteq\mathbf{R}\) be the partial solution to the problem built by ant k and assume that the ant is located at node r i , then
represents the set of non visited neighbours nodes that can be reached by ant k from node r i . That is, for ant k a node r j is visible from node r i if and only if r j has not been previously visited, its inclusion in the partial solution R k does not exceed the fixed development effort bound B and does not break functional interactions.
In the multi-objective ACO, there will be a pheromone matrix τ g for each one of the objectives, g ∈ O (for NRP the set of objectives is O = {s, e}, where s represents satisfaction and e represents effort) and the solution constructed by one ant is based on a weighted combination of these pheromone matrices. The weights \(\lambda_g^k\), that ant k assigns to the different objectives, measure the relative importance of the optimization criteria and should be distributed uniformly over the different regions of the Pareto front. For the NRP case, if the colony has z ants, then the weights for users’ satisfaction and development effort used by the ant k ∈ [0, z − 1] are defined respectively as
Note that weights are kept fixed over the ant’s lifetime (i.e. time expended by the ant to build its solution).
In the ACS algorithm, each ant builds, in a progressive way, a solution to the problem. During the construction process of the solution, ant k selects from node r i the next node r j to visit applying a pseudorandom proportional rule (Dorigo and Gambardella 1997) that takes into account the weights \(\lambda_g^k\) (Doerner et al. 2004):
where q is a random number uniformly distributed in [0, 1], q 0 ∈ [0, 1] is a parameter that determines a trade-off between exploitation (q ≤ q 0) and exploration, and \(u\in N_i^k\) is a node randomly selected. This selection is made by the ant k, which selects randomly from node r i the next node u = r j to visit with a probability \(p_{ij}^k\) given by Doerner et al. (2004):
where the parameters α and β reflect the relative influence of the pheromone with respect to the heuristic information. For example, if α = 0 the nodes with higher heuristic information values will have a higher probability of being selected (the ACO algorithm will be close to a classical greedy algorithm). If β = 0 the nodes with higher pheromone value will be preferred in order to be selected. From these two examples, it is easy to deduce that is needed a balance between heuristic information and pheromone level.
While building its solution each ant k in the colony updates pheromone locally. If it chooses the transition from node r i to r j , then it has to update the pheromone level of the corresponding arc for each objective g applying the following rule:
where φ ∈ [0, 1] is the pheromone decay coefficient and τ 0 is the initial pheromone value, which is defined as \(\tau_0 = 1/|{\textbf R}|\). Each time an arc is visited, its pheromone level decreases making it less attractive for subsequent ants. Thus, this local update process encourages the exploration of other arcs avoiding premature convergence.
Once all ants in the colony have built a solution, only the two ants that have obtained the best solutions reinforce pheromone on the arcs that are part of the best solutions. They update pheromone globally for each objective g ∈ O and each arc, (i, j), included in the best solutions applying the following rule:
where ρ ∈ [0, 1] is the pheromone evaporation rate and \(\Delta \tau_{ij}^g\) represents the increase of pheromone with respect to objective g.
In the NRP case, we have two objectives, O = {s, e}, satisfaction and effort, so, for a given best solution \({\hat {\mathbf R}}\), we define two pheromone increments (\(\Delta \tau_{ij}^s\) for satisfaction and \(\Delta \tau_{ij}^e\) for effort) as:
where \(sat({\hat {\mathbf R}})\) and \(ef\/f({\hat {\mathbf R}})\) are the evaluations of the best solution (see (2) and (3)) with respect to each objective.
For example, Fig. 3 shows an example of the steps followed by the ant k during an iteration. A thin arrow represents a candidate path for the ant and a bold arrow is a path yet crossed. Figure 3a shows the set of six requirements \(\textbf{R} = \{r_1, r_2, r_3, r_4, r_5, r_6\}\) with associated development efforts and customers satisfaction sets, \(\textbf {E} = \{3, 4, 2, 1, 4, 1\}\), \(\textbf{S} = \{1, 2, 3, 2, 5, 4\}\), respectively. Also, consider the set of functional dependencies \(\textbf{F} = \{ r_1 \Rightarrow r_3, r_1 \Rightarrow r_5, r_2 \Rightarrow r_4, r_2 \Rightarrow r_5, r_5 \Rightarrow r_6, r_3\odot r_4, r_4 \oplus r_5\}\) and that the development effort bound B is set to a value of 11. Figure 3b to d depict the steps followed by ant k. Initially (see Fig. 3b), the ant chooses randomly a requirement from the set {r 1, r 2} that contains the visible requirements (i.e. those verifying requirements interactions and whose effort limit is lower than B). Suppose that it selects r 2 as the initial node and adds it to its solution, \(\textbf{R}^k = \{r_2\}\). Then the ant obtains the set of non visited neighbours nodes from r 2 is \(N_2^k= \{r_1\}\) and arcs reaching to r 2 have been deleted because they could never be used. In this example, we are going to assume that the ant only uses heuristic information in order to build its solution \(\textbf{R}^k\), so at each step it will choose the vertex with the highest μ ij value from the set of non visited neighbours nodes. Now the ant adds r 1 to its solution \(\textbf{R}^k= \{r_2, r_1\}\) and searches for a new requirement to add from this node as it is depicted in Fig. 3c. In this situation the ant’s set of neighbours nodes is \(N_1^k=\{ r_3 - r_4, r_5\}\) and using only heuristic information the next node to travel to is r 3 − r 4 (note that this node is consequence of the combination interaction r 3 ⊙ r 4. Finally, Fig. 3d shows that once the ant has added r 3 − r 4 to its solution, \(\textbf{R}^k = \{r_2, r_1, r_3, r_4\}\), it has to stop because there are not any other visible vertex due to the exclusion relationship r 4 ⊕ r 5.

Search process in ACS
4 Experimental Evaluation
In this section, we describe the aspects related with the design of the experiments for making the performance evaluation of the multi-objective ACO algorithm proposed. First, we present the data used in the experiments. Then, we briefly describe other two metaheuristic algorithms used in the experiments. Finally, we define the set of quality measures applied and the comparison methodology we have followed.
4.1 Datasets
For testing the effectiveness of our proposed ACS we have used two datasets. The first dataset is taken from Greer and Ruhe (2004). It has 20 requirements and 5 customers. The development effort associated to each requirement and the level of priority or value assigned by each customer to each requirement are shown in Table 1. The customers’ weights are given in the 1 to 5 range, following a uniform distribution (see Table 2). These values (and also those of the level of priority of each requirement) can be understood as linguistic labels such as: without importance (1), less important (2), important (3), very important (4), extremely important (5). Each requirement has an associate effort estimate in terms of score between 1 and 10. Also, we consider a set of implication and combination interactions between requirements. The reason for not including exclusion interactions is that its presence leads to different alternatives which can be considered as independent NRP instances (see Section 2.3). The main reason to use this dataset resides in its wide use in the evaluation of other studies of distinct instances of NRP (Finkelstein et al. 2009; Zhang et al. 2007; Durillo et al. 2009) and, as far as we know, the lack of other available real datasets due to the privacy policies followed by software development companies. At the time of performing the experiments we have set the development effort boundary as a percentage of the total development effort needed to include all the requirements in a software product. Then we have considered the 30, 50 and 70% of the total development effort, which respectively translates into an effort bound of 25, 43 and 60 effort units in our experiments. The change in the effort limit allows us to have, in a simple way, different instances of the problem on which to test the algorithms.
The second dataset has been generated randomly with 100 requirement, 5 customers and 44 requirements interactions, according to the NRP model (see Table 3). The relative importance of the customers is given in the second row of Table 2. This dataset was defined because in real agile software projects development, in the initial timeboxes, we are faced with the problem of selecting requirements from a wider set. Therefore, the number of requirements has been incremented from 20 to 100. The development effort values of each requirement are given in the 1 to 20 range. We had fixed 20 units (4 weeks) as the maximum development effort for a requirement, considering the timebox limit defined in agile methods (e.g. Scrum proposes iteration in the range 2 to 4 weeks). The customers values of level of priority of requirements are in the range of 1 to 3, because when customers have to make an assignment of the benefit that will imply the inclusion of a given requirement, they prefer to use a coarse grained scale instead of one of finer granularity. Usually, they simply place requirements in one of three categories: inessential (1), desirable (2) or mandatory (3) (Wiegers 2003; Simmons 2004).
Following the same considerations made on dataset 1, we have set the development effort boundary using the same percentages (30, 50 and 70 %) of the total development effort needed to include all the requirements in a software product, which respectively translates into an effort bound of 312, 519 and 726 effort units in our experiments. So, we will test ACS using six instances of NRP.
4.2 Metaheuristic Techniques Applied in Experimentation
Many metaheuristic techniques have been applied to the requirement selection problem, a review of them can be found at del Sagrado et al. (2010b). We select two algorithms against with our multi-objective ant colony system will be evaluated for solving the NRP: Greedy Randomized Adaptive Search Procedure (GRASP) and Non-dominated Sorting Genetic Algorithm (NSGA-II).
The first one is a metaheuristic algorithm that generates a good approximation to the efficient set of solutions of a multi-objective combinatorial optimization problem (Vianna and Arroyo 2004). GRASP was first introduced by Feo and Resende (1989). Survey papers on GRASP include Feo and Resende (1995), Pitsoulis and Resende (2003), and Resende and Ribeiro (2003). This algorithm proceeds iteratively by first building a greedy randomized solution and then improving it through a local search. The greedy randomized solution is built from a list of elements ranked by a greedy function by adding elements to the solution set of the problem. The greedy function is in charge of measuring the profit of including an element in the solution with respect to the cost of its inclusion. In our approach, the greedy function used measures the quality of a requirement based on users satisfaction with respect to the effort (i.e. s i /e i ) according to the following ratio:
where λ s and λ e are the weights associated with each objective as defined in (9). This measure is a productivity metric that weighs the profit of including a requirement with respect to the resources involved in their development. The local search acts, in an iterative way, trying to replace the current solution by a better one located in its neighbourhood. GRASP terminates when no better solution can be found in the neighbourhood.
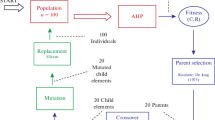
The fast Elitist Non-dominated Sorting Genetic algorithm (NSGA-II) was proposed by Deb et al. (2002). The word elitist refers to the fact that only the best individuals found so far are transferred to the next population. During each generation, a population is constructed by combining the parent and the child population. Individuals represent the possible solutions, that is, an individual is a set of requirements. Each individual is evaluated with respect to the two objective functions defined in (4), where the total effort is multiplied by − 1 in order to transform the second objective into a maximization problem, so that the NSGA-II algorithm will try to maximize each one of them. Each generation represents the evolution of the population. The idea is that by means of crossover and mutation the new children and mutated individuals have even better fitness values than the original ones. Better individuals have a higher probability of stating at the Pareto front, whose cardinality is limited by the population defined in the execution. In the case of NRP, the crossover and mutation methods are more specific and difficult than in other problems because we need to take into account the resources bound in order to obtain new valid individuals (see del Sagrado et al. 2010a). The works of Durillo et al. (2011) and Zhang and Harman (2010) show that NSGA-II can solve NRP offering a set of comparable solutions with those obtained by other metaheuristics.
4.3 Performance Measures
We have calculated the optimal Pareto front of the problem defined by the first dataset, in order to compare it against those calculated by the metaheuristic optimization techniques. However, when the number of requirements grows, dataset 2, obtaining the optimal Pareto front becomes an intractable problem. So, our approach here is to compare the results using several quality indicators, giving an insight on the quality of the results achieved for all the executed algorithms. Therefore, we use the following indicators with the purpose of conducting a comparative measure of diversity and convergence of the solutions obtained:
-
The number of non dominated solutions found (#Solutions). Pareto fronts with a higher number of non dominated solutions are preferred.
-
The size of the space covered by the set on non-dominated solutions found (Hypervolume) (Zitzler and Thiele 1999). For a two dimensional problem, for each solution i ∈ Q, a vector v i is built with respect to a reference point W, and the solution i is considered as the diagonal corner of an hypercube. Hypervolume is the volume occupied by the union of all of these hypercubes:
$$ {HV }=volume \left( \bigcup\limits^{| Q |}_{i=1} v_i \right) $$(17)Pareto fronts whit higher hypervolume values are preferred.
-
The extent of spread achieved among the obtained solutions (Δ-Spread) (Durillo et al. 2009).
$$ {\Delta(F)}=\frac{d_f + d_l + \sum^{n-1}_{i=1}{|d_i- \bar d|}}{d_f + d_l+(n-1)* \bar d} $$(18)where the Euclidean distance between two consecutive solutions \({\hat {\mathbf R}}_i\) and \({\hat {\mathbf R}}_{i+1}\), d i is computed as
$$ d_i = \sqrt{(sat({\hat {\mathbf R}}_{i+1})-sat({\hat {\mathbf R}}_{i}))^2 + (ef\/f({\hat {\mathbf R}}_{i+1})-ef\/f({\hat {\mathbf R}}_{i}))^2} $$(19)\(\bar{d}\) is the average of these distances, d f , d l are, respectively, the Euclidean distances of the first, \({\hat {\mathbf R}}_1\), and last, \({\hat {\mathbf R}}_n\), obtained solutions to the extreme solutions \({\hat {\mathbf R}}_f\) and \({\hat {\mathbf R}}_l\) of the optimal Pareto front, and n is the number of solutions in the obtained Pareto front F. Pareto fronts with smaller spread are preferred.
-
A measure that evaluates the uniformity of the distribution of non-dominated solutions found (Spacing) (Schott 1995). If the problem has N objectives and its Pareto front has n solutions, the spacing of F is defined as:
$$ {Spacing(F)}=\frac{\sum^n_{j=1}\left( \sum^N_{i=1}\left( 1-\frac{|d_{ij}|}{\bar d_i} \right)^2 \right)^{1/2}}{n*N} $$(20)where, \(\bar{d}_i\) is the mean value of the magnitude of the i − th objective in the set F and d ij is the value of the i-th objective for the j-th solution in F. Pareto fronts with higher spacing are preferred.
Pareto fronts with a higher number of non-dominated solutions, smaller spread, higher spacing and higher hypervolume are preferred. The average and standard deviation of all of these quality indicators are computed.
4.4 Comparison Methodology
In order explore the applicability of multi-objective ACO for solving NRP, we will compare its performance on the datasets with that of the multi-objective metaheuristics approaches selected. All algorithms are executed for a maximum of 10,000 fitness functions evaluations. Taking this fact into account, it is worth to note that, for the parameters setting we have used default values to explore different search behaviours in the algorithms. This choice, as Arcuri and Fraser (2013) points out, “is a reasonable and justified one, whereas parameter tuning is a long and expensive process that might or might not pay off in the end”. Thus, the comparison of the results is done in four steps:
-
1.
For each dataset and each development effort bound, we have performed 100 consecutive executions of each of the metaheuristic search techniques, using different parameters settings representative of the different behaviours that the algorithms can exhibit. We compute the average (as measure of central tendency) and standard deviation (as measure of statistical dispersion) of the number of solutions in the Pareto-front, of the quality indicators, and of the execution time.
-
2.
With these values at hand, we have analyzed each technique separately. The scores of the five quality indicators are ranked, and we select the parameters setting that exhibits the best average ranking.
-
3.
Once a parameter setting has been established for each one of the algorithms (GRASP, NSGA-II and ACS), the average values of their indicators are visually compared, using Kiviat graphs. This step allows us evaluate the goodness of our ACS proposal, comparing it against the other two search methods used.
-
4.
The Pareto fronts returned by each of the metaheuristic search techniques are compared using the non-parametric significance Mann-Whitney U test, which is a non-parametric statistical hypothesis test for assessing whether one of two samples of independent observations tends to have larger values than the other. The comparison is made based on the values computed for the productivity metric given by
$$ Productivity({\hat {\mathbf R}}) = \frac{sat({\hat {\mathbf R}})}{eff({\hat {\mathbf R}})} $$(21)for each solution \({\hat {\mathbf R}}\) in the Pareto front. This metric give us an insight of the profit returned by the solutions according to the software development process.
5 Analysis of the Experimental Results
Tables 8, 9 and 10 included in the Appendix collect the results of the experiments returned by GRASP, NSGA-II and ACS for the different datasets, requirements interactions and effort bounds used. We have highlighted with a star symbol the best values of the quality indicators and the parameters setting with the best average ranking. Next, we analyze these results following the comparison methodology previously exposed.
The GRASP algorithm receives as input parameters the number of iterations (each iteration consists of two phases: construction and local search) and a number in the 0 to 1 range that controls the amount of greediness and randomness (values close to zero favors a greedy behaviour, whereas values close to one favor a random behaviour). In most of the problems considered the value 0.9, that favor a random behaviour to explore wider areas, obtains the best results. The values obtained by GRASP for the quality indicators in the different datasets are shown in Table 8.
The execution time of NSGA-II depends on the number of generations developed. We look for a balance in the number of function evaluations performed by the algorithm, by adjusting the size of the populations and the number of iterations. So, in our tests, the size of the population have been fixed to 20 and 40 in dataset 1, and 100 and 125 in dataset 2, keeping the number of functions evaluation at 10,000. The mutation probability is kept fixed at a value equal to 1/n, where n is the number of requirements (i.e. 0.05 for dataset 1, and 0.01 for dataset 2) and we use a high crossover probability, assigning it a value in {0.8, 0.9}, to favor recombination of individuals. Best values have been obtained when using a higher population size with the lowest crossover probability (i.e. 40 individuals and 0.8) in the case of dataset 1 and the highest crossover probability (i.e. 125 individuals and 0.9) in dataset 2. Table 9 contains the quality indicators results obtained by NSGA-II in the different datasets.
The number of ants in the colony has a direct impact on execution time of ACS algorithm. We use as number of ants n/2, where n is the number of requirements. We fix the pheromone evaporation rate ρ = 0.01 (we also set the pheromone decay coefficient φ to 0.01) and the parameter q 0 = 0.95, favouring exploration. For the (α, β) pair of parameters, we have used different combinations (i.e. (0, 1) (1, 0) (1, 1) (1, 2) (1, 5)), reflecting the importance of using local information (i.e. pheromone) with respect to heuristic information in the search. We highlight that the best average values for the ranking of quality indicators are obtained by ACS (see Table 10) when both local and heuristic information are used in the search, but given more importance to heuristic information than to pheromone, that is, α ≥ 1, α ≤ β.
Once, we have selected for each algorithm, a parameters setting taking into account the best average ranking of the quality indicators values obtained (see Tables 4 and 5), we proceed to make a visual comparison using the Kiviat graphs. Figure 4 shows Kiviat graphs depicting the quality indicators dataset and each development effort. With respect to dataset 1 (see Fig. 4a–c) ACS obtains the best values, except in spacing and execution time in one case (see, Fig. 4a). The differences between ACS and GRASP are mainly present in the hypervolume and spread, but both have similar execution times. NSGA-II and GRASP obtain Pareto fronts with similar hypervolume and spread values, but NSGA-II spends more execution time than the others. In the case of dataset 2 (see Fig. 4d–f), ACS obtains the best values in hypervolume, spacing and spread, although GRASP obtains a higher number of solutions but the non-dominated solutions found cover less space than the Pareto fronts built by ACS and NSGA-II which have similar hypervolume values. However, we detect a significantly worse execution time in ACS.

Kiviat graph comparing metaheuristic algorithms
Figure 5 represents a selected Pareto front according to the quality measures, for each algorithm and each problem. For the first dataset we have also obtained and depicted the Pareto optimal front. ACS and NSGA-II have very few differences compared to the optimum. However GRASP presents large differences but with fronts containing the greater number of solutions, this same trend is shown in the second dataset.

Pareto fronts for datasets 1 and 2
Our analysis concludes performing a Mann-Whitney U test on the values for the productivity metric (see (21)) of each solution in the Pareto fronts obtained. Its results are shown in Tables 6 and 7. In all cases the Pareto fronts obtained by GRASP show differences with those obtained by ACS and NSGA-II. For dataset 1 with effort bounds of 30 and 50 %, these differences are marginally significant (P< 0.05), but are significantly different (P<0.01) when considering the 70 % effort bound and highly significant (P<0.001) for dataset 2 in all cases. With respect to the optimal Pareto front in the dataset 1, GRASP exhibits not significant differences for 30 %, marginally significant differences (P< 0.05) for 50 % and significantly differences (P<0.01) for 70 % efforts bounds, respectively. Whereas fronts coming from the algorithms ACS and NSGA-II are not significantly different (P≥0.05), with the exception of dataset 2 with a 70 % effort bound which exhibits marginally significant differences (P< 0.05). There are no significant differences between the optimal Pareto front and those obtained by ACS and NSGA-II. These results confirm the graphical representation of the selected Pareto fronts (see Fig. 5).
6 Threats to Validity
The results obtained in this research work are subject to the limitations which are inherent to any SBSE empirical study. It is worth to discuss the validity of the results, in order to provide a complete understanding of limitations and extent that the work has. In the literature (Wohlin et al. 2012; Ali et al. 2010), we can find different ways to classify aspects of validity and threats to validity. We are going to follow the types of threats proposed by Ali et al. (2010) that comprise four aspects of the validity: construct validity, internal validity, conclusion validity and external validity.
Construct validity reflects if the measures and scales used capture properly the concepts they need to represent. In this paper, the objects studied are set of requirements and the associated data are estimates provided by software engineers or customers (e.g cost and value added estimates). This fact leads to one possible validity threat due to subjectivity and accuracy (i.e. in real software development projects, the values associated to requirements are gathered as an answer from a closed set to a simple statement). Nonetheless, development teams use estimations in every day work both for exploring tradeoffs in release planning and decision-making. Related to the effectiveness measures we use quality measures related to the diversity and convergence of the sets of requirements selected. Specifically, the number of solutions, hypervolume, spread and spacing measures refer to the quality of the Pareto fronts obtained by the different search-based metaheuristic techniques applied, whilst the time expended refers to performance.
Internal validity regards to the analysis of the performance of the metaheuristic search techniques applied (i.e. parameter settings and biased selection of datasets that can favor a certain technique). In our experiments we have used default parameter settings with the idea of preserving the inner nature of the metaheuristic techniques and exploring different search behaviours in the algorithms. With respect to the quality of the problem instances we have used two datasets, probably a more significant number of datasets seems necessary, but, typically, real world datasets are considered confidential by the companies that own them. So, we have preferred to extend the available dataset by changing the effort limits, as others authors (Jiang et al. 2010) do, instead of generate and employ a greater number synthetic datasets. We think that, in this way, a biased selection in favor of a certain technique is more or less avoided.
Conclusion validity is concerned with the relationship between approach and outcome, ensuring that there is a right statistical relationship between them. In the case of our paper, the proposed multi-objective ACO approach automates the search for optimal or near-optimal sets of requirements, within a given effort bound, that balance stakeholders’ priorities while keeping requirements interactions. As conclusion the evidence suggest that this approach is feasible. This conclusion is based on the statistical comparison of the experiments carried out on the datasets. In order to avoid the randomness all experiments were executed several times, so we have performed 100 consecutive executions on the same hardware platform. The variables measured are the quality indicators showing their average and dispersion values. As baseline for comparison, we have used two metaheuristic techniques (i.e. GRASP and NSGA-II) that have a very different nature and we believe that are sufficiently representative and appropriate. By other hand, the Pareto fronts returned are assessed in pairs using the non-parametric significance Mann-Whitney U test on a productivity metric of the solutions from the point of view of the software project. The significance level chosen was 95 % looking for a compromise in the adoption of a technique between its performance and robustness. The results obtained suggest that our multi-objective ACO is a good enough search method that offers software developers, who must decide what is the best set of requirements (according to business strategies) that has to be considered in the next software release, several alternatives among the whole set of candidate requirements proposed by customers.
External validity deals with the generalization of observed results. For our study, this is a major threat to validity. First, as greater the complexity of a real software project, greater the ability for generalization. But real software projects are difficult to obtain due to the privacy policies followed by software development companies. Second, the generalization domain of our study is wide, as is the domain of human activities in which software is present. Thus, the set of stakeholders and requirements for a software project focused on the development of a computer game is significantly different from that of an accounting software system. As consequence, it is difficult to estimate, using only the results of this study, the extent in which our proposed ACS algorithm can help software development teams. However, we believe that for any software developer is considerably helpful to have these techniques available for determining which candidate requirements of a software product should be included in a certain release.
7 Conclusions and Further Works
In this paper, we study the applicability of multi-objective Ant Colony Optimization algorithms in the field of Software Engineering, specifically within the field of analysis and study of requirements for a software project. ACO has already been applied in other fields like testing, but not to requirements from the multi-objective perspective.
Our paper formally defines the Next Release Problem including interactions between requirements. As value added, we propose a method to reduce all the interactions of NRP in order to manage the problem as a basic instance of NRP, facilitating the execution of metaheuristics that do not take them into account. We develop our own multi-objective ant colony system (ACS) for finding a non-dominated solution set for NRP considering functional requirements interactions, and apply two other techniques (GRASP, NSGA-II) in order to evaluate our system.
GRASP has shown a bad performance in our experiments with NRP, but it will be useful to examine how it behaves when using other greedy functions (different from the one we have proposed) designed specifically for this problem. During the adaptation of NSGA-II to tackle NRP we have found several difficulties with crossover and mutation operations due to the restrictions imposed by NRP. These restrictions have force us to develop a repair operator, in order to ensure that the solutions built in an evolutionary way satisfy the constraints imposed by effort bound and requirements interactions. Our multi-objective ACS obtains non dominated solution sets slightly better than those found by NSGA-II, and GRASP. ACS can be applied efficiently to solve NRP, in order to obtain the Pareto front that allows software developers to take decisions about the set of features that must to be included in the next software release.
The use of metaheuristic techniques constitute a valuable aid for experts who must decide what is the set of requirements that has to be considered in the next development stages when they face to contradictory goals. Our approach combine computational intelligence and the knowledge experience of the human experts with the idea of obtaining a better requirements selection than that produced by expert developer’s judgment alone. The actual approaches in Requirements Engineering usually are assisted by requirements management tools. These tools assist the development team in the management of each iteration. Here is where we think that our proposal algorithm can be useful as an aid, by its inclusion as a new facility.
As future lines of work we plan to study the quality of the solution sets found and improve the model of requirements selection between increments in a software development project, that is to say, consider human and dynamic aspects. By other hand we are developing an experience, where novel software developers (students) solve NRP alone, and next they perform the same tasks with the aid and support of metaheuristic techniques, with the objective of evaluating human competitiveness.
References
Albrecht AJ, Gaffney JE (1983) Software function, source lines of code, and development effort prediction: a software science validation. IEEE Trans Softw Eng 9(6):639–648
Ali S, Briand LC, Hemmati H, Panesar-Walawege RK (2010) A systematic review of the application and empirical investigation of search-based test case generation. IEEE Trans Softw Eng 36(6):742–762
Arcuri A, Fraser G (2013) Parameter tuning or default values? An empirical investigation in search-based software engineering. Empir Softw Eng 18(3):594–623
Bagnall AJ, Rayward-Smith VJ, Whittley I (2001) The next release problem. Inf Softw Technol 43(14):883–890
Baker P, Harman M, Steinhöfel K, Skaliotis A (2006) Search based approaches to component selection and prioritization for the next release problem. In: Proceedings of 22nd IEEE international conference on software maintenance (ICSM 2006). IEEE Computer Society, Philadelphia, pp 176–185
Boehm BW (1981) Software engineering economics. Prentice Hall, Englewood Cliffs
Brooks FP (1995) The mythical man-month (anniversary edn). Addison-Wesley Longman Publishing Co., Inc., Boston
Carlshamre P (2002) Release planning in market-driven software product development: provoking an understanding. Requir Eng 7(3):139–151
Carlshamre P, Sandahl K, Lindvall M, Regnell B, och Dag JN (2001) An industrial survey of requirements interdependencies in software product release planning. In: Proceedings of 5th IEEE international symposium on requirements engineering (RE 2001). IEEE Computer Society, Toronto, pp 84–93
Cheng BHC, Atlee JM (2007) Research directions in requirements engineering. In: Proceedings of international conference on software engineering, ISCE 2007. Workshop on the future of software engineering (FOSE 2007). Minneapolis, pp 285–303
Coello CAC, Lamont GB, Veldhuizen DAV (2007) Evolutionary algorithms for solving multi-objective problems evolutionary algorithms for solving multi-objective problems. Springer, New York
Davis AM (2003) The art of requirements triage. IEEE Comput 36(3):42–49
Deb K (2001) Multi-objective optimization using evolutionary algorithms. Wiley, New York
Deb K, Agrawal S, Pratap A, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
del Sagrado J, del Águila IM (2009) Ant colony optimization for requirement selection in incremental software development. In: Proceedings of the 1st International Symposium on Search Based Software Engineering (SSBSE ’09). IEEE, Cumberland Lodge, Windsor
del Sagrado J, del Águila I, Orellana F (2010a) Ant colony optimization for the next release problem: a comparative study. In: Proceeding of Second International Symposium on Search Based Software Engineering (SSBSE 2010), Benevento, Italy, pp 67–76
del Sagrado J, del Águila IM, Orellana FJ, Túnez S (2010b) Requirements selection: knowledge based optimization techniques for solving the next release problem. In: Proceedings of the 6th Workshop on Knowledge Engineering and Software Engineering (KESE6). Karlsruhe, Germany, CEUR-WS.org, CEUR Workshop Proceedings, vol 636
del Sagrado J, del Águila IM, Orellana FJ (2011) Requirements interaction in the next release problem. In: Proceedings of 13th annual Genetic and Evolutionary Computation Conference (GECCO 2011). Dublin, Ireland, pp 241–242
del Sagrado J, del Águila IM, Orellana FJ (2012) Metaheuristic aided software features assembly. In: Proceeding of 20th European Conference on Artificial Intelligence (ECAI 2012) Including Prestigious Applications of Artificial Intelligence (PAIS-2012) System Demonstrations Track. Montpellier, France, pp 1009–1010
de Souza JT, Maia CLB, Ferreira T, do Carmo RAF, Brasil M (2011) An ant colony optimization approach to the software release planning with dependent requirements. In: Proceedings of the 3rd International Symposium on Search Based Software Engineering (SSBSE ’11), vol 6956. Springer, Szeged, Hungary, pp 142–157
Doerner KF, Gutjahr WJ, Hartl RF, Strauss C, Stummer C (2004) Pareto ant colony optimization: a metaheuristic approach to multiobjective portfolio selection. Ann Oper Res 131(1–4):79–99
Dorigo M, Gambardella LM (1997) Ant colony system: a cooperative learning approach to the traveling salesman problem. IEEE Trans Evol Comput 1(1):53–66
Dorigo M, Stützle T (2004) Ant colony optimization. MIT Press, Cambridge, MA
Dorigo M, Birattari M, Stutzle T (2006) Ant colony optimization. IEEE Comput Intell Mag 1(4):28–39
Durillo J, Zhang Y, Alba E, Nebro A (2009) A study of the multi-objective next release problem. In: Proceeding of 1st international symposium on search based software engineering (SSBSE 2009). Cumberland Lodge, Windsor, pp 49–58
Durillo JJ, Zhang Y, Alba E, Harman M, Nebro AJ (2011) A study of the bi-objective next release problem. Empir Softw Eng 16(1):29–60
Feo TA, Resende MGC (1989) A probabilistic heuristic for a computationally difficult set covering problem. Oper Res Lett 8(2):67–71
Feo T, Resende M (1995) Greedy randomized adaptive search procedures. J Global Optim 6:109–133
Finkelstein A, Harman M, Mansouri SA, Ren J, Zhang Y (2008) “Fairness analysis” in requirements assignments. In: Proceeding of 16th IEEE international requirements engineering conference (RE 2008). Barcelona, pp 115–124
Finkelstein A, Harman M, Mansouri SA, Ren J, Zhang Y (2009) A search based approach to fairness analysis in requirement assignments to aid negotiation, mediation and decision making. Requirement Eng 14(4):231–245
Garey MR, Johnson DS (1990) Computers and intractability: a guide to the theory of NP-completeness. Freeman, New York
Greer D, Ruhe G (2004) Software release planning: an evolutionary and iterative approach. Inf Softw Technol 46(4):243–253
Häckel S, Fischer M, Zechel D, Teich T (2008) A multi-objective ant colony approach for pareto-optimization using dynamic programming. In: Proceedings of genetic and evolutionary computation conference (GECCO 2008). ACM, Atlanta, pp 33–40
Harman M (2007) The current state and future of search based software engineering. In: Future of software engineering, FOSE ’07, pp 342–357
Harman M, Jones BF (2001) Search-based software engineering. Inf Softw Technol 43(14):833–839
Iredi S, Merkle D, Middendorf M (2001) Bi-criterion optimization with multi colony ant algorithms. In: Proceedings of evolutionary multi-criterion optimization, first international conference (EMO 2001). Zurich, pp 359–372
Jiang H, Zhang J, Xuan J, Re Z, Hu Y (2010) A hybrid ACO algorithm for the next release problem. In: Proceedings of the 2nd international conference on software engineering and data mining (SEDM ’10). IEEE, Chengdu, pp 166–171
Johnson J (2003) CHAOS chronicles v3.0. Tech. rep.
Karlsson J, Olsson S, Ryan K (1997) Improving practical support for large-scale requirement prioritising. Requirement Eng 2(1):51–60
Kotonya G, Sommerville I (1998) Requirements engineering: processes and techniques. Wiley, New York
Momoh J, Ruhe G (2006) Release planning process improvement an industrial case study. Software Process Improvement and Practice 11(3):295–307
Pitsoulis L, Resende M (2003) Greedy randomized adaptive search procedures. Oxford University Press, pp 168–183
Resende M, Ribeiro C (2003) Greedy randomized adaptive search procedures. Kluwer Academic Publishers, Dordrecht, pp 219–249
Ruhe G, Saliu MO (2005) The art and science of software release planning. IEEE Softw 22(6):47–53
Saliu MO, Ruhe G (2007) Bi-objective release planning for evolving software systems. In: Proceedings of the 6th joint meeting of the European software engineering conference and the ACM SIGSOFT international symposium on foundations of software engineering. Dubrovnik, Croatia, pp 105–114
Schott J (1995) Fault tolerant design using single and multicriteria genetic algorithm optimization. PhD thesis, Massachusetts Institute of Technology, M.S., USA
Simmons E (2004) Requirements triage: what can we learn from a “medical” approach? IEEE Softw 21(4):86–88
Srinivas N, Deb K (1994) Muiltiobjective optimization using nondominated sorting in genetic algorithms. Evoltionary Computation 2:221–248
Vianna DS, Arroyo JEC (2004) A GRASP algorithm for the multi-objective knapsack problem. In: Proceedings of 24th International Conference of the Chilean Computer Science Society (SCCC 2004), pp 69–75
Wiegers KE (2003) Software requirements. Microsoft Press, Redmon, WA, USA
Wohlin C, Runeson P, Höst M, Ohlsson M, Regnell B, Wesslén A (2012) Experimentation in software engineering: an introduction. Springer, Berlin
Zhang Y, Harman M (2010) Search based optimization of requirements interaction management. In: Proceedings of Second International Symposium on Search Based Software Engineering (SSBSE 2010). Benevento, Italy, pp 47–56
Zhang Y, Harman M, Mansouri SA (2007) The multi-objective next release problem. In: Proceedings of Genetic and Evolutionary Computation Conference (GECCO 2007). London, England, UK, pp 1129–1137
Zitzler E, Thiele L (1999) Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans Evol Comput 3(4):257–271
Acknowledgements
This research has been funded by the Spanish Ministry of Education, Culture and Sport under project TIN2010-20900-C04-02. We wish also thank to anonymous reviewers for their useful comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Mark Harman
Appendix: Experiments results
Appendix: Experiments results
Rights and permissions
About this article
Cite this article
del Sagrado, J., del Águila, I.M. & Orellana, F.J. Multi-objective ant colony optimization for requirements selection. Empir Software Eng 20, 577–610 (2015). https://doi.org/10.1007/s10664-013-9287-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-013-9287-3