
Abstract
This study compared the performance of different interpolation methods for mapping soil salinity of three different agricultural fields having the same land use but different dataset characteristics. Four common spatial interpolation methods including global polynomial interpolation (GPI), inverse distance weighted (IDW), ordinary kriging (OK), and radial basis functions (RBF) were employed for mapping soil EC. The performance of interpolation methods in predicting soil EC was evaluated based on mean bias error, root mean square error, mean absolute percentage error, and coefficient of determinations criteria. Results showed that dataset characteristics, including central tendency and distribution, were significantly different among the studied fields. Experimental semivariogram and fitted model parameters indicated that three studied fields were also different in their spatial dependence strength. Considering all of the performance assessment measures used, the best interpolation method for fields A and C was OK and IDW for field B. The performance of interpolation methods was found to be affected by data characteristics of the studied fields, which were mostly ascribed to management practices. This study suggests in order to obtain accurate mapping of soil salinity in agricultural fields, it is essential to first find the best spatial interpolation method compatible with the characteristics of the collected data from the selected agricultural land.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Soil salinity is a serious problem for agricultural lands, especially in arid and semiarid areas where a high percentage of the irrigated lands are located (Abuelgasim and Ammad 2018). Soil salinity adversely affects soil and water quality and crop production and eventually leads to land degradation (Daliakopoulos et al. 2016). In order to implement efficient agronomic and environmental management, as well as soil reclamation programs to prevent any further salinization of agricultural lands, accurate soil salinity mapping is essential (Allbed et al. 2014; Gebbers and de Bruin 2010).
Soil is a heterogeneous, diverse, and dynamic system where characteristics continuously change temporally and spatially on both large and small scales (McBratney et al. 2003). The temporal–spatial variability of soil characteristics is controlled by a variety of factors associated with soil formation and landscape (i.e., climate, parent material, and topography) as well as land management– and land use–related factors (Denton et al. 2017; Douaik et al. 2008). Soil salinity is a continuous variable with spatial dependence reported for scales ranging from a few meters to several kilometers (Zewdu et al. 2017), and therefore, it must be studied in a way that also considers spatial variability (Denton et al. 2017; Gorji et al. 2015).
Accurate mapping of soil attributes, like soil salinity, needs an intensive dataset which properly covers the spatial variability of soil salinity throughout the field (Denton et al. 2017). Meanwhile, there are numerous factors such as accessibility, surveying cost, and topography that limit the amount of spatial data needed to describe the variability of the soil with a resolution sufficient for precise decision making (McBratney et al. 2003; Simakova 2011). To intensify data density and produce estimated data at unsampled locations based on already prepared data on sampled locations, a variety of classical and geostatistical interpolation methods have been employed (Li and Heap 2011). While classic statistical techniques do not include any spatial information associated with the data in their interpolating procedure, geostatistical interpolators do incorporate information about the spatial position of the sample points during data processing (Webster and Oliver 2001).
Spatial variability of soil salinity and the performance of interpolators in agricultural fields can be influenced by inherent characteristics of the field, land use, sampling design, management practices, as well as implemented interpolation techniques (Juan et al. 2011; Ahmed et al. 2017; Zewdu et al. 2017). This study aimed to analyze the spatial variability of topsoil salinity and evaluate the performance of four different interpolation methods including global polynomial interpolation (GPI), inverse distance weighting (IDW), radial basis function (RBF), and ordinary kriging (OK) techniques for mapping spatial distribution of soil salinity (i.e., soil EC) in three different agricultural lands with similar land use but different management systems in the northern plains of Varamin city in the Tehran province, Iran.
Materials and methods
Study area and data collection
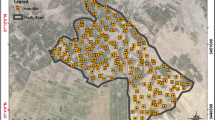
The study area is located in the northern plain of Varamin city in the Tehran province, Iran. The geographical coordinates of the study area lie between Universal Transverse Mercator (UTM) easting from 567,600 to 573,000 and UTM northing from 3,908,880 to 3,913,200. The area has a semiarid continental climate with mean annual precipitation and mean annual temperature of 156 mm and 17.8 °C, respectively. The average elevation of the study area is 1300 m above mean sea level. Three different fields, simply labeled fields A, B, and C, each with an area of 80 ha were selected according to the similarity of their agricultural land use. All three fields were under cultivation of wheat with different irrigation, fertilizing, and tillage practices. The position of the three selected agricultural fields and the distribution of sampling points is shown in Fig. 1.

Location of the study area and the distribution of sampling points across the three selected agricultural fields
The soil moisture and temperature regimes of the region are Torric and Thermic, respectively. The soil texture in each field was homogeneous with textural classes of sandy loam, loam, and sandy clay loam for fields A, B, and C, respectively. With a pH above neutral, all soils were alkaline. The means of total neutralizing value (TNV) of the three fields showed that all soils were calcareous. Soil bulk density ranged from 1.28 to 1.60 g cm−3 throughout the study area, while field B had the highest BD followed by fields C and A, respectively. The organic carbon content of the study area decreases from fields A to C with the mean values of 12.0, 8.3, and 6.8 g kg−1 for A, B, and C fields, respectively. The characteristics of soils in the three studied fields are presented in Table 1. A total of 35 discrete samples were systematically sampled from each field at the vertices of a 150 × 150-m grid. The total number of soil samples collected was thus 105 from a depth of 0 to 30 cm across the entire study area. UTM spatial coordination of each sample point was recorded by a GPS instrument. All soil samples collected were air dried, sieved (< 2 mm), and soil solution electrical conductivity (EC), as a measure of soil salinity, was determined using a soil saturated paste extract (Rhoades 1996).
Descriptive statistics of dataset
Exploratory statistical analysis was first investigated to understand the general character of the datasets. Mean, variance, standard deviation, the coefficient of variation, minimum and maximum values, skewness, and kurtosis of data were determined using the SPSS V22 software. The normality of the data from the three selected fields was also evaluated using the Kolmogorov–Smirnov test. Whenever initial analysis indicated that the dataset lacked a normal frequency distribution, before proceeding with geostatistical analysis, the dataset was properly transformed to obtain a nearly normal distribution. As required, the e data were then back-transformed for mapping and interpretation (Webster and Oliver 2001).
Spatial analysis of soil salinity
Spatial dependence of soil salinity was investigated by means of semivariogram analysis (Goovaerts 1997). In geostatistical analysis, a semivariogram is a function describing the degree of spatial dependence of a regional (spatial dependent) variable and measures the variance between the response variable (y-axis) as a function of distance in lags (x-axis). A semivariogram is usually characterized by three parameters including the nugget, sill, and range (Chiles and Delfiner 1999). The nugget refers to the variability in the field data that cannot be explained by the distance between the observations. The sill refers to the maximum observed variability in the data and corresponds to the variance of the data as normally estimated in statistics. The difference between the sill and the nugget (structural variance) represents the amount of observed variation that can be explained by distance between observations. The range in semivariogram is the maximum distance in which field data are spatially correlated (Goovaerts 1997). An experimental semivariogram calculates the variance of pairs of data separated by a vector (eq. 1) (Isaaks and Srivastava 1989). A hypothetical example of a semivariogram and its different parts is illustrated in Fig. 2.
where γ(h) is the semivariogram, N(h) is the number of data pairs separated by the lag distance h, and Z(xi) and Z(xi + h) are the values of the measured variable at spatial locations i and i + h, respectively.

General schematic of a semivariogram illustrating the different elements
In this study, experimental semivariograms were fitted to a variety of theoretical models, namely spherical, exponential, and Gaussian models and the best models were selected based on the minimum error using coefficient of determination (R2) and residual sum of squares (RSS) as indicators (Chiles and Delfiner 1999). The semivariograms were calculated in different directions to include geometric and zonal anisotropies (Goovaerts 1997). Geometric and zonal anisotropy, the variability of the target variable along with spatial directions, was also considered during variography. The geometric anisotropy occurs when the range varies with the direction of the semivariogram for the constant sill. The zonal anisotropy occurs when both the range and sill vary with the direction of the semivariogram (Isaaks and Srivastava 1989).
Interpolation methods and mapping
Four of the most common interpolation methods, including GPI, IDW, OK, and RBF, were applied for mapping soil salinity in the three studied fields. ArcMap 10.2 (ESRI, CA, USA) was used for spatial dependence analysis, interpolation and consequent mapping of soil EC in all three fields.
In global polynomial interpolation (GPI), a two-dimensional polynomial equation of the first, second, or a higher degree was fit to the input sample points during interpolation to capture coarse-scale patterns in the data (Yao et al. 2014). For n + 1 interpolation nodes (xi), polynomial interpolation defines a linear bijection as below:
where Πn is the vector space of polynomials of degree at most n.
Inverse distance weighting (IDW) produces estimations by launching a neighborhood search of points and weighting these points by a power function (Yao et al. 2013). A distance reverse power function of every point from neighboring points is defined to describe the rate of correlations and similarities between neighbors as below (Setianto and Triandini 2013).
where Z*(x0) is the value of variable Z at the unsampled location x0, estimated based on the data from the surrounding samples, Z(xi); di is the distance between known point xi and unknown point x0 and p is the user-defined exponent for weighting; and n is the total number of predicted for each validation case.
Ordinary kriging (OK) is a geostatistical interpolation method that gives weights to the surrounding measured values to derive a prediction for an unsampled location by incorporating the spatial dependence expressed by the semivariogram in estimation procedure (Johnston et al. 2003). The basic equation for interpolation by kriging at an unsampled location is given as Eq. 5.
where Z(x0) is the value of variable Z at the unsampled location x0 and λi = weights associated with the data points, which takes in account the spatial relationship of the sampled points. Z(xi) is the observed value of Z at sampled locations xi (Xie et al. 2011).
Cross-validation was conducted by varying model parameters and the numbers of the closest neighboring samples from 3 to 10 until the highest estimation accuracy was reached (Webster and Oliver 2001).
Radial basis function (RBF) is a form of artificial neural networks, which provides a very flexible and general way of interpolation in multi-dimensional spaces, even for unstructured data where it is often impossible to apply a polynomial or spline interpolation (Lin and Chen 2004). Each basis function has a different shape and results in a slightly different interpolation surface having the general form described by Eq. 6 (Jakobsson et al. 2009).
where the approximating function s(x) is represented as a sum of N radial basis functions, each associated with a different center xl, and weighted by an appropriate coefficient γl. The weights γl can be estimated using the matrix methods of linear least squares, because the approximating function is linear in the weights γl. The φ value depends only on the distance from the origin (Buhmann 2003).
Assessment of method performance
The following evaluation criteria including mean bias error (MBE), mean absolute percentage error (MAPE), root mean square error (RMSE), and R2 were calculated for each method to select the optimal model (Seyedmohammadi et al. 2016; Yao et al. 2013). MBE index was used to measure average bias of employed models and to indicate overall overestimation and underestimation of each models’ prediction. MAPE is an accuracy measure based on percentage (or relative) errors, RMSE measures the average magnitude of the error, and R2 indicates the degree of closeness of the predicted data to the measured validation points. When MBE is different from 0, then model has a bias. Positive and negative values of MBE indicate over and underestimation of the interpolation method, respectively. The lowest MAPE and RMSE value indicated the most accurate estimation. The closer the R2 value to 1, the higher the prediction accuracy. The MBE, MAPE, and RMSE are calculated as follows:
where n is the number of validation points, pi is the predicted value at point i, and oi is the observed value at point i.
The degree of similarity in salinity mapping between the four interpolators for each of the studied fields was also analyzed using Cohen’s kappa coefficient (κ). Kappa assumes its theoretical maximum value of 1 only when categorizing of observed points is completely identical.
Results
Descriptive statistics of the data
Exploring descriptive statistics of the collected data indicated that soil salinity was substantially different regarding central tendency and variability statistics through the three studied fields (Table 2).
The EC of the soil samples ranged from 670 to 2840, 1030 to 3110, and 540 to 7120 μS cm−1 in fields A, B, and C, respectively. ANOVA and Duncan multiple range tests at the α error level 0.05 (Table 2) showed that the mean soil EC in field A (1419 μS cm−1) was significantly different from fields B (2020 μS cm−1) and C (2150 μS cm−1). The standard deviation of data was significantly higher for field C (with Std.dev of 1760 μS cm−1) compared to fields A and B. The variation of EC data in field C was found to be very high regarding the coefficient of variation (CV) value of 0.82. Fields A and B with CV values of 0.48 and 0.33 exhibited almost the same amount of considerable heterogeneity (Table 2). The skewness values of all three datasets were positive (skewed right), and the asymmetry was obvious for fields A and C with values of 0.62 and 1.41, respectively. While an excess kurtosis value of 0 is expected for a normal distribution, all three variables had nonzero negative kurtosis values. Values of negative kurtosis for fields A and B indicated a mean distribution that had a flatter peak, fatter shoulders, and thinner tails than a normal distribution. In contrast, the positive kurtosis value of field C indicated that the data distribution had heavier tails than the normal distribution (Joanes and Gill 1998). Histograms of the measured soil EC (Fig. 3) allowed the variability of data to be visually confirmed. While the Kolmogorov–Smirnov normality test indicated a normal distribution of data from field B, the data from fields A and C were not normally distributed. However, after log-transformation, a normal data distribution was obtained for the transformed data. Therefore, log-transformed datasets were used in the Kriging interpolation method, which strictly demands normality of the dataset.

Histograms of EC values of the three investigated fields including field A (a), field B (b) and field C (c).
Spatial dependence analysis
The optimized experimental semivariograms and associated fitted models of soil EC for each of the three studied fields are presented in Fig. 4. No significant geometric and zonal anisotropy was detected during variography procedure via calculating semivariogram in various directions. Therefore, isotropic semivariograms were calculated for all the fields. The Gaussian model fitted well experimental semivariograms of fields A and C, while the best-fitted model for field B was the spherical model. The parameters of the fitted models on experimental semivariograms for fields A, B, and C are presented in Table 3. The coefficients of determination (R2) of all fitted models ranked as A > C > B, while RSS values ranked as A < B < C. Therefore, theoretical models were best fitted for field A, followed by field C and B. According to the variography results, spatial dependence of soil EC was different amongst the three studied fields. While fields A and C showed strong spatial dependency with C/C0 + C values of 0.99 and 0.95, field B showed only a moderate spatial dependence with C/C0 + C equal to 0.54 (Shi et al. 2007). According to semivariograms parameters, soil EC in field C had the greatest effective range (3642 m), which was significantly higher than either of the other two fields: A (2341 m) and B (1920 m).

Experimental semivariograms and fitted models of soil EC in fields a, b, and c
Interpolation method performance
The performance assessment for the four interpolation methods used here based on cross-validation results is presented in Table 4.
For field A, all employed methods except OK underestimated soil EC according to the MBE criterion. The lowest RMSE and highest R2 corresponded to the OK method with values of 0.17 and 0.87, respectively. Overall the performance of the four interpolation methods in this field was ranked as OK > IDW > RBF > GPI based on these assessment criteria. For field B, IDW (with a power value of 1) showed the best performance with R2, RMSE, MAPE, and MBE values of 0.89, 0.32, 0.18, and 0.09, respectively. In this field, all methods overestimated soil EC except OK which underestimated EC based on the MBE value of − 0.13. Overall ranking of the method performance in field B decreased in the order IDW > OK > RBF > GPI. For field C, the OK method generated more accurate results for predicting soil EC than either the RBF, IDW, and GPL models. The MBE measure showed that OK and IDW underestimated soil EC while RBF and GPI overestimated it. MAPE values ranged from 0.15 to 0.56 in field C. Considering all evaluation criteria, method performance in field C was decreased in the order OK > RBF > IDW > GPI. Comparing MAPE (as it provides the possibility of EC comparisons among fields with different mean) and R2 values across the three fields showed that the most accurate interpolation results were obtained for field B followed by field A and C. A ranking of methods based on their good performance is also presented in Table 4, where overall the results indicated that OK interpolation method generally performed better than all other models in predicting soil EC in terms of all three assessment indicators regardless of the field studied.
The κ values between different interpolation methods were determined for each of the studied fields separately (Table 5) The highest similarity in EC values for sampled points was found between OK and IDW (κ = 0.91) for field A, between RBF and GPI (κ = 0.72) for field B, and between OK and IDW (κ = 0.95) for field C. The κ values for field B were generally smaller than those of either field A and C which indicated poor agreement amongst interpolation methods in field B. The greatest difference in κ values was also observed between GPI and other interpolators in field C.
While a more precise mapping of soil EC was obtained by applying OK in fields A and C, for field B, the IDW method gave superior results. However, OK produced smoother maps compared to all other methods (Fig. 5). The percentage of the area, covered by the same level of soil salinity, is illustrated in Table 6. Comparison of salinity mapping in Table 6 indicated that the area of delineated map units for the different levels of soil salinity in each field was significantly different for different interpolation methods.

Soil EC mapping based on OK, IDW, RBF, and GPI interpolation methods in a, b, and c agricultural fields from the Varamin area
Discussion
The results showed that spatial distribution of soil EC in the three studied fields could be described with Gaussian (for fields A and C) and spherical (for field B) models. The Gaussian model normally has higher response to the variance increase against distance rather than the spherical model (Goovaerts 1997). The value of nugget effect for EC in the A and C fields was relatively small which suggests low random variance, strong autocorrelation of data, and large spatial continuity between the neighboring points in the study area (Chiles and Delfiner 1999). The larger effective range for field C indicated that this field had a more widespread spatial structure than either fields A or B. Therefore, the virtual range that data can be used to estimate the amount of soil EC at unknown points is larger in this field (Juan et al. 2011). While for field B, EC showed weaker spatial structure than the other fields; it may show a stronger spatial structure on a smaller scale with an extended dataset (Simakova 2011). The smaller effective range of soil EC in field B can probably be ascribed to management practices (non-intrinsic) impacts rather than intrinsic processes which are typically associated with strong spatial structure and large effective range values (Kavianpoor et al. 2012). The average value of RMSE in field A was significantly higher than the other two fields, which indicated a greater probability that errors occur in this field.
In agreement with many previous studies, the dissimilar performance of the given interpolation methods in the three different fields indicated that the performance of interpolation methods is site-dependent (Li and Heap 2011; Yao et al. 2013). For example, in this research for all employed methods, the worst performance was obtained for field C. This observation can be ascribed to greater heterogeneity and a short autocorrelation range of EC in this field compared to field A. In the case of field B with moderate spatial dependency, the performance of the IDW method was slightly better than the OK method simply because IDW relies on the similarity of neighboring sample points to predict the unmeasured points. Over and underestimation of methods also seems to be site and dataset dependent. For example, all the methods overestimated ECs in field B, while they mostly underestimated ECs were in field A.
According to the classical descriptive statistics, field C showed the greatest variability with the highest CV value; however, spatial dependence analysis indicated that field B had the weakest spatial structure amongst the three investigated fields. Comparison between field A and C, both with strong spatial dependency and the same semivariogram model (Gaussian model), indicated that field A, with a lower CV value than field C, showed stronger spatial structure. Thus, it was concluded that, while spatial structure was not directly linked to data variability, it certainly may be negatively affected by CV (Kumari et al. 2018). Yao et al. (2013) and Zhu and Lin (2010) reported that the performance of a spatial interpolation method depends not only on the features of the method itself but also on the sample pattern and data characteristics such as data variation. Kumari et al. (2018) reported that the quality of the dataset in different case studies for a given variable influences the accuracy of different interpolation methods. Different systems of land management in soils with the same parent materials and land use may result in different dataset characteristics. Li and Heap (2011) pointed out that data variation has significant effects on the performance of the methods. Generally, as the variation in the dataset increases, the accuracy of interpolation methods decreases and the magnitude of decrease is method dependent. Many researchers reported that data normality, and sample pattern might also affect the performance of spatial interpolation methods (Kumari et al. 2018; Li and Heap 2011; Seyedmohammadi et al. 2016).
Regardless of the field of study, comparison between interpolation methods showed that while OK generally had superior performance to other methods, it was not always the best interpolation method in all fields, but it was found to be the best method in location A and B and the second best method in field C. The two basic assumptions of OK are that observations are spatially autocorrelated and data is normally distributed (Zimmerman et al. 1999). The performance of the OK method increased as the spatial dependency of data increased. Thus, OK performed very well when the collected data had a acceptable degree of homogeneity and structural spatial dependency, as it includes spatial dependency information during the prediction. The OK method can also mitigate the negative effects of high data heterogeneity on interpolation performance when strong structural dependency exists, as happened in the case of field C. Similar results were reported by Seyedmohammadi et al. (2016) for predicting groundwater EC by spatial interpolation methods. According to the evaluation criteria, the effectiveness of the RBF methods was significantly better than the GPI method. RBF had a slightly better performance for estimating EC compared to IDW in field C. Previously, Li and Heap (2011) reported that IDW was highly sensitive to sample density and data variation (CV). Although increasing sampling density can improve the performance of both geostatistical and deterministic interpolation methods, the performance of deterministic methods is more sensitive to sampling density as these methods rely only upon information provided by values of known points for predicting the values of unknown points (Kumari et al. 2018). In all cases, the GPI method which is based on global interpolation and is not a precise interpolation was found to be the worst interpolation method. According to Xiao et al. (2016), the GPI method is only suitable when the variability of the dataset is relatively small and it is not very accurate when extreme values are present.
Whenever the Cohen’s kappa results showed strong agreement between interpolators, this meant that both interpolators were mapping soil salinity in a similar manner. However, it is worth noting that even if two interpolators strongly agree, this does not necessarily mean that their prediction and the subsequent mapping is correct, because both models could be equally poorly estimating results. For instance, in the case of field A and C, highest similarity (according to κ values) belonged to interpolation methods that were also the best predictive methods, however in field B poor predictors (i.e., GPI and RBF) recorded the highest κ value (McHugh 2012).
Comparison of delineated map units by employing the four interpolation methods in each field indicated that significantly different management zones may be discriminated in a given field by employing different interpolation approaches. For instance, for field A, while the GPI method covered 100% of the area for salinity at level 1, the optimal OK method assigned only 75% of this area at this level of salinity. The GPI method significantly underestimated EC which resulted in a uniform map and elimination of higher EC level zones compared to other methods. Likewise, underestimation of the OK interpolator resulted in removal of the highly saline zone for field B where more precise mapping was obtained using IDW method. In the case of field C, while visual mappings of OK, IDW, and RBF were almost similar, different mappings of GPI were due to overestimation of this interpolator. So it is crucial to discriminate the management zones of soil salinity based on the most accurate produced maps with simultaneous consideration variety of assessment criteria (Gebbers and de Bruin 2010).
Conclusions
In this study, OK and IDW methods were considered to be optimal methods for producing salinity maps in agricultural lands. The output maps of such interpolation methods can help in applying precise and more suitable site specific management, maintain, and conserve soil in different land use applications. Both interpolation method features and data properties, which are often site-dependent, affect the performance of interpolation approaches. Results of this study suggest that in an area with strong spatial dependence of the target variable, geostatistical interpolation methods perform much better than the distance-based and deterministic methods in predicting the spatially continuous surface. Since utilization of proper interpolation methods is crucial for producing a precise map, the best interpolation method should first be investigated among common interpolation techniques in each specific agricultural land.
Abbreviations
- EC:
-
electrical conductivity
- GPI:
-
global polynomial interpolation
- IDW:
-
inverse distance weighted
- MAPE:
-
mean absolute percentage error
- MBE:
-
mean bias error
- OK:
-
ordinary kriging
- R 2 :
-
coefficient of determination
- RBF:
-
radial basis functions
- RSS:
-
residual sum of squares
- TNV:
-
mean total neutralizing values
- κ:
-
Cohen’s kappa coefficient
References
Abuelgasim, A., & Ammad, R. (2018). Mapping soil salinity in arid and semi-arid regions using Landsat 8 OLI satellite data. Remote Sensing Applications: Society and Environment, 13, 415–425.
Ahmed, H., Muhammad, T. S., Muhammad, I., & Fayyaz, H. (2017). Comparative study of interpolation methods for mapping soil pH in the apple orchards of Murree, Pakistan. Soil and Environment, 36, 70–76.
Allbed, A., Kumar, L., & Sinha, P. (2014). Mapping and modelling spatial variation in soil salinity in the Al Hassa oasis based on remote sensing indicators and regression techniques. Remote Sensing, 6, 1137–1157.
Buhmann, M. D. (2003). Radial basis functions: theory and implementations. Cambridge, New York: Cambridge University Press ISBN 978-0511040207.
Chiles, J. P., & Delfiner, P. (1999). Geostatistics: modeling spatial uncertainty. New York: Wiley.
Daliakopoulos, I. N., Tsanis, I. K., Koutroulis, A., Kourgialas, N. N., Varouchakis, A. E., Karatzas, G. P., & Ritsema, C. J. (2016). The threat of soil salinity: a European scale review. Science of the Total Environment, 573, 727–739.
Denton, O. A., Aduramigba-Modupe, V. O., Ojo, A. O., Adeoyolanu, O. D., Are, K. S., Adelana, A. O., Oyedele, A. O., Adetayo, A. O., & Oke, A. O. (2017). Assessment of spatial variability and mapping of soil properties for sustainable agricultural production using geographic information system techniques (GIS). Cogent Food & Agriculture, 3, 1279366.
Douaik, A., Meirvenne, M. V., & Toth, T. (2008). Stochastic approaches for space-time modeling and interpolation of soil salinity. In G. Metternicht & A. Zinck (Eds.), Remote sensing of soil salinization: impact on land management (pp. 273–290). CRC Press.
Gebbers, R., & de Bruin, S. (2010). Application of geostatistical simulation in precision agriculture. In M. A. Oliver (Ed.), Geostatistical applications for precision agriculture (pp. 269–303). Dordrecht: Springer Netherlands.
Goovaerts, P. (1997). Geostatistics for natural resources characterization. Oxford: Oxford University Press.
Gorji, T., Tanik, A., & Sertel, E. (2015). Soil salinity prediction, monitoring and mapping using modern technologies. Procedia Earth and Planetary Science, 15, 507–512.
Isaaks, E. H., & Srivastava, R. M. (1989). Applied geostatistics. New York: Oxford University Press.
Jakobsson, S., Andersson, B., & Edelvik, F. (2009). Rational radial basis function interpolation with applications to antenna design. Journal of Computational and Applied Mathematics, 233, 889–904.
Joanes, D. N., & Gill, C. A. (1998). Comparing measures of sample skewness and kurtosis. Journal of the Royal Statistical Society: Series D (The Statistician), 47, 183–189.
Johnston, K., Ver Hoef, J., Krivoruchko, K., & Lucas, N. (2003). Using ArcGIS Geostatistical Analyst. Redlands: ESRI press.
Juan, P., Mateu, J., Jordan, M. M., Mataix-Solera, J., Meléndez-Pastor, I., & Navarro-Pedreño, J. (2011). Geostatistical methods to identify and map spatial variations of soil salinity. Journal of Geochemical Exploration, 108, 62–72.
Kavianpoor, H., Esmali, Ouri, A., Jafarian Jeloudar, Z., & Kavian, A. (2012). Spatial variability of some chemical and physical soil properties in Nesho mountainous rangelands. American Journal of Environmental Engineering, 2(1), 34–44.
Kumari, N., Sakai, K., Kimura, S., Nakamura, S., Yuge, K., Gunarathna, M., Ranagalage, M., & Duminda, D. M. S. (2018). Interpolation methods for groundwater quality assessment in tank cascade landscape: a study of ulagalla cascade, Sri Lanka. Applied Ecology and Environmental Research, 16(5), 5359–5380.
Li, J., & Heap, A. D. (2011). A review of comparative studies of spatial interpolation methods in environmental sciences: performance and impact factors. Ecological Informatics, 6, 228–241.
Lin, G. F., & Chen, L. H. (2004). A spatial interpolation method based on radial basis function networks incorporating a semivariogram model. Journal of Hydrology, 288, 288–298.
McBratney, A. B., Mendonça Santos, M. L., & Minasny, B. (2003). On digital soil mapping. Geoderma, 117, 3–52.
McHugh, M. L. (2012). Interrater reliability: the kappa statistic. Biochemica Medica, 22(3), 276–282.
Rhoades, J. D. (1996). Salinity: electrical conductivity and total dissolved solids. In Methods of soil analysis part 3—chemical methods (pp. 417–435). Madison: Soil Science Society of America, American Society of Agronomy.
Setianto, A., & Triandini, T. (2013). Comparison of kriging and inverse distance weighted (IDW) interpolation methods in lineament extraction and analysis. Journal of Applied Geology, 5(1), 21–29.
Seyedmohammadi, J., Esmaeelnejad, L., & Shabanpour, M. (2016). Spatial variation modelling of groundwater electrical conductivity using geostatistics and GIS. Modeling Earth Systems and Environment, 2, 1–10.
Shi, J., Wang, H., Xu, J., Wu, J., Liu, X., Zhu, H., & Yu, C. (2007). Spatial distribution of heavy metals in soils: a case study of Changxing, China. Environmental Geology, 52, 1–10.
Simakova, M. S. (2011). Small-scale soil mapping. Eurasian Soil Science, 44, 1036.
Webster, R., & Oliver, M. (2001). Geostatistics for environmental scientists (Statistics in Practice). Wiley.
Xiao, Y., Gu, X., Yin, S., Shao, J., Cui, Y., Zhang, Q., & Niu, Y. (2016). Geostatistical interpolation model selection based on ArcGIS and spatio-temporal variability analysis of groundwater level in piedmont plains, northwest China. SpringerPlus, 5, 425.
Xie, Y., Chen, T. B., Lei, M., Yang, J., Guo, Q. J., Song, B., & Zhou, X. Y. (2011). Spatial distribution of soil heavy metal pollution estimated by different interpolation methods: accuracy and uncertainty analysis. Chemosphere, 82, 468–476.
Yao, X., Fu, B., Lu, Y., Sun, F., Wang, S., & Liu, M. (2013). Comparison of four spatial interpolation methods for estimating soil moisture in a complex terrain catchment. PLoS One, 8(1), e54660.
Yao, L., Huo, Z., Feng, S., Mao, X., Kang, S., Chen, J., Xu, J., & Steenhuis, T. S. (2014). Evaluation of spatial interpolation methods for groundwater level in an arid inland oasis, northwest China. Environmental Earth Sciences Steenhuis, 71, 1911–1924.
Zewdu, S., Suryabhagavan, K. V., & Balakrishnan, M. (2017). Geo-spatial approach for soil salinity mapping in Sego Irrigation Farm, South Ethiopia. Journal of the Saudi Society of Agricultural Sciences, 16, 16–24.
Zhu, Q., & Lin, H. S. (2010). Comparing ordinary kriging and regression kriging for soil properties in contrasting landscapes. Pedosphere, 20, 594–606.
Acknowledgments
This research was supported by ETKA organization, Iran. The authors thank Mr. Hossein Mahmoudi for field and laboratory assistance. The authors are also grateful to the anonymous reviewers who considerably improved the quality of this manuscript prior to publication.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Fazeli Sangani, M., Namdar Khojasteh, D. & Owens, G. Dataset characteristics influence the performance of different interpolation methods for soil salinity spatial mapping. Environ Monit Assess 191, 684 (2019). https://doi.org/10.1007/s10661-019-7844-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-019-7844-y