
Abstract
Human health is “at risk” from exposure to sub-lethal elemental occurrences at a local and or regional scale. This is of global concern as good-quality drinking water is a basic need for our wellbeing. In the present study, the “probability kriging,” a geostatistical method that has been used to predict the risk magnitude of the areas where the probability of dissolved mercury concentration (dHg) is higher than the World Health Organization (WHO) permissible limit. The method was applied to geochemical data of dHg concentration in 100 drinking groundwater samples of Lucknow monitoring area (1222 km2) located within the Ganga Alluvial Plain, India. Threefold (high to extreme risk) and twofold (moderate risk) higher dHg concentration values than the WHO permissible limit were observed in all of the groundwater samples. The generated prediction map using the probability kriging method shows that the probability of exceedance of dHg is the highest in the northwestern part of the Lucknow monitoring area due to anthropogenic interferences. The hotspots with high to very high probability are potentially alarming in the urban sector where 32.4% of the total population is residing in 6.8% of the total area. Interpolation of local estimates results in an easily readable and communicable human health risk map. It may help to consider substantial remediation measures for managing drinking water resources of the Ganga Alluvial Plain, which is among the anthropogenic mercury emission–dominated regions of the world.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Human health risk assessment is a process intended to estimate the exposure and harm caused by a toxic substance to a given population. It requires hazard identification, hazard characterization, exposure assessment, and risk evaluation (IPCS 2004). Mercury is a persistent globally distributed pollutant that can spread widely (~ 1000 km) through the atmosphere (Wang et al. 2003). It is considered as one of the top ten chemicals posing a major human health concern. This is because of the highest degree of mobility of mercury, immortal property, and superlative toxicity even at low concentration in the natural environment. Once existed only in natural environments, mercury thoroughly circulated in a variety of forms ranging from elemental metal (Hgo), dissolved form in water (dHg), cinnabar (HgS), and oxidized form (HgO) to organo-metallic compounds such as methylmercury (Fernández-Martínez et al. 2005). Atmospheric deposition in the form of rainfall precipitate, evapotranspiration, and anthropogenic discharge results in infiltration and accumulation of inorganic mercury in aquatic ecosystems where it bioaccumulates in fish and shellfish. Food is the main source of organic mercury in non-occupationally exposed populations. The famous “Minamata” incidence is a significant example of the lethal impact of organic mercury exposure to human health. The incidence received worldwide attention and raised awareness towards the intake of bioaccumulating mercury (Weiner 2000). Excessive concentration of mercury is objectionable in potable water as it induces harmful effects on the central and peripheral nervous system, digestive and immune systems, and lungs and kidneys, and may be fatal (Houston 2014). Therefore, mercury undoubtedly poses a potential threat to ecology and human health and as a result, the assessment of mercury contamination has been addressed in some recent publications worldwide (Richardson 2014; Stahl et al. 2014; Raj et al. 2017).
India is one of the fastest growing economies of the world and the demands and supply for the ever-increasing consumption of mercury classify India as a potential “hotspot” in the global environmental scenario. In India, coal is primarily used as a source of fuel for energy production due to unavailability or inadequate supply of any alternatives. Coal combustion represents the most important anthropogenic source of mercury released to the atmosphere annually, accounting for about 53% (120.85 tons/year) of the total emission of mercury in the atmosphere (Mukherjee et al. 2009). In 2008, total mercury emission from Indian coal-based thermal power plants was estimated to be 38.54 metric tons/year (Das et al. 2015). The spontaneous in situ burning of the coal seam (Raju et al. 2016) and anthropogenic coal combustion in thermal power plants contribute to about 53% of the total global mercury emission in the atmosphere and are followed by solid 31% municipal and 3% medical waste (Chakraborty et al. 2013). Coal burning thus introduces mercury into the atmosphere that gets discharged to groundwater resources as wet or dry precipitate and ultimately causes risks to the environment and human health (Pacyna et al. 2010; Amos et al. 2014). Unavailability of adequate analytical laboratory facilities and lack of proper water purification techniques for dHg in drinking water resources has induced a potential threat to human health in Indian subcontinent (Bhowmik et al. 2015; Raj et al. 2017). Rural areas are spatially scattered and often exhibit fewer population counts in comparison to urban areas in terms of population distribution. Consequently, rural areas are often neglected and are not taken into much consideration by administrative authorities for water quality management where health risk from exposure to contaminant water is more severe. At United Nations Minamata Convention 2013, India agreed on the abatement of mercury emission and its related products in the environment. At present, there is no firm monitoring, planning, or technique for decontamination of dHg in drinking water resources. In the northern part of India, the Ganga Alluvial Plain provides drinking water resource to nearly 50 million of human population and hence, dHg contamination in drinking water resources is a matter of great concern. Therefore, it is crucial to identify the potential “hotspots” and to quantify the population of human health at risk from exposure to the higher dHg concentration in drinking groundwater resources.
Mapping of health risk assessment: a brief review
Since last decade, health risk assessment due to contaminated water consumption has been studied worldwide (Kavcar et al. 2009; Muhammad et al. 2011; Törnqvist et al. 2011). As the pollutant concentration values are rarely available for every possible location, geostatisticians have focused on predicting the pollutant concentrations at unsampled locations (Adhikary et al. 2011). Geographical Information System (GIS)–based geostatistical interpolation techniques visualizes the continuity and variability of unsampled data by creating a continuous prediction surface onto a geographical space. Kriging, one of the widely accepted interpolation techniques, has the advantage of considering the spatial structure of the variable, i.e., known spatially correlated distance or direction biases in the data points. It also estimates the error of interpolation (Childs 2004). Kriging is an interpolation tool, defines a “stochastic” theory for the study of spatial behavior of territorial variables. In recent years, a nonparametric approach–based geostatistical kriging or cokriging estimator (indicator or probability kriging) has been widely practiced to predict the probabilistic information of an unsampled point Z[x, y] from unconditional data (Juang and Lee 2000; Passarella et al. 2002; Goovaerts et al. 2005). Adhikary et al. 2011 estimated the performance of indicator and probability kriging and suggested that the probability kriging method, which incorporates the information about order relations, can improve the accuracy of the probability of point Z[x, y] being higher than a threshold value. Kriging-based prediction models when integrated with other parameters, like geochemical data and population data among others, could provide meaningful regional-scale visuals of the area and human population count at risk (Webster et al. 1994; Oliver et al. 1998; Berke 2004; Bhowmik et al. 2015). However, studies on quantitative assessment of the spatial extent and total human population at risk from exposure to trace element concentration in drinking water are limited. In the present study, probabilistic information of dHg higher than the threshold in the groundwater of Lucknow monitoring area is predicted from the regional count data and it has been integrated with the human population dataset for human health risk mapping of Lucknow monitoring area in the central Ganga Alluvial Plain, northern India (Fig. 1).

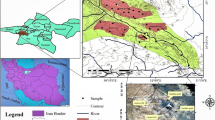
[Upper left] Map showing spatial extent of the Ganga Alluvial Plain along with the location of Lucknow in the northern part of India. [Lower left] Rectified subset of standard 3–2-1 color standard False Color Composite (FCC) of Advance Spaceborne Thermal Emission and Reflection Radiometer (ASTER) image of the study area (Lucknow monitoring area) showing the rural (marked southwestern part), urban (marked central part), and mixed farming (marked northwestern part) sectors used for the mapping of Human Health Risk assessment. Color variations in red and cyan are attributed to rural and urban parts, respectively of the Lucknow monitoring area. [Right] Lucknow monitoring area showing selected sampling locations (L1–L100) used for the analysis of dHg concentration in drinking Groundwater. It also displays three classified sectors, namely rural, urban, and mixed farming which are presently used for the assessment of human health risk due to mercury in drinking groundwater. The line (represented in yellow) from point A-H corresponds to the cross-sectional line of the fence diagram as indicated in Fig. 2
Material and methods
Study area
Lucknow monitoring area (80° 45′–81° 05′ E, 26° 40′–27° 00′ N, 123 m above mean sea level) is situated on both banks of the Gomati River in the central part of the Ganga Alluvial Plain as shown in Fig. 1. Out of the total monitoring area of 1222 km2, Lucknow city is spread over an urban area of nearly 400 km2. The monitoring area is further divided into three land use–based prominent sectors, named “urban (central),” “rural (southeastern),” and “mixed farming (northwestern)” sectors. The area corresponding to three subsets are demarcated on standard 3–2-1 color standard False Color Composite (FCC) of Advance Spaceborne Thermal Emission and Reflection Radiometer (ASTER) image of the study area (Lucknow monitoring area as shown in Fig. 1. The idea of dividing study area into three land use–based prominent sectors was to indicate the possibility of regional and local (point) geogenic or anthropogenic source for dHg contamination that may be independent of rural-urban processes operating in the alluvial plain. Geologically, sub-surface part of the monitoring area is composed of unconsolidated alluvial deposits originated through the weathering and erosion of the Himalayan region. These deposits are made up of interlayered 1–2-m thick fine sand and silty mud (Fig. 2; Singh 1996).

Fence diagram of Lucknow city (CGWB 2009). The uppermost unconfined aquifer comprises a sandy layer and lies between 8 and 35 m below ground level depth
Based on the hydrological studies, a five-tier aquifer system exists in the Lucknow monitoring area where the Gomati River is directly connected to the first aquifer group (CGWB 2009). The upper unconfined aquifer comprises of a sandy layer occurring 8–35 m below ground level and ranges in thickness from 15 to 25 m. This aquifer supports all the hand pumps and shallow tube wells and acts as a primary source of drinking water in the Lucknow monitoring area. Presently, ~ 70% of the drinking water supply of the urban area and 100% of the rural area depends on this groundwater resource (Singh et al. 2015). Table 1 represents a five-tier aquifer system of the study area. The identification of regional and local mercury sources is a simple tool to provide useful insights for more focused assessment of mercury contamination in drinking water resources. Thermal power plants located in and around the Ganga Alluvial Plain act as a prominent regional source (Rai et al. 2013). Dry deposition of mercury from these thermal power plants and abundance of brick kilns could act as a regional source for mercury emission in the environment (Fig. 3a). Mercury is also released from local point sources such as from chemicals used in mixed farming, from municipal solid wastes, petroleum combustion, and e-wastes containing compact fluorescent lamps, fluorescent tube lights, mercury vapor lamps, mercury-based cosmetics (skin lightening soaps/creams, mascara, and eye makeup cleansing products), and medical wastes (thermometers, sphygmomanometers, and dental amalgam, etc.) (Singh et al. 2014). The agro-chemicals used in combined mango-cum-poultry farming could be the possible reason of high dHg in the groundwater of mixed farming sector which indicates high human interference in the northwestern part of Lucknow monitoring area (Fig. 3b). Municipal solid wastes (Fig. 3c), Electronic wastes containing fluorescent lamps-tube lights (CFLs), Hg-based cosmetics (Fig. 3d), and medical wastes could be the local point source. These local mercury sources may be strongly linked with high dHg contamination in the ambient groundwater as well as in biotic components such as fishes and lichens of the region (Agarwal et al. 2007; Saxena et al. 2007)

Field photographs showing the regional, local point sources of dHg in Lucknow monitoring area: a widespread existence of brick kilns in (marked by an open arrow on Google image) Alamnagar (L-35) at the rural-urban fringes of Lucknow. The Ganga Alluvial Plain accounts for 65% of total brick production and nearly 263 brick kilns were in Lucknow alone (Pangtey et al. 2004). b Mango orchard along with poultry farming structure at Mohan [photo credit: Jitendra Kumar Yadav]. c Dumping site of municipal solid waste located near right bank of the Gomati River (foreground) at sampling site L34. Lucknow city presently generates approximately 1.5 × 105 kg/day municipal solid waste (Archana et al. 2014). d Temporary dumping ground of electronic wastes (tube lights and compact fluorescence lamps are visible) in backyards of the Works Department of Lucknow University (old campus) at sampling site L55 [photographed on 7th June, 2016]. [refer Fig. 1 for location of L34, L-35, and L55]
Sampling techniques and analytical procedures
A total of 100 groundwater samples (L1–L100) have been collected from a regularly spaced lattice of a systematic 2′ × 2′(2 min × 2 min) grid during the pre-monsoon season (May and June 2010) to find the dHg concentration in drinking water resources of the Lucknow monitoring area (Fig. 1). The sample locations have been chosen in such a way as to give the best representation of the entire Lucknow monitoring area. Drinking groundwater samples have been collected in dried, pre-cleaned 250 ml polyethylene bottles. In the laboratory, samples were filtered through a < 0.45-μm membrane filter and were analyzed for dHg by an Inductively Coupled Plasma-Mass Spectrophotometer (ICP-MS, ERAN DRC II Perkin Elmer SCIEX Instrument) with a detection limit of < 0.5 ng/l. The accuracy of the chemical analysis was verified by calculating the ion-mass balance, which was seen to be within the acceptable limit (± 3%). The descriptive statistics of dHg concentrations in all drinking groundwater samples are presented in Table 2.
Data source and analysis
In Lucknow monitoring area, dHg concentrations in all groundwater samples (n = 100) vary from 9.74 to 61.42 μg/l. All these values exceed the threshold limit (6 μg/l) of inorganic dHg in drinking water as per WHO norms (WHO 2011). The average dHg concentrations in the rural, urban, and mixed farming sectors were 14.3 μg/l, 14.6 μg/l, and 27.8 μg/l, respectively. Figure 4 displays box and whisker plot showing the distribution of dHg concentrations in urban, rural, and mixed farming sector of the Lucknow monitoring area. The mixed farming sector has the highest dHg concentration with > 50% of values being above 24.8 μg/l. The values are distributed in the ranges of 10–15 μg/l and 15–20 μg/l, which accounts for about 66% and 26% of total groundwater samples, respectively. The dHg concentrations are more pronounced in the northwestern part, i.e., the mixed farming area of the Lucknow monitoring area with concentrations > 20 μg/l. Seven percent of total groundwater samples have dHg concentrations > 20 μg/l as shown in the frequency distribution graph in Fig. 5. These high concentrations of dHg (> 20 μg/l) in the monitoring area are especially noticeable at Baruwa (L-01, 31.30 μg/l), Bazidnagar (L-02, 27.70 μg/l), Gopramau (L-21, 61.42 μg/l), and Kankarabad (L-22, 35.17 μg/l).

Box and Whisker plot representing the distribution of dHg concentration (in μg/l) in drinking groundwater of the rural, urban, and mixed farming sectors of Lucknow monitoring area. Refer Fig. 1 for all sample locations and sectors sites

dHg concentration (in μg/l) in groundwater samples (n = 100) collected from Lucknow monitoring area. Refer Fig. 1 for all sample locations
Analysis indicates that the urban and rural sectors have a relatively uniform dHg concentration (12–15 μg/l). This indicates the presence of a local source of mercury which is independent of rural and urban processes. The high dHg concentrations (> 16 μg/l) in the mixed farming sector may be linked with anthropogenic interferences.
The exceedance of dHg in the groundwater samples at different locations (i = 100) is reflected in terms of risk magnitude(Rm). It represents the scale of risk to human health and is computed as a function of the mercury values above prescribed WHO threshold limit (WHOt = 6 μg/l) for drinking water using Eq. 1.
It has been observed that all groundwater samples are much above the prescribed threshold limit of the WHO limit. The dHg concentration values over onefold of WHOt (Rm > 1) indicate potential risk to human health from exposure to contaminated drinking water in the area of concern. Rm is classified as low risk (1–2), moderate risk (2–3), high risk (3–4), very high risk (4–5), and extreme risk (> 5) with magnitudes representing two-, three-, four-, five-, and more than fivefolds exceedance in dHg concentration values, respectively. The regional Rm database has been interpolated using best-fitted semivariogram function to predict the probable areas of health risk in Lucknow monitoring area. Subsequently, the probability of exceedance of dHg concentration in drinking groundwater where it is higher than the threshold value (Rm > 1) has been also mapped. All statistical analyses were done using ArcGIS 10 Geostatistical Analysis package. The overall methodology adopted in this study has been shown in Fig. 6.

Schematic diagram showing data processing and methodology adopted in the present study for the mapping of human health risk from exposure to dHg in drinking water resources of Lucknow monitoring area
Geostatistical modeling
Kriging technique and semivariogram function
To interpolate the estimates of random variables [Z(xi); i ∈ {1 … n}] from a regional Rm database onto a smoothed continuous surface, spatial dependency, i.e., spatial autocorrelation between the random variables has been determined. The spatial variation of the random variable (Z) can be expressed within the framework of a linear model as a sum of structural components having trend or constant mean surface [μ(xi)], stationary regionalized (spatially autocorrelated) variable [δ(xi)], and spatially uncorrelated random noise (δ’)
For geostatistical modeling, the structure of spatial correlation between random variable is estimated through the semivariogram (Berke 2004). The difference in the values of the spatially auto-correlated random variable is a function of distance (h) between them and can be expressed as:
Here,γ(h) is defined as the “semivariance” depicted in empirical “semivariogram” that allows us to model the structure of the random variable for appropriate spatial prediction at unknown locales using the “semivariogram function” (Carrat and Valleron 1992). This function has been depicted below.
Here, n is the number of pairs of sample point Z(xi) separated by distance h at points(xi) and (xi + h). The observed empirical semivariogram estimate model is fitted by the weighted least squares technique. The close fitting of the empirical semivariogram to the model indicates that an appropriate model choice for spatial prediction of unknown variables has been made (Berke 2004). The derived value of semivariance (γ) from semivariogram model is substituted into Eq. 3 to obtain weights (λi) by introducing the Lagrange Multiplier (ε) (Carrat and Valleron 1992).
Finally, spatial prediction (Z’) at a point can be estimated from observed values [Z(xi); i ∈ {1 … n}][Z(x0) by putting the weight λi in Eq. 5.
Likewise, spatial prediction of the regional count data (Rmderived from dHg concentration using Eq. 1) has been mapped and further interpreted.
Probability kriging
Probability kriging assumes cokriging estimates to have indicator values I(xi; zth) and uniform value U(xi) assigned as the main and the auxiliary variable, respectively. Indicator values are the binary codes (0 or 1) transformed from random variables [Z(xi); i ∈ {1 … n}] (regional Rm database) through a desirable threshold using the indicator function. The indicator functions are derived from the structure of spatially auto-correlated indicator values best fitted to the indicator semivariogram model (Eq. 7).
The uniform value represents the order relation of observed values and is defined as:
Here, r denotes the rank of the rth order statistic z(r) located at xi and n is the total number of observations (Goovaerts 1997; Adhikary et al. 2011). Similarly, semivariance is depicted from the best-fitted uniform value U(xi) to the semivariogram model as given by Eq. 9.
Probability kriging estimates the autocorrelation between each variable, i.e., the indicator I(xi; zth) and uniform value U(xi) and their cross-correlation is depicted by cross-semivariogram given in Eq. 10.
Finally, the binary variable, i.e., I’(x0; zth) is spatially predicted through a desirable threshold indicator (zth) at point (x0) by putting up on weight λi and \( {\lambda}_{u_i} \)i associated with indicator I(xi; zth) and uniform value U(xi), respectively by Eq. 11.
Results and discussion
Spatial distribution of risk magnitude
The Rm derived from Eq. 1 reflects the locales of potential “hotspots” of health risk from exposure to dHg contamination in drinking groundwater of Lucknow monitoring area. Regional Rm data is used as a point data for direct interpolation of the degree of risk. An empirical semivariogram function derived from the spatial structure of Rm is best fitted to the spherical model using the weighted least squares method. The semivariance and its corresponding values of the nugget, sill, and range obtained from the best-fitted model were noted. The theoretical model indicates nugget effect (C0 = 0.33) with a sill (C0 + C1) and range of influence (C2) of 2.52 (Rm)2 and 18.1 km, respectively (Fig. 7). The Rm variable showed a strong spatial dependence within a range of 18.1 km. The measure of the unexplained variability or nugget (13%) is low compared to the total variance or sill (2.52) suggesting > 87% {[(Sill − Nugget) × 100]/Sill} of the semivariance of the Rm could be modeled by the variogram over a range of 18.1 km. Small nugget effect indicate geostatistically small uncontrolled variability associated with Rm provides ordinary kriging as appropriate prediction method for direct interpolation of the original values of the regional Rm data. The semivariogram parameters were used to generate thematic spatial distribution map of Rm by ordinary kriging method with predicted average standard error of 0.48. Figure 8 represents the spatial distribution of risk magnitude (Rm) in Lucknow monitoring area. A major portion of the area falls under the moderate risk (Rm ranges from 2 to 3), indicating a regional source of dHg concentration independent of rural and urban processes. The northwestern part of Lucknow monitoring area has been classified under the high to extreme risk magnitude (Rm ranges from 3 to > 5), and this part has a spatial extent of 131.68 km2 (10% of the total monitoring area). About 1045.25 km2, which is 85% of the total monitoring area, is at moderate risk (Table 3).

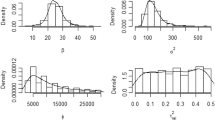
Best-fitted spherical semivariogram estimated from regional Risk Magnitude (Rm) data to generate thematic Rm map of Lucknow monitoring area

Spatial distribution of risk magnitude (Rm) in Lucknow monitoring area. Rm is classified as low (1–2), moderate (2–3), high (3–4), very high (4–5), and extremely high (> 5) representing 2, 3, 4, 5, and > 5 folds exceedance of dHg concentration. Note that the northwestern part of Lucknow monitoring area is classified as above high risk magnitude
Human health risk probability
Risk magnitude (Rm) is used as an empirical test variable for probability kriging estimates to predict the areas in which the probability of exceedance of risk to human health is higher. The best-fitted semivariograms of the indicator values and uniform values transformed from regional (Rm) database are shown in Fig. 9a, b, respectively. The corresponding semivariogram parameters (nugget, sill, and range) of the indicator and uniform value evaluate the probability of higher health risk than the threshold value (Rm = 1) with the predicted average standard error of 0.44 (Table 4). The generated prediction map indicates all area at risk and shows a variable degree of health risk probability from low to extremely high. The probability of exceedance of dHg from the threshold value is the highest (0.8–1.0) in the north-western parts and gradually decreases to lowest (0.0–0.2) towards the east and south-eastern parts of the Lucknow monitoring area (Fig. 10). The decrease in health risk probability in the southeastern direction may be linked with the regional slope of the Lucknow monitoring area and/or regional flow of the groundwater. The predicted probability data were further integrated with the population count data (Census of India 2011) of Lucknow monitoring area to map the human population count at risk. The result showed that 60% of the human population counts residing in about 706.6 km2 area (58% of the total area) and occupying the western half of the Lucknow monitoring area are above high health risk probability (Table 5; Fig. 11).

The best-fitted semivariograms of a indicator values and b uniform values transformed from regional Rm database. The parameters derived from semivariogram model have been used in probability kriging for generation of health risk probability map of the Lucknow monitoring area

Health risk probability map of the Lucknow monitoring area showing the places where the probability of exceedance of dHg concentration in drinking groundwater is higher than the threshold value. The probability of exceedance of Hg from the threshold value is highest (0.8–1.0) in the northwestern part and gradually decreases to lowest (0.0–0.2) towards east and southeast of the Lucknow monitoring area

Human health risk map showing the spatial overlay of predicted probability data over the dispersion of human population counts at the ward or village level. Contours show the spatial distribution of probability of risk to human health. The figure indicates that 60% of the human population counts reside in about 706.6 km2 area (58% of the total area) which occupies the western half of the Lucknow monitoring area and is above the probability of high health risk
With the help of the present study, the understanding of variation in health risk probability of urban (central), rural (southeastern), and mixed farming (northwestern) parts of the Lucknow monitoring area is significant to investigate the possible contamination source of dHg that may be independent of rural-urban processes operating in the alluvial plain. The estimates of the risk probability and corresponding human population count at risk in three different sectors, i.e., the rural, urban, and mixed farming sectors are given in Table 6. Results show that mixed farming (NW) part of the Lucknow monitoring area has very high to extreme risk probability of dHg contamination. The contaminated area occupies 147 km2 affecting only 4.68% of the total population which is mainly rural. Rural sector is at low to moderate risk probability occupying 147 km2 affecting only 5.66% of the total population. Health risk from exposure to dHg contamination is potentially alarming in the urban sector where 32.4% of the population residing in 6.8% of the total Lucknow monitoring area, especially in the western parts, is at high to very high risk probability. Therefore, high and low risk probability in the northwestern and southeastern part is represented by mixed farming and rural parts, respectively. It indicates the possibility of regional and local (point) non-geogenic source for dHg that may be independent of rural-urban processes operating in the alluvial plain.
Conclusions
In northern India, Lucknow monitoring area of the Ganga Alluvial Plain experienced high to very high probability risk to human health from the exposure of dHg through drinking water resource. The results indicate that nearly two-thirds of the human population residing in about 58% of the total area was classified above the probability of high health risk. The Ganga Alluvial Plain is one of the densest congregations of the human populations in the world. Therefore, mapping human health risk from dHg exposure plays a significant role in the sustainable environmental development of the region on a global scale. It is important to note that the present study is based on a single chemical data source (mercury in drinking water resource) and does not refer human health risk assessment by the mercury exposure in other environmental components (such as in soils and in air). Moreover, population figures by sex, age, and area were not considered for the present study. With the help of these datasets, health risk assessment could be more reliable in the future studies. This seems to be more important in further research because the real risk value of total mercury exposure could be much higher, and the mapping of human health risk could be more productive by considering more robust parameter as mentioned above to take substantial remediation measures on a long-term basis.
References
Adhikary, P. P., Dash, C. J., Bej, R., & Chandrasekharan, H. (2011). Indicator and probability kriging methods for delineating Cu, Fe, and Mn contamination in groundwater of Najafgarh Block, Delhi, India. Environmental Monitoring and Assessment, 176(1), 663–676.
Agarwal, R., Kumar, R., & Behari, J. R. (2007). Mercury and lead content in fish species from the River Gomti, Lucknow, India, as biomarkers of contamination. Bulletin of Environmental Contamination Toxicololgy, 78, 108–112. https://doi.org/10.1007/s00128-007-9035-8.
Amos, H. M., Jacob, D. J., Kocman, D., Horowitz, H. M., Zhang, Y., Dutkiewicz, S., Horvat, M., Corbitt, E. S., Krabbenhoft, D. P., & Sunderland, E. M. (2014). Global biogeochemical implications of mercury discharges from rivers and sediment burial. Environmental Science & Technology, 48(16), 9514–9522.
Archana, A. D., Yunus, M., & Dutta, V. (2014). Assessment of the status of municipal solid waste management (MSWM) in Lucknow - capital city of Uttar Pradesh, India. IOSR-Journal of Environmental Science, Toxicology and Food Technology, 8(5), 41–49.
Berke, O. (2004). Exploratory disease mapping: kriging the spatial risk function from regional count data. International Journal of Health Geographics., 3, 18. https://doi.org/10.1186/1476-072X-3-18.
Bhowmik, A. K., Alamdar, A., Katsoyiannis, I., Shen, H., Ali, N., Ali, S. M., Bokhari, H., Schäfer, R. B., & Eqani, S. A. M. A. S. (2015). Mapping human health risks from exposure to trace metal contamination of drinking water sources in Pakistan. Science of the Total Environment, 538, 306–316.
Carrat, F., & Valleron, A. J. (1992). Epidemiologic mapping using the “kriging” method: application to an influenza-like epidemic in France. American Journal of Epidemiology, 135, 1293–1300.
Census of India (2011). District Census Handbook, Lucknow, Uttar Pradesh, Series-10, Part XII-B, Directorate of Census Operation, Uttar Pradesh.
Central Ground Water Board (CGWB) (2009). Groundwater brochure of Lucknow District, Uttar Pradesh. Central Groundwater Board, Ministry of Water Resources, Govt. of India.
Chakraborty, L. B., Qureshi, A., Vadenbo, C., & Hellweg, S. (2013). Anthropogenic mercury flows in India and impacts of emission controls. Environmental Science and Technology, 47, 8105–8113. https://doi.org/10.1021/es401006k.
Childs, C. (2004). Interpolating surfaces in ArcGIS spatial analyst. ESRI Education Services.
Das, T. B., Choudhury, A., & Senapati, R. N. (2015). Mercury emissions from coal fired power plants of India. International Journal of Energy Sustainability and Environmental Engineering, 2(1), 21–24.
Fernández-Martínez, R., Loredo, J., Ordonez, A., & Rucandio, M. I. (2005). Distribution and mobility of mercury in soils from an old mining area in Mieres, Asturias (Spain). Science of the Total Environment, 346(1), 200–212.
Goovaerts, P. (1997). Geostatistics for natural resource evaluation. New York: Oxford University.
Goovaerts, P., AvRuskin, G., Meliker, J., Slotnick, M., Jacquez, G., & Nriagu, J. (2005). Geostatistical modeling of the spatial variability of arsenic in groundwater of Southeast Michigan. Water Resources Research, 41(7).
Houston, M. C. (2014). The role of mercury in cardiovascular disease. Journal of Cardiovascular Diseases & Diagnosis, 2, 170. https://doi.org/10.4172/2329-9517.1000170.
International Programme on Chemical Safety (IPCS). (2004). International programme on chemical safety, project on the harmonization of approaches to the assessment of risk from exposure to chemicals, 19–20 August. Geneva: WHO Headquarters.
Juang, K. W., & Lee, D. Y. (2000). Comparison of three nonparametric kriging methods for delineating heavy metal contaminated soils. Journal of Environmental Quality, 29, 197–205.
Kavcar, P., Sofuoglu, A., & Sofuoglu, S. C. (2009). A health risk assessment for exposure to trace metals via drinking water ingestion pathway. International Journal of Hygiene and Environmental Health, 212, 216–227.
Muhammad, S., Shah, M. T., & Khan, S. (2011). Health risk assessment of heavy metals and their source apportionment in drinking water of Kohistan region, northern Pakistan. Microchemical Journal, 98, 334–343.
Mukherjee, A. B., Bhattacharya, P., Sarkar, A., & Zevenhoven, R. (2009). Mercury emissions from industrial sources in India and its effects in the environment (Vol. 4, pp. 81–112). New York: Springer.
Oliver, M. A., Webster, R., Lajaunie, C., & Muir, K. R. (1998). Binomial co-kriging for estimating and mapping the risk of childhood cancer. Journal of Mathematics Applied in Medicine and Biology, 15, 279–297.
Pacyna, E. G., Pacyna, J. M., Sundseth, K., Munthe, J., Kindbom, K., Wilson, S., Steenhuisen, F., & Maxson, P. (2010). Global emission of mercury to the atmosphere from anthropogenic sources in 2005 and projections to 2020. Atmospheric Environment, 44(2010), 2487–2499.
Pangtey, B. S., Kumar, S., Bihari, V., Mathur, N., Rastogi, S. K., & Srivastava, A. K. (2004). An environmental profile of brick kilns in Lucknow. Journal of Environmental Science and Engineering, 46, 239–244.
Passarella, G., Vurro, M., D'agostino, V., Giuliano, G., & Barcelona, M. J. (2002). A probabilistic methodology to assess the risk of groundwater quality degradation. Environmental Monitoring and Assessment, 79(1), 57–74.
Rai, V. K., Raman, N. S., & Choudhary, S. K. (2013). Mercury in thermal power plants – a case study. International Journal of Pure and Applied Bioscience, 1(2), 31–37.
Raj, D., Chowdhury, A., & Maiti, S. K. (2017). Ecological risk assessment of mercury and other heavy metals in soils of coal mining area: a case study from the eastern part of a Jharia coal field, India. Human and Ecological Risk Assessment, 23(4), 767–787. https://doi.org/10.1080/10807039.2016.1278519.
Raju, A., Singh, A., Kumar, S., & Pati, P. (2016). Temporal monitoring of coal fires in Jharia Coalfield, India. Environmental Earth Sciences, 75. https://doi.org/10.1007/s12665-016-5799-7.
Richardson, G. M. (2014). Mercury exposure and risks from dental amalgam in Canada: the Canadian health measures survey 2007-2009. Human and Ecological Risk Assessment, 20, 433–447. https://doi.org/10.1080/10807039.2012.743433.
Saxena, S., Upreti, D. K., & Sharma, N. (2007). Heavy metal accumulation in lichens growing in north side of Lucknow city, India. Journal of Environmental Biology, 28(1), 49–51.
Singh, I. B. (1996). Geological evolution of ganga plain: an overview. Journal of the Palaeontological Society of India, 41, 99–137.
Singh, R. D., Jurel, S. K., Tripathi, S., Agrawal, K. K., & Kumari, R. (2014). Mercury and other biomedical waste management practices among dental practitioners in India. BioMed Research International, article ID 272750. https://doi.org/10.1155/2014/272750
Singh, A., Srivastav, S. K., Kumar, S., & Chakrapani, G. J. (2015). A modified-DRASTIC model (DRASTICA) for assessment of groundwater vulnerability to pollution in an urbanized environment in Lucknow, India. Environmental Earth Sciences. https://doi.org/10.1007/s12665-015-4558-5.
Stahl, R. G., Jr., Kain, D., Bugas, P., Grosso, N. R., Guiseppi-Elie, A., & Liberati, M. R. (2014). Applying a watershed-level, risk-based approach to addressing legacy mercury contamination in the South River, Virginia: planning and problem formulation. Human and Ecological Risk Assessment, 20(2), 316–345. https://doi.org/10.1080/10807039.2014.844053.
Törnqvist, R., Jarsjö, J., & Karimov, B. (2011). Health risks from large-scale water pollution: trends in Central Asia. Environmental International., 37, 435–442.
Wang, D., Shi, X., & Wei, S. (2003). Accumulation and transformation of atmospheric mercury in soil. Science of the Total Environment, 304(1), 209–214.
Webster, R., Oliver, M. A., Muir, K. R., & Mann, J. R. (1994). Kriging: the local risk of a rare disease from a register of diagnoses. Geographical Analysis, 26, 168–185.
Weiner, E. R. (2000). Applications of environmental chemistry: a practical guide for environmental professionals. Florida: CRC press LLC.
WHO (2011). World Health Organization, guidelines for drinking-water quality, 4th edn. Geneva. www.who.int/who_dwg_2011.pdf.
Acknowledgements
The authors thank Prof. Indra Bir Singh, the University of Lucknow, for his encouragement and suggestions in the present study. We also appreciate the corporation and support provided by the editorial staff of “Environmental Monitoring and Assessment, Special Issue: Geospatial Technology in Environmental Health Applications.” We would also like to thank anonymous reviewers for their suggestions and valuable comments that helped to improve the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Geospatial Technology in Environmental Health Applications.
Rights and permissions
About this article

Cite this article
Raju, A., Singh, A., Srivastava, N. et al. Mapping human health risk by geostatistical method: a case study of mercury in drinking groundwater resource of the central ganga alluvial plain, northern India. Environ Monit Assess 191 (Suppl 2), 298 (2019). https://doi.org/10.1007/s10661-019-7427-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-019-7427-y