
Abstract
In this study, landslide risk assessment for Izmir city (west Turkey) was carried out, and the environmental effects of landslides on further urban development were evaluated using geographical information systems and remote sensing techniques. For this purpose, two different data groups, namely conditioning and triggering data, were produced. With the help of conditioning data such as lithology, slope gradient, slope aspect, distance from roads, distance from faults and distance from drainage lines, a landslide susceptibility model was constructed by using logistic regression modelling approach. The accuracy assessment of the susceptibility map was carried out by the area under curvature (AUC) approach, and a 0.810 AUC value was obtained. This value shows that the map obtained is successful. Due to the fact that the study area is located in an active seismic region, earthquake data were considered as primary triggering factor contributing to landslide occurrence. In addition to this, precipitation data were also taken into account as a secondary triggering factor. Considering the susceptibility data and triggering factors, a landslide hazard index was obtained. Furthermore, using the Aster data, a land-cover map was produced with an overall kappa value of 0.94. From this map, settlement areas were extracted, and these extracted data were assessed as elements at risk in the study area. Next, a vulnerability index was created by using these data. Finally, the hazard index and the vulnerability index were combined, and a landslide risk map for Izmir city was obtained. Based on this final risk map, it was observed that especially south and north parts of the Izmir Bay, where urbanization is dense, are threatened to future landsliding. This result can be used for preliminary land use planning by local governmental authorities.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Landslides cause enormous casualties and severe economic losses in mountainous regions worldwide (Schuster 1996). Preventing or reducing mass movements always involves systematic and rigorous processes to stabilize or manage slopes (Fell and Hartford 1997). Since this is seldom sufficiently recognized, new and more effective methodologies need to be developed in order to increase the understanding of landslide risk and to enable rational decisions to be made on the allocation of funds for landslide risk management (Guzzetti 2000; Sterlacchini et al. 2007).
The risk concept for landslide hazard assessment was discussed by many authors (Varnes 1984; Brabb 1984; Einstein 1998; Carrara et al. 1991; Fell 1994; Soeters and van Westen 1996; Aleotti and Chowdhury 1999; Chung and Fabbri 1999; Hearn and Griffiths 2001; Cardinali et al. 2002; Dai et al. 2002; Gorsevski et al. 2003; Glade and Crozier 2005; Guzzetti et al. 2006; Lee and Pradhan 2006; Remondo et al. 2008; Van Westen et al. 2008; Zezere et al. 2008; Guzzetti et al. 2009; Wu et al. 2009; Pradhan and Youssef 2010; Das et al. 2011; Jaiswal et al. 2011a, b; Peters-Guarin et al. 2011; Nefeslioglu and Gokceoglu 2011; Pradhan et al. 2011; Tang et al. 2011). Briefly, risk is a function of hazard and vulnerability parameters, which are obtained from elements at risk. Hazard means the probability of occurrence within a specified period of time and within a given area of a potentially damaging phenomenon (Varnes 1984). The population, properties and economic activities (including public services) at risk in a given area correspond to the “elements at risk” parameter (Newman and Strojan 1998). “Vulnerability”—commonly expressed on a scale of 0 (no loss) to 1 (total loss)—is often placed in context using either monetary terms, such as loss experienced by a given property, or to loss of life (Glade and Crozier 2005; Jaiswal et al. 2010).
Landslide risk assessment must also be considered in urban planning strategies due to the fact that landslides adversely affect settlement areas. The landslides in the Izmir city are generally located in residential and new urban areas. This circumstance therefore requires a comprehensive landslide risk management study. For this purpose, this paper aimed to create a landslide risk map for Izmir city. Landslide susceptibility assessment has been carried out using landslide-conditioning parameters based on the logistic regression model. Landslide-conditioning parameters were collected and transformed into a spatial database. Logistic regression values for each of these parameters were computed using GIS tools. Landslide occurrence areas were detected in Izmir city by interpreting aerial photographs and detailed field surveys. Then, a landslide inventory map was obtained and was used to assess the frequency and distribution of shallow landslides in the study area. The methodological approach is shown schematically in Fig. 1.

Flow diagram showing the approach used to model landslide risk in this study
Study area
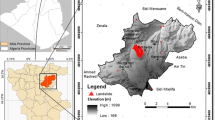
Izmir is the third largest metropolitan city located on the western coast of Turkey (Fig. 2) with a population of 3.5 million and has become well-known as a centre for art, culture, tourism and trade activities throughout the 5,000 years of its history. The Bornova Melange, which overlies the basement rocks in the Izmir region, underwent intense tectonic deformation during and after sedimentation (Erdoğan 1990; Koca 1995; Kıncal 2005). Bornova melange rocks are made up of interbedded sandstone–shale, limestone lenses, limestone and serpentinite bodies, mafic volcanics, chert and their complexes such as Dededağı and Kızılkalesi Formations. Neogene sedimentary rocks, consisting of conglomerate, sandstone, siltstone, mudstone and limestone, discordantly overlie the melange, and the contact between the melange and the Neogene units is faulted within the study area (Fig. 3). The Upper Miocene and Pliocene volcanic rocks are widespread in and around the city of Izmir and discordantly overlie the sedimentary rock units (Fig. 3). The volcanic rocks mainly consist of dacitic tuffs, dacitic lava, andesitic tuff, agglomerate and lava subunits (Fig. 3). Andesitic volcanics in the southern part of Izmir Bay overlie the clayey and marly levels of sedimentary rocks (Kıncal and Koca 2009). These volcanics generally have tuffs at the base and are continuous with agglomerate and andesitic lavas, in that order (Kıncal et al. 2009; Akgun 2011). Slope failures in natural slopes have been observed as a result of seismic activity in the region. An earthquake with M S = 6.0 in 1992 and a sequence of three earthquakes with M S = 5.5, 5.9 and 5.9 in 2005 occurred in the region (KOERI 2008). Slope instability can develop after earthquakes with magnitudes of ≥4.0 on the Richter scale in the shale mountain slopes, particularly rock mass slides on steeply dipping slopes, greater than 35° (Keefer 1984). Although there are no any records about the relationship between the landslides and the occurred earthquakes in the area, it is considered as the most powerful triggering factor. This result should be concluded because Aegian region is one of the most earthquake prone continental region in the world. In this context, earthquake should be considered as a primary triggering factor for landslide occurrence rather than precipitation.

Location map of the study area

Landslide information of the area
To carry out a landslide hazard assessment, the primary data are the landslide inventory. In order to produce a detailed and reliable landslide inventory map, extensive field surveys and detailed observations in the study area were performed. A total of 30 landslides were identified and mapped in the period from 1995 to 2008, and the mode of failure was observed to be planar slide, toppling and rotation for the slide masses according to the landslide classification proposed by Varnes (1978). The areal extent of the smallest observable slide is approximately 0.236 km2 and the largest 3.957 km2 (Fig. 3). The range of failure depth of the rotational and planar slides change between 2 and 3 m. The landslides mapped in the area were separated into two groups that occurred in the south and the north parts of the study area. It is observed that ten landslides that had occurred in the northern part and seven that are observed in the south part of the area (60% of the total of landslides) were used to calibrate the logistic regression analysis; the remainder (40% of the total of landslides) were used for validation.
During the landslide inventory mapping of the area, landslide locations were prepared through the drawing of main scarp distinguished from the accumulation/depletion zone or rupture zone (Yılmaz 2009; Akgun 2011). All of the mapped landslides are presented in Fig. 3, and some site characteristics can be found in Table 1. Landslides which occurred in the area have a close relationship to the settlement areas. This situation constitutes a considerable engineering problem for Izmir city. In Fig. 4, this relationship is shown. On close inspection of Fig. 4, it is clearly seen that the most landslides have occurred in the suburb areas. This is also evidence for a lack of planning during the process of urbanization and its consequences. Uncontrolled slope cutting for constructing building foundations and other civil structures accelerated the landslide occurrence on the slopes where the lithology is susceptible to landslides, and this situation adversely affected to these structures.

Some views from the mapped landslides and settlement–landslide occurrence relationships
Hazard modelling
In this study, landslide risk assessment started with the creation and assessment of a probabilistic susceptibility model, and then the developed susceptibility map was transformed into a hazard index model. Susceptibility analysis was performed by correlation between known shallow-seated landslides and six spatial parameters which controls the instability: lithology, slope gradient, slope aspect, distance to drainage, distance to roads and distance to fault lines (Fig. 5). These data were chosen as landslide-conditioning parameters because of the fact that landslides which occurred in the area are frequently seen in the weathered rocks, on the steep and north facing slopes. Additionally, these landslides are close to the drainage lines and roads in the area. Due to the cataclastic deformation along the fault zones, some of which are active and some of which are dormant faults, the rocks are crushed and weathered which causes the instability of the slopes. Because of all these reasons, the mentioned parameters were chosen to be use as landslide controlling parameters, and it was thought that they should be taken into account in detail.

Landslide-conditioning parameters for the study area (a slope gradient, b slope aspect, c distance from drainage, d distance from fault lines, e distance from roads) (Akgun 2011)
A susceptibility model was created by using logistic regression method, which reflects the relative spatial probability of landslide occurrence. In the case of landslide susceptibility mapping, the purpose of logistic regression is to find the best fitting model to describe the relationship between the presence or absence of a landslide, which is the dependent variable, and a set of independent parameters, such as slope angle, lithology and distance to drainage (Ayalew and Yamagishi 2005; Lee 2005; Duman et al. 2006; Lee 2007; Akgun and Bulut 2007; Nefeslioglu et al. 2008; Pradhan et al. 2008, 2010, 2011; Nandi and Shakoor 2009; Oh and Lee 2010; Pradhan 2010a, b, 2011; Pradhan and Lee 2010a, b; Akgun 2011; Gao and Yin 2011). In logistic regression, the dependent variable is coded as “1” or “0” to indicate the presence or absence of a landslide, respectively. Coefficients determined in the logistic regression can be used to estimate ratios for each of the independent variables. The logistic model representing the maximum likelihood regression model can be expressed in its simplest form as:
where P is the probability of an event occurring. P is the estimated probability of occurrence in the current situation. Since z can vary from −∞ to +∞, the probability varies from 0 to 1 on an S-shaped curve and Z is defined as:
where B o is the intercept of the model and n is the number of independent variables. The B i (i = 0, 1, 2, …, n) are the slope coefficients of the logistic regression model and the X i (i = 0, 1, 2, …, n) are the independent variables. Based on Eqs. 1 and 2, the equation of logistic regression can be written in the following extended form:
Using the equations given above, coefficients of each parameter’ type and a constant were determined, and the results are shown in Eq. 4.
where the logistic regression coefficients of slopeb and lithologyb parameters are given in Table 2. In the logistic regression assessment, slope aspect and lithology data were processed as categorical data, whereas the remaining data were processed as numerical data.
With the help of these coefficients, a landslide susceptibility index map was produced. For the purpose of easy visual interpretation of this index map, the values in the map were classified into five classes by equal area approach, and the final landslide susceptibility map was produced (Fig. 6). Based on this susceptibility map, 11.57% of the total area is found to have a very low susceptibility. Low, medium and high susceptibility zones constitute 30.65%, 24.44% and 19.81% of the area, respectively. The very high susceptibility area is 13.53% of the total study area (Akgun 2011). To test the predictive capability of the susceptibility model, an assessment was carried out by comparing the susceptibility map with the past landslides that were separated for validation step. For this purpose, the AUC method (Lee et al. 2004) was used. The AUC is a good indicator to check the prediction performance of the model, and the largest AUC, varying from 0.5 to 1.0, is the most ideal model (Fig. 6). The AUC value of ROC curve for logistic regression-based landslide susceptibility map was found to be 0.810. This result shows that there is a fair agreement between the prediction accuracy and the occurrence of landslides in the study area.

Landslide susceptibility map obtained by logistic regression model and the AUC assessment of the produced susceptibility map (Akgun 2011)
The transformation of landslide susceptibility map into a hazard map requires consideration of landslide triggering parameters (Prabu and Ramakrishnan 2009; Kouli et al. 2010; Nefeslioglu et al. 2011). For this purpose, two triggering parameters were taken into account: precipitation and seismicity. Seismicity is considered as the main triggering factor for landslides recorded in the landslide inventory database. Due to the fact that the resulting seismic hazard curve in terms of maximum peak ground acceleration (PGA) is called the “best estimate” seismic hazard for Izmir, the PGA data were used as a primary landslide triggering data in this study (Fig. 7) (RADIUS 1997; Deniz et al. 2010). Corresponding to a return period of 475 years (10% probability of exceedance in 50 years), a PGA map was reproduced, considering the analysis combination composed of the most likely assumptions (Deniz et al. 2010). In order to produce the PGA map, the attenuation relationships of Gulkan and Kalkan (2002) and Boore et al. (1997) were used. These equations are stated below.
where r = (r 2cl + h 2)1/2, Y = horizontal component of the peak ground acceleration (PGA) in grams, M = moment magnitude, rcl = the closest horizontal distance to the surface projection of the rupture in kilometres and h = fictitious depth, computed by regression analysis as 4.48 and 5.57 km, respectively, for Eqs. 5 and 6. When reproducing the PGA map, the only mentioned PGA map, which was produced for rock sites, was initially optimized to the scale of study because the scale of the used map is less than the scale of the study area. For this purpose, the used map was georeferenced according to the study area frame. Then, some of the PGA contours, which cannot be obtained from the used PGA map due to the scale mismatch, were reproduced by using projection approach. After these processes, the reproduced PGA contours were interpolated by triangulation interpolation method using the ArcGIS software, and finally, the reproduced PGA map for the study area was obtained. Based on the reproduced PGA map, the values obtained for Izmir city and its close vicinity range between 0.05 and 0.35 g with a mean of 0.20 g (Fig. 7).

Although there are no rainfall-induced landslides recorded in the incomplete national landslide inventory, precipitation was also considered as a secondary triggering factor. Precipitation in Izmir city causes extreme events such as flooding and overflowing. For that reason, we analysed the annual long-term average precipitation values for the period 1975–2006 (General Directory of Meteorological Services 2010). The annual long-term average precipitation density map was made by the data obtained from seven rainfall stations in and around Izmir city. For the distribution of the rainfall values in the range 587 to 700 mm, the inverse distance interpolation method was used (Fig. 8).

Annual long-term average precipitation density map of the study area
After obtaining the two landslide triggering parameters, the landslide susceptibility map and the triggering parameters were overlaid. Before overlaying the triggering parameters and landslide susceptibility map, they must be standardized to a common dimensionless scale because the scales of these data were different from each other. To perform this process, the Eq. 7 was used (Malczewski 1999).
where X ij is the standardized score for the ith alternative and jth attribute, X ij is the raw score and X max − j and X min − j is the maximum and minimum score for the jth attribute, respectively (Malczewski 1999; Sener et al. 2006). In the new scale, 0 corresponded to the lowest value and 1 corresponded to the highest value. As a result of this process, the hazard index map was obtained (Fig. 9). In the hazard map, the potential event and its probability of occurrence were combined. The hazard levels were expressed as probability in quantitative forms, namely from low (0) to high (1). The accuracy of the hazard map was evaluated by the AUC assessment methodology. For this purpose, the landslide inventory data, which were separated as test data, were compared with the hazard map. Based on this assessment, the AUC value for the hazard map obtained was found to be 0.85 (Fig. 9) and the prediction accuracy of 85.42%. Overall, the case of the hazard map showed a higher accuracy than the susceptibility map.

Landslide hazard index map of the study area and the AUC assessment of the produced hazard map
Vulnerability assessment
When attempting to assess landslide risk, vulnerability to landslides is often considered as equivalent to complete loss of the assets or total destruction of the elements at risk, for all landslides and landslide types and for all assets or elements at risk in an investigated area (Carrara et al. 1991). The simplification is made to make the problem more manageable because information on the vulnerability of specific assets or individual elements at risk is generally lacking (Galli and Guzzetti 2007). Mathematically, landslide vulnerability (V L) can be expressed as;
where D L is the assessed (definite) or the expected (forecasted) damage to an element given the occurrence of a hazardous landslide (L) (Einstein 1998). In Eq. 8, vulnerability is the probability of total loss to a specific element or the proportion of damage to an element, given the occurrence of a landslide (Vandine et al. 2004). In both cases, vulnerability is expressed on a scale from 0 to 1, 0 meaning no damage and 1 expressing complete loss or destruction (Galli and Guzzetti 2007). Vulnerability to landslides is expressed in economic (monetary, quantitative) and heuristic (qualitative) scales (Alexander 2005). When using economic measurements, vulnerability is most commonly expressed in terms of the element value such as monetary, intrinsic and utilitarian values. When expressed heuristically, landslide vulnerability is described in a qualitative (descriptive) term, which means the expected or definite damage to an element at risk (Alexander 2005). Considering all the concepts mentioned above, a vulnerability dataset was prepared for the study area. Initially, a land-cover map based on remote sensing approach was created. For this purpose, Aster Level 3A satellite image data acquired in 2004 was used. The image was rectified based on a 1:25,000-scale topographical sheet. The data were resampled using the first-degree polynomial transformation and the nearest neighbour algorithm so that the original brightness values of pixels were kept unchanged (Sunar and Kaya 1997; Chen 2002). The resultant root mean square error (RMSE) for the image was found to be 0.5526 pixels. This value is acceptable as the maximum tolerable RMSE value (Jensen 2000). To classify the image, the multi-layer perceptron (MLP) classifier of the Idrisi software was applied (Eastman 2004). The MLP classifier is a machine-learning classifier and has been used effectively in various single-date land-cover mapping studies (Huang and Jensen 1997; De Fries and Chan 2000; Kavzoglu and Mather 2003). In almost all cases, this classifier has proven superior to conventional classifiers such as maximum likelihood and minimum distances and often provides overall accuracy improvements of 10–20% (Rogan and Chen 2004). At the end of the classification process of the image, a land-cover map of the area was obtained with a 94.00% overall kappa accuracy index. This was calculated by the kappa analysis, which is a discrete multivariate technique used in accuracy assessment (Congalton and Mead 1983) (Table 3). As a result of the classification process, six land-cover classes such as settlement, dense and sparse vegetation, bare land, coastal wetland and wetland were identified (Fig. 10). Among these classes, “settlement” was extracted from the classified land-cover map to produce a vulnerability map. The settlement class includes buildings, roads, airports, pipelines, powerlines, access for remote facilities etc. Based on the classified image data, the developed areas cover an area of 197.95 km2. This extracted data constituted the elements at risk data. Due to a lack of required information about the direct loss inventory for the study area, all the developed area data were evaluated as elements at risk data. Therefore, the developed areas were assigned to 1, with remaining areas assigned as 0 (Fig. 10).

Land-cover map obtained by classification of Aster satellite data and vulnerability map of the study area
Risk modelling and results
Risk analysis aims to determine the probability that a specific hazard will cause harm, and it investigates the relationship between the frequency of damaging events and the intensity of the consequences (Guzzetti et al. 2009). Varnes (1984) explained the application of risk concept to landslide and other mass movements. With reference to this study, landslide risk assessment aims to determine the expected degree of loss due to a landslide and the expected number of lives lost, people injured, damage to property and disruption of economic activity. The first explanation refers to “specific risk” (R s), and the second explanation corresponds to “total risk” (R t) concepts. Specific landslide risk is commonly expressed by the product of landslide hazard (H L) and landslide vulnerability (V L), or:
In this equation, H L and V L are the probabilities.
To determine landslide risk, risk assessment procedures can be separated into two categories; quantitative (probabilistic) and qualitative (heuristic) approaches (Guzzetti et al. 2009). Quantitative approach aims to establish the probability of loss of life (Fell and Hartford 1997; Guzzetti 2000; Guzzetti et al. 2005), or the expected damage due to a slope failure (Bunce et al. 1997; Guzzetti et al. 2004). Establishing the probability of a loss requires a catalogue of landslides and their consequences.
In order to determine landslide risk in the Izmir city, the quantitative approach was used. For this purpose, the obtained landslide hazard and vulnerability maps were combined with each other in a direct specific risk map using the Eq. 9, and a final landslide risk index map was obtained. To aid visual interpretation, the produced risk index map was divided into categorical risk areas. Thus, the landslide risk classes were clearly identified. When classifying the landslide risk index into categorical classes, a standard deviation method was applied. This classifier is generally proposed for this purpose because it uses the mean values to generate class breaks (Ayalew and Yamagishi 2005). Based on this method, five risk classes were distinguished, very low, low, moderate, high and very high (Fig. 11). According to this risk map, 9.83% (19.41 km2) of the settlement areas is very low risk and the low-, moderate- and high-risk zones form 49.29% (97.34 km2), 25.64% (50.64 km2) and 9.34% (18.44 km2) of the settlement areas, respectively. About 5.90% (11.67 km2) of the settlement areas is estimated to be very high risk.

Landslide risk map of the study area
Concluding remarks
In international landslide literature, it is possible to find a huge number of studies performed on landslide susceptibility. However, the number of studies on the assessment of landslide hazard and risk in literature is limited. Even though the algorithms for landslide hazard and risk evaluations are able to be defined exactly, they involve highly complex processes during the application stage. Uncertainties in calculation of runout distances, transformation of susceptibility values to hazards rates and determination of vulnerability functions for the elements at risk constitute the main limitations for landslide hazard and risk studies (Nefeslioglu and Gokceoglu 2011). According to Gokceoglu and Sezer (2009), one of the important topics to be considered in the near future is landslide risk. Even though there are limitations in this study, the aim was to produce a landslide risk map for the Izmir city. The Izmir city was chosen for such a study because there are several landslides which were triggered by both earthquakes and rainfalls, in the city, and these landslides have adversely affected the existing and newly planning residential areas. Landslide susceptibility was firstly produced for the study area, and these data constituted the base of the risk mapping studies. Since Izmir city is one of the most active areas in Turkey in terms of seismicity, finding good earthquake data are relatively easy. In addition to this, due to the fact that there were an adequate and appropriate number of meteorological stations, sufficient rainfall data could be collected. After all these data production stages, to produce a landslide risk map for the study area was possible. According to the obtained risk map, the most risky areas were determined to be located on the southern and southeastern parts of the Izmir Bay. At the same time, these parts are the most populated areas of Izmir city. The areas with high and moderate risk generally concentrate on the northern parts of the Izmir Bay. These areas should be focused for detail study because this is where current processes of urbanization are concentrated. Finally, although several landslide susceptibility studies were carried out in Turkey, this study is one of the pioneer attempts for the Izmir city in terms of landslide risk mapping studies for Turkey. It is evident that the quantitative risk approach is based on probabilistic calculations and the numerical parameters. High-quality data and determination of suitable parameters for the assessment of landslide risk of a region have crucial importance. Moreover, the risk assessment is more dynamic process when compared with the susceptibility or hazard assessments because the risk values and the elements at risks can be changed depending on urban development, infrastructure construction etc. In addition, it is possible that the necessary data for the landslide risk assessments can be collected by simple and applicable methods if the technological facilitates are used. As a final conclusion, the landslide risk assessment tools can be designed as dynamic systems. This idea can be realized because the developments in computer and GIS technologies provide these facilities.
The final stage of the landslide risk assessment is the risk management. As stated by van Westen et al. (2006), the various components of landslide risk assessment should be integrated in risk information/management systems which should be developed as spatial decision support systems for local authorities dealing with risk management. If the landslide risk assessments are considered by the local authorities and/or decision makers, the risk assessments will contribute to increase in the quality of the daily life of the communities.
References
Akgun, A. (2011). A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: a case study at İzmir, Turkey. Landslides. doi:10.1007/s10346-011-0283-7.
Akgun, A., & Bulut, F. (2007). GIS-based landslide susceptibility for Arsin-Yomra (Trabzon, North Turkey) region. Environmental Geology, 51, 1377–1387.
Aleotti, P., & Chowdhury, R. (1999). Landslide hazard assessment: Summary review and new perspectives. Bulletin of Engineering Geology and the Environment, 58, 21–44.
Alexander, E. D. (2005). Vulnerability to landslides. In T. Glade, M. G. Anderson, & M. J. Crozier (Eds.), Landslide risk assessment (pp. 175–198). New York: Wiley.
Avşar, M. (1997) General assessment of landslides in Izmir metropolitan area. Unpublished M.S. thesis, The Graduate School of Natural and Applied Sciences, Dokuz Eylul University: Izmir, 136 p.
Ayalew, L., & Yamagishi, H. (2005). The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology, 65, 15–31.
Boore, D. M., Joyner, W. B., & Fumal, T. E., (1997). Equations for estimating horizontal response spectra and peak acceleration from Western North American earthquakes: a summary of recent work. Seismological Research Letters, 68(1), 128–153.
Brabb, E. E. (1984) Innovative approach to landslide hazard and risk mapping. In: Proceedings of the 4th international symposium on landslides, Vol. 1, Toronto, Canada, pp. 307–324.
Bunce, C. M., Cruden, D. M., & Morgenstern, N. R. (1997). Assessment of the hazard from rockfall on a highway. Canadian Geotechnical Journal, 34(3), 344–356.
Cardinali, M., Reichenbach, P., Guzzetti, F., Ardizzone, F., Antonini, G., Galli, M., et al. (2002). A geomorphological approach to estimate landslide hazard and risk urban and rural areas in Umbria, central Italy. Natural Hazards Earth System Sciences, 2, 57–72.
Carrara, A., Cardinalli, M., Detti, R., Guzetti, F., Pasqui, V., & Reichenbach, P. (1991). GIS techniques and statistical models in evaluating landslide hazard. Earth Surface Process Landforms, 16(5), 427–445.
Chen, X. (2002). Using remote sensing and GIS to analyse land cover change and its impacts on regional sustainable development. International Journal of Remote Sensing, 23, 107–124.
Chung, C. J., & Fabbri, A. G. (1999). Probabilistic prediction models for landslide hazard mapping. Photogrammetric Engineering Remote Sensing, 65, 1389–1399.
Congalton, R. G., & Mead, R. A. (1983). A quantitative method to test for consistency and correctness in photointerpretation. Photogrammetric Engineering and Remote Sensing, 49, 69–74.
Dai, F. C., Lee, C. F., & Ngai, Y. Y. (2002). Landslide risk assessment and management: An overview. Engineering Geology, 64(1), 65–87.
Das, A. M., Kumar, N. S., & Kanti, M. S. (2011). Landslide hazard and risk analysis in India at a regional scale. Disaster Advances, 4(2), 26–39.
De Fries, R. S., & Chan, J. C.-W. (2000). Multiple criteria for evaluating machine learning algorithms for land cover classification from satellite data. Remote Sensing of Environment, 74, 503–515.
Deniz, A., Korkmaz, A. K., & Irfanoglu, A. (2010). Probabilistic seismic hazard assessment for İzmir, Turkey. Pure and Applied Geophysics, 167, 1475–1484.
Duman, T. Y., Can, T., Gokceoglu, C., Nefeslioglu, H. A., & Sonmez, H. (2006). Application of logistic regression for landslide susceptibility zoning of Cekmece Area, Istanbul, Turkey. Environmental Geology, 51, 241–256.
Eastman, R. (2004). IDRISI Kilimanjaro: guide to GIS and image processing. Worcester: Clark Labs, Clark University.
Einstein, H. H. (1998). Special lecture: Landslide risk assessment procedure. In C. Bonnard (Ed.), Landslides (pp. 1075–1090). Rotterdam: Balkema.
Erdoğan, B. (1990). Stratigraphy and tectonic evolution of İzmir–Ankara zone between İzmir and Seferihisar. TAPG Bulletin, 2(1), 1–20 (in Turkish).
Fell, R. (1994). Landslide risk assessment and acceptable risk. Canadian Geotechnical Journal, 31, 261–272.
Fell, R., & Hartford, D. (1997). Landslide risk management. In D. M. Cruden & R. Fell (Eds.), Landslide risk management (pp. 51–109). Rotterdam: Balkema.
Galli, M., & Guzzetti, F. (2007). Landslide vulnerability criteria: A case study from Umbria, central Italy. Environmental Management, 40, 649–664.
Gao, H.-X., & Yin, K.-L. (2011). GIS-based spatial prediction of landslide hazard risk. Journal of Natural Disasters, 20(1), 31–36.
General Directory of Meteorological Services of Turkey (2010). http://www.dmi.gov.tr/veridegerlendirme/il-ve-ilceler-istatistik.aspx?m=IZMIR. Accessed 16 Dec 2010.
Glade, T., & Crozier, M. J. (2005). A review of scale dependency in landslide hazard and risk analysis. In T. Glade, M. G. Anderson, & M. J. Crozier (Eds.), Landslide risk assessment (pp. 75–138). Chichester: Wiley.
Gokceoglu, C., & Sezer, E. (2009). A statistical assessment on international landslide literature (1945–2008). Landslides, 6, 345–351.
Gorsevski, P. V., Gessler, P. E., & Jankowski, P. (2003). Integrating a fuzzy kmeans classification and a Bayesian approach for spatial prediction of landslide hazard. Journal Geographical Information Systems, 5, 223–251.
Gulkan, P., & Kalkan, E., (2002). Attenuation modeling of recent earthquakes in Turkey. Journal of Seismology, 6(3), 397–409.
Guzzetti, F. (2000). Landslide fatalities and evaluation of landslide risk in Italy. Engineering Geology, 58, 89–107.
Guzzetti, F., Reichenbach, P., & Ghigi, S. (2004). Rockfall hazard and risk assessment in the Nera River Valley, Umbria Region, central Italy. Environmental Management, 34, 191–208.
Guzzetti, F., Stark, C. P., & Salvati, P. (2005). Evaluation of flood and landslide risk to the population of Italy. Environmental Management, 36, 15–36.
Guzzetti, F., Galli, M., Reichenbach, P., Ardizzone, F., & Cardinali, M. (2006). Landslide hazard assessment in the Collazzone area, Umbria, central Italy. Natural Hazards Earth System Sciences, 6, 115–131.
Guzzetti, F., Reichenbach, P., Ardizzone, F., Cardinali, M., & Galli, M. (2009). Landslide hazard assessment, vulnerability estimation and risk evaluation. An example from the Collazzone Area (Central Umbria, Italy). Geogr Fis Dinam Qual, 32, 183–192.
Hearn, G. J., & Griffiths, J. S. (2001). Landslide hazard mapping and risk assessment. Geological Society, London, Engineering Geology Special Publications, 18, 43–52.
Huang, X., & Jensen, R. (1997). A machine-learning approach to automated knowledge-base building for remote sensing image analysis with GIS data. Photogrammetric Engineering and Remote Sensing, 63, 1185–1194.
Jaiswal, P., van Westen, C. J., & Jetten, V. (2010). Quantitative landslide hazard assessment along a transportation corridor in southern India. Engineering Geology, 116(3–4), 236–250.
Jaiswal, P., Van Westen, C. J., & Jetten, V. (2011a). Quantitative estimation of landslide risk from rapid debris slides on natural slopes in the Nilgiri hills, India. Natural Hazards and Earth System Science, 11(6), 1723–1743.
Jaiswal, P., van Westen, C. J., & Jetten, V. (2011b) Quantitative assessment of landslide hazard along transportation lines using historical records. Landslides, 8(3), 279–291.
Jensen, J. R. (2000). Introductory digital image processing: A remote sensing perspective. Upper Saddle River: Prentice Hall.
Kandilli Observatory and Earthquake Research Institute (KOERI) (2008). http://www.koeri.boun.edu.tr. Accessed 12 Apr 2008.
Kavzoglu, T., & Mather, P. M. (2003). The use of back-propagating artificial neural networks in land cover classification. International Journal of Remote Sensing, 24, 4907–4938.
Keefer, D. K. (1984). Landslides caused by earthquakes. Geological Society of America Bulletin, 95(2), 406–421.
Kıncal, C. (2005) Engineering geological evaluation of geological units outcrop in and around the Izmir City Centre with the help of geographical information systems and remote sensing techniques. Unpublished Ph.D. thesis, The Graduate School of Natural and Applied Sciences, Dokuz Eylul University, Izmir, 342 p. (in Turkish).
Kıncal, C., & Koca, M. Y. (2009). A proposed method for drawing the great circle representing dip angle and strike changes. Environmental and Engineering Geoscience, 15, 145–165.
Kıncal, C., Akgün, A., & Koca, M. Y. (2009). Landslide susceptibility assessment in the Izmir (West Anatolia, Turkey) city center and its near vicinity by the logistic regression method. Environmental Earth Sciences, 59, 745–756.
Koca, M. Y. (1995) Slope stability assessment of the abandoned andesite quarries in and around the Izmir city centre. Unpublished Ph.D. thesis, Dokuz Eylul University, Izmir 430 p.
Kouli, M., Loupasakis, C., Soupios, P., & Vallianatos, F. (2010). Landslide hazard zonation in high risk areas of Rethymno Prefecture, Crete Island, Greece. Natural Hazards, 52(3), 599–621.
Lee, S. (2005). Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. International Journal of Remote Sensing, 26(7), 1477–1491.
Lee, S. (2007). Comparison of landslide susceptibility maps generated through multiple logistic regression for three test areas in Korea. Earth Surface Processes and Landforms, 32(14), 2133–2148.
Lee, S., & Pradhan, B. (2006). Probabilistic landslide hazards and risk mapping on Penang Island, Malaysia. Journal Earth System Science, 115(6), 661–672.
Lee, S., Choi, J., & Min, K. (2004). Probabilistic landslide hazard mapping using GIS and remote sensing data at Boeun, Korea. International Journal of Remote Sensing, 25, 2037–2052.
M.T.A. (2000). Geological map of Turkey, 1,25.000-scaled Izmir sheet. Izmir: MTA.
Malczewski, J. (1999). GIS and multicriteria decision analysis. New York: Wiley.
Nandi, A., & Shakoor, A. (2009). A GIS-based landslide susceptibility evaluation using bivariate and multivariate statistical analyses. Engineering Geology, 110, 11–20.
Nefeslioglu, H. A., & Gokceoglu, C. (2011). Probabilistic risk assessment in medium scale for rainfall induced earthflows: Catakli catchment area (Cayeli, Rize, Turkey). Mathematical Problems in Engineering, Article ID 280431.
Nefeslioglu, H. A., Gokceoglu, C., & Sonmez, H. (2008). An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Engineering Geology, 97, 171–191.
Nefeslioglu, H. A., Gokceoglu, C., Sonmez, H., & Gorum, T. (2011). Medium-scale hazard mapping for shallow landslide initiation: The Buyukkoy catchment area (Cayeli, Rize, Turkey). Landslides. doi:10.1007/s10346-011-0267-7.
Newman, M. C., & Strojan, C. L. (1998). Risk assessment: Logic and measurement. Chelsea: Ann Arbor.
Oh, H.-J., & Lee, S. (2010). Cross-validation of logistic regression model for landslide susceptibility mapping at Geneoung areas, Korea. Disaster Advances, 3(2), 44–54.
Peters-Guarin, G., Mccall, M. K., & Van Westen, C. (2011). Coping strategies and risk manageability: Using participatory geographical information systems to represent local knowledge. Disasters. doi:10.1111/j.1467-7717.2011.01247.x.
Prabu, S., & Ramakrishnan, S. S. (2009). Combined use of socio economic analysis, remote sensing and GIS data for landslide hazard mapping using ANN. Journal of the Indian Society of Remote Sensing, 37(3), 409–421.
Pradhan, B. (2010a). Remote sensing and GIS-based landslide hazard analysis and cross-validation using multivariate logistic regression model on three test areas in Malaysia. Advances in Space Research, 45(10), 1244–1256.
Pradhan, B. (2010b). Landslide susceptibility mapping of a catchment area using frequency ratio, fuzzy logic and multivariate logistic regression approaches. Journal of the Indian Society of Remote Sensing, 38(2), 301–320.
Pradhan, B. (2011). Manifestation of an advanced fuzzy logic model coupled with geo-information techniques to landslide susceptibility mapping and their comparison with logistic regression modelling. Environmental and Ecological Statistics, 18(3), 471–493. doi:10.1007/s10651-010-0147-7.
Pradhan, B., & Lee, S. (2010a). Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environmental Modeling Software, 25(6), 747–759.
Pradhan, B., & Lee, S. (2010b). Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environmental Earth Sciences, 60(5), 1037–1054.
Pradhan, B., & Youssef, A. M. (2010). Manifestation of remote sensing data and GIS on landslide hazard analysis using spatial-based statistical models. Arabian Journal of Geosciences, 3(3), 319–326.
Pradhan, B., Lee, S., Mansor, S., Buchroithner, M. F., Jallaluddin, N., & Khujaimah, Z. (2008). Utilization of optical remote sensing data and geographic information system tools for regional landslide hazard analysis by using binomial logistic regression model. Applied Remote Sensing, 2, 1–11.
Pradhan, B., Lee, S., & Buchroithner, M. F. (2010). Remote sensing and GIS-based landslide susceptibility analysis and its cross-validation in three test areas using a frequency ratio model. Photogrammetrie, Fernerkundung, Geoinformation, 2010(1), 17–32. doi:10.1127/1432-8364/2010/0037.
Pradhan, B., Mansor, S., Pirasteh, S., & Buchroithner, M. (2011). Landslide hazard and risk analyses at a landslide prone catchment area using statistical based geospatial model. International Journal of Remote Sensing, 32(14), 4075–4087.
RADIUS. (1997). Risk assessment tools for diagnosis of urban areas against seismic disaster Izmir earthquake master program. Istanbul: Bogazici University Kandilli Observatory.
Remondo, J., Bonachea, J., & Cendrero, A. (2008). Quantitative landslide risk assessment and mapping on the basis of recent occurrences. Geomorphology, 94(3–4), 496–507.
Rogan, J., & Chen, D. M. (2004). Remote sensing technology for mapping and monitoring land cover and land-use change. Progress in Planning, 61(4), 301–325.
Schuster, R. L. (1996). Socioeconomic significance of landslides. In A. K. Turner & R. L. Schuster (Eds.), Landslides—investigation and mitigation. Transp. Res. Board Spec. Report 247 (pp. 12–35). Washington, DC: National Research Council.
Sener, B., Suzen, M. L., & Doyuran, V. (2006). Landfill site selection by using geographic information systems. Environmental Geology, 49, 376–388.
Soeters, R., & Van Westen, C. J. (1996). Slope instability recognition analysis and zonation. In K. T. Turner & R. L. Schuster (Eds.), Landslides: Investigation and mitigation. Transportation Research Board National Research Council, special report no 247 (pp. 129–177). Washington, DC: National Research Council.
Sterlacchini, S., Frigerio, S., Giacomelli, P., & Brambilla, M. (2007). Landslide risk analysis: A multi-disciplinary methodological approach. Natural Hazards Earth System Science, 7, 657–675.
Sunar, F., & Kaya, S. (1997). An assessment of geometric accuracy of remotely sensed images. International Journal of Remote Sensing, 18, 3069–3074.
Tang, C., Zhu, J., & Qi, X. (2011). Landslide hazard assessment of the 2008 Wenchuan earthquake: A case study in Beichuan area. Canadian Geotechnical Journal, 48(1), 128–145.
Van Westen, C. J., Van Asch, T. W. J., & Soeters, R. (2006). Landslide hazard and risk zonation—why is it still so difficult? Bulletin of Engineering Geology and the Environment, 65, 167–184.
Van Westen, C. J., Castellanos, E., & Kuriakose, S. L. (2008). Spatial data for landslide, susceptibility, hazard, and vulnerability assessment: An overview. Engineering Geology, 102, 112–131.
Vandine, D. F., Moore, G., Wise, M., Vanbuskirk, C., & Gerath, R. (2004). Technical terms and methods. In M. Wise, G. Moore, & D. Vandine (Eds.), Landslide risk case studies in forest development planning and operations. B.C. Ministry of Forests Forest Science Program, abstract of land management handbook 56 (pp. 13–26). Victoria: B.C. Ministry of Forests, Forest Science Program.
Varnes, D. J. (1978). Slope movement types and processes. In R. L. Schuster & R. J. Krizek (Eds.), Landslides analysis and control Special report, vol 176 (pp. 12–33). New York: Transportation Research Board, National Academy of Sciences.
Varnes, D. J. (1984). Landslide hazard zonation: a review of principles and practice (p. 63). Paris: UNESCO.
Wu, Y.-P., Yin, K.-L., & Jiang, W. (2009). Early warning of landslide risk in Yongjia County, Zhejiang Province. Journal of Natural Disasters, 18(2), 124–130.
Yilmaz, I. (2009). Landslide susceptibility using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat-Turkey). Computers and Geosciences, 35(6), 1125–1138.
Zezere, J. L., Garcia, R. A. C., Oliveira, S. C., & Reis, E. (2008). Probabilistic landslide risk analysis considering direct costs in the area north of Lisbon. Geomorphology, 94(3–4), 467–495.
Acknowledgements
The authors would like to thank Prof. Dr. M. Yalcın Koca from Dokuz Eylul University and Prof. Dr. Candan Gokceoglu from Hacettepe University for their constructive comments to this study and Mr. Raşit Özkan for his help during the field surveying.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Akgun, A., Kıncal, C. & Pradhan, B. Application of remote sensing data and GIS for landslide risk assessment as an environmental threat to Izmir city (west Turkey). Environ Monit Assess 184, 5453–5470 (2012). https://doi.org/10.1007/s10661-011-2352-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10661-011-2352-8